
F. Farnir, L. Massart, E. Moyse, N. Moula Faculté de ... 8 Biostatistique.pdf · L’analyse de la...
53
L’analyse de la variance F. Farnir, L. Massart, E. Moyse, N. Moula Faculté de Médecine Vétérinaire Université de Liège
Transcript of F. Farnir, L. Massart, E. Moyse, N. Moula Faculté de ... 8 Biostatistique.pdf · L’analyse de la...

L’analyse de la variance
F. Farnir, L. Massart, E. Moyse, N. Moula
Faculté de Médecine Vétérinaire
Université de Liège

Nouvelles questions
� Imaginons le problème suivant:
◦ Les chats présentent 3 groupes sanguins (A, B et AB).
◦ On souhaite savoir si la concentration d’un anticorps
particulier dépend du groupe sanguin.
◦ De plus, le sexe pourrait avoir un effet sur cette
concentration, ce qu’on souhaite vérifier.
◦ En outre, l’effet éventuel du groupe sanguin pourrait
ne pas être le même chez les mâles et chez les
femelles.
◦ Comment vérifier (tester) toutes ces hypothèses ?

Nouvelles questions
� L’approche statistique
◦ Dans les 3 questions posées, on veut tester la dépendance d’une variable continue (la concentration) sur une ou plusieurs variables discrètes (le groupe sanguin, le sexe ou leurcombinaison)
◦ On peut mettre ces questions sous la formed’hypothèses (nulles) statistiques à tester
� ��: �� � �� � ���� ��: ��| � ��| � ���|� ���: ��| � ��| � ����: ��,� � ��,� � ��,� � ��,� � ��,�� � ��,��

Nouvelles questions
� L’approche statistique (suite)
◦ Ces hypothèses nulles généralisent ce qui a été vu
précédemment (test de t) dans plusieurs directions:
� Comparaison de n (≥ 2) moyennes

Nouvelles questions
� L’approche statistique (suite)
◦ Ces hypothèses nulles généralisent ce qui a été vu
précédemment (test de t) dans plusieurs directions:
� Plusieurs effets testés simultanément

Nouvelles questions
� L’approche statistique (suite)
◦ Ces hypothèses nulles généralisent ce qui a été vu
précédemment (test de t) dans plusieurs directions:
� Interactions entre effets

Analyse de la variance
� Ce chapitre va traiter du premier problème (comparaison de
≥ 2 groupes) via une technique appelée « analyse de la
variance à 1 critère » (ANOVA1)
� Les chapitres suivants aborderont les autres questions en
utilisant des « analyses de la variance à 2 critères (avec
interaction) » (ANOVA2 - ANOVA2h - ANOVA2i)
� Nous commençons donc avec le test de l’hypothèse nulle:
��: �� � �� � ⋯ � ��où 1 … � correspondent à des conditions différentes, et �� est la
moyenne d’un caractère étudié correspondant à la condition i.

Analyse de la variance (1 critère)
� Revenons au problème relatif à la concentration d’anticorps chez le chat en fonction du groupe sanguin
� L’hypothèse (nulle) que nous souhaitons tester est ici:
��: �� � �� � ���
qui pourrait aussi s’écrire: ��: � �� � ���� � ���◦ Remarque: la troisième égalité découle des 2 premières
� L’hypothèse alternative �� est qu’au moins une des égalités est incorrecte.

Analyse de la variance (1 critère)
� Une fois l’hypothèse nulle établie, nous pouvons
récolter des données pour nous aider à accepter (ou
réfuter) celle-ci:
A b Ab
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes 104

Analyse de la variance (1 critère)
� On constate que les moyennes d’échantillons sont
différentes, ce qui n’est pas suffisant pour en déduire
que les moyennes des populations correspondantes le
sont aussi:
� L’approche que nous allons prendre est basée sur l’idée
détaillée dans les diapositives suivantes.
� Nous commençons par détailler la notation utilisée.
100 111 102Moyennes

Analyse de la variance (1 critère)
� Le premier indice donne le groupe, le second identifie
le numéro d’observation à l’intérieur du groupe:
A b Ab
���������
���������
������������
���. ���. ����.
Groupes
Moyennes ��..

Analyse de la variance (1 critère)
� L’idée de base est la suivante:
◦ On suppose que les données de chaque groupe constituent un
échantillon extrait d’une population normale, chacune des
populations ayant la même variance. Formellement:
���~� ��, �� , ���~� ��, �� , ����~� ���, ��
◦ Si ��: �� � �� � ��� � � est vraie, les distributions
correspondantes sont � �, �� et sont donc confondues, alors
qu’au moins une des distributions diffère des autres par sa
moyenne si �� est vraie.

