
Credential Management für heterogene RFID-Lösungen in ... · Danksagung Die Arbeit entstand...
149
Transcript of Credential Management für heterogene RFID-Lösungen in ... · Danksagung Die Arbeit entstand...

Technische Universität Ilmenau
Fakultät für Informatik und AutomatisierungInsitut für Praktische Informatik und Medieninformatik
Fachgebiet Telematik/Rechnernetze
Diplomarbeitzum Erlangen des akademischen Grades Diplominformatiker
Credential Management für heterogene
RFID-Lösungen in Logistik-Anwendungen
Marcel Henseler
Januar 2008
Eingereicht am: 28. Januar 2008verantwortlicher Hochschullehrer: Prof. Dr.-Ing. Günter Schäfer
Betreuer: Prof. Dr.-Ing. Günter SchäferInventarisierungsnummer: 2008-01-16/010/INF02/2253
Matrikel: 2002Matrikelnummer: 34796


Danksagung
Die Arbeit entstand im Fachgebiet Telematik/Rechnernetze an der Technischen UniversitätIlmenau und wurde von Prof. Dr.-Ing. Günter Schäfer betreut. Ich möchte ihm für die vielenDiskussionen, Hinweise und Anregungen danken. Auch hatte man im Fachgebiet immerZeit für mich, wenn sonstige Probleme auftraten. Ich bedanke mich weiter bei Dipl.-Inf.Michael Roÿberg für die stete Hilfsbereitschaft.Weiter möchte ich Prof. Dr. (USA) Martin Dietzfelbinger danken. Er half mit Anre-
gungen für die verwendeten Datenstrukturen der Arbeit und deren Betrachtung aus derSicht der theoretischen Informatik. Dabei entstanden die für die Datenstrukturen wichtigenBeweise.Meinem Mitbewohner Michael Endlich danke ich für die Hilfe beim Verständnis der
Beweise für die Datenstrukturen und Hinweise bezüglich der Ausarbeitung.Als letztes gilt der besondere Dank meinen Eltern. Sie haben mir das gute Studium erst
ermöglicht und mich in allen Situationen vollständig unterstützt. Ohne diese Hilfe wäredas Studium viel schwieriger gewesen. Auch haben Sie mir bei der Kontrolle der Arbeitgeholfen und viele kleine Fehler gefunden, die zu beheben waren.
2008-01-16/010/INF02/2253 iii

iv 2008-01-16/010/INF02/2253

Inhaltsverzeichnis
1 Einleitung 1
1.1 Gegenstand der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Zielsetzung/Aufgabenstellung . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Grundlagen 3
2.1 Auto ID Technologien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Supply Chain Management . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.3 RFID Technologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.4 GNY Logik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.5 Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.5.1 Binärbaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.5.2 B+-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5.3 Hashtabelle mit Verkettung . . . . . . . . . . . . . . . . . . . . . . . 192.5.4 Hashtabelle mit linearem Sondieren . . . . . . . . . . . . . . . . . . . 20
2.6 OMNeT++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.7 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 Ausgangspunkt 29
3.1 Abstraktes Szenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.2 Ziele des Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.3 Sicherheitsaspekte beim Einsatz von RFID-Systemen in unternehmensüber-
greifenden Logistik-Szenarien . . . . . . . . . . . . . . . . . . . . . . . . . . 323.3.1 Sicherheitsaspekte zwischen verschiedenen Ebenen . . . . . . . . . . 323.3.2 Data-on-Network . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.3.3 Data-on-Tag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.4 Ansätze zur Lösung der Sicherheitsprobleme . . . . . . . . . . . . . . . . . . 383.4.1 Sicherungsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.4.2 Pseudoanonymisierung . . . . . . . . . . . . . . . . . . . . . . . . . . 403.4.3 Zugri�skontrolle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.5 Auswahl der RFID Technologie . . . . . . . . . . . . . . . . . . . . . . . . . 443.6 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4 Protokoll und Systemaufbau 47
4.1 Systemaufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.2 Anonymisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.3 Zugri�skontrolle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.4 Datenintegrität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.5 Key Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.5.1 Schlüssel für die Kommunikation . . . . . . . . . . . . . . . . . . . . 554.5.2 Schlüssel für die Speicherung der Daten auf dem Tag . . . . . . . . . 55
4.6 Nachrichtenaustausch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.6.1 Authentisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.6.2 Datenaustausch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.7 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
2008-01-16/010/INF02/2253 v

Inhaltsverzeichnis
5 Untersuchung des Protokolls mit Hilfe der GNY Logik 69
5.1 Authentisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 695.2 Datenaustausch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 745.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
6 Konkretisierung des Beispielszenarios 83
6.1 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 836.2 Darstellung eines Zyklus am Beispiel des Generators . . . . . . . . . . . . . 846.3 Lastmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 856.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
7 Implementierung im Rahmen einer Simulationsstudie 91
7.1 Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 917.2 Testumgebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 927.3 Anforderungen an die Datenstruktur . . . . . . . . . . . . . . . . . . . . . . 947.4 Datenbankstruktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 947.5 Mögliche Datenstrukturen für den Index . . . . . . . . . . . . . . . . . . . . 967.6 Realisierte Datenstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
7.6.1 Binärbaum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 997.6.2 B+-Baum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1017.6.3 Hashtabelle mit Verkettung . . . . . . . . . . . . . . . . . . . . . . . 1037.6.4 Hashtabelle mit linearem Sondieren . . . . . . . . . . . . . . . . . . . 105
7.7 Auswertung Simulationsergebnisse . . . . . . . . . . . . . . . . . . . . . . . 1157.8 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
8 Zusammenfassung und Ausblick 123
A Regeln der GNY Logik 131
A.1 Erhalt von Nachrichten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131A.2 Glaube . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132A.3 Frische . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133A.4 Erkennbarkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134A.5 Interpretation von Nachrichten . . . . . . . . . . . . . . . . . . . . . . . . . 135A.6 Kompetenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
B Benutzerhinweise zur Verwendung der Simulation 139
C Thesen 141
D Eidesstattliche Erklärung 143
vi 2008-01-16/010/INF02/2253

1 Einleitung
Der Einsatz von RFID und anderen Auto-ID-Technologien nimmt einen zunehmend wich-tigeren Platz sowohl in Logistikanwendungen als auch in anderen Szenarien ein. Geradewenn dabei mehrere Institutionen zusammenarbeiten, spielen sicherheitsrelevante Fragen,wie Verschlüsselung oder Autorisierung bei Zugri�, eine sehr wichtige Rolle. Dies gilt ins-besondere dann, wenn unterschiedliche Partner unter Nutzung der genannten Technologienzusammenarbeiten wollen oder müssen, diese aber Informationen nur selektiv o�en legenmöchten oder die Kooperation und der Austausch von Informationen nur über einen zeitlichbegrenzten Zeitraum erfolgen sollen.Zunächst wird betrachtet in welchem Gebiet die Arbeit angesiedelt ist. Danach werden
die Ziele de�niert, die erreicht werden sollen und zum Schluss wird in dem Kapitel einÜberblick über den Aufbau der Arbeit gegeben.
1.1 Gegenstand der Arbeit
Die Arbeit befasst sich mit der RFID Technologie in der Verwendung im Supply ChainManagement. Die RFID Technologie ist eine Weiterentwicklung des Barcode. Es ermöglichtdas berührungslose Auslesen von Informationen der sogenannten RFID Label oder Tags.Damit können Informationen schneller und einfacher ausgelesen und verändert werden alsmit dem Barcode. Die Technik ist im Supply Chain Management gut einsetzbar, weil esdort darum geht, dass die Produktionsketten von Waren möglichst ohne Störungen arbeitenund falls es doch Störungen gibt, sollen diese möglichst schnell gelöst werden. Durch denschnellen Zugri� auf die Daten sind ein reibungsloser Ablauf und eine schnelle Lösung einesProblems möglich.Um die Verwendung der RFID Technologie zu ermöglichen, sind verschiedene Aspekte zu
betrachten, zum einen wirtschaftliche und zum anderen technische Aspekte. Im Folgenden�ndet eine Beschränkung auf die technischen Aspekte statt. Die technischen Aspekte bezie-hen sich auf Fragestellungen der Leistungsfähigkeit der Hardware und sicherheitsrelevanterProbleme. Im Schwerpunkt werden die sicherheitsrelevanten Probleme betrachtet.
1.2 Zielsetzung/Aufgabenstellung
Aufbauend auf vorhandenen Arbeiten zum Einsatz von RFID-Tags in den Betriebsarten�Data on Network� und �Data on Tag� sollen geeignete Protokolle gefunden beziehungsweiseentwickelt werden, die die Probleme beim Einsatz der Technologie lösen. Danach sollen fürzentrale Punkte der Protokolle praktische Lösungen entwickelt und in einer Simulationevaluiert werden.Für einen Einsatz ist es wichtig zu gewährleisten, dass eine Anonymisierung vorhanden
ist, damit nicht von Angreifern Informationen aus Bewegungspro�len abgeleitet werdenkönnen. Dafür muss ein geeignetes Verfahren zur Pseudoanonymisierung gefunden oderentwickelt werden. Weiter ist wichtig sicherzustellen, dass ein feingranularer, selektiver oderzeitlich beschränkter Zugri� auf Informationen und deren gezielte Modi�kation möglich ist.Für die Umsetzung ist ein Sicherheitsmodell, die Art der Speicherung und ein Protokoll zuentwickeln, welches diesen selektiven Zugri� ermöglicht.Nachdem Lösungen für die Sicherheitsprobleme erstellt wurden, ist zu prüfen wie der
praktische Einsatz realisiert werden kann. Für zentrale Bestandteile des entwickelten Sze-
2008-01-16/010/INF02/2253 1

1 Einleitung
narios sind praktische Lösungen zu �nden. Diese sind in einer Simulation darzustellen undzu evaluieren.Bei der Entwicklung der jeweiligen Bestandteile ist zu beachten, dass neben vollautoma-
tischen Systemen auch Personen das entwickelte System nutzen können. Bei einer Verwen-dung des Systems von Personen darf die Anzahl der notwendigen Operationen nur sehrgering sein. Auch ist zu beachten, dass die Leistungsfähigkeit der RFID-Tags im Hinblickauf Rechenleistung und Speicherplatz sehr beschränkt ist.
1.3 Aufbau der Arbeit
Die Arbeit ist in acht Kapitel aufgeteilt. Zunächst werden im zweiten Kapitel die Grundla-gen beschrieben, die für den Rest der Arbeit notwendig sind. Hier wird zunächst die AutoID Technologien und deren hauptsächliches Anwendungsgebiet betrachtet, bevor spezielldie RFID Technologie eingegangen wird. Für die Arbeit werden verschiedene Methoden undWerkzeuge benötigt, deren grundlegenden Aspekte dargestellt werden. Im darauf folgen-den Kapitel wird der Ausgangspunkt der Arbeit betrachtet. Dabei werden die gewünschtenZiele und eventuell vorhandene Lösungsmöglichkeiten dargestellt. Anschlieÿend wird dieArbeit in zwei groÿe Teile gegliedert. Der erste Teil befasst sich mit der Erstellung undÜberprüfung eines Protokolls, dass die gewünschten aufgestellten Anforderungen erfüllt.Dieser Teil beinhaltet den kompletten entworfenen Aufbau des Systems, sowie die Kom-munikation untereinander. Es werden für die einzelnen Teilprobleme Lösungen entwickelt,bevor die Kommunikation zwischen den Teilkomponenten entworfen und geprüft wird.Der zweite groÿe Teil befasst sich mit der Auswahl und Evaluierung geeigneter zentralerDatenstrukturen für die möglichst e�ziente Lösung der Authentisierung. Zur Evaluati-on der Lösungen wird zunächst ein praktisches Beispiel als Szenario gewählt. Mit einementwickelten Lastmodell werden später die Datenstrukturen bewertet. Es werden einzelnemögliche Datenstrukturen erläutert und deren prinzipielle Funktionsweise erklärt. Die Im-plementierungen dieser werden dann dargestellt und mit Hilfe einer erstellten Simulationund des Lastmodells analysiert. Die Ergebnisse werden schlieÿlich ausgewertet und darausein Vorschlag für mögliche sinnvolle Datenstrukturen erarbeitet. Zum Schluss wird eineZusammenfassung der Arbeit dargelegt und ein Ausblick auf weitere zukünftige Arbeitengegeben.
2 2008-01-16/010/INF02/2253

2 Grundlagen
Nachdem im Einführungskapitel eine Übersicht über die Arbeit und dabei wichtige Aspek-te gegeben wurde, werden in diesem Kapitel vertiefende Grundlagen zu den einzelnenAspekten dargestellt, die für das weitere Verständnis der Arbeit notwendig sind. Zunächstwird der RFID Technologie näher dargestellt. Dazu folgt als Erstes ein allgemeiner Über-blick über die verschiedenen Auto ID Technologien, zu denen auch die RFID Technologiegehört. Danach wird konkret auf die RFID Technologie eingegangen, die verschiedene Aus-prägungen hat. Schlieÿlich wird der Einsatzbereich der RFID Technologie betrachtet. ImAnschluss werden wichtige verwendete Werkzeuge kurz dargestellt. Die Werkzeuge sindeinerseits die GNY Logik, mit der später das entwickelte Protokoll untersucht wird, sowieder Simulator OMNeT++, der zur Analyse der entwickelten Datenstrukturen für die prak-tische Realisierung des Protokolls verwendet wird. Für die Evaluation von verschiedenenDatenstrukturen in Kapitel 7 werden hier die verwendeten Datenstrukturen dargestellt.
2.1 Auto ID Technologien
Als Auto ID Technologien werden Verfahren bezeichnet, die die automatische Identi�kationvon Objekten ermöglichen. Wenn die automatische und schnelle Identi�kation von Objek-ten möglich ist, können daraus Informationen gewonnen werden. Damit lässt sich zum Bei-spiel heraus�nden, in welcher Position der Versandkette bestimmte Pakete in der Logistiksind. Auch ist durch eine Vielzahl von Informationen die Optimierung der Prozesse mög-lich. Dieses Ziel hat das Supply Chain Management. Genaueres dazu ist in Abschnitt 2.2nachzulesen. Zu den Auto-ID Technologien gehören unter anderem der Barcode, die RFIDTechnologie, biometrische Verfahren, der Magnetstreifen, die Texterkennung, die Smart-card und die Spracherkennung [11]. Für die Identi�kation von Waren sind die meisten derVerfahren nicht geeignet. Dazu zählen die biometrischen Verfahren und die Spracherken-nung. Die Verwendbarkeit von Smartcards und des Magnetstreifen ist ungefähr gleich. DasProblem hierbei ist, dass kein kontaktloses Auslesen der Daten möglich ist. Es muss immerein physischer Kontakt vorhanden sein. Das ist je nach Ware bei der Erkennung mit einemmobilen Handlesegerät mittels eines Mitarbeiters möglich. Für das automatische Auslesender Daten ist es jedoch ungeeignet. Die Smartcard ist zusätzlich auch teurer als der Ma-gnetstreifen, welcher jedoch Nachteile in Umgebungen mit starken Magnetfeldern hat. DieTexterkennung kann zur automatischen Identi�kation genutzt werden. Der Vorteil davonist, dass auf den Etiketten natürlich sprachliche Erkennungselemente stehen können. Diesekönnen dann automatisch erkannt und auch von Menschen verwendet werden. Problema-tisch für die automatische Erkennung ist dabei, dass die Etiketten sauber und gut lesbarsein müssen. Auÿerdem wird für die Erkennung viel Rechenleistung benötigt. Um dieseProbleme zu umgehen, wurde der Barcode entwickelt. Der Barcode ist weniger emp�ndlichgegen Verschmutzungen als die normaler Texterkennung, da der Barcode explizit für dasEinsatzszenario entwickelt wurde. Es ist im Wesentlichen auch eine Texterkennung, beider die Buchstaben nur Symbole sind. Der Barcode besteht in der ursprünglichen Versionaus vertikalen Strichen unterschiedlicher Stärke. Mit Hilfe der verschieden starken Strichewird durch den Barcode die Ware identi�ziert. Dabei kann je nach verwendetem Verfahrendie Identi�kation aus einer Zahl oder einem Textbezeichner mit Zahlen erfolgen. Mit Hilfedes Kennzeichens kann dann in der Warendatenbank das Teil identi�ziert werden. Der ammeisten eingesetzte Barcode ist der Strichcode. Der EAN Strichcode wird zum Beispiel von
2008-01-16/010/INF02/2253 3

2 Grundlagen
automatischen Kassen zur Identi�kation der gekauften Waren verwendet. Ein Beispiel füreinen Strichcode ist in Abbildung 2.1 zu sehen.
Abbildung 2.1: Barcode vom Typ EAN 13 [2]
Zusätzlich wurde später ein 2D Strichcode entwickelt. Dieser besteht aus einem zweidi-mensionalen Bild, dass aus verschiedenen Schwarz-Weiÿ Pixeln zusammengesetzt ist. Esexistieren, wie beim Strichcode, verschiedene Kodierungsverfahren. Das Auslesen erfolgthier beispielsweise mit einer Kamera. In das Bild ist eine erhebliche Redundanz eingear-beitet, damit das Etikett auch verschmutzt oder teilweise zerstört gelesen werden kann.Bekannte Verwendung �ndet der 2D Strichcode bei maschinellen Briefmarken oder denOnlinefahrkarten der Bahn. In Abbildung 2.2 ist ein Beispiel für einen 2D Strichcode zusehen.
Abbildung 2.2: 2D Barcode vom Typ PDF417 mit Inhalt �Wikipedia� [2]
Zurzeit ist der Strichcode das am meisten verwendete Verfahren zur automatischen Iden-ti�kation von Waren. Dafür gibt es mehrere Gründe. Zum einen ist der Barcode kosten-günstig. Er besteht nur aus einem auf Papier gedruckten Etikett. Zum Anderen ist derBarcode leicht auslesbar. Für das Auslesen wird nur eine Sichtverbindung mit geringerEntfernung zum Etikett benötigt. Durch den nicht benötigten Kontakt mit dem Etikett istein automatisches Auslesen möglich, aber es ist ein Abstand in einem gewissen Rahmen zugewährleisteten. Das letzte der oben genannten Verfahren ist die RFID Technologie. Diesehat ähnliche Vorteile. Zusätzlich ist bei der RFID Technologie kein Sichtkontakt mit demTag notwendig. Genaueres ist in Abschnitt 2.3 nachzulesen.
2.2 Supply Chain Management
Ein Hauptverwendungsgebiet für die Nutzung der RFID Technologie ist das Supply ChainManagement, welches in Quelle [28] beschrieben wird. Das Ziel ist dabei die Optimierungder Wertschöpfungskette. Die Wertschöpfungsketten werden oft immer komplexer. Meh-rere Unternehmen sind daran beteiligt. Die Zusammenarbeit wird immer intensiver. DieKonsequenz daraus ist, dass immer mehr Abhängigkeiten entstehen. Falls an einer Stelleder Wertschöpfungskette ein Problem auftritt, wird sofort die komplette Kette beein�usst.Durch die Auslagerung von Arbeiten wird die Abhängigkeit der Unternehmen voneinan-der gröÿer. Durch die zusätzlichen Verringerungen der Lagerkapazität sinken zusätzlich diePu�erzeiten, in denen die notwendigen Waren�üsse durch Lagerbestände gedeckt werdenkonnten. Durch die steigenden Ver�echtungen zwischen den Unternehmen ist ein übergrei-fendes Management der Prozesse notwendig. Dadurch kann im Fall von Unregelmäÿigkeiten
4 2008-01-16/010/INF02/2253

2.3 RFID Technologie
in der Wertschöpfungskette auf diese reagiert werden. Die Lösung des Problems erfolgt dannnicht nur unternehmensintern, sondern auch die abhängigen Unternehmen werden über dasVorkommnis informiert. Die Reaktionszeiten müssen dabei kurz sein, da je schneller dieInformation vorhanden ist, desto besser darauf reagiert werden kann. Dafür ist eine au-tomatische Weiterleitung der Nachrichten notwendig. Die Kommunikation der Teilnehmeruntereinander erfolgt über eine Netzwerk. Bei der Informationsübermittlung müssen Sicher-heitsaspekte beachtet werden. So sollen nur freigegebene Daten an die Partnerunternehmenweitergeleitet werden, damit keine Firmengeheimnisse ö�entlich werden. Das Supply ChainManagement befasst sich mit dieser Optimierung der Wertschöpfungskette, vor allem aberder Logistikkette. Dabei treten immer mehr unternehmensübergreifende Optimierungenin den Vordergrund. Durch die Optimierungen soll die E�ektivität des Systems gesteigertwerden. Probleme dabei sind die Wahrung der Balance zwischen Weiterleitung von Infor-mationen und Wahrung von Unternehmensdaten. Es muss entschieden werden, wie starkdie Kooperation mit den Partnern sein soll. Damit Optimierungen möglich sind, müssenvielfältige Daten gesammelt werden. Dazu sind kostengünstige Methoden zur Datener-fassung notwendig. Zurzeit wird dafür hauptsächlich der Barcode verwendet. Das gröÿteProblem beim Supply Chain Management ist jedoch die immer steigende Komplexitätder Wertschöpfungsketten. Dadurch muss unter anderem auch entschieden werden, welcheVerbesserungen lokal und welche global erfolgen. Ziel der ganzen Anpassungen ist einemöglichst störungsfrei und e�zient ablaufende Wertschöpfungskette. Falls dann dennochProbleme auftreten, soll auf diese möglichst schnell und e�ektiv reagiert werden können.
2.3 RFID Technologie
Zunächst ist eine Klärung des Begri�es RFID sinnvoll, damit auf die Funktionsweise unddie Anwendungsgebiete der Technologie geschlossen werden kann. RFID ist die Abkürzungfür Radio Frequency Identi�cation. Das ist übersetzt die Identi�kation über Radiowellen.Gemeint ist damit, dass Objekte die ein RFID Etikett haben, mit Hilfe eines Lesegerätesüber Radiowellen ausgelesen und identi�ziert werden können. Die RFID Etiketten wer-den dabei auch als RFID Tag oder RFID Label bezeichnet. Die Identi�kation erfolgt überdas aktive Auslesen der gespeicherten Daten auf dem Tag mit einem Lesegerät. Durchdie Radiotechnologie ist ein kontaktloses Auslesen der Tags ohne Sichtverbindung mög-lich. Die Daten können zum Beispiel durch andere Verpackungen ausgelesen werden. DerAusleseabstand und die Durchdringbarkeit von anderen Materialien werden dabei von dereingesetzten Technologie beein�usst. Dazu später jedoch mehr. Das Lesegerät hat dabeifolgende Funktionalität. Es kann alle Tags in seiner Reichweite erkennen, ein entsprechen-den Tag selektieren und die gespeicherten Daten des Tags zuverlässig auslesen. Für dieRFID Technologie existieren verschiedene Normen, damit die Interoperabilität der Tagsund der Lesegeräte verschiedener Hersteller gesichert ist. Maÿgeblich sind die Normen ISO14443 [1] und ISO 15693. Die Normen spezi�zieren dabei unter Anderem das physischeÜbertragungsverfahren zwischen Tag und Lesegerät. Dabei wird das MAC Protokoll spe-zi�ziert, mit dem auf die Tags zugegri�en wird. In dem Standard ist auch das Protokollzur Kommunikation spezi�ziert. Die Tags gibt es in verschiedenen Bauformen, je nachVerwendungsgebiet. So existieren zum Beispiel RFID Tags in Form von Chipkarten oderals Dongle zur Zugangskontrolle. Es existieren auch groÿe Tags mit groÿen Antennen inKunsto�hüllen um Container zu identi�zieren und zu verfolgen. Eine weitere wichtige Formist der RFID Tag als Smart Label. Das ist ein RFID Tag der auf ein Trägermaterial, zumBeispiel auf Papier oder Folie, aufgebracht ist. Diese Tags dienen als Transponder für Wa-ren oder Paketen und Paletten in der Logistik. Genauso vielfältig wie die Bauformen derTransponder sind die Einsatzgebiete. Die Label können zum Beispiel als Echtheitsnach-weis der Produkte oder als Zutrittskontrolle verwendet werden. Eine Diebstahlsicherung
2008-01-16/010/INF02/2253 5

2 Grundlagen
ist ebenfalls realisierbar. Auch können die Tags genutzt werden, um Wartungsinformatio-nen für Teile zu speichern auf denen diese angebracht sind. Ein wichtiges Einsatzgebietist die Verfolgung von Objekten und damit verbunden die Logistik. Das ist die in dieserArbeit hauptsächlich angenommene Verwendung der RFID Technologie. Das Verfolgen vonObjekten hat dabei verschiedene Sicherheitsprobleme, die gelöst werden müssen. Das istein Hauptbestandteil der Arbeit und wird somit extra behandelt. Damit die verschiedenenEinsatzgebiete der Technologie realisiert werden können, existieren viele verschiedene Aus-führungen. Die Tags lassen sich dabei physisch nach der Art des Funkinterface, der Art derSpeicherung der Daten und der Art der Energieversorgung einteilen. Auf logischer Ebenewird nach der Art des Zugri�es bei mehreren vorhandenen Tags unterschieden sowie wiedie Daten auf den Tags gespeichert werden [6]. Die Art der Speicherung wird in Abschnitt3.3 genauer betrachtet, da sich daraus jeweils verschiedene Sicherheitsprobleme ergeben,die für die weitere Arbeit wichtig sind.
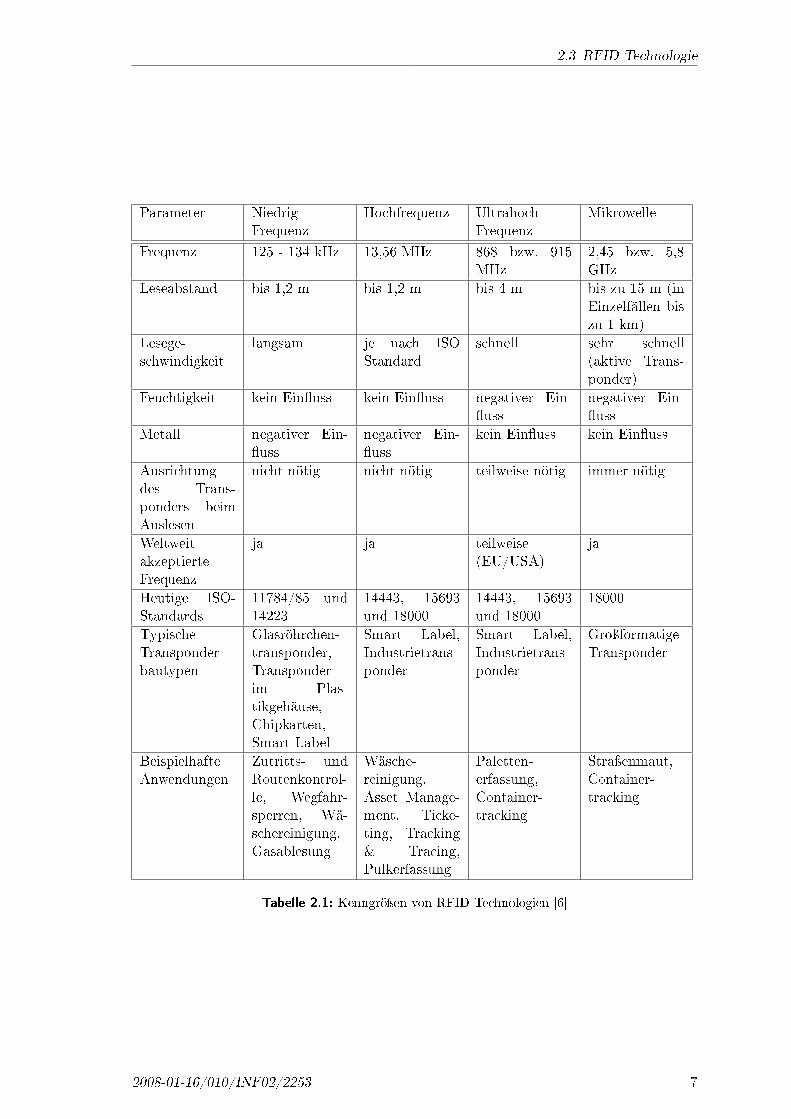
Funkinterface Die Arbeitsfrequenz der RFID Tags hat einen wesentlichen Ein�uss aufdas Einsatzgebiet. Bei der Einteilung ist die Frequenz der Funkschnittstelle entscheidend.Der Ein�uss der Frequenz auf die Eigenschaften ist in Tabelle 2.1 dargestellt. Bei höherenAbleseabständen sinkt die Energie des Funkfeldes, so dass weniger Energie für den Tagvorhanden ist. Die gebräuchlichsten Tags haben eine Sendefrequenz von 13,56 MHz. Siesind ein Kompromiss zwischen Gröÿe und der Beein�ussbarkeit von Störungen. Technischgesehen ist das der am weitesten entwickelte Bereich. Es gibt dort Tags mit vielfältigerFunktionalität. So existieren Tags die symmetrische Kryptographie erlauben. Eine Über-sicht der verschiedenen Eigenschaften der Tags in Abhängigkeit von der Frequenz derFunkinterface ist in Tabelle 2.1 zu sehen.
Speichermedium Für die Speicherung der Daten auf den RFID Tags existieren verschie-dene Technologien, welche in Quelle [6] dargestellt sind. Die Art der Speicherung beein-�usst dabei die Verwendungsmöglichkeiten der Tags entscheidend. Grundsätzlich gibt eszwei verschiedene Transponderarten. Zum einen Tags, die nur gelesen werden können undzum anderen Tags, die gelesen und auch beschrieben werden können. Bei den Transpon-dern, die nur gelesen werden können, wird meist ein ROM verwendet. Dieses wird bei derHerstellung programmiert. Da im späteren Betrieb keine Daten auf den Tag gespeichertwerden können, ist das gespeicherte Datum meist die feste ID des Tags. Mit Hilfe der festenID können dann die zugehörigen Daten zum Tag in einer Datenbank zugeordnet werden.Die andere Art der Tags kann zusätzlich zum Auslesen auch beschrieben werden. Dabei�nden verschiedene Techniken Anwendung. Dazu zählen unter Anderem das EPROM, dasEEPROM und das Flash-ROM. Die Techniken ermöglichen das mehrfache Überschreibender Daten. Für das EEPROM sind je nach Modell etwa 106 bis 108 Zyklen möglich. Pro-bleme ergeben sich beim Überschreiben der Daten. Dafür sind jeweils höhere Spannungennotwendig als für das Lesen der Daten. Durch die höheren benötigten Spannungen undden dabei �ieÿenden Strom ist das Schreiben der Daten energieintensiv. Je nach verwen-deter Technologie ist der Energieverbrauch unterschiedlich, aber jeweils signi�kant. BeimEPROM wird zum Löschen und Beschreiben ein externer Programmierer benötigt. Deshalbist die Technologie für einen RFID Tag nicht geeignet. Bei der Flash-ROM Technologie er-folgt das Schreiben durch das vorherige Löschen eines ganzen Blockes und darauf folgenddas Schreiben der Daten auf den gelöschten Block. Dabei muss auch nur bei der Änderungoder beim Schreiben eines Bytes zunächst der ganze Block gelöscht und dann mit dengeänderten Daten neu geschrieben werden. Dafür wird dann insgesamt relativ viel Energiebenötigt. Weil bei der RFID Technologie oft nur wenige Daten pro Vorgang geschriebenwerden und das jeweils lange dauert und viel Energie verbraucht, wird die Technologiemeist auf RFID Tags nicht verwendet. Verwendung �ndet meist das EEPROM. Dieses be-
6 2008-01-16/010/INF02/2253
2.3 RFID Technologie
Parameter Niedrig-Frequenz
Hochfrequenz Ultrahoch-Frequenz
Mikrowelle
Frequenz 125 - 134 kHz 13,56 MHz 868 bzw. 915MHz
2,45 bzw. 5,8GHz
Leseabstand bis 1,2 m bis 1,2 m bis 4 m bis zu 15 m (inEinzelfällen biszu 1 km)
Lesege-schwindigkeit
langsam je nach ISOStandard
schnell sehr schnell(aktive Trans-ponder)
Feuchtigkeit kein Ein�uss kein Ein�uss negativer Ein-�uss
negativer Ein-�uss
Metall negativer Ein-�uss
negativer Ein-�uss
kein Ein�uss kein Ein�uss
Ausrichtungdes Trans-ponders beimAuslesen
nicht nötig nicht nötig teilweise nötig immer nötig
WeltweitakzeptierteFrequenz
ja ja teilweise(EU/USA)
ja
Heutige ISO-Standards
11784/85 und14223
14443, 15693und 18000
14443, 15693und 18000
18000
TypischeTransponder-bautypen
Glasröhrchen-transponder,Transponderim Plas-tikgehäuse,Chipkarten,Smart Label
Smart Label,Industrietrans-ponder
Smart Label,Industrietrans-ponder
GroÿformatigeTransponder
BeispielhafteAnwendungen
Zutritts- undRoutenkontrol-le, Wegfahr-sperren, Wä-schereinigung,Gasablesung
Wäsche-reinigung,Asset Manage-ment, Ticke-ting, Tracking& Tracing,Pulkerfassung
Paletten-erfassung,Container-tracking
Straÿenmaut,Container-tracking
Tabelle 2.1: Kenngröÿen von RFID-Technologien [6]
2008-01-16/010/INF02/2253 7

2 Grundlagen
nötigt zum Schreiben der Daten zwar auch höhere Spannungen, jedoch können nur einzelneBytes geschrieben werden und es wird kein externes Schreibgerät benötigt.Auf RFID Tags können aber auch RAM Technologien zur Speicherung von Daten ver-
wendet werden. Dazu zählen das DRAM, das SRAM und das FRAM. DRAM ist dabeinicht geeignet. Zur Erhaltung der Daten benötigt es regelmäÿige Au�rischungen. SRAMbenötigt dagegen keine Au�rischungen zur Speicherung der Daten. Dafür ist der technischeAufwand gröÿer als beim DRAM und der Stromverbrauch gröÿer. Die beiden RAM Tech-nologien können auf RFID Tags nur zur Speicherung von Zwischenergebnissen verwendetwerden, weil die Daten nach Abschaltung der Spannung, dass heiÿt Abschaltung des Aus-lesefeldes, verloren. Dagegen existiert das FRAM. Dieses speichert die Daten ähnlich wieein DRAM. Dabei werden die Daten jedoch nicht durch elektrische Ladungen in einemKondensator repräsentiert, sondern durch eine elektrische Polarisation in einem ferroma-gnetischen Material. Das FRAM ist dabei kompatibel zu üblichen EEPROMs. Es übertri�tdessen Daten bezüglich Speicherungsdauer, Auslese- und Schreibgeschwindigkeit. Da dieTechnologie noch relativ neu ist, �nden es noch keine Anwendung in RFID Tags.
Energieversorgung Die RFID Tags können in zwei Kategorien bezüglich der Energiever-sorgung eingeordnet werden. Es existieren zum einen die passiven Tags und zum anderendie aktiven Tags [6].Die passiven Tags besitzen keine eigene Energieversorgung. Die benötigte Energie zur
Ausführung von Operationen wird aus dem elektromagnetischen Feld des Lesegerätes ge-wonnen. Über einen Kondensator als Zwischenspeicher wird die eingehende Energie gepuf-fert, um die Elektronik gleichmäÿig zu versorgen. Problematisch dabei ist, dass die über-tragbare Energie sehr gering ist. Diese hängt dabei von der aufgewendeten Energie desLesegerätes, der Entfernung vom Lesegerät und der Gröÿe der Antenne ab. Für die Ener-giegewinnung ist damit eine hohe Sendeleistung für das Feld, ein kleiner Ausleseabstandund eine groÿe Antenne des Tags vorteilhaft. Die drei Parameter können jedoch nicht opti-mal sein, weil dann die praktische Anwendung der Technologie nicht mehr sinnvoll ist. Ausden Gegebenheiten müssen die passiven RFID Tags so konstruiert werden, dass möglichstwenig Energie verbraucht wird. Um die Kriterien zu erfüllen, können die Tags nicht aussehr vielen Transistoren bestehen und die Taktrate ist beschränkt. Durch die Begrenzungder Anzahl der Transistoren ist auch der mögliche Funktionsumfang der Tags begrenzt. Soist die asymmetrische Kryptographie auf den RFID Tags nicht anwendbar, weil dazu zukomplexe und damit energieintensive Schaltkreise notwendig sind. Symmetrische Krypto-graphie, wie der DES oder AES Algorithmus kann jedoch auch auf passiven Tags mit einervertretbaren Anzahl von Transistoren realisiert werden [23] [9].Die zweite Art der Energieversorgung erfolgt über eine integrierte Batterie. Der Vorteil
dabei ist der mögliche Einsatz komplexerer Schaltungen, weil der Tag nicht von der Ener-gieversorgung des Feldes des Lesegerätes abhängig ist. Auch können Daten in einem RAMzwischengespeichert werden, weil die Energieversorgung des RAM nicht beim Abschaltendes Feldes unterbrochen wird. Durch die eigenständige Energieversorgung sind auch gröÿe-re Auslesereichweiten möglich, da nur die Daten und keine Energie zum Betrieb übertragenwerden muss. Aktive Tags haben aber auch Nachteile. Durch den Einbau einer Batteriewerden die Tags zunächst gröÿer. Auÿerdem werden der Fertigungsaufwand und die Ma-terialkosten höher, wodurch der Herstellungspreis steigt. Ein Problem tritt auf, wenn derEnergievorrat der Batterie verbraucht oder durch Selbstentladung erschöpft ist. Der Tagist dann unbrauchbar, weil die Elektronik keine Energie mehr aus der Batterie enthält. DieTags können dann eingesammelt und recycelt werden, damit nicht unnötig Müll entsteht.Die Frage ist auch wie lange eine Batterie den Tag mit Energie versorgen kann. So kannein Angreifer zum Beispiel die Energie des Tags erschöpfen, indem er sinnlose Anfragenan den Tag stellt, die dieser bearbeiten muss. Auch ist ein Jamming der Sendefrequenz
8 2008-01-16/010/INF02/2253

2.3 RFID Technologie
des Tags möglich, so dass die Kommunikation des Tags unterbunden werden kann. Daskann auch bei passiven Tags passieren, jedoch wird bei den aktiven Tags Energie ausder Batterie verbraucht, ohne das eine Informationsübertragung erfolgt. Die Probleme desRessourcenerschöpfens muss durch die Programmierung des Tags berücksichtigt werden.
Im Allgemeinen ist es erstrebenswert passive Tags einzusetzen, da diese billiger und we-niger anfällig sind. Nur in speziellen Anwendungsgebieten, in denen zum Beispiel groÿeAuslesereichweiten notwendig sind und der Preis der Tags von nicht entscheidender Wich-tigkeit ist, werden aktive Tags eingesetzt. Ein Beispiel für diesen Einsatz ist die Verwendungvon aktiven Tags zur Identi�kation von Schi�scontainern.
Zugri�sverfahren Ein Zugri�sverfahren ist notwendig, damit bei mehreren Tags im Be-reich des Lesegerätes einzelne Tags selektiert und mit diesen kommuniziert werden kann.Für das MAC Protokoll existieren im Standard ISO 14443 für RFID Tags zwei verschiedeneVerfahren [1]. Zum Einen das Aloha Verfahren und zum Anderen das Tree-Walking Verfah-ren. Wenn die Kommunikation von den Tags gesteuert wird, also dezentral, wird meist dasAloha Verfahren verwendet. Wenn aber wie in dem hier betrachteten Fall das Lesegerät dieTags ausliest, also zentral, wird meist das Tree-Walking Verfahren verwendet. Das AlohaVerfahren funktioniert auf folgende Weise. Das Lesegerät sendet ein Anfrage-Kommando analle Tags. Die Tags antworten auf die Anfrage nach einer jeweils zufälligen Verzögerung mitder eigenen ID. Dabei kann es zu Kollisionen kommen. Diese treten jedoch selten auf, weildie Zeit für das Senden der eigenen ID viel kleiner ist als die Zykluszeit des Vorgang, ausdem die zufällige Wartezeit bestimmt ist. Wenn bei dem Vorgang eine Kollision aufgetretenist, wird der Zyklus wiederholt bis alle Tags identi�ziert wurden. Damit bei den folgen-den Zyklen die Kollisionswahrscheinlichkeit sinkt, kann das Lesegerät bereit identi�zierteTags anweisen, nicht erneut die ID auf die Anfrage auszusenden. Das Aloha Verfahren mitdem die weiteren Daten transportiert werden, ist wie bekannt nicht sehr e�zient. Das istjedoch kein groÿer Nachteil, weil die Menge der kommunizierten Daten relativ gering ist.Das andere benutzte Verfahren ist das Tree-Walking Verfahren. Dieses Verfahren arbeitetiterativ auf einem binären Suchbaum, der durch die IDs repräsentiert wird. Das Lesegerätsendet zunächst eine Identi�zierungsanfrage. Die Anfrage enthält dabei die ID, die gesuchtwerden soll und eine Bitmaske wie viele hochwertige Bits der ID gültig sind. Das ergibtden gesuchten Prä�x der IDs. Die Anfrage wird von allen Tags verarbeitet und von denTags, auf die der Prä�x zutri�t, wird die eigene ID gesendet. Wenn dabei eine Kollisionauftritt, kann das Lesegerät das erste Bit bei dem die Kollision auftritt erkennen. Bei einerKollision weiÿ das Lesegerät, dass mehrere Tags das gleiche Prä�x wie das Angegebenehaben. Um die Kollision aufzulösen, wird nun erneut eine Anfrage gesendet. Diese enthältnun den bisher bekannten Prä�x der um eins verlängert wurde. Wenn nun keine Kollisio-nen mehr auftreten, kann die einzige ID in dem Teilbaum ermittelt werden. Falls wiederKollisionen auftreten, geht die Suche wie eben in diesem Teilbaum weiter. Nachdem dereine Teilbaum fertig durchsucht wurde, wird mit dem anderen Teilbaum gleich verfahren,indem die vorhin hinzugefügten Bits des Prä�xes geändert werden und der ganze Vorgangin dem Teilbaum wiederholt wird, bis keine Kollisionen mehr auftreten und damit alle Tagsidenti�ziert werden. Der Vorgang ist als Beispiel in Abbildung 2.3 illustriert.
Das Tree-Walking wird beim Vorgang nur zur Suche der in Bereich des Lesegerät vor-handenen Tags benutzt. Wenn das Tag, auf das zugegri�en wird, bekannt ist, wird diesesmittels einer Auswahlanfrage mit der kompletten ID ausgewählt. Die Anfrage verarbei-ten alle Tags. Nur der ausgewählte Tag antwortet dann auf alle folgenden Anfragen. Alleanderen Tags verhalten sich ruhig, bis diese ebenfalls selektiert werden oder eine neueSuchanfrage erhalten. Durch das Verfahren wird sichergestellt, dass das Lesegerät immernur mit einem RFID Tag kommuniziert.
2008-01-16/010/INF02/2253 9

2 Grundlagen
Abbildung 2.3: Beispiel zur Suche von 1010 mittels Tree-Walking [6]
Betriebsart Wie im Abschnitt Speichermedium dargestellt, existieren verschiedene Artenvon Tags. Von den einen Tags kann nur gelesen werden, während auf die andere Art derTags auch geschrieben werden kann. Die Art der Unterscheidung hat auch Auswirkungenauf den Ort, wo die Daten zu den entsprechenden Tags gespeichert werden und damit aufdie Betriebsart. Unterschieden wird hierbei zwischen Data-on-Network und Data-on-Tag.Beim Ersteren werden die Daten auf Servern im Netzwerk gespeichert. Dabei wird diefeste ID des Tag als Schlüssel für eine zentrale Datenbank verwendet, in der alle Daten zudem Tag gespeichert werden. Auf dem Tag selbst sind keine Daten gespeichert. Die andereBetriebsrat ist Data-on-Tag. Hierbei werden alle Daten direkt auf dem Tag gespeichert.Dazu ist ein wiederbeschreibbarer Tag notwendig. Das hat den Vorteil, dass keine Netzwer-kinfrastruktur notwendig ist, um den Tag auszulesen. Nachteilig daran ist aber, dass jederdie Daten lesen kann, der den Tag hat. Das sind die beiden Hauptbetriebsarten. Es exis-tieren auch Mischversionen, wo nur Teile der Daten auf dem Tag gespeichert sind und derRest auf Servern im Netzwerk. Aus der Betriebsart ergeben sich auch sicherheitstechnischeAspekte. Diese Aspekte werden im separatem Abschnitt 3.3 behandelt.
Vergleich RFID und Barcode Der Barcode ist die zur Zeit meist verwendete Auto IDTechnologie. Es ist günstig in der Herstellung und kann durch Sichtkontakt ausgelesenwerden. Nach dem Auslesen des Barcode wird dann mittels der erhaltenen ID in einerzentralen Datenbank die gesuchte Information gelesen oder dem Barcode eine bestimmteInformation zugeordnet. Die Arbeitsweise kommt der RFID Technologie in der BetriebsartData-on-Network sehr nahe. Der einzige wesentliche Unterschied und der Vorteil der RFIDTechnologie ist, dass kein Sichtkontakt zum Auslesen der ID notwendig ist. Dadurch istein schnelleres Auslesen mehrerer IDs, zum Beispiel einer Palette, möglich. Das kein Sicht-kontakt notwendig ist, hat aber auch Sicherheitsprobleme. So kann jeder, der ein Lesegerätin Reichweite der RFID Tags hat, die ID auslesen. Durch die nahe Verwandtschaft beimZugri�svorgang und die geringen Kosten von nur lesbaren RFID Tags, ersetzt die RFIDTechnologie teilweise kontinuierlich den Barcode als Auto ID Technologie. Weitere Vorteilebezüglich der Lokalität der gespeicherten Daten und damit die Verhinderung eines zen-tralen Datenpools wird erst durch die RFID Technologie in der Betriebsart Data-on-Tagermöglicht.
10 2008-01-16/010/INF02/2253

2.4 GNY Logik
Zusammenfassung Die verschiedenen Eigenschaften der RFID Technologie haben ver-schiedene Auswirkungen. Die wesentliche Eigenschaft der RFID Technologie ist, dass einAuslesen und Beschreiben ohne Sichtkontakt über einen begrenzten Abstand zum Lesege-rät möglich ist. Deshalb muss eine geeignete Zugri�skontrolle und ein Kommunikations-protokoll entwickelt werden, damit nur berechtige Teilnehmer sicher auf zugelassene Datenzugreifen können. Eine weitere wesentliche Eigenschaft ist, das die Identi�kation der Tagsmit einer ID vorgenommen wird. Da, wenn die ID fest ist, Bewegungspro�le erstellt wer-den können, ist ein Verfahren zu entwickeln, dass eine Pseudoanonymisierung ermöglicht.Weiter ist wichtig, dass durch den geringen Energieverbrauch bestimmt die Tags eine re-lativ geringe Funktionalität und wenig Speicherplatz haben. Dies müssen alle entwickeltenVerfahren berücksichtigen. Die Betriebsart der Tags hat einen wichtigen Ein�uss auf dieVerfahren, wobei die Betriebsart Data-on-Tag mehr Flexibilität und eine bessere Pseudo-anonymisierung ermöglicht.
2.4 GNY Logik
Für die Kommunikation zwischen verschiedenen Teilnehmern sind Protokolle notwendig,damit die Kommunikation erfolgreich funktioniert. Die Funktionalität der entwickeltenProtokolle kann relativ leicht überprüft werden. Die Überprüfung der Protokolle auf Si-cherheit und eventuelle Schwachstellen erweist sich jedoch als schwierig. So hatte das ersteNeedham-Schroeder Protokoll eine Schwachstelle [8]. Um das Finden von Fehlern zu er-leichtern wurden formale Überprüfungsmethoden entwickelt. Eine solche Methode ist dieBAN Logik. Eine Weiterentwicklung ist die in dieser Arbeit verwendete GNY Logik [12].Mit Hilfe von formalen Regeln kann auf gewünschte Ziele geschlossen werden. Dabei wer-den auch gleich die notwendigen Vorbedingungen sichtbar. In der GNY Logik existierenFormeln und Aussagen. Die Formeln sind noch einmal unterteilt. Zum einen die norma-len Formeln und und Formeln, die nicht vom Empfänger kommen. Die zweiten Formelnsind eine Teilmenge der normalen Formeln. Formeln sind dabei Variable die auf einenBitstring verweisen. Wenn zwei Formeln X und Y existieren, ist auch (X,Y) eine Formel.Eine Ver- und Entschlüsselung der Formeln ist ebenfalls möglich (XK , X
−1K ). Das gilt auch
für asymmetrische Kryptographie. Eine weitere mögliche Operation ist das Bilden einerEinweg Hashfunktion H(X). Zum Schluss existiert noch eine leicht umkehrbare und bi-jektive Funktion F (X). Mit Hilfe dieser Formeln können Aussagen dargestellt werden. Esexistieren acht grundsätzliche Arten von Aussagen. Diese Arten werden jetzt dargestellt.P /X: P erhält die Formel X. Entweder kann P X direkt erhalten, oder X entsteht durch
das Ausführen einer Funktion auf das Erhaltende, zum Beispiel eine Entschlüsselung.P 3 X: P besitzt Formel X. Das heiÿt, dass P hat vor dem aktuelle Schritt X von
jemandem erhalten, oder X besitzt die Information seit Beginn der Sitzung. Eine weitereMöglichkeit ist, dass P X selbst erzeugt hat und X damit auch besitzt.P |∼X: P hat X gesendet. Dabei kann X eine Nachricht selbst sein, oder X aus der
Nachricht errechnet worden sein.P |≡ ](X): P glaubt, dass X frisch ist. Das heiÿt, X wurde bis jetzt noch nicht für die
gleiche Funktion im aktuellen Protokolllauf verwendet. Meist dient die Eigenschaft zurErkennung von Wiedereinspielungen, da dort die Frische nicht gegeben ist. Zufallszahlenoder Zeitstempel erfüllen diese Eigenschaft.P |≡φ(X): P glaubt, dass X erkennbar ist. X ist erkennbar, wenn P vorher bestimmte
Teile von X kennt und damit X von zufälligen Bitmustern unterscheiden kann. Die er-kennbaren Teile können zum Beispiel Bezeichner der Teilnehmer sein, die an erwartetenPositionen stehen.P |≡P S←→ Q: P glaubt an ein geeignetes Geheimnis zwischen P und Q. S ist dabei nur
den beiden Partnern und eventuell einem vertrauenswürdigem Dritten bekannt.
2008-01-16/010/INF02/2253 11

2 Grundlagen
P |≡ +K7→ Q: P glaubt an den ö�entlichen Schlüssel von Q. Diese Bedingung ist erfülltwenn sichergestellt ist, dass der ö�entliche Schlüssel, den P hat, auch der richtige ö�entlicheSchlüssel von Q ist. Der private Schlüssel von Q wird nicht ö�entlich. Deshalb gilt dieAussage mit dem privaten Schlüssel von Q nicht.P |≡C: P glaubt an C. Da heiÿt, dass P glaubt, dass C korrekt ist.Die Letzte verwendete Grundform sind Formeln, die nicht vom Empfänger kommen
und neu sind. Die Formeln sind deshalb vom Empfänger nicht bekannt. Dargestellt wirddies durch einen Stern vor einer Formel ?X. Die Erzeugung der Sternchen erfolgt bei derFormalisierung des Protokolls.Mit den Grundbestandteilen ist es mit den logischen Regeln und Postulaten möglich
Folgerungen zu ziehen. Alle diese Regeln sind im Anhang 5 dargestellt. Bevor das jedochmöglich ist, muss das Protokoll formalisiert werden. Dazu wird jede einzelne Nachrichtin zwei formalisierte Teile aufgespaltet. Wenn A eine Nachricht X an B sendet (A->B:X) erfolgt folgende Auftrennung. A sendet X (A |∼X) und B empfängt X B / X. DieserVorgang wird für alle Nachrichten durchgeführt. Nachdem das erfolgt ist, wird der Sternfür die Frische der Formeln eingefügt. Dazu wird geschaut, ob die jeweilige Teilformel schonbeim Empfänger bekannt ist. Wenn nein, ist dieser Teil neu und erhält damit den Stern,andernfalls nicht. Zum Schluss werden alle Zeilen gelöscht, die das Senden von Nachrichtenbeinhalten (A |∼X). Nur die Teile, die dem Empfang der Nachrichten enthalten, bleibenbestehen (B / X).Mit dem formalisierten Protokoll sind nun Untersuchungen mit der GNY möglich. Da-
mit die Ergebnisse benutzt werden können um die Ziele nachzuweisen, müssen die Zielezunächst auch formalisiert werden. Das erfolgt durch die Aufstellung von entsprechendenAussagen aus den Anforderungen.Die GNY Logik ist ein geeignetes Mittel zur Untersuchung von Protokollen. Es ist aber
kein mathematischer Beweis der Korrektheit der Protokolle, jedoch wurden in der Vergan-genheit Fehler in diesen mit Hilfe der GNY Logik gefunden. Wenn ein Fehler mit Hilfeder Logik gefunden wurde existiert dieser auch. Wenn kein Fehler gefunden wird, heiÿt esnicht, dass kein Fehler vorhanden sein kann.
2.5 Datenstrukturen
In Kapitel 7 werden zur Lösung der in Abschnitt 3.2 aufgestellten quantitativen Fragenverschiedene Datenstrukturen evaluiert. Dafür werden herkömmliche Datenstrukturen derInformatik gewählt, die im Hinblick auf das spezielle Zugri�smuster des noch zu entwi-ckelnden Szenarios untersucht werden. Da es bekannte Datenstrukturen sind, werden siein diesem Kapitel dargestellt. Verwendet werden der Binärbaum, der B+-Baum und ver-schiedene Hashtabellen. Für die notwendige Sondierung wird zum einen die Verkettungund zum anderen das lineare Sondieren benutzt. Beim Verfahren mit linearem Sondierenwird neben einer normalen Hashtabelle auch ein Tabelle mit Subhashtabellen benutzt, inder jeweils zwei Verschiedene Löschverfahren benutzt werden.
2.5.1 Binärbaum
Der Binärbaum ist eine einfache und häu�g verwendete Art eines Baumes. Durch seineEinfachheit und hohe E�zienz wird er oft als Hauptspeicherdatenstruktur eingesetzt. Des-halb wurde der Baum für die Simulation verwendet. Der Baum dient dabei als Vergleich füreine Standarddatenstruktur. Der Vorteil des Binärbaumes ist, dass er mit jeder Baumebenedie Anzahl der darin enthaltenden Datenelemente halbiert, wenn der Baum nicht entartet.Wenn das Einfügen und Löschen von Daten an zufälligen Stellen geschieht, entartet derBaum nicht, so dass die Zugri�szeit von O(log2n) entsteht. Ein einzelner Knoten besteht
12 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
aus einem Vergleichselement, den Verweisen auf die beiden Nachfolger und dem Verweisauf die Daten zu dem Vergleichselement. Das Suchen einer Elementes erfolgt dabei aufeinfache Weise. Es wird das zu suchende Element immer mit dem Vergleichselement desaktuellen Knoten verglichen. Wenn die Werte gleich sind, ist das Element gefunden. Fallsnicht, wird rekursiv im linken Teilbaum weiter gesucht, falls das gesuchte Element kleinerals das Vergleichselement ist, andernfalls im rechten Teilbaum. Wenn das Element bishernicht gefunden wurde und der nächste Knoten nicht vorhanden ist, weil der Baum dortzu Ende ist, ist das Element nicht im Baum vorhanden. Der Pseudocode für den Vorgangist in Listing 2.1 enthalten. Das einzufügende Element ist jeweils �idP�. Die Daten auf die�idP� verweisen soll, werden durch �tag� dargestellt.
Listing 2.1: Suche einer Pseudo ID im Binärbaum1 BinIndexAuth::posStruct BinIndexAuth::lookup(char idP[10]){2 posStruct pos;3 pos.father = NULL;4 pos.el = NULL;5 if (bRoot == NULL){6 return pos;7 } else {8 binIndex ∗el = bRoot;9 while (el != NULL){10 pos.el=el;11 if (!memcmp(el−>idP, idP, 10)){12 return pos;13 } else if (memcmp(idP, el−>idP, 10) < 0) {14 pos.father=el;15 el = el−>left;16 } else if (memcmp(idP, el−>idP, 10) > 0){17 pos.father=el;18 el = el−>right;19 }20 }21 if (el == NULL){22 pos.el = NULL;23 pos.father = NULL;24 }25 }26 return pos;27 }
Eine weitere notwendige Operation ist neben dem Suchen eines Elementes das Einfügeneines Elementes. Hier wird zunächst wie eben das Element gesucht. Falls das Elementgefunden wurde, ist das Element schon enthalten und es muss geprüft werden, ob es nureine Kollision des Elementes ist. Wenn ja wird weiter gesucht, als ob das Element nichtschon vorhanden ist. Zum Schluss des Vorgangs ist man in einem Knoten, der keinenNachfolger da hat, wo das einzufügende Element stehen muss. An diese Stelle wird nun einneuer Knoten erzeugt, der das einzufügende Element enthält. Der Pseudocode dafür ist inListing 2.2 zu sehen.
Listing 2.2: Einfügen einer Pseudo ID im Binärbaum1 bool BinIndexAuth::insert(char idP[10], tagStruct ∗ tag){2 if (bRoot == NULL){3 bRoot = new binIndex();4 memcpy(bRoot−>idP, idP, 10);5 bRoot−>tag = tag;6 bRoot−>left = NULL;7 bRoot−>right = NULL;8 } else {9 binIndex ∗father = NULL, ∗el = bRoot;10 while (el != NULL){11 if (!memcmp(el−>idP, idP, 10)){12 return false;13 } else if (memcmp(idP, el−>idP, 10) < 0){14 father = el;15 el = el−>left;
2008-01-16/010/INF02/2253 13

2 Grundlagen
16 } else {17 father = el;18 el = el−>right;19 }20 }21 el = father;22 if (memcmp(idP, el−>idP, 10) < 0){23 el−>left = new binIndex();24 el = el−>left;25 } else {26 el−>right = new binIndex();27 el = el−>right;28 }29 memcpy(el−>idP, idP, 10);30 el−>tag = tag;31 el−>left = NULL;32 el−>right = NULL;33 }34 return true;35 }
Die letzte notwendige Operation ist das Löschen eines Elementes. Dazu wird zunächst derKnoten des Elementes gesucht. Hier sind nun verschiedene Fälle zu unterscheiden. Wennder Knoten keinen Nachfolger hat, dann wird der Knoten einfach gelöscht und im Vater desKnoten wird der Verweis auf ihn gelöscht. Wenn der Knoten nur einen Nachfolger hat, kannder zu löschende Knoten einfach entfernt werden und im Vater des zu löschenden Knotenwird der Knoten durch den einzigen Nachfolger des Knoten ersetzt. Der schwierigste Fallist das Löschen des Knoten, wenn er zwei Nachfolger hat. Eine Version ist das Ersetztendes Knoten durch das kleinste Element im rechten Teilbaum. Dazu wird der jeweiligeKnoten gesucht. Das Element dieses Knoten wird dann als Datum in den zu löschendenKnoten eingetragen. Jetzt muss an der ehemaligen Position noch die Verlinkung angepasstwerden. Wenn der ehemalige Knoten keinen rechten Nachfolger hat, kann der Knoteneinfach gelöscht werden und damit auch die Verlinkung des Vaters gelöscht werden. Wennder Knoten einen rechten Nachfolger hat, wird der Nachfolger des Knoten als Nachfolgerdes Vaters gesetzt. In Listing 2.3 ist des dazugehörige Pseudocode.
Listing 2.3: Löschen einer Pseudo ID im Binärbaum
1 bool BinIndexAuth::remove(char idP[10]){2 posStruct pos;3 pos.father = NULL;4 pos.el = bRoot;5 if (bRoot == NULL)6 return false;7 }8 binIndex ∗father = pos.father, ∗el = pos.el;9 bool found = false;10 while (el != NULL){11 if (!memcmp(el−>idP, idP,10)){12 found = true;13 if (el−>left == NULL && el−>right == NULL){14 // keine Nachfolger15 lösche Knoten16 entferne Knoten aus Verweisen des Vaters17 } else if (el−>left != NULL && el−>right != NULL){18 // zwei Nachfolger vorhanden19 A = Suche im rechten Teilbaum das kleinste Element (unteres linkes Ende im Baum)20 Füge das Vergleichselement von A in den zu löschenden Knoten ein21 entferne Knoten der A enthielt, wenn A keinen weiteren Nachfolger hat,22 sonst füge rechten Nachfolger des Knoten A als Nachfolger des Vater des Knoten A23 } else if (el−>left == NULL){24 // nur rechter Nachfolger25 entferne den Knoten26 Setze rechten Teilbaum direkt als Nachfolger des Vaters des zu löschenden Knoten27 } else if (el−>right == NULL){28 // nur linker Nachfolger29 entferne den Knoten30 Setze linken Teilbaum direkt als Nachfolger des Vaters des zu löschenden Knoten
14 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
31 }32 break;33 } else if (memcmp(idP, el−>idP, 10) < 0){34 father = el;35 el = el−>left;36 } else {37 father = el;38 el = el−>right;39 }40 }41 return found;42 }
2.5.2 B+-Baum
Die B-Bäume sind eine Standarddatenstruktur für Datenbanken. Die Knotengröÿe ist da-bei auf die Blockgröÿe des Datenträgers optimiert, das heiÿt ein Knoten hat die maximalmögliche Anzahl an Vergleichselementen, die in den Knoten mit der gegebenen Blockgrö-ÿe passen. Die B-Bäume sind balancierte Bäume. Bei der späteren Evaluierung wird derB+-Baum verwendet. Er zeichnet sich dadurch aus, dass ein Knoten aus mehreren Ver-gleichselementen besteht und dass die Daten nur in den Blättern gespeichert werden unddie inneren Knoten nur zur Lokalisation der richtigen Blätter verwendet werden.Die Suche in einem B+-Baum ist noch relativ einfach. Es wird in jedem Knoten folgendes
durchgeführt. In einem inneren Knoten wird mit Hilfe der Vergleichselemente gesucht,welcher Knoten der richtige Nachfolger für den gesuchten Wert ist. Das wird mit jedemweiteren inneren Knoten gemacht, bis der aktuelle Knoten ein Blatt ist. Hier wird nunermittelt, ob das gesuchte Element vorhanden ist. Wenn ja wird es zurückgegeben, wennnein ist der Wert nicht enthalten und auch dies wird zurückgegeben. Der Pseudocode dafürist in Listing 2.4 zu sehen.
Listing 2.4: Suche einer Pseudo ID im B+-Baum
1 BPlusAuth::posStruct BPlusAuth::lookup(char idP[10]){2 // init the pos of the searched element to not in tree3 posStruct pos;4 pos.el = NULL;5 pos.number = −1;6 if (bRoot == NULL){7 // if tree empty elemnt not in tree8 return pos;9 } else {10 // if element in tree do normal lookup like in an binary tree11 bPlusIndex ∗el = bRoot;12 while (el != NULL){13 pos.el = el;14 if (! el−>leaf){15 // if node is an inner node search the next node to use to �nd the idP16 for(int i=0; i<el−>count; i++){17 if (memcmp(idP, el−>idP[i],10) < 1){18 el = el−>childs[i ];19 break;20 }21 }22 if (pos.el == el && memcmp(idP, el−>idP[el−>count−1], 10) == 1){23 el = el−>childs[el−>count];24 }25 } else {26 // if node is a leaf , search the exact idP in the node and return the position of it27 char nullK[16];28 memset(nullK, 0, 16);29 for(int i=0; i<el−>count; i++){30 if (!memcmp(idP, el−>idP[i], 10)){31 pos.el = el;32 pos.number = i;33 return pos;34 }
2008-01-16/010/INF02/2253 15

