
Intelligenz im Chaos: Collaborative Tagging als neue Form der Sacherschließung Christof Niemann.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 1
Empirie II: Wortarten im Kontext (Tagging) Morphologieanalyse und Lexikonaufbau (12. Vorlesung) Dozent: Gerold Schneider
Übersicht • Was ist Tagging? • Statistisches Tagging • Übergangswahrscheinlichkeiten, Hidden Markov Models
• Regel-basiertes Tagging (Brill-Tagging) • Lernphase, Anwendungsphase, Typische Fehler
• Ein Vergleich von statistischem und regelbasiertem Tagging für das Deutsche • Ein Vergleich von statistischem und regelbasiertem Tagging für das Französische • Kombination von statistischem und constraint-basiertem Tagging

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 2
Was ist Tagging? Allgemein: Die Zuweisung eines 'Tags' (Markierungssymbol) an eine Texteinheit. Meist: Die Zuweisung eines eindeutigen Wortartsymbols an eine Wortform im Kontext. Tagging folgt meist auf die morphologische Analyse oder ist selbst lexikonbasiert. Es kann entweder statistisch oder regelbasiert ablaufen. Beispiel: Morphologische Analyse: Tagger: Junge [Adj, N] Adj Männer [N] N gehen [finV, infV] finV zu [Präp, Adv, iKonj, Adj] Präp ihr. [Pron, Det] Pron
nach Smith (S.86): 5% der Types sind ambig. Da diese jedoch sehr häufig sind, entspricht das bis zu 20% der Token. nach Charniak (S.49): Im Brown-Corpus sind 11% der Types ambig. Das entspricht jedoch 40% der Token.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 3
Tag-Sets Das Tag-Set umfasst die Menge der Tags, die von einem Tagger vergeben werden.
Tag-Set Number of Tags
Brown Corpus 87
Lancaster-Oslo/Bergen 135
Lancaster UCREL 165
London-Lund Corpus of Spoken English 197
Penn Treebank 36 + 12

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 4
Bsp.: Der Xerox Part-of-Speech-Tagger Basiert auf dem LOB (Lancester-Oslo-Bergen) Tag-Set. Dieses enthält rund 120 Tags für die Wortarten plus Tags für die Satzzeichen. Ausgangstext: You can drink from a can of beer and fly home like a fly. You live your lives as a man would do time and again. Do you think that a buffalo can buffalo a buffalo?
Der analysierte Text: You/PPSS can/MD drink/VB from/IN a/AT can/NN of/IN beer/NN and/CC fly/NN home/NN like/CS a/AT fly/NN ./SENT You/PPSS live/VB your/PP$ lives/NNS as/RBC a/AT man/NN would/MD do/DO time/NN and/CC again/RB ./SENT Do/DO you/PPSS think/VB that/CS a/AT buffalo/NN can/MD buffalo/VB a/AT buffalo/NN ?/SENT
http://www.rxrc.xerox.com/research/mltt/demos/ . Es gibt Versionen für DE, FR, NL, EN, ES, PT, IT, RU, Ungarisch (weitere in Entwicklung)