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ Graphiquement:
H0 H1

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ Nous allons estimer la variance �� de 2 manières
différentes.
◦ La première méthode est une estimation intra-
groupe: on estime la variance dans chaque groupe
(elles sont supposées identiques), et on fait une
moyenne pondérée (par la taille du groupe) de ces
estimations. Formellement:
�!"#$� � %� & 1 ∗ �� ( %�� & 1 ∗ ��� ( %� & 1 ∗ ��%� & 1 ( %�� & 1 ( %� & 1

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ Comme:
� �� � ∑ *+,-.+,/0!+1� où 2�� � ��� & ���.
� ��� � ∑ *+3,-.+3,/0!+31� où 2��� � ���� & ����.
� �� � ∑ *3,-.3,/0!31� où 2�� � ��� & ���.� % � %� ( %�� ( %� et % � # 56789: � 3
◦ �!"#$� � ∑ *+,-.+,/0 <∑ *+3,-.+3,/0 <∑ *3,-.3,/0!1!=

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ La seconde méthode est une estimation entre
groupes: si �� est vraie, chaque groupe peut être vu
comme un échantillon.
� La moyenne de chaque échantillon (���., ����., ���.) estime �� La variance de ces moyennes estime
>-! , où n est la taille des
échantillons (cfr cours de BMV1). Si les tailles des échantillons
diffèrent, il est aisé de montrer que:
�!"?#� � ∑ !,∗ @�,.1@�.. -.=,/0 !=1�

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ Pour cette seconde méthode, si �� est fausse:
� Les moyennes de groupes estiment des valeurs différentes
(��, ��A :B ��), et auront donc tendance à être plus
différentes que quand �� est vraie.
� Autrement dit, la variance de ces moyennes aura tendance à
être supérieure à >-! .

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ En résumé:
� Si �� est vraie, �!"#$� et �!"?#� estiment la même variance
(��). Le rapport de ces deux variances a donc une distribution
connue (voir chapitre précédent):
C,.DEF-C,.DFG- ~H!=1�,!1!=
� Si �� est fausse, �!"#$� < �!"?#� en général, et donc:
C,.DEF-C,.DFG- I H!=1�,!1!=

Analyse de la variance (1 critère)
� L’idée de base est la suivante (suite):
◦ On pourra donc faire la distinction entre �� et �� en
regardant la valeur de F calculée comme expliqué ci-
dessus:
� On définit une valeur HC?J�K comme une valeur de F qu’on
excède par hasard qu’avec une probabilité L� Si H M HC?J�K, on accepte �� puisqu’il n’y a pas d’évidence
d’une valeur « anormalement » élevée de F (à ce seuil)
� Si H I HC?J�K, on rejette ��: la valeur de F semble
anormalement élevée, traduisant le fait que �!"?#� >> �!"#$�

Analyse de la variance (1 critère)
� Revenons à notre exemple et calculons les deux
variances
A b Ab
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes 104

Analyse de la variance (1 critère)
� Calcul de la variance intra-groupes
A b Ab
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes
�!"#$� � 104 & 100 � ( 106 & 100 � ( ⋯ ( 101 & 101 �9 & 3 � 352
6

Analyse de la variance (1 critère)
� Calcul de la variance inter-groupes
A b Ab
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes
�!"?#� � 3 ∗ 100 & 104 � ( 3 ∗ 111 & 104 � ( 3 ∗ 101 & 104 �3 & 1 � 222
2
104

Analyse de la variance (1 critère)
� La valeur de F vaut donc:
H � C,.DEF-C,.DFG- � ��� �⁄
�U� V⁄ � 1.892� Si on fixe un seuil L = 0.05, la valeur de la distribution
de F avec 2 et 6 degrés de liberté qu’on ne dépasse par
hasard que dans L % des cas est:
qf(0.95,2,6) = 5.143

Analyse de la variance (1 critère)
� Comme F = 1.892 < Fseuil = 5.143, il n’y a pas d’évidence
d’une valeur significativement plus grande de �!"?#� par
rapport à �!"#$� .
� Par conséquent, l’hypothèse nulle est acceptée: il n’y a
pas de différence significative entre les groupes
sanguins (au seuil L � 5%)
◦ Remarque: une alternative de calcul serait de calculer
directement la probabilité que F dépasse 1.892:
1-pf(1.892,2,6) = 0.231
Comme cette valeur est > L � 5%, on accepte ��

Analyse de la variance (1 critère)
� Modèle mathématique
◦ L’ANOVA1 repose sur un modèle mathématique linéaire, qui
prend la forme suivante:
��Y � � ( L� ( :�Y
◦ Ce modèle exprime le fait que chaque observation ��Y est
considérée comme la somme de 3 contributions:
� ��Y est l’observation j faite dans le groupe i,
� � est une moyenne générale, commune à toutes les observations,
� L� est l’effet du groupe i sur Y, commun à toutes les observations du groupe i,
� :�Y est le résidu, spécifique à l’observation ��Y, représentant la part de cette
observation que le modèle n’explique pas.

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Utiliser un modèle mathématique consiste essentiellement en
deux étapes:
1. Obtenir une estimation des paramètres du modèle sur base des
observations.
2. Tester des hypothèses sur les paramètres du modèle sur base de ces
estimateurs et de leur variabilité.
◦ Dans le cadre de l’ANOVA1:
� Les paramètres à estimer sont � et les L�� Une hypothèse d’intérêt est (parmi d’autres possibles):
��: L� � L� � ⋯ � LZ où g est le nombre de groupes

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ L’estimation des paramètres d’un modèle se fait en général via
des méthodes telles que la méthode des moindres carrés ou du
maximum de vraisemblance (voir cours BMV1)
◦ Nous emploierons ici une méthode plus intuitive et qui mène au
même résultat:
� � est estimée par la moyenne ��.. de toutes les observations,
� L� est estimé par l’écart entre la moyenne ���. du groupe i et la moyenne
générale,
� :�Y est estimé par l’écart entre l’observation ��Y et la moyenne de son groupe.
� Formellement, on peut écrire l’identité suivante:
��Y � ��.. ( ���. & ��.. ( ��Y & ���.
�̂ L\� :̂�Y

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Partons de cette identité pour arriver aux tests d’hypothèses:
��Y � ��.. ( ���. & ��.. ( ��Y & ���.⟹ ��Y & ��.. � ���. & ��.. ( ��Y & ���.◦ On élève les deux membres au carré:
��Y & ��.. � � ���. & ��.. � ( ��Y & ���. � ( 2 ∗ ���. & ��.. * ��Y & ���.◦ On somme sur toutes observations:
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�( ^ ^ 2 ∗ ���. & ��.. ∗ ��Y & ���.
_
Y
_
�

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Le dernier terme de cette expression:
^ ^ 2 ∗ ���. & ��.. ∗ ��Y & ���._
Y
_
�� 2 ∗ ^ ���. & ��..
_
�^ ��Y & ���.
_
Y� 0
car la somme des écarts par rapport à une moyenne vaut 0.
◦ L’expression précédente vaut donc:
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�◦ On exprime souvent cette égalité sous la forme:
`ab � `ac ( `adoù SCT = “somme des carrés totaux”
SCM = “somme des carrés due au modèle”SCE = “somme des carrés due aux résidus”

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Interprétation de
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�◦ La variation totale, mesurée par SCT, se décompose en 2 sources
de variation:
� La variation qui vient de ce que le modèle tente d’expliquer, à savoir
celle existant entre les moyennes des groupes (SCM)
� La variation qui vient de ce que le modèle n’explique pas (SCE)

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Interprétation de
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�◦ La proportion de la variation qui est due au modèle se calcule
simplement par:
e� � f�fg

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Une vue mémo-technique de l’expression:
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�
��Y
Gr. 3 Gr. 4Gr. 1 Gr. 2
���. ��..
« Pythagore »

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ Le lien avec le calcul de F utilisé plus haut:
^ ^ ��Y & ��.. �_
Y
_
�� ^ ^ ���. & ��.. �
_
Y
_
�( ^ ^ ��Y & ���. �_
Y
_
�◦ Les trois sommes de carrés fournissent des estimateurs de
variances:
� �!"?#� � ∑ ∑ @�,.1@�.. -_h_,!i1� � f�
!i1�
� �!"#$� � ∑ ∑ @,h1@�,. -_h_,!1!i � fj
!1!i
� "k"$K?� � ∑ ∑ @,h1@�.. -_h_,!1� � fg
!1�� Remarque: % & 1 � %Z & 1 ( % & %Z

