
Das Kohorten-Modell zur Worterkennung · Das Kohorten-Modell zur Worterkennung Marslen-Wilson &...
19
Das Kohorten-Modell zur Worterkennung Marslen-Wilson & Tyler 1980 Mögliche Modelle a) Autonomes serielles Modell Semantische Verarbeitung Syntaktische Verarbeitung Wortverarbeitung Phomenverarbeitung Autonome Komponenten, die allein den Zugriff aufbestimmt Wissensquellen haben, geben ihr Resultat an andere Komponenten weiter
Transcript of Das Kohorten-Modell zur Worterkennung · Das Kohorten-Modell zur Worterkennung Marslen-Wilson &...

Das Kohorten-Modell zur WorterkennungMarslen-Wilson & Tyler 1980
Mögliche Modelle a) Autonomes serielles Modell
Semantische Verarbeitung
Syntaktische Verarbeitung
Wortverarbeitung
Phomenverarbeitung
Autonome Komponenten, die allein den Zugriff aufbestimmt Wissensquellen haben, geben ihr Resultat an andere Komponenten weiter
Das Kohorten-Modell zur WorterkennungMarslen-Wilson & Tyler 1980
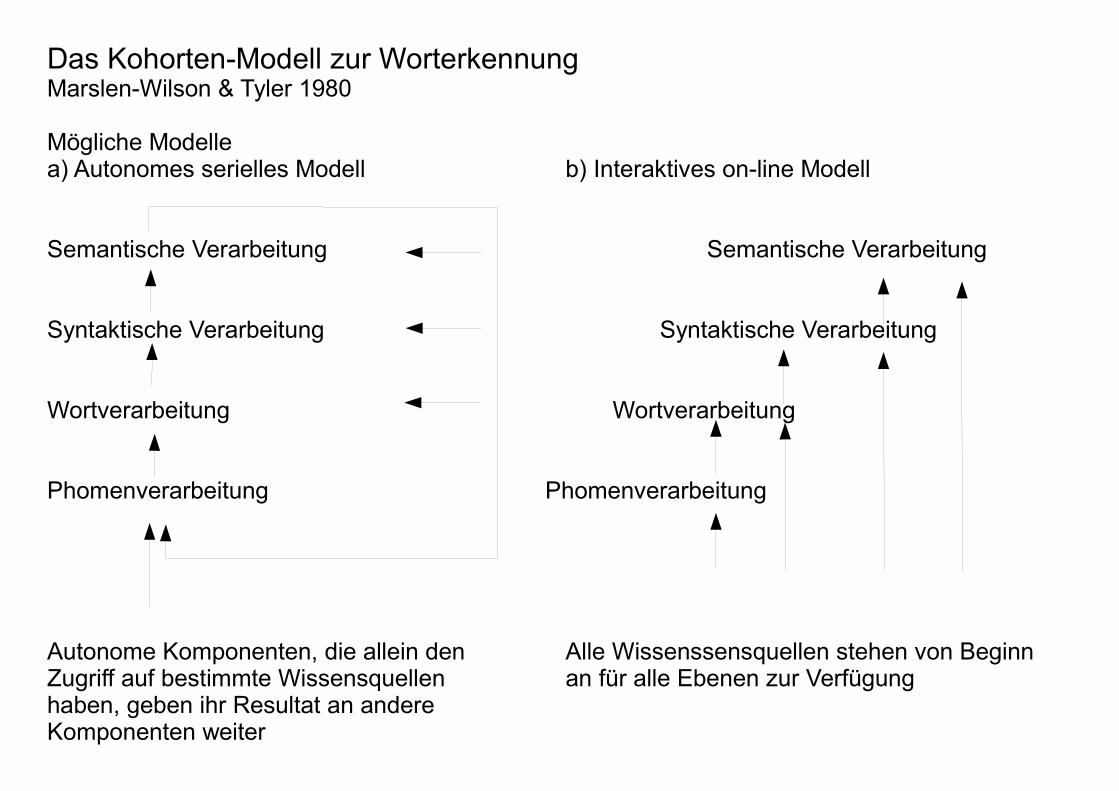
Mögliche Modelle a) Autonomes serielles Modell b) Interaktives on-line Modell
Semantische Verarbeitung Semantische Verarbeitung
Syntaktische Verarbeitung Syntaktische Verarbeitung
Wortverarbeitung Wortverarbeitung
Phomenverarbeitung Phomenverarbeitung
Autonome Komponenten, die allein den Alle Wissenssensquellen stehen von BeginnZugriff auf bestimmte Wissensquellen an für alle Ebenen zur Verfügunghaben, geben ihr Resultat an andere Komponenten weiter