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 5
Anforderungen an einen Tagger (nach [Cutting et al. 92] S.133) Robustheit
Der Tagger kann beliebigen Input verarbeiten (incl. unbekannte Wörter, Sonderzeichen). Effizienz
Der Tagger arbeitet schnell. Genauigkeit
Der Tagger arbeitet mit einer geringen Fehlerrate (< 5%). Anpassbarkeit
Der Tagger kann an besondere Anforderungen eines Texttyps angepasst werden. Wiederverwertbarkeit
Der Tagger kann leicht für neue Aufgabengebiete eingesetzt werden.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 6
Statistisches Tagging Annahme: die Wahrscheinlichkeit der Aufeinanderfolge von Wortarten ist unterschiedlich. Ausgangspunkt ist einmal die Wahrscheinlichkeit, dass ein gegebenes Wort mit Wahrscheinlichkeit P die Wortart POS1 hat. Die Wahrscheinlichkeit der Wortartenübergänge werden dann berechnet (z.B. indem man manuell disambiguiert ODER abwechselnd manuell disambiguiert, tagged und korrigiert) und über mehrere Wörter hinweg (Tri-Tupel, Quad-Tupel) die maximale Wahrscheinlichkeit der Übergänge ermittelt. Grundlage: Hidden Markov Modelle (HMM) • basieren auf Markov-Ketten. Markov-Ketten entsprechen endlichen Automaten, bei denen jede Kante
mit einer Wahrscheinlichkeit versehen ist. Die Summe aller Kanten, die den selben Knoten verlassen, muss 1 ergeben.
• sind eine Verallgemeinerung von Markov-Ketten, in denen ein gegebener Knoten (Zustand) mehrere ausgehende Kanten hat, die das gleiche Symbol tragen. Deshalb ist es nicht möglich, aufgrund der Ausgabe zu erschliessen, welche Zustände berührt wurden (-> hidden).
• die Wahrscheinlichkeit jedes Zustands hängt ab vom Vorgängerzustand. • die Hidden Markov Modelle sind ein stochastischer Prozess, der über den Markov-Ketten liegt und
Sequenzen von Zuständen berechnet. • Aus all diesen Sequenzen findet man mit Hilfe spezieller Algorithmen die beste Sequenz (z.B. mit
Viterbi-Algorithmus).

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 7
Ein Beispiel aus: [Feldweg 96]. die auf der Bank sitzende Frau. folgende Mehrdeutigkeiten:
(.) die auf der Bank sitzende Frau
(.) REL ART DEM
PREP PREF
REL ART DEM
N ADJ N
PREF = Verbpräfix, entsprechend PTKVZ (Partikel Verbzusatz) im STTS Tagset

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 8
Man ordnet den Übergängen zwischen den Wortarten Wahrscheinlichkeiten zu.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 9
Schliesslich wird jeder Wortform-Wortart-Kombination eine Wahrscheinlichkeit zugeordnet:
Für jeden möglichen Pfad durch ein solches Netz lässt sich durch Multiplikation der auf dem Pfad liegenden Werte eine Gesamtwahrscheinlichkeit berechnen. Formal betrachtet handelt es sich bei diesem Verfahren um ein Hidden-Markov-Modell erster Ordnung. Ein solches Modell ist definiert über:

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 10
1. die Menge von n Symbolen V = {w1, ..., wn} In unserem Beispiel bildet das Vokabular (= die Menge der Wortformen) die Menge V.
2. die Menge von m Zuständen S = {s1, ..., sm} Diese Menge entspricht den möglichen Wortarten.
3. einer Menge von m2 Übergangswahrscheinlichkeiten zwischen Zuständen P = {p(s1|s1), ..., p(si|sj)}, 1 < i,j, < m Hier die Übergangswahrscheinlichkeiten zwischen Wortarten.
4. einer Menge von Observationswahrscheinlichkeiten L = {p(w1|s1), ..., p(wk|sl)}, 1 < k < n, 1 < l < m Dies entspricht der Menge der lexikalischen Wahrscheinlichkeiten: gegeben die Wortart s, wie hoch ist die Wahrscheinlichkeit von Wortform w?
5. Für eine gegebene Folge von i Symbolen, kann mit Hilfe dieses Modells die wahrscheinlichste Folge bestimmt werden durch: max(s) vom produkt(j=1 bis i) von p(sj|sj-1) × p(wj|sj)

