
sRDP-orientierte Statistik und...
25
1 Seminarunterlagen Salzburg, HLW Annahof Brigitte Wessenberg sRDP-orientierte Statistik und Wahrscheinlichkeitsrechnung mit TI82 stats Inhalt Arbeit mit Listen, Grundlagen Statistische Kenngrößen 1. Trainingseinheit Häufigkeitsverteilung 2. Trainingseinheit Regression 3. Trainingseinheit Elementare Wahrscheinlichkeit 4.Trainingseinheit Binomialverteilung 5. Trainingseinheit Normalverteilung 6. Trainingseinheit Lösungen aller Trainingseinheiten Februar 2013
Transcript of sRDP-orientierte Statistik und...

1
Seminarunterlagen Salzburg, HLW Annahof
Brigitte Wessenberg
sRDP-orientierte
Statistik und Wahrscheinlichkeitsrechnung
mit TI82 stats
Inhalt
Arbeit mit Listen, Grundlagen
Statistische Kenngrößen
1. Trainingseinheit
Häufigkeitsverteilung
2. Trainingseinheit
Regression
3. Trainingseinheit
Elementare Wahrscheinlichkeit
4.Trainingseinheit
Binomialverteilung
5. Trainingseinheit
Normalverteilung
6. Trainingseinheit
Lösungen aller Trainingseinheiten
Februar 2013

2
I Grundlage: Arbeit mit Listen
Statistische Daten müssen in Listen vorliegen.
Es liegen 6 vordefinierte Listen vor: L1 bis L6: Tastenfolge 2nd 1 bis 2nd 6
1. Dateneingabe direkt aus dem Hauptfenster: Listenelemente in geschwungene Klammer und in Liste 1 abspeichern:
{1,2,3,4,5,6} sto> 2nd 1
2. Dateneingabe in STAT
STAT/ 1 EDIT/ Daten in die Liste eingeben
Wie geht man vor, wenn die Listen nicht leer sind?
Mehrere Möglichkeiten:
a) Überschreiben, einzelne Elemente löschen mit DEL
b) Cursor in den Listenkopf/ DEL … löscht die Liste gesamt
c) Cursor in den Listenkopf / Clear/enter … löscht die Elemente der Liste
d) STAT/ 4 CLEAR LIST/ 2nd 1, 2nd 2, 2nd 3, usw
e) STAT/5 SetUpEDITOR (möglichst selten verwenden!)
f) MEM (2nd +) / 4 Clr all Lists (vor allem bei Listen mit Formeleingaben )
Wie geht man vor, wenn man eine neue Liste einfügen will?
ZB Liste 0
Cursor in Listenkopf 1 setzen/ INS/L / alpha 0 (Nach Ins erscheint „NAME=, bereits auf Alpha geschaltet!
für die Ziffer 0 muss alpha ausgeschaltet werden)
3. Formeleingabe bei STAT
Rechenoperationen, die im Listenkopf eingegeben werden, werden für alle Listenelemente übernommen:
Cursor in Listenkopf / Enter/ LIST (2nd STAT)/OPS/5 seq (Berechnungsterm, Variable, Anfang, Ende)
zB Man möchte eine Liste mit den natürlichen Zahlen von 10 bis 30
Listenkopf/enter/ LIST (2nd STAT)/OPS/5 seq (x, x, 10, 30)
Es werden die Zahlen von 10 bis 30 angezeigt. Nachteil, die Formel ist nicht erhalten und ist nicht
veränderbar.
Gibt man dagegen den Befehl in Anführungszeichen, dann kann die Formel verändert werden:
Listenkopf/enter/ “ LIST (2nd STAT)/OPS/5 seq (x, x, 10, 30)
4. Eingabe von Zufallszahlen
Wir geben in die Liste L1 6 Zufallszahlen im Intervall [4; 10] ein.
Möglichkeiten:
a) Die 6 Zahlen beliebig wählen und einzeln bei STAT von L1 eingeben
b) Hauptfenster: Math/ PRB (1x nach links)/5 randInt(4,10,6) Stornieren in L1

