Proseminar im Grundstudium - Uni Trier: Willkommen · Empirik als auch der Statistik. Dazu zählen...
32
I UNIVERSITÄT TRIER Fachbereich IV Proseminar im Grundstudium: Einführung in die statistische Datenanalyse Einstieg in SPSS WS 2003/2004 Veranstaltungsnummer 4076 Veranstalter: Prof. Dr. Harald Spehl, Dipl.-Volksw. Lutz Benson, Mag. rer. soc. oec. Renate Brandner-Weiß Abgabe: 14.01.2004 Andreas Hillesheim Barbara Schieder
-
Upload
truongnhan -
Category
Documents
-
view
215 -
download
0
Transcript of Proseminar im Grundstudium - Uni Trier: Willkommen · Empirik als auch der Statistik. Dazu zählen...

I
UNIVERSITÄT TRIER
Fachbereich IV
Proseminar im Grundstudium:
Einführung in die statistische Datenanalyse
Einstieg in SPSS
WS 2003/2004
Veranstaltungsnummer 4076
Veranstalter: Prof. Dr. Harald Spehl,
Dipl.-Volksw. Lutz Benson,
Mag. rer. soc. oec. Renate Brandner-Weiß
Abgabe: 14.01.2004
Andreas Hillesheim Barbara Schieder

1
1 Einführung
Ursprünglich stand SPSS für Statistical Package for Social Sciences. Dieses
weitgehend komplette und leicht zu bedienende Statistik-Programmpaket wurde
Mitte der 60er Jahre in den USA an der Stanford University of San Francisco und
später an der University of Chicago zur Auswertung statistischer Daten vor allem
in den Wirtschafts- und Sozialwissenschaften entwickelt.
Es war (ursprünglich) für IBM Corporation entwickelt worden, doch im Zuge der
Verbreitung von Personal Computers wurde auch SPSS zu Beginn der 80er Jahre
als PC-Version angeboten. Eingebunden in das von Microsoft Corporation
entwickelte Betriebssystem Windows und wegen der hohen
Nutzungsfreundlichkeit fand SPSS eine weltweite Anwendung, weit über die
Grenzen der Wirtschafts- und Sozialwissenschaften hinaus. Heute wird es ebenso
von fast allen wichtigen Betriebssystemen beziehungsweise Computertypen
unterstützt (so zum Beispiel Windows, Unix, Mac-OS). Nicht zuletzt deshalb
steht heute die Abkürzung SPSS für Superior Performing Software System.
Dem Nutzer von heute ist es durch einfaches Anklicken von Symbolen oder durch
Aktivieren von Dialogfeldern möglich, die ausgewählten statistischen Analysen
herbeizuführen und sachgemäß darzustellen. Die Kenntnis der erforderlichen
syntaktischen Programmregeln können dabei vernachlässigt werden1.
2 Grundlagen
SPSS für Windows verfügt über ein leistungsfähiges System für statistische
Analysen und Datenmanagement. Hierfür setzen wir die bereits erlernten
Grundlagen der Empirik und Statistik der bisherigen Semester voraus, um eine
gewisse Basis herzustellen. Um das Programm bedienen zu können, bedarf es
trotz allem im Vorfeld der Klärung einiger theoretischer Grundlagen sowohl der
Empirik als auch der Statistik. Dazu zählen die zentralen Begriffe für SPSS, die
häufigsten Analysemethoden, sowie die strukturelle Oberfläche von SPSS.
2.1 Zentrale Begriffe des SPSS
1 Vgl. Eckstein, Peter P. (1999), S. 2.

2
Als Voraussetzung für die Arbeit mit SPSS müssen zu Beginn einige Begriffe der
statistischen Datenerhebung geklärt werden. Es wird Bezug genommen auf
Beobachtungseinheiten und Merkmale sowie Variable, Datenmatrix und Daten-
Editor zur Darstellung der Variablendefinition und Datenverarbeitung.
2.1.1 Beobachtungseinheiten und Merkmale
Der erste für SPSS wichtige Begriff lautet Fälle oder Beobachtungseinheiten. Er
sollte uns bereits aus der Statistik und der Empirik bekannt sein. Fälle
beziehungsweise Beobachtungseinheiten liefern die bei einer empirischen Studie
notwendigen Daten. Es handelt sich dabei zum Beispiel um die beobachteten
Personen.
Weiterhin spielen Merkmale eine wichtige Rolle. Merkmale sind die bei der
empirischen Studie beobachteten Eigenschaften der Fälle.2
2.1.2 Variable
Des Weiteren haben Variablen in SPSS eine zentrale Position inne. Während
ihnen in der Literatur zur statistischen Datenanalyse eine Gleichbedeutung mit
dem Begriff Merkmal zukommt, entsprechen sie in SPSS den Spaltenvektoren.3
Variablen sind auch eindeutig durch Variablennamen gekennzeichnet. Bezüglich
der Namensgebung sind jedoch einige Regeln zu beachten, die in Abschnitt 3.1
„Variablen definieren“ ausführlich erläutert werden.
Da es in SPSS insgesamt acht verschiedene Variablentypen gibt, beschränken wir
uns auf die wichtigsten drei, mit denen die meisten Projekte auskommen. Es
handelt sich dabei um numerische Variablen, alphanumerische Variablen, die so
genannten Stringvariablen, und um Datumsvariablen.4 Daneben gibt es noch
Komma und Punkt, die sich nur durch die Ländereinstellung der Windows-
Systemsteuerung unterscheiden, ansonsten aber gleich sind. Des Weiteren zählen
wissenschaftliche Notation, Dollar und Spezielle Währung dazu. Die
wissenschaftliche Notation findet vor allem Anwendung, wenn es sich um die
Bearbeitung von sehr kleinen oder sehr großen Zahlen handelt. Zum Beispiel wird
244.000 in 2,4 mal 105 zerlegt und als 2,4E+05 dargestellt; analog ist die
Vorgehensweise bei sehr kleinen Werten. Auf die Anwendungen Dollar und
2 Vgl. Baltes-Götz, Bernhard (2001), S. 9. 3 Vgl. ebenda, S. 9. 4 Vgl. ebenda, S. 13f.