Das Kohorten-Modell zur WorterkennungMarslen-Wilson & Tyler 1980
Keines der beiden Modelle schließt semantische Effekte auf die Phonemverarbeitung aus.
Modell a)
- verlangt, dass es eine Rückkopplung gibt(Frage: wann und warum setzt die ein?)
- macht die Vorhersage, dass semantische Effekteerst spät eintreten
Modell b)
- arbeitet auch ohne Rückkopplung
- macht die Vorhersage, dass semantische Effektezu jedem Zeitpunkt auftreten können

Experimentelles Setting
Faktor 1:Wörter müssen in drei verschiedenen Arten von Prosakontexten erkannt werden:
= das Zielwort
N „normale“ ProsaThe church was broken into last night. Some thieves stole most of the lead off the roof.

Experimentelles Setting
Faktor 1:Wörter müssen in drei verschiedenen Arten von Prosakontexten erkannt werden:
= das Zielwort
N „normale“ ProsaThe church was broken into last night. Some thieves stole most of the lead off the roof.
S „syntaktische“ Prosathe power was located into great water.No buns puzzle some in the lead of the text.

Experimentelles Setting
Faktor 1:Wörter müssen in drei verschiedenen Arten von Prosakontexten erkannt werden:
= das Zielwort
N „normale“ ProsaThe church was broken into last night. Some thieves stole most of the lead off the roof.
S „syntaktische“ Prosathe power was located into great water.No buns puzzle some in the lead of the text.
Z „zufällige“ WortfolgenInto was power water the great located.Some to no puzzle buns in lead text the off.

Experimentelles setting
Faktor 2:das Zielwort wird auf drei verschiedene Weisen charakterisiert:
I „Identität“Drücken Sie auf den Knopf, sobald Sie das Wort „lead“ hören.

Experimentelles setting
Faktor 2:das Zielwort wird auf drei verschiedene Weisen charakterisiert:
I „Identität“Drücken Sie auf den Knopf, sobald Sie das Wort „lead“ hören.
R „Reim“Drücken Sie auf den Knopf, sobald Sie ein Wort hören, das sich auf „lead“ reimt.

Experimentelles setting
Faktor 2:das Zielwort wird auf drei verschiedene Weisen charakterisiert:
I „Identität“Drücken Sie auf den Knopf, sobald Sie das Wort „lead“ hören.
R „Reim“Drücken Sie auf den Knopf, sobald Sie ein Wort hören, das sich auf „lead“ reimt.
K „Kategorie“Drücken Sie auf den Knopf, sobald Sie ein Wort hören, das ein Metall bezeichnet.