2 Grundlagen
35 }36 pos.el = el;37 pos.number = −1;38 return pos;39 }40 }41 }42 return pos;43 }
Das Einfügen und Löschen von Elementen aus dem B+-Baum ist komplexer. Die Kom-plexität ergibt sich durch eventuell notwendige Änderungen an einzelnen Knoten im Baum.Zunächst wird mittels des Lookup gesucht, an welcher Stelle im Baum das neue Elementeingefügt werden muss. Wenn das Blatt schon vorhanden ist, wird das neue Element andie richtige Stelle des Blattes eingefügt und die restlichen Daten des Knoten dabei nachrechts verschoben. Wenn im Blatt jetzt nicht zu viele Daten sind, ist der Vorgang beendet.Wenn der Knoten aber zu groÿ ist, muss der Knoten aufgeteilt werden. Dazu dient �split-node�. Es teilt den Knoten in zwei Knoten auf, die jeweils die Hälfte der Daten enthaltenund fügt den neuen Knoten beim Vater ein. Dieser Vorgang wird solange mit den Väternfortgeführt, bis nicht mehr zu viele Elemente in den Knoten sind. Der Pseudocode dazuist in Listing 2.5 zu sehen.
Listing 2.5: Aufteilung eines Knoten im B+-Baum
1 void BPlusAuth::splitNode(bPlusIndex ∗ left){2 // compute the split postion of the node and create an new one and set the global attributes of the node3 int splitPos = (left−>count / 2) + (left−>count % 2);4 bPlusIndex ∗ right = createNode();5 right−>leaf = left−>leaf;6 right−>father = left−>father;7 // divide the node to split by copying all the data after the splitpos to the new node and deleating it from
the old8 int max = left−>count;9 for (int i=splitPos; i < max; i++){10 verschiebe alle Daten ab der Splitposition in den neuen Knoten11 }12 // the same as above for the most right child13 right−>childs[max−splitPos] = left−>childs[max];14 left−>childs[max] = NULL;15 if (right−>childs[max−splitPos] != NULL)16 right−>childs[max−splitPos]−>father = right;1718 if ( left−>father == NULL){19 // if the node to split has no father create one and insert the new left and new right node in it20 bPlusIndex ∗ father = createNode();21 father−>leaf = false;22 father−>count = 1;23 memcpy(father−>idP[0], left−>idP[splitPos−1], 10);24 father−>childs[0] = left ;25 father−>childs[1] = right;26 if (! left−>leaf){27 // if the left node is an inner node the most right element can be removed because its right child is28 // now the most left child of the right node29 left−>count−−;30 memset(left−>idP[left−>count], '\0', 10);31 left−>childs[left−>count+1]=NULL;32 }33 bRoot = father;34 left−>father = father;35 right−>father = father;36 } else {37 // if the node to split has a father , insert the new right node into it , it the same way as in method "
insert"38 bPlusIndex ∗ father = left−>father;39 int ∗ maxPos = &(father−>count);40 int pos = ∗maxPos;41 char idP[10];42 memcpy(idP, left−>idP[left−>count−1], 10);43 for(int i=0; i < ∗maxPos; i++){
16 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
44 if (memcmp(idP, father−>idP[i], 10) < 1){45 pos = i;46 break;47 }48 }49 for (int i=∗maxPos; i>pos; i−−){50 memcpy(father−>idP[i], father−>idP[i−1], 10);51 father−>childs[i+1] = father−>childs[i];52 }53 memcpy(father−>idP[pos], idP, 10);54 father−>childs[pos] = left ;55 father−>childs[pos+1] = right;56 (∗maxPos)++;5758 if (! left−>leaf){59 // if the left node is an inner node the most right element can be removed because its right child is60 // now the most left child of the right node61 left−>count−−;62 memset(left−>idP[left−>count], '\0', 10);63 left−>childs[left−>count+1]=NULL;64 }6566 // if father of node to split is now to big, split this node recursive67 if (∗maxPos > bCount)68 splitNode(father) ;69 }70 }
Das Löschen eines Elementes erfolgt ähnlich. Hier muss jedoch nicht der Überlauf, son-dern zunächst ein auftretenden Unterlauf behandelt werden. Zunächst wird mittels Lookupder Knoten gesucht, in dem der zu löschende Wert ist. Danach wird der Wert aus dem Kno-ten gelöscht und alle nachfolgenden Werte um eins nach links geschoben. Zum Schluss wirdgeprüft, ob der Knoten noch mehr oder gleich der Hälfte der maximal möglichen Elementehat. Wenn ja ist der Vorgang beendet. Wenn nein wird mittels �mergenode� der Unterlaufbehandelt. Der Pseudocode für das Löschen ist in Listing 2.6 zu sehen.
Listing 2.6: Löschen einer Pseudo ID aus dem B+-Baum
1 bool BPlusAuth::remove(char idP[10]){2 // set the start postion to remove a element from the tree to the root3 posStruct pos;4 pos.el = bRoot;5 pos.number = −1;6 // if the given position , where the elemnt to delete is , search this position7 pos = lookup(idP);8 bPlusIndex ∗ node = pos.el;9 // delete the data in the node and copy the data after the position one step forward for valid node structure10 memset(node−>idP[pos.number], '\0', 10);11 node−>count−−;12 for (int i=pos.number; i<node−>count; i++){13 memcpy(node−>idP[i], node−>idP[i+1], 10);14 node−>tags[i] = node−>tags[i+1];15 }16 memset(node−>idP[node−>count], '\0', 10);17 node−>tags[node−>count] = NULL;1819 // if the tree is empty, delete it20 if (bRoot == node && node−>count==0){21 deleteNode(node);22 //delete bRoot;23 bRoot = NULL;24 }2526 // if the node is now to small after deleteing an element, merge it with an other node27 if (node && node−>count < bCount/2)28 mergeNode(node);2930 return true;31 }
2008-01-16/010/INF02/2253 17

2 Grundlagen
Der Vorgang des Zusammenführen mehrerer Knoten ist folgender. Zunächst wird derKnoten ermittelt, mit dem der aktuelle Knoten zusammengeführt wird. Hier wird derKnoten links vom aktuellen Knoten angenommen, wenn dieser vorhanden ist. Sonst wirdder rechte Knoten benutzt. Wenn der Knoten kein Blatt ist, muss für das Zusammenfügender beiden Knoten zunächst ein neu einzufügendes Vergleichselement gesucht werden. Dasist hier das am weitesten rechte Element im linken Teilbaum. Jetzt werden alle Daten desrechten Knoten in den linken Knoten verschoben. Danach wird der Vater entsprechendangepasst, in dem der rechte Knoten entfernt wird und der Knoten dann aktualisiert wird.Dabei muss beachtet werden, ob der Vater jetzt nicht mehr benötigt wird. Das ist der Fall,wenn der Vater die Wurzel des Baumes ist und nun nur noch einen Nachfolger enthält.Dann ist der Knoten über�üssig und kann gelöscht werden. Damit hat der Baum eine neueWurzel und die Höhe des Baumes ist um eins gesunken. Nachdem alle Schritte durchgeführtwurden, müssen nun wieder die Randbedingungen der Knoten überprüft und gegebenenfallsangepasst werden. Wenn der zusammengeführte Knoten jetzt zu groÿ ist, muss es mittels�splitNode� aufgeteilt werden. Dadurch, dass ein Nachfolger aus dem Vater entfernt wurde,kann dort ebenfalls ein Unterlauf auftreten. Dieser wird wieder mit �mergeNode� behoben.Die Aufrufe erfolgen dabei rekursiv, bis alle Bedingungen erfüllt sind. Der Pseudocode für�mergeNode� ist in Listing 2.7 zu sehen.
Listing 2.7: Zusammenführen mehrerer Knoten im B+-Baum1 void BPlusAuth::mergeNode(bPlusIndex ∗ el){2 // to merge a node search the node left to the merge node and if no one there choose the right one (in the
father)3 bPlusIndex ∗ father = el−>father;4 if (father == NULL)5 return;6 int pos = −1;7 for (int i=0; i<father−>count+1; i++){8 if (father−>childs[i] == el){9 pos = i;10 break;11 }12 }13 int leftPos = −1;14 int rightPos = −1;15 bPlusIndex ∗ leftEl = NULL;16 bPlusIndex ∗ rightEl = NULL;17 if (pos>0){18 leftPos = pos−1;19 rightPos = pos;20 } else {21 leftPos = pos;22 rightPos = pos+1;23 }2425 leftEl = father−>childs[leftPos];26 rightEl = father−>childs[rightPos];2728 // if the node to merge is not a leaf , search and insert the most right element in the left subtree29 // for using it as new split element in the merged node30 if (! el−>leaf){31 bPlusIndex ∗ temp = leftEl;32 char idP[10];33 while (temp != NULL && temp−>count > 0){34 memcpy(idP, temp−>idP[temp−>count−1], 10);35 temp = temp−>childs[temp−>count];36 }37 char nullC[10];38 memset(nullC, 0, 10);39 if (!memcmp(idP, nullC, 10))40 memcpy(idP, father−>idP[leftPos], 10);41 memcpy(leftEl−>idP[leftEl−>count], idP, 10);42 leftEl−>count++;43 }44 // copy all data of the right node to the left one45 int leftCount = leftEl−>count;
18 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
46 int rightCount = rightEl−>count;47 for (int i=leftCount; i<leftCount+rightCount; i++){48 kopiere alle Elemente vom rechten Knoten in den linken Knoten und passe die Verweise auf die Kinder an49 }50 if (! leftEl−>leaf){51 // set last references right52 leftEl−>childs[leftEl−>count] = rightEl−>childs[rightCount];53 leftEl−>childs[leftEl−>count]−>father = leftEl; // set new father of the child of the old right node54 }5556 // update father after merging the node − delete idP between the left and right node and move all elements
right of left node one to left57 for (int i=leftPos; i<father−>count−1; i++){58 memcpy(father−>idP[i], father−>idP[i+1], 10);59 father−>childs[i+1] = father−>childs[i+2];60 }61 if (father−>childs[father−>count] == NULL){62 memset(father−>idP[father−>count−1], '\0', 10);63 }6465 // if father had more than one element or is not the root adjust parameters of the father ,66 // else the root node has only one element and can be deleted and the merged node is the new root67 if (father−>count > 1 || father−>father != NULL){68 father−>count−−;69 memset(father−>idP[father−>count], '\0', 10);70 father−>childs[father−>count+1] = NULL;71 } else {72 bRoot = leftEl;73 deleteNode(father);74 father = NULL;75 leftEl−>father = NULL;76 }7778 // delete now unused node79 deleteNode(rightEl);80 rightEl = NULL;8182 //if node is now to big split it83 if ( leftEl−>count > bCount)84 splitNode( leftEl ) ;8586 // if the father of the merged node is now to small merge it recursivly87 if (father != NULL && father−>count < bCount/2)88 mergeNode(father);89 }
2.5.3 Hashtabelle mit Verkettung
Eine Hashtabelle ist eine häu�g eingesetzte Datenstruktur. Im Arbeitsspeicher wird dabeihäu�g die Variante gewählt, die Kollisionen mit Hilfe der Verkettung au�öst. Die E�zienzder Datenstruktur hängt dabei bei einer geeigneten Hashfunktion nur von dem Füllungs-grad ab. Je höher dieser ist, desto mehr Kollisionen treten auf, die aufgelöst werden müssen.Damit wächst dann die Anzahl der Elemente in einem Korb und somit sinkt die E�zienz.Bei geeigneter Gröÿe ist ein durchschnittlicher Aufwand für den Zugri� von O(1) zu er-warten.Neben der Hashfunktion sind keine weiteren schwierigen Operationen notwendig. Beim
Lookup wird zunächst mittels der Hashfunktion die erwartete Position des Elementes er-mittelt. Dann wird an die entsprechende Stelle geschaut. Dabei wird die ganze eventuellvorhandene Liste durchsucht, bis das Element gefunden wurde. Wenn es nicht gefundenwurde, ist es nicht enthalten. Zu sehen ist der dazugehörige Pseudocode in Listing 2.8
Listing 2.8: Suche eines Elementes in der Hashtabelle
1 HashAuth::hashEntry HashAuth::lookup(char idP[10]){2 int pos = getHashBucket( numBuckets, idP);3 bucketElement ∗ b = hashTable[pos];4 if (b != NULL){
2008-01-16/010/INF02/2253 19

2 Grundlagen
5 histBucketSize. collect (b−>size());6 for (hashIter = b−>begin(); hashIter != b−>end(); hashIter++){7 if (!memcmp(hashIter−>idP, idP, 10)){8 return ∗hashIter;9 }10 }11 }12 hashEntry erg;13 memset(erg.idP, '\0', 10);14 erg.tag = NULL;15 return erg;16 }
Das Einfügen erfolgt ähnlich, wie das Suchen. Beim Einfügen wird ebenfalls die Stelleberechnet, an die die Zuordnung gehört. Dann wird eine neue Liste erzeugt, oder dasElement an die vorhandene Liste angefügt. Dies ist auch im Pseudocode in Listing 2.9 zusehen.
Listing 2.9: Einfügen eines Elementes in die Hashtabelle1 bool HashAuth::insert(char idP[10], tagStruct ∗ tag){2 int pos = getHashBucket( numBuckets, idP);3 if (hashTable[pos] == NULL){4 hashTable[pos] = new bucketElement;5 }6 hashEntry el;7 memcpy(el.idP, idP, 10);8 el .tag = tag;9 hashTable[pos]−>push_back(el); // bei Statistik Aufwand der Operation beachtet10 return true;11 }
Die letzte notwendige Operation ist das Löschen einer Zuordnung. Dabei wird zunächstwie bei der Suche vorgegangen. Wenn das Element gefunden wurde, wird es aus der Listegelöscht und wenn die Liste leer ist, wird auch die Liste gelöscht. Wenn das Elementnicht in der Hashtabelle ist, kann es auch nicht gelöscht werden. Das wird beachtet undgegebenenfalls zurückgegeben. Der Vorgang ist als Pseudocode in Listing 2.10 dargestellt.
Listing 2.10: Löschen eines Elementes aus der Hashtabelle1 bool HashAuth::remove(char idP[10]){2 int pos = getHashBucket( numBuckets, idP);3 bucketElement ∗ b = hashTable[pos];4 for (hashIter = b−>begin(); hashIter != b−>end(); hashIter++){5 if (!memcmp(hashIter−>idP, idP, 10)){6 b−>erase(hashIter); // Aufwand für Statistik beachtet7 if (b−>size() == 0){8 delete hashTable[pos];9 hashTable[pos] = NULL;10 }11 return true;12 }13 }14 return false;15 }
2.5.4 Hashtabelle mit linearem Sondieren
Eine Hashtabelle hat unter optimalen Bedingungen einen Zugri�saufwand von O(1). DieseZugri�sgeschwindigkeit bleibt erhalten, solange nicht zu viele Kollisionen auftreten. Gene-rell müssen auftretende Kollisionen behandelt werden. Dafür existieren verschiedene Ver-fahren. Die Möglichkeit der Verkettung ist für externe Datenträger nicht geeignet, da dieDaten dann nicht hintereinander liegen, sondern die Festplatte die neue Position anfahrenmuss. Deshalb ist es sinnvoll den externen Datenträger als Feld des Typs Zuordnung zuverwenden. Alle Operationen müssen auf diesem Feld ablaufen, ohne das um viele Posi-tionen gesprungen werden muss. Neben der Verkettung zur Kollisionsau�ösung existieren
20 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
verschiedene Lösungen. Das einfachste Verfahren ist das lineare Sondieren. Bei einer Kol-lision wird einfach in die nächste Speicherstelle geschaut, ob dort frei ist. Wenn nein wirdentsprechend immer ein Zelle weiter geschaut bis eine leere Position gefunden wird. Damitergibt sich eine Suchadresse von 0, +1, +2, ... oder bei wechselseitigem Suchen von 0, -1,+1, -2, +2, ... . Ein weiteres Verfahren ist das quadratische Sondieren. Hier wird bei derAu�ösung von Kollisionen an Positionen mit quadratischem Abstand zur errechneten Posi-tion gesucht. Das ergibt dann Suchadressen von 0, -1, +1, -2, +2, -4, +4, ... . Eine weitereMöglichkeit ist das mehrfache Hashen. Dabei werden mehrere Hashfunktionen h1 bis hxverwendet. Zunächst wird mit h1 die Suchposition ermittelt. Tritt eine Kollision auf, wirddas Element mit h2 gehascht und dort wieder geschaut. Tritt immer noch eine Kollisionauf, wird mit h3 fortgefahren und so weiter. Es ist anzunehmen, dass die letzte Version ambesten streut und das lineare Sondieren am wenigsten E�ektiv ist. Das ist der Fall, jedochist die E�ektivität stark vom Füllungsgrad der Hashtabelle ab. Bei einem nicht sehr hohenFüllungsgrad von 70 bis 80 Prozent, ist das lineare Sondieren nicht wesentlich schlechterals die anderen Verfahren. Zu beachten bei der Auswahl der Kon�iktau�ösung ist auch,dass oft in der Hashtabelle gelöscht werden muss. Dafür existieren verschiedene Lösungen,die in Abschnitt 2.5.4.1 dargestellt werden. Hashtabellen sind auch sehr speicherplatzef-�zient. Es wird zwar mehr Speicherplatz belegt als notwendig, da ein gewisser Freiraumexistieren muss, aber die zu speichernden Daten sind geringer. Es müssen nur die Datenselbst gespeichert werden und nicht wie bei Bäumen die noch dazugehörigen Verweise.Der Füllungsgrad sollte bestenfalls 80 Prozent nicht übersteigen, damit nicht zu viele
Kollisionen auftreten. Nachteilig an einer Hashtabelle ist, dass keine dynamische Gröÿenan-passung möglich ist. Es existieren zwar solche Algorithmen, jedoch werden die Zugri�e dannkomplizierter.
2.5.4.1 Löschstrategie
Wenn im Index sehr oft gelöscht wird, muss dieser Vorgang sehr e�zient sein. Das Löschenvon Einträgen hängt dabei auch von der Art der Au�ösung der Kollisionen ab. Ein einfachesVerfahren ist mit allen Sondierungsarten möglich. Das zweite ist nur mit dem linearenSondieren möglich.Das einfache Verfahren führt ein indirektes Löschen durch. Hierbei wird beim Löschen
der Eintrag nicht direkt gelöscht, sondern als gelöscht markiert. Damit verschwindet derEintrag nicht aus der Tabelle. Beim Einfügen von neuen Elementen können leere und nurals gelöscht markierte Stellen für den Eintrag verwendet werden. Beim Suchen von Datenmuss solange gesucht werden bis das Element gefunden wurde, oder eine leere Positionerreicht ist, oder bis die Tabelle einmal komplett durchlaufen wurde.Das zweite Verfahren löscht die Einträge direkt. Es funktioniert nur bei linearem Son-
dieren. Der Löschvorgang ist dabei etwas komplizierter. Zunächst wird der zu löschendeEintrag einfach gelöscht. Jetzt entsteht das Problem, dass nun nicht mehr alle Elementein der Hashtabelle gefunden werden. Der Grund dafür ist, dass die Elemente bei denenvorher eine Kollision auftrat nicht mehr gefunden werden, weil diese hinter der berech-neten Position stehen, aber vor der Position die erzeugte Leerzelle ist. Deshalb muss dieentstehende Lücke mit einem passenden Element gefüllt werden, damit die Suche weiterfunktioniert. Dazu wird ab der aktuellen Position folgendes ausgeführt. Es werden nachein-ander die erwarteten Positionen der nachfolgenden Elemente berechnet. Wenn das Elementvor oder auf die gelöschte Position passt, wird das Element auf diese Position verschobenund dann der Vorgang mit der neuen leeren Stelle wiederholt. Die Suche nach passendenElementen wird solange fortgesetzt, bis eine leere Position gefunden wurde. Nach dieserPosition kann kein passendes Element gefunden werden, da dann das Element auf der lee-ren Position stehen müsste. Der Vorteil dieses Verfahrens ist, dass beim Löschen immernur lokal begrenzt Operationen ausgeführt werden und dass der Füllungsgrad bei gleich
2008-01-16/010/INF02/2253 21

2 Grundlagen
viel Elementen immer konstant bleibt und nicht wie beim ersten Verfahren ständig steigt.Nachteilig ist jedoch, dass das Verfahren nur bei linearem Sondieren funktioniert. Das istjedoch kein wirklicher Nachteil, da lineares Sondieren bei entsprechenden Füllungsgradennicht signi�kant langsamer ist als die anderen Sondierungsarten.
2.5.4.2 Hashtabelle mit Unterkörben
Da die externen Datenträger in Blöcken aufgeteilt sind, ist es sinnvoll in die Hashtabellenoch kleinere Hashtabellen einzufügen. Auch ist dann das einfache Verfahren des Löschensmöglich, da die einzelnen Unterkörbe klein genug für den Arbeitsspeicher sind und damitdie schnelle Bearbeitung einer Subhashtabelle möglich ist.
Löschen durch Markieren Beim Löschen durch Markieren wird das lineare Sondierenverwendet. Für die Datenstruktur sind wieder die drei Operationen Lookup, Remove undInsert notwendig. Alle diese Operationen sind relativ einfach. Es wird jeweils die erwar-tete Position berechnet und dann entsprechend gehandelt. Beim Lookup wird nach demberechnen des Korbes und des Subkorbes geprüft, ob an dieser Stelle der gewünschte Wertist. Wenn ja ist der Vorgang beendet. Wenn nein wird solange jeweils eine Speicherstelleweiter gesucht, bis der Wert gefunden wurde oder die Zelle wirklich leer ist und nicht nurals gelöscht markiert. Dieser Vorgang ist in Listing 2.11 zu sehen.
Listing 2.11: Suche eines Elementes in der Hashtabelle mit Subkörben 1
1 HashExternHashAuth::hashPos HashExternHashAuth::lookup(char idP[10]){2 hashPos erg;3 int pos = getHashBucket( numBuckets, idP);4 int pos2 = getHashBucket( numSubBuckets, idP);5 erg.bucketNumber = pos;6 erg.subBucketNumber = −1;7 int i=pos2;8 do{9 if (hashTable[pos]. �lledBucketBits [2∗ i /8] & 1<<(i%8)){10 // subBucket �lled11 if (!memcmp(hashTable[pos].el[i].idP, idP, 10)){12 erg.bucketNumber = pos;13 erg.subBucketNumber = i;14 return erg;15 }16 }17 i = (i+1) % numSubBuckets;18 } while (i!=pos2 && ((hashTable[pos].�lledBucketBits[1+2∗i/8] & 1<<(i%8)) > 0));19 return erg;20 }
Das Einfügen funktioniert ähnlich. Es wird zunächst wieder der Korb und Subkorb ermit-telt, wo die Position der einzufügenden Zuordnung ist. Danach wird die erste freie Stelle abdieser Stelle gesucht. Frei zum Einfügen ist entweder eine wirklich leere Stelle oder eine alsgelöscht markierte. Dort wird die neue Zuordnung gespeichert und die Bits zum markierender Zelle als gelöscht und leer entsprechend gesetzt. Der Vorgang wird abgebrochen fallskein freier Platz mehr vorhanden ist. Dies wird der aufrufenden Methode auch mitgeteilt.In Listing 2.12 ist der Code dafür zu sehen.
Listing 2.12: Einfügen eines Elementes in die Hashtabelle mit Subkörben 1
1 bool HashExternHashAuth::insert(char idP[10], tagStruct ∗ tag){2 int pos = getHashBucket( numBuckets, idP);3 int pos2 = getHashBucket(numSubBuckets, idP);4 int i=pos2;5 do{6 if ((hashTable[pos]. �lledBucketBits [2∗ i /8] & 1<<(i%8)) == 0){7 if ((hashTable[pos]. �lledBucketBits [2∗ i/8+1] & 1<<(i%8)) == 0)8 hashTable[pos].numPseudoFilled++;9 hashTable[pos]. �lledBucketBits [2∗ i /8] |= 1<<(i%8);
22 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
10 hashTable[pos]. �lledBucketBits [2∗ i/8+1] |= 1<<(i%8);11 memcpy(hashTable[pos].el[i].idP, idP, 10);12 hashTable[pos].el [ i ]. tag = tag;13 hashTable[pos].numFilled++;14 return true;15 }16 i = (i+1)%numSubBuckets;17 } while (i!=pos2);18 return false;19 }
Beim Löschen wird zunächst wieder die erwartete Position berechnet. Danach wird wiebeim Lookup solange gesucht, bis das Element gefunden wurde. Wenn dabei eine leereStelle auftritt bevor das Element steht oder der ganze Subkorb durchlaufen wurde, wirdder Vorgang abgebrochen, da das Element nicht vorhanden ist. Wenn das Element gefundenwurde, wird die Zelle als gelöscht markiert, aber nicht als leer. Der Vorgang ist in Listing2.13 zu sehen.
Listing 2.13: Löschen eines Elementes in der Hashtabelle mit Subkörben 1
1 bool HashExternHashAuth::remove(char idP[10]){2 int pos = getHashBucket( numBuckets, idP);3 int pos2 = getHashBucket( numSubBuckets, idP);4 int i = pos2;5 do{6 if ((hashTable[pos]. �lledBucketBits [2∗ i /8] & 1<<(i%8)) && !memcmp(hashTable[pos].el[i].idP, idP, 10)){7 hashTable[pos]. �lledBucketBits [2∗ i /8] −= (1<<(i%8));8 memset(hashTable[pos].el[i ]. idP, 0, 10);9 hashTable[pos].el [ i ]. tag = NULL;10 hashTable[pos].numFilled−−;11 return true;12 }13 i = (i+1)%numSubBuckets;14 } while(i!=pos2 && ((hashTable[pos].�lledBucketBits[1+2∗i/8] & 1<<(i%8)) > 0));15 return false;16 }
Direktes Löschen Nachdem das indirekte Löschen betrachtet wurde, wird nun auf dasdirekte Löschen genauer eingegangen. Die Variante, die Elemente direkt aus der Tabellelöscht, benötigt das lineare Sondieren. Die Version arbeitet fast genauso, wie die Versionmit Löschen durch Markieren. Der Lookup ist identisch. Es wird die Position berechnetum danach von dieser Stelle an das Element zu �nden oder eine leere Position zu erkennen.Dann ist klar, dass das Element nicht in der Hashtabelle ist. Der zugehörige Code ist inListing 2.14 zu sehen.
Listing 2.14: Suche eines Elementes in der Hashtabelle mit Subkörben 2
1 HashExternHash2Auth::hashPos HashExternHash2Auth::lookup(char idP[10]){2 hashPos erg;3 int pos = getHashBucket( numBuckets, idP);4 int pos2 = getHashBucket( numSubBuckets, idP);5 erg.bucketNumber = pos;6 erg.subBucketNumber = −1;7 int i=pos2;8 do{9 if (hashTable[pos]. �lledBucketBits [ i /8] & 1<<(i%8)){10 // subBucket �lled11 if (!memcmp(hashTable[pos].el[i].idP, idP, 10)){12 erg.subBucketNumber = i;13 return erg;14 }15 }16 i = (i+1) % numSubBuckets;17 } while (i!=pos2 && (hashTable[pos].�lledBucketBits[i/8] & 1<<(i%8)) > 0);18 return erg;19 }
2008-01-16/010/INF02/2253 23

2 Grundlagen
Das Insert funktioniert ähnlich. Nachdem die Position des Elementes berechnet wurde,wird die erste freie Stelle in dem Subkorb gesucht. Darin wird das Element eingetragenund die Zelle als belegt markiert (Listing 2.15).
Listing 2.15: Einfügen eines Elementes in die Hashtabelle mit Subkörben 21 bool HashExternHash2Auth::insert(char idP[10], tagStruct ∗ tag){2 int pos = getHashBucket( numBuckets, idP);3 int pos2 = getHashBucket(numSubBuckets, idP);4 int i=pos2;5 do{6 if ((hashTable[pos]. �lledBucketBits [ i /8] & 1<<(i%8)) == 0){7 hashTable[pos]. �lledBucketBits [ i /8] |= 1<<(i%8);8 memcpy(hashTable[pos].el[i].idP, idP, 10);9 hashTable[pos].el [ i ]. tag = tag;10 hashTable[pos].numFilled++;11 return true;12 }13 i = (i+1)%numSubBuckets;14 } while (i!=pos2);15 return false;16 }
Die letzte Operation ist das Löschen. Das ist etwas komplexer als bei dem Löschendurch Markieren. Zunächst wird wieder die erwartete Position berechnet. Dann wird abdieser Stelle das zu löschende Element gesucht. Das erfolgt wie beim Lookup. Wenn dasElement gefunden wurde, beginnt der eigentliche Löschvorgang. Das Element wird zunächstgelöscht. Jetzt wird die entstehende Lücke mit einem geeigneten Element gefüllt. Dazu wirdab der nächsten Position ein Element gesucht, dass an die gelöschte Position passt. Deshalbwird die Position des Elementes berechnet und geprüft ob die Bedingung erfüllt ist. Wenn jawird das gefundene Element an die gelöschte Position verschoben und der Vorgang beginntfür die alte Stelle des verschobenen Elementes von neuem. Wenn eine leere Zelle gefundenwurde, ist der ganze Vorgang beendet, weil danach keine passenden Elemente mehr stehenkönnen. Zu sehen ist der Vorgang in Listing 2.16.
Listing 2.16: Löschen eines Elementes in der Hashtabelle mit Subkörben 21 bool HashExternHash2Auth::remove(char idP[10]){2 int pos = getHashBucket( numBuckets, idP);3 int pos2 = getHashBucket( numSubBuckets, idP);4 int i = pos2;5 do{6 if ((hashTable[pos]. �lledBucketBits [ i /8] & 1<<(i%8)) && !memcmp(hashTable[pos].el[i].idP, idP, 10)){7 hashTable[pos]. �lledBucketBits [ i /8] −= (1<<(i%8));8 memset(hashTable[pos].el[i ]. idP, 0, 10);9 hashTable[pos].el [ i ]. tag = NULL;10 hashTable[pos].numFilled−−;11 for(int j=(i+1)%numSubBuckets; j!=i; j=(j+1)%numSubBuckets){12 if ((hashTable[pos]. �lledBucketBits [ j/8] & 1<<(j%8)) == 0){13 return true;14 }15 int bucket = getHashBucket(numSubBuckets, hashTable[pos].el[j].idP, zuf2);16 if (( i<j && (bucket <= i || bucket > j)) || ( i>j && bucket > j && bucket <= i)){17 memcpy(hashTable[pos].el[i].idP, hashTable[pos].el [ j ]. idP, 10);18 memset(hashTable[pos].el[j ]. idP, 0, 10);19 hashTable[pos].el [ i ]. tag = hashTable[pos].el[ j ]. tag;20 hashTable[pos].el [ j ]. tag = NULL;21 hashTable[pos]. �lledBucketBits [ i /8] |= 1<<(i%8);22 hashTable[pos]. �lledBucketBits [ j/8] −= (1<<(j%8));23 i = j;24 }25 }26 return true;27 }28 i = (i+1)%numSubBuckets;29 } while(i!=pos2 && ((hashTable[pos].�lledBucketBits[i/8] & 1<<(i%8)) > 0));30 return false;31 }
24 2008-01-16/010/INF02/2253

2.5 Datenstrukturen
2.5.4.3 Hashtabelle ohne Subkörbe
Nachdem eine Version vorgestellt wurde, die mit einer Aufteilung der Hashtabelle in meh-rere Subhashtabellen arbeitet, stellt sich die Frage, ob die Unterteilung Vorteile ergibt.Dazu kann eine Hashtabelle ohne weitere Unterteilung benutzt werden. Ein Nachteil derKonstruktion ist, dass immer direkt gelöscht werden muss, da ein Neuaufbau der Tabelleim Hauptspeicher nicht möglich ist und der Vorgang damit extrem lange dauern würde.Deshalb wird zur Au�ösung der Kollisionen wieder das lineare Sondieren verwendet. DieFunktionsweise ist die gleiche wie bei der zweiten Variante mit Subkörben. Der einzige Un-terschied ist, dass quasi nur ein Korb vorhanden ist und die Körbe der jetzigen Hashtabelleden Subkörben der anderen Version entsprechen. Somit ist die Funktionsweise gleich.Beim Lookup wird zunächst die erwartete Position des Datums berechnet. Danach wird
von dieser Position immer einen Platz weiter gesucht bis der aktuelle Eintrag der Gesuchteist. Die Suche wird auch beendet, wenn ein leerer Platz erreicht wird oder die Tabelleeinmal durchsucht wurde, weil dann das Element nicht in der Tabelle sein kann. Der Codedazu ist in Listing 2.17 zu sehen.
Listing 2.17: Suche einer Pseudo ID in der Hashtabelle ohne Subkörbe1 HashExternLinearAuth::hashPos HashExternLinearAuth::lookup(char idP[10]){2 hashPos erg;3 int pos = getHashBucket( numBuckets, idP);4 erg.bucketNumber = pos;5 int i=pos;6 do{7 if (hashTable.�lledBucketBits [ i /8] & 1<<(i%8)){8 // subBucket �lled9 if (!memcmp(hashTable.el[i].idP, idP, 10)){10 erg.bucketNumber = i;11 return erg;12 }13 }14 i = (i+1) % numBuckets;15 } while (i!=pos && (hashTable.�lledBucketBits[i/8] & 1<<(i%8)) > 0);16 erg.bucketNumber = −1;17 return erg;18 }
Das Einfügen einer Zuordnung mittels Insert funktioniert fast genau wie beim Einfügenvon Elementen in die Hashtabelle mit Subkörben bei direktem Löschen. Zunächst wird dieStelle ermittelt, an die das Element gehört. Dann wird an der Stelle die erste freie Positionermittelt und das Element dort eingefügt. Der Code dazu ist in Listing 2.18 zu sehen.
Listing 2.18: Einfügen einer Zuordnung in die Hashtabelle ohne Subkörbe1 bool HashExternLinearAuth::insert(char idP[10], tagStruct ∗ tag){2 int pos = getHashBucket( numBuckets, idP);3 int i=pos;4 do{5 if ((hashTable.�lledBucketBits [ i /8] & 1<<(i%8)) == 0){6 hashTable.�lledBucketBits [ i /8] |= 1<<(i%8);7 memcpy(hashTable.el[i].idP, idP, 10);8 hashTable.el[ i ]. tag = tag;9 return true;10 }11 i = (i+1)%numBuckets;12 } while (i!=pos);13 return false;14 }
Die letzte notwendige Operation ist das Löschen einer Zuordnung aus der Datenstrukturmittels Remove. Dazu wird zunächst wie beim Lookup das Element gesucht. Danach wirddas Element gelöscht. Jetzt wird aber die aktuellen Position für jedes nachfolgende Elementermittelt und überprüft, ob es auch an der Position des gelöschten Elementes stehen kann.Wenn ja wird das Element dorthin verschoben und die Suche für ein Element für die
2008-01-16/010/INF02/2253 25

2 Grundlagen
gelöschte Position wird wie beschrieben wiederholt. Der Vorgang ist zu Ende, wenn eineleere Zelle erreicht ist. Nach dieser Zelle kann ein Ersatzelement nicht stehen, da dannzwischen der errechneten Position und dem gesuchten Element eine Leerzelle ist, was nichterlaubt ist. Der Vorgang ist als Code in Listing 2.19 zu sehen.
Listing 2.19: Löschen einer Zuordnung aus der Hashtabelle ohne Subkörbe
1 bool HashExternLinearAuth::remove(char idP[10]){2 int pos = getHashBucket( numBuckets, idP);3 int i = pos;4 do{5 if ((hashTable.�lledBucketBits [ i /8] & 1<<(i%8)) && !memcmp(hashTable.el[i].idP, idP, 10)){6 hashTable.�lledBucketBits [ i /8] −= (1<<(i%8));7 memset(hashTable.el[i].idP, 0, 10);8 hashTable.el[ i ]. tag = NULL;9 for(int j=(i+1)%numBuckets; j!=i; j=(j+1)%numBuckets){10 if ((hashTable.�lledBucketBits [ j/8] & 1<<(j%8)) == 0){11 return true;12 }13 int bucket = getHashBucket(numBuckets, hashTable.el[j].idP);14 if (( i<j && (bucket <= i || bucket > j)) || ( i>j && bucket > j && bucket <= i)){15 memcpy(hashTable.el[i].idP, hashTable.el[ j ]. idP, 10);16 memset(hashTable.el[j].idP, 0, 10);17 hashTable.el[ i ]. tag = hashTable.el[j ]. tag;18 hashTable.el[ j ]. tag = NULL;19 hashTable.�lledBucketBits [ i /8] |= 1<<(i%8);20 hashTable.�lledBucketBits [ j/8] −= (1<<(j%8));21 i = j;22 }23 }24 return true;25 }26 i = (i+1)%numBuckets;27 } while(i!=pos && ((hashTable.�lledBucketBits[i/8] & 1<<(i%8)) > 0));28 return false;29 }
2.6 OMNeT++
Der Simulator OMNeT++ wird in der Arbeit zur Evaluierung der implementierten Daten-strukturen verwendet.Die erste Version von OMNeT++ erschien im August 1998. Sie wurde von András Varga
am Department of Telecommunications an der Technischen Universität Budapest entwi-ckelt und wird unter anderem von ihm weiterentwickelt. OMNeT++ ist ein auf Eventsbasierender Simulator, der modular ausgerichtet ist. OMNeT++ ist dabei eine Software-Sammlung. Diese besteht aus dem Kern, welcher nur die grundlegende Funktionalität bein-haltet, die zur Simulation von diskreten Events notwendig sind. Es sind weitere Werkzeugevorhanden, die die Erstellung und Auswertung von Simulationsprogrammen vereinfachen.Für weitergehende Funktionalität, wie Protokollsimulation und Ähnliches existieren Frame-works. Die Frameworks sind leicht integrierbar. Der Kern selbst ist in C++ geschrieben undumfasst alle Teile, die zur auf Events basierenden Simulation notwendig sind. Die Funktio-nalität der Simulation ist in eigenständigen Modulen realisiert. Diese können hierarchischaufgebaut sein und können selbst implementiert werden. Die Kommunikation zwischen denModulen erfolgt mit Nachrichten. Die Typen der Nachrichten, die bei der Kommunikationübertragen werden, können selbst de�niert werden. Die Nachrichten werden vom Sendergeneriert und gesendet und vom Empfänger empfangen und dann verarbeitet. Die Strukturder Netzwerke und der Module wird in einer eigenen Sprache spezi�ziert, der NEtwork De-scription language (NED). Die Sprache ist speziell für diese Bedürfnisse entwickelt worden.OMNeT++ selbst bietet zwei Betriebsmodi. Zum einen den gra�schen Modus, in wel-
chem unter anderem schrittweise simuliert werden kann und somit die Auswirkungen jedes
26 2008-01-16/010/INF02/2253
2.7 Zusammenfassung
Abbildung 2.4: Überblick über die gra�schen Ober�äche von OMNeT++ [26]
Schrittes sofort visualisiert werden. Der Modus ist hilfreich, um die Funktionsfähigkeit derSimulation zu testen. Der zweite Modus ist der Batch Modus. In dem Modus werden die Si-mulationen ohne gra�sche Ausgabe auf der Kommandozeile ausgeführt. Das ist hilfreich zurSimulation vieler und groÿer Modelle, nachdem deren Funktionalität sichergestellt ist. DerModus ist erheblich schneller als der gra�sche Modus. In Abbildung 2.4 ist die gra�scheOber�äche von OMNeT++ mit einer Netzwerkstruktur, der hierarchischen Modularitätund den Histogrammen einiger Warteschlangen zu sehen. Diese und weitere Informationenkönnen dem Handbuch von OMNeT++ entnommen werden [24].
2.7 Zusammenfassung
In diesem Kapitel wurde zunächst gezeigt, welche Technologien im geplanten Einsatzsze-nario verwendet werden können. Dazu werden auch die Ziele dargestellt, die durch denEinsatz der Technologie erreicht werden sollen. Danach wird die RFID-Technologie all-gemein betrachtet, damit bekannt ist, welche grundsätzlichen Randbedingungen gegebensind, die für die Arbeit Bedeutung haben. Da in der Arbeit das später entwickelte Pro-tokoll formal untersucht wird, wurde die dafür verwendete Technik vorgestellt. Danachwurden die später in der Arbeit verwendeten Datenstrukturen dargestellt. Der letzte Teilder Arbeit benutzt eine Simulation, um Antworten auf quantitative Fragen zu erhalten.Der dabei verwendete Simulator wurde deshalb kurz vorgestellt.
2008-01-16/010/INF02/2253 27

28 2008-01-16/010/INF02/2253

3 Ausgangspunkt
Die RFID-Technologie ermöglicht die Verbesserung bisher eingesetzter Techniken, sowieneue Anwendungsgebiete. Diesen vorteilhaften Aspekten stehen jedoch auch Nachteile ge-genüber. Das sind zum gröÿten Teil Sicherheitsprobleme. Zur Darstellung der Problemeim Zusammenhang wird zunächst ein abstraktes Szenario dargestellt, in dem die RFID-Technologie verwendet werden soll. Aus dem Szenario werden dann die notwendigen Zieleabgeleitet. Danach werden die Sicherheitsaspekte der RFID-Technologie im gewünschtenEinsatzgebiet betrachtet. Zur Lösung der verschiedenen Aspekte der Probleme existierenunterschiedliche Ansätze, die im weiteren dargestellt werden. Im letzten Abschnitt diesesKapitels wird für eine mögliche praktische Realisierung der Arbeit ein RFID Tag ausge-wählt, der die notwendige Flexibilität der Lösung ermöglicht.
3.1 Abstraktes Szenario
Die Motivation der Arbeit ist der Einsatz von RFID-Systemen in Logistikketten, die unter-nehmensübergreifend sind. Am Beginn der Kette wird eine Ware produziert. Der Wert derWare ist so hoch, dass es sinnvoll ist einen RFID-Tag auf dem Produkt anzubringen. Aufdem Tag sind Informationen gespeichert, die den Transport, die Reparatur oder ähnlichesunterstützen und beschleunigen. Die Ware verlässt das Unternehmen und wird zu anderenteilnehmenden Unternehmen transportiert. Dabei wird der Transport von weiteren exter-nen Unternehmen übernommen. Die angelieferte Ware wird dort in die eigenen Produkteintegriert. Bei Einbau der Teile in komplexere Produkte werden die gespeicherten Datenverarbeitet und aktualisiert. Nach dem Ende der Integration der Einzelteile in Produk-te können weitere unternehmensübergreifende Abläufe des Transportierens und Einbausstatt�nden. Zum Ende wird das vollständige Produkt an den Verbraucher ausgeliefert. Beieinem Defekt oder Wartungsarbeiten des Produktes werden die auf dem Tag gespeicher-ten Informationen ausgewertet und zur Beschleunigung der Arbeit benutzt. Einzelne Teile,die bei Defekt ausgetauscht werden, werden über externe Dienstleister zum Produzentgeschickt, der eine Überholung der Teile vornehmen kann, wenn es sinnvoll ist. Danachwerden die reparierten Teile wieder in den Zyklus integriert. Das abstrakte Szenario ist inAbbildung 3.1 dargestellt.Da viele der höherwertigen Produkte hergestellt und mit einem Tag versehen werden,
existieren davon sehr viele auf die zugegri�en werden können muss. Die Anzahl der ver-wendeten Tags kann mehrere Milliarden erreichen.
3.2 Ziele des Systems
Das Hauptziel ist die Erfüllung der Bedürfnisse aller teilnehmenden Unternehmen. Dasabstrakte Ziel ist in einzelne Ziele zerlegbar. Die einzelnen Teilziele sind folgende.
1. Anonymität
• Es sollen keine Bewegungspro�le der Waren erstellt werden können.
• Auch berechtigte Teilnehmer sollen nicht die reale ID der Tags erhalten
2. Zugri�sschutz
2008-01-16/010/INF02/2253 29

3 Ausgangspunkt
Abbildung 3.1: Abstraktes Szenario
• Es sollen nur berechtigte Teilnehmer auf die Daten der Tags zugreifen können.
a) Der Zugri� auf die Daten soll nur möglich sein, wenn der Tag in Reichweitedes zugreifenden Lesegeräte ist.
b) Der Zugri� für erlaubte Teilnehmer soll nur auf de�nierten Bereichen mitbestimmten Rechten möglich sein.
3. Integritätsschutz
• Falls unerlaubte Modi�kationen auftreten müssen diese erkannt werden.
4. Informationsschutz
• Wenn ein Angreifer die Daten physisch aus dem Tag ausgelesen hat, darf erdaraus keine verwertbaren Informationen erhalten.
5. Skalierbarkeit
• Das entwickelte System muss sehr gut mit der Anzahl der Tags skalieren.
6. Realisierbarkeit
• Das System muss mit verfügbarer RFID Technologie realisierbar sein
7. Speicherplatze�zienz
• Alle Anforderungen müssen mit möglichst wenig Speicherplatzverbrauch reali-siert werden.
Die Anforderung 1 ist notwendig, weil aus Bewegungspro�len Lieferbeziehungen abge-leitet werden können. Die Beziehungen sind jedoch teilweise Firmengeheimnisse, die nichtö�entlich werden sollen. Weil die Lesegeräte der Teilnehmer die reale ID der Tags nichtbenötigen und sich daraus teilweise zusätzlich Bewegungspro�le erstellt werden können,ist Anforderung 1 entstanden. Die nächsten zu erfüllenden Bedingungen betre�en den Zu-gri�sschutz. Ein Zugri�, wie in Anforderung 2 dargestellt, soll nur möglich sein wenn er
30 2008-01-16/010/INF02/2253

3.2 Ziele des Systems
berechtigt ist, weil sonst ein beliebiger Personenkreis Daten aus den Tags lesen oder schrei-ben kann und damit Firmengeheimnisse auslesen und auch unternehmensrelevante Datenverändern kann. Ein Präzisierung stellt die Anforderung 2a da. Der Grund dafür ist, dasses nicht möglich sein soll zentrale Auswertungen der Daten zu ermöglichen, da wenn dasProdukt in Besitz des Anwender ist, dieser das nicht wünscht und das Produkt sonst even-tuell nicht annehmen würde. Da zwischen den teilnehmenden Unternehmen verschiedeneVertrauensbeziehungen bestehen und für viele Aufgaben der Teilnehmer nur Teildaten derTags notwendig sind, ist aus Grund der Datensparsamkeit die Bedingung 2b entstanden.Die Anforderung 3 ist notwendig, da sonst Modi�kationen nicht erkannt werden und damitein Angreifer ungültige Daten in das System einfügen kann, die interne Entscheidungenunberechtigt beein�ussen. Da ein Angreifen möglicherweise die Zugri�skontrolle des Tagdurch einen physischen Zugri� umgehen kann und die gleiche Bedingungen wie in Anforde-rung 2 bestehen, ist Bedingung 4 notwendig. Der Einsatz des zu entwickelnden Konzepteserfolgt mit mehreren Milliarden Tags. Damit dies funktioniert ist Anforderung 5 erfor-derlich. Da die Entwicklung praktisch einsetzbar sein soll, ist Anforderung 6 zu erfüllen.Die RFID Tags haben alle einen stark beschränkten Speicherplatz auf dem möglichst vieleInformationen gespeichert werden sollen. Deshalb ist es notwendig, dass die entwickeltenVerfahren speichere�zient arbeiten, welches mit Anforderung 7 sichergestellt werden soll.Aus den Anforderungen ergeben sich folgende zu realisierende Punkte.
1. Wie wird die Anonymisierung der Tags ermöglicht?
2. Wie wird gewährleistet, dass verlorene oder angegri�ene Tags von berechtigten Teil-nehmern trotzdem gelesen werden können?
3. Wie wird der Zugri� auf die Daten der Tags kontrolliert?
4. Wie werden Veränderungen der Daten erkannt?
5. Welche Schlüssel werden verwendet und wie erfolgt die Verteilung?
6. Wie wird gewährleistet, dass die Lesegeräte nicht die reale ID des Tag erhalten?
7. Wie wird sichergestellt, dass die Kommunikation der Teilnehmer untereinander ge-schützt ist?
8. Wie erfolgt die Authentisierung des Tags?
9. Wie wird realisiert, dass möglichst wenig Speicher genutzt wird?
Neben diesen eben beschriebenen qualitativen Fragestellungen ergeben sich auch quan-titative Fragen.
1. Mit welchen Datenstrukturen ist ein praktischer Einsatz des Systems möglich?
2. Welche Parametrisierung der Datenstrukturen ist sinnvoll?
3. Welchen Ein�uss hat die Anzahl der Tags auf die Geschwindigkeit?
4. Welchen Ein�uss haben die anderen Parameter der Datenstrukturen auf die Perfor-manz?
5. Hat die Höhe der Einzelfehlerrate einen wesentlichen Ein�uss auf den Aufwand beimZugri� auf die Datenstruktur?
2008-01-16/010/INF02/2253 31

3 Ausgangspunkt
3.3 Sicherheitsaspekte beim Einsatz von RFID-Systemen inunternehmensübergreifenden Logistik-Szenarien
Motiviert durch das abstrakte Szenario werden zunächst die Vor- und Nachteile der RFIDTechnologie betrachtet.Die Nachteile sind dabei in gesamten Verwendungskontext des Supply Chain Mana-
gement zu sehen. Die daraus entstehenden Sicherheitsprobleme sind im Abschnitt 3.3.1dargestellt. In den beiden darauf folgenden Abschnitten werden speziell die unterschied-lichen Sicherheitsprobleme in Abhängigkeit der verwendeten Betriebsart der RFID Tagserörtert.
3.3.1 Sicherheitsaspekte zwischen verschiedenen Ebenen
Zur genauen Analyse der Sicherheitsprobleme der RFID Technologie im gesamten Kontextdes Supply Chain Management ist es hilfreich das System in Teilsysteme zu zerlegen,um die darin auftretenden Probleme einzeln zu betrachten. Das gesamte System mussdabei in die einzelnen Aspekte, sowie die Kommunikation der einzelnen Teilsysteme zerlegtwerden. Ein dafür entwickeltes generisches Modell ist aus [13], wo auch die Analyse derProbleme dargestellt ist. Es betrachtet die einzelnen Ebenen der Kommunikation innerhalbeines Unternehmens, sowie die Kommunikation der Unternehmen miteinander. Innerhalbeines Unternehmens kann die Verwendung der RFID Technologie in verschiedene Ebeneneingeteilt werden. Die Bezeichnung der Ebenen ist dabei in Tabelle 3.1 zu sehen.
Ebene Funktionalität
Tag-Ebene Physisches Bereitstellen von TagsSensor-Ebene Lesen und ggf. Schreiben von RFID-TagsAufbereitungs-Ebene Pu�ern, Formatieren, Filtern, Aggregieren der Leseereig-
nissePersistenz-Ebene Speichern der relevanten DatenAustausch-Ebene Bereitstellung von Abfrageschnittstellen für interne und ex-
terne SystemeAnwendungs-Ebene Bereitstellung von weiteren Anwendungen
Tabelle 3.1: Funktionalitäten und Ebenen des Modells [13]
Zur Verwendung der RFID Technologie in unternehmensübergreifenden Kooperationensind weitere Komponenten notwendig. Zunächst muss das Lesegerät wissen, welchen Ser-ver es befragen muss um Informationen über den Tag zu erfahren. Für diese Lokalisationist der Au�ndungsdienst verantwortlich. Damit kann theoretisch jedes Lesegerät Informa-tionen über jeden RFID Tag erhalten. Das ist nicht wünschenswert, so dass deshalb einAuthentisierungsdienst eingeführt wird, welcher erst nach erfolgreicher Authenti�kationdes Readers den Zugri� auf erlaubte Teildaten der Tags ermöglicht. Damit ein globalesModell entstehen kann, müssen alle Teilnehmer betrachtet werden. Eine Wertschöpfungs-kette besteht dabei aus mindestens einem Hersteller, einem Verkäufer und dem dazwischenliegendem Transporteur. Das daraus entstehende globale Modell ist in Abbildung 3.2 zusehen.In der Abbildung sind neben den internen Kommunikationsschnittstellen A bis E, die
externen Schnittstellen F und G sowie die Schnittstellen H und I für die globalen Sonder-dienste zu sehen. Anwendungen tauschen keine Informationen aus, da diese nur Auswer-tungen der vorhandenen Daten vornehmen. Diese Daten werden durch die Austauschebe-ne übertragen. Im Folgenden wird in Speziellem auf die einzelnen Probleme zwischen denSchnittstellen der Ebenen von der untersten bis zu obersten Ebene eingegangen. Dabei wird
32 2008-01-16/010/INF02/2253

3.3 Sicherheitsaspekte beim Einsatz von RFID-Systemen in unternehmensübergreifendenLogistik-Szenarien
Abbildung 3.2: Modell einer generischen RFID gestützten Wertschöpfungskette [13]
zunächst auf die vertikalen Schnittstellen eingegangen, bevor die horizontalen Schnittstel-len zwischen den Unternehmen betrachtet werden. Die Ausführungen beziehen sich auf diein Quelle [13] enthaltenden Informationen.
3.3.1.1 Sicherheitsaspekte in vertikaler Richtung
Zur besseren Übersichtlichkeit, werden zunächst die Sicherheitsprobleme in vertikaler Rich-tung des Modells betrachtet. Das sind die Probleme, die innerhalb eines teilnehmendenUnternehmens entstehen.
Tag-Ebene In der Tag-Ebene existieren viele unterschiedliche Probleme. Zur besserenÜbersicht werden diese jetzt als Aufzählung aufgelistet.
• Durch die Verfolgung der Tags können Bewegungspro�le erstellt werden
� Es können damit Lieferbeziehungen zwischen verschiedenen Teilnehmern derWarenkette erstellt werden.
� Wenn das Produkt dann beim Verbraucher ist, kann zusätzlich indirekt auchein Bewegungspro�l des Verbrauchers ermittelt werden.
• Ein Angreifer kann Informationen von der Tags lesen und einspielen.
� Wenn kein Sicherheitsmechanismus vorhanden ist, können die Informationenauf den Tags von beliebigen Lesegeräten ausgelesen werden und somit könnenvertrauliche Informationen ö�entlich werden.
� Für das einspielen können ungeschütze Tags mit Informationen beschrieben wer-den, die dem System schaden.
2008-01-16/010/INF02/2253 33

3 Ausgangspunkt
� Ausgemusterte Tags können reaktiviert und benutzt werden, um mit Informa-tionen beschrieben in den Kreislauf wieder eingefügt zu werden.
� Das ist durch eine nicht vollständige Ausführung der Deaktivierung, oder durcheine nicht unumkehrbare KILL Funktion möglich.
� Ein Beispiel für das Einspielen von Informationen ist ein Art RFID-Virus, wel-cher in der Persistenz-Ebene das gesamte Datenhaltungssystem in�zieren kann[25].
• Durch die unverschlüsselte Kommunikation zwischen Lesegerät und Tag ist das Mit-lesen und Verändern von Informationen möglich.
� Damit können Informationen gewonnen werden, die vertraulich sein können.
� Durch die nicht vorhandenen Sicherungsmaÿnahmen kann sich ein Angreiferzum Tag als Lesegerät und zum Lesegerät als Tag ausgeben und damit miteinem Man-in-the-Middle Angri� Informationen während der Kommunikationändern.
• Es sind Änderungen von Informationen möglich, ohne dass die Daten vom Tag ver-ändert werden müssen.
� Durch ein Entfernen der Tags von dem vorgesehenen Produkt und das Aufbrin-gen auf ein anderes Produkt können Lieferungen falsch ankommen, oder Warenin Sicherheitskritische Bereiche kommen, da es für das vertauschte Produkt er-laubt ist. Solche Fehler können schwer zu erkennen und zu beheben sein.
• Die Verhinderung der Kommunikation ist ebenfalls möglich.
� Durch das Benutzen eines Störsenders kann die Kommunikation mit dem Tagwirksam verhindert werden.
� Das Problem ist durch die Benutzung der Funktechnologie begründet und kannnicht verhindert werden. Es muss mit der Möglichkeit gerechnet und diese tole-riert werden können.
� Für aktive Tags muss eine Lösung gefunden werden, da durch das Jamming dieEnergie der Batterie verbraucht wird, obwohl keine Informationen übertragenwerden. Das Problem dabei ist, dass bei leerem Energiespeicher der Tag dannnicht mehr benutzt werden kann.
� Durch das Jamming oder viele sinnlose Lese- und Schreiboperationen sind dieaktiven Tags dann viel schneller nicht mehr benutzbar als geplant und müssenersetzt werden.
Sensor-Ebene Die Sensorebene besteht aus dem Lesegerät selbst und einem Controller,welcher die Kommunikation zur Aufbereitungsebene realisiert. Ein Hauptangri�spunkt istdabei das Lesegerät selbst. Je nach Mobilität und Gröÿe kann es relativ leicht gegen einmanipuliertes Lesegerät ausgetauscht werden. Dieses Gerät kann dann verschiedene An-gri�e ermöglichen. Es ist dann möglich, dass das Lesegerät als ein anderes Auftritt. Damitkann es im Namen des anderes Lesegerätes Operationen auf den Tags ausführen, sowie diehöheren Ebenen im System beein�ussen. Es entsteht also nicht nur der Schaden durch denAngri� selbst, sondern als Quelle wird fälschlicherweise ein anderes Gerät vermutet, dassdann deaktiviert und ausgetauscht wird. Durch die Dauer des Austausches und den damitverbundenen Vorgang können hohe Kosten entstehen. Die manipulierten Lesegeräte kön-nen viele Angri�e auf der Tag Ebene dann nicht nur von externen Elementen ermöglichen,sondern auch aus dem System selbst. Diese Angri�e sind meist schwerer diagnostizierbarund sind damit schwierig behebbar. Durch die relative Nähe des Lesegerätes zum RFID
34 2008-01-16/010/INF02/2253

