
Mathematische Behandlung des Risikos in der Portfolio...
26
Mathematische Behandlung des Risikos in der Portfolio-Optimierung Seminararbeit von Michael Manger FAKULT ¨ AT F ¨ UR MATHEMATIK UND PHYSIK MATHEMATISCHES INSTITUT Datum: 5. M¨ arz 2008 Betreuung: Prof. Dr. L. Gr¨ une
Transcript of Mathematische Behandlung des Risikos in der Portfolio...

Mathematische Behandlung desRisikos in der Portfolio-Optimierung
Seminararbeit
von
Michael Manger
FAKULTAT FUR MATHEMATIK UND PHYSIK
MATHEMATISCHES INSTITUT
Datum: 5. Marz 2008 Betreuung:
Prof. Dr. L. Grune

Inhaltsverzeichnis
Abbildungsverzeichnis I
1 Einleitung 3
2 Ein-Schritt-Optimierung 5
2.1 Risiko . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Bewertung von Portfolios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Optimale Anlagestrategien . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Probleme und Kritik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Dynamische-Portfolio-Optimierung 13
3.1 Binomialmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Optimale Steuerung des Portfolios . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2.1 Endkosten L(x) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.2 laufende Kosten l(x,u) . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.3 laufene Kosten und Endkosten . . . . . . . . . . . . . . . . . . . . . . 19
3.2.4 Transaktionskosten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Literaturverzeichnis 23
I

II INHALTSVERZEICHNIS

Abbildungsverzeichnis
2.1 Korrelation Bild . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Effizienz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Kapitalmarktlinie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 Modellstruktur ein Zeitschritt . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Endkostenfunktion L(x) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 laufende Kosten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Steuerung in Abhangigkeit von b . . . . . . . . . . . . . . . . . . . . . . . . 19
3.5 laufende Kosten und Endkosten . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.6 Transaktionskosten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1

2 ABBILDUNGSVERZEICHNIS

Kapitel 1
Einleitung
In dieser Arbeit wird gezeigt, wie man ein optimales Portfolio, bestehend aus N risikobehaf-
teten Anlagen, berechnet. Dabei wird zuerst die Einschritt-Optimierung beschrieben, die in
der Literatur erstmals in den 60’er Jahren als”Mean-Variance-Theorie“ auftauchte. Bevor
darauf eingegangen werden kann, muss jedoch geklart werden, aufgrund welcher Daten wir
ein Modell erstellen und wie dieses aussieht.
Fur jede der N Aktien haben wir uns eine erwartete Rendite µ und ein Risiko σ berechnet.
Ein naiver Ansatz berechet diese aus dem Erwartungswert der vergangen Renditen und deren
Standardabweichung, was in [1] beschrieben wird. Kompliziertere Schatzverfahren konnen in
dieser Arbeit nicht betrachtet werden. Die Verteilung unseres optimalen Portfolios auf die
einzelnen Aktien wird mit den Variablen xi, (i = 1, . . . , N) beschrieben, die den Anteil der
i-ten Aktie am Gesamtportfolio angibt.
Ein Investor kann viele Ziele haben. In letzter Zeit hort man immer haufiger von Fonds, die
in”dividendenstarke“ Aktien anlegen. Deren Investmentziel ist die Maximierung der Divi-
dendenrendite. Genauso sollte kein Investor das Kurs-Gewinn-Verhaltnis (KGV) vollig außer
Acht lassen. Ein sehr hohes KGV kann eine Ubertreibung aufzeigen und deutet auf hohe Ri-
siken hin. Ein niedriges KGV kann jedoch auf ein Nachholpotential einer Aktie hindeuten
und somit zusatzliche Renditechancen versprechen. Investoren, die das KGV als Anlagegrund
verwenden, wahlen daher Titel mit minimalem KGV. Ein standiges umschichten kann den
Ertrag eines Portfolios aufgrund hoher Transaktionskosten negativ beeinflussen. Daher kann
es das Ziel eines Anlegers sein, moglichst wenige Umschichtungen vornehmen zu mussen und
ein langerfristig bestehendes Portfolio auszustellen. Er strebt also nach einem minimalen
Depotumsatz.
Alle diese Kriterien sind allerdings nur kunstliche Entscheidungshilfen. Denn samtliche Ziele
eines Investor lassen sich durch zwei ubergeordnete Ziele zusammenfassen: Er mochte so viel
Ertrag wie moglich und dabei das geringst mogliche Risiko eingehen.
3

4 Kapitel 1: Einleitung
Aus den letzten beiden Zielen wird nun ein mathematisches Modell erstellt. Die Maximierung
der Ertrags bedeute eine Maximierung der erwarteten Rendite des Portfolios, d. h.
max E[x] = xTµ =N∑i=1
xiµi (1.1)
Als Maß fur das Risiko wird (analog zu Vorlesung [4]) die Standardabwichung σ oder - in
diesem Fall - die Varianz des Porfolios herangezogen. Analog zu [1] lasst sich das Risiko eines
Portfolios wie folgt modellieren:
σ2 = VAR[RP ] = E[(RtP − µP )2]
=T∑t=1
(RP−µP )2
T
=T∑t=1
[NP
i=1xi(R
ti−µi)]
2
T
=T∑t=1
N∑i=1
N∑j=1
xi(Rt
i−µi)(Rtj−µj)
Txj
= xTΣx
wobei Σ die Kovarianzmatrix der Anlagerenditen Ri ist. Die zum Risiko gehorende Zielfunk-
tion lautet also:
minxTΣx (1.2)
Um die Modellierung zu vervollstandigen, fehlen noch zwei Nebenbedingungen, die zum einen
garantieren, dass das gesamte Kapital K angelegt wird, und zum zweiten darauf achten, dass
keine Aktie leerverkauft (Definition in Vortrag von Matrin Schimalla) wird:
N∑i=1
xi = 1 (1.3)
0 ≤ xi ≤ 1 ∀i ∈ 1, .., N (1.4)
Fassen wir die Grunduberlegungnen nochmals in einem Bicriteriellen Optimierungsproblem
zusammen:
Problem 1.1
max z1(x) =N∑i=1
xi · µi maximiere Ertrag
min z2(x) =N∑i=1
N∑j=1
xiΣijxj minimiere Risiko
s.t.N∑i=1
xi = 1 Kaptial wird voll investiert
0 ≤ xi ≤ 1 ∀i ∈ 1, .., N keine Leerverkaufe
(P)

