
Stefan Hanenberg (University of Duisburg-Essen)laemmel/esecourse/slides/ctrlexp2.pdf · Grundlage...
54
Analyse von Experimenten Stefan Hanenberg (University of Duisburg-Essen)
Transcript of Stefan Hanenberg (University of Duisburg-Essen)laemmel/esecourse/slides/ctrlexp2.pdf · Grundlage...

Analyse von Experimenten
Stefan Hanenberg(University of Duisburg-Essen)

Eine Intuitive Einführung

Intuitive Einführung (1) – siehe vorherige Vorlesung
● Beispiel und Diskussion● Ich glaube, dass die Programmiersprache Java besser
als Smalltalk für die Durchführung von Softwareprojekten geeignet ist.
Wie kann ich den Nachweis erbringen?

Intuitive Einführung (2) – siehe vorherige Vorlesung
● ....
● Zweite Idee● Ich lasse von 4 Stundenten “HelloWorld” schreiben, 2 Stundenten
in Java, 2 Stundenten in Smalltalk. Dann vergleiche ich, welche der beiden Gruppen schneller war.
● Wie vergleiche ich? ● Arithmetische Mittel? Mediane? ● Muss ich “Ausreißer” beachten? Sind 4 Probanden ausreichend?● ....

Intuitive Einführung (3) – stats4runaways...
● Grundsätzliches Vorgehen bei der Auswertung
● Anwendung von Inferenzstatistik, d.h. Durchführung eines Signifikanztests
● Berechnung eines p-Werts (Wahrscheinlichkeit eines alpha-Fehlers)
● Wenn p-Wert < 0.05, dann „wurde etwas gefunden“, ansonsten kein Unterschied gefunden

Intuitive Einführung (3) – stats4runaways...
● Beispiel: Java/Smalltalk Entwicklungszeit
● Proband/Sprache/Zeit:
– Stefan/Smalltalk/2h, Michael/Java/1h, Thorsten/Java/4h, Manuel/Smalltalk/8h, Rainer/Smalltalk/6h, Klaus/Java/1h
● „Es sieht so aus, als ob Smalltalk-Programmierer länger brauchen“● Durchführung eines Signifikanztests
(hier Mann-Whitney-U-Test)
– Ergebnis: p=0.2
– Kein Unterschied zwischen Java und Smalltalk gefunden (obwohl Mediane unter arithmetische Mittel unterschiedlich!)
Java
Smalltalk0 1 8

Ziele
● Erlernen von ● Validen Methoden, um Experimente
auszuwerten– Welche Tests gibt es?– Wann werden diese angewendet? (für
welchen Experimentaufbau)● Grenzen dieser Methoden
– Welche Annahmen haben die Tests?

Agenda
● Messdaten und Skalen
● Deskriptive Statistik
● Inferenzstatistik
● Verteilungen
● Signifikanztests
– Mittelwertvergleiche● Wilcoxon, Mann-Whitney-U-Test, t-Test
– Multiple Vergleiche● Korrekturen● Varianzanalyse
● Abbildung von Signifiganztests auf Versuchsaufbauen
● Werkzeugunterstützung
● SPSS & R

Messdaten und Skalen (1)
● Messdaten haben eine unterschiedliche Natur
● Skalen
● NominalskalaWerte folgen keiner Ordnung, aber man kann Werte unterscheiden, Bsp: weiblich, männlich
● OrdinalskalaWerte sind geordnete, aber man kann den Abstand der Werte nicht Bewerten („sehr gut“ ist nicht „doppelt so viel wie gut“), Bsp.: sehr schlecht, schlecht, gut, sehr gut
● Intervallskala: Werte sind geordnet, Unterschiede können beziffert werden, eber es gibt “keinen Nullpunkt“, Bsp.: 10° C, 15° C, 66° C,
● VerhältnisskalaMessdaten sind “vollständig vergleichbar“, d.h. 10*Datum = 2*5*Datum, etc.

