Lab Validation Brief EMC Isilon als Grundlage für einen ... · TeraGen führt einen Benchmark für...
24
Gesponsert von EMC Isilon | März 2016 EMC Isilon als Grundlage für einen Scale-out-Data-Lake Wichtige Funktionen für den Aufbau einer Big Data-Infrastruktur Lab Validation Brief Von Ashish Nadkarni, IDC Storage Team
Transcript of Lab Validation Brief EMC Isilon als Grundlage für einen ... · TeraGen führt einen Benchmark für...

Gesponsert von EMC Isilon | März 2016
EMC Isilon als Grundlage für einen
Scale-out-Data-LakeWichtige Funktionen für den
Aufbau einer Big Data-Infrastruktur
Lab Validation Brief
Von Ashish Nadkarni, IDC Storage Team

PG 2
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
IDC-Validierung wichtiger Funktionen von EMC Isilon in Big Data-Workflows1. Multiprotokollfunktionen 2. Verfügbarkeit 3. Sicherheit und Compliance 4. Vereinfachter Betrieb
IDC-MeinungIDC ist der Ansicht, dass EMC Isilon eine einfach zu bedienende, hochgradig skalierbare und effiziente EDLP-Plattform (Enterprise Data Lake Platform) ist*. IDC hat validiert, dass ein gemeinsames Speichermodell auf Basis des Data Lake sogar Servicelevel der Enterprise-Klasse bieten kann und dabei eine bessere Performance aufweist als dedizierte COTS-Speicher (Commodity off the Shelf) für Hadoop-Workloads. *Der EMC Isilon-Scale-out-Data-Lake ist eine Enterprise Data Lake Platform (EDLP), die auf dem verteilten OneFS-
Dateisystem basiert.
Lab Validation Brief – Zusammenfassung
Freigaben
Archiv
Mobil
Cloud Agieren
Oberfläche
Analysen
Batch

PG 3
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Funktion/Validierung – Zusammenfassung Der EMC Isilon-Scale-out-Data-Lake ist eine ideale Plattform für die Multiprotokollaufnahme von Daten. Das ist eine wichtige Funktion in Big Data-Umgebungen, in denen Daten schnell und zuverlässig über Protokolle aufgenommen werden müssen, die dem Workload, der die Daten erzeugt, am nächsten kommen. Mit OneFS können Daten über NFSv3, NFSv4, SMB 2.0, SMB 3.0 sowie HDFS aufgenommen werden. Damit ist die Plattform sehr gut geeignet für komplexe Big Data-Workflows.
Validierungsprozess Für diese Validierung wurde der EMC Isilon-Scale-out-Data-Lake für den Zugriff über NFSv3, SMB 3.0 und über HDFS vom Hadoop-Cluster konfiguriert. Der HDFS- und NFS-Zugriff wurde über den Master-Node auf dem Hadoop-DAS-Cluster eingerichtet. Der Download einer großen Datei wurde simuliert (Wikipedia-Wiki-Daten, 10 GB). Die Komprimierung der Datei wurde beibehalten. Der Zugriff auf die Datei und die Analyse der Datei erfolgte kontinuierlich über HDFS, während die Datei über NFS in den EMC Isilon-Scale-out-Data-Lake kopiert wurde. Außerdem wurde über SMB 3.0 auf die Datei zugegriffen, während sie über HDFS bzw. NFS gelesen und geschrieben wurde.
Hinweise: • Isilon OneFS verwendet die DNS-Zonendelegation und dann nachfolgend DNS Round Robin zum
Ausgleichen eingehender Verbindungen.
• In HDFS ist keine solche eigene Funktion verfügbar, was zu Jobfehlern führt, wenn der Daten-Node ausfällt. Sobald der Node als fehlgeschlagen markiert ist, übergehen HDFS-Aufrufe den fehlgeschlagenen Node.
Validiert: Gleichzeitige Aufnahme über NFS, SMB und HDFS
IDC hat die robusten Multiprotokollfunktionen der OneFS-Plattform validiert. Diese Validierung beinhaltet die Möglichkeit der Plattform, Benutzerzugriffsberechtigungen über Protokolle hinweg beizubehalten.
4