Kapitel 2
Ein-Schritt-Optimierung
Im folgenden Kapitel wird versucht, obiges Problem statisch, d. h. ohne die Moglichkeit
spaterer Umschichtungen, zu losen. Eine Orientierung dazu boten [2] und [3]. Zuerst wird
dabei noch einmal naher auf den Begriff”Risiko“ eines Portfolios eingegangen. Anschließend
werden Kriterien fur eine optimale Losung des Problems gesucht. Da beide Zielfunktionen
(1.1) und (1.2) stark konkurrieren, wird es so gut wie nie Portfolios geben, die beide Ziel-
funktionen optimieren. Diesem Problem widmet sich der zweite Abschnitt des Kapitels, in
dem festgestellt wird, dass es im Allgemeinen unendlich viele “optimale”
Portfolios gibt.
Im letzten Abschnitt wird gezeigt, wie man aus diesen Portfolios mit Hilfe eines risikolosen
Bonds und dessen Zinssatz r ein eindeutiges optimales Portfolio bekommt.
2.1 Risiko
Wie oben beschrieben wird das Risiko mit xTΣx bewertet. Analog zur obigen Herleitung der
Varianz des Portfolios kann man diese auch darstellen als:
VAR[RP ] =N∑i=1
x2iVAR[Ri]︸ ︷︷ ︸
Varianzanteil
+N∑
i,j=1i 6=j
xi ·COV[Ri, Rj] · xj
︸ ︷︷ ︸Kovarianzanteil
Zusatzlich zur Summe der Risiken der einzelnen Anlagen kommen also noch stochastische
Abhangigkeiten, die sich bei negativem Kovarianzwert gunstig und bei positivem Kovari-
anzwert ungunstig im Sinne der Zielfunktion (1.2) auswirken. Will man das Risiko seines
Portfolios senken, so fugt man ihm also eine Anlage hinzu, deren Kovarianzteil zu den bishe-
rigen Anlagen des Portfolios negativ ist. Welche dieser Anlagen hinzugefugt wird, lasst sich
jedoch nicht nur aufgrund der Kovarianz aussagen. Der Betrag der Kovarianz hangt nicht
nur vom Gleich- oder Gegenlauf der Renditen ab, sondern auch von deren Große. Aus einem
5

6 Kapitel 2: Ein-Schritt-Optimierung
großen Kovarianzwert lasst sich daher nicht auf einen großer Gleichlauf schließen. Als Maß
fur die Abhangigkeit der Kursverlaufe fuhren wir daher die Korrelation ρ ein:
Definition 2.1 Der Korrelationskoeffizient ρ zweier Aktien berechnet sich durch
ρ12 =1
T
T∑t=1
(Rt
1 − µ1
σ1
)(Rt
2 − µ2
σ2
)=
COV[R1, R2]√VAR[R1]
√VAR[R2]
Wobei
µk = Erwartungswert der Aktie K (k = 1, 2)
σk = Risiko der Aktie K (k = 1, 2)
Rtk =Rendite der Aktie k (k = 1, 2) im Zeitschritt t
Der Wert der Korrelation zweier Renditen liegt zwischen −1 (bei komplettem Gegenlauf der
zwei Aktien) und +1 (bei komplettem Gleichlauf der Aktien). Daraus ergeben sich folgende
drei Szenarien, deren ausfuhrliche Herleitungen mit Beweisen in [2] stehen.
1. ρ12 = −1
Im Falle maximaler negativer Korrelation ist eine risikolose Anlage bei
x1 =σ2
σ1 + σ2
moglich. Ist x1 großer diesem Wert, so ist das Portfolio im µ-σ-Diagramm auf der
Strecke von Anlagemoglichkeit 1 und der risikolosen Anlagekombination. Ist x1 kleiner
als im risikolosen Fall, so befindet sich das Portfolio im Diagramm auf der Strecke von
Anlagemoglichkeit 2 und der risikolosen Moglichkeit.
2. ρ12 = 1
Jedes Portfolio befindet sich auf der Strecke zwischen den beiden Anlagemoglichkeiten.
Die zugehorige Geradengleichung lautet:(σPµP
)=
(σ2
µ2
)+ x1
(σ1 − σ2
µ1 − µ2
)Bei maximaler positiver Korrelation lasst sich das Risiko der risikoarmsten Anla-
gemoglichkeit durch kein Portfolio unterbieten.
3. −1 < ρ12 < 1
In diesem Fall laßt sich das Risiko unter das der risikoarmsten Anlage senken, ein
risikoloses Portfolio wie im ersten Fall ist jedoch nicht moglich. µ und σ der Portfolios
liegt links der Verbindungsgerade von
(µ1
σ1
)und
(µ2
σ2
)im µ-σ-Diagramm
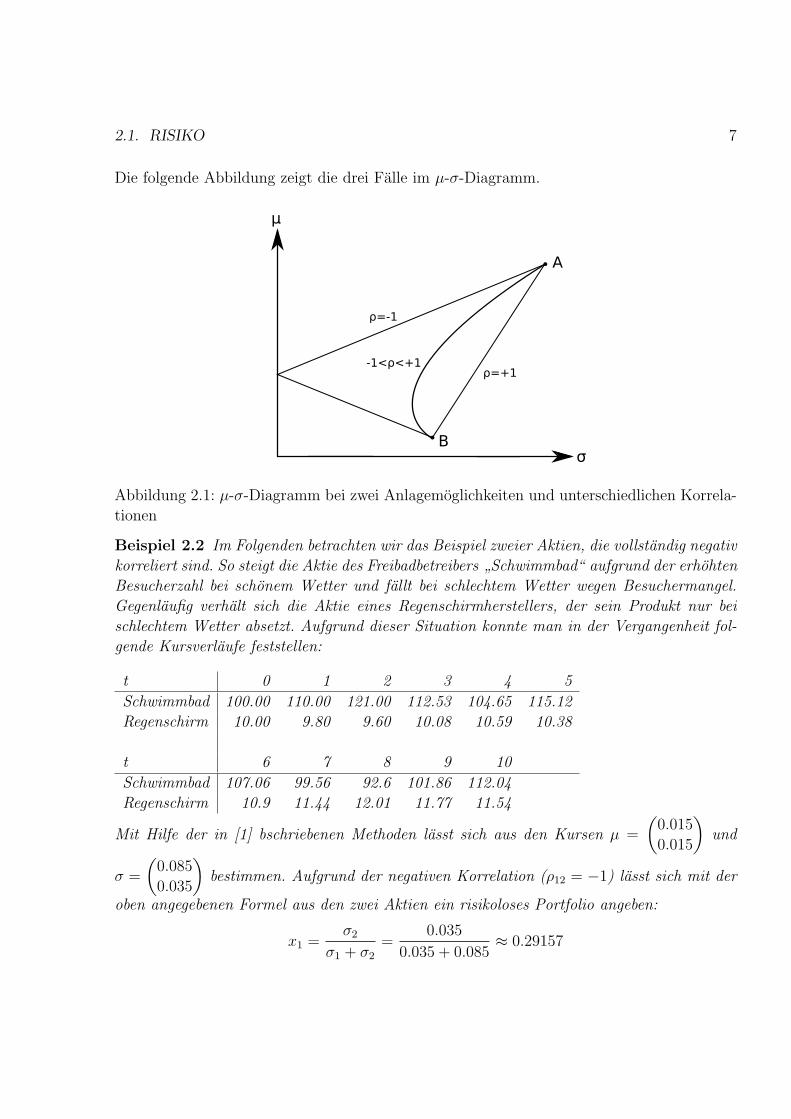
2.1. RISIKO 7
Die folgende Abbildung zeigt die drei Falle im µ-σ-Diagramm.
Abbildung 2.1: µ-σ-Diagramm bei zwei Anlagemoglichkeiten und unterschiedlichen Korrela-
tionen
Beispiel 2.2 Im Folgenden betrachten wir das Beispiel zweier Aktien, die vollstandig negativ
korreliert sind. So steigt die Aktie des Freibadbetreibers”
Schwimmbad“ aufgrund der erhohten
Besucherzahl bei schonem Wetter und fallt bei schlechtem Wetter wegen Besuchermangel.
Gegenlaufig verhalt sich die Aktie eines Regenschirmherstellers, der sein Produkt nur bei
schlechtem Wetter absetzt. Aufgrund dieser Situation konnte man in der Vergangenheit fol-
gende Kursverlaufe feststellen:
t 0 1 2 3 4 5
Schwimmbad 100.00 110.00 121.00 112.53 104.65 115.12
Regenschirm 10.00 9.80 9.60 10.08 10.59 10.38
t 6 7 8 9 10
Schwimmbad 107.06 99.56 92.6 101.86 112.04
Regenschirm 10.9 11.44 12.01 11.77 11.54
Mit Hilfe der in [1] bschriebenen Methoden lasst sich aus den Kursen µ =
(0.015
0.015
)und
σ =
(0.085
0.035
)bestimmen. Aufgrund der negativen Korrelation (ρ12 = −1) lasst sich mit der
oben angegebenen Formel aus den zwei Aktien ein risikoloses Portfolio angeben:
x1 =σ2
σ1 + σ2
=0.035
0.035 + 0.085≈ 0.29157