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 11
Beim beschriebenen Modell handelt es sich um ein Hidden-Markov-Modell erster Ordnung. Übergangswahrscheinlichkeiten werden dabei nur für direkt benachbarte Zustände berücksichtigt (Bigram-Modell). Es sind jedoch auch Modelle höherer Ordnung möglich. Parametergewinnung Das Tagging mittels HMM ist prinzipiell sprachunabhängig. Voraussetzung ist jedoch, dass die in den Gleichungen 1-4 aufgeführten Parameter bekannt sind. Die Gewinnung der Parameter ist jedoch das eigentliche Problem.
1. Einfach: Bestimmung des Vokabulars 2. Schwieriger: Festlegung des Tag-Sets (Wortartenmenge und -abgrenzung). Siehe
Diskussion über die Wortartenklassifikation in der 1. Vorlesung.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 12
3. Sehr komplex: Gewinnung von Übergangswahrscheinlichkeiten und Observationswahrscheinlichkeiten. Präzise allgemeingültige Werte kennt man nicht . Diese Parameter müssen geschätzt werden (i. A. berechnet aus bereits getaggten Korpora).
1. für die meisten Sprachen sind keine hinreichend grossen, getaggten Textkorpora verfügbar. Möglichkeiten: • Verringerung der Anzahl der zu schätzenden Parameter (z.B. individuelle Werte
nur für hochfrequente Wortformen; ansonsten Werte für die Ambiguitätsklasse (= Menge aller Wortformen mit den gleichen Tags) berechnen)
• Gewinnung von Werten aus ungetaggten Textkorpora: zufällige Auswahl von Wahrscheinlichkeiten und Abgleich der gewonnenen Tags mit einem Vollformenlexikon; sich wiederholende Taggingvorgänge
2. vermeintliche Nullübergänge müssen abgefangen werden, denn Nullübergänge haben grosse Auswirkungen. Lösung: Ersetzen der Nullübergänge durch sehr kleine Wahrscheinlichkeiten
3. kein Korpus kann wirklich allgemeingültig und ausgewogen sein

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 13
Einsatzgebiete für Tagger (teilweise nach [Church 93] S.7) • Sprachsynthese • Spracherkennung • Information Retrieval • Bedeutungsdisambiguierung • Lexikographie • Syntax (Vorverarbeitung)