3.3 Sicherheitsaspekte beim Einsatz von RFID-Systemen in unternehmensübergreifendenLogistik-Szenarien
Tags ist auch die Zerstörung des Tags durch die Erzeugung eines übermäÿig starken Feldesmöglich oder die Kommunikation kann durch Jamming wie in der Tag-Ebene beschriebengestört werden.
Aufbereitungs-Ebene Die Aufbereitungsebene ist zur Vermittlung der Kommunikationzwischen den Lesegeräten und der Speicherung der Daten zuständig. Durch die Menge derEingabedaten ist keine exakte Speicherung aller Daten möglich. Daraus ergibt sich, dass dieDaten vor der Speicherung in der Datenbank von der Aufbereitungsebene gegebenenfallsaggregiert werden, bevor die Daten gespeichert werden. Die Aufbereitungsebene bestehtdafür aus Servern. Damit sind die Risiken der Ebene ebenso wie bei anderen Servern. Dazuzählen zum Beispiel das Knacken von Passwörtern und damit der unerlaubte Zugri� auf dieServer. Auÿerdem kann auf die Server eventuell Schadsoftware eingeschleust werden, diedas ganze System gefährden können. Eine weitere Angri�smöglichkeit ist das Ausnutzenvon Schwachstellen der Software selbst oder einem Denial-of-Service Angri�. Ein speziel-ler möglicher Angri� ist dabei zum Beispiel die SQL-Injektion [25]. Durch das möglicheEinfügen oder Löschen von Informationen kann das ganze System beein�usst werden. Eskönnen zum Beispiel durch die gefälschten Informationen Entscheidungen getro�en werdendie kontraproduktiv zu den notwendigen Entscheidungen sind. Dabei können dann hoheSchäden entstehen. Die möglichen Gegenmaÿnahmen sind in der normalen Serversicherheitzu suchen, so zum Beispiel die Verwendung von Firewalls, Zerti�katen zur Authenti�kation,die Verschlüsselung der Kommunikation und vieles andere mehr.
Persistenz-Ebene Für die Speicherung der Daten werden meist relationale Datenbankeneingesetzt. Damit sind auch die Angri�spunkte die gleichen wie bei anderen Datenbankser-vern. Zusätzlich zu Angri�en auf die Datenbank selbst existieren noch die Angri�e auf denServer selbst. Somit sind die Probleme die gleichen, wie bei den Servern der Aufbereitungs-ebene. Zur Lösung der Probleme ist unter anderem das Prüfen der zu speichernden Datenauf Plausibilität unerlässlich. Zur Wahrung der Arbeitsfähigkeit bei Ausfall von einzelnenKomponenten oder der Server selbst, ist ausreichende Redundanz zu gewährleisten.
Austausch-Ebene Die Probleme der Aufbereitungsebene sind ähnlich wie die der zweivorhergehenden Ebenen. Es existiert hier aber eine zusätzliche Sicherheitsaufgabe. Dasist durch die gewollte Kommunikation zwischen den Austauschebenen der verschiedenenTeilnehmer gegeben. Diese Anforderungen sind jedoch in horizontaler Richtung, so dassdieser Sachverhalt weiter unten besprochen wird.
Anwendungs-Ebene Die Anwendungsebene besteht aus Applikationen zur Analyse dergespeicherten Daten, sowie zu deren Verwaltung. Hierbei entstehen dann die gängigen Pro-bleme der Anwendungssicherheit. So müssen alle Angaben der Benutzer auf Plausibilitätgeprüft werden, damit kein schädlicher Code eingeschleust werden kann. Auÿerdem mussder Zugri� auf die verschiedenen Teilbereiche des Systems beschränkt werden, um zu ge-währleisten, dass nur berechtigte Personen Zugri� auf die jeweiligen Daten haben. Dasist in der Anwendungsebene gegenüber anderen Ebenen besonders wichtig, da hier vieleverschiedene Personen Zugri� auf die Daten haben. Deshalb ist auch das Problem der zu-verlässigen Authenti�kation zu lösen. Hierbei muss nicht nur auf die technischen Aspektegeachtet werden, sondern es muss auch möglichst das Social Engineering erschwert werden.
3.3.1.2 Sicherheitsaspekte in horizontaler Richtung
Nachdem hier zunächst auf die Sicherheitsprobleme in vertikaler Richtung des Modellseingegangen wurde, werden im Folgenden die Sicherheitsprobleme in horizontaler Richtung
2008-01-16/010/INF02/2253 35

3 Ausgangspunkt
des Modells betrachtet. Das sind die Probleme, die durch die Zusammenarbeit zwischenmehreren Teilnehmern entstehen. Dabei existieren die Probleme auf der Tagebene sowieauf der Austauschebene.
Tag-Ebene Die Sicherheitsprobleme auf der Tagebene entstehen durch den physischenTransport der Tags von einem Punkt zu einem anderen Punkt. Auf diesem Weg könnendie Tags von unberechtigten Lesegeräten ausgelesen werden. Dabei können dann die Infor-mationen auf den Tags selbst ausgewertet werden und es können Bewegungspro�le erstelltwerden. Die Probleme sind dabei die gleichen wie bei den Problemen der Tag-Ebene in ver-tikaler Richtung. Problematisch ist dabei jedoch der potenziell viel gröÿere Angreiferkreis.Es können nicht nur Mitarbeiter der jeweiligen Abteilungen die Tags angreifen, sondern allePersonen die sich während des Transportes in der Nähe des Tags be�nden. Die Informatio-nen der Tags sind dabei aber nur lokal verfügbar. Zur Ermittlung von Bewegungspro�lensind deshalb an mehreren Stellen Lesegeräte notwendig, die der Angreifer in seinem Besitzhat. Unterschiede ergeben sich hierbei auch bei der Betriebsart der Tags. Bei Data-on-Network erfährt der Angreifer nur die ID, während er bei Data-on-Tag auch alle auf demTag gespeicherten Informationen erhält. Genauere Unterschiede werden in den entspre-chenden Abschnitten dargestellt 3.3.2 3.3.3. Durch den Zugri� von verschiedenen Parteienauf den Tag muss eine Rechteverwaltung vorhanden sein, die die jeweiligen Anforderungenauf die Zugri�rechte der Parteien ermöglicht.
Austausch-Ebene Die Sicherheitsprobleme auf der Austauschebene sind durch den ge-wünschten Austausch von Informationen mit anderen Partnern bedingt. Es muss sicherge-stellt werden, dass keine unberechtigten Teilnehmer oder Partner beliebige Informationenauslesen und schreiben zu können. Dafür sind die Authentizität der Teilnehmer sowie dieVerschlüsselung der Kommunikation notwendig. Auch ist es sinnvoll Anfragen an die Servernur von ausgewählten anderen Servern zu erlauben. Zusätzlich sollte auch die Plausibilitätder Anfragen überprüft werden, falls ein berechtigter Server von einem Angreifer über-nommen wird und damit Daten auslieÿs oder verändert, obwohl er das zwar eigentlichdarf, aber es ungewöhnlich ist und somit einen Angri� nahe legt. Bei der Überprüfung aufPlausibilität kann dann gleichfalls das Einschleusen schädlicher Codestücke unterbundenwerden. Des Weiteren sind die üblichen Kriterien der Serversicherheit zu gewährleisten.
3.3.2 Data-on-Network
Nachdem zunächst die Sicherheitsprobleme auf allgemeiner Ebene erläutert wurden, wer-den im Folgenden zunächst die speziellen Probleme der RFID Tags in der BetriebsartData-On-Network erläutert. Im nächsten Abschnitt werden die gleichen Betrachtungen fürdie RFID Tags in der Betriebsart Data-on-Tag vorgenommen.Die generelle Architektur bei der Verwendung der RFID Tags in der Betriebsart Data-
on-Network ist in Abbildung 3.3 zu sehen.Auf den Tags ist nur eine ID gespeichert. Die ID lieÿt das Lesegerät aus. Damit kön-
nen dann das Lesegerät und die verwendete Software alle gespeicherten Informationen zudem Tag in einer globalen Datenbank suchen und auch neue Daten hinzufügen. Zusätz-lich kann ein separates Frontend unabhängig von der Kontrolle des Tags die gespeichertenDaten zum Tag auslesen und analysieren. Problematisch an den Vorgängen sind mehrereAspekte. Erstens wird durch die die feste ID auf dem Tag meist nur ein lesbarer und nichtbeschreibbarer Tag verwendet. Problematisch daran ist, dass jedes physikalisch passendeLesegerät die ID des Tags auslesen kann. Wenn ein Angreifer nun viele dieser Lesegeräte anverschiedenen Stellen hat, so kann er Bewegungspro�le für die Tags und somit die Warenerstellen. Er weiÿ zwar nicht, welche Waren konkret wo sind, wenn die IDs keine Strukturhaben, jedoch können aus dem Bewegungspro�l selbst Informationen gewonnen werden.
36 2008-01-16/010/INF02/2253

3.3 Sicherheitsaspekte beim Einsatz von RFID-Systemen in unternehmensübergreifendenLogistik-Szenarien
Abbildung 3.3: Data-on-Network: allgemeine Architektur [31]
So können zum Beispiel Lieferbeziehungen erkannt werden. Ein weiteres Problem ist, dassdie Daten zentral gespeichert sind. Es kann zwar vorteilhaft sein, alle Daten zu den Tagsimmer zugri�sbereit zu haben, zum Beispiel bei Defekt eines Tags, es ist aber ein Sicher-heitsproblem. Es kann damit auf die Daten des Tags zugegri�en werden, obwohl sich derTag nicht unter direkter Kontrolle be�ndet, wenn der Tag einmal im Zugri� war und somitdie ID des Tag bekannt ist. Je nach Anwendungsfall ist es jedoch wünschenswert, dass dieDaten zum zugehörigen Tag nur zugreifbar sind, wenn sich der Tag auch unter Kontrolledesjenigen be�ndet, der die Daten zu dem Tag auslesen will. Problematisch ist zusätzlich,dass bei einem erfolgreichem Angri� auf die globale Datenbank oder nicht korrekter Zu-gri�skontrollen berechtigte oder unberechtigte Parteien Informationen aus der Datenbankgewinnen können. Es ist festzustellen, dass die Einführung der RFID-Technologie in derBetriebsart Data-on-Network in der Praxis trotz der Sicherheitsprobleme teilweise fort-geschritten ist, weil die Verwendung fast wie bei einem Barcode erfolgt. Der Barcode istdabei etwas sicherer als die einfache RFID-Technologie, weil bei diesem zum Auslesen eineSichtverbindung bestehen muss und nicht nur eine Funkverbindung.
3.3.3 Data-on-Tag
Im vorigen Abschnitt wurden die speziellen Sicherheitsprobleme der RFID Technologie inder Betriebsart Data-on-Network dargestellt. In diesem Abschnitt werden die Probleme inder Betriebsart Data-on-Tag dargestellt.In Abbildung 3.4 ist generelle Architektur der Betriebsart Data-on-Tag der RFID Tech-
nologie zu sehen.Der Vergleich mit Abbildung 3.4 zeigt, dass hier keine globale Datenbank vorhanden
ist. Stattdessen liest das Lesegerät direkt die Daten vom Tag aus und leitet diese an dasFrontend weiter. Da keine zentrale Datenbank vorhanden ist, können Daten nicht zentralausgewertet werden. Es ist somit immer ein physischer Zugri� auf den Tag notwendig,um die Daten auszulesen. Dass die Daten direkt auf den Tags gespeichert sind, hat aberauch Nachteile: Wenn die Daten nicht verschlüsselt sind, kann jeder Angreifer die Datenauslesen. Ein weiteres Problem ist, was geschieht wenn der Tag defekt ist. Da die Datendes Tags nicht global gespeichert werden, sind alle gespeicherten Daten verloren. Damitnicht jedes Lesegerät alle Daten vom Tag erhält ist eine Zugri�skontrolle notwendig. DieZugri�skontrolle muss dabei an die beschränkten Fähigkeiten des Tags angepasst sein.Selbst wenn die Zugri�skontrolle korrekt realisiert wurde, besteht ein weiteres Problem. EinAngreifer könnte die Daten des Tags physisch auslesen, also die Zugri�skontrolle umgehen.Der Vorteil der Betriebsart Data-on-Tag ist, dass der Besitzer des Tags die volle Souve-
2008-01-16/010/INF02/2253 37

3 Ausgangspunkt
Abbildung 3.4: Data-on-Tag: generelle Architektur [31]
ränität über die auf dem Tag gespeicherten Daten hat. Nur ein in unmittelbarer Umgebungdes Tags vorhandenes Lesegerät kann auf die Daten des Tags zugreifen. Das Verfolgen derTags ist wie in der anderen Betriebsart möglich. Da jedoch durch die direkte Speicherungder Daten auf dem Tag leistungsfähigere Tags eingesetzt werden, ist die Realisierung derVerhinderung des Verfolgens einfacher möglich. Zurzeit werden nicht sehr viele Tags inder Betriebsart Data-on-Tag eingesetzt. Oft wird das nur dort gemacht, wo keine ständigeNetzwerkverbindung vorhanden ist und somit die Speicherung der Daten im Netz nichtmöglich ist. Hier bietet die Betriebsart Data-on-Tag den Vorteil, dass das Lesegerät keinenKontakt mit externen Einheiten benötigt, um die Daten des Tags auszulesen.
3.4 Ansätze zur Lösung der Sicherheitsprobleme
Bisher wurden die vorhanden Probleme bei der Verwendung der RFID Technologie darge-stellt. Im Folgenden werden die Probleme kategorisiert und bekannte Lösungen dargestellt,wenn diese vorhanden sind.Es existieren fünf technische Sicherheitsziele. Das sind Vertraulichkeit, Datenintegrität,
Zurechenbarkeit, Verfügbarkeit und kontrollierter Zugang. Zur Erreichung dieser Ziele sinddie folgenden Sicherheitsdienste notwendig. Das sind die Authentisierung, die Datenintegri-tät, die Vertraulichkeit, die Zugri�skontrolle und die Nicht-Abstreitbarkeit/Zurechenbar-keit. Zusätzlich muss bei der RFID Technologie das Verfolgen der Tags verhindert werden.Das ist eine spezielle Form des Dienstes Vertraulichkeit.
3.4.1 Sicherungsverfahren
Der Dienst Authentisierung ist dabei ein Grunddienst, der Vorbedingung ist, um die ande-ren Dienste verwirklichen zu können. Aus diesem Grund wurde und wird auf dem Gebietdes Authentisierungsdienstes geforscht. Es existieren zahlreiche Verö�entlichungen zu demThema (Übersichtsartikel [15]). Dabei sind zwei verschiedene Herangehensweisen zu be-trachten. Die eine Sicht versucht die Authentisierung ohne Hilfe starker Kryptoalgorithmen,wie DES oder AES, zu erreichen. Die Sichtweise beachtet zwar die geringe Rechenleistungder RFID Tags, jedoch sind die meisten entstandenen Protokolle nicht sicher. Beispiels-weise wurde von Vajda und Buttyan im Jahre 2003 mehrere für preiswerte RFID Tagsgeeignete Protokolle entwickelt [29]. In einem Artikel von Defend, Fu und Juels aus demJahr 2007 wurde festgestellt, dass die einfachen Protokollversionen von Vajda und But-tyan nicht sicher sind [7]. Ein weiteres Beispiel ist das EMAP Protokoll aus 2006 [22], indem 2007 Schwachstellen entdeckt wurden [16]. Gemeinsamkeit der Protokolle ist, dass
38 2008-01-16/010/INF02/2253

3.4 Ansätze zur Lösung der Sicherheitsprobleme
versucht wurde mit Hilfe verschiedener Verwendung von XOR als Verschlüsselungsfunkti-on Sicherheit zu gewährleisten. Wie festzustellen ist, scheint die Fehlerwahrscheinlichkeitdieser Protokollart groÿ zu sein, wie auch weitere Beispiele zeigen. Die neu entwickeltenProtokolle werden zwar auf Fehler untersucht, aber werden diese meist erst Jahre später ge-funden, so dass sie nicht für den zeitnahen Einsatz geeignet sind. Die zweite und scheinbarerfolgreichere Möglichkeit ist die Benutzung der gängigen symmetrischen Verschlüsselungs-funktionen wie DES oder AES. Die Realisierbarkeit wird dabei in den Artikeln [23] und[9] gezeigt. Es werden dabei speziell auf wenig Hardwarebedarf optimierte Algorithmenverwendet. Dabei ist die Geschwindigkeit der Berechnungen nicht so hoch wie bei denoriginalen Implementierungen, aber die angepassten Implementierungen sind ausreichendschnell. So verwendet der optimierte 128 Bit AES Algorithmus nur 3628 so genannter GateEquivalente (GE), während ein 128 Bit Kryptoprozessor aus circa 173000 GE besteht. Da-für benötigt der Kryptoprozessor nur 10 Takte um ein Wort zu verschlüsseln, während dieoptimierte Version 992 Takte benötigt. Ähnliches gilt für den DES Algorithmus der mitseinen 56 Bit Schlüssellänge aus 1848 GE besteht und für die Verschlüsselung eines Wor-tes nur 144 Takte benötigt. Es ist festzustellen, dass die Verwendung von symmetrischerKryptographie in RFID Tags möglich und sinnvoll ist.Es wurde auch untersucht, ob asymmetrische Kryptographie in RFID Tags möglich ist.
In [5] wurde ermittelt, dass Public Key Kryptographie möglich ist. Jedoch ist der Aufwandsehr groÿ und vor allem ist die Berechnungszeit lang. Der untersuchte asymmetrische Al-gorithmus basiert auf den elliptischen Kurven. Das ist eine mögliche Basis, die mit sehrgeringem Hardwareeinsatz möglich ist. Es werden circa 15000 GE für den Algorithmusbenötigt. Für einen Verschlüsselungsvorgang werden jedoch etwas 175000 Taktzyklen be-nötigt. Das ist um Gröÿenordnungen langsamer als bei der symmetrischen Kryptographie.Mit Hilfe der symmetrischen Kryptographie wurden Authentisierungsprotokolle entwickelt,so zum Beispiel in [9]. Durch die Verwendung herkömmlicher Verschlüsselungsalgorithmenist auch der Einsatz herkömmlicher Authentisierungsprotokolle, wie des Otway-Rees Pro-tokoll [21] möglich. Auch kann bei dem Entwurf neuer Protokolle oder der Anpassungbestehender Protokolle mit herkömmlichen Mitteln die Sicherheit der Protokolle überprüftwerde, so zum Beispiel der BAN oder GNY Logik. In Tabelle 3.2 ist eine Zusammenfassungüber die Eignung der möglichen Authentisierungsprotokolle gegeben. Daraus ergibt sich,dass für die Arbeit symmetrische Kryptogra�e eingesetzt wird. Unterstützt wird dies auchdadurch, dass passive Tags existieren und zu kaufen sind, die symmetrische Kryptographiebeherrschen.
Eigenschaft ohne herkömmlicheKrypt.
symmetrischeKrypt.
asymmetrischeKrypt.
Sicherheit − + +Geschwindigkeit + o −Einfachheit + o −Eignung − + −/ o
Tabelle 3.2: Authentisierungsverfahren
Auf Basis des Authentisierungsdienstes können jetzt die anderen Sicherheitsdienste rea-lisiert werden.Die Datenintegrität kann auf herkömmliche Weise geregelt werden. Für jedes Datum
kann eine Prüfsumme erstellt und gespeichert werden, damit im Nachhinein geprüft werdenkann, ob die Daten manipuliert wurden. Eine Verbesserung zur Prüfung der Datenintegritätwird in Abschnitt 4.4 dargestellt, weil bei der Sicherung relativ kleiner Datenmengen mitjeweils einer extra Prüfsumme relativ viel Speicherplatz benötigt wird.
2008-01-16/010/INF02/2253 39

3 Ausgangspunkt
Damit nicht beliebige Teilnehmer die Daten durch Überschreiben der Prüfsumme un-gültig machen, oder Daten überschreiben und auslesen können, muss der SicherheitsdienstZugri�skontrolle realisiert werden. Hierfür eignen sich die herkömmlichen Verfahren, wie dieZugri�skontrolllisten. Die Verwaltung der Rechte erfolgt dabei mit der Role-Based-AccessControl. Die Zugri�skontrolle wird im separaten Abschnitt 4.3 genauer erläutert.Der Sicherheitsdienst Vertraulichkeit kann durch die Verschlüsselung aller Daten erreicht
werden. Hierbei ist zusätzlich zur Verschlüsselung der Kommunikation über das Funkin-terface auch die verschlüsselte Speicherung der Daten auf dem Tag oder in der Datenbankgemeint. Damit können nur Partner mit den korrekten Schlüsseln die Informationen ausden Daten erhalten.Es ergibt sich die Frage ob mehrere Tags gleiche Schlüssel für die Verschlüsselung der
Daten und Schlüssel zur Ermöglichung der Kommunikation benutzen können und dannein Group-Key-Managements dieser Schlüssel möglich ist. Da im Einsatzszenario der Aus-tausch von Schlüsseln nur sehr begrenzt möglich ist, weil auf Tags relativ lange nichtzugegri�en wird und damit kein Austausch möglich ist, ist es nicht sinnvoll, Gruppen-schlüssel zu wählen. Somit sind alle auf dem Tag gespeicherten Schlüssel individuell, damitbei der Kompromittierung eines Schlüssels kein Austausch der Schlüssel auf anderen Tagsnotwendig ist. Eine Optimierung für das betrachtete Einsatzszenario ist im Abschnitt 4.5zu lesen.Es bleibt als letztes Problem der Sicherheitsdienst Nicht-Abstreitbarkeit/Zurechenbar-
keit. Es ist die Frage ob ein solcher Dienst sinnvoll ist. Er dient zum Nachweis von vorge-nommenen Operationen. Wenn jedoch ein Nachweis für Personen auÿerhalb des Systemsmöglich sein soll wird ist ein externer vertrauenswürdiger Dritter notwendig. Für den Be-nutzung innerhalb der Teilnehmer ist die Nachweisbarkeit nicht wirklich sinnvoll. Auÿerdemist dieser Dienst zurzeit nicht sinnvoll realisierbar. Der Tag kann zurzeit keine asymmetri-sche Kryptographie und auch die Speicherung der Signaturen auf dem Tag ist auf Grundder beschränkten Kapazität des Tags nicht möglich. Lösungen für dieses Problem sind nurbei der Speicherung aller Daten in einer globalen Datenbank möglich, wo jedes Lesege-rät die Änderung der Daten mit einer Signatur bestätigen kann. Dafür wäre dann einePublic-Key Infrastruktur und viel Speicherplatz in den Datenbanken notwendig.
3.4.2 Pseudoanonymisierung
Um ein Verfolgen von Tags zu verhindern, existieren verschiedene Verfahren. Sie basierendarauf, dass der Tag nie seine richtige ID nach auÿen gibt und somit nicht verfolgt werdenkann. Im Folgenden wird auf drei verschiedene Verfahren eingegangen, die von Bedeutungsind, wobei das erste Verfahren nur den Beginn der Entwicklung zeigen soll. Ein weiteresVerfahren, das KILL Kommando [3] für die RFID Tags, sei hier ebenfalls erwähnt. Sobaldein RFID Tag das KILL Kommando erhält, deaktiviert sich der Tag selbst. Er reagiert dannnicht mehr auf Ausleseversuche. Ab diesem Zeitpunkt kann man somit den Tag nicht mehrverfolgen. Bis dahin arbeitet der Tag aber normal und gibt immer seine reale ID herausund ist somit nicht anonym. Das KILL Kommando ist zum Beispiel sinnvoll, wenn einProdukt in der Produktionskette verfolgt werden soll, aber ab einem bestimmten Zeitpunkt,zum Beispiel dem Verkauf, nicht mehr. Dann kann der Tag mit dem KILL Kommandodeaktiviert werden. Das Problem dabei ist, dass das Kommando nicht umkehrbar sein darfund somit ist man auf die Korrektheit der Implementierung des Herstellers angewiesen.Eine endgültige Lösung zur Deaktivierung des Tag ist dann gleich die physische Zerstörungvon Teilen des Tags, zum Beispiel durch ein sehr starkes Magnetfeld.
Hash-Lock Das Hash-Lock Verfahren [30] ist mehr ein Verfahren zur Authentisierung alseines für die Anonymisierung. Es wird hier dargestellt, weil es der Beginn der Entwicklungvon Pseudonymisierungsverfahren war. Bei dem Verfahren ist ein Tag immer in einem von
40 2008-01-16/010/INF02/2253

3.4 Ansätze zur Lösung der Sicherheitsprobleme
zwei Zuständen. Nur im zweiten Zustand ist ein Zugri� auf die reale ID des Tags und denTag selbst möglich. Der erste Zustand dient dabei zur Authentisierung. In dem Zustandgibt der Tag nur seine Pseudo ID heraus. Diese besteht aus dem Hash von dem zum Taggehörenden Schlüssel. Das Lesegerät erhält nun die Pseudo ID und ermittelt den zugehöri-gen Schlüssel, mit Hilfe der ihm bekannten Schlüssel aller Tags. Den ermittelten Schlüsselschickt das Lesegerät an den Tag. Der Tag überprüft nun mit Hilfe der Hashfunktion, obder gesendete Schlüssel zum gesendeten Hash passt. Anschlieÿend ist der Tag im zweitenZustand und verhält sich wie ein ungeschützter Tag. Sobald der Tag nicht mehr in demFeld des Lesegerätes ist, schaltet es in den gesperrten Zustand. Wie man sieht, gibt derTag seine reale ID ohne Authentisierung nicht heraus, dafür immer seine gleiche PseudoID. Damit ist der Tag dann verfolgbar. Die praktische Realisierung der Pseudoanymisie-rung ist dabei leicht möglich. Das Lesegerät muss nur Zugri� auf eine Datenbank haben,in der die Zuordnung Hash(K) und K steht. Das Lesegerät muss dann Hash(K) suchen,um dann K zu erhalten, welches es an den Tag senden muss. Eine andere Möglichkeit istdas Ausprobieren des richtigen Schlüssels, indem nacheinander alle bekannten Schlüsselgehasht werden und das Ergebnis mit dem gesuchten Hash verglichen wird. Dies ist jedochnicht e�zient.Es wurde schnell erkannt, dass das Verfahren keine vollständige Anonymisierung ermög-
licht und so entstanden Modi�kationen des Verfahrens, bei denen die Pseudo ID wechselte.Ein Beispiel dafür ist der Randomized Hash Lock [30]. Das Verfahren ist wie beim norma-len Hash-Lock, nur die Pseudo ID wird anders gebildet. Die Bildung erfolgt auch aus demAnwenden einer Hashfunktion. Die Daten dafür sind jedoch nicht nur ein Schlüssel, sondernauch eine Zufallszahl. Damit ändert sich die Pseudo ID immer. Damit das Lesegerät denSchlüssel zum Tag ermitteln kann, sendet der Tag dann zusätzlich zum Hash auch die inden Hash einge�ossene Zufallskomponente. Da die Hashfunktion nicht umkehrbar ist, kannman den Tag nicht verfolgen, wenn nicht der Schlüssel des Tags bekannt ist. Die prakti-sche Realisierung ist für eine groÿe Anzahl von Tags schwierig möglich. Da eine sehr groÿeAnzahl von Zuordnungen Hash(K, R) zu K existiert, muss das Lesegerät immer für allebekannten Schlüssel die Hashfunktion mit Hilfe der gesendeten Zufallszahl ausprobieren,bis der entsprechende Schlüssel gefunden wurde. Das ist bei groÿen Datenmengen nichtmehr e�zient möglich.
Hash-Ketten Ein Grundverfahren zur Verhinderung der Verfolgung vom RFID Tags istdas bilden von Hash-Ketten. Bei jedem Auslesen des Tags wird dabei eine neue Pseudo IDgebildet. Die Bildung erfolgt dabei durch ein bestimmtes Anwenden der Hashfunktion aufdie aktuelle Pseudo ID. Das Problem hierbei ist die Länge der Hash-Ketten. Diese sindpotenziell sehr lang und können nicht komplett gespeichert werden. So muss das Lesegerätzu einem erkannten Hash versuchen die reale ID zu ermitteln, um mit der Kommunikationfortzuführen. Dafür existieren einige Verfahren, die mit erhöhtem Speicheraufwand denVorgang gegenüber einfachem Ausprobieren erheblich beschleunigen können [4]. Dabei wirddavon ausgegangen, dass der Zugri� auf einzelne Teildaten sehr schnell erfolgt, was nur imHauptspeicher gewährleistet ist. Je nach Verfahren sind verschiedene Sicherheitskriterienerfüllt. Im einfachsten Fall kann aus der aktuellen Pseudo ID nicht eine vorherige PseudoID ermittelt werden und somit ist es nicht möglich festzustellen, wo der Tag vorher war. Beieinfachem Hashing ist es jedoch möglich aus der aktuellen Pseudo ID die nächste PseudoID zu ermitteln und somit den Tag in der Zukunft zu verfolgen. Das wurde erkannt undso entstand folgendes Verfahren [20]. In Abbildung 3.5 ist die Vorgehensweise zu sehen.Das Verfahren verwendet zwei verschiedene Hashfunktionen. Der Tag speichert seinen
inneren ID Status si. Diesen verwendet er jedoch nicht als Pseudo ID. Die Pseudo ID wirdaus dem inneren Zustand mit Hilfe der Hashfunktion G ermittelt. Nach dem verwenden derPseudo ID ai wird der innere Zustand durch die Hashfunktion H neu gesetzt. Daraus wird
2008-01-16/010/INF02/2253 41

3 Ausgangspunkt
Abbildung 3.5: Hashing Schema für Berechnung Pseudo ID [20]
dann mittels G wieder die aktuelle Pseudo ID errechnet. Der Vorteil des Schemas gegenübereinem normalen Hashing ist, dass zusätzliche Sicherheit in Bezug auf das einfache Verfahrenbesteht. Neben der nicht vorhandenen Möglichkeit des Ermittelns von alten Pseudo IDdurch die Nichtinvertierbarkeit von G und H, kann auch von der aktuellen Pseudo ID ainicht auf die nächste Pseudo ID ai+1 geschlossen werden. Das ist nicht möglich, weil dazuder interne Zustand si des Tag notwendig ist. Dieser wird vom Tag nicht ausgegeben und dieHashfunktion ist nicht invertierbar. Durch die Unkenntnis von si kann auch nicht si+1 undsomit die nächste Pseudo ID ai+1 ermittelt werden. Das ist nur möglich, wenn der Angreifereinen Zustand sx des Tag, zum Beispiel durch physisches Auslesen, erhält. Dann ist esmöglich, alle folgenden Pseudo ID des Tag ab dem Zustand si zu ermitteln. Problematischist bei dem Verfahren, dass die Authentisierung, wie bei dem reinen Hashverfahren vorallem bei einer groÿen Anzahl von Tags sehr aufwendig ist.
Speicherung von mehren Pseudo ID Eine weitere Möglichkeit der Pseudoanonymisie-rung ist neben den genannten Verfahren das Speichern von mehreren Pseudo ID auf demTag. Ein Tag erhält dabei bei der Initialisierung einen Satz von zufällig generierten PseudoIDs. Dieser Satz von Daten wird ebenfalls auf einem Server gespeichert. Bei jedem Auslese-versuch gibt der Tag dann aus den gespeicherten Daten eine ID als seine aktuelle Pseudo IDaus. Da die Daten zufällig generiert sind, besteht kein Zusammenhang zwischen verschie-denen Pseudo ID. Damit ist der Tag prinzipiell nicht verfolgbar. Das Problem ist jedoch,dass nur endlich viele IDs auf den Tag gespeichert werden können. Eingeschränkt wird dieAnzahl der speicherbaren Pseudo ID durch den stark beschränkten Speicherplatz auf denRFID Tags. Da die Anzahl der Pseudo ID beschränkt ist, ist die Anzahl der möglichenAuthentisierungen begrenzt. Eine Lösungsmöglichkeit ist die Wiederverwendung der be-reits verbrauchten Pseudo ID, wenn keine Nichtverwendeten zur Verfügung stehen. Damitergibt sich ein Zyklus. Ist dieser einmal ermittelt wird der Tag verfolgbar. Zur Abmilderungdes Problems kann der Tag bei jeder erfolgreichen Authentisierung einen neuen Satz IDserhalten, der die verbrauchten IDs ersetzen. Damit ist der Tag aber immer noch zwischenzwei erfolgreichen Authentisierungen verfolgbar. Das Verfahren ist im Gegensatz zu denanderen Verfahren nicht rechenintensiv. Zur Authentisierung benötigt das Lesegerät eineVerbindung zu der Datenbank, wo die Pseudo ID der Tags gespeichert sind. Die Ermittlungder realen ID des Tags funktioniert dann auf folgende Weise. Das Lesegerät sucht dannin der Datenbank die vom Tag übermittelte Pseudo ID. Wenn der Eintrag gefunden ist,erhält das Lesegerät sofort die zugehörige ID. Das Verfahren erfordert zwar keine aufwen-digen Berechnung aber viel Speicherplatz, da zu jedem Tag alle ausgegebenen Pseudo IDgespeichert werden müssen. Für eine sehr groÿe Anzahl von Tags scheint die grundsätzlicheVerwendung dieses Verfahren vorteilhaft. Es wird zwar insgesamt viel Speicherplatz auf den
42 2008-01-16/010/INF02/2253

3.4 Ansätze zur Lösung der Sicherheitsprobleme
Servern benötigt, jedoch ist die Zuordnung der Pseudo ID zur realen ID des Tag nur durcheinen Zugri� auf die Datenstruktur notwendig, ohne viele Berechnungen durchzuführenwie bei der Hash-Kette durchzuführen. Damit skaliert das Verfahren mit der Anzahl derTags relativ gut.Die verschiedenen Verfahren der Pseudoanonymisierung haben verschiedene Eigenschaf-
ten, die den möglichen Einsatz beein�ussen. Die Tabelle 3.3 gibt eine zusammenfassendeSicht auf die relevanten Eigenschaften.
Eigenschaft Hash-Lock Hash-Kette (normal/opt.) Speicherung Pseudo ID
Anonymisierung - + oSpeichere�zienz + +/o -/oRechene�zienz + -/o +Skalierbarkeit o/+ -/o +
Eignung - o +
Tabelle 3.3: Pseudoanonymisierung
Wie die Tabelle zeigt ist Hash-Lock zur Anonymisierung ungeeignet. Die beiden einzelnenVerfahren Hash-Kette und Speicherung mehrerer Pseudo ID haben jeweils spezielle Vor-und Nachteile. Der Einsatz eines Verfahrens ist im Szenario nicht sinnvoll. In Abschnitt4.2 wird gezeigt, wie das verwendete Verfahren, eine Kombination der beiden Verfahren,die Vorteile vereint und die Nachteile ausgleicht.
3.4.3 Zugri�skontrolle
Für die Verwaltung der später realisierten Rechte muss ein geeignetes Verfahren benutztwerden. Für diesen Zweck wurden drei verschiedenen Verfahren entwickelt. Zum einen dieDiscretionary Access Control, die Mandatory Access Control und zum dritten die Role-Based Access Control [10].Bei der Discretionary Access Control können die Anwender die Rechte für die eigenen
Objekte beliebig setzen. Damit ist es eine lokale Rechteverwaltung. Problematisch daranist, dass keine zentrale Kontrolle und Setzung der Rechte möglich ist. In dem Einsatz-szenario ist das nicht vertretbar, weil durch Änderung der Zugri�srechte ein zusätzlicherInformations�uss möglich wird. Auch können gut gemeinte Änderungen nicht beabsichtigteNebenwirkungen haben, wenn die Änderung nicht gut bedacht ist. Deshalb ist diese Artder Rechteverwaltung für das Einsatzszenario nicht geeignet.Bei der Mandatory Access Control werden die Rechte auf die Objekte global festgelegt,
damit ist es eine globale Rechteverwaltung. An einer zentralen Stelle wird bestimmt, werwelche Zugri�srechte hat. Die Rechte können von den Parteien nicht geändert werden.Eine Änderung ist nur über die globale Instanz möglich. Damit erfolgt die Verwaltungzentral. Bei Änderungen kann die zentrale Instanz den Wunsch der Änderung des Rechtsmit entsprechenden Modellen prüfen, ob der Änderungswunsch berechtigt ist und dabeikeine nicht gewünschten Informations�üsse entstehen. Wenn alle Kriterien erfüllt sind,wird das Recht geändert. Diese Art der Verteilung scheint optimal für das Einsatzszenario.Problematisch dabei ist aber, dass die Rechte für jedes einzelne Subjekt de�niert undverwaltet werden müssen.Die dritte Art der Verteilung der Rechte ist die Role-Based Access Control. Die Rech-
teverwaltung erfolgt hier global. Jedes teilnehmende Subjekt kann verschiedene Rollenausführen, die verschiedene Rechte ermöglichen. Die jeweils gewünschten Operationen sinddie Transaktionen. Die Ermittlung der Rechte basiert auf der Benutzung von Rollen fürdie Transaktionen. Für jede Rolle und Transaktion wird bestimmt, ob die Rolle die Trans-aktion ausführen kann. Zu einer Zeit kann ein Subjekt nur eine aktive Rolle haben. Wenn
2008-01-16/010/INF02/2253 43

3 Ausgangspunkt
ein Subjekt einen Zugri� ausführen will, entspricht das einer Transaktion. Das Subjektwählt seine aktive Rolle aus und es wird vom System geprüft, ob die Transaktion mir dergewählten Rolle erlaubt ist.Die Role-Based Access Control vereinfacht die Verwaltung der Rechte gegenüber der
beiden anderen System erheblich. Im System existieren viele verschiedene Tags mit vielenDatenbereichen mit unterschiedlichen Rechten. Zusätzlich nehmen viele unterschiedlicheParteien mit sehr vielen Lesegeräten teil. Daraus ergibt sich eine Vielzahl von möglichenRechten. In der Realität sind jedoch viele der Rechte gleich. Damit entsteht bei herkömm-licher Verteilung der Rechte ein enormer Aufwand mit hohem Fehlerpotential. Eine Ver-einfachung entsteht daraus, dass viele gleichartige Tags existieren. So sind zum Beispiel dieverschiedenen Tags an demselben Produkt gleich. Deshalb ist es sinnvoll die Tags zu grup-pieren. Damit entsteht eine viel kleinere Anzahl an Gruppen. Wenn eine Transaktion aufeinem Objekt einer Gruppe erlaubt ist, ist sie es auch auf einem anderen Objekt der glei-chen Gruppe. Das Gleiche gilt für die Subjekte. Am System nehmen zum Beispiel mehrereverschiedene Transporteure teil. Die verschiedenen Subjekte sollen jedoch die gleichen odersehr ähnliche Rechte haben. Hier erfolgt wieder eine Gruppierung. Die vielen verschiedenenSubjekte werden auf wenige Rollen abgebildet. Somit muss für die Verteilung der Rechtenach Erstellung der Rollen und Transaktionen nur die Kombination Rolle zu Transaktionerlaubt oder verweigert werden. Damit ist es auch einfach möglich, neue Subjekte oderTags hinzuzufügen. Die Subjekte müssen den Rollen zugeordnet werden und die Tags einerGruppe, die für die Transaktionen notwendig sind. Eine Änderung der Rechte selbst �ndetdabei nicht statt. Durch die geringe Fluktuation der Rechte ist die Verwaltung der Rechtekonsistent und wenig fehleranfällig möglich.
3.5 Auswahl der RFID Technologie
Wie in Abschnitt 2.3 gezeigt, existieren für RFID Tags grundsätzlich zwei verschiedeneBetriebsmodi. Zum einen können die Daten nur im Netz gespeichert werden und der Tagbesitzt nur eine ID (Data-on-Network). Die andere Möglichkeit ist, dass alle Daten auf demTag gespeichert sind und keine Daten im Netz (Data-on-Tag). Es besteht auch die Möglich-keit die beiden Verfahren zu kombinieren, damit einige Daten ohne Netzzugri� auslesbarsind. Die bisherigen Forschungen sind hauptsächlich auf dem Gebiet der Speicherung derDaten im Netz vollzogen worden. Dies wurde dadurch unterstützt, dass in dieser Betriebs-art der Barcode einfach ersetzt werden kann und daran, dass die Tags relativ preiswert sind.Sobald jedoch Sicherheitsfunktionen, wie Pseudoanonymisierung integriert werden, werdendie Tags auch teurer. Entweder wird mehr Speicherplatz auf dem Tag benötigt oder mehrBerechnungsfunktionen. Da in Zukunft die Kosten für intelligentere Tags sinken werden,sind die Kosten zunächst nicht der entscheidende Faktor. Die Verwendung der Betriebs-art Data-on-Tag hat verschiedene Vorteile, die in Abschnitt 3.3 besprochen wurden. DieseVorteile und die kaum existierenden Publikationen in der Betriebsart haben dazu geführt,dass für diese Arbeit RFID Tags in der Betriebsart Data-on-Tag verwendet werden. Wennetwas anderes gilt, wird das extra angeführt. Die vorausgesetzte Funktionalität des Tagsist folgende: Der Tag ist ein passiver Tag, der keine integrierte Energiequelle hat. Der Taghat einen wiederbeschreibbaren Speicher, der die Daten auch nach Verlust der Energiever-sorgung erhält. Des Weiteren kann der Tag einfache arithmetische Funktionen berechnen.Eine wesentliche Eigenschaft ist die Unterstützung von symmetrischer Kryptographie. Mitder symmetrischen Kryptographie ist die Realisierung eines Zufallszahlengenerators undeiner Hashfunktion möglich. Der Tag beherrscht asymmetrische Kryptographie nicht, dadas bei passiven Tags nicht sinnvoll möglich ist.Für die mögliche praktische Realisierung der Arbeit wurde ein passender Tag gesucht, da-
mit die Ergebnisse relativ leicht realisiert werden können. Eine Recherche ergab, dass von
44 2008-01-16/010/INF02/2253

3.6 Zusammenfassung
verschiedenen Herstellern wie EM Microelectronic, In�neon, NXP Semiconductors (ehe-mals Philips), STMicroelectronics und Texas Instruments viele einfache Tagtypen existie-ren. Sobald jedoch Tags mit mehr Funktionalität notwendig sind, existieren diese zur Zeitnur von NXP. Diese Abspaltung von Philips entwickelt und produziert die am weitestenentwickelten RFID Tags. Für die Realisierung der Arbeit kommen zwei verschiedene Tagsin Frage. Das sind der NXP Mifare DESFire8 [18] und der NXP Mifare Pro X [19]. Der ersteTag kann dabei jedoch nur Grundfunktionalitäten realisieren. Das sind die Zugri�skontrolleund die verschlüsselte Speicherung der Daten mit Wahrung der Integrität. Der Grund da-für ist die fehlende Flexibilität des Tags durch die feste Programmierung. Der Tag arbeitetnach ISI 14443 im 13,56 MHz Band. Er unterstützt DES. Die möglichen Zugri�srechte aufTeilbereiche sind Lesen, Schreiben und die Rechte ändern. Der Tag besitzt ein integriertesAuthentisierungsprotokoll, welches jedoch nicht o�en gelegt ist. Damit ist es nicht möglichfestzustellen, wie sicher dieses ist. Der Tag besitzt, je nach Modell, ein bis vier Kilobytenicht �üchtigen Speicher. Das vier Kilobyte Modell kostet dabei pro Stück circa $1,30.Der andere und für die Arbeit besser geeignete Tag ist der NXP Mifare Pro X. Er hat diegleiche Funktionalität und Parameter, wie der Mifare DESFire. Ein Hauptunterschied istdie Möglichkeit der freien Programmierung des Betriebssystems des Tags. Damit könnendann fast alle gewünschten Funktionen selbst realisiert werden. Ein weiterer Unterschiedsind die verfügbaren Kapazitäten. Es gibt Modelle mit 4, 8 oder 16 Kilobyte Speicher. DasBetriebssystem ist dabei in einem separaten ROM gespeichert. Der Tag funktioniert auchals kontaktbehaftete Smartcard. Die Funktionalität ist aber in beiden Modi gleich. Durchden gröÿeren Hardwareaufwand kann der Tag asymmetrische Kryptographie, jedoch sinktder Ausleseabstand auf maximal zehn Zentimeter und die Kosten steigen. Damit kann derTag zwar für eine Demonstration genutzt werden, aber ist für den Masseneinsatz nicht ge-eignet. In der Arbeit würde der asymmetrische Teil für die prototypische Implementierungnicht benötigt. Für den realen Einsatz mit einer Stückzahl von mehreren Milliarden würdeein angepasster Chip entwickelt, der die gewünschten Anforderungen erfüllt und trotzdempreiswert ist. Aus diesen Gründen würde die prototypische Realisierung der Arbeit aufeinem NXP Mifare Pro X erfolgen.
3.6 Zusammenfassung
In diesem Kapitel wurde zunächst ein abstraktes Szenario beschrieben, dass das Zielein-satzgebiet der RFID Technologie dieser Arbeit beschreibt. Durch das Szenario entstehendann die Anforderungen und damit die Ziele des Systems. Die Sicherheit des Systems mussgewährleistet sein, damit nicht unberechtigte Personen Informationen gewinnen können.Es dürfen dabei auÿenstehende Personen und Angreifer keine verwertbaren Informationenerhalten, zum Beispiel Bewegungspro�le. Am System beteiligte Personen dürfen dagegenauf Informationen zugreifen. Jedoch darf kein Zugri� auf Informationen möglich sein, aufdie der Teilnehmer keine Rechte hat. Aus den Zielen wurden dann die einzelnen Sicher-heitsaspekte des gesamten Systems untersucht. Dabei wurden auf die Sicherheitsproblemeinnerhalb eines Unternehmens eingegangen. Zusätzlich wurden auch die Probleme zwischenden verschiedenen teilnehmenden Parteien betrachtet, da diese Beziehungen untereinanderein wesentlicher Faktor bei der Entwicklung einer Lösung für das Szenario ist. Neben denallgemeinen Problemen wurden danach speziell die Probleme der RFID Technologie bezüg-lich der Betriebsart der Tags betrachtet. Dabei hat die jeweilige Betriebsart unterschiedlicheVor- und Nachteile, die für einen praktischen Einsatz abgewogen werden müssen. Nachdemdie Probleme bekannt sind, wurden mögliche Lösungen aus der Literatur für die Problemedargestellt. Dabei ist festzustellen, dass für die Anonymisierung, die Integritätssicherungund die Zugri�skontrolle keine Lösungen existieren, die die Anforderungen vollständig er-füllen. Deshalb muss für diese Probleme eine geeignete Lösung entwickelt werden, die in der
2008-01-16/010/INF02/2253 45

3 Ausgangspunkt
Kombination mit einem zu entwickelnden Kommunikationsprotokoll die Ziele des Systemslöst. Zum Schluss wurde erläutert welcher Typ von RFID Tag generell in dieser Arbeitverwendet wird und welcher konkrete Tag für eine praktische Realisierung genutzt werdenkönnte.
46 2008-01-16/010/INF02/2253

4 Protokoll und Systemaufbau
Zur Lösung der qualitativen Fragestellungen aus Abschnitt 3.2 werden die verschiedenSicherheitsziele betrachtet. Zunächst wird ein Verfahren entwickelt, welches die Anonymi-sierung sicherstellt und trotzdem das Au�nden von verlorenen oder angegri�enen Tagsermöglicht. Danach wird gezeigt, wie ein wirksame Zugri�skontrolle möglich ist. DamitVeränderungen der Daten erkannt werden können, wird gezeigt wie die Datenintegritätsichergestellt werden kann. Die Fragen, wie die Kommunikation der Teilnehmer unterein-ander sicher ermöglicht ist, und wie es möglich ist, dass das Lesegerät nicht die reale IDdes Tag erhält und wie die Authentisierung ermöglicht wird, wird im Protokoll gezeigt.
4.1 Systemaufbau
Durch die Ziele ist der Aufbau des Systems begründet. Für die Anonymisierung ist es not-wendig, dass ein Teil des Systems die Zuordnung der Pseudo ID zur realen ID des Tagsvornimmt. Das ist notwendig, damit die individuellen Schlüssel, welche für die Berech-nung der neuen Pseudo ID oder den Zugri� auf die Daten notwendig sind, für den Tagbestimmt werden können. Die Stelle ist der globale Authentisierungsserver. Die Daten zurZuordnung sind damit zwar in Servern im Netz gespeichert, jedoch werden die Nutzda-ten auf den Tags direkt gespeichert. Der Server ist für die Zuordnung der realen ID zurPseudo ID zuständig. Das wird jedoch nur vollzogen, wenn ein authentisierter Teilnehmerdas Recht hat auf den Tag zuzugreifen. Weiter berechnet es auch die nächsten Pseudo IDdes Tags. Zusätzlich stellt der Server ein zeitlich begrenztes Ticket für den authentisiertenTeilnehmer für den Autorisierungs-/Keyserver aus. Die Idee dafür ist aus Kerberos [27].Der Autorisierungs-/Keyserver ist für die Verwaltung der individuellen Schlüssel für dieTags in seinem Zuständigkeitsbereich verantwortlich. Der Autorisierungs-/Keyserver gibtdie Schlüssel jedoch nur heraus, wenn ein authentisierter Teilnehmer eine entsprechendeAnfrage an den Autorisierungs-/Keyserver stellt und der Server feststellt, dass der Teil-nehmer dies darf. Der Autorisierungs-/Keyserver ist somit Teil der Zugri�skontrolle. DieTeilung der Aufgaben zwischen Autorisierungs-/Keyserver und Authentisierungsserver hatverschiedene Gründe. Erstens wird durch das Modell der notwendige Aufwand pro Authen-tisierung auf verschiedene Server verteilt. Der Authentisierungsserver kann dabei die Auf-gaben auf die verschiedenen Autorisierungs-/Keyserver verteilen. Mehrere Autorisierungs-/Keyserver haben neben der Verteilung der Aufgaben den Vorteil, dass immer die für dieTags zuständige Institution für den Betrieb der eigenen Server verantwortlich ist. Zusätz-lich hat die Teilung der beiden Aufgaben den Vorteil, dass die Authentisierung und dieZugri�skontrolle getrennt sind und somit nicht an einer Stelle alle Informationen gespei-chert sind, so dass die Betreiber der Server nicht einen zentralen Zugri� auf alle Datenhaben um daraus Informationen zu gewinnen. Die Parallelisierung der Authentisierungs-server ist auch wünschenswert, aber nicht so einfach realisierbar, da die Pseudo ID wegender Anonymisierung unstrukturiert sind. Ein Backup des Authentisierungsserver ist jedochrelativ einfach möglich. Deshalb wird hier angenommen, dass nur ein Authentisierungsser-ver existiert. Der Aufbau ist nochmals in Abbildung 4.1 zu sehen.In der Abbildung sind der Authentisierungsserver, die Autorisierungs-/Keyserver, die
Lesegeräte und die Tags zu sehen. Die dargestellten Verbindungen sind die Kommunika-tionswege. Wie zu sehen ist, ist keine direkte Kommunikation des Tags mit einem Servermöglich. Durch die Übertragung der Daten über Funk zwischen Tag und Lesegerät muss
2008-01-16/010/INF02/2253 47

4 Protokoll und Systemaufbau
Abbildung 4.1: Prinzipieller Systemaufbau
das Lesegerät immer als Relay für die Kommunikation dienen. Auch ist keine direkte Kom-munikation zwischen dem Authentisierungsserver und Autorisierungs-/Keyserver vorgese-hen. Der Grund dafür ist, dass die beiden Server nicht abhängig voneinander arbeiten.Die einzige Verbindung ist das Ticket vom Authentisierungsserver für den Autorisierungs-/Keyserver. Dieses kann jedoch ohne zusätzlichen Aufwand über das Lesegerät versendetwerden.
4.2 Anonymisierung
Die RFID Tags sind im realen Einsatz auf beweglichen Produkten. Durch das Auslesender Tags auf den Produkten können auch ohne zu wissen, welche Daten gespeichert sind,Informationen gewonnen werden. Die daraus erstellten Bewegungspro�le können vertrauli-che Informationen aufdecken. Die Erstellung der Pro�le muss verhindert werden. Das wirddurch die Pseudoanonymisierung gewährleistet.In Abschnitt 3.4.2 wurden die beiden grundlegenden Verfahren dargestellt. Zum einen
die Hash-Ketten und zum anderen die Speicherung der Pseudo ID auf dem Tag. Wün-schenswert ist die Verwendung der Hashketten, da das maximale Sicherheit gewährleistet.Im Betrieb können die Ketten aber beliebig lang werden. Ohne Angri�e kann das Problemder Länge der Ketten damit gelöst werden, dass in der Datenbank immer der aktuell ver-wendete Wert als Startwert gespeichert wird. Damit muss bei einem Zugri� nicht immerdie gesamte Kette durchsucht werden, sondern es kann direkt bei der letzten bekanntenStartposition mit der Suche gestartet werden. Das ist jedoch sehr aufwendig, da immerfür alle Tags ausprobiert werden muss, ob der Hash des Datenwertes die aktuelle PseudoID ist. Nach einem Angri� müssen möglicherweise tausende von Pseudo IDs für einen Tagberechnet werden, um die ID des Tags zu erhalten. Die Tiefe muss jedoch mit allen Tagserreicht werden. Damit ist das Verfahren sehr langsam und sehr anfällig für Denial-of-Service Angri�e. Es existieren zwar Verfahren zur Beschleunigung, jedoch sind diese nurbei der Speicherung der Pseudo ID im Arbeitsspeicher sinnvoll möglich. Deshalb wird ein
48 2008-01-16/010/INF02/2253

4.2 Anonymisierung
modi�ziertes Hash Verfahren verwendet. Das beinhaltet zwei verschiedene Phasen, einernormalen Phase und einer Resynchronisierungsphase. Die erste Phase besteht komplettaus einer Hashkette. Die Art der Berechnung der Kette ist
PseudoIDneu = HMACK(PseudoIDalt)
Der dabei verwendete Schlüssel ist für jeden Tag verschieden und nur der Tag und derAuthentisierungsserver besitzen den Schlüssel. Die Konstruktion ist anders als in Abschnitt3.4.2. Dort tritt ein Problem auf, wenn beim inneren Zustand eine Kollision auftritt. Dannsind alle nachfolgenden Pseudo IDs gleich. Um das zu verhindern �ieÿt hier in die PseudoID eine für jeden Tag unterschiedliche Komponente ein, der individuelle Schlüssel. Damitist bei einer Kollision nur eine Pseudo ID gleich, die nachfolgenden sind dann wiederunterschiedlich, da die Schlüssel der Tags unterschiedlich sind. Der innere Zustand, welcherhier der Schlüssel ist, wird zwar nicht geändert, jedoch hat das keine Auswirkung auf dieMöglichkeit der Ermittlung der Pseudo ID von einem Angreifer. Dem Angreifer ist es nichtmöglich, aus der aktuelle Pseudo ID die nächste Pseudo ID zu berechnen, weil der Angreiferden Schlüssel nicht hat. Weiterhin ist es durch die Hashfunktion nicht möglich, bereitsverwendete Pseudo IDs zu ermitteln. Das gelingt selbst dann nicht, wenn es dem Angreifergelingt den Schlüssel für den Tag zu ermitteln, zum Beispiel durch physisches Auslesen desTags. Wenn der Angreifer den Schlüssel des Tags hat, kann er jedoch alle nachfolgendenPseudo ID des Tags ermitteln. Das ist das gleiche Problem, wie in der anderen Version,wenn der Angreifer den variablen inneren Zustand des Tags kennt. Die Ermittlung dernachfolgenden Pseudo IDs ist aber nur bei diesem einen Tag möglich, da die Schlüssel fürjeden Tag individuell sind. Falls eine Kompromitierung bekannt wird, kann der Schlüsselbei der nächsten Authentisierung des Tag ausgetauscht werden. Es muss dann aber davonausgegangen werden, dass der Tag über die Zeit seit der letzten Änderung des Schlüsselsverfolgt werden konnte.In der ersten Phase wird nach jedem Zugri� oder nach einer de�nierten Zeit des Zugri�s
immer eine neue Pseudo ID generiert. Dabei ist vollständige Anonymität gewährleistet. DieZuordnung der Pseudo ID zu der realen ID wird im Authentisierungsserver gespeichert.Da keine unendliche Menge Speicher vorhanden ist, wird nur eine wählbare Anzahl vonZuordnungen gespeichert. Durch die Speicherung von mehr als einer Zuordnung pro Tagkönnen gelegentliche Fehler, wie die Unterbrechung der Kommunikation, bei den Authen-tisierungsvorgängen korrigiert werden. Wenn der Authentisierungsserver keine Zuordnungvon der Pseudo ID �ndet, beginnt die zweite Phase des Protokolls. Dieser Fall kann auf-treten, wenn zu viele Fehler entstanden sind oder ein Angri� auftrat, der das Ziel hattedie Pseudo IDs zu erschöpfen. In dieser Phase erfolgt die Resynchronisierung. Dieser Teilbasiert auf der Idee der Speicherung der Pseudo ID. Jedoch erfolgt die Speicherung nichtdirekt. Der Vorgang ist der gleiche wie im ersten Teil, nur die Pseudo ID wird anders be-rechnet. Damit bei der Resynchronisierung keine Erschöpfung auftreten kann, werden dieverschiedenen Pseudo ID als Zyklus angelegt. Bei jeder Resynchronisierungsanfrage wirddie nächste Pseudo ID des Zyklus herausgegeben. Die Berechnung der Zyklus erfolgt wiefolgt.
PseudoID = HMACK(feste Zufallszahl, Zaehler)
Zaehler = (Zyklusnummer + 1) modulo Zykluslaenge
Der Schlüssel K kann dabei der gleiche sein wie bei der normalen Berechnung der PseudoID. Der Zähler wird dabei bei jeder neuen Anfrage um eins erhöht. Durch die Verwendungdes Modulos wird eine endliche Menge von Pseudo ID gewährleistet. Durch den Zyklus istdie Verfolgung des Tags möglich, nachdem ein Zyklus ausgelesen wurde. Um das zu erschwe-ren, ist vor der Ausgabe der nächsten Pseudo ID des Zyklus eine Wartezeit einzuhalten.Die Realisierung der Wartezeit ist durch einen Zähler im Tag, welcher bei vorhandenem
2008-01-16/010/INF02/2253 49

4 Protokoll und Systemaufbau
Feld pro Takt oder Ähnlichem hoch zählt, möglich. Die Präzision der Zeitmessung ist da-bei zweitrangig. Das Auslesen der Pseudo ID erfolgt auf folgende Weise. Ein Lesegerät willden Tag auslesen. Nachdem der Resynchronisierungsvorgang gewünscht wurde, schaltetdas Lesegerät das Feld nicht aus, bis die Wartezeit des Tags verstrichen ist. Nach dieserZeitspanne erhält das Lesegerät die aktuelle Pseudo ID des Resynchronisierungsvorgangs.Mit der Datenbank ist dann die Zuordnung der realen ID zu dieser Pseudo ID möglich.Wenn die Energieversorgung des Tags unterbrochen wird, muss bei wieder hergestellterVersorgung nochmals die gesamte Wartezeit abgewartet werden, bevor der Tag eine neuePseudo ID herausgibt. Nachdem eine Resynchronisierung erfolgreich abgeschlossen wurde,wird die zur Berechnung der Pseudo ID verwendete Zufallszahl vom Authentisierungsserverneu erzeugt und der Tag aktualisiert die Zahl auf seinem Datenspeicher. Durch fehlerhafteLesegeräte oder unvollständige Authentisierungsanfragen kann bei einem Resynchronisie-rungsvorgang nicht notwendigerweise von einem Angri� ausgegangen werden. Deshalb istes sinnvoll die Wartezeiten nicht konstant zu halten, sondern von kleinen zu groÿen Wer-ten zu steigern. Dabei kann die Wartezeit zunächst exponentiell gesteigert werden bis eineobere Grenze erreicht wird. Beispielsweise kann die Zeit wie folgt ermittelt werden.
Wartezeit = Minimum(2 · 2Zyklusnummer Sekunden, 10 Minuten)
Das Beispiel ergibt ab einer Zyklusnummer von neun die maximale Wartezeit. Es ist auchmöglich die Zeit weiter exponentiell zu steigern. Damit ergibt sich jedoch folgendes Pro-blem. Wenn eine Ware zur Reparatur kommt, soll der Tag ausgelesen werden. Wenn fürdie Wartezeit kein Maximum vorgegeben wird, muss vor der Reparatur der Ware, die dasAuslesen des Tags bedingt, eine unbestimmt groÿe Zeit gewartet werden. Das behindert dienormale Arbeit in unangemessener Weise. Das Verfolgen eines Tag ist erst dann möglich,wenn der gesamte Zyklus bekannt ist. Das dauert bei den Beispielparametern und einerZykluslänge von 15 circa eine Stunde. Je nach Wahl der Parameter kann diese Zeit beliebigvariiert werden. Die Zeit ist nur maÿgebend zwischen zwei erfolgreichen Authentisierun-gen, weil dort der Zyklus neu generiert wird. In Tabelle 4.1 ist eine zusammenfassendeBewertung des entwickelten Verfahrens im Vergleich mit den vorhandenen Verfahren ausAbschnitt 3.4.2 dargestellt.
Eigenschaft entw. Verfahren Hash-Kette Speicherung Pseudo ID
Anonymisierung +/o + oSpeichere�zienz o +/o -/oRechene�zienz + -/o +Skalierbarkeit + -/o +
Eignung + o +
Tabelle 4.1: Pseudoanonymisierung im Vergleich
Wie in der Tabelle erkennbar ist, werden durch das neu entwickelte Verfahren die Vortei-le beider Verfahren kombiniert. Dabei kommen aber die Nachteile kaum zum Tragen. DerGrad der Anonymisierung ist dabei nicht ganz so hoch, wie bei der Hash-Kette, weil die Re-synchronisierung einen Zyklus enthält, welcher, nach durch die Parameter bestimmte Zeit,das Verfolgen des Tags ermöglicht. Durch die Parameter kann aber bestimmt werden, dassdie Zeit so groÿ wird, dass das Verfolgen praktisch nicht relevant ist. Die Speicherplatz-e�zienz ist auch nur durchschnittlich. Sie ist zwar besser, als beim kompletten Speichernder Pseudo ID, aber nicht so gut wie bei der Hash-Kette, weil auf dem Server mehr Datengespeichert werden müssen. Auf dem Tag müssen nur zwei weitere Zustände, den Anfangs-zustand und die Nummer im Zyklus, gespeichert werden.
50 2008-01-16/010/INF02/2253