Vorversuch
Marslen-Wilson 1975 deutet an, dass Kontexteffekte auftreten können,bevor das Wort vollständig gehört wurde
Annahmen
alle drei Charakterisierungen ( I, R, K) verlangen Worterkennungsprozesse
I verlangt nur dieses
R und K verlangen einen weiteren Verarbeitungsschritt:
die Eigenschaften eines gelesenen Wortes müssen überprüft werden, ob sie in Bezug auf Reim (formal) oder Kategorie (semantisch) Zielwörter sind
R: erst Wort identifizieren, dann Reim prüfen
K: erst Wort identifizieren, dann semantische Eigenschaften
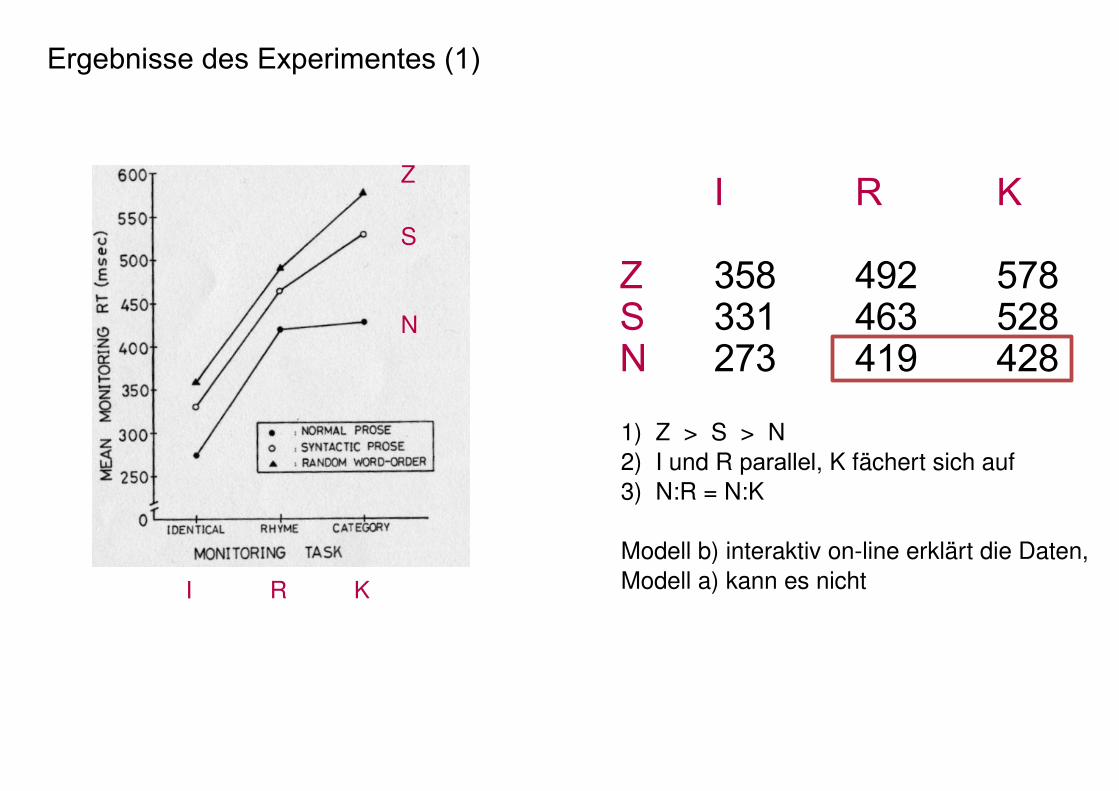
Ergebnisse des Experimentes (1)
N
S
Z
I R K
I R K
Z 358 492 578S 331 463 528N 273 419 428
1) Z > S > N 2) I und R parallel, K fächert sich auf3) N:R = N:K
Modell b) interaktiv online erklärt die Daten,Modell a) kann es nicht

Ergebnisse des Experimentes (2)
- das Verhältnis der Reaktionszeiten zur Wortlänge:N:I 273 msec zu 369 msec
273 msec – 75 msec (zur Einleitung der Reaktion)= 200 msec= Länge der ersten beiden PhonemeAlso: sehr frühzeitige Erkennung
- wie stark erschwert R die Aufgabe?N:R 419 msec zu 369 msec
419 msec – 369 msec= 50 msecAlso: frühzeitige Reaktion
- wie stark erschwert K die Aufgabe?Z und S: konstant 80 msecN : gar nichtAlso: frühzeitige Reaktion, N:K ist sogar kürzer als R:S
Interaktionseffekt zwischen Art des Kontextes und der Charakterisierung

eine „Kohorten“-basierte interaktive Theorie der Worterkennung
i) Es gibt für jedes Wort der Sprache spezielle Erkenner/Erkennungselemente(recognition elements), die auf akustisch-phonetische Muster im Input reagieren können und charakteristisch für dieses Wort sind.
ii) Früh bei der Erkennung eines Wortes werden also alle die Erkenner aktiv,deren Worte mit den initialen Phonemen beginnen. Diese anfänglicheGruppe von Wort-Kandidaten ist die wortinitiale Kohorte.
iii) Im weiteren Verlauf der Erkennung wird diese Kohorte verkleinert, weil die Wörter herausfallen, deren Informatinen nicht mehr zum gehörten oder zum Kontext passen.
iv) Wenn die Kohorte nur noch aus einemElement besteht, ist ein Wort erkannt.

eine „Kohorten“-basierte interaktive Theorie der Worterkennung
i) Es gibt für jedes Wort der Sprache spezielle Erkenner/Erkennungselemente(recognition elements), die auf akustisch-phonetische Muster im Input reagieren können und charakteristisch für dieses Wort sind.
ii) Früh bei der Erkennung eines Wortes werden also alle die Erkenner aktiv,deren Worte mit den initialen Phonemen beginnen. Diese anfänglicheGruppe von Wort-Kandidaten ist die wortinitiale Kohorte.
iii) Im weiteren Verlauf der Erkennung wird diese Kohorte verkleinert, weil die Wörter herausfallen, deren Informatinen nicht mehr zum gehörten oder zum Kontext passen.
iv) Wenn die Kohorte nur noch aus einemElement besteht, ist ein Wort erkannt.