PG 4
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
IDC-Schlussfolgerung Unternehmen fällt es aus folgenden Gründen leicht, Workflows über den EMC Isilon-Scale-out-Data-Lake aufzubauen:
• Er ermöglicht die Verwendung vorhandener und bekannter Dateiprotokollmechanismen (anstelle von Hadoop-spezifischen Mechanismen, für die spezielle Änderungen auf Anwendungsebene erforderlich sind).
• Die Funktionen für die Performanceoptimierung machen ihn zu einer idealen Plattform für unternehmensweite Datenspeicher/-analyse mit zentralem Repository.
• Die Verwendung nativer Protokolle ermöglicht lokale Analysen (unter Vermeidung von Migrationen), sorgt für schnellere Datenworkflows und lässt Unternehmen schneller Einblicke gewinnen.
Robuste Funktionen für die Multiprotokollaufnahme vereinfachen den Aufbau eines Big Data-Workflows in einem Data Lake, der auf der EMC Isilon-Scale-out-Data-Lake-Plattform basiert.
Wichtiges Ergebnis: Funktionen für die Multiprotokollaufnahme
Aufnahme über NFS (v3, v4), SMB (2.0, 3.0) und HDFS
Der gleichzeitige Multiprotokoll-Lese-/Schreibzugriff von verschiedenen Benutzern, ob lokal oder verzeichnisbasiert, ermöglicht die gleichzeitige Verarbeitung von Big Data-Workflows.
Fähigkeit Warum ist das wichtig?

PG 5
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• Der EMC Isilon-Scale-out-Data-Lake wurde mit SSD-basierter Zwischenspeicherung, das Hadoop-
DAS-Cluster dagegen mit SAS-Laufwerken mit 10.000 U/min konfiguriert.
• IDC ist der Meinung, dass das Hadoop-DAS-Cluster mit internen SSDs eine deutliche Verbesserung der Performance zeigen kann.
Funktion/Validierung – Zusammenfassung Der EMC Isilon-Scale-out-Data-Lake bietet für Hadoop-Cluster, die über OneFS auf HDFS zugreifen, gegenüber Clustern, die über einen lokalen (internen) Speicher auf HDFS zugreifen, eine hervorragende Lese- und Schreibperformance.
Validierungsprozess Für diese Validierung wurden 3 Standardbenchmarktests verwendet: TeraGen, TeraSort und TeraValidate. TeraGen führt einen Benchmark für die sequenzielle Schreibperformance durch. TeraSort bietet einen guten Benchmark für gemischte Lese-/Schreibtests. TeraValidate führt einen Benchmark der Leseperformance durch. Die Ergebnisse der jeweiligen Skripte sind in der Tabelle oben zusammengefasst. Das Hadoop-Data-Lake-Cluster hat über HDFS über die API auf den EMC Isilon-Scale-out-Data-Lake zugegriffen, das Hadoop-DAS-Cluster hat lokal auf HDFS zugegriffen. Für Parameter, die an die jeweiligen „Tera“-Jobs übergeben wurden, wurden auf beiden Hadoop-Clustern exakt dieselben Werte verwendet. In dieser Konfiguration ist der EMC Isilon-Scale-out-Data-Lake bei Schreibvorgängen nahezu 3-mal schneller und bei Lese-/Schreibvorgängen und Lesevorgängen mehr als 1,5-mal schneller. Ganz ähnlich bieten 10-GbE-Verbindungen trotz des Netzwerkzugriffs bedeutende Bandbreitenverbesserungen (MB/s) für Lese- und Schreibvorgänge.
Validiert: HDFS-Performance im Data Lake
IDC hat die Performanceprofile von DAS und EDLP mithilfe von bekannten Hadoop-Benchmarkjobs validiert, die mit der Hadoop-Distribution bereitgestellt werden.
Sek. Insgesamt MB/Sek. Sek. Insgesamt MB/Sek. Sek. Insgesamt MB/Sek.
594,652 1.681,66 1.558,159 641,78 353,112 2.831,96
1.652,761 605,05 2.405,953 415,64 547,05 1.827,99
TeraGen TeraSort TeraValidate
Hadoop-Data-Lake-Cluster
Hadoop-DAS-Cluster
4