3
c) Wenn eine Gruppe die gleichen Zufallszahlen haben soll, dann gibt man eine beliebige mehrstellige Zahl
ein, alle die gleiche.
zB Hauptfenster: 123 / STO/ MATH/PRB/1 rand/Enter/Enter vorweg eingeben… CODE
dann erst den Befehl für die Zufallszahlen und stornieren in Liste 1
5. Graphische Aufbereitung von Listenelementen
Grafik: 2nd STAT/PLOT (Über Y)/ Enter1/ Enter/ On/ enter Histogramm wählen/xList … L1
Freq (absolute Häufigkeit = 1)
ZOOM 9 für grobe Voreinstellung, mit window nachjustieren
xmin = linke Grenze der untersten Klasse
xmax = rechte Grenze der obersten Klasse
Xscl = Balkenbreite im Histogramm
II Statistische Kenngrößen und ihre Darstellung
1. Die wichtigsten Kenngrößen im TI82stats
Arithmetisches Mittel … ̅
Standardabweichung n- gewichtet … σ für Grundgesamtheit bzw. Stichproben mit n > 30 (Näherung)
Standardabweichung (n-1) gewichtet …s für Stichproben
Anzahl … n
Minimum … Min
1. Quartil … Q1
Median … Med
2. Quartil … Q2
Maximum … Max.
2. Berechnung und Grafik – eindimensionale Daten
A1 a) Operieren Von 10 Kindern wurde die Körpergröße gemessen: Größe x in cm: 138; 132,5; 137,5; 132,5; 142,5; 131,5; 130; 138; 137; 135 Berechnen Sie die statistischen Kenndaten. Stellen Sie die Daten passend in einem Boxplotdiagramm und in einem Balkendiagramm dar. b)Interpretieren, Argumentieren
Interpretieren Sie beide Boxplots in
Hinblick auf die statistischen
Kenngrößen.
Vergleichen Sie die Aussage über die
Messung bei Buben und Mädchen.

4
a) STAT/EDIT/ enter/ L1: Daten x eingeben… STAT/CALC/1-Var Stats enter/ eingeben ins Fenster L1,L2/enter/ mit dem Cursor nach unten, dann erhält man die 2. Seite.
Darstellung als BOXPLOT:
2nd / STAT PLOT/ Plot1/enter/On/ enter/ mit Cursor Typ auswählen. Boxplot mit Mittellinie wählen ,
Vorletzte Option enter / Xlist: L1/ Freq Vorsicht, der Cursor blinkt mit A, es ist Schreiben von Buchstaben
eingeschaltet. wir brauchen die Zahl 1, daher Alpha und dann 1
Window mit Zoom vorwählen: Zoom 9 / ZoomStat/ enter.
Der Boxplot wird relativ hoch oben gezeichnet. Eine weitere Messung könnte man ebenfalls zeichnen
lassen, die würde dann darunter platziert.
Man sieht, es handelt sich nicht um eine symmetrische sondern um eine linksschiefe Verteilung: die Werte
links vom Median streuen innerhalb des Rechteckes mehr, als rechts davon.
Balken- oder Säulendiagramm gibt es in Ti82stats nicht.
Das Histogramm kann man zeichnen mit einer Balkenbreite, die durch die Schrittweite in Window scl
festgelegt werden kann.
Festlegung des Bildausschnitts mit Zoom stat und hinterher in window nachjustieren!
Streudiagramm oder Liniendiagramm kommen hier nicht in Frage, sie benötigen eine 2. Liste.

5
Trainingseinheit 1:

6
3. Klasseneinteilung beim Histogramm
1. A2 30 Kinder wurden gemessen und gewogen, Größe x in cm: 138; 132,5; 137,5; 132,5; 142,5; 131,5; 130; 138; 137; 135 134; 130,5; 139,5; 130,5; 140,5; 133,5; 131; 136; 135; 132 136; 131,5; 134,5; 133,5; 132,5; 141,5; 140; 128; 127; 130
2. a) Operieren Stellen Sie die Daten in einem Histogramm mit einer passenden Klasseneinteilung dar. b) Argumentieren Erklären Sie, welche Information Sie entnehmen können, wenn Sie die Daten mit einem Boxplotdiagramm darstellen.
a) TE:
Eine solche große Menge erfordert die Einteilung in Klassen. Die Wahl der Klassen ist üblicherweise so
festgelegt, dass man als Merkregel ungefähr die Wurzel aus n nimmt, aber nie mehr als max. 9-10 Klassen.
In unserem Fall sind 5 oder 6 Klassen günstig.
Man macht die Klasseneinteilung zunächst automatisch mit Zoom 9 Stat und bessert dann in Window nach.
Wichtig! Ein Wert am oberen Rand des Balkens wird immer dem nächsten Balken rechts zugezählt. Der
untere Wert gehört zur Klasse, der obere nicht. Klassen sind bei TI82 OBEN OFFENE INTERVALLE! [….)
Mit 7 Klassen von Zoom Stat Mit 6 Klassen mit 5 Klassen
Mit trace und cursor kann man die einzelnen Werte erhalten:
usw