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 14
Genauigkeit statistischer Tagger Statistische Tagger erreichen eine Genauigkeit von rund 94-97% bei einem Tag-Set wie dem STTS mit rund 50 Tags. Besonderes Handicap für Tagger sind: • unbekannte Wörter (d.h. Wortformen, die im Trainingskorpus nicht vorkamen);
insbesondere auch fremdsprachige Einschübe • weite Abhängigkeiten im Satz, die über das Bigram- bzw. Trigram-Fenster hinausgehen. ... weil wir diese Probleme schon kennen/VVFIN. Wir sollten diese Probleme schon kennen/VVINF. Die Frauen, die/ART Kinder und alte Männer wurden evakuiert. Die Frauen, die/PRELS Kinder und alte Männer evakuierten, wurden geehrt.
• Aufzählungen, die keine vollständigen Sätze bilden Vorsicht! Bei Sätzen, die im Durchschnitt ~20 Wörter lang sind, bedeutet eine Fehlerrate von 4%, dass 56% aller Sätze (also jeder zweite Satz) ein falsch getaggtes Wort enthalten. Für eine Fehlerrate von 4% bei den Sätzen müsste die Fehlerrate bei den Wörtern auf 0,2% sinken.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 15
Regel-basiertes Tagging (Brill-Tagging) Lit.: [Brill 92], [Brill 94] Die CL-Gruppe in Zürich hat den Brill-Tagger für das Deutsche trainiert. Vorteile von regelbasierten Systemen: • weniger Information zu verwalten • Übersichtlichkeit der Regeln • leichte Veränderbarkeit des Taggers (Publikation) • bessere Portabilität
Brills Tagger: • lernt Regeln selbständig • kommt ohne externes Lexikon aus. (Baut eigenes Lexikon auf) • basiert auf einem getaggten Corpus.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 16
Lernphase des Taggers 6. Zuerst werden POS-Wahrscheinlichkeiten aus einem getaggten Korpus (hier Brown Corpus) ermittelt.
Damit wird ein Vollformenlexikon aufgebaut. (z.B. die höchste Wahrscheinlichkeit für run ist Verb) 7. Lexikalische Regeln: Präfix- und Suffixwahrscheinlichkeiten werden aus dem getaggten Korpus
automatisch ermittelt. (z.B. ein Wort auf -ous ist wahrscheinlich Adjektiv) 8. Kontextregeln: Der Algorithmus wendet seine gelernten POS-Wahrscheinlichkeiten an und vergleicht
seine Tagging-Ergebnisse mit den im getaggten Corpus vorgegebenen und leitet Änderungsregeln zu vorgegebenen Regelmustern ab: Change tag `a' to tag `b' when:
1. The preceding (following) word is tagged `z'. 2. The word two before (after) is tagged `z'. 3. One of the two preceding (following) words is tagged `z'. 4. One of the three preceding (following) words is tagged `z'. 5. The preceding word is tagged `u' and the following word is tagged `z'. 6. The preceding (following) word is tagged `u' and the word two before (after) is tagged `z'. 7. The preceding (following) word is `w'. 8. The word two before (after) is `w'. 9. One of the two preceding (following) words is `w'. 10. The current word is `v' and the preceding (following) word is `w'. 11. The current word is `w' and the preceding (following) word is tagged `z'.
Für jede Regelvariante <tag_a, tag_b, Variantennummer> wird berechnet, wie oft sie richtige und wie oft sie falsche Ergebnisse liefert. Die Differenz ergibt die Verbesserungssumme. Die Regelvariante mit der besten Verbesserungssumme wird angewendet.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 17
Bsp. für Kontextregeln: Der Tagger markiert ursprünglich 159 Wörter als Verben, die Nomen sein sollten. Mit der Regel "Ändere Tag von Verb zu Nomen, falls eines der zwei vorhergehenden Wörter als Determiner getaggt ist." werden 98 Fälle (von den 159) korrigiert, aber es werden 18 andere Fehler erzeugt. Die Verbesserungssumme ist also (98-18=) 80. Bsp. für zwei vom englischen System ermittelte Regeln: 1. TO IN Next-tag AT
Ein mit TO (to-Infinitiv) getaggtes Wort wird mit IN (Präposition) getaggt, falls das nächste Wort mit AT (Artikel) getaggt ist. 2. VBN VBD Prev-Word-is-cap Yes
Ein mit VBN (Past Part. Verb) getaggtes Wort wird mit VBD (Past Verb) getaggt, falls das vorhergehende Wort mit Grossbuchstaben beginnt (d.h. ein Eigenname ist). Bsp. für eine vom deutschen System ermittelte Regel: VVFIN VAFIN Next1or2or3tag VVPP Diese Regel kommt bei Verben zum Einsatz, die gemäss Lexikon sowohl Voll- als auch Hilfsverben sein können, also vor allem bei sein und haben.. Sie transformiert ein finites Hauptverb (VVFIN) in ein finites Hilfsverb (VAFIN) falls ein Partizip innerhalb der folgenden drei Worte folgt.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 18
Anwendungsphase des Taggers 4. Jedem Wort wird das nach dem Lexikon wahrscheinlichste Tag zugewiesen. 5. Unbekannte Wörter, die mit einem Grossbuchstaben beginnen, werden als Namen
angesehen. 6. Unbekannte Wörter, die mit einem Kleinbuchstaben beginnen, werden aufgrund ihrer
Endung klassifiziert, aufgrund der lexikalischen Regeln aus der Lernphase (z.B. blablaous als Adj). Zusätzlich wird für unbekannte Wörter eine Sammlung von aus dem Trainingskorpus extrahierten Bigrammen (wie beim statistischen Tagging) zu Hilfe gezogen.
7. Die in der Lernphase gelernten Kontextregeln werden angewendet. (siehe Beispiele oben) Der Algorithmus für die englische Version hat eine Fehlerquote von 7,9%, wenn nur die Schritte 1-3 angewendet werden. Wenn auch die 71 automatisch ermittelten Kontextregeln eingesetzt werden, verbessert sich das System von 7,9% auf 5,1% Fehlerrate.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 19
Typische Taggingfehler (im Deutschen) Faule und übereifrige Kontextregeln
Zur obigen Regel VVFIN VAFIN Next1or2or3tag VVPP : Steht ein Partizip weiter weg als drei Tags vom provisorisch als Vollverb getaggten Kandidaten, so vermag sie das Vollverb nicht mehr in ein Hilfsverb zu verwandeln. Umgekehrt auch: Der Brief ist lang. richtig getaggt, aber die Regel verwandelt das ist im folgenden Satz zu unrecht in ein Hilfsverb: Der Brief ist lang, erreicht hat er aber nichts. Eine richtige Syntaxanalyse könnte hier Abhilfe schaffen, wäre aber rechnerisch wesentlich aufwendiger. Ohne Syntaxregeln hat der Tagger auch grosse Schwierigkeiten, die Relativpronomen der, die, den etc. von Artikeln zu unterscheiden. Eifrige lexikalische Regeln
Mit Worten, die nicht im Lexikon stehen, stellen lexikalische Regeln allerlei sinnvolles und sinnloses an. Während die weiter oben zitierte Regel bar hassuf 3 ADJD 5 meist sinnvoll ist, wird durch sie das unbekannte Wort Privatbar auch zu einem Adjektiv gemacht. Da viele Adverbien in -ch enden, wird der unbekannte Hirsch durch eine ähnlich fleissige Regel vorläufig leider zum Adjektiv.