Messdaten und Skalen (2)
● Für unterschiedliche Skalen müssen unterschiedliche Verfahren eingesetzt werden● Z.B. gibt es „keinen Durchschnitt von weiblich und
männlich“

Deskriptive Statistiken - Lagemaße
● Lagemaße geben ersten Anhaltspunkt, wo sich „die meisten Messpunkte“ befinden

Deskriptive Statistiken - Lagemaße
● Arithmethisches Mittel● Anfällig gegen Ausreißer
● Median● „Stabiler“ gegen Ausreißer● Anfällig gegen „Knubbel“
● Gestutztes Mittel● Entfernen der oberen/unteren 10%
dann Mittelwert

Deskriptive Statistiken - Lagemaße
● Quantile● Unterteilung der Messwerte in Abschnitte des
gleichen Umfangs
● Beispiel:● Messreihe: 5, 10, 99, 150, 1000● Arithmetisches Mittel: x=252,2● Median: 99● Erstes Quintil = 7,5

Deskriptive Statistiken - Streuungsmaße
● Streuungsmaße geben an, wie weit die Messwerte verteilt sind

Deskriptive Statistiken - Streuungsmaße
● Spannweite● Differenz aus max und min
● Varianz● Durchschnittliche, quadratische
Abweichung von Mittelwert● Summe der Quadrate wird auch als
Quadratsumme (QS) bezeichnet
● Standardabweichung (=Streuung)● Wurzel der Varianz

Deskriptive Statistiken – Weitere Kennzahlen
● Schiefe (...selbstsprechend...)● Exzeß (Breite des Gipfels)

Datenvisualisierung (1)
● Histogramme● Beschreiben die Anzahl der Daten, die sich in
einem Bereich befinden (Näherung an Verteilung)
● Boxplots● Beschreiben, wie sich Daten um Median herum
verteilen
● Punktstreudiagramms● ....

Datenvisualisierung
● Zweck● Eindruck von der Beschaffenheit der Daten
vermitteln● Vergleich der Daten mit „bekannten Formen“ von
Daten (Verteilungen)● Identifizierung von Ausreißern und
Unregelmässigkeiten

Datenvisualisierung - Histogramm
● Beschreiben die Anzahl der Daten, die sich in einem Bereich befinden (Näherung an Verteilung)
● Daten werden in n Bereiche gegliedert (x-Achse), Vertikale beschreibt relative Häufigkeit der Daten in diesem Bereich
● Beispiel ● 1, 1, 2, 5, 6, 7, 8, 10, 15, 100● Zahlen „knubbeln“ sich am Anfang,
hinten ein Ausreißer

Datenvisualisierung - Histogramm
● Histogramme werden genutzt, um zu prüfen, ob Messdaten normalverteilt sind („Glockenkurve“)
● Hier: leicht linksschiefe Verteilung, „annähernd normalverteilt“

Datenvisualisierung - Boxplot
● Beschreiben, wie sich Daten um Median herum verteilen
● Beispiel● 1, 1, 2, 5, 6, 7, 8, 10, 15, 100● 100 ist ein Ausreißer● die meisten Werte zwischen
0 und 10● Max-Wert (ohne Ausreißer) bei 15

Datenvisualisierung – Punkt/Streu Diagramm
● Visualisierung von 2-Dimensionalen Daten● Vermittelt ersten Eindruck Korrelation zwischen
Daten● Beispiel
● (1/15), (2/18), (4/23), (8/40)● Punkt/Streu-Diagram
legt Korrelation (wennauch nicht sehr starke) nah

Normalverteilung
● Für eine Reihe von statistischen Tests ist es notwendig zu wissen, ob Daten (oder Differenzen, etc.) normalverteilt sind
● Festellung auf Normalverteilung
1. Anschauen der Histogramme, ob Normalverteilung „plausibel“
2. Durchführung von Signifikanztests auf Normalverteilung (später)

Signifikanztests – AB Experimente
● Vergleich von Mittelwerten (bzw. zentrale Tendenz)
● Anwendung: AB-Experiment● Unterscheidung
● Normalverteilt (t-Test)● Nicht-normalverteilt (Mann-Whitney-U-Test /
Wilcoxon-Test)● Between-subject (ungepaarte Vergleiche)● Within-subject (gepaarte Vergleiche)

Grundlage Signifikanztests
● Signifikanztests
● Überprüfen der Nullhypothese H0 (Mittelwert 1=Mittelwert 2),
bzw. Annahme der Alternativhypothese H1
● Problem
– H0 kann richtig sein, aber durch statistischen Test
fällt Aussage für H1 => alpha-Fehler (Fehler 1. Art)
– H1 kann richtig sein, aber durch statistischen Test
fällt Aussage für H0 => beta-Fehler (Fehler 2. Art)