4.3 Zugri�skontrolle
4.3 Zugri�skontrolle
Nicht jede teilnehmende Partei darf auf alle Daten des Tags zugreifen. Es soll den Lese-geräten nur ein selektiver Zugri� ermöglicht werden, der aktuell erlaubt ist. Dafür sindim Protokoll, welches in Abschnitt 4.6 dargestellt wird, Vorkehrungen getro�en. Zunächstmuss jedoch geklärt werden, wie die Rechteverwaltung und Durchsetzung der Rechte funk-tioniert.Für die Verwaltung wurden verschiedenen Verfahren entwickelt, welche in 3.4.3 darge-
stellt wurden. Für das zu entwickelnde Konzept ist die Role-Based-Access Control die besteVersion. Sie ermöglicht die Abbildung der vielen teilnehmenden Subjekte und Rechte aufwenige Rollen und Transaktionen. Deshalb ist die Anzahl der global Festzusetzen Rechterelativ gering. Auch ist ein einfaches hinzufügen von Teilnehmern und Tags notwendig, dadie Teilnehmer nur den Rollen und die Tags in Gruppen für die Transaktionen eingeordnetwerden müssen. Damit ist eine geeignete bestehende Verwaltungsform gewählt und es musskeine neue entwickelt werden.Die Realisierung der Zugri�skontrolle, die die Rechteverwaltung umsetzen muss, erfolgt
im Zusammenspiel des Autorisierungs-/Keyserver und des RFID Tag. Der Tag übernimmtdabei die endgültige Entscheidung, ob der Zugri� erlaubt ist. Wenn ein Lesegerät Zugri� aufeinen Datenbereich wünscht, schickt es eine entsprechende Anfrage an den Autorisierungs-/Keyserver. Der Autorisierungs-/Keyserver prüft nun, ob mit der Rolle des Lesegerätsdie Transaktion erlaubt ist. Ist das der Fall, signiert der Autorisierungs-/Keyserver dieTransaktion mit dem individuellen symmetrischen Schlüssel, den nur der Autorisierungs-/Keyserver und der Tag kennt. Die Transaktion, die Signatur und weitere notwendigenDaten leitet das Lesegerät an den Tag weiter. Dieser prüft, ob die erhaltende Signatur derTransaktion gültig ist. Ist das der Fall wird die Transaktion ausgeführt. Andernfalls ist dieTransaktion nicht gültig und wird damit auch nicht ausgeführt. Durch das Zusammenspielist sichergestellt, dass nur Transaktionen ausgeführt werden, die aktuell erlaubt sind.Die Rechte für den Tag selbst sind Lesen, Schreiben und Anhängen. Lesen und Schreiben
sind übliche Rechte. Das Anhängen erlaubt das Anfügen von Daten an schon vorhandene.Dabei darf kein Lesen oder Schreiben der Daten möglich sein. Die Anwendung dafür ist zumBeispiel die Protokollierung, an welchen Standorten der Tag ausgelesen wurde. Dabei darfnur der aktuelle Standort gespeichert, aber nicht ausgelesen werden, wo der Tag war, oderbereits gespeicherte Daten dürfen nicht verändert werden. Die Realisierung des Lesensund Schreibens ist trivial. Es reicht, einfach den jeweiligen Zugri� zu erlauben oder zuverweigern. Für die Realisierung des Anhängens ist zusätzliche Logik im Tag notwendig.Eine mögliche Lösung ist in Abbildung 4.2 dargestellt.
Abbildung 4.2: Verfahren zur Realisierung des Recht �Anhängen�
Die Idee ist, dass ein vom Tag selbst verwalteter Index auf die aktuelle aktive Stelle zeigt.Wenn nun ein Anhängen, also ein Schreibzugri� erfolgt, lenkt der Tag den Schreibzugri� aufdie aktuell aktive Stelle um. Nach dem Schreibvorgang setzt der Tag den Index automatischum eine Position weiter. Damit ist gewährleistet, dass ein Teilnehmer, der nur das Recht�Anhängen� hat, keine bisherigen Daten Lesen oder Überschreiben kann. Dafür sind dienormalen Rechte Lesen oder Schreiben notwendig. Problematisch an dem Verfahren ist,
2008-01-16/010/INF02/2253 51

4 Protokoll und Systemaufbau
dass die einzelnen Teildaten jeweils einzeln verschlüsselt werden müssen und nicht derganze Bereich auf einmal verschlüsselt wird. Grund dafür ist, dass dann der Teilnehmeralle Daten lesen und zusätzlich auch schreiben können muss. Dies widerspricht aber demRecht Anhängen.
4.4 Datenintegrität
Die RFID Tags be�nden sich im relativ freien Umlauf. Es besteht die Möglichkeit, dass einAngreifer durch physischen Zugri� auf den Tag die Daten unter Umgehung der Zugri�s-kontrolle verändern kann. Auch ist nicht ausgeschlossen, dass Daten fehlerhaft gespeichertwerden. Damit eine Datenänderung erkannt werden kann, wird häu�g ein Message Authen-tication Code (MAC) verwendet. Der MAC besteht dabei aus einer Prüfsumme, die miteinem Schlüssel gebildet wird. Bei der Überprüfung des MACs ist der verwendete Schlüs-sel notwendig, um die Korrektheit zu veri�zieren. Damit ist sichergestellt, dass der MACvon einer Person stammt, die den notwendigen Schlüssel hat. Ein Angreifer kann deshalbkeinen MAC generieren und somit keine eingeschleusten Daten als gültig markieren.Es sollen möglichst viele Daten auf möglichst günstigen Tags gespeichert werden, so dass
die vorhandene Kapazität des Tags begrenzt ist. Ein MAC benötigt jedoch Speicherplatz.Das in der Arbeit erstellte Konzept sieht vor, dass die Daten verschiedener Parteien mitverschiedenen Zugri�srechten jeweils individuell verschlüsselt werden. Durch die Speiche-rung mit einer Vielzahl von verschiedenen Zugri�srechten ergibt sich, dass die jeweils zuverschlüsselnden Datenmengen relativ klein sind. Zum Beispiel wird als symmetrischer Ver-schlüsselungsalgorithmus AES mit 128 Bit angenommen. Eine Möglichkeit zur Ermittlungder MAC ist die Nutzung des HMAC mit MD5 als Hashfunktion, welcher eine Prüfsummevon 128 Bit ausgibt. Bei herkömmlicher Verwendung des MACs, wird für jeden Daten-bereich, der mit einem Schlüssel verschlüsselt wurde, ein MAC berechnet [27]. Das ergibtjedoch, dass im betrachteten Szenario, in dem Daten mit vielen verschiedenen Schlüsselverschlüsselt sind, einen groÿen Overhead, da immer relativ wenig Daten mit dem gleichenSchlüssel verschlüsselt werden. Ein Beispiel dafür ist in Tabelle 4.2 zu sehen.
Physisches Abbild Speichergröÿe in Byte
{ Hersteller, 16Produkt, 24MAC(Hersteller,Produkt) } K1 16 + 8
{ Produktionsdatum, 8Produktionsort, 24MAC( Produktionsdatum, Produktionsort) } K2 16 + 0
{ nächstes Ziel, 20Zeit Schreibzugri�, 8MAC(nächstes Ziel, Zeit Schreibzugri�) } K3 16 + 4
{ Etappenziel für Versand, 20MAC(Etappenziel für Versand) } K4 16 + 12
{ Zugehöriges KFZ, 17MAC(Zugehöriges KFZ) } K5 16 + 15
Tabelle 4.2: Beispiel für die Verwendung des MACs auf herkömmliche Art
In dem Beispiel sind für 137 Byte Nutzdaten, 80 Byte MAC Daten und 39 Byte für dieAu�üllung der Daten auf ein Vielfaches von 16 Byte bei der Verwendung der Blockchif-fre im CBC-Modus notwendig. Die tatsächliche Ausnutzung der zur Verfügung stehendenKapazität beträgt damit in diesem Beispiel rund 54 Prozent. Mit dem Verfahren sind auf
52 2008-01-16/010/INF02/2253

4.4 Datenintegrität
realen RFID Tags nur wenige Daten speicherbar, weil Tags mit groÿer Kapazität teuersind. Es ist eine Möglichkeit zu �nden, bei der MAC Erstellung Speicherplatz zu sparen,ohne an Sicherheit zu verlieren. Eine Idee ist die Speicherung des MAC nicht für jeden miteinem Key verschlüsselten Block, sondern den MAC über einen oder mehrere Blöcke ver-schlüsselter Daten zu berechnen und zu speichern. Anschaulich ist das Prinzip in Tabelle4.3 zu sehen.
Physisches Abbild Speichergröÿe in Byte
{ DATA1 } K1
MAC(DATA1, ... , DATAx){ DATA2 } K2
...{ DATAx } KX
Tabelle 4.3: Idee zur speichere�zienten Berechnung des MACs
Es werden nicht für jeden verschlüsselten Bereich ein MAC berechnet und gespeichert.Um Speicherplatz zu sparen wird der MAC über mehrere Blöcke, die mit verschiedenenSchlüsseln verschlüsselt sein können, erzeugt. Die Prüfsumme wird über den verschlüssel-ten Daten gebildet, damit bei der Prüfung der Integrität die Teilnehmer die notwendigenDaten lesen können, ohne daraus Informationen zu gewinnen, da diese nicht die notwendi-gen Schlüssel haben, wenn das nicht erlaubt ist. Das verwendete Verfahren speichert denMAC deutlich e�zienter, weil weniger MACs gespeichert werden müssen. Es entsteht da-bei jedoch ein Problem. Jeder Teilnehmer der Schreibzugri� auf den Bereich des MAC aufdem Tag hat, kann die mit dem MAC gesicherten Daten durch überschreiben des MACals ungültig markieren. Dieses Problem wird durch die Zugri�skontrolle jedoch so weiteingeschränkt, dass das Verfahren sinnvoll eingesetzt werden kann. Da eine Zugri�skon-trolle existiert kann nicht jeder beliebiger Teilnehmer den MAC ändern. Das Lesegerätmuss durch das Protokoll Schreibzugri� auf den Teilbereich, wo der MAC gespeichert isthaben. Den hat das Lesegerät nur, falls es Schreibzugri� auf ein durch den MAC geschütz-ten Bereich hat. Aus Gründen der E�zienz ist es sinnvoll den Speicherplatz auf dem Tagin mehrere Blöcke einzuteilen. Damit kann das Lesegerät nur den MAC überschreiben, indessen Schutzbereich es Schreibzugri� hat. Damit kann das Lesegerät aber nur den MACdes Blockes verändern. Veränderungen weiterer Daten im Block sind nicht möglich, dadas durch die Zugri�skontrolle des Tags unterbunden wird. Damit der Angreifer zumin-dest einen Teilschaden erstellen kann, muss er sich gegenüber dem Authentisierungsserverauthentisiert haben. Damit ist ein einfacher Angri� nicht möglich. Eine weitere Angri�s-möglichkeit ist das eventuell mögliche physische Schreiben auf den Tag unter Umgehungder Zugri�skontrolle. Dann kann der Angreifer alle Daten auf dem Tag beliebig ändern.Der Angri� wird jedoch erkannt, weil der Angreifer nicht den notwendigen Schlüssel zurBerechnung des MAC hat. Damit stimmt dann bei einem Zugri� auf dem Tag durch einLesegerät der gespeicherte MAC nicht mit dem erwarteten Wert überein. Das einzige Pro-blem das auftritt ist, dass bei einem erfolgreichen Angri� alle Daten der mit dem MACgeschützten Daten als ungültig markiert sind. Deshalb können die Daten, die durch denMAC geschützt werden nicht mehr verwendet werden. Um das Problem zu verringern, kannder Speicherplatz in mehrere Blöcke zerlegt werden.Das Zugri�sverfahren auf den Tag ist bei dem Verfahren Folgendes: Wenn ein Lesegerät
Daten von dem Tag lesen will, liest es zunächst neben den eigentlichen Daten noch die fürdie Berechnung des MACs notwendigen Daten und den MAC selbst. Jetzt überprüft dasLesegerät den MAC. Da der MAC über die verschlüsselten Daten berechnet wird und dasLesegerät nicht die Schlüssel zur Entschlüsselung der anderen Daten hat, kann es durchdas Lesen der anderen Daten des MAC Block keine Informationen extrahieren. Nachdemdie Daten gelesen wurden und damit der Tag den Zugri� erlaubt hatte, berechnet das
2008-01-16/010/INF02/2253 53

4 Protokoll und Systemaufbau
Lesegerät nun den MAC und überprüft diesen. Den Schlüssel zur Berechnung erhält esdabei nur vom Autorisierungs-/Keyserver nach vorheriger Authentisierung. Nachdem dieDaten als gültig erkannt wurden, können die gewünschten Daten interpretiert werden.Wenn das Lesegerät die Daten modi�ziert hat und die Daten auch auf den Tag schreibenwill, geschieht Folgendes. Der Tag erhält vom Lesegerät die geänderten Daten und denneu berechneten MAC für den ganzen Datenblock. Der Tag prüft nun, ob er das Gerät dieDaten schreiben darf und wenn ja, schreibt es die Daten in seinen Speicher.
Es existiert noch ein weiteres Problem. Wie erkennt das Lesegerät, ob es einen richtigenSchlüssel zur Berechnung des MACs oder zur Entschlüsselung der Daten erhalten hat. Daskann durch zufällige Fehler in der Datenbank des Autorisierungs-/Keyserver oder durchandere zufällige Fälle entstehen, die nicht korrigiert wurden. Eine andere Möglichkeit istein sehr weit fortgeschrittener Angri� auf das mit dem Lesegerät kommunizierenden Server.Eine Lösung ist die Speicherung und Übertragung des Schlüssels mit einer Signatur desAutorisierungs-/Keyserver. Das Lesegerät kann dann mit dem ö�entlichen Schlüssel desAutorisierungs-/Keyserver überprüfen, ob der Schlüssel korrekt ist.
Für das obige Beispiel ergibt sich dann bei der Benutzung nur eines Blockes das inAbbildung 4.3 dargestellte Speicherbild.
Abbildung 4.3: Beispiel zur speichere�zienten Berechnung des MACs
In diesem Fall werden für 137 Byte Nutzdaten 16 Byte Nutzdaten benötigt. Das ergibteine Speicherplatze�zienz von circa 90 Prozent. Durch die Erhöhung der Anzahl an Blö-cken zur Erhöhung der Sicherheit oder zur Verringerung der über die Funkschnittstelleübertragenden Daten sinkt die E�zienz der Datenspeicherung auf folgenden Wert.
E�zienz = Durchschnittliche Blockgröÿe / (Durchschnittliche Blockgröÿe + Gröÿe desMAC)
54 2008-01-16/010/INF02/2253

4.5 Key Management
4.5 Key Management
Für die Kommunikation und Speicherung von Daten werden verschiedene symmetrischeSchlüssel notwendig. Die symmetrischen Schlüssel sind notwendig, weil der Einsatz asym-metrischer Kryptographie nicht sinnvoll möglich. Damit die Verfahren funktionieren wer-den an verschiedene Stellen unterschiedliche Schlüssel benötigt. In diesem Abschnitt wirddiese Verwaltung dargestellt. Es wird zwischen zwei Arten von Schlüsseln unterschieden.Zunächst werden die Schlüssel, die für die Kommunikation der Teilnehmer notwendig sind,betrachtet. Danach wird auf die Schlüssel, die für die Speicherung der Daten auf den Tagsnotwendig sind, eingegangen.
4.5.1 Schlüssel für die Kommunikation
Die Kommunikation der Teilnehmer muss verschlüsselt erfolgen, damit die Vertraulichkeiterreicht werden kann. Deshalb sind ein Sicherheitsmodell und eine Verwaltung der jeweili-gen Schlüssel notwendig. Der Tag T hat nur eine begrenzte Rechenkapazität, so dass wiebereits beschrieben nur symmetrische Kryptographie zwischen T und dem Lesegerät Rverwendet werden kann. Das ergibt das Probleme, dass der Schlüssel sicher über einen un-sicheren Kanal übertragen werden müssen. Für die Kommunikation muss immer ein neuerSitzungsschlüssel generiert werden, damit bei eventueller Kompromittierung des Sitzungs-schlüssels nur die Informationen der einen Sitzung ermittelt werden können. Das erfolgt miteinem Protokoll, dass in Abschnitt 4.6 vorgestellt wird. Der Schlüssel ist danach nur T undR bekannt. Für die Aushandlung ist eine sichere Kommunikation zwischen R und dem Au-thentisierungsserver A beziehungsweise Autorisierungs-/Keyserver K notwendig. Die dafürnotwendigen Schlüssel werden dynamisch ausgehandelt. Eine Realisierung benutzt dazuein normales SSL Protokoll mit Zerti�katen. Damit kann dann auch die Authentisierungvon A, K und R vorgenommen werden. Die Kommunikation von A mit K erfolgt im Pro-tokoll nicht direkt, sondern über R. Der Grund dafür ist, dass das Ticket von A für Kvon R mehrmals verwendet werden kann. Damit R die Kommunikation nicht mitlesen oderverändern kann, wird die Kommunikation über einen dynamischen Schlüssel zwischen Aund K verschlüsselt. Der Schlüssel wird dabei automatisch regelmäÿig gewechselt und istnur A und K bekannt. Die Aushandlung kann direkt erfolgen, obwohl sonst keine direkteKommunikation zwischen A und K verwendet wird. Für T ist es später wichtig, feststellenzu können, ob die Nachricht von K, durch R oder jemand anderen verändert wurde. Da-für erstellt K eine Integritätsprüfsumme. Zur Erstellung wird ein Schlüssel benötigt. DerSchlüssel ist ein statischer symmetrischer Schlüssel, welcher für jeden Tag anders ist. NurK und T haben diesen Schlüssel. In Tabelle 4.4 ist eine Zusammenfassung der verwendetenSchlüssel zur Kommunikation dargestellt.
4.5.2 Schlüssel für die Speicherung der Daten auf dem Tag
Für die Speicherung der Daten auf dem Tag wurde in 4.3 und 4.4 ein spezielles Verfahrenentwickelt. Das Verfahren nutzt verschiedene symmetrische Schlüssel für unterschiedlicheDatenbereiche. Ziel ist es, möglichst wenig Schlüssel zu verwenden, damit die Verwaltungeinfacher wird. Auÿerdem gehen dadurch nicht zu viele Daten durch das Au�üllen derNutzdaten auf die Blocklänge des Verschlüsselungsalgorithmus verloren.Die Kriterien sind Folgende: Zur Überprüfung der Integrität muss eine Partei alle Da-
ten eines Integritätsblockes lesen. Dabei darf sie aber nur Informationen aus den Datengewinnen, auf die sie Lesezugri� hat. Durch die Bedingung müssen Daten mit verschie-denen Schlüsseln in einem Integritätsblock verschlüsselt werden, wenn nicht alle Parteienauf die Teildaten Lesezugri� haben. Für die Aufteilung wird zuerst eine Tabelle mit allenParteien und deren Rechten auf die verschiedenen Datenblöcke erstellt. Ein Beispiel für
2008-01-16/010/INF02/2253 55

4 Protokoll und Systemaufbau
Schlüssel Beschreibung
KA,R dynamischer symmetrischer Schlüssel zwischen dem Authentisierungsser-ver und dem Leser, zur Verschlüsselung der Kommunikation, Aushand-lung durch SSL
KR,K dynamischer symmetrischer Schlüssel zwischen dem Autorisierungs-/Keyserver und dem Leser, zur Verschlüsselung der Kommunikation,Aushandlung durch SSL
KA,K dynamischer symmetrischer Schlüssel zwischen jeweils einemAuthentisierungs- und einem Autorisierungs-/Keyserver, zur Ver-schlüsselung des �Tickets� zur Identi�kation des Tag für K von A,Aushandlung durch SSL, wird regelmäÿig gewechselt
KK,T statischer symmetrischer Schlüssel, zur Überprüfung der Integrität derNachrichten vom Autorisierungs-/Keyserver durch den Tag, wird bei derInitialisierung des Tag erzeugt und im Autorisierungs-/Keyserver unddem Tag gespeichert, ändert sich prinzipiell nicht
KR,T dynamischer symmetrischer Schlüssel zwischen dem Lesegerät und demTag, zur Verschlüsselung der Kommunikation, wird durch die Authenti-sierung ausgehandelt, basiert auf realer ID des Tag und Zufallskompo-nenten
Tabelle 4.4: Schlüssel zur Kommunikation
zwei Parteien ist in Tabelle 4.5 zu sehen.
Datum Partei X Partei Y
1 - -2 - RW3 - R4 RW -5 R -6 RW R7 RW RW8 R RW9 R R
Tabelle 4.5: vollständige Rechte
In der Tabelle sind alle möglichen Rechtekombinationen vorhanden. Das Recht �Anhän-gen� entspricht hier dem Recht �Schreiben�, da die Realisierung des Anhängens vom Tagselbst durch das Schreibrecht abgebildet wird. Aus der Tabelle werden nun die Leserechteextrahiert. Die Schreibrechte sind zunächst nicht relevant, weil zur Prüfung der Integritätdie Daten nur gelesen werden müssen. Der Fall das jemand nur das Recht �Schreiben� hat,wird gesondert behandelt. Für jedes Datum, bei dem eine Partei das Recht �Schreiben�hat, muss ein extra Schlüssel verwendet werden. Das ist notwendig, da sonst ein Teilnehmerbei der Überprüfung der Integrität der Daten auf die er nur Schreibrechte hat, diese auchentschlüsseln könnte. Dieser Fall sollte in Realität jedoch selten auftreten. Deshalb kanntrotz dieser Einschränkung mit dem Verfahren die Anzahl der notwendigen Schlüssel starkverringert werden. Die Extraktion der Rechte am Beispiel ist in Tabelle 4.4 zu sehen.Wie oben erklärt, ist es möglich nicht für jedes Datum einen separaten Schlüssel zu
verwenden, wenn die gleichen Leserechte vorhanden sind. Daraus ergibt sich eine einfachherstellbare Gruppierung. Die Rechte werden als Bits interpretiert. Wenn das Recht vor-
56 2008-01-16/010/INF02/2253

4.6 Nachrichtenaustausch
handen ist, ist es eine �1�, sonst eine �0�. Da mehrere Parteien vorhanden sind, wird jedeStelle der entstehenden Binärzahl für eine Partei verwendet. Die Binärzahl ist der Index.Die Datenfelder werden mit Hilfe des Indexes aufsteigend sortiert. Damit stehen Datenbe-reiche mit gleichem Index und und gleichen Rechten zusammen. Somit kann ein Schlüsselfür jede zusammenhängende Gruppe verteilt werden. In der Realität existieren nicht alletheoretisch möglichen Rechtekombinationen. Durch das Verfahren können somit Schlüsseleingespart werden. Im Beispiel ist die Schlüsselvergabe in Tabelle 4.5 zu sehen.
Datum Partei X Partei Y
1 - -2 - X3 - X4 X -5 X -6 X X7 X X8 X X9 X X
Abbildung 4.4: extrahierte Leserechte
Datum Schlüssel
1 -2 A3 A4 B5 B6 C7 C8 C9 C
Abbildung 4.5: verwendete Schlüssel
Die Anzahl der notwendigen Schlüssel variiert dabei. Je mehr Parteien auf Dateneinträgegleichartige Rechte haben, desto weniger Schlüssel werden benötigt. Im schlimmsten Fallsind 2Anzahl Teilnehmer − 1 Schlüssel notwendig. In realen Szenarien sind es viel weniger,wie ein entwickeltes Beispiel in Tabelle 4.6 zeigt. Das Beispiel entstand durch plausibleAnnahmen im beabsichtigten Einsatzszenario. Die verschiedenen Parteien werden dabeidurch A(Hersteller), B(Werk1), C(Werk2) und D(Transporteur) repräsentiert.
Datum A B C D Schlüssel
Hersteller rw r r - 1Produkt rw r r - 1
Produktionsdatum rw r - - 2Produktionsort rw r - - 2nächstes Ziel rw rw - r 3
Zeit Schreibzugri� rw rw - rw 3Etappenziel für Versand - - - rw 4
Zugehöriges KFZ - rw - - 5
Tabelle 4.6: konkretes Beispiel für Schlüsselvergabe
Im entwickeltem Beispiel werden fünf verschiedene Schlüssel, statt theoretisch 31, benö-tigt.Das Verfahren für die Reduktion der notwendigen Schlüssel für die Wahrung der Zu-
gri�srechte bei der Integritätsprüfung ist relativ einfach, löst aber das Problem bei demsonst viele Schlüssel notwendig sind.Im Folgenden werden die in Tabelle 4.7 dargestellten Bezeichner für die Schlüssel zur
Speicherung der Daten verwendet.
4.6 Nachrichtenaustausch
Zunächst wird in diesem Abschnitt das entwickelte Protokoll dargestellt und erklärt, bevorin Abschnitt 5 das Protokoll im Hinblick auf die zu erreichenden Ziele untersucht wird. In
2008-01-16/010/INF02/2253 57
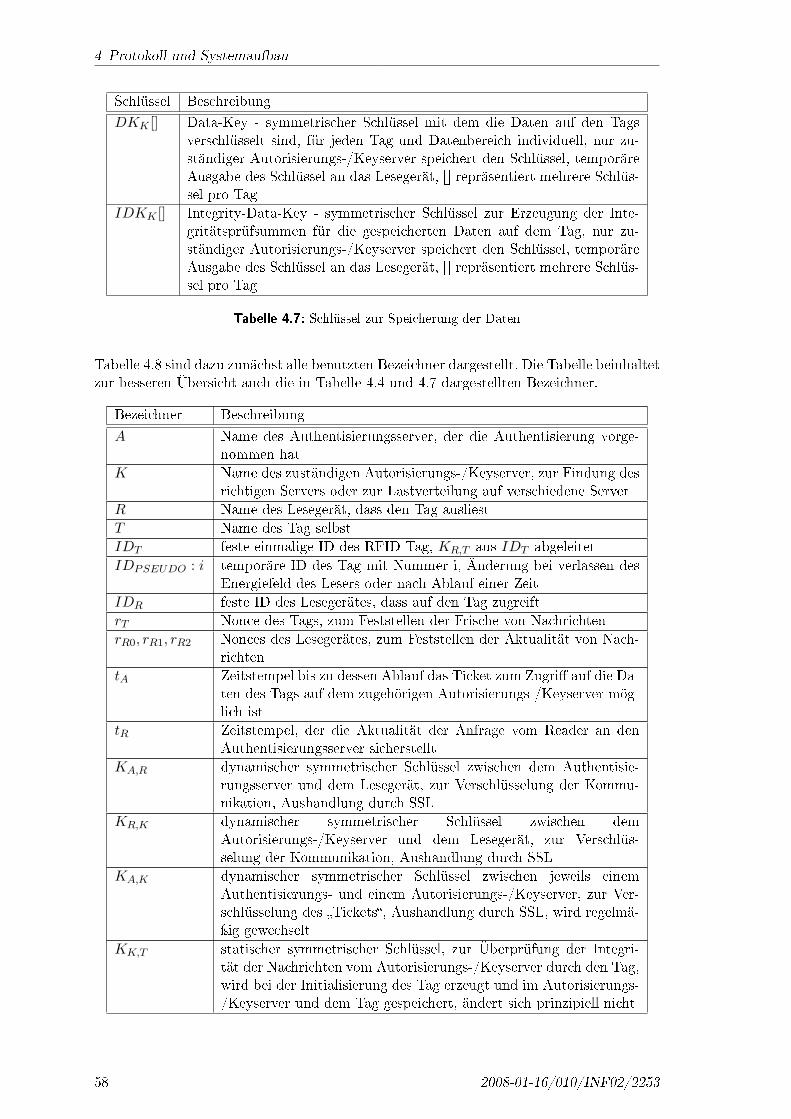
4 Protokoll und Systemaufbau
Schlüssel Beschreibung
DKK [] Data-Key - symmetrischer Schlüssel mit dem die Daten auf den Tagsverschlüsselt sind, für jeden Tag und Datenbereich individuell, nur zu-ständiger Autorisierungs-/Keyserver speichert den Schlüssel, temporäreAusgabe des Schlüssel an das Lesegerät, [] repräsentiert mehrere Schlüs-sel pro Tag
IDKK [] Integrity-Data-Key - symmetrischer Schlüssel zur Erzeugung der Inte-gritätsprüfsummen für die gespeicherten Daten auf dem Tag, nur zu-ständiger Autorisierungs-/Keyserver speichert den Schlüssel, temporäreAusgabe des Schlüssel an das Lesegerät, [] repräsentiert mehrere Schlüs-sel pro Tag
Tabelle 4.7: Schlüssel zur Speicherung der Daten
Tabelle 4.8 sind dazu zunächst alle benutzten Bezeichner dargestellt. Die Tabelle beinhaltetzur besseren Übersicht auch die in Tabelle 4.4 und 4.7 dargestellten Bezeichner.
Bezeichner Beschreibung
A Name des Authentisierungsserver, der die Authentisierung vorge-nommen hat
K Name des zuständigen Autorisierungs-/Keyserver, zur Findung desrichtigen Servers oder zur Lastverteilung auf verschiedene Server
R Name des Lesegerät, dass den Tag ausliestT Name des Tag selbstIDT feste einmalige ID des RFID-Tag, KR,T aus IDT abgeleitetIDPSEUDO : i temporäre ID des Tag mit Nummer i, Änderung bei verlassen des
Energiefeld des Lesers oder nach Ablauf einer ZeitIDR feste ID des Lesegerätes, dass auf den Tag zugreiftrT Nonce des Tags, zum Feststellen der Frische von NachrichtenrR0, rR1, rR2 Nonces des Lesegerätes, zum Feststellen der Aktualität von Nach-
richtentA Zeitstempel bis zu dessen Ablauf das Ticket zum Zugri� auf die Da-
ten des Tags auf dem zugehörigen Autorisierungs-/Keyserver mög-lich ist
tR Zeitstempel, der die Aktualität der Anfrage vom Reader an denAuthentisierungsserver sicherstellt
KA,R dynamischer symmetrischer Schlüssel zwischen dem Authentisie-rungsserver und dem Lesegerät, zur Verschlüsselung der Kommu-nikation, Aushandlung durch SSL
KR,K dynamischer symmetrischer Schlüssel zwischen demAutorisierungs-/Keyserver und dem Lesegerät, zur Verschlüs-selung der Kommunikation, Aushandlung durch SSL
KA,K dynamischer symmetrischer Schlüssel zwischen jeweils einemAuthentisierungs- und einem Autorisierungs-/Keyserver, zur Ver-schlüsselung des �Tickets�, Aushandlung durch SSL, wird regelmä-ÿig gewechselt
KK,T statischer symmetrischer Schlüssel, zur Überprüfung der Integri-tät der Nachrichten vom Autorisierungs-/Keyserver durch den Tag,wird bei der Initialisierung des Tag erzeugt und im Autorisierungs-/Keyserver und dem Tag gespeichert, ändert sich prinzipiell nicht
58 2008-01-16/010/INF02/2253
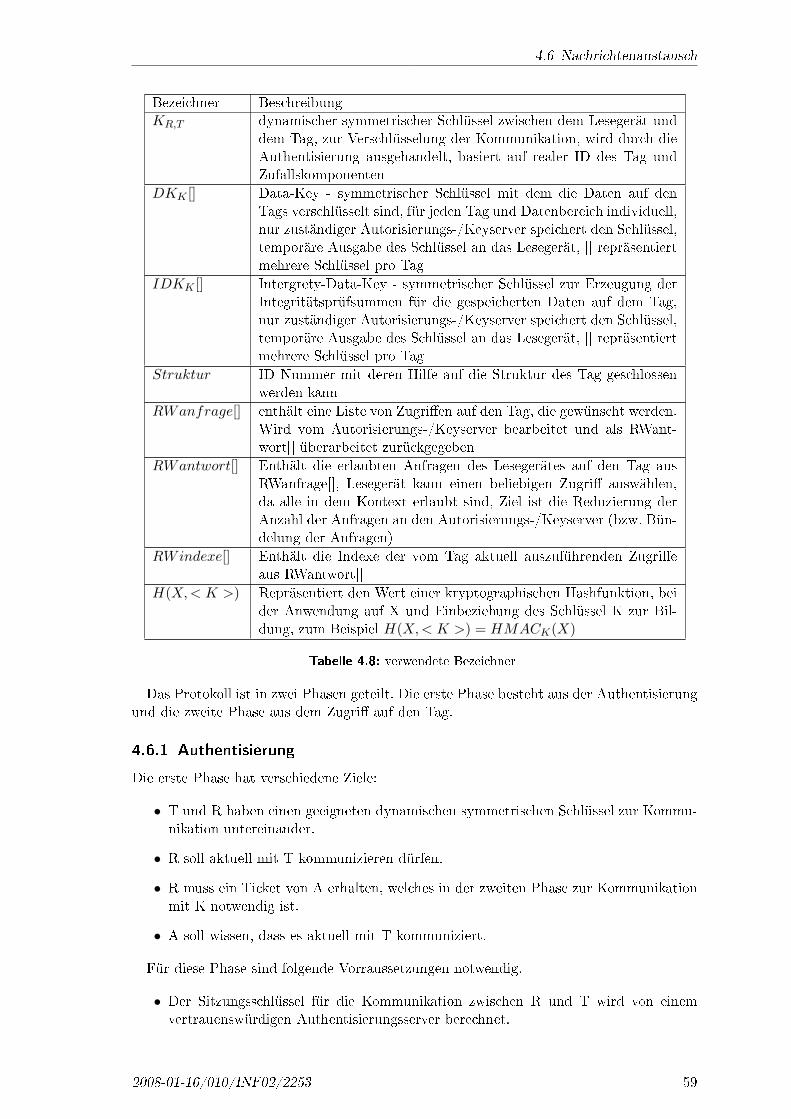
4.6 Nachrichtenaustausch
Bezeichner BeschreibungKR,T dynamischer symmetrischer Schlüssel zwischen dem Lesegerät und
dem Tag, zur Verschlüsselung der Kommunikation, wird durch dieAuthentisierung ausgehandelt, basiert auf realer ID des Tag undZufallskomponenten
DKK [] Data-Key - symmetrischer Schlüssel mit dem die Daten auf denTags verschlüsselt sind, für jeden Tag und Datenbereich individuell,nur zuständiger Autorisierungs-/Keyserver speichert den Schlüssel,temporäre Ausgabe des Schlüssel an das Lesegerät, [] repräsentiertmehrere Schlüssel pro Tag
IDKK [] Intergrety-Data-Key - symmetrischer Schlüssel zur Erzeugung derIntegritätsprüfsummen für die gespeicherten Daten auf dem Tag,nur zuständiger Autorisierungs-/Keyserver speichert den Schlüssel,temporäre Ausgabe des Schlüssel an das Lesegerät, [] repräsentiertmehrere Schlüssel pro Tag
Struktur ID Nummer mit deren Hilfe auf die Struktur des Tag geschlossenwerden kann
RWanfrage[] enthält eine Liste von Zugri�en auf den Tag, die gewünscht werden.Wird vom Autorisierungs-/Keyserver bearbeitet und als RWant-wort[] überarbeitet zurückgegeben
RWantwort[] Enthält die erlaubten Anfragen des Lesegerätes auf den Tag ausRWanfrage[], Lesegerät kann einen beliebigen Zugri� auswählen,da alle in dem Kontext erlaubt sind, Ziel ist die Reduzierung derAnzahl der Anfragen an den Autorisierungs-/Keyserver (bzw. Bün-delung der Anfragen)
RWindexe[] Enthält die Indexe der vom Tag aktuell auszuführenden Zugri�eaus RWantwort[]
H(X,< K >) Repräsentiert den Wert einer kryptographischen Hashfunktion, beider Anwendung auf X und Einbeziehung des Schlüssel K zur Bil-dung, zum Beispiel H(X,< K >) = HMACK(X)
Tabelle 4.8: verwendete Bezeichner
Das Protokoll ist in zwei Phasen geteilt. Die erste Phase besteht aus der Authentisierungund die zweite Phase aus dem Zugri� auf den Tag.
4.6.1 Authentisierung
Die erste Phase hat verschiedene Ziele:
• T und R haben einen geeigneten dynamischen symmetrischen Schlüssel zur Kommu-nikation untereinander.
• R soll aktuell mit T kommunizieren dürfen.
• R muss ein Ticket von A erhalten, welches in der zweiten Phase zur Kommunikationmit K notwendig ist.
• A soll wissen, dass es aktuell mit T kommuniziert.
Für diese Phase sind folgende Vorraussetzungen notwendig.
• Der Sitzungsschlüssel für die Kommunikation zwischen R und T wird von einemvertrauenswürdigen Authentisierungsserver berechnet.
2008-01-16/010/INF02/2253 59

4 Protokoll und Systemaufbau
• A und R haben einen gemeinsamen symmetrischen Schlüssel zur Kommunikation.
• A und T haben einen gemeinsamen symmetrischen Schlüssel, zur Berechnung derPseudo ID.
• R glaubt an die korrekte Funktionsweise und Kompetenz von A über KR,T .
Die erste Phase umfasst folgende Nachrichten.
1. R→ T : Anfrage, rR1 (4.6.1.1)
2. T → R : IDPseudo : i, rT , H(IDPseudo : i, rT , < KA,T >) (4.6.1.2)
3. R→ A :{IDPseudo : i, IDR,rT , rR1, tR,
H(IDPseudo : i, rT , < KA,T >)}KA,R
(4.6.1.3)
4. A→ R :{K,A, IDPseudo : i,Struktur, tKAK ,
{IDR, IDT ,K, tA}KA,K, rR1,KR,T , rA
}KA,R
(4.6.1.4)
5. R→ T : rA, {rR2, rT }KR,T(4.6.1.5)
6. T → R : {rR2}KR,T(4.6.1.6)
Eine gra�sche Veranschaulichung der ersten Phase ist in Abbildung 4.6 zu sehen.
Abbildung 4.6: Gra�sche Darstellung des ersten Teilprotokolls
Das Protokoll beginnt mit Schritt eins. Die Nachricht 4.6.1.1 initialisiert den Authen-tisierungsvorgang. Dazu wird eine Anfrage gestellt und ein Nonce übertragen. rR1 �ieÿtdabei später in den zu erzeugenden Sitzungsschlüssel zwischen T und R ein. Damit kannR sicher sein, dass der Schlüssel aktuell ist.Mit der Nachricht 4.6.1.2 initiiert der Tag den Authentisierungsvorgang. Es sendet dabei
die aktuell gültige Pseudo ID aus, die A dann benutzt, um T zu identi�zieren und damitaus der Pseudo ID die reale ID zu ermitteln. Die Pseudo ID ist für externe Beobachterzufällig. Der Aufbau und die Funktionsweise wurden in Abschnitt 4.2 dargestellt. T sendet
60 2008-01-16/010/INF02/2253

4.6 Nachrichtenaustausch
auch ein Nonce an R. Die Zahl �ieÿt ebenfalls in den zu erzeugenden Sitzungsschlüsselein. Zusätzlich wird die Zahl benutzt, damit T überprüfen kann, dass die Nachricht 4.6.1.5aktuell ist. Zusätzlich sendet der Tag die gebildete Integritätsprüfsumme. Die Prüfsummewird mit dem gemeinsamen symmetrischen Schlüssel mit A gebildet. Deshalb kann A späterüberprüfen, ob die gesendete Pseudo ID wirklich von T kam, oder ob ein Zufallsbitmustergesendet wurde, das zufällig die Form einer aktuellen Pseudo ID hat. Zusätzlich wird diePrüfsumme dazu verwendet, mögliche Kollisionen bei der Pseudo ID aufzulösen.R leitet dann die erhaltenden Daten mit Nachricht 4.6.1.3 weiter. Zusätzlich werden noch
einige Informationen hinzugefügt. Dazu gehört die eigene ID des Lesegerätes zu Identi�ka-tionszwecken, die zuvor an T gesendete Nonce zur Schlüsselgenerierung und Überprüfungder Aktualität von Nachricht 4.6.1.4, sowie der Zeitstempel tR. Dieser wird von R er-zeugt und verhindert, dass die Nachricht nicht mehrfach an A gesendet werden kann, daA das feststellen kann. Die komplette Nachricht wird verschlüsselt an A gesendet. Derdafür notwendige Sitzungsschlüssel wurde im Vorfeld der Kommunikation ausgehandelt,zum Beispiel durch SSL. Das ist sinnvoll, da ein Lesegerät mit nur einem oder sehr weni-gen Authentisierungsservern kommuniziert und damit bei mehreren Auslesevorgängen derSchlüssel nicht immer geändert werden muss, sondern nur nach einem de�nierten Zeitin-tervall.Im nächsten Schritt, ermittelt A aus der Pseudo ID des Tags die reale ID. Dann wird ge-
prüft, ob R mit diesem Tag kommunizieren darf. Ist das der Fall, generiert A die Nachricht4.6.1.4. Darin sind mehrere Informationen enthalten: Zunächst werden die teilnehmen-den Partner genannt. Dazu gehören A und der für den Tag zuständige Autorisierungs-/Keyserver K. Damit R die Nachricht dem richtigen Tag zuordnen kann, wird auch diePseudo ID des Tags mitgesendet. Weiter enthält die Nachricht die Struktur ID des Tag,damit R weiÿ, wie die Daten auf T organisiert sind, um sinnvolle Anfragen stellen zukönnen. Der nächste Teil der Nachricht ist tKAK , {IDR, IDT ,K, tA}KA,K
. Der Teil reprä-sentiert das Ticket von A für K, damit dieser später überprüfen kann, ob die Anfragenvon R an K für den Zugri� auf T erlaubt sind. Dafür notwendig sind die ID von R, diereale ID von T, der Name des zuständigen Autorisierungs-/Keyserver K. Das Ticket ent-hält zusätzlich die Ablaufzeit des Tickets. Die ist notwendig, damit das Ticket nur übereinen begrenzten Zeitraum gültig ist. Das Ticket darf nur von A und K verwertbar sein.Deshalb wird das Ticket mit einem gemeinsamen Schlüssel zwischen A und K verschlüs-selt. Der Schlüssel wird regelmäÿig geändert, so dass auch die Information tKAK enthaltenist. Es repräsentiert den Zeitpunkt zu dem das Ticket verschlüsselt wurde. Damit kannK den zugehörigen Schlüssel ermitteln. Neben diesen Informationen werden noch weitereInformationen übertragen. Das sind das Nonce von R und die notwendigen Informationenüber den von A erstellten Sitzungsschlüssel für die Kommunikation zwischen T und R.Das sind der Sitzungsschlüssel KR,T selbst, sowie das zur Bildung herangezogene Noncedes Authentisierungsservers. Der Schlüssel wird wie folgt gebildet:
KR,T = H(IDT , rT , rR1, rA, < KA,T >)
Die Form der Darstellung ist wie in der GNY Logik. In der Praxis wird dafür ein HMACbenutzt:
KR,T = HMACKA,T(IDT , rT , rR1, rA)
Durch die von allen Teilnehmern erzeugten Nonces ist sichergestellt, dass jeder Teil-nehmer sicher sein kann, dass der Schlüssel aktuell ist. Alle diese Informationen werdenverschlüsselt von A an R gesendet.Nach dem Erhalt der Nachricht hat R den verwendeten Sitzungsschlüssel mit T. T
hat den Schlüssel zur Zeit noch nicht. T kann diesen erst berechnen, wenn T von R dieInformation aus der Nachricht hat, die R benutzt um festzstellen ob T den Schlüssel hat.R must nun feststellen, ob T den Schlüssel hat, damit eine Kommunikation erfolgen kann.
2008-01-16/010/INF02/2253 61

4 Protokoll und Systemaufbau
Dazu wird Nachricht 4.6.1.5 verwendet. Sie enthält das von A generierte Nonce, das fürdie Schlüsselerzeugung für T notwendig ist. Zusätzlich wird ein mit dem Sitzungsschlüsselvon R verschlüsseltes generiertes Nonce und das am Beginn von T generierte Nonce an Tgesendet. Mit rT kann T feststellen, dass die Nachricht keine Wiedereinspielung ist. rR2
ist dafür gedacht, dass R feststellen kann, dass T den Schlüssel besitzt, da es in Nachricht4.6.1.6 von T zu R zurückgeschickt wird.Mit der enthaltenden Information rA, des Nonce rR1 von R aus Nachricht 4.6.1.1, des
selbst generierten Nonce rT , sowie der realen ID des Tag berechnet T nun den Sitzungs-schlüssel KR,T . Mit diesem Schlüssel werden die zusätzlichen Daten entschlüsselt. Mit rTüberprüft T, ob die Nachricht kein Wiedereinspielung ist. Sollte dies der Fall sein, generiertT die Nachricht 4.6.1.6. Diese enthält nur das verschlüsselte, von R erhaltende, Nonce. Rerhält die Nachricht und entschlüsselt diese. Wenn das erhaltende Nonce dem gesendetenentspricht, weiÿ R, dass T den Sitzungsschlüssel kennt. Damit ist der Authentisierungsvor-gang abgeschlossen.Die Untersuchung des Teilprotokolls erfolgt in Abschnitt 5.1.
4.6.2 Datenaustausch
Die erste Phase des Protokolls stellt die Authentisierung von R und T sicher. Für denEinsatz muss ein weiteres Teilprotokoll entwickelt werden, welches den Zugri� auf denTag regelt. Das ist das hier vorgestellte Protokoll für den Datenaustausch. Die Ziele sindfolgende:
• Das Hauptziel ist, dass zum Schluss die Daten auf dem Tag aktualisiert sind unddamit die Daten selbst sowie die Integritätsprüfwerte.
• R hat die notwendigen Schlüssel für die Entschlüsslung der Daten und Überprüfungder Integritätsprüfsummen auf dem Tag.
• Dafür ist in einem Zwischenschritt notwendig, dass K die reale ID des Tags besitzt.
• Damit die Schlüssel genutzt werden können, hat R die Daten von T erhalten, falls Rzur Kommunikation mit T berechtigt ist.
• Zur Wahrung der Zugri�skontrolle muss T die RWAntwort[] haben.
• Wenn das gegeben ist und R auf T schreibt, muss T die Daten von R erhalten haben.
Die Voraussetzungen für das Teilprotokoll bestehen aus den durch das Authentisierungs-protokoll sichergestellten Bedingungen und folgenden zusätzlichen Bedingungen.
• R und K haben einen geeigneten Schlüssel zur Kommunikation.
• R glaubt, dass K kompetent ist und K die Autorität über die Daten- und Integri-tätsschlüssel hat.
• T und K haben einen geeigneten Schlüssel zur Wahrung der Integrität der Nachrich-ten von K für T.
• T glaubt zusätzlich an die Kompetenz von K und die Autorität von K über dieRWAntwort[].
• K glaubt an die Kompetenz von A und dessen Autorität über die reale ID des Tags.
62 2008-01-16/010/INF02/2253
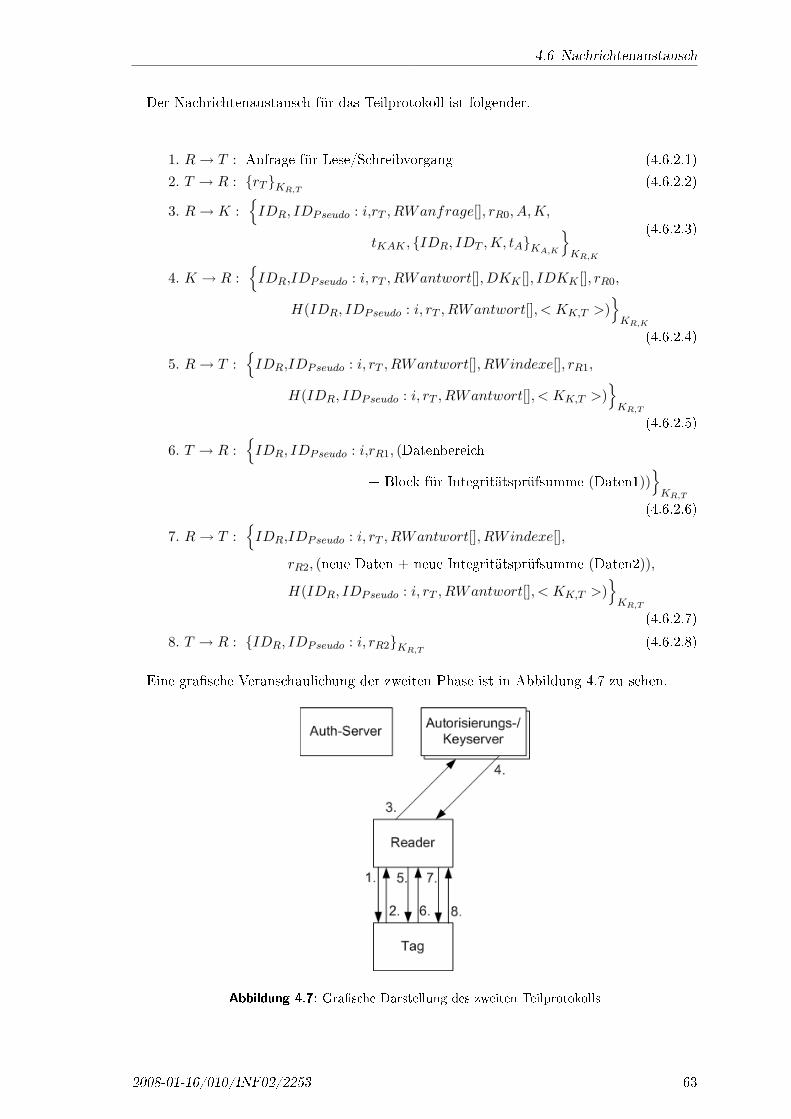
4.6 Nachrichtenaustausch
Der Nachrichtenaustausch für das Teilprotokoll ist folgender.
1. R→ T : Anfrage für Lese/Schreibvorgang (4.6.2.1)
2. T → R : {rT }KR,T(4.6.2.2)
3. R→ K :{IDR, IDPseudo : i,rT , RWanfrage[], rR0, A,K,
tKAK , {IDR, IDT ,K, tA}KA,K
}KR,K
(4.6.2.3)
4. K → R :{IDR,IDPseudo : i, rT , RWantwort[], DKK [], IDKK [], rR0,
H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,K
(4.6.2.4)
5. R→ T :{IDR,IDPseudo : i, rT , RWantwort[], RWindexe[], rR1,
H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,T
(4.6.2.5)
6. T → R :{IDR, IDPseudo : i,rR1, (Datenbereich
+ Block für Integritätsprüfsumme (Daten1))}KR,T
(4.6.2.6)
7. R→ T :{IDR,IDPseudo : i, rT , RWantwort[], RWindexe[],
rR2, (neue Daten + neue Integritätsprüfsumme (Daten2)),
H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,T
(4.6.2.7)
8. T → R : {IDR, IDPseudo : i, rR2}KR,T(4.6.2.8)
Eine gra�sche Veranschaulichung der zweiten Phase ist in Abbildung 4.7 zu sehen.
Abbildung 4.7: Gra�sche Darstellung des zweiten Teilprotokolls
2008-01-16/010/INF02/2253 63

4 Protokoll und Systemaufbau
Die Nachrichten haben folgende Bedeutung: Zur Initialisierung der Anfrage sendet R dieNachricht 4.6.2.1 an T. Dieser reagiert darauf mit der Nachricht 4.6.2.2. Darin enthaltenist ein verschlüsseltes Nonce des Tags. Die Zahl wird später benutzt, um die Aktualitätder Nachrichten 4.6.2.5 und 4.6.2.7 zu prüfen.
Das Lesegerät startet mit Nachricht 4.6.2.3 die Anfrage an denAutorisierungs-/Keyserver. Dabei sind die ID des Lesegerätes und die Pseudo ID desTags enthalten. Beide IDs sind zur späteren Zuordnung der Nachricht zu den beidenParteien sinnvoll. Notwendig für den Vorgang sind das Nonce des Tags, die gewünschteZugri�sanfrage für den Tag und ein Nonce von R. Diese wird von R benutzt umfestzustellen, ob die Nachricht 4.6.2.4 aktuell ist. Weiter enthalten sind die Servernamenvon A und K, sowie das Ticket von A und das dazugehörige Erstellungsdatum. DieServernamen sind enthalten, damit K weiÿ, dass die Nachricht für ihn ist und A istnotwendig, damit K weiÿ von wem das Ticket verschlüsselt wurde. Damit eineEntschlüsselung möglich ist, wird der Zeitstempel benötigt, zu dem das Ticket erstelltund damit verschlüsselt wurde. Das ist notwendig, weil der Schlüssel regelmäÿig geändertwird. Das Ticket besteht aus der realen ID des Tag und der ID des Lesegerätes. Beidesind notwendig, damit K feststellen kann ob die RWanfrage[] erlaubt ist. K istenthalten, damit K sicher sein kann, dass das Ticket für K erstellt wurde. Das Ticket hateine begrenzte Gültigkeit, die durch tA beschränkt wird.
Nach dem Erhalt der Nachricht 4.6.2.3 wertet K die Nachricht aus. Dabei überprüft Kzunächst die Gültigkeit des Tickets. Wenn das erfolgreich abgeschlossen wurde, prüft K obdie gewünschte Anfrage von R auf T erlaubt ist. Dazu wird die interne Datenbank von Kabgefragt, die die Rechte wie in Abschnitt 4.3 gezeigt. Alle gültigen Einträge werden vonRWAnfrage[] inRWAntwort[] kopiert. Zusätzlich werden die für die Anfrage notwendigenSchlüssel aus der Datenbank ausgelesen. Damit das Ergebnis von R verwendet werden kann.wird Nachricht 4.6.2.4 erstellt. Diese enthält wieder die einzelnen IDs der Teilnehmer zuIdenti�kationszwecken. Das Nonce des Tag und von R sind ebenfalls wieder enthalten,damit T und R später die Aktualität der Nachricht überprüfen können. Weiter enthält dieNachricht die eben erstellte RWAntwort[] und die notwendigen Schlüssel. DKK [] dientzur Entschlüsselung und Verschlüsselung der Daten auf dem Tag, während IDKK [] zurPrüfung der Integrität der Daten verwendet wird. Beide Arrays können dabei mehrereSchlüssel enthalten, weil auch die RWAntwort[] mehrere Anfragen enthalten kann. Dasnächste und letzte Datum ist für den Zugri�sschutz ein entscheidendes. K signiert dieRWAntwort[] und die weiteren Daten mit einem Schlüssel, den nur K und T kennen. Dasist notwendig, damit T feststellen kann, dass die Nachricht die es später von R erhält nichtmodi�ziert wurde, seit K sie gesendet hat.
R erhält nun die Antwort. Er kann dann überprüfen, ob die RWAntwort[] seinerRWAnfrage[] entspricht und ob die Nachricht aktuell ist. Jetzt kann R die Anfrage an Tsenden. Die Nachricht 4.6.2.5 entsteht. Diese enthält wieder die ID der teilnehmendenPartner. Das Nonce des Tags ist ebenfalls zur Überprüfung der Aktualität der Nachrichtenthalten. Zusätzlich fügt R eine neues Nonce ein, damit R die Aktualität von Nachricht4.6.2.6 überprüfen kann. Weiter enthält die Nachricht die von K erhaltende RWAntwortund eine Liste von R aktuell gewünschten Operation auf T aus der RWAntwort inRWIndexe. Als Letztes wird die erhaltende Integritätsprüfsumme von K an den Tagübertragen.
T erhält die Nachricht und vollzieht folgende Schritte. Es überprüft zunächst mittelsder ID, ob beide Partner korrekt sind. Danach wird mittels rT die Aktualität der Nach-richt überprüft. Im nächsten Schritt wird mittels der Integritätsprüfsumme überprüft, obdie RWAntwort[] nicht verändert wurde. Wenn die Prüfungen abgeschlossen sind, geht Tdavon aus , dass es die Anfragen aus RWAntwort[] ausführen kann. Mittels RWIndexe[]führt es nun die gewünschten Anfragen aus. Das Ergebnis wird dann mit Nachricht 4.6.2.6
64 2008-01-16/010/INF02/2253

4.7 Zusammenfassung
an R gesendet. Dazu werden wieder die ID der Teilnehmer übertragen. Weiterhin wirddas Nonce von R übertragen, damit R die Aktualität der Nachricht feststellen kann. Dieweiteren Informationen sind dann die Daten selbst. Diese bestehen aus den gewünsch-ten verschlüsselten Daten und die zur Überprüfung der Integrität der Daten notwendigenInformationen.R erhält die Nachricht und wertet sie aus. Zunächst wird geprüft, ob die Teilnehmer
wieder stimmen und ob die Nachricht aktuell ist. Danach kann R die Daten auswerten.Dazu wird zunächst die Integrität der Daten geprüft, bevor R die Daten entschlüsseltund dann die Informationen weiter verarbeiten kann. Dazu werden die in Nachricht 4.6.2.4von K erhaltenen Schlüssel verwendet. Wenn noch weitere Leseanfragen ausgeführt werdensollen, wird der Vorgang wieder mit Nachricht 4.6.2.5 begonnen. Wenn alle Leseanfragenabgearbeitet sind und keine Schreibanfragen vorgenommen werden sollen, ist der Vorganghier beendet. Andernfalls wird mit dem nächsten Schritt fortgefahren.Für eine Schreibanfrage wird die Nachricht 4.6.2.7 generiert. Darin enthalten sind die
IDs der Partner zu Identi�kationszwecken, das Nonce des Tag zur Überprüfung der Ak-tualität der Nachricht und eine neues Nonce von R zur Überprüfung der Aktualität derNachricht 4.6.2.8. Damit der Tag weiÿ, welche Operationen er ausführen soll, werden dieRWAntwort[] und die ausgewählten Operationen in RWIndexe[] übertragen. Damit dieAnfrage sinnvoll ist, werden die benötigten Daten übertragen. Dazu gehören die neuenverschlüsselten Daten, sowie die zugehörige neue Prüfsumme. Damit der Tag überprüfenkann, ob die RWAntwort[] korrekt ist, wird wieder die Prüfsumme von K übertragen.Der Tag überprüft die Aktualität der Nachricht und ob die Teilnehmer aus der Nach-
richt die aktuellen Teilnehmer sind. Dann wird mittels der Prüfsumme überprüft, ob dieRWAntwort[] nicht verändert wurde. Ist das der Fall, werden die gewünschten Zugri�eRWIndexe[] aus RWAntwort[] durchgeführt. Dazu werden die übertragenen Daten andie gewünschten Stellen des Tags geschrieben und die Integritätsprüfsumme aktualisiert.Wenn die Vorgänge abgeschlossen sind, erstellt T eine Nachricht für R, damit R weiÿ, dassder Vorgang abgeschlossen ist. Dazu wird die ID der Teilnehmer übertragen und das Noncevon R.R erhält die Nachricht und überprüft diese auf Aktualität mittels des Nonce. Jetzt
können gegebenenfalls neue Schreibanfragen an den Tag gesandt werden. Das erfolgt mitGenerierung einer neuen Nachricht 4.6.2.7. Wenn keine Schreibvorgänge mehr vorgenom-men werden sollen, ist das Teilprotokoll zum Zugri� auf den Tag beendet. Der Nachweisfür die Korrektheit wird in Abschnitt 5.2 erbracht.
4.7 Zusammenfassung
In diesem Kapitel wurde die konkrete Lösung für das aufgestellte abstrakte Szenario entwi-ckelt. Um die Probleme e�ektiv lösen zu können, wurde zunächst der Aufbau des Systemsentwickelt. Schon bei der Erstellung des Aufbaus war anzunehmen, dass eine zentrale Stelledie Datenstruckturen des Authentisierungsserver sind. Der Grund dafür ist, dass die bisherverwendeten Methoden der Anonymisierung für das Szenario mit mehreren Milliarden Tagsnicht geeignet sind. Im folgenden wird für alle Anforderungen aus 3.2 dargestellt, warumdie entwickelte Lösung die Bedingungen erfüllt.
Wie wird die Anonymisierung der Tags ermöglicht? In 4.2 wurde ein Verfahren zurAnonymisierung entwickelt, welches mit zwei verschiedenen Phasen die Probleme der zweiverbundenen bekannten Verfahren so weit löst, dass ein praktischer Einsatz möglich ist.Die Anonymisierung erfolgt dabei hauptsächlich durch die Hash-Kette. Die Pseudo IDswerden dabei regelmäÿig gewechselt und nicht wiederholt. Dadurch das keine Wiederho-lung einer Pseudo ID auftritt und ein Auÿenstehender, durch den verwendeten Schlüssel
2008-01-16/010/INF02/2253 65