8 Kapitel 2: Ein-Schritt-Optimierung
Bei 1000e anzulegendes Kapital wurde sich dann folgender Kursverlauf des Portfolios erge-
ben:
t 0 1 2 3 4 5
Portfolio 1000 1014.99 1032.89 1042.20 1055.35 1071.01
t 6 7 8 9 10
Portfolio 1084.34 1100.73 1120.82 1130.82 1144.20
Das Portfolio steigt also schwankungsfrei (bis auf Rundungsungenauigkeiten) in jedem Zeit-
schritt mit dem Faktor 1.015.
2.2 Bewertung von Portfolios
Da die beiden Ziele - Maximierung des Ertrags und Minimierung des Risikos - meist mit-
einander konkurrieren, wird man im allgemeinen kein Portfolio finden, das beide Kriterien
gleichzeitig optimal erfullt. Daher mussen Kriterien gefunden werden, unter denen das Pro-
blem als gelost angesehen wird, d. h. wann wir ein Portfolio als”optimal“- oder besser
effizient - ansehen. Solange man ein Portfolio noch in eine Zielfunktionsrichtung verbesser
kann, ohne dass sich der andere Zielfunktionswert verschlechtert, ist es sicher nicht effizi-
ent. Erst wenn keine Verbesserung einer der beiden Zielfunktionen mehr moglich ist ohne
die zweie Zielfunktion zu verschlechtern, sind wir effizient. Aus [1] stammt dazu folgende
Definition:
Definition 2.3 Ein Portfolio P ist effizient, wenn die folgenden beiden Bedingungen zutref-
fen:
• Jedes andere Portfolio Q mit mindestens gleich großer erwarteter Rendite wie P (d. h.
µq ≥ µp) besitzt ein großeres Risiko als P (d. h. σq > σp)
• Jedes andere Portfolio Q mit hochstens gleich großem Risiko (d. h. σq ≤ σp) besitzt
eine kleinere erwarteter Rendite als P (d. h. µq < µp)
Die zwei extremsten effizienten Portfolios sind dabei das ertragsmaximale und das risi-
kominimale Portfolio (auch Minimum-Variance-Portfolio genannt). Eine hohere Rendite als
die der renditestarksten Aktie kann dabei nicht erwartet werden. Lost man das Problem (P)
nur mit der zweiten Zielfunktion, so bekommt man das Portfolio mit dem geringsten Risiko.
Jedoch sind auch alle Portfolios auf der Effizienzlinie zwischen den beiden Extremwerten
effizient.

2.3. OPTIMALE ANLAGESTRATEGIEN 9
Abbildung 2.2: µ-σ-Diagramm bei N Anlagen: Jede Kombination im Regenschirm ist durch
ein Portfolio erreichbar, doch nur Portfolios auf der Effizienzlinie sind effizient
In der Abbildung sieht man, dass die moglichen Portfolios, die man aus N Anlage-
moglichkeiten kombinieren kann, eine”regenschirmartige“ Flache im µ-σ-Diagramm bilden.
Auf der Effizienzlinie befinden sich dabei die effizienten Portfolios.
2.3 Optimale Anlagestrategien
Ein Anleger kann allerdings nicht alle Portfolios auf der Effizienzlinie nachbilden, sondern
muss sich fur ein Portfolio entscheiden.
Dies kann mit Hilfe einer Nutzenfunktion geschehen. Nutzenfunktionen sollten streng mo-
noton wachsen - um ein Anwachsen des Vermogens zu belohnen - und konkav sein - um die
Risikoaversion zu beschreiben. Ublicherweise benutzt man die logarithmische Nutzenfunkti-
on U(K) = log(K) oder die quadratische Nutzenfunktion U(K) = K − bK2, wobei K das
Kapital und b ein Parameter der Risikoaversion ist. Bei der quadratischen Funktion muss
noch K ≤ 12b
gefordert werden, damit nur der steigende Teil der Funktion betrachtet wird.
Da die Nutzentheorie schon im 1. Seminarvortrag behandelt wurde, wird hier nicht weiter
darauf eingeganden. Fur interessierte Leser werden die Ausfuhrungen in [3] konkretisiert und
fortgesetzt.
Zur Bestimmung eines eindeutigen optimalen Portfolios kann jedoch auch eine risikoloser
Bond hinzugezogen werden. Daher betrachten wir nun ein Portfolio Q bestehend aus dem
risikobehafteten Portfolio P (mit erwarteter Rendite µP und Risiko σP ) und dem risikolosen
Bond B mit Zinssatz r. Mit α wird der Anteil bezeichnet, den der Bond B am Gesamt-
portfolio Q hat. Aufgrund dieser Daten lasst sich die erwartete Rendite des Portfolios Q

10 Kapitel 2: Ein-Schritt-Optimierung
berechnen:
µQ = αr + (1− α)E[RP ]
= αr + (1− α)µP= µP + α(r − µP )
Da der Bond B kein Risiko hat, und daher sowohl VAR[r] = 0 und COV[r, ·] = 0 gilt, lasst
sich die Varianz von Q wie folgt berechnen:
σ2Q = Var[αr + (1− α)RP ]
= α2Var[r] + 2α(1− α)Cov[r, R] + (1− α)2σ2P
= (1− α)2σ2P
µQ und σQ liegen also auf der folgenden Gerade:
(σQµQ
)=
(σPµP
)− α
(σP
µP − r
)(2.1)
Hat sich ein Investor entschieden, welches Risiko σQ er einzugehen bereit ist, so lasst sich α
schreiben als:
α(σQ) = 1− σQσP
Setzt man dies nun in die Renditegleichung ein, so erhalt man
µQ = µP + α(r − µP )
= µP + (1− σQ
σP)(r − µP )
= µP + (r − µP )− σQ
σP(r − µP )
= r + µP−rσP
σQ
Das optimale Portfolio P ∗ maximiert somit µP−rσP
. Der Anleger kann sich nun - je nach
Risikoaversion - einen Punkt auf der sogenannten Kapitalmarktlinie aussuchen, die im µ-σ-
Diagramm auf der Verbindungsgeraden von
(0
r
)und
(σP ∗
µP ∗
)liegt. Kann der Anleger auch
einen Kredit mit Zinssatz r aufnehmen (α ∈ (−∞, 1]), so ist jeder Punkt auf der Halbgera-
den im 1. Quadranten erreichbar.

2.4. PROBLEME UND KRITIK 11
Abbildung 2.3: Im optimalen Portfolio P ∗ tangiert die Kapitalmarktlinie die Effizienzlinie
2.4 Probleme und Kritik
Das großte Problem wurde durch einen kurzen Verweis auf [1] schon in der Einleitung um-
gangen: Wie bekomme ich gute Schatzungen fur µ und Σ. Die erste, haufigste und einfachste
Herangehensweise ist die Betrachtung der Vergangenheit mit Hilfe von Zeitreihenanalysen.
Man erwartet in Zukunft die gleichen Renditen und das gleiche Risiko, wie es in der Vergan-
genheit beobachtet wurde. Als alleinige Berechnungsgoße sollten vergangene Kurse jedoch
nicht dienen, zumal man bei der hier besprochenen Theorie nicht umschichtet, sobald man
merkt, dass man falsch gelegen hat. Eine Hinzunahme weiterer Kenngroßen wie das in der
Einleitung erwahnte Kurs-Gewinn-Verhaltnis kann Hinweise darauf geben, ob man sich bei-
spielsweise in eine Spekulationsblase bewegt. Mit einem im Sektorvergleich uberhohten KGV
kann, auch bei guten Vergangenheitsdaten, auf einen weniger steilen Kursverlauf geschlossen
werden. Auch die Ableitungen der vergangenen Renditeverlaufe ∂µ∂t
und ∂σ∂t
konnen zur Kon-
kretisierung der Daten hinzugezogen werden. Auch eine Betrachtung der Zukunft durch das
Verhalten der Kurse von Optionen und Futures kann zur Prognose der Renditen verwendet
werden.
In der dynamischen Portfoliooptimierung kann man zusatzlich dynamische Schatzer verwen-
den, die versuchen, die Dynamik der Großen nachzubilden. In den seltensten Fallen sind die
Ergebnisse erkennbar besser als bei der”naiven“ Zeitreihenanalyse, was man schon daran
sieht, dass nur wenige aktiv gemanagte Fonds ihren Leitindex uberbieten.
Desweiteren ist es fraglich, ob die Renditen normalverteilt sind, wie beim oben besprochenen
Modell angenommen wird. Es kann sein, dass es wenige große negative Einzelrenditen gibt
(z. B. Crashs) und dafur viele kleine positive Einzelrenditen. Eine wichtige Eigenschaft der
Normalverteilung - die Symmetrie - ist daher fraglich.
Ein weiterer Kritikpunkt ist, dass die Kovarianzmatrix die ganze Zeit als konstant ange-

12 Kapitel 2: Ein-Schritt-Optimierung
nommen wird. Leider ist es so, dass bei Crashs (d. h. in volatilen Markten) Korrelationen
zunehmen, also gerade dann, wenn Diversifikation helfen soll. Da man im oben beschriebe-
nen Modell nicht umschichtet, kann man auf veranderte Begebenheiten nicht reagieren und
gegensteuern.
Diese Beschrankung wird im nachsten Kapitel aufgelost und es wird versucht, eine optimale
Steuerungsstrategie fur das risikobehaftete Portfolio numerisch herzuleiten.

Kapitel 3
Dynamische-Portfolio-Optimierung
Aufbauend auf der Vorlesung”Stochastische Dynamische Optimierung“ [4] wird in diesem
Kapitel versucht, eine optimale Steuerungsstrategie fur das Portfolio bestehend aus zwei
risikobehafteten Anlagemoglichkeiten zu finden. Dies geschieht mit Hilfe der in der Vorlesung
vorgestellen numerischen Methoden.
3.1 Binomialmodell
Zuerst muss das zeitdiskrete stochastische System modelliert werden. Dazu betrachten wir
den Ansatz aus der Vorlesung. In jedem Zeitschritt steigt der Kurs der Aktie mit Wahr-
scheinlichkeit 12
um einen Faktor h > 1 und sinkt mit Wahrscheinlihkeit 12
um einen Faktor
l < 1. Falls der Erwartungswert µ und die Varianz σ2 der stetigen Renditen vorliegt, lassen
sich h und l mittels der Formel aus Aufgabe 1 des 2. Ubungsblattes aus µ und σ berech-
nen. Gehen µ und σ aus diskreten Renditen hervor, so lautet die Formel h = µ + σ und
l = µ−σ. Allerdings haben wir bei zwei Aktien zwei voneinander abhangige Zufallsvariablen
Zit : Ω→ hi, li(i = 1, 2). Die Wahrscheinlichkeiten PZi
t(hi) = PZi
t(li) = 1
2bleiben zwar
weiterhin unverandert, allerdings ist die Wahrscheinlichkeit fur den Gleich- bzw. Gegenlauf
der zwei Aktien unbekannt. Die Wahrscheinlichkeiten PZ1t Z
2t(h1, h2) und PZ1
t Z2t(l1, l2), die
den Gleichlauf der zwei Aktien beschreiben, sind jeweils gleich. Selbiges gilt fur die Wahr-
scheinlichkeiten eines Gegenlaufs der Aktie, d. h. PZ1t Z
2t(h1, l2) = PZ1
t Z2t(l1, h2). Mit Hilfe
der bekannten Korrelation ρ12 lasst sich die Wahrscheinlichkeit fur einen Gleichlauf zweier
Aktien wie folgt berechnen:
13

14 Kapitel 3: Dynamische-Portfolio-Optimierung
ρ12 = COV[R1,R2]√VAR[R1]
√VAR[R2]
= E[(R1−µ1)(R2−µ2)]√E[(R1−µ1)2]
√E[(R2−µ2)2]
=
4Pi=1
(R1(ωi)−µ1)(R2(ω4)−µ2)P (ωi)s2P
i=1(R1(ωi)−µ1)P (ωi)
s2P
i=1(R2(ωi)−µ2)P (ωi)
= (h1−µ1)(h2−µ2)P (h1h2)+(h1−µ1)(l2−µ2)P (h1l2)+(l1−µ1)(h2−µ2)P (l1h2)+(l1−µ1)(l2−µ2)P (l1l2)√(h1−µ1)2 1
2+(l1−µ1)2 1
2
√(h2−µ2)2 1
2+(l2−µ2)2 1
2
(#)=
[(h1−l1
2)(
h2−l22
)+(l1−h1
2)(
l2−h22
)]2P (h1h2)+[(h1−l1
2)(
l2−h22
)+(l1−h1
2)(
h2−l22
)](1−2P (h1h2))
12
q(
h1−l12
)2+(l1−h1
2)2
q(
h2−l22
)2+(l2−h2
2)2
= [(h1−l1)(h2−l2)+(l1−h1)(l2−h2)]2P (h1h2)+[(h1−l1)(l2−h2)+(l1−h1)(h2−l2)](1−2P (h1h2))√(h1−l1)2+(l1−h1)2
√(h2−l2)2+(l2−h2)2
= [2(h1h2−h1l2−l1h2+l1l2)−2(h1l2−h1h2−l1l2+l1h2)]2P (h1h2)+2(h1l2−h1h2−l1l2+l1h2)2(h1−l1)(h2−l2)
= 4P (h1h2)(h1h2−h1l2−l1h2+l1l2)−(h1h2−h1l2−l1h2+l1l2)(h1h2−h1l2−l1h2+l1l2)
= 4phh − 1
wobei P (h1h2) eine Abkurzung fur PZ1t Z
2t(h1, h2) bezeichnet, und an der Stelle (#) ver-
wendet wurde, dass
• µi = hi+ti2
• P (h1h2) + P (h1l2) + P (l1h2) + P (l1l2) = 2P (h1h2) + 2P (h1l2) = 1
Somit sind die Wahrscheinlicheiten
PZ1t Z
2t(h1, h2) = PZ1
t Z2t(l1, l2) =
ρ12 + 1
4
und
PZ1t Z
2t(h1, l2) = PZ1
t Z2t(l1, h2) =
1
2− ρ12 + 1
4=
1− ρ12
4

3.2. OPTIMALE STEUERUNG DES PORTFOLIOS 15
Abbildung 3.1: Aus zwei unabhangigen Binarbaumen wird durch hinzufugen der Korrelation
ein Quartarbaum
Mit Hilfe dieser Zufallszahlen definieren wir folgenden stochastischen Prozess:
f(x, u, z) =
(x1(z1u+ z2(1− u))
z1uz1u+z2(1−u)
)
Hiebei ist
• x1 das Gesamtkapital K
• x2 der Anteil der ersten Anlage am Gesamtkapital
• u die Steuerung, die den Anteil der ersten Anlage am Gesamtkapital neu festlegt.
• z =
(z1
z2
)die oben beschriebene Zufallsvariable
3.2 Optimale Steuerung des Portfolios
Um eine optimale Steuerung fur das Portfolio berechnen zu konnen, muss man das folgende
stochastische dynamische Optimierungsproblem losen:
Problem 3.1 Gegeben:
• stochastisches Kontrollsystem mit Losung Xt = Xt(x0, u)
• laufende Ertragsfunktion l : Rn × U → R

16 Kapitel 3: Dynamische-Portfolio-Optimierung
• Diskontfaktor β ∈ (0, 1]
• End-Ertragsfunktion L : Rn → R
• Zeithorizont 0, 1, . . . , T
Das auf dem Zeithorizont zu losende Optimierungsproblem lautet:
maximiere JT (x0,u) := E
T−1∑t=0
βtl(Xt, ut) + βTL(XT )
Die optimale Wertefunktion VT : Rn → R ist definiert durch
VT (x0) := supu∈Ux0
JT (x0,u)
Da das hier behandelte Problem auf endlichem Zeithorizont gelost wird, kann der Diskont-
faktor als β = 1 gewahlt werden. Im folgenden wird durch Anpassen der Endkosten L(x)
und der laufenden Kosten l(x, u) auf numerischen Weg eine optimale Steuerungsstrategie
gesucht. Dabei wird die erste Steuerung mit der Effizienzkurve der statischen Portfolioop-
timierung verglichen. Zuletzt wird durch Hinzufugen von Transaktionskosten realitatsnahe
Steuerung betrieben.
Beispiel 3.2 Die in den folgenden Kapitel getroffenen Schlussfolgerungen beziehen sich auf
eine Auswertung eines Beispiels. Die Daten hierfur sind:
h1 = 1.3 l1 = 0.9 h2 = 1.1 l1 = 0.95 ρ12 = −0.356348
Damit ist die erste Anlage sowohl die risikoreichere als auch die ertragsreichere Anlage.
Die Portfolios sind Effizient nach Definition 2.3 wenn der Anteil von x2 mindestens 23,73%
des Gesamtporfolios ausmacht. Im Punkt x2 = 0.237, dem Min-Variance-Portfolio, betragt
die Rendite 4,28 %. Im ertragsmaximalen Portfolio (x2 = 1) ist die erwartete Rendite 10%.
Alle Portfolios mit x2 ∈ [0.237, 1.0] sind in diesem Beispiel effizient.
Im Folgenden wird versucht, durch Anpassen der Funktionen l(x, u) fur die laufenden Kos-
ten und L(x) fur die Endkosten eine optimale Steuerung zu berechnen. Dabei werden un-
terschiedliche Ansatze vorgestellt und am Ende bewertet. Der Zeithorizont ist dabei stets
T = 10 und der Diskontfaktor wird auf β = 1 gesetzt.
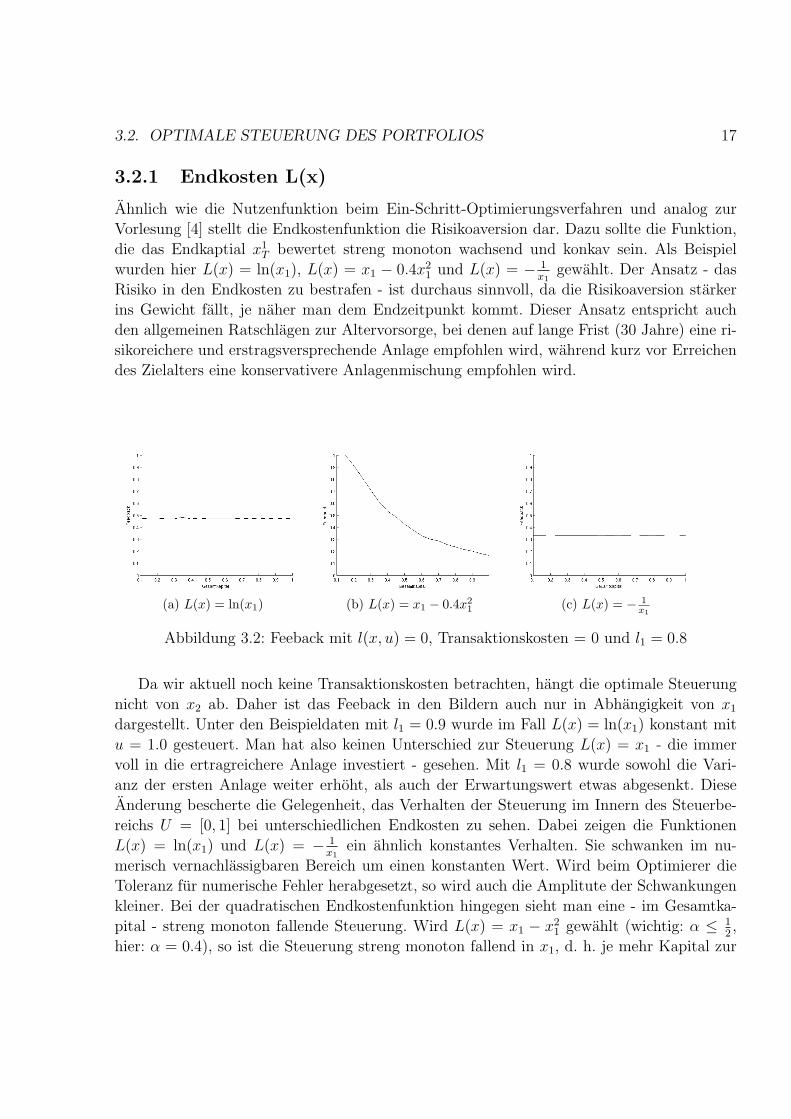
3.2. OPTIMALE STEUERUNG DES PORTFOLIOS 17
3.2.1 Endkosten L(x)
Ahnlich wie die Nutzenfunktion beim Ein-Schritt-Optimierungsverfahren und analog zur
Vorlesung [4] stellt die Endkostenfunktion die Risikoaversion dar. Dazu sollte die Funktion,
die das Endkaptial x1T bewertet streng monoton wachsend und konkav sein. Als Beispiel
wurden hier L(x) = ln(x1), L(x) = x1 − 0.4x21 und L(x) = − 1
x1gewahlt. Der Ansatz - das
Risiko in den Endkosten zu bestrafen - ist durchaus sinnvoll, da die Risikoaversion starker
ins Gewicht fallt, je naher man dem Endzeitpunkt kommt. Dieser Ansatz entspricht auch
den allgemeinen Ratschlagen zur Altervorsorge, bei denen auf lange Frist (30 Jahre) eine ri-
sikoreichere und erstragsversprechende Anlage empfohlen wird, wahrend kurz vor Erreichen
des Zielalters eine konservativere Anlagenmischung empfohlen wird.
(a) L(x) = ln(x1) (b) L(x) = x1 − 0.4x21 (c) L(x) = − 1
x1
Abbildung 3.2: Feeback mit l(x, u) = 0, Transaktionskosten = 0 und l1 = 0.8
Da wir aktuell noch keine Transaktionskosten betrachten, hangt die optimale Steuerung
nicht von x2 ab. Daher ist das Feeback in den Bildern auch nur in Abhangigkeit von x1
dargestellt. Unter den Beispieldaten mit l1 = 0.9 wurde im Fall L(x) = ln(x1) konstant mit
u = 1.0 gesteuert. Man hat also keinen Unterschied zur Steuerung L(x) = x1 - die immer
voll in die ertragreichere Anlage investiert - gesehen. Mit l1 = 0.8 wurde sowohl die Vari-
anz der ersten Anlage weiter erhoht, als auch der Erwartungswert etwas abgesenkt. Diese
Anderung bescherte die Gelegenheit, das Verhalten der Steuerung im Innern des Steuerbe-
reichs U = [0, 1] bei unterschiedlichen Endkosten zu sehen. Dabei zeigen die Funktionen
L(x) = ln(x1) und L(x) = − 1x1
ein ahnlich konstantes Verhalten. Sie schwanken im nu-
merisch vernachlassigbaren Bereich um einen konstanten Wert. Wird beim Optimierer die
Toleranz fur numerische Fehler herabgesetzt, so wird auch die Amplitute der Schwankungen
kleiner. Bei der quadratischen Endkostenfunktion hingegen sieht man eine - im Gesamtka-
pital - streng monoton fallende Steuerung. Wird L(x) = x1 − x21 gewahlt (wichtig: α ≤ 1
2,
hier: α = 0.4), so ist die Steuerung streng monoton fallend in x1, d. h. je mehr Kapital zur

18 Kapitel 3: Dynamische-Portfolio-Optimierung
Verfugung steht, desto weniger risikoreich wird gesteuert.
3.2.2 laufende Kosten l(x,u)
In diesem Abschnitt wahlen wir stets L(x) = x1 und betrachten das Verhalten der optimalen
Steuerung bei Hinzuname von laufenden Kosten. Um das Risiko uber die Zeit hinweg gering
zu halten, kann man mittels laufender Kosten einen Strafterm fur das eingegangene Risiko
ansetzten. Abhangig von einem Parameter b, der den Grad der Risikoaversion darstellt, kann
man l(x, u) setzten als
l(x, u) = −b · x1 ·(u, 1− u
)Σ
(u
1− u
)(3.1)
Die Losung durch Anwenden dieser Kosten ist eine von x unabhangige Steuerung.
Abbildung 3.3: Steuerung abhangig vom Gesamtkapital mit b = 10
Die Steuerung ist jedoch nicht linear im Faktor b. Bei obigem Beispiel 3.2 ist die optimale
Steuerung in Abhangigkeit von b wie folgt:
b 1 1.25 1.3 1.5 2 2.5 3 4 5
Steuerung 1 1 0.99 0.87 0.69 0.59 0.52 0.45 0.4
b 6 7 8 10 15 20 25 50 100
Steuerung 0.37 0.35 0.33 0.31 0.28 0.27 0.26 0.24 0.23
Die risikominimale Steuerung ist hier in der dynamischen Optimierung mit u = 0.23 genau
wie x1 im statischen Min-Variance-Portfolio. Grafisch sieht die Steuerung in Abhangigkeit
von b (in diesem Beispiel) einer”
1x
+ minimales Risiko - Funktion“ ahnlich. Diese Annahme
muss jedoch erst durch weitere Beispiele gepruft werden.
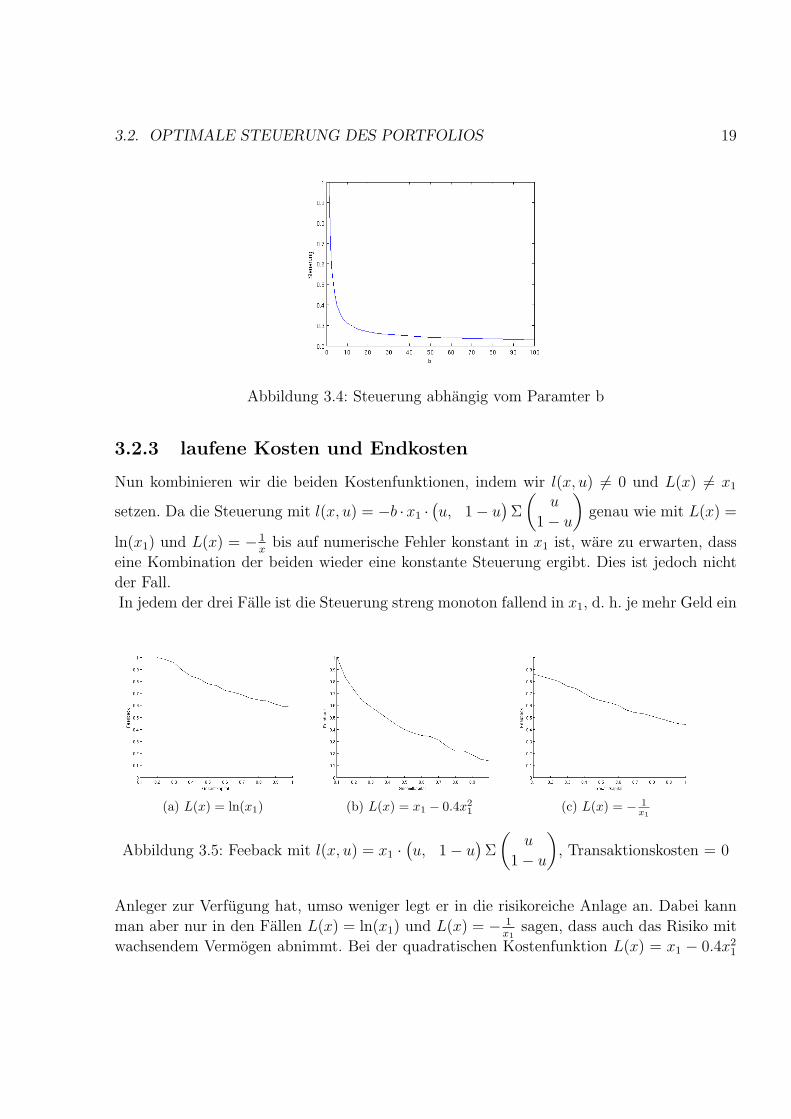
3.2. OPTIMALE STEUERUNG DES PORTFOLIOS 19
Abbildung 3.4: Steuerung abhangig vom Paramter b
3.2.3 laufene Kosten und Endkosten
Nun kombinieren wir die beiden Kostenfunktionen, indem wir l(x, u) 6= 0 und L(x) 6= x1
setzen. Da die Steuerung mit l(x, u) = −b ·x1 ·(u, 1− u
)Σ
(u
1− u
)genau wie mit L(x) =
ln(x1) und L(x) = − 1x
bis auf numerische Fehler konstant in x1 ist, ware zu erwarten, dass
eine Kombination der beiden wieder eine konstante Steuerung ergibt. Dies ist jedoch nicht
der Fall.
In jedem der drei Falle ist die Steuerung streng monoton fallend in x1, d. h. je mehr Geld ein
(a) L(x) = ln(x1) (b) L(x) = x1 − 0.4x21 (c) L(x) = − 1
x1
Abbildung 3.5: Feeback mit l(x, u) = x1 ·(u, 1− u
)Σ
(u
1− u
), Transaktionskosten = 0
Anleger zur Verfugung hat, umso weniger legt er in die risikoreiche Anlage an. Dabei kann
man aber nur in den Fallen L(x) = ln(x1) und L(x) = − 1x1
sagen, dass auch das Risiko mit
wachsendem Vermogen abnimmt. Bei der quadratischen Kostenfunktion L(x) = x1 − 0.4x21
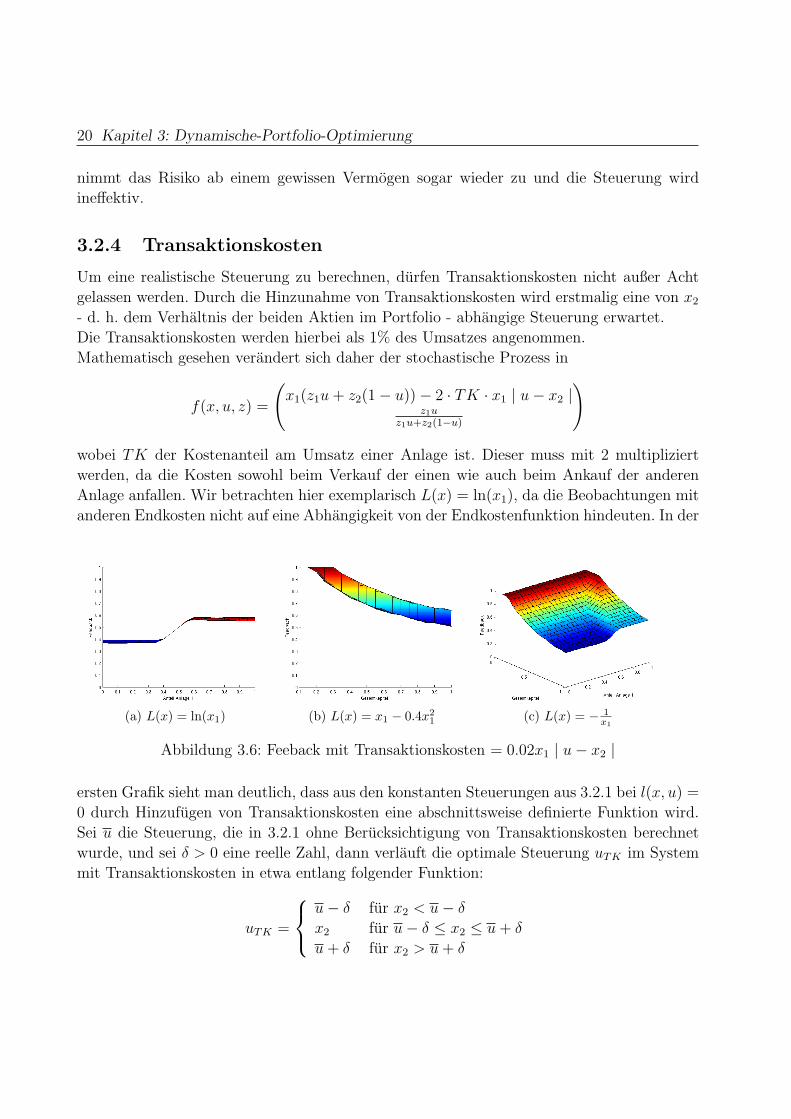
20 Kapitel 3: Dynamische-Portfolio-Optimierung
nimmt das Risiko ab einem gewissen Vermogen sogar wieder zu und die Steuerung wird
ineffektiv.
3.2.4 Transaktionskosten
Um eine realistische Steuerung zu berechnen, durfen Transaktionskosten nicht außer Acht
gelassen werden. Durch die Hinzunahme von Transaktionskosten wird erstmalig eine von x2
- d. h. dem Verhaltnis der beiden Aktien im Portfolio - abhangige Steuerung erwartet.
Die Transaktionskosten werden hierbei als 1% des Umsatzes angenommen.
Mathematisch gesehen verandert sich daher der stochastische Prozess in
f(x, u, z) =
(x1(z1u+ z2(1− u))− 2 · TK · x1 | u− x2 |
z1uz1u+z2(1−u)
)
wobei TK der Kostenanteil am Umsatz einer Anlage ist. Dieser muss mit 2 multipliziert
werden, da die Kosten sowohl beim Verkauf der einen wie auch beim Ankauf der anderen
Anlage anfallen. Wir betrachten hier exemplarisch L(x) = ln(x1), da die Beobachtungen mit
anderen Endkosten nicht auf eine Abhangigkeit von der Endkostenfunktion hindeuten. In der
(a) L(x) = ln(x1) (b) L(x) = x1 − 0.4x21 (c) L(x) = − 1
x1
Abbildung 3.6: Feeback mit Transaktionskosten = 0.02x1 | u− x2 |
ersten Grafik sieht man deutlich, dass aus den konstanten Steuerungen aus 3.2.1 bei l(x, u) =
0 durch Hinzufugen von Transaktionskosten eine abschnittsweise definierte Funktion wird.
Sei u die Steuerung, die in 3.2.1 ohne Berucksichtigung von Transaktionskosten berechnet
wurde, und sei δ > 0 eine reelle Zahl, dann verlauft die optimale Steuerung uTK im System
mit Transaktionskosten in etwa entlang folgender Funktion:
uTK =
u− δ fur x2 < u− δx2 fur u− δ ≤ x2 ≤ u+ δ
u+ δ fur x2 > u+ δ

3.2. OPTIMALE STEUERUNG DES PORTFOLIOS 21
Auch die zweite Grafik (mit l(x, u) = x1 ·(u, 1− u
)Σ
(u
1− u
)) bestatigt diese Annahme,
da die in 3.2.3 dargestellte Steuerung hier von einem δ-Schlauch zentriert umgeben wird. Die
dritte Grafik zeigt diese Steuerung in allen drei Dimensionen.
3.2.5 Zusammenfassung
In der obigen Ausfuhrung wurden viele Kombinationsmoglichkeiten vorgestellt. Eine gute
Moglichkeit, die statische Mean-Variance-Theorie nachzustellen, bietet dabei das Zielfunk-
tional
supu∈Ux0
E
T−1∑t=0
−b · x1t ·(ut, 1− ut
)Σ
(ut
1− ut
)+ x1
T
das in 3.2.2 vorgestellt wurde. Hier ware es gut, eine Linearitat von b herzustellen, indem
man die Kosten durch einen Skalierungsfaktor erganzt. Mit b = 0 risikolos und b = 1 stark
risikobehaftet konnte man dann fur jedes Problem einen Risikoaversionsgrad zwichen 0 und
1 wahlen. Dafur muss jedoch beachtet werden, dass das Feedback nicht immer gleich von b
abhangt, sondern die einzelnen Problemdaten mit eingehen mussen.
Ein weiteres sinnvolles Zielfunktional, das aber nicht so gut vergleichbar mit der statischen
Optimierung ist, ist
supu∈Ux0
E N(xT )
Hier stellt N eine konkave, streng monoton steigende Nutzenfunktion dar, wie sie schon
in 3.2.1 erwahnt wurden. Allerdings muss hierbei darauf geachtet werden, dass gerade bei
langeren Zeitraumen das Risiko nicht zu schwach ins Gewicht fallt. Viele hier nicht vor-
gefuhrte Beispiele ergaben bei L(X) = ln(X) eine ertragsmaximierende Steuerung u = 1 als
Optimalsteuerung. Außerdem sollte darauf geachtet werden, dass im Fall ohne Berucksichtigung
von Transaktionskosten stets eine effiziente Steuerung gewahlt wird. Dies wird z. B. von der
quadratischen Nutzenfunktion nicht garantiert.
Die Kombination der beiden Zielfunktionale, bei der man in den laufenden Kosten das Risi-
ko und in den Endkosten eine Nutzenfunktion modelliert, ist schwerer zu bewerten. Durch
ihre Abhangigkeit von x1 ergibt sich das erste Problem, denn in den Beispielen wurde das
Gesamtkapital, das mehrere tausend Euro betragen kann, auf das Intervall [0,1] skaliert. Die
optimale Steuerung ist risikoreicher je weniger Geld ein Anleger zur Verfugung hat. Doch
wie ordnet man einen bestimmten Betrag ein; was ist wenig Geld, was viel? Außerdem ist es
fragwurdig, ob die Risikobereitschaft eines Anlegers automatisch von seinem Gesamtkapital
abhangen soll. Viel besser ware es, jeder konne seinen Grad der Risikoaversion komplett
selbst bestimmen. Ein zweiter Punkt ist, dass man hier zwei Konzepte vermischt. Denn so-

