






Sprachen
Seiten
Rechtliche


Optimierung
Zielsetzungen:• Systematische Sichtweise• Verschiedene Strategien• Werkzeuge aber keine Rezepte
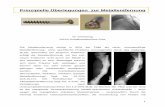
Analyse
Input OutputSystem
Im ersten Schritt der Analyse eines Problems müssen möglichst alle Inputs und Outputs gefunden werden
z.B. HPLC: Inputs: Säulenmaterial, pH, Elutionsmittel, Gradienten, TemperaturOutputs: Retentionszeit, Form und Fläche der Signale
z.B. Optimierung einer ReaktionInput: Konzentrationen, Temperatur, Druck, Katalysator, ...Output: Ausbeute
z.B. Ernährung und Gesundheit
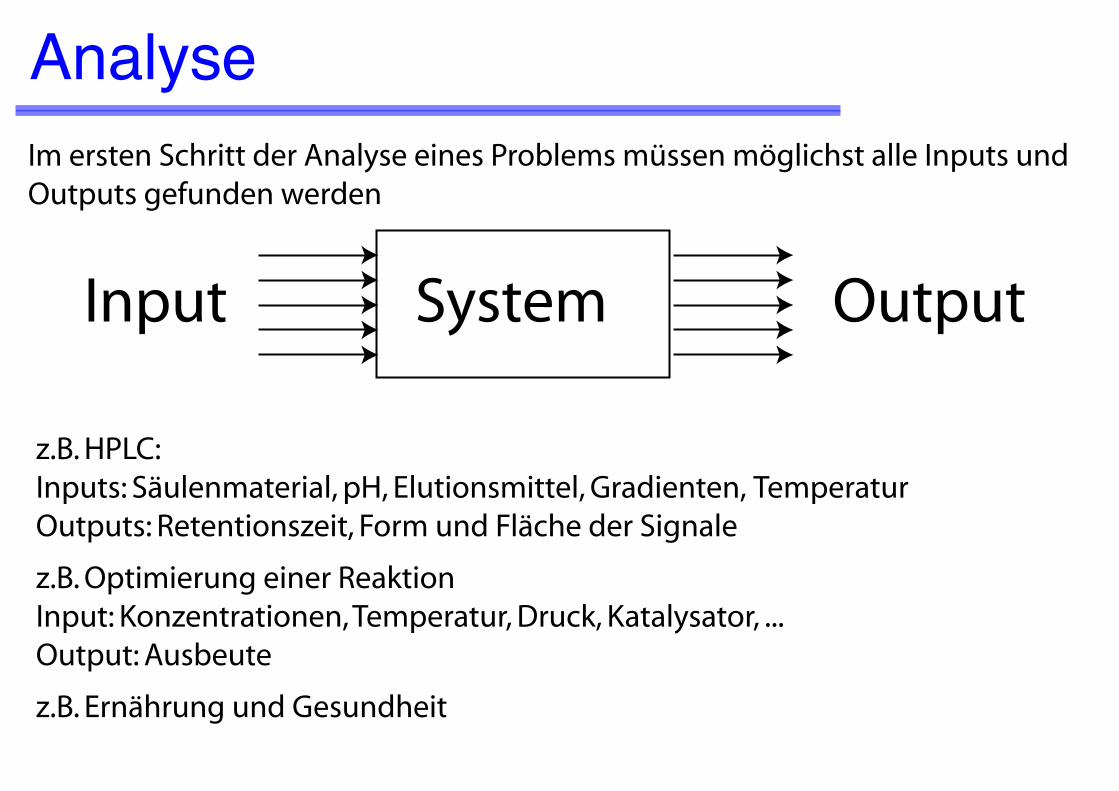
Faktoren und irrelevante InputsFaktoren sind Inputs, die den Output beeinflussen
Auffinden relevanter FaktorenVerhindern unkontrollierter Einwirkungen (z.B. Korrelation der Zeit, mit Konzentrationen, Temperatur, Sonneneinstrahlung ...) --> Randomisierung: zeitlich, räumlich
FaktorenOutputSystem
IrrelevanteEinwirkungen
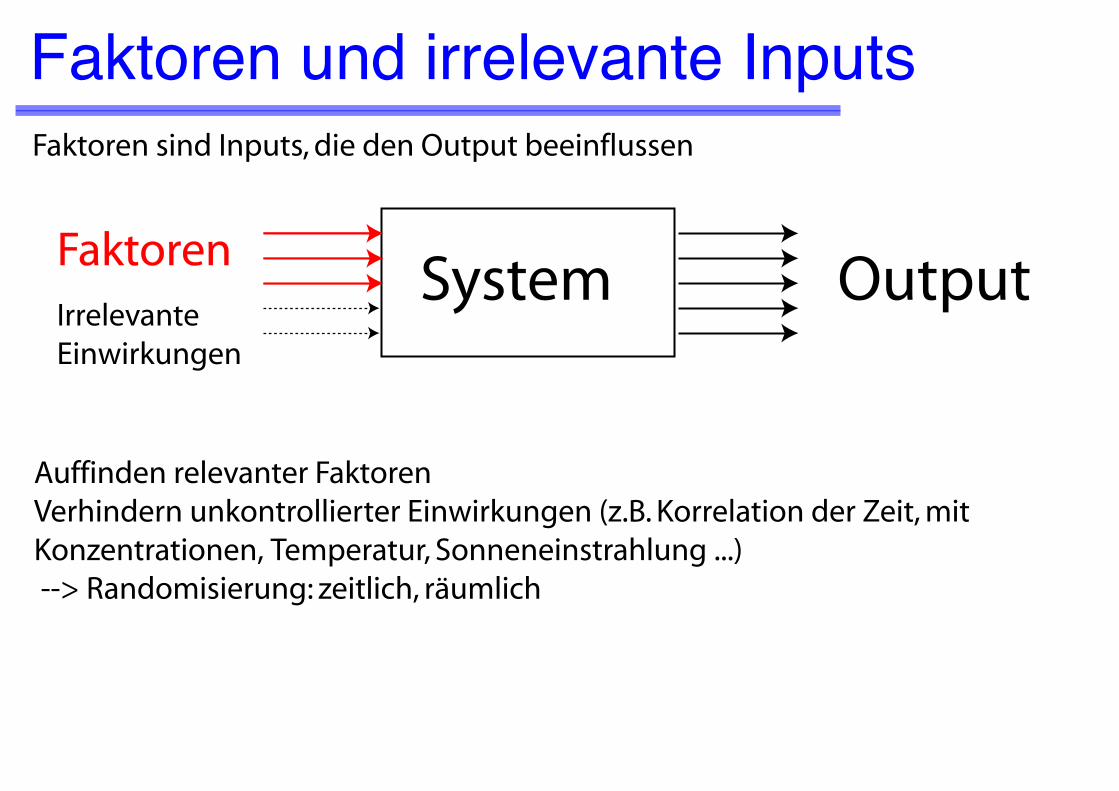
Kontrollierbare und nicht kontrollier-bare Faktoren
Input
irrelevant
relevant(Faktoren)
kontrollierbar
nicht kontrollierbar
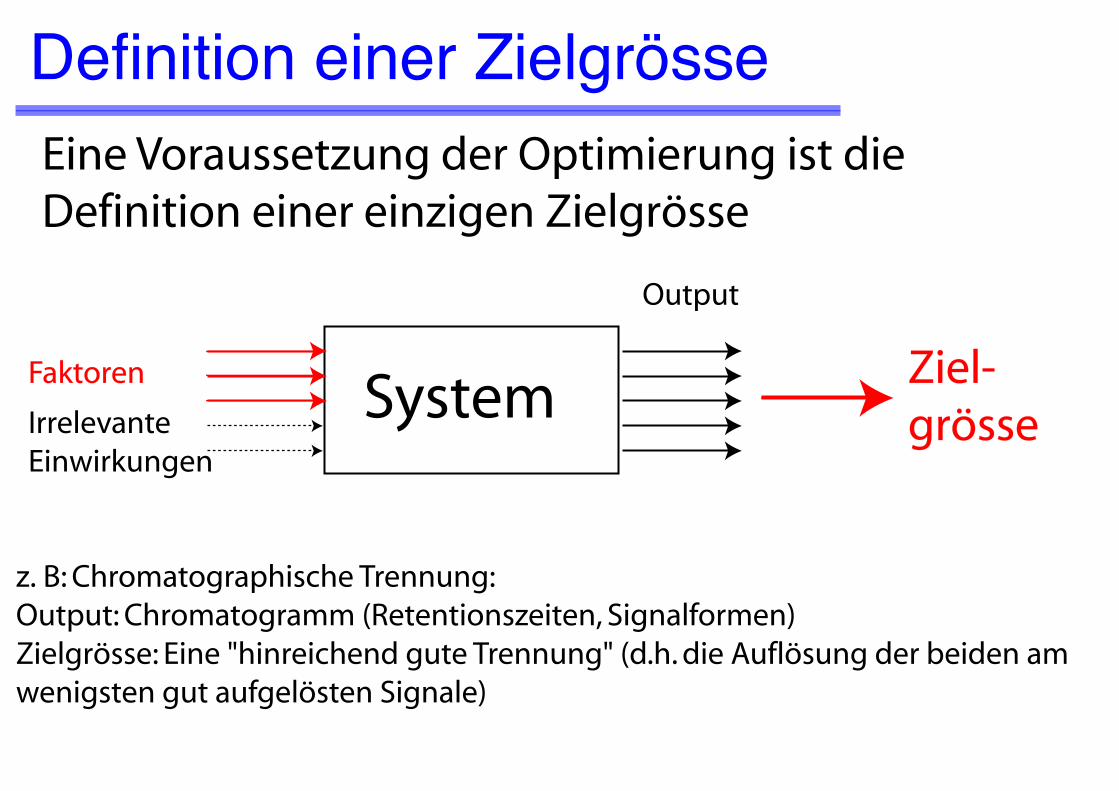
Definition einer ZielgrösseEine Voraussetzung der Optimierung ist die Definition einer einzigen Zielgrösse
z. B: Chromatographische Trennung:Output: Chromatogramm (Retentionszeiten, Signalformen)Zielgrösse: Eine "hinreichend gute Trennung" (d.h. die Auflösung der beiden am wenigsten gut aufgelösten Signale)
Faktoren Ziel-grösse
Output
SystemIrrelevanteEinwirkungen

Vorbereitung der Optimierung
VOR der Optimierung müssen:
• eine Zielgrösse definiert werden
• der Bereich der Variablen definiert werden
• die Anzahl der Versuche festgelegt werden
• die Strategie festgelegt werden

Optimierungsmethoden
• Modellierung der Antwortfläche (Anpassung eines linearen Modells)
• Direkte Methoden (Simplex, ein Faktor das Mal)
• Erste Ableitungen (Box-Wilson Methode)
• Stochastische Optimierungsmethoden (Simulated Annealing, Genetische Algorithmen)

Wahl der OptimierungsmethodeJe nach Problem und Vorinformation kann die eine oder andere Methode
vorteilhaft sein
Gefahr lokaler Minima: Keine Methode garantiert das Auffinden des globalen Optimums
Modellierung der Antwortfläche: Vorteilhaft für die Feinoptimierung
Stochastische Methoden: Vorteilhaft um globale Minima zu suchen

