
Vergleich von Gruppen I - Persönliche...
42
Vergleich von Gruppen I t-Test und einfache Varianzanalyse (One Way ANOVA) Werner Brannath VO Biostatistik im WS 2006/2007
Transcript of Vergleich von Gruppen I - Persönliche...

Vergleich von Gruppen It-Test und einfache Varianzanalyse (One Way ANOVA)
Werner Brannath
VO Biostatistik im WS 2006/2007

Inhalt
Der unverbundene t-Test mit homogener VarianzBeispielModellTeststatistik und p-WertNullverteilung
Einfache Varianzanalyse (One Way ANOVA)Vom t-Test zur ANOVAOne Way ANOVA für drei GruppenOne Way ANOVA für k Gruppen

Der unverbundene t-Test für homogene Varianzen
I Zum Vergleich zweier unverbundener Stichprobenbezüglich eines metrischen Merkmals.
I Testet ob die Mittelwerte der Grundgesamtheit(Erwartungswerte) verschieden sind.
I Setzt voraus, dass die arithmetischen Mittelwerte in jederGruppe normalverteilt sind.
I Setzt voraus, dass die Varianzen der Beobachtungenin beiden Gruppen gleich gross sind, d.h. die Varianzenhomogen sind.

Beispiel für t-Test für zwei unverbundene Stichproben
Geburtsgewicht von 50 Kindern mit schwerem „idiopathicrespiratory distress syndrom”
Überlebende Kinder (n1 = 23)1.130 1.575 1.680 1.760 1.930 2.015 2.0902.600 2.700 2.950 3.160 3.400 3.640 2.8301.410 1.715 1.720 2.040 2.200 2.400 2.5502.570 3.005
Verstorbene Kinder (n2 = 27)1.050 1.175 1.230 1.310 1.500 1.600 1.7201.750 1.770 2.275 2.500 1.030 1.100 1.1851.225 1.262 1.295 1.300 1.550 1.820 1.8901.940 2.200 2.270 2.440 2.560 2.730

Boxplots
Baby verstorben Baby lebt
1.0
1.5
2.0
2.5
3.0
3.5
Geb
urts
gew
icht
(kg
)

Mittelwerte und Standardabweichungen
Überlebende Kinder (n1 = 23):
Mittelwert y1 =Pn1
j=1 y1j
n1= 2.307
Standardabweichung s1 =
√Pn1j=1(y1j−y1)2
n1−1 = 0.665
Verstorbene Kinder (n2 = 27):
Mittelwert y2 =Pn2
j=1 y2j
n1= 1.692
Standardabweichung s2 =
√Pn2j=1(y2j−y2)2
n2−1 = 0.518

Fragestellung im Beispiel
Sind die Unterschiede im mittleren Geburtsgewicht durchreinen Zufall erklärbar, d.h. gilt . . .
H0 : Die beiden Gruppen haben (in Wirklichkeit) ein identischesmittleres Geburtsgewicht.
oder sind die Unterschiede nicht alleine durch Zufall erklärbar,d.h. gilt . . .
H1 : Die beiden Gruppen unterscheiden sich in ihrem mittlerenGeburtsgewicht.

Vergleich der Gruppen
I Differenz der Mittelwerte: y1 − y2 = 0.615
I Gemeinsame Varianz
s2 =(n1 − 1) · s2
1 + (n2 − 1) · s22
n1 + n2 − 2
=22 · 0.6652 + 26 · 0.5182
48= 0.348
I Gemeinsame Standardabweichung: s =√
s2 = 0.590

Zweiseitiger unverbundener t-Test mit homogenenVarianzen (Software R)
> t.test(sirdsa,sirdsd,var.equal=T)
Two Sample t-test
data: sirdsa and sirdsdt = 3.6797, df = 48, p-value = 0.0005902alternative hypothesis: true differencein means is not equal to 0
sample estimates:mean of x mean of y2.307391 1.691741
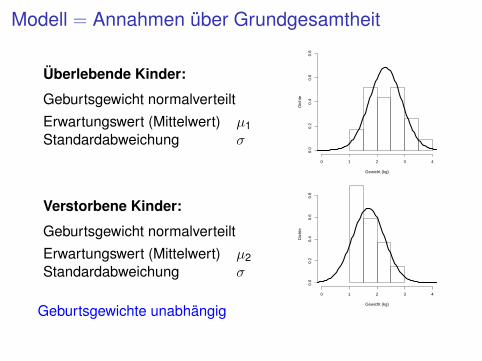
Modell = Annahmen über Grundgesamtheit
Überlebende Kinder:
Geburtsgewicht normalverteiltErwartungswert (Mittelwert) µ1Standardabweichung σ
Gewicht (kg)
Dic
hte
0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
Verstorbene Kinder:
Geburtsgewicht normalverteiltErwartungswert (Mittelwert) µ2Standardabweichung σ
Gewicht (kg)D
icht
e0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
Geburtsgewichte unabhängig
Dichten der Normalverteilung
−10 −5 0 5 10
0.0
0.1
0.2
0.3
0.4
Dic
hte
versch. Mittelwerte
−2 0 4
−10 −5 0 5 10
0.0
0.2
0.4
0.6
0.8
Dic
hte
versch. Standardabw.
0.51 1.5