G. Schneider: Morphologieanalyse und Lexikonaufbau, SS 2000 Page 20
Ein Vergleich von statistischem und regelbasiertem Tagging für das Deutsche von Martin Volk und Gerold Schneider (Publikation)
==> Brills These: Regelbasiertes Tagging ist genauso gut wie probabilistisches Tagging. Mit Hilfe eines Lexikons kann es noch verbessert werden. Untersuchte Tagger: 1. Statistischer Tagger: TreeTagger von der
Universität Stuttgart (entwickelt von Helmut Schmid)
2. Regelbasierter Tagger: Brill-Tagger Korpus rund 70'000 Wörter aus der Frankfurter Rundschau (manuell getaggt) • Trainingskorpus (7/8): 60'710 Tokens • Testkorpus (1/8): 8'887 Tokens; mit einer
durchschnittlichen Mehrdeutigkeit von 1,5 Tags/Token für alle Token, die im Lexikon enthalten sind. 1342 Tokens aus dem Testkorpus kommen im Trainingskorpus nicht vor und sind deshalb nicht im Lexikon enthalten.
Tagset STTS (Stuttgart-Tübingen Tagset) mit 54 Tags einschl. 3 Tags für Satzzeichen Training • Beim TreeTagger: Dauer ungefähr 2
Minuten; Ausgabe-Datei rund 630 kByte. Das Lexikon muss vor dem Training berechnet werden und wird in die Ausgabe-Datei hineinkompiliert.
• Beim BrillTagger: Dauer rund 30 Stunden (!!); Ausgabe:
1. Vollformen-Lexikon mit 14'147 Einträgen (212 kByte)
2. 329 Kontext-Regeln (8 kByte) 3. 378 Lexikalische Regeln (9 kByte) 4. Bigram-Liste mit 42'270 Einträgen (609
kByte)

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 21 -
-
Tagging des Testkorpus mit dem TreeTagger
ambiguity tokens in % correct in % lexical errors in % disambig.
errors in %
0 1342 15.10 1128 84.05 214 15.95 0 0.00
1 5401 60.77 5330 98.69 71 1.31 0 0.00
2 993 11.17 929 93.55 3 0.30 61 6.14
3 795 8.95 757 95.22 0 0.00 38 4.78
4 260 2.93 240 92.31 0 0.00 20 7.69
5 96 1.08 83 86.46 0 0.00 13 13.54
total 8887 100.00 8467 95.27 288 3.24 132 1.49
Fehlertypen
• Lexical errors: Das korrekte Tag ist nicht im Lexikon, und der Tagger rät ein inkorrektes Tag.
• Disambiguation errors: Das korrekte Tag ist im Lexikon, aber der Tagger wählt ein falsches Tag.

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 22 -
-
Tagging des Testkorpus mit dem Brill-Tagger
ambiguity tokens in % correct in % lexical errors in % disambig.
errors in %
0 1342 15.10 1094 81.52 248 18.48 0 0.00
1 5401 60.77 5330 98.69 71 1.31 0 0.00
2 993 11.17 906 91.24 3 0.30 84 8.46
3 795 8.95 758 95.35 0 0.00 37 4.65
4 260 2.93 245 94.23 0 0.00 15 5.77
5 96 1.08 87 90.62 0 0.00 9 9.38
total 8887 100.00 8420 94.75 322 3.62 145 1.63
G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 23 -
-
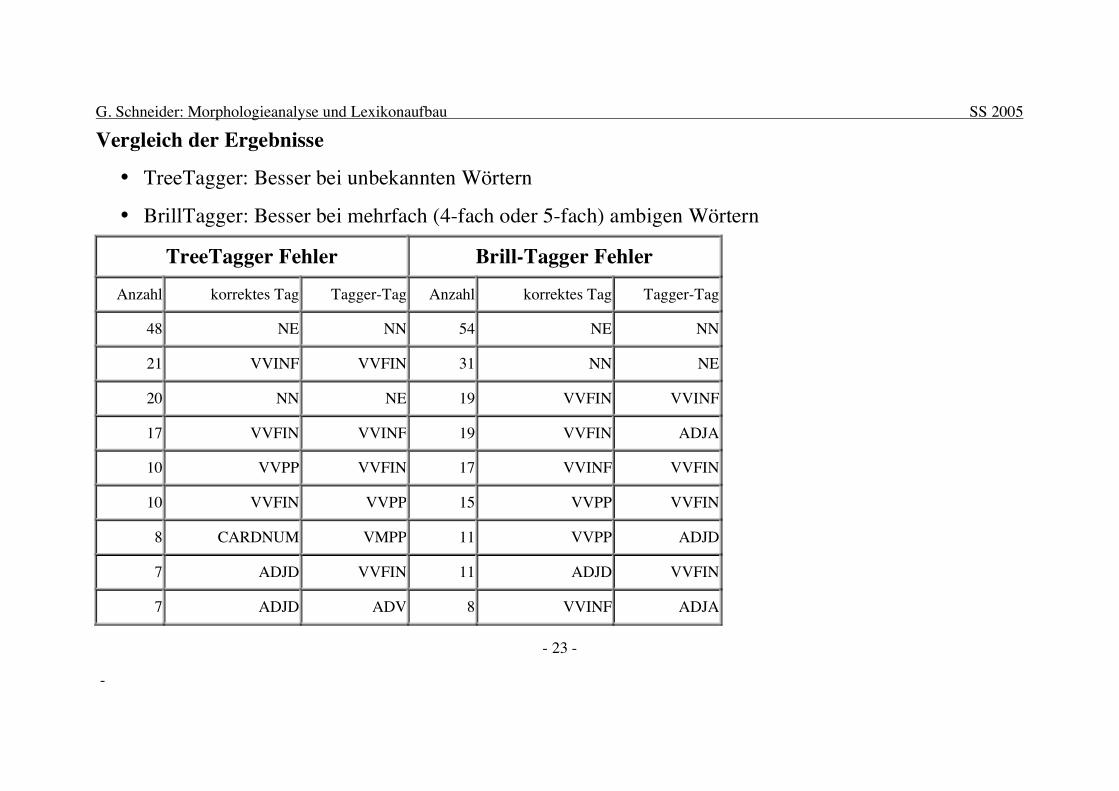
Vergleich der Ergebnisse
• TreeTagger: Besser bei unbekannten Wörtern
• BrillTagger: Besser bei mehrfach (4-fach oder 5-fach) ambigen Wörtern
TreeTagger Fehler Brill-Tagger Fehler Anzahl korrektes Tag Tagger-Tag Anzahl korrektes Tag Tagger-Tag
48 NE NN 54 NE NN
21 VVINF VVFIN 31 NN NE
20 NN NE 19 VVFIN VVINF
17 VVFIN VVINF 19 VVFIN ADJA
10 VVPP VVFIN 17 VVINF VVFIN
10 VVFIN VVPP 15 VVPP VVFIN
8 CARDNUM VMPP 11 VVPP ADJD
7 ADJD VVFIN 11 ADJD VVFIN
7 ADJD ADV 8 VVINF ADJA