Modellierung der Antwortfläche1. Das allgemeine lineare Modell zweiten Grades anpassen:
z.B. (für zwei unabhängige Variablen):yi = bo + b1x1i + b2x2i + b11x1i2 + b22x2i2 + b12x1ix2i + ei
2. Erste Ableitung gleich null setzen:z. B. dy/dx1 = b1 + 2 b11x1 + b12x2 = dy/dx2 = b2 + 2 b22x2 + b12x1 = 0und für x1 und x2 lösen
3. Kontrollieren, dass alle zweiten Ableitungen das gleiche Vorzeichen haben (positiv für minima)
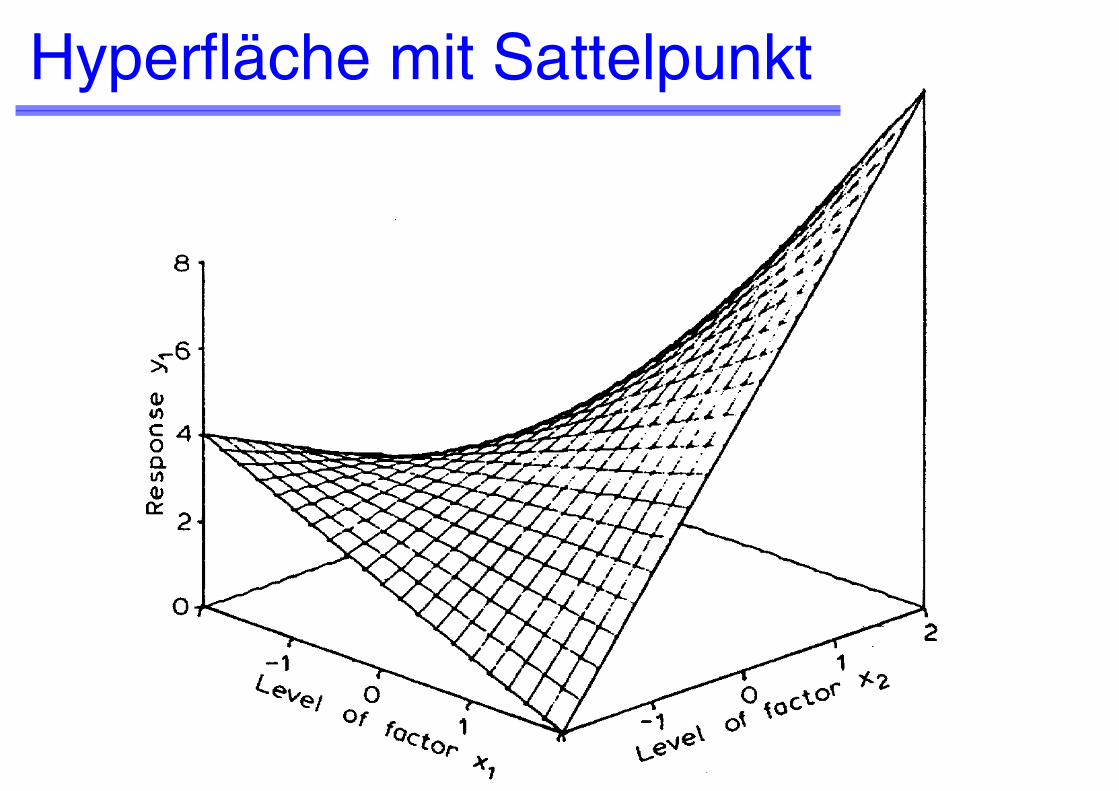
Hyperfläche mit Sattelpunkt
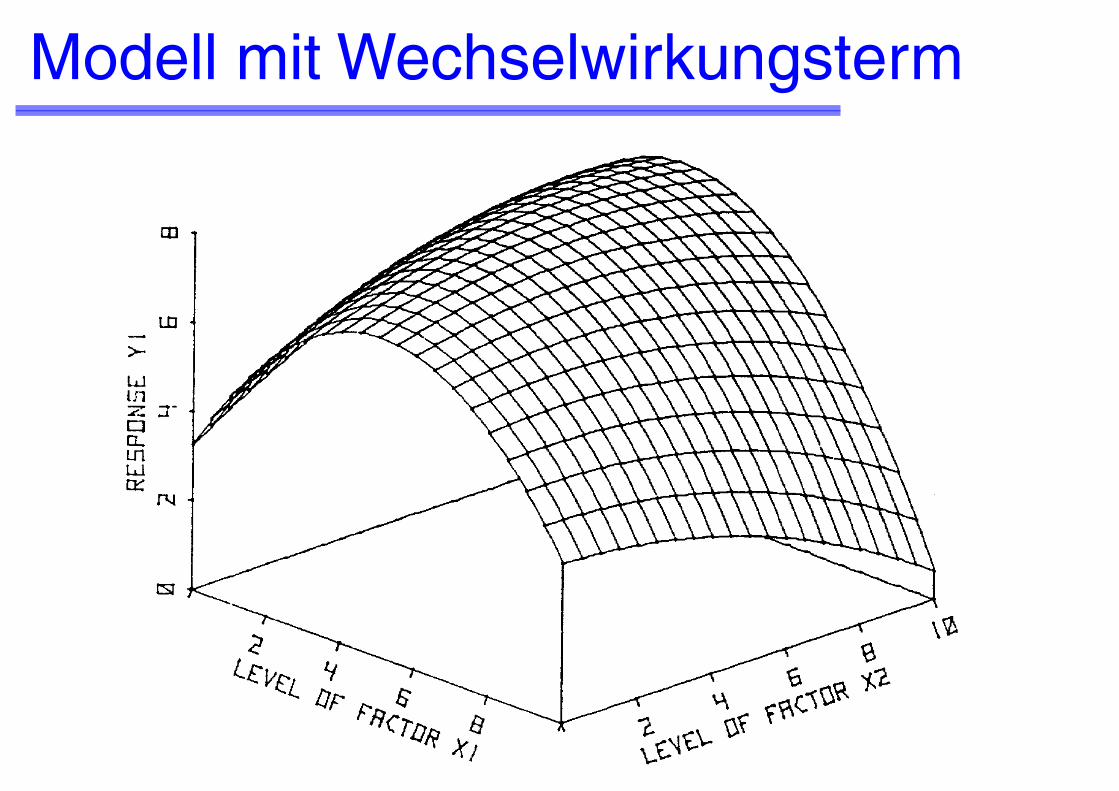
Modell mit Wechselwirkungsterm
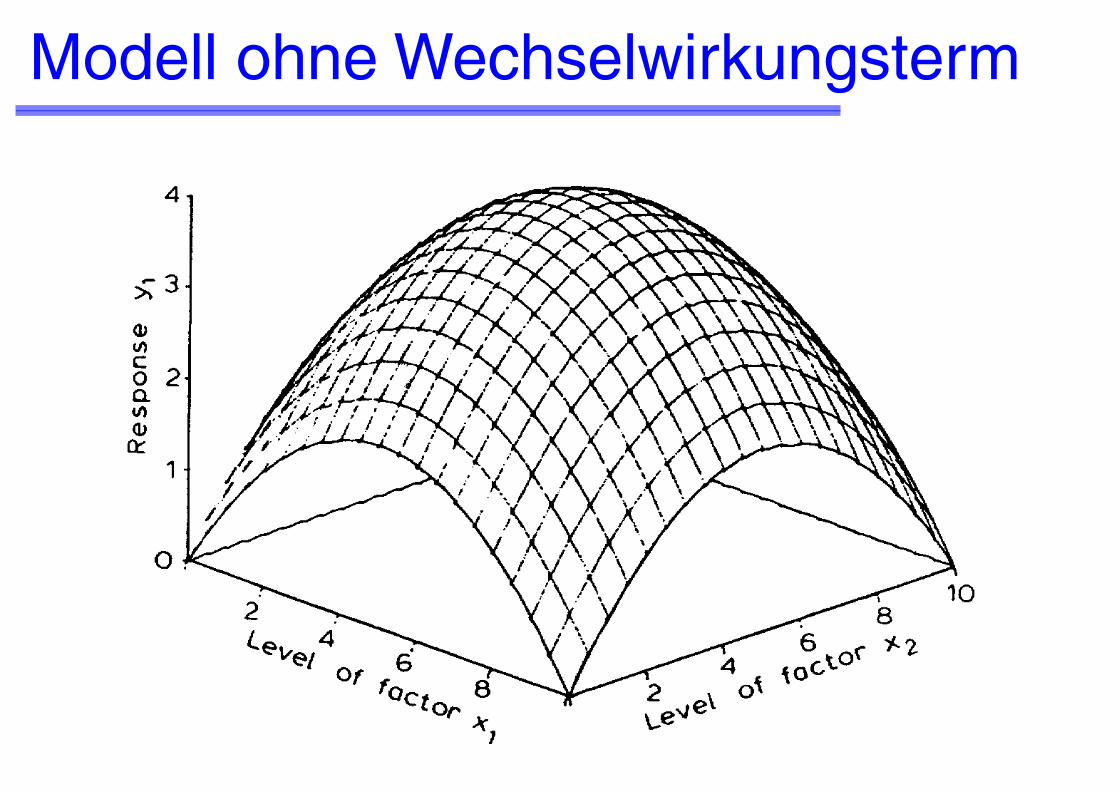
Modell ohne Wechselwirkungsterm
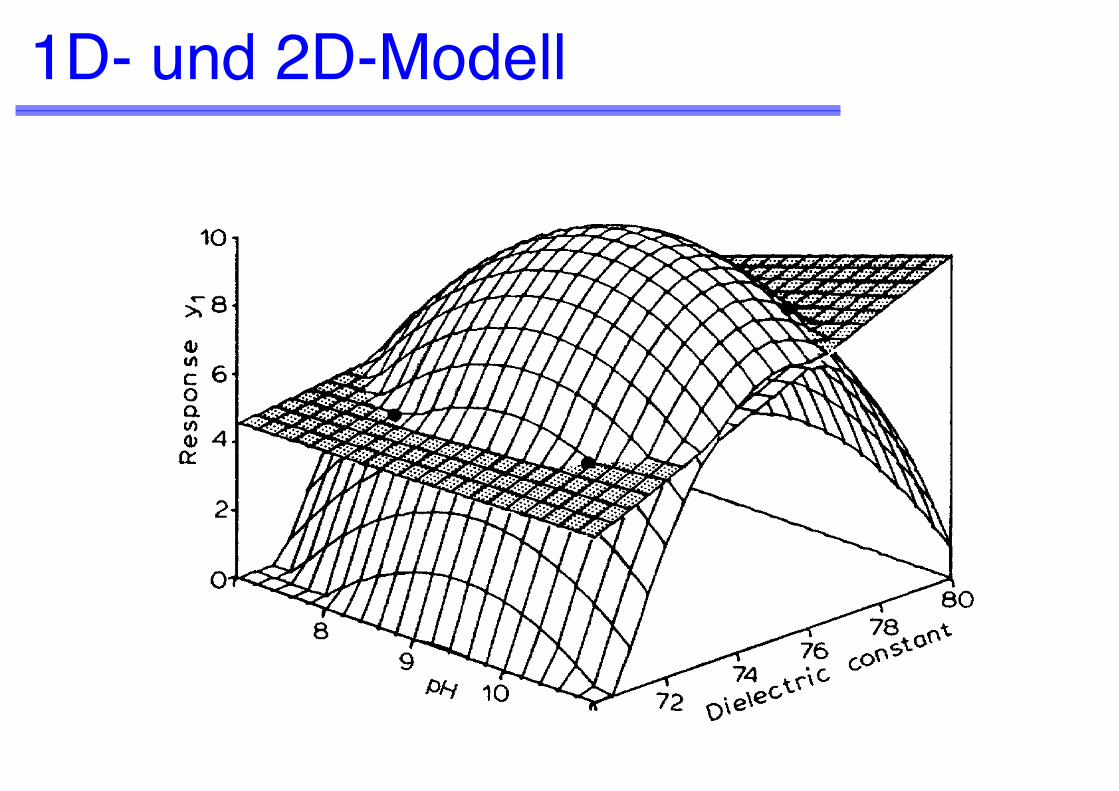
1D- und 2D-Modell

