
Inhalt - Wladislaw | Startseite · Software Qualität Zusammenfassung (WS 10/11) Zusammengestellt...
26
Software Qualität Zusammenfassung (WS 10/11) Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de 1 Software Qualität Zusammenfassung (WS 10/11) Inhalt Software Qualität Zusammenfassung (WS 10/11) .................................................................................. 1 1. Grundlagen .................................................................................................................................. 3 1.1 Einordnung ................................................................................................................................ 3 1.2 Der Qualitätsbegriff ................................................................................................................... 3 1.3 Zusammenspiel der Qualitätsmerkmale ................................................................................... 4 1.4 Qualitätszielbestimmung........................................................................................................... 4 1.5 Fehler ......................................................................................................................................... 4 1.6 Klassifikation und Überblick über die Prüftechniken ................................................................ 5 2. Funktionsorientierter Test............................................................................................................... 6 2.1 Grundlagen ................................................................................................................................ 6 2.2 Funktionale Äquivalenzklassen ................................................................................................. 6 2.3 Zustandsbasierter Test .............................................................................................................. 7 2.4 Ursache-Wirkungs-Analyse ....................................................................................................... 7 2.5 Testen mit Entscheidungstabellen und –bäumen ..................................................................... 8 2.6 Syntaxtest .................................................................................................................................. 8 2.7 Transaktionsflussbasiertes Testen ............................................................................................ 9 3. Kontrollflussorientierter Test .......................................................................................................... 9 3.1 Grundlagen ................................................................................................................................ 9 3.2 Anweisungsüberdeckungstest C 0 .............................................................................................. 9 3.3 Zweigüberdeckungstest C 1 ........................................................................................................ 9 3.4 Pfadüberdeckungstest C 2 , C 2a .................................................................................................. 10 3.5 Techniken zum Test von Schleifen C 2b , C 2c .............................................................................. 10 3.6 Bedingungsüberdeckungstest C 3 ............................................................................................. 11
Transcript of Inhalt - Wladislaw | Startseite · Software Qualität Zusammenfassung (WS 10/11) Zusammengestellt...

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
1
Software Qualität Zusammenfassung (WS 10/11)
Inhalt Software Qualität Zusammenfassung (WS 10/11) .................................................................................. 1
1. Grundlagen .................................................................................................................................. 3
1.1 Einordnung ................................................................................................................................ 3
1.2 Der Qualitätsbegriff ................................................................................................................... 3
1.3 Zusammenspiel der Qualitätsmerkmale ................................................................................... 4
1.4 Qualitätszielbestimmung ........................................................................................................... 4
1.5 Fehler ......................................................................................................................................... 4
1.6 Klassifikation und Überblick über die Prüftechniken ................................................................ 5
2. Funktionsorientierter Test ............................................................................................................... 6
2.1 Grundlagen ................................................................................................................................ 6
2.2 Funktionale Äquivalenzklassen ................................................................................................. 6
2.3 Zustandsbasierter Test .............................................................................................................. 7
2.4 Ursache-Wirkungs-Analyse ....................................................................................................... 7
2.5 Testen mit Entscheidungstabellen und –bäumen ..................................................................... 8
2.6 Syntaxtest .................................................................................................................................. 8
2.7 Transaktionsflussbasiertes Testen ............................................................................................ 9
3. Kontrollflussorientierter Test .......................................................................................................... 9
3.1 Grundlagen ................................................................................................................................ 9
3.2 Anweisungsüberdeckungstest C0 .............................................................................................. 9
3.3 Zweigüberdeckungstest C1 ........................................................................................................ 9
3.4 Pfadüberdeckungstest C2, C2a .................................................................................................. 10
3.5 Techniken zum Test von Schleifen C2b, C2c .............................................................................. 10
3.6 Bedingungsüberdeckungstest C3 ............................................................................................. 11

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
2
3.7 LCSAJ-Test ................................................................................................................................ 11
3.8 McCabe-Überdeckung ............................................................................................................. 12
3.9 Zusammenfassung ................................................................................................................... 12
4. Datenflussorientierter Test ........................................................................................................... 13
4.1 Grundlagen .............................................................................................................................. 13
4.2 Defs / Uses-Test ....................................................................................................................... 13
4.3 Required k-Tuples Test ............................................................................................................ 14
4.4 Datenkontext-Überdeckung .................................................................................................... 15
4.5 Bewertung des Datenflussorientierten Tests ......................................................................... 16
5. Spezielle dynamische Testtechniken ............................................................................................. 16
5.1 Diversifizierender Test ............................................................................................................. 16
5.2 Bereichstest (Domain Testing) ................................................................................................ 17
5.3 Zufallstest (Random Test) ........................................................................................................ 18
5.4 Error Guessing ......................................................................................................................... 19
5.5 Zusicherungen (Assertions) ..................................................................................................... 19
5.6 Grenzen des Software Tests .................................................................................................... 19
6. Statische Codeanalyse ................................................................................................................... 19
6.1 Grundlagen .............................................................................................................................. 19
6.2 Stilanalyse ................................................................................................................................ 20
6.3 Slicing ....................................................................................................................................... 20
6.4 Anomalieanalyse ..................................................................................................................... 20
7. Manuelle Prüfung .......................................................................................................................... 21
7.1 Grundlagen .............................................................................................................................. 21
7.2 Formale Inspektion .................................................................................................................. 21
7.3 Konventionelles Review .......................................................................................................... 21
7.4 Review in Kommentartechnik ................................................................................................. 21
7.5 Bewertung ............................................................................................................................... 21
8. Formale Verfahren ........................................................................................................................ 22
8.1 Grundlagen .............................................................................................................................. 22
8.2 Modellbasierte Modellprüfung ............................................................................................... 22
Quellennachweis ............................................................................................................................... 26

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
3
1. Grundlagen
1.1 Einordnung
konventionelle Analysetypen
• Kompilation (automatisch): Überprüfung der Syntax und (eingeschränkt) der Semantik
• Eingaben (dynamisch): Überprüfung der Ausgaben
• Durchsicht des Codes (statisch): Überprüfung von Details des Codes
Zielsetzung der Software-Qualität
Durch konstruktiv vorausschauende und analytisch prüfende Maßnahmen soll die Qualität eines
Software-Produkts auf eine systematische Weise gesteigert werden.
Problematik
Fehler entstehen zu einem großen Teil in der Entwurfsphase. Diese Fehler fallen aber in der Regel
erst sehr spät auf (�Badewannenkurve). Es ist daher sehr teuer, diese Fehler zu beseitigen, vor allem
da alleine durch die Fehlerbeseitigung wiederum Folgefehler entstehen.
Aus diesen Gründen sollte mit der Qualitätssicherung nicht erst nach der Programmierung begonnen
werden, sondern sie sollte das Projekt permanent begleiten.
1.2 Der Qualitätsbegriff
Wege zur Qualität
• Qualitätssicherung: Summe aller konstruktiven oder analytischen Maßnahmen
• Qualitätsmanagement: Summe aller organisatorischen Maßnahmen
Hierarchie
Begriffe Beispiel
Qualitätsmerkmal Formschönheit
Qualitätsteilmerkmal Symmetrie, Farbbrillanz
Qualitätsmaß Anzahl der Pixel, haben alle Kanten rechten
Winkel zueinander
Ausprägung 4000, ja/nein
Qualitätsmerkmale
• Korrektheit: Fehlerfreiheit gegenüber Spezifikation, beobachtetes Verhalten entspricht dem
gewünschten Verhalten
• Vollständigkeit: alle Funktionen aus der Spezifikation wurden realisiert
• Sicherheit: keine Gefährdung von Menschen und Umwelt und ein begrenztes Risiko dazu
o Safety: Abwesenheit von Gefährdung
o Security: Datensicherheit
• Zuverlässigkeit: Verfügbarkeit einer bestimmten Leistung des Systems
o Dependability: Eignung des Systems eine bestimmte Leistung zu erbringen
o Reliability: Wahrscheinlichkeit, dass das System leistungsfähig bleibt
� MTTF: Mean time to failure (Zeitspanne bis zum ersten Ausfall) = Summe der
Zeiten bis zum ersten Fehler / Anzahl der Systeme
� MTBF: Mean time between failure (Zeitspanne bis Ausfall) = Summe der
Laufzeiten / Anzahl der Fehler