3
Spezielle Währung wird nicht eingegangen, da sie für die Anwendungsbereiche
hinsichtlich der PbSf unnötig sind.5
Abb. 1 Dialogbox „Variablentyp definieren“
Numerische Variable können als Wert jede beliebige reelle Zahl, auch mit
vorangestelltem Plus- oder Minuszeichen, annehmen. Außerdem sind
Dezimaltrennzeichen gültig.6 Sie sind deshalb besonders für Merkmale wie Größe
und Gewicht geeignet.7
Stringvariable, auch Zeichenkettenvariablen genannt, haben als Wert eine Folge
von Zeichen wie zum Beispiel Buchstaben und Ziffern, aber auch Sonderzeichen.
Sie haben eine maximale Länge von 255 Zeichen.8 Eine Voreinstellung gibt acht
Zeichen an. Stringvariable werden in kurze und lange Variablen unterschieden.
Wenn die Länge acht Zeichen nicht überschreitet, handelt es sich um eine kurze,
wenn es sich um mehr als acht Zeichen handelt, um eine lange Stringvariable.
Dies lässt sich leicht in der Quellvariablenliste überprüfen. Für kurze Variable
steht , analog dazu steht für lange Variable . Stringvariablen werden nur bei
solchen Menüs in der Quellvariablenliste angezeigt, in denen man sie auch
verwenden kann.9 Ihr besonderer Aufbau eignet sich speziell für Merkmale wie
Familienname oder das Geschlecht. Dabei wird das Merkmal alphanumerisch
kodiert, zum Beispiel mit den Werten weiblich und männlich.10 Ansonsten können
Stringvariable auch leicht als numerische Variable definiert werden.
5 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 51ff. 6 Vgl. ebenda, S. 51. 7 Vgl. Baltes-Götz, Bernhard (2001), S. 13. 8 Vgl. ebenda, S. 14. 9 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 54. 10 Vgl. Baltes-Götz, Bernhard (2001), S. 14.

4
Datumsvariable geben als Wert, wie der Name bereits sagt, Datumsangaben
wieder. Es wird eine Liste von unterschiedlichen Formen der Datums- oder
Zeitangaben in einer Auswahlbox vorgestellt. Hier kann man zwischen den
verschiedensten Möglichkeiten der Darstellung wählen. Angefangen bei der
üblichen Form des tt.mm.jjjj, über die Verwendung von Wochenanzahl und
Quartalen, bis hin zu dem exakten Minuten- und Sekundenformat. Sie sind
deshalb für Merkmale wie zum Beispiel Geburtsdaten besonders geeignet.11
2.1.3 Datenmatrix und Daten-Editor
Weitere zentrale Einheiten des SPSS bilden Datenmatrix und Daten-Editor.
Datenmatrix wird auch als Datentabelle bezeichnet. Es stehen hierbei die
Spaltenvektoren aller Merkmale nebeneinander und bilden eine Tabelle, wobei es
sich bei den Spalten um die Variablen und bei den Zeilen um die einzelnen Fälle
handelt. Der Daten-Editor ist eine Ebene höher anzusehen. Er stellt die Basis der
Datenmatrix dar, da die Werte der Datenmatrix hier eingegeben werden, laufend
eingesehen werden und darin auch überarbeitet werden können.12 Der Daten-
Editor selbst ist unterteilt in die Registerkarten Datenansicht und
Variablenansicht.
Abb. 1 SPSS Daten-Editor
Zu Beginn müssen die Variablen in der Variablenansicht bekannt gemacht
werden. Dabei hat man auch eine Matrix vor sich, wobei die Variablen die Zeilen
und die Variablenattribute die Spalten darstellen. Hier kann man die
Variablentypen auswählen, die Anzahl der Dezimalstellen bestimmen und auch
das Variablenlabel festlegen. Dies ist vor allem für die grafische Darstellung
später wichtig, da die Labels zum Beispiel die Achsenbeschriftung wieder geben. 11 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 53. 12 Vgl. Baltes-Götz, Bernhard (2001), S. 9.

5
Sobald die Variablen bekannt sind, kann man zur Datenansicht wechseln und die
Werte eingeben.13
2.2 Wichtige Analysemethoden
Im Folgenden werden drei Analysemethoden anhand einer Beschreibung ihrer
Anwendungsgebiete theoretisch vorgestellt. Die Besonderheiten der Methoden
werden in den darauf folgenden Punkten der Gliederung anhand einiger Beispiele
praktisch dargestellt und erklärt.
2.2.1 Häufigkeiten und deskriptive Statistiken
Die erste und auch zentrale Analysemethode ist die der deskriptiven Statistiken
und Häufigkeiten. Zu erreichen ist diese Anwendung über die Option
´Analysieren´ in der Menüleiste des Daten-Editors. Hier werden
Statistikmethoden dargestellt, die jedoch nicht grundsätzlich alle zu den
deskriptiven Statistiken zählen. Vielmehr überschneiden sich die Methoden. Im
Folgenden werden nun die wichtigsten der deskriptiven Statistiken und
Häufigkeiten vorgestellt.14
Abb. 2 Daten-Editor, Häufigkeiten und Deskriptive Statistiken
13 Vgl. SPSS-Programm, Daten-Editor 14 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 167.

6
So kann man mit der Befehlsfolge ´Analysieren´, ´Berichte´, ´Fälle
zusammenfassen´ oder ´Bericht in Zeilen` beziehungsweise ´Bericht in Spalten`
ein einfaches Auflisten von Fällen erreichen.15
Analog kommt man über den Unterpunkt ´Deskriptive Statistiken` zu einer
Beschreibung der eindimensionalen Verteilungen. Es sind vor allem die
eindimensionalen Häufigkeitstabellen zu erwähnen, die über das Kommando
´Häufigkeiten´ erstellt werden. Im Fall von Mehrfachantworten dient das
gleichnamige Menü. Die Darstellung von univariaten statistischen Maßzahlen
funktioniert für alle Messniveaus in ´Häufigkeiten´. Jedoch wird bei
intervallskalierten Daten meist das Programm ´Deskriptive Statistiken´
verwenden, aus dem einfachen Grund, weil es schneller ist. Eine dritte
Möglichkeit der Erstellung ist die der ´Explorativen Datenanalyse´, die eine
Ergänzung zu der eindimensionalen deskriptiven Statistik darstellt. Denn hier
können außer den oben genannten auch robuste Lageparameter berechnet werden.
Darunter versteht man die „auf besondere Weise berechnete Mittelwerte, bei
denen der Einfluß von Extremwerten ausgeschaltet oder reduziert wird“16. Um zur
grafischen Darstellung zu kommen, dient ebenfalls das Menü ´Häufigkeiten´.
Damit können Kreis- und Balkendiagramme sowie Histogramme erstellt werden.
Letztere auch über ´Explorative Datenanalyse´.17
Neben der eindimensionalen Häufigkeitsverteilung gibt es auch die der Zwei- und
Mehrdimensionalität. Die zentrale Rolle spielen hierbei zwei- und
mehrdimensionale Kreuztabellen, die über die Befehlsfolge ´Analysieren´,
´Deskriptive Statistiken´ und ´Kreuztabellen´ aufgerufen werden.
Mehrfachantworten werden ebenso wie bei der eindimensionalen Verteilung mit
dem Menü ´Mehrfachantworten´ behandelt. Im Hinblick auf
Zusammenhangsmaße ist deutlich zu machen, dass der Menüpunkt
´Kreuztabellen´ über eine große Anzahl verfügt, die die verschiedenen
Messniveaus abdecken. Die grafische Darstellung wird von Boxpots und den
Stengel Blatt(Stem-undLeaf-)Plots übernommen18, die dem Vergleich von
Gruppen dienen. Aufrufen kann man sie über die ´Explorative Datenanalyse´.
15 Vgl. ebenda, S. 167. 16 Janssen, Jürgen/ Laatz, Wilfried (1999), S. 191. 17 Vgl. ebenda, S. 167. 18 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 191.

7
Außerdem steckt in dem Menü ´Kreuztabellen´ direkt die Möglichkeit der
´gruppierten Balkendiagramme´.19
Weitere statistische Auswertungen bieten die Punkte schließende Statistik für
eindimensionale Verteilung, sowie die für Zusammenhänge. Bei der
eindimensionalen Verteilung wird dabei der Standardfehler für Mittelwerte
angeboten, der die Grundlage für das Konfidenzintervall ist, und über die Befehle
´Häufigkeiten´, ´Deskriptive Statistik´ und ´Explorative Datenanalyse´ aufzurufen
ist. Schließende Statistik für Zusammenhangsmaße wird anhand eines
Signifikanztestes angeboten. Im Menü ´Kreuztabellen´ ist das der Chi-Quadrat-
Test.20
Die letzte Auswertung besteht in der Prüfung der Anwendungsbedingungen für
statistische Verfahren. Um Normalverteilungsvoraussetzungen zu überprüfen
bietet das Kommando ´Explorative Datenanalyse´ die Möglichkeit zweier
Normalverteilungsdiagrammen und zweier Normalverteilungstests. Die
Überprüfung der Voraussetzungen gleicher Varianzen innerhalb der
Vergleichsgruppen erfolgt über „Boxplots“, „Streuung gegen Zentralwert-Plot
(Streubreite vs. mittleres Niveau)“ oder den „Levene-Test“. Das Menü
´Häufigkeiten´ bietet außerdem eine Normalverteilungskurve, die zur
Überprüfung über das Histogramm gelegt wird.21
2.2.2 Regressionsanalyse
Eine weitere wichtige Analyse erfolgt über die Regressionsanalyse, ein
beschreibendes, deskriptives Analysewerkzeug. Ihr Hauptaugenmerk liegt auf der
Untersuchung und Quantifizierung von Abhängigkeiten zwischen metrisch
skalierten Variablen. Das Wesentliche hierbei ist, die Abhängigkeit der
abhängigen Variablen von einer oder mehreren unabhängigen Variablen anhand
einer linearen Funktion darzustellen. Das zu lösende statistische Problem besteht
darin, anhand von Stichprobenbefunden die unbekannten Regressionsparameter
zu schätzen. In der Praxis verwendet man meist das Schätzverfahren der Kleinst-
Quadrate-Schätzung. Dabei bezeichnet man das abhängige Merkmal Y als
`Regressand`; das erklärende Merkmal X heißt `Regressor`. Es wird als eine nicht
stochastische Instrument zw. Kontrollvariable gedeutet, die in der Regel nur fest
19 Vgl. ebenda, S. 167. 20 Vgl. ebenda, S. 168. 21 Vgl. ebenda, S. 168.

8
vorgegebene Werte annimmt22. Da in der ökonomischen Realität meist keine
eindeutige Abhängigkeit zwischen X und Y nachgewiesen werden kann, nimmt
man zumindest an, dass sie im Mittel besteht. `ß0` und `ß1`sind dabei die
unbekannten Regressionsparameter in der Grundgesamtheit, wobei ß0 auch als
Regressionskonstante und der Parameter ß1 als Regressionskoeffizient bezeichnet
wird. Die Anzahl der unabhängigen Variablen bestimmt, ob es sich um eine
Einfachregression (eine unabhängige Variable) oder eine Mehrfach-
beziehungsweise multiple Regression (zwei oder mehr unabhängige Variable)
handelt. Die Durchführung der Regressionsanalyse: S.374f Buch, Janssen.
2.2.3 Korrelationsanalyse
Die Korrelationsanalyse (Zusammenhangsanalyse, von lat. con: zusammen mit,
relatio: Beziehung) hat bei der multivariaten Statistik die Aufgabe, zwischen
mindestens zwei Merkmalen die Intensität und die Richtung von
Zusammenhängen mittels geeigneter Maßzahlen zu messen. Dabei muss
berücksichtigt werden, ob die Merkmalsausprägungen auf einer nominalen,
ordinalen oder kardinalen beziehungsweise metrischen Skala erhoben wurden.
Dementsprechend unterscheidet man in der statistischen Methodenlehre zwischen
der Kontingenz- (lat: contingentia: Zufälligkeit), der Rang- und der
Maßkorrelationsanalyse23.
Abb. Dateneditor: Korrelationsanalyse
Auf der Basis von Kontingenztabellen (Kreuztabellen) wird die
Zusammmenhangsanalyse als Kontingenzanalyse bezeichnet. Im Weiteren wird
ausschließlich ein Verfahren der bivariaten Kontingenzanalyse vorgestellt. Es 22 Vgl. Eckstein, Peter P. (1999), S. 218. 23 Vgl. Eckstein, Peter P. (1999), S. 175.

9
werden lediglich diejenigen Verfahren dargestellt, die vor allem in den
Wirtschafts- und Sozialwissenschaften eine praktische Anwendung erfahren.
Grundlage dieser Analysen sind sogenannte Kontingenztabellen, die in der Regel
nur für nominal oder ordinal skalierte Merkmale erstellt werden. Man
charakterisiert eine solche Tabelle wie folgt:
„ Für eine Stichprobe mit einem Umfang von n Merkmalsträgern, an denen die
Merkmale X und Y mit r und c sich voneinander unterscheidenden
Merkmalsausprägungen xj (j=1,2,…,r, r<n) und yk (k=1,2,…,c, c<n) erhoben
wurden, heißt die Anzahl, mit der das Ausprägungspaar (xj, yk) beobachtet wurde,
absolute Häufigkeit n(xj, yk)=njk des Ausprägungspaares (…)24.“
Bei der Erstellung einer Kreuztabelle ist grundsätzlich variabel, welches Merkmal
bezüglich seiner Ausprägungen in Zeilen und welches in Spalten aufgeführt
werden soll, denn es wird darauf abgezielt, eine Aussage über die Stärke und die
Richtung eines statistischen Zusammenhangs zwischen den beiden Merkmalen
herzustellen. Bildhaft verdeutlich wird diese Tatsache z.B. mit Hilfe eines 3-D-
Balkendiagramms.
Abb. Beispiel Kreuztabelle
Wenn bei einer Kontingenztabelle die Anzahl der Ausprägungen gleich ist, r = c,
so heißt diese Tabelle quadratisch, ansonsten rechteckig. Die Bezeichnung r steht
für `row` (engl. für Zeile) und c für `column` (engl. für Spalte). Ein Sonderfall ist
die Kontingenztabelle für dichotome Merkmale, bei der r = c = 2 und r mal c = 4
ist. Diese bezeichnet man dann als `quadratische Vierfeldertafel`. Die
zweidimensionale oder bivariate Häufigkeitsverteilung ist an der Menge aller r
mal c Ausprägungspaare und den dazugehörigen absoluten Häufigkeiten n(xj; yk)
zu erkennen. Die Merkmale X und Y einer Kontingenztabelle heißen statistisch
24 Vgl. Eckstein, Peter P. (1999), S. 176.

10
unabhängig, wenn für die beiden Merkmale X und Y alle r bzw. alle c
Konditionalverteilungen übereinstimmen.
Abb. Beispiel Balkendiagramm einer Kreuztabelle
2.3 Die Oberfläche von SPSS für Windows
SPSS beinhaltet insgesamt fünf Fenster, mit denen gearbeitet wird. Den ersten
beiden kommt dabei eine zentrale Bedeutung zu. Sie werden bei der Arbeit mit
SPSS immer benötigt. Dabei handelt es sich um den Daten-Editor und den SPSS-
Viewer, auch bekannt unter der Bezeichnung Ausgabefenster.25
Der Daten-Editor erscheint jeweils beim öffnen des SPSS-Programms. Die
anderen Fenster müssen durch entsprechende Befehle selbst geöffnet werden.
Dazu benötigt man im Daten-Editor die Befehlsfolge ´Datei´, ´Neu´, und wählt
dann das jeweils gewünschte Fenster.26
25 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 6. 26 Vgl. SPSS-Programm, Daten-Editor.

11
Abb. 2 SPSS Daten-Editor, Option „Datei“
2.3.1 Daten-Editor
Der Daten-Editor erscheint jeweils beim Start des SPSS-Programmes. Dabei
erscheint in der Titelleiste der Name der jeweiligen Datei. Zu Beginn wird sie
immer mit „Unbenannt“ dargestellt. Außerdem zeigt die Titelleiste auch den
Namen des Fensters an. In diesem Fall ist das „SPSS Daten-Editor“.
Abb. Titelleiste SPSS Daten-Editor
Bei dem Daten-Editor handelt sich um die zentrale Arbeitseinheit des SPSS, die
Arbeitsdatei. Sie setzt sich zusammen aus der Datenmatrix und dem
Deklarationsteil. Hier werden Daten eingegeben, geändert und gelöscht oder er
wird einfach zum einsehen der Daten geöffnet. Weitere Einzelheiten des Daten-
Editors werden in Punkt 4 „Menüleiste des Daten-Editors“ vorgestellt und
behandelt.27
2.3.2 SPSS Viewer
In der Titelleiste des SPSS Viewers befindet sich der Name der Ausgabedatei, die
zuerst immer als „Ausgabe 1“ gekennzeichnet ist. Auch hier wird der Name des
Fensters angezeigt: „SPSS Viewers“.
Abb. Titelleiste SPSS Viewer
Im SPSS Viewer wird der Output der Arbeit angegeben. 28 Auf der linken Seite
erscheint eine Gliederung, die so genannte Navigationszone, rechts, im
Inhaltsfenster, die eigentliche Arbeit in Form von Tabellen, Graphiken und
Textausgaben. Daneben können auch protokollierte SPSS-Anweisungen,
Warnungen, Anmerkungen und Titelzeilen erscheinen.29 Mit der Navigationszone
kann man schnell innerhalb des Inhaltsfensters hin und her springen, um
27 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 6. 28 Vgl. Janssen, Jürgen /Laatz, Wilfried (1999), S. 6. 29 Vgl. Baltes-Götz, Bernhard (2001), S. 53.

12
gewünschte Teile des Outputs zu verschieben oder ein- beziehungsweise
auszublenden. Im SPSS Viewer kann man nicht nur die grafischen Ergebnisse der
statistischen Auswertung einsehen, man kann diese Grafiken auch direkt im
Viewer überarbeiten und verändern. Dies wird vom Diagramm-Editor
übernommen. Die Symbolleiste des SPSS Viewers enthält neben den üblichen
Schaltflächen auch einige zusätzliche: Seitenansicht, Exportieren, Letzte
Ausgaben Anwählen.30
Daten-Editor und SPSS Viewer sind die zwei zentralen Einheiten des SPSS.
Daneben gibt es noch den Diagramm-Editor, den Syntax-Editor und den Skript-
Editor.
2.3.3 Diagramm-Editor
Der Diagramm-Editor wird auch als Grafikfenster bezeichnet. Er wird eigentlich
nur benötigt, wenn die im SPSS Viewer enthaltenden Graphiken weiter
überarbeitet werden müssen. Um dorthin zu gelangen, benötigt man im SPSS
Viewer einen Doppelklick auf die zu überarbeitende Grafik. Die Bearbeitung
geschieht beispielsweise in Form von Farb- oder Schriftänderungen, oder auch
über Datenverbesserungen.31 Außerdem kann man hier den Dateityp ändern,
Achsen vertauschen und 3D-Steudiagramme rotieren lassen.32
2.3.4 Syntax-Editor
Der Syntax-Editor ist hilfreich bei der Editierung von Befehlstexten und deren
Ergänzungen. Man kann eine Befehlsdatei erstellen, speichern und auch starten.33
Dabei können die SPSS-Befehle selbst erstellt werden oder aus anderen
Programmen importiert werden. Um Zugriff auf die Befehle zu bekommen dient
das Menü ´Ausführen´. Es gibt vier verschieden Möglichkeiten die Befehle zu
starten.
30 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 70. 31 Vgl. ebenda. S.7. 32 Vgl. SPSS-Programm, Suchen: Diagramm-Editor. 33 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 7.

13
Abb. Syntax-Editor
Über den Unterpunkt ´Alles´ werden alle Befehle des Syntax-Editors gestartet, die
Option ´Auswahl´ bietet sich an, wenn nur bestimmte Befehle ausgeführt werden
sollen. Dazu werden die gewünschten mit dem Cursor markiert. Analog gilt das
Verfahren bei ´Aktueller Befehl´. Hier wird jedoch nur ein Befehl ausgewählt und
angewandt. Die letzte der vier möglichen Optionen lautet ´Bis Ende´. Damit lässt
sich eine Auswahl treffen, mit der ab einem ausgewählten Befehl alle
nachfolgenden bis zum Ende ausgeführt werden.34
2.3.5 Skript-Editor
Bei dem fünften und letzten Fenster des SPSS handelt es sich um den Skript-
Editor. Es ist möglich, Skripte des SPSS in einer speziellen Skriptsprache zu
erstellen, zu speichern und zu starten. Dieses Fenster wird vor allem bei der
Bearbeitung des Outputs benötigt.35
3 Datenmanagement
Der SPSS Daten-Editor ist ein in Zeilen und Spalten aufgeteiltes Arbeitsblatt, mit
dessen Hilfe im Wesentlichen das SPSS Datenmanagement bewerkstelligt wird.
Die Zeilen des Arbeitsblattes entsprechen den statistischen Merkmalsträgern. Die
Anzahl der Arbeitsblattzeilen, die mit Daten belegt sind (auch solche mit
„Missing values“), ist immer mit dem Umfang der statistischen Gesamtheit
beziehungsweise Stichprobe identisch.
Die bereits angesprochenen Merkmalsträger werden im SPSS- System mit dem
Begriff des Falles bezeichnet, obwohl dieser in der Statistik schon den Vorgang
beschreibt. Zwar kann man einen Vorgang beziehungsweise Fall als kleinste
34 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 78. 35 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 7.

14
statistische Einheit verstehen, doch gilt diese Gesetzmäßigkeit nicht umgekehrt,
d.h. nicht jede statistische Einheit ist gleich auch ein Vorgang.
Die Spalten des Arbeitsblattes entsprechen den Erhebungsmerkmalen. Sie
besitzen den Namen Variable in der SPSS- Terminologie.
Die Größe des Arbeitsblattes und damit die Größe der zu erstellenden Datei hängt
von der Speicherkapazität ab36.
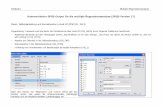
3.1 Variablendeklaration
Der Vorgang einer SPSS- Variablendefinition ist durch die Festlegung eines
zulässigen Namens, eines geeigneten Typs und Spaltenformats, von Labels und
fehlenden Werten für eine Variable gekennzeichnet37.
Voraussetzung für den Vorgang der Definition ist das Geöffnetsein des SPSS
Daten-Editors. Als aktives Fenster muss hierbei die zweite Registerkarte
Variablenansicht zu sehen sein. Diese ist ebenfalls als Matrix aufgebaut. In den
Zeilen werden die einzelnen Variablen bekannt gemacht. Die Spalten geben die
Attribute der Variablen wieder, die man für jede neu bestimmen kann.
Abb. SPSS Daten-Editor, Variablenansicht
Bei der Namensgebung, für die die Spalte „Name“ zuständig ist, müssen folgende
Regeln berücksichtigt werden:
Variablennamen dürfen aus maximal acht Zeichen bestehen, wobei der erste ein
Buchstabe sein muss. Die restlichen Zeichen können sich aus Buchstaben, Ziffern,
Symbolen (@, #, _, $) oder dem Punkt zusammensetzen, dieser darf allerdings
nicht am Ende stehen. Leerzeichen, sowie die Zeichen !, ?, ` und * sind hierbei
jedoch verboten. Die Entwicklung von SPSS hat auch vor den Regeln der
Variablennamen nicht halt gemacht. Waren früher Umlaute verboten, sind diese 36 Vgl. Eckstein, Peter P., (1999), S. 18. 37 Vgl. Eckstein, Peter P. (1999), S. 18.

15
mittlerweile akzeptiert. Jedoch muss bei dem Datentransfer zu Rechnern anderer
Betriebssysteme aufgepasst werden, da bei den alten Versionen zum Beispiel das
Wort „größe“ leicht zu „gr+fle“ umgewandelt wird. Außerdem dürfen folgende
Wörter nicht verwendet werden: ALL, AND, BY, EQ, GE, GT, LE, LT, NE,
NOT, OR, TO, WITH, da es sich dabei um Schlüsselwörter der
Kommandosprache in SPSS handelt. Die Groß- beziehungsweise Kleinschreibung
kann vernachlässigt werden. Jeder Variablenname darf innerhalb einer Analyse
nur einmal verwendet werden.38
Bei der Variablendeklaration ist der Variablentyp per Voreinstellung auf den Typ
Numerisch festgelegt.39 Die restlichen Typen, die man manuell noch einstellen
könnte, wurden bereits in Abschnitt 2.1.2 „Variable“ vorgestellt.
Die Attribute Spaltenformat und Dezimalstellen können deren Anzeige-
Eigenschaften bestimmen. Spaltenformat dient der Bestimmung der Anzahl der
anzuzeigenden Stellen. Dezimalstellen legen die Anzahl der anzuzeigenden
Dezimalstellen fest.40 Mit Hilfe des Dialogfelds `Spaltenformat definieren` kann
sowohl die Spaltenbreite durch Angabe einer gewünschten Zeichenanzahl als auch
die Ausrichtung durch das Aktivieren der jeweiligen Schaltfläche festgelegt
werden.41
Um später, zum Beispiel beim Ausdrucken, das Lesen und Bearbeiten von
Ergebnislisten zu vereinfachen ist es sinnvoll, die Variable mit Hilfe von Labels
(Beschriftung) zu versehen. Der eigentliche Grund ist aber darin zu sehen, dass
die Labels die späteren Diagramm- und Achsenbeschriftungen sind. Eine
Labeldefinition ist allerdings nicht zwingend notwendig, da sie für die
Berechnungen keinerlei Bedeutung haben.42
3.2 Arbeiten mit Variaben: Einfügen, Löschen, Verschieben, Speichern
Die Dateneingabe beziehungsweise deren Korrektur in der Variablenansicht kann
unter Verwendung der Maus und auch mit Hilfe von Funktionstasten wie Return
oder den Cursortasten geschehen. Eine für die Dateneingabe aktivierte Datenzelle,
auch Datenfeld genannt, erscheint dick umrandet. Außerdem erscheint im
Zelleneditor der Mauszeiger als ein senkrechter Strich. Jeder Dateneintrag in ein
38 Vgl. Baltes-Götz, Bernhard (2001), S. 19. 39 Vgl. Baltes-Götz, Bernhard (2001), S. 36. 40 Vgl. Baltes-Götz, Bernhard (2001), S. 36. 41 Vgl. Eckstein, Peter P. (1999), S. 18. 42 Vgl. Baltes-Götz, Bernhard (2001), S. 36.

16
Datenfeld wird gleichzeitig vor dem Zelleneditor in der Datenansicht in der Form
`Zeilennummer: Variablenname` vermerkt.
Abb. Benennung des Dateneintrags `Zeilennummer – Variablenname`
Datenfeldinhalte können durch Markieren und darauffolgendes Drücken der Taste
`Entf` gelöscht werden. Dies ist auch über den Menüpunkt `Bearbeiten – Löschen`
möglich.
Mit Hilfe der `Drag & Drop` Funktion kann man Daten beliebig oft verschieben.
Solange eine Variable noch keine Werte enthält, können die beschriebenen
Verschiebungsaktionen auch in der Variablenansicht des Datenfensters
durchgeführt werden.
Es wird beim Speichern zwischen dem ersten und jedem weiteren Vorgang
unterschieden. Man speichert das erste Mal, wie bei allen Windows-
Anwendungen üblich über den Pfad `Datei – Speichern unter`. Bei jedem
weiteren Mal kann das in der Menüleiste dafür vorgesehene Zeichen der Diskette
verwendet werden43.
3.3 Attribute auf andere Variable übertragen
Um die Gleichheit aller Variablenattribute gewährleisten zu können, müssen diese
eine einheitliche Definition erhalten. Dabei ist nach einer erstmaligen Deklaration
lediglich einer Variablen ein einfaches Übertragen auf alle folgenden Variablen
möglich. Dazu markiert man die komplette erste Variable per Mausklick auf der
ihr zugehörigen am linken Bildschildrand befindliche Zeilennummer und kopiert
die Attribute mit `STRG + C` oder über die Menüoption `Bearbeiten – Kopieren`.
Man markiert nun die entsprechenden anderen Variablen z.B. durch Anklicken
der 2. Variablen und dann bei gedrückter Umschalt-Taste zusätzlich der letzten
Variablen. Die Attribute erhalten durch den Vorgang `STRG + V` oder den
Menübefehl `Bearbeiten – Einfügen` ebenfalls Gültigkeit bei den übrigen
43 Vgl. Baltes-Götz, Bernhard (2001), S. 40.

17
ausgewählten Variablen. Dieser Vorgang kann durch gleiche Vorgehensweise auf
nur ausgewählte Variable erfolgen, ohne dabei die Gesamtheit aller Variablen zu
berühren.44
Abb. Gesamte Variablenansicht
3.4 Daten bearbeiten
Das SPSS- Datei- und Datenmanagement umfasst eine Vielzahl von
verschiedenen charakteristischen Bearbeitungsvorgängen. Dazu gehören z.B. das
Zählen, Auswählen oder Löschen von Merkmalsträgern, bzw. das Einfügen,
Verschieben, Berechnen, Umkodieren oder Löschen von Variablen sowie das
Zusammenfügen oder Aufteilen von SPSS- Datendateien.
Beispielhaft wird an dieser Stelle das Zusammenfügen von gleichartig
strukturierten SPSS- Dateien aufgezeigt. Gleichartig strukturiert heißen hierbei
Datendateien, die eine gleiche Anzahl gleichartig definierter Variablen besitzen.
Dabei liegt eine besondere Gewichtung auf der Festlegung gleicher
Variablennamen und gleicher Variablentypen. Der passende Pfad dazu lautet
`Daten – Dateien zusammenfassen – Fälle hinzufügen: Datei lesen – Fälle
hinzufügen aus`. Bei SPSS- Dateien mit jeweils gleichartig definierten Variablen
gleicher Anzahl werden diese durch SPSS automatisch als „gepaarte Variablen“
gesehen und zu einer zusammengefasst45.
44 Vgl. Baltes-Götz, Bernhard (2001), S. 41. 45 Vgl. Eckstein, Peter P. (1999), S 32

18
Abb. Zusammenfassen gleich strukturierter Dateien
Eine andere oft genutzte Funktion ist das Einfügen einer Variablen, die jeden
Merkmalsträger mit einem Identifikator versieht. Dazu reicht es meist aus, die
Identifikation mit Hilfe eines Nummernschlüssels darzustellen. Dazu wird die
Menge der natürlichen Zahlen auf die Merkmalsträger abgebildet, d.h. die
einzelnen Merkmalsträger werden nummeriert. Man geht wie folgt vor:
`Transformieren – Berechnen – Variable berechnen`. Mit der Funktion
`$casenum` (lat. casus – der Fall) wird eine zusätzliche Spalte beigefügt, welche
eine neue numerische Variable mit dem Variablennamen `nr` trägt. Das Zählen
bzw. Nummerieren wird automatisch übernommen46.
Abb. Dialogfeldausschnitt: Variablen nummerieren
4 Menüleiste des Daten-Editors
In der Menüleiste des Daten-Editors befinden sich die zentralen
Bearbeitungsgrundlagen des SPSS. Diese zehn Optionen werden im Folgenden
anhand ihrer Bedeutung für SPSS erläutert.
46 Eckstein, Peter P. (1999), S. 34.

19
Abb. 5 SPSS Daten-Editor, Menüleiste
Weil die Punkte Datei, Ansicht, Daten, Extras, Fenster und Hilfe für das Thema
„Einstieg in SPSS“ nicht von allzu großer Wichtigkeit sind, wird nur kurz ihre
jeweilige Funktion dargestellt. Dagegen wird auf die richtig wichtigen
Bearbeitungsgrundlagen Bearbeiten, Transformieren, Analysieren und Grafiken
speziell eingegangen.
4.1 Datei, Ansicht, Daten, Extras, Fenster, Hilfe
Das Menü Datei enthält Möglichkeiten zum öffnen neuer, aber auch alter Dateien,
wie zum Beispiel der Fenster Daten, Syntax, Ausgabe, Textausgabe und Skript.
Diese Fenster entsprechen denen in Punkt 2.3 vorgestellten wichtigsten Fenstern
des SPSS. Des Weiteren kann man mittels der Option Datei Dateien erstellen und
speichern, sowie die verschiedensten SPSS-Dateien und Dateien von Datenbank-
und Tabellenkalkulationsprogrammen importieren.47
Der Menüpunkt Ansicht befasst sich mit den Status- und Symbolleisten, die
eingeblendet oder ausgeblendet werden können. Man kann die Schriftarten
bestimmen und festlegen, ob Gitterlinien auftauchen sollen und ob Werte als
Label oder als Wert angezeigt werden sollen.48
Die Option Daten dient der Definition der Variableneigenschaften und des
Datums sowie dem Einfügen von Fällen und Variablen. Außerdem verfügt die
Option über die Möglichkeit SPSS-Datendateien komplett zu ändern, zum
Beispiel über Fälle sortieren, transponieren, umstrukturieren und aggregieren.
Man kann die Datei auch aufteilen und Fälle auswählen und gewichten.49
Extras versammelt unterschiedliche Funktionen, die zum Beispiel Informationen
zu den Variablen anzeigen können oder das Arbeiten mit Datensets und Skripten.
Des Weiteren findet sich dort ein Menü-Editor, der die Anpassungen des SPSS-
Menüs übernimmt.50
47 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 9. 48 Vgl. Baltes-Götz, Bernhard (2001), S. 24. 49 Vgl. SPSS-Programm, Daten-Editor, Menüpunkt Daten. 50 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 9.

20
Über Fenster kann man schnell auf die offenen oder aktiven Fenster des SPSS
zugreifen, oder alle Fenster minimieren.51
Das Menü Hilfe der Menüleiste bietet schnellen Zugriff auf das Lernprogramm
und den Statistik-Assistent. Außerdem gibt es Informationen zu dem SPSS-
Programm wieder.52 Hierauf wird in Punkt 7 „Hilfe-Programme“ genauer Bezug
genommen.
4.2 Bearbeiten
Die Option Bearbeiten beinhaltet die Befehle zum Ausschneiden, Kopieren,
Einfügen, Löschen und Suchen von Daten. Sie dient auch dem rückgängig
machen der letzten Arbeitsschritte.53 Außerdem findet sich dort der Menüpunkt
Optionen, der zu den Dialogboxen für die Grundeinstellungen der SPSS-Bereiche
führt. Hier lassen sich deren Eigenschaften ändern.54
Abb. Daten-Editor, Menü Bearbeiten
4.3 Transformieren
Transformieren bedeutet vor allem die Berechnung neuer Variablen und eine
Veränderung der bereits bestehenden Variablen55, zum Beispiel in Form von
Kodieren. Dies ist auf verschiedene Art möglich: zum einen in dieselben
Variablen, zum andern in andere Variablen. Außerdem lassen sich die Variablen
auch automatisch umkodieren. Des Weiteren kann man mittels dieses
Menüpunktes die Häufigkeit von Werten in Fällen zählen, eine Rangfolge bilden,
51 Vgl. SPSS-Programm, Daten-Editor, Menüpunkt Fenster. 52 Vgl. Baltes-Götz, Bernhard (2001), S. 25. 53 Vgl. ebenda, S. 24. 54 Vgl. Jansen, Jürgen/ Laatz, Wilfried (1999), S. 9. 55 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 9.

21
Zeitreihen erstellen und Zufallszahlen für den Startwert bestimmen, aber auch
fehlende Werte ersetzen.56
Abb. Daten-Editor, Menü Transformieren
4.4 Analysieren
Unter dieser Option finden sich die statistischen Auswertungsmethoden von
SPSS. Deshalb hieß diese Option vor einigen Jahren, zumindest 1999, auch noch
„Statistik“.57
Abb. Daten-Editor, Menü Analysieren
Einige dieser Methoden sind bereits aus den Punkt 2.2 „Wichtige
Analysemethoden“ bekannt, so zum Beispiel Deskriptive Statistiken, Regression 56 Vgl. SPSS-Programm, Menüpunkt Transformieren. 57 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 9.

22
und Korrelation. Natürlich sollten auch die restlichen Analysemethoden nicht
außer Acht gelassen werden, jedoch im Rahmen dieses Proseminars würde es zu
weit gehen.
4.5 Grafiken
Mit der Option Grafiken lassen sich die Ergebnisse des Menüs Analysieren
grafisch darstellen, anhand von Diagrammen und Grafiken.58 Die wichtigsten und
am häufigsten gebrauchten Grafiken sind Streudiagramme, Histogramme, Balken-
und Kreisdiagramme. Bei diesem Menüpunkt ist zu beachten, dass über den
Unterpunkt Interaktiv zu den aktuellen Darstellungen gelangt werden kann.
Abb. Diagramm-Editor, Menü Grafiken
5 Pivot- Editor
Pivot heißt aus dem französischen übersetzt „Drehzapfen“.
Unter dem Pivotieren einer Tabelle versteht man bei SPSS die Operationen des
Austauschens ihrer Zeilen-, Spalten- und Schichtendimensionen, aber auch die
Änderung der Schachtelungsordnung sowie Verstecken von Zellen59.
58 Vgl. Janssen, Jürgen/ Laatz, Wilfried (1999), S. 9. 59 Vgl. Baltes-Götz, Bernhard (2001), S. 115.

23
Abb. Pivot- Leisten
5.1 Starten
Um den Pivot- Editor zu starten und eine Tabelle zu bearbeiten benutzt man einen
einfachen Doppelklick. Man gelangt auch über das Kontextmenü zu dieser
Funktion. Es ist empfehlenswert mit dem Menübefehl `PIVOT – Pivotleisten` ein
gesondertes Fenster zu öffnen. Man erkennt je eine Leiste für die Zeilen, Spalten
und Schichten der Tabelle inklusive eines Pivotsymbols für die dargestellte
Tabellendimension60.
Abb. Pivot- Editor starten
5.2 Dimensionen verschieben
Die Darstellung einer Dimension in Form einer Spalte, Zeile oder Schicht kann
man durch Verschieben des Pivotsymbols festlegen. Dies kann bei einem
späteren Ausdruck von großer Bedeutung sein, um die Übersichtlichkeit der
Tabelle zu gewährleisten. So kann man Einfluss auf den benötigten Platz der
Tabelle nehmen61.
60 Vgl. Baltes-Götz, Bernhard (2001), S. 115. 61 Vgl. Baltes-Götz, Bernhard (2001), S. 118.

24
Abb. Beispieltabelle
5.3 Gruppierungen
Es ist möglich, mehrere Kategorien einer Dimension mit einem Gruppenetikett zu
versehen. Dies geschieht über die Benutzung der Maus, indem man einen
Rechtsklick auf das Kategorienetikett macht und aus dem Kontextmenü die
Funktion `Gruppierung aufheben` auswählt. Analog dazu können so auch
Gruppierungen aufgehoben werden.
Zusätzlich kann die Anzahl der Dezimalstellen verändert werden. Dies und
weitere Eigenschaften der Zellen können unter `Format – Zelleneigenschaften`
nach belieben variiert werden62.
5.4 Kategorien aus- und einblenden
Wenn eine SPSS- Tabelle zu unübersichtlich oder unzweckmäßig erscheint,
besteht die Möglichkeit, Kategorien einer Dimension auszublenden. Dazu müssen
die Tasten `STRG` und `ALT` gedrückt werden, gleichzeitig einen Rechtsklick auf
das Kategorienetikett. Man wählt nun aus dem Kontextmenü `Kategorie
ausblenden`. Um diesen Vorgang oder bereits vorangegangene Ausblendungen
rückgängig zu machen, kann man in der Menüleiste über `Ansicht – Alles
einblenden` die ursprüngliche Tabelle zurück erhalten.
62 Vgl. Baltes-Götz, Bernhard (2001), S. 117.