Anzahl Parameter
Faktoren, n Parameter, (n+1)(n+2)/22 6*3 104 155 21
*z. B. bo, b1, b11, b2, b22, b12

Anzahl notwendiger Versuche
Die Anzahl anzupassender Parameter entspricht der minimalen Anzahl der notwendigen Versuche
Die Kombination der unabhängigen Variablen muss richtig ausgewählt werden
Zusätzliche Versuche sind nötig, wenn die Messfehler abgeschätzt werden sollen und der "lack of fit" geprüft werden soll
--> Versuchsplanung

Anzahl notwendiger Versuche
n Messungenf Faktorenkombinationen (verschiedne Kombinationen der
unabhänigen Variablen)p Modellparameter
Resultieren: n-f Freiheitsgrade für die Schätzung des Messfehlersf-p Freihetisgrade für die Prüfung der Qualität des Modells

Versuchsplanung
Bestimmung der Kombination der Faktoren bei der man messen soll:
Faktorielle Pläne
Zentraler Plan
Zentral zusammengesetzter Plan
"D-optimaler" Plan
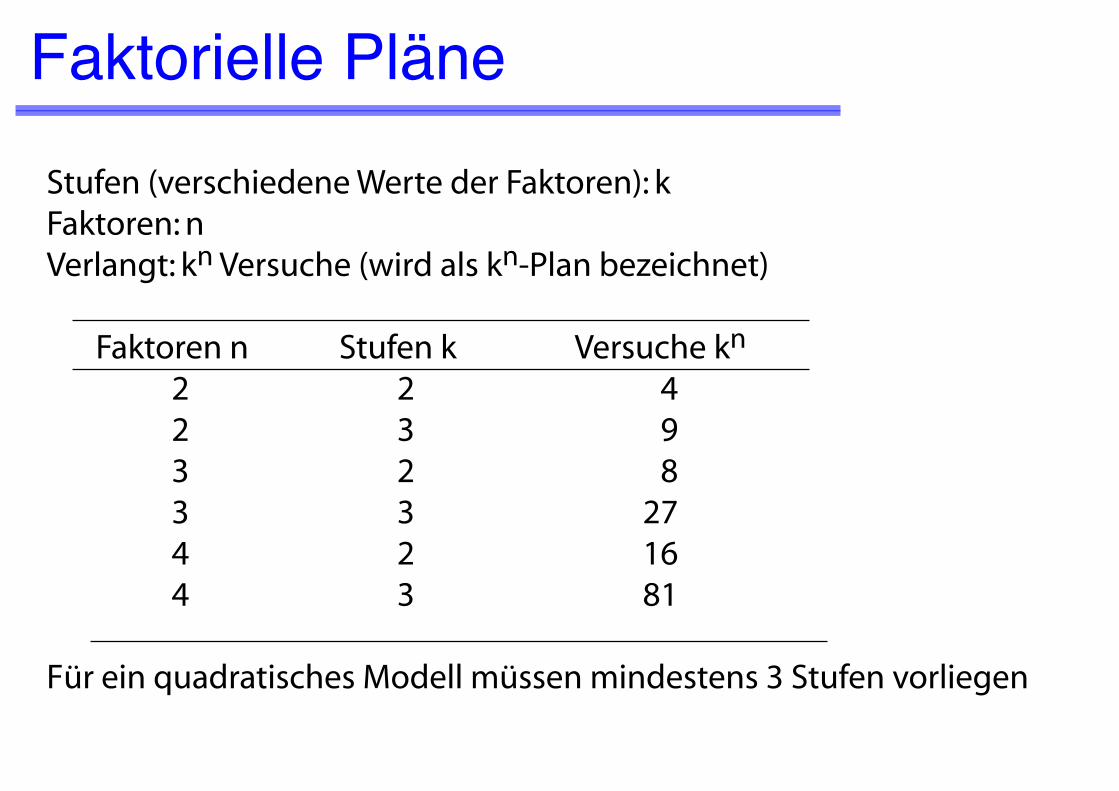
Faktorielle PläneStufen (verschiedene Werte der Faktoren): kFaktoren: nVerlangt: kn Versuche (wird als kn-Plan bezeichnet)
Faktoren n Stufen k Versuche kn 2 2 4 2 3 9 3 2 8 3 3 27 4 2 16 4 3 81
Für ein quadratisches Modell müssen mindestens 3 Stufen vorliegen
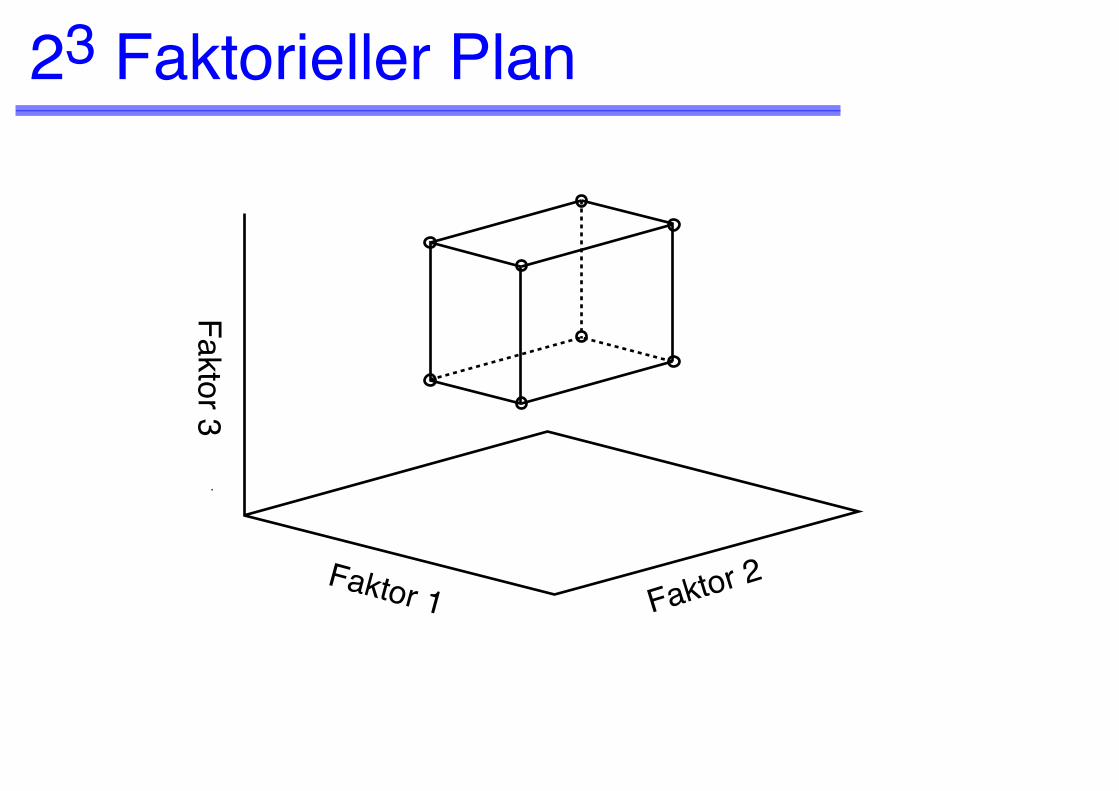
23 Faktorieller Plan
Faktor 1 Faktor 2
Faktor 3
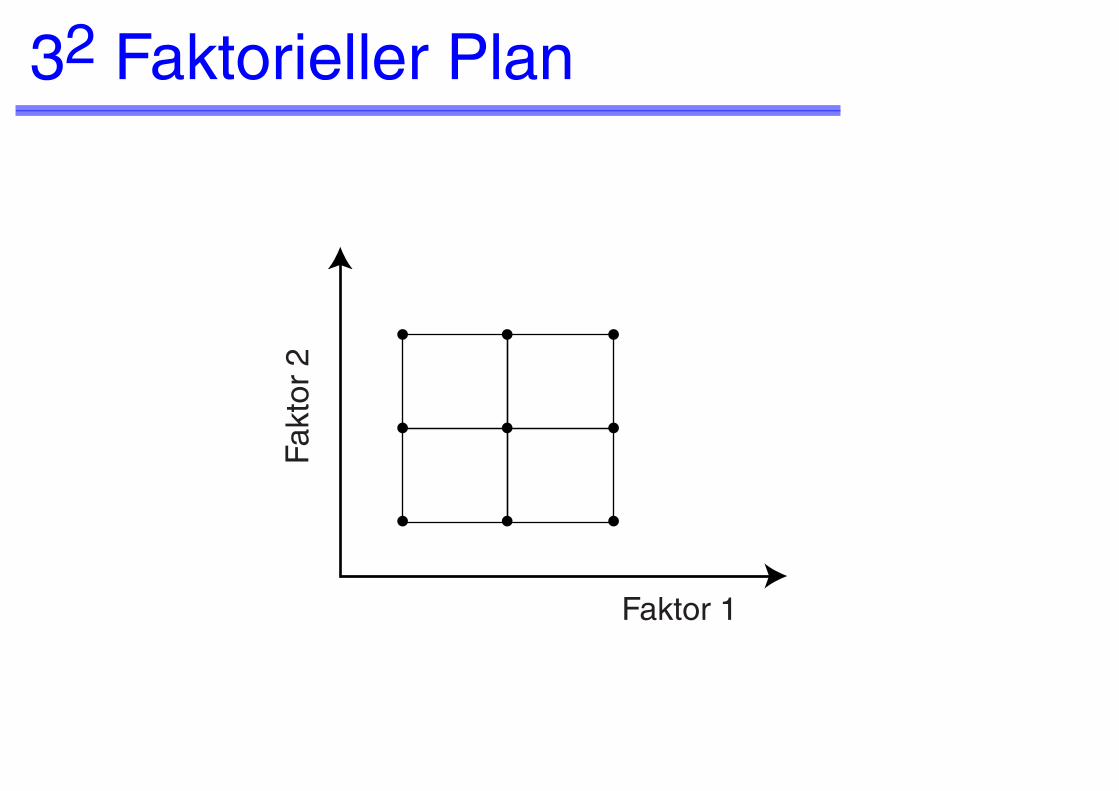
32 Faktorieller Plan
Faktor 1
Fakt
or 2
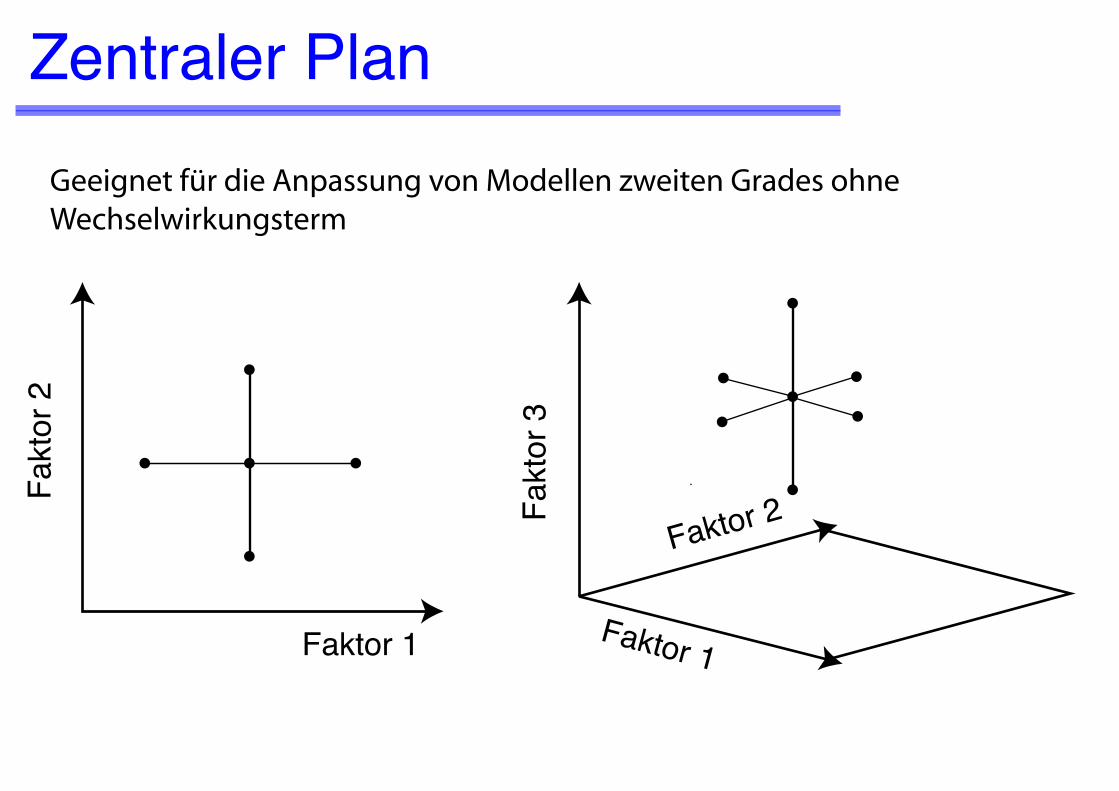
Zentraler Plan
Faktor 1
Fakt
or 2
Geeignet für die Anpassung von Modellen zweiten Grades ohne Wechselwirkungsterm
Faktor 1
Faktor 2Fakt
or 3