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
4
� MTTR: Mean time to repair (Zeitspanne für Reparatur) = Summe der
Reparaturzeiten / Anzahl der Reparaturen
• Verfügbarkeit: (Availability) Fähigkeit funktionstüchtig zu sein = MTBF / (MTBF + MTTR)
• Robustheit: Eigenschaft auch in ungewöhnlichen Situationen ordnungsgemäß zu arbeiten
• Effizienz: Produkt erfüllt Anforderungen bei geringem Ressourcenverbrauch (Zeit, Speicher)
• Benutzbarkeit: angenehme und einfache Benutzbarkeit des Systems ohne
Funktionalitätseinbußen
• Portabilität: Grad der Eigenschaft eine Software auf eine andere Umgebung zu übertragen
• Änderbarkeit: Grad der Einfachheit ein System zu verändern und anzupassen
• Testbarkeit: Eigenschaft der Software, ob sie sich gut testen lässt.
• Transparenz: Eigenschaft wie ordentlich die Software aufgebaut wurde (Module, Struktur,
Methoden, Pakete)
• Wartbarkeit: Einfachheit der Fehlerfindung und –korrektur und
Erweiterbarkeit
1.3 Zusammenspiel der Qualitätsmerkmale
Die Qualitätsmerkmale lassen sich über das magische Dreieck allgemein in
Verbindung setzen.
1.4 Qualitätszielbestimmung
• Das Qualitätsziel muss passend zum Projekt oder Fall bestimmt werden.
Verfahren
1. Festlegung der Qualitätsmerkmale
2. Darstellung der Wechselwirkungen der Qualitätsmerkmale
3. Begriffsdefinitionen
4. Bestimmung der Qualitätsmaße (Metriken)
5. Bestimmung der Ziel-Ausprägungen für die Qualitätsmaße (Qualitätsanforderungen)
1.5 Fehler
• Failure: Entspricht einem Fehlverhalten (Software liefert falsche Ausgaben), das Programm
ist aber lauffähig.
• Fault, Defect: Hierbei handelt es sich um einen allgemeinen Fehler oder Defekt des
Programms, der dazu führt, dass es nicht lauffähig ist.
• Error: Dies tritt auf, wenn das Programm einen ungültigen Zustand erreicht hat und kann als
Ursache für einen Defekt gelten.
Fehlerklassifikation
• Syntaxfehler
• Semantische Fehler
• Fehler durch Parallelität
• Numerische Fehler
• Portabilitätsfehler
• Optimierungsfehler
• Spezifikationsfehler
Qualität
Zeit Kosten
Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
5
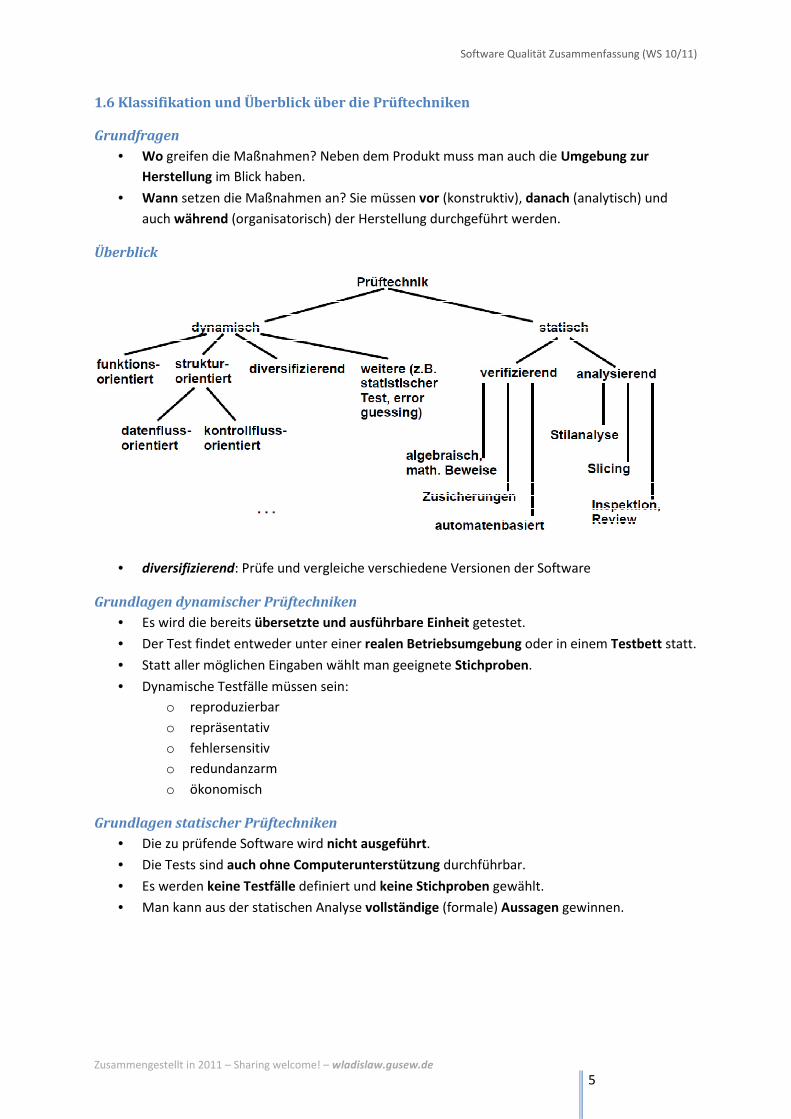
1.6 Klassifikation und Überblick über die Prüftechniken
Grundfragen
• Wo greifen die Maßnahmen? Neben dem Produkt muss man auch die Umgebung zur
Herstellung im Blick haben.
• Wann setzen die Maßnahmen an? Sie müssen vor (konstruktiv), danach (analytisch) und
auch während (organisatorisch) der Herstellung durchgeführt werden.
Überblick
• diversifizierend: Prüfe und vergleiche verschiedene Versionen der Software
Grundlagen dynamischer Prüftechniken
• Es wird die bereits übersetzte und ausführbare Einheit getestet.
• Der Test findet entweder unter einer realen Betriebsumgebung oder in einem Testbett statt.
• Statt aller möglichen Eingaben wählt man geeignete Stichproben.
• Dynamische Testfälle müssen sein:
o reproduzierbar
o repräsentativ
o fehlersensitiv
o redundanzarm
o ökonomisch
Grundlagen statischer Prüftechniken
• Die zu prüfende Software wird nicht ausgeführt.
• Die Tests sind auch ohne Computerunterstützung durchführbar.
• Es werden keine Testfälle definiert und keine Stichproben gewählt.
• Man kann aus der statischen Analyse vollständige (formale) Aussagen gewinnen.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
6
2. Funktionsorientierter Test
2.1 Grundlagen
• Aus der Spezifikation und der Soll-Funktionalität werden die Testdaten abgeleitet.
• Getestet wird auf
o Vollständigkeit
1. Ist die Spezifikation durch die Testfälle abgedeckt?
2. Ist die Spezifikation vollständig umgesetzt?
o Korrektheit
1. Stimmen die Ergebnisse des Tests mit den Erwartungen überein?
• Es gibt eine Vielzahl verschiedener funktionsorientierter Testtechniken.
2.2 Funktionale Äquivalenzklassen
• Wir fassen Eingaben in Gruppen
zusammen, die ähnliche Ausgaben
generieren (Äquivalenzklassenbildung).
• Für alle der Äquivalenzklassen wählen wir
anschließend gute (stellvertretende und
möglichst redundanzfreie) Stichproben.
• Zu jeder gültigen Äquivalenzklasse
existiert auch eine ungültige
Äquivalenzklasse, die im Test ebenfalls getestet werden muss.
Eingabe gültige Äquivalenzklassen ungültige Äquivalenzklassen
x1 = Material A1: Ton
A2: Marmor
A3: Granit
UA1: alle ∉ {Ton, Marmor, Granit}
x2 = Kantenlänge A4: 17cm ≤ Wert ≤ 68cm UA2: Wert < 17cm
UA3: Wert > 68cm
x3 = Menge A5: 1 ≤ Wert ≤ 9999 UA4: Wert < 1 UA5: Wert > 9999
x4 = Auftragsnummer A6: (^F.*2$) UA6: (^[^F].*2$) (ohne ‚F‘ am Anfang)
UA7: (^F.*[^2]$) (ohne ‚2‘ am Ende)
Aus der Äquivalenzklassentabelle lassen sich anschließend die Testfälle generieren:
Testfall Äquivalenz-Kl. x1 x2 x3 x4
1 A1, A4, A5, A6 Ton 17 1 F2
2 UA1, A4, A5, A6 Holz 26 4999 F0000000002
3 A2, UA2, A5, A6 Marmor 16 2 F123542
4 A3, UA3, A5, A6 Granit 69 9998 Fabcsefgh2
5 A1, A4, UA4, A6 Ton 68 0 Fabcd12342
6 A2, A4, UA5, A6 Marmor 18 10000 F12345abcd2 7 A3, A4, A5, UA6 Granit 67 200 Eabsdef2
8 A3, A4, A5, UA7 Granit 30 5000 Fabsdef3
• Pro Testfall sollten möglichst viele gültige Äquivalenzklassen abgedeckt werden.
• Pro Testfall darf immer nur maximal eine ungültige Äquivalenzklasse getestet werden (So
stellt man sicher, dass die Ursache von evtl. Fehlern sofort gefunden werden kann).
• Hier existiert kein Minimalkriterium (wie die Zweigüberdeckung beim strukturorient. Test)