Teststatistik t
n1, n2 Stichprobenumfänge; y1, y2 die Mittelwerte
s die gemeinsame Standardabweichung
Teststatistik des unverbundenen t-Tests
t =1√
1n1
+ 1n2
· (y1 − y2)/s
Je grösser der Absolutwert von t desto unplausibler H0.

Der p-Wert als Plausibilitätswert für H0
Man denke an zweite unabhängige Studie ebenfalls mitzwei Stichproben der Größe n1 = 23 und n2 = 27,
Stichproben aus einer Grundgesamtheit in der
I die Nullhypothese H0 : µ1 = µ2 gilt,
I ansonsten alles wie in der Grundgesamtheitunserer Studie ist, d.h.:
die Geburtsgewichte normalverteilt sind unddie Varianz σ2 wie in unserer Studie ist.

Der p-Wert als Plausibilitätswert für H0
Bezeichnen mit t∗ die t-Teststatistik der zweiten Studie.
Defintion des p-Werts
Mit welcher Wahrscheinlichkeit ist der Absolutwert von t∗
grösser als der Absolutwert von t?
p −Wert = P(t2∗ > t2)
Welche Verteilung hat t2∗ ?

Bestimmung der H0-Verteilung von t2
Quadrat der t-Teststatistik
t2 =(y1 − y2)
2(1n1
+ 1n2
)· s2
=(y1 − y2)
2
σ2 ·(
1n1
+ 1n2
) /s2
σ2
= Zähler/Nenner

Verteilung vom Zähler
y1 − y2 normalverteilt mit E(y1 − y2) = µ1 − µ2
und Var(y1 − y2) = Var(y1) + Var(y2) = σ2
n1+ σ2
n2.
Falls H0 : µ1 = µ2, dann
√Zähler =
y1 − y2√σ2
n1+ σ2
n2
∼ N(0, 1)
Damit ist auch die H0-Verteilung vom Zähler bekannt!

Definition der χ2k -Verteilung
DefinitionZ1, Z2, . . . , Zk unabhäng und N(0, 1)-verteilt
Man nennt die Verteilung der Zufallsvariablen
X 2 = Z 21 + Z 2
2 + . . . + Z 2k
die χ2-Verteilung mit k Freiheitsgraden, kurz X 2 ∼ χ2k
BeispielWenn H0 : µ1 = µ2 dann Zähler ∼ χ2
1

Dichten der χ2k -Verteilungen
0 5 10 15
0.00
0.05
0.10
0.15
0.20
0.25
Dic
hte
Freiheitsgrade
1 248

Summeneigenschaft
Summeneigenschaft der χ2-VerteilungenWenn
X 21 ∼ χ2
k1und X 2
2 ∼ χ2k2
und X 21 und X 2
2 sind unabhängig, dann ist
X 21 + X 2
2 ∼ χ2k1+k2
BeispielX 2
1 ∼ χ222 und X 2
2 ∼ χ226, dann X 2
1 + X 22 ∼ χ2
48

Verteilung vom Nenner
Nenner:s2
σ2 =(n1 − 1) · s2
1σ2 + (n2 − 1) · s2
2σ2
n1 + n2 − 2
Es ist bekannt, dass
(n1 − 1) ·s2
1σ2 ∼ χ2
n1−1 und (n2 − 1) ·s2
2σ2 ∼ χ2
n2−1
Ausserdem sind s1 und s2 unabhängig.

Verteilung vom Nenner
Wegen der Summeneigenschaft der χ2-Verteilung
X 2 = (n1 − 1) ·s2
1σ2 + (n2 − 1) ·
s22
σ2 ∼ χ2n1+n2−2
Somit ist die Verteilung von
Nenner = {(n1 − 1) ·s2
1σ2 + (n2 − 1) ·
s22
σ2 }/(n1 + n2 − 2)
die χ2-Verteilung mit n1 + n2 − 2 Freiheitsgraden geteilt durchn1 + n2 − 2
Symbolisch: Nenner ∼ χ2n1+n2−2/(n1 + n2 − 2).