25
Abb. Kategorie ausblenden
6 SPSS- Ausgaben in andere Anwendungen übernehmen
Die im SPSS- Programm erstellten bzw. bearbeiteten Daten können in andere
gängigere Microsoft- Programme wie z.Β. das Textverarbeitungsprogramm Word
oder das Tabellenkalkulationsprogramm Excel übertragen werden. Dabei werden
verschiedene Vorgehensweisen unterschieden, wobei die Übertragung der Daten
wesentlich variiert.
Abb. Einfügen von SPSS- Dateien auf zwei verschiedene Arten
6.1 Graphische Übertragung
Um die in SPSS erstellten graphischen Objekte in Microsoft- Programme
einzubinden, kann der einfache Befehl durch Betätigen der Tasten `STRG – K`
gleichzeitig betätigt werden. Man beachte das `K`! Ebenso ist dies über den
Menüpunkt `Bearbeiten – Objekte kopieren` möglich. In dem gewünschten
Zielprogramm muss zum Einfügen wahlweise `STRG – V` oder der etwas
umständlichere Weg über `Bearbeiten – Einfügen` vollzogen werden. Bei diesem
Vorgang werden sowohl die Daten als auch das Layout übernommen. Letzteres

26
kann allerdings im neuen Bearbeitungsprogramm verändert und nach eigenen
Wünschen entsprechend angepasst werden.
6.2 RTF- Übertragung
Das Kürzel `RTF` steht für `RICH-TEXT-FORMAT`. Bei dieser Art der
Übertragung der SPSS- Daten werden nur die Daten an sich und nicht die
vollständige Darstellung dieser übertragen. Die uns bekannten Wege `STRG – C`
oder `Bearbeiten – Einfügen` werden hierzu genutzt. Als Resultat einer solchen
Übertragung erhält man z.B. in Word eine einfache Tabelle mit den in SPSS
erstellten Daten. Vorteil ist die geringere Speicherkapazität und die damit
verbundene erleichterte Handhabung der Daten. Ein anderes gewichtiges
Argument von RTF, welches man sowohl positiv für den Autoren als auch negativ
für den `Endverbraucher` sehen kann, ist die Tatsache, dass bei dieser
Vorgehensweise nicht nur wie bei der oberen Übertragung das Design
verwendungsgerecht dargestellt werden kann, sondern zusätzlich die Daten im
neuen Zielprogramm eine Veränderung durch den Autoren erfahren können. Es ist
also möglich die Daten nachträglich zu ändern und sogar die Auswertung zu
verfälschen.
7 Hilfe-Programme
Wie bereits erwähnt, handelt es sich bei SPSS um ein umfangreiches und relativ
komplexes Computerprogramm, mit dem es gilt empirische und statistische
Auswertungen und deren grafische Darstellung durchzuführen. Dies führt zu
vielen Fragen und Problemen im Umgang mit SPSS, die anhand der Vielzahl der
Hilfe-Programme von SPSS gelöst werden können und sollen. Diese sind
hauptsächlich im Menü Hilfe der Menüleiste des Daten-Editors zu finden.

27
Abb. Menüleiste, Option „Hilfe“
7.1 Das Online-Hypertext-Handbuch
Zum Online-Hypertext-Handbuch gelangt man einfach über die Menüleiste des
Daten-Editors. Die Befehlsfolge Hilfe, Themen führt direkt zu der Registerkarte
Inhalt, die SPSS in geregelter Ordnung schlagwortartig wiedergibt.63 Des
Weiteren hat man die Möglichkeiten über die Registerkarten Index und Suchen
gewählte SPSS-Begriffe anzugeben und auf eine Erklärung oder Beschreibung der
gezielten Suche zu warten.
Abb. SPSS-Base (Hilfethemen), Registerkarten
7.2 Das SPSS-Lernprogramm
Das Lernprogramm von SPSS ist eine gute Möglichkeit den Umgang mit SPSS zu
üben und kennen zulernen. Es ist ebenfalls über den Menüpunkt Hilfe zu
erreichen. Dort wählt man dann den zweiten Gliederungspunkt Lernprogramm.
Man gelangt nun direkt auf die Einführungsseite. Wenn man unten rechts auf
Inhaltsverzeichnis klickt, wird die Einteilung des Lernprogramms sichtbar:
63 Vgl. Baltes-Götz, Bernhard (2001), S. 25.

28
Abb. SPSS-Lernprogramm, Inhaltsverzeichnis
Anhand dieses interaktiven Lernprogramms kann eine Lektion nach der anderen
parallel zu SPSS durchgearbeitet werden, indem man die Tastenkombination ALT
und PFEIL-PFEIL drückt.64
7.3 Kontextsensitive Hilfe zu den Dialogboxen
Alle Dialogboxen, nicht nur die in SPSS, besitzen als Standardeinrichtung eine
Hilfe-Schaltfläche. Damit lassen sich die nötigen Informationen zu den möglichen
Arbeitsschritten aufrufen.65
7.4 Der Statistik-Assistent
Der Statistik-Assistent ist ebenfalls über den Menüpunkt Hilfe zu erreichen, wenn
man dort den Statistik-Assistent anklickt. Dieser öffnet nacheinander einige
Dialogboxen, die Fragen zur gewünschten statistischen Auswertung und deren
Darstellung stellen.
64 Vgl. Baltes-Götz, Bernhard (2001), S. 26. 65 Vgl. Baltes-Götz, Bernhard (2001), S. 26.

29
Abb. Statistik-Assistent
Durch die entsprechende Wahl der Antwortmöglichkeiten wird der Anwender
schließlich zur richtigen Auswertungsanalyse geführt.66
Abb. Dialogbox „Verfahren“ (Ergebnis des „Assistenten-Fragebogens“)
66 Vgl. Baltes-Götz, Bernhard (2001), S. 27.

30
7.5 Weitere Möglichkeiten
Neben den bereits genannten Hilfe-Programmen gibt es noch Syntax-Handbücher
und Informationen zu SPSS im Internet sowie die Benutzerberatung.
Online-Syntax-Handbücher sind über die Befehle ´Hilfe´, ´Syntax Guide` im
Daten-Editor aufzurufen. Sie sind aber nur lesbar, wenn die Handbücher im PDF-
Format installiert worden sind. Nun sind die Möglichkeiten des SPSS-Programms
über ihre umfangreiche Kommandosprache aufzurufen.67
Natürlich bietet auch das Internet sehr viele Informationen zu SPSS. Die
wichtigste Seite ist die Homepage der SPSS Inc.. Sie lautet:
http://www.spss.com.68 Hier finden sich allgemeine Informationen zur
Anwendung von SPSS, aber auch Fallbeispiele, die SPSS anschaulich darstellen
und dem Anwender den Einstieg erleichtern.
Die letzte Möglichkeit Hilfe zu bekommen bietet zum Beispiel auch das URT,
Universitätsrechenzentrum Trier, in Form der Benutzerberatung. Es ist allerdings
vorteilhaft die angebotenen SPSS-Kurse wahrzunehmen und sie zu besuchen. Sie
werden zum einen per Crashkurse und zum anderen per …. angeboten.
67 Vgl. Baltes-Götz, Bernhard (2001), S. 27. 68 Vgl. Baltes-Götz, Bernhard (2001), S. 28.

31
Literaturverzeichnis Baltes-Götz, Bernhard (2001):
Statistische Datenanalyse mit SPSS 10 für Windows, Universitäts- Rechenzentrum Trier 2001 Eckstein, Peter (1999): Angewandte Statistik mit SPSS, 2. Auflage, Wiesbaden 1999.
Janssen, Jürgen / Laatz, Wilfried (1999): Statistische Datenanalyse mit SPSS für Windows, 3. Auflage, Springer Verlag / Berlin 1999 Programm: SPSS 11.5 für Windows