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
7
2.3 Zustandsbasierter Test
Aus der Spezifikation wird ein grafischer
Zustandsautomat erstellt. Dieser dient als Basis für
die Erzeugung der Zustandsübergangstabelle.
Nach dem Ausfüllen der Zustandsübergangstabelle
mit der Information aus der Spezifikation bzw. dem grafischen Zustandsautomaten fällt in der Regel
auf, dass einige Felder leer sind. Dies sind Lücken der Spezifikation, die nun festgelegt werden
müssen, um die Vollständigkeit des Tests zu ermöglichen.
Der Test ist dann vollständig, wenn folgende Kriterien alle abgedeckt sind:
1. alle Zustände
2. alle Zustandsübergänge
3. alle Fehlerzustände
4. alle Pfadkombinationen
2.4 Ursache-Wirkungs-Analyse
Dieses Verfahren setzt daran an, dass jede Eingabe eine
Ausgabe bzw. ein Resultat zur Folge hat. Aus der Spezifikation kann man alle solchen Ursache-
Wirkungs-Beziehungen erschließen. Das gesamte Verfahren gestaltet sich wie folgt:
1. Identifikation und Bezeichnung der Ursachen und Wirkungen (aus Spezifikation)
2. Ursachen-Wirkungs-Graph erstellen
3. Abhängigkeiten und Einschränkungen ergänzen
4. Umformung in eine Entscheidungstabelle
5. Jede Spalte der Tabelle ergibt einen Testfall
Ursache-Wirkungs-Graph
Basiselemente (Wirkrichtung ist jeweils von links
nach rechts)
Elemente zur Beschreibung von Einschränkungen
Erstellung der Entscheidungstabelle
Der Ursache-Wirkungs-Graph wird in eine Tabelle
umgewandelt, indem man jeweils eine Wirkung auswählt
und diese zunächst als eintretend und dann als nicht
eintretend annimmt. Dabei gibt es je nach Verknüpfungsart
verschiedene Möglichkeiten minimale und sinnvolle
Eingabekombination zu generieren:

Zusammengestellt in 2011 – Sharing welcome!
Jede so gefundene Ursachenkombination
wenig Spalten in der Tabelle entstehen.
Don’t Care Termen entfernt.
2.5 Testen mit Entscheidungstabellen und
• Vorteile:
o Vollständigkeit der Abdeckung, da alle Bedingungen berücksichtigt werden
o Konsistenz: gleiche Ursachenkonfiguration führt zu gleichen Aktionen
o Konsolidierung: Regeln können zusammenge
o Redundanzelimination
Verwendung von Don’t Care
Termen
• Nachteile:
o Umfang wächst exponentiell
Anzahl der Bedingungen
• Die Entscheidungstabelle
einen Entscheidungsbaum
werden.
2.6 Syntaxtest
Durch das Erstellen eines Syntaxd
zum Code kann die Software auf korrekte
Syntax getestet werden. Dabei wird durch eine
definierte Grammatik und ein Lexikon
Terminal- und Nichtterminalsymbolen
Syntax überprüft. Die Erzeugung der Testfälle
erfolgt durch Testvollständigkeitskriterien:
• Vollständige Pfadüberdeckung
o Vollständige Pfadüberdeckung
ohne Schleifen
� Kantenüberdeckung
• Knotenüberdeckung
Software Qualität Zusammenfassung (WS 10/11)
Sharing welcome! – wladislaw.gusew.de
Beispiel einer Analyse:
1. W1 = 1 (ODER/1)
Z1 = 1 (UND/1)
Z1 = 0 (UND/0)
Z2 = 0 (UND/0)
Z2 = 1 (
2. W1 = 0 (ODER/0)
Z1 = 0 (UND/0)
Z2 = 0 (UND/0)
Ursachenkombination ergibt eine Spalte in der Tabelle. Es sollten möglichst
wenig Spalten in der Tabelle entstehen. Redundanzen werden anschließend durch Verwendung von
2.5 Testen mit Entscheidungstabellen und –bäumen
der Abdeckung, da alle Bedingungen berücksichtigt werden
: gleiche Ursachenkonfiguration führt zu gleichen Aktionen
: Regeln können zusammengefasst werden
Redundanzelimination:
Verwendung von Don’t Care-
Umfang wächst exponentiell mit
Anzahl der Bedingungen
Die Entscheidungstabelle kann auch in
Entscheidungsbaum überführt
Syntaxdiagramms
zum Code kann die Software auf korrekte
Syntax getestet werden. Dabei wird durch eine
Lexikon von
Nichtterminalsymbolen die
Die Erzeugung der Testfälle
igkeitskriterien:
Vollständige Pfadüberdeckung
Vollständige Pfadüberdeckung
Kantenüberdeckung
Knotenüberdeckung
Software Qualität Zusammenfassung (WS 10/11)
8
Beispiel einer Analyse:
W1 = 1 (ODER/1)
Z1 = 1 (UND/1)
Z1 = 0 (UND/0)
Z2 = 0 (UND/0)
Z2 = 1 (UND/1)
W1 = 0 (ODER/0)
Z1 = 0 (UND/0)
Z2 = 0 (UND/0)
Es sollten möglichst
durch Verwendung von
der Abdeckung, da alle Bedingungen berücksichtigt werden
: gleiche Ursachenkonfiguration führt zu gleichen Aktionen

Zusammengestellt in 2011 – Sharing welcome!
2.7 Transaktionsflussbasiertes Testen
Hierbei wird das System durch ein
der sequenzielle Ablauf auf diese Weise auch getestet.
3. Kontrollflussorientierter Test
3.1 Grundlagen
Für die Erstellung der nötigen Testverfahren muss ein
vorliegen. Um diesen Graph zu erstellen muss die Struktur des Codes also beka
Der Test ist dynamisch, da über vorher festgelegte Eingaben ein bestimmtes Verhalten des
Programms während der Laufzeit erwartet wird. Diese Testweise hat eine
Bedeutung und kann weitgehend von
(Minimalkriterium) ist eine vollständige Zweigüberdeckung
• Erzeugter Kontrollflussgraph
3.2 Anweisungsüberdeckungstest C
• alle Knoten des Graphen (=Anweisungen) werden mind. einmal ausgefü
• Anweisungsüberdeckungsgrad
• Für den Anweisungsüberdeckungsgrad
Kontrollflussgraphen zählen.
• Da die Fehlererkennungsquote
schwach und in der Praxis selten (meist als Bestandteil anderer Testverfahren).
3.3 Zweigüberdeckungstest C
• alle Kanten des Graphen (=Zweige) werden mind. einmal durchlaufen
• Zweigüberdeckungsgrad
Software Qualität Zusammenfassung (WS 10/11)
Sharing welcome! – wladislaw.gusew.de
2.7 Transaktionsflussbasiertes Testen
Hierbei wird das System durch ein Sequenzdiagramm dargestellt und
auf diese Weise auch getestet.
3. Kontrollflussorientierter Test
Für die Erstellung der nötigen Testverfahren muss ein Kontrollflussgraph des Programmausschnitts
vorliegen. Um diesen Graph zu erstellen muss die Struktur des Codes also bekannt sein (
, da über vorher festgelegte Eingaben ein bestimmtes Verhalten des
Programms während der Laufzeit erwartet wird. Diese Testweise hat eine hohe praktische
und kann weitgehend von Werkzeugen unterstützt werden. Der minimal akzeptierte Test
vollständige Zweigüberdeckung. Das ‚C‘ steht für „Coverage
Erzeugter Kontrollflussgraph
3.2 Anweisungsüberdeckungstest C0
des Graphen (=Anweisungen) werden mind. einmal ausgeführt
Anweisungsüberdeckungsgrad
den Anweisungsüberdeckungsgrad muss man die Anweisungen und nicht die Knoten des
Kontrollflussgraphen zählen.
Fehlererkennungsquote alleine nur ca. 18% beträgt, ist dieser Test
raxis selten (meist als Bestandteil anderer Testverfahren).
3.3 Zweigüberdeckungstest C1
des Graphen (=Zweige) werden mind. einmal durchlaufen
Zweigüberdeckungsgrad
Software Qualität Zusammenfassung (WS 10/11)
9
des Programmausschnitts
nnt sein (White Box).
, da über vorher festgelegte Eingaben ein bestimmtes Verhalten des
hohe praktische
erden. Der minimal akzeptierte Test
Coverage“.
hrt
muss man die Anweisungen und nicht die Knoten des
alleine nur ca. 18% beträgt, ist dieser Test eigenständig zu
raxis selten (meist als Bestandteil anderer Testverfahren).