eine „Kohorten“-basierte interaktive Theorie der Worterkennung
i) Es gibt für jedes Wort der Sprache spezielle Erkenner/Erkennungselemente(recognition elements), die auf akustisch-phonetische Muster im Input reagieren können und charakteristisch für dieses Wort sind.
ii) Früh bei der Erkennung eines Wortes werden also alle die Erkenner aktiv,deren Worte mit den initialen Phonemen beginnen. Diese anfänglicheGruppe von Wort-Kandidaten ist die wortinitiale Kohorte.
iii) Im weiteren Verlauf der Erkennung wird diese Kohorte verkleinert, weil die Wörter herausfallen, deren Informatinen nicht mehr zum gehörten oder zum Kontext passen.
iv) Wenn die Kohorte nur noch aus einemElement besteht, ist ein Wort erkannt.

eine „Kohorten“-basierte interaktive Theorie der Worterkennung
i) Es gibt für jedes Wort der Sprache spezielle Erkenner/Erkennungselemente(recognition elements), die auf akustisch-phonetische Muster im Input reagieren können und charakteristisch für dieses Wort sind.
ii) Früh bei der Erkennung eines Wortes werden also alle die Erkenner aktiv,deren Worte mit den initialen Phonemen beginnen. Diese anfänglicheGruppe von Wort-Kandidaten ist die wortinitiale Kohorte.
iii) Im weiteren Verlauf der Erkennung wird diese Kohorte verkleinert, weil die Wörter herausfallen, deren Informatinen nicht mehr zum gehörten oder zum Kontext passen.
iv) Wenn die Kohorte nur noch aus einemElement besteht, ist ein Wort erkannt.
