
RST - Labor - TitleFrame · Das OSPF (Open Shortest Path First) – Protokoll ist ein...
34
RST - Labor Semester: I7I Architektur eines Routers Datum: 12.05.2008 Seite (1 von 34) RST - Labor Architektur eines Routers Ausarbeitung von: Wolfgang Schüschke, 32780 Dimitri Zielke, 134793 Semester: I7I Ort: Hochschule Bremen – Fachbereich 4, Elektrotechnik & Informatik Datum: Email Kontakt: 12.05.2008 Wolfgang Schüschke [[email protected]] Dimitri Zielke [[email protected]] 1. Deckblatt
Transcript of RST - Labor - TitleFrame · Das OSPF (Open Shortest Path First) – Protokoll ist ein...

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (1 von 34)
RST - Labor
Architektur eines Routers
Ausarbeitung von: Wolfgang Schüschke, 32780
Dimitri Zielke, 134793
Semester: I7I
Ort: Hochschule Bremen – Fachbereich 4,
Elektrotechnik & Informatik
Datum:
Email Kontakt:
12.05.2008
Wolfgang Schüschke
Dimitri Zielke
1. Deckblatt

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (2 von 34)
2. Inhaltsverzeichnis 1. Deckblatt ......................................................................................................................................... 1
2. Inhaltsverzeichnis ............................................................................................................................ 2
3. Abbildungsverzeichnis ..................................................................................................................... 3
4. Tabellenverzeichnis ......................................................................................................................... 3
5. Motivation ....................................................................................................................................... 4
6. Geschichte ....................................................................................................................................... 5
7. Aufgaben des Routers ..................................................................................................................... 7
7.1. Arbeitsweise eines Routers ..................................................................................................... 7
7.2.1. RIP - Protokoll .................................................................................................................. 8
7.2.2. OSPF – Protokoll .............................................................................................................. 8
7.2.3. Arbeitsweise OSPF – Protokoll ........................................................................................ 9
7.2.4. BGP – Protokoll ................................................................................................................ 9
8. Architektur eines Routers .............................................................................................................. 12
8.1. Routingablauf ........................................................................................................................ 12
8.2. Unterschied Hochgeschwindigkeitsnetze ............................................................................. 12
8.3. Switching Fabric ..................................................................................................................... 13
8.3.1. Shared Memory Switching ............................................................................................ 14
8.3.2. Shared Bus ..................................................................................................................... 15
8.3.3. Crossbar ......................................................................................................................... 15
8.3.4. Output Ports .................................................................................................................. 16
8.3.5. Probleme der Input / Output Ports ............................................................................... 16
8.4. Routing Table ......................................................................................................................... 17
8.5. Suchalgorithmen in „Routing Table“ ..................................................................................... 17
8.5.1. Longest Matching Prefix ................................................................................................ 17
8.5.2. Binärbäume ................................................................................................................... 19
8.5.3. Dynamic Prefix Trie ........................................................................................................ 19
8.5.4. Binary Tree with Chunks ................................................................................................ 20
8.5.5. Hashing mit Binary Search ............................................................................................. 21
8.5.6. Gegenüberstellung ........................................................................................................ 21
8.5.7. Fazit Suchstrategie......................................................................................................... 22
9. Routermodelle Small, Home Office / Business.............................................................................. 23
9.1. Chipsatz ................................................................................................................................. 26
9.2. Intel IXP2XXX Netzwerk Prozessoren [Quelle: RM92IXP] ..................................................... 27
10. Fazit ........................................................................................................................................... 31
11. Quellen ...................................................................................................................................... 32

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (3 von 34)
3. Abbildungsverzeichnis Abbildung 1 – Honeywell DDP-516 ......................................................................................................... 5
Abbildung 2 – DEC pdp11/05 .................................................................................................................. 5
Abbildung 3 – Beispielgraph zum Pfadvektoralgorithmus .................................................................... 11
Abbildung 4 – Grundarchitektur eines Routers ..................................................................................... 12
Abbildung 5 – Grundarchitektur eines Hochleistungsrouters ............................................................... 13
Abbildung 6 – Input Port ....................................................................................................................... 13
Abbildung 7 – Switching Fabric ............................................................................................................. 14
Abbildung 8 – Switching Fabric als Shared Memory ............................................................................. 14
Abbildung 9 – Shared Bus Beispiel ........................................................................................................ 15
Abbildung 10 – Crossbar Beispiel .......................................................................................................... 16
Abbildung 11 – Output Port .................................................................................................................. 16
Abbildung 12 – Longest Matching Prefix ............................................................................................... 18
Abbildung 13 – Dynamic Prefix Trie ...................................................................................................... 19
Abbildung 14 – Binary Tree with Chunks .............................................................................................. 20
Abbildung 15 – Hashing mit Binary Search ........................................................................................... 21
Abbildung 16 – Small, Home Office Router ........................................................................................... 23
Abbildung 17 – AR7VWi Block Schaltbild .............................................................................................. 24
Abbildung 18 – Basic Bridge / Router based on AR7 ............................................................................. 24
Abbildung 19 – Cisco 7301 .................................................................................................................... 25
Abbildung 20 – Innenansicht Cisco 7301............................................................................................... 26
Abbildung 21 – Blockschaltbild BCM 1250 ............................................................................................ 26
Abbildung 22 – Intel IXP2400 Netzwerk Prozessor Blockschaltbild ...................................................... 28
Abbildung 23 – Intel XScale Blockschaltbild .......................................................................................... 29
Abbildung 24 – Blockschaltbild Microengine ........................................................................................ 30
4. Tabellenverzeichnis Tabelle 1 – Gegenüberstellung Suchalgorithmen ................................................................................. 21
Tabelle 2 – Intels Netzwerk Prozessoren .............................................................................................. 27

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (4 von 34)
5. Motivation
Das Thema Internet wird immer mehr zum Alltag. Fast jeder hat es mittlerweile zu Hause oder bei
der Arbeit. Doch niemand macht sich Gedanken was ein Router überhaupt ist, was in diesem Gerät
steckt, wie diese Geräte arbeiten.
Uns hat das Thema interessiert, da wir selbst bei einem Internetprovider arbeiten, und täglich mit
solchen Geräten konfrontiert werden, sei es, dass wir Kundenendgeräte per Telnet oder SSH-Zugang
konfigurieren, oder auf einem der Backbone-Geräte Statistiken oder Konfigurationen prüfen.
Interessant ist die Arbeit die so ein Backbone-Router verrichten muss, und das in einer möglichst
kurzen Zeit.
In den folgenden Abschnitten wollen wir speziell auf die Architektur eines Routers eingehen,
Hardware vorstellen und die Leistung dieser Geräte verdeutlichen.

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (5 von 34)
6. Geschichte
Die Entwicklung des Internets und der im Nachfolgenden entstehenden Technologien entstand mit
der Entwicklung des ARPANET, durch die 1957 vom Department of Defense(DoD) ins Leben gerufene
Advanced Research Projects Agency (ARPA).
Die Entstehung der Abteilung wird als Antwort der USA auf die Sputnik Mission der Russen während
des Kalten Krieges gesehen.
Die USA wollten damit erreichen, dass sie auf
der Technologie Seite einen Vorsprung
erarbeiten können.
Die Entwicklung und die Konzepte zur
Umsetzung des Netzwerkes entstanden in den
60er Jahren, dies war der Grundstock für die
ersten Paket Netzwerke (PS-
Networks/Packetswitching Networks).
Die ersten Paket-Verwaltungsrechner waren aus
der "Honeywell Serie" einem 16Bit Computer
mit klassischer Akkumulator Technik und einem
zusätzlichen Register. [Quelle: G61]
Diese Rechner waren die Vorfahren der
heutigen Router und wurden „Interface
Message Processor“ (IMP) genannt, Hersteller
war BBN-Technologies.
Der Honeywell 16 wurde im Verlauf der Entwicklung des Netzwerks durch den Pluribus
Multiprozessor ersetzt, dies war die zweite Generation der IMP.
Ein Pluribus mit 6 Prozessoren wurde als Netzwerkswitch genutzt um zwischen den unterschiedlich
angebundenen Netzwerken zu verbinden.
Der Baustein ist in der Lage, bis zu 378
unterschiedliche Verbindungen aufrecht zu
halten und zu verwalten.
Der Pluribus hatte MIMD für symmetrische
Multiprozessorsysteme und zusätzlich ein
Pseudo-Interrupt Device (PID) implementiert,
um Prozesse abzuarbeiten und Prozesse zu
priorisieren.
Außerdem war bereits ein "STAGE" System als
Betriebssystem implementiert um Fehler zu
erkennen, wenn möglich zu beseitigen und
Deadlocks zwischen den einzelnen Prozessoren zu verhindern. Eine tiefgehende Erklärung des
Betriebssystems würde den Rahmen sprengen. [Quelle: G62]
Der erste Router wird an der Stanford University entwickelt. Das Grundsystem bildet ein DEC
PDP11/05, der später durch einen Motorola68000 ersetzt wurde. [Quelle: G63]
Quelle: http://www.series16.adrianwise.co.uk/history/ddp_516.html
Abbildung 1 – Honeywell DDP-516
Quelle: http://www.museen-sh.de/ml/digi_einzBild.php?pi=485_0166
Abbildung 2 – DEC pdp11/05

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (6 von 34)
Das NCP-Protokoll (Network Control Protocol) wird Anfang 1983 im ARPANET durch TCP/IP vollends
abgelöst.
Im Jahr 1984 sind bereits über 1000 Hosts über das ARPANET miteinander verbunden, 1987 über
10.000 und 1989 bereits 100.000. Im Jahre 1990 hört das ARPANET auf zu existieren und wird durch
das Internet vollends abgelöst.
Das World Wide Web wird 1991 vom Schweizer CERN (Conseil Européen pour la Recherche
Nucléaire) ans Netz gebracht.
Mit der massiv ansteigenden Anzahl an Nutzern werden immer neuere Techniken für die
Datenverarbeitung im Internet notwendig. Das Internet ist zu einem Medium für Jedermann
geworden und nicht mehr nur für Firmen, Wissenschaftler und dem Militär.

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (7 von 34)
7. Aufgaben des Routers
Die Hauptaufgabe eines Routers liegt darin, mehrere Rechnernetze zu koppeln. Das bedeutet, dass
im Router eintreffende Netzwerkpakete eines Protokolls analysiert und auf der Basis der Netzwerk
Layer-3 Schicht weitergeleitet werden. Diese Weiterleitung von Paketen nennt man auch „routen“.
Desweiteren führen Router Routingalgorithmen durch, um geeignete Wege zu ermitteln.
7.1. Arbeitsweise eines Routers Klassische Router arbeiten auf der Schicht 3 des OSI-Referenzmodells. Ein Router besitzt für jedes an
ihn angeschlossene Netz eine Schnittstelle. Beim Eintreffen von Daten muss ein Router den richtigen
Weg zum Ziel und damit die passende Schnittstelle bestimmen, über welche die Daten weiterzuleiten
sind.
Um diese Funktion zu gewährleisten, bedient sich der Router einer lokal vorhandenen
Routingtabelle, die angibt, über welchen Anschluss des Routers bzw. welche Zwischenstation
welches Netz erreichbar ist. Eine Default-Route auf dem Router sorgt dafür, dass alle Pakete, die
keinen geeigneten Eintrag in der Routingtabelle besitzen, dort hingeleitet werden.
Höherwertige Router haben mittlerweile auch ein sogenanntes Policy Based Routing. Hierbei wird die
Routingentscheidung nicht nur auf Layer-3 getroffen, sondern auch der gewünschte Dienst
berücksichtigt. Damit ist gemeint, dass hier eine Default Route für HTTP eine andere sein kann als
zum Beispiel die Route für SMTP.
Routingprotokolle dienen der Verwaltung des Routing-Vorgangs und der Kommunikation zwischen
den Routern. Die Router tauschen ihre Routing-Tabellen anhand von Routingprotokollen wie RIP
oder OSPF untereinander aus. [Quelle: A71]

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (8 von 34)
7.2. Wichtige Routingprotokolle
7.2.1. RIP - Protokoll Das Routing Information Protokoll (RIP), ist ein Protokoll auf Basis des Distanzvektoralgorithmus
(Seite 9). Es dient der dynamischen Erstellung der Routingtabellen von Routern. RIP wird in den
Protokollen IP und IPX verwendet. Aktuell gibt es dieses Protokoll in drei Version RIP v1, RIP v2 und
RIP NG.
Das RIP v1 besaß seiner Zeit noch keine Subnetzmaske und wurde auch schnell gegen die RIP v2
Version getauscht. Das RIP NG Protokoll ist eine Erweiterung des RIP v2 und unterstützt IPv6.
Sobald ein Router unter Strom steht und sein Bootvorgang abgeschlossen ist, befindet er sich in dem
Zustand, dass er nur sich und seine direkt angeschlossenen Netzwerke kennt.
Daraufhin sendet der Router seine Routingtabelle an benachbarte Router. Mit diesen Informationen
ergänzt der Router seine Routingtabelle und lernt somit, welche Netzwerke jeweils über welche
Router aus erreicht werden und welche Kosten damit verbunden sind.
Um Änderungen im Netzwerk zu erkennen, wird das Senden der Routingtabellen (Advertisement) bei
IP alle 30 Sekunden wiederholt. Dabei wird immer die gesamte Routingtabelle an alle Nachbarn
gesendet. Die Informationen breiten sich relativ langsam im Netz aus. Bei zum Beispiel 15 Hops
beträgt die Ausbreitung bereits 15 Minuten. Ein Hop ist der nächste Router in einem Netzwerk.
Da die Advertisements über UDP gesendet werden, ist eine Übertragung auch nicht zuverlässig.
Im Gegensatz zu anderen Routingprotokollen wie OSPF und NLSP kennt RIP immer nur seine direkten
Nachbarn. Die Kosten, die auch als Metrik bezeichnet werden, bestimmen den Aufwand, um ein Netz
zu erreichen. Beim IP Protokoll wird hierzu allein der Hop Count verwendet. Dieser bezeichnet die
Anzahl der Router, die entlang eines Pfades bis zum Zielnetz durchlaufen werden müssen.
Beim IPX Protokoll wird zusätzlich noch der Tick Count benutzt, dieser bezeichnet die Verzögerung
eines Paketes durch alle Router bis zum Zielnetz.
Nachteile des RIP Protokolls:
RIP erlaubt nur Netze mit einer maximalen Länge von 15 Routern. Das bedeutet, dass der längste
Pfad maximal über 15 Router gehen darf. Außerdem hat das Protokoll eine lange Konvergenzzeit.
Damit ist die Zeit gemeint, die vergeht, bis eine Routingänderung allen Routern bekannt ist. Das
Protokoll eignet sich nur bei kleinen bis mittleren Netzstrukturen. [Quelle: A72R]
7.2.2. OSPF – Protokoll Das OSPF (Open Shortest Path First) – Protokoll ist ein Link-State-Protokoll, das von der IETF (Internet
Engineering Task Force) im Jahre 1988 entwickelt wurde, um die Anforderungen sehr großer
Netzwerke zu erfüllen. Das Link-State-Protokoll arbeitet mit dem Link-State-Algorithmus, welcher
eine Liste aller Nachbar-Router anlegt, mit denen er eine bidirektionale Verbindung hält.
Die aktuelle Version OSPFv2 wird in RFC 2328 beschrieben. Das OSPF Protokoll ist ein dynamisches
Routing-Protokoll innerhalb eines autonomen Systems. Besonders bei großen Netzen ist es
leistungsstark. OSPF verwendet die Kosten eines Pfades als Metrik und kann bei gleichen Kosten
lastverteilt arbeiten. Kosten werden bei OSPF standardmäßig aus der verfügbaren Bandbreite
berechnet.

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (9 von 34)
Zur Berechnung der Kosten wird folgende Formel verwendet:
Kosten = 108
𝐵𝑎𝑛𝑑𝑏𝑟𝑒𝑖𝑡𝑒
Die Kosten addieren sich für jedes ausgehende Interface eines OSPF Routers.
7.2.3. Arbeitsweise OSPF – Protokoll Der Kernbestand von OSPF ist die Nachbarschaftsdatenbank, die eine Liste aller benachbarten Router
enthält, zu denen eine bidirektionale Verbindung besteht. Die Routinginformationen werden mittels
Flooding (Überschwemmen eines Netzwerkes mit Paketen) übermittelt.
Um den Umfang der auszutauschenden Informationen möglichst gering zu halten, wählen OSPF
Router einen designierten Router sowie einen Reserve Router, die als Schnittstellen für den
Austausch dienen.
Der OSPF-Router, dessen Multi-Access-Schnittstelle die höchste Router-Priorität besitzt, wird zum
designierten Router ernannt. Haben zwei Router die gleiche Priorität, wird der Router mit der
höheren Router-ID gewählt. Als Router-ID wird die IP-Adresse eines Loopback-Interfaces oder des
Interfaces mit der numerisch höchsten IP-Adresse automatisch gewählt. Ein Loopback-Interface ist
ein virtuelles Interface welches die Eigenschaft besitzt immer Up (verfügbar) zu sein. [Quelle: AR72O]
OSPF Router tauschen ihre Informationen über die erreichbaren Netze mit sogenannten LSA-
Nachrichten (Link State Advertisements) aus. LSA Nachrichten sind Informationen, die ein Router
über die Nachbarstationen und deren Pfadkosten enthält. Sie werden mittels Broadcast-
Datenpaketen an benachbarte Router gesendet. OSPF garantiert ein schleifenfreies Routing im
Gegensatz zum RIP Protokoll, weil es das sogenannte Kreisrouting verhindert und defekte Wege
vorzeitig erkennt. Damit ist ein Aufschaukeln der Zeit praktisch nicht möglich, da defekte Wege
vorher kenntlich gemacht werden. Es besitzt außerdem ein „Hello Protokoll“ zur Überwachung der
Nachbarn. Gut geeignet ist das OSPF Protokoll für große skalierbare Netze. Skalierbare Netze sind
Netze, die zum Beispiel bei einer doppelten Last sich dieser Last anpassen können und nicht wegen
dieser zusammenbrechen. Um die erhöhte Last zu bewerkstelligen, wird die Rechenleistung erhöht
oder eine dynamische Zuordnung der Übertragungsbandbreite und Übertragungsgeschwindigkeit
ausgehandelt. Bei der Zuordnung von Übertragungskapazitäten erreicht man durch die Skalierung
eine hohe Flexibilität in der Anpassung der Übertragungskanäle an die jeweiligen Anwendungen. Der
Nutzungsgrad der gesamten Übertragungsstrecke steigt beträchtlich gegenüber einer festen
Bandbreitenzuordnung, was sich letzt endlich auf die Kosten auswirkt. [Quelle: AR72O]
7.2.4. BGP – Protokoll Das BGP (Border Gateway Protokoll) ist ein Routingprotokoll, das beschreibt, wie Router
untereinander die Verfügbarkeit von Verbindungswegen zwischen Netzen autonomer Systemen
handhaben. Dieses Protokoll ist pfadvektorbasierend. Seine Funktionsweise ist stark an
Distanzvektoralgorithmen und an dem RIP Protokoll angelehnt. Jedoch wird dem vorkommenden
Problem der Routingschleifen vorgebeugt. Ein BGP-Router teilt beim Senden von
Verfügbarkeitsinformationen („Updates“) dem Kommunikationspartner nicht nur mit, dass er einen
bestimmten Abschnitt des Internets erreichen kann, sondern auch die komplette Liste aller
Autonomer Systeme, die IP-Pakete bis zu diesem Abschnitt passieren müssen.
Dabei steht sein eigenes Autonomes System an erster Stelle und das Ziel des Autonomen Systems an
letzter. Merkt der Kommunikationspartner nun, dass das Autonome System, dem er selbst angehört,

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (10 von 34)
bereits in dieser Liste vorhanden ist, so verwirft das System dieses Update und vermeidet die besagte
Routingschleife.
Die Stärke dieses Protokolls liegt darin, verschiedene optionale Routingpfade in einer einzigen
Routingtabelle zu vereinen. Beim Einsatz innerhalb eines Autonomen Systems müssen BGP-
Verbindungen zwischen allen Routern des Autonomen Systems eingerichtet werden, so dass eine
vollständige Vermaschung entsteht. Das bedeutet, dass der BGP Router seine Datenbank für die
Routen zu allen erreichbaren Autonomen Systemen einrichtet, in dem er sich Routinginformationen
von anderen Routern, insbesondere von den benachbarten Routern, bezieht.
Da jeder BGP-Router über Routen-Informationen von anderen, insbesondere der benachbarten BGP-
Routern verfügt, baut sich jeder BGP-Router eine Datenbank für die Routen zu allen erreichbaren
Autonomen Systemen auf. Das Update der Routingtabelle zwischen den BGP-Routern geschieht
mittels TCP Übertragung. Damit ist der Empfang von Änderungen gewährleistet. Es wird nur die
jeweilige Änderung durchgeführt, die auch betroffen ist. Dadurch wird der hohe Durchsatz des
Vergleichens in der Routingtabelle aufrecht erhalten, da diese mittels Updates nicht zu stark
beeinträchtigt ist. Die Größe der Tabelle mit den Routen-Informationen lag Ende 2005 bei
ca. 170.000 Einträgen bei über 26.000 Autonomen Systemen. Das derzeit eingesetzte BGP-Protokoll
liegt bei Version 4. [Quelle: AR72B]
Schwächen von BGP
BGP weist eine Reihe von Schwächen auf. Das Protokoll besitzt kein Load Balancing (Lastverteilung),
das heißt, es wird immer nur eine mögliche Route ausgewählt. Die Hop-Länge wird ebenfalls nicht
berücksichtigt, nur die Anzahl der Autonomen Systeme ist wichtig. Unterschiedliche
Linkgeschwindigkeiten werden ebenfalls nicht berücksichtigt, Routen werden hauptsächlich nach der
Länge ausgewählt, es sei denn eine definierte Regel erlaubt diese Route nicht.
Beispiel: Ein Knotenpunkt ist über einen Fremdprovider besser zu erreichen, aber eine vorgegebene
Regel untersagt diesen Weg.
Sicherheitsaspekte sind schwach berücksichtig. Beispielsweise könnte ein Angreifer durch Spoofing
Routen zwischen Providern ändern oder löschen.
Es wird aus Speicherplatz- und Skalierungsgründen immer nur eine beste Route an die Nachbarn
übermittelt. Das Übertragen mehrerer guter Routen könnte bei Strecken oder Router-Ausfällen
jedoch eine schnellere Reaktion ermöglichen. [Quelle: AR72B2]
Distanzvektoralgorithmus Der Distanzvektoralgorithmus bestimmt den kürzesten Pfad von jedem Knoten zu jedem anderen
Knoten, da eine kleine Distanz eine schnellere und kostengünstigere Verbindung beinhaltet.
Um diese Information zu erfahren, führt jeder Knoten einen Vektor mit Distanzen zu seinen
Nachbarknoten. In regelmäßigen Abständen wird diese Information aktualisiert. Dazu sendet jeder
Knoten seinen eigenen Distanz-Vektor jeweils zu allen Nachbarknoten. Somit hat jeder Knoten die
Distanz-Vektoren seiner Nachbarn. [Quelle: AR72D]
Pfadvektoralgorithmus
Ein pfadvektorbasierender Algorithmus hat eine ähnliche Struktur wie der Distanzvektoralgorithmus.
Der Unterschied liegt darin, dass hier die Kosten der Distanz zu anderen Nachbarknoten nicht
berücksichtigt werden. Das heißt wenn ein Weg zwar kurz, aber ausgelastet ist, wird er trotzdem
gewählt. Zusätzlich wissen alle Knoten die günstigsten Pfade Ihrer Nachbarknoten, und tauschen
diese untereinander aus. Mit dieser Information kann der benachbarte Knoten nach eigenen

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (11 von 34)
individuellen Bewertungskriterien den Nachbarn aussuchen, über den er einen bestimmten Knoten
erreichen möchte.
Beispiel:
Quelle: http://et.ti.uni-mannheim.de/content/lehre/nt2/skript/NaTe2_Kap13.pdf
Abbildung 3 – Beispielgraph zum Pfadvektoralgorithmus
Wenn der Router im Knoten F den günstigsten Pfad zum Knoten D sucht, und er von seinen Nachbarn
zuletzt die folgenden Informationen bekommen hat.
Vom Knoten B: ich benutze den Pfad B-C-D
Vom Knoten G: ich benutze den Pfad G-C-D
Vom Knoten I: ich benutze den Pfad I-F-G-C-D
Vom Knoten E: ich benutze den Pfad E-F-G-C-D
dann läuft folgender Prozess ab.
Verworfen werden sofort die beiden letzten Pfade, da sie den eigenen Knoten mit enthalten. Es
bleiben somit die Pfade über B und G. Diese übrigen Pfade bewertet er nach eigenem Ermessen.
Eventuell liegt eine Information vor, dass niemals über B gegangen werden darf, somit bleibt nur
noch der Pfad: F-G-C-D übrig. [Quelle: AR72P]
B C
D
A
F
E
I
G
H
J

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (12 von 34)
8. Architektur eines Routers
Grundarchitektur eines Routers:
Quelle: http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/Routerstruktur.gif
Abbildung 4 – Grundarchitektur eines Routers
Ein Router besteht aus mehreren Netzwerkadaptern, die eine Verbindung zu den jeweiligen Netzen,
die mit dem Router verbunden sind, herstellen. Diese Adapter sind meist über einen Systembus mit
der CPU des Routers verbunden. Die CPU hält wiederum im Hauptspeicher des Rechners die
Routingtabelle bereit.
8.1. Routingablauf Wenn ein Netzwerkadapter ein Datenpaket bekommt, so geschieht dieser Transport auf Schicht 2
des OSI Referenz Modells. Der Header des IP Pakets wird extrahiert und zur weiteren Verarbeitung
an die CPU gereicht. Die CPU entnimmt aus dem Paketkopf die IP-Adresse des Zielrechners.
Ist der Router nicht selbst das Ziel, sucht die CPU in der Routingtabelle nach einer passenden Next-
Hop-Information. Die Next-Hop-Information beinhaltet die Nummer des Netzwerkadapters, über den
das IP-Paket weitergeleitet werden soll, zum anderen aber auch die IP-Adresse des Next-Hop.
Diese IP-Adresse übergibt die CPU nun zusammen mit dem IP-Paket an den entsprechenden
Netzwerkadapter. Dieser Adapter generiert daraus ein Schicht-2 Paket und sendet es ab.
8.2. Unterschied Hochgeschwindigkeitsnetze Bei Hochgeschwindigkeitsnetzen zum Beispiel im Gigabitbereich ist die oben dargestellte Architektur
eines Routers nicht mehr identisch. Die CPU und der Systembus müssten dabei die Summe der
Übertragungsraten aller angeschlossenen Netzwerke verarbeiten können.
Bei solchen Hochleistungsroutern übernimmt das Weiterleiten von IP-Paketen der jeweilige
Netzwerkadapter. Die Netzwerkadapter erhalten zu diesem Zweck eine eigene CPU und einen
eigenen Speicher, in dem sich eine Kopie der zentralen Routingtabelle des Routers befindet.
Trifft bei diesem Routermodell ein IP-Paket bei einem der Adapter ein, bestimmt dieser den Next-
Hop und leitet es direkt an den entsprechenden Ausgangsadapter weiter. Die CPU des Routers ist

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (13 von 34)
somit nur noch für die Ausführung der Routingprotokolle und die Verwaltung der zentralen
Routingtabelle sowie anderer administrativer Aufgaben zuständig.
Die zentrale Routingtabelle wird im Fall einer Änderung in die Speicher der einzelnen
Netzwerkadapter kopiert. [Quelle: AR8]
Grundarchitektur eines Hochleistungsrouters:
Abbildung 5 – Grundarchitektur eines Hochleistungsrouters
8.3. Switching Fabric
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abbildung 6 – Input Port
Line Termination ist die physikalische Anschlussleitung. Der „Datalink Processing“ Block arbeitet auf
der Schicht-2 des OSI Referenzmodells (Sicherungsschicht). Aufgabe dieses Blocks ist es, die
ankommenden Daten in Pakete zu teilen, und diese Pakete auf Übertragungsfehler zu prüfen.
Das fehlerfreie Paket wird anschließend an den „Lookup and Forwarding“ Block geleitet. Die Aufgabe
dieses Blocks ist das Auswerten der Zieladresse aus dem IP-Paket. Anschließend muss der geeignete
Weg mit Hilfe der Routingtabelle ermittelt werden. Daraufhin wird das Paket über die Switching
Fabric an den Ausgang geleitet.
Input Port
Switching
Fabric
Line
Termination
Data Link
Processing
Lookup and
Forwarding
Haupt
CPU
Routing-
tabelle
Netzadapter A
Lokale CPU
Lokale
Routingtabelle
Netz A
Netzadapter B
Lokale CPU
Lokale
Routingtabelle
Netz B
Netzadapter C
Lokale CPU
Lokale
Routingtabelle
Netz C
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (14 von 34)
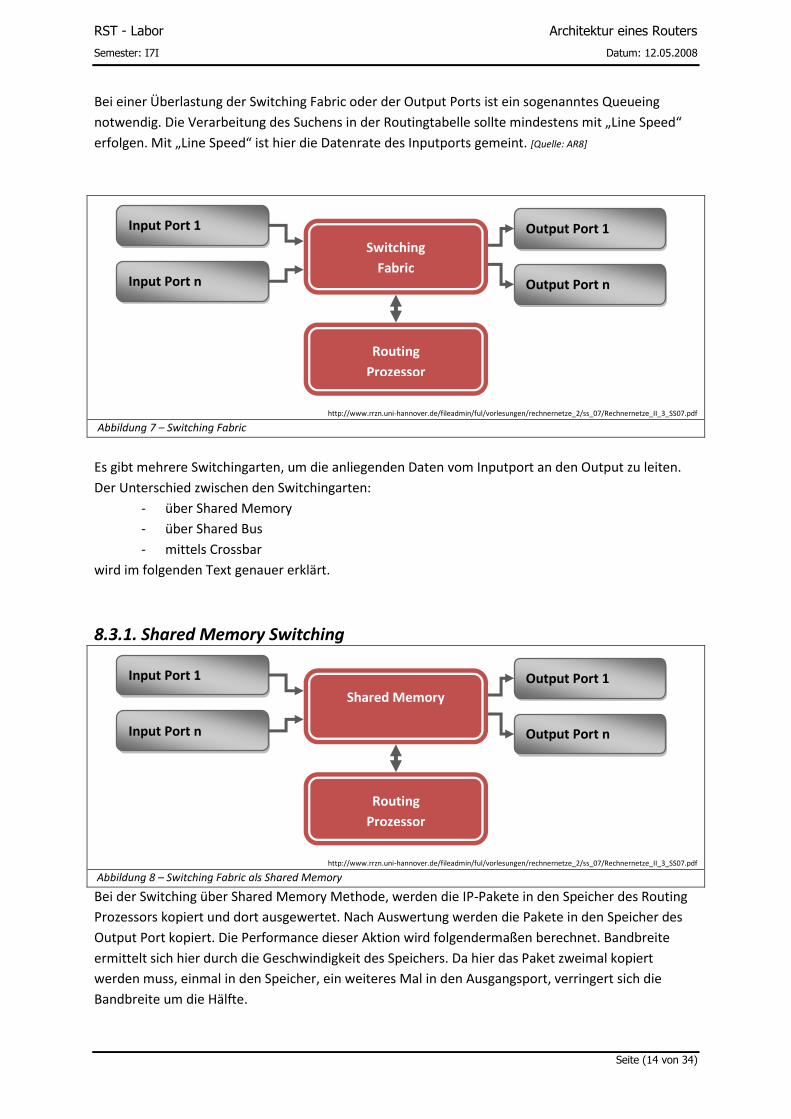
Bei einer Überlastung der Switching Fabric oder der Output Ports ist ein sogenanntes Queueing
notwendig. Die Verarbeitung des Suchens in der Routingtabelle sollte mindestens mit „Line Speed“
erfolgen. Mit „Line Speed“ ist hier die Datenrate des Inputports gemeint. [Quelle: AR8]
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abbildung 7 – Switching Fabric
Es gibt mehrere Switchingarten, um die anliegenden Daten vom Inputport an den Output zu leiten.
Der Unterschied zwischen den Switchingarten:
- über Shared Memory
- über Shared Bus
- mittels Crossbar
wird im folgenden Text genauer erklärt.
8.3.1. Shared Memory Switching
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abbildung 8 – Switching Fabric als Shared Memory
Bei der Switching über Shared Memory Methode, werden die IP-Pakete in den Speicher des Routing
Prozessors kopiert und dort ausgewertet. Nach Auswertung werden die Pakete in den Speicher des
Output Port kopiert. Die Performance dieser Aktion wird folgendermaßen berechnet. Bandbreite
ermittelt sich hier durch die Geschwindigkeit des Speichers. Da hier das Paket zweimal kopiert
werden muss, einmal in den Speicher, ein weiteres Mal in den Ausgangsport, verringert sich die
Bandbreite um die Hälfte.
Input Port 1
Input Port n
Routing
Prozessor
Output Port 1
Output Port n
Shared Memory
Input Port 1
Input Port n
Routing
Prozessor
Output Port 1
Output Port n
Switching
Fabric

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (15 von 34)
Vorteil dieser Architektur ist, dass Port und der Routing Prozessor sich gemeinsam den Speicher
teilen. Dieser Ansatz erfordert lediglich den Austausch von Speicheradressen, nicht aber den Inhalt.
Der Nachteil liegt darin, dass das Speicher-Management aufwändig ist, besonders bei Routern die
modular aufgebaut sind. Dieses Verfahren wird in Routern mittlerer Leistungsklasse verwendet. Ein
modularer „Shared Memory Router“ ist zum Beispiel der Cisco 4500-CH. [Quelle: AR83]
8.3.2. Shared Bus Bei der Shared Bus Methode wird das Switching über einen gemeinsamen Bus realisiert. IP-Pakete
werden direkt von Input Port an den Output Port geleitet. Hier kann jeweils nur ein IP-Paket über den
gesamten Bus übertragen werden. Die Performance wird dadurch bestimmt, indem die Angabe über
den maximalen Durchsatz der Bandbreite des Busses angegeben wird. Dieses Verfahren setzt die
Nutzung einer lokalen Routingtabelle in Input Ports voraus und wird in Routern einfacher und
mittlerer Leistungsklassen eingesetzt.
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abbildung 9 – Shared Bus Beispiel
Bei der Shared Bus Methode gelangt das IP-Paket (hier blau) vom Input Port direkt zum Output.
Während dieses Vorgangs kann das IP-Paket in rot nicht durch geleitet werden (gelbes X). Erst wenn
der Bus wieder frei ist, kann die Rote Verbindung zum Ausgangsport aufgebaut werden.
8.3.3. Crossbar Das Switching über Crossbar ist ein Verfahren, bei dem sämtliche Input und Output Ports über eine
Matrix miteinander verknüpft sind. Es ermöglicht mehrere parallele Vermittlungen gleichzeitig. Sollte
es aber vorkommen, dass zwei IP-Pakete von unterschiedlichen Eingangsports auf den gleichen
Ausgang gelangen wollen, so kann jeweils nur ein IP-Paket bearbeiten werden.
Die Performance hängt hierbei sehr stark vom Verkehrsmix ab. Im schlechtesten Fall entsteht ein
Verkehr von allen Input Ports auf einen Output Port. Im besten Fall verkehren die Daten von allen
Input Ports auf jeweils unterschiedliche Output Ports. Dieses Verfahren wird meist in
Hochleistungsroutern eingesetzt. Eine Verbesserung dieses Verfahrens wäre mit parallel anliegenden
Crossbars möglich. Alle Router der Cisco 12.000 Serie sind Crossbar-Switch-basierende Router. [Quelle: AR83C]
Routing
Prozessor
Output Port 1
Output Port 2
Output Port n
Input Port 1
Input Port 2
Input Port n
Shared Bus
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (16 von 34)
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
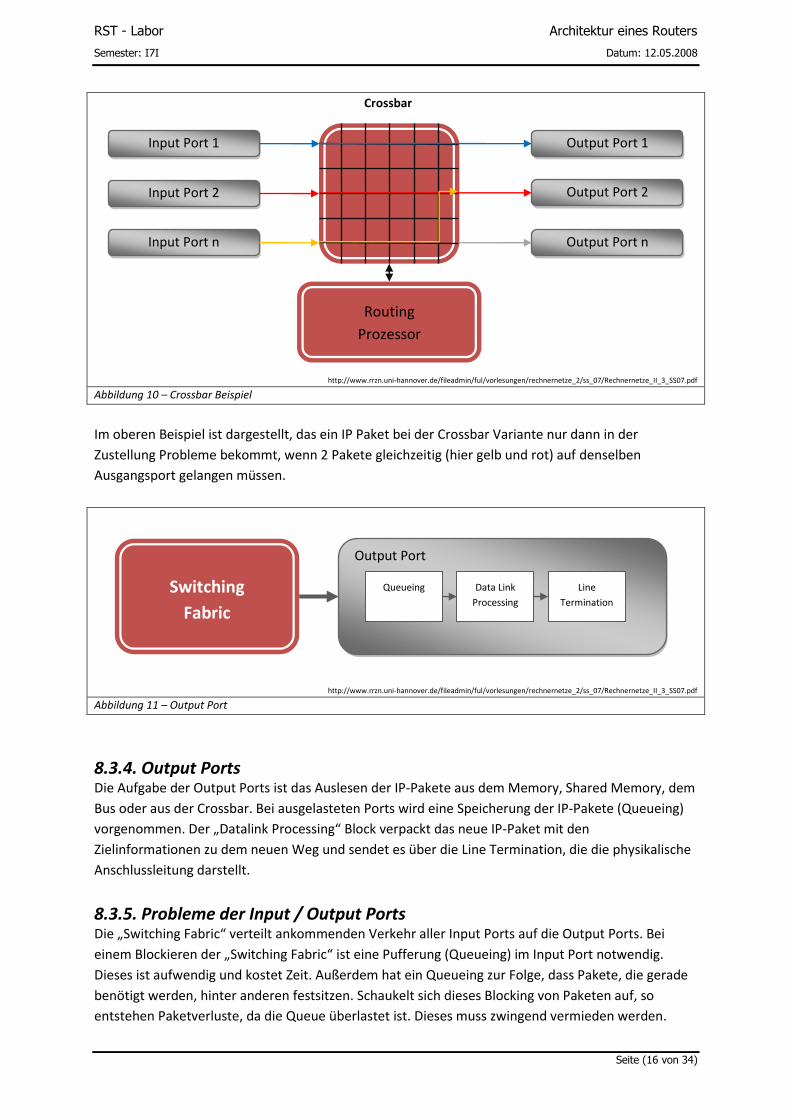
Abbildung 10 – Crossbar Beispiel
Im oberen Beispiel ist dargestellt, das ein IP Paket bei der Crossbar Variante nur dann in der
Zustellung Probleme bekommt, wenn 2 Pakete gleichzeitig (hier gelb und rot) auf denselben
Ausgangsport gelangen müssen.
http://www.rrzn.uni-hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abbildung 11 – Output Port
8.3.4. Output Ports Die Aufgabe der Output Ports ist das Auslesen der IP-Pakete aus dem Memory, Shared Memory, dem
Bus oder aus der Crossbar. Bei ausgelasteten Ports wird eine Speicherung der IP-Pakete (Queueing)
vorgenommen. Der „Datalink Processing“ Block verpackt das neue IP-Paket mit den
Zielinformationen zu dem neuen Weg und sendet es über die Line Termination, die die physikalische
Anschlussleitung darstellt.
8.3.5. Probleme der Input / Output Ports Die „Switching Fabric“ verteilt ankommenden Verkehr aller Input Ports auf die Output Ports. Bei
einem Blockieren der „Switching Fabric“ ist eine Pufferung (Queueing) im Input Port notwendig.
Dieses ist aufwendig und kostet Zeit. Außerdem hat ein Queueing zur Folge, dass Pakete, die gerade
benötigt werden, hinter anderen festsitzen. Schaukelt sich dieses Blocking von Paketen auf, so
entstehen Paketverluste, da die Queue überlastet ist. Dieses muss zwingend vermieden werden.
Switching
Fabric
Output Port
Queueing Data Link
Processing
Line
Termination
Routing
Prozessor
Output Port 1
Output Port 2
Output Port n
Input Port 1
Input Port 2
Input Port n
Crossbar

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (17 von 34)
Eine Vermeidungsstrategie ist es, zu jedem Input Port, N separate Queues für jeden Outputport zu
führen. Damit erreicht man, dass die Pakete bereits im Input Port schon nach Zielen sortiert werden
und hintereinander zugeführt werden können. [Quelle: AR83C]
8.4. Routing Table Eine Routing Table beinhaltet das Zielnetz mit ihrer Subnetzmaske und dem ausgehenden Zielport.
8.5. Suchalgorithmen in „Routing Table“ Eine lineare Suchstrategie kommt wegen der zahlreichen Einträgen in der „Routing Table“ nicht in
Frage, da die Suche viel zu langsam wäre. Folgende Suchverfahren werden in Routingtabellen
verwendet:
- Longest Matching Prefix
- Binärbäume
- Dynamic Prefix Trie
- Binary Tree with Chunks
- Hashing mit Binary Search
8.5.1. Longest Matching Prefix Um in der Routingtabelle nicht einen Eintrag pro IP-Adresse zu verschwenden, werden bei dieser
Methode mehrere hintereinander liegende IP-Adressen, die eine identische Next-Hop-Information
aufweisen in einem Eintrag zusammengefasst.
Ein Eintrag enthält dann neben der Next-Hop-Information einen Adresspräfix (Vorsilbe), der den
Bereich der zusammengefassten Adressen beschreibt.
Zum Beispiel werden die fiktiven Adressen 1110 und 1111, wenn sie identische Next-Hop-
Informationen besitzen, in einem Eintrag mit dem Präfix 111 zusammengefasst. Auf diese Weise
können allerdings nur Adressen zusammengefasst werden, die durch einen gemeinsamen Präfix
eindeutig beschreibbar sind.
So weisen die Adressen 1101 und 1110 zwar das gemeinsame Präfix 11 auf, allerdings beschreibt
dieses Präfix auch andere Adressen wie z.B. 1100 und 1111. Die Zuordnung des Präfixes zu den
beiden Adressen ist hier also nicht eindeutig. Trotzdem können auf diese Weise ganze Bereiche von
Adressen in einem Eintrag zusammengefasst werden. In der Regel können immer mindestens alle
Rechneradressen der einzelnen Organisation zusammengefasst werden. Das Adresspräfix des
Eintrags entspricht dann der Netzadresse dieser Organisation. Nur wenn ein Router sich innerhalb
einer Organisation befindet, muss er eine genauere Zuordnung vornehmen.
Eine weitere Zusammenfassung von Einträgen ergibt sich wie folgt:
Angenommen alle IP-Adressen, die das gemeinsame Präfix P1 = 111 aufweisen, besitzen identische
Next-Hop-Informationen und werden in einem einzigen Eintrag in der Routingtabelle
zusammengefasst. Dieser Eintrag deckt dann einen bestimmten Bereich (A) aus dem IP-Adressraum
ab (siehe Abbildung 9).
In diesem Bereich A befindet sich nun ein kleinerer Teilbereich B von IP-Adressen, die eine von den
übrigen Adressen im Bereich A abweichende Next-Hop-Information besitzen. Dieser Bereich B sei

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (18 von 34)
durch das Präfix P2 = 11101 repräsentiert. Auf diese Weise würde der Bereich A in drei Teilbereiche
aufgespalten, die durch drei Einträge in der Routingtabelle mit den Präfixen P1a = 11100, P2 = 11101
und P 1b = 1111 beschrieben werden müssten, wobei die Einträge mit P1a und P1b identische Next-
Hop-Informationen enthalten würden.
Stattdessen speichert man nur zwei Einträge mit den Präfixen P1 und P2.
Wird nun für eine Adresse nach einem Eintrag mit passendem Präfix gesucht, so wählt man den
Eintrag mit dem längsten passenden Präfix.
Für Adressen aus dem Bereich B ist P2 der „Longest Matching Prefix“ und für Adressen aus den
übrigen Teilbereichen von A ist es P1. Auf diese Weise ist eine eindeutige Zuordnung von Adressen zu
einem bestimmten Tabelleneintrag sichergestellt.
Abbildung 9: Longest Matching Prefix: P2 verdeckt im Bereich B das kürzere Präfix P1.
Man könnte nun annehmen, eine Routingtabelle enthält zu jedem Next-Hop, den der Router kennt,
nur genau ein Paar (Präfix, Next-Hop). Das wäre die Idealsituation. Vielmehr ist es so, dass wie oben
angedeutet, bestimmte Adressen und Adressbereiche mit identischer Next-Hop-Information nicht
durch ein gemeinsames Präfix eindeutig
beschrieben werden können und daher
mehrere Einträge belegen. Auch können
Adressbereich mit identischer Next-Hop-
Information nicht zusammenhängend sein.
Das führt dazu, dass Tabellen größer werden
als einige tausend Einträge. Dies und die
Tatsache, dass bei schnellen Netzen nur wenig
Zeit zum Weiterleiten eines Paketes bleibt,
fordert eine entsprechend schnellen
Suchfunktion. Aber auch die Verwaltungs-
funktionen der Tabelle, wie Einfügen oder
Löschen von Präfixen, dürfen nicht zu
aufwendig realisiert werden, da mit
Änderungen von Routinginformationen im
Sekundenbereich oder häufiger zu rechnen ist. Auch spielt die Größe der Tabelle eine Rolle. Zum
einen kostet Speicherplatz Geld. Zum zweiten kann die Ausführungsgeschwindigkeit der Operationen
auf der Tabelle gesteigert werden, wenn diese klein genug ist, um in den Second-Level-Cache eines
Prozessors zu passen. Eine andere wichtige Frage in diesem Zusammenhang ist, ob die Realisierung in
Software oder in Hardware erfolgen soll. Denn bei hohen Datenübertragungsraten stellt sich die
Frage, ob eine Realisierung in Software zur Zeit schnell genug ist. Andererseits ist eine
Sofwarerealisierung einer Hardwarelösung vorzuziehen, da sie bei Änderungen einfacher angepasst
werden kann, sei es, weil man eine bessere Datenstruktur für die Routingtabelle entwickelt hat, oder
weil der Speicher erweitert werden muss, weil die Tabelle zu groß geworden ist. Die Erweiterung des
Speichers kann bei einer Hardwarelösung schwierig sein, wenn die Anzahl der vorhandenen
Adressleitungen erschöpft ist. [Quelle: AR8]
http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/LMP.gif
Abbildung 12 – Longest Matching Prefix

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (19 von 34)
8.5.2. Binärbäume Jeder Baumknoten entspricht einem Eintrag der Routingtabelle. Er ist folglich ein Paar aus dem Präfix
und der Next-Hop Information. In der Wurzel befindet sich ein Defaulteintrag mit einem Präfix der
Länge 0.
Dieses Präfix passt somit zu jeder beliebigen Adresse. Der Next-Hop-Eintrag der Wurzel enthält die
Adresse des sogenannten Default-Routers. Zu diesem Router werden alle IP-Pakete mit Adressen
weitergeleitet, die der Router noch nicht kennt. Die Suche nach dem „Longest Matching Prefix“
beginnt bei der Wurzel. Wenn das Präfix des jeweils aktuellen Knotens zur IP-Adresse passt, wird der
Knoten als bestes Ergebnis gemerkt. Passt das Präfix zur Adresse, wird die Suche im linken Teilbaum
fortgesetzt, ansonsten im rechten. Die Suche ist beendet, sobald man ein Blatt erreicht hat. Der
gemerkte Knoten enthält dann das Longest Matching Prefix.
Ein Nachteil liegt jedoch im Binärbaum. Durch ungeschicktes Einfügen und Löschen von Einträgen
kann ein Binärbaum aus der Balance geraten. Im schlimmsten Fall entwickelt er sich zu einer linearen
Liste, die einen hohen Suchaufwand beinhaltet. Dieses muss durch entsprechende
Balancemaßnahmen bei den Einfüge- und Löschoperationen verhindert werden. Das Ausbalancieren
eines Binärbaumes ist jedoch recht komplex, da dabei unter Umständen die Struktur des ganzen
Baumes verändert werden muss. Wünschenswert sind deshalb Einfüge- und Löschoperationen, die
ein Ungleichgewicht des Baumes von vornherein weitgehend vermeiden.
8.5.3. Dynamic Prefix Trie Der Aufbau eines Baumknotens ist in Abbildung 10 dargestellt. Er enthält drei Zeiger, die auf den
übergeordneten Knoten und auf den linken und rechten Unterbaum verweisen. Weiterhin enthält
ein Knoten Zeiger auf zwei Präfixe (Keys). Das Indexfeld enthält die Nummer der Bitstelle, ab der die
beiden Präfixe des Knotens einen Unterschied aufweisen. Dabei bildet das Präfix, das an dieser Stelle
eine Null enthält, immer den LeftKey und das Präfix mit einer Eins an dieser Position den RightKey.
Der Index erhöht sich mit jeder Baumebene um mindestens Eins.
Da die Datenstruktur auf einem Trie beruht, ist eine
maximale Tiefe des Baumes garantiert. Das sind bei IPv4
maximal 32 und bei IPv6 maximal 128 Ebenen.
Die Präfixsuche läuft ab, indem man erst an einem Ast
hinab bis zu einem Blatt wandert. Dabei entscheidet das
Adressbit mit der Nummer, die durch das Indexfeld des
jeweiligen Knoten beschrieben wird, ob mit dem linken
oder rechten Unterbaum fortgefahren wird. Auf dem
Rückweg ist dann das erste passende Präfix das gesuchte
Longest Matchig Prefix.
Dieser Suchalgorithmus ist sehr einfach, so dass eine
Beschleunigung der Suche durch eine
Hardwarerealisierung möglich ist. Die Einfüge- und Löschoperationen haben lediglich lokal begrenzte
Auswirkungen auf die Struktur des Baumes, da aufgrund der festen maximalen Tiefe des Baumes
keine Ausgleichsoperationen benötigt werden. [Quelle: AR8]
http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/DP-Trie-Strukt.gif Abbildung 13 – Dynamic Prefix Trie

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (20 von 34)
8.5.4. Binary Tree with Chunks Der Ansatz der „Binary Tree with Chunks“ Strategie beruht ebenfalls auf einen binären Trie.
Vorstellen kann man sich zunächst einen Baum mit 32 Ebenen, der eine statische Struktur aufweist.
An der Wurzel befindet sich der Defaulteintrag mit der Präfixlänge Null. Ebene 1 enthält die Präfixe
der Länge 1, Ebene 2 die Präfixe der Länge 2, usw. In der untersten (32.) Ebene befinden sich dann
232 Blätter, die die Gesamtzahl der möglichen IP-Adressen repräsentieren.
Diese Struktur wäre bei direkter Umsetzung viel zu groß. Zur Realisierung wird der Baum deshalb in
drei Stufen unterteilt. Die erste Stufe umfasst die Ebenen 0 bis 16 des Baumes, die zweite Stufe die
Ebenen 17 bis 24 und die dritte Stufe die Ebenen 25 bis 32 (Abbildung 11).
http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/BinBaumWChunks.gif
Abbildung 14 – Binary Tree with Chunks
Diese Struktur ist als Softwarelösung in Hochleistungsroutern auf Basis von IPv4 entwickelt worden.
Sie ist auf eine möglichst schnelle Präfixsuche optimiert. Eine Hardwarelösung wäre durchaus
möglich.
Aufbau der Datenstruktur
Die erste Stufe wird im Wesentlichen durch ein Bitfeld mit 216 Einträgen realisiert. Diese
entsprechen den möglichen Blättern der ersten Stufe. Jeder nicht leere Eintrag repräsentiert
entweder ein Präfix oder einen Verweis auf jeweils einen Unterbaum in der nächsten Stufe. Die
zweite und dritte Stufe bestehen aus einer Anzahl Unterbäumen, die der Anzahl der Verweise in der
jeweils nächst höheren Stufe entspricht.
Die Unterbäume heißen Chunks und besitzen die gleiche Struktur, wie die erste Ebene mit dem
Unterschied, dass das Bitfeld lediglich 28 = 256 Einträge umfasst. Da jede der unteren Ebenen 8 Bit
einer IP-Adresse umfasst, muss für IPv6 die Anzahl der Ebenen um 12 weitere auf insgesamt 15
erhöht werden. Die Suche nach dem Longest Matching Prefix weist in den einzelnen Stufen einen
konstanten Aufwand auf. Dadurch werden für die Suche in der gesamten Tabelle maximal 3 Schritte
(IPv4) bzw. 15 Schritte (IPv6) benötigt.
Eine weitere Beschleunigung der Suche entsteht durch die Kompaktheit dieser Datenstruktur.
Bei einem Umfang der Tabelle (bei IPv4) von 30.000 - 40.000 Einträgen beträgt die Größe der Tabelle
nur ca. 150 - 170 kBytes. Sie passt deshalb vollständig in den 2nd-Level-Cache einer Intelmaschine.
Einfüge- und Löschoperationen sind nicht vorgesehen worden. Die Idee ist vielmehr, dass die
Datenstruktur als reine Suchtabelle dient. Daneben befindet sich eine zweite Tabelle im Router, die
zum Einfügen und Löschen von Präfixen besser geeignet ist. Wenn sich diese Tabelle geändert hat,
wird aus ihr eine neue Suchtabelle generiert und gegen die alte ausgetauscht. [Quelle: AR8]
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (21 von 34)
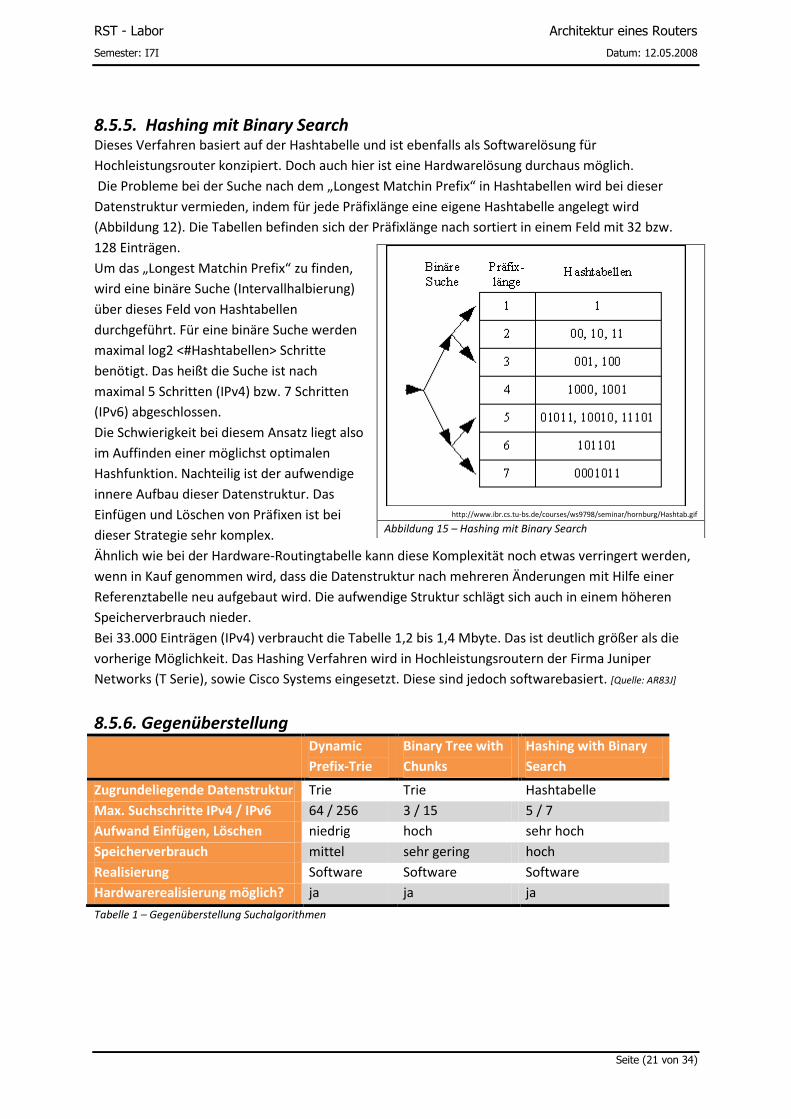
8.5.5. Hashing mit Binary Search Dieses Verfahren basiert auf der Hashtabelle und ist ebenfalls als Softwarelösung für
Hochleistungsrouter konzipiert. Doch auch hier ist eine Hardwarelösung durchaus möglich.
Die Probleme bei der Suche nach dem „Longest Matchin Prefix“ in Hashtabellen wird bei dieser
Datenstruktur vermieden, indem für jede Präfixlänge eine eigene Hashtabelle angelegt wird
(Abbildung 12). Die Tabellen befinden sich der Präfixlänge nach sortiert in einem Feld mit 32 bzw.
128 Einträgen.
Um das „Longest Matchin Prefix“ zu finden,
wird eine binäre Suche (Intervallhalbierung)
über dieses Feld von Hashtabellen
durchgeführt. Für eine binäre Suche werden
maximal log2 <#Hashtabellen> Schritte
benötigt. Das heißt die Suche ist nach
maximal 5 Schritten (IPv4) bzw. 7 Schritten
(IPv6) abgeschlossen.
Die Schwierigkeit bei diesem Ansatz liegt also
im Auffinden einer möglichst optimalen
Hashfunktion. Nachteilig ist der aufwendige
innere Aufbau dieser Datenstruktur. Das
Einfügen und Löschen von Präfixen ist bei
dieser Strategie sehr komplex.
Ähnlich wie bei der Hardware-Routingtabelle kann diese Komplexität noch etwas verringert werden,
wenn in Kauf genommen wird, dass die Datenstruktur nach mehreren Änderungen mit Hilfe einer
Referenztabelle neu aufgebaut wird. Die aufwendige Struktur schlägt sich auch in einem höheren
Speicherverbrauch nieder.
Bei 33.000 Einträgen (IPv4) verbraucht die Tabelle 1,2 bis 1,4 Mbyte. Das ist deutlich größer als die
vorherige Möglichkeit. Das Hashing Verfahren wird in Hochleistungsroutern der Firma Juniper
Networks (T Serie), sowie Cisco Systems eingesetzt. Diese sind jedoch softwarebasiert. [Quelle: AR83J]
8.5.6. Gegenüberstellung Dynamic
Prefix-Trie
Binary Tree with
Chunks
Hashing with Binary
Search
Zugrundeliegende Datenstruktur Trie Trie Hashtabelle
Max. Suchschritte IPv4 / IPv6 64 / 256 3 / 15 5 / 7
Aufwand Einfügen, Löschen niedrig hoch sehr hoch
Speicherverbrauch mittel sehr gering hoch
Realisierung Software Software Software
Hardwarerealisierung möglich? ja ja ja
Tabelle 1 – Gegenüberstellung Suchalgorithmen
http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/Hashtab.gif
Abbildung 15 – Hashing mit Binary Search

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (22 von 34)
8.5.7. Fazit Suchstrategie Der Dynamic Prefix-Trie ist eine ausgewogene Lösung. Er bietet eine Suchfunktion mit garantierter
maximaler Laufzeit und ebenso effizienter Einfüge- und Löschoperationen. Da die Suche aber bis zu
128 Schritte benötigt, eignet er sich eher für Router in Umgebungen mit niedrigeren Daten-
übertragungsraten oder als zentrale Routingtabelle in Hochleistungsroutern. Die beiden anderen
Verfahren (Binary Tree with Chunks und Hashing with Binary Search) bieten aufgrund ihrer Auslegung
als „Hochleistungstabellen“ die schnellsten Suchfunktionen. Sie machen jedoch das Einfügen und
Löschen von einzelnen Einträgen sehr aufwendig. Deshalb setzen diese Verfahren eine zentrale
Routingtabelle voraus, aus der bei Bedarf eine neue Suchtabelle erzeugt werden kann. Der „Binary
Tree with Chunks“ scheint für IPv4 die sinnvollere Alternative zu sein, da er bei ungefähr gleicher
Suchgeschwindigkeit eine einfachere Struktur aufweist und weniger Speicher verbraucht.
Bei IPv6 steigt bei dieser Lösung die Suchdauer linear mit der Zahl der Adressbits an. Das „Hashing
with Binary Search“ weist dabei einen logarithmischen Anstieg auf, so dass die Geschwindigkeit der
Suche bei IPv6 hierbei dann höher liegt als beim „Binary Tree with Chunks“. Welches der beste
Lösungsweg ist, hängt stark vom geplanten Einsatzgebiet ab.

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (23 von 34)
9. Routermodelle Small, Home Office / Business
Modell: SMC7904WBRA [Quelle: RM9SMC]
Der SMC 7904WBRA ist ein Wireless LAN-Router für den Home / Smalloffice Bereich (SOHO). Der
Router ist ein Standard Gerät in der Klasse und ab knapp 70 € zu haben.
Der Router hat vier 10/100 MBit/s Ethernet Ports,
einen ADSL2+/ ADSL Port und unterstützt
natürlich WLAN.
Auf der DSL Seite sind verschiedene Einstellungen
und Features möglich. Da über die DSL
Schnittstelle ATM läuft, unterstützt der Router die
unterschiedlichen Bit-Raten, die vom Provider
eingestellt und gewährleistet werden. Es werden
die folgenden Modi unterstützt:
UBR - Unspecified Bit Rate (unbestimmte Bitrate),
der Defaulttyp für „normalen“ Traffic.
Hier bekommt man an Bandbreite, was übrig ist, nachdem der QoS-Traffic abgewickelt ist.
CBR - Constant Bit Rate (konstante Bitrate), hier wird eine Spitzenrate (Peak Cell Rate, PCR)
angefordert, die dann garantiert wird.
VBR - Variable Bit Rate, hier „bestellt“ man eine durchschnittliche Zellenrate, die man aber um einen
bestimmten Betrag für eine bestimmte Zeit überschreiten darf (gibt es in Echtzeit- (RT-VBR) und Non-
Echtzeit-Varianten (NRT-VBR)).
Der VPI und VCI ist im Gerät konfigurierbar und ermöglicht somit auch das Einstellen von höher
priorisierten Pfaden durch das Backbone des Providers.
Der Chipsatz bietet auf der DSL/ATM Seite desweiteren noch OAM (Operation, Administration and
Maintenance) zur Fehlerlokalisierung und Behebung auf ATM Strecken.
Der Chipsatz stellt auf der WLAN-Seite WEP mit 64 und 128 Bit Schlüssellänge und WPA-PSK zur
Verfügung.
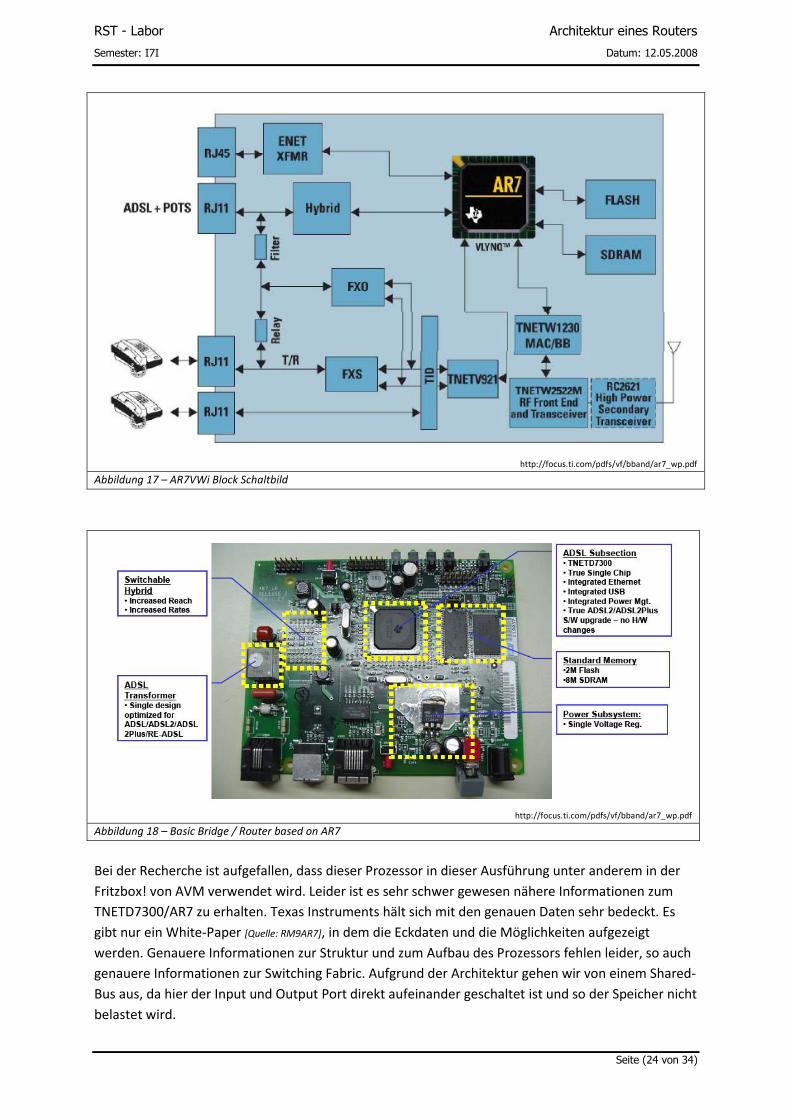
Im Gerät ist ein von Texas Instruments entwickeltes Board verbaut, welches sich in vielen Geräten
dieser Kategorie befindet. Herzstück bildet ein TNETD7300 MIPS32 Prozessor, der die wesentlichen
Aufgaben übernimmt.
Abbildung 16 – Small, Home Office Router
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (24 von 34)
http://focus.ti.com/pdfs/vf/bband/ar7_wp.pdf
Abbildung 17 – AR7VWi Block Schaltbild
http://focus.ti.com/pdfs/vf/bband/ar7_wp.pdf
Abbildung 18 – Basic Bridge / Router based on AR7
Bei der Recherche ist aufgefallen, dass dieser Prozessor in dieser Ausführung unter anderem in der
Fritzbox! von AVM verwendet wird. Leider ist es sehr schwer gewesen nähere Informationen zum
TNETD7300/AR7 zu erhalten. Texas Instruments hält sich mit den genauen Daten sehr bedeckt. Es
gibt nur ein White-Paper [Quelle: RM9AR7], in dem die Eckdaten und die Möglichkeiten aufgezeigt
werden. Genauere Informationen zur Struktur und zum Aufbau des Prozessors fehlen leider, so auch
genauere Informationen zur Switching Fabric. Aufgrund der Architektur gehen wir von einem Shared-
Bus aus, da hier der Input und Output Port direkt aufeinander geschaltet ist und so der Speicher nicht
belastet wird.