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
10
Zur Berechnung nimmt man primitive Zweige. Solche Zweige folgen unmittelbar nach
Verzweigungsknoten oder nach dem Startknoten. Ganz egal, welche Zweige vorher
auftraten, sie mussten abgegangen worden sein, damit die primitiven Zweige gegangen
werden können. Dies geschieht aus Gründen der Vereinfachung und der Vermeidung eines
nicht-linearen Zusammenhangs zwischen der Überdeckungsrate und der Testfallanzahl.
• eine vollständige Zweigüberdeckung impliziert gleichzeitig eine vollständige
Anweisungsüberdeckung
• Die Fehlererkennungsquote liegt bei ca. 21 % bis 70 %, wobei logische Fehler weit stärker, als
Datenfehler erkannt werden.
3.4 Pfadüberdeckungstest C2, C2a
• alle Pfade des Graphen (unterschiedliche Wege durch den gesamten Graph)
• Problem: in realen Software-Modulen ist die Pfadanzahl unwirtschaftlich oder sogar
unendlich hoch
• Dieser Test besitzt die höchste Fehlererkennungsquote. Wegen dem extremen Aufwand ist
er aber ohne praktische Bedeutung.
3.5 Techniken zum Test von Schleifen C2b, C2c
• Bei Schleifen führen die Anzahl der Pfade durch die Schleife und der damit verbundene
Aufwand schnell an die Grenzen der Testbarkeit.
• Eine Abhilfe bietet die Unterteilung der Schleifenpfade in Äquivalenzklassen. Für jede
Äquivalenzklasse werden anschließend geeignete Stellvertreter gewählt und getestet.
Boundary interior coverage (Grenze-Inneres-Überdeckung) C2b
• Besteht aus zwei untergeordneten Testarten für Schleifen (Kombination sinnvoll)
1. Boundary Test (Grenztest)
� keine Betretung der Schleife
� eine Betretung aber keine Wiederholung der Schleife
2. Interior Test (Inneres-Test)
� Schleife wird betreten und mindestens einmal wiederholt
• Sind Kontrollstrukturen innerhalb der Schleife vorhanden, so steigt die Anzahl der
Äquivalenzklassen stark an (hoher Testaufwand). Zusätzlich existieren nicht ausführbare
Pfade. Aus diesen Gründen setzt man auf den Einsatz von Heuristiken und verwendet den
modifizierten Boundary interior Test.
Modifizierter Boundary Interior Test
Dies bildet einen Rahmen für die Boundary Interior Coverage und sorgt für die Zweigüberdeckung.
1. Teste alle ausführbaren Pfade ohne Schleifen.
2. Erstelle Testfälle für jede Schleife (boundary interior):
o abweisende Schleifen (muss nicht unbedingt ausgeführt werden [z.B. for, while])
� 1 x alle ausführbaren Teilpfade (ohne eingeschachtelte Schleifen)
o abweisende und nicht abweisende Schleife (z.B. do-while-Schleife)
� mind. 2 x alle ausführbaren Teilpfade (ohne eingeschachtelte Schleifen)
3. Teste zusätzlich alle noch nicht getesteten Zweige (zur Gewährleistung der
Minimalkriteriums: Zweigüberdeckung).

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
11
Strukturierter Pfadtest C2c
• Die Wiederholungsanzahl der Schleifen wird beschränkt (Iterationen <= k).
• Ein Strukturierter Pfadtest mit k = 2 ist identisch mit dem Boundary interior coverage.
3.6 Bedingungsüberdeckungstest C3
• Bei dieser Testart wird die Logik der Bedingungen analysiert und gründlich überprüft.
• Man unterscheidet zwischen
o komplexe Entscheidung (enthält verknüpfte atomare Entscheidungen)
o atomare Entscheidung (z.B. y < 5)
• Zweigüberdeckung ist ab dem Bedingungs- /Entscheidungsüberdeckungstest gegeben.
• Wichtigster Bestandteil des Tests sind eine Wahrheitstabelle der Bedingung und eine daraus
generierte reduzierte Wahrheitstabelle, bei der Kombinationen, die zu dem gleichen
Ergebniswert führen, zusammengefasst werden.
• Überdeckung bedeutet, dass die Werte für eine Variable (komplexe oder atomare
Entscheidung) sowohl mal für Wahr als auch für Falsch getestet werden.
• Grundsätzlich gilt, dass die unvollständige Evaluation (logischer Term wird nicht vollständig
ausgewertet) leistungsfähiger ist als die vollständige Evaluation (vollständige Auswertung).
Einfacher Bedingungsüberdeckungstest C3a
• Überdeckung aller atomaren Teilentscheidungen
Bedingungs- /Entscheidungsüberdeckungstest
• Überdeckung aller atomaren Teilentscheidungen
• Überdeckung der Gesamtentscheidungen
Modifizierter Bedingungs-/Entscheidungsüberdeckungstest
• Überdeckung aller atomaren Teilentscheidungen
• Überdeckung der Gesamtentscheidungen
• Untereinander unabhängige Testfälle bezüglich atomarer Teilentscheidungen und
Wahrheitswert der Gesamtentscheidung (Toggeln eines Wahrheitswertes)
Mehrfach-Bedingungsüberdeckungstest C3b
• Überdeckung aller Zweige auf Objektcodeebene (d.h. aller atomaren Entscheidungen)
• Überdeckung aller atomaren Teilentscheidungen (alle Kombinationen werden getestet)
Minimaler Mehrfach-Bedingungsüberdeckungstest C3c
• Überdeckung aller atomaren Teilentscheidungen
• Überdeckung der Gesamtentscheidungen
• Überdeckung der Teilentscheidungen
3.7 LCSAJ-Test
Konzipiert wurde dieses Testverfahren eigentlich für
Programmcode mit Sprunganweisungen. Dabei sollen
alle linearen Codesequenzen (ohne Sprünge) überdeckt
werden (Linear Code Sequence and Jump). Dazu notiert
man Tripel in der Form
(erste Anweisung, letzte Anweisung, Sprungziel)

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
12
Zu diesen Tripeln erzeugt man anschließend eine minimale Anzahl von Testfällen, durch die jedes
der LCSAJ-Tripel überdeckt wird.
• Überdeckungsgrad =
• Ist der Überdeckungsgrad = 1, so liegt eine vollständige Zweigüberdeckung vor.
• Leistungsfähigkeit = ca. 85 % (Schwerpunkt: Kontrollflussfehler und Berechnungsfehler)
3.8 McCabe-Überdeckung
Der McCabe-Test wird auch als Basic Path Test bezeichnet, da ein zu dem Programmcode erstellter
Kontrollflussgraph in eine minimale Menge von Elementarpfaden zerlegt wird mit diesen dann die
Testfälle erzeugt werden.
• Pfaddarstellung erfolgt in Vektorschreibweise � � �01�, wobei die Zahl in der n-ten Zeile des
Vektors die Häufigkeit des Abschreitens der n-ten Kante im Kontrollflussgraphen wiedergibt.
Zu jedem Elementarpfad kann man einen solchen Vektor erstellen.
• Ein bestimmter Testfall lässt sich dann durch eine Linearkombination der Vektoren für die
Elementarpfade darstellen:
• Charakteristische Zahlen zu dem Kontrollflussgraphen:
o |E| als Anzahl der Kanten
o |N| als Anzahl der Knoten
o |B| als zyklomatische Zahl (|B| = |E| - |N| + 2), die der Anzahl von benötigten
Elementarpfaden entspricht und den Verzweigungsgrad des Programms beschreibt.
Erzeugung der Elementarpfade:
1. Zuerst unter Ausklammerung der Schleife alle unabhängigen Pfade bilden, die jeweils eine
der möglichen Kombinationen durchlaufen.
2. Ist eine Schleife in dem Programm, so muss von diesen Pfaden einer um einen
Schleifendurchlauf ergänzt werden.
3.9 Zusammenfassung