7
II Häufigkeitsverteilung
1. Diagramme bei gegebener Häufigkeit
A3: Bei einer Schularbeit ergab sich folgende Notenverteilung:
Note 1 2 3 4 5
Anzahl 3 6 10 7 2
a) Operieren Stellen Sie die Verteilung der Noten in einem Liniendiagramm, unterlegt von einem Histogramm, dar. Geben Sie Mittelwert und Standardabweichung an b) Argumentieren Überprüfen Sie durch entsprechend dokumentierte Berechnungen, ob die folgende Darstellung die Verteilung der Noten aus der obigen Tabelle richtig beschreibt.
a) STAT/EDIT/ enter/ L1: Noten eingeben…/L2: absolute Häufigkeiten eingeben
STAT/ CALC/1-VARS STAT/enter/ L1,L2/ enter
Mittelwert ̅ und Standardabweichung σx ablesen.
2nd / STAT PLOT/ Plot1/enter/On/ enter/ mit Cursor Typ Histogramm auswählen / Xlist: L1/ Freq: L2
Zoom 9 und nachbessern in Window!
(Stabdiagramm gibt es in TI82 nicht)
2nd / STAT PLOT/ Plot2/enter/On/ enter/ mit Cursor Typ Linie auswählen / Xlist: L1/ Freq: L2
Graph
b) Man kann hier händisch die Prozent berechnen 3/28; 6/28; 10/28; 7/28; 2/28 Darstellung ist eine
Näherung auf ganze Prozentzahlen

8
Oder man rechnet mit Ti 82 die relativen Häufigkeiten aus:
STAT/ EDIT/In den Kopf zu L3 gehen, eingeben: 2nd L2/2nd LIST : MATH/5 sum (2nd L2)/ enter
2. Die „statistische“ Verteilungsfunktion Die kumulative Verteilungsfunktion beschreibt die Häufigkeiten von x >(,≥,<,≤) a Jedes Element der kum. VTL-Liste wird dabei durch die Summe der Daten bis incl. zur entsprechenden Zeile der Daten-Liste gebildet. Üblicherweise nimmt man die relativen (prozentuellen) Häufigkeiten. Aber es macht auch manchmal Sinn, wenn man die absoluten Häufigkeiten angibt.
A4: 100 Kandidaten haben einen Test absolviert, bei dem es Bewertungspunkte gab.
a) Operieren Bei dem Test ergab sich folgende absolute Häufigkeit an Punkten
Punkte 1 2 3 4 5 6 7 8 9 10
Anzahl 3 5 8 3 30 32 10 4 3 2
Stellen Sie die Verteilungsfunktion der Punkte in Prozent in einer Tabelle und in einem Liniendiagramm dar.
b) Interpretieren Sie die folgende Grafik in Bezug auf die folgenden Fragestellungen: - Wie viele Kandidaten haben weniger als 5 Punkte erzielt. - Wie viele Kandidaten haben genau 5 bis genau 8 Punkte erreicht. - Wie viel Prozent der Kandidaten haben mehr als 6 Punkte erreicht.
c) Argumentieren: Erklären Sie, wie man von der kumulierten Verteilungsfunktion auf eine Liste der absoluten Häufigkeiten kommt.
3 8
15 19
50
80
91 95 98 100
0
20
40
60
80
100
120
1 2 3 4 5 6 7 8 9 10
kum. abs. Häufigkeitl
Punkteanzahl

9
a) Operieren STAT, EDIT / L1 Daten: Punkte 1 bis 10 eingeben / L2: absolute Häufigkeit eingeben/ L3: im Kopf: L1/100 enter/ L4 im Kopf: 2nd LIST/ops/ 6 cumsum(L3) / enter
2nd STAT PLOT / Plot1 enter/ on (alle anderen früheren Plots deaktivieren – OFF) Liniendiagramm (2) wählen. x: L1, y L4) quit/ zoom 9
b) Interpretieren Vorsicht: „Wie viele Kandidaten“ fragt nach der absoluten Häufigkeit! einfach ablesen: weniger als 5 bedeutet bis incl.4 ≤ 4 19 Kandidaten ablesen bis 8 incl. sind 95, davon auszuschließen bis 4 incl sind 19 95 – 19 = 76 Kandidaten Mehr als 6 bedeutet von 7 bis 10: 100 – (Zahl bis incl.6) = 100 - 80, d.s. 20/100 = 20% c) Argumentieren: Die erste Zahl ist bereits eine absolute Häufigkeit. H1 = 3, die 2. Zahl H2 = 8 - 3 = 5, usw. man bildet die Differenz zweier aufeinanderfolgender Kum. Häufigkeiten. Berechnen mit TI82 (hier nicht verlangt) Wir geben die abgelesenen Zahlen in eine Liste: zB. L2, In den Kopf L3:“ 2nd LIST/ OPS/5 seq(L2(x+1)-L2(x), x,1,9)“ gibt die Liste der absoluten Häufigkeiten – allerdings ohne das 1. Element. Dieser Befehl entspricht einem kürzeren Befehl: 2nd List/OPS/ 7“ ΔList (L2) enter

10
Trainingseinheit 2:
11
III Regression – Zusammenhangsanalyse
1. Die lineare Regression
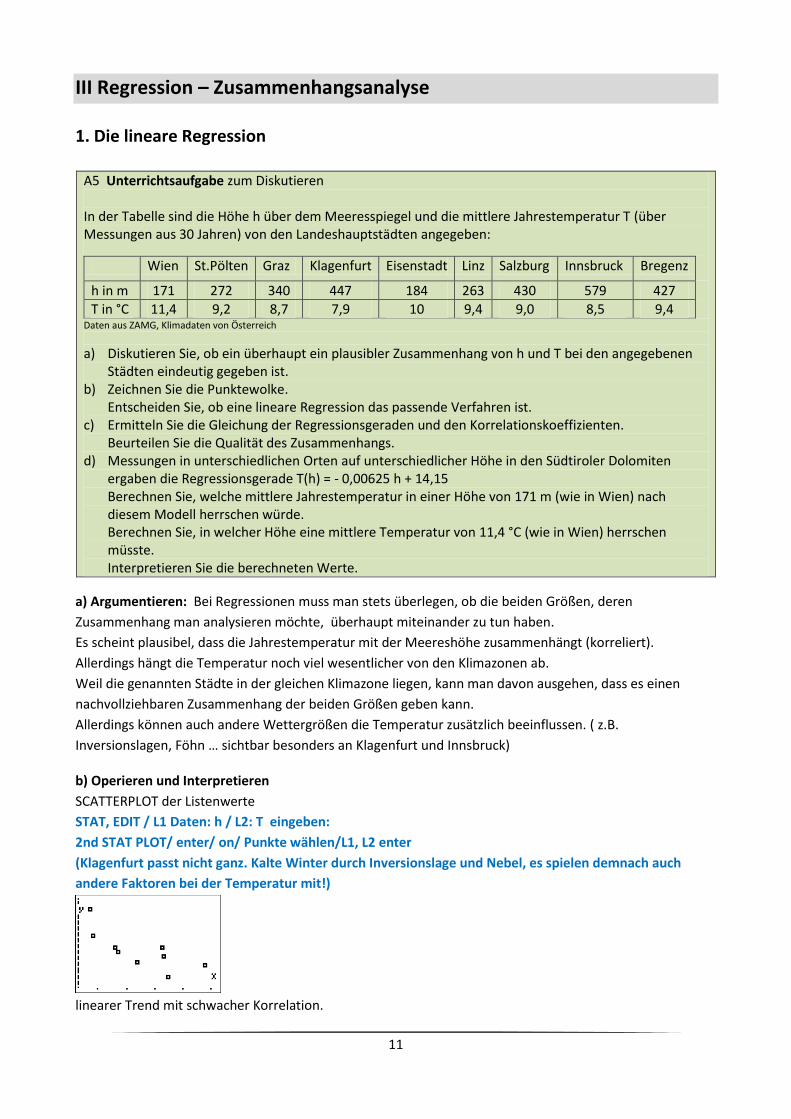
A5 Unterrichtsaufgabe zum Diskutieren In der Tabelle sind die Höhe h über dem Meeresspiegel und die mittlere Jahrestemperatur T (über Messungen aus 30 Jahren) von den Landeshauptstädten angegeben:
Wien St.Pölten Graz Klagenfurt Eisenstadt Linz Salzburg Innsbruck Bregenz
h in m 171 272 340 447 184 263 430 579 427
T in °C 11,4 9,2 8,7 7,9 10 9,4 9,0 8,5 9,4 Daten aus ZAMG, Klimadaten von Österreich
a) Diskutieren Sie, ob ein überhaupt ein plausibler Zusammenhang von h und T bei den angegebenen Städten eindeutig gegeben ist.
b) Zeichnen Sie die Punktewolke. Entscheiden Sie, ob eine lineare Regression das passende Verfahren ist.
c) Ermitteln Sie die Gleichung der Regressionsgeraden und den Korrelationskoeffizienten. Beurteilen Sie die Qualität des Zusammenhangs.
d) Messungen in unterschiedlichen Orten auf unterschiedlicher Höhe in den Südtiroler Dolomiten ergaben die Regressionsgerade T(h) = - 0,00625 h + 14,15 Berechnen Sie, welche mittlere Jahrestemperatur in einer Höhe von 171 m (wie in Wien) nach diesem Modell herrschen würde. Berechnen Sie, in welcher Höhe eine mittlere Temperatur von 11,4 °C (wie in Wien) herrschen müsste. Interpretieren Sie die berechneten Werte.
a) Argumentieren: Bei Regressionen muss man stets überlegen, ob die beiden Größen, deren
Zusammenhang man analysieren möchte, überhaupt miteinander zu tun haben.
Es scheint plausibel, dass die Jahrestemperatur mit der Meereshöhe zusammenhängt (korreliert).
Allerdings hängt die Temperatur noch viel wesentlicher von den Klimazonen ab.
Weil die genannten Städte in der gleichen Klimazone liegen, kann man davon ausgehen, dass es einen
nachvollziehbaren Zusammenhang der beiden Größen geben kann.
Allerdings können auch andere Wettergrößen die Temperatur zusätzlich beeinflussen. ( z.B.
Inversionslagen, Föhn … sichtbar besonders an Klagenfurt und Innsbruck)
b) Operieren und Interpretieren
SCATTERPLOT der Listenwerte
STAT, EDIT / L1 Daten: h / L2: T eingeben:
2nd STAT PLOT/ enter/ on/ Punkte wählen/L1, L2 enter
(Klagenfurt passt nicht ganz. Kalte Winter durch Inversionslage und Nebel, es spielen demnach auch
andere Faktoren bei der Temperatur mit!)
linearer Trend mit schwacher Korrelation.
12
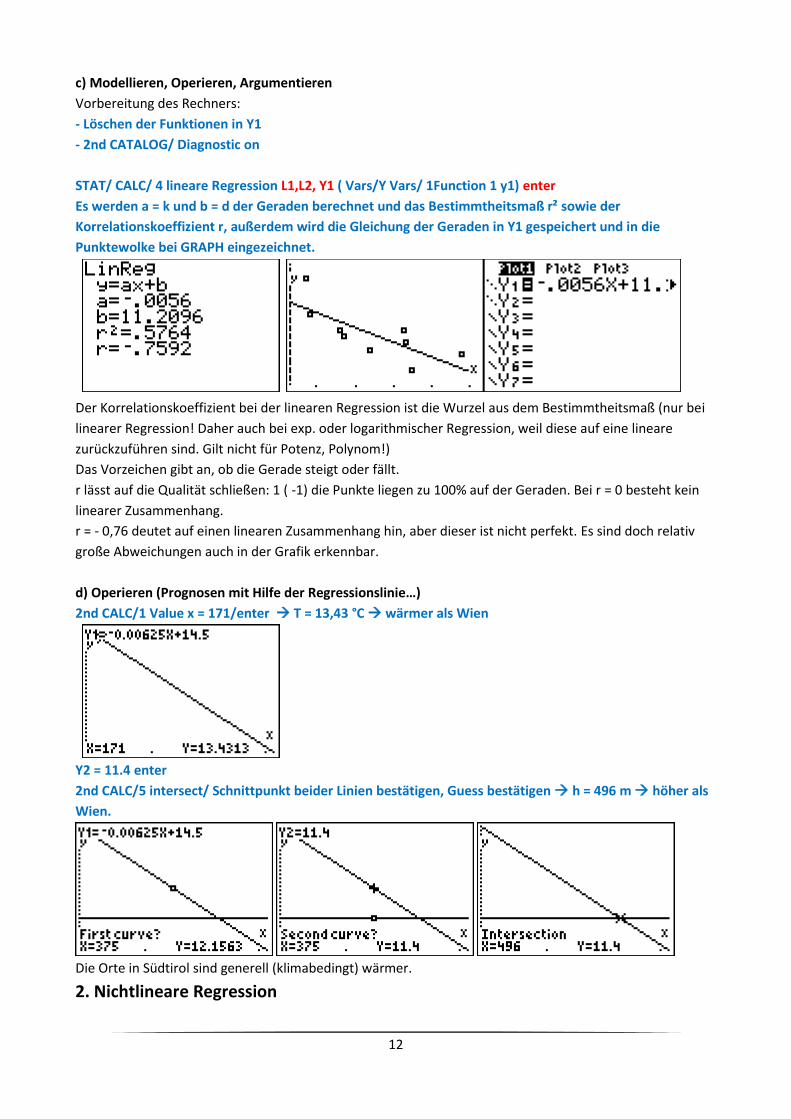
c) Modellieren, Operieren, Argumentieren
Vorbereitung des Rechners:
- Löschen der Funktionen in Y1
- 2nd CATALOG/ Diagnostic on
STAT/ CALC/ 4 lineare Regression L1,L2, Y1 ( Vars/Y Vars/ 1Function 1 y1) enter
Es werden a = k und b = d der Geraden berechnet und das Bestimmtheitsmaß r² sowie der
Korrelationskoeffizient r, außerdem wird die Gleichung der Geraden in Y1 gespeichert und in die
Punktewolke bei GRAPH eingezeichnet.
Der Korrelationskoeffizient bei der linearen Regression ist die Wurzel aus dem Bestimmtheitsmaß (nur bei
linearer Regression! Daher auch bei exp. oder logarithmischer Regression, weil diese auf eine lineare
zurückzuführen sind. Gilt nicht für Potenz, Polynom!)
Das Vorzeichen gibt an, ob die Gerade steigt oder fällt.
r lässt auf die Qualität schließen: 1 ( -1) die Punkte liegen zu 100% auf der Geraden. Bei r = 0 besteht kein
linearer Zusammenhang.
r = - 0,76 deutet auf einen linearen Zusammenhang hin, aber dieser ist nicht perfekt. Es sind doch relativ
große Abweichungen auch in der Grafik erkennbar.
d) Operieren (Prognosen mit Hilfe der Regressionslinie…)
2nd CALC/1 Value x = 171/enter T = 13,43 °C wärmer als Wien
Y2 = 11.4 enter
2nd CALC/5 intersect/ Schnittpunkt beider Linien bestätigen, Guess bestätigen h = 496 m höher als
Wien.
Die Orte in Südtirol sind generell (klimabedingt) wärmer.
2. Nichtlineare Regression

13
Es gibt bei TI82 stats 10 verschiedene Regressionsverfahren.
Vorbereitung des Rechners:
-y1 ( oder ein anderes Y muss für die Gleichung der Kurve frei gemacht werden.
-Diagnostic on ( mit Catalog), damit das Bestimmtheitsmaß angezeigt wird.
A6: Die Kostenfunktion bei der Herstellung eines Produkts wird anhand von Daten aus einer Untersuchung erstellt. x … Produktionsmenge in Mengeneinheiten (ME) K(x) … Gesamtkosten bei der Produktion von x ME in Geldeinheiten (GE)
x 20 30 40 60 80
K(x) 143 181 322 411 642
a) Zeichen Sie die Punktewolke. Legen Sie Polynomfunktionen Grad 2 bis 4 als Regressionslinien zugrunde Beurteilen Sie die Qualität und Eignung der Kurven. b) Mit den Daten der Tabelle wurden exponentielle, logarithmische, logistische Regression, sowie Power
Regression ( a ∙ xb) vorgenommen. Wählen Sie, welche davon am besten passt und begründen Sie Ihre Auswahl.
a)
STAT/ CALC/ 5 QuadReg L1,L2, Y1 ( Vars/Y Vars/ 1Function 1 y1) enter
STAT/ CALC/ 6 CubicReg L1,L2, Y1 ( Vars/Y Vars/ 1Function 1 y1) enter
STAT/ CALC/ 5 QuartReg L1,L2, Y1 ( Vars/Y Vars/ 1Function 1 y1) enter