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 24 -
-
Tagging des Testkorpus mit einer Kombination von Gertwol und Tagger
Um das Problem der Erkennung unbekannter Wörter einzudämmen, kann man ein `externes' Lexikon zuschalten. Z.B. kann man alle unbekannten Wörter zunächst von Gertwol analysieren lassen, die Gertwol-Ausgabe auf die möglichen Tags abbilden und dann dem Tagger-Lexikon hinzufügen. Dadurch kann man die Tagger-Genauigkeit weiter verbessern. Die besten Ergebnisse erzielten wir mit der Kombination von Gertwol und dem TreeTagger.
ambiguity tokens in % correct in % lexical errors in % disambig.
errors in %
0 109 1.23 72 66.06 37 33.94 0 0.00
1 6307 70.97 6209 98.45 98 1.55 0 0.00
2 1224 13.77 1119 91.42 10 0.82 95 7.76
3 852 9.59 805 94.48 2 0.23 45 5.28
4 296 3.33 266 89.86 0 0.00 30 10.14
5 99 1.11 86 86.87 0 0.00 13 13.13
total 8887 100.00 8557 96.29 147 1.65 183 2.06

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 25 -
-
Ein Vergleich von statistischem und regelbasiertem Tagging für das Französische Lit.: [Chanod und Tapanainen 95]: "Tagging French - comparing a statistical and a constraint-based method"; Online-Version (Postscript 130 KByte). Die untersuchte statistische Methode entspricht der von Cutting et al. entwickelten und führte auch für Französisch zu 96,8% korrektem Tagging. Das Ändern der `Parser-Tendenz' (engl. bias) ist manchmal sehr kompliziert. Die Sequenz Det N N/V Präp (Wie in Le train part à cinq heures.)
wird oft falsch disambiguiert. Der Tagger bevorzugt die N-Lesart für das Verb. Zwei Tendenzen wurden hinzugefügt: Auf ein Singular-Nomen folgt meist kein Nomen. Auf ein Singular-Nomen folgt oft ein Singular-3.Pers.-Verb.
Danach wurde der obige Satz richtig disambiguiert, aber die Fehlerrate insgesamt stieg um 50%.

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 26 -
-
Die constraint-basierte Methode (nach Chanod, Tapanainen) Motivation:
1. In einem Zeitungscorpus mit 1 Mio laufenden Wörtern machen die 16 häufigsten ambigen Wortformen 50% aller Ambiguitäten aus. (Zwei Drittel aller Ambiguitäten gehen auf die 97 häufigsten Wortformen zurück.)
2. Die häufigsten ambigen Wortformen sind korpusunabhängig. Methode:
1. Für die häufigsten ambigen Wortformen werden Regeln aufgestellt, die kontextuelle Bedingungen angeben. (Dadurch wird z.B. die Mehrdeutigkeit zwischen Clitic und Determiner für le oder la geklärt.) Je le veux. (Ich will es.) Je travaille dans le jardin. (Ich arbeite im Garten.)
Einige dieser häufigsten ambigen Wortformen haben sehr seltene Lesarten: Die Hilfsverben a und est können auch Nomen sein. Für diese Fälle wird genau festgelegt, wie der Kontext aussehen muss, damit diese Wortformen die seltene Lesart haben können. In allen anderen Fällen wird die wahrscheinlichere Lesart angenommen.