PG 6
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• Ein NFS-Gateway wurde auf einem der Daten-Nodes im Hadoop-DAS-Cluster installiert und auf
dem Master-Node gemountet. Die native NFS-Funktion in Hadoop wird über einen Java-basierten Benutzerprozess, nicht über die System-NFS-Daemons bereitgestellt.
• Die NFS-Leseperformance in Isilon wird aufgrund von Treffern beim Lesevorgang deutlich verbessert (Flash-basierte L3-Zwischenspeicherung), während die Java-NFS-Implementierung über begrenzte Zwischenspeicherfunktionen verfügt.
Funktion/Validierung – Zusammenfassung Die SmartFlash-L3-Zwischenspeicherfunktionen von OneFS sind gut geeignet, um die Protokollperformance (Lese-/Schreibperformance) während der Multiprotokollaufnahme in den EMC Isilon-Scale-out-Data-Lake beizubehalten. Das ist eine wichtige Funktion in Big Data-Umgebungen, da Analyse-Workloads während der Datenaufnahme nicht angehalten und die Aufnahme- und Analyseprozesse nicht serialisiert werden können. Darüber hinaus ist die Lese-/Schreibperformance in Umgebungen wichtig, in denen die Analyse-Workloads mit Dateien verwendet werden, die ständig aktualisiert werden.
Validierungsprozess Für diese Validierung wurde der UNIX-Befehl „dd“ verwendet, um einen Satz von Blöcken in eine Datei zu schreiben und diese Blöcke dann zu lesen. (Bei diesem Test wurde der UNIX-Befehl „dd“ verwendet, um sequenziell eine Datei mit Nullen und einer Größe von 10 GB zu schreiben und zu lesen.) Die Tests wurden auf gemounteten NFS-Dateisystemen vom EMC Isilon-Scale-out-Data-Lake und dem Hadoop-DAS-Cluster durchgeführt. Die Ergebnisse der Tests sind oben zusammengefasst. Der EMC Isilon-Scale-out-Data-Lake bietet eine 4,2-mal schnellere Schreibperformance und eine 37-mal schnellere Leseperformance.
Validiert: NFS-Performance während der Multiprotokollaufnahme
IDC hat validiert, dass die NFS-Performance von EDLP aufgrund von Optimierungen auf der OneFS-Plattform, z. B. nativer NFS-Daemon und L3-Zwischenspeicherung, deutlich höher als bei einem Hadoop-DAS-Cluster ist.
Hadoop-NFS-Lese-/Schreibperformance
Hadoop-Data-Lake-Cluster
Hadoop-DAS-Cluster
NFS-Schreibvorgang Sek. Insgesamt MB/Sek.
34,4362 290,39
145,816 68,58
NFS-Lesevorgang Sek. Insgesamt MB/Sek.
10,3208 968,92
381,847 26,19
4

PG 7
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
IDC-Schlussfolgerung Die Zwischenspeicher- und SSD-basierten Tiering-Funktionen des EMC Isilon-Scale-out-Data-Lake machen diesen zu einer für gemeinsame Hadoop-Umgebungen mit gemischtem Profil geeigneten performanceoptimierten Plattform. Er bietet jedoch auch die Wirtschaftlichkeit eines kapazitätsoptimierten Speichers und macