Prädiktion von Aktienkursen mit Neuronalen...
77
Prädiktion von Aktienkursen mit Neuronalen Netzen Bachelorarbeit von Daniel Handloser An der Fakultät für Informatik Institut für Anthropomatik und Robotik Erstgutachter: Prof. Dr. Alexander Waibel Zweitgutachter: Prof. Dr.-Ing. Tamim Asfour Betreuender Mitarbeiter: Dr.-Ing. Jan Niehues Bearbeitungszeit: 11. Januar 2017 – 10. Mai 2017 KIT – Die Forschungsuniversität in der Helmholtz-Gemeinschaft www.kit.edu
Transcript of Prädiktion von Aktienkursen mit Neuronalen...

Prädiktion von Aktienkursen mitNeuronalen Netzen
Bachelorarbeitvon
Daniel Handloser
An der Fakultät für InformatikInstitut für Anthropomatik und Robotik
Erstgutachter: Prof. Dr. Alexander WaibelZweitgutachter: Prof. Dr.-Ing. Tamim AsfourBetreuender Mitarbeiter: Dr.-Ing. Jan Niehues
Bearbeitungszeit: 11. Januar 2017 – 10. Mai 2017
KIT – Die Forschungsuniversität in der Helmholtz-Gemeinschaft www.kit.edu


Ich versichere hiermit, die vorliegende Arbeit selbststandig und ohne fremde Hilfe ange-fertigt zu haben. Die verwendeten Hilfsmittel und Quellen sind im Literaturverzeichnisvollstandig aufgefuhrt.
Karlsruhe, den 5. Mai 2017


Abstract
Diese Arbeit untersucht Kurzmitteilungen der Plattform Twitter uber Unternehmen ausdem Dow Jones Industrial Average (DJIA) und dem Deutschen Aktienindex (DAX). Mitden Daten soll die Entwicklung des Aktienkurses dieser Unternehmen prognostiziert wer-den.
Zwischen Mitte Dezember 2016 und Anfang Februar 2017 wurden circa 20 Millionen Kurz-mitteilungen uber die 30 großten amerikanische Aktienkunternehmen aus dem DJIA unddie 30 großten deutschen Aktienunternehmen aus dem DAX gesammelt. Mit Hilfe vonverschiedenen Neuronalen Netzen wurde versucht, mit Twitterdaten auf eine Vorhersagefur den Aktienkurs an einem Folgetag zu schließen.
Dazu wurden zwei Ansatze verfolgt. Im ersten Ansatz wurde bei der Pradiktion mittels Sen-timentanalyse bestimmt, wie positiv oder negativ die Aussage eines Tweets ist. Mit dieserInformation wird uberpruft, ob es einen Zusammenhang zwischen dem durchschnittlichenSentiment an einem Tag und dem Verlauf des Aktienkurs am nachsten Tag gibt.
Beim zweiten Ansatz – der direkten Pradikation – wird der Datensatz in einen Trainings-und Testdatensatz aufgeteilt. Mit den Zusammenhangen aus Tweets und Aktienkursenim Trainingsdatensatz wird versucht, mit den Tweets im Testdatensatz auf die Kurse indiesem Zeitraum zu schließen.
Mit der Pradiktion uber die Sentimentanalyse wird in 49% der Fallen richtig vorhergesagt,ob der Aktienkurs am nachsten Tag fallt oder steigt. Bei der direkten Pradiktion wird in61% der Falle richtig prognostiziert, ob der Aktienkurs vier Tage spater steigt oder fallt.
v


Inhaltsverzeichnis
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Uberblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Stand der Forschung 32.1 Textklassifikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Sentimentanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Vorhersagen mit sozialen Netzwerken . . . . . . . . . . . . . . . . . . . . . . 4
2.2.1 Prognosen auf Aktienmarkten . . . . . . . . . . . . . . . . . . . . . . 4
3 Grundlagen Neuronale Netze 73.1 Kunstliches Neuron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.2.1 Feedforward Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2.2 Rekurrente Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.3 Schichten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3.1 Feedforward-Netze . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.3.1.1 Reshape-Schicht . . . . . . . . . . . . . . . . . . . . . . . . 103.3.1.2 Convolutional-Schicht . . . . . . . . . . . . . . . . . . . . . 103.3.1.3 Pooling-Schicht . . . . . . . . . . . . . . . . . . . . . . . . . 103.3.1.4 Vollvernetzte Schicht . . . . . . . . . . . . . . . . . . . . . 11
3.3.2 Rekurrente Neuronale Netze . . . . . . . . . . . . . . . . . . . . . . . 113.3.2.1 Long Short-Term Memory (LSTM) . . . . . . . . . . . . . 11
3.4 Kostenfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.4.1 Kreuzentropie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.5 Lernen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.5.1 Lernverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5.1.1 Uberwachtes Lernen . . . . . . . . . . . . . . . . . . . . . . 133.5.2 Lernrate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.5.3 Backpropagation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5.3.1 Große des Batches . . . . . . . . . . . . . . . . . . . . . . . 143.6 Updatefunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.6.1 Stochastic Gradient Descent . . . . . . . . . . . . . . . . . . . . . . . 143.6.2 Adadelta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.6.3 Root Mean Square Propagation . . . . . . . . . . . . . . . . . . . . . 143.6.4 Adam . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.6.5 Nadam . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.7 Aktivierungsfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.7.1 ReLU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.7.2 Sigmoid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.7.3 Softmax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.7.4 tanh . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
vii

viii Inhaltsverzeichnis
3.8 Regularisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.8.1 Dropout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.8.2 L2-Regularisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Implementierung und Methodik 194.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.2 Pradiktion mittels Sentimentanalyse . . . . . . . . . . . . . . . . . . . . . . 19
4.2.1 Aufbau des Netzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.2.2 Transformation fur die Pradiktion der Aktienkurse . . . . . . . . . . 21
4.3 Direkte Pradiktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.3.1 Word Embeddings . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.3.1.1 GloVe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224.3.2 Aufbau der Neuronalen Netze . . . . . . . . . . . . . . . . . . . . . . 22
4.3.2.1 Max Pooling-Netz . . . . . . . . . . . . . . . . . . . . . . . 224.3.2.2 Convolution-Netz . . . . . . . . . . . . . . . . . . . . . . . 224.3.2.3 LSTM-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.4 Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.4.1 Tweets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.4.2 Aktienkurse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
5 Evaluation 275.1 Pradiktion mittels Sentimmentanalyse . . . . . . . . . . . . . . . . . . . . . 28
5.1.0.1 Anpassung des Datensatzes . . . . . . . . . . . . . . . . . . 305.1.1 Korrelation mit den Aktienkursen . . . . . . . . . . . . . . . . . . . 31
5.1.1.1 Diskussion der Ergebnisse . . . . . . . . . . . . . . . . . . . 325.2 Direkte Pradiktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.2.1 Max Pooling-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325.2.1.1 Optimierungen und ihre Auswrikungen . . . . . . . . . . . 325.2.1.2 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2.2 Convolution-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.2.2.1 Optimierungen und ihre Auswirkungen . . . . . . . . . . . 375.2.2.2 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.2.3 LSTM-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.2.3.1 Optimierungen und ihre Auswirkungen . . . . . . . . . . . 415.2.3.2 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2.4 Anpassung des Datensatzes . . . . . . . . . . . . . . . . . . . . . . . 455.2.4.1 Storfaktoren . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2.5 Selektion der Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.3 Vergleich der Pradiktionsmoglichkeiten . . . . . . . . . . . . . . . . . . . . . 465.4 Vergleich der drei Datensatze . . . . . . . . . . . . . . . . . . . . . . . . . . 475.5 Zeitfenster der Vorhersage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485.6 Alternative Analagestrategie . . . . . . . . . . . . . . . . . . . . . . . . . . . 485.7 Ergebnisse fur DAX- und DJIA-Unternehmen im Vergleich . . . . . . . . . 495.8 Vergleich Arbeiten der Literatur . . . . . . . . . . . . . . . . . . . . . . . . 50
6 Zusammenfassung und Ausblick 51
7 Abkurzungsverzeichnis 53
8 Anhang 558.1 Pradiktion mittels Sentimentanalyse . . . . . . . . . . . . . . . . . . . . . . 568.2 Max Pooling-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578.3 LSTM-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
viii

Inhaltsverzeichnis ix
8.4 Convolutional-Netz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Abbildungsverzeichnis 61
Bibliography 63
ix



1. Einleitung
1.1 Motivation
Dass sich Mitteilungen auf Twitter auf den Aktienmarkt auswirken konnen, wurde wah-rend der Prasidentschaftswahl 2016 in den USA wiederholt in den Medien diskutiert.[1][2]Grund dafur war Donald Trump, der vermehrt durch seine Außerungen uber verschiedeneUnternehmen aufgefallen ist. Bei positiven Tweets des 45. Prasidenten der VereinigtenStaaten uber die Unternehmen Ford und ExxonMobil stieg der Aktienkurs zum Beispielam selben Tag um je 4,6% und 1,8% an.[1] Außerte er sich zum Beispiel negativ uberLockheed Martin, so fiel der Kurs am selben Tag um 1,3%.[1] Obwohl sich alle Kurse ubereinen langeren Zeitraum anschließend wieder in die entgegengesetzte Richtung entwickel-ten, ist zumindest kurzfristig ein Zusammenhang zwischen Donald Trumps Tweets undden Aktienkursen der Unternehmen zu erkennen.
Naheliegend ist die Vermutung, dass solche Zusammenhange nicht nur zwischen DonaldTrumps Tweets und dem Aktienmarkt existieren. Daher untersucht diese Arbeit den Zu-sammenhang zwischen der offentlichen Meinung uber ein Unternehmen und dessen Akti-enkurs auf Basis von Twitterdaten.
1.2 Uberblick
Das Kapitel 2 verschafft einen Uberblick uber den aktuellen Forschungsstand der Text-klassifikation. Im darauffolgenden Grundlagenteil werden Neuronale Netze eingefuhrt.
In Kapitel 4 werden verschiedene Analysemethoden vorgestellt. Im ersten Teil ”Pradiktionmittels Sentimentanalyse” wird fur jede Nachricht auf Twitter ein Sentiment berechnet.Dieses sagt aus, wie positiv oder negativ der Inhalt ist. Damit wird untersucht, ob sichpositive oder negative Meinungen auf Twitter auf den Aktienkurs eines Unternehmensauswirken. Der zweite vorgestellte Ansatz ist die direkte Pradiktion. Hier soll von Neuro-nalen Netzen direkt anhand von Tweets entschieden werden, ob der Aktienkurs an einemspateren Tag fallt oder steigt.
Kapitel 5 beschaftigt sich mit der Evaluation der Arbeit. Hier werden verschiedene Op-timierungen und ihre Auswirkungen vorgestellt, sowie die Ergebnisse interpretiert undmiteinander verglichen.
Im letzten Kapitel werden einige mogliche Verbesserungen fur die Zukunft vorgestellt unddie Ergebnisse der Arbeit werden zusammengefasst.
1


2. Stand der Forschung
Natural Language Processing ist ein Teilbereich der Informatik und Linguistik, der sichmit der Interaktion von Computern und naturlicher Sprache beschaftigt.
Mittels Data Mining und Natural Language Processing eroffnen sich viele Moglichkeiten,die Flut an Textdaten aus dem Internet zu sammeln, zu filtern und daraus Informationenzu gewinnen. Textklassifikation und Sentimentanalyse stellen zwei zentrale Bausteine zurBewaltigung dieser Herausforderung dar.[3]
2.1 Textklassifikation
Die Klassifikation von Texten lasst sich mittels Machine Learning durchfuhren. Oft verwen-dete Ansatze sind Naive Bayes, Maximum Entropy Classification (MEC), Support VectorMachines (SVM)[4] und Neuronale Netze[5].Abhangig von der Domane und den verwendeten Parametern werden unterschiedliche Er-gebnisse erzielt, so dass keine Methode die eindeutig besten Resultate liefert.[4][5]. EinVorteil von der SVM gegenuber Neuronaler Netze ist die effizientere Berechnung.[6]. Beieiner Kombination beider Verfahren, in der das Neuronale Netz die Vektorreprasentationdes Texte festlegt und die SVM die Klassifikation ubernimmt, konnen so zum Beispielbessere Ergebnisse als mit den einzelnen Verfahren erreicht werden.[6].
2.1.1 Sentimentanalyse
Ein verbreiteter Anwendungsfall von Textklassifikation ist die Sentimentanalse. Ziel derAnalyse ist es, die geaußerte Haltung (oder Sentiment) in einem Text als positiv odernegativ zu klassifizieren.[7]
Die aktuellen Methoden beruhen hauptsachlich darauf, dass der Verfasser in Teilen seinesTextes explizit seine Meinung und emotionalen Standpunkt ausdruckt. Werkzeuge, die er-kennen, wenn implizit ein Sentiment geaußert wird, sind noch relativ wenig erforscht.[3][8]
Die Ergebnisse einer Sentimentanlyse auf einem großen Datenbestand lassen sich durchaufsummieren von Sentimentwerten recht einfach zusammenfassen. Allerdings existierenauch komplexere Methoden, mit denen Sentiments strukturierter zusammengefasst wer-den. Diese sind Gegenstand der aktuellen Forschung.[9] Beispiele dafur sind vor allemprobabilistische Modelle wie Probabilistic Latent Semantic Analysis (PLSA) und LatentDirichlet Analysis (LDA).[9]
3

4 2. Stand der Forschung
2.2 Vorhersagen mit sozialen Netzwerken
Vorhersagen mit Hilfe von Daten aus sozialen Netzwerken wurden bereits in sehr vielenBereichen erstellt.
Mit Hilfe des Worterbuchansatzes Linguistic Inquiry and Word Count (LIWC) wurdenzum Beispiel Vorhersagen zu den Bundestagswahlen getroffen (Tumasjan et al. 2010[10]).
Zudem wurde die Ausbreitung von Krankheiten untersucht (Culotta, 2010[11]), indemuberpruft wurde, ob in Tweets spezielle Schlusselworter vorkommen. Bei der Vorhersageder Influenzaausbreitung in den Vereinigten Staaten wurde eine Korrelation von 95% mitder nationalen Gesundheitsstatistik erreicht.
Zwischen dem Umsatz von Kinofilmen und den Eintragen auf Blogs im Internet uber Filmekonnte ebenfalls eine positive Korrelation gezeigt werden (Mishne und Glance, 2006[12]).
2.2.1 Prognosen auf Aktienmarkten
Auch Prognosen auf Aktienmarkten wurden bereits mit einer Vielzahl von Datenquel-len durchgefuhrt. Unter anderem wurden Blogs, Empfehlungen von Sicherheitsanalysten,Suchanfragen im Internet, Foren zum Thema Aktienmarkt oder Nachrichten in der Fi-nanzbranche als Grundlage fur Prognosen auf dem Aktienmarkt zu Rate gezogen.[13] ImFolgenden soll allerdings auf die Arbeiten eingegangen werden, die sich mit der Analysevon Informationen auf Twitter beschaftigten.
Die wohl bekannteste Arbeit zur Bestimmung von Aktienkursen mit Hilfe von Twitterstammt aus dem aus dem Jahr 2011 von Johan Bollen und Huina Mao.[14] Untersuchtwurden hier die Auswirkungen von Tweets auf den DJIA. Dabei wurde ein Zusammenhangzwischen Tweets und Aktienindex nach drei bis vier Tagen festgestellt. Zur Analyse derTweets wurden zwei Werkzeuge verwendet. Zum einen der OpinionFinder, welcher Textenach positivem und negativem Sentiment klassifizert. Zum anderen das Google-Profile ofMood States (GPOMS), welches die Haltung eines Textes in sechs Dimensionen (”Calm”,”Alert”, ”Sure”, ”Vital”, ”Kind” und ”Happy”) analysiert. Wahrend sich Ersteres fur dieseArbeit als wenig aussagekraftig herausstellte, wurde fur das GPOMS mit der Dimension”Calm” eine positive Korrelation mit dem DJIA drei bis vier Tage spater festgestellt. Beider Vorhersage, ob der Schlusskurs des Index steigt oder fallt, wurde eine Accuracy von87.6% erreicht.
Die Arbeit ”Tweets and Trades: the Information Content of Stock Microblogs”[15] unter-sucht erstmals nur Nachrichten, die sich auch spezifisch auf den Finanzmarkt beziehen. Be-rucksichtigt werden nur die Tweets die ein Dollarzeichen gefolgt von einem Aktien-Symbolenthalten. Das sorgt dafur, dass der Datensatz vor allem Nachrichten mit direktem Bezugzum Aktienmarkt enthalt. Mittels Naıve Bayesian wurden die Texte in drei Kategorienklassifiziert: Kaufen, behalten und verkaufen. In der Arbeit wurde lediglich eine statistischunsignifikante Korrelation von 0,5% zwischen Tweets und dem Aktienkurs des genanntenUnternehmen einen Tag spater festgestellt. In die umgekehrte Richtung – vom Aktienkursauf die Twitterdaten einen Tag spater – wurde eine signifikante Korrelation von 13,2%festgestellt. Zudem zeigte sich fur den betrachteten Datensatz, dass Nutzer mit hoherAnzahl an Followern und vielen Retweets die besseren Prognosen uber den Aktienmarktabgeben.[15] Außerdem wurde eine Korrelation von 44,1% zwischen der Anzahl an Nach-richten zu einem Unternehmen auf Twitter und dem Transaktionsvolumen der zugehorigenAktie an der Borse festgestellt.[15]
Im gleichen Jahr wurde in der Arbeit ”Predicting Stock Market Indicators Through Twitter”[16] ebenfalls ein Zusammenhang zwischen der allgemeinen Stimmung auf Twitter und
4

2.2. Vorhersagen mit sozialen Netzwerken 5
einem Aktienindex festgestellt. Die Arbeit fand eine positive Korrelation zwischen Tagen,an denen viel Angst, Freude und Sorge auf Twitter ausgedruckt wird, und einem sinkendenKurs des DJIA am nachsten Tag. An Tagen, an denen weniger emotionale Mitteilungenverschickt werden, steigt der Index laut den Autoren. Fur die Dimension ”Hope” wurdeeine Korrelation von 38,1% mit der Entwicklung des DJIA festgestellt.
Eine Arbeit von Sam Paglia aus dem Jahr 2013 untersucht die Tweets von Nachrich-tenunternehmen und versucht damit, den Wert des Aktienindex Standard & Poor’s 500(S&P 500) zu prognostizieren. Fur die Vorhersage, ob der Tagesschlusskurse am nachstenBorsentag fallt oder steigt, wurde eine Accuracy von 59% erreicht.[17]
Die Vorhersage eines Aktienindexes mit Hilfe von der offentlichen Meinung auf Twitterwurde bereits ausfuhrlich in verschiedenen Arbeiten behandelt. Fur die feingranularerePradiktion von Aktienkursen einzelner Unternehmen existieren bisher nur wenige Ver-offentlichungen. In dieser Arbeit werden daher Twitterdaten verwendet, die explizit einAktienunternehmen nennen. Mit Hilfe dieser Daten wird analysiert, ob der Aktienkurs aneinem spateren Tag fallt oder steigt. Betrachtet wird demnach nicht die allgemeine offent-liche Meinung auf Twitter, sondern die offentliche Meinung zu konkreten Unternehmen.Damit soll der Aktienkurs von spezifischen Unternehmen prognostiziert werden.
5


3. Grundlagen Neuronale Netze
Ein kunstliches Neuronales Netz besteht aus Schichten mit kunstlichen Neuronen. DieStruktur und Funktion stellt eine Abstraktion des Nervensystems und speziell des Gehirnsvon Tieren und Menschen dar.
Die Einsatzbereiche von neuronalen Netzen befinden sich vor allem in Feldern wie Sprach-und Bilderkennung, in denen Losungen mit traditioneller logischer Programmierung nurschwer erreichbar sind.[18]
3.1 Kunstliches Neuron
Ein Netz besteht aus mindestens einem oder mehreren parallel arbeitenden Neuronen.[19]Diese senden sich Informationen in Form von Aktivierungssignalen uber gerichtete Ver-bindungen zu.[20] Jedes Neuron erhalt eine oder mehrere Eingaben und gibt eine Ausgabezuruck.
Das McCulloch-Pitts-Neuron (Abbildung 3.1) ist ein einfaches und weit verbreitetes Neuro-nenmodell, das 1943 vorgestellt wurde. Die Eingabesignale xi werden mit den entsprechen-den Gewichten wi multipliziert, bevor sie das Neuron erreichen. Die gewichteten Eingabenxi∗wi werden aufsummiert und ergeben die Aktivierungsspannung Σ. θ ist der Schwellwert(engl. Bias), ab dem eine bestimmte Ausgabe erzeugt wird. Das Aktivierungspotenzial uergibt sich als Differenz von Σ und θ. Ist u > θ, wird ein erregendes Signal erzeugt. Andern-falls ist das Signal hemmend. Die Aktivierungsfunktion g sorgt dafur, dass die Ausgabe desNeurons innerhalb eines bestimmten Wertebereichs liegt. Daraus entsteht das endgultigeAusgabesignal y, das wiederum als Eingabe fur weitere Neuronen dienen kann.[18]
x1
g(.)
w1
x2
xn
−θθ
uyw2
wn
∑
Abbildung 3.1: McCulloch-Pitts-Neuron[18]
7

8 3. Grundlagen Neuronale Netze
3.2 Aufbau
Der Aufbau eines Neuronalen Netzes legt fest, wie die verschiedenen Neuronen mitein-ander verbunden werden.[18] Typischerweise besteht ein Netz aus einer Eingabeschicht,eventuellen verstecken Schichten und einer Ausgabeschicht.
Die Eingabeschicht nimmt Informationen entgegen. Diese Eingaben werden in der Regeleinheitlich normalisiert. Auch die Ausgabeschicht besteht aus Neuronen. Diese erzeugtdie endgultigen Ergebnisse des Netzes. Dazwischen konnen sich beliebig viele versteckteSchichten befinden, die ebenfalls aus Neuronen bestehen.[18]
Die Anzahl der Neuronen in der Ausgabeschicht hangt von der Problemstellung ab. BeiRegressionsproblemen enthalt die Ausgabeschicht in der Regel ein Neuron, wahrend beiKlassifizierungsproblemen die Anzahl der Neuronen der Anzahl der Klassen entspricht.
Generell wird zwischen einschichtigen und mehrschichtigen Feedforward-Netzen, rekurren-ten neuronalen Netzen und Mesh-Netzen unterschieden. Auf die fur diese Arbeit relevantenVarianten wird im Folgenden eingegangen.[18]
3.2.1 Feedforward Netz
Feedforward-Netze zeichnen sich dadurch aus, dass eine Schicht immer nur mit der nach-folgenden Schicht verbunden ist.
Ein einschichtiges Feedforward-Netz besteht aus einer Eingabeschicht mit n Eingabenund m Ausgaben. Die Informationen fließen in eine Richtung – von der Eingabe- zurAusgabeschicht.[18]
1 y1
y
x1
2 y2
ym
x2
xn
Input layer
2
m
Output neural layer
Abbildung 3.2: Einschichtiges Feedforward[18]
Mehrschichtige Feedforward-Netze besitzen mindestens eine versteckte Schicht. Abbildung3.3 zeigt ein solches Netz mit einer Eingabeschicht mit n Eingabesignalen, zwei verstecktenSchichten mit n1 und n2 Neuronen und einer Ausgabeschicht mit m Neuronen. Die Variablem entspricht dabei auch der Anzahl der Ausgabewerte des Netzes.[18]
8

3.3. Schichten 9
1 y
1
1
x1
y1
y2
2
2
3
x2
2
ym
x3
xn
3
n1
4
m
Input layer1st Hidden neural
layern2
2nd Hidden neurallayer
Output neurallayer
Abbildung 3.3: Dreischichtiges Feedforward[18]
3.2.2 Rekurrente Netze
Bei rekurrenten neuronalen Netzen werden die Ausgaben der Neuronen als Ruckmeldungan Neuronen der vorherigen Schichten gegeben. Diese Ruckkopplung wird durch ruckge-richtete (rekurrente) Kanten erzeugt. So ist es moglich, ein Ergebnis an vorherige Schichtenweiterzuleiten.[18]
Die Motivation fur rekurrente Netze ruhrt vor allem von einer Schwache der Feedforward-Netze. Wenn ein Feedforward-Netz zum Beispiel ein Wort in einem Satz betrachtet, stehendiesem keine Informationen uber die vorherigen Worter in dem Satz zur Verfugung. Durchdie Ruckkopplung in rekurrenten Neuronalen Netzen ist es moglich, Informationen uberdie vorherigen Eingaben zu speichern.
1
x1
y1
1
x2 2
1
ym
xn
n1
m
Feedback
1
Abbildung 3.4: Rekurrentes Netz[18]
3.3 Schichten
Zwischen der Ein- und Ausgabeschicht kann ein Neuronales Netz eine Vielzahl verschie-dener Schichten enthalten. Im Folgenden werden vier Schichten vorgestellt, die in dieserArbeit verwendet wurden.
9

10 3. Grundlagen Neuronale Netze
3.3.1 Feedforward-Netze
3.3.1.1 Reshape-Schicht
Eine Reshape-Schicht Li wird eingesetzt, um die Ausgabe der vorherigen Schicht Li-1 andie Eingabe der darauffolgenden Schicht Li+1 anzupassen. Die Schicht nimmt einen Tensorentgegen und wandelt ihn in einen Tensor mit der gleichen Anzahl an Elementen um.[21]
Dabei wird die Dimension der Eingabe verandert ohne die Daten zu verandern. Ein Beispielware das Uberfuhren einer 2× 2-Matrix in eine 4× 1-Matrix.
3.3.1.2 Convolutional-Schicht
Abbildung 3.5: Die funfte Anwendung einer Maske in einer Convolutional-Schicht[22]
Eine Convolutional-Schicht verringert die Anzahl der Ausagaben im Verhaltnis zur Eingabemit Hilfe einer Faltung (engl. Convolution). Dabei wird schrittweise eine Maske (engl.Kernel), die kleiner oder gleich groß wie die Eingabematrix ist, uber die Eingabe bewegt.Die Elemente der Matrix werden mit den Gewichten der Maske verrechnet, aufsummiertund ergeben dann ein Element in der Ausgabematrix. Die Anzahl, wie oft die Maske aufdie Eingabe angewandt wurde, entspricht so der Anzahl der Ausgabeelemente.
In einer Schicht konnen mehrere Masken angewandt werden. Eine Maske wird bei der ge-samten Eingabe mit den gleichen Gewichten verwendet. Man spricht hier auch von Sharedweights, da die Gewichte bei allen Anwendungen der Maske gleich bleiben. In der Bildver-arbeitung sorgt das dafur, dass im gesamten Bild die gleichen Muster erkannt werden. Einweiterer Vorteil ist, dass weniger Parameter optimiert werden mussen, was die Verarbei-tung beschleunigt.[23]
3.3.1.3 Pooling-Schicht
Abbildung 3.6: Max-Pooling [24]
Mit Pooling werden Informationen reduziert. Die Reduktion der Daten bringt verschiede-ne Vorteile mit sich. Zum einen verringert sich der Speicherbedarf und die Berechnungs-geschwindigkeit wird erhoht. Zum anderen wird verhindert, dass sich die Gewichte und
10

3.3. Schichten 11
Schwellwerte des Netzes zu sehr an die Trainingsdaten anpassen und dadurch nicht mehrgeneralisieren konnen. Tritt letzteres doch auf, spricht man von Overfitting. Verwendetwird die Pooling-Schicht oft nach einer Convolutional-Schicht. Dadurch wird die Vielzahlan Parametern, die die Convolutional-Schicht ausgibt, reduziert. Im Idealfall werden soStorfaktoren beseitigt und relevante Informationen behalten.[18]
Eine Variante des Poolings ist das Max-Pooling. Dabei wird, wie bei allen Pooling-Schichten,eine Fenstergroße festgelegt. Die Eingabematrix wird in Fenster unterteilt und von jedemFenster wird lediglich das maximale Element in die Eingabe ubernommen. Ist die Großteder Eingabe durch die Fenstergroße teilbar, so sind alle Fenstern gleich groß. Ansonsten istdas letzte Fenster echt kleiner als die Fenstergroße.[25] In Abbildung 3.6 wird Max-Poolingauf eine 4× 4-Matrix mit einem 2× 2-Fenster angewandt.
3.3.1.4 Vollvernetzte Schicht
In einer vollvernetzten Schicht Li dient die Ausgabe jedes Neurons als Eingabe aller Neu-ronen in der Schicht Li+1. Ein Beispiel dafur ist Abbildung 3.3.
3.3.2 Rekurrente Neuronale Netze
Klassiche rekurrente Neuronale Netze eignen sich zum Beispiel, um das letzte Wort in demSatz ”Die Baume stehen im Wald” vorherzusagen. Mochte man jedoch das letzte Wort imText ”Ich bin in England aufgewachsen [...] Ich spreche fließend Englisch” vorhersagen, solasst sich aus den unmittelbar bevorstehenden Informationen ableiten, dass es sich bei demletzten Wort um eine Sprache handelt. Theoretisch ist ein rekurrentes Netz auch in derLage, Langzeitabhangigkeiten zu erkennen. Doch je großer der Abstand zwischen den In-formationen ist, desto hoher die Wahrscheinlichkeit, dass das Netz keinen Zusammenhangzum anfanglichen Satz herstellen kann.[26].
Die Moglichkeit, Abhangigkeiten uber mehrere Eingaben hinweg zu erkennen, lasst sichmit dem Time Delay Neural Network (TDNN), einem Feedforward-Netz, umsetzen.[27]Ein rekurrentes Netz mit dieser Funktionalitat ist das Long Short-Term Memory (LSTM).
3.3.2.1 Long Short-Term Memory (LSTM)
Abbildung 3.7: LSTM[28]
Die Abbildung 3.7 illustriert ein LSTM mit Eingabe xt und Ausgabe ht fur Berechnung t.
11

12 3. Grundlagen Neuronale Netze
Charakteristisch ist vor allem das Gedachtnis (horiziontaler Pfeil oben in der Abbildung),das eine Liste von Zustanden speichert. Die drei Gatter ”Vergessen”, ”Eingabe” und ”Aus-gabe” (in der Abbildung in blau, grun und orange) legen fest, ob und inwiefern der Zustandverandert wird. Diese bestehen jeweils aus einer Sigmoid-Schicht (σ) und einer punktwei-sen Multiplikation (x). Die Aktivierungsfunktion Sigmoid (siehe 3.7.2) sorgt dafur, dassdie Ausgabe zwischen 0 und 1 liegt. Fur das Gatter bedeutet 0 komplett geschlossen und1 komplett geoffnet.[28]
Das Vergessen-Gatter entscheidet anhand von xt und ht, welche Informationen des Ge-dachtnisses verworfen werden sollen. Die Ergebnisse werden mit dem aktuellen Inhalt desGedachtnis multipliziert. Im nachsten Schritt wird entschieden, welche neuen Informatio-nen im Gedachtnis gespeichert werden sollen. Das geschieht in zwei Teilen (Eingabe inAbbildung 3.7.2). Zuerst entscheidet die Schicht σ, welche Werte wie stark gewichtet wer-den sollen. Dann wird in der Schicht tanh fur jeden Eintrag im Gedachtnis ein neuer Wertberechnet. Anschließend werden die Ergebnisse multipliziert. Das Gedachtnis wird danndurch eine Addition verandert.[28]
Abhangig vom Gedachtnis wird eine Ausgabe erzeugt. Die Schicht σ (in der Abbildungim Bereich Ausgabe) entscheidet, welche Teile des Gedachtnis fur die Ausgabe verwendetwerden. Die Werte aus dem Gedachtnis werden mit tanh auf den Wertebereich −1 bis 1abgebildet. Die Ausgabe ergibt sich dann nach der Gewichtung mit den Ergebnissen vonσ. [28]
Neben dem vorgestellten Modell, existieren zahlreiche Modifikationen und Verbesserungenfur verschiedene Anwendungsbereiche.[28] Allgemein lasst sich festhalten, dass es fur Pro-bleme wie Sprachkomprimierung[29] und Handschriftenerkennung[30] LSTM aktuell diebesten Ergebnisse liefert.
3.4 Kostenfunktion
Die Kostenfunktion (engl. Loss function) gibt die Abweichung zwischen der Ausgabe desNetzes und dem gewunschten Resultat an. Ziel ist es, diese Funktion zu minimieren.
3.4.1 Kreuzentropie
Kreuzentropie ist eine Kostenfunktion, die oft fur Klassifizierungsprobleme verwendetwird.[31]
Fur die prognostizierte Wahrscheinlichkeitsverteilung y und die tatsachliche Verteilung y′
ist sie definiert als[32]
Hy′(y) = −∑i
y′i log(yi).
3.5 Lernen
Die charakteristische Eigenschaften von Neuronalen Netzen ist die Fahigkeit, aus Musternin den eingegebenen Daten systematisch zu lernen. Nachdem ein Netz die Zusammenhangevon Ein- und Ausgabe erlernt hat, soll durch Generalisieren auch eine Losung fur beliebigeEingabewerte produziert beziehungsweise angenahert werden konnen.[18]
Das Lernen geschieht, indem im Training die Gewichte und Schwellenwerte der Neuronenverandert werden. Der bekannteste Algorithmus zum Trainieren von neuronalen Netzenist die Backpropagation (oder auch Fehlerruckfuhrung).
12

3.5. Lernen 13
3.5.1 Lernverfahren
Grundsatzlich existieren drei verschiedene Lernverfahren fur neuronale Netze: uberwachtes(supervised), unuberwachtes (unsupervised) und bestarkendes Lernen (reinforced learning).Fur diese Arbeit wird ein uberwachtes Lernverfahren eingesetzt.
3.5.1.1 Uberwachtes Lernen
Beim uberwachten Lernen erhalt das Netz eine Eingabe. Die zugehorige Ausgabe wir dannmit dem Wert verglichen, der tatsachlich hatte erzeugt werden sollen. Durch Vergleich dergewunschten und der tatsachlichen Ausgabe werden Anderungen an den Gewichten undSchwellwerten des Netzes vorgenommen.[33]
3.5.2 Lernrate
Die Lernrate legt fest, wie stark die Gewichte beim Training verandert werden. Die An-passung der Gewichte wird mit Algorithmen wie der Backpropagation durchgefuhrt.
Die Lernrate ist essenziell fur ein gutes Ergebnis eines Neuronalen Netzes. Ist sie zu gering,so ist die Gefahr hoch, dass ein lokales Minimum statt dem globalen angenahert wird. Istdie Lernrate zu hoch und die Gewichte werden in jeder Iteration sehr stark verandert,ist es moglich, dass ein globales Minimum ubersprungen wird oder dass um ein globalesMinimum herum oszilliert wird.[34]
Um zu vermeiden, dass eine zu extreme Lernrate gewahlt wird, kann die Lernrate uberverschiedene Epochen verandert werden. Ein Ansatz ist es, mit einer großen Lernrate zubeginnen, um moglichst schnell an das globale Minimum zu kommen, und diese dann zuverkleinern, um das globale Minimum nicht zu uberschreiten.[34]
3.5.3 Backpropagation
Fur diese Arbeit wurde ein uberwachtes Lernverfahren mit dem Backpropagations-Algorithmusverwendet, weshalb hier auf diesen eingegangen wird.
Backpropagation ist ein weitverbreiteter Algorithmus fur die Optimierung von NeuronalenNetzen.[35] Der Algorithmus kann in drei Schritte unterteilt werden.
1. Im ersten Schritt wird durch alle Schichten des Netzes von der Eingabe- bis zurAusgabeschicht propagiert (oder verbreitet). Das heißt, eine Eingabe wird in dasNeuronale Netz gegeben, jedes Neuron berechnet zu einer Eingabe eine entsprechendeAusgabe und am Ende gibt die letzte Schicht das Ergebnis zur Eingabe aus.
2. Im zweiten Schritt wird mittels Kostenfunktion (engl. Loss function) die Abweichungzwischen der Ausgabe des Netzes und dem tatsachlichen Ergebnis berechnet. Furjedes Neuron in der Ausgabeschicht ergibt sich so ein Fehler.
3. Daraufhin wird der Fehler so lange ruckpropagiert, bis jedes Neuron jeder Schichteinen Fehlerwert erhalten hat.
Mit diesen Fehlerwerten wird der Gradient der Kostenfunktion berechnet. Der Gradientgibt die Richtung der großten Steigung an. Da der Fehler minimiert werden soll, wird dasVorzeichen umgedreht. Anschließend wird der Wert an die sogenannte Updatefunktionweitergereicht. Diese nimmt als Eingabe die Richtung, in die verandert werden soll, unddie Lernrate entgegen und passt die Gewichte so an, dass die Kostenfunktion minimiertwird.[35]
13

14 3. Grundlagen Neuronale Netze
3.5.3.1 Große des Batches
Die Große des Batches legt fest, wie viele Tweets beim Training auf einmal durch dasNeuronale Netz propagiert werden, bevor die Gewichte der kunstlichen Neuronen angepasstwerden.
Je kleiner ein Batch ist, desto mehr Storfaktoren wirken sich auf die Gewichte in denkunstlichen Neuronen aus. Je großer ein Batch ist, desto hoher ist die Berechnungszeit furden Gradienten.[36]
3.6 Updatefunktion
Bei der Backpropagation werden die Gewichte und Schwellenwerte durch eine Updatefunk-tion angepasst. Ziel ist es statt einem lokalen Minimum das globale Minimum zu finden. ImFolgenden werden Stochastic Gradient Descent (SGD) und einige Modifikationen davon,die im Bereich des maschinellen Lernens haufiger verwendet werden, vorgestellt.[35]
3.6.1 Stochastic Gradient Descent
SGD ist eine Approximation des Gradientenverfahrens. Hier wird ein Naherungswert furden Gradienten bestimmt. Von diesem aus wird in Richtung des negativen Gradientengegangen. Es wird der negative statt dem positiven Gradienten angenahert, da die Kos-tenfunktion minimiert und nicht maximiert werden soll. Der Gradient g wird uber denFehler des Neurons berechnet. Ein Parameter p wird mit einer Lernrate l und dem Gradi-enten λ wie folgt angepasst:
p = p− l ∗ λ
Die Lernrate legt fest, um welchen Faktor das Gewicht verandert werden soll.
3.6.2 Adadelta
Adadelta ist eine Updatefunktion, bei der die Lernrate adaptiv bestimmt wird. Daher mussdiese nicht mehr manuell angepasst werden.[37]
3.6.3 Root Mean Square Propagation
Bei Root Mean Square Propagation (RMSProp) wird die Lernrate fur jeden Parameterindividuell angepasst. Um die nachste Lernrate zu berechnen, wird das gleitende Mittelder Großen der letzten Gradienten fur jedes Gewicht berechnet. Die Lernrate wird danndurch diesen Wert dividiert.[35]
Im ersten Schritt wird das gleitende Mittel E[g2]t berechnet. Sei γ der Prozentwert, derbestimmt wie viel Information verworfen wird und g der Gradient. Dann ist das gleitendeMittel fur den Zeitpunkt t wie folgt definiert:
E[g2]t = γE[g2]t−1 + (1− γ)g2t
Damit ergibt sich die Updatefunktion θ:
θt+1 = θt −η√
E[g2]t + εgt
14

3.7. Aktivierungsfunktion 15
3.6.4 Adam
Adaptive Moment Estimation (Adam) ist ein Verfahren, um fur jeden Parameter adaptivLernraten zu berechnen. Das Verfahren speichert den Durchschnitt mt von den vorherigenGradienten und den Durchschnitt vt von den vorherigen quadrierten Gradienten.[35] Diesesind Schatzungen des ersten und zweiten Momentums.
Das Momentum ist die Summe der vorherigen Gradienten, die in einem Vektor gespei-chert wird. Dieser Vektor beschleunigt das Gradientenverfahren, wenn sich der Gradientnur wenig verandert. Wenn der Gradient stark oszilliert, verlangsamt der Momentums-Vektor jedoch das Gradientenverfahren.[38] Die Variablen β1, β2 geben an, um wie viel dieParameter jeweils abklingen sollen:
mt = β1mt−1 + (1− β1)gt,
vt = β2vt−1 + (1− β2)g2t .
Da mt und vt als Nullvektoren initialisiert werden, tendieren diese gegen Null. Um das zuverhindern, wird das erste und zweite Momentum wie folgt abgeschatzt:
mt =mt
1− βt1,
vt =vt
1− βt2.
Die Updatefunktion θ ergibt sich dann als[38]
θt+1 = wt −η√vt + ε
mt.
[35]
3.6.5 Nadam
Die bereits vorgestellte Funktion Adam verwendet Momentum. Nesterov Adam Optimizer(Nadam) ist eine Erweiterung dazu, die stattdessen Nesterov-Momentum verwendet.
3.7 Aktivierungsfunktion
Die Aktivierungsfunktion entscheidet uber die Form der Ausgabe eines kunstlichen Neu-rons. Die Funktion ist nicht linear, was erst zur Nichtlinearitat eines Neuronalen Netzesfuhrt.3.1 Die Ausgabe kann in unterschiedlichen Wertebereichen liegen und zum Beispielalle reellen Zahlen enthalten oder alle Zahlen im Intervall [0, 1]. Vor allem fur die Ausga-beschicht spielt die Aktivierungsfunktion eine große Rolle, da sie das Format der Ausgabefestlegt.
3.7.1 ReLU
Die Aktivierungsfunktion ReLU ist definiert als
g(x) = max(0, x).
Die Funktion ist fur eine Eingabe x null, falls x ≤ 0 und entspricht ansonsten x. Alseinfacher Schwellwert ist ReLu die simpelste der hier vorgestellten Aktivierungsfunktionen,was Vorteile fur die Dauer des Trainings eines Neuronalen Netzes mit sich bringt.
15

16 3. Grundlagen Neuronale Netze
3.7.2 Sigmoid
Die Funktion Sigmoid ist definiert als
g(xi) =1
1 + e−xi.
Mathematisch betrachtet nimmt die Funktion einen reellen Wert entgegen und gibt einenWert im Intervall [0, 1] zuruck.
3.7.3 Softmax
Fur einen Vektor der Große k sei Softmax definiert als
g(xi) =exi∑kj=0 e
xj.
Die Funktion berechnet die Wahrscheinlichkeit fur jede Klasse eines Klassifizierungspro-blems.
Wie bei Sigmoid liegt die Ausgabe im Intervall von [0, 1]. Die Summe aller Wahrschein-lichkeiten ergibt immer 1. Bei Klassifikationsproblemen enthalt die Ausgabeschicht mitAktivierungsfunktion Softmax so viele Neuronen wie Klassen bestimmt werden sollen. Derausgegebene Wert gibt fur die Eingabe an, mit welcher Wahrscheinlichkeit sie in der an-gegebenen Klasse liegt.
3.7.4 tanh
Die Ausgabe der tanh-Aktivierungsfunktion liegt im Intervall zwischen [−1, 1].
tanh(x) =2
1 + e−2x− 1
Die Funktion hat in der Nahe von null und eins einen flachen Verlauf. Werden viele kleineWerte multipliziert, um den Gradienten zu berechnen, spricht man vom Vanishing Gradi-ent-Problem, was bei tanh auftreten kann.[26]
3.8 Regularisierung
In Neuronalen Netzen mit vielen Parametern ist Overfitting ein haufiges Problem. MitRegularisierung wird versucht das Problem zu losen.
3.8.1 Dropout
Eine Moglichkeit der Regularisierung sind Dropout-Schichten. Diese sorgen dafur, dasseine zufallig bestimmter Prozentsatz der Neuronen ausgeschaltet wird und im nachstenBerechnungsschritt nicht berucksichtigt wird. Dadurch wird verhindert, dass die Neuro-nen sich zu stark an die Trainingsdaten anpassen und dadurch nicht mehr generalisierenkonnen.[39]
Auf wie viel Prozent der Neuronen der Dropout angewendet wird, muss anhand der Ergeb-nisse des Netzes entschieden werden. Ist der Prozentsatz zu klein, kann das Netz zu starkauf die Trainingsdaten abgestimmt werden und erzielt dadurch schlechtere Ergebnisse aufden Testdaten. Wenn der Prozentsatz des Dropouts zu groß ist, verschlechtern sich dieErgebnisse auf den Trainings- und den Testdaten.
16

3.8. Regularisierung 17
3.8.2 L2-Regularisierung
Bei der L2-Regularisierung wird der Kostenfunktion der sogenannten Regularisierungs-term hinzugefugt. Dieser besteht aus der Summe der quadrierten Gewichte des gesamtenNetzes multipliziert mit λ
2n . Dabei ist λ der Regularisierungsparameter und n die Großedes Trainingsdatensatzes.[40]
Fur die Kreuzentropie ergibt sich dadurch folgende Gleichung:
Hy′(y) = −∑i
y′i log(yi) +λ
2n
∑w
w2.
17


4. Implementierung und Methodik
4.1 Motivation
Ziel dieser Arbeit ist es, mit Hilfe von Tweets vorherzusagen, ob der Aktienkurs eines Un-ternehmens an einem Folgtetag fallt oder steigt. Dazu wurden zwei verschiedene Ansatzeverwendet.Bei der Pradiktion mittels Sentimentanalyse wird mit einer bestehenden Anwendung be-stimmt, wie positiv oder negativ die Aussage eines Tweets ist. Mit dieser Information wirduberpruft, ob es einen Zusammenhang zwischen dem durchschnittlichen Sentiment an ei-nem Tag und dem Verlauf des Aktienkurs am nachsten Tag gibt.Bei der direkten Pradikation wird der Datensatz in einen Trainings- und Testdatensatzaufgeteilt. Mit den Zusammenhangen aus Tweets und Aktienkursen im Trainingsdaten-satz wird versucht, mit den Tweets im Testdatensatz auf die Kurse in diesem Zeitraum zuschließen.
Die anfangliche Implementierungsarbeit bestand daraus, Daten zu sammeln. Das Vorgehendazu wird im Abschnitt Daten erklart.
4.2 Pradiktion mittels Sentimentanalyse
Mit dem Werkzeug Stanford Natural Language Processing (SNLP) lassen sich umfangrei-che Analysen auf Texten ausfuhren. SNLP allgemein unterstutzt mehrere Sprachen, dieSentimentanalyse ist jedoch nur in englischer Sprache verfugbar.[41]
Fur jeden Tweet in englischer Sprache wurde mit Hilfe eines Recursive Neural TensorNetwork (RNTN) ein Sentiment errechnet. Dieses reicht von sehr negativ uber negativ,neutral, positiv bis sehr positiv.
Das RNTN nimmt Satze variabler Lange als Eingabe entgegen. Hier werden Satze immerzusammenhangend betrachtet. Daraus ergeben sich einige Vorteile im Gegensatz zur Be-trachtung einzelner Worter. Zum Beispiel kann erkannt werden, auf was sich Negationenbeziehen, was bei Bag-of-Words-Ansatzen oft ein Problem darstellt.[42] Ein Bag-of-Wordsist eine Reprasentation eines Textes, bei der Grammatik und Reihenfolge der Worter igno-riert werden. Ein Text besteht in dieser Reprasentation aus der Menge der enthaltenenWorter mit der Information, wie oft ein Wort vorkommt.[43]
Wahrend Bag-of-Words-Ansatze bei langeren Dokumenten vor allem durch Worter mitstarkem Sentiment wie ”Super” oder ”Fantastisch” gute Ergebnisse erzielen, so erzielt der
19

20 4. Implementierung und Methodik
Ansatz nur begrenzt gute Ergebnisse, wenn es darum geht, kurzere Texte (wie zum BeispielTweets) in mehr als eine Klasse einzuteilen. Hier konnen mit dem RNTN deutlich bessereErgebnisse erzielt werden.[44]
Das Training fur das RNTN basiert auf einem Datensatz der ”Stanford Sentiment Tree-bank”, einem komplett-annotierten Syntaxbaum. Dieser baut auf Nutzerbewertungen zuFilmen von der Plattform Rotten Tomatoes auf.[45] Der Datensatz wurde von drei Perso-nen manuell annotiert.
4.2.1 Aufbau des Netzes
Abbildung 4.1: Text als Binarbaum reprasentiert
Mit einem rekursiven Neuronenmodell (engl. recursive neural model) lassen sich Textevariabler Lange mit Hilfe von Vektoren darstellen. Dafur wird die Eingabe in einen Bi-narbaum gewandelt. Jedes Blatt des Baumes ist ein Vektor, der ein Wort in der Eingabereprasentiert. Mit Hilfe verschiedener Kompositionen g werden von den Blattern aus dieElternknoten berechnet. Das Berechnen der Vektoren pi ∈ Rd fur Vektoren der Lange dmit einem Rekurrente Neuronalen Netz (RNN) funktioniert fur das Beispiel in Abbildung4.1 wie folgt:
p1 = f
(W
[bc
]), p2 = f
(W
[ap1
]), (4.1)
dabei sei f die Aktivierungsfunktion tanh und W ∈ Rd×2d die Gewichte, die trainiertwerden sollen.
Bei einem rekurrenten Neuronalen Netz (RNN) konnen sich Eingabevektoren nur implizituber die nicht-lineare Aktivierungsfunktion austauschen. Um die Interaktion zwischen denEingabevektoren zu erhohen, verwendet das RNTN die gleiche Komposition fur alle Knotenim Binarbaum.
Sei V [1:d] ∈ R2d×2d×d ein Tensor, der mehrere Bilinearformen definiert, dann lasst sich dasProdukt zweier Tensoren h ∈ Rd wie folgt berechnen:
hi =
[bc
]TV [1:d]
[bc
]. (4.2)
Damit berechnet das RNTN p1 wie folgt:
p1 = f
([bc
]TV [1:d]
[bc
]+W
[bc
]). (4.3)
20

4.3. Direkte Pradiktion 21
Der zweite Elternvektor in Abbildung 4.1 wird mit den gleichen Gewichten bestimmt:
p2 = f
([ap1
]TV [1:d]
[ap1
]+W
[ap1
]). (4.4)
Anhand der Formeln lasst sich erkennen, dass das RNN ein Spezialfall des RNTN ist, beidem V = 0 ist. Im Gegensatz zum vorher vorgestellten rekursiven Modell kann so einZusammenhang zwischen Eingabevektoren hergestellt werden.
4.2.2 Transformation fur die Pradiktion der Aktienkurse
Die Sentimentanalyse teilt jeden Tweet in eine der funf Klassen ein: sehr negativ (0),negativ (1), (2), positiv (3) und sehr positiv (4). Um zu bestimmen, ob der Aktienkursfallt oder steigt, wird dieses Ergebnis auf zwei Klassen reduziert: Kurs steigt (0) undKurs fallt (1). Dafur wird der Grenzwert g gebildet, fur den die meisten Pradiktionen imTrainingsdatensatz korrekt sind. Damit lasst sich jeder Tweet t mit der Funktion b(t) ineiner der beiden Klassen einteilen:
b(t) =
{0, falls Sentiment ≥ g1, sonst
}.
4.3 Direkte Pradiktion
Ein Ansatz, um die Pradiktion mittels Sentimentanalyse zu verbessern, ware es, das RNTNmit Tweets zu trainieren, anstelle von Filmbewertungen. Dafur mussten jedoch die Satz-bestandteile der Tweets manuell annotiert werden. Deshalb werden im Folgenden dreiNeuronale Netze vorgestellt, die sich mit der Information trainieren lassen, ob der Aktien-kurs des erwahnten Unternehmens am nachsten Tage gestiegen oder gefallen ist. Dadurchwird eine direkte Pradiktion des Aktienkurses moglich.
Bei dem ersten neuronalen Netz handelt es sich um ein rudimentares Feedforward-Netzmit einer Max-Pooling und zwei vollvernetzten Schichten. Das zweite Netz ist mit einerConvolutional-Schicht ein komplexeres Feedforward-Netz. Bei dem letzten Netz handelt essich um ein Rekurrentes Neuronales Netz (RNN) mit einer LSTM-Schicht.
Die Worten in den Tweets werden mit Word Embeddings reprasentiert, was im FolgendenAbschnitt naher erlautert wird. Darauf folgt eine Ubersicht uber den Aufbau der Netzeund ein anschließender Uberblick uber die Hyperparameter, die gewahlt wurden, um dieErgebnisse der drei Neuronalen Netze moglichst zu maximieren.
4.3.1 Word Embeddings
Worter lassen sich fur die Berechnungen in Neuronalen Netzen als Vektoren von reellenZahlen darstellen. Diese Art von Darstellung nennt sich auch Word Embeddings.
Mathematisch betrachtet handelt es sich dabei um eine Einbettung, also eine Abbildung,bei der ein Objekt als Teil eines anderen Objekts aufgefasst werden kann. Die Abbildunggeht von einem Raum mit einer Dimension pro Wort auf einen kontinuierlichen Vektorraummit wesentlich geringerer Dimension.
Mit Word Embeddings ist es moglich, semantische Bedeutungen in einen geometrischenRaum zu ubertragen. Die Vektoren fur einzelne Worter werden so gewahlt, dass der Ab-stand zwischen zwei Vektoren eine Aussage uber die Semantik der beiden Worter darstellenkann.[46]
21

22 4. Implementierung und Methodik
An einem Beispiel lassen sich diese semantische Zusammenhange wie folgt erklaren. Seiv(x) der zugehorige Vektor fur das Wort x, dann gilt[47]
v(Paris)− v(Frankreich) ≈ v(Deutschland)− v(Berlin)
Neben der Moglichkeit Word Embeddings in der ersten Schicht zu erstellen, lassen sich auchbereits trainierte Vektoren verwenden. Die bereits trainierten Vektoren, die fur diese Arbeitverwendet wurden, wurden mit dem Global Vectors for Word Representation (GloVe)-Algorithmus erstellt.
4.3.1.1 GloVe
GloVe ist ein Algorithums, mit dem sich Worter als Vektoren reprasentieren lassen.[48]
Die verwendeten Vektoren haben eine Dimension von 100 und stammen aus einem Daten-satz mit 400.000 Worter aus der englischen Wikipedia.[49] Aus dem Datensatz mit denbereits trainierten Embeddings wird ein Worterbuch WGloV e erstellt, das fur jedes Wortden zugehorigen Vektor w ∈ R1×d enthalt. Aus den Eingabedaten wir ein WorterbuchWEingabe mit den am haufigsten vorkommenden Wortern erstellt. Jedes Wort wird dabeiauf einen der Indizes 1, ..., | WEingabe | abgebildet. Mit Hilfe dieser beider Worterbucherlasst sich eine Embedding-Matrix E ∈ Rd×|WEingabe| erstellen. Jede Spalte in E steht furein Wort aus wEingabe der Eingabedaten. Kommt dieses Wort in wGloV e vor, enthalt dieZeile den entsprechenden Vektor, falls nicht, enthalt die Zeile den Nullvektor mit der Lange100.
4.3.2 Aufbau der Neuronalen Netze
4.3.2.1 Max Pooling-Netz
Das erste Neuronale Netz fur die direkte Pradiktion ist ein Feedorward-Netz bestehend ausMax Pooling- und vollvernetzten Schichten. Im Folgenden wird naher auf dessen Aufbaueingegangen.
Auf die Embedding-Schicht folgt eine eindimensionale Max Pooling-Schicht mit Fenster-große vier. Damit wird versucht, aus der Embedding-Matrix Storfaktoren zu entfernen.
Nach einer Dropout und einer Flatten-Schicht folgen zwei vollvernetzte Schichten. Zwi-schen diesen liegt wieder eine Dropout-Schicht. In der ersten vollvernetzten Schicht befin-den sich 128 Neuronen. Die zweite vollvernetzte Schicht ist die Ausgabeschicht des Netzes.Sie besitzt zwei Neuronen, die durch die Aktivierungsfunktion Softmax die Wahrschein-lichkeit fur jede der zwei Klassen angeben.
4.3.2.2 Convolution-Netz
Das Convolutional-Netz ist einer Erweiterung des zuvor vorgestellten Max Pooling-Netzes.Durch eine weitere Schicht wird die Komplexitat des Netzes erhoht, was es im Idealfallermoglicht, Muster in den Trainingsdaten zu erkennen, die das Max Pooling-Netz nochnicht erkannt hat.
Auf die Convolutional-Schicht folgt eine Pooling-Schicht. Das Hauptziel der Convolutional-Schicht ist es, sich wiederholende Muster in den Trainingsdaten zu erkennen. Die Faltope-ration (engl. Convolution) wendet hierzu einen Filter auf die Eingabematrix an. Anstelleeines einzelnen Filters konnen auch parallel mehrere Filter, von denen jeder eine FeatureMap erzeugt, angewandt werden. Diese ergeben wiederum eine Feature Map Matrix.
Auf die Ausgabe der Convolutional-Schicht wird elementweise eine Aktivierungsfunktionangewandt. Nach dieser Funktion, werden die Daten als Eingabe in die Pooling-Schicht
22

4.3. Direkte Pradiktion 23
Abbildung 4.2: Aufbau des Max-Pooling-Netzes
gegeben. Hauptziel dieser Schicht ist es, Daten zusammenzufassen und den Umfang derDaten zu verkleinern. Genauer wird hier das Verfahren Max-Pooling angewandt.
Nach der Convolutional- und Pooling-Schicht folgt eine Reshape-Schicht gefolgt von einervollvernetzten Softmax-Schicht. Diese berechnet jeweils die Wahrscheinlichkeit, dass derAktienkurs am nachsten Tag fallt oder steigt.
Im Bereich des maschinellen Lernen spricht man von ”Feature Extraction”, wenn es dar-um geht, aus Daten Informationen (Features) abzuleiten, die nicht redundant sind. DieseVereinfachung kommen den folgenden Lerniterationen und der Gerneralisierung zu Gute.Die Convolutional-Schicht in Verbindung mit der Aktivierungsfunktion und der Pooling-Schicht stellt einen nicht-linearen Feature Extractor dar. Dadurch kann das Netz aus denEingabedaten eine umfangreiche Reprasentation in Form von Features erstellen.[50]
4.3.2.3 LSTM-Netz
Statt einer Convolutional-Schicht enthalt dieses Netz eine LSTM-Schicht. Damit lassensich auch Zusammenhange erkennen, die zeitlich weiter auseinanderliegen.
Alle Eingabedaten wurden auch hier auf die gleiche Lange gebracht. Alternativ ware esauch moglich, Daten unterschiedlicher Lange an das LSTM zu geben.
Die rekurrente LSTM-Schicht besitzt ein ”Gedachtnis” der Große 128. Diese entscheidetauch uber die Ausgabedimensionalitat. Nach einer Dropout- folgt die erste vollvernetz-
23

24 4. Implementierung und Methodik
Abbildung 4.3: Aufbau des Convolution-Netzes
te Schicht mit Sigmoid-Aktivierungsfunktion. Wie bei den vorherigen beiden Netzen be-sitzt diese 128 Neuronen. Nach einer Dropout-Schicht folgt dann wieder eine vollvernetzteSchicht mit Softmax-Aktivierungsfunktion.
24

4.4. Daten 25
Abbildung 4.4: Aufbau des LSTM-Netzes
4.4 Daten
4.4.1 Tweets
Mit uber 300 Millionen aktiven Nutzern ist Twitter eine der großten Informationsquellenim Internet.[51] Wegen der hohen Anzahl an Nutzern und der Vielzahl an Nachrichtenwurde die Plattform benutzt, um fur diese Arbeit Stimmungsbilder fur verschiedene Un-ternehmen erstellen zu konnen.
Uber den Zeitraum vom 21. Dezember 2016 bis zum 3. Februar 2017 wurden von der Platt-form circa 20 Millionen Tweets gesammelt. Twitter stellt dafur die sogenannten StreamAPI zur Verfugung. Damit lasst sich uber einen HTTP-Request nach Tweets suchen, dieverschiedene Schlagworter enthalten. In Echtzeit werden dann entsprechende Tweets zu-ruckgegeben. Alternativ stellt Twitter die Serach API zur Verfugung. Diese liefert Tweetsder letzten sieben Tage. Die Auswahl dieser ist eher auf Relevanz als auf Vollstandigkeitausgelegt. Eine offizielle API die Tweets liefert, die noch weiter zuruck liegen, existiertjedoch nicht.[52]Jede Antwort auf die Anfrage beinhaltet neben dem Text mit maximal 140 Zeichen weitereInformationen. Dazu zahlt der Name des Autors, die Anzahl der Personen, die ihm folgen,und ein Zeitstempel. Außerdem wird optional der Standort des Autors geliefert, falls erdiesen aktiviert hat.
Die Anfragen wurden uber ein Java-Programm gestellt. Dieses enthalt eine Liste von allenDOW30- und DAX30-Unternehmen. Diese werden mit der Anfrage an die API uberge-ben. Groß-/Kleinschreibung spielt bei den Anfragen keine Rolle, weshalb die Antwortenzusatzlich gefiltert wurden. So wird zum Beispiel erreicht, dass das Symbol ”BEI” fur dieBeiersdorf AG auch nur in Großbuchstaben vorkommt und nicht zum Beispiel als deutschesWort ”bei”. Weiter muss das ubergebene Wort nicht alleinstehend sein. Deshalb entfernt
25

26 4. Implementierung und Methodik
das Programm auch alle Tweets, die auf die Suchanfrage zu ”Bayer” zutreffen, aber tat-sachlich zum Beispiel das Wort ”Bayern” beinhalten.
Die Aktienunternehmen konnen in den Tweets in einer von drei Schreibweisen vorkommen.Zum einen, indem der Name eines der 60 Unternehmen enthalten ist (Name). Außerdemkann das Aktiensymbol, uber das sich das Unternehmen an der jeweiligen Borse eindeu-tig identifizieren lasst, im Tweet vorkommen (Symbol). Oder es wird ein Dollarzeichen,gefolgt von dem jeweiligen Aktiensymbol, erwahnt ($Symbol). Letztere Erwahnung wirdublicherweise auf Twitter benutzt, wenn sich uber Aktienkurse ausgetauscht wird.[53].
Ein Vorteil der $Symbol-Tweets ist es, dass mit sehr hoher Wahrscheinlichkeit die Redevon dem Unternehmen ist, wahrend ohne das Dollarzeichen viele andere Bedeutungenmoglich sind. Ein Nachteil ist, dass im Vergleich zu den anderen Schreibweisen deutlichweniger Tweets geschrieben werden. Am 10. Januar waren fur das Symbol ”MMM” zumBeispiel uber 78.000 Tweets gesammelt, von denen lediglich 685 die Zeichenkette ”$MMM”enthielten.
Fur das Trainieren und Uberprufen der Neuronalen Netze zur direkten Pradiktion und furdas Testen der Pradiktion mittels Sentimentanalyse wurden zwei gleich große, disjunkteDatensatze verwendet. In jedem Datensatz gehort eine Halfte der Tweets zur Klasse ”Kurssteigt” (0) und die andere zu ”Kurs fallt” (1). Da die Klassen im ursprunglichen Datensatzungleich groß sind, wurden aus der großeren Klasse mit einem Pseudo-Zufallsverfahren soviele Tweets entnommen, dass beide Klassen gleich stark vertreten sind.
Zudem wurden alle Texte auf die gleiche Lange gebracht. Der langste Tweet im Datensatzenthalt 70 durch Leerzeichen getrennte Zeichen. Da aber nur wenige Randfalle mehr als20 Worter enthalten, wurde die maximale Lange der als Zahlen reprasentierten Worterauf 20 beschrankt. An kurzere Zeichenketten wurde so oft die Zahl Null vorne angehangt,bis dieser aus 20 Zahlen bestand, langere Texte wurden abgeschnitten. Die Lange 20 imVergleich zu 70 brachte keine Einbußen bei der Accuracy mit sich, beschleunigte jedochdas Training um ein Vielfaches.
Die Reprasentation von Wortern als Zahlen sei an einem Beispiel wie folgt erklart: An-genommen das englische Wort ”I” kame in allen Texten am haufigsten vor und das Wort”am”am dritthaufigsten. Wenn ein Worterbuch mit den 20.000 am haufigsten auftretendenWortern gewahlt wird, dann sahe der Tweet ”I am” in Ganzzahlen ubersetzt zum Beispielso aus: ”0 0 0 ... 0 20000 19998” und bestande aus 20 Zahlen.
4.4.2 Aktienkurse
Uber die Yahoo Finance API[54] lassen sich Anfragen mit Symbolen und einem Zeitraummachen. Auf diese Anfrage wird mit einer CSV-Datei geantwortet, die fur das Unternehmenin dem gegebenen Zeitraum Informationen zum Aktienkurs liefert. Die Datei enthalt furjeden Tag, an dem die Borse geoffnet war, verschiedene Informationen: Kurs zur Offnungund Schluss der Borse und die Hochst- und Tiefstwerte des Tages.Diese Daten wurden nach dem Auslesen (wie die Twitter-Daten) in einer Datei im JSON-Format abgespeichert.
Jeder Tweet wird mit Hilfe der Daten in zwei Klassen eingeteilt: Kurs fallt und Kurs steigt.Das geschieht indem der Schlusskurs des Tages, an dem der Tweet verfasst wurde, mit demSchlusskurs eines spateren Tages verglichen wird. Uberpruft wurden die Abstande von einbis vier Tagen. Angenommen das Zeitfenster ist eins und ein Tweet wurde am Freitagerstellt. Da die Borse am Samstag und Sonntag geschlossen ist, wurde der Tweet fur diePrognose vom nachsten Borsentag genutzt (in diesem Fall Montag), statt ihn nicht in diePrognose mit einfließen zu lassen.
26

5. Evaluation
Die Methoden zur direkten Pradiktion und der Pradiktion mittels Sentiment dienen alsbinare Klassifikatoren, die jeden Tweet in eine der zwei Klassen ”Kurs steigt” oder ”Kursfallt” einordnen. Aus der relativen Haufigkeit der Fehler, bei denen ein Tweet in die falscheKlasse eingeordnet wurde, lassen sich quantitative Maße ableiten. Diese ermoglichen es,die Netze zu vergleichen und zu beurteilen.
Die Ausgabe der Neuronalen Netze lasst sich in vier Kategorien einteilen:
• Richtig positiv (RP): der steigende Kurs wurde korrekt bestimmt
• Falsch positiv (FP): vorhergesagt wurde ein steigender Kurs, dieser fallt jedoch
• Richtig negativ (RN): Kurs wurde korrekt als fallend bestimmt
• Falsch negativ (FN): Kurs wurde als fallend bestimmt, tatsachlich steigt er
Mit diesen Informationen uber die Ausgabe der neuronalen Netze zu den Testdaten lasstsich die Accuracy (auch Korrektsklassifikationsrate) berechnen:
Accuracy =RP +RN
RP +RN + FP + FN
Die Trainings- und Testdaten enthalten fur jede Klasse gleich viele Tweets. So wird ver-mieden, dass ein Großteil der Eingaben zu einer Klasse gehort und ein Neuronales Netzdaraus lernt, generell viel in diese Klasse einzuordnen.
Sind beide Klassen gleich stark vertreten, ist es zum Beispiel dennoch moglich, dass 70%der Tweets uber Microsoft zur Klasse der fallenden Kurse gehoren und 70% der Tweetsuber Apple zu der Klasse der steigenden Kurse gehoren. Teilt ein Klassifizierer alle Tweetsuber Mircrosoft in die Klasse der fallenden Kurse ein und alle Apple-Tweets in die Klasseder steigende Kurse, erzielt der eine Accuracy von 70%. Daher sollte vor allem bei einerhohen Accuracy uberpruft werden, auf welchen genauen Daten das Ergebnis zu Standekam. Deshalb werden im Folgenden weitere quantitaive Maße eingefuhrt.
Die Precision (auch positiver Vorhersagewert oder Relevanz genannt) gibt an, wie viele derpositiv klassifizierten Ergebnisse korrekt als positiv klassifiziert wurden. Fur diese Arbeitentspricht das dem Anteil der als steigend klassifizierten Tweets unter allen als positivklassifizierten Tweets.
27

28 5. Evaluation
Precision =RP
RP + FP
Wenn keine falsch-positiven (FP) Entscheidungen getroffen wurden, sei Precision = 1.
Der Recall (auch Richtig-positiv-Rate, Sensitivitat oder Trefferquote) gibt den Anteil derkorrekt als Kurs steigend (TP) klassifizierte Tweets von allen Tweets, die tatsachlich zurKlasse der steigenden Kurse gehoren, an:
Recall =RP
RP + FN
Fur den Fall, dass keine richtig-positiven (RP) Ergebnisse erzielt wurden, sei Recall = 1.
Um die Netze anhand eines Werts vergleichen zu konnen, wird das kombinierte Maß F1verwendet. F1 bildet das harmonische Mittel von Precision und Recall.
F1 = 2 ∗ 11
Recall + 1Precision
= 2 ∗ Precision ∗RecallPrecision+Recall
Fur den Randfall, dass der Nenner Null wird, sei F1 = 1.
Alle Tweets wurden in drei Datensatze aufgeteilt:
• Symbol enthalt Tweets, die das Borsensymbol eines Unternehmens erwahnen
• Tweets in $Symbol erwahnen das Symbol mit vorgestelltem Dollarzeichen
• In Name sind alle Tweets enthalten, die eines der Aktienunternehmen mit demUnternehmensname erwahnen.
Da die $Symbol-Tweets anfanglich die besten Resultate lieferten, wurden die Optimierun-gen auf diesem Datensatz vorgenommen. Dieser wird im Folgenden fur alle NeuronalenNetze im Detail betrachtet und anschließend mit den restlichen Datensatzen verglichen.
Jeder Datensatz wurde in zwei gleichgroße, disjunkte Trainings- und Testdatensatze auf-geteilt. Die Ergebnisse im Folgenden beziehen sich immer auf den Testdatensatz. Die Neu-ronalen Netze zur direkten Pradiktion wurden auf dem Trainingsdatensatz trainiert.
5.1 Pradiktion mittels Sentimmentanalyse
Im Durchschnitt ist das Sentiment der Tweets negativ, wenn diese mit dem RNTN ana-lysiert werden. Dafur kann es mehrere Grunde geben. Zum einen ist das Neuronale Netzmit Filmbewertungen trainiert, was sich thematisch nur wenig mit Tweets uber Aktien-unternehmen uberschneidet. Zum anderen sind Tweets oft nicht grammatisch korrekt undenthalten viele Abkurzungen, wofur das Werkzeug ebenfalls nicht trainiert ist.
Um die Pradiktion mittels Sentimentanalyse mit der direkten Pradiktion vergleichen zukonnen, wurde eine einfache Anlagestrategie zur Evaluation eingesetzt. Fur die Sentimentsder Tweets wurde ein Grenzwert bestimmt. Liegt das Sentiment unter diesem Grenzwert,ist die Aussage eher negativ und die Prognose lautet ”Kurs fallt”. Ist das Sentiment großeroder gleich wie der Grenzwert, ist die Aussage positiv und es wird ein steigender Kurspradiziert.
Sei ein positiver Tweet uber ein Unternehmen ein Indikator fur einen steigenden Aktienkursam nachsten Tag und ein negativer Tweet ein Indikator fur einen fallenden Kurs, so erreicht
28

5.1. Pradiktion mittels Sentimmentanalyse 29
0,0
10
,0
20
,0
30
,0
40
,0
50
,0
60
,0
70
,0
Acc
ura
cy (
%)
$F_
1$
(%
)D
urc
hsc
hn
itt
Acc
ura
cyD
urc
hsc
hn
itt
F1
Abb
ild
ung
5.1
:A
ccura
cyu
nd
F1
pro
Unte
rneh
men
fur
das
RN
TN
29

30 5. Evaluation
die Vorhersage auf den gesammelten Testdaten zu $Symbol vom 11. Januar bis zum 3.Februar 2017 eine Accuracy von 49,7% (siehe Abbildung 5.1).
Im Durchschnitt wurde die beste Accuracy mit 49,7% auf dem Datensatz $Symbol erzielt.Wird die Accuracy fur einzelne Unternehmen betrachtet, konnen einige Unterschiede fest-gestellt werden. Wahrend General Electric (GE) zum Beispiel mit 63% einen vergleichs-weise hohen Wert erreicht, lag DuPont lediglich bei 38%. Fur die Unternehmen tretenbeide Klassen ungefahr ausgeglichen auf und es wurden nicht ubermaßig viele Tweets ineine Klasse eingeteilt. Das legt nahe, dass fur den Datensatz nicht behauptet werden kann,dass positive Tweets mit einer positiven Entwicklung des Aktienkurses zusammenhan-gen. Obwohl fur einige Unternehmen ein solcher Zusammenhang besteht, so ist fur andereUnternehmen wie DuPont ein positiver Tweet im Durchschnitt eher ein Indiz fur einenfallenden Kurs.
Unternehmen mit durchschnittlicher Accuracy haben nicht unbedingt einen durchschnitt-lichen Recall oder eine durchschnittliche Precision. Coca-Cola zum Beispiel liegt mit einerAccuracy von 52% leicht uber dem Durchschnitt. Precision und Recall liegen mit 17% und16% jedoch deutlich unter dem jeweiligen Durchschnitt. Die Erklarung dafur sind sehrwenige richtig-positive Entscheidungen, dafur aber viele richtig-negative Entscheidungen.Tatsachlich waren auch nur wenige richtig-positive Bewertungen moglich, da der Coca-Cola-Kurs im Zeitraum des Testdatensatz (11. Januar bis 3. Februar) ofter gefallen alsgestiegen ist (siehe Abbildung 5.2).
Auch bei General Electric (GE) existieren große Unterschiede zwischen einzelnen Metriken.Mit 63 % ist GE das Unternehmen mit der hochsten Accuracy, besitzt aber gleichzeitigmit 20% den zweitniedrigsten Wert fur F1. Hier wurden wesentlich mehr richtig-negativeals richtig-positive Ergebnisse fur das Unternehmen erzielt. Die Borsenschlusskurse sindbis auf zwei Tage im Zeitraum des Testdatensatzes immer gefallen.[55] Die Korrelation mitdem tendenziell negativen Sentiment ist hier vergleichsweise hoch. Gleichzeitig zeigt dasErgebnis, dass steigende Kurse nur schlecht vorhergesagt werden konnen.
Abbildung 5.2: Entwicklung der Coca-Cola Aktie im Testdatenzeitraum
Die Accuracy liegt im Durchschnitt sehr nahe an 50%, was auch dem Prozentsatz einerzufallig ausgewahlten Entscheidung uber fallende oder steigende Kurse entspricht. DasErgebnis motivierte die direkte Pradiktion, mit der versucht wird, bessere Resultate zuerzielen.
5.1.0.1 Anpassung des Datensatzes
Wie eingangs bereits erwahnt, enthalten Tweets oft Storfaktoren, was die Sentimentanalyseerschwert. Das Bereinigen der Tweets lasst die Accuracy der Sentimentanalyse mit dem
30

5.1. Pradiktion mittels Sentimmentanalyse 31
Abbildung 5.3: Sentiments vor und nach der Anpassung der Tweets
RNTN fur das ”IMDB dataset” zum Beispiel um 3,9% auf 85.5% steigern.[56]
Bei den Daten dieser Arbeit wurde daher auch versucht, Storfaktoren zu beseitigen. Dabeiwurden URLs, Nutzernahmen und Hashtags aus den Texten entfernt. Dies fuhrte dazu,dass das durchschnittliche Sentiment neutraler wurde, wie in Abbildung 5.3 zu sehen ist.Die Accuracy erhohte sich dadurch jedoch lediglich um knapp ein Prozent und die Tweetshaben immer noch eine starke negative Tendenz. Mogliche Storfaktoren, die diese Tendenzauslosen konnen, sind Rechtschreibfehler und Umgangssprache.
5.1.1 Korrelation mit den Aktienkursen
Wie im vorherigen Kapitel bereits erwahnt wurde, teilt die Sentimentanalyse mit demRNTN jeden Tweet in funf Klassen von sehr negativ bis sehr positiv ein. Da jedoch nurbestimmt wird, ob der Aktienkurs am nachsten Tag fallt oder steigt, werden diese funfKlasse auf lediglich zwei Klassen uberfuhrt. Das fuhrt zum Informationsverlust. Um denZusammenhang der funf Klassen und dem Aktienkurs einzelner Unternehmen feststellenzu konnen, wurde mit Hilfe einer linearen Regression der Korrelationskoeffizient zwischenSentiment und Aktienkurs berechnet. Dafur wurde fur jedes Unternehmen an jedem Tagein durchschnittliches Sentiment gebildet und mit den jeweiligen Aktienkursen an dem Taggebildet. Hier wurden die tatsachlichen Kurswerte verwendet und nicht nur die Informati-on, ob der Kurs steigt oder fallt.
Die Aussage des Korrelationskoeffizienten soll an einem Beispiel verdeutlicht werden. Wur-de der Aktienkurs eines Unternehmens sich jeden Tag um den gleichen Prozentsatz wiedas durchschnittliche Sentiment des Unternehmens verandern, dann waren diese mit 100%perfekt positiv korreliert. Entwickelt sich das durchschnittliche Sentiment immer um dennegativen Prozentsatz in die andere Richtung, so lage die Korrelation bei -100%.
Die hochste Korrelation ergibt sich mit 7,13% fur Tweets aus dem Datensatz Symbol. Auchhier konnten wieder große Unterschiede zwischen den einzelnen Unternehmen festgestelltwerden. Beispielsweise korrelieren Tweets, die das Symbol ”AAPL” fur Apple enthaltenzu 51,36% fur alle Tage an denen die Borse geoffnet war. Die Kurznachrichten mit denZeichen ”KO” fur Coca-Cola korrelieren dagegen stark negativ mit -25,03%. Fast keineKorrelation ergab sich bei ”UTX” (United Technologies) mit 0,46% und bei ”PFE” (Pfizer)
31

32 5. Evaluation
Tabelle 5.1: (Absolute) Korrelationen des RNTN-Sentiments mit den Aktienkursen
$Symbol Symbol Name
Korrelation [%] 1,53 5,57 7,13
absolute Korrelation [%] 17,84 18,87 15,19
mit 0,18%.Fur alle gesammelten Tweets der Unternehmen des DJIA lasst sich feststellen, dass derDurchschnitt der Sentimente nur wenig mit dem Kurs des DJIA korreliert.
Die Betrachtung des Durchschnitts der absoluten Korrelationen in Tabelle 5.1 zeigt einenmehr als doppelt so großen Zusammenhang. Das heißt die Stimmung der Kurzmitteilungenandert sich auch, wenn sich der Aktienkurs verandert. Allerdings geht die Veranderungje nach Unternehmen teilweise in die entgegengesetzte Richtung. Das heißt, wenn dasdurchschnittliche Sentiment steigt, fallt der Aktienkurs oder umgekehrt.
Die Korrelationen der $Dollar-Tweets lagen zwischen -10,1% und 7,86%. Die hochsteKorrelation ergab sich fur Tweets uber Microsoft mit dessen Aktienkurs am FolgendenTag mit 52,78%
5.1.1.1 Diskussion der Ergebnisse
Wie vorhergehend bereits erwahnt, kann das schlechte Ergebnis der Pradiktion mittels Sen-timent damit zusammenhangen, dass das verwendete Werkzeug nicht auf Twitter-Datentrainiert wurde.
Angenommen das Sentiment ware jedoch akkurat, so ist noch nicht gesagt, dass ein Zu-sammenhang zwischen einem positiven Tweet und einem steigenden Aktienkurs besteht.In der Arbeit von Bollen et. al.[57] wurde beispielsweise kein signifikanter Zusammenhangzwischen positiver Stimmung auf Twitter und dem DJIA festgestellt. Allerdings wurdeein Zusammenhang zwischen der Gelassenheit (”Calm”) in Tweets und dem Aktienindexfestgestellt.
Fur alle drei Datensatze liegt die absolute Korrelation zwischen Sentiment und Aktienkursbei uber 15%. Das lasst die Schlussfolgerung zu, dass Veranderungen des durchschnittlichenSentiments mit Marktbewegungen korrelieren. Offen ist die Frage, warum fur manche Un-ternehmen ein sehr positives Sentiment zu fallenden Kursen und fur andere zu steigendenKursen fuhrt.
Angenommen es besteht eine signifikante Korrelation zwischen den Nachrichten im Daten-satz und den Aktienkursen der Unternehmen. Dann sollte es auch Neuronale Netze geben,die diese Zusammenhange erlernen und auf andere Texte anwenden konnen. Daher wird imFolgenden versucht, solche Zusammenhange zu erkennen, ohne den Fokus auf das positiveoder negative Sentiment der Tweets zu legen.
5.2 Direkte Pradiktion
5.2.1 Max Pooling-Netz
Mit dem Max Pooling-Netz konnten bessere Ergebnisse erzielt werden als mit dem RNTN.Das Netz erreichte bei der Vorhersage des folgenden Tages eine Accuracy von 55% (sieheTabelle 8.2 im Anhang).
5.2.1.1 Optimierungen und ihre Auswrikungen
Die Ergebnisse von Neuronalen Netzen lassen sich mit einer Vielzahl von Hyperparameternbeeinflussen. Im Folgenden werden einige verschiedene Optimierungen und deren Ergeb-nisse vorgestellt.
32

5.2. Direkte Pradiktion 33
Word Embeddings
0 5 10 15 20 25 30Epoche
0.510
0.515
0.520
0.525
0.530
0.535
0.540
0.545Ge
naui
gkei
tGloVe trainiertGloVe nicht trainiertOne hot
Abbildung 5.4: Unveranderte und veranderte GloVe-Embeddings im Vergleich mit Embed-dings ohne GloVe
Zum Erstellen der Word Embeddings wurden drei Ansatze verglichen. Im ersten Ansatzwurde jedes Wort auf einen Vektor mit zufalligen, gleichverteilten Werten abgebildet. DieReprasentation wurde in der Embedding-Schicht anschließend beim Training des Neuro-nalen Netz angepasst. Die zwei weiteren Ansatze verwenden bereits vortrainierte WordEmbeddings, die mit dem Algorithmus GloVe erstellt wurden. Diese wurden einmal unver-andert ubernommen und einmal – wie im ersten Ansatz – im Training weiter angepasst.
Wie in Abbildung 5.4 zu sehen ist, wurde die hochste Accuracy mit den GloVe-Embeddingsin der zweiten Epoche erreicht, wenn diese beim Lernen vom Netz angepasst werden. Uber30 Epochen hinweg wurde kein besseres Resultat erzielt. Es fallt zusatzlich auf, dass mitden unveranderten GloVe-Embeddings die konstantesten Ergebnisse erzielt werden.
Pooling-Schicht
Das Reduzieren mehrerer Werte auf einen Wert beim Pooling kann auf mehrere Artengeschehen. Neben dem maximalen Wert kann beispielsweise der Durchschnittswert gebildetwerden. Damit wird versucht, Ausreißer zu eliminieren. Mit dem sogenannten AveragePooling wurde nach ein und funf Epochen je eine Accuracy erreicht, die um ein Prozentgeringer war als die beim Max Pooling.
Beim Global Max Pooling wurde nach einer und funf Epochen die gleiche Accuracy wiebeim Max Pooling erreicht, wenn die Nachkommastellen der Prozentzahl vernachlassigtwerden. Verwendet wurde Schlussendlich Max Pooling.
Max Pooling Fenstergroße
In der Max Pooling-Schicht wurde mit kleineren Fenstergroßen eine hohere Accuracy er-zielt, wie in Tabelle 5.2.1.1 zu sehen ist. Nach funf Epochen ergab sich die hochste Accuracyfur die Fenstergroße 20 mit 54%, was zwei Prozent hoher ist als die Accuracy der Fenster-großen zwei, vier und acht.
33
34 5. Evaluation
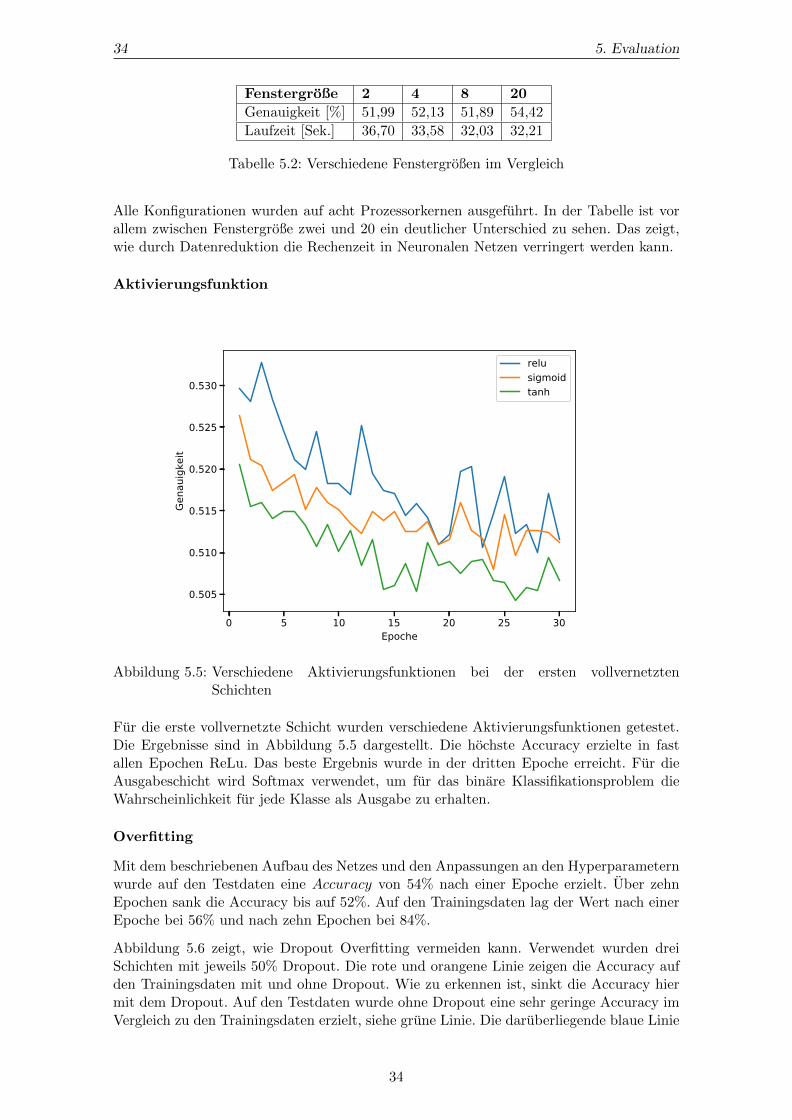
Fenstergroße 2 4 8 20
Genauigkeit [%] 51,99 52,13 51,89 54,42
Laufzeit [Sek.] 36,70 33,58 32,03 32,21
Tabelle 5.2: Verschiedene Fenstergroßen im Vergleich
Alle Konfigurationen wurden auf acht Prozessorkernen ausgefuhrt. In der Tabelle ist vorallem zwischen Fenstergroße zwei und 20 ein deutlicher Unterschied zu sehen. Das zeigt,wie durch Datenreduktion die Rechenzeit in Neuronalen Netzen verringert werden kann.
Aktivierungsfunktion
0 5 10 15 20 25 30Epoche
0.505
0.510
0.515
0.520
0.525
0.530
Gena
uigk
eit
relusigmoidtanh
Abbildung 5.5: Verschiedene Aktivierungsfunktionen bei der ersten vollvernetztenSchichten
Fur die erste vollvernetzte Schicht wurden verschiedene Aktivierungsfunktionen getestet.Die Ergebnisse sind in Abbildung 5.5 dargestellt. Die hochste Accuracy erzielte in fastallen Epochen ReLu. Das beste Ergebnis wurde in der dritten Epoche erreicht. Fur dieAusgabeschicht wird Softmax verwendet, um fur das binare Klassifikationsproblem dieWahrscheinlichkeit fur jede Klasse als Ausgabe zu erhalten.
Overfitting
Mit dem beschriebenen Aufbau des Netzes und den Anpassungen an den Hyperparameternwurde auf den Testdaten eine Accuracy von 54% nach einer Epoche erzielt. Uber zehnEpochen sank die Accuracy bis auf 52%. Auf den Trainingsdaten lag der Wert nach einerEpoche bei 56% und nach zehn Epochen bei 84%.
Abbildung 5.6 zeigt, wie Dropout Overfitting vermeiden kann. Verwendet wurden dreiSchichten mit jeweils 50% Dropout. Die rote und orangene Linie zeigen die Accuracy aufden Trainingsdaten mit und ohne Dropout. Wie zu erkennen ist, sinkt die Accuracy hiermit dem Dropout. Auf den Testdaten wurde ohne Dropout eine sehr geringe Accuracy imVergleich zu den Trainingsdaten erzielt, siehe grune Linie. Die daruberliegende blaue Linie
34

5.2. Direkte Pradiktion 35
zeigt, wie Dropout die Ergebnisse auf den Testdaten vebessert und dafur sorgt, dass dasNetz mehr generalisiert als zuvor.
2.5 5.0 7.5 10.0 12.5 15.0 17.5
Epoche
0.5
0.6
0.7
0.8
0.9
Genauigkeit
Abbildung 5.6: Entwicklung der Accuracy auf den Test- und Trainingsdaten uber mehrereEpochen
5.2.1.2 Ergebnisse
Die Accuracy aller Tweets liegt bei 55% (siehe auch Abbildung 5.7). Zusatzlich wurde diedurchschnittliche Accuracy betrachtet, wenn alle Unternehmen gleich gewichtet werden.Der Schnitt pro Unternehmen liegt zwei Prozent unter diesem Wert. Demnach ist dieAccuracy fur Unternehmen im Durchschnitt hoher, wenn fur diese mehr Tweets existieren.Tatsachlich werden 27% aller Tweets Apple zugeordnet. Alle anderen Unternehmen habeneinen wesentlich kleineren Anteil an der Menge der Tweets und keines besitzt uber 10% ander Gesamtmenge. Mit einer Accuracy von 60% erzielt Apple auch ein hoheres Ergebnisals die anderen Unternehmen im Schnitt und hebt damit das Gesamtergebnis an.
Die hochste Accuracy erreichte Chevron mit 84% gefolgt von General Electric mit 83%.Durch nahere Betrachtung der Ergebnisse beider Unternehmen soll im Folgenden eineErklarung fur das uberdurchschnittliche Ergebnis gefunden werden.
Im Fall von Chevron fiel der Aktienkurs an 16 von den 21 betrachteten Tagen. Das Netzklassifizierte nur 2% der 635 Tweets uber Chevron in die Klasse ”Kurs steigend”und erzielteso eine sehr hohe Accuracy. Precision und Recall sind null, da kein Tweet richtig-positiveingeordnet wurde. Bei Betrachtung der Trainingsdaten zu Chevron zeigt sich, dass auchhier mit 71% ein großer Teil der Tweets mit ”Kurs fallend” klassifiziert wurde.
Hier zeigt sich, dass eine hohe Accuracy nicht zwingend mit dem Inhalt der Tweets zu-sammenhangen muss. Denn wenn der Kurs sich im Trainings- und Testzeitraum gleichentwickelt, kann das Netz uberdurchschnittliche Ergebnisse erzielen, indem es nur anhanddes Unternehmens klassifiziert und den Rest der Informationen vernachlassigt. Im Fallvon Chevron ware es moglich, dass das Neuronale Netze die negative Entwicklung in denTrainingsdaten auf die Testdaten ubertragen hat.
35

36 5. Evaluation
0,0
10
,0
20
,0
30
,0
40
,0
50
,0
60
,0
70
,0
80
,0
90
,0
Acc
ura
cy (
%)
F1 (
%)
Du
rch
sch
nit
t A
ccu
racy
Du
rch
sch
nit
t F1
Abb
ild
ung
5.7:
Acc
ura
cyu
nd
F1
pro
Unte
rneh
men
fur
das
Max
Pool
ing-N
etz
36

5.2. Direkte Pradiktion 37
Bei dem Unternehmen mit der zweithochsten Accuracy ist dem nicht mehr so. GeneralElectric erreichte eine Accuracy von 83%. Im Testdatensatz ist der Aktienkurs an 19 von 21Tagen gefallen. Im Trainingsdatensatz gehoren lediglich 40% der Tweets zur Klasse ”Kursfallt”. Das Neuronale Netze konnten hier demnach nicht aus einer Mehrheit einer Klassein den Trainingsdaten auf eine Mehrheit in den Testdaten schließen. Dennoch klassifiziertedas Netz 91% der Tweets mit ”Kurs fallend” und erzielte so eine hohe Accuracy. An denzwei Tagen, an denen der Kurs von General Electric stieg, wurden 16% der Tweets richtigklassifiziert (Recall). Von allen Klassifizierungen fur fallende Kurse waren nur 23% richtig(Precision). Relativ betrachtet wurden so mehr falsche Pradiktionen fur steigende als furfallende Kurse gemacht.
Die durchschnittliche Precision liegt bei 57%, der durchschnittliche Recall bei 47%. Dierichtig-positiven Prognosen sind demnach im Verhaltnis zu allen positiven Kursentwicklun-gen niedriger als im Verhaltnis zu allen positiven Prognosen. In andern Worten existierenweniger falsch-positive als falsch-negative Prognosen, da gilt:
Precision < Recall =RP
RP + FP<
RP
RP + FN⇒ FN < FP
Der großte Unterschied zwischen Precision und Recall existiert zwischen den Unternehmen3M und Travelers Company. Fur beide Unternehmen stellt sich daher die Frage, warumofter falsche negative als falsche positive Prognosen geliefert wurden. Fur beide Unter-nehmen wurden uber 97% negative Prognosen gemacht. Von den sehr wenigen positivenPrognosen waren alle korrekt, weshalb die bestmogliche Precision erreicht wurde. Da derKurs der beiden Unternehmen nicht ubermaßig stark fiel, waren sehr viele der Pradiktionenfur sinkende Kurse nicht korrekt. Dadurch kommt es zu einem sehr niedrigen Recall.
5.2.2 Convolution-Netz
Das Convolutional-Netz erreichte eine Accuracy von 54% fur die Vorhersage des nachs-ten Tages. Vor mehreren Optimierungen war diese um zwei Prozent geringer. Diese Ver-besserungen werden im folgenden Abschnitt vorgestellt. Anschließend wird naher auf dieErgebnisse eingegangen.
5.2.2.1 Optimierungen und ihre Auswirkungen
Anzahl der Convolutional-Schichten
Ein ”Deep Convolutional Neural Network” kann aus sehr vielen aufeinanderfolgendenConvolutional- und Max-Pooling-Schichten bestehen. Daher wurde mit ein bis drei Kombi-nationen aus beiden Schichten getestet, wie sich die Anzahl der Schichten auf die Accuracyauswirkt. Fur jede zusatzliche Kombination aus Convolutional- und Max-Pooling-Schichtsank die Accuracy auf den Test- und Trainingsdaten um circa ein Prozent.
Duch die zusatzlichen Schichten bekommt das Neuronale Netz zusatzliche Gewichte undwird dadurch komplexer. Jedoch verschlechterten zusatzliche Schichten die Accuracy. Daskann damit zusammenhangen, dass der Trainingsdatensatz zu klein und das Problem nichtkomplex genug fur das Neuronale Netz ist.
Anzahl Filter in Convolutional-Schicht
Fur verschiedene Anzahl an Filtern ergab sich die hochste Accuracy mit 53% fur 128 Filter.Im Vergleich dazu wurde mit 64 und 256 Neuronen eine um jeweils ein Prozent geringereAccuracy erzielt. Mit mehr Filtern steigt die Anzahl der Parameter im Netz. Dadurch kames zum Overfitting. Mit weniger Filter sank sowohl die Accuracy auf den Trainingsdaten-als auch auf den Testdaten.
37
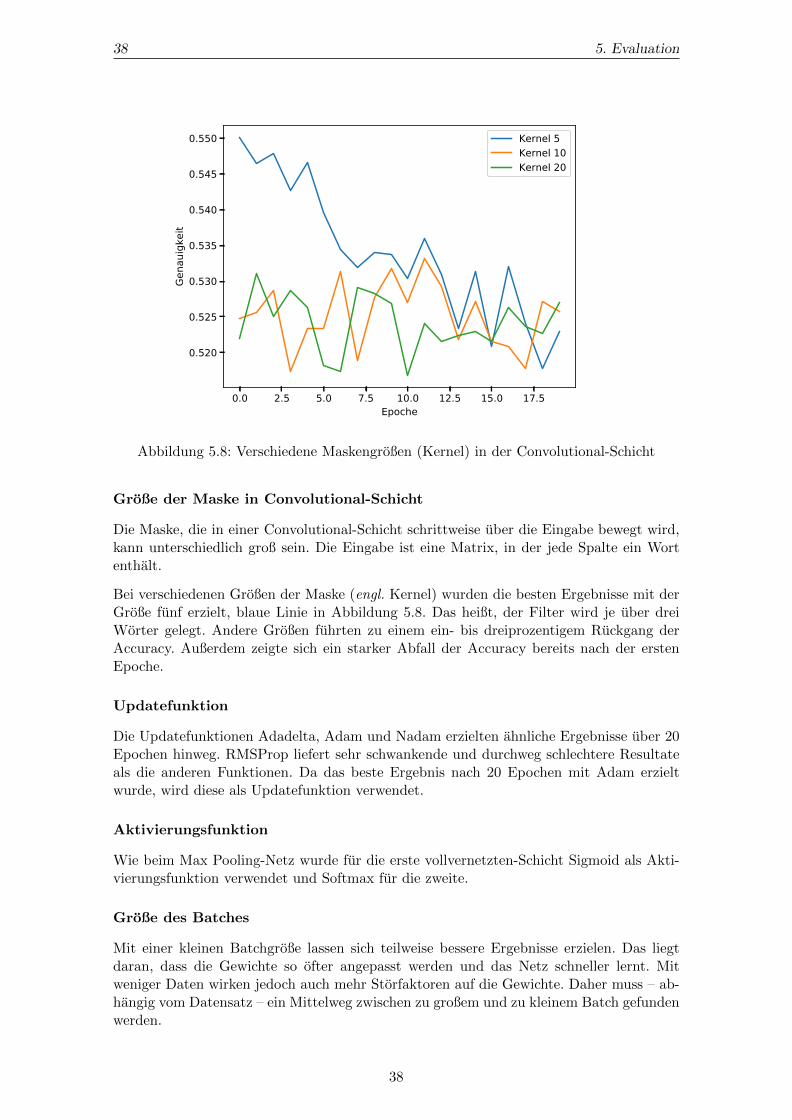
38 5. Evaluation
0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5Epoche
0.520
0.525
0.530
0.535
0.540
0.545
0.550
Gena
uigk
eit
Kernel 5Kernel 10Kernel 20
Abbildung 5.8: Verschiedene Maskengroßen (Kernel) in der Convolutional-Schicht
Große der Maske in Convolutional-Schicht
Die Maske, die in einer Convolutional-Schicht schrittweise uber die Eingabe bewegt wird,kann unterschiedlich groß sein. Die Eingabe ist eine Matrix, in der jede Spalte ein Wortenthalt.
Bei verschiedenen Großen der Maske (engl. Kernel) wurden die besten Ergebnisse mit derGroße funf erzielt, blaue Linie in Abbildung 5.8. Das heißt, der Filter wird je uber dreiWorter gelegt. Andere Großen fuhrten zu einem ein- bis dreiprozentigem Ruckgang derAccuracy. Außerdem zeigte sich ein starker Abfall der Accuracy bereits nach der erstenEpoche.
Updatefunktion
Die Updatefunktionen Adadelta, Adam und Nadam erzielten ahnliche Ergebnisse uber 20Epochen hinweg. RMSProp liefert sehr schwankende und durchweg schlechtere Resultateals die anderen Funktionen. Da das beste Ergebnis nach 20 Epochen mit Adam erzieltwurde, wird diese als Updatefunktion verwendet.
Aktivierungsfunktion
Wie beim Max Pooling-Netz wurde fur die erste vollvernetzten-Schicht Sigmoid als Akti-vierungsfunktion verwendet und Softmax fur die zweite.
Große des Batches
Mit einer kleinen Batchgroße lassen sich teilweise bessere Ergebnisse erzielen. Das liegtdaran, dass die Gewichte so ofter angepasst werden und das Netz schneller lernt. Mitweniger Daten wirken jedoch auch mehr Storfaktoren auf die Gewichte. Daher muss – ab-hangig vom Datensatz – ein Mittelweg zwischen zu großem und zu kleinem Batch gefundenwerden.
38
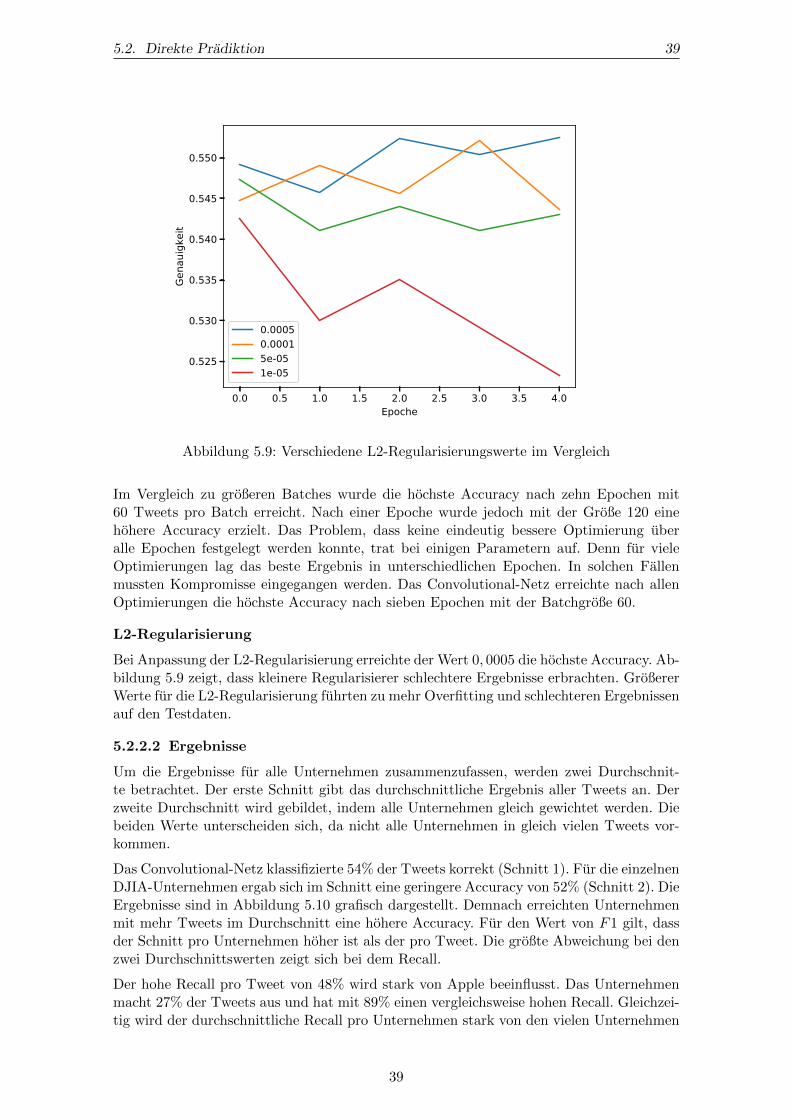
5.2. Direkte Pradiktion 39
0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0Epoche
0.525
0.530
0.535
0.540
0.545
0.550Ge
naui
gkei
t
0.00050.00015e-051e-05
Abbildung 5.9: Verschiedene L2-Regularisierungswerte im Vergleich
Im Vergleich zu großeren Batches wurde die hochste Accuracy nach zehn Epochen mit60 Tweets pro Batch erreicht. Nach einer Epoche wurde jedoch mit der Große 120 einehohere Accuracy erzielt. Das Problem, dass keine eindeutig bessere Optimierung uberalle Epochen festgelegt werden konnte, trat bei einigen Parametern auf. Denn fur vieleOptimierungen lag das beste Ergebnis in unterschiedlichen Epochen. In solchen Fallenmussten Kompromisse eingegangen werden. Das Convolutional-Netz erreichte nach allenOptimierungen die hochste Accuracy nach sieben Epochen mit der Batchgroße 60.
L2-Regularisierung
Bei Anpassung der L2-Regularisierung erreichte der Wert 0, 0005 die hochste Accuracy. Ab-bildung 5.9 zeigt, dass kleinere Regularisierer schlechtere Ergebnisse erbrachten. GroßererWerte fur die L2-Regularisierung fuhrten zu mehr Overfitting und schlechteren Ergebnissenauf den Testdaten.
5.2.2.2 Ergebnisse
Um die Ergebnisse fur alle Unternehmen zusammenzufassen, werden zwei Durchschnit-te betrachtet. Der erste Schnitt gibt das durchschnittliche Ergebnis aller Tweets an. Derzweite Durchschnitt wird gebildet, indem alle Unternehmen gleich gewichtet werden. Diebeiden Werte unterscheiden sich, da nicht alle Unternehmen in gleich vielen Tweets vor-kommen.
Das Convolutional-Netz klassifizierte 54% der Tweets korrekt (Schnitt 1). Fur die einzelnenDJIA-Unternehmen ergab sich im Schnitt eine geringere Accuracy von 52% (Schnitt 2). DieErgebnisse sind in Abbildung 5.10 grafisch dargestellt. Demnach erreichten Unternehmenmit mehr Tweets im Durchschnitt eine hohere Accuracy. Fur den Wert von F1 gilt, dassder Schnitt pro Unternehmen hoher ist als der pro Tweet. Die großte Abweichung bei denzwei Durchschnittswerten zeigt sich bei dem Recall.
Der hohe Recall pro Tweet von 48% wird stark von Apple beeinflusst. Das Unternehmenmacht 27% der Tweets aus und hat mit 89% einen vergleichsweise hohen Recall. Gleichzei-tig wird der durchschnittliche Recall pro Unternehmen stark von den vielen Unternehmen
39

40 5. Evaluation
0,0
10
,0
20
,0
30
,0
40
,0
50
,0
60
,0
70
,0
80
,0
90
,0
Apple
American Express
Boeing
Caterpillar
Cisco
Chevron
DuPont
Disney
General Electric
Goldman Sachs
Home Depot
IBM
Intel
Johnson & Johnson
JPMorgan Chase
Coca-Cola
McDonald's
3M
Merck
Microsoft
Nike
Pfizer
Procter & Gamble
Travelers Companies
United Healh
United Technologies
Visa
Wal-Mart
Exxon Mobil
Acc
ura
cy (
%)
F_1
(%
)D
urc
hsc
hn
itt
Acc
ura
cyD
urc
hsc
hn
itt
F1
Abb
ild
ung
5.10:
Acc
ura
cyu
nd
F1
pro
Unte
rneh
men
fur
das
Convo
luti
onal
-Net
z
40

5.2. Direkte Pradiktion 41
mit niedrigem Recall beeinflusst, die nur in wenigen Tweets erwahnt werden. Chevron,Nike und Exxon Mobil haben den geringsten Recall unter allen Unternehmen. Fur alledrei Unternehmen wurden weniger als 10% Pradiktionen fur steigende Kurse gemacht.Gleichzeitig sind fur alle drei Unternehmen uber 70% der Tweets in den Testdaten mitfallendem Kurs klassifiziert.
Das Netz klassifizierte fur die drei Unternehmen viele Tweets als negativ. Dadurch wurdennur wenige steigende Kurse richtig pradiziert. Und im Verhaltnis dazu wurden viele fallendeKurse falsch eingeordnet. Dies fuhrte zu dem geringen Recall. Gleichzeitig wurde in zwei derdrei Falle so viele richtige Klassifikationen fur fallende Kurse gemacht, dass die Accuracyuber dem Durchschnitt lag. Im dritten Fall (Nike) stieg der Kurs in den meisten Fallenund die Mehrheit der negativen Klassifikationen war falsch.
Fur Precision und F1 zeigt sich wie beim Recall, dass Unternehmen, die selten in denTweets vorkommen, in der Regel schlechtere Ergebnisse erzielen als jene, die oft erwahntwerden.
5.2.3 LSTM-Netz
Das LSTM erreichte anfangs lediglich eine Accuracy von 52%. Durch die im Folgendenvorgestellten Optimierungen konnte dieser Wert auf 54% gesteigert werden. Im Anschlussdaran werden die Ergebnisse, die mit dem Netz erzielt wurden, naher vorgestellt.
5.2.3.1 Optimierungen und ihre Auswirkungen
Die Hyperparameter wurden teilweise parallel optimiert. Daher steigt das Ergebnis imFolgenden nicht notwendigerweise mit jeder Optimierung.
Updatefunktion
2 4 6 8 10Epoche
0.490
0.495
0.500
0.505
0.510
0.515
0.520
0.525
0.530
Gena
uigk
eit
rmspropAdamAdagradSGD
Abbildung 5.11: Updatefunktionen im Vergleich fur das LSTM-Netz
Als Updatefunktion wurde der Algorithmus RMSProp verwendet. Nach zehn Epochenlieferte dieser leicht bessere Ergebnisse als die Funktionen Adam, Adagrad und SGD. Bisauf die ersten drei Epochen beim SGD schneiden jedoch alle vier Funktionen sehr ahnlichab und unterschieden sich meist nur um 0,5%.
41
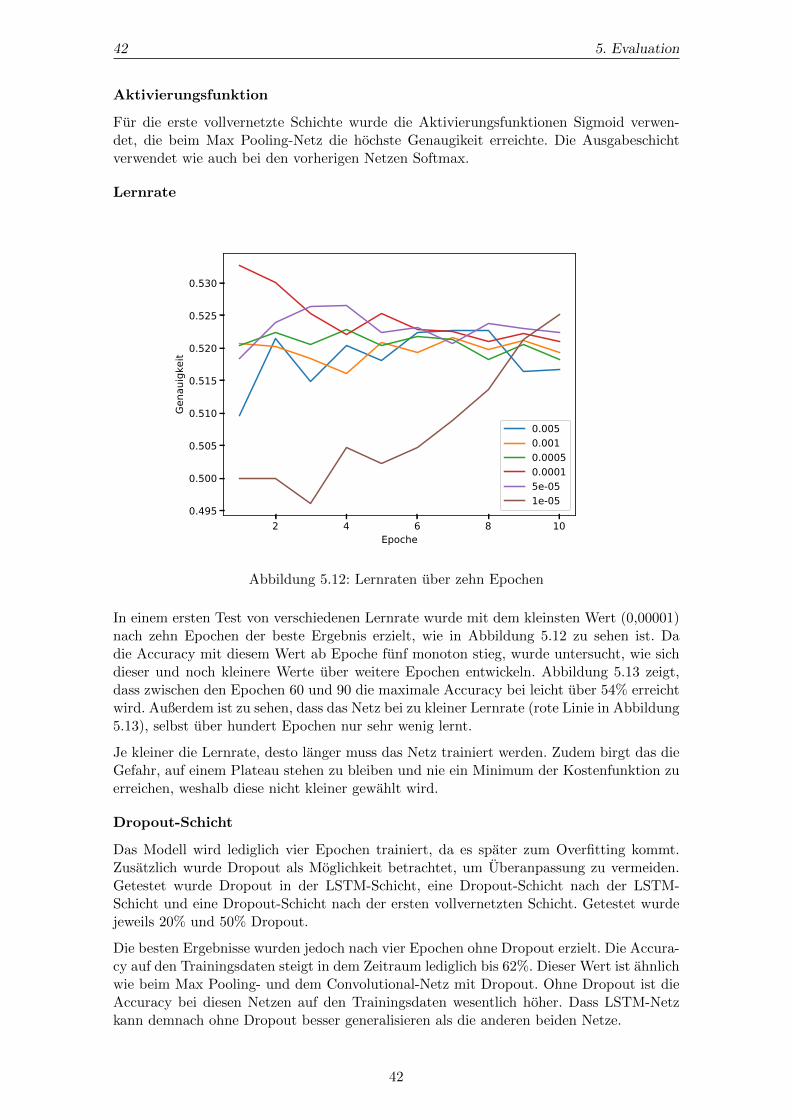
42 5. Evaluation
Aktivierungsfunktion
Fur die erste vollvernetzte Schichte wurde die Aktivierungsfunktionen Sigmoid verwen-det, die beim Max Pooling-Netz die hochste Genaugikeit erreichte. Die Ausgabeschichtverwendet wie auch bei den vorherigen Netzen Softmax.
Lernrate
2 4 6 8 10Epoche
0.495
0.500
0.505
0.510
0.515
0.520
0.525
0.530
Gena
uigk
eit
0.0050.0010.00050.00015e-051e-05
Abbildung 5.12: Lernraten uber zehn Epochen
In einem ersten Test von verschiedenen Lernrate wurde mit dem kleinsten Wert (0,00001)nach zehn Epochen der beste Ergebnis erzielt, wie in Abbildung 5.12 zu sehen ist. Dadie Accuracy mit diesem Wert ab Epoche funf monoton stieg, wurde untersucht, wie sichdieser und noch kleinere Werte uber weitere Epochen entwickeln. Abbildung 5.13 zeigt,dass zwischen den Epochen 60 und 90 die maximale Accuracy bei leicht uber 54% erreichtwird. Außerdem ist zu sehen, dass das Netz bei zu kleiner Lernrate (rote Linie in Abbildung5.13), selbst uber hundert Epochen nur sehr wenig lernt.
Je kleiner die Lernrate, desto langer muss das Netz trainiert werden. Zudem birgt das dieGefahr, auf einem Plateau stehen zu bleiben und nie ein Minimum der Kostenfunktion zuerreichen, weshalb diese nicht kleiner gewahlt wird.
Dropout-Schicht
Das Modell wird lediglich vier Epochen trainiert, da es spater zum Overfitting kommt.Zusatzlich wurde Dropout als Moglichkeit betrachtet, um Uberanpassung zu vermeiden.Getestet wurde Dropout in der LSTM-Schicht, eine Dropout-Schicht nach der LSTM-Schicht und eine Dropout-Schicht nach der ersten vollvernetzten Schicht. Getestet wurdejeweils 20% und 50% Dropout.
Die besten Ergebnisse wurden jedoch nach vier Epochen ohne Dropout erzielt. Die Accura-cy auf den Trainingsdaten steigt in dem Zeitraum lediglich bis 62%. Dieser Wert ist ahnlichwie beim Max Pooling- und dem Convolutional-Netz mit Dropout. Ohne Dropout ist dieAccuracy bei diesen Netzen auf den Trainingsdaten wesentlich hoher. Dass LSTM-Netzkann demnach ohne Dropout besser generalisieren als die anderen beiden Netze.
42

5.2. Direkte Pradiktion 43
0 20 40 60 80 100Epoche
0.49
0.50
0.51
0.52
0.53
0.54
Gena
uigk
eit
1e-055e-061e-065e-07
Abbildung 5.13: Lernraten uber 100 Epochen
43

44 5. Evaluation
0,0
10
,0
20
,0
30
,0
40
,0
50
,0
60
,0
70
,0
80
,0
90
,0
Acc
ura
cy (
%)
F_1
(%
)D
urc
hsc
hn
itt
Acc
ura
cyD
urc
hsc
hn
itt
F1
Abb
ild
ung
5.14
:A
ccura
cyu
nd
F1
pro
Unte
rneh
men
fur
das
LST
M-N
etz
44

5.2. Direkte Pradiktion 45
5.2.3.2 Ergebnisse
Das Neuronale Netz mit einer LSTM- gefolgt einer vollvernetzten Schicht erreichte proTweet eine Accuracy von 54% und einen F1-Wert von 55%.
Die Ergebnisse der einzelnen Unternehmen sind in Abbildung 5.14 zu sehen. Diese sindim Durchschnitt, wenn jedes Unternehmen gleich gewichtet wird, geringer als die durch-schnittlichen Metriken fur alle Tweets gesamt betrachtet. Demnach werden die besserenErgebnisse von den Unternehmen erzielt, fur die mehr Tweets vorliegen.
Vor allem beim Recall ist der Unterschied der beiden Durchschnitte auffallend groß, wasauch zu einer großen Diskrepanz der Werte bei der Metrik F1 fuhrt. Werden alle Unterneh-men gleich gewichtet, liegt der Recall bei 37%. Wenn jeder Tweet gleich gewichtet wird,liegt der Recall bei 56%. Das Unternehmen mit dem niedrigsten Recall von zwei Prozentwird mit einem Prozent auch in unterdurchschnittlich wenigen Tweets erwahnt.
Allerdings lasst sich nicht fur alle Unternehmen aus vielen Tweets auf hohe Ergebnisse inden vier Metriken folgern. Beispielsweise hat American Express den zweithochsten Recall,wird aber auch nur in einem Prozent der Tweets erwahnt. Fur dieses Unternehmen lagenim Trainingszeitraum 84% der Tweets in der Klasse ”Kurs steigt”. Das Neuronale Netzklassifizierte den Großteil der Tweets in den Testdaten ebenfalls mit ”Kurs steigt”, waszu vielen richtig-positiven Klassifizierungen fuhrte. Dadurch kam es auch zu einem hohenRecall.
Hier zeigt sich erneut, dass die Neuronale Netze die Moglichkeit haben, den Namen einesUnternehmens generell mit fallenden oder steigenden Kursen zu assoziieren, wenn es inden Trainingsdaten sehr oft gestiegen oder gefallen ist. Daher wurden in einem Test alleAktiensymbole aus den Tweets entfernt (siehe 5.2.5 Selektion der Daten).
Ein Beispiel fur ein unterdurchschnittliches Ergebnis trotz vieler Tweets ist Microsoft. DasUnternehmen macht sechs Prozent der betrachteten Tweets im Trainingsdatensatz undacht Prozent im Testdatensatz aus, was deutlich uber dem Durchschnitt liegt. Dennochwurde in den Trainingsdaten lediglich ein F1-Wert von 21% erreicht. Der Wert ist sogering, da nur 11% der Tweets am folgenden mit ”Kurs steigt” klassifiziert wurden. ImTestdatensatz gehoren 58% der Tweets zu dieser Klasse, also nicht deutlich viel mehr alsdie Halfte. Dass das ubermaßig hohe Auftreten einer Klasse fur das Unternehmen in denTrainingsdaten von dem Neuronalen Netz auf die Testdaten ubertragen wurde, scheintdaher weniger wahrscheinlich. Eine andere Begrundung fur diese Entwicklung ist, dass dieTweets zu Microsoft im Testzeitraum wenig mit dem Aktienkurs korrelieren. In diesemFall wurde das bedeuten, dass es in den Tweets viele Indikatoren fur fallende Kurse gab,der Kurs aber tatsachlich nicht gefallen ist.
Zusammenfassend lasst sich sagen, dass auch bei dem LSTM-Netz zwischen den Unter-nehmen große Unterschiede existieren. Dabei scheinen extreme Ergebnisse von sehr vielenFaktoren abzuhangen und eine eindeutige Begrundung fur sehr hohe und sehr niedrigeWerte ist nur schwer zu bestimmen.
5.2.4 Anpassung des Datensatzes
5.2.4.1 Storfaktoren
Im Vergleich zu oft fur die Sentimentanalyse verwendendeten Datensatzen wie ”The LargeMovie Review Dataset” (oft auch kurz ”IMDB dataset” genannt) und dem ”Rotten Toma-toes Dataset” enthalt dieser Datensatz sehr viele URLs, Nutzernamen (mit ”@” markiert),Hashtags (mit ”#” markiert) und Emojis.
45

46 5. Evaluation
Um moglichst viele dieser Storfaktoren vor der Sentimentanalyse zu entfernen, wurden alleURLs, Nutzernamen und Hashtags entfernt.
Zudem wurden nur Nutzer mit uber 100 Follower berucksichtigt, um Spam zu vermeiden.Außerdem wurden englisch- und deutschsprachige Tweets nur getrennt betrachtet.
5.2.5 Selektion der Daten
Die einzelnen Worter in den Texten werden anstelle von Buchstaben durch je eine Ganzzahlreprasentiert. Diese steht fur die Haufigkeit, mit der das Wort uber alle Tweets verteilt vor-kommt, wobei das Wort mit der hochsten Zahl am haufigsten vorkommt. Fur das Trainingund die Uberprufung des Neuronalen Netzes wurden lediglich die 20.000 am haufigsten vor-kommenden Worter betrachtet. Ein großeres Worterbuch brachte keine Verbesserung derAccuracy mit sich, ein kleineres Worterbuch mit 5000 und 2000 Wortern verschlechtertedie Accuracy beim Max Pooling-Netz um ein beziehungsweise drei Prozent.
Eine mogliche Verbesserung der Ergebnisse der Neuronalen Netz ist das Loschen der Er-wahnung der Aktienunternehmen, sodass zum Beispiel fur ein Aktienunternehmen, dessenKurs in den Trainingsdaten immer gefallen ist, das Netz nicht den Zusammenhang zwi-schen Name des Unternehmens und fallendem Kurs erlernt. Fur diesen Datensatz ergabsich jedoch mit dem Max Pooling-Netz eine Einbuße von drei Prozent bei der Accuracy.
Fur jeden Tweet ist die Anzahl der Follower des Autors im Datensatz enthalten, alsodie Anzahl der Personen, die den Autor auf Twitter abonniert hat. Werden nur Tweetsberucksichtigt, deren Autoren mindestens 100 Follower haben, so lasst sich die Accuracybeim Max Pooling-Netz uber funf Epochen um ein Prozent auf 53% steigern.
5.3 Vergleich der Pradiktionsmoglichkeiten
Im Folgenden wird die Pradiktion mittels Sentimentanalyse mit der direkten Pradiktionverglichen. Wie im vorherigen Teil der Evaluation basieren die Ergebnisse auf den DJIA-Unternehmen im Datensatz $Symbol.
Die Tabelle 5.3 zeigt, dass die direkte Pradiktion besser abgeschnitten hat als die Bestim-mung mittels Sentimentanalyse. Dass mit der Sentimentanalyse schlechtere Ergebnisseerzielt wurden als mit einem Zufallsexperiment, kann verschiedene Grunde haben. Zumeinen ist das RNTN auf einer anderen Domane trainiert worden als Kurzmitteilungen.Zum anderen muss keine positive Korrelation zwischen dem durchschnittlichen Sentimentauf Twitter uber ein Unternehmen und dessen Aktienkurs bestehen.
Die drei Neuronalen Netze zur direkten Pradiktion schnitten mit 54% und 55% Accura-cy besser ab als das vorgestellte Zufallsexperiment. Zumindest bei der Accuracy hat sichgezeigt, dass mit komplexeren Netzen auf den verwendeten Daten nicht unbedingt bes-sere Ergebnisse erzielt werden. Hier war vor allem Overfitting ein Problem. Betrachtetman genauer, wie die endgultigen Metriken zu Stande kamen, so fallt auf, dass das Max
Pro Tweet Pro UnternehmenPradiktionsart Name
Accuracy [%] F1 [%] Accuracy [%] F1 [%]
Mittels Sentimentanalyses RNTN 49,7 39,6 49,0 22,5
Max Pooling 55,3 51,2 53,2 26,4Convolution 53,7 51,0 53,2 29,6DirektLSTM 54,0 54,8 51,9 37,8
Tabelle 5.3: Endergebnisse aller Neuronalen Netze im Vergleich
46

5.4. Vergleich der drei Datensatze 47
Pooling-Netz uber den Testzeitraum viele Tweets uber ein Unternehmen hauptsachlich ineine Klasse eingeteilt hat. So wurden vor allem gute Ergebnisse erzielt, wenn die Aktietatsachlich hauptsachlich gestiegen oder gefallen ist. Dahingegen waren die Klassifizierun-gen von den letzten beiden Netzen ausgeglichener. Das lasst den Schluss zu, dass dasConvolutional- und das LSTM-Netz ihr Potenzial auf einem großeren Datensatz, bei demidealerweise die Klassen pro Unternehmen gleich oft auftreten, besser ausschopfen konntenund hier bessere Ergebnisse als das Max-Pooling-Netz erzielen konnten.
Bei der Metrik F1 schneidet das LSTM-Netz am Besten ab. Der Wert wird durch diemeisten richtig der Klasse der steigenden Kurse zugeordneten Klassifizierungen erreicht.Sowohl im Verhaltnis zu allen Klassifizierungen ”Kurs steigt” als auch im Verhaltnis zu dentatsachlich zur Klasse ”Kurs steigt”. Die Pradiktionen des Netzes sind im Vergleich zu denanderen Netzen am ausgeglichensten. Die restlichen Netze haben mehr Tweets zur Klasseder fallenden Kurse zugeordnet. Tatsachlich sind jedoch beiden Klassen exakt gleich vieleTweets zugeordnet.
Wird der Durchschnitt aus Accuracy und F1 zur Bewertung der vier Methoden verwen-det, so erzielt das LSTM-Netz die besten Ergebnisse mit 54%. Darauf folgt das MaxPooling-Netz mit 53%. Das Convolutional-Netz erreicht 52% und die Pradiktion mittelsSentimentanalyse lediglich 45%.
5.4 Vergleich der drei Datensatze
Accuracy [%] F1 [%] Anzahl Tweets [Tsd.]
$Symbol 54,0 54,8 60
Symbol 52,9 48,4 1.396
Name 50,1 51,9 2.806
Tabelle 5.4: Ergebnisse auf den verschiedenen Datensatzen im Vergleich
Im vorhergehenden Teil der Evaluation wurden die Ergebnisse vorgestellt, die fur Tweetsaus dem Datensatz $Symbol erreicht wurden. Das sind jene Tweets, die ein Dollarzeichen,gefolgt von dem Symbol eines Aktienunternehmens, enthalten. Zum Vergleich werden imFolgenden die Ergebnisse der restlichen betrachteten Datensatze vorgestellt.
Dass durch die drei verschiedenen Schreibweisen sehr unterschiedliche Tweets gesammeltwurden, soll an zwei Beispielen verdeutlicht werden. Ein relevanter Tweet im Datensatz$Symbol ist zum Beispiel folgender:
Appeals court revives lawsuit claiming allegedly created iOS app monopoly.Read more: [Link] $AAPL
Nicht relevant fur das Unternehmen Visa mit dem Aktiensymbol V ist beispielsweise:
New on Ebay! Grand Theft Auto GTA V 5 (PS4) Brand New Sealed GameUK.
Der Vergleich der Schreibweisen basiert auf den Ergebnissen des LSTM-Netzes, welchesim vorherigen Abschnitt im Durchschnitt die besten Resultate geliefert hat.
Wie Tabelle 5.4 zeigt, wurden die besten Ergebnisse auf dem kleinsten Datensatz erzielt. Imvorherigen Kapitel wurde bereits erwahnt, dass dieser vermutlich die wenigsten Storsignaleund den relevantesten Inhalt enthalt, da wenig andere Bedeutungen fur die Schreibweisemit dem Dollarzeichen existieren. Die Vermutung liegt nahe, dass die Ergebnisse fur denDatensatz $Symbol weiter verbessert werden konnten, wenn dieser so viele Daten enthaltenwurde, wie die anderen Datensatze.
47

48 5. Evaluation
5.5 Zeitfenster der Vorhersage
Abbildung 5.15: Ergebnisse fur die Pradiktion des Aktienkurses fur verschieden viele Tageim Voraus
Die Ergebnisse im vorhergehenden Teil betrachteten jeweils den Zusammenhang zwischeneinem Tweet und dem Aktienkurs am folgenden Tag. Zusatzlich werden im Folgendendie Resultate zwei, drei und vier Tage nach dem Erstellen des Tweets untersucht. DieErgebnisse stammen von dem LSTM-Netz.
In Abbildung 5.15 ist zu sehen, dass fur zwei, drei und vier Tage im Voraus bessere Re-sultate erzielt wurden als fur einen Tag im Voraus.
Diese Tendenz ist die gleich wie in der Arbeit von Bollen[14], in der ein Zusammenhangzwischen der Stimmung auf Twitter und dem Atkienkurs drei bis vier Tage spater gefundenwurde.
Sei der Durchschnitt aus Accuracy und F1 das Maß fur den Vergleich anhand eines Werts,dann wird das beste Ergebnis fur die Pradiktion vier Tage nach der Erstellung des Tweetserzielt. Hier wurde eine Accuracy von 61% und ein F1-Wert von 60% erreicht.
5.6 Alternative Analagestrategie
Wurde die Accuracy fur jeden Tweet als Anlagestrategie auf dem Aktienmarkt verwendetwerden, wurde das bei 20 Millionen Tweets bis zu 20 Millionen Transaktionen bedeuten.Da diese Strategie unpraktikabel ware und um besser analysieren zu konnen, wie die Ac-curacy jeweils zu Stande kommt, wird das LSTM-Netz im Folgenden zusatzlich anhandeiner einfacheren aber realistischeren Anlagestrategie verglichen. Hierbei soll fur jedes Un-ternehmen fur jeden Tag entscheiden werden, ob die Aktie des Unternehmens am nachstenTag steigt oder fallt. Diese Entscheidung ist fur jeden Tag wahr oder falsch. Die Ergebnisselassen sich wieder mit den bereits vorgestellten Metriken bewerten. Diese Strategie sei imFolgenden ”Pradiktion pro Unternehmen” genannt.
Die Pradiktion pro Unternehmen liefert eine Accuracy von 52%, wenn fur jeden Tag ent-schieden wird, ob der Kurs steigt oder fallt. Im Vergleich dazu wird bei jedem Unternehmenim Schnit 51% Accuracy erzielt, wenn fur jeden Tweet entschieden wird, wie sich der Kursentwickelt. Erwartungsgemaß sind die Vorhersagen, die alle Tweets an einem Tag betrach-ten, ofter korrekt als die Pradiktionen, die nur auf einem Tweet basieren.
Auch beim F1-Wert erzielt die Pradiktion pro Unternehmen mit 38% bessere Ergebnisseals die Pradiktion pro Tweet fur jedes Unternehmen. Dieser Wert liegt bei 33%.
48

5.7. Ergebnisse fur DAX- und DJIA-Unternehmen im Vergleich 49
Bei der Pradiktion pro Unternehmen steigt der Kurs im Schnitt an 9,2 Tagen und fallt an11,8 Tagen. Im Vergleich zum gesamten Datensatz sind die beiden Klassen pro Unterneh-men nicht gleich stark vertreten.
In den vorherigen Teilen wurde fur jeden Tweet einzeln bestimmt, ob der Aktienkurs falltoder steigt. Hier wurde als Vergleich eine Strategie betrachtet, die zufallig entscheidet,zu welcher Klasse ein Kurs gehort. Damit wird eine Accuracy von 50% erzielt. Da diebeiden Klassen bei der Pradiktion pro Unternehmen nicht mehr gleich groß sind, kann die50%-Marke nicht mehr zum Vegleich genutzt werden.
Daher wird statt dem Zufall eine andere einfache Anlagestrategie verwendet, mit der dieErgebnisse verglichen werden konnen. Dabei wird fur jeden Tag die gleiche Kursverande-rung prognostiziert wie am aktuellen Tag. Das heißt, wenn der Kurs heute steigt, wirdprognostiziert, dass er auch morgen steigt. Anhand dieser Strategie lasst sich das Ergebnisder Pradiktion pro Unternehmen bewerten.
Die Vergleichsstrategie erreicht eine Accuracy von 64% und ein F1-Wert von 60%. Dem-nach scheint die Vorhersage pro Unternehmen mit 52% wenig vielversprechend. Allerdingsbesitzt die Vergleichsstrategie den Vorteil, dass sie Informationen uber die Aktienkursevom Vortag im Testzeitraum besitzt. Die Neuronalen Netze hingegen, erhalten lediglichInformationen aus dem Trainingszeitraum, der zeitlich vor dem Testzeitraum liegt.
5.7 Ergebnisse fur DAX- und DJIA-Unternehmen im Ver-gleich
Der Anteil an Tweets uber DJIA-Unternehmen ist etwa zehn mal großer als der an Anteilan Tweets uber DAX-Unternehmen. Da die Große des Datensatzes Auswirkungen auf dieLeistungsfahigkeit eines Neuronalen Netzes hat, wurden die Netze mit den Daten zu denDJIA-Unternehmen optimiert. Mit dem LSTM-Netz, welches die besten Resultate lieferte,werden im Folgenden die Ergebnisse fur die DAX-Unternehmen vorgestellt.
Die Pradiktion der Kurse der DAX-Unternehmen basierte auf deutschsprachigen Tweets.Die Ergebnisse sind in Tabelle 5.7 dargestellt. Fur die drei Datensatze ergab sich diehochste Accuracy fur den Datensatz Name. Auch dieser lag nur knapp uber den 50%, diemit der Entscheidung per Zufall getroffen werden konnte. Hauptsachlich kann das an dergeringen Anzahl an Daten im Vergleich zu den DJIA-Unternehmen liegen.
In Tabelle 5.7 sind die Ergebnisse fur verschieden viele Tage im Voraus fur den Datensatz$Symbol aufgelistet. Fur zwei und drei Tage nach dem Erstellen der Tweets wurde imSchnitt der hochste F1-Wert und die hochste Accuracy erreicht. Interessant ist die Beob-achtung, dass auch hier die beste Prognose nicht fur einen Tag im Voraus gemacht wurde,wie es vielleicht naheliegend ware.
DAX DJIA
Datensatz Accuracy F1 Accuracy F1
$Symbol 45,8 34,3 54,0 54,8
Symbol 50,9 42,1 52,9 48,4
Name 51,5 44,0 50,1 51,9
Tabelle 5.5: Die Ergebnisse fur DAX- und DJIA-Unternehmen im Vergleich
49

50 5. Evaluation
DAX DJIA
Tage Differenz Accuracy F1 Accuracy F1
1 45,8 34,3 54,0 54,8
2 51,5 63,0 60,1 56,8
3 57,5 52,4 56,8 62,9
4 55,0 62,4 60,6 60,3
Tabelle 5.6: Prognosen fur verschieden viele Tage im Voraus
5.8 Vergleich Arbeiten der Literatur
Die besten Ergebnisse dieser Arbeit wurden bei der Pradiktion der Aktienkurse aller Unter-nehmen im DJIA uber vier Tage im Voraus erzielt. Diese werden daher zum Vergleich mitanderen Arbeiten genutzt. Da der verwendete Datensatz fur diese Arbeit erstellt wurde,lassen sich die Ergebnisse nur begrenzt mit anderen Arbeiten vergleichen. Twitter unter-bindet die Veroffentlichung von Daten, die uber deren Plattform gesammelt wurden. Dahersind zu den betrachteten anderen Arbeiten in diesem Bereich keine Datensatze veroffent-licht worden oder diese wurden bereits geloscht. Im Folgenden wird dennoch versucht, dieAnsatze und Ergebnisse anderer Arbeiten mit dieser zu vergleichen.
Eine Arbeit von Sam Paglia aus dem Jahr 2013 versucht mit den Tweets von Nachrichten-unternehmen den Aktienindex S&P 500 am nachsten Borsentag zu prognostizieren. DieArbeit untersucht die Auswirkungen auf den nachsten Borsentag. Zudem wird in der Arbeitvon Paglia versucht, einen Index zu prognostizieren, wahrend in dieser Arbeit jedes Un-ternehmen eines Indexes separat prognostiziert wird. Mit einem Naive-Bayes-Klassifikatorwurde eine Accuracy von 59% erreicht. Precision und Recall lagen bei 50,2% und 20,8%.[17]Das entspricht einem F1-Wert von 29%. Wahrend die Accuracy von dieser Arbeit nur leichtuber der von Paglia lag, so wurde mit 60% ein deutlich hoherer F1-Wert erreicht.
Die Arbeit von Bollen[14] untersuchte beliebige Tweets, die nicht unbedingt ein Aktienun-ternehmen erwahnen. Das Sentiment der Tweets wird als Indikator fur die Stimmung inder Offentlichkeit gewahlt. Daraus wird fur jeden betrachteten Tag prognostiziert, ob derSchlusskurs des DJIA steigt oder fallt. Der Kurs konnte mit einer Accuracy von 86,7%vorhergesagt werden. Betrachtet wurden in der Arbeit von Bollen beliebige Tweets, diekeine Verbindung zum DJIA oder den darin enthaltenen Unternehmen besitzen mussen.Da so nicht die Kurse der einzelnen Unternehmen im DJIA bewertet werden konnen, istein direkter Vergleich auch hier nur eingeschrankt sinnvoll. Die Accuracy ist jedoch um26% hoher als der in dieser Arbeit erreichte Wert. Das kann an einer Kombination derfolgenden drei Erklarungen liegen:
• Die allgemeine Stimmung auf Twitter ist ein besserer Indikator fur den Kurs desDJIA, als die Tweets uber ein Unternehmen ein Indikator fur den Kurs dieses Un-ternehmens sind.
• Der großere Beobachtungszeitraum der Tweets fuhrt zu einer besseren Klassifizie-rung. Wahrend diese Arbeit knapp zwei Monate betrachtet, betrachtet die von Bollenuber neun Monate.[14]
• Die Sentimentanalyse mit dem GPOMS fur die Dimension ”Calm” ist erfolgsverspre-chender fur die Pradiktion von Aktienkursen als die direkte Pradiktion mit dem hiervorgestellten Neuronalen Netz.
50

6. Zusammenfassung und Ausblick
In der Einleitung wurden Donald Trumps Außerungen auf Twitter und deren Auswir-kungen auf den Aktienmarkt erwahnt. Daraufhin wurde die Vermutung aufgestellt, dassauch die Mitteilungen aller Twitter-Nutzer einen Einfluss auf diesen Markt haben konnen.In der Tat, ließen sich Aktienkurse mit Hilfe von Twitter-Daten zu einem gewissen Maßvorhersagen.
Die vorgestellten Neuronalen Netze erzielten eine Genauigkeit von bis zu 61%. Dabei wurdeprognostiziert, ob der Aktienkurs eines Unternehmen in vier Tagen fallt oder steigt.
Es zeigte sich, dass die Vorhersage fur zwei- bis drei Tage in die Zukunft bessere Ergebnisseerzielt als fur den folgenden Tag.
Zudem stellte sich heraus, dass mit Tweets, die explizit das Aktiensymbol eines Unterneh-mens erwahnen, eine bessere Prognose geliefert werden kann, als wenn lediglich der Namedes Unternehmens genannt wird.
Im Vergleich zu englischsprachigen Tweets, die schon in mehreren Arbeiten untersuchtwurden, zeigt sich, dass mit deutschsprachigen Tweets auch Pradiktionen fur den deut-schen Aktienmarkt moglich sind. Hier wurde fur die Prognose drei Tage in die Zukunfteine Accuracy von 58% erreicht. Jedoch ist festzuhalten, dass das Volumen der Tweets inenglischer Sprache bedeutend großer ist, als das in deutscher Sprache.
Im Folgenden werden einige Vorschlage gemacht, wie die in dieser Arbeit erzielten Er-gebnisse verbessert werden konnten. Bei der Pradiktion mittels Sentimentanalyse ist einerster moglicher Verbesserungsansatz das Trainieren des RNTN mit Texten, die ebenfallsStorfaktoren wie Umgangssprache und Rechtschreibfehler enthalten. Wenn dadurch einausgeglicheneres Sentiment mit weniger negativer Tendenz auf dem Datensatz entsteht, sokonnten eventuell auch bessere Ergebnisse erreicht werden.
Fur die Verbesserung der direkten Pradiktion werden im Folgenden einige Verbesserungs-vorschlage gemacht. Einmal ware es denkbar, ein Neuronales Netz zu konstruieren, welchesmehr Informationen erhalt als Tweets und die binare Klasse des Tweets. Mogliche Zusatz-informationen waren die Aktienkurse vergangener Tage, ein Zeitstempel, wann der Tweeterstellt wurde und weitere Informationen, von denen der Aktienkurs abhangen konnte. EinBeispiel fur letzteren Vorschlag ist der Olpreis bei Olunternehmen oder Autoherstellern.Zudem konnte die Anzahl der Follower und der Retweets in die Vorhersage mit einfließen.
51

52 6. Zusammenfassung und Ausblick
Dass diese weitere Informationen zu vielversprechenden Ergebnissen fuhren konnten, hateine Vergleichsstrategie in der Evaluation gezeigt. Bei der wurde die Entwicklung des Ak-tienkurs am vorherigen Tag als Prognose fur den kommenden Tag gewahlt. Damit wurdeeine Accuracy von 64% erreicht.
Eine weitere Verbesserung konnte durch Vergroßern des Datensatzes erreicht werden.Denkbar ist es, dass die bestehenden Neuronalen Netze mit einem großeren Datensatzbessere Resultate erzielen. Bei dem vorgestellten Convolutional-Netz hat sich beispielswei-se gezeigt, dass ein großeres Netz mit mehr Convolutional-Schichten schnell zu komplexfur den verhaltnismaßig kleinen Datensatz wird. Mit einem großeren Datensatz konnte dasPotenzial eines großeren Netzen eventuell besser genutzt werden.
Der dritte Verbesserungsvorschlag fur die direkte Pradiktion richtet sich an die Reprasen-tation der Tweets. Durch Word Embeddings wurde in dieser Arbeit jedes Wort als Vektordargestellt. Eine andere Moglichkeit ware es, einen ganzen Textes als Vektor fester Lan-ge zu reprasentieren. Dieser Vektor enthalt Informationen uber das gesamte Dokument.Mit diesem Vorgehen lassen sich bei der Sentimentanalyse von Tweets teilweise bessereResultate erzielen, als mit Word Embeddings.[58]
52

7. Abkurzungsverzeichnis
Adam Adaptive Moment Estimation
DJIA Dow Jones Industrial Average
GloVe Global Vectors for Word Representation
GPOMS Google-Profile of Mood States
LDA Latent Dirichlet Analysis
LIWC Linguistic Inquiry and Word Count
LSTM Long Short-Term Memory
MEC Maximum Entropy Classification
Nadam Nesterov Adam Optimizer
PLSA Probabilistic Latent Semantic Analysis
RMSProp Root Mean Square Propagation
RNN Rekurrentes Neuronales Netz
RNTN Recursive Neural Tensor Network
SGD Stochastic Gradient Descent
SNLP Stanford Natural Language Processing
S&P 500 Standard & Poor’s 500
SVM Support Vector Machines
TDNN Time Delay Neural Network
53


8. Anhang
55

56 8. Anhang
8.1 Pradiktion mittels Sentimentanalyse
Tabelle 8.1: Bewertung des RNTN pro Tweet
.
Name Accuracy (%) Precision (%) Recall (%) F1 (%)Apple 50,2 45,2 74,6 56,3American Express 51,7 43,4 32,1 37,0Boeing 54,1 38,3 58,8 46,4Caterpillar 44,6 36,5 51,7 42,8Cisco 52,0 34,2 45,1 38,9Chevron 56,0 40,3 60,8 48,4DuPont 38,1 28,7 75,4 41,5Disney 46,3 38,7 34,9 36,7General Electric 63,2 24,6 16,1 19,5Goldman Sachs 52,9 39,6 35,0 37,1Home Depot 40,8 34,1 52,2 41,3IBM 45,8 38,4 76,4 51,1Intel 44,4 33,9 62,6 44,0Johnson & Johnson 50,1 29,4 52,4 37,6JPMorgan Chase 40,4 33,7 74,5 46,4Coca-Cola 52,4 16,7 15,5 16,1McDonald’s 49,6 46,3 65,9 54,43M 49,8 38,5 55,9 45,6Merck 48,2 23,9 43,8 30,9Microsoft 46,4 31,4 64,9 42,4Nike 54,4 38,8 38,6 38,7Pfizer 42,6 27,9 59,5 38,0Procter & Gamble 47,7 29,3 50,0 37,0Travelers Companies 49,4 35,1 76,5 48,1United Healh 43,8 28,5 59,9 38,6United Technologies 59,6 29,0 30,0 29,5Visa 54,1 36,4 48,3 41,5Wal-Mart 53,9 30,3 29,1 29,7Exxon Mobil 57,9 38,6 29,3 33,3Schnitt 49,7 34,1 50,7 39,6
56

8.2. Max Pooling-Netz 57
8.2 Max Pooling-Netz
Tabelle 8.2: Ergebnisse des Max Pooling-Netzes pro Unternehmen
Name Accuracy (%) Precision (%) Recall (%) F1 (%)Apple 60,4 61,7 93,2 74,3American Express 42,5 29,2 78,7 42,6Boeing 54,6 85,7 3,6 6,9Caterpillar 58,6 50,0 26,7 34,8Cisco 49,3 60,7 48,5 53,9Chevron 83,6 0,0 0,0 0,0DuPont 46,1 47,1 13,2 20,6Disney 41,3 44,8 2,9 5,4General Electric 82,5 23,3 15,6 18,7Goldman Sachs 49,1 35,1 26,2 30,0Home Depot 50,4 65,5 26,6 37,8IBM 39,2 80,3 30,1 43,8Intel 50,9 43,3 59,3 50,1Johnson & Johnson 45,4 85,7 3,6 6,9JPMorgan Chase 49,9 46,8 58,1 51,8Coca-Cola 45,0 88,2 9,3 16,9McDonald’s 54,4 40,0 1,0 1,93M 45,8 100,0 1,3 2,5Merck 47,3 39,3 54,7 45,7Microsoft 55,6 48,8 3,7 6,8Nike 34,2 0,0 0,0 0,0Pfizer 77,5 36,1 16,7 22,8Procter & Gamble 53,6 11,1 2,1 3,6Travelers Companies 31,9 100,0 3,1 6,0United Healh 59,0 15,6 4,2 6,6United Technologies 53,3 6,3 11,1 8,1Visa 52,6 66,9 46,9 55,1Wal-Mart 64,4 45,5 7,0 12,1Exxon Mobil 61,1 46,2 1,7 3,3Schnitt pro Unternehmen 53,1 48,4 22,4 23,1Schnitt pro Tweet 55,3 56,7 46,6 51,2
57

58 8. Anhang
8.3 LSTM-Netz
Tabelle 8.3: Resultate des LSTM-Netzes
Name Accuracy (%) Precision (%) Recall (%) F1 (%)Apple 60,5 61,4 95,6 74,8American Express 32,9 28,2 95,4 43,6Boeing 54,2 58,4 6,7 12,0Caterpillar 57,1 48,3 48,5 48,4Cisco 55,5 61,4 73,5 66,9Chevron 81,3 12,5 5,6 7,8DuPont 48,2 53,3 19,8 28,9Disney 43,5 60,0 9,3 16,2General Electric 59,2 12,0 33,9 17,7Goldman Sachs 49,6 38,0 33,4 35,5Home Depot 58,7 62,6 67,8 65,1IBM 46,2 81,5 40,8 54,4Intel 45,2 41,6 79,1 54,5Johnson & Johnson 44,2 52,0 10,3 17,2JPMorgan Chase 46,5 45,4 75,2 56,6Coca-Cola 39,4 48,2 16,8 24,9McDonald’s 52,9 31,0 3,1 5,73M 49,6 78,3 11,5 20,1Merck 39,5 38,6 83,3 52,8Microsoft 56,1 51,8 13,3 21,2Nike 34,7 55,6 1,9 3,8Pfizer 61,1 23,9 43,6 30,9Procter & Gamble 53,9 28,3 9,2 13,9Travelers Companies 38,4 77,3 17,5 28,6United Healh 55,8 28,6 18,5 22,4United Technologies 34,4 15,6 57,8 24,5Visa 55,2 65,0 60,5 62,7Wal-Mart 51,6 33,9 39,5 36,5Exxon Mobil 60,2 37,8 4,0 7,2Schnitt pro Unternehmen 50,5 45,9 37,1 32,9Schnitt pro Tweet 54,0 54,1 55,6 54,8
58

8.4. Convolutional-Netz 59
8.4 Convolutional-Netz
Tabelle 8.4: Metriken fur das Convolutional-Netz pro Tweet
Name Accuracy (%) Precision (%) Recall (%) F1 (%)Apple 58,5 61,2 88,7 72,4American Express 30,2 23,8 71,3 35,6Boeing 54,7 71,4 5,2 9,7Caterpillar 57,7 48,0 23,3 31,4Cisco 52,1 62,6 54,0 57,9Chevron 80,2 0,0 0,0 0,0DuPont 47,8 53,3 13,2 21,2Disney 43,1 56,3 10,9 18,2General Electric 78,6 15,4 14,7 15,0Goldman Sachs 44,2 32,5 31,6 32,0Home Depot 57,9 65,5 54,5 59,5IBM 36,2 77,7 26,4 39,5Intel 52,9 45,2 63,4 52,7Johnson & Johnson 44,2 52,2 9,3 15,9JPMorgan Chase 53,2 49,6 50,8 50,2Coca-Cola 46,1 68,2 18,6 29,3McDonald’s 50,6 33,6 9,2 14,43M 46,1 56,0 9,0 15,5Merck 49,5 39,5 46,1 42,6Microsoft 55,2 48,8 22,5 30,8Nike 33,7 41,2 2,7 5,1Pfizer 62,9 18,7 25,6 21,6Procter & Gamble 53,9 25,0 7,1 11,0Travelers Companies 34,1 65,0 13,4 22,2United Healh 59,0 21,1 6,7 10,2United Technologies 44,7 12,5 33,3 18,2Visa 52,5 66,5 47,4 55,4Wal-Mart 59,0 33,0 16,3 21,8Exxon Mobil 55,9 18,4 4,0 6,6Schnitt pro Unternehmen 51,5 43,5 26,9 28,1Schnitt pro Tweet 53,7 54,5 48,0 51,0
59


Abbildungsverzeichnis
3.1 McCulloch-Pitts-Neuron[18] . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Einschichtiges Feedforward[18] . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Dreischichtiges Feedforward[18] . . . . . . . . . . . . . . . . . . . . . . . . . 93.4 Rekurrentes Netz[18] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.5 Die funfte Anwendung einer Maske in einer Convolutional-Schicht[22] . . . 103.6 Max-Pooling [24] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.7 LSTM[28] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.1 Text als Binarbaum reprasentiert . . . . . . . . . . . . . . . . . . . . . . . . 204.2 Aufbau des Max-Pooling-Netzes . . . . . . . . . . . . . . . . . . . . . . . . . 234.3 Aufbau des Convolution-Netzes . . . . . . . . . . . . . . . . . . . . . . . . . 244.4 Aufbau des LSTM-Netzes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5.1 Accuracy und F1 pro Unternehmen fur das RNTN . . . . . . . . . . . . . . 295.2 Entwicklung der Coca-Cola Aktie im Testdatenzeitraum . . . . . . . . . . . 305.3 Sentiments vor und nach der Anpassung der Tweets . . . . . . . . . . . . . 315.4 Unveranderte und veranderte GloVe-Embeddings im Vergleich mit Embed-
dings ohne GloVe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.5 Verschiedene Aktivierungsfunktionen bei der ersten vollvernetzten Schichten 345.6 Entwicklung der Accuracy auf den Test- und Trainingsdaten uber mehrere
Epochen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.7 Accuracy und F1 pro Unternehmen fur das Max Pooling-Netz . . . . . . . . 365.8 Verschiedene Maskengroßen (Kernel) in der Convolutional-Schicht . . . . . 385.9 Verschiedene L2-Regularisierungswerte im Vergleich . . . . . . . . . . . . . 395.10 Accuracy und F1 pro Unternehmen fur das Convolutional-Netz . . . . . . . 405.11 Updatefunktionen im Vergleich fur das LSTM-Netz . . . . . . . . . . . . . . 415.12 Lernraten uber zehn Epochen . . . . . . . . . . . . . . . . . . . . . . . . . . 425.13 Lernraten uber 100 Epochen . . . . . . . . . . . . . . . . . . . . . . . . . . 435.14 Accuracy und F1 pro Unternehmen fur das LSTM-Netz . . . . . . . . . . . 445.15 Ergebnisse fur die Pradiktion des Aktienkurses fur verschieden viele Tage
im Voraus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
61


Literaturverzeichnis
[1] N. Popper. A little birdie told me: Playing the market on trumptweets. [Online]. Available: https://www.nytimes.com/2017/02/16/business/dealbook/trump-tweets-stock-market-trading-bots.html? r=0
[2] S. Greenstone. When trump tweets, this bot makes money. [Online]. Available: http://www.npr.org/2017/02/04/513469456/when-trump-tweets-this-bot-makes-money
[3] X. H. Cambria, Schuller, “New avenues in opinion miningand sentiment analysis,” 2013. [Online]. Available: http://sentic.net/new-avenues-in-opinion-mining-and-sentiment-analysis.pdf
[4] V. Pang, Lee, “Thumbs up? sentiment classification using machine learningtechniques,” 2002. [Online]. Available: http://www.cs.cornell.edu/home/llee/papers/sentiment.pdf
[5] J. Y. W. J. C. C. D. M. A. Y. N. u. C. P. Richard Socher, Alex Perelygin,“Recursive deep models for semantic compositionality over a sentiment treebank,”2013. [Online]. Available: http://nlp.stanford.edu/˜socherr/EMNLP2013 RNTN.pdf
[6] Y. Cao, R. Xu, and T. Chen, Combining Convolutional Neural Network and SupportVector Machine for Sentiment Classification. Singapore: Springer Singapore, 2015,pp. 144–155. [Online]. Available: http://dx.doi.org/10.1007/978-981-10-0080-5 13
[7] “Sentiment analysis and ontology engineering : An environment of computa-tional intelligence,” Cham, 2016. [Online]. Available: http://swbplus.bsz-bw.de/bsz468158650cov.htmhttp://dx.doi.org/10.1007/978-3-319-30319-2
[8] S. Greene and P. Resnik, “More than words: Syntactic packaging and implicit senti-ment,” in Proceedings of human language technologies: The 2009 annual conferenceof the north american chapter of the association for computational linguistics. As-sociation for Computational Linguistics, 2009, pp. 503–511.
[9] S. Z. Kim, Ganesan, “Comprehensive review of opinion summarization,” 2011.[Online]. Available: https://s3-us-west-2.amazonaws.com/mlsurveys/134.pdf
[10] A. Tumasjan, T. O. Sprenger, P. G. Sandner, and I. M. Welpe, “Predicting electionswith twitter: What 140 characters reveal about political sentiment.” ICWSM, vol. 10,no. 1, pp. 178–185, 2010.
[11] A. Culotta, “Detecting influenza outbreaks by analyzing twitter messages,” arXivpreprint arXiv:1007.4748, 2010.
[12] G. Mishne, N. S. Glance et al., “Predicting movie sales from blogger sentiment.” inAAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, 2006, pp.155–158.
[13] E. M. C. Francesco Corea, “The power of micro-blogging: How to usetwitter for predicting the stock market,” 2015. [Online]. Available: https://ideas.repec.org/a/ejn/ejefjr/v3y2015i4p1-7.html
63

64 Literaturverzeichnis
[14] J. Bollen, H. Mao, and X. Zeng, “Twitter mood predicts the stock market,” Journalof computational science, vol. 2, no. 1, pp. 1–8, 2011.
[15] P. G. S. I. M. W. Timm O. Sprenger, Andranik Tumasjan, “Tweets andtrades: the information content of stock microblogs,” 2013. [Online]. Available:http://onlinelibrary.wiley.com/doi/10.1111/j.1468-036X.2013.12007.x/full
[16] X. Zhang, H. Fuehres, and P. A. Gloor, “Predicting stock market indicatorsthrough twitter “i hope it is not as bad as i fear”,” Procedia - Socialand Behavioral Sciences, vol. 26, pp. 55 – 62, 2011. [Online]. Available:http://www.sciencedirect.com/science/article/pii/S1877042811023895
[17] S. PAGLIA, “Using twitter to gauge news effect on stock market moves.”
[18] I. N. da Silva, “Artificial neural networks : A practical course,” Cham, 2017.[Online]. Available: http://swbplus.bsz-bw.de/bsz477158021cov.htmhttp://dx.doi.org/10.1007/978-3-319-43162-8
[19] M. A. Nielsen, Neural Networks and Deep Learning. Determination Press, 2015.
[20] C. B. F. K. C. M. M. S. Rudolf Kruse, Christian Borgelt, ComputationalIntelligence, Seite 7. Springer Fachmedien Wiesbaden, 2015. [Online]. Available:http://link.springer.com/book/10.1007%2F978-3-658-10904-2
[21] (2017) Tensorflow documentation: Reshape. [Online]. Available: https://www.tensorflow.org/api docs/python/tf/reshape
[22] (2017) Grafik convolution-schicht. [Online]. Available: http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
[23] D. Britz. (2017) Understanding cnn for nlp. [Online]. Available: http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
[24] (2017) Max pool illustration. [Online]. Available: https://cambridgespark.com/content/tutorials/convolutional-neural-networks-with-keras/index.html
[25] D. Scherer, A. Muller, and S. Behnke, “Evaluation of pooling operations in convolu-tional architectures for object recognition,” Artificial Neural Networks–ICANN 2010,pp. 92–101, 2010.
[26] S. Hochreiter, “Untersuchungen zu dynamischen neuronalen netzen,” Master’s thesis,Institut fur Informatik, Technische Universitat, Munchen, 1991.
[27] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recogni-tion using time-delay neural networks,” IEEE transactions on acoustics, speech, andsignal processing, vol. 37, no. 3, pp. 328–339, 1989.
[28] (2017) Understanding lstms. [Online]. Available: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[29] (2016) Large text compression benchmark. [Online]. Available: http://www.mattmahoney.net/dc/text.html#1218
[30] A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, and J. Schmidhu-ber, “A novel connectionist system for unconstrained handwriting recognition,” IEEEtransactions on pattern analysis and machine intelligence, vol. 31, no. 5, pp. 855–868,2009.
[31] (2017) Why you should use cross-entropy error instead of classi-fication error or mean squared error for neural network classifiertraining. [Online]. Available: https://jamesmccaffrey.wordpress.com/2013/11/05/why-you-should-use-cross-entropy-error-instead-of-classification-error-or-mean-squared-error-for-neural-network-classifier-training/
64

Literaturverzeichnis 65
[32] (2017) Mnist for ml beginners. [Online]. Available: https://www.tensorflow.org/getstarted/mnist/beginners
[33] (2017) Supervised learning. [Online]. Available: https://www.coursera.org/learn/machine-learning/lecture/1VkCb/supervised-learning
[34] K. W. Gunter Daniel Rey. (2017) Neuronale netze. [Online]. Available: http://www.neuronalesnetz.de/downloads/neuronalesnetz de.pdf
[35] S. Ruder, “An overview of gradient descent optimization algorithms,” CoRR, vol.abs/1609.04747, 2016. [Online]. Available: http://arxiv.org/abs/1609.04747
[36] M. Li, T. Zhang, Y. Chen, and A. J. Smola, “Efficient mini-batch training for stocha-stic optimization,” in Proceedings of the 20th ACM SIGKDD international conferenceon Knowledge discovery and data mining. ACM, 2014, pp. 661–670.
[37] M. D. Zeiler, “ADADELTA: An Adaptive Learning Rate Method,” ArXiv e-prints,Dec. 2012.
[38] T. Dozat, “Incorporating nesterov momentum into adam,” Stanford University, Tech.Rep., 2015.[Online]. http://cs229. stanford. edu/proj2015/054 report. pdf, Tech. Rep.,2015.
[39] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov,“Dropout: A simple way to prevent neural networks from overfitting,” J. Mach.Learn. Res., vol. 15, no. 1, pp. 1929–1958, Jan. 2014. [Online]. Available:http://dl.acm.org/citation.cfm?id=2627435.2670313
[40] M. Nielsen, “Neural networks and deep learning,” 2017. [Online]. Available: http://neuralnetworksanddeeplearning.com/chap3.html#overfitting and regularization
[41] Using stanford corenlp on other human languages. [Online]. Available: http://stanfordnlp.github.io/CoreNLP/human-languages.html
[42] R. Socher, A. Perelygin, J. Y. Wu, J. Chuang, C. D. Manning, A. Y. Ng, C. Potts et al.,“Recursive deep models for semantic compositionality over a sentiment treebank,” inProceedings of the conference on empirical methods in natural language processing(EMNLP), vol. 1631. Citeseer, 2013, p. 1642.
[43] Nyu lecture: Bag-of-words models. [Online]. Available: http://cs.nyu.edu/˜fergus/teaching/vision 2012/9 BoW.pdf
[44] H. Wang, D. Can, A. Kazemzadeh, F. Bar, and S. Narayanan, “A system for real-timetwitter sentiment analysis of 2012 us presidential election cycle,” in Proceedings of theACL 2012 System Demonstrations. Association for Computational Linguistics, 2012,pp. 115–120.
[45] B. Pang and L. Lee, “Seeing stars: Exploiting class relationships for sentimentcategorization with respect to rating scales,” in Proceedings of the 43rd AnnualMeeting on Association for Computational Linguistics, ser. ACL ’05. Stroudsburg,PA, USA: Association for Computational Linguistics, 2005, pp. 115–124. [Online].Available: https://doi.org/10.3115/1219840.1219855
[46] (2016) Using pre-trained word embeddings in a keras model. [Online]. Available:https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html
[47] D. Selivanov, “Glove word embeddings,” 2016. [Online]. Available: https://cran.r-project.org/web/packages/text2vec/vignettes/glove.html
65

66 Literaturverzeichnis
[48] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors forword representation,” in Empirical Methods in Natural Language Processing(EMNLP), 2014, pp. 1532–1543. [Online]. Available: http://www.aclweb.org/anthology/D14-1162
[49] (2017) Stanford nlp data sets. [Online]. Available: https://nlp.stanford.edu/data/
[50] A. Severyn and A. Moschitti, “Twitter sentiment analysis with deep convolutionalneural networks,” in Proceedings of the 38th International ACM SIGIR Conferenceon Research and Development in Information Retrieval. ACM, 2015, pp. 959–962.
[51] (2017) About twitter inc. [Online]. Available: https://about.twitter.com/company
[52] (2017) Twitter serach api documentation. [Online]. Available: https://dev.twitter.com/rest/public/search
[53] (2009) On twitter, $ is the new #. [Online]. Available: https://www.wired.com/2009/02/on-twitter-is-t/
[54] (2017) Finance quotes api for yahoo finance (java). [Online]. Available:https://github.com/sstrickx/yahoofinance-api
[55] (2017) Historische kurse von general electric bei yahoo finance. [Online]. Available:https://de.finance.yahoo.com/quote/GE/history?p=GE
[56] Y. Bao, C. Quan, L. Wang, and F. Ren, The Role of Pre-processing in TwitterSentiment Analysis. Cham: Springer International Publishing, 2014, pp. 615–624.[Online]. Available: http://dx.doi.org/10.1007/978-3-319-09339-0 62
[57] X. Z. Johan Bollena, Huina Maoa, “Twitter mood predicts the stock market,” 2010.[Online]. Available: https://arxiv.org/pdf/1010.3003.pdf
[58] S. Vosoughi, P. Vijayaraghavan, and D. Roy, “Tweet2vec: Learning tweet embeddingsusing character-level cnn-lstm encoder-decoder,” in Proceedings of the 39th Internatio-nal ACM SIGIR conference on Research and Development in Information Retrieval.ACM, 2016, pp. 1041–1044.
66