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (25 von 34)
Cisco 7301 Series Router [Quelle: RM9C73SR]
Der Preis für dieses Gerät, liegt knapp bei 10.000€.
Der Router hat nur eine Höheneinheit, passt also in einen normalen 19 Zoll Schrank.
Der Router kann bis zu 16.000 PPP-Sessions
verwalten und verarbeiten. Die Praxis zeigt, dass
hier bei knapp 12.000 Schluss ist. Gründe sind
sogenannte „Heavy Subs“ Kunden, die sehr viele
Connections aufbauen und damit sehr viel Traffic
generieren.
Der Router kann 1MPPS – „Million Packets per
Second“ verarbeiteten. Das heißt, das
Inspizieren des Header der IP-Pakete und das
Berechnen der Routing Informationen erfolgt
„on the Fly“.
Das Gerät ist mit drei Gigabit Ethernet Ports
ausgestattet, die wahlweise mit Glasfaser oder Kupfer angeschlossen werden können.
Der Cisco7301 wird mit 256MB ausgeliefert, der Speicher kann auf bis zu einem 1GB aufgestockt
werden. In diesem Speicher werden die Routing Tabellen abgelegt. Bei 1GB kann eine Routing
Tabelle bis zu einer Million Einträge enthalten.
Zusätzlich zum installierten DRAM ist es möglich, eine 256MB Flash-ROM Karte einzusetzen, um hier
von einem sauberen IOS zu starten, bzw. um IOS Updates zu machen.
Als CPU läuft ein BCM1250, zwei 64 BIT MIPS Prozessoren mit 700Mhz Takt, der in folgenden Seiten
noch näher erläutert wird.
Einsatzgebiete für diesen Router sind die „Campus Class/Carrier Class“, Bereiche mit vielen Nutzern,
die allerdings noch nicht in der gehobenen „Carrier Class“ unterwegs sind. Mit dem Verwalten von
bis zu 16.0000 Sessions kommt es bei größeren Providern schnell zum Erweitern der Lokation, da die
Marke der zuvor genannten 12.000 Kunden in Ballungsgebieten sehr schnell erreicht ist.
Das Switching zwischen dem Input und Output Port wird bei diesem Model über die Shared Memory
Methode geregelt. In der 7000er Reihe von Cisco werden Crossbar Verfahren erst ab der Modelreihe
7600 angeboten. [Quelle: RM9C7SR]
Die Router unterstützen mit Hilfe von Zusatzmodulen QoS „Quality of Service“. Mit der damit
verbundenen Priorisierung ist es möglich, VoIP ohne großen Verlust netzintern anzubieten. Das
Terminieren von Dial/UP Subscribern, die sich über das Telefonnetz anmelden, ist mithilfe des
Vorschaltens eines Routers (z.B. EWSD“ Electronic World Switch Digital“, eine Provider
Telefonanlage) möglich. Dieser Router stellt die Verbindung zum PSTN (Public Switched Telephone
Network) her.
Der Router ist außerdem in der Lage, zwischen IPv6 und IPv4 Netzwerken zu routen.
http://www.hardware.com/products/cnet/I166697.jpg
Abbildung 19 – Cisco 7301

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (26 von 34)
Abbildung 20 – Innenansicht Cisco 7301
9.1. Chipsatz Der Chipsatz der in den Cisco Routern diese Klasse eingesetzt wird ist ein BCM1250 von der Firma
Broadcom. [Quelle: RM91BCM] Es handelt sich hierbei um einen Dualprozessorkern mit zwei 64Bit MIPS
Prozessoren. Die Taktfrequenz der CPU ist von 600MHz bis 1GHz einstellbar. Bei den Cisco Geräten
werden 700Mhz angelegt. Jeder Prozessor hat einen 32KB großen Instruktions- und Daten Cache.
Wie im Blockdiagramm zu sehen ist, werden der L2-Cache, die beiden Prozessoren, die DMA
Controller und die I/O-Bridges mit einem 256Bit breiten Bus angebunden. Dieser „fast on chip
multiprozessor bus“ arbeitet mit einer halben Taktfrequenz des CPU Taktes.
Der L2-Cache ist ein Shared Cache der beiden Prozessoren. Der 4-Wege Assoziative Cache ist ECC-
Protected. Der 4-Wege Cache kann umgangen werden, um der CPU einen schnellen und direkten
Zugriff auf den RAM zu ermöglichen.
Der DDR-Memory Controller hat zwei je 64Bit breite Datenbuskanäle, die mit 200MHz Taktrate, bzw.
400 MHz Datenrate angesteuert werden.
Abbildung 21 – Blockschaltbild BCM 1250

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (27 von 34)
9.2. Intel IXP2XXX Netzwerk Prozessoren [Quelle: RM92IXP] Intel hat für den Netzwerkbereich eine Prozessorreihe entworfen die sich speziell um das
Verarbeiten von Netzwerk spezifischen Paketen kümmert. Diese Prozessoren sind programmierbar
und arbeiten laut Intel mit „Wire-Speed“. Anders als die in vielen „High End“ Routern eingesetzten
ASIC s (Application Specific Integrated Circuit) sollen die von Intel entwickelten Prozessoren ähnliche
Leistungen bringen. Updates und Änderungen an der Software sollen allerdings einfacher möglich
sein. Die Anwendungsgebiete sind hier in der Netzwerktechnik vielfältig ausgelegt, Routing, Packet
Inspection, Traffic Management usw.
Intel hat in dieser Serie bisher fünf Netzwerkprozessoren veröffentlicht:
Name Anwendungsgebiet Durchsatz
Intel® IXP2855 Network Processor Secure applications OC-192/10 GbE
Intel® IXP2805 Network Processor Edge and core applications OC-192/10 GbE
Intel® IXP2400 Network Processor Access and edge applications OC-48/2.5 GbE
Intel® IXP2350 Network Processor Access and edge applications 2 Gbps
Intel® IXP2350 Network Processor Access and edge applications 1 Gbps
Tabelle 2 – Intels Netzwerk Prozessoren
Um auf diese Reihe einzugehen, schauen wir uns den Intel IXP2400 NP einmal genauer an.
Der Prozessor hat acht programmierbare „Multithreaded Mircoengines“, die für Packet Forwarding
und Trafficmanagement genutzt werden. Im folgenden Text werden die Implementierten „Features“
des Prozessors erläutert. In Abbildung 19 ist ein Blockschaltbild des Prozessors dargestellt, dass die
einzelnen Busse, Busbreiten und Schnittstellen des Prozessors zeigt.
• „Hyper Task Chaining processing Technoloy“ ermöglicht das Inspizieren von Paketen bei
einem Durchsatz von 2,5Gb/s. Beim Hyper Task Chaining werden einige
Weiterentwicklungen der IXP1XXX Reihe umgesetzt, um eine möglichst geringe Latenz beim
Verarbeiten der Daten zu haben. Dies beinhaltet das Ansprechen der benachbarten Register,
das Weiterleiten von Daten und Statusinformationen an die angrenzenden Microengines.
• “Reflector mode pathways“ wird von Intel die Kommunikation zwischen den einzelnen
Microengines genannt, die über 32 Bit breite unidirektionale Busse geführt wird. Über dieses
Bussystem werden auch die internen Prozessor und Speicher-Resourcen angesprochen.
• Außerdem sind Ring/Cycle-Buffer Register eingeführt worden, um Anforderungen an die
Software Pipelines schnell und flexibel zu verteilen. Ein Ring-Buffer ist wie der Name bereits
sagt, wie ein als Ring angeordneter Buffer – es gibt also keinen Anfang und kein Ende. Das
Schreiben in den Buffer erfolgt nach dem FIFO-Prinzip. Wenn der Buffer voll ist, wird das
erste hinzugefügte Element wieder entfernt. Zur Organisation werden drei Pointer benötigt,
die den Anfang, das Ende der Daten und auf den Buffer selber zeigen. Für den Entwickler gibt
es hier die Möglichkeit „Erzeuger-Verbraucher“ Beziehungen zwischen den Microengines
aufzubauen und dadurch eine Beschleunigung der Bearbeitungszeit zu erreichen.
• Um die Zugriffszeit auf die von außen angebundenen Speicher zu verringern, sind die
Register um 16 Einträge für Content Addressable Memory (CAM) erweitert. Die Einträge sind
den einzelnen Microengines zugewiesen, um eine schnellere Adressierung zu ermöglichen.
Der CAM ist als verteilter Cache angelegt und erlaubt mehrfache Threads und das