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
13
4. Datenflussorientierter Test
4.1 Grundlagen
Wie schon beim Kontrollflussorientierten Test, wird auch hierbei ein Kontrollflussgraph verwendet
und erweitert. Dabei wird der Datenfluss in dem Programm analysiert und Testfälle erstellt, die
dynamisch geprüft werden. Die Testvollständigkeit wird festgelegt durch die Abdeckung von
Datenzugriffen mit Testfällen. Im Gegensatz zum Kontrollflussorientierten Test existieren hierfür nur
wenige Werkzeuge. Trotzdem ist dieser Testtyp als sehr relevant anzusehen, da er besser für
Objektorientierte Programmierung geeignet ist, als der Kontrollflussorientierte Test.
• Erweiterung des Kontrollflussgraphen durch Datenflussattribute (� attributierter
Kontrollflussgraph)
o Definition einer Variable (def) im Knoten [Schreibzugriff auf Variable]
o Berechnende Benutzung (c-use) im Knoten [Lesezugriff auf Variable]
o Prädikative Benutzung (p-use) bei Kanten [Lesezugriff auf Variable]
• Grenzen von Methoden oder Modulen (nin und nout) enthalten
o Informationimport (def)
o Informationsexport (c-use)
4.2 Defs / Uses-Test
• Vollständigkeitskriterien sind Überdeckungen der defs, c-uses und p-uses
• Menge dcu
o für jede Definition werden alle nachfolgenden c-uses notiert, wobei zwischen
Definition und c-use keine andere Definition derselben Variablen vorkommen darf
(definitionsfreier Pfad).
• Menge dpu
o für jede Definition werden alle nachfolgenden p-uses notiert, wobei zwischen
Definition und p-use keine andere Definition derselben Variablen vorkommen darf
(definitionsfreier Pfad).
All Defs Kriterium
• Erstellung von Testpfaden, bei denen jede Definition durchlaufen wird und mit mindestens
einem zugehörigen c-use oder p-use zugegriffen wird.
• keine Anweisungs- oder Zweigüberdeckung
All p-Uses Kriterium
• Erstellung von Testpfaden, bei denen zu jeder Definition jeder p-use getestet werden muss.
• Zweigüberdeckung
All c-Uses Kriterium
• Erstellung von Testpfaden, bei denen zu jeder Definition jeder c-use getestet werden muss.
• keine Anweisungs- oder Zweigüberdeckung
All c-Uses / Some p-Uses Kriterium
• Erstellung von Testpfaden, bei denen zu jeder Definition jeder c-use getestet werden muss.
Falls zu einer Definition keine c-uses existieren, testet man mindestens einen zugehörigen
p-use.
• keine Anweisungs- oder Zweigüberdeckung, aber subsummiert das all Defs Kriterium.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
14
All p-Uses / Some c-Uses Kriterium
• Erstellung von Testpfaden, bei denen zu jeder Definition jeder c-use getestet werden muss.
Falls zu einer Definition keine c-uses existieren, testet man mindestens einen zugehörigen
p-use.
• Anweisungs- und Zweigüberdeckung und subsummiert das all Defs und all p-Uses Kriterium.
All Uses Kriterium
• Erstellung von Testpfaden, bei denen zu jeder Definition sowohl jeder c-use, als auch jeder p-
use getestet werden muss.
• Überdeckt alle bisher genannten Kriterien.
All du-Path Kriterium
• Entspricht dem All Uses Kriterium, wobei alle möglichen Pfade zu jeweils einem zu testenden
c- oder p-use durchlaufen werden müssen (und es nicht genügt, nur einen dieser Pfade zu
nehmen).
• Zwar keine Pfadüberdeckung, aber dies ist der aufwändigste Datenflussorientierte Testtyp.
Subsummationsbeziehungen
4.3 Required k-Tuples Test
• Subsummiert den all-defs-Test und die Zweigüberdeckung
• Variablenzugriffstypen
o definierend (d) – entspricht den defs vom Defs-Uses-Test
o referenzierend (r) – entspricht den c- und p-uses vom Defs-Uses-Test
o Die Variablenzugriffe sind im Kontrollflussgraphen immer an den Knoten vermerkt
(nicht mehr an den Kanten wie beim Defs-Uses-Test).
• Knoten nin und nout enthalten (im Gegensatz zu dem Defs-Uses-Test) alle Definitionen (nin)
und alle Referenzen (nout) der Variablen.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
15
Modifikationsleitfaden für den attributierten Kontrollflussgraphen
1. Zuordnung von d- und r-Nutzungen an die Knoten.
2. Einfügen von nin mit Definitionen und nout mit Referenzen aller Variablen, die im Programm
vorkommen.
3. Zusammenfassung linearer Anweisungssequenzen (Segmenten) zu einem Knoten (maximal
kollabieren).
4. Befindet sich in einem Knoten eine Definition und anschließend eine Referenz der gleichen
Variablen (dr-Interaktion), so muss der Knoten aufgetrennt werden.
dr-Interaktion
Eine dr-Interaktion ist eine Kennzeichnung eines Teilpfades durch das Programm, wobei nur der
Anfangs- sowie der Endpunkt notiert werden. Den Anfangspunkt bestimmt eine Definition einer
Variablen. Der Endpunkt muss (für dieselbe Variable) definitionsfrei erreicht werden können und
einer Referenz entsprechen. Beispiele:
• 2-dr-Interaktion: {[d1(x), r7(x)]}
• 3-dr-Interaktion: {[d4(kopie), r5(kopie)], [d5(kopie), r6(kopie)]}
Testvollständigkeitskriterien
1. Zu jeder dr-Interaktion im Kontrollflussgraphen erstellt man einen Teilpfad für das
Programm, der den Pfad durch die dr-Interaktion einbezieht und alle möglichen jeweils
nächstfolgenden Knoten berücksichtigt. Dies gewährleistet die Zweigüberdeckung. Beispiel:
1. zu der 2-dr-Interaktion {[din(zahl), r3(zahl)]} gibt es folgende Teilpfade:
i. nin, n1, n2, n3, nout
ii. nin, n1, n3, n4
iii. nin, n1, n3, nout
2. Liegt der Definitions- oder Referenzknoten in einer Schleife, so werden Teilpfade erstellt, die
a. eine minimale Anzahl der Schleifenausführungen (mind. eine Wiederholung)
b. eine nicht-minimale (mehr als eine Wiederholung) überdecken.
Vorgehensweise für das Required-k-Tupels Kriterium
1. Alle j-dr-Interaktionen (mit j ≥ k ≥ 2) des Kontrollflussgraphen bestimmen mit paarweise
verschiedenen Knoten.
2. Aus den j-dr-Interaktionen die Menge der möglichen Interaktionen-Teilpfade bestimmen mit
der Berücksichtigung aller möglichen unmittelbaren Nachfolgeknoten.
3. Schleifenkriterium sicherstellen
a. Teilpfade mit minimaler Ausführung bilden
b. Teilpfade mit nicht-minimaler Ausführung bilden
4. Testpfade bestimmen, die alle Teilpfade abdecken.
5. Eingabedaten finden, die die Überdeckung der gefundenen Teilpfade realisieren.
4.4 Datenkontext-Überdeckung
Bestandteile vom Datenkontext sind die elementaren Datenkontexte ec(nx), wobei sich der ec auf
einen Knoten nx bezieht. Inhalt des elementaren Datenkontexts sind alle Variablendefinitionen, die in
dem Knoten nx referenziert werden und den Knoten nx definitionsfrei über einen Teilpfad erreichen.
Die Reihenfolge der einzelnen Variablendefinitionen kann ungeordnet (ec) sowie geordnet (oec)sein.
• ec(nx) = [d1(x1), d2(x2), …, dk(xk)]