4 Protokoll und Systemaufbau
zur Erzeugung der Hashkette, aus einer aktuelle Pseudo ID weder eine alte noch späterePseudo ID ermitteln kann, ist eine Verfolgung des Tags möglich. Problematisch dagegenist die zweite Phase des Protokolls, mit der das Finden verlorener RFID Tags möglichist. Hier ist eine Verfolgung prinzipiell möglich, da die Pseudo ID in einem Zyklus rot-tieren, bis eine erfolgreiche Authentisierung vorgenommen werden konnte. Nachdem diesjedoch erfolgt ist wird der Zyklus jedoch getauscht und für die Verfolgung des Tag musswieder zunächst der gesamte Zyklus ermittelt werden. Bei der Ermittlung des Zyklus istauch der Schutz der Verfolgung vorhanden. Es soll möglichst lange dauern bis der Zyklusermittelt werden kann. Deshalb wird nicht sofort nach einer Anfrage die aktuelle PseudoID des Zyklus herausgegeben. Dies macht der Tag erst nachdem eine bestimmte Warte-zeit überschritten wurde. Die Wartezeit beginnt immer von neuem wenn das Auslesefeldan den Tag angelegt wird. So muss der Tag immer die gesamte Wartezeit im Feld desLesegerätes sein, damit es die aktuelle Pseudo ID des Tag erhält. Wenn mit der aktuellePseudo ID keine erfolgreiche Authentisierung erfolgt steigt die Wartezeit an. Die Zeit biseine Verfolgung möglich ist, wird damit durch die Länge der Kette und die Wartezeit nachnicht erfolgreichen Authentisierungen bestimmt. Ein Tag ist damit bei zwischen zwei auf-einanderfolgenden erfolgreichen Authentisierungen verfolgbar, wenn der Angreifer genugZeit hat, um einen Zyklus der Pseudo IDs zu ermitteln. Die Zeit muss deshalb so gewähltwerden, dass dies unrealisitisch ist, aber der praktische Einsatz noch möglich ist.
Wie wird gewährleistet, dass verlorene oder angegri�ene Tags von berechtigten Teil-
nehmern trotzdem gelesen werden können? Durch die zweite Phase des Authentisie-rungsverfahren aus 4.2 ist das möglich. Wenn ein Tag verloren scheint, kann der Authenti-sierungsserver die Resynchronisierung starten. Dabei gibt der Tag nach einer Wartezeit dieaktuelle Pseudo ID eines Zyklus zur Resynchronisation des Tag heraus. Nur der Authen-tisierungsserver hat, neben dem Tag, den gesamten Zyklus für den jeweiligen Tag gespei-chert und kann somit daraus die reale ID des Tag ermitteln. Damit können die berechtigtenTeilnehmer, die Zugri� auf den Authentisierungsserver haben den Tag wieder�nden. Pro-blematisch an der Syncronisation ist die notwendige Wartezeit. Sie kann fast null sein oderaber auch sehr lang. Deshalb ist eine oberer Schranke für die Wartezeit zu de�nieren, damitder Tag innerhalb einer bestimmten Zeit gefunden wird.
Wie wird der Zugri� auf die Daten der Tags kontrolliert? In Abschnitt 4.3 wur-de ein Verfahren entwickelt, die das ermöglicht. Dabei erfolgt das Zusammenspiel vomAutorisierungs-/Keyserver, der die Zugri�sentscheidung fällt, und dem Tag, als ausführen-der Instanz. Der Tag kann dabei wegen der erhaltenden Prüfsumme, die mit einem Schlüsselerstellt wurde, den nur Autorisierungs-/Keyserver und Tags kennen, vom Autorisierungs-/Keyserver sicher sein, dass die Entscheidung vom Autorisierungs-/Keyserver getro�enwurde. Der Tag muss somit nur den Zugri� erlauben oder ablehnen wenn eine entspre-chende Anfrage kommt. Der Tag erhält mit der Anfrage wer auf die Daten wo zugreifendarf. Ermittelt wird das vom Autorisierungs-/Keyserver, der diese Entscheidung aufgrundder Zuordnung der Teilnehmer zu Rollen und der gewünschten Transaktionen fällt. Dienotwendigen Informationen werden dabei extern verwaltet und müssen gültig sein. Da fürden Zugri� auf den Tag eine erfolgreiche Authentisierung notwendig ist und die Anfragean den Autorisierungs-/Keyserver erst danach möglich ist, kann der Tag sicher sein, dasser nur berechtigte Teilnehmern, die aktuell den Zugri� auf die erlaubten Bereiche haben,den Zugri� ermöglicht.
Wie werden Veränderungen der Daten erkannt? Damit auch die Veränderung von Da-ten auf dem Tag erkannt werden kann, wurde in Abschnitt 4.4 ein Verfahren zum Schutzder Datenintegrität entwickelt. Es beachtet im Besonderen, dass die Speicherplatze�zienz
66 2008-01-16/010/INF02/2253

4.7 Zusammenfassung
bei der Speicherung der Daten auf dem Tag sehr wichtig ist, da die Speicherkapazitätder Tags sehr beschränkt ist. Das Verfahren nutzt dabei aus, dass sich Teilnehmer unter-einander mehr Vertrauen als allen Anderen. Durch die Berechnung der Prüfsumme überDatengruppen kann viel Speicherplatz gespart werden. Durch die vorhandene Zugri�skon-trolle ist sichergestellt, dass die Prüfsumme eines Bereiches nur überschrieben werden kann,wenn der Teilnehmer Schreibzugri� auf ein Datum hat, welches Ein�uss auf die Prüfsummehat. Da der Teilnehmer jedoch keine anderen Daten ändern kann, die bei der Berechnungder Daten mit ein�ieÿen kann er nur Daten als gültig markieren auf die Schreibrechte vor-handen sind. Da die Prüfsumme über den verschlüsselten Daten erzeugt wird, kann derTeilnehmer auch keine zusätzlichen Informationen aus den Daten erhalten, die zur Prüfungder Integritätsprüfsumme notwendig sind. Er erhält zwar die entsprechenden Daten, hat je-doch nicht den notwendigen Schlüssel zur Interpretation. Damit werden keine zusätzlichenInformationen herausgegeben.
Welche Schlüssel werden verwendet und wie erfolgt die Verteilung? Damit der Einsatzder entwickelten Verfahren möglich ist, benötigen die Verfahren entsprechende Schlüssel.Das Verfahren, wie die Schlüssel verwaltet werden wurde deshalb in Abschnitt 4.5 darge-stellt. Es wird dabei zwischen Schlüsseln unterschieden, die für die Kommunikation not-wendig sind und Schlüssel für die Datenspeicherung. Für die Schlüssel, die mehrere Tagshaben wird kein Group Key Management verwendet, da es im Szenario schlecht einsetz-bar ist, weil nicht ohne unvorhersehbare Latenzen Schlüssel zurückgezogen werden können.Deshalb erhalten alle Tags individuelle Schlüssel zur Kommunikation und Speicherung derDaten. Bei der Minimierung der Schlüssel pro einzelnen Tag für die Speicherung der ver-schiedenen Daten auf einem Tag werden die verschieden Schlüssel zusammengefasst, wenndas möglich ist, damit möglichst wenig Schlüssel benötigt werden und der Speicherplatzauf dem Tag e�zient genutzt werden kann. Da jeder Tag individuelle Schlüssel hat istgewährleistet, dass wenn einzelne Schlüssel bekannt werden nicht das gesamte System anSicherheit verliert. Nur wenn einzelne Schlüssel zur Speicherung bekannt werden, könneneventuell weitere Daten auf dem gleichen Tag gelesen werden, von dem der Schlüssel be-kannt wurde.
Wie wird gewährleistet, dass die Lesegeräte nicht die reale ID des Tag erhalten?
Nachdem die Probleme des Systems prinzipiell gelöst worden sind, wurde ein Kommuni-kationsprotokoll in Abschnitt 4.6 entwickelt, welches die Realisierung des Gesamtsystemsmöglich macht. Das Protokoll besteht dabei grundsätzlich aus zwei Phasen, einer Authen-tisierungsphase und einer Zugri�sphase auf den Tag. Die Analyse des Protokolls erfolgt imnächsten Kapitel. Aus dem Protokoll ist aber zu erkennen, dass das Lesegerät nicht diereale ID des Tag in Nachricht 4.6.2.3 erhält, sonder diese Information mit einem Schlüs-sel zwischen A und K verschlüsselt ist ({IDR, IDT ,K, tA}KA,K
), den R nicht hat. Damiterhält R nicht die reale ID des Tag. Auch an den anderen Stellen des Protokolls erhält Rnicht die reale ID des Tag. Damit ist die Anforderung erfüllt.Die nächsten beiden Fragen werden im nächsten Kapitel beantwortet.
Wie wird realisiert, dass möglichst wenig Speicher genutzt wird? Da die RFID Tagsrelativ wenig Speicher haben müssen alle Entwicklungen wenig Speicher benutzen. DieAnonymisierung benötigt wenig Speicher weil nur einzelne Werte und nicht alle Wertegespeichert werden müssen. Für die Erzeugung der Hashkette sind nur zwei Werte notwen-dig. Einmal die aktuelle Pseudo ID der Kette und dann den Schlüssel zur Erzeugung derneuen Pseudo ID. Der Zyklus für den Zyklus benötigt genauso wenig Informationen. Esbenötigt einen Startwert und einen Zähler, da der Zyklus durch das Hashen von Startwertund Zähler erzeugt wird. Für den Zyklus benötigt der Tag auch noch die Zykluslänge. Es
2008-01-16/010/INF02/2253 67

4 Protokoll und Systemaufbau
ist zu sehen, dass dabei weniger Informationen benötigt werden, als wenn zum Beispiel derZyklus komplett gespeichert wird.Die Zugri�skontrolle benötigt keinen festen Speicher auf dem Tag. Es müssen nur die
erhaltenden Daten entschlüsselt und ausgewertet werden. Dabei werden jedoch nur Zu-standsinformationen benötigt.Die Lösung zur Realisierung wurde auf geringen Speicherplatzverbrauch optimiert wie
auch in dem Beispiel in dem Abschnitt 4.4 zu sehen ist. So wird die E�zienz im Beispiel von63 Prozent auf 90 Prozent gesteigert. Im Allgemeinen hängt die Steigerung der E�zienzvon der konkreten Datenverteilung ab, jedoch ist die Steuerung deutlich.Damit wurden alle bis jetzt bearbeiteten Fragen beantwortet und erklärt warum sie gelöst
sind. Die noch bestehenden Fragen der Sicherheit werden im nächsten Kapitel beantwortet.
68 2008-01-16/010/INF02/2253

5 Untersuchung des Protokolls mit Hilfe der GNY
Logik
In diesem Abschnitt der Arbeit wird mit Hilfe der GNY Logik aus Abschnitt 2.4 dassKommunikationsprotokoll im Hinblick auf die Ziele des Protokolls untersucht. Dabei wer-den die Regeln der GNY Logik, welche auch im Anhang 5 stehen, verwendet. Damit dieUntersuchung möglich ist, werden in den Teilabschnitten zunächst die Ziele formalisiert.Danach wird das Protokoll in die notwendige Form umgewandelt, um dann anschlieÿenddie Untersuchung im Hinblick auf die Ziele durchzuführen.
5.1 Authentisierung
Das Ziel des Teilprotokolls ist die Authentisierung von T und R. T soll sicher sein, dassR aktuell zur Kommunikation mit T berechtigt ist. Das wird dadurch repräsentiert, dassR den aktuellen Sitzungsschlüssel für die Kommunikation zwischen T und R hat. Dasist sinnvoll, da R den Schlüssel nur erhält, wenn A das für korrekt erachtet und T andie Kompetenz von A glaubt. Damit A den Schlüssel generieren kann, muss es zunächstdie aktuelle Pseudo ID von T in Erfahrung bringen, damit A daraus die reale ID des Tagsableiten kann. Weiter sollen R und T den Sitzungsschlüssel besitzen und an diesen glauben.Zusätzlich müssen beide Parteien sicher sein, dass der Partner den Schlüssel auch hat. Rbenötigt für den zweiten Teil des Protokolls das Ticket von A. Formalisiert in GNY Logikergeben sich dann folgende Ziele.
A 3 IDT (5.1.0.1)
R 3 KR,T (5.1.0.2)
R |≡RKR,T←−−→ T (5.1.0.3)
R |≡T 3 KR,T (5.1.0.4)
T 3 KR,T (5.1.0.5)
T |≡RKR,T←−−→ T (5.1.0.6)
T |≡R 3 KR,T (5.1.0.7)
R 3 tKAK , {IDT , IDR,K, tA}KA,K(5.1.0.8)
Damit die Ziele in der Untersuchung hergeleitet werden können, sind verschiedene Vor-bedingungen notwendig. Für das erste Teilprotokoll sind das folgende Annahmen. R glaubtan die Kompetenz von A und die Autorität von A über den erzeugten Sitzungsschlüssel.Das ist sinnvoll, weil im Szenario nur ein Authentisierungsserver existiert und auf die kor-rekte Arbeitsweise von A vertraut werden kann. Weiter glaubt R an die Frische der selbsterzeugten Nonces. R hat zusätzlich einen symmetrischen Schlüssel zur Kommunikationmit A und glaubt an diesen Schlüssel. Das Gleiche gilt für A in Beziehung zu R, auchbezüglich des generierten Nonce. Die Annahme mit dem Schlüssel ist sinnvoll, da die Aus-handlung vor Beginn der Kommunikation beispielsweise mit SSL ausgehandelt wurden. Dashat zusätzlich den Vorteil, dass die Authentisierung von R gegen T und entgegengesetztvorgenommen werden kann. Formalisiert ergeben sich folgende Voraussetzungen:
2008-01-16/010/INF02/2253 69

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
R |≡A Z⇒ A |≡ ? (5.1.0.9)
R |≡A Z⇒ RKR,T←−−→ T (5.1.0.10)
R |≡ ](rR1) (5.1.0.11)
R |≡ ](rR2) (5.1.0.12)
R 3 KA,R (5.1.0.13)
R |≡AKA,R←−−→ R (5.1.0.14)
T |≡ ](rT ) (5.1.0.15)
T |≡AKA,T←−−→ T (5.1.0.16)
T 3 IDT (5.1.0.17)
A |≡RKR,T←−−→ T (5.1.0.18)
A |≡AKA,T←−−→ T (5.1.0.19)
Zur Durchführung der Untersuchung muss das Protokoll zunächst in eine für die GNYLogik passende Form konvertiert werden. Für das Teilprotokoll 4.6.1 ergibt sich dann fol-gende Form.
T / ?rR1 (5.1.0.20)
R /(?IDPseudo : i, ?rT , ?H(IDPseudo : i, rT , < KA,T>)
)(5.1.0.21)
A / ?{?IDPseudo : i, ?IDR, ? rT , ?rR1, ?tR,
?H(IDPseudo : i, rT , < KA,T>)}KA,R
(5.1.0.22)
R /
(?{?K, ?A,IDPseudo : i, ?tKAK , ? {?IDT , IDR,K, ?tA}KA,K
,
?Struktur, ?KR,T , ?rA, rR1
}KA,R
; A |≡RKR,T←−−→ T
) (5.1.0.23)
T /
(?rA, ?{?rR2, rT }KR,T
;R |≡RKR,T←−−→ T
)(5.1.0.24)
R /
(?{rR2}KR,T
;T |≡RKR,T←−−→ T
)(5.1.0.25)
Im umgewandelten Protokoll müssen noch einige Teile erklärt werden. In Nachricht5.1.0.21 wird angenommen, dass T die Nachricht nur sendet, wenn er an die eigene Pseu-do ID glaubt. Das ist plausibel, da T die Pseudo ID immer selbst nur aus gespeichertenInformationen generiert. Weiter wird in Nachricht 5.1.0.23 angenommen, dass A an den er-zeugten Sitzungsschlüssel glaubt. Die Erklärung dafür erfolgt im Beweis unten. Eine weitereStelle ist in Nachricht 5.1.0.24. R sendet die Nachricht nur, wenn R an den Sitzungsschlüs-sel glaubt. Die Begründung warum das gilt, ist aus Nachricht 5.1.0.23 nachweisbar. DerNachweis steht unten. Die letzte zu erklärende Stelle ist in Nachricht 5.1.0.25. Hier wirdangenommen, dass T ebenfalls an den Sitzungsschlüssel glaubt. Diese Annahme wird untenaus Nachricht 5.1.0.24 beweisen.Jetzt erfolgt die eigentliche Untersuchung. Das erfolgt am Anfang ausführlich, um das
Verfahren zu erkennen. Danach wird zur Übersicht nur noch angegeben, aus welchen Aus-drücken mit welcher Regel das Ergebnis ableitbar ist. Die Untersuchungen wurden komplettdurchgeführt, aber die Ausführlichkeit ist nicht übersichtlich und damit hier nicht geeignet.
70 2008-01-16/010/INF02/2253

5.1 Authentisierung
Nachricht 5.1.0.20
T / ?rR1
Aus der Nachricht ist schlieÿbar, dass T das aktuelle Nonce von R erhalten hat. Das istdurch Anwenden der Regeln T1 und P1 schlieÿbar.
T1 :T / ?rR1
T / rR1(5.1.0.26)
P1 :T / rR1
T 3 rR1, P1 :
T / ?rR1
T 3 ?rR1(5.1.0.27)
Nachricht 5.1.0.21
R /(?IDPseudo : i, ?rT , ?H(IDPseudo : i, rT , < KA,T>)
)Mit der gleichen Anwendung der Regeln, kann auch die nächste Nachricht ausgewertet
werden. Zusätzlich wird zum Aufspalten der Daten die Regel T2 verwendet werden.
T1 :R / ?IDPseudo:i, ?rT , ?H(IDPseudo : i, rT , < KA,T>)
R / ?IDPseudo : i, R / ?rT , R / ?H(IDPseudo : i, rT , < KA,T>)(5.1.0.28)
T2 :R / ?IDPseudo:i
R / IDPseudo : i, T2 :
R / ?rTR / rT
, T2 :R / ?H(IDPseudo : i, rT , < KA,T>)R / H(IDPseudo : i, rT , < KA,T>)
(5.1.0.29)
P1 :R / IDPseudo:i
R 3 IDPseudo : i(5.1.0.30)
P1 :R / rTR 3 rT
(5.1.0.31)
P1 :R / H(IDPseudo : i, rT , < KA,T>)R 3 H(IDPseudo : i, rT , < KA,T>)
(5.1.0.32)
Jetzt ist nachgewiesen, dass R die Pseudo ID des Tags, das Nonce von T, sowie diePrüfsumme von T über diese Daten hat. Alle diese Daten sind notwendig um die nächsteNachricht von R zu generieren. Das ist die Nachricht 5.1.0.22.
Nachricht 5.1.0.22
A / ?{?IDPseudo : i, ?IDR, ? rT , ?rR1, ?tR,
?H(IDPseudo : i, rT , < KA,T>)}KA,R
Mit Hilfe der Regeln T3 und dem Schlüssel 5.1.0.13 aus der Voraussetzung, sowie derRegel T1 lässt sich Folgendes schlieÿen:
A / ?IDPseudo : i, A / ?IDR, A / ?rT , A / ?tR, A / ?H(IDPseudo : i, rT , < KA,T>)(5.1.0.33)
Mit Hilfe der Regeln T2 und P1 kann dann gefolgert werden, dass A alle Teildaten hat.
A / IDPseudo : iA 3 IDPseudo : i
,A / rTA 3 rT
,A / IDR
A 3 IDR,A / ?H(IDPseudo : i, rT , < KA,T>)A 3 H(IDPseudo : i, rT , < KA,T>)
,A / ?tRA 3 tR(5.1.0.34)
2008-01-16/010/INF02/2253 71

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
Mit dem Wissen aus 5.1.0.33 und 5.1.0.34, sowie der Vorbedingung 5.1.0.16 und demWissen das die Nachricht frisch ist, kann mit Regel I3 gefolgert werden, dass A glaubt,dass T die Pseudo ID und das Nonce gesendet hat und zur Signatur den gemeinsamenSchlüssel verwendet hat. Die Nachricht wird mit Hilfe der Pseudo ID als frisch erkannt,weil keine Pseudo ID mehrmals verwendet wird.
A |≡T |∼ IDPseudo : i, rT , < KA,T> (5.1.0.35)
Aus dieser Information 5.1.0.35 und der Frische der Nachricht, kann mit Hilfe der RegelI6 gefolgert werden, dass A glaubt, dass T die Pseudo ID und das Nonce des Tag hat.
A |≡T 3 IDPseudo : i, rT (5.1.0.36)
Für den weiteren Nachweis ist es wichtig, dass A die reale ID des Tags besitzt. A weiÿ,dass T die erhaltende Pseudo ID hat 5.1.0.35. Mit Hilfe der Pseudo ID von T (5.1.0.34),der Datenbank von A und der Prüfsumme von A 5.1.0.34 kann A die reale ID des Tagsermitteln. Damit besitzt A die reale ID des Tag 5.1.0.1.
A 3 IDT (5.1.0.37)
Nachricht 5.1.0.23
R /
(?{?K, ?A,IDPseudo : i, ?tKAK , ? {?IDT , IDR,K, ?tA}KA,K
,
?Struktur, ?KR,T , ?rA, rR1
}KA,R
; A |≡RKR,T←−−→ T
)Ein weiteres Teilziel ist, dass R den Sitzungsschlüssel erhalten hat 5.1.0.2. Dieses Ziel
ist direkt aus der Nachricht mittels der Regel T3 und dem Schlüssel 5.1.0.13 aus denVoraussetzungen, sowie den Regeln T1 und P1 herleitbar. Dabei ergibt sich auch dasTeilziel 5.1.0.8.
R 3 KR,T , R 3 tKAK , {IDT , IDR,K, tA}KA,K(5.1.0.38)
Mit Hilfe der Nachricht 5.1.0.23, den Vorbedingungen 5.1.0.13 und 5.1.0.14 über denSchlüssel KA,R, sowie der Erkennbarkeit und Aktualität der Nachricht mittels rR1 5.1.0.11kann mit der Regel I1 geschlossen werden, dass R glaubt, dass A die Nachricht gesendethat.
R |≡A |∼ (?K, ?A, IDPseudo : i, ?Struktur, ? {?IDT , IDR,K, ?tA}KA,K, ?KR,T , rR1)
(5.1.0.39)
Aus diesem Wissen 5.1.0.39, der Vorbedingung, dass R an die Kompetenz von A glaubt5.1.0.9 und der Prüfung der Aktualität mittel der Vorbedingung 5.1.0.11 kann mit J2geschlossen werden, dass R glaubt, dass A glaubt, dass A an den Sitzungsschlüssel zwischenR und T glaubt.
R |≡A |≡A |≡RKR,T←−−→ T (5.1.0.40)
72 2008-01-16/010/INF02/2253

5.1 Authentisierung
Weiter kann durch den Einsatz der Regeln J3 und J1 aus demWissen 5.1.0.40, der Vorbe-dingung 5.1.0.9, sowie dem Glaube von R an die Autorität von A über den Sitzungsschlüs-sel 5.1.0.10 ein weiteres Teilziel gefolgert werden. R glaubt dann an den Sitzungsschlüsselzwischen R und T 5.1.0.3.
R |≡RKR,T←−−→ T (5.1.0.41)
Nachricht 5.1.0.24
T /
(?rA, ?{?rR2, rT }KR,T
;R |≡RKR,T←−−→ T
)Durch einfache Anwendung der Regeln T2, T1 und P1 ergibt sich, dass R das Nonce
von A hat.
T 3 rA (5.1.0.42)
Da T jetzt das eigene Nonce, das Nonce von R 5.1.0.27 und das Nonce von A 5.1.0.42hat, kann T jetzt den Sitzungsschlüssel berechnen und hat diesen damit. Somit ist dasTeilziel 5.1.0.5 erreicht.
T 3 KR,T
(= H(IDT , rT , rR1, rA, < KA,T >)
)(5.1.0.43)
Weiter ist hieraus ableitbar, dass T an den Sitzungsschlüssel glaubt 5.1.0.6. Grund dafürist, dass T den Schlüssel selbst generiert hat. Die dabei zusätzlich benutzten Nonces vonA und R kann R zwar modi�ziert haben, jedoch würde T daraus einen anderen Schlüsselberechnen. Den berechneten Schlüssel kann R jedoch nicht erzeugen, da R nicht die dafürnotwendige reale ID des Tags hat. Deshalb ist sichergestellt, wenn T die Nachricht 5.1.0.24entschlüsseln kann und sein Nonce wiedererkennt, dass die beiden Nonces nicht manipuliertsind. Somit kann T an den Schlüssel glauben.
T |≡RKR,T←−−→ T (5.1.0.44)
Mit der Regel I1 kann aus der Nachricht 5.1.0.24 das Teilziel 5.1.0.7 geschlossen wer-den. Dazu wird zusätzlich benötigt, dass T den Schlüssel KR,T 5.1.0.43 besitzt. Weiternotwendig ist der Glaube von T an diesen gemeinsamen Sitzungsschlüssel 5.1.0.44 und dieErkennbarkeit und Aktualität der Nachricht mittels des Nonce 5.1.0.15.
T |≡R 3 KR,T (5.1.0.45)
Nachricht 5.1.0.25
R /
(?{rR2}KR,T
;T |≡RKR,T←−−→ T
)Die letzte Nachricht der Authentisierungsphase ist die Nachricht 5.1.0.25. Mit Hilfe der
Regel I3 kann das letzte Teilziel 5.1.0.4 nachgewiesen werden. Dafür notwendig ist dieNachricht selbst, dass R den Sitzungsschlüssel hat und daran glaubt 5.1.0.38 und 5.1.0.41,sowie die Erkennbarkeit und Aktualität der Nachricht mittels des Nonce 5.1.0.12.
R |≡T 3 KR,T (5.1.0.46)
Mit der letzten Aussage sind alle Teilziele des Protokolls untersucht worden. Das Teil-protokoll erfüllt damit den gewünschten Zweck und das Verfahren kann mit dem zweitenTeilprotokoll fortfahren.
2008-01-16/010/INF02/2253 73

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
5.2 Datenaustausch
Nachdem im vorherigen Abschnitt untersucht wurde, ob das erste Teilprotokoll die ge-wünschten Ziele erfüllt, wird das nun auch für das zweite Teilprotokoll durchgeführt. Daszweite Teilprotokoll ist das Protokoll zum Zugri� auf die Daten des Tags. Es wurde inAbschnitt 4.6.2 ausführlich erklärt.Das Protokoll hat verschiedene Ziele. Das Hauptziel ist die korrekte Ausführung der ge-
wünschten Operationen, wenn diese erlaubt sind. Dazu muss R zunächst an die Daten- undIntegritätsschlüssel für die Interpretation der Daten von T glauben. Ein Zwischenschrittdafür ist, dass K ebenfalls an die Schlüssel glaubt. Damit R an die Schlüssel glauben kann,muss K zunächst die Schlüssel aus der Datenbank lesen. Dazu muss K die reale ID desTags haben und daran glauben. Dafür muss K glauben, dass A an die reale ID des Tagsglaubt. Im weiteren Verlauf des Protokolls, soll R bei einem Lesevorgang die Daten desTags erhalten und veri�zieren, dass T die Daten auch hat. Für die Realisierung der Zugri�s-kontrolle ist T mit verantwortlich. Deshalb muss T an die RWAntwort[] glauben. Dafürmuss T zunächst glauben, dass auch K daran glaubt. Falls R einen Schreibzugri� auf denTag durchführen will, muss zusätzlich Folgendes für T gelten. T soll die �Daten2� haben.Dafür muss zunächst nachgewiesen werden, dass T glaubt, dass R die �Daten2� hat. EineFormalisierung der eben beschriebenen Ziele in GNY Form ist im Folgenden dargestellt.
R |≡K 3 (DKK [], IDKK []) (5.2.0.47)
R 3 (DKK [], IDKK []) (5.2.0.48)
R |≡T 3 Daten1 (5.2.0.49)
R 3 Daten1 (5.2.0.50)
R |≡T 3 rR2 (5.2.0.51)
T |≡K 3 RWantwort[] (5.2.0.52)
T 3 RWantwort[] (5.2.0.53)
T |≡R 3 Daten2 (5.2.0.54)
T 3 Daten2 (5.2.0.55)
K |≡A 3 IDT (5.2.0.56)
K 3 IDT (5.2.0.57)
Damit die Ziele untersucht werden können, sind verschiedene Vorbedingungen notwen-dig. Ein Teil sind die Nachbedingungen des ersten Teilprotokolls und der andere Teil derVorbedingungen ist neu. Die Ziele des ersten Teilprotokolls und die Vorbedingungen fürdas zweite Teilprotokoll sind die Folgenden.R hat und glaubt an den Sitzungsschlüssel mit T. Weiter hat R das Ticket für den Zugri�
auf den Tag über K. T hat und glaubt ebenfalls an den Sitzungsschlüssel T. A glaubt an diereale ID des Tag, da A nur dann das Ticket für K erstellt hat. Die zusätzlichen Vorausset-zungen sind wie folgt. R hat einen gemeinsamen Schlüssel mit K und glaubt an diesen. FürK gilt das Gleiche. Die Annahme ist sinnvoll, da dieser Schlüssel vorher zum Beispiel perSSL ausgehandelt wird und dabei gleichzeitig die Authentisierung über Zerti�kate erfolgtist. Alle Teilnehmer glauben an die Frische der selbst erzeugten Nonce. Weiter glaubt Ran die Kompetenz von K und dessen Autorität über die Daten- und Integritätsschlüssel.Das ist plausibel, da die Anzahl der Autorisierungs-/Keyserver im System beschränkt istund sie so gesichert sind, dass auf die korrekte Arbeitsweise vertraut werden kann. Diegespeicherten Schlüssel werden bei Initialisierung des Tags gespeichert und dann nicht ver-ändert, so dass davon ausgegangen werden kann, dass die Daten in K richtig gespeichertsind. Weiter haben K und T einen gemeinsamen Schlüssel zur Integritätsprüfung, an den
74 2008-01-16/010/INF02/2253

5.2 Datenaustausch
beide glauben. Dieser Schlüssel wird ebenfalls bei der Initialisierung des Tags generiert,so dass die gleichen Aussagen wie eben gelten. Für die Ausführung der Zugri�sprüfungbenötigt T die RWAntwort[] von K. Deshalb muss T an die Autorität von K über dieRWAntwort[] glauben. Die Gründe dafür sind die gleichen, wie bei den auf K gespeicher-ten Schlüsseln. Damit T die Daten von richtig interpretieren kann, muss es K vertrauen. Kbenötigt für seine Funktion das Ticket von A. Damit das ausgewertet werden kann, mussK den gemeinsamen Schlüssel mit A haben und daran glauben. Zusätzlich muss K an dieKompetenz von A sowie die Autorität über die reale ID des Tags glauben. Das ist sinnvoll,da die Anzahl von A und K beschränkt ist und diese jeweils so gut gesichert sind, dassauf die korrekte Funktion vertraut werden kann. Diese Vorbedingungen sind in GNY Formaufgelistet folgende:
R |≡KKK,R←−−→ R (5.2.0.58)
R 3 KK,R (5.2.0.59)
R |≡RKR,T←−−→ T (5.2.0.60)
R 3 KR,T (5.2.0.61)
R |≡ ](rR0), R |≡ ](rR1), R |≡ ](rR2) (5.2.0.62)
R |≡K Z⇒ K |≡ ? (5.2.0.63)
R |≡K Z⇒ (DKK [], IDKK []) (5.2.0.64)
R 3 tKAK , {IDR, IDT , tA}KA,K(5.2.0.65)
T |≡KKK,T←−−→ T (5.2.0.66)
T 3 KK,T (5.2.0.67)
T |≡K Z⇒ RWantwort[] (5.2.0.68)
T |≡RKR,T←−−→ T (5.2.0.69)
T 3 KR,T (5.2.0.70)
T |≡ ](rT ) (5.2.0.71)
T |≡K Z⇒ K |≡ ? (5.2.0.72)
K |≡AKA,K←−−→ K (5.2.0.73)
K 3 KA,K (5.2.0.74)
K |≡A Z⇒ A |≡ ? (5.2.0.75)
K 3 (DKK [], IDKK []) (5.2.0.76)
K |≡ ](tA) (5.2.0.77)
K |≡A Z⇒ IDT (5.2.0.78)
K |≡KKK,R←−−→ R (5.2.0.79)
K 3 KK,R (5.2.0.80)
K |≡KKK,T←−−→ T (5.2.0.81)
K 3 KK,T (5.2.0.82)
K 3 RWAntwort[] (5.2.0.83)
A 3 IDT (5.2.0.84)
Damit jetzt mit Hilfe der Vorbedingungen auf die Ziele geschlossen werden kann, mussder Nachrichtenaustausch aus 4.6.2 zunächst in die GNY Form umgewandelt werden. Dasumgewandelte Protokoll ist im Folgenden zu sehen.
2008-01-16/010/INF02/2253 75

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
R / ? {?rT }KR,T(5.2.0.85)
K /
(?{?IDR, ?IDPseudo : i, ?rT , ?RWanfrage[], ?rR0, ?A, ?K,
?tKAK , ? {?IDR, ?IDT ,K, ?tA}KA,K
}KR,K
) (5.2.0.86)
R /
(?{IDR, IDPseudo : i, rT , RWantwort[], ?DKK [], ?IDKK [], rR0,
?H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,K
) (5.2.0.87)
T /
(?{?IDR, IDPseudo : i, rT , ?RWantwort[], ?RWindexe[], ?rR1,
?H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,T
) (5.2.0.88)
R / ? {IDR, IDPseudo : i, rR1, ?(Daten1)}KR,T(5.2.0.89)
Ende falls Lesevorgang (5.2.0.90)
T /
(?{IDR, IDPseudo : i, rT , RWantwort[], RWindexe[], ?rR2,
H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >),
?(Daten2)}KR,T
) (5.2.0.91)
R / ? {IDR, IDPseudo : i, rR2}KR,T(5.2.0.92)
Mit allen bisherigen Informationen ist es möglich mit Hilfe der GNY Logik die Ziele desProtokolls zu untersuchen.
Nachricht 5.2.0.85
R / ? {?rT }KR,T
Aus der Nachricht kann mit Hilfe der Regeln T1, T3 mit dem Sitzungsschlüssel 5.2.0.61und der Regel P1 geschlossen werde, dass R das Nonce hat.
R 3 rT (5.2.0.93)
Nachricht 5.2.0.86
K /
(?{?IDR, ?IDPseudo : i, ?rT , ?RWanfrage[], ?rR0, ?A, ?K,
?tKAK , ? {?IDR, ?IDT , ?tA}KA,K
}KR,K
)Mit Hilfe der Regeln T1, T3 mit dem Schlüssel 5.2.0.80, sowie der Regel I2 kann ermittelt
werden, dass K glaubt, dass A die Informationen des Ticket gesendet hat. Dazu wirdfür die Regel I2 zusätzlich zur entschlüsselten Nachricht folgendes benötigt. K muss dengemeinsamen Schlüssel mit A haben 5.2.0.74 und diesen als geeignet betrachten 5.2.0.73.Weiter muss die Nachricht erkennbar und aktuell sein. Dazu benutzt K den Zeitstempel,den A in dem Ticket gespeichert hat 5.2.0.77. Die Struktur der Nachricht, wird durch dieBezeichner von K sichergestellt.
76 2008-01-16/010/INF02/2253

5.2 Datenaustausch
K |≡A |∼ (IDR, IDT , tA) (5.2.0.94)
Mit Hilfe der Regel I6 kann jetzt ermittelt werden, dass K glaubt, dass A die reale IDdes Tags hat. Dafür verwendet die Regel, dass K glaubt, dass A die reale ID gesendet hat(5.2.0.94) und dass die Nachricht durch den enthaltenden Zeitstempel frisch ist. Damitergibt sich das gewünschte Ziel 5.2.0.56.
K |≡A 3 IDT (5.2.0.95)
Aus der Nachricht selbst kann mit der Regel I1 und zweimal I3 mit den Schlüsseln5.2.0.80 und 5.2.0.74 ermittelt werden, dass K die reale ID des Tags hat 5.2.0.57.
K 3 IDT (5.2.0.96)
Nachricht 5.2.0.87
R /
(?{IDR, IDPseudo : i, rT , RWantwort[], ?DKK [], ?IDKK [], rR0,
?H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,K
)Mit Hilfe Regel I1 kann geschlossen werden, dass R glaubt, dass K die Nachricht gesendet
hat. Dazu wird neben der Nachricht verwendet, dass R den Sitzungsschlüssel mit K hat5.2.0.59 und an diesen glaubt 5.2.0.58. Weiter ist die Nachricht durch das Nonce des Tagsaktuell 5.2.0.62 und die Nachricht ist durch die verwendeten Bezeichner der Teilnehmererkennbar.
R |≡K |∼ (IDR, IDPseudo : i, ..., rR0) (5.2.0.97)
Mit der Regel I6 und der bisherigen Erkenntnis 5.2.0.97 und der Frische der Nachrichtdurch das Nonce 5.2.0.62 kann geschlossen werden, dass R glaubt, dass K die gesendetenSchlüssel hat 5.2.0.47.
R |≡K 3 (DKK , IDKK) (5.2.0.98)
Es kann auch aus der Nachricht selbst und dem notwendigen Schlüssel 5.2.0.59 ermitteltwerden, dass R die Daten- und Inergritätsschlüssel hat 5.2.0.48.
R 3 (DKK , IDKK) (5.2.0.99)
Die GNY Logik erlaubt keine Folgerungen über Schlüssel, die nicht zur Kommunikationzwischen verschiedenen Partnern, sondern zur Speicherung von Daten verwendet werden.Deshalb kann hier nur gefolgert werden, dass R die beiden Schlüsseltabellen DKK [] undIDKK [] besitzt. Durch logische Folgerungen kann R aber glauben, dass beide Tabellen zurSpeicherung der Daten und Ermittlung der Prüfsummen geeignet sind. R weiÿ, dass K dieSchlüssel hat (5.2.0.98) und es selbst auch (5.2.0.99). Die Schlüssel sind durch das Nonce inder Nachricht aktuell (5.2.0.62). R glaubt weiter, dass K die Kompetenz über die Schlüsselhat (5.2.0.64) und K korrekt arbeitet (5.2.0.63). Daraus ist logisch ableitbar, dass R dieSchlüssel von K zur Verarbeitung der Daten des Tag für geeignet hält.
2008-01-16/010/INF02/2253 77

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
Nachricht 5.2.0.88
T /
(?{?IDR, IDPseudo : i, rT , ?RWantwort[], ?RWindexe[], ?rR1,
?H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >)}KR,T
)Die Nachricht kann genau wie die vorherige Nachricht ausgewertet werden. Nachdem
die Nachricht mittels T3 und Schlüssel 5.2.0.70 entschlüsselt wurde, wird jedoch zuerstdie Regel I3 anstatt der Regel I1 angewendet, bevor die gleichen Regeln J2, J3 und J1angewendet werden. Die Regel I3 benötigt dazu die Prüfsumme, die T von K empfangen hat5.2.0.88, um die Unverändertheit der Nachricht von K zu prüfen, dass T die Informationender Nachricht erhalten hat 5.2.0.88, dass T an den gemeinsamen Schlüssel mit K glaubt5.2.0.66 und das die Nachricht mittels des Nonce des Tag 5.2.0.71 auf Frische getestetwerden kann. Daraus ergibt sich, dass T glaubt, dass K die Nachricht gesendet hat unddiese nicht verändert wurde.
T |≡K |∼ (IDR, IDPseudo : i, rT , RWantwort[], < KK,T >) (5.2.0.100)
Mit der Regel I6 kann wieder aus 5.2.0.100 und der Frische der Nachricht durch dasNonce des Tags (5.2.0.71) geschlossen werden, dass T glaubt, dass K die RWantwort[]besitzt (5.2.0.101).
T |≡K 3 RWantwort[] (5.2.0.101)
Direkt aus der Nachricht kann mit der Regel T3 und dem notwendigen Schlüssel 5.2.0.70und den Regeln T1 und T2 ermittelt werden, dass T die RWantwort[] hat (5.2.0.102).
T 3 RWantwort[] (5.2.0.102)
Mit der GNY Logik tritt hier das gleiche Problem auf, wie in der letzten Nachricht,so dass hier wieder logisch gefolgert werden muss. T glaubt, dass K korrekt arbeitet(5.2.0.72) und die Kompetenz über die RWantwort[] besitzt (5.2.0.68). Die RWantwort[]in der Nachricht ist durch das Nonce (5.2.0.71) als aktuell erkennbar. Daraus und dassT glaubt, dass K die RWantwort[] hat (5.2.0.101) und es selbst auch (5.2.0.102) kannlogisch geschlossen werden, dass die RWantwort[] für die Zugri�skontrolle geeignet ist.Das die RWantwort[] nicht verändert wurde, ist durch die Prüfsumme H(IDR, IDPseudo :i, rT , RWantwort[], < KK,T >) gesichert.
Nachricht 5.2.0.89
R / ? {IDR, IDPseudo : i, rR1, ?(Daten1)}KR,T(5.2.0.103)
Durch einfaches Entschlüsseln und Aufspalten der Nachricht mit den Regeln T3, T2 undP1 kann geschlossen werden, dass R die Daten1 hat 5.2.0.50. Dazu ist neben der Nachrichtselbst nur der Sitzungsschlüssel zwischen R und T notwendig (5.2.0.61).
R 3 Daten1 (5.2.0.104)
78 2008-01-16/010/INF02/2253

5.2 Datenaustausch
Aus der Nachricht, kann R mit Hilfe der Regel I1 schlieÿen, dass R glaubt, dass T dieNachricht gesendet hat. Dazu ist neben der Nachricht noch folgendes notwendig. R hatden gemeinsamen Schlüssel mit T 5.2.0.61 und glaubt an diesen 5.2.0.60. Weiter ist dieNachricht durch die Bezeichner der Teilnehmer erkennbar und R kann die Nachricht durchsein Nonce 5.2.0.62 als frisch erkennen.
R |≡T |∼ (IDR, IDPseudo : i, rR1, Daten1) (5.2.0.105)
Damit kann jetzt mit der Hilfe der Regel I6 geschlossen werden, dass R glaubt, dass Tdie gesendeten Daten hat 5.2.0.49. Dafür wird neben 5.2.0.105 nur noch die Frische derNachricht mittels des Nonce 5.2.0.62 benötigt.
R |≡T 3 (IDR, IDPseudo : i, rR1, Daten1) (5.2.0.106)
Weitere sinnvolle Folgerungen sind aus dieser Nachricht nicht mehr möglich, da nichtangenommen werden kann, dass R an die Kompetenz von T glaubt.
Nachricht 5.2.0.91
T /
(?{IDR, IDPseudo : i, rT , RWantwort[], RWindexe[], ?rR2,
H(IDR, IDPseudo : i, rT , RWantwort[], < KK,T >),
?(Daten2)}KR,T
)Durch Anwenden der Regeln T3, T2 und P1 auf die Nachricht kann geschlossen werden,
dass T die Daten2 hat 5.2.0.55. Dazu ist neben der Nachricht selbst nur der Sitzungsschlüs-sel zwischen R und T 5.2.0.70 notwendig.
T 3 Daten2 (5.2.0.107)
Hier kann mit den gleichen Regeln I1 und I6, wie bei der vorherigen Nachricht geschlos-sen werden, dass T glaubt, dass R die gesendeten Daten hat 5.2.0.54. Dazu wird nebender Nachricht selbst folgendes benötigt. T hat den gemeinsamen Sitzungsschlüssel mit R5.2.0.70 und glaubt an diesen 5.2.0.69. Weiter ist die Nachricht durch die verwendeten Be-zeichner erkennbar und die Frische ist mit Hilfe des Nonce des Tag 5.2.0.71 nachweisbar.Damit ergeben sich die gewünschten Folgerungen.
T |≡R |∼ (IDR, IDPseudo : i, rT , ..., Daten2) (5.2.0.108)
T |≡R 3 (IDR, IDPseudo : i, rT , ..., Daten2) (5.2.0.109)
Weitere Folgerungen sind aus dieser Nachricht ebenfalls nicht möglich, da T nicht an dieKompetenz von R glauben kann.
Nachricht 5.2.0.92
R / ? {IDR, IDPseudo : i, rR2}KR,T(5.2.0.110)
Die Nachricht dient dazu festzustellen, dass R weiÿ, dass T die vorherige Nachricht unddamit die Daten, die es schreiben soll erhalten hat. Dass Speichern ist ein Seitene�ekt, der
2008-01-16/010/INF02/2253 79

5 Untersuchung des Protokolls mit Hilfe der GNY Logik
durch die GNY Logik nicht ausdrückbar ist. Deshalb wird jetzt gefolgert, dass R glaubt,dass T das aktuelle Nonce von R besitzt (5.2.0.51).Mit der Regel I1 kann aus der Nachricht selbst, dass R den gemeinsamen Schlüssel mit T
besitzt und daran glaubt (5.2.0.61 und 5.2.0.60), dass die Nachricht durch die enthaltendenIDs von R erkennbar ist und dass die Nachricht durch das enthaltende Nonce frisch ist(5.2.0.62), ermittelt werden, dass R glaubt, dass T die Nachricht gesendet hat.
R |≡T |∼ IDR, IDPseudo : i, rR2 (5.2.0.111)
Aus der Erkenntnis 5.2.0.111 kann mit Hilfe der Regel I6 und dem Wissen, dass dieNachricht durch das Nonce aktuell ist (5.2.0.62), ermittelt werden, dass R glaubt, dass Tdas Nonce von R hat (5.2.0.51).
R |≡T 3 rR2 (5.2.0.112)
Da R glaubt, dass T das aktuelle Nonce von R besitzt (5.2.0.112), kann davon aus-gegangen werden, dass T auch die zu schreibenden Daten erhalten hat. Es kann jedochnicht garantiert werden, dass T die Daten auf den Tag schreibt, da nicht sicher ist, dassT korrekt arbeitet. Wenn T jedoch nicht kompromittiert wurde, kann davon ausgegangenwerden, dass T die Daten erfolgreich aktualisiert hat.Mit dem Nachweis der Erreichbarkeit der Ziele wurde in diesem Teil gezeigt, dass die
Ziele vom Protokoll unter Annahme der Vorbedingungen erreicht werden und somit derpraktische Einsatz verantwortungsvoll möglich ist.
5.3 Zusammenfassung
In diesem Kapitel wurde das in Abschnitt 4.6 entwickelte Protokoll auf eventuelle Si-cherheitsprobleme untersucht. Die Untersuchung sollte folgende Fragen aus Abschnitt 3.2beantworten:
• Wie wird sichergestellt, dass die Kommunikation der Teilnehmer untereinander ge-schützt ist?
• Wie erfolgt die Authentisierung des Tags?
Die Authentisierung erfolgt durch das entwickelte Protokoll. Dabei wird die Art der An-onymisierung auch gleich zur Authenti�zierung mit benutzt. Der Authentisierungsserverermittelt zu der Pseudo ID des Tags die reale ID. Damit hat es Zugri� auf die individu-ellen Schlüssel des Tags und kann überprüfen, ob die Annahme der realen ID zur erhal-tenden Pseudo ID stimmt. Mit der realen ID des Tags und den Zufallskomponenten vomTag, dem Lesegerät und dem Authentisierungsserver wird der Sitzungsschlüssel zwischendem Tag und dem Lesegerät ermittelt. Damit kann nach dem erfolgreichen Abschluss desAuthentisierungsprotokolls die Kommunikation zwischen dem Tag und dem Lesegerät ver-schlüsselt erfolgen, da beide Teilnehmer den Sitzungsschlüssel haben und ihn für geeignetzur Kommunikation halten. Der Tag weiÿ zudem, dass das Lesegerät aktuell mit dem Tagkommunizieren darf.Nachdem die sichere Kommunikation über die Funkschnittstelle möglich ist, kann der
Zugri� auf den Tag erfolgen. Da die Zugri�skontrolle durch die Aufteilung der Funktionenin das Tre�en der Zugri�sentscheidung vom Autorisierungs-/Keyserver und das Ausführen
80 2008-01-16/010/INF02/2253

5.3 Zusammenfassung
der Kontrolle vom Tag geteilt ist, müssen die dafür jeweils notwendigen Informationenvorhanden sein. Der Autorisierungs-/Keyserver erhält durch das Protokoll die reale IDdes Tags und kann damit aus der Anfrage des Lesegerätes die Entscheidung tre�en, obder Zugri� erlaubt ist. Durch das Protokoll wird sichergestellt, dass der Tag diese Ent-scheidung unverändert erhält und damit den Zugri� kontrollieren kann. Weiter erhält dasLesegerät die Schlüssel zur Ver- und Entschlüsselung der Daten des Tags und die Schlüsselzur Berechnung der Integritätsprüfsummen über die gespeicherten Daten. Damit kann dasLesegerät die vom Tag gelesenen Daten auswerten und neue Daten auf den Tag schreiben.Das Protokoll gewährleistet weiter, dass bei einem Lesevorgang das Lesegerät die Daten desTags erhält und deren Unverändertheit prüfen kann. Beim Schreibvorgang wird auÿerdemsichergestellt, dass der Tag die zu schreibenden Daten erhalten hat. Bei allen Nachrichtenwird geprüft, ob es Wiedereinspielungen sind.Durch die Untersuchung hat sich herausgestellt, dass alle gewünschten Ziele erreicht
wurden und damit der Einsatz des Protokolls sinnvoll möglich ist.
2008-01-16/010/INF02/2253 81

82 2008-01-16/010/INF02/2253

6 Konkretisierung des Beispielszenarios
Der bisherige Teil der Arbeit betrachtet vor allem die qualitativen Fragestellungen. Dabeiwurde ein geeignetes Protokoll entwickelt, dass die gegebenen Sicherheitsanforderungen er-füllt. Jetzt sollen Antworten für die quantitativen Fragestellungen ermittelt werden. Dafürsind zunächst kritische Punkte im System zu �nden und praktische Realisierung dafür zuerarbeiten. Für die Realisierung des Protokolls in der Praxis, ist ein realistisches Beispiels-zenario notwendig. Mit dem Szenario können geeignete Datenstrukturen entwickelt werden,die für die kritischen Abschnitte des Protokolls eingesetzt werden können. Es wurde einSzenario aus der Automobilindustrie gewählt, da dort vielfältige Ver�echtungen und Zyklenexistieren. Das Szenario ist eine konkretisierte Form des in Abschnitt 3.1 dargestellten.
6.1 Aufbau
In der Automobilindustrie ist das Supply Chain Management sehr wichtig. Es bestehenVer�echtungen zwischen der Zuliefererindustrie, den Autowerken, den Werkshändlern undZubehörhändler, sowie den verschiedenen Werkstätten. Die produzierten Teile werden Just-In-Time zum nächsten Glied in der Kette transportiert. Es existieren keine gröÿeren Lagermehr, so dass Verzögerungen in einem Teilstück nur begrenzt ausgeglichen werden können.Durch die Arbeitsweise werden Kosten verringert. Damit diese Einsparungen nicht durchzeitweiligen Stillstand der Produktion zerstört werden, ist eine intensive Kommunikationnotwendig. Damit können bevorstehende Probleme erkannt und darauf reagiert werden.Das Szenario ist in Abbildung 6.1 zu sehen. Es entstand durch durch die Betrachtung dernotwendigen Vorgänge im Gesamtsystem, da in der Literatur kein geeignetes Szenario zu�nden ist.
Abbildung 6.1: Beispielszenario der Automobilindustrie
Der Hersteller ist dabei der Produzent der Teile in der Zuliefererindustrie. Das Werk sinddie Herstellungsorte der Personenkraftwagen der Automobilhersteller. Die WHändler sind
2008-01-16/010/INF02/2253 83

6 Konkretisierung des Beispielszenarios
die Werkshändler beziehungsweise die Autohäuser der Automobilhersteller. Die ZHändlersind die freien Zubehörhändler, sowie die freien Autohändler. Die Werkstatt sind die frei-en sowie die an Hersteller gebundenen Reparaturwerkstätten. Ein Element repräsentierteine ganze Gruppe von gleichartigen Elementen. Zum Beispiel repräsentiert das ElementWerk die circa 60 Werke der Automobilhersteller in Deutschland. In Deutschland gibt esweiterhin circa 250 Elemente der Hersteller, 3000 WHändler, 1000 ZHändler sowie circa6000 Werkstätten. Die Pfeile in der Abbildung repräsentieren den Transport der Warendurch einen Transporteur oder Spediteur. Dabei sagt die Abbildung nichts darüber aus,wer an wen liefert. So kann ein einzelner Transporteur Teile von einem Hersteller zu ver-schiedenen Werken transportieren oder von verschiedenen Hersteller zu einem Werk. Dievielfältigen Möglichkeiten sind an jeder Transportstelle in der Abbildung möglich. Hier-durch ist auch eine Sicherheitsanforderung bestimmt. Es darf nicht möglich sein, bei dereingesetzten Technologie, dass Lieferbeziehungen durch Dritte aufgedeckt werden können.Die Prozentangaben repräsentieren den angenommenen Fluss von Teilen im System. DieWerte sind nur plausibel angenommen, da keine konkreten Zahlen aus der Literatur be-kannt sind. Alle Angaben beziehen sich dabei auf einzelne Teile. Nur zwischen Werk undWHändler wird davon abgewichen. Hier wird unterschieden, ob die Teile bereits in einenNeuwagen eingebaut wurden, oder ob sie zu Zwecken der Reparatur einzeln transportiertwerden. Die Unterscheidung ist für das Lastmodell der später entwickelten Architekturwichtig.Zur praktischen Anwendung ist angedacht, dass alle höherwertigen Teile in einem Auto-
mobil, wie zum Beispiel ein Steuergerät, ein RFID Tag erhalten. Auf diesem können dannjeweils passende Informationen gespeichert sein, die unter anderem auch Wartungsinfor-mationen und Transportinformationen erhalten. Die Tags können dann zum Managementin der Kette, als auch zur Unterstützung von Reparaturarbeiten verwendet werden. EineSchätzung der Anzahl der verwendeten Tags ergibt folgende Zahlen. Es gibt zurzeit etwa 55Millionen Kraftfahrzeuge (KFZ) in Deutschland [14]. Bei angenommenen 200 RFID Tagspro KFZ ergibt sich im Endausbau eine Gröÿenordnung von 11 Milliarden zu verwaltendenTags.
6.2 Darstellung eines Zyklus am Beispiel des Generators
Im Folgenden wird ein Beispielzyklus eines Bauteils beschrieben, für welches die Verwen-dung eines RFID Tag sinnvoll erscheint. Das Bauteil ist der Generator, der umgangssprach-lich auch Lichtmaschine genannt wird. Dieser ist für die Erzeugung der elektrischen Energiedes Fahrzeuges notwendig. Er ist ein wichtiges Element, da ohne elektrische Energie einFahrzeug nicht lau�ähig ist. Der Generator wird von verschiedenen Herstellern produziertund auch in verschiedene Fahrzeuge eingebaut. Teilweise werden in fast gleichen Model-len Generatoren von verschiedenen Herstellern eingebaut. Zusätzlich interessant an demBeispiel ist die Reparatur eines Defektes an einem Generator. Wie viele der höherwerti-gen Teile an einem Fahrzeug, ist es als Austauschteil erhältlich. Das bedeutet, dass beider Reparatur des defekten Teiles kein neues Teil eingebaut wird und das alte entsorgtwird, sondern dass ein bereits regeneriertes und funktionsfähiges Teil eingebaut wird. Dasdefekte Teil wird an den Hersteller zurückgesandt. Dort wird es zerlegt und defekte Teilewerden ersetzt. Wenn es die Qualitätsansprüche des Herstellers erfüllt, steht das nun prak-tisch neue Teil wieder als Austauschteil für defekte Teile bereit. Ein konkreter Zyklus istin Abbildung 6.2 zu sehen.Es sind auch andere Wege möglich. Der Hersteller fertigt zunächst das Bauteil. Dabei
wird auf das Produkt der RFID Tag angebracht. Es speichert zum Beispiel die Herstellungs-und Transportdaten. Der Generator kann dann entweder zu einem Automobilherstelleroder zu einem Zubehörhändler transportiert werden. Dafür können für den Transporteur
84 2008-01-16/010/INF02/2253

6.3 Lastmodell
Abbildung 6.2: Warenzyklus am Beispiel des Generators
zum Beispiel die Zielinformationen gespeichert werden, oder auch Zwischenziele. Wennder Generator zum Zubehörhändler transportiert wurde, kann der Generator anschlieÿendzu einer Werkstatt transportiert oder an den Endverbraucher ausgehändigt werden. DerTeil des Endverbrauchers ist nicht direkt modelliert, da bei diesem Teil des Zyklus keineweiteren Informationen auf dem Tag verändert werden. Falls der Generator an den Au-tomobilhersteller geliefert wurde, können wiederum verschiedene Fälle eintreten: Erstenskann der Generator in einen Fahrzeug eingebaut werden. Der zweite Fall ist die Verwen-dung des Teils als Ersatzteil. Bei beiden Vorgängen werden wiederum Daten auf dem Taggespeichert oder aktualisiert. Bei den Fällen erfolgt die Auslieferung der Ware an denWerkshändler. Der Transport wird dabei von einem Transporteur vorgenommen, der aus-gewählte Daten auf dem Tag lesen, schreiben oder aktualisieren kann. In der Werkstattkann das Teil dann mit dem gesamten Auto an den Endverbraucher ausgeliefert werden,eine nochmalige Aktualisierung der Daten auf dem Tag inbegri�en. Eine andere Möglich-keit ist die Lieferung der Teile an die angeschlossene Werkstatt. Nachdem der Generator,entweder über den Werkshändler oder Zubehörhändler, in der Werkstatt angekommen isterfolgt die Reparatur des Fahrzeuges. Dazu erfolgt eine Fehlerdiagnose am Fahrzeug. Nachder Diagnose, die ebenfalls durch einen Zugri� auf die Daten des Tags unterstützt wird,erfolgt die Reparatur. Dabei wird das defekte Teil durch ein neues Teil oder Austauschteilersetzt und diese Information ebenfalls auf beiden Teilen vermerkt. Das defekte Teil wirddann zu dem Hersteller transportiert, der eine mögliche Überholung des Teiles vornimmt.Beim Transport helfen wiederum die Daten des RFID Tag. Damit ist ein Zyklus abge-schlossen und beginnt von vorn. Es existieren noch kleine mögliche Nebenwege. So kanndas Teil vom Werkshändler oder Zubehörhändler an den Endverbraucher verkauft werden.Die andere Richtung ist ebenfalls möglich. Dabei bringt der Endverbraucher das defekteTeil wieder zum entsprechenden Händler, der dann den Versand zum Hersteller organisiert.An dem Beispiel ist zu sehen, dass selbst in dem vereinfachten Modell viele Wege möglich
sind. Durch die in der Realität noch viel gröÿere Komplexität ist eine schnelle und genaueKommunikation der teilnehmenden Partner notwendig. Diese Kommunikation kann durchdie auf dem Tag gespeicherten Daten technisch unterstützt werden.
6.3 Lastmodell
Für die Bewertung der später entwickelten Datenstrukturen ist es notwendig ein entspre-chendes Anfrage- oder Lastmodell zu entwickeln, dass die Realität hinreichend genau abbil-det. Mit dem Lastmodell können die Datenstrukturen dann getestet und bewertet werden.Das Lastmodell für das dargestellte Modell basiert auf verschiedenen Annahmen und An-näherungen, da keine konkreten Daten bekannt sind. Das Modell geht von dem Einsatzsze-nario in Deutschland aus. In Deutschland sind zurzeit etwa 55 Millionen KFZ zugelassenund die Anzahl der Neuzulassungen sind etwa 3,5 Millionen pro Jahr laut Kraftfahrzeug-bundesamt mit Stand Januar 2007. Durch die zunehmende Anzahl an hochwertigen Teilen,
2008-01-16/010/INF02/2253 85