14
Die quadratische und die kubische Regression passen sich den Messwerten gut an. Die Gleichung 4. Grades
passt gar nicht, obwohl das Bestimmtheitsmaß hier = 1 ist.!
b)
Exp. Regression passt sich gut an. Von der Sache her wäre sie geeignet für Fixkosten von 94,6 GE.
Logarithmische Regression passt nicht, obwohl das Bestimmtheitsmaß und der Korrelationskoeffizient
nahe bei 1 liegen. Aber sie ist bei x = 0 nicht definiert und nahe 0 ergeben sich negative Kosten.
Power Regression passt sich gut an, hat eine hohe Korrelation. Von der Sache her passt sie nicht, dann die
Kosten bei x = 0 wären 0 > keine Fixkosten.
Die logistische Kurve passt sich auch gut an, sie hätte Fixkosten von ca. 84 GE. Die Kosten hätten allerdings
einen oberen Grenzwert von 1228,4 GE. Das ist nicht wahrscheinlich.
Am besten eignet sich die exponentielle Regression.
Trainingseinheit 3

15
IV Elementare Wahrscheinlichkeit
1. Laplace Definition der Wahrscheinlichkeit:
P(E) = g (E) / m (E)
Verhältnis der für das Auftreten eines Ereignisses E günstigen Fälle zu den insgesamt möglichen Fällen.
A7 Von den 50 Mitarbeitern einer Firma sprechen 10 keine Fremdsprache, 25 nur Englisch, 10 nur Russisch und 5 Englisch und Russisch. a) Stellen Sie die Situation in einer Skizze dar, ( falls Mengendiagramm bekannt ist) b) Berechnen Sie die Wahrscheinlichkeit, dass ein zufällig ausgewählter Mitarbeiter
i. beide Fremdsprachen spricht, ii. Englisch spricht,
iii. nicht Russisch spricht, iv. mindestens eine Fremdsprache spricht
a) Modellieren
b) Operieren
i. g : m = 5 : 50 = 0,1 = 10%
ii. g : m =30 : 50 = 0,6 = 60%
iii. g ∙ m = 35 : 50 = 0,7 = 70%
iv. mindestens 1 bedeutet: 1 oder 2
1 sprechen 35, 2 sprechen 5 also g : m = 40 : 50 = 0,8 = 80 %.
oder alle weniger keine: 1 - 10 : 50 = 0,8 = 80%