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
16
Der Datenkontext (Definitionenkontext) DC(nx) enthält wiederum alle elementaren Datenkontexte
des jeweiligen Knotens nx. Er kann ebenfalls sowohl ungeordnet (DC) als auch geordnet sein (ODC).
• DC(nx) = [ec1(nx), ec2(nx), …]
• ODC(nx) = [oec1(nx), oec2(nx), …]
Testvollständigkeit
Ein Test ist dann vollständig, wenn alle existierenden Möglichkeiten, den Variablen Werte
zuzuweisen mindestens einmal geprüft wurden.
• Für alle Knoten aus den elementaren Datenkontexten in DC(n) wird mindestens ein Kontext-
Teilpfad bezüglich DC(n) abgelaufen.
• Der geordnete Test ist leistungsfähiger in den Fällen, wenn mehrere geordnete
Datenkontexte für einen Knoten existieren. Denn dann kann die Beachtung der Reihenfolge
der auszuführenden Knoten die Anzahl der gesamten Testfälle erhöhen.
Vorgehensweise zur Datenkontext-Überdeckung
1. alle (geordneten) elementaren Datenkontexte zu allen Knoten bilden
2. Datenkontexte der Knoten zusammenfassen
3. zu den Datenkontexten aller Knoten Subpfade bilden
4. Testpfade bestimmen, die alle Subpfade abdecken
5. Eingabedaten finden, die zur Ausführung aller Testpfade führen
Bewertung
• geordnete Datenkontext-Überdeckung subsummiert die einfache Datenkontext-Überd.
• all-defs-Kriterium wird überdeckt
• keine Anweisungs- und Zweigüberdeckung (da keine Anweisungen ohne Datenkontext
getestet werden und nicht alle Verzweigungsrichtungen durchlaufen werden müssen)
4.5 Bewertung des Datenflussorientierten Tests
• Testverfahren neuer und moderner als strukturorientierte Techniken (OOP).
• Testwerkzeuge sind nur unzureichend verfügbar (schwerer zu Realisieren als
kontrollflussorientierte Techniken), deshalb ist diese Technik in der Praxis weniger oft
vertreten.
• Zweigüberdeckung sollte am besten immer sichergestellt werden.
5. Spezielle dynamische Testtechniken
5.1 Diversifizierender Test
Alle diversifizierenden Testtechniken haben gemeinsam, dass sie nicht die Korrektheit des
Programms gegen eine vorgegebene Spezifikation, sondern mehrere verschiedene Versionen eines
Programms zu testen haben. Eine zweite Version des Programms ersetzt somit die Spezifikation.
Back to Back – Test
Man testet mehrere Versionen einer Software (die zuvor von mehreren Team parallel entwickelt
wurden � heterogenen Fehlertoleranz) und bestimmt die gemeinsame Fehlermenge dieser
verschiedenen Versionen, indem für die Testdaten aufgezeichnete bzw. zufallsorientiert gewonnene
Daten verwendet werden. Der Testaufwand ist damit wegen der doppelten Entwicklung sehr hoch,
aber die Tests können automatisch durchgeführt werden.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
17
Mutationen
Zu Beginn nimmt man an, dass die zu testende Software korrekt ist. Dann erstellt man aus dieser
Software Mutationen, die einfache Fehler enthalten, wie z.B.
• Definitionen und Referenzen von anderen Variablen
• Verfälschung von arithmetischen Ausdrücken, Relationen und Boole’ scher Ausdrücke
• Modifikation von Anweisungen
Wenn beim Test der Mutanten (nach den Mutationstransformationen) das Verhalten des
Programms sich nicht geändert hat, dann sind die jeweiligen Mutanten als solche nicht identifiziert.
Aus der Anzahl der un- und identifizierten Mutanten kann dann auf die Gesamtanzahl der Fehler im
Programm geschlossen werden (prädizierender Mutationen-Test):
#Fehler ≈ #gefundenen Fehler * (# erzeugte Mutanten / # identifizierte Mutanten)
Man unterscheidet zwischen zwei Mutationen-Test-Arten
1. schwacher Mutationen Test
Die Testmenge muss hierbei alle Mutanten identifizieren, dadurch kann man die
Überdeckung messen. Es wird der Code im Detail analysiert.
2. starker Mutationen Test
Hier werden Mutanten, die das Verhalten des Gesamtprogramms nicht verändern (konnten)
nicht berücksichtigt. Wir können dann hiermit die Leistung einer Testmenge bestimmen.
Für die Generation der Mutanten und die Fehlerbestimmung ist eine gute Werkzeugunterstützung
notwendig, da sonst der Aufwand enorm mit dem Programmumfang steigen würde.
• für die Praxis nicht geeignet, aber sinnvoll für die Ermittlung der Leistungsfähigkeit von
anderen Testverfahren.
Regressionstest
Bei diesem Testtyp ist es das wesentliche Ziel, herauszufinden, ob eine Änderung oder Erweiterung
des Programms die bisherige Funktionalität stört (Seiteneffekte). Damit wird eine Reihe von
Testfällen nach einer Modifizierung auf das Programm angewendet. Wenn alle Testfälle erfolgreich
abgeschlossen worden sind, dann überdeckt die neue Version die Funktionalität des
ursprünglicheren Programms. Gegebenenfalls kann dann die Testfallmenge um weitere Testfälle
ergänzt werden.
• Wiederholung von Testfällen als wesentliches Merkmal
• wichtig und häufig gefordert (für große und langlebige Projekte)
• sehr gute Unterstützung durch ein Regressionstestwerkzeug (z.B. SilkTest etc.)
5.2 Bereichstest (Domain Testing)
Diese Testart greift direkt nach der Erzeugung der Äquivalenzklassen (siehe Funktionsorientierten
Test). Hierbei wird dem Test vorgeschrieben, wie er die Testdaten zu wählen hat. Dazu liegt die
Erfahrung zu Grunde, dass Eingabedaten, die an den Grenzen der Äquivalenzklassen liegen, ein
höheres Testpotenzial haben, als zufällige Werte. Mit steigender Dimension der Eingabevariablen
steigen die Anzahlen der Testdaten also um 2n x (n + 1) * #Grenzpunkte an. Bei unendlich großen
Bereichen (tritt z.B. bei beliebig langen Arraylängen auf) setzt man künstlich eine Grenze

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
18
(Grenzinduktion). Als Voraussetzung zur erfolgreichen Ausführung dieser Testart muss der
Wertebereich geordnet sein.
Pfadbereichstest
Bei der Testausführung unterscheidet man zwischen
• Bereichsfehler (Ausführung eines falschen Programmpfads)
• Berechnungsfehler (korrekter Pfad wird abgelaufen, aber Ausgabewert falsch berechnet)
Um dies zu testen werden zunächst die Pfadbedingungen für die einzelnen Pfade formuliert. Dann
werden die damit verbundenen Pfadbereiche gebildet und die Eingabedaten zu jedem Pfadbereich
bestimmt. Die Testbeschreibung enthält dann folgende Elemente:
• D[Pi] – Eingabedaten, die zur Ausführung vom Pfadbereich Pi führen
• C[Pi] – Ausgabewert, der vom Pfadbereich Pi berechnet wird
• { (D[Pi], C[Pi]), (D[Pj], C[Pj]) } – Darstellung des Programms (unendliche Menge, wenn
Schleifen oder ähnliches enthalten)
Der Pfadbereichstest ist aus der Erfahrung, das Fehler an Bereichsgrenzen auftreten (vor oder nach
Verzweigungen im Kontrollfluss), deswegen liegt diesem Testtyp die Heuristik, dass Fehler sich an
den Bereichsgrenzen häufen, zugrunde.
Test fehleroffenbarender Unterbereiche
Der Eingabedatenbereich wird definiert durch den Programmcode und die Spezifikation.
• Gültigkeit (Mindestanforderung – Test ist gültig, wenn ein unkorrektes Programm durch
einen Test als solches erkannt werden kann.)
• Zuverlässigkeit (alle erzeugten Tests sind entweder erfolgreich oder schlagen fehl)
Mit diesen beiden Testkriterien lassen sich dann die Eingabewerte abstrakt vorgeben (z.B. Test soll
eine mindestens eine negative und eine positive Zahl als Eingabe erhalten, sowie immer die Null).
Der Nachteil dieses Testtyps ist der, dass im Zweifelsfall das Programm erschöpfend getestet werden
muss, um ein ideales Testkriterium zu erfüllen. Das kann dadurch verhindert werden, indem z.B. auf
bestimmte Fehler eingegrenzt wird und nicht auf alle Fehler getestet werden muss.
5.3 Zufallstest (Random Test)
Hierbei erstellt man aus allen Möglichkeiten, die für Eingabedaten zur Verfügung stehen zufällig eine
Menge von Testdaten, mit denen das Programm abläuft. Die Eingabedaten können
• komplett zufällig erzeugt werden (alle Testdaten sind unter Umständen gleich)
• aus Partitionen des Eingabebereichs zusammengestellt werden (durch Spezifikation oder
Strukturinformation wird der Eingabebereich vorher partitioniert)
• auch einer Häufigkeitsverteilung (gewonnen aus der praktischen Anwendung) gewonnen
werden
Der Zufallstest kann relativ effizient sein, da er schnell implementiert ist und seine Kosten gering
sind. Günstig ist es, wenn man die Erzeugung der Testdaten sowohl ganz zufällig als auch aus
Partitionen durchführen lässt.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
19
5.4 Error Guessing
Hierbei werden die Testdaten so gewählt, dass der Tester vermutet, auf Fehler zu stoßen.
• Testdatenerzeugung ist regellos und birgt viele Nachteile
• sinnvoll, wenn ergänzend zu einer systematischen Testtechnik (z.B.
Äquivalenzklassenbildung) eingesetzt
5.5 Zusicherungen (Assertions)
Mit Assertions (z. T. als Bestandteil der Sprache) sollten Programmierfehler abgefangen werden, um
vor allem bei der Entwicklung des Programms auftretende Fehler leicht aufzuspüren.
Etwas anders verhält es sich mit Exceptions, die auch Ausnahmefehler signalisieren können, die
eventuell durch falsche Eingaben hervorgerufen worden sind. Exceptions bleiben in der Regel auch in
der Release-Version des Programms enthalten. Man kann Exceptions intern im Programm abfangen,
ignorieren oder anzeigen lassen.
5.6 Grenzen des Software Tests
• Anforderungen sind nur selten komplett klar und vollständig (Interpretation des
Programmierers)
• Programmkomplexität wächst während des Entwicklungsprozesses sehr stark an
• Testfallkonstruktion hat nur eingeschränkte Werkzeugunterstützung
• Andere Einflussfaktoren: fehlende Managementunterstützung, Wissenslücken beim Personal
und Zeitprobleme im Entwickleralltag.
6. Statische Codeanalyse
6.1 Grundlagen
• Software wird nicht ausgeführt und es müssen auch keine Testfälle erstellt werden.
• Aus der Analyse des Quellcodes (White-Box) können keine vollständigen Aussagen über die
Korrektheit oder Zuverlässigkeit getroffen werden.
• Automatisierbarkeit durch Software ist möglich.
• Quellcodestrukturen können durch Tabellen, Diagramme oder Graphen dargestellt werden.
o Strukturdiagramm als Aufrufdiagramm
o Variablen-Cross-Reference-Tabelle