Grundlage Signifikanztests
● Beispiel● Ziehen einer Kugel aus Urne, in der rote und blaue
Kugeln sind
● H0: Es sind gleich viele rote wie blaue in der Urne
● Test ergibt Ablehnung von H0 => alpha-Fehler
[Wikipedia]
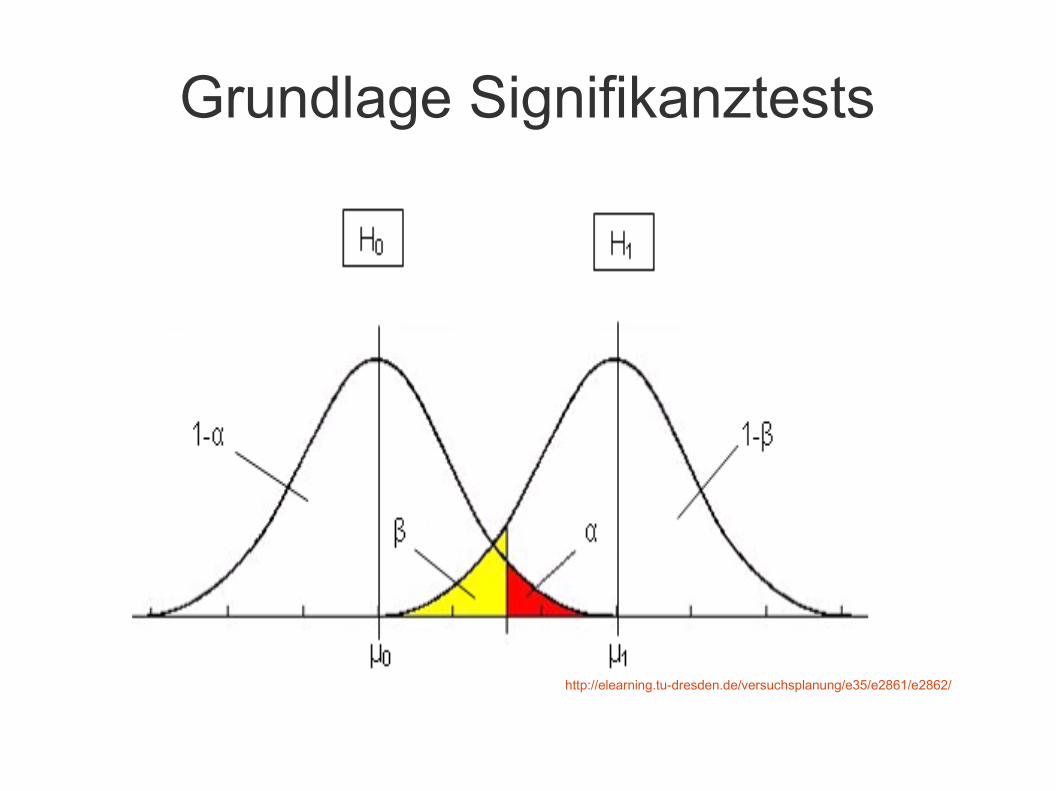
Grundlage Signifikanztests
http://elearning.tu-dresden.de/versuchsplanung/e35/e2861/e2862/

Grundlage Signifikanztests● Signifikanztests ergeben p-Wert, der die Größe des alpha-Fehlers
bestimmt bei Hypothese H0, dass es keinen Unterschied gibt.
● Alpha-Level (auch Signifikanzniveau) gibt an, mit welchem alpha-Fehler „man Leben kann“, z.B. alpha = 0.05 besagt, dass eine 5% Wahrscheinlichkeit des alpha-Fehlers toleriert wird
● Alpha-Grenze ist willkürlich gewählt und domänenabhängig● Medizin: alpha = 0.01
● Psychology: alpha = 0.05
● Physik: alpha = 0.00000.....1
● Softwaretechnik: meist 0.05 (...aber keiner weiss, warum...)

Prüfen auf Normalverteilung
● Problem● Einige Signifikanztests erwarten normalverteilte
Daten
● Lösung
1. Plausibilität durch Histogramme
2. Durchführen eines Signifikanztests – Kolmogorow-Smirnow-Test– Shapiro-Wilk-Test (für kleine Stichproben)

Prüfen auf Normalverteilung: SPSS-Beispiel 1
p > 0.05, Abweichung von Normalverteilung nicht-signifikant => Normalverteilung darf angenommen werden (!)