6 Konkretisierung des Beispielszenarios
wie Steuergeräten ist auszunehmen, dass die Anzahl der RFID Tags pro Fahrzeug circa150-200 sein wird. Das ergibt pro Jahr einen Zuwachs von etwa 500-700 Millionen RFIDTags. Im Endausbau des Modells sind es circa 11 Milliarden RFID Tags die verwaltet undauf die zugegri�en wird. Die enorme Anzahl der Tags ist ein entscheidendes Kriteriumfür die zu entwickelnden Datenstrukturen. Diese müssen sehr skalierbar sein. Der Zugri�auf die einzelnen Tags erfolgt dabei auf verschiedene Art und Weise. Eine Übersicht derhäu�gsten Zugri�sarten ist in Abbildung 6.3 zu sehen.
Abbildung 6.3: Zugri�sarten im Beispielszenario
Die beiden hauptsächlichen Arten sind einmal der Einzelzugri� und der Blockzugri�. Beieinem Einzelzugri� werden die Daten einzeln ausgelesen und es besteht dabei kein Zusam-menhang mit dem Auslesen anderer Tags. Beim Blockzugri� erfolgt das Auslesen der Dateneines Tag dagegen abhängig vom Zugri� auf die Daten der anderen Tags. Ein Beispiel dafürist das Einlesen der Daten der Tags auf einer Palette. Die Palette kann dabei eine Gröÿevon 2 bis 1000 Elementen haben. Das ist im Szenario durch die Gröÿe der Elemente unddie Gröÿe der Palette realistisch. Der Zugri� auf die Tags erfolgt dabei nacheinander, dasheiÿt es werden alle Tags so schnell wie möglich hintereinander ausgelesen. Der Zeitabstandzwischen dem Auslesen der Tags wird dabei nur durch die physikalische Schnittstelle unddas MAC Protokoll bestimmt. Es wurde eine separate einfache Simulation des MAC Pro-tokoll Walking-Tree erstellt. Dabei wurde das Auslesen einer ganzen Palette mit zufälligenIDs untersucht. Das Ergebnis der Simulation ist, dass die Abstände zwischen den einzel-nen Anfragen der Tags einer Palette relativ konstant. Im Durchschnitt tritt eine Kollisionzwischen zwei Anfragen auf. Wenn die praktischen Werte des NXP Mifare DESFire [18]angenommen werden ergibt sich ein Abstand von 4 ms für die MAC Zugri�szeit zwischenzwei aufeinanderfolgenden Authentisierungen.Eine weitere Unterscheidung der Zugri�e auf die Tags ist nach der Art der Zwischenan-
kunftszeiten. Diese können im Beispiel konstant oder zufällig sein. Die konstante Zeit istzum Beispiel auf einem Flieÿband gegeben, dass mit konstanter Geschwindigkeit die Wa-ren transportiert und wo der Abstand zwischen den Waren relativ konstant ist. Das istder Standardfall eines Flieÿbandes in einer Produktionskette. Die zufälligen Zwischenan-kunftszeiten entstehen beispielsweise bei der Reparatur von Teilen. Unter der realistischenAnnahme, dass Teile zufällig defekt werden, werden die Teile auch zu zufälligen Zeitpunktenrepariert. Das ergibt dann bei der Überlagerung vieler solcher Vorgänge einen Zugri� mitexponentialverteilten Eigenschaften. Alle auftretenden Zugri�e sind in die vier Kategorieneinordbar.
86 2008-01-16/010/INF02/2253
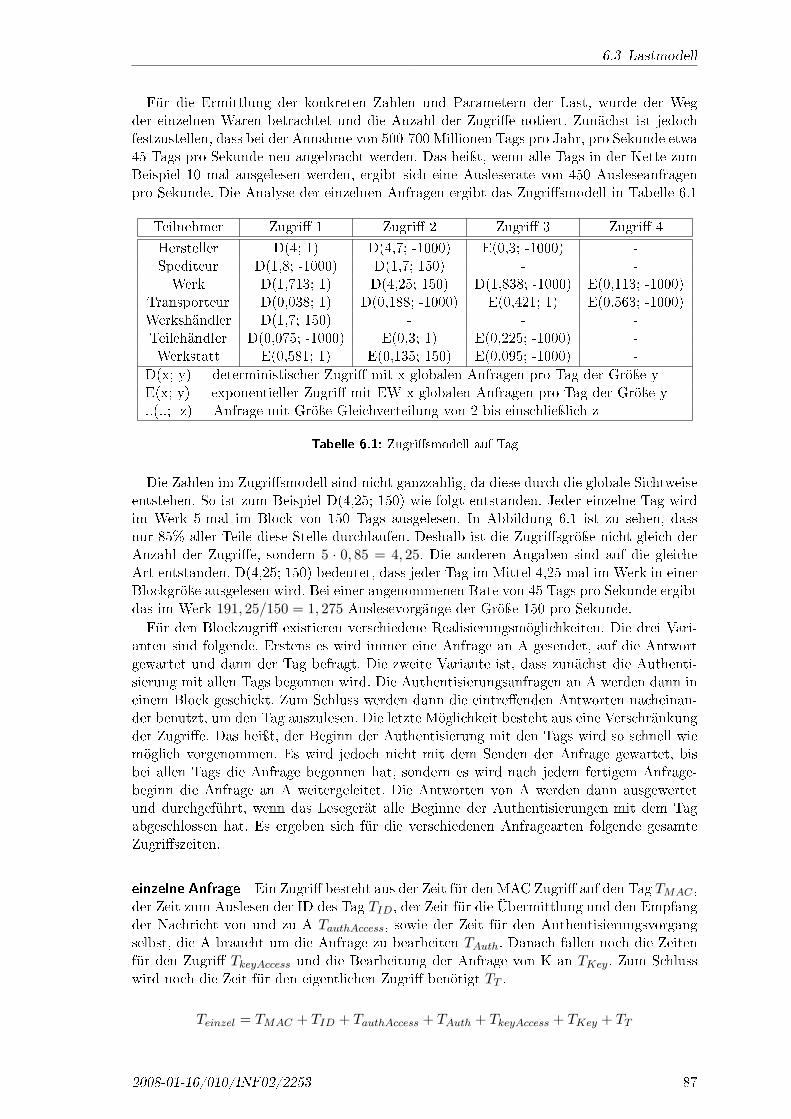
6.3 Lastmodell
Für die Ermittlung der konkreten Zahlen und Parametern der Last, wurde der Wegder einzelnen Waren betrachtet und die Anzahl der Zugri�e notiert. Zunächst ist jedochfestzustellen, dass bei der Annahme von 500-700 Millionen Tags pro Jahr, pro Sekunde etwa45 Tags pro Sekunde neu angebracht werden. Das heiÿt, wenn alle Tags in der Kette zumBeispiel 10 mal ausgelesen werden, ergibt sich eine Ausleserate von 450 Ausleseanfragenpro Sekunde. Die Analyse der einzelnen Anfragen ergibt das Zugri�smodell in Tabelle 6.1
Teilnehmer Zugri� 1 Zugri� 2 Zugri� 3 Zugri� 4
Hersteller D(4; 1) D(4,7; -1000) E(0,3; -1000) -Spediteur D(1,8; -1000) D(1,7; 150) - -Werk D(1,713; 1) D(4,25; 150) D(1,838; -1000) E(0,113; -1000)
Transporteur D(0,038; 1) D(0,188; -1000) E(0,421; 1) E(0.563; -1000)Werkshändler D(1,7; 150) - - -Teilehändler D(0,075; -1000) E(0,3; 1) E(0,225; -1000) -Werkstatt E(0,581; 1) E(0,135; 150) E(0,095; -1000) -
D(x; y) = deterministischer Zugri� mit x globalen Anfragen pro Tag der Gröÿe yE(x; y) = exponentieller Zugri� mit EW x globalen Anfragen pro Tag der Gröÿe y..(..; -z) = Anfrage mit Gröÿe Gleichverteilung von 2 bis einschlieÿlich z
Tabelle 6.1: Zugri�smodell auf Tag
Die Zahlen im Zugri�smodell sind nicht ganzzahlig, da diese durch die globale Sichtweiseentstehen. So ist zum Beispiel D(4,25; 150) wie folgt entstanden. Jeder einzelne Tag wirdim Werk 5-mal im Block von 150 Tags ausgelesen. In Abbildung 6.1 ist zu sehen, dassnur 85% aller Teile diese Stelle durchlaufen. Deshalb ist die Zugri�sgröÿe nicht gleich derAnzahl der Zugri�e, sondern 5 · 0, 85 = 4, 25. Die anderen Angaben sind auf die gleicheArt entstanden. D(4,25; 150) bedeutet, dass jeder Tag im Mittel 4,25-mal im Werk in einerBlockgröÿe ausgelesen wird. Bei einer angenommenen Rate von 45 Tags pro Sekunde ergibtdas im Werk 191, 25/150 = 1, 275 Auslesevorgänge der Gröÿe 150 pro Sekunde.Für den Blockzugri� existieren verschiedene Realisierungsmöglichkeiten. Die drei Vari-
anten sind folgende. Erstens es wird immer eine Anfrage an A gesendet, auf die Antwortgewartet und dann der Tag befragt. Die zweite Variante ist, dass zunächst die Authenti-sierung mit allen Tags begonnen wird. Die Authentisierungsanfragen an A werden dann ineinem Block geschickt. Zum Schluss werden dann die eintre�enden Antworten nacheinan-der benutzt, um den Tag auszulesen. Die letzte Möglichkeit besteht aus eine Verschränkungder Zugri�e. Das heiÿt, der Beginn der Authentisierung mit den Tags wird so schnell wiemöglich vorgenommen. Es wird jedoch nicht mit dem Senden der Anfrage gewartet, bisbei allen Tags die Anfrage begonnen hat, sondern es wird nach jedem fertigem Anfrage-beginn die Anfrage an A weitergeleitet. Die Antworten von A werden dann ausgewertetund durchgeführt, wenn das Lesegerät alle Beginne der Authentisierungen mit dem Tagabgeschlossen hat. Es ergeben sich für die verschiedenen Anfragearten folgende gesamteZugri�szeiten.
einzelne Anfrage Ein Zugri� besteht aus der Zeit für den MAC Zugri� auf den Tag TMAC ,der Zeit zum Auslesen der ID des Tag TID, der Zeit für die Übermittlung und den Empfangder Nachricht von und zu A TauthAccess, sowie der Zeit für den Authentisierungsvorgangselbst, die A braucht um die Anfrage zu bearbeiten TAuth. Danach fallen noch die Zeitenfür den Zugri� TkeyAccess und die Bearbeitung der Anfrage von K an TKey. Zum Schlusswird noch die Zeit für den eigentlichen Zugri� benötigt TT .
Teinzel = TMAC + TID + TauthAccess + TAuth + TkeyAccess + TKey + TT
2008-01-16/010/INF02/2253 87

6 Konkretisierung des Beispielszenarios
Bei einer angenommenen MAC Zeit von 3ms + 1ms für jede Kollision, einer Auslesezeitder ID von 2,5 ms, einer Zugri�szeit von 2 · 50ms = 100ms für jeweils A und K, einerBearbeitungszeit von 20ms in beide fällen, sowie der Bearbeitungszeit für den Tag von 2,5ms für das Lesen von einem Datenblock, ergibt sich folgende Zeit.
Teinzel = 3ms+ 2,5ms+ 100ms+ 20ms+ 100ms+ 20ms+ 2,5ms = 248ms
Die Berechnung erfolgt dabei stark vereinfachend und soll nur die Unterschiede zwischenden verschiedenen Verfahren deutlich machen. Bei dem Vergleich der Verfahren existiertnoch die Zeit TKollision, die die zusätzliche notwendige Zeit für alle auftretenden Kollisionenbeinhaltet.
einzelne Anfragen nacheinander Das Verfahren ist sehr einfach und ist auch leicht be-rechenbar. Die gesamte Zugri�sdauer ist die Anzahl der ausgelesenen Tags mal die Zeitfür einen kompletten Zugri�svorgang. Dabei ist die zusätzliche Zeit für die auftretendenKollisionen zu betrachten. Beispielsweise wird von 500 Elementen ausgegangen.
Tgesamt = TKollision + #Anzahl Tags · Teinzel = 508ms+ 500 · 248ms ≈ 124,5s
Die Zeit für die Kollisionen wurde in einer Simulation ermittelt. Diese ergab, dass imSchnitt beim ersten Auslesen eines Tag 9 Kollisionen auftreten, bei den darauf folgendenim Schnitt 1 Kollision. Eine Kollision muss mit etwa 1ms zusätzlicher Zeit berücksichtigtwerden.
Blockanfrage Bei der Blockanfrage werden zunächst alle Authentisierungen begonnen,bevor nach Abschluss des Beginns alle Anfragen an A gesendet werden und dann dieeintre�enden Antworten einzeln bearbeitet werden. Dabei ist zunächst die Zeit für denersten Teil zu bestimmen zu dem dann die Gesamtzeit die A benötigt und die Bearbeitungeiner Anfrage addiert wird. Hier wird jetzt angenommen, dass A vier Anfragen parallelverarbeiten kann und somit die Bearbeitungszeit für eine Anfrage im Schnitt 5ms ist.
Tgesamt = TKollision + #Anzahl Tags · (TMAC + TID) + TauthAccess
+#Anzahl Tags · TAuth + TkeyAccess + TKey + TT
Beim Einsetzen der Zahlen ergibt sich folgende Zeit.
Tgesamt = 508ms+ 500 · (3ms+ 2,5ms) + 100ms+ 500 · 5ms+100ms+ 20ms+ 2,5ms = 5980,5ms ≈ 6,0s
Verschränkung Bei der Verschränkung der Anfragen ist die Zeit wie folgt zusammenge-setzt. Die Gesamtzeit wird durch die langsamste Zeit bestimmt. Wenn die durchschnittlicheZeit die A für einen Vorgang braucht 5ms ist und die Auslesezeit der ID jeweils 5,5 msbeträgt, ist die Auslesezeit der ID der beschränkende Faktor.
Tgesamt = TKollision + #Anzahl Tags · (TMAC + TID) + TauthAccess + TAuth
+TkeyAccess + TKey + TT
Das Einsetzen ergibt folgendes Ergebnis.
88 2008-01-16/010/INF02/2253

6.4 Zusammenfassung
Tgesamt = 508ms+ 500 · (3ms+ 2,5ms) + 100ms+ 20ms+100ms+ 20ms+ 2,5ms = 3500,5ms ≈ 3,5s
Durch die Berechnung ist klar ersichtlich, dass das erste Verfahren praktisch nicht an-wendbar ist, da so im Beispiel zwei Minuten nötig sind um auf eine Palette zuzugreifen.Das zweite Verfahren ist bereits wesentlich schneller. Eingesetzt wird jedoch das letzte Ver-fahren, weil dieses am schnellsten ist. Das Verfahren wird deshalb für die Ausleseabständeeinzelner Tags bei Blockanfragen verwendet.
6.4 Zusammenfassung
In diesem Abschnitt wurde gezeigt, wie das abstrakte Szenario aus Abschnitt 3.1 konkreti-siert wurde. Bei diesem Vorgang wurde zunächst der Aufbau eines beispielhaften Warenzy-klus in der Automobilindustrie dargestellt und mit Zahlen unterlegt. Damit die einzelnenVerzweigungen und Übergänge besser zu verstehen sind, wird der gesamte Zyklus am kon-kreten Beispiel des Generators dargestellt. Für die Simulation des Systems ist ein geeignetesLastmodell notwendig, wenn die Dimensionierung der beteiligten Komponenten notwen-dig ist. Deshalb wurde ein entsprechendes Lastmodell entwickelt, dass die verschiedenenmöglichen Anfragearten beachtet.
2008-01-16/010/INF02/2253 89

90 2008-01-16/010/INF02/2253

7 Implementierung im Rahmen einer
Simulationsstudie
Für den praktischen Einsatz des entwickelten Konzeptes ist es notwendig geeignete Daten-strukturen zu �nden, die eine e�ziente Zuordnung der Pseudo ID zu der realen ID ermög-lichen. Dabei muss das spezielle Zugri�smuster auf die Datenstrukturen durch den Au-thentisierungsvorgang beachtet werden. Am Anfang werden dazu zunächst die gewünsch-ten Ziele de�niert. Darin wird auch gezeigt, welches die zentralen Punkte des Konzeptessind, die zu betrachten sind. Danach wird die entwickelte Simulationsumgebung betrachtet,die entwickelt wurde um die entwickelten Datenstrukturen zu evaluieren. Danach beginntdie Entwicklung der Datenstrukturen mit einer Aufstellung der speziellen Anforderungen,die durch den Authentisierungsvorgang gegeben ist, bevor die möglichen Datenstrukturendargestellt werden. Ein Teil der möglichen Datenstrukturen wurden ausgewählt und im-plementiert. Mit Hilfe der Testumgebung wird dann geprüft, wie die ausgewählten Daten-strukturen die Ziele erreichen. Danach wird eine vergleichende Bewertung der realisiertenDatenstrukturen im Einsatzszenario vorgenommen. Mit Hilfe der erhaltenden Ergebnissewird ein Vorschlag erstellt, welche Datenstruktur mit welcher Parametrisierung für denpraktischen Einsatz sinnvoll ist. Zum Schluss werden die einzelnen Ergebnisse zusammen-gefasst dargestellt.
7.1 Ziele
Das Hauptziel ist die Auswahl und Parametrisierung der für das Szenario geeigneten Da-tenstrukturen. Hierfür müssen zunächst die zentralen Aufgaben identi�ziert werden, bevordafür geeignete Datenstrukturen entwickelt werden. Ein wesentliches Kriterium ist dieSkalierbarkeit der Lösung. Das heiÿt, der notwendige Aufwand bei der Vergröÿerung derAnzahl der teilnehmenden Tags in Bezug auf Geschwindigkeit und notwendigen Speicher-platz sollte minimal sein, damit ein praktischer Einsatz möglich ist. Die Geschwindigkeithängt dabei stark davon ab, ob die Daten im Arbeitsspeicher oder auf einem externen Da-tenträger gespeichert werden. Deshalb ist die Skalierbarkeit je Gruppe zu untersuchen. DieGeschwindigkeit kann durch verschieden Werte dargestellt werden. Bei der Speicherungder Daten im Arbeitsspeicher wirkt neben dem Speicherzugri� hauptsächlich die Rechen-leistung beschränkend. Bestimmt wird die Rechenleistung dabei hauptsächlich von derGeschwindigkeit der Berechnung von einfachen Hashoperationen und in besonderem vonkryptographischen Hashfunktionen, die für die Realisierung des Protokolls notwendig sind.Bei der Speicherung der Daten auf einem externen Datenträger kann die Rechenleistungvernachlässigt werden, da der Zugri� auf den externen Datenträger dominierend ist. Es istauÿerdem sinnvoll, den notwendigen Speicherplatz für die Datenstrukturen zu ermitteln.Die Geschwindigkeit ist zwar der dominierende Faktor, jedoch muss die Datenstrukturrealisierbar sein und somit mit begrenztem Speicherplatz funktionsfähig und schnell sein.Das Protokoll ermöglicht die Speicherung verschieden langer Hash-Ketten zur Authen-
tisierung der Tags. Es stellt sich damit die Frage, welche Länge sinnvoll ist, um nichtunnötig viel Speicherplatz zu benötigen und damit eventuell den Zugri� auf die Daten-struktur zu verlangsamen. Zusätzlich ist die Anzahl der Resynchronisierungen möglichstklein zu halten, weil diese relativ aufwendig sind.Der kritische Punkt für den Prozess ist der Authentisierungsserver, da nur ein logischer
Server verwendet werden kann. Es könnten zwar durch eine Strukturierung der Pseudo
2008-01-16/010/INF02/2253 91

7 Implementierung im Rahmen einer Simulationsstudie
ID mehrere Authentisierungsserver verwendet werden, jedoch wären die Tags dann wie-der beschränkt verfolgbar, da die Struktur den Lesegeräten bekannt sein muss, um zuwissen an wen die Authentisierungsanfrage gestellt werden muss. Da das nicht erwünschtist, kann nur ein Authentisierungsserver benutzt werden. Ein weiterer Server, der eineEngstelle sein kann, ist der Autorisierungs-/Keyserver. Jedoch ist eine Verteilung derAutorisierungs-/Keyserver möglich und bereits im Protokoll vorgesehen. Der Authenti-sierungsserver teilt dem Lesegerät mit, welchen Autorisierungs-/Keyserver es fragen soll.Damit realisiert der Authentisierungsserver eine Lastverteilung. Das ist möglich, da je-der Autorisierungs-/Keyserver nur für einen de�nierten Anteil von Tags verantwortlichsein muss und für seine Aufgabe dabei keine extra Daten benötigt. Der Autorisierungs-/Keyserver muss zu einer Anfrage bestimmen, ob diese erlaubt ist und dann die notwendi-gen Schlüssel ausliefern. Da die Schlüssel bei jedem Tag unterschiedlich sind, ergibt sich proTag ein individueller Datensatz, der nicht mit anderen Datensätzen zur Optimierung ver-schmolzen werden kann. Die Parallelisierung stellt damit kein Problem dar. Weiter werdenbeim Autorisierungs-/Keyserver sehr selten die Daten geändert. Beim Authentisierungs-server erfolgt die Änderung der gespeicherten Daten bei jedem Authentisierungsvorgang.Weitere Komponenten, wie die Lesegeräte, die Tags und das Netzwerk stellen keine Eng-pässe dar, weil die jeweiligen Komponenten einzeln nur sehr geringe Anforderungen haben.Erst durch die Bündelung der einzelnen Anfragen entstehen die sehr hohen Anforderungenan den Authentisierungsserver. Aus den genannten Gründen sind die Engstellen des ge-samten Systems der Authentisierungsserver mit der Applikation, die die Authentisierungvornimmt und die dazugehörigen Datenstrukturen. Die Datenstrukturen haben dabei ei-ne entscheidende Bedeutung, weil nicht sehr viel Rechenleistung benötigt wird, um dieAuthentisierung zu realisieren, dabei aber viele Zugri�e auf die Datenstruktur notwendigsind.
7.2 Testumgebung
Damit die Ziele quantitativ bewertet werden können, wurde eine Testumgebung auf Basisvon OMNeT++ entwickelt. Eine Darstellung der gra�schen Ober�äche ist in Abbildung7.1 zu sehen.Das dargestellte System ist die Realisierung der Teilnehmer des Protokolls aus Abbil-
dung 4.1. Es existiert jeweils ein Authentisierungs- und Autorisierungs-/Keyserver. Weitervorhanden sind ein Verbindungsnetzwerk und die teilnehmenden Partner. Alle Kompo-nenten sind als Module realisiert. Die Teilnehmer bestehen dabei aus Submodulen, die dieeinzelnen Lastmodelle realisieren. Dabei ist jedes Submodul für ein Lastmodell verantwort-lich, dass durch die Bilder zusätzlich verdeutlicht werden soll. Die Verbindungen zwischenden Komponenten erfolgt durch ein herkömmliches geroutetes Netzwerk. Dabei sind dieParameter so gewählt, dass das Netz keine Beschränkung ist, sondern die Kanäle beliebigschnell sind und die Latenz beliebig klein ist. Die Annahme ist möglich, da nicht das Netzals solches untersucht werden soll, sondern die Datenstrukturen. In einem realen Netzwerkkommen zu den normalen Bearbeitungszeiten noch die Kommunikationszeiten hinzu.Die Implementierung der Simulation erfolgt dabei generisch. Der Authentisierungs- und
der Autorisierungs-/Keyserver sind dabei einzelne feste Module. Die Teilnehmer sind eben-falls durch Module realisiert. Jedoch haben alle Module der Teilnehmer den gleichen Typ.Das Modul besteht dabei aus vier Submodulen, die das jeweilige Lastmodell enthalten soll.Das spezielle Modell selbst und dessen Parameter sind nicht fest einprogrammiert, sondernin der omnetpp.ini frei parametrisierbar. Es ist die deterministische und exponentielleVerteilung der Zwischenankunftszeiten realisiert. Dabei kann jeweils angegeben werden,ob nach der Zeitperiode nur ein Tag ausgelesen wird, oder ob mehrere nacheinander in ei-nem Block ausgelesen werden sollen. Die Zeiten zwischen dem Auslesen der einzelnen Tags
92 2008-01-16/010/INF02/2253

7.2 Testumgebung
Abbildung 7.1: Darstellung der Simulationsumgebung
in einer Blockanfrage sind durch die Zeit für den MAC Zugri� bestimmt und beachtet. DieParameter der erzeugten Last der einzelnen Applikationen werden durch die Ergebnisseder Beispielbetrachtung in Tabelle 6.1 de�niert.
Die Realisierung der einzelnen Datenstrukturen im Authentisierungsserver erfolgt eben-falls generisch. Es existiert zwar eine Authentisierungsapplikation, jedoch bindet diese dieDatenstruktur durch ein Objekt ein. Die Algorithmen sind dabei abgeleitete Klassen einerabstrakten Klasse. Deshalb kann jede Datenstruktur individuell implementiert werden unddie Auswahl des Algorithmus und seiner Parameter erfolgt in der omnetpp.ini. Damitkönnen verschiedene Algorithmen mit unterschiedlichen Parametern verglichen werden,ohne die Simulation neu übersetzen zu müssen.
Zur Beurteilung der verschiedenen Algorithmen werden zur Laufzeit die notwendigenDaten gesammelt und am Ende der Simulation in einer angegebenen Datei gespeichert.Durch die Möglichkeit der mehrmaligen Ausführung der Simulation mit verschiedenen Pa-rametern können nacheinander ohne Aufsicht die Statistiken für verschiedene Algorithmenund Parameter erstellt werden. Nach den Durchläufen können dann die Simulationen aus-gewertet werden.
2008-01-16/010/INF02/2253 93

7 Implementierung im Rahmen einer Simulationsstudie
7.3 Anforderungen an die Datenstruktur
Um erkennen zu können, welche speziellen Anforderungen an die Datenstruktur gestelltwerden, wird zunächst dargestellt, welche Schritte bei einer Authentisierung erfolgen. Beijedem Authentisierungsvorgang erhält der Authentisierungsserver die Pseudo ID des Tags.Der Server muss dann die zu der Pseudo ID passende reale ID des Tags ermitteln. Dadabei Kollisionen entstehen können, wenn mehrere Tags die gleiche Pseudo ID haben,muss das Ergebnis noch kontrolliert werden. Dafür überprüft der Server mit Hilfe derzusätzlich gesendeten Informationen des Tags und dem in der Datenbank gespeichertenfür jeden Tag individuellem Schlüssel, ob die Annahme korrekt ist. Weiter holt der Tagaus der Datenbank ein Index, der die Datenaufteilung des Tags repräsentiert. Mit denInformationen der realen ID des Tag und der Struktur des Tags generiert der Server seineAntwort für das Lesegerät. Der wesentliche Teil des ganzen Vorganges ist die Zuordnungder Pseudo ID zur realen ID. Um diesen Vorgang möglichst schnell zu gestalten, ist eineoptimierte Datenstruktur notwendig. Die Datenstruktur muss eine sehr schnelle Zuordnungermöglichen, aber sie muss auch e�zient mit dem verwendeten Speicher umgehen.Spezielle Anforderungen an die Datenstrukturen entstehen durch die besondere Arbeits-
weise bei der Authentisierung. Bei jeder Authentisierung werden drei Operationen benötigt.Das sind Lookup, Remove und Insert. Die Operation Lookup ordnet der Pseudo ID diereale ID des Tag zu. Mit Insert wird eine neue Zuordnung von Pseudo ID und realer IDgespeichert. Zuletzt kann mit Remove eine Zuordnung Pseudo ID zu realer ID aus der Da-tenbank gelöscht werden. Bei einer Authentisierung werden alle Operationen ausgeführt.Mittels eines Lookup wird zunächst die reale ID des Tag ermittelt. Damit wird dann auf dieDatenstruktur des Tags zugegri�en. Jetzt werden mittels Remove alle Zuordnungen Pseu-do ID zu reale ID gelöscht, die vor der aktuell verwendeten Pseudo ID benutzt wurden,sowie die gerade verwendete Zuordnung. Danach wird der Pool der gespeicherten Zuord-nungen mit Insert aufgefüllt. Pro Authentisierungsvorgang werden damit die folgendenOperationen in angegebener Anzahl durchgeführt.
Operationen = 1 Lookup + 1 Remove+ 1 Insert + n · (1 Remove+ 1 Insert)
Bei der Berechnung ist n die Anzahl der nicht verwendeten und damit übersprungenenID. Wegen diesem Zugri�sverhalten ist es sehr wichtig, dass der Aufwand zum Löschenund Einfügen sehr gering sein sollte. Im Durchschnitt sollte dieser Aufwand O(1) sein.Ebenfalls sollte der Lookup im mittleren Fall nur einen Aufwand von O(1) haben.
7.4 Datenbankstruktur
Um eine schnelle Zuordnung der Pseudo ID zur realen ID zu ermöglichen, ist es sinnvollmehrere aktuelle gültige Pseudo ID zu speichern, um daraus dann die reale ID des Tagsermitteln zu können. Da kein Speicher verschwendet werden soll, ist es sinnvoll die ge-speicherten Informationen in einen Index und die eigentlichen Daten zu trennen. Das istsinnvoll, da alle Informationen für einen Tag, die der Authentisierungsserver benötigt, aneiner gemeinsamen Stelle stehen und nicht jeweils mehrfach bei der jeweiligen Pseudo ID.Dadurch ist auch die Wartbarkeit gewährleistet. Zunächst wird die Struktur der Datenbetrachtet, um dann später genauer auf die Struktur des Indexes einzugehen. Die Strukturder Daten hat dabei keinen wesentlichen Ein�uss auf die Geschwindigkeit, ist aber wichtigfür die Speicherplatze�zienz.Es gilt zunächst zu klären, welche Daten gespeichert werden müssen. Eine Übersicht ist
in Tabelle 7.1 zu sehen.Die Gröÿe der realen ID und Pseudo ID ist an den vorhandenen Standard ISO 14443
angelehnt. Die möglichen Gröÿen sind 32, 56 und 80 Bit. Die gröÿte Bitlänge wurde gewählt,
94 2008-01-16/010/INF02/2253

7.4 Datenbankstruktur
Datum Gröÿe Beschreibung
IDT 80 Bit reale ID des TagsZufallszahl 80 Bit eine Zufallszahl für den ResynchronisierungsvorgangK1A,T 128 Bit Schlüssel, um aus einer aktuellen Pseudo ID die nächste
Pseudo ID zu berechnenK2A,T 128 Bit Schlüssel zur Überprüfung Authentizität des TagsStruktur 32 Bit Indexzahl, die Struktur des Tags repräsentiertPseudo IDs n·80 Bit n vorausberechnete gültige Pseudo IDs für den Tag
Tabelle 7.1: notwendige Daten für Authentisierungsserver
weil damit fast keine Kollisionen entstehen, wohingegen bei 56 Bit mehrere Kollisionen beimehreren Milliarden Tags auftreten. Die Schlüssel sind jeweils 128 Bit lang, weil ein AESAlgorithmus mit 128 Bit Schlüssellänge gewählt wurde. Die Struktur ist nur ein Index, sodass dort eine 32 Bit Zahl reicht. Die Zufallszahl für den Resynchronisierungsvorgang istebenso wie die anderen IDs 80 Bit lang, weil dort sonst auch Kollisionen auftreten können,die durch die Berechnung der Pseudo ID für den Resynchronisierungsvorgang nicht behobenwerden. Die einzig variable Komponente an den zu speichernden Daten ist die Anzahl dergespeicherten Pseudo ID. Hier sind zwei verschiedene Varianten denkbar. Es können alleim Index gespeicherten Pseudo ID gespeichert werden. Der Vorteil dabei ist, dass soforterkannt werden kann, wie viele Pseudo ID bei dem Authentisierungsvorgang übersprungenwurden und welche das sind. Damit ist sofort ersichtlich, welche aus dem Index entferntwerden müssen. Nachdem die neuen Pseudo ID berechnet wurden, können diese dann direktwieder eingetragen werden. Der Nachteil an dem Verfahren ist der notwendige Speicherplatzpro Tag, der direkt von der Anzahl der gespeicherten Pseudo ID abhängt. Die gesamteGröÿe der gespeicherten Daten ergibt sich damit.
Gröÿe = 80Bit+ 80Bit+ 128Bit+ 128Bit+ 32Bit+ n · 80Bit = 56Byte+ n · 10Byte
Mit beispielsweise zehn gespeicherten Pseudo ID ergibt sich ein notwendiger Speicher-platz von 156 Byte. Bei mehr gespeicherten Pseudo ID steigt der notwendige Speicherplatzlinear.Eine weitere mögliche Variante benötigt mehr Rechenzeit, benötigt dafür aber weniger
Speicherplatz. Hier werden nicht alle im Index enthaltenen Pseudo ID gespeichert, son-dern nur die erste und letzte Pseudo ID der zurzeit gültigen Hash-Kette. Damit werdenunabhängig von der Anzahl der gespeicherten Pseudo ID immer 76 Byte benötigt.
Gröÿe = 80Bit+ 80Bit+ 128Bit+ 128Bit+ 32Bit+ 2 · 80Bit = 76Byte
Damit ist der notwendige Speicherplatz nur rund die Hälfte der anderen Version. Die Va-riante hat aber den Nachteil des erhöhten Rechenaufwandes, wenn bei der AuthentisierungPseudo IDs übersprungen wurden. Bei Erhalt einer Pseudo ID muss der Server zunächstsolange die nächste Pseudo ID des Tags berechnen, bis die gelieferte Pseudo ID erreicht ist.Danach können dann, wie beim ersten Verfahren, die neuen Pseudo ID generiert werden,wobei der Ausgangspunkt das Ende der Hashkette ist. Zum Schluss müssen dann nochder Beginn und das Ende der Hashkette wieder gespeichert werden. Der Rechenaufwandist höher als bei der ersten Variante, weil bei der zusätzlichen Berechnung der nächstenPseudo ID jeweils einmal eine kryptographische Hashfunktion berechnet werden muss.Das ausgewählte Verfahren ist das zweite. Es benötigt zwar mehr Rechenleistung, dafür
aber deutlich weniger Speicherplatz. Die Rechenleistung ist hier jedoch nicht der kritische
2008-01-16/010/INF02/2253 95

7 Implementierung im Rahmen einer Simulationsstudie
Faktor, weil die Daten für das Szenario, wegen der Gröÿe, auf einem externen Datenspei-cher gespeichert werden und der Zugri� auf diesen den Engpass darstellt und nicht dieRechenleistung.
7.5 Mögliche Datenstrukturen für den Index
Damit eine bessere Wartung möglich ist und keine Redundanz bei der Datenhaltung vor-kommt, wird der Zugri� der Daten über einen Index realisiert. Gespeichert wird im Indexdie Zuordnung Pseudo ID und Speicheradresse, wo die Daten für den referenzierten Tagstehen. Der Grund dafür ist, dass damit direkt von der Pseudo ID auf die Daten des Tagszugegri�en werden kann, ohne die Speicherposition über einen weiteren Index ermitteln zumüssen. Durch die Struktur ist für die Ermittlung der Daten zu dem Tag nur ein weitererZugri� notwendig, wenn die Zuordnung Pseudo ID zu Speicheradresse bekannt ist. Eineandere Lösung ist die Speicherung der Zuordnung Pseudo ID zu realer ID des Tags. Da-mit muss dann zunächst zu der realen ID die Speicheradresse der Daten ermittelt werden.Das ist ein nicht notwendiger Aufwand, der das Verfahren verlangsamt. Für die nachträg-liche Verwaltung des Index ist die Speicherung der Zuordnung reale ID zu Speicheradressezusätzlich sinnvoll, da damit einzelne Tag gelöscht werden können oder ähnliches, wenndie reale ID des Tags vorhanden ist. Die Speicheradresse kann beispielsweise der logischeBlock in der Datenbank sein. Für die Gröÿe ist eine 64 Bit Zahl sinnvoll, da 32 Bit fürdie groÿe Anzahl der Tags nicht ausreichen. Damit wird zusätzlich im Index Speicherplatzgespart, da die Gröÿe der realen ID 80 Bit ist, und somit pro Zuordnung nur 18 statt 20Byte verwendet werden. Das Format der verwendeten Zuordnungen ist in Abbildung 7.2dargestellt.
Abbildung 7.2: verwendetes Indexformat
Für die Struktur des Indexes sind verschiedene Datenstrukturen möglich. Grundsätzlichzu unterscheiden sind Bäume, Hashtabelle und Heaps. Theoretisch sind auch Listen, Felderund der gleichen möglich, jedoch ist die Zugri�sgeschwindigkeit bei diesen einzeln viel zulangsam. Die komplexeren Datenstrukturen verwenden jedoch diese einfachen Typen, sodass diese indirekt Verwendung �nden. Eine Übersicht zu den möglichen Kandidaten istin Abbildung 7.3 zu sehen.
Abbildung 7.3: mögliche Datenstrukturen für Index
96 2008-01-16/010/INF02/2253

7.5 Mögliche Datenstrukturen für den Index
Die Datenstruktur Heap ist ein Haufen, der eine spezielle Struktur hat. Die Struktur istdarauf ausgelegt, dass das Finden des Minimums oder Maximums des ganzen Haufen sehre�zient erfolgt. Für die Realisierung werden meist Bäume verwendet, die die Bedingung desHeap erfüllen. Eine Bedingung ist zum Beispiel, dass alle Nachfolger im Baum jedes Knotenkleiner sind als der jeweilige Knoten selbst. Anwendung �nden Heaps zum Beispiel beiWarteschlangen mit Prioritäten. Da für den zu erstellenden Index keine solche Bedingungoder Ordnung existiert, sondern zufällig auf die Daten zugegri�en wird, ist ein Heap keinesinnvolle Datenstruktur für dieses Einsatzszenario. Die zwei weiteren Datenstrukturen, dieBäume und die Hashtabelle scheinen dagegen geeignet zu sein.
Bäume bestehen aus Knoten, Blättern und Kanten. Jeder Knoten kann mehrere Nachfol-ger haben. Ein Knoten ohne einen Nachfolger ist ein Blatt. Im Baum besteht eine de�nierteOrdnung, das heiÿt bei der Suche oder dem Einfügen oder Löschen eines Elementes ist im-mer nur eine Stelle im Baum die richtige. Damit das möglich ist, enthält jeder KnotenVergleichselemente. Eine Ordnung ist zum Beispiel, dass alle Elemente, die kleiner als dasVergleichselement sind im linken Teilbaum der Vergleichselementes stehen. Damit ist ein-deutig de�niert, wo ein Element im Baum steht. Bei den Bäumen wird dabei zwischenbalancierten und nicht balancierten Bäumen unterschieden. In nicht balancierten Bäumenwerden die Daten nur unter Beachtung der Baumbedingung eingefügt. Deshalb sind es dieeinfachsten Bäume. Ein Beispiel dafür ist der Binärbaum, bei dem jeder Knoten maximalzwei Nachfolger hat. Damit ist der Aufwand für die Suche eines Elementes maximal dieHöhe des Baumes. Im optimalen Fall ergibt das einen Aufwand von O(log2(n)). Proble-matisch ist jedoch, dass der Baum zur Liste entarten kann. Dabei werden beispielsweisebeim Aufnehmen von Daten, die Daten immer an die an weitesten linke Position des Bau-mes eingefügt. Damit ist der Suchaufwand im schlimmsten Fall O(n). Zur Lösung diesesProblems wurden die balancierten Bäume entwickelt. Diese Bäume haben eine zusätzlicheBedingung. Die Di�erenz der maximalen Höhe des Baumes und der minimalen Höhe desBaumes ist maximal eins. Dies wird bei jedem Einfügen oder Löschen von Elementen ge-prüft und gegebenenfalls wird der Baum angepasst, damit die Bedingung wieder erfüllt ist.Zwei wichtige Vertreter der Kategorie sind der AVL Baum und die B-Bäume. Bei einemAVL-Baum hat ein Knoten ebenfalls wie der Binärbaum maximal zwei Nachfolger. Da-mit ist der AVL-Baum ein balancierter Binärbaum. Einsatz �ndet der AVL-Baum, sowieder Binärbaum, bei Hauptspeicherdatenstrukturen. Die Realisierung erfolgt dabei meistmit einer Verbindung der Elemente durch Zeiger oder als Feld, welches als Baum inter-pretiert wird. Demgegenüber steht die Gruppe der B-Bäume. Bekannt sind der B-Baum,der B+-Baum und der B*-Baum. Gleich ist bei allen Typen, dass ein Knoten nicht nurein Vergleichselement und damit maximal zwei Nachfolger hat, sondern das mehrere Ver-gleichselemente vorhanden sind. Damit kann ein Knoten auch mehr als zwei Nachfolger ha-ben. Die maximale Anzahl an Nachfolgern ist die Anzahl der Vergleichselemente plus eins.Der Grund, warum mehrere Vergleichselemente sinnvoll sind, ist das Anwendungsgebiet.B-Bäume werden hauptsächlich bei der Speicherung von Daten auf externen Datenträgernverwendet. Die Datenträger sind dabei in Blöcke gleicher Gröÿe unterteilt. Das Lesen einesByte ist damit genauso aufwendig, wie das Lesen des ganzen Blockes. Das wird durch dasZusammenfassen mehrere physischer Blöcke zu einem logischen Block erweitert. Das istmöglich, weil das Lesen mehrerer einzelner Blöcke kaum aufwendiger ist, als das Leseneines Blockes. Grund dafür ist, dass die Positionierungszeiten der Datenträger bei kleinenBlockgröÿen der entscheidende Geschwindigkeitsfaktor sind. Praktische Blockgröÿen sindzum Beispiel vier Kilobyte. Da der Aufwand gröÿere Blöcke zu lesen kaum höher ist, als fürkleine Blöcke, werden die gröÿeren Blöcke verwendet. Die Anzahl der Nachfolger eines Kno-ten wird dabei so gewählt, dass die notwendigen Daten den logischen Block möglichst gutauslasten. Dadurch, dass ein Knoten mehrere Nachfolger hat, wird die Höhe des Baumesund damit der Suchaufwand reduziert. Die notwendigen Operationen auf einen Block sind
2008-01-16/010/INF02/2253 97

7 Implementierung im Rahmen einer Simulationsstudie
vernachlässigbar, da die externen Datenträger der Flaschenhals sind. Die B-Bäume sindwie bereits gesagt ebenfalls balanciert. Damit ergibt sich die Höhe des Baumes und damitein Suchaufwand von O(logm(n), wobei m die Anzahl der Nachfolger eines Knoten ist. DieFrage ist, wann werden nun neue Knoten eingefügt und wann werden Knoten gelöscht.Neue Knoten werden eingefügt, wenn der Platz in einem Knoten nicht mehr ausreicht undKnoten werden gelöscht, wenn weniger als die Hälfte der maximal möglichen Elementein einem Knoten sind. Die verbliebenen Knoten werden dabei auf andere Knoten verteilt.Zum Schluss gilt immer die Bedingung, dass die Auslastung jedes Knoten auÿer der Wurzelmindestens 50 Prozent ist. Die verschiedenen Arten der B-Bäume haben dabei folgende Un-terschiede. Bei dem normalen B-Baum enthält jeder Knoten nicht nur die Verweise auf dieNachfolger, sondern auch die Verweise auf die gespeicherten Daten der Vergleichselemente.Beim B+-Baum enthalten die Knoten nur Verweise auf die Nachfolger, während nur in denBlättern die Verweise auf die Daten der enthaltenden Elemente stehen. Der B*-Baum istprinzipiell wie der B+-Baum, jedoch ist die Auslastung der einzelnen Knoten mindesten2/3. Das bedingt, dass bei einem Unterlauf drei Knoten zu zwei Knoten zusammengefasstwerden müssen und beim Einfügen anders herum. Da die Auslastung der Knoten gröÿerist als beim B+ Baum, ist der Baum etwas �acher und damit der Zugri� schneller.
Die letzte dargestellte Datenstruktur ist die Hashtabelle. Im Gegensatz zu den Bäu-men kommt man dem Speicherort des Elementes nicht Stück für Stück näher, sondernberechnet die Stelle, wo das Element stehen soll. Damit kann auf das Element direkt zuge-gri�en werden. Für die Ermittlung der Speicherposition wird auf das gesuchte Element eineHashfunktion angewandt. Die Aufgabe der Hashfunktion ist dabei, dass aus dem Wert desgesuchten Elementes direkt eine Zahl errechnet wird, die in einem angegebenem Bildbe-reich liegt. Dabei soll die Hashfunktion gleichmäÿig streuen, das heiÿt auch bei ähnlichenEingangswerten kommt es zu stark unterschiedlichen Ausgangswerten. Zusätzlich sollenalle Werte des Bildbereiches gleichmäÿig oft benutzt werden. Der Grund dafür sind dieKollisionen. Wenn bei zwei Eingangswerten der Hashfunktion der gleiche Ausgangswerterreicht wird, tritt eine Kollision auf. Diese muss behandelt werden. Deshalb muss bei demdirekten Zugri� auf die Speicherstelle überprüft werden, ob der gesuchte Wert enthaltenist. Für die Au�ösung existieren verschiedene Varianten. Eine einfache Möglichkeit ist dasVerketten der Elemente. Wenn an einer Position mehrere Elemente stehen sollen, werdendie Elemente in eine Liste eingefügt. Bei der Suche des Elementes, muss dann gegebenen-falls die ganze Liste an der Position durchsucht werden, um festzustellen, ob das Elemententhalten ist. Dieses Verfahren ist im Hauptspeicher leicht zu realisieren. Eine weitere Va-riante ist das Sondieren. Hierbei wird beim Auftreten einer Kollision ein anderer freierPlatz gesucht. Dafür existieren verschiedene Versionen. Zum Beispiel wird beim linearenSondieren die Speicherstelle solange um eins erhöht, bis eine freie Position gefunden wurde.Beim quadratischen Sondieren wird jeweils 1, 2, 4, 16, ... Positionen von der errechnetenPosition gesucht und das Element eingefügt. Noch eine weitere Version führt eine weitereHashfunktion auf das Element aus, um bei einer Kollision eine weitere Position zu er-rechnen. Beim Suchen der Elemente werden die verschiedenen Verfahren beachtet, so dassdas Element gefunden wird, wenn es in der Tabelle vorhanden ist. Es ist zu sehen, dassder Speicherbereich ausreichend groÿ sein muss, damit alle Werte hinein passen. Dabeidürfen aber nicht zu viele Kollisionen auftreten, damit das Verfahren nicht langsam wird.Der Speicherbereich beim Sondieren muss damit gröÿer sein, als die Anzahl der zu spei-chernden Elemente. Damit das Verfahren sinnvoll ist, darf die Auslastung des Bereichesnicht über 70-80 Prozent sein. Wenn die Bedingung gegeben ist, ist der durchschnittlicheSuchaufwand O(1). Durch die zu beachtende Auslastung muss die erwartete Anzahl derzu speichernden Elemente vorher bekannt sein. Es existieren jedoch auch Verfahren, diedie Hashtabelle dynamisch vergröÿern können. Der Aufwand wird dabei jedoch gröÿer, sodass es nur benutzt wird wenn es signi�kante Vorteile bringt oder notwendig ist.
98 2008-01-16/010/INF02/2253

7.6 Realisierte Datenstrukturen
7.6 Realisierte Datenstrukturen
Im vorherigen Abschnitt wurde besprochen, welche Datenstrukturen als Index grundsätz-lich möglich und sinnvoll sind. Zur Auswahl einer geeigneten Datenstruktur wurden exem-plarisch erfolgversprechende Strukturen implementiert, um diese dann in der Simulationmit dem Lastmodell zu testen und zu bewerten. Die Auswahl �el bei den Hauptspeicherda-tenstrukturen auf den Binärbaum und eine verkettete Hashtabelle. Für die Speicherung desIndex auf einem externen Datenträger wurden der B+-Baum und verschiedene Varianteneiner Hashtabelle realisiert. Nur zur Überprüfung der Funktion der Simulationsumgebungwurde eine lineare Liste verwendet. Im Folgenden wird erklärt, warum die jeweilige Da-tenstruktur verwendet wurde. Danach wird gezeigt wie die Realisierung erfolgte, bevoreine Bewertung der Datenstruktur vorzunehmen ist. Zum Schluss wird nach den einzelnenBewertungen eine vergleichende Bewertung vorgenommen.Die Bewertung der verschiedenen Datenstrukturen erfolgt durch Zählung der notwendi-
gen Zugri�e auf diese, die für ein vollständige korrekte Authentisierung nach dem Protokollaus Abschnitt 4.6 notwendig sind. Im Folgenden wird dies als Anzahl Zugri�e oder Auf-wand bezeichnet. Der Aufwand ist durch die speziellen Zugri� auf die Datenstrukturenbestimmt und wurde in Abschnitt 7.3 dargestellt. Pro erfolgreicher Authentisierung sindfolgende Zugri�e auf die Datenstruktur notwendig.
Operationen = 1 Lookup+ 1 Remove+ 1 Insert + n · (1 Remove+ 1 Insert)
Der Parameter n ist dabei die Anzahl der überprungenden Pseudo ID, der von derEinzelfehlerwahrscheinlichkeit abhängig ist.
7.6.1 Binärbaum
Der Binärbaum, der in Abschnitt vorgestellt 2.5.1 wurde, wird nun auf seine Leistungsfä-higkeit in Bezug auf Performanz im Einsatzszenario untersucht.Durch das zufällige Erscheinen der einzufügenden Pseudo IDs erfolgt das Einfügen und
Löschen von Daten an zufälligen Stellen. Deshalb entartet der Baum nicht, so dass dieZugri�szeit von O(log2n) erhalten bleibt. Ein einzelner Knoten besteht aus einem Ver-gleichselement, den Verweisen auf die beiden Nachfolger und der Speicheradresse für dieDaten zu dem Vergleichselement. Das Vergleichselement ist 80 Bit groÿ. Die anderen Wertesind jeweils 64 Bit groÿ, da 32 Bit nicht für die gewünschte Anzahl von Tags ausreichendsind. Damit ergibt sich eine gesamte Knotengröÿe von 34 Byte. Da ein Knoten immer einePseudo ID repräsentiert, ist der belegte Speicherplatz des Baumes n · 34 Byte. Wie zusehen ist, sind 18 Byte Nutzdaten enthalten. Damit sind 16 Byte für die Verlinkung desBaumes notwendig. Das ergibt eine Speicherplatze�zienz von nur 18/34 ≈ 53%.Die in Abschnitt 2.5.1 dargestellten Algorithmen müssen in Bezug auf das Szenario leicht
angepasst werden. Es muss beachtet werden, dass Kollisionen bei den Pseudo IDs auftre-ten können. Deshalb muss mit Hilfe der zusätzlichen Information aus dem entwickeltenProtokoll geprüft werden, ob eine Kollision aufgetreten ist oder nicht und eventuell weitergesucht werden.Nachdem bekannt ist, wie die Datenstruktur und die Algorithmen für den Binärbaum
funktionieren, ist eine Bewertung vorzunehmen. Zunächst wurde die Skalierbarkeit ermit-telt. Dazu wurde bei sonst konstanten Parametern, die Anzahl der Tags schrittweise von1000 auf 3 Millionen erhöht. Die restlichen konstanten Parameter sind folgende. Die Anzahlder gespeicherten Pseudo IDs ist 5 (prefetch). Die Wahrscheinlichkeit für zufällige Fehler,die das überspringen einer Pseudo ID zur Folge haben, ist 10% (skipRate). Der letzteParameter, die Fehlerrate mit der eine Resynchronisation notwendig ist, ist ein Promille(blockSkipRate). Die graphische Darstellung der Ergebnisse ist in Abbildung 7.4 zu sehen.
2008-01-16/010/INF02/2253 99
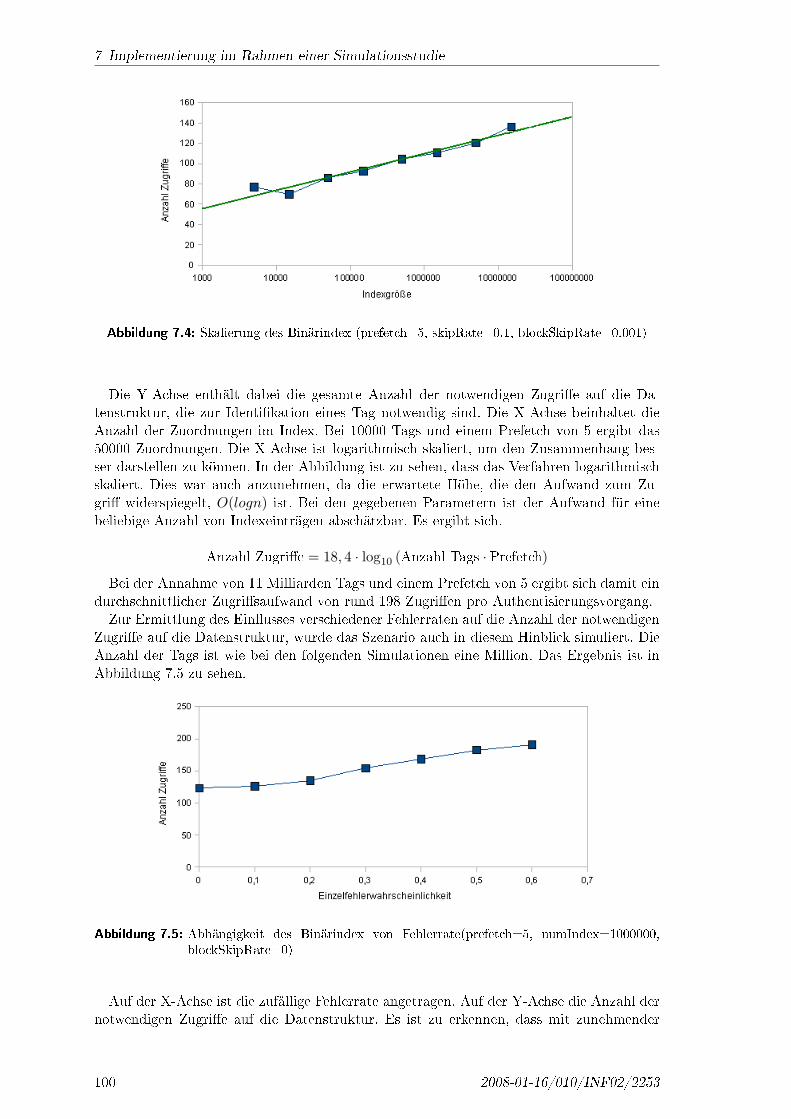
7 Implementierung im Rahmen einer Simulationsstudie
Abbildung 7.4: Skalierung des Binärindex (prefetch=5, skipRate=0.1, blockSkipRate=0.001)
Die Y-Achse enthält dabei die gesamte Anzahl der notwendigen Zugri�e auf die Da-tenstruktur, die zur Identi�kation eines Tag notwendig sind. Die X-Achse beinhaltet dieAnzahl der Zuordnungen im Index. Bei 10000 Tags und einem Prefetch von 5 ergibt das50000 Zuordnungen. Die X-Achse ist logarithmisch skaliert, um den Zusammenhang bes-ser darstellen zu können. In der Abbildung ist zu sehen, dass das Verfahren logarithmischskaliert. Dies war auch anzunehmen, da die erwartete Höhe, die den Aufwand zum Zu-gri� widerspiegelt, O(logn) ist. Bei den gegebenen Parametern ist der Aufwand für einebeliebige Anzahl von Indexeinträgen abschätzbar. Es ergibt sich.
Anzahl Zugri�e = 18, 4 · log10 (Anzahl Tags · Prefetch)
Bei der Annahme von 11 Milliarden Tags und einem Prefetch von 5 ergibt sich damit eindurchschnittlicher Zugri�saufwand von rund 198 Zugri�en pro Authentisierungsvorgang.Zur Ermittlung des Ein�usses verschiedener Fehlerraten auf die Anzahl der notwendigen
Zugri�e auf die Datenstruktur, wurde das Szenario auch in diesem Hinblick simuliert. DieAnzahl der Tags ist wie bei den folgenden Simulationen eine Million. Das Ergebnis ist inAbbildung 7.5 zu sehen.
Abbildung 7.5: Abhängigkeit des Binärindex von Fehlerrate(prefetch=5, numIndex=1000000,blockSkipRate=0)
Auf der X-Achse ist die zufällige Fehlerrate angetragen. Auf der Y-Achse die Anzahl dernotwendigen Zugri�e auf die Datenstruktur. Es ist zu erkennen, dass mit zunehmender
100 2008-01-16/010/INF02/2253

7.6 Realisierte Datenstrukturen
Fehlerrate mehr Zugri�e auf die Datenstruktur notwendig sind. Der Grund dafür ist, dassauch die übersprungenen Zuordnungen der Pseudo ID zur realen ID aus der Datenstrukturentfernt und neue wieder eingefügt werden müssen. Dabei ergibt sich eine obere Grenze,wenn alle gespeicherten Zuordnungen gelöscht und neu eingefügt werden müssen. Es istjedoch nicht sinnvoll so hohe Fehlerraten zuzulassen, da dann der aufwendige Resynchro-nisationsvorgang durchgeführt werden muss, der hier nicht näher betrachtet wird. Aus derAbbildung ist zu erkennen, dass bei sinnvollen Fehlerwahrscheinlichkeiten kein wesentlicherzusätzlicher Aufwand notwendig ist. So sind bei einer Fehlerwahrscheinlichkeit von zehnProzent nur zwei bis drei Prozent mehr Zugri�e notwendig.
7.6.2 B+-Baum
Die B-Bäume sind eine Standarddatenstruktur für Datenbanken. Die Knotengröÿe ist dabeiauf die Blockgröÿe des Datenträgers optimiert, das heiÿt ein Knoten hat die maximalmögliche Anzahl an Vergleichselementen, die in den Knoten mit der gegebenen Blockgröÿepassen. Die B-Bäume sind balancierte Bäume. Realisiert wurde der B+-Baum. Er zeichnetsich dadurch aus, dass ein Knoten aus mehreren Vergleichselementen besteht und dass dieDaten nur in den Blättern gespeichert werden und die inneren Knoten nur zur Lokalisationder richtigen Blätter verwendet werden. Die für den B+-Baum notwendigen Algorithmenwurden in Abschnitt 2.5.2 dargestellt.Nachdem die Funktionsweise des B+-Baum bekannt ist, erfolgt im Folgenden die Be-
wertung der Datenstruktur. Zunächst wird wieder die Skalierbarkeit der Datenstrukturbetrachtet. Hierbei wird bei sonst festen Parametern die Indexgröÿe variiert. Als Block-gröÿe wurde hier vier Kilobyte angenommen, da dies eine oft verwendete Blockgröÿe inDatenbanken ist. Das Ergebnis ist in Abbildung 7.6 zu sehen.
Abbildung 7.6: Skalierung des BPlusIndex (prefetch=5, skipRate=0.1, blockSkipRate=0.001,blockSize=4096)
Die X-Achse, welche die Gröÿe eines Knoten repräsentiert, ist logarithmisch skaliert, dadie Datenstruktur ein Baum ist und somit das Ergebnis besser dargestellt wird. Die Y-Achse spiegelt die Anzahl der notwendigen Zugri�e auf die Datenstruktur wieder. Es ist zusehen, dass die einzelnen Datenpunkte nicht zu einer Gerade verbunden werden können. Inder Abbildung existieren Sprünge. Der Grund dafür ist der Baum selbst. Der B+-Baum istein balancierter Baum, bei der alle linken Teilbäume eines beliebigen Knoten die gleicheTiefe haben, wie die rechten Teilbäume. Die Daten liegen auÿerdem immer in den Blättern.Deshalb ist jeder Suchvorgang im Baum so aufwendig, wie die Tiefe des Baumes. Da dieTiefe ganzzahlig ist, entstehen die Sprünge. Bei einer Blockgröÿe von 4096 Byte könnenpro Knoten maximal 227 Elemente gespeichert werden. Die Berechnung ist
2008-01-16/010/INF02/2253 101

7 Implementierung im Rahmen einer Simulationsstudie
Anzahl Elemente = (Blockgröÿe− 8)/(18)
Es ist diese Menge an Elementen möglich, weil bei n Vergleichselementen der Gröÿe 80Bit, n+1 Nachfolger der Gröÿe 64 Bit notwendig sind. Damit ergibt sich eine maximaleKapazität des Baumes bei m Ebenen von (Anzahl Elemente)m Dies ergibt im Simulati-onsbeispiel bei 2 Ebenen 51529 mögliche Elemente. Da jedoch nicht alle Knoten maximalgefüllt sind, sondern der Füllungsgrad zwischen 50 und 100 Prozent schwankt, sind bei50000 Elementen schon drei Ebenen notwendig. Da jeder Authentisierungsvorgang aus 3Teilen besteht (Lookup, Remove, Insert) und jeder Vorgang jeweils einen Aufwand im Le-sen von der Tiefe des Baumes hat, sind damit 9 Lesezugri�e notwendig. Beim Einfügen undLöschen von Elementen sind auch noch etwa 2 Schreibzugri�e notwendig. Die restlichenfehlenden Zugri�e entstehen durch das Überspringen von nicht benutzten Pseudo IDs undnotwendigen Anpassungen des Baumes. Die Anzahl der notwendigen Zugri�e ist damit beisonst konstanten Parametern wie folgt berechenbar.
Anzahl Zugri�e = 2, 22 + 3, 27⌈·log(0,75·Anzahl Elemente)(Anzahl Zuordnungen)
⌉Bei der Annahme das 11 Milliarden Tags, mit jeweils 5 Zuordnungen bei sonst gleichen
Parametern gespeichert werden, ergibt das eine Baumhöhe von 5 und rund 18,6 Zugri�eauf die Datenstruktur, die zur Suche der Zuordnung der Pseudo ID zur realen ID und derAktualisierung der Datenstruktur notwendig sind.Nachdem die Skalierbarkeit des B+-Baum getestet wurde, wird nun die Abhängigkeit
der notwendigen Zugri�e von der Blockgröÿe untersucht. Dazu wird die Blockgröÿe von512 Byte exponentiell auf 32768 Byte gesteigert. 512 Byte sind die typische minimaleBlockgröÿe von Festplatten. Die Ergebnisse der Simulation sind in Abbildung 7.7 zu sehen.
Abbildung 7.7: Abhängigkeit des BPlusIndex von Blockgröÿe (prefetch=5, skipRate=0.1, blockS-kipRate=0.001, numTags=1000000)
Die X-Achse repräsentiert die Blockgröÿe und ist logarithmisch skaliert. Die Datenpunk-te sind nicht sinnvoll zu verbinden, da Sprünge existieren. Der Grund für die Sprüngeist, wie bei der Skalierung, dass der B+-Baum balanciert ist und die Höhe des Baumesganzzahlig ist. Somit kann auch die Anzahl der notwendigen Zugri�e wie bei der Skalie-rung berechnet werden. Nur wird diesmal die Anzahl der Elemente in einem Block mit deranderen gegebenen Blockgröÿe berechnet.
Anzahl Elemente = (Blockgröÿe− 8)/(18)
102 2008-01-16/010/INF02/2253