Zentraler Plan: Anzahl Versuche
Faktoren n Versuche 2 n + 1 1 3 2 5 3 7 4 9
Modell zweiten Grades ohne Wechselwirkungsterme
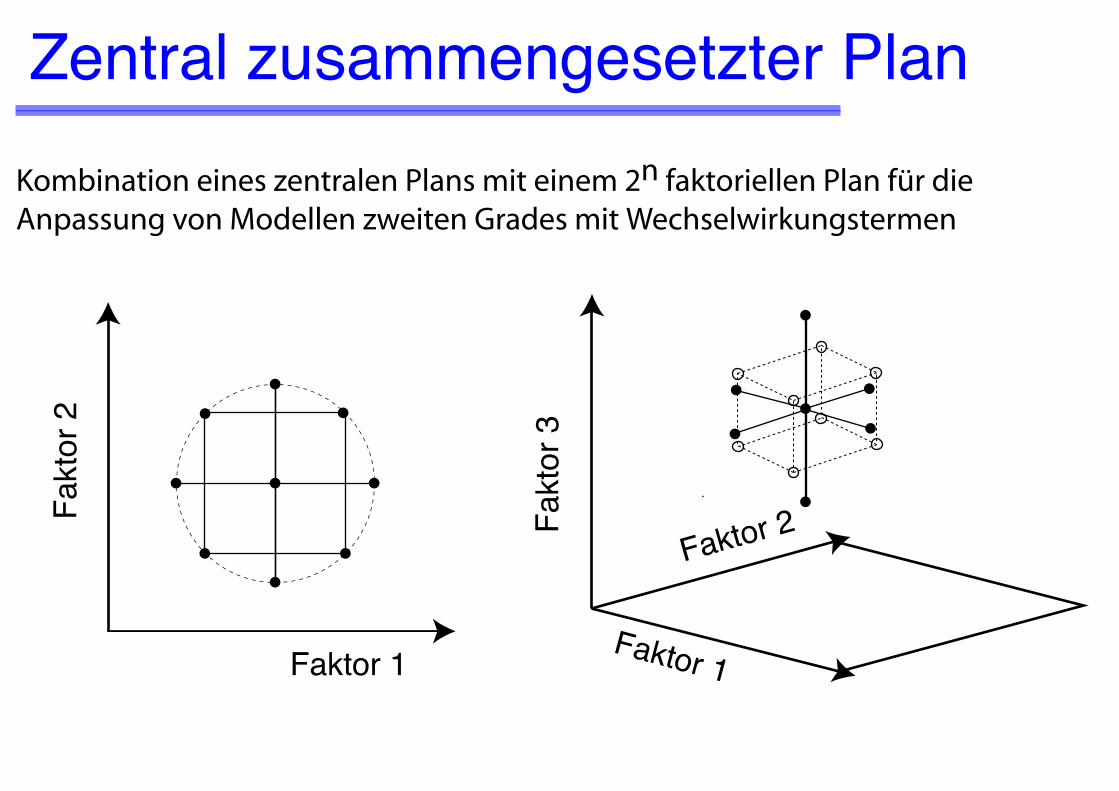
Zentral zusammengesetzter Plan
Faktor 1
Fakt
or 2
Kombination eines zentralen Plans mit einem 2n faktoriellen Plan für die Anpassung von Modellen zweiten Grades mit Wechselwirkungstermen
Faktor 1
Faktor 2Fakt
or 3
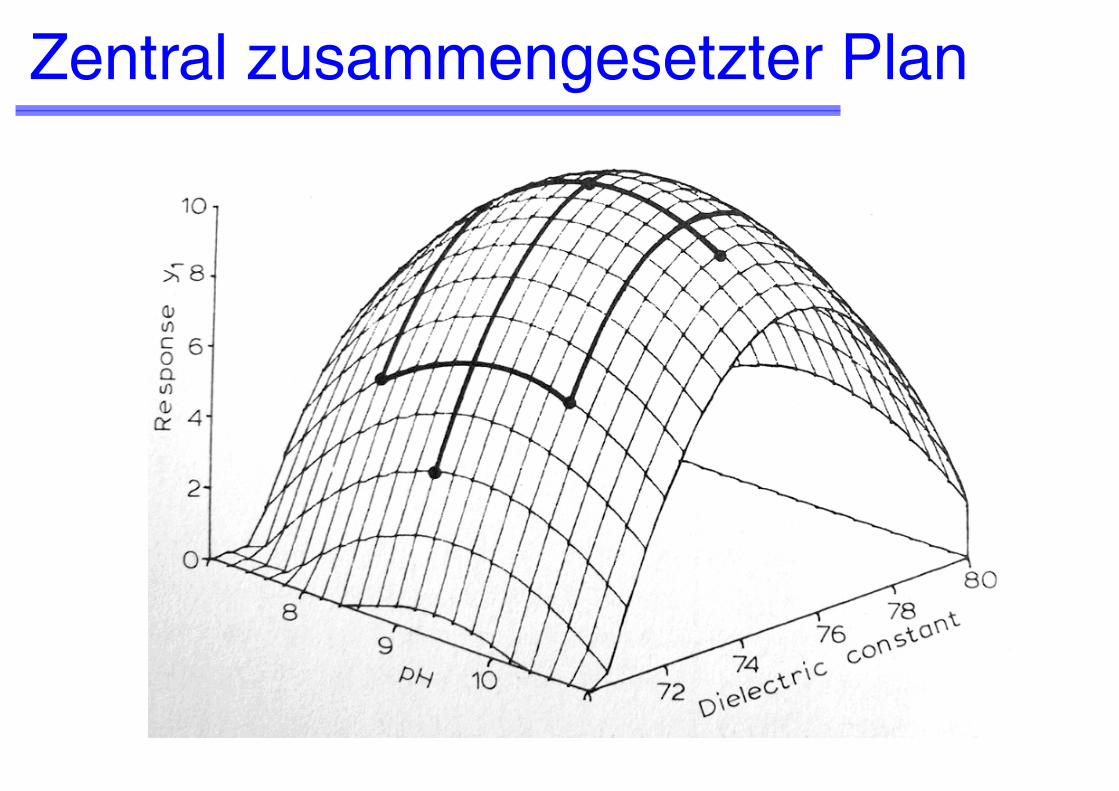
Zentral zusammengesetzter Plan
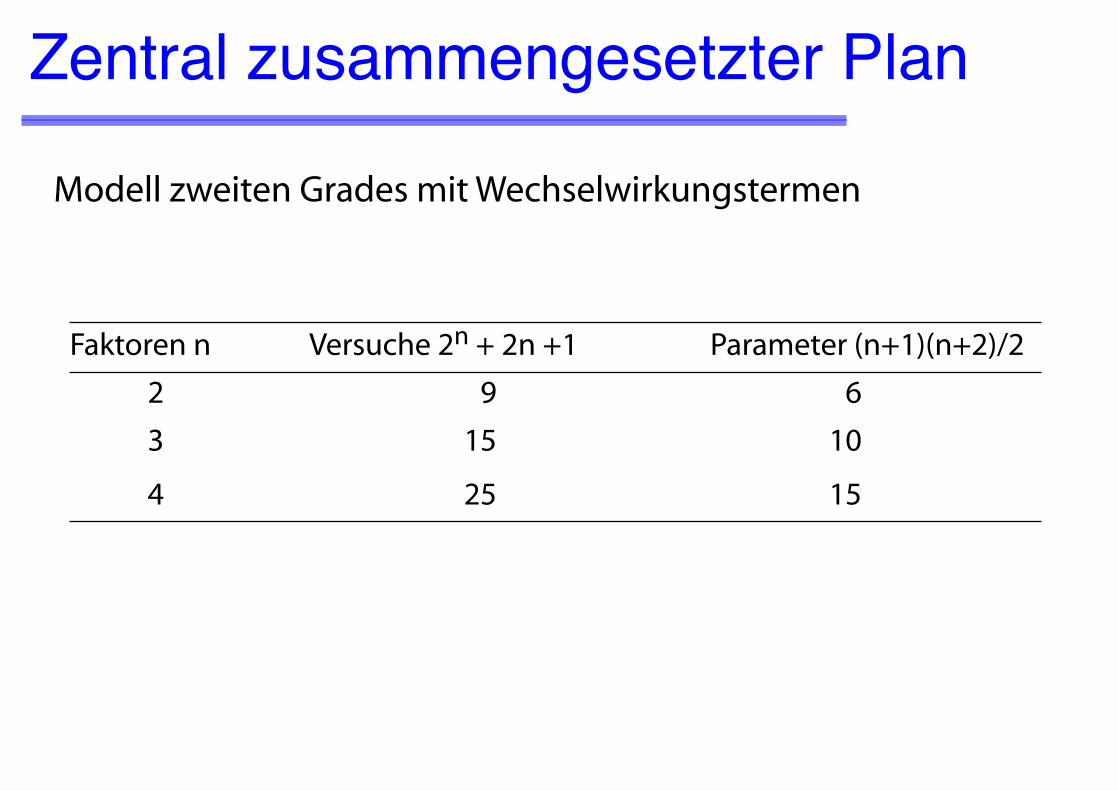
Zentral zusammengesetzter Plan
Faktoren n Versuche 2n + 2n +1 Parameter (n+1)(n+2)/2
2 9 6
3 15 10
4 25 15
Modell zweiten Grades mit Wechselwirkungstermen