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 27 -
-
Für schwierigere Fälle werden kontextuelle Heuristiken aufgestellt. Bsp. Unterscheidung zwischen des als Determiner bzw. kontrahierter Präposition-Determiner Jean mange des pommes. Jean aime le bruit des vagues.
Eindeutige Regelung nur über Verbsubkategorisierung möglich. Hier Heuristiken: • Det-Lesart, wenn des am Satzanfang • Prep-Det-Lesart, wenn des hiner einem Substantiv
2. Für weitere Probleme werden nicht-kontextuelle Heuristiken aufgestellt. Sie entsprechen lexikalischen Wahrscheinlichkeiten. (Die Autoren raten, welche Lesart wahrscheinlicher ist.) Bsp.: Präposition vor Adjektiv Pronomen vor Partizip Perfekt
Werden nur auf die Fälle angewendet, die durch die vorherigen Schritte nicht disambiguiert werden konnten.
System: Regeln und Heuristiken sind als Transducer implementiert.

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 28 -
-
39 Regeln 25 kontextuelle Heuristiken 11 nicht-kontextuelle Heuristiken
Leistung: Test A: Corpus mit 255 Sätzen (5752 Wörter) => 54% Wörter sind mehrdeutig. Nach Anwendung aller Regeln: 1,3% Fehlerrate (s. Tabelle 1) Test B: Zeitungscorpus mit 12.000 Wörtern (mit Schreibfehlern und vielen Eigennamen) Nach Anwendung aller Regeln: 2,5% Fehlerrate (s. Tabelle 2)
Kombination von statistischem und constraint-basiertem Tagging Versuchsanordnung:
1. Einsatz des constraint-basierten Taggers ohne die nicht-kontextuellen Heuristiken (Aus Zeitungskorpus mit 12.000 Wörtern bleiben 1400 mehrdeutig.)
2. Einsatz des statistischen Taggers unabhängig vom vorherigen Lauf des constraint-basierten Taggers. Für die Fälle, wo der constraint-basierte Tagger keine Eindeutigkeit herstellt, wird

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 29 -
-
das vom statistischen Tagger ermittelte Tag genommen. (Erzeugt 220 Fehler auf die 1400 Mehrdeutigkeiten.)
3. Die verbleibenden Mehrdeutigkeiten (0,5%) werden durch die nicht-kontextuellen Heuristiken behandelt. (Erzeugt nur 150 Fehler auf die 1400 Mehrdeutigkeiten.)
Fehleranalyse 1. Fehler durch Mehr-Wort-Ausdrücke (15 Fehler).
Lösung: Lexikalisierung der Ausdrücke 2. korrigierbare Fehler (41 Fehler)
Lösung: Korrektur und Ergänzung der Regeln (das vorliegende Ergebnis wurde unter Zeitbegrenzung erzielt.) Bsp.: "Prep + Clitic + Fin-Verb" war nicht verboten und wurde anwendet auf à l'est
3. problematische (schwer zu korrigierende) Fehler (28 Fehler)

G. Schneider: Morphologieanalyse und Lexikonaufbau SS 2005
- 30 -
-
(to be updated) Tagger zum Testen Ein frei verfügbarer Tagger für das Deutsche, der mit statistischen Methoden arbeitet, findet sich im Morphy-System der Universität Paderborn. Dieser Tagger läuft unter MS-DOS und Windows95 auf PCs. Ein weiterer verfügbarer Tagger für das Deutsche wurde an der Universität Stuttgart entwickelt. Er nennt sich TreeTagger und läuft unter SunOS und Linux. Es gibt auch eine Windows Demoversion. Gerold Schneider, Martin Volk


