7.6 Realisierte Datenstrukturen
Anzahl Zugri�e = 2, 22 + 3, 27⌈·log(0,75·Anzahl Elemente)(Anzahl Zuordnungen)
⌉Als nächster Punkt wird die Anzahl der Zugri�e in Abhängigkeit von der Einzelfehlerrate
betrachtet. Dabei wird die Einzelfehlerrate bei sonst konstanten Parametern von 0 auf 60Prozent erhöht. Das Ergebnis ist in Abbildung 7.8 zu sehen.
Abbildung 7.8: BPlusIndex bei verschiedenen Fehlerraten (numTags=1000000, prefetch=5, bele-gung=1, blockSkipRate=0.001)
In der Gra�k ist auf der X-Achse die Einzelfehlerwahrscheinlichkeit und auf der Y-Achsedie korrespondierende Anzahl notwendiger Zugri�e dargestellt. Die Abbildung ergibt wiebei den anderen Verfahren einen etwa linearen Zusammenhang. Bei null Prozent Fehlerratewerden circa 13,6 Zugri�e auf den Baum benötigt. Mit jeden zehn Prozent steigt die Anzahlder Zugri�e um circa 1,75. Das ergibt dann folgende Gerade.
Anzahl Zugri�e = 13, 6 + 17, 5 · Fehlerwahrscheinlichkeit
7.6.3 Hashtabelle mit Verkettung
Eine Hashtabelle ist eine häu�g eingesetzte Datenstruktur. Im Arbeitsspeicher wird dabeihäu�g die Variante gewählt, die Kollisionen mit Hilfe der Verkettung au�öst. Die E�zienzder Datenstruktur hängt dabei bei einer geeigneten Hashfunktion nur von dem Füllungs-grad ab. Je höher dieser ist, desto mehr Kollisionen treten auf, die aufgelöst werden müssen.Damit wächst dann die Anzahl der Elemente in einem Korb und somit sinkt die E�zienz.Bei geeigneter Gröÿe ist ein durchscnittlicher Aufwand von O(1) zu erwarten. Damit solltedas Verfahren sehr gut mit der Anzahl der Tags skalieren. Die Funktionsweise der Daten-struktur ist in Abschnitt 2.5.3 dargestellt.Der notwendige Speicherplatz zur Speicherung der Daten setzt sich dabei aus zwei Kom-
ponenten zusammen. Zunächst wird pro Korb ein Zeiger benötigt, der auf jeweils eineZuordnung zeigt. Eine Zuordnung besteht aus der Pseudo ID und der Speicheradresse fürdie ausführlichen Daten. Zusätzlich ist für die Zuordnung ein weiterer Zeiger notwendig,der auf die nächste Zuordnung zeigt, damit die Kollisionen aufgelöst werden können. Beider Annahme von 64 Bit für alle Zeiger und 80 Bit für die Pseudo ID ergibt sich folgendernotwendiger Speicherplatz.
Speicherplatz = n · 8Byte+m · (10Byte+ 8Byte+ 8Byte) = n · 8Byte+m · 26Byte
In der Gleichung entspricht n der Anzahl der Körbe der Hashtabelle. Die Anzahl dereingefügten Elemente ist m. Bei der Annahme das m = n ist der notwendige Speicherplatz
2008-01-16/010/INF02/2253 103
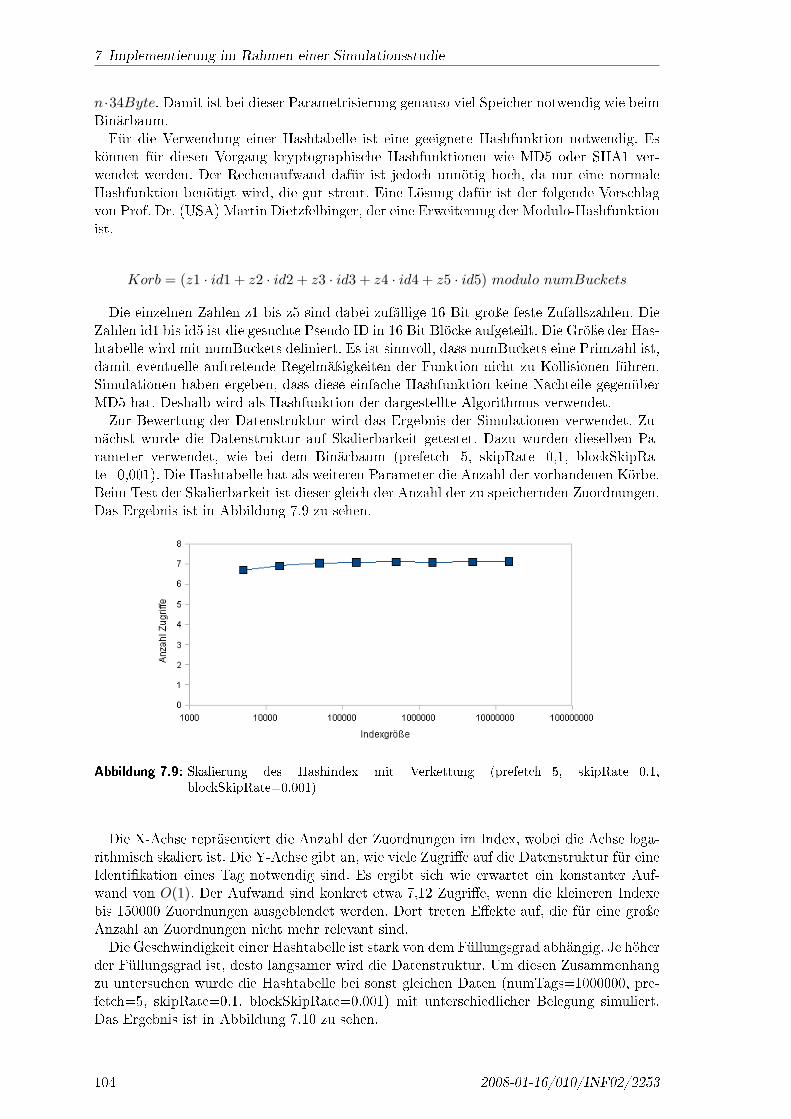
7 Implementierung im Rahmen einer Simulationsstudie
n·34Byte. Damit ist bei dieser Parametrisierung genauso viel Speicher notwendig wie beimBinärbaum.Für die Verwendung einer Hashtabelle ist eine geeignete Hashfunktion notwendig. Es
können für diesen Vorgang kryptographische Hashfunktionen wie MD5 oder SHA1 ver-wendet werden. Der Rechenaufwand dafür ist jedoch unnötig hoch, da nur eine normaleHashfunktion benötigt wird, die gut streut. Eine Lösung dafür ist der folgende Vorschlagvon Prof. Dr. (USA) Martin Dietzfelbinger, der eine Erweiterung der Modulo-Hashfunktionist.
Korb = (z1 · id1 + z2 · id2 + z3 · id3 + z4 · id4 + z5 · id5) modulo numBuckets
Die einzelnen Zahlen z1 bis z5 sind dabei zufällige 16 Bit groÿe feste Zufallszahlen. DieZahlen id1 bis id5 ist die gesuchte Pseudo ID in 16 Bit Blöcke aufgeteilt. Die Gröÿe der Has-htabelle wird mit numBuckets de�niert. Es ist sinnvoll, dass numBuckets eine Primzahl ist,damit eventuelle auftretende Regelmäÿigkeiten der Funktion nicht zu Kollisionen führen.Simulationen haben ergeben, dass diese einfache Hashfunktion keine Nachteile gegenüberMD5 hat. Deshalb wird als Hashfunktion der dargestellte Algorithmus verwendet.Zur Bewertung der Datenstruktur wird das Ergebnis der Simulationen verwendet. Zu-
nächst wurde die Datenstruktur auf Skalierbarkeit getestet. Dazu wurden dieselben Pa-rameter verwendet, wie bei dem Binärbaum (prefetch=5, skipRate=0,1, blockSkipRa-te=0,001). Die Hashtabelle hat als weiteren Parameter die Anzahl der vorhandenen Körbe.Beim Test der Skalierbarkeit ist dieser gleich der Anzahl der zu speichernden Zuordnungen.Das Ergebnis ist in Abbildung 7.9 zu sehen.
Abbildung 7.9: Skalierung des Hashindex mit Verkettung (prefetch=5, skipRate=0.1,blockSkipRate=0.001)
Die X-Achse repräsentiert die Anzahl der Zuordnungen im Index, wobei die Achse loga-rithmisch skaliert ist. Die Y-Achse gibt an, wie viele Zugri�e auf die Datenstruktur für eineIdenti�kation eines Tag notwendig sind. Es ergibt sich wie erwartet ein konstanter Auf-wand von O(1). Der Aufwand sind konkret etwa 7,12 Zugri�e, wenn die kleineren Indexebis 150000 Zuordnungen ausgeblendet werden. Dort treten E�ekte auf, die für eine groÿeAnzahl an Zuordnungen nicht mehr relevant sind.Die Geschwindigkeit einer Hashtabelle ist stark von dem Füllungsgrad abhängig. Je höher
der Füllungsgrad ist, desto langsamer wird die Datenstruktur. Um diesen Zusammenhangzu untersuchen wurde die Hashtabelle bei sonst gleichen Daten (numTags=1000000, pre-fetch=5, skipRate=0.1, blockSkipRate=0.001) mit unterschiedlicher Belegung simuliert.Das Ergebnis ist in Abbildung 7.10 zu sehen.
104 2008-01-16/010/INF02/2253
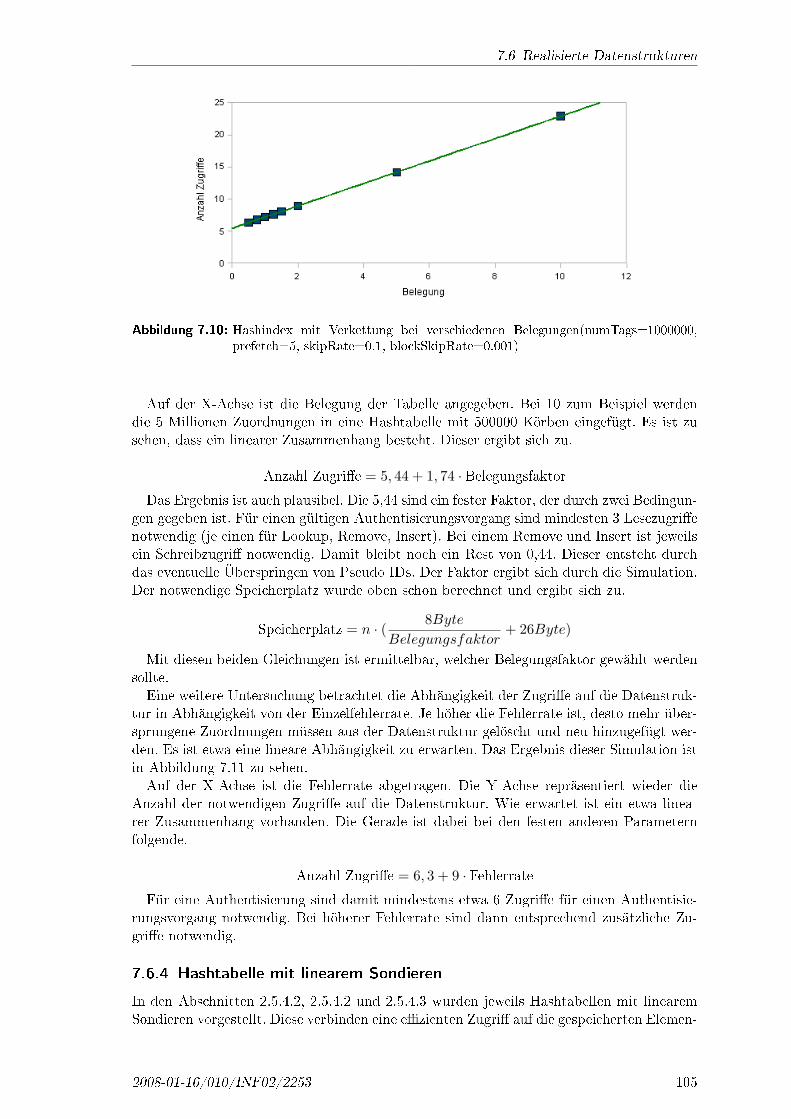
7.6 Realisierte Datenstrukturen
Abbildung 7.10: Hashindex mit Verkettung bei verschiedenen Belegungen(numTags=1000000,prefetch=5, skipRate=0.1, blockSkipRate=0.001)
Auf der X-Achse ist die Belegung der Tabelle angegeben. Bei 10 zum Beispiel werdendie 5 Millionen Zuordnungen in eine Hashtabelle mit 500000 Körben eingefügt. Es ist zusehen, dass ein linearer Zusammenhang besteht. Dieser ergibt sich zu.
Anzahl Zugri�e = 5, 44 + 1, 74 · BelegungsfaktorDas Ergebnis ist auch plausibel. Die 5,44 sind ein fester Faktor, der durch zwei Bedingun-
gen gegeben ist. Für einen gültigen Authentisierungsvorgang sind mindesten 3 Lesezugri�enotwendig (je einen für Lookup, Remove, Insert). Bei einem Remove und Insert ist jeweilsein Schreibzugri� notwendig. Damit bleibt noch ein Rest von 0,44. Dieser entsteht durchdas eventuelle Überspringen von Pseudo IDs. Der Faktor ergibt sich durch die Simulation.Der notwendige Speicherplatz wurde oben schon berechnet und ergibt sich zu.
Speicherplatz = n · ( 8ByteBelegungsfaktor
+ 26Byte)
Mit diesen beiden Gleichungen ist ermittelbar, welcher Belegungsfaktor gewählt werdensollte.Eine weitere Untersuchung betrachtet die Abhängigkeit der Zugri�e auf die Datenstruk-
tur in Abhängigkeit von der Einzelfehlerrate. Je höher die Fehlerrate ist, desto mehr über-sprungene Zuordnungen müssen aus der Datenstruktur gelöscht und neu hinzugefügt wer-den. Es ist etwa eine lineare Abhängigkeit zu erwarten. Das Ergebnis dieser Simulation istin Abbildung 7.11 zu sehen.Auf der X-Achse ist die Fehlerrate abgetragen. Die Y-Achse repräsentiert wieder die
Anzahl der notwendigen Zugri�e auf die Datenstruktur. Wie erwartet ist ein etwa linea-rer Zusammenhang vorhanden. Die Gerade ist dabei bei den festen anderen Parameternfolgende.
Anzahl Zugri�e = 6, 3 + 9 · FehlerrateFür eine Authentisierung sind damit mindestens etwa 6 Zugri�e für einen Authentisie-
rungsvorgang notwendig. Bei höherer Fehlerrate sind dann entsprechend zusätzliche Zu-gri�e notwendig.
7.6.4 Hashtabelle mit linearem Sondieren
In den Abschnitten 2.5.4.2, 2.5.4.2 und 2.5.4.3 wurden jeweils Hashtabellen mit linearemSondieren vorgestellt. Diese verbinden eine e�zienten Zugri� auf die gespeicherten Elemen-
2008-01-16/010/INF02/2253 105
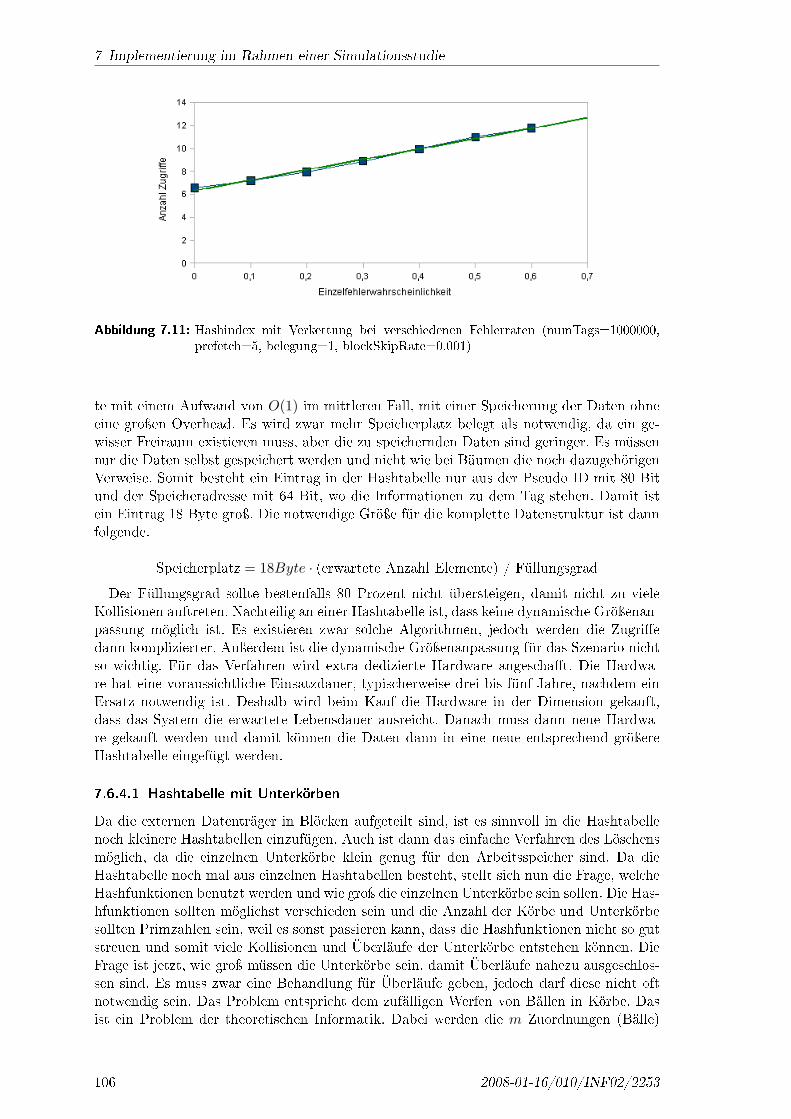
7 Implementierung im Rahmen einer Simulationsstudie
Abbildung 7.11: Hashindex mit Verkettung bei verschiedenen Fehlerraten (numTags=1000000,prefetch=5, belegung=1, blockSkipRate=0.001)
te mit einem Aufwand von O(1) im mittleren Fall, mit einer Speicherung der Daten ohneeine groÿen Overhead. Es wird zwar mehr Speicherplatz belegt als notwendig, da ein ge-wisser Freiraum existieren muss, aber die zu speichernden Daten sind geringer. Es müssennur die Daten selbst gespeichert werden und nicht wie bei Bäumen die noch dazugehörigenVerweise. Somit besteht ein Eintrag in der Hashtabelle nur aus der Pseudo ID mit 80 Bitund der Speicheradresse mit 64 Bit, wo die Informationen zu dem Tag stehen. Damit istein Eintrag 18 Byte groÿ. Die notwendige Gröÿe für die komplette Datenstruktur ist dannfolgende.
Speicherplatz = 18Byte · (erwartete Anzahl Elemente) / Füllungsgrad
Der Füllungsgrad sollte bestenfalls 80 Prozent nicht übersteigen, damit nicht zu vieleKollisionen auftreten. Nachteilig an einer Hashtabelle ist, dass keine dynamische Gröÿenan-passung möglich ist. Es existieren zwar solche Algorithmen, jedoch werden die Zugri�edann komplizierter. Auÿerdem ist die dynamische Gröÿenanpassung für das Szenario nichtso wichtig. Für das Verfahren wird extra dedizierte Hardware angescha�t. Die Hardwa-re hat eine voraussichtliche Einsatzdauer, typischerweise drei bis fünf Jahre, nachdem einErsatz notwendig ist. Deshalb wird beim Kauf die Hardware in der Dimension gekauft,dass das System die erwartete Lebensdauer ausreicht. Danach muss dann neue Hardwa-re gekauft werden und damit können die Daten dann in eine neue entsprechend gröÿereHashtabelle eingefügt werden.
7.6.4.1 Hashtabelle mit Unterkörben
Da die externen Datenträger in Blöcken aufgeteilt sind, ist es sinnvoll in die Hashtabellenoch kleinere Hashtabellen einzufügen. Auch ist dann das einfache Verfahren des Löschensmöglich, da die einzelnen Unterkörbe klein genug für den Arbeitsspeicher sind. Da dieHashtabelle noch mal aus einzelnen Hashtabellen besteht, stellt sich nun die Frage, welcheHashfunktionen benutzt werden und wie groÿ die einzelnen Unterkörbe sein sollen. Die Has-hfunktionen sollten möglichst verschieden sein und die Anzahl der Körbe und Unterkörbesollten Primzahlen sein, weil es sonst passieren kann, dass die Hashfunktionen nicht so gutstreuen und somit viele Kollisionen und Überläufe der Unterkörbe entstehen können. DieFrage ist jetzt, wie groÿ müssen die Unterkörbe sein, damit Überläufe nahezu ausgeschlos-sen sind. Es muss zwar eine Behandlung für Überläufe geben, jedoch darf diese nicht oftnotwendig sein. Das Problem entspricht dem zufälligen Werfen von Bällen in Körbe. Dasist ein Problem der theoretischen Informatik. Dabei werden die m Zuordnungen (Bälle)
106 2008-01-16/010/INF02/2253

7.6 Realisierte Datenstrukturen
zufällig in n Körbe der Hashtabelle geworfen. Der erwartete Füllungsgrad ist µ = m/n. Esist zu berechnen wie groÿ die Wahrscheinlichkeit ist, dass bei gegebenen Parametern undeiner Reserve ε, ein Korb überläuft. Die Wahrscheinlichkeit wird hier pA genannt.
pA(n, µ, ε) = Pr(bei A mit m = µn gibt es ein Fach mit ≥ (1 + ε)µ Bällen)
Die Wahrscheinlichkeit muss nach oben abgeschätzt werden. In [17] auf Seite 103 wirddie Wahrscheinlichkeit mit Experiment B abgeschätzt. Dabei wird n mal unabhängig einePoisson-verteilte Zufallsvariable gezogen. Der Beweis wurde ursprünglich von ProfessorDietzfelbinger an der TU Ilmenau erstellt.
pB(n, µ, ε) = Pr(bei B gibt es ein Fach mit ≥ (1 + ε)µ Bällen)
Es wurde ermittelt, dass:
pA(n, µ, ε) ≤ 2pB(n, µ, ε)
Für Experiment B ist klar:
pB(n, µ, ε) = n · P (X ≥ (1 + ε)µ)
Dabei ist X Poisson(µ)-verteilt. Um X zu analysieren, überlegt man so: Für i ≥ (1+ ε)µgilt
P (X = i+ 1)/P (X = i) =e−µµi+1/(i+ 1)!
e−µµi/(i)!=
µ
i+ 1<
11 + ε
und deshalb
Pr(X ≥ (1 + ε)µ) ≤ P (X = d(1 + ε)µe) ·∑i≥0
11 + ε
= P (X = d(1 + ε)µe) · 1 + ε
ε
Und:
P (X = d(1 + ε)µe) = e−µ · µd(1+ε)µe
d(1 + ε)µe!
Die Fakultät k! ist abschätzbar mit k! ≥√
2πk(k/e)k. Damit ergibt sich durch einsetzen.
Pr(X ≥ (1 + ε)µ) ≤(
eε
(1 + ε)1+ε
)µ· 1 + ε
ε√
2π(1 + ε)µ
Wenn alles zusammengefasst wird ergibt sich das Ergebnis.
pA(n, µ, ε) ≤ 2n ·(
eε
(1 + ε)1+ε
)µ·√
1 + ε
2πε2µ
Für einige Beispiele sind die notwendigen Sicherheitsreserven in Tabelle 7.2 zu sehen.
Anzahl Elemente Fehlerwahrscheinlichkeit Reservefaktor notwendige Gröÿe
900 0.358e-4 0,25 11251400 0.174e-4 0,20 16804000 1.191e-3 0,11 44405000 0.400e-4 0,10 5500
Tabelle 7.2: Subkorbgröÿe bei insgesamt 5 gespeicherten Pseudo IDs bei 11 Milliarden Tags
2008-01-16/010/INF02/2253 107

7 Implementierung im Rahmen einer Simulationsstudie
In der Tabelle ist zu erkennen, dass bei sinnvollen Subkorbgröÿen von 4000 oder mehrsehr wenig zusätzlicher Speicherplatz notwendig ist, damit sehr selten Überläufe auftreten.Dabei ist der Füllungsgrad der Hashtabelle dann so hoch, dass der Zugri� darauf nichtmehr e�zient ist. Deshalb wird der Füllungsgrad in der Praxis nicht so hoch sein, wie esfür die Überlaufwahrscheinlichkeit notwendig ist. Deshalb müssen noch weniger Überläufebehandelt werden.
Löschen durch Markieren Es wurde das Verfahren mit den Subkörben jeweils mit denbeiden Löschverfahren realisiert. Dabei wurde jeweils lineares Sondieren verwendet. Dienotwendigen Algorithmen für die Verwaltung der Datenstruktur sind in Abschnitt 2.5.4.2dargestellt.Zunächst wurde das Verfahren auf Skalierbarkeit getestet. Zu erwarten ist, dass die
Anzahl der notwendigen Zugri�e relativ konstant ist. Das Ergebnis der Simulation ist inAbbildung 7.12 zu sehen.
Abbildung 7.12: Skalierung des Hashindex mit Subkörben 1 (prefetch=5, skipRate=0.1, blockS-kipRate=0.001, blockSize=4096, belegung=0.7, subBucketSize=5715 (4000/0.7),rebuildRatio=0.9)
Die Kurve ist wie erwartet. Die Anzahl der Zugri�e auf die Datenstruktur liegt nur un-wesentlich über den minimal erwarteten fünf Zugri�en, drei Lesezugri�e und zwei Schreib-zugri�e. Damit ist ein Aufwand von O(1) gegeben.Der nächste zu betrachtende Faktor ist der Ein�uss der Blockgröÿe auf die Anzahl der
notwendigen Zugri�e. Die Ergebnisse der Simulationen sind in Abbildung 7.13 zu sehen.Hier ist das Ergebnis auch wie erwartet. Mit steigender Blockgröÿe nähert sich die Anzahl
der notwendigen Zugri�e einer unteren Schranke an. Der Grund dafür ist die Art derSondierung. Durch das lineare Sondieren bilden sich bei Kollisionen kleine Gruppen. Es istlogisch, dass wenn mehr Daten mit einmal gelesen werden, die Wahrscheinlichkeit steigt,dass die lokale Gruppe komplett eingelesen wurde und somit ein weiterer Zugri� entfällt.Bei den gegebenen Parametern ist der Grenzwert etwa 5,45. Es ist jedoch auch zu erkennen,dass die Blockgröÿe keinen entscheidenden Ein�uss auf die Geschwindigkeit hat. Selbst mitder kleinsten sinnvollen Blockgröÿe von 512 Byte werden nur knapp 6 Zugri�e benötigt.Eine groÿe Blockgröÿe ergibt somit nur eine Beschleunigung von circa neun Prozent. Damitist die Blockgröÿe kein entscheidendes Kriterium.Der nächste wichtige Faktor bei einer Hashtabelle ist der Belegungsfaktor oder Füllungs-
grad. Er ist der Quotient aus der Anzahl der belegten Tabellenplätze und der Anzahl dervorhandenen Tabellenplätze. Die Erwartung ist, dass die Tabelle bis zu einem Füllungsgradvon 70 bis 80 Prozent sehr e�ektiv ist. Die Simulationsergebnisse sind in Abbildung 7.14zu sehen.
108 2008-01-16/010/INF02/2253
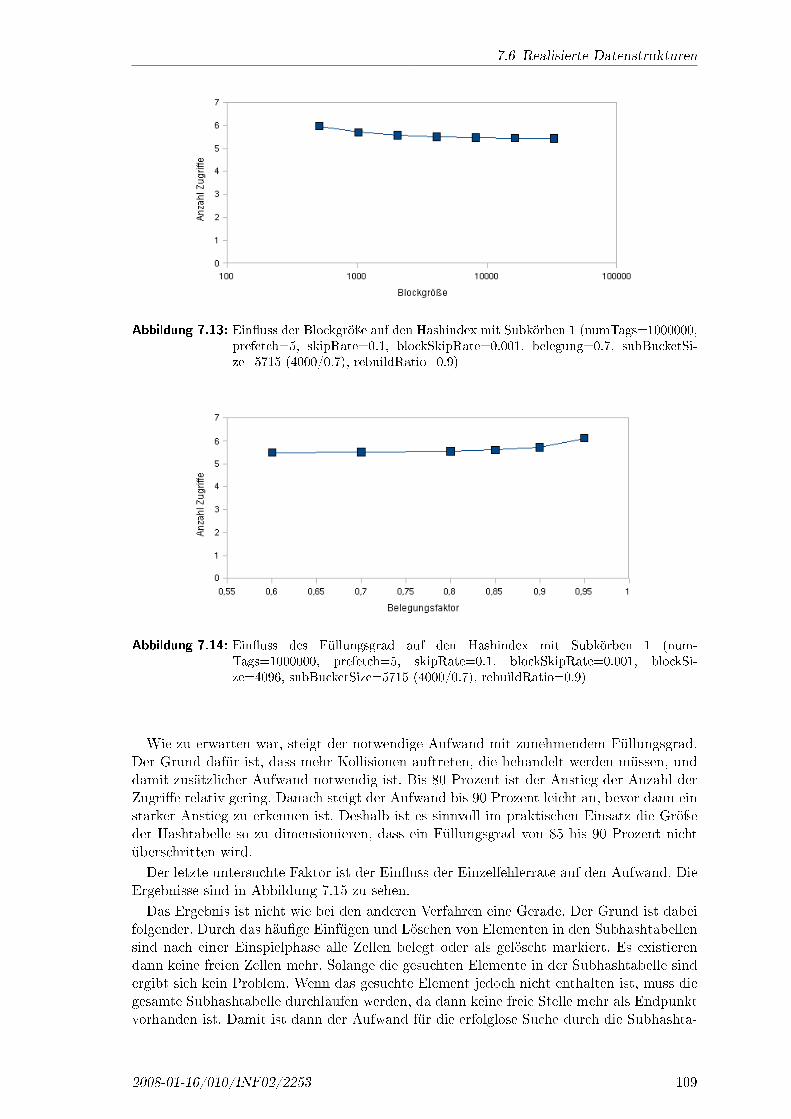
7.6 Realisierte Datenstrukturen
Abbildung 7.13: Ein�uss der Blockgröÿe auf den Hashindex mit Subkörben 1 (numTags=1000000,prefetch=5, skipRate=0.1, blockSkipRate=0.001, belegung=0.7, subBucketSi-ze=5715 (4000/0.7), rebuildRatio=0.9)
Abbildung 7.14: Ein�uss des Füllungsgrad auf den Hashindex mit Subkörben 1 (num-Tags=1000000, prefetch=5, skipRate=0.1, blockSkipRate=0.001, blockSi-ze=4096, subBucketSize=5715 (4000/0.7), rebuildRatio=0.9)
Wie zu erwarten war, steigt der notwendige Aufwand mit zunehmendem Füllungsgrad.Der Grund dafür ist, dass mehr Kollisionen auftreten, die behandelt werden müssen, unddamit zusätzlicher Aufwand notwendig ist. Bis 80 Prozent ist der Anstieg der Anzahl derZugri�e relativ gering. Danach steigt der Aufwand bis 90 Prozent leicht an, bevor dann einstarker Anstieg zu erkennen ist. Deshalb ist es sinnvoll im praktischen Einsatz die Gröÿeder Hashtabelle so zu dimensionieren, dass ein Füllungsgrad von 85 bis 90 Prozent nichtüberschritten wird.
Der letzte untersuchte Faktor ist der Ein�uss der Einzelfehlerrate auf den Aufwand. DieErgebnisse sind in Abbildung 7.15 zu sehen.
Das Ergebnis ist nicht wie bei den anderen Verfahren eine Gerade. Der Grund ist dabeifolgender. Durch das häu�ge Einfügen und Löschen von Elementen in den Subhashtabellensind nach einer Einspielphase alle Zellen belegt oder als gelöscht markiert. Es existierendann keine freien Zellen mehr. Solange die gesuchten Elemente in der Subhashtabelle sindergibt sich kein Problem. Wenn das gesuchte Element jedoch nicht enthalten ist, muss diegesamte Subhashtabelle durchlaufen werden, da dann keine freie Stelle mehr als Endpunktvorhanden ist. Damit ist dann der Aufwand für die erfolglose Suche durch die Subhashta-
2008-01-16/010/INF02/2253 109
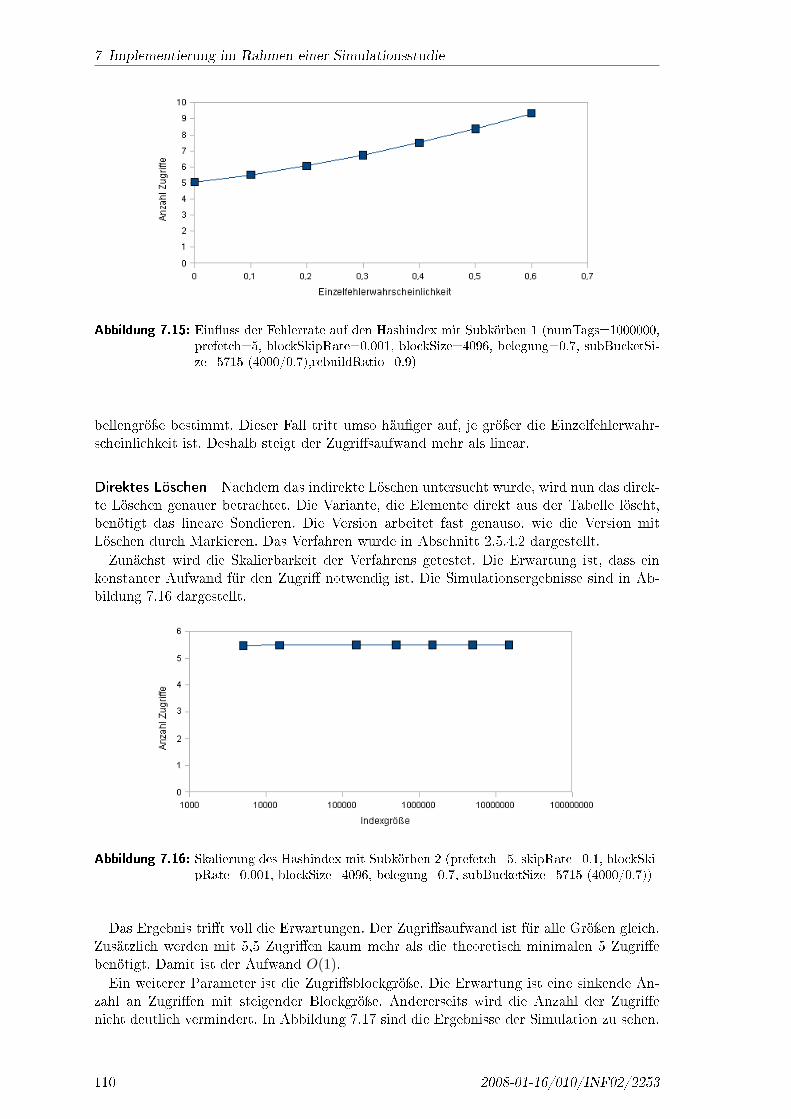
7 Implementierung im Rahmen einer Simulationsstudie
Abbildung 7.15: Ein�uss der Fehlerrate auf den Hashindex mit Subkörben 1 (numTags=1000000,prefetch=5, blockSkipRate=0.001, blockSize=4096, belegung=0.7, subBucketSi-ze=5715 (4000/0.7),rebuildRatio=0.9)
bellengröÿe bestimmt. Dieser Fall tritt umso häu�ger auf, je gröÿer die Einzelfehlerwahr-scheinlichkeit ist. Deshalb steigt der Zugri�saufwand mehr als linear.
Direktes Löschen Nachdem das indirekte Löschen untersucht wurde, wird nun das direk-te Löschen genauer betrachtet. Die Variante, die Elemente direkt aus der Tabelle löscht,benötigt das lineare Sondieren. Die Version arbeitet fast genauso, wie die Version mitLöschen durch Markieren. Das Verfahren wurde in Abschnitt 2.5.4.2 dargestellt.Zunächst wird die Skalierbarkeit der Verfahrens getestet. Die Erwartung ist, dass ein
konstanter Aufwand für den Zugri� notwendig ist. Die Simulationsergebnisse sind in Ab-bildung 7.16 dargestellt.
Abbildung 7.16: Skalierung des Hashindex mit Subkörben 2 (prefetch=5, skipRate=0.1, blockSki-pRate=0.001, blockSize=4096, belegung=0.7, subBucketSize=5715 (4000/0.7))
Das Ergebnis tri�t voll die Erwartungen. Der Zugri�saufwand ist für alle Gröÿen gleich.Zusätzlich werden mit 5,5 Zugri�en kaum mehr als die theoretisch minimalen 5 Zugri�ebenötigt. Damit ist der Aufwand O(1).Ein weiterer Parameter ist die Zugri�sblockgröÿe. Die Erwartung ist eine sinkende An-
zahl an Zugri�en mit steigender Blockgröÿe. Andererseits wird die Anzahl der Zugri�enicht deutlich vermindert. In Abbildung 7.17 sind die Ergebnisse der Simulation zu sehen.
110 2008-01-16/010/INF02/2253

7.6 Realisierte Datenstrukturen
Abbildung 7.17: Ein�uss der Blockgröÿe auf den Hashindex mit Subkörben 2 (numTags=1000000,prefetch=5, skipRate=0.1, blockSkipRate=0.001, belegung=0.7, subBucketSi-ze=5715 (4000/0.7))
Der Aufwand sinkt von etwa sechs Zugri�en bei einer Blockgröÿe von 512 Byte auf etwa5,5 Zugri�e bei unendlich groÿer Blockgröÿe. Das Einsparpotenzial ist damit wieder neunbis zehn Prozent, wie bei dem anderen Löschverfahren auch. Insgesamt ist das Verfahrendabei um die Hälfte schneller, zeigt aber sonst das gleiche Verhalten.Das Verhalten wird wahrscheinlich auch beim Belegungsfaktor ähnlich sein. Es ist aber
anzunehmen, dass die Belegung beim direkten Löschen etwas gröÿer sein kann, weil nichterst beim Erreichen des Schwellwertes die Werte gelöscht werden, sondern direkt. DasErgebnis ist in Abbildung 7.18 zu sehen.
Abbildung 7.18: Ein�uss des Füllungsgrad auf den Hashindex mit Subkörben 2 (num-Tags=1000000, prefetch=5, skipRate=0.1, blockSkipRate=0.001, blockSi-ze=4096, subBucketSize=5715 (4000/0.7))
Bis zu einem Füllungsgrad von 80 Prozent bleibt der Aufwand für den Zugri� nahezukonstant. Danach steigt der Aufwand bis 90 Prozent kontinuierlich an. Nach der Markewird der Aufwand schnell sehr groÿ und damit wird das Verfahren ine�zient. In der Praxissind damit Füllungsgrade bis 90 Prozent gut einsetzbar.Die Fehlerrate ist ein weiterer wichtiger Faktor für die Geschwindigkeit des Verfahrens.
Die Ergebnisse der Variierung der Fehlerrate ist in Abbildung 7.19 zu sehen.Das Ergebnis ist den anderen wieder stark ähnlich. Im Besonderen ist zu erkennen, dass
bei einer Fehlerrate von null der theoretisch minimal notwendige Aufwand erreicht wird.
2008-01-16/010/INF02/2253 111
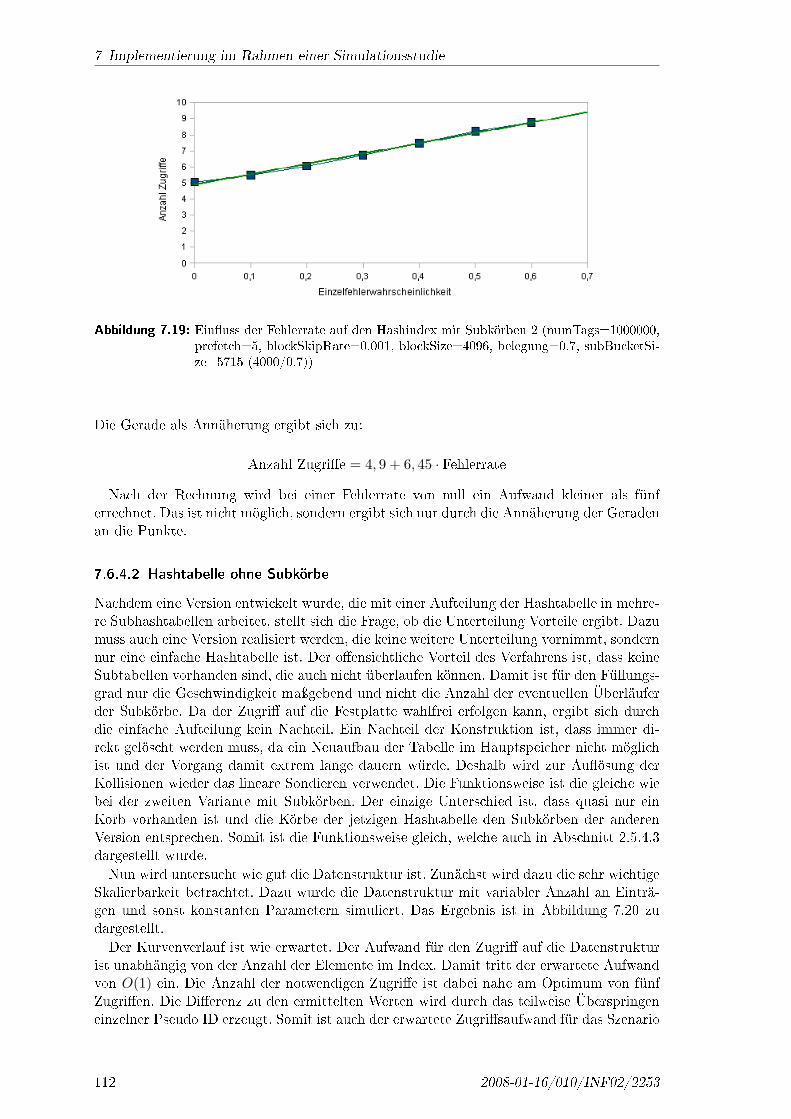
7 Implementierung im Rahmen einer Simulationsstudie
Abbildung 7.19: Ein�uss der Fehlerrate auf den Hashindex mit Subkörben 2 (numTags=1000000,prefetch=5, blockSkipRate=0.001, blockSize=4096, belegung=0.7, subBucketSi-ze=5715 (4000/0.7))
Die Gerade als Annäherung ergibt sich zu:
Anzahl Zugri�e = 4, 9 + 6, 45 · Fehlerrate
Nach der Rechnung wird bei einer Fehlerrate von null ein Aufwand kleiner als fünferrechnet. Das ist nicht möglich, sondern ergibt sich nur durch die Annäherung der Geradenan die Punkte.
7.6.4.2 Hashtabelle ohne Subkörbe
Nachdem eine Version entwickelt wurde, die mit einer Aufteilung der Hashtabelle in mehre-re Subhashtabellen arbeitet, stellt sich die Frage, ob die Unterteilung Vorteile ergibt. Dazumuss auch eine Version realisiert werden, die keine weitere Unterteilung vornimmt, sondernnur eine einfache Hashtabelle ist. Der o�ensichtliche Vorteil des Verfahrens ist, dass keineSubtabellen vorhanden sind, die auch nicht überlaufen können. Damit ist für den Füllungs-grad nur die Geschwindigkeit maÿgebend und nicht die Anzahl der eventuellen Überläuferder Subkörbe. Da der Zugri� auf die Festplatte wahlfrei erfolgen kann, ergibt sich durchdie einfache Aufteilung kein Nachteil. Ein Nachteil der Konstruktion ist, dass immer di-rekt gelöscht werden muss, da ein Neuaufbau der Tabelle im Hauptspeicher nicht möglichist und der Vorgang damit extrem lange dauern würde. Deshalb wird zur Au�ösung derKollisionen wieder das lineare Sondieren verwendet. Die Funktionsweise ist die gleiche wiebei der zweiten Variante mit Subkörben. Der einzige Unterschied ist, dass quasi nur einKorb vorhanden ist und die Körbe der jetzigen Hashtabelle den Subkörben der anderenVersion entsprechen. Somit ist die Funktionsweise gleich, welche auch in Abschnitt 2.5.4.3dargestellt wurde.Nun wird untersucht wie gut die Datenstruktur ist. Zunächst wird dazu die sehr wichtige
Skalierbarkeit betrachtet. Dazu wurde die Datenstruktur mit variabler Anzahl an Einträ-gen und sonst konstanten Parametern simuliert. Das Ergebnis ist in Abbildung 7.20 zudargestellt.Der Kurvenverlauf ist wie erwartet. Der Aufwand für den Zugri� auf die Datenstruktur
ist unabhängig von der Anzahl der Elemente im Index. Damit tritt der erwartete Aufwandvon O(1) ein. Die Anzahl der notwendigen Zugri�e ist dabei nahe am Optimum von fünfZugri�en. Die Di�erenz zu den ermittelten Werten wird durch das teilweise Überspringeneinzelner Pseudo ID erzeugt. Somit ist auch der erwartete Zugri�saufwand für das Szenario
112 2008-01-16/010/INF02/2253
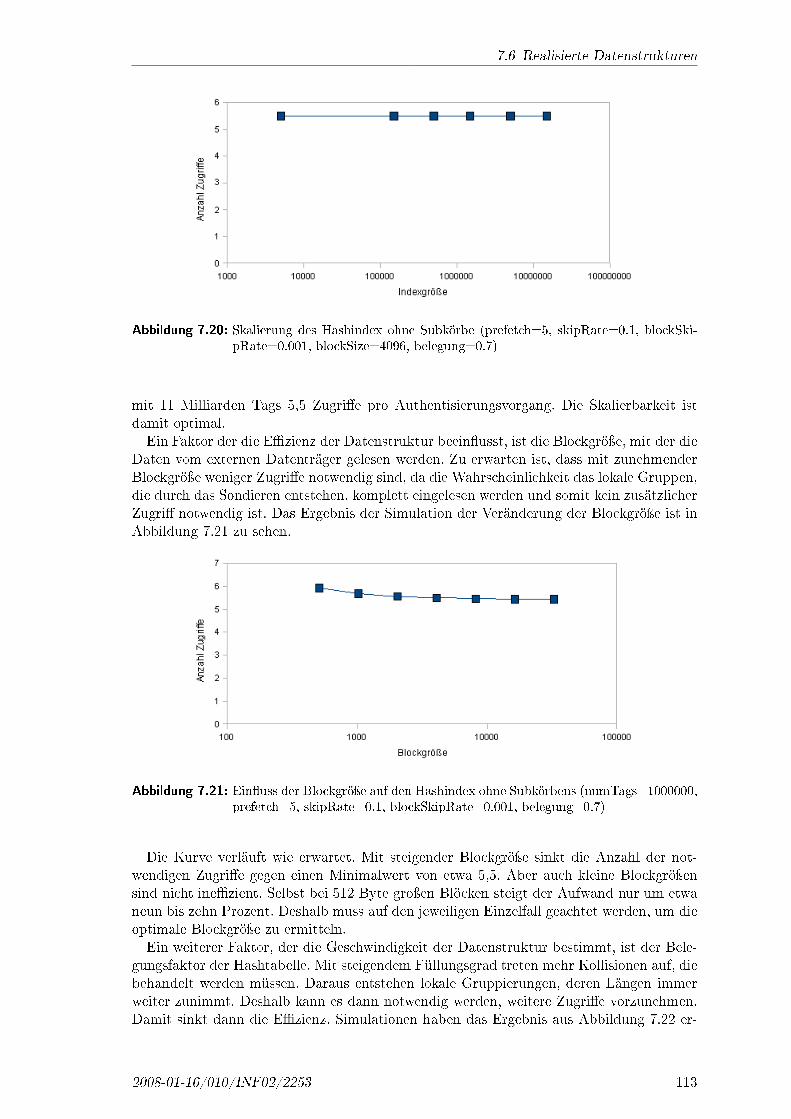
7.6 Realisierte Datenstrukturen
Abbildung 7.20: Skalierung des Hashindex ohne Subkörbe (prefetch=5, skipRate=0.1, blockSki-pRate=0.001, blockSize=4096, belegung=0.7)
mit 11 Milliarden Tags 5,5 Zugri�e pro Authentisierungsvorgang. Die Skalierbarkeit istdamit optimal.Ein Faktor der die E�zienz der Datenstruktur beein�usst, ist die Blockgröÿe, mit der die
Daten vom externen Datenträger gelesen werden. Zu erwarten ist, dass mit zunehmenderBlockgröÿe weniger Zugri�e notwendig sind, da die Wahrscheinlichkeit das lokale Gruppen,die durch das Sondieren entstehen, komplett eingelesen werden und somit kein zusätzlicherZugri� notwendig ist. Das Ergebnis der Simulation der Veränderung der Blockgröÿe ist inAbbildung 7.21 zu sehen.
Abbildung 7.21: Ein�uss der Blockgröÿe auf den Hashindex ohne Subkörbens (numTags=1000000,prefetch=5, skipRate=0.1, blockSkipRate=0.001, belegung=0.7)
Die Kurve verläuft wie erwartet. Mit steigender Blockgröÿe sinkt die Anzahl der not-wendigen Zugri�e gegen einen Minimalwert von etwa 5,5. Aber auch kleine Blockgröÿensind nicht ine�zient. Selbst bei 512 Byte groÿen Blöcken steigt der Aufwand nur um etwaneun bis zehn Prozent. Deshalb muss auf den jeweiligen Einzelfall geachtet werden, um dieoptimale Blockgröÿe zu ermitteln.Ein weiterer Faktor, der die Geschwindigkeit der Datenstruktur bestimmt, ist der Bele-
gungsfaktor der Hashtabelle. Mit steigendem Füllungsgrad treten mehr Kollisionen auf, diebehandelt werden müssen. Daraus entstehen lokale Gruppierungen, deren Längen immerweiter zunimmt. Deshalb kann es dann notwendig werden, weitere Zugri�e vorzunehmen.Damit sinkt dann die E�zienz. Simulationen haben das Ergebnis aus Abbildung 7.22 er-
2008-01-16/010/INF02/2253 113
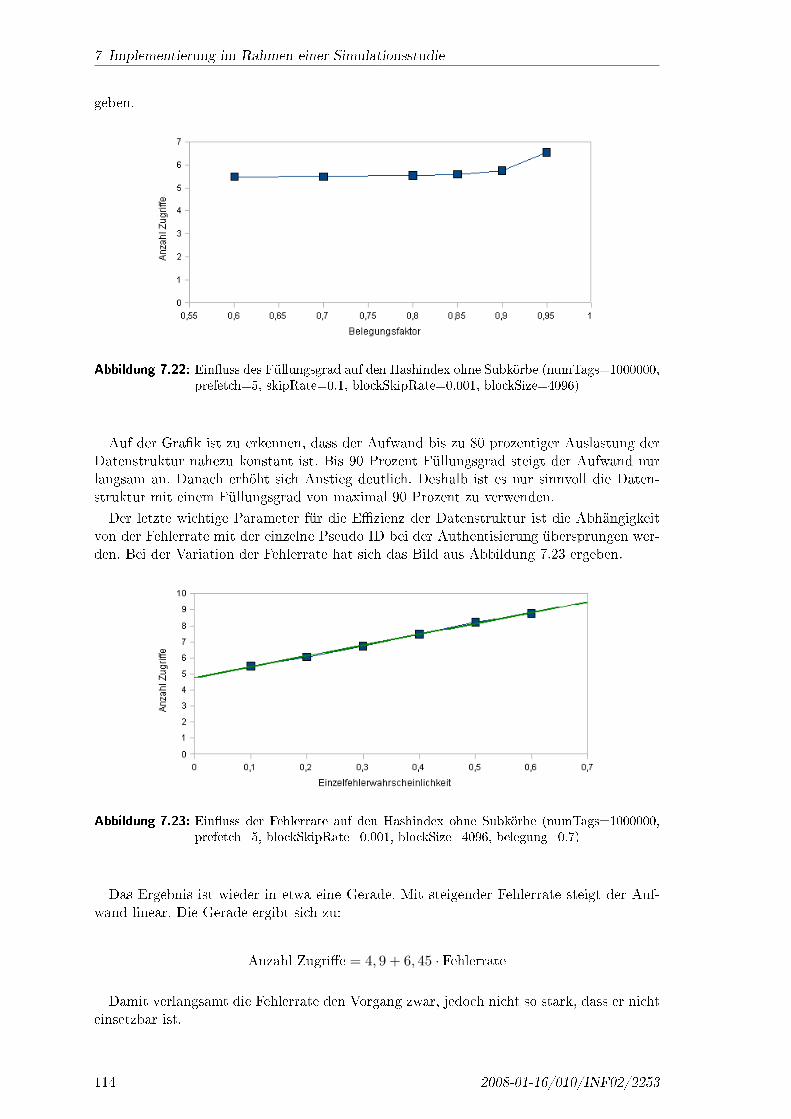
7 Implementierung im Rahmen einer Simulationsstudie
geben.
Abbildung 7.22: Ein�uss des Füllungsgrad auf den Hashindex ohne Subkörbe (numTags=1000000,prefetch=5, skipRate=0.1, blockSkipRate=0.001, blockSize=4096)
Auf der Gra�k ist zu erkennen, dass der Aufwand bis zu 80 prozentiger Auslastung derDatenstruktur nahezu konstant ist. Bis 90 Prozent Füllungsgrad steigt der Aufwand nurlangsam an. Danach erhöht sich Anstieg deutlich. Deshalb ist es nur sinnvoll die Daten-struktur mit einem Füllungsgrad von maximal 90 Prozent zu verwenden.
Der letzte wichtige Parameter für die E�zienz der Datenstruktur ist die Abhängigkeitvon der Fehlerrate mit der einzelne Pseudo ID bei der Authentisierung übersprungen wer-den. Bei der Variation der Fehlerrate hat sich das Bild aus Abbildung 7.23 ergeben.
Abbildung 7.23: Ein�uss der Fehlerrate auf den Hashindex ohne Subkörbe (numTags=1000000,prefetch=5, blockSkipRate=0.001, blockSize=4096, belegung=0.7)
Das Ergebnis ist wieder in etwa eine Gerade. Mit steigender Fehlerrate steigt der Auf-wand linear. Die Gerade ergibt sich zu:
Anzahl Zugri�e = 4, 9 + 6, 45 · Fehlerrate
Damit verlangsamt die Fehlerrate den Vorgang zwar, jedoch nicht so stark, dass er nichteinsetzbar ist.
114 2008-01-16/010/INF02/2253
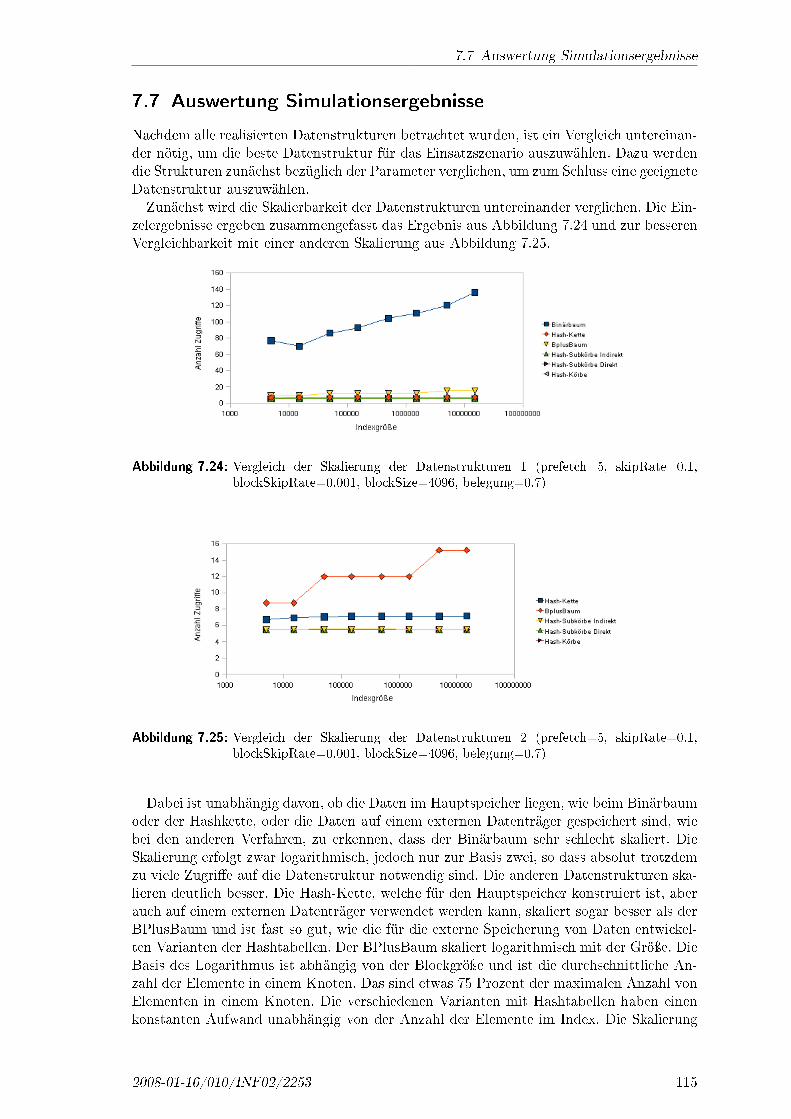
7.7 Auswertung Simulationsergebnisse
7.7 Auswertung Simulationsergebnisse
Nachdem alle realisierten Datenstrukturen betrachtet wurden, ist ein Vergleich untereinan-der nötig, um die beste Datenstruktur für das Einsatzszenario auszuwählen. Dazu werdendie Strukturen zunächst bezüglich der Parameter verglichen, um zum Schluss eine geeigneteDatenstruktur auszuwählen.Zunächst wird die Skalierbarkeit der Datenstrukturen untereinander verglichen. Die Ein-
zelergebnisse ergeben zusammengefasst das Ergebnis aus Abbildung 7.24 und zur besserenVergleichbarkeit mit einer anderen Skalierung aus Abbildung 7.25.
Abbildung 7.24: Vergleich der Skalierung der Datenstrukturen 1 (prefetch=5, skipRate=0.1,blockSkipRate=0.001, blockSize=4096, belegung=0.7)
Abbildung 7.25: Vergleich der Skalierung der Datenstrukturen 2 (prefetch=5, skipRate=0.1,blockSkipRate=0.001, blockSize=4096, belegung=0.7)
Dabei ist unabhängig davon, ob die Daten im Hauptspeicher liegen, wie beim Binärbaumoder der Hashkette, oder die Daten auf einem externen Datenträger gespeichert sind, wiebei den anderen Verfahren, zu erkennen, dass der Binärbaum sehr schlecht skaliert. DieSkalierung erfolgt zwar logarithmisch, jedoch nur zur Basis zwei, so dass absolut trotzdemzu viele Zugri�e auf die Datenstruktur notwendig sind. Die anderen Datenstrukturen ska-lieren deutlich besser. Die Hash-Kette, welche für den Hauptspeicher konstruiert ist, aberauch auf einem externen Datenträger verwendet werden kann, skaliert sogar besser als derBPlusBaum und ist fast so gut, wie die für die externe Speicherung von Daten entwickel-ten Varianten der Hashtabellen. Der BPlusBaum skaliert logarithmisch mit der Gröÿe. DieBasis des Logarithmus ist abhängig von der Blockgröÿe und ist die durchschnittliche An-zahl der Elemente in einem Knoten. Das sind etwas 75 Prozent der maximalen Anzahl vonElementen in einem Knoten. Die verschiedenen Varianten mit Hashtabellen haben einenkonstanten Aufwand unabhängig von der Anzahl der Elemente im Index. Die Skalierung
2008-01-16/010/INF02/2253 115