22 Kapitel 3: Dynamische-Portfolio-Optimierung
wohl durch die laufenden Kosten als auch durch die Nutzenfunktion in den Endkosten findet
eine Gewichtung des Risikos statt.
Bei der Bestimmung eines passenden Zielfunktionals gibt es noch weitere Moglichkeiten. So
kann man beispielsweise einen Diskontfaktor β ∈ [0, 1) einfuhren, der weiter in der Zukunft
liegende Ertrage und Risiken weniger stark gewichtet. Dies ist gerade bei unendlichem An-
lagehorizont zwingend erforderlich. Desweiteren wurde nicht betrachtet, wie sich die Steue-
rungen in Abhangigkeit von der Lange des Zeithorizonts T verhalten. Naturlich fallen die
Endkosten starker ins Gewicht je kleiner der Horizont ist. Ein Effekt, der wie oben bereits
erwahnt, durchaus erwunscht ist.
3.3 Ausblick
In diesem Kapitel wurde gezeigt, wie man mittels Methoden der optimalen Steuerung zwei
risikoreiche Anlagemoglichkeiten gewichtet und umschichtet. In der Realitat mochte man
jedoch mehr als zwei Anlagemoglichkeiten mischen. Hier stoßt das Binomialmodell schnell
an seine Grenzen. Bei N Anlagemoglichkeiten gibt es (2N)T Pfade im Modellbaum. Diese
Anzahl kann durch die hier benutzen numerischen Methoden gehandhabt werden, da durch
das gridgen-File aus der Vorlesung [4] immer nur Schritt fur Schritt gerechnet wird. Diese
Methode funktioniert aber nur fur 3 oder 4 Anlagen, da pro Anlage der Zusatandsvektor eine
Dimension zunimmt. Aber nicht nur das exponentielle Wachstum des Baumes ist problema-
tisch. Schon bei 3 Anlagemoglichkeiten ist die Wahrscheinlichkeit der acht Verzweigungen
in einem Schritt nicht mehr eindeutig bestimmbar. Dafur musste man zusatzlich zur Kova-
rianzmatrix noch die Schiefe bestimmen. Bei N Anlagemoglichkeiten wird die Berechnung
noch komplizierter und man braucht N-te Momente fur eine eindeutige Wahrscheinlichkeits-
verteilung. Die Frage ist jedoch schon bei der Schiefe, ob diese wirklich schatzbar ist.

Literaturverzeichnis
[1] M. Adelmaier, E. Warmuth, Finanzmathematik fur Einsteiger ; Vieweg Verlag, 2003.
[2] J. Kremer, Einfuhrung in die diskrete Finanzmathematik ; Springer Verlag, 2006
[3] Paolo Brandimarte, Numerical methods in finance - a MATLAB-based introduction;
Wiley Verlag, 2002.
[4] L. Grune Stochastische Dynamische Optimierung ;Vorlesungsskript, Universitat Bay-
reuth, SS 2007
23


