Verteilung von t2
t2 = Zähler/Nenner
I Zähler ∼ χ21
I Nenner ∼ χ2n1+n2−2/(n1 + n2 − 2),
I Zähler und Nenner sind unabhängig.
Die Verteilung von t2 heißt
F -Verteilung mit 1 und n1 + n2 − 2 Freiheitsgraden.

ANOVA für Geburtsgewichte
> summary(aov(sirds ∼ Gruppe))
Df Sum Sq Mean Sq F value Pr(>F)Gruppe 1 4.71 4.71 13.5 0.0006Residuals 48 16.69 0.35
ANOVA für zwei Gruppen ist equivalent zum t-Test:
F value . . . ist identisch zu t2 = 3.862
Pr(>F) . . . ist identisch zum p-Wert des t-Tests
Erkläre als nächstes Mean Sq und Sum Sq !

Definition von Mean Sq
t2 =(y1 − y2)
2/
( 1n1
+ 1n2
)
{(n1 − 1) · s21 + (n2 − 1) · s2
2}/(n1 + n2 − 2)
=Mean Sq Gruppe
Mean Sq Residuals=
4.710.35
= 13.5

Defintion von Sum Sq Residual
Sum Sq Residuals
Sum Sq Residuals = (n1 − 1) · s21 + (n2 − 1) · s2
2
=
n1∑j=1
(y1j − y1)2 +
n2∑j=1
(y2j − y2)2
I . . . ist Summe der Abweichungsquadrate der individuellenBeobachtungen vom jeweiligen Gruppenmittelwert;
I . . . wird auch Quadratsumme innerhalb der Gruppen (sumof squares within groups) genannt.

Sum Sq Gruppe bei zwei Gruppen
Betrachten den Gesamtmittelwert:
y =
∑n1j=1 y1j +
∑n2j=1 y2j
n1 + n2=
n1
n1 + n2· y1j +
n2
n1 + n2· y2j
Man kann ausrechnen, dass
Sum Sq Gruppe = (y1 − y2)2/
(1n1
+1n2
)
= n1 · (y1 − y)2 + n2 · (y2 − y)2

Definition Sum Sq Gruppe
Sum Sq Gruppe
Sum Sq Gruppe = n1 · (y1 − y)2 + n2 · (y2 − y)2
I . . . ist Summe der Abweichungsquadrate der zweiGruppenmittelwerte zum Gesamtmittelwert;
I . . . wird Quadratsumme zwischen den Gruppen (sum ofsquares between groups) genannt.

Beziehung zwischen Sum Sq und Mean Sq
Mean Sq Gruppe =Sum Sq Gruppe
1
Mean Sq Residuals =Sum Sq Residuals
(n1 + n2 − 2)
F Statistic =Mean Sq Gruppe
Mean Sq Residual

Verteilungen unter H0 : µ1 = µ2
Mean Sq Gruppe ∼ χ21/1
Mean Sq Residuals ∼ χ2n1+n2−2/(n1 + n2 − 2)
F Statistic ∼χ2
n1+n2−2/(n1 + n2 − 2)
χ21/1
= F1,n1+n2−2

Vergleich von drei Gruppen - Beispiel
22 Patienten mit künstlicher Beatmung wurdendrei Beatmungsgruppen per Zufall zugeteilt (randomisiert)
I Gruppe A: 50% Stickoxid und 50% Sauerstoffgemisch für24 Stunden.
I Gruppe B: 50% Stickoxid und 50% Sauerstoffgemisch nurwärend der Operation.
I Gruppe C: kein Stickoxid, 35-50% Sauerstoff für 24Stunden.
Endpunkt: Die Wirkung der Beatmung wird durch dieBlutplättchenzahl nach 24 stündiger Beatmung beurteilt.

Beispiel: Fragestellung
Unterscheiden sich die drei Methoden inihrer Wirkung auf die Bluttplättchenzahl?