Analyse de la variance (1 critère)
� Modèle mathématique (suite)
◦ L’additivité des sommes de carrés et des degrés de liberté
correspondants conduit à une disposition pratique des résultats,
appelée « table d’analyse de la variance »:
Modèle
Erreur
Total
Source
SCM
SCE
SCT
SC
%Z & 1% & %Z
% & 1
DL
SCM/ %Z & 1SCE/ % & %Z
SCT/ % & 1
CM
CMM/CME
F
Cfr Tbl
P(>F)
Additif Additif

Analyse de la variance (1 critère)
� Revenons à notre exemple:
� Vérification: SCM + SCE = 222 + 352 = 574 = SCT
A b Ab
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes
`ac � 3 ∗ 100 & 104 � ( 3 ∗ 111 & 104 � ( 3 ∗ 101 & 104 � � 222
104
`ad � 104 & 100 � ( 106 & 100 � ( ⋯ ( 101 & 101 � � 352`ab � 104 & 104 � ( 106 & 104 � ( ⋯ ( 101 & 104 � � 574

Analyse de la variance (1 critère)
� La table d’analyse de la variance est donc:
� Remarque: la valeur dans la dernière colonne s’obtient (p.e.) via:
pf(1,892,df1=2,df2=6,lower.tail=F)
� Comme la valeur-p est > L � 5%, l’hypothèse nulle est acceptée: il n’y
a pas de différence de concentration de l’anticorps testé entre groupes
sanguins.
Modèle
Erreur
Total
Source
222
352
574
SC
268
DL
111
58,67
71,75
CM
1,892
F
0,231
P(>F)

Analyse de la variance (1 critère)
� Un autre exemple:
◦ Le traitement utilisé améliore-t-il la concentration en anticorps
chez des individus immuno-déficients ?
◦ L’hypothèse nulle est: ��: �g � �f,
où �g et �f représentent les concentrations moyennes en
anticorps chez les individus traités et chez les contrôles,
respectivement.
◦ Les données récoltées sont les suivantes:
Traités Contr.
45
50
49
41
45
48 43Moyennes 46

Analyse de la variance (1 critère)
� Un autre exemple:
`ac � 3 ∗ 48 & 46 � ( 2 ∗ 43 & 46 � � 30`ad � 45 & 48 � ( 50 & 48 � ( ⋯ ( 45 & 43 � � 22`ab � 45 & 46 � ( 50 & 46 � ( ⋯ ( 45 & 46 � � 52
Traités Contr.
45
50
49
41
45
48 43Moyennes 46
Modèle
Erreur
Total
Source
30
22
52
SC
134
DL
30
22/3
13
CM
90/22
F
0,136
P(>F)

Analyse de la variance (1 critère)
� Un autre exemple:
� Une solution alternative est de passer par le test de t,
puisqu’il n’y a que deux groupes:
B!0<!-1� � ���. & ���.`ad%� ( %� & 2 ∗ 1%� ( 1%�
_ � 48 & 43223 ∗ 13 ( 12_ � 2.023
et 9 B!0<!-1� I 2.023 � 0,068
Traités Contr.
45
50
49
41
45
48 43Moyennes 46

Analyse de la variance (1 critère)
� Remarques sur cet exemple:
◦ On sait que: �!"#$� � fj!1� � fj
!0<!-1�◦ On peut montrer facilement que: �!"?#� � `ac � @�0.1@�-. -
0.0< 0
.0
en utilisant: `ac � %� ∗ ���. & ��.. � ( %� ∗ ���. & ��.. �et: ��.. � %� ∗ ���. ( %� ∗ ���. / %� ( %�◦ Par conséquent, on obtient que: H�,!0<!-1� � B!0<!-1��◦ Les résultats fournis par les deux méthodes sont identiques, à ceci
près que le test de F teste l’hypothèse alternative bilatérale ��: �g n �f alors que t pourrait tester une alternative unilatérale.

Analyse de la variance (1 critère)
� Remarques sur cet exemple (suite):
◦ Remarquez que dans notre exemple:
� B� � 2.023� � 4.09 � H� Si on avait considéré un test biltéral, on aurait obtenu:
9 H�,� I 4.09 � 0.1369 B� M &2.023 ( 9 B� I 2.023 � 2 ∗ 0.068 � 0.136

Analyse de la variance (1 critère)
� Considérons à présent un test d’égalité des moyennes sur les données
suivantes:
� La valeur F obtenue est ici: H�,o � 5.91 et 9 H�,o I 5.91 � 0.02� Il y a donc des différences significatives (au seuil L � 5%)entre
certaines moyennes, mais le test ne dit pas lesquelles...
� Nous allons présenter une approche permettant de savoir quelles
moyennes diffèrent de quelles autres.
A B C
104
106
90
120
112
101
98
104
101
100 111 101
Groupes
Moyennes 100
D
90
86
88
88

Analyse de la variance (1 critère)
� Tests a posteriori (post-hoc tests)
◦ L’idée est comparer les moyennes 2 à 2 en utilisant une version
« améliorée » du test de t de comparaison de deux moyennes
◦ L’amélioration provient de l’utilisation de l’estimateur de la variance erreur
commun à tous les groupes plutôt que de l’estimateur basé seulement sur
les deux groupes testés:
B!1!i � ��� & ��Y`j ∗ 1%� ( 1%Y
_
� ��� et ��Y sont les moyennes comparées ��� I ��Y ,
� % & %Z sont les degrés de liberté associés à la variance erreur,
� %� et %Y sont les tailles respectives des deux groupes

Analyse de la variance (1 critère)
� Tests a posteriori (post-hoc tests)
◦ On peut effectuer le test classiquement ou, de manière alternative,
utiliser la valeur seuil de t pour obtenir une différence que la
différence doit excéder pour être significative:
B!1!i L ∗ `j ∗ 1%� ( 1
%Y_ � ��� & ��Y p$q � r`s
où r`s signifie « Least Significant Difference », soit la plus petite
différence de moyennes qui soit significative au seuil choisi

Analyse de la variance (1 critère)
� Tests a posteriori (post-hoc tests): exemple
◦ Reprenons notre exemple
◦ %� � %A � %f � %t � 3◦ `j � �U�
V_ ⟹ r`s � 12,15
◦ BV L � 5% � 1,9432◦ En conclusion: �t M �f et �t M �A, les autres différences n’étant
pas significatives au seuil choisi.
A B C
100 111 101
Groupes
Moyennes
D
88

Analyse de la variance (1 critère)
� Tests a posteriori (post-hoc tests): remarque
◦ Si on compare de nombreux groupes, on effectue un grand nombre
de comparaisons 2 à 2 (p.e. pour 10 groupes, il faut faire 45
comparaisons...), ce qui peut augmenter le taux d’erreur de type 1.
◦ En effet, si �� est vraie, la probabilité de n’avoir aucun faux positifs
lors de n tests est: 9 � 1 & L ! si on suppose les tests
indépendants, et donc, la probabilité d’au moins un faux-positif est:L� � 1 & 1 & L !Exemple: si L � 0.05 et n = 45, L� � 0.90...
◦ Si on veut obtenir une valeur raisonnable pour L�, il faut choisir un
seuil de signification pour les tests individuels qui vaudra:
L � 1 & 1 & L�.Exemple: si L� � 0.05 et n = 45, L � 0.0011

Analyse de la variance (1 critère)
� Tests a posteriori (post-hoc tests): remarque
◦ Cette correction du seuil de signification à adopter est appelée
« correction de Bonferroni »
� Le seuil peut être calculé de manière approximative via L u vw!
� Très souvent, les tests ne sont pas indépendants et la correction de Bonferroni
« surcorrige » le seul de signification, ce qui pénalise la puissance du dispositif.

Résumé:
1. L’analyse de la variance (ANOVA) est une
technique permettant de comparer 2 ou plus de 2
moyennes.
2. Les données de chaque échantillon (“lot”) sont
supposées normales et homosédastiques: yij ~
N(µi,σe)
3. L’hypothèse nulle testée est: H0: µ1 = µ2 = … = µk =
µ, ce qui revient à dire que toutes les observations
proviennent de la même distribution yij ~ N(µ,σe)
4. La table d’ANOVA est une table permettant une
disposition pratique des calculs à effectuer pour
tester H0.
Analyse de la variance (1 critère)

Résumé (suite):
5. L’ ANOVA est équivalente au test de t quand on
doit comparer 2 moyennes et généralise ce dernier
quand on doit comparer plus de 2 moyennes.
6. L’ ANOVA est un test global d’égalité des
moyennes. Des tests ultérieurs (LSD, …)peuvent
être utilisés pour identifier les moyennes qui
diffèrent des autres.
Analyse de la variance (1 critère)
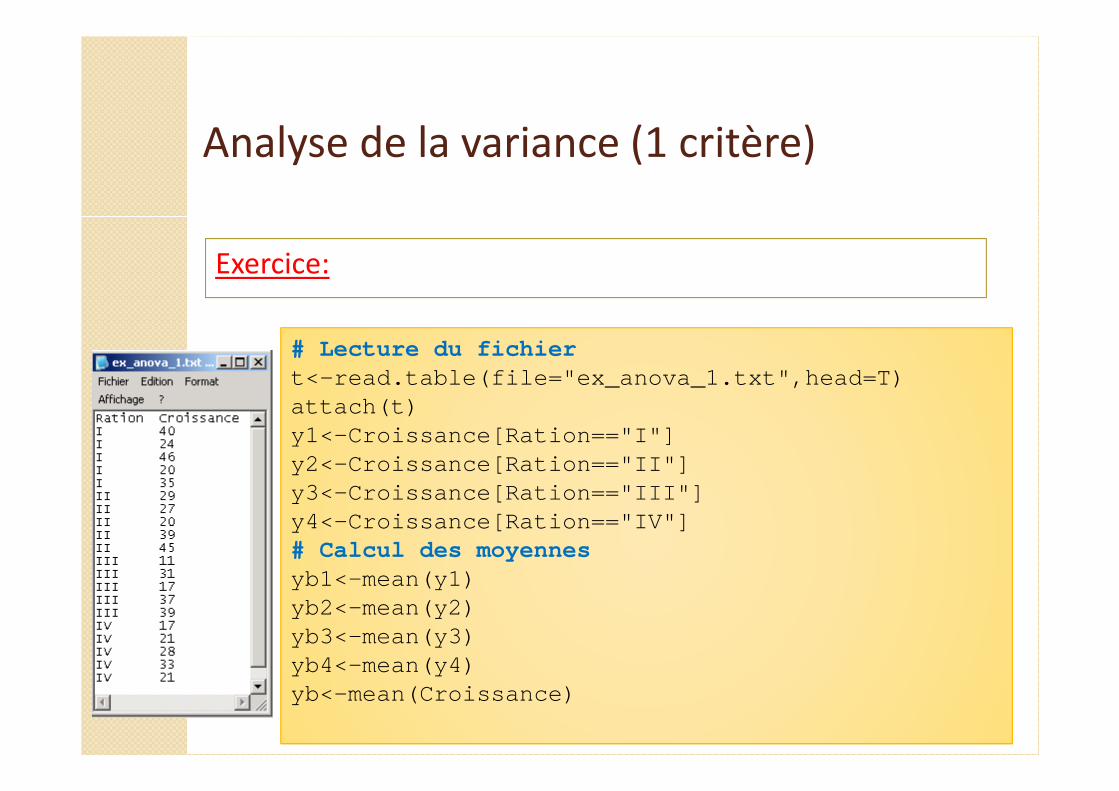
Exercice:
# Lecture du fichiert<-read.table(file="ex_anova_1.txt",head=T)attach(t)y1<-Croissance[Ration=="I"]y2<-Croissance[Ration=="II"]y3<-Croissance[Ration=="III"]y4<-Croissance[Ration=="IV"]# Calcul des moyennesyb1<-mean(y1)yb2<-mean(y2)yb3<-mean(y3)yb4<-mean(y4)yb<-mean(Croissance)
Analyse de la variance (1 critère)

Exercice:
)**2 # SCM et dlMSCM<-5*(yb1-yb)**2+5*(yb2-yb)**2+5*(yb3-yb )**2
+5*(yb4-yb)**2dlM<-3# SCE et dlESCE<-sum((y1-yb1)**2,(y2-yb2)**2,(y3-yb3)**2,
(y4-yb4)**2)dlE<-4*(5-1)# SCT et dlTSCT<-sum((y1-yb)**2,(y2-yb)**2,(y3-yb)**2,
(y4-yb)**2)dlT<-4*5-1
Analyse de la variance (1 critère)

Exercice:
# FF<-(SCM/dlM)/(SCE/dlE)p<-pf(F,dlM,dlE,lower.tail=F)p[1] 0.4751976# Résultat non significatif: pas de différence# de croissance entre les rations
Analyse de la variance (1 critère)

Exercice:
# Une manière plus simple...modele<-aov(Croissance~Ration)summary(modele)
Df Sum Sq Mean Sq F value Pr(>F)Ration 3 270 90 0.874 0.475Residuals 16 1648 103 # Même résultat non significatif !
Analyse de la variance (1 critère)


