7 Implementierung im Rahmen einer Simulationsstudie
erfolgt damit in O(1). Alle drei verschiedenen Versionen der Hashtabellen skalieren prak-tisch gleich. Alle sind sehr nahe am optimalen Fall. Eine Hochrechnung des Aufwandes aufdie erwartete Indexgröÿe von 55 Milliarden Zuordnungen bei 11 Milliarden Tags und je-weils fünf gespeicherten Zuordnungen ist in Tabelle 7.3 und 7.4 zu sehen. Die angegebenenWerte sind Erwartungswerte und werden nicht genau eintre�en.
Verfahren Anzahl Zugri�e
Binärbaum 198Hash-Kette 7,1
Tabelle 7.3: Vergleich der Skalierbarkeit der Hauptspeicherdatenstrukturen
Verfahren Anzahl Zugri�e
BPlusBaum 18,6Hash-Subkörbe Indirekt 5,5Hash-Subkörbe Direkt 5,5
Hash-Körbe 5,5
Tabelle 7.4: Vergleich der Skalierbarkeit der Datenstrukturen für externe Datenträger
Es ist zu erkennen, dass für den realen Einsatz, in Bezug auf Skalierbarkeit, die Versionender Hashtabelle mit direktem Löschen am besten sind, unabhängig davon ob mit oder ohneSubkörbe. Der Aufwand bei einem BPlusBaum ist demgegenüber etwa 3,4-mal so hoch unddamit das System um diesen Faktor langsamer.Für die Verfahren, die für externe Datenträger benutzt werden, ist die Blockgröÿe des
Datenträgers wichtig. Die zusammengefassten Erkenntnisse aus den Einzeluntersuchungensind in Abbildung 7.26 zu sehen.
Abbildung 7.26: Vergleich des Ein�uss der Blockgröÿe auf die Datenstrukturen (num-Tags=1000000, prefetch=5, skipRate=0.1, blockSkipRate=0.001, belegung=0.7)
In der Abbildung ist zu sehen, dass der BPlusBaum deutlich von der Blockgröÿe desZugri�es pro�tiert. Das ist auch zu erwarten, da mit gröÿerer Blockgröÿe die Höhe desBaumes abnimmt und somit der Zugri� schneller wird. Jedoch erreicht die E�zienz desBPlusBaums nicht die E�zienz der Hashverfahren, da dafür die durchschnittliche Höhedes Baumes nahe eins sein müsste. Die verschiedenen Hashverfahren pro�tieren nur sehrgering von den gröÿeren Blockgröÿen. Der Grund dafür ist, dass eigentlich ein Zugri� vonwenigen Byte reicht um das Element zu �nden. Nur durch Kollisionen entstehen gröÿerelokale Gruppen. Von gröÿeren Blockgröÿen kann in diesem Fall pro�tiert werden, da dieWahrscheinlichkeit steigt, dass die ganze lokale Gruppe eingelesen werden kann und damit
116 2008-01-16/010/INF02/2253
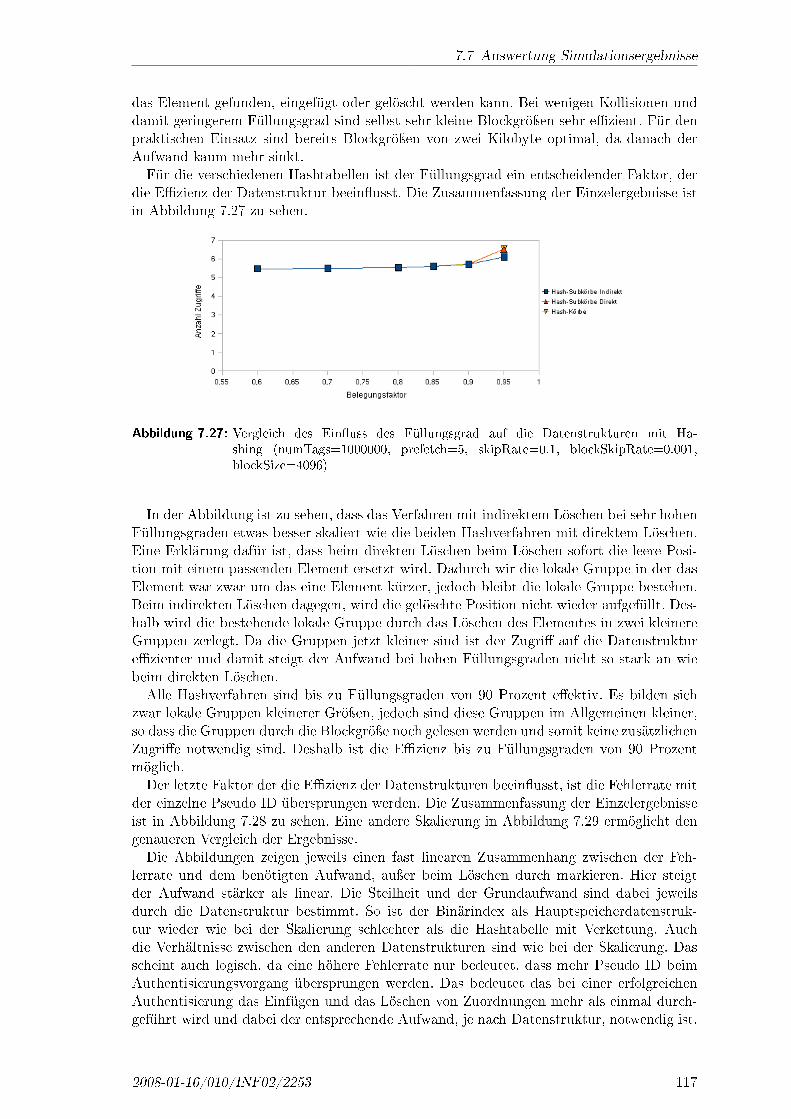
7.7 Auswertung Simulationsergebnisse
das Element gefunden, eingefügt oder gelöscht werden kann. Bei wenigen Kollisionen unddamit geringerem Füllungsgrad sind selbst sehr kleine Blockgröÿen sehr e�zient. Für denpraktischen Einsatz sind bereits Blockgröÿen von zwei Kilobyte optimal, da danach derAufwand kaum mehr sinkt.Für die verschiedenen Hashtabellen ist der Füllungsgrad ein entscheidender Faktor, der
die E�zienz der Datenstruktur beein�usst. Die Zusammenfassung der Einzelergebnisse istin Abbildung 7.27 zu sehen.
Abbildung 7.27: Vergleich des Ein�uss des Füllungsgrad auf die Datenstrukturen mit Ha-shing (numTags=1000000, prefetch=5, skipRate=0.1, blockSkipRate=0.001,blockSize=4096)
In der Abbildung ist zu sehen, dass das Verfahren mit indirektem Löschen bei sehr hohenFüllungsgraden etwas besser skaliert wie die beiden Hashverfahren mit direktem Löschen.Eine Erklärung dafür ist, dass beim direkten Löschen beim Löschen sofort die leere Posi-tion mit einem passenden Element ersetzt wird. Dadurch wir die lokale Gruppe in der dasElement war zwar um das eine Element kürzer, jedoch bleibt die lokale Gruppe bestehen.Beim indirekten Löschen dagegen, wird die gelöschte Position nicht wieder aufgefüllt. Des-halb wird die bestehende lokale Gruppe durch das Löschen des Elementes in zwei kleinereGruppen zerlegt. Da die Gruppen jetzt kleiner sind ist der Zugri� auf die Datenstrukture�zienter und damit steigt der Aufwand bei hohen Füllungsgraden nicht so stark an wiebeim direkten Löschen.Alle Hashverfahren sind bis zu Füllungsgraden von 90 Prozent e�ektiv. Es bilden sich
zwar lokale Gruppen kleinerer Gröÿen, jedoch sind diese Gruppen im Allgemeinen kleiner,so dass die Gruppen durch die Blockgröÿe noch gelesen werden und somit keine zusätzlichenZugri�e notwendig sind. Deshalb ist die E�zienz bis zu Füllungsgraden von 90 Prozentmöglich.Der letzte Faktor der die E�zienz der Datenstrukturen beein�usst, ist die Fehlerrate mit
der einzelne Pseudo ID übersprungen werden. Die Zusammenfassung der Einzelergebnisseist in Abbildung 7.28 zu sehen. Eine andere Skalierung in Abbildung 7.29 ermöglicht dengenaueren Vergleich der Ergebnisse.Die Abbildungen zeigen jeweils einen fast linearen Zusammenhang zwischen der Feh-
lerrate und dem benötigten Aufwand, auÿer beim Löschen durch markieren. Hier steigtder Aufwand stärker als linear. Die Steilheit und der Grundaufwand sind dabei jeweilsdurch die Datenstruktur bestimmt. So ist der Binärindex als Hauptspeicherdatenstruk-tur wieder wie bei der Skalierung schlechter als die Hashtabelle mit Verkettung. Auchdie Verhältnisse zwischen den anderen Datenstrukturen sind wie bei der Skalierung. Dasscheint auch logisch, da eine höhere Fehlerrate nur bedeutet, dass mehr Pseudo ID beimAuthentisierungsvorgang übersprungen werden. Das bedeutet das bei einer erfolgreichenAuthentisierung das Einfügen und das Löschen von Zuordnungen mehr als einmal durch-geführt wird und dabei der entsprechende Aufwand, je nach Datenstruktur, notwendig ist.
2008-01-16/010/INF02/2253 117
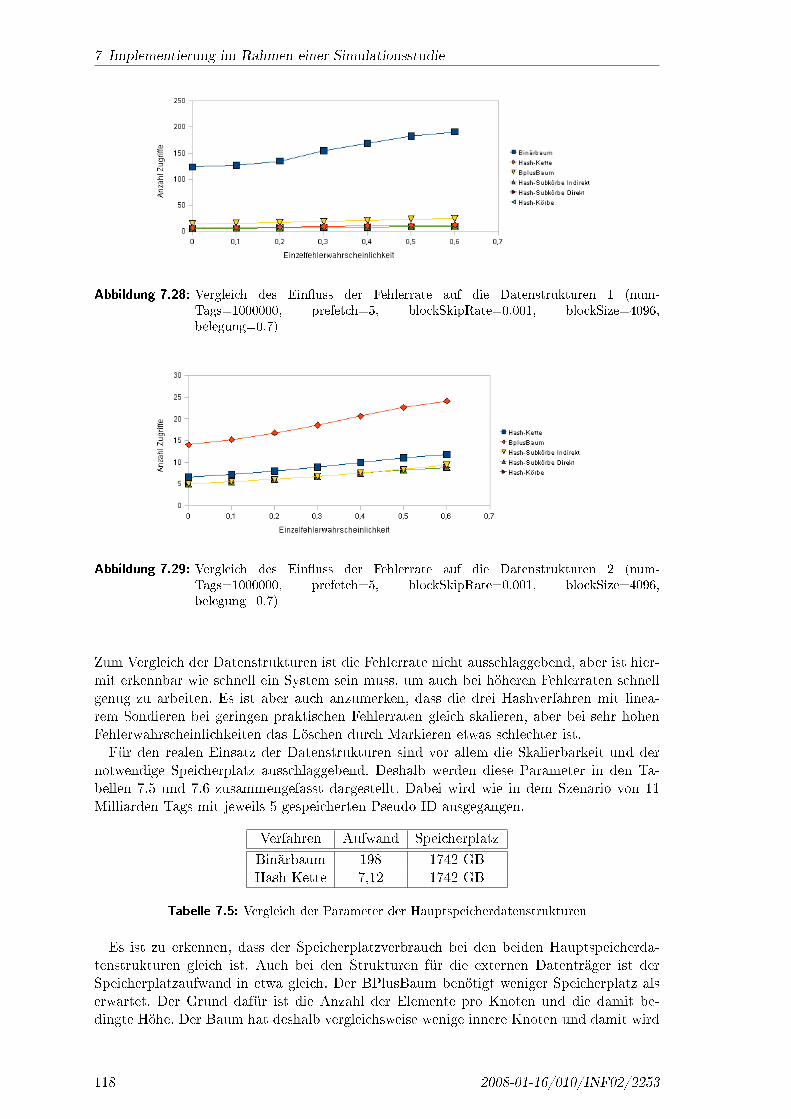
7 Implementierung im Rahmen einer Simulationsstudie
Abbildung 7.28: Vergleich des Ein�uss der Fehlerrate auf die Datenstrukturen 1 (num-Tags=1000000, prefetch=5, blockSkipRate=0.001, blockSize=4096,belegung=0.7)
Abbildung 7.29: Vergleich des Ein�uss der Fehlerrate auf die Datenstrukturen 2 (num-Tags=1000000, prefetch=5, blockSkipRate=0.001, blockSize=4096,belegung=0.7)
Zum Vergleich der Datenstrukturen ist die Fehlerrate nicht ausschlaggebend, aber ist hier-mit erkennbar wie schnell ein System sein muss, um auch bei höheren Fehlerraten schnellgenug zu arbeiten. Es ist aber auch anzumerken, dass die drei Hashverfahren mit linea-rem Sondieren bei geringen praktischen Fehlerraten gleich skalieren, aber bei sehr hohenFehlerwahrscheinlichkeiten das Löschen durch Markieren etwas schlechter ist.Für den realen Einsatz der Datenstrukturen sind vor allem die Skalierbarkeit und der
notwendige Speicherplatz ausschlaggebend. Deshalb werden diese Parameter in den Ta-bellen 7.5 und 7.6 zusammengefasst dargestellt. Dabei wird wie in dem Szenario von 11Milliarden Tags mit jeweils 5 gespeicherten Pseudo ID ausgegangen.
Verfahren Aufwand Speicherplatz
Binärbaum 198 1742 GBHash-Kette 7,12 1742 GB
Tabelle 7.5: Vergleich der Parameter der Hauptspeicherdatenstrukturen
Es ist zu erkennen, dass der Speicherplatzverbrauch bei den beiden Hauptspeicherda-tenstrukturen gleich ist. Auch bei den Strukturen für die externen Datenträger ist derSpeicherplatzaufwand in etwa gleich. Der BPlusBaum benötigt weniger Speicherplatz alserwartet. Der Grund dafür ist die Anzahl der Elemente pro Knoten und die damit be-dingte Höhe. Der Baum hat deshalb vergleichsweise wenige innere Knoten und damit wird
118 2008-01-16/010/INF02/2253

7.8 Zusammenfassung
Verfahren Aufwand Speicherplatz
BPlusBaum 18,6 1239 GBHash-Subkörbe Indirekt (belegung=0.8) 5,5 1153 GBHash-Subkörbe Direkt (belegung=0.8) 5,5 1153 GB
Hash-Korb (belegung=0.8) 5,5 1153 GB
Tabelle 7.6: Vergleich der Parameter der Datenstrukturen für externe Datenträger
wenig Speicherplatz nicht für Nutzdaten verwendet. Die Hashtabellen sind erwartungs-gemäÿ groÿ. Alle Hashtabellen kommen mit wenig Freiraum gut aus. Deshalb ist dortauch der notwendige Speicherplatz geringer. Es sind insgesamt in den Kategorien keinesigni�kanten Speicherplatzunterschiede vorhanden. Deshalb ist das vernachlässigbar unddie Entscheidung kann als Hauptkriterium die Geschwindigkeit beachten. Da die Verfahrenmit Subkörben genauso gut sind, wie die einfache Variante der Hashtabelle ohne Subkörbe,sollte auch die einfache Version eingesetzt werden. Der Vorteil des einfacheren Verfahrensist, dass keine Behandlung von eventuellen Überläufern der Subkörbe realisiert werdenmuss und somit die Komplexität geringer ist als bei der einfacheren Version.Zu dem oben genannten Speicherplatz werden noch weitere Daten benötigt und damit
mehr Speicherplatz. Die eigentlichen Informationen zu den Tags werden wie in Abschnitt7.4 beschrieben extra gespeichert und benötigen pro Tag einen Speicherplatz von 76 Byte.Damit wird hier ein Speicherplatz von zusätzlich 779 GB benötigt. Weiter ist noch ein extraIndex auf die reale ID des Tags zu den gespeicherten Daten sinnvoll. Das ergibt bei einemHashindex mit 80 Prozent Füllungsgrad und 18 Byte pro Zuordnung etwa 231 GB Daten.Neben diesen Daten sind auch noch Informationen für den Resynchronisierungsvorgangnotwendig. Bei 15 gespeicherten Zuordnungen für die Resynchronisierung ergibt dies beieinem Hashindex mit 80 Prozent Belegung und wieder 18 Byte pro Zuordnung nochmals3458 GB notwendigen Speicherplatz. Damit ergibt sich ein gesamter Speicherplatzbedarfvon 5621 GB für das gesamte System. Festplattensysteme mit etwa 6 TB Kapazität sindheute ohne weiteres erwerbbar. Bei einer angenommenen Lebensdauer der Hardware von 5Jahren und damit einem Drittel der derzeitigen Lebensdauer der KFZ in Deutschland reichtfür den Einsatz des Systems zunächst ein Festplattensystem mit 2 TB Nettokapazität.
7.8 Zusammenfassung
Dieses Kapitel dient zur Lösung der quantitativen Fragen aus dem Abschnitt 3.2. Damiteine Beantwortung möglich ist, wurden zunächst nochmals die genauen Ziele de�niert. Fürdie spätere Evaluierung der Datenstrukturen wurde eine geeignete Testumgebung erstellt.Danach wurden die speziellen Anforderungen an die Datenstruktur dargestellt, weil durchdie verwendete Anonymisierung ein spezielles Zugri�sverhalten auf die Daten bedingt ist.Für den Zugri� auf die Daten sind grundsätzlich verschiedene Vorgehensweisen möglich.Die Möglichkeiten wurden dargestellt und die beste von diesen ausgewählt. Der verwendeteIndex wurde genauer betrachtet. Dabei wurde die Auswahl der möglichen und sinnvollenDatenstrukturen betrachtet. Danach erfolgten die genauen Darstellungen der realisiertenStrukturen und deren Implementierungen. Nachdem die Algorithmen in der Simulationvorhanden waren, erfolgte für jede Datenstruktur eine Evaluation. Aus den einzelnen Aus-wertungen wurde eine vergleichende Evaluation erstellt, die die Antworten auf die meistenquantitativen Fragen gibt. Die restlichen Fragen werden an anderen Stellen des Kapitelsgelöst.
Mit welchen Datenstrukturen ist ein praktischer Einsatz des Systems möglich? DieLösung dieser Frage erfolgt in Abschnitt 7.7. Es wurde ermittelt, dass eine Hashtabelle
2008-01-16/010/INF02/2253 119

7 Implementierung im Rahmen einer Simulationsstudie
benötigt wird, damit die Performanz hoch genug für einen praktischen Einsatz ist. Sinnvollist die Wahl einer einfachen Hashtabelle mit linearem Sondieren und direktem Löschen,da dort wenig Aufwand notwendig ist, aber die besten Ergebnisse entstehen. Die Bäumesind dagegen nicht geeignet, weil die Leistung schlechter ist und meist mehr Speicherplatzbenötigt wird als bei der Hashtabelle. Sie wachsen zwar im Gegensatz zu der verwendetenHashtabelle dynamisch, jedoch ist dies im Einsatzszenario, wie dargestellt, kein Problem.
Welche Parametrisierung der Datenstrukturen ist sinnvoll? Folgende generelle Para-meter sind sinnvoll. Die Anzahl der im Voraus gespeicherten Pseudo ID sollte etwa fünfsein. Bei einer angenommenen Einzelfehlerrate von zehn Prozent sind beträgt die Wahr-scheinlichkeit, dass eine Resynchronisierung notwendig ist 0,01 Promille. Für die Parameterder Resynchronisierung können endgültig keine genauen Angaben gemacht werden, da esvom gewünschten Grad der Anonymisierung und den vertretbaren Wartezeiten in der Pra-xis abhängig ist. Bei einer exponentiellen Steigerung der Wartezeit von zwei Sekundenbis maximal zehn Minuten und einer Zykluslänge von 15 ist die Anonymisierung für eineZeit von minimal 77 Minuten nach der letzten erfolgreichen Anonymisierung gewährleistet.Durch eine Änderung der Funktion der Wartezeit und der Zykluslänge ist dieser Wert freiwählbar.Die Parametrisierung der Datenstruktur für den Index ist dagegen relativ einfach. Die
Simulationen haben ergeben, dass die ausgewählte Datenstruktur bis zu Füllungsgradenvon 90 Prozent e�ektiv funktioniert. Deshalb muss die zu wählende Hardware so dimensio-niert werden, dass zum Ende der Lebensdauer die Anzahl der zu erwartenden Tags mög-lichst höchstens 90 Prozent der möglichen Anzahl von speicherbaren Tags entspricht. Es istauch sinnvoll noch eine Sicherheitsreserve zu lassen, damit eventuelle Fehleinschätzungenausgeglichen werden können. Mit den Annahmen für das Szenario ist im Endausbau dienotwendige Kapazität etwas 6 bis 7 Terabyte, wenn noch eine entsprechende Reserve miteinbezogen wird. Die Berechnung erfolgt in Abschnitt 7.7. Die Blockgröÿe als Parameterist für die Hashtabelle relativ unbedeutend. Hier kann die minimal vom System unterstützesinnvolle Blockgröÿe verwendet werden. Schon ab einer Blockgröÿe von vier Kilobyte istkeine Verbesserung bei der Geschwindigkeit mehr zu erkennen.
Welchen Ein�uss hat die Anzahl der Tags auf die Geschwindigkeit? Weil die Skalier-barkeit der Datenstruktur in Bezug auf die Anzahl der vorhandenen Tags ein besonderswichtige Anforderung ist, wurde eine Datenstruktur gewählt, die das möglichst gut gewähr-leistet. Die verwendete Hashtabelle hat einen Aufwand von O(1). Damit hat die Anzahlder vorhandenen Tags keinen Ein�uss auf die Geschwindigkeit des Systems.
Welchen Ein�uss haben die anderen Parameter der Datenstrukturen auf die Perfor-
manz? Wie bereits bei der Frage der sinnvollen Parametrisierung festgestellt ist der ent-scheidende Parameter für die verwendete Datenstruktur der Füllungsgrad. Die Blockgröÿehat nur einen unwesentlichen Ein�uss auf das System.
Hat die Höhe der Einzelfehlerrate einen wesentlichen Ein�uss auf den Aufwand beim
Zugri� auf die Datenstruktur? Wie in der Auswertung zu sehen ist, hat die Wahrschein-lichkeit mit der einzelne Pseudo ID übersprungen werden, nur etwa einen linearen Ein�ussauf den notwendigen Aufwand. Bei einer unrealistischen Fehlerwahrscheinlichkeit von 50Prozent steigt der notwendige Aufwand pro Zugri� um etwa 60 Prozent. Es ist jedoch zubeachten, dass bei einer steigenden Fehlerrate die Wahrscheinlichkeit für eine aufwendigeResynchronisierung steigt. Bei einer Einzelfehlerwahrscheinlichkeit von 50 Prozent und dengegebenen Parametern ist diese dann etwa drei Prozent. Das scheint nicht viel, jedoch ist
120 2008-01-16/010/INF02/2253

7.8 Zusammenfassung
dann zusätzliche Kommunikation und ein zusätzlicher Aufwand für die Resychronisations-datenstruktur notwendig, so dass diese Wahrscheinlichkeit viel kleiner sein sollte.Durch die Beantwortung der qualitativen Fragen aus den Zielen des System wurde ge-
zeigt, dass und wie diese Ziele erreicht wurden. Dir anderen quantitativen Fragen wurdenbereits in früheren Kapiteln beantwortet, so dass jetzt alle Ziele bearbeitet und geeigneteLösungen gefunden wurden.
2008-01-16/010/INF02/2253 121

122 2008-01-16/010/INF02/2253

8 Zusammenfassung und Ausblick
In dieser Arbeit wurden Lösungen für den Einsatz der RFID-Technologie in Logistikkettenentwickelt.Ein Teil betrachtet die Sicherheitsaspekte des gesamten System. Es wurde ein Protokoll
entwickelt, dass die sichere Ausführung der gewünschten Funktionen ermöglicht. Es soll vonberechtigten Teilnehmern möglich sein, auf zugelassenen Teilinformationen des Tags mitde�nierten Rechten zuzugreifen. Ein Zugri� auf die Daten des Tag soll nur möglich sein,wenn der Tag aktuell unter Kontrolle des Teilnehmers ist, der auf die Daten des Tag zugrei-fen will. Es sollen sonst keine Informationen aus den RFID Tags ermittelt werden können.Die Realisierung muss mit der geringen Funktionalität der RFID-Tags funktionieren.Für das entwickelte Protokoll wurden die Probleme der Anonymisierung, Integritätssi-
cherung und Zugri�skontrolle betrachtet und gelöst. Das Protokoll umfasst die Authenti-sierung und den Zugri� auf den Tag. Die Authentisierung stellt sicher, dass bekannt ist,wer mit wem Nachrichten austauscht. Dabei werden keine sensiblen Informationen nachauÿen gegeben. Die Kommunikation der Teilnehmer erfolgt nach der Authentisierung ver-schlüsselt, damit keine Informationen aus der Kommunikation gewonnen werden können.Die de�nierten Ziele des Protokolls wurden mit der GNY untersucht.Die Anonymisierung erfolgt ändern der ID, der das Tag bei jedem Vorgang nach auÿen
gibt, die Pseudo ID. Diese wird nach jedem wegfallen des angelegten Auslesefeldes undnach einer bestimmten Gültigkeitszeit gewechselt. Es wird ein Modell mit zwei Phasenbenutzt. Einer normalen Phase und einer Phase zur Resynchronisierung, damit auf Tagszugegri�en werden kann, die zum Beispiel durch einen Angri� aus dem Takt der erstenPhase gekommen sind. Die erste Phase basiert auf einer Hashkette und die zweite Phaseauf der Speicherung von mehreren Pseudo ID. Mit der Hashkette wird die neue PseudoID jeweils aus der alten Pseudo ID und einem Schlüssel gebildet, den der Tag und derAuthentisierungsserver gemeinsam haben. In der zweiten Phase wird die Pseudo ID auseinem Zyklus von Pseudo IDs gewählt. Die Erzeugung einer ID erfolgt aus einem Geheimnis,dass nur Tag und Authentisierungsserver haben und einer Zahl, die die Position der IDim Zyklus repräsentiert. Das Verfahren verbindet die Vorteile der verschiedenen Verfahrenmiteinander, wobei Nachteile gröÿtenteils überdeckt werden. Das Verfahren stellt damiteine signi�kante Verbesserung der bisher verwendeten Verfahren dar, weil das entwickelteVerfahren eine einstellbaren Grad der Anonymisierung sicherstellt, sehr gut skaliert undzusätzlich berücksichtigt, dass der Tag nur wenig Speicherplatz hat.Für die Integritätssicherung wurde ein Verfahren entwickelt, welches den begrenzten
Speicherplatz der RFID-Tags berücksichtigt. Die Realisierung benutzt dabei nicht für je-des einzelne Datum eine Prüfsumme, wie es üblich ist, sondern bildet die Prüfsumme überBlöcke von Daten. Damit wird Speicherplatz eingespart, weil nicht so viele Prüfsummenbenötigt werden. Das Verfahren hat jedoch eine problematische Seite. Die Teilnehmer müs-sen sich untereinander teilweise vertrauen, da jede Teilnehmer, der Schreibzugri� auf eineTeilbereich hat die Prüfsumme des Blockes beliebig überschreiben kann. Damit können ge-speicherte Daten als ungültig erklärt werden, aber die gespeicherten Informationen werdennicht geändert. Das gröÿere Vertrauen der Teilnehmer ist jedoch gegeben, da die Unter-nehmen die gelieferten Teile in die eigenen Produkte integrieren und sie auf die Funktionder gelieferten Teile ebenfalls vertrauen müssen und das auch können.Die entwickelte Zugri�skontrolle arbeitet mit zwei Ebenen. Es gibt eine kontrollieren-
de Instanz und eine Ausführende. Die kontrollierende Instanz sind leistungsfähiger Ser-
2008-01-16/010/INF02/2253 123

8 Zusammenfassung und Ausblick
ver in einem Netzwerk, die leicht überprüfen kann ob die gewünschten Anfragen erlaubtsind. Die ausführende Instanz ist der einfache RFID Tag. Für jeden Zugri� auf den Tagbenötigt ein Teilnehmer die Erlaubnis des für den Tag verantwortlichen Autorisierungs-/Keyservers. Das Lesegerät sendet die gewünschten Zugri�e auf den Tag an den entspre-chenden Autorisierungs-/Keyserver. Da für die Überprüfung der Rechte die Role-BasedAccess Control (RBAC) verwendet wird sendet das Lesegerät auch seine aktuelle Rollemit. Der Server überprüft nun mit den gespeicherten Informationen, ob mit der aktuelleRolle des Tag die gewünschten Transaktionen erlaubt sind. Die erlaubten Transaktionenwerden dann mit einer Prüfsumme versehen, die der Tag überprüfen kann und an das Le-segerät gesendet, welches dann die gewünschte Anfrage an den Tag sendet. Der Tag nimmtjetzt die Zugri�skontrolle vor, indem er mit der Prüfsumme des Servers überprüft, ob dieAnfrage erlaubt ist. Wenn das der Fall ist wird die Anfrage erlaubt und andernfalls abge-lehnt. Mit dem Verfahren ist sichergestellt, dass nur berechtigte Teilnehmer auf de�nierteTeilbereiche mit bestimmten Rechen zugreifen können. Die Verwaltung der Rechte ist durchdie RBAC einfach, da bei neuen Tags oder Teilnehmern nur eine richtige Eingruppierungder Elemente notwendig ist und bei den Rechten nichts geändert werden muss.
In einem weiteren groÿen Teil der Arbeit wurde untersucht, welche Datenstrukturensinnvoll sind um den praktischen Einsatz des entwickelten Protokolls zu ermöglichen. Diezentrale Stelle ist der Authentisierungsserver, der die Authentisierung der Tags vornimmtund im Gegensatz zu den Autorisierungs-/Keyservern schlecht verteilt werden kann. Diebenutzen Datenstrukturen sollen dabei sehr skalierbar sein, da das System mit bis zumehreren Milliarden Tags arbeiten muss. Die ausgesuchten Datenstrukturen sind in ei-ne entwickelte Simulationsumgebung integriert worden. Mit Hilfe von Simulationen undeinem ermittelten Lastmodell wurden die verschiedenen Datenstrukturen bewertet. Da-bei ist das Ergebnis entstanden, dass einfache Hashtabellen mit linearem Sondieren diebesten Ergebnisse liefern. Bäume können zwar einfach dynamisch wachsen, jedoch ist de-ren Geschwindigkeit immer kleiner als die Hashtabelle, vor allem bei einer groÿen Anzahlvon Elementen. Problematisch ist jedoch die fehlende Dynamik der Hashtabellen. Generellist das ein Problem, jedoch im vorliegenden Fall nicht, da ein dediziertes System für dieAnwendung benutzt wird und es eine voraussichtliche Lebensdauer hat. Damit kann dieHashtabelle so dimensioniert werden, dass sie für die Einsatzdauer der Hardware genügendgroÿ ist. Am Ende der Lebensdauer muss das System ersetzt werden und die Daten auf einneues System migriert werden. Dafür kann dann ein entsprechend gröÿeres System verwen-det werden, dass dann durch die Daten des alten Systems gefüllt werden kann. Damit stelltdie fehlende Dynamik kein entscheidendes Problem dar. Bei sinnvollen Parametern ist beider Hashtabelle für eine einzelne Operation fast immer nur ein Zugri� auf den Speicheroder den externen Datenträger notwendig. Das heiÿt für jeden Lese- und Schreibvorgangist nur ein Zugri� notwendig. Damit ergeben sich für die Identi�kation eines Tags unddie Aktualisierung der Datenstrukturen nur fünf Zugri�e als Minimum. Dieses Minimumwird nahezu erreicht. Ein weiterer Vorteil der Hashtabellen ist, dass weniger Speicherplatzbenötigt wird als bei den realisierten Bäumen.
Die entwickelten Verfahren haben aber gewisse Nachteile, die in Zukunft zu lösen sind.Zum einen ist die fehlende Möglichkeit der Verteilung des Authentisierungsservers. DerAutorisierungs-/Keyserver kann leicht parallelisiert werden, der Authentisierungsserver je-doch nicht. Der Grund ist fehlende Strukturierung der Pseudo IDs, damit keine Infor-mationen gewonnen werden können. Für eine Lösung des Problems muss die Pseudo IDstrukturiert werden, ohne dass ein Auÿenstehender das erkennen kann. Hierfür ist existiertbisher keine Lösung. Wenn die geheimen Strukturierung möglich ist, dann ist eine Par-allelisierung leicht möglich, indem die Anfragen immer an einen Authentisierungsservergesendet werden, der für diesen Tag zuständig ist. Es müsste jedoch immer der gleicheServer verwendet werden, da sonst die gespeicherten Pseudo IDs auf verschiedenen Au-
124 2008-01-16/010/INF02/2253

thentisierungsservern nicht mehr übereinstimmen und damit Probleme auftreten.Ein weiteres Problem ist, dass sich die Teilnehmer untereinander in einem beschränk-
ten Rahmen vertrauen müssen, damit die Integrität der Daten speichere�zient geschütztwerden können. Das erscheint zunächst kein Problem, da die Teilnehmer sich auch bei dengelieferten Teilen untereinander vertrauen, jedoch ist es wünschenswert, dass nicht sovielVertrauen notwendig ist, da auch Lesegeräte defekt oder kompromittiert sein können. Einemögliche Lösung ist die Einführung eines kleinen MACs von wenigen Bytes, beispielsweisezwei Byte, der für jedes Datum gespeichert wird. Damit sinkt die Wahrscheinlichkeit füreinen möglichen Angri� sehr stark und wird nicht mehr praktikabel, weil nur Teilnehmermit Schreibrechten auf einen Block den zugehörigen MAC ändern können. Hier muss ge-klärt werden, ob das Verfahren so sinnvoll ist und andernfalls müssen andere Lösungengefunden werden.Das letzte Problem ist die Verfolgbarkeit des Tags bei in der Phase der Resynchronisie-
rung. Wenn ein Angreifer genügend Zeit hat, ist eine Verfolgung des Tags möglich. Dazu istjedoch schon ein Aufwand notwendig, der durch die Parameter des Resynchronisierungs-vorganges bestimmt werden kann. Es stellt sich die Frage, ob noch eine weitere Möglichkeitexistiert den Aufwand für den Angreifer zu erhöhen, ohne den Einsatz der Entwicklungdurch zu lange Auslesezeiten für die Teilnehmer einzuschränken.
2008-01-16/010/INF02/2253 125

126 2008-01-16/010/INF02/2253

Literaturverzeichnis
[1] ISO 14443
[2] http: // de. wikipedia. org/ wiki/ Barcode
[3] Auto-ID Center: 860MHz - 930MHz Class I Radio Frequency Identi�cation TagRadio Frequency & Logical Communication Interface Speci�cation / Auto-ID Cen-ter/EPCglobal. 2002. � Forschungsbericht
[4] Avoine, Gildas ; Oechslin, Philippe: A Scalable and Provably Secure Hash BasedRFID Protocol. In: International Workshop on Pervasive Computing and Communi-
cation Security � PerSec 2005. Kauai Island, Hawaii, USA : IEEE Computer SocietyPress, March 2005, S. 110�114
[5] Batina, Lejla ; Guajardo, Jorge ; Kerins, Tim ; Mentens, Nele ; Tuyls, Pim ;Verbauwhede, Ingrid: Public-Key Cryptography for RFID-Tags. In: InternationalWorkshop on Pervasive Computing and Communication Security � PerSec 2007. NewYork, USA : IEEE Computer Society Press, March 2007
[6] Bundesamt für Sicherheit in der Informationstechnik: Risiken und Chan-
cen des Einsatzes von RFID-systemen. 2004
[7] Defend, Benessa ; Fu, Kevin ; Juels, Ari: Cryptanalysis of Two Lightweight RFIDAuthentication Schemes. In: International Workshop on Pervasive Computing and
Communication Security � PerSec 2007. New York, USA : IEEE Computer SocietyPress, March 2007
[8] Denning, D. ; Sacco, G.: Timestamps in Key Distributed Protocols. In: Commu-nication of the ACM 24 (1981), Nr. 8, S. 533�535
[9] Feldhofer, Martin ; Dominikus, Sandra ; Wolkerstorfer, Johannes: StrongAuthentication for RFID Systems using the AES Algorithm. In: Joye, Marc (Hrsg.); Quisquater, Jean-Jacques (Hrsg.) ; IACR (Veranst.): Workshop on Cryptographic
Hardware and Embedded Systems � CHES 2004 Bd. 3156. Boston, Massachusetts,USA : Springer-Verlag, August 2004 (Lecture Notes in Computer Science), S. 357�370
[10] Ferraiolo, D. ; Kuhn, R.: Role-Based Access Controls. In: 15th NIST-NCSC
National Computer Security Conference, 1992, S. 554�563
[11] Finkenzeller, Klaus: RFID Handbook : Fundamentals and Applications in Contact-
less Smart Cards and Identi�cation. John Wiley & Sons, 2003
[12] Gong, Li ; Needham, Roger ; Yahalom, Raphael: Reasoning About Belief in Cryp-tographic Protocols. In:Cooper, Deborah (Hrsg.) ; Lunt, Teresa (Hrsg.): Proceedings1990 IEEE Symposium on Research in Security and Privacy, IEEE Computer Society,1990, S. 234�248
[13] Grummt, Eberhard ; Werner, Kerstin ; Ackermann, Ralf: SicherheitsanalyseRFID-basierter Wertschöpfungsketten. In: D.A.CH Security 2007, 2007
[14] Kraftfahrt-Bundesamt: Fahrzeuge - Bestand am 1. Januar 2007 - http: // www.
kba. de/ Abt3_ neu/ FZ/ Bestand/ b_ eckdaten. htm
2008-01-16/010/INF02/2253 127

Literaturverzeichnis
[15] Lehtonen, Mikko ; Staake, Thorsten ; Michahelles, Florian ; Fleisch, Elgar:From Identi�cation to Authentication - A Review of RFID Product Authentication
Techniques. Graz, Austria : Printed handout of Workshop on RFID Security � RFI-DSec 06, July 2006
[16] Li, Tieyan ; Deng, Robert H.: Vulnerability Analysis of EMAP - An E�cient RFIDMutual Authentication Protocol. In: Second International Conference on Availability,
Reliability and Security � AReS 2007. Vienna, Austria, April 2007
[17] Mitzenmacher, Michael ; Upfal, Eli: Probability and Computing : Randomized
Algorithms and Probabilistic Analysis. Cambridge University Press, 2005. � ISBN0521835402
[18] NXP: Datenblatt NXP Mifare DESFire8. http://www.nxp.com/acrobat/other/
identification/SFS075530.pdf,
[19] NXP: Datenblatt NXP Mifare Pro X. http://www.nxp.com/acrobat/other/
identification/sfs051814.pdf,
[20] Ohkubo, Miyako ; Suzuki, Koutarou ; Kinoshita, Shingo: Cryptographic Approachto �Privacy-Friendly� Tags. In: RFID Privacy Workshop. MIT, MA, USA, November2003
[21] Otway, Dave ; Rees, Owen: E�cient and timely mutual authentication. In: SIGOPSOper. Syst. Rev. 21 (1987), Nr. 1, S. 8�10. � ISSN 0163�5980
[22] Peris-Lopez, Pedro ; Hernandez-Castro, Julio C. ; Estevez-Tapiador, Ju-an M. ; Ribagorda, Arturo: EMAP: An E�cient Mutual Authentication Protocolfor Low-cost RFID Tags. In: OTM Federated Conferences and Workshop: IS Work-
shop � IS'06 Bd. 4277, Springer-Verlag, November 2006 (Lecture Notes in ComputerScience), S. 352�361
[23] Poschmann, Axel ; Leander, Gregor ; Schramm, Kai ; Paar, Christof: A Family
of Light-Weight Block Ciphers Based on DES Suited for RFID Applications. Graz,Austria : Printed handout of Workshop on RFID Security � RFIDSec 06, July 2006
[24] Quong, Russell W.: User Manual von OMNeT++ version 3.2 http: // www.
omnetpp. org/ doc/ manual/ usman. html
[25] Rieback, Melanie R. ; Crispo, Bruno ; Tanenbaum, Andrew S.: Is Your CatInfected with a Computer Virus?. In: PerCom, 2006, S. 169�179
[26] Schäfer, Günter: Vorlesung Simulative Evaluation of Internet Protocol Functions.2006
[27] Schäfer, Günther: Netzsicherheit - Algorithmische Grundlagen und Protokolle.dpunkt.verlag, 2003
[28] Strassner, Martin: RFID im Supply Chain Management - Auswirkungen und Hand-
lungsempfehlungen am Beispiel der Automobilindustrie. Deutscher Universitätsverlag,2005
[29] Vajda, I. ; Buttyan, L.: Lightweight Authentication Protocols for Low-Cost RFID
Tags. 2003
128 2008-01-16/010/INF02/2253

Literaturverzeichnis
[30] Weis, Stephen A. ; Sarma, Sanjay E. ; Rivest, Ronald L. ; Engels, Daniel W.:Security and Privacy Aspects of Low-Cost Radio Frequency Identi�cation Systems.In: Security in Pervasive Computing Bd. 2802, 2004 (Lecture Notes in ComputerScience), S. 201�212
[31] Werner, Kerstin ;Grummt, Eberhard ;Groÿ, Stephan ;Ackermann, Ralf: Data-on-Tag: An Approach to Privacy friendly Usage of RFID Technologies. In: RFIDSysTech 2007, 2007
2008-01-16/010/INF02/2253 129

130 2008-01-16/010/INF02/2253

A Regeln der GNY Logik
In diesem Abschnitt sind alle Regeln der GNY Logik aus dem Artikel [12] mit identi-schen Bezeichnungen aufgeführt. Die Übersicht dient dazu den Nachweis aus Abschnitt 5nachvollziehen zu können.Bei den Regeln gilt, wenn ein Postulat für X gilt, so gilt es auch für ?X, aber nicht
umgekehrt.
A.1 Erhalt von Nachrichten
Falls P eine Formel erhält, die es vorher nicht kannte, dann erhält P auch nur die Formelohne den Neuigkeitswert.
T1 :P / ?X
P / X
Falls P zwei Formeln X und Y erhält, so erhält es auch nur eine Formel.
T2 :P / (X,Y )P / X
Falls P eine mit einem symmetrischen Schlüssel K verschlüsselte Formel X erhält und P inBesitz des Schlüssels K ist, dann erhält P die Formel X.
T3 :P / {X}K , P 3 K
P / X
Falls P eine mit dem ö�entlichen Schlüssel +K verschlüsselte Formel X erhält und P denzum ö�entlichen Schlüssel passenden privaten Schlüssel besitzt, dann erhält P die Formel.
T4 :P / {X}+K , P 3 −K
P / X
Falls P das Ergebnis der Funktion F aus den Formel X und Y erhält und P eine FormelX besitzt, dann erhält P auch die Formel Y, da die Funktion F einfach umkehrbar ist.
T5 :P / F (X,Y ), P 3 X
P / Y
Falls P eine mit dem privaten Schlüssel -K verschlüsselte Formel X erhält und P denzum privaten Schlüssel passenden ö�entlichen Schlüssel besitzt, dann erhält P die Formel.
T6 :P / {X}−K , P 3 +K
P / X
2008-01-16/010/INF02/2253 131

A Regeln der GNY Logik
A.2 Glaube
Falls P die Formel X erhält, dann besitzt P die Formel X.
P1 :P / X
P 3 X
Falls P die Formeln X und Y besitzt, so besitzt P auch die beiden Formeln aneinander-gefügt und die Funktion F dieser Verkettung.
P2 :P 3 X,P 3 Y
P 3 (X,Y ), P 3 F (X,Y )
Falls P die Verkettung der Formeln X und Y besitzt, so besitzt P auch eine Teilformelder Verkettung.
P3 :P 3 (X,Y )P 3 X
Falls P die Formel X besitzt, dann besitzt P auch den Hash der Formel X.
P4 :P 3 X
P 3 H(X)
Falls P die Funktion der Verkettung der Formeln X und Y besitzt und P auch die FormelX besitzt, dann besitzt P die Formel Y.
P5 :P 3 F (X,Y ), P 3 X
P 3 Y
Falls P den symmetrischen Schlüssel K und die Formel X besitzt, dann besitzt P auchdie mit dem Schlüssel K ver- oder entschlüsselte Formel X.
P6 :P 3 K,P 3 X
P 3 {X}K , P 3 {X}−1K
Falls P den ö�entliche Schlüssel +K und die Formel X besitzt, dann besitzt P die mitdem ö�entlichen Schlüssel +K verschlüsselte Formel X.
P7 :P 3 +K,P 3 XP 3 {X}+K
Falls P den privaten Schlüssel -K und die Formel X besitzt, dann besitzt P die mit demprivaten Schlüssel -K verschlüsselte Formel X.
P8 :P 3 −K,P 3 XP 3 {X}−K
132 2008-01-16/010/INF02/2253

A.3 Frische
A.3 Frische
Falls P glaubt, dass die Formel X frisch ist, dann ist auch die Verkettung der Formeln Xund Y und das Ergebnis der Anwendung der Funktion F auf die Formel X frisch.
F1 :P |≡ ](X)
P |≡ ](X,Y ), P |≡ ](F (X))
Falls P glaubt, dass die Formel X frisch ist und P den symmetrischen Schlüssel K besitzt,dann glaubt P auch, dass das Ergebnis der Ver- und Entschlüsselung der Formel X mitdem Schlüssel K frisch ist.
F2 :P |≡ ](X), P 3 K
P |≡ ]({X}K), P |≡ ]({X}−1K )
Falls P glaubt, dass die Formel X frisch ist und P den ö�entlichen Schlüssel +K be-sitzt, dann glaubt P auch, dass das Ergebnis der Verschlüsselung der Formel X mit demö�entlichen Schlüssel +K frisch ist.
F3 :P |≡ ](X), P 3 +KP |≡ ]({X}+K)
Falls P glaubt, dass die Formel X frisch ist und P den privaten Schlüssel -K besitzt,dann glaubt P auch, dass das Ergebnis der Verschlüsselung der Formel X mit dem privatenSchlüssel -K frisch ist.
F4 :P |≡ ](X), P 3 −KP |≡ ]({X}−K)
Falls P glaubt, dass der ö�entliche Schlüssel +K frisch ist, dann glaubt P auch, dass derkorrespondierende private Schlüssel -K frisch ist.
F5 :P |≡ ](+K)P |≡ ](−K)
Falls P glaubt, dass der private Schlüssel -K frisch ist, dann glaubt P auch, dass derkorrespondierende ö�entliche Schlüssel +K frisch ist.
F6 :P |≡ ](−K)P |≡ ](+K)
Falls P glaubt, dass die Formel X erkennbar ist und P glaubt, dass der Schlüssel K frischist und P den symmetrischen Schlüssel K besitzt, dann glaubt P, dass das Ergebnis derVer- und Entschlüsselung der Formel X mit dem Schlüssel K frisch ist.
F7 :P |≡φ(X), P |≡ ](K), P 3 KP |≡ ]({X}K), P |≡ ]({X}−1
K )
2008-01-16/010/INF02/2253 133

A Regeln der GNY Logik
Falls P glaubt, dass die Formel X erkennbar ist und P glaubt, dass der ö�entliche Schlüs-sel +K frisch ist und P den Schlüssel +K besitzt, dann glaubt P, dass das Ergebnis derVerschlüsselung der Formel X mit dem ö�entlichen Schlüssel +K frisch ist.
F8 :P |≡φ(X), P |≡ ](+K), P 3 +K
P |≡ ]({X}+K)
Falls P glaubt, dass die Formel X erkennbar ist und P glaubt, dass der private Schlüs-sel -K frisch ist und P den Schlüssel -K besitzt, dann glaubt P, dass das Ergebnis derVerschlüsselung der Formel X mit dem privaten Schlüssel -K frisch ist.
F9 :P |≡φ(X), P |≡ ](−K), P 3 −K
P |≡ ]({X}−K)
Falls P glaubt, dass die Formel X frisch ist und P die Formel X besitzt, dann glaubt Pauch, dass der Hash der Formel X frisch ist.
F10 :P |≡ ](X), P 3 XP |≡ ](H(X))
Falls P glaubt, dass der Hash der Formel X frisch ist und P diesen Hash besitzt, dannglaubt P auch, dass die Formel X frisch ist.
F11 :P |≡ ](H(X)), P 3 H(X)
P |≡ ](X)
A.4 Erkennbarkeit
Falls P glaubt, dass die Formel X erkennbar ist, dann glaubt P auch, dass die Verkettungder Formeln X und Y sowie das Ergebnis der Funktion F auf die Formel X erkennbar ist.
R1 :P |≡φ(X)
P |≡φ(X,Y ), P |≡φ(F (X))
Falls P glaubt, dass die Formel X erkennbar ist und P den symmetrischen Schlüssel Kbesitzt, dann glaubt P auch, dass das Ergebnis der Ver- und Entschlüsselung der FormelX mit dem Schlüssel K erkennbar ist.
R2 :P |≡φ(X), P 3 K
P |≡φ({X}K), P |≡φ({X}−1K )
Falls P glaubt, dass die Formel X erkennbar ist und P den ö�entlichen Schlüssel +Kbesitzt, dann glaubt P auch, dass das Ergebnis der Verschlüsselung der Formel X mit demSchlüssel +K erkennbar ist.
R3 :P |≡φ(X), P 3 +KP |≡φ({X}+K)
134 2008-01-16/010/INF02/2253

A.5 Interpretation von Nachrichten
Falls P glaubt, dass die Formel X erkennbar ist und P den privaten Schlüssel -K besitzt,dann glaubt P auch, dass das Ergebnis der Verschlüsselung der Formel X mit dem Schlüssel-K erkennbar ist.
R4 :P |≡φ(X), P 3 −KP |≡φ({X}−K)
Falls P glaubt, dass die Formel X erkennbar ist und die Formel X besitzt, dann glaubtP auch, dass der Hash der Formel X erkennbar ist.
R5 :P |≡φ(X), P 3 XP |≡φ(H(X))
Falls P den Hash der Formel X besitzt, dann glaubt P auch, dass die Formel X erkennbarist.
R6 :P 3 H(X)P |≡φ(X)
A.5 Interpretation von Nachrichten
Falls P die neue mit dem symmetrischen Schlüssel K verschlüsselte Formel X erhält und Pden Schlüssel K besitzt und an dessen Eignung als Schlüssel zwischen P und Q glaubt undP glaubt, dass die Formel X erkennbar ist und P glaubt, dass die Verkettung der Formel Xmit dem Schlüssel K frisch ist, dann glaubt P, dass Q ursprünglich Nachricht X gesendethat und P glaubt, dass Q das Ergebnis der Verschlüsselung der Formel X mit dem SchlüsselK gesendet hat und P glaubt, dass Q den Schlüssel K hat.
I1 :P / ? {X}K , P 3 K,P |≡P
K←→ Q,P |≡φ(X), P |≡ ](X,K)P |≡Q |∼X,P |≡Q |∼ {X}K , P |≡Q 3 K
Falls P eine neue Nachricht bestehend aus dem mit dem ö�entlichen Schlüssel +K ver-schlüsselten Verkettung der Formel X mit einem Geheimnis S erhält und P den privatenSchlüssel -K und das Geheimnis S hat und P an seinen ö�entlichen Schlüssel glaubt und Pdas Geheimnis S als geeigneten symmetrischen Schlüssel für die Kommunikation zwischenP und Q hält und P die Verkettung der Formel X mit dem Geheimnis S erkennt und dieVerkettung aus Formel X, Geheimnis S und ö�entlichem Schlüssel +K für P frisch ist,dann glaubt P, dass Q die Verkettung der Formel X mit dem Geheimnis S und auch dessenVerschlüsselung mit dem ö�entlichen Schlüssel +K gesendet hat und P glaubt, dass Q denö�entlichen Schlüssel +K hat.
I2 :
P / ? {X,< S >}+K , P 3 (−K,S), P |≡ +K7→ P, P |≡P S←→ Q,
P |≡φ(X,S),P |≡ ](X,S,+K)P |≡Q |∼ (X,< S >), P |≡Q |∼ {X,< S >}+K , P |≡Q 3 +K
2008-01-16/010/INF02/2253 135

A Regeln der GNY Logik
Falls P den neuen Hash der Verkettung der Formel X und des Geheimnisses S erhaltenhat und P die Formel X und S besitzt und S ein geeigneter symmetrischer Schlüssel fürdie Kommunikation zwischen P und Q ist und für P die Verkettung aus der X und S frischist, dann glaubt P, dass Q die Verkettung von X und S und den Hash dieser Verkettunggesendet hat.
I3 :P / ?H(X,< S >), P 3 (X,S), P |≡P S←→ Q,P |≡ ](X,S)
P |≡Q |∼ (X,< S >), P |≡Q |∼H(X,< S >)
Falls P eine Nachricht bestehend aus dem mit dem privaten Schlüssel -K verschlüsseltenFormel X erhält und P den ö�entlichen Schlüssel +K besitzt und P an den ö�entlichenSchlüssel von Q glaubt und P die Formel X erkennt, dann glaubt P, dass Q die Formel Xund auch dessen Verschlüsselung mit dem privaten Schlüssel -K gesendet hat.
I4 :P / {X}−K , P 3 +K,P |≡ +K7→ Q,P |≡φ(X)
P |≡Q |∼X,P |≡Q |∼ {X}−K
Falls P eine Nachricht bestehend aus dem mit dem privaten Schlüssel -K verschlüsseltenFormel X erhält und P den ö�entlichen Schlüssel +K besitzt und P an den ö�entlichenSchlüssel von Q glaubt und P die Formel X erkennt und P glaubt, dass die Verkettungaus der Formel X und dem ö�entlichen Schlüssel +K frisch ist, dann glaubt P, dass Q dieVerkettung des Schlüssels -K und der Formel X hat.
I5 :P / {X}−K , P 3 +K,P |≡ +K7→ Q,P |≡φ(X), P |≡ ](X,+K)
P |≡Q 3 (−K,X)
Falls P glaubt, dass Q die Formel X gesendet hat und die Formel X für P frisch ist, dannglaubt P, dass die Formel X hat.
I6 :P |≡Q |∼X,P |≡ ](X)
P |≡Q 3 X
Falls P glaubt, dass Q die Verkettung der Formeln X und Y gesendet hat, dann glaubtP, dass Q die Teilformel X gesendet hat.
I7 :P |≡Q |∼ (X,Y )P |≡Q |∼X
A.6 Kompetenz
Falls P glaubt, dass Q die Kompetenz über die Aussage C hat und P glaubt, dass Q andie Aussage C glaubt, dann glaubt P an die Aussage C.
J1 :P |≡Q Z⇒ C,P |≡Q |≡C
P |≡C
136 2008-01-16/010/INF02/2253

A.6 Kompetenz
Falls P glaubt, dass Q vertrauenswürdig ist und korrekt arbeitet und P glaubt, dass Qdie Formel X unter der Bedingung der Aussage C gesendet, dann glaubt P, dass Q an dieAussage C glaubt.
J2 :P |≡Q Z⇒ Q |≡ ?, P |≡Q |∼ (X;C)
P |≡Q |≡C
Falls P glaubt, dass Q vertrauenswürdig ist und korrekt arbeitet und P glaubt, dass Qglaubt, dass Q an die Aussage C glaubt, dann glaubt P, dass Q an die Aussage C glaubt.
J3 :P |≡Q Z⇒ Q |≡ ?, P |≡Q |≡Q |≡C
P |≡Q |≡C
2008-01-16/010/INF02/2253 137

138 2008-01-16/010/INF02/2253
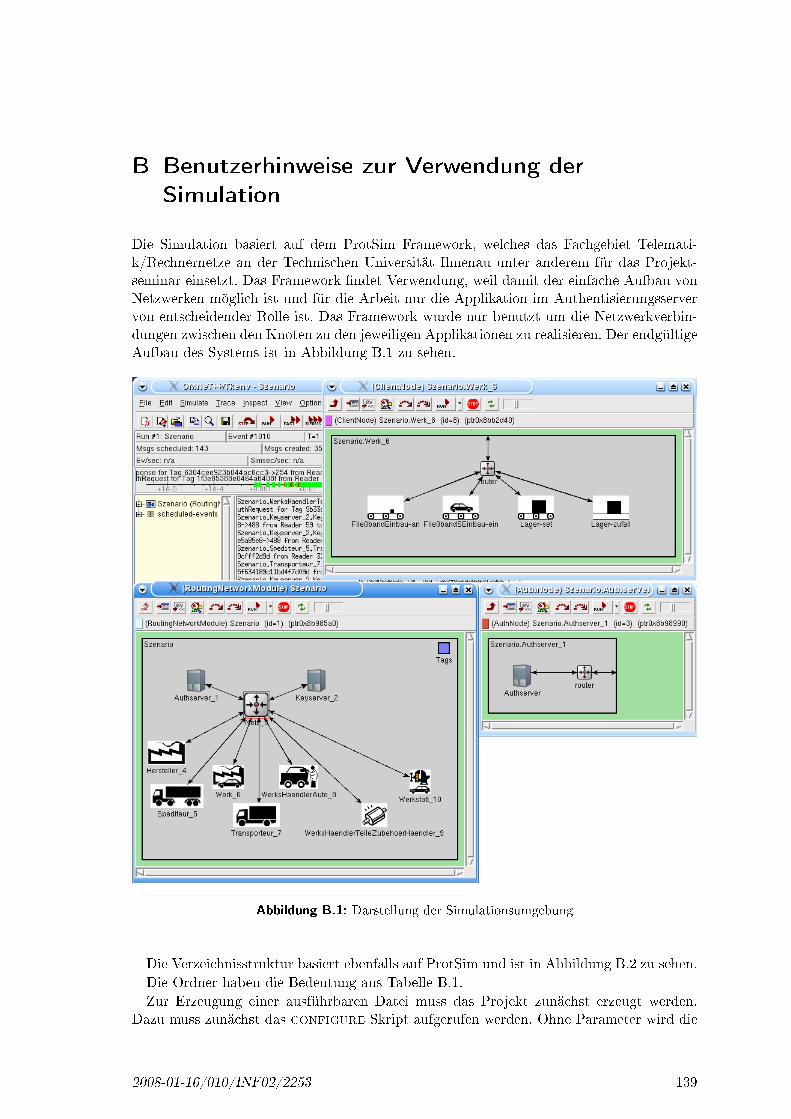
B Benutzerhinweise zur Verwendung der
Simulation
Die Simulation basiert auf dem ProtSim Framework, welches das Fachgebiet Telemati-k/Rechnernetze an der Technischen Universität Ilmenau unter anderem für das Projekt-seminar einsetzt. Das Framework �ndet Verwendung, weil damit der einfache Aufbau vonNetzwerken möglich ist und für die Arbeit nur die Applikation im Authentisierungsservervon entscheidender Rolle ist. Das Framework wurde nur benutzt um die Netzwerkverbin-dungen zwischen den Knoten zu den jeweiligen Applikationen zu realisieren. Der endgültigeAufbau des Systems ist in Abbildung B.1 zu sehen.
Abbildung B.1: Darstellung der Simulationsumgebung
Die Verzeichnisstruktur basiert ebenfalls auf ProtSim und ist in Abbildung B.2 zu sehen.Die Ordner haben die Bedeutung aus Tabelle B.1.Zur Erzeugung einer ausführbaren Datei muss das Projekt zunächst erzeugt werden.
Dazu muss zunächst das configure Skript aufgerufen werden. Ohne Parameter wird die
2008-01-16/010/INF02/2253 139

B Benutzerhinweise zur Verwendung der Simulation
Abbildung B.2: Verzeichnisstruktur der entwickelten Simulation
Ordner Beschreibung
bitmaps Bilder für die Gestaltung der gra�schen Ober�ächecommon Grundelemente für das ProtSim Frameworkextern/md5 Verwendeter MD5 Algorithmus, der separat zu erzeugen istmessages Alle verwendeten Nachrichtentypen, auch die für Auth- und
Autorisierungs-/Keyservernetworks Beschreibung der Struktur des Szenariosnodes Beschreinug der einzelnen Knotentypenrouting Routingalgorithmus für das Netzsupport Hilfsfunktionenuserapps Ort für alle realisierten Algorithmen/Datenstrukturen. Stammverzeichnis mit con�gure Skript und Kon�guartionsdatei
Tabelle B.1: Bedeutung der Ordner
gra�sche Ober�äche für OmNet++ gewählt. Mit cmdenv als Parameter die Konsolenver-sion. Dann kann mittels make das Projekt erzeugt werden. Die Ausführung erfolgt danndurch Ausführung der Datei sim. Vor der erstmaligen Verwendung der Simulation ist je-doch einmal der verwendete MD5 Algorithmus zu übersetzen. Das geschieht durch denAufruf von make im Unterverzeichnis extern/md5. Für die Auswahl und Parametrisie-rung der gewünschten Last sowie die Auswahl und Parametrisierung der Datenstrukturkann die omnetpp.ini angepasst werden. Die verschiedenen Datenstrukturen sind dabei alsKind der abstrakten Klasse �Auth� aus dem Verzeichnis userapps realisiert. Der Authen-tisierungsserver mit der Applikation �AuthAppl� aus dem gleichen Verzeichnis erzeugt jenach Parameter in der omnetpp.ini die ausgewählte Datenstruktur als Objekt. Bei neuhinzugefügten Algorithmen muss die Authentisierungsapplikation deshalb auch angepasstwerden, aber nur um die Erzeugung des Objektes. Der Autorisierungs-/Keyserver wirddurch die Klasse �KeyAppl� realisiert, muss jedoch nicht angepasst werden. Zur Erzeugungder Last für die Server wird die Klasse �Reader� verwendet. Je nach Parametrisierung wirdhier Last mit dem gewünschten Modell für jedes einzelne Lasterzeugungsmodul generiert.Dabei wird auch eine Annäherung an das MAC Protokoll des Tags vorgenommen. Dieletzte feste Klasse ist �TagsDB�. Die Klasse dient zur Verwaltung der Tags und speichertdabei den lokalen Zustand aller Tags und führt die notwendigen Operationen der Tagsaus. Die anderen Dateien im Unterverzeichnis userapps sind die realisierten Klassen für diejeweiligen Datenstrukturen.
140 2008-01-16/010/INF02/2253

C Thesen
1. Der unternehmensübergreifende Einsatz der RFID Technologie benötigt ein wirksa-mes Sicherheitskonzept, damit nur berechtigte Teilnehmer auf de�nierte Daten mitbestimmten Zugri�srechten Zugri� erhalten und keine Verfolgung der Tags möglichist.
2. Für die Realisierung des Konzeptes ist es sinnvoll, das System in die Tags, die Lese-geräte, den Authentisierungsserver und die Autorisierungs-/Keyserver zu gliedern.
3. Durch die Kombination der bisher bekannten Verfahren der Hash-Kette und derSpeicherung der Pseudo IDs entsteht ein Anonymisierungsverfahren, das wenig Spei-cherplatz benötigt und trotzdem schnell arbeitet.
4. Die Resynchronisierungsphase der Authentisierung ermöglicht die Identi�zierung an-gegri�ener Tags.
5. Das entwickelte Verfahren der Integritätssicherung ermöglicht durch das Zusammen-fassen von Prüfsummen den e�zienten Einsatz des vorhanden Speicherplatzes.
6. Die Aufteilung der Zugri�skontrolle auf den Tag, als ausführender Instanz, und denAutorisierungs-/Keyserver, als bestimmende Autorität, ermöglicht die Realisierungkomplexer Zugri�srichtlinien auch mit den geringen Ressourcen der Tags.
7. Das entwickelte Protokoll ermöglicht die Authentisierung des Tags gegen das Lese-gerät, die vertrauliche Kommunikation zwischen den Teilnehmer und den Zugri� aufdie Daten des Tag unter Beachtung der Zugri�skontrolle.
8. Für den praktischen Einsatz ist die Geschwindigkeit des Authentisierungsdienstes,der die Datenstrukturen verwaltet, entscheidend.
9. Um die Lokalität der Kollisionsau�ösung auszunutzen zu können, kann die Methodedes linearen Sondierens für die Hashtabellen auf dem externen Datenträger verwendetwerden.
10. Der Zugri� auf Hashtabellen ist e�zienter als auf Bäume, ohne in der Praxis diefehlende Dynamik der Hashtabellen als Nachteil zu haben.
11. Hashtabellen sind durch die Lokalität der Kollisionsau�ösungen bis zu Füllungsgra-den von 90 Prozent einsetzbar.
Ilmenau, 28. Januar 2008 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2008-01-16/010/INF02/2253 141

142 2008-01-16/010/INF02/2253

D Eidesstattliche Erklärung
Ich versichere durch meine eigenhändige Unterschrift, dass diese Ausarbeitung von mirselbständig und ohne Benutzung anderer als der angegebenen Quellen und Hilfsmittelangefertigt wurde. Alle Stellen, die wörtlich oder sinngemäÿ aus verö�entlichten und un-verö�entlichten Schriften entnommen sind, habe ich als solche kenntlich gemacht. DieseAusarbeitung wurde noch nicht an anderer Stelle für Prüfungszwecke vorgelegt.
Ilmenau, 28. Januar 2008 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2008-01-16/010/INF02/2253 143









![© SNC Social Networks Consulting GmbH [zurück] [weiter]zurückweiter Die Online-Informationssoftware für heterogene Kooperationsverbände.](https://static.fdokument.com/doc/165x107/55204d7049795902118c17e1/-snc-social-networks-consulting-gmbh-zurueck-weiterzurueckweiter-die-online-informationssoftware-fuer-heterogene-kooperationsverbaende.jpg)