Beispiel: Blutplättchenzahl
Gruppe A Gruppe B Gruppe Bn = 8 n = 9 n = 5
243 206 241251 210 258275 226 270291 249 293347 255 328354 273380 285392 295
309
arithm. Mittel 316.6 256.4 278.0Standardabw. 58.7 37.1 33.8

Beispiel: Boxplots der Blutblättchenzahl
A B C
200
250
300
350
Gruppe
Blu
tplä
ttche
nzah
l

Beispiel: Vergleich der Mittelwerte
Sind die Unterschiede in der mittleren Blutplättchenzahl durchreinen Zufall erklärbar, d.h. gilt . . .
H0 : Die drei Beatmungsmethoden wirken (in Wirklichkeit)gleich auf die durchschnittliche Blutplättchenzahl.
oder sind die Unterschiede nicht alleine durch Zufall erklärbar,d.h. gilt . . .
H1 : Die Beatmungsmethoden unterscheiden sich in ihrerWirkung auf die durchschnittliche Blutplättchenzahl.

ANOVA für Blutplättchenzahl
> summary(aov(Foliate Group,data=redcell))
Df Sum Sq Mean Sq F value Pr(>F)Group 2 15516 7758 3.7113 0.04359Residuals 19 39716 2090
Im folgenden betrachten wir:I Sum Sq Group und Sum Sq GroupI Mean Sq Group und Mean Sq GroupI F value und seine Verteilung.

Defintion der Qudratsummen
Quadratsumme zwischen den Gruppen
Sum Sq Gruppe = n1 · (y1− y)2 +n2 · (y2− y)2 +n3 · (y3− y)2
Quadratsumme innerhalb der Gruppen
Sum Sq Residuals =
= (n1 − 1) · s21 + (n2 − 1) · s2
2 + (n3 − 1) · s23
=
n1∑j=1
(y1j − y1)2 +
n2∑j=1
(y2j − y2)2 +
n3∑j=1
(y3j − y3)2

Mittlere Qudratsummen
Mean Sq Gruppe =Sum Sq Gruppe
2
Mean Sq Residuals =Sum Sq Residuals
(n1 + n2 + n3 − 3)
F Statistic =Mean Sq Gruppe
Mean Sq Residual

Verteilungen unter H0 : µ1 = µ2 = µ3
Mean Sq Gruppe ∼ χ22/2
Mean Sq Residuals ∼ χ2n1+n2+n3−3/(n1 + n2 + n3 − 3)
F Statistic ∼ F2,n1+n2+n3−3

ANOVA mit k Gruppen
k . . . Gruppen
ni . . . Stichprobengrösse der Gruppe i (i = 1, . . . , k )
N =∑k
i=1 ni . . . Gesamtzahl der Beobachtungseinheiten
µi . . . Mittelwert der Grundegesamtheit in Gruppe i
σ2 . . . gemeinsame Varianz in der Grundgesamtheit
Modell
yij = µi + εij , εij ∼ N(0, σ2) unabhängig
Hypothesen
H0 : µ1 = · · · = µk , H1 : µi 6= µj für mind. eine i und j

Defintion der Qudratsummen bei k Gruppen
Quadratsumme zwischen Gruppen (between groups)
Sum Sq Gruppe =k∑
i=1
ni · (yi − y)2
Quadratsumme innerhalb der Gruppen (within groups)
Sum Sq Residuals =k∑i1
(ni − 1) · s2i =
k∑i=1
ni∑j=1
(yij − yi)2

Mittlere Qudratsummen
Mean Sq Gruppe =Sum Sq Gruppe
k − 1
Mean Sq Residuals =Sum Sq Residuals
(N − k)
F Statistic =Mean Sq Gruppe
Mean Sq Residual

Verteilungen unter H0 : µ1 = µ2 = . . . = µk
Mean Sq Gruppe ∼ χ2k−1/k − 1
Mean Sq Residuals ∼ χ2N−k/(N − k)
F Statistic ∼ Fk−1,N−k




![Die Abtei Pomposa - Persönliche Webseitenhomepage.univie.ac.at/dorothea.weber/Exkursion11/Pomposa.pdf · 1 Die Abtei Pomposa (lat. Pomposia, [„die Schöne“?]) Benediktinermönche](https://static.fdokument.com/doc/165x107/5b5d93b07f8b9ad2198eb59d/die-abtei-pomposa-persoenliche-1-die-abtei-pomposa-lat-pomposia-die.jpg)
![5Polynomring - Persönliche Webseitenhomepage.univie.ac.at/eleonore.faber/files/Skriptum_kap5_polynomring.pdf · a ∈ A heißt algebraisch ¨uber R ⇔∃P ∈ R[x] Polynom in einer](https://static.fdokument.com/doc/165x107/5e0ba9dcd13ead01885b4cd1/5polynomring-persnliche-a-a-a-heit-algebraisch-uber-r-aafp-a-rx.jpg)