16
2. Anzahl bestimmen über Kombinatorik (alles über Math/ PRB)
Fakultät: A8
Berechnen Sie die Anzahl, wie oft 10 Bilder B1 bis B10 unterschiedlich aufgehängt werden.
10 Math/ cursor 1x nach links drücken, PRB (oder rechts 3x) / 4 ! enter
Permutation nPr A9 Man soll aus 30 Personen 4 zufällig auswählen als Spielleiter, 1. Assistent, 2. Assistent, 3. Assistent. Wie viele unterschiedliche Möglichkeiten der Auswahl gibt es.
30 Math/ cursor 1x nach links drücken, PRB (oder rechts 3x) / 2 nPr enter/ 4 enter
657720
Kombination nCr A10 Aus einer Gruppe von 50 Personen werden wahllos 10 ausgewählt. a) Wie viele Möglichkeiten gibt es, unterschiedliche Personen zu wählen? b) Wie groß ist die Wahrscheinlichkeit, dass eine ganz bestimmte Person zufällig unter den 10 Auserwählten ist?
50 Math/ cursor 1x nach links drücken, PRB (oder rechts 3x) / 3 nCr enter/ 10 enter
1,027 ∙ 10 10
3. Wahrscheinlichkeit mit Pfadregeln (Baumgraphen)
A11
Bei einem Spiel fischt man kleine Dosen. In jeder 7. Dose ist 1 Euro. a) Stellen Sie die Situation grafisch in einer Skizze dar. b) Berechnen Sie, wie viele Dosen vorhanden sein müssen, damit man mit 95% Wahrscheinlichkeit
mindestens 1 Euro bekommt.
a) Modellieren
usw…

17
b) Operieren
g … n/7 , m … n P(1€) = 1/7 beim 1. Zug, P(0€) = 6/7
P (mindestens 1 € ) = 1- P( 0 €) = 1 - (6/7) n = 0,95
Solver: Math0 / Cursor nach oben, Gleichung mit Minus statt = eingeben / enter
Cursor auf x, alpha solve
19,43 ca 20 Dosen!
A12
In einem Korb liegen 6 rote, 4 blaue und 2 grüne Ostereier. Jemand nimmt ohne Hinschauen 2 Eier heraus. a) Berechnen Sie, wie wahrscheinlich es ist, dass beide die gleiche Farbe haben. b) Berechnen Sie die Wahrscheinlichkeit, dass ein Ei rot, das andere grün ist. c) Zeichnen Sie ein Baumdiagramm nur mit jenen Ästen, die man für die Lösung der Frage benötigt, wie
wahrscheinlich man 2 Eier mit unterschiedlicher Farbe zieht.
a) Modellieren, Operieren
Pfadregeln: (30 + 12+2) / 132 = 1/3 ≈ 33%
b) Modellieren, Operieren
Pfadregel: 12 / 132 = 9%
c) Modellieren
Trainingseinheit 4

18
V. Binomialverteilung
A13
Die Fertigung von elektronischen Bauteilen erfolgt mit einem konstanten Ausschussanteil von p = 4%. a) Berechnen Sie die Wahrscheinlichkeit, dass bei einer Entnahme von n = 50 Teilen
- genau 2 Teile defekt sind -mindestens 2 Teile defekt sind - höchstens 2 Teile defekt sind
b) Stellen Sie die Wahrscheinlichkeitsverteilung für 0 bis 6 defekte Teile bei n = 50 grafisch dar. c) Ermitteln Sie, wie viele defekte Teile bei n = 50 ungefähr 86 % ausmachen.
a) Operieren
2 Teile genau: 2nd DISTR / alpha A binompdf (n,p,k) …pdf, wenn man einen Wert k genau haben möchte.
mindestens 2 Teile = 2 und alle darüber oder alle weniger 0 und 1 = 1- P(0,1)
1- binomcdf ( n,p,k) cdf für kumuliert bis k k = 1
Höchstens 2 Teile: P(0,1,2) = binomcdf(n,p,k) k = 2
b) Modellieren, Operieren
In Listen eingeben:
L1: 0 bis 6, L2in den Kopf: binompdf (50,0.04,L1)
STAT PLOT/on/ Histogramm/ L1/ L2 Zoom 9 und in window nachjustieren. Mit trace kann man die
einzelnen Werte abtasten…
c) P(X≤x) ≤ 0,8
Formel: binomcdf(50, 0.04, x) = 0,86
Für die Berechnung gibt man die Gleichung mit dieser Formel in den Solver ein, Ergebnis:
x = ungefähr bei 3
(Differenz geht nicht ganz auf 0! sondern 0,00087…)
Probe: binomcdf(50, 0.04, 3) = 0,8609