D-Optimaler Plan
Ein Versuchsplan mit einer gegebenen Anzahl von Experimenten ist D-optimal, wenn die Determinante der Varianz-Kovarinazmatrix der Parameter (Det(XTX)-1) minimal ist.
Dies ist gelichbedeutend mit dem Kriterium, dass die Determinante der "Informationsmatrix" (XTX) maximal sein soll da:
Det(XTX) = 1/Det(XTX)-1
Die oben diskutierten Pläne sind meist D-optimal. Der hier gezeigte Zusammenhang erlaubt es aber, Pläne mit beliebiger Anzahl von Versuchen optimal zu gestalten.
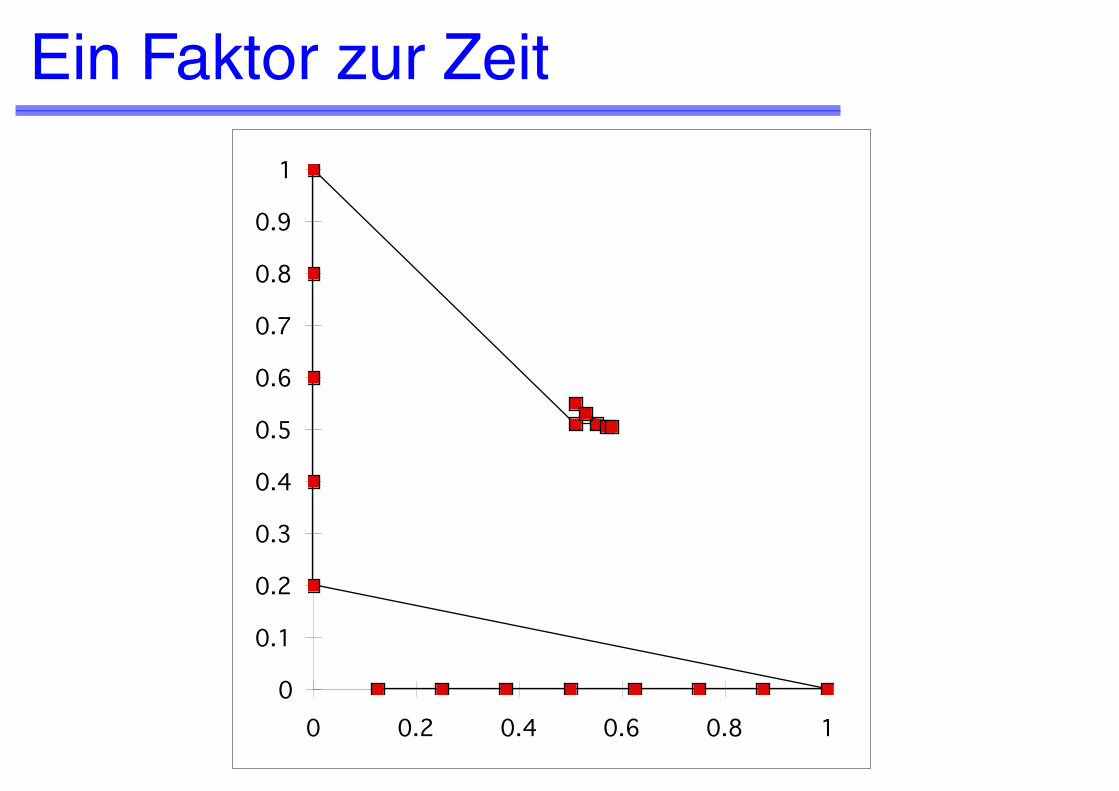
Ein Faktor zur Zeit
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
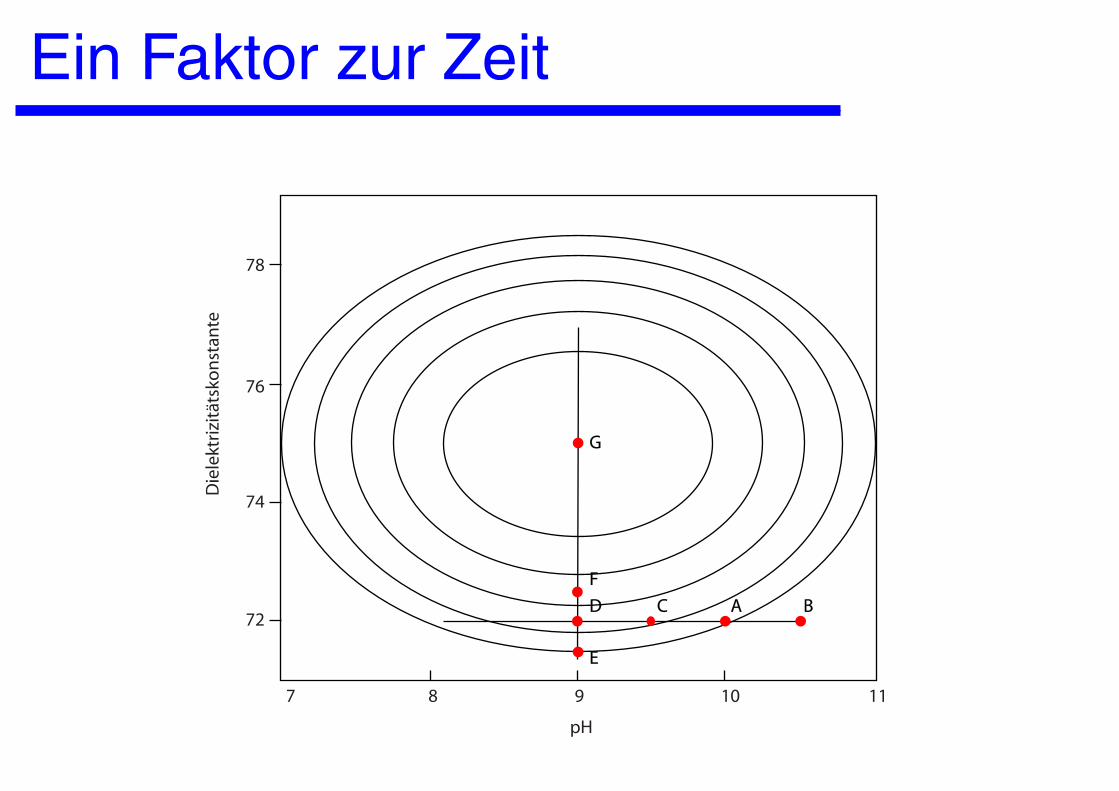
Ein Faktor zur Zeit
8 9 10 117
Die
lekt
rizi
täts
kon
stan
te
78
76
74
72
pH
G
F
D
E
C A B
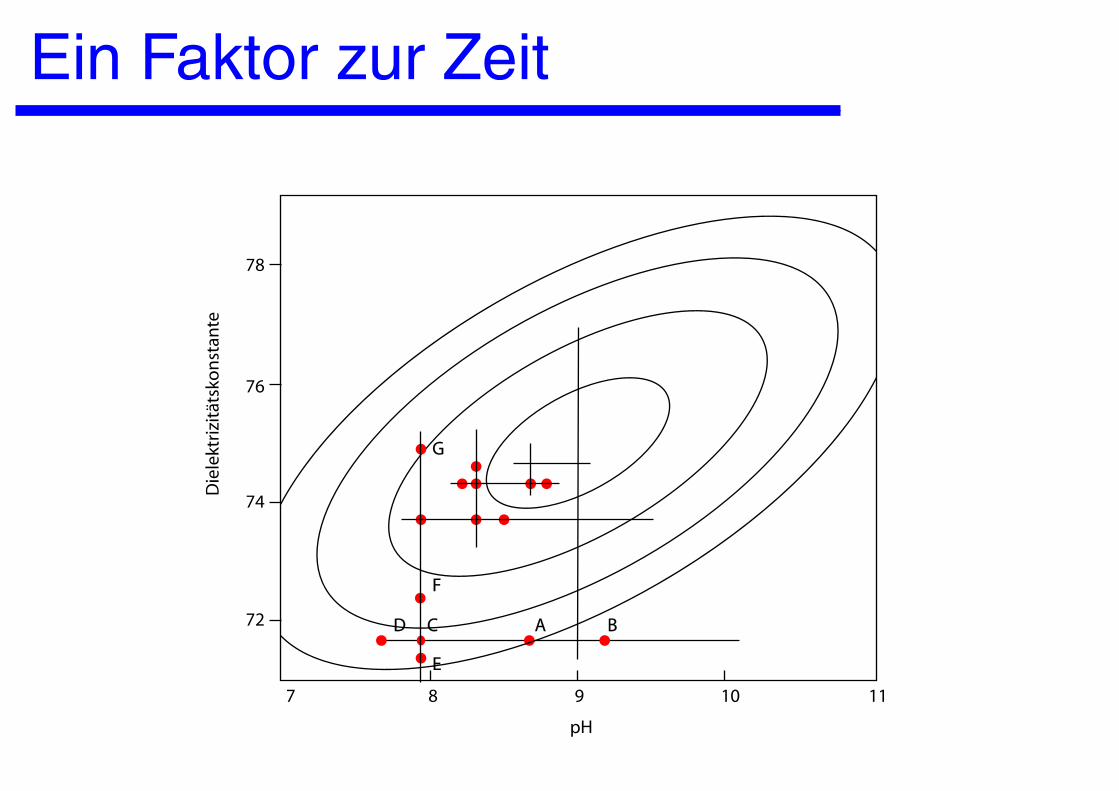
Ein Faktor zur Zeit
8 9 10 117
Die
lekt
rizi
täts
kon
stan
te
78
76
74
72
pH
G
F
D
E
C A B
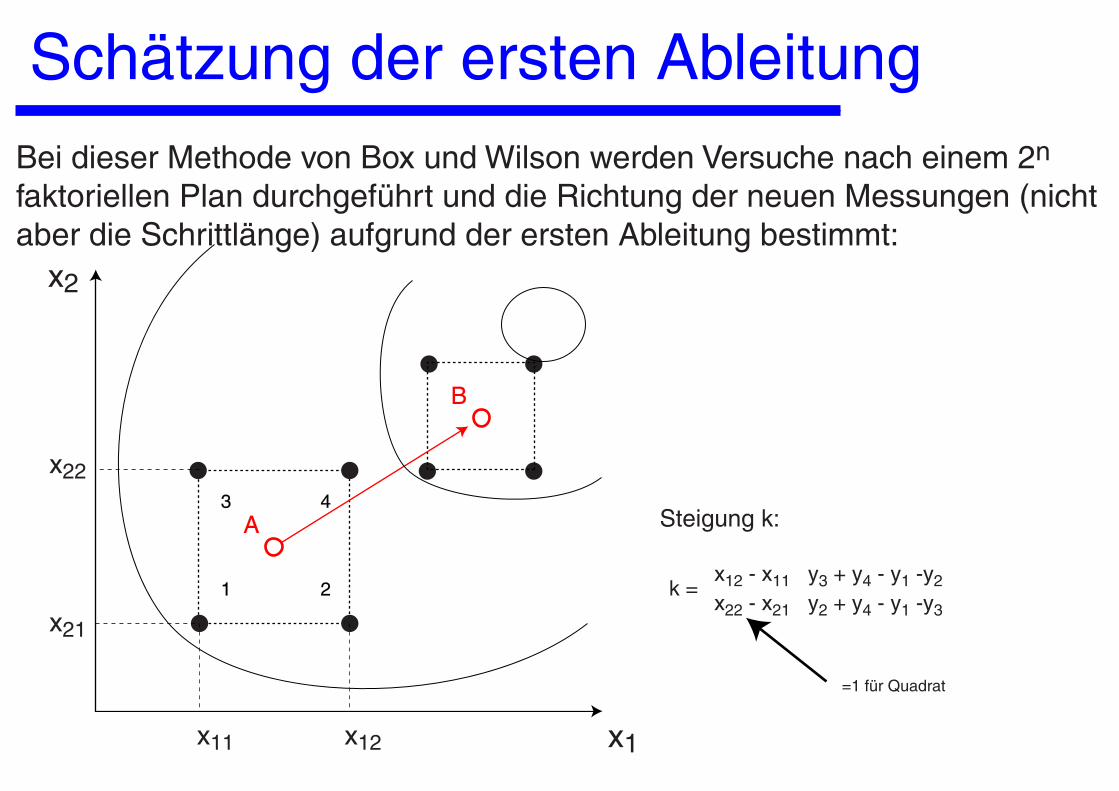
Schätzung der ersten AbleitungBei dieser Methode von Box und Wilson werden Versuche nach einem 2n faktoriellen Plan durchgeführt und die Richtung der neuen Messungen (nicht aber die Schrittlänge) aufgrund der ersten Ableitung bestimmt:
x1
x2
x11 x12
x21
x22
x12 - x11 y3 + y4 - y1 -y2
x22 - x21 y2 + y4 - y1 -y3k =1 2
3 4
=1 für Quadrat
A
B
Steigung k:

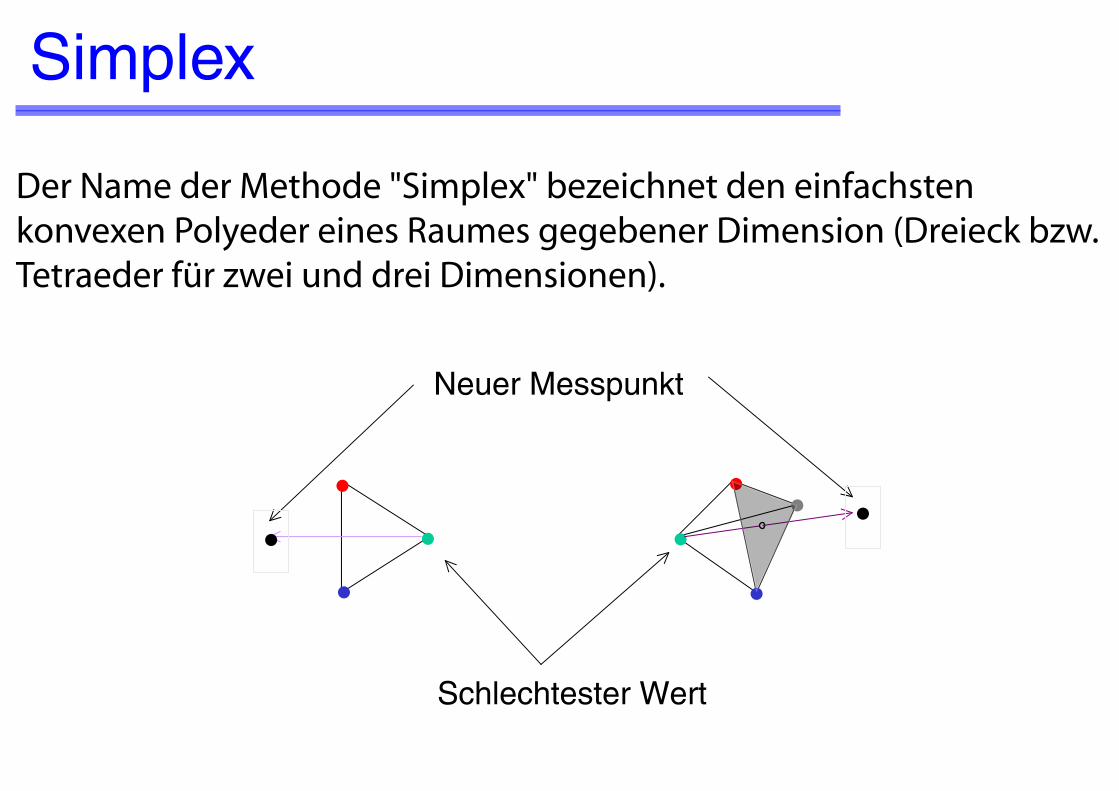
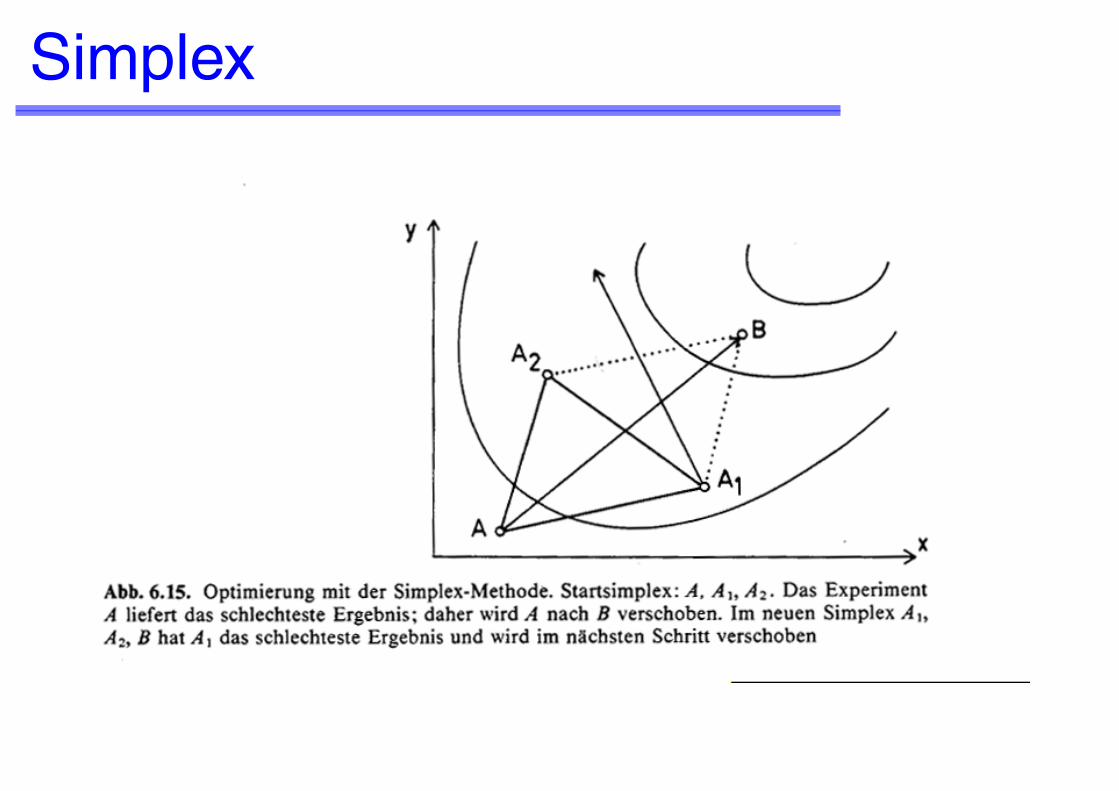
SimplexIn einem N-dimensionalen Faktorenraum startet man mit N+1 Experimenten, jedes bei einer anderen Kombination der Faktoren. Die N+1 Punkte definie-ren den Startsimplex.
Aufgrund der Antworten errechnet man aus den Faktorenwerten des Startsimplex die Faktoren des nächsten Experiments. Dazu bestimmt man den Schwerpunkt "centroid" wie folgt: Von den N+1 Faktorenkombinationen wird diejenige mit der schlechtesten Antwort gestrichen. Der Durchschnitt der anderen Faktorenkombinationen definiert den Schwerpunkt.
Für die nächste Messung erhält man die Faktorenkombination durch Spiegelung der Faktorenwerte der schlechtesten Antwort über den Schwerpunkt. Die weiteren Schritte erfolgen nach dem gleichen Prinzip.
Simplex
Der Name der Methode "Simplex" bezeichnet den einfachsten konvexen Polyeder eines Raumes gegebener Dimension (Dreieck bzw. Tetraeder für zwei und drei Dimensionen).
••
••
•
•
•
Schlechtester Wert
Neuer Messpunkt
• •
Simplex
Modifizierter Simplex
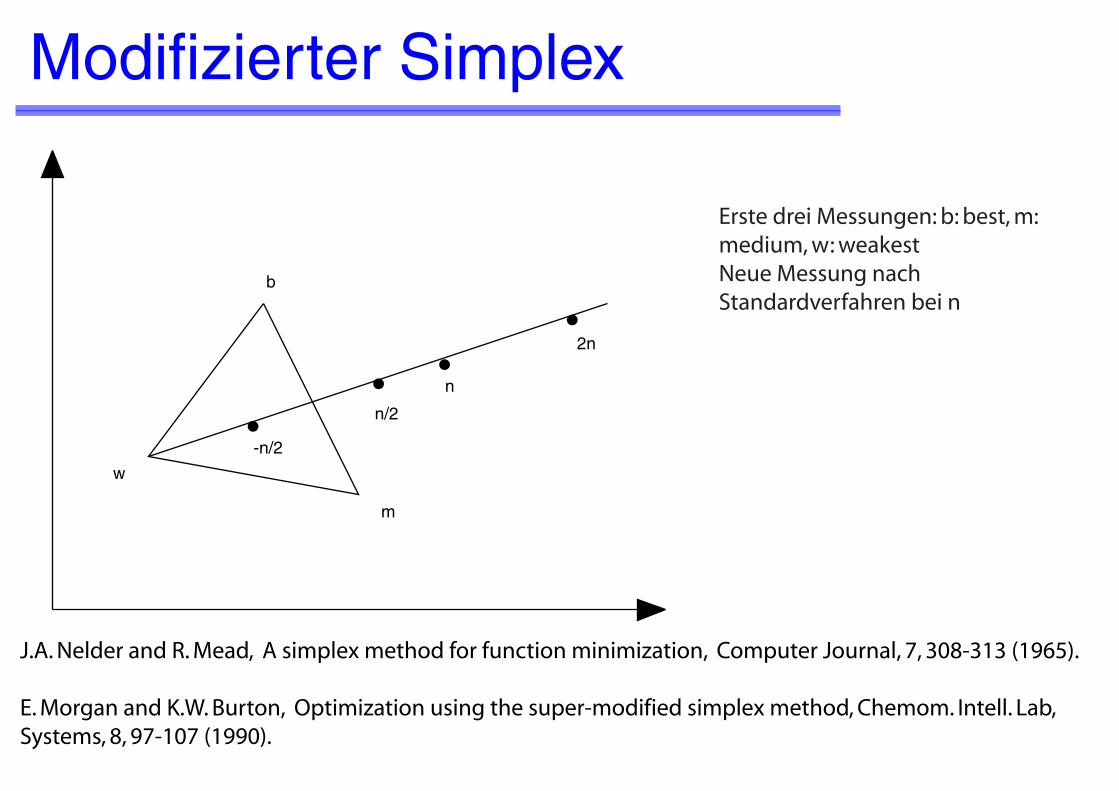
J.A. Nelder and R. Mead, �A simplex method for function minimization, �Computer Journal, 7, 308-313 (1965).
E. Morgan and K.W. Burton, �Optimization using the super-modified simplex method, Chemom. Intell. Lab, Systems, 8, 97-107 (1990).
m
w
b
••
••
n
2n
n/2
-n/2
Erste drei Messungen: b: best, m: medium, w: weakestNeue Messung nach Standardverfahren bei n
Modifizierter Simplex
m
w
b
••
••
n
2n
n/2
-n/2
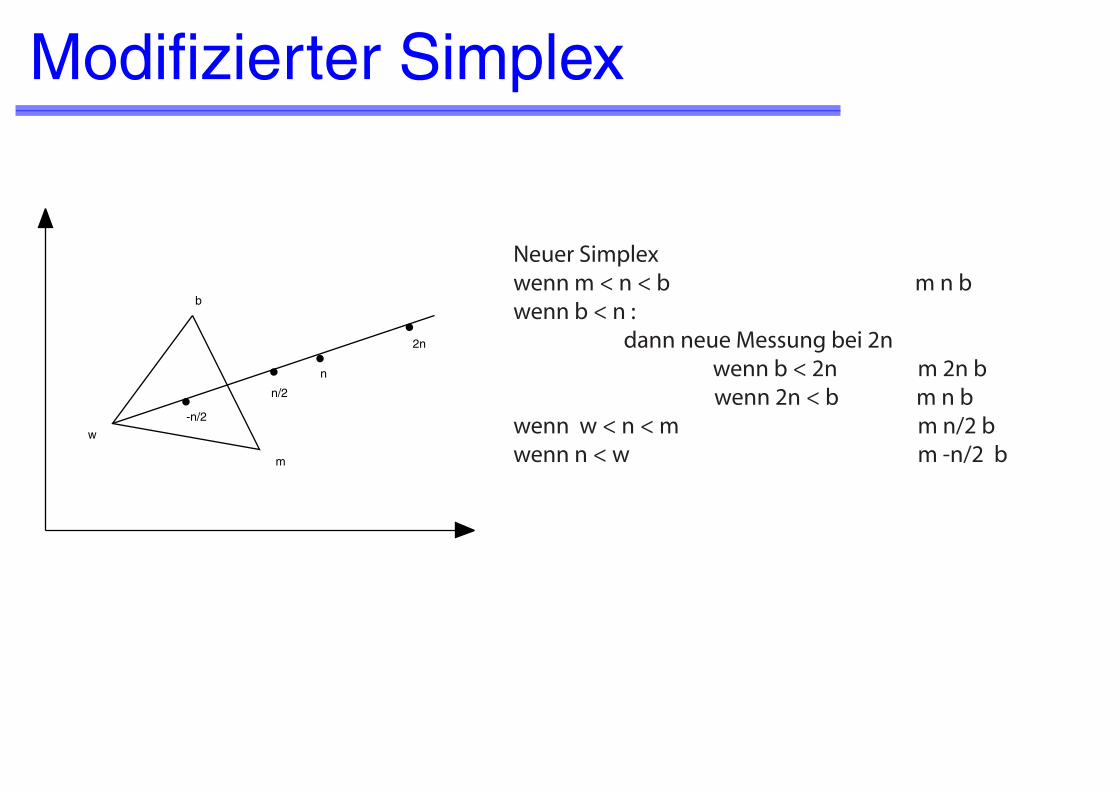
Neuer Simplex wenn m < n < b m n bwenn b < n : dann neue Messung bei 2n wenn b < 2n m 2n b wenn 2n < b m n bwenn w < n < m m n/2 bwenn n < w m -n/2 b