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (28 von 34)
gleichzeitige Verändern voneinander abhängigen Daten, während gleichzeitig die
Datenkohärenz gewährleistet ist.
Abbildung 22 – Intel IXP2400 Netzwerk Prozessor Blockschaltbild
Das Kernstück des IXP2400 ist ein Intel XScale Core mit einem 32Bit RISC Prozessor, der an die ARM
Architektur angelehnt ist. [Quelle: RM92XS] Intel ist Lizenznehmer von ARM und ist anhand der
erworbenen Lizenz auch berechtigt Veränderungen an der Architektur vorzunehmen.
• Die MMU (Memory Management Unit) ermöglicht Zugriffschutz und die Übersetzung von virtueller zu physikalischer Adresse.
• In der MMU werden außerdem die Caching Regeln für den Instruction Cache und den Data Cache festgelegt.
• Identifizieren von Code als cachable oder non cachable. • Auswahl zwischen Data Cache und Mini Data Cache. • Write-back oder Write-through data caching. • Aktivieren der „Data-Write allocation policy“, zum Bestimmen wie und in welchen Cache
Datenblöcke abgelegt werden. Dies wird im folgenden Absatz genauer erläutert.
Der Instruction Cache ist bei der XScale Architektur als 32KByte, 32-Wege Satz Assoziativer Cache
ausgelegt. Der Cache hat eine Breite von 32Byte. Alle Cache Anfragen die einen „miss“ liefern
erstellen automatisch eine 32Byte Leseanfrage an den externen Speicher.
Der Data Cache ist ebenfalls ein 32KByte, 32-Wege Satz Assoziativer Cache, wird allerdings noch
durch einen Mini Data Cache erweitert, der 2Kbyte groß ist und 2-Wege Satz assoziativ ist. Daten
können nur in einem der beiden Caches abgelegt werden. Allerdings werden die Daten in beiden
Caches parallel gesucht. In welchem Cache load/store Operationen durchgeführt werden, hängt
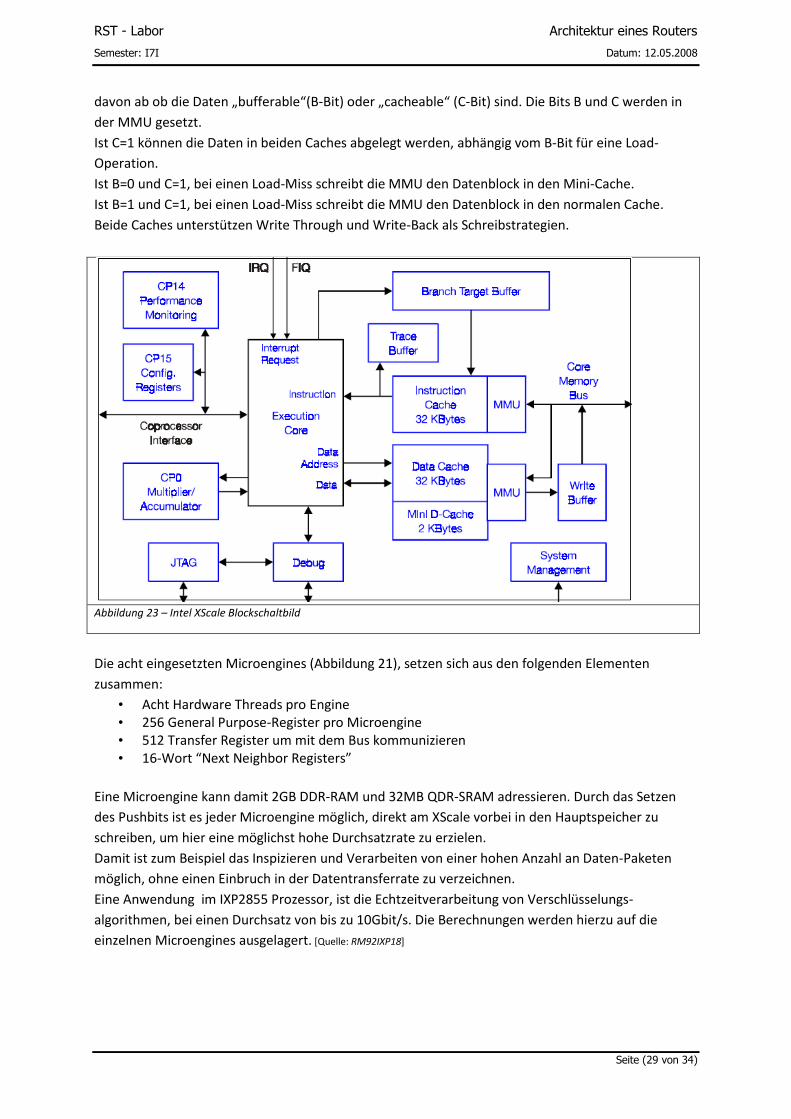
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (29 von 34)
davon ab ob die Daten „bufferable“(B-Bit) oder „cacheable“ (C-Bit) sind. Die Bits B und C werden in
der MMU gesetzt.
Ist C=1 können die Daten in beiden Caches abgelegt werden, abhängig vom B-Bit für eine Load-
Operation.
Ist B=0 und C=1, bei einen Load-Miss schreibt die MMU den Datenblock in den Mini-Cache.
Ist B=1 und C=1, bei einen Load-Miss schreibt die MMU den Datenblock in den normalen Cache.
Beide Caches unterstützen Write Through und Write-Back als Schreibstrategien.
Abbildung 23 – Intel XScale Blockschaltbild
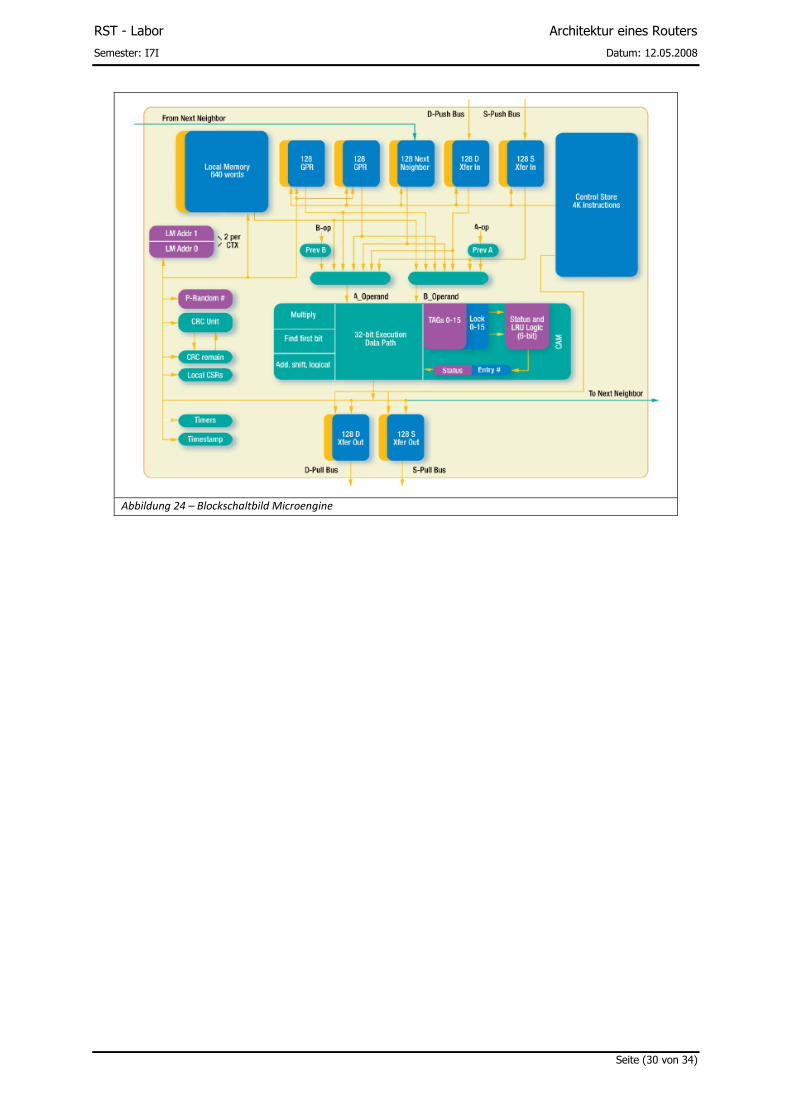
Die acht eingesetzten Microengines (Abbildung 21), setzen sich aus den folgenden Elementen
zusammen:
• Acht Hardware Threads pro Engine • 256 General Purpose-Register pro Microengine • 512 Transfer Register um mit dem Bus kommunizieren • 16-Wort “Next Neighbor Registers”
Eine Microengine kann damit 2GB DDR-RAM und 32MB QDR-SRAM adressieren. Durch das Setzen
des Pushbits ist es jeder Microengine möglich, direkt am XScale vorbei in den Hauptspeicher zu
schreiben, um hier eine möglichst hohe Durchsatzrate zu erzielen.
Damit ist zum Beispiel das Inspizieren und Verarbeiten von einer hohen Anzahl an Daten-Paketen
möglich, ohne einen Einbruch in der Datentransferrate zu verzeichnen.
Eine Anwendung im IXP2855 Prozessor, ist die Echtzeitverarbeitung von Verschlüsselungs-
algorithmen, bei einen Durchsatz von bis zu 10Gbit/s. Die Berechnungen werden hierzu auf die
einzelnen Microengines ausgelagert. [Quelle: RM92IXP18]
RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (30 von 34)
Abbildung 24 – Blockschaltbild Microengine

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (31 von 34)
10. Fazit
Leider war es nicht so einfach Backbone Router miteinander zu vergleichen, da höherwertige Geräte
in etwa identisch arbeiten und die wesentlichen Unterschiede in der Architektur der Prozessoren von
den Herstellern nicht Preis gegeben werden.
Es wäre schön gewesen direkte Benchmarks zwischen ähnlich teuren Geräten zu finden, um eine
Aussage zu treffen, welche Router die beste Performance liefern. Ein Benchmark wurde von Intel
gefunden, da aber kein direkter Vergleich mit einem anderen Gerät möglich war, ist dieser nicht
aussagekräftig. [Quelle: F10IB]
In unserer Ausarbeitung haben wir zwei Geräte in zwei unterschiedlichen Preisklassen angesprochen,
den SMC7904WBRA für knapp 100€ und einen Cisco 7301 für knapp 10.000€. In der Preiskategorie
zwischen diesen beiden Geräten, befindet sich zum Beispiel die Cisco 2800 Serie für mittlere bis
große Firmen. [Quelle: F10C28SR]
Diese Geräte sind modular aufgebaut und können nach Bedarf erweitert werden. Sie unterscheiden
sich im grundlegenden Aufbau allerdings nicht viel von den kleineren Geräten.
Nach oben hin ist den Geräten und den Preisen keine Grenze gesetzt. Beispiele für Hersteller solcher
Geräte wären Redback 1 und Juniper2, die sich auf die Produktion und Herstellung von
Hochleistungsroutern im Providerumfeld spezialisiert haben.
Alles in allem kann man dieses Themengebiet als sehr umfangreich und schnelllebig bezeichnen. Die
immer mehr auf Netzwerk beruhenden Systeme in einzelnen Firmen und Institutionen verursachen
immer mehr Traffic und verlangen damit immer leistungsfähigere Geräte, die diese Flut an Daten
verarbeiten können.
1 http://www.redback.com
2 http://www.juniper.net

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (32 von 34)
11. Quellen
[Quelle: G61]
URL: http://www.series16.adrianwise.co.uk/
Abruf: Februar 2008
[Quelle: G62]
URL: http://research.microsoft.com/~gbell/computer_structures_principles_and_examples/csp0394.htm
Abruf: Januar 2008
[Quelle: G63]
URL: http://ufaqs.com/wiki/en/pd/PDP11.htm
Abruf: Januar 2008
[Quelle: AR71]
URL: http://www.itwissen.info/definition/lexikon//_RORO_ROrouterRO_RORouter.html
Lexikon IT Wissen, Abruf: Januar 2008
[Quelle: AR72R]
URL: http://www.at-mix.de/routing_information_protocol.htm
Abruf: Januar 2008
[Quelle: AR72O]
URL: http://www.pmgas.net/fhwork/ccnp/OSPFvsEIGRP.pdf, Seite 2
Abruf: 15. März 2008
[Quelle: AR72B]
URL: http://de.wikipedia.org/wiki/Border_Gateway_Protocol
Abruf: Januar 2008
[Quelle: AR72B2]
URL: http://www.itwissen.info/definition/lexikon//_BGPBGP_BGPborder%20gateway%20protocolBGP_
BGPBGP-Protokoll.html
Abruf: Januar 2008
[Quelle: AR72D]
URL: http://et.ti.uni-mannheim.de/content/lehre/nt2/skript/NaTe2_Kap13.pdf
Abruf: Februar 2007
[Quelle: AR72P]
URL: http://et.ti.uni-mannheim.de/content/lehre/nt2/skript/NaTe2_Kap13.pdf
Abruf: Februar 2007
[Quelle: AR8]
URL: http://www.ibr.cs.tu-bs.de/courses/ws9798/seminar/hornburg/IPv6-Routing.html
Abruf: Februar 2008

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (33 von 34)
[Quelle: AR83]
URL: http://www.rcionline.net/cisco_routers.htm
Abruf: 15. März 2008
[Quelle: AR83C]
URL: http://www.rrzn.uni-
hannover.de/fileadmin/ful/vorlesungen/rechnernetze_2/ss_07/Rechnernetze_II_3_SS07.pdf
Abruf: Januar 2008
[Quelle: AR83J]
URL: http://www.juniper.net/products_and_services/t_series_core_platforms/
Abruf: März 2008
[Quelle: RM9SMC]
URL: http://www.smc.com/files/AX/ds_7904WBRA.pdf
Abruf: Januar 2008
[Quelle: RM9AR7]
URL: http://focus.ti.com/pdfs/bcg/ar7_wp.pdf
Abruf: Dezember 2007
[Quelle: RM9C73SR]
URL:
http://www.cisco.com/en/US/docs/routers/7300/install_and_upgrade/7301/7301_install_and_config_guide/5
418o.pdf
Abruf: Februar 2008
[Quelle: RM9C70SR]
URL: http://www.telnetworksusa.com/cisco/pdf/7000.pdf
Abruf: Februar 2008
[Quelle: RM91BCM]
URL: http://pdf1.alldatasheet.com/datasheet-pdf/view/85240/BOARDCOM/BCM1250.html
Abruf: Januar 2007
[Quelle: RM92IXP]
URL: http://www.intel.com/design/network/products/npfamily/ixp2xxx.htm
Abruf: Dezember 2007
[Quelle: RM92XS]
URL: ftp://download.intel.com/design/intelxscale/27347302.pdf
Abruf: Januar 2008
[Quelle: RM92IXP18]
URL: http://download.intel.com/design/network/ProdBrf/30943001.pdf
Abruf: Januar 2008

RST - Labor
Semester: I7I
Architektur eines Routers
Datum: 12.05.2008
Seite (34 von 34)
[Quelle: RM9C70SR]
URL: http://www.telnetworksusa.com/cisco/pdf/7000.pdf
Abruf: Februar 2008
[Quelle: F10IB]
URL: http://www.intel.com/design/network/products/npfamily/IXP2400_IPv6.pdf Abruf Januar 2008 [Quelle: F10C28SR]
URL: http://www.cisco.com/en/US/products/ps5854/prod_models_home.html Abruf: März 2008
















![RSerPool – Reliable Server Pooling - Uni Stuttgart...SigTran-Beispiel [draft-ietf-rserpool-arch-12.txt] Reliable Server Pooling RSerPool, IKR-Workshop, 8, Rg Anwendungsszenarien](https://static.fdokument.com/doc/165x107/5f2e09c687efe9440e6473af/rserpool-a-reliable-server-pooling-uni-stuttgart-sigtran-beispiel-draft-ietf-rserpool-arch-12txt.jpg)