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
20
6.2 Stilanalyse
• Programmierregeln (Konventionen) helfen sich in dem Code zurechtzufinden.
• Einhaltung bestimmter Qualitätseigenschaften
o Syntaxbeschränkungen (aus ersichtlichen Gründen)
o Inhalt und Form des Codes wird in Richtlinien festgelegt
o Freiheiten der Sprache werden ausdrücklich eingeschränkt
6.3 Slicing
Beim Slicing wird zu einer bestimmten Codezeile die Information über die Definition und
Referenzierung (auch rekursiv) einer Variablen zur Verfügung gestellt. So erleichtert man dem Pro-
grammierer die Fehlersuche beim Debugging nach dem Auftreten eines Fehlers in genau dieser Zeile.
Das statische Slicing wird aus dem attributierten Kontrollflussgraphen abgeleitet. Dazu wird der
betroffene Knoten mit anderen vorherigen oder nachfolgenden Knoten verbunden, wenn eine
Datenflussabhängigkeit (durchgezogene Kante) oder Kontrollflussabhängigkeit (gestrichelte Kante)
besteht. Beim dynamischen Slicing setzt man für die Eingabevariablen konkrete Werte ein.
• Sinnvoll bei komplizierten und unübersichtlichen Programmen
• unterstützt Fehlersuche und Programmverständnis
6.4 Anomalieanalyse
Mit einer Anomalie beschreibt man Abweichungen im Programm, die durch eine Anomalieprüfung
auf verdächtige Stellen im Programmcode führen können. Insbesondere verwendet man häufig die
Datenflussanomalieanalyse. Dazu teilt man die Interaktionen in folgende Typen ein und stellt den
Datenfluss anschließend durch eine Sequenz dieser Interaktionen dar (z.B. [u d r r u]):
• Definition (d)
• Referenzierung (r)
• Undefinition (u)
• Nicht benutzt (empty= e)
Datenflussanomalien (unsinnige Datenflüsse):
• Typ [u r] – Referenz auf undefinierten Wert
• Typ [d d] – zwei aufeinanderfolgende Definitionen ohne Benutzung
• Typ [d u] – Definition wird gefolgt von Undefinition
Andere Anomalien sind die Schnittstellen-, die Variablendeklarations- und die Kontrollflussanomalie.
Dieser Testtyp ist gut als Ergänzung zu dynamischen Testverfahren einsetzbar, da er vor allem
Berechnungsfehler gut erkennt, gut automatisierbar ist und eine gute Fehlerlokalisierung bietet.
Nachteilig ist jedoch die Lieferung vieler Scheinfehler.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
21
7. Manuelle Prüfung
7.1 Grundlagen
Die Manuelle Prüfung kann parallel zu den dynamischen und statischen Prüftechniken angewandt
werden. Diese Prüfung wird von einem Entwickler persönlich vorgenommen. Dies ist das
allgemeinste von allen Prüfverfahren, das jedoch den großen Nachteil hat, dass es aufwendig ist
(und somit teuer) und man es nicht automatisieren kann. Während einer Inspektion werden in der
Regel Reviews durchgeführt. Man kann Reviews klassifizieren
• formell vs. informell (gibt es fest definierte Regeln, an die man sich halten muss?)
• spontan vs. geplant (muss es in bestimmten Zeitabständen durchgeführt werden?)
• moderiert vs. unmoderiert (sind Entwickler gleichberechtigt oder gibt es Hierarchien?)
7.2 Formale Inspektion
In gemeinsamen Sitzungen mit Entwicklern sollen Fehler effizient gefunden werden und die Qualität
der Dokumente und des Arbeitsprozesses verbessert werden. Der Inspektionsprozess ist hierbei
streng formal und hat feste Phasen:
1. Planungsphase (Organisation)
2. Überblicksphase (Rollenverteilung
und Hintergründinfo)
3. Vorbereitungsphase (Inspektoren
suchen eigenständig nach Fehlern)
4. Inspektionssitzung (Sammlung der
Einzelergebnisse, gemeinsame Suche
nach weiteren Fehlern)
5. Nachbearbeitungsphase (Autor prüft
alle gefundenen Fehler und sucht
Lösungen)
6. Überprüfungsphase (Nochmaliges Durchgehen aller Fehlerkorrekturen und Unklarheiten)
7.3 Konventionelles Review
Diese Technik basiert weitgehend auf der formalen Inspektion, bietet aber eine höhere Flexibilität,
weniger Aufwand und ist für einen vielfältigeren Einsatz gedacht. Dazu löst man sich von der
strengen Vorgabe zu den einzelnen Phasen und nimmt sich Freiheiten bei einigen Merkmalen. Gerne
wird bei diesem, in der Praxis häufig anzufindenden Verfahren, eine Checkliste verwendet, die man
in einem Team Punkt für Punkt am Programm gemeinsam durchgeht.
7.4 Review in Kommentartechnik
Ohne eine Inspektionssitzung schreiben die Prüfer (Entwickler) Auffälligkeiten der Programme beim
Durchschauen als Kommentar nieder, die dann an die Kollegen verteilt werden. Dieses Verfahren hat
den kleinsten Aufwand, ist aber auch am wenigsten leistungsfähig. Die Prüfung dieser
geschriebenen „Berichte“ ist aber durch den losen Prozessablauf nicht immer gewährleistet.
7.5 Bewertung
Die Manuelle Prüfung kann bei einem guten Einsatz ein Einsparpotential von bis zu 25 % liefern. Die
Leistungsfähigkeit der einzelnen Verfahren stuft sich dabei genauso ab, wie die Reihenfolge in dieser
Zusammenfassung.

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
22
8. Formale Verfahren
8.1 Grundlagen
Diese Verfahren sind alle verifizierend, d.h. mit ihnen ist man in der Lage mathematisch zu
beweisen, dass ein Programm eine bestimmte Eigenschaft erfüllt. Dabei vergleicht die formale
Verifikation idealerweise eine formale Spezifikation (Soll-Zustand) mit der formalen Modellierung
(Ist-Zustand). Das bedeutet, dass man vor der Verifikation aus dem Programm noch ein formales
Modell in einem Zwischenschritt generieren muss. Genau der gleiche Ablauf ist auf der
Spezifikationsseite notwendig. Damit erkennt man hier auch schon einen wesentlichen Nachteil des
Verfahrens.
Die Formalisierung geschieht zum einen auf einer soliden mathematischen Basis, die zum einen
durch Grammatiken, reguläre Ausdrücke und Automatentheorie und zum anderen durch
spezifische höhere formale Methoden ergänzt wird. Jede dieser Sprachen besitzt die Aspekte:
• Syntax (Struktur und Aufbau eines oder mehreren Ausdrücke)
• Semantik (Bedeutung der Ausdrücke)
• Pragmatik (Implizite Aussagen in einem Ausdruck / Absicht)
Daneben kann man bei der Semantik wiederum unterscheiden, wie sie
interpretiert werden soll:
• Programmbeschreibung (Was tut das Programm?)
• Programmspezifikation (Was soll es tun?)
• Programmverifikation (Macht es, was es tun soll?)
Es gibt u. a. noch weitere formale Verfahren, die hier aber nicht thematisiert werden:
• Zusicherungsverfahren nach Floyd und Hoare (regelbasiert)
• Abstrakte Interpretation, symbolischer Test
• Algebraische Verfahren (algebraische Spezifikation)
8.2 Modellbasierte Modellprüfung
Für dieses Verfahren existieren vorwiegend zwei Spezifikationsarten
• LTL (durch Büchi-Automaten und Automateninklusion)
• CTL (erschöpfende Erreichbarkeit und Suchalgorithmen über dem Modellgraphen)
Der Ablauf der Modellprüfung sieht wie folgt aus

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
23
1. Übersetze ein Programm in eine Kripke-Struktur.
2. Zeitliche Eigenschaften (Abfolge) werden über die
Temporallogik beschrieben.
3. Die formalisierte Spezifikation wird in einem
Modellprüfer dazu verwendet, um das
Programmmodell zu testen.
4. Wenn das Modell gegen die Spezifikation verstößt,
kann dieser Verstoß mit einem Beispiel angegeben werden, das gleichzeitig eine gute
Debugging-Hilfe ist. Das Programm und das Modell werden berichtigt.
5. Wenn aus dem Modell die Spezifikation folgt, dann ist die Eigenschaft enthalten und es wird
mit der nächsten weitergemacht, bis alle getestet wurden.
Kripke-Struktur
Sie entspricht einem endlichen Automaten ohne Ein- oder Ausgabealphabet aber mit einer
Markierungsfunktion der Zustände (zum Beschriften der Knoten mit einer atomaren Aussage). Dabei
hat jeder Zustand zwingend mind. einen Nachfolger.
Eine Kripke-Struktur M = (S, S0, R, L) besteht aus
• endlicher Zustandsmenge S
• Menge von Anfangszuständen S0 ⊆⊆⊆⊆ S
• totale Übergangsrelation R ⊆⊆⊆⊆ S x S
• Beschriftung der Zustände mit atomaren Aussagen AP L: S ���� 2AP
Es sind folgende Ausdrücke über die Kripke-Struktur machbar
• Aussage p ∈∈∈∈ AP gilt in einem Zustand s ∈∈∈∈ S, wenn gilt p ∈∈∈∈ L(s), also genau dann, wenn p in
der Beschriftung von s enthalten ist.
• Zustand s‘ ∈∈∈∈ S ist Folgezustand eines Zustands s ∈∈∈∈ S, wenn gilt (s, s‘) ∈∈∈∈ R, also wenn eine
solche Übergangsfunktion überhaupt existiert.
• Eine unendliche Sequenz (z.B. π =
s0s1s2…) über den Zuständen aus S nennt
man Pfad von M in s0.
• Ein besonderer Pfad, der bei einem
Zustand aus der Menge der
Anfangszustände beginnt, nennt man
Ablauf von M.
Die Menge aller Pfade von M in einem
bestimmten Zustand kann in einem Berechnungsbaum dargestellt werden (mit unendlicher Tiefe, da
ja jeder Zustand einen Folgezustand besitzen muss).
Temporale Logik
Der wesentliche Unterschied der Logik ist der, dass eine Aussage nur unter einer bestimmten
Modalität (beschrieben durch eine Reihenfolge) wahr oder falsch ist. Es gibt einige Ausprägungen:
• Aussagenlogik vs. Prädikatenlogik (Variabl., Konstanten, Funktionen, Prädikate, Quantoren)

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
24
• global vs. kompositional (auf gesamtes oder nur ein Teilprogramm ausgerichtet)
• Zeitpunkte vs. Zeitintervalle (betrifft die Auswertung über einem Modell)
• diskret vs. kontinuierlich („Zeit als Integer oder als Real“)
• Vergangenheit vs. Zukunft (meist genügt nur die Zukunft zu betrachten)
• verzweigt vs. linear (gibt es mehrere parallele Zukünfte oder nur eine)
Temporale Sprachen enthalten häufig eine Teilmenge der folgenden Bestandteile:
Temporale Sprache CTL*
Ausstattung:
• Boolesche Operatoren: Nicht ⋅, ⋅ Und ⋅, ⋅ Oder ⋅, ... • Pfadquantoren: E ⋅, A ⋅ • Temporale Quantoren: ⋅ U ⋅, ⋅ R ⋅, X ⋅, F ⋅, G ⋅
Bedeutung der Beschreibungselemente:
• Die Pfadquantoren werden immer in einem Zustand interpretiert (Zustandsformeln).
o E φ = für den Pfad ab dem aktuellen Knoten (einschließlich) gilt immer φ
o A φ = für jeden Pfad, der ab dem aktuellen Zustand beginnt gilt immer φ
• Die Temporalen Operatoren werden immer auf einem Pfad interpretiert (Pfadformeln).
o X φ = gültig nur dann, wenn im nächsten Zustand φ gilt
o φ1 U φ2 = gültig nur dann, wenn irgendwann φ2 gilt und bis dahin immer φ1
o G φ = gültig nur dann, wenn überall auf dem Pfad φ gilt
Backus-Naur Schreibweise der Syntax:

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
25
Temporale Sprache LTL (Linear Time Logic)
Für die LTL wird für jede Verzweigung in der Kripke-Struktur eine zusätzliche Ablaufsequenz erstellt,
sodass jede Sequenz aus dieser Sammlung linear ist. Daraus folgt, dass es nur noch Pfadformeln gibt.
Aufbauend auf der Aussagenlogik werden die booleschen Verknüpfungen um zusätzliche temporale
Operatoren erweitert:
o Temporaler Schrittoperator (next) = X
� Temporaler Allquantor (always) = G
◊ Temporaler Existenzquantor (eventually) = F
U Bedingte Allquantifizierung (until) = U
Backus-Naur Schreibweise der Syntax:
Man kann die daraus entstehenden Aussagen kategorisieren:
• Sicherheitseigenschaften
� ¬ (a ∧ b) = Aussage a und b sind niemals beide gleichzeitig wahr
• Fairness-Eigenschaften
� ◊ a = Aussage a ist unendlich oft gültig
• Lebendigkeitseigenschaften
� (a → ◊ b) = Immer wenn a gilt, dann gilt auch irgendwann wieder b
Mit diesen Sprachelementen kann man auch komplizierte Beziehungen der einzelnen Knoten einer
Kripke-Struktur in einer Formel ausdrücken.
Temporale Sprache CTL (Computation Tree Logic)
Hier gibt es nun wieder die Verzweigungsmöglichkeit, wobei der Nachfolgezustand
nichtdeterministisch eintritt. Es sind somit nur noch Zustandsformeln möglich, die mit
Pfadquantoren gebildet werden. Temporale Operatoren müssen paarweise mit einem Pfadquantor
verwendet werden (z.B. EX, AF aber nicht EA oder E).
E o, A o Temporaler Schrittoperatoren (next) = EX, AX
E �, A � Temporaler Allquantoren (always) = EG, AG
E ◊, A ◊ Temporaler Existenzquantor (eventually) = EF, AF
E U, A U Bedingte Allquantifizierung (until) = EU, AU

Software Qualität Zusammenfassung (WS 10/11)
Zusammengestellt in 2011 – Sharing welcome! – wladislaw.gusew.de
26
Quellennachweis • Vorlesungsfolien zur Vorlesung „Software Qualitätsmanagement“ an der Universität
Osnabrück von Jun.-Prof. Dr.-Ing. Elke Pulvermüller im WS 2010/2011
• „Software-Qualität“ von Dirk W. Hoffmann erschienen 2008 im Springer-Verlag, Berlin
• „Software-Qualität“ von Peter Liggesmeyer erschienen 2009 im Spektrum Akademischer
Verlag, Heidelberg


