Stochastische Optimierungsmethoden
Mit Einzelversuchen:� Simulated Annealing
Mit Populationen: Evolutonäre Algorithmen� Genetische Algorithmen
Vorteil: Lokale Minima können überwunden werden
Nachteil: Nahe zum Optimum nicht effizient � --> Hybridmethoden
Aber: Keine Methode kann das Auffinden des globalen Optimums garantieren!
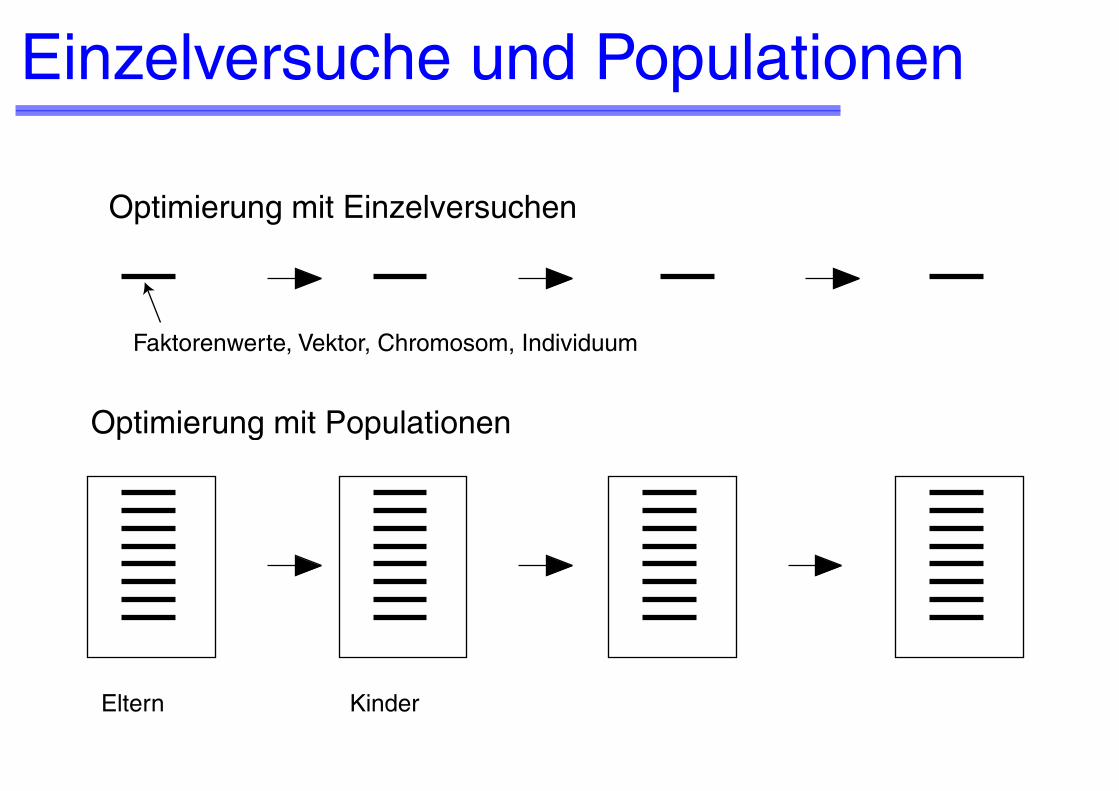
Einzelversuche und Populationen
Optimierung mit Einzelversuchen
Optimierung mit Populationen
Faktorenwerte, Vektor, Chromosom, Individuum
Eltern Kinder

Simulated Annealing
1. Bei einer zufällig generierten Faktorenkombination (a) wird „gemessen“ (Antwort Ea)
2. Die Faktoren werden durch zufälligen Störungen verändert3. Eine neue Faktorenkombination (n) wird mit der relativen Wahrscheinlichkeit P
akzeptiert: P = 1 wenn En<Ea
P = e-(En-Ea)/c wenn En>Ea
c Temperaturparameter, wird während der Optimierung schrittweise verkleinert
4. Auswirkung: lokale Energieminima können überwunden werden. Durch die schrittweise Verkleinerung von c nimmt die Wahrscheinlichkeit, mit der ein schlechterer Wert akzeptiert wird, ab.
*Annealing: Glühen, Härten, Tempern

Genetische Algorithmen
Optimierung mit Populationen statt Einzelzuständen
Die Startpopulation wird durch zufällige Faktorenkombinationen erzeugt
Die nächste Generation wird durch die genetischen Operationen erzeugt:�Cross-Over und �Mutation
Die Wahrscheinlichkeit dafür, dass ein Individuum bei der Erzeugung der neuen Population zu den Eltern aufgenommen wird, hängt von seiner Qualität (Fitness) ab
Die Faktoren können binär kodiert oder auch reele Zahlen sein
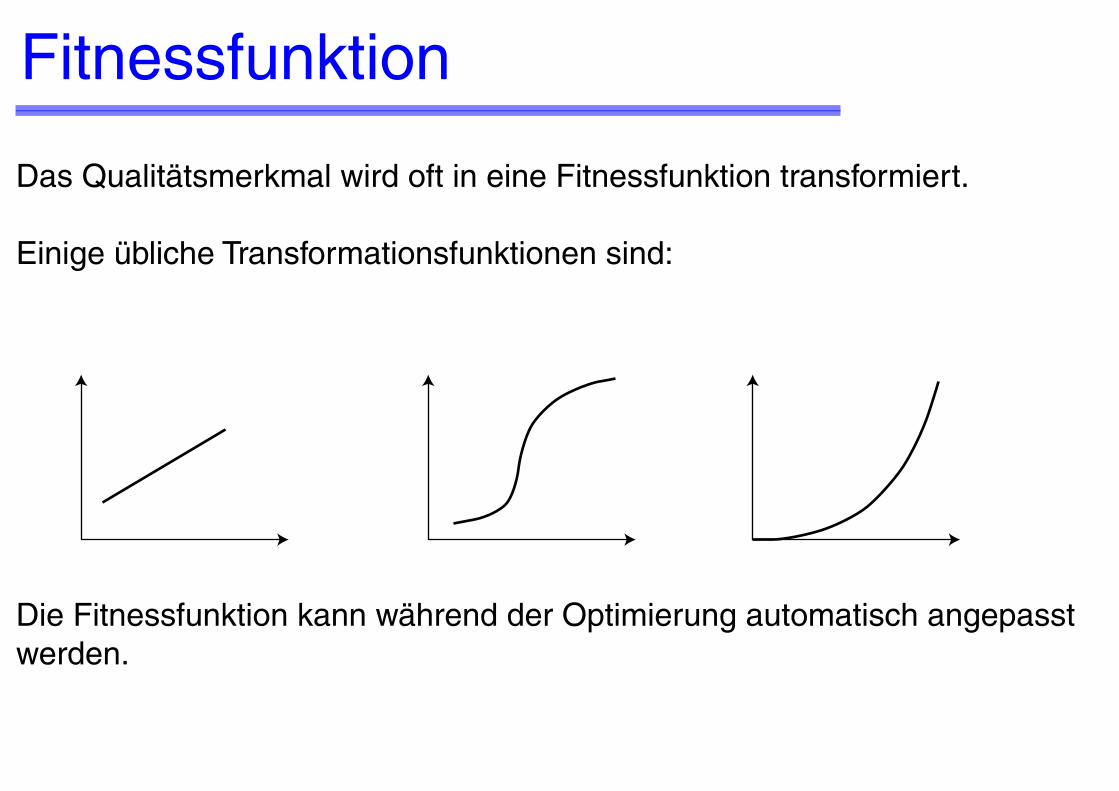
Fitnessfunktion
Das Qualitätsmerkmal wird oft in eine Fitnessfunktion transformiert.
Einige übliche Transformationsfunktionen sind:
Die Fitnessfunktion kann während der Optimierung automatisch angepasst werden.

Selektionsmethoden
Roulettrad:�Die Wahrscheinlichkeit der Selektion ist dem Fitness proportional
Linear Ranking: �Die Wahrscheinlichkeit der Selektion hängt von der Position in der Rangliste ab
Truncation selection: �Die besten n Individuen werden mit gleicher Wahrscheinlichkeit selektiert
Tournament selection:�Es werden zufällig n Individuen ausgewählt, das beste von ihnen wird selektiert

Cross-Over
Beim Cross-Over werden gewisse zufällig ausgewählte Faktoren zwischen zwei für die Erzeugung eines Kindes ausgewählten Individuen ausgetauscht
Single-point cross-over:
aaaaa|aaa aaaaabbb
|
bbbbb|bbb bbbbbaaa
Uniform cross-over
aaaaaaaa abaaabba
/ \ __ /-\_
bbbbbbbb babbbaab
The cross-over point is randomly chosen
For each parameter a parent is randomly selected. The second child is the opposite.

MutationBei der Binärkodierung bedeutet die Mutation, dass an den zufällig ausgewählten
Positionen 0 durch 1 und umgehehrt erstezt werden.
Bei reeller Kodirung, wird an die Faktoren bei den zufällig ausgewählten Positionen jeweils eine Zufallszahl addiert. Der Bereich der Zufallszahlen soll der Aufgabe sinnvoll angepasst werden (z. B. -30 – +30 bei einer Optimierung der Konformation).