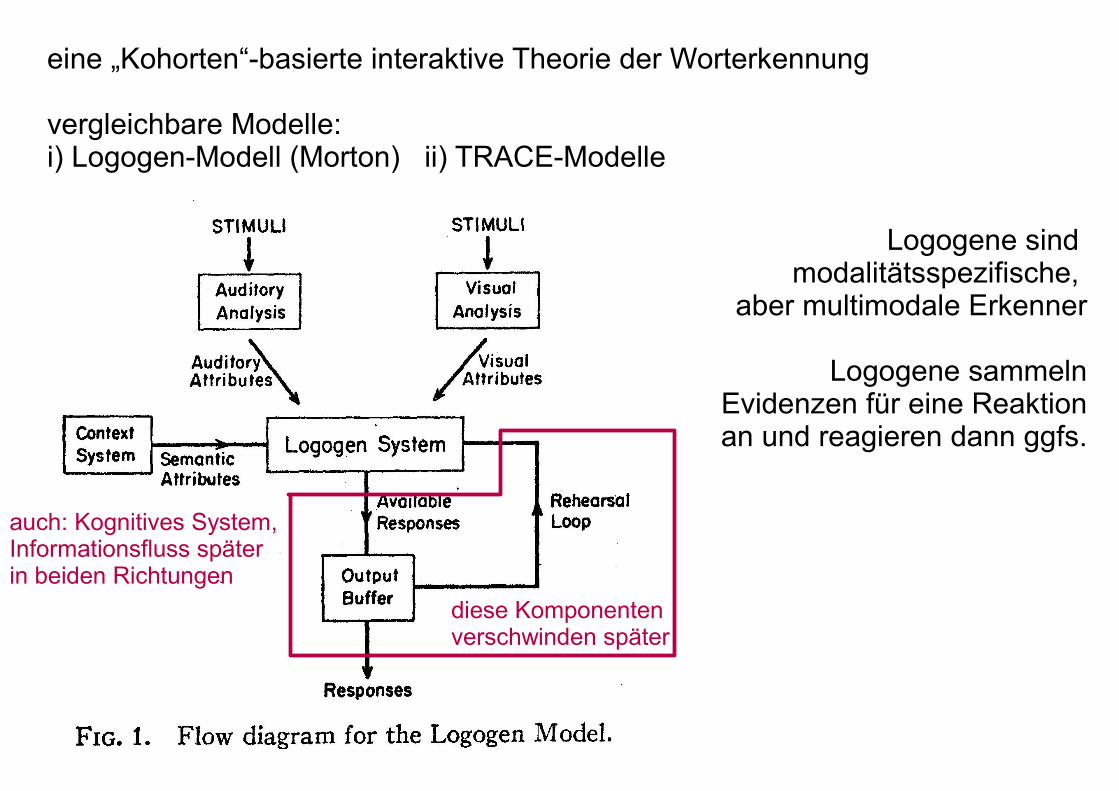
eine „Kohorten“-basierte interaktive Theorie der Worterkennung
vergleichbare Modelle:i) Logogen-Modell (Morton) ii) TRACE-Modelle
Logogene sind modalitätsspezifische,
aber multimodale Erkenner
Logogene sammelnEvidenzen für eine Reaktionan und reagieren dann ggfs.
auch: Kognitives System,Informationsfluss späterin beiden Richtungen
diese Komponentenverschwinden später
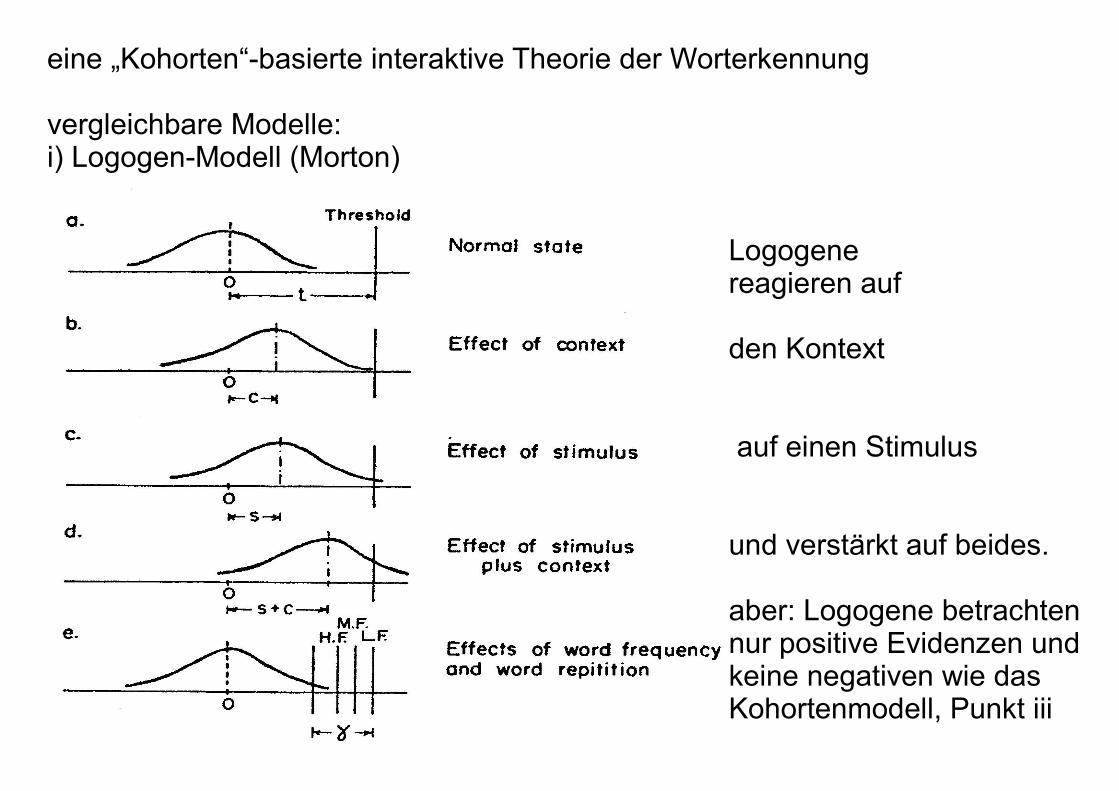
eine „Kohorten“-basierte interaktive Theorie der Worterkennung
vergleichbare Modelle:i) Logogen-Modell (Morton)
Logogene reagieren auf
den Kontext
auf einen Stimulus
und verstärkt auf beides.
aber: Logogene betrachten nur positive Evidenzen undkeine negativen wie dasKohortenmodell, Punkt iii

eine „Kohorten“-basierte interaktive Theorie der Worterkennung
offene Fragen:
Was passiert, wenn nach einiger Zeit die Kohorte leer ist,z.B. wenn ein Pseudowort wahrgenommen wird wie z.B. Kirpe?
Was passiert bei Sprachen wie dem bretonischen, wo z.B. der Pluraleines Nomens einen Wechsel der Coda hat?
Wie sehen Erkenner prozedural aus?








![· 2012-02-16 · 517974 ISÄC, Dan Die Kohorten- und Ä1enkaste11e von Giläu = Castrele de cohortä si alä de la Giläu / von Dan I sac . Zaläu [s. n.] , 1997. 112 24 cm. (Führer](https://static.fdokument.com/doc/165x107/5e31a70284e1445d8b1fd0c8/2012-02-16-517974-isc-dan-die-kohorten-und-1enkaste11e-von-gilu-castrele.jpg)