19
Trainingseinheit 5
VI. Normalverteilung
1. Normalverteilung und die Inverse A14 Eine Maschine soll Metallstäbe mit einem Längen-Sollwert von 12 cm herstellen. Die Länge schwankt mit einer Standardabweichung von σ = 2 mm. a) Berechnen Sie die Wahrscheinlichkeit, dass die Stablänge
- weniger als 11,9 cm beträgt -zwischen 11,7 und 12,3 cm liegt -höchstens 1 mm vom Sollwert abweicht
b) Die Grafik zeigt die Dichtefunktion der Normalverteilung. -Erklären Sie, wie Sie vorgehen, um die Toleranzgrenzen bei 5% Ausschuss relativ genau abschätzen zu können. -Zeichnen Sie die Toleranzgrenzen ungefähr ein, wenn der Ausschussanteil höchstens 5% betragen soll.
a) Operieren:
2nd DISTR / 2 normalcdf (also kumulativ!) (untere Grenze, obere Grenze, µ,σ)

20
b) Interpretieren und Argumentieren
5% Ausschuss heißt, dass 2,5% zu lang sind und 2,5% zu kurz. Die Toleranzgrenzen liegen links und rechts
von µ so, dass um den Sollwert eine Fläche von 95% an Wahrscheinlichkeit für tolerierte Längen entsteht.
Der 2σ-Bereich schließt ca. 95,4% ein, das heißt, man hat es ungefähr mit dem 2σ-Bereich zu tun, setzt
demnach die Grenzen ca. 4mm – eine Spur weniger 3,93 mm - links und rechts vom Sollwert.
Man zeichnet die Normalverteilung mit
2nd DISTR/Draw/1 shadeNorm (Untere Grenze, obere Grenze, µ, σ)
Window vorher einstellen ! sonst nochmals
eingeben im Hauptfenster mir 2nd entry /enter
Löschen mit 2nd DRAW/1 Clr draw.
Jede Zeichnung wieder löschen, weil sie sonst beim nächsten BSP unterlegt ist!
A15
Eine Maschine soll Metallstäbe mit einem Längen-Sollwert von 12 cm herstellen. Die Länge schwankt mit einer Standardabweichung von σ = 2 mm. Berechnen Sie die Toleranzgrenzen, wenn der Ausschussanteil höchstens 7 % betragen soll.
Wenn Prozent gegeben sind, dann muss man schauen, diese in die Form P (X≤ a) zu bringen, dann kann
man mit der Umkehrung InvNorm (p, µ, σ) arbeiten.
In diesem Fall liegen die Grenzen symmetrisch. Ein möglicher Lösungsweg: Der linke Spitz beträgt 3,5%.
Das liefert die untere Grenze.
2nd DISTR/3 invNorm (3.5, 12, 0.2) = 11,637…ergibt die untere Grenze der gesuchten Fläche.
Die obere Grenze bekommen wir mit µ + (µ-11,637..) = 2µ - 11,637.. ≈12,36
2. Berechnung der Normalverteilung über die Speicherung einer allgemeinen Formel
Nutzung der Datenbank GDB mit Hilfe des Funktionsblocks.
Man gibt Formeln, die man braucht in den Y-Editor ein
zB Y0 = normcdf(U,O,M,S) - P ein.
2nd DRAW (über Programmtaste) / STO (hier lassen sich Bilder pic, Formeln GDB speichern) /
3 StoreGDB 0 / enter
Unter GDB 0 ist nun diese Formel in Y0 gespeichert. Sie kann jederzeit im solver aufgerufen werden
Im Hauptfenster:
2nd DRAW (über Programmtaste) / STO/4 recall / GDB0
Reaktion: Done ( Damit kommt das gespeicherte Funktionsgebilde- der gesamte Y1 bis Y0-Block wird
überschrieben! VORSICHT!)
Im Solver:
MATH0/ eqn: 0 = VARS/Y-VARS/1 Function/Y0 enter

21
Nun gibt im Solver man die Werte ein und kann alle Normalverteilungen berechnen! In unserem Beispiel
berechnet man zunächst die untere Grenze. Die Fläche bis zum Mittelwert ist 0,5.
U = gesucht, O = 12, M = 12; S = 0,2 , P = 0,35 ( Vorsicht die Hälfte), Cursor auf U, Alpha solve
Dann die U = 12, alles andere gleich und Cursor auf O, alpha solve
Probe: U, O die berechneten Werte einsetzen, Cursor auf P / Alpha solve
Trainingseinheit 6:

22
Lösungen der Trainingseinheiten:
1:

23
2:
3. E(t) = 0,0202 t
2 – 0,2137t + 13,8471
Die Werte der Tabelle werden recht gut durch eine nach oben offene quadratische Funktion beschrieben. Allerdings würde der Funktionswert für t = 0 a nicht in diese Funktion passen, es liegt bei t = 0 noch kein Umsatz vor. Sinngemäße ähnliche Argumentationen sind möglich.
0
5
10
15
20
0 10 20 30Jah
resu
msä
tze
in M
io.€
Jahre nach der Gründung

24
4:
5:

25
6:


