Prüfen auf Normalverteilung: SPSS-Beispiel 2
p < 0.05, Abweichung von Normalverteilung nicht-signifikant => Normalverteilung darf nicht angenommen werden (!)
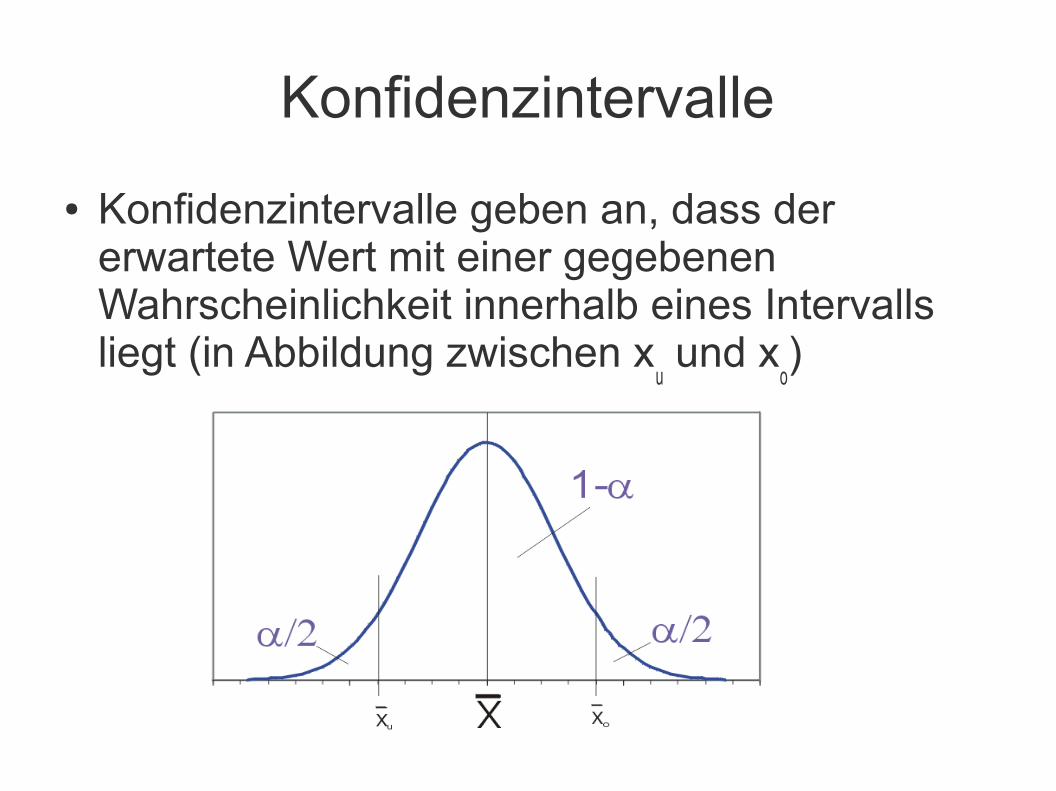
Konfidenzintervalle
● Konfidenzintervalle geben an, dass der erwartete Wert mit einer gegebenen Wahrscheinlichkeit innerhalb eines Intervalls liegt (in Abbildung zwischen x
u und x
o)

Konfidenzintervalle
● Konfidenzintervalle geben somit an, wie stark die Streuung um den Mittelwert ist

T-Test (unabhängige Stichproben)
● Annahme
- Normalverteilte Daten (beide Datenreihen)
- Unabhängig erhobene Daten
- Varianzhomogenität (Gleichheit der Varianzen beider Reihen)● Hypothese
Erwartungswert beider Datenreihen ist gleich● Berechnung (nach Bortz, Schuster, Statistik für Human- und Sozialwissenschaftler, 2007)
1. Standardfehler der Differenzen
2. Zielgröße (mit n1+n2-2 Freiheitsgraden)

t-Test in SPSS
● SPSS führt automatisch Levene-Test für Varianzhomogenität durch
● Wenn Levene-Test signifikant, wird anderes Testverfahren verwendet, dass keine Varianzhomogenität unterstellt.

t-Test in SPSS
● Varianzhomogenität ist gegeben (p=1.0), kein signifikanter Unterschied (p=0.292)

T-Test (abhängige Stichproben)
● Annahme
- Normalverteilte Differenzen
- Gepaart erhobene Daten● Hypothese
Erwartungswert beider Datenreihen ist gleich● Berechnung (nach Bortz, Schuster, Statistik für Human- und Sozialwissenschaftler, 2007)
1. Standardabweichung der Differenzen
2. Zielgröße (mit n-1 Freiheitsgraden)

Paired t-Test in SPSS
● Kein sign. Unterschied.....ABER.... Test hätte nicht durchgeführt werden dürfen (Differenzen nicht normalverteilt, da Shapiro-Wilk < 0.05)
STOP!!!

Vereinfachung von t-Test Annahmen
● T-Tests dürften unabhängig von Normalverteilungsannahme durchgeführt werden, wenn Anzahl der Daten pro Treatmentstufe > 30 liegt.
● Aber was, wenn Normalverteilung nicht vorliegt und Vereinfachung nicht gilt?
=> Nicht-parametrische Tests– Mann-Whitney-U-Test (between subject)
– Wilcoxon-Test (within-subject)

Mann-Whitney U-Test● Keine Annahme bzgl. Verteilung (zulässig für ordinale Daten)
● Verfahren: Ermittlung von Rängen ● Beispiel aus (Bortz, Schuster, Statistik für Human- und
Sozialwissenschaftler, 2007)
1. Zuordnung der einzelnen Werte zu einem Rang (über beide Gruppen hinweg)
2. Bestimmung der Rangsummen T1, T
2
3. Auszählen der Prüfgröße U (=Summe der Anzahl der größeren Ränge in anderen Gruppe), bzw. Berechnen des Wertes nach
4. Berechnung des Erwartungswertes, der Streuung und des z-Werts

Mann-Whitney U-Test - SPSS
● p-Wert = 0.314 => kein signifikanter Unterschied
● im Vergleich zum t-Test KEIN Konfidenzintervall
● Rangsummen zeigen Tendenz (aber nur dann anzumerken, wenn p-Wert signifikant)

Wilcoxon-Test
● Keine Annahme bzgl. Verteilung (zulässig für ordinale Daten)
● Verfahren: Ermittlung von Rängen bei gepaarten Daten (within-subject)
● Beispiel aus (Bortz, Schuster, Statistik für Human- und Sozialwissenschaftler, 2007)
1. Absolutwerte der Rangdifferenzen
2. Bestimmung der Rangsummen T = Rangsumme der Werte mit häufig vorkommenderem Vorzeichen und T' (weniger häufig vorkommen)
3. Vergleich des kritischen Wertes mit T
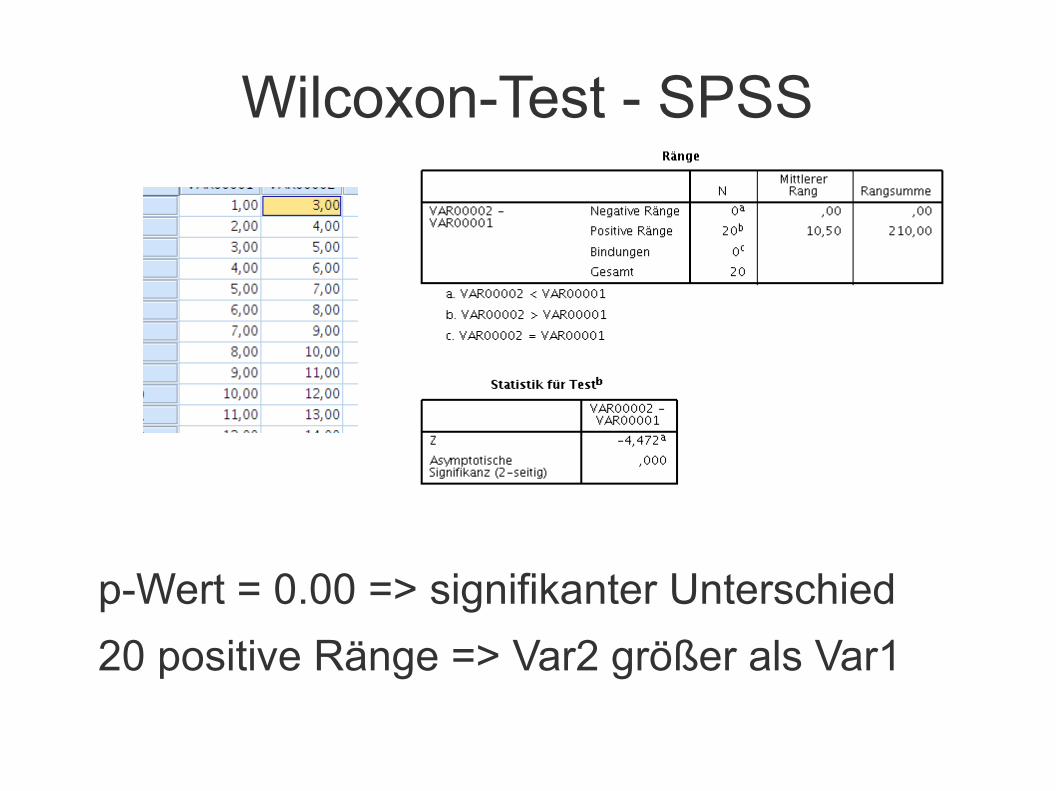
Wilcoxon-Test - SPSS
p-Wert = 0.00 => signifikanter Unterschied
20 positive Ränge => Var2 größer als Var1

Multiple Vergleiche (mehr als 2 Treatments)
● Problem● Wenn ich n Reihen miteinander vergleiche, dann
gibt es einen „kumulierten alpha-Fehler“
=> Jeder Einzelvergleich besitzt den alpha-Fehler, entsprechend ergibt die Menge der Vergleiche einen größeren alpha-Fehler
● Konservative Methode: Bonferroni-Korrektur● Reduktion: alpha' = alpha/n

Mehrfaktorielle Varianzanalysen(1)
(hier nicht mehr im Detail erläutert)
● Generelle Idee● Effekt auf abhängige Variable AV durch zwei
Faktoren A und B wird durch folgendes Modelle erklärt:
AV = A + B +A*B + err
● Dabei treten die Variablen A und B sowohl als Einzelbestandteile als auch als Kombination auf

Mehrfaktorielle Varianzanalysen (2)
● Fragestellung für Mehrfaktorielle ANOVA● Ist unabhängig Variable A signifikant?● Ist unabhängige Variable B signifikant?● Gibt es eine Interaktion zwischen beiden Variablen?
● Interaktion● Zwei variablen interagieren, wenn ich durch
verschiebung beider variablen einen unterschiedlichen Einfluß auf Zielgröße habe

Mehrfaktorielle ANOVA – SPSS (1)
● Frage (Mock): Wirkt sich Rauchen auf die Anzahl der Programmierfehler aus?
● 2 UV: Rauchen (J/N), Geschlecht(M/W)● AV: Programmierfehler● Mögliche Interaktion
● Es kann sein, dass sich Rauchen für die unterschiedlichen Geschlechter (signifikant) unterschiedlich auswirkt

Mehrfaktorielle ANOVA – SPSS (2)
● Hands on....

Abbildung auf Versuchsaufbauten
● AB-Tests● Mittelwertvergleiche (Wilcoxon, U-Test, t-Test)
● AB/BA-Vergleiche● Unter Annahme eines counterbalance Effekts
– Mittelwertvergleiche (Wilcoxon, U-Test, t-Test)● Wenn kein counterbalance Effekt
– Varianzanalyse, Reihenfolge als Variable(!)

AB/BA-Vergleich
● Annahme: Programmiertechnik A und B (PT)● Messpunkt: Programmierzeit (T)● Zusätzliche Variable: Position (P)● Modell: T = Störvariable + PT + Pos + PT*Pos● Ziel:
● Nachweis der Signifikanz von PT● Keine signifikante Interaktion PT*Pos● Keine Signifikanz von Pos
(es existiert alternative Analyse, hier jedoch ignoriert)

AA/AB-Vergleich
● Annahme: Programmiertechnik A und B (PT)● Messpunkt: Programmierzeit (T)● Zusätzliche Variable: Position (P)● Modell: T = Störvariable + PT + Pos + PT*Pos● Ziel
● Nachweis der Interaktion!

Offene Punkte
● Überprüfung von Zusammenhangshypothesen (Korrelation, Regression, Repeated Measures ANOVA)
● Was passiert, wenn Messpunkte nicht objektiv quantifizierbar sind (Cohen's Kappa)?
● Wie lässt sich die Teststärke ermitteln (reicht mein Testverfahren, um Unterschied zu
●
● Nachvollziehen von konkretem Experiment...(was wollen wir tun)?

Literatur
● Bortz, Schuster, Statistik für Human- und Sozialwissenschaftler, Springer, 2007

Analyse von Experimenten
Stefan Hanenberg(University of Duisburg-Essen)