Sharing
Es ist vorteilhaft, wenn ein Individuum einer Population nahe zum Optimum liegt und die anderen Individuen andere Teile der Suchfläche belegen:
Deshalb wird oft eine zusätzliche Mutation eingeschaltet, wenn ein neu erzeugtes Individuum zu ähnlich zu einem anderen ist.
Dadurch verhindert man, dass alle Individuen in die Nähe des gleichen Minimums kommen (premature convergence). Diese Strategie nennt man (etwas irreführend) "sharing" (sharing: teilend, gemeinsame Benutzung)

Generation gap, Elitism
Um die besten Individuen nicht zur verlieren, werden die n besten einer Population unverändert, d. h. ohne genetischen Operationen in die nächste Generation übernommen (normalerweise sollte n klein sein).
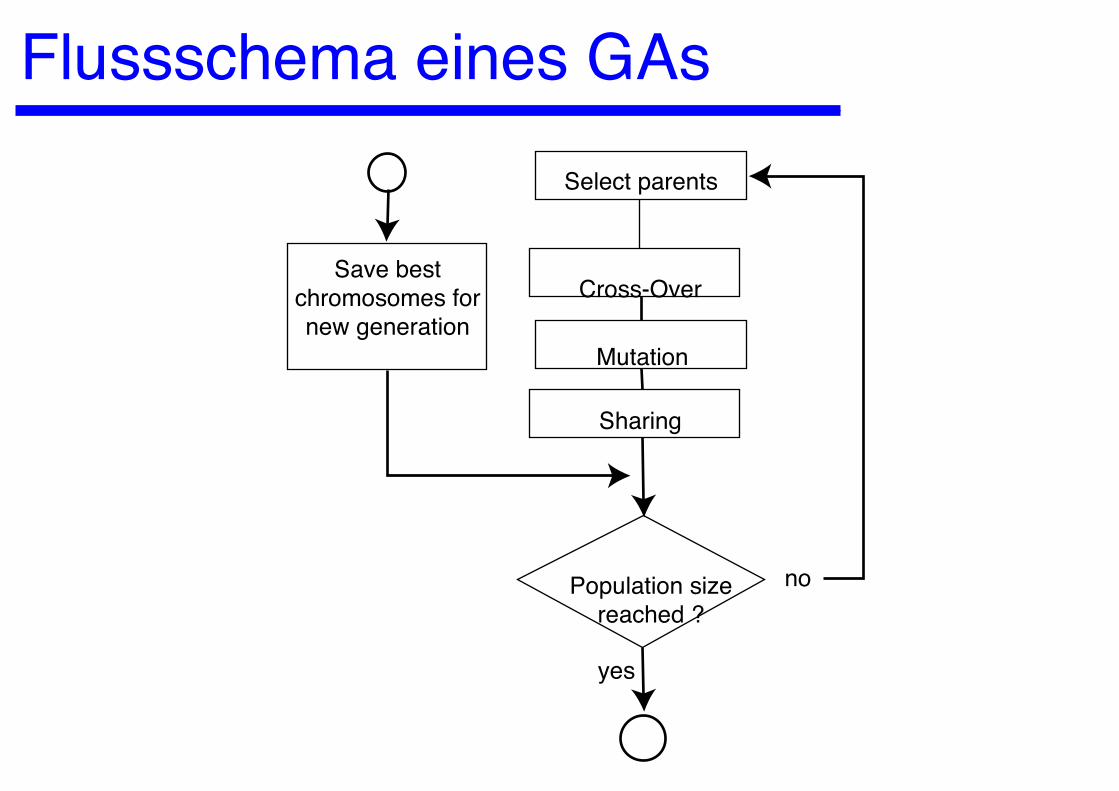
Flussschema eines GAsSelect parents
Cross-Over
Mutation
Sharing
Population sizereached ?
Save best chromosomes for new generation
no
yes

Auswahl von Wellenlängen, Literatur(1) Wavelengths selection and optimization of pattern recognition methods using the genetic algorithm. Smith, B. M.; Gemperline, P. J. Anal. Chim. Acta 2000, 423, 167-177.
(2) Genetic algorithms as a tool for wavelength selection in multivariate calibration. Jouan-Rimbaud, D.; Massart, D.-L.; Leardi, R.; De Noord, O. E. Anal. Chem. 1995, 68, 4295-4301.
(3) Genetic algorithm-based wavelength selection for near infrared determination of glucose in biological matrices: Initialization strategies and effects of spectral resolution. Ding, Q.; Small, G. W.; Arnold, M. A. Anal. Chem. 1998, 70, 4472-79.

NIR Optimierung: ProblemstellungOptimierung der Zuordnung einer Probe zu verschiedenen Substanzgruppen. Von jeder Substganzgruppe liegt ein Satz von Spektren vor.
Vorgehen: Hauptkomponentenanalyse und dann
entweder Mahalabonis-Distanz, des Spektrums von den Zentren der Spektren einzelner Gruppen, oder SIMCA: Summe der Fehlerquadrate zwischen dem Spektrum der der für die einzelnen Gruppen vorausgesagten Spektren
Zu optimieren:Spektren oder ihre Derivate benützen?Wieviele Hauptkomponenten benützen?Mahalabonis oder Simca?Welche Wellenlängen wählen?
Fragen: Wie sieht ein Chromosom aus? Wie definiert man die Fitness-Funktion?
Wavelengths selection and optimization of pattern recognition methods using the genetic algorithm. Smith, B. M.; Gemperline, P. J. Anal. Chim. Acta 2000, 423, 167-177.

Wahl der FitnessfunktionJedes Individuum (Chrmosom) beschreibt:Rohspektren oder erste Derivate?Mahalanobis oder Simca?Anzahl Hauptkomponenten die berücksichtigt werden sollen?Welche Wellenlängen werden berücksichtigt?
Mit jedem Individuum werden alle Testobjekte klassifiziert. Der Anteil der richtigen Zuordnung ist Pr und der falschen Zuordnung Pf. Die Fitnessfunktion ist dann:
Fitness = Pr2 + (1 - Pf)
2
Pr Pf Fitness1 0 1.414213560.9 0.1 1.272792210.8 0.2 1.131370850.5 0.5 0.707106780.2 0.8 0.282842710.1 0.9 0.141421360 1 00
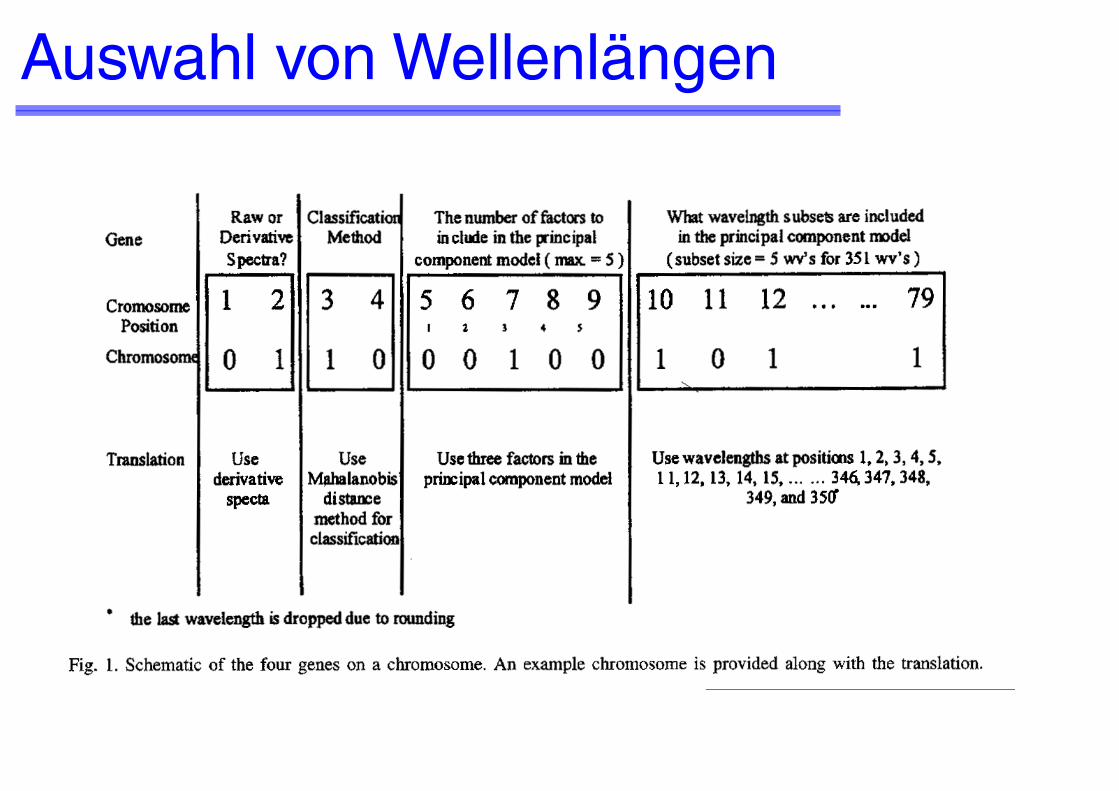
Auswahl von Wellenlängen
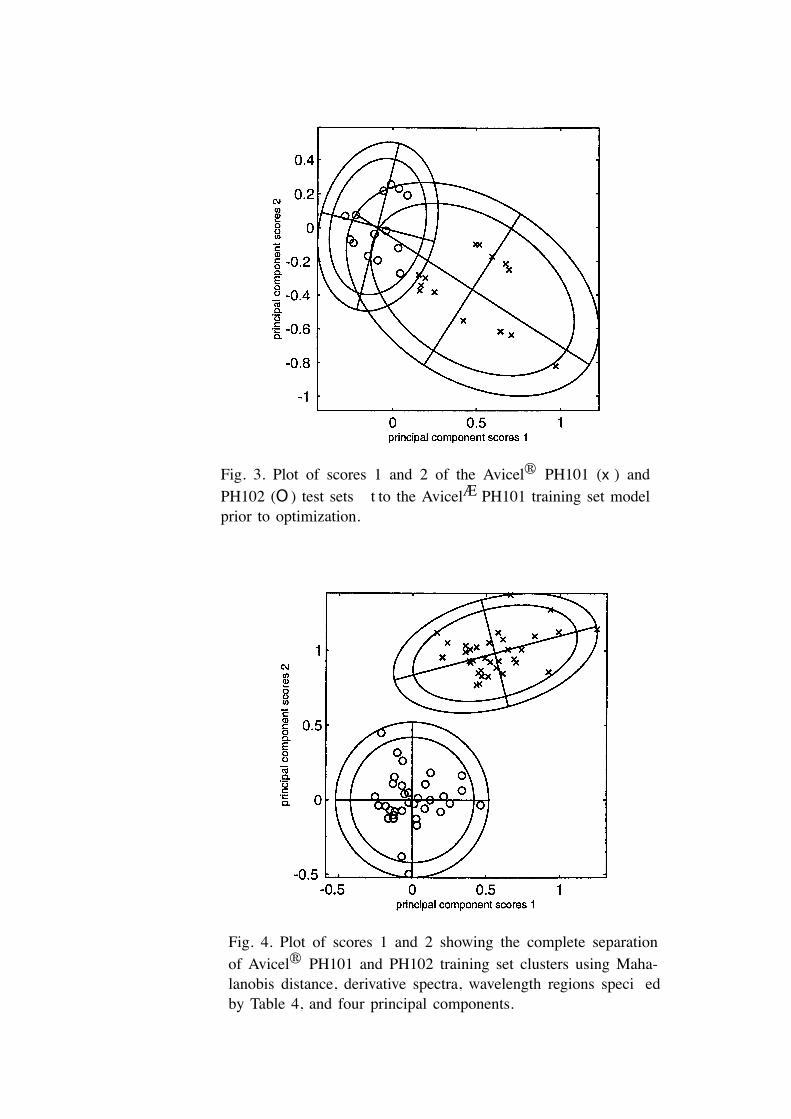
Fig. 4. Plot of scores 1 and 2 showing the complete separationof Avicel® PH101 and PH102 training set clusters using Maha-lanobis distance, derivative spectra, wavelength regions speci� edby Table 4, and four principal components.
Fig. 3. Plot of scores 1 and 2 of the Avicel® PH101 (x ) andPH102 (O ) test sets � t to the AvicelÆ PH101 training set modelprior to optimization.
Top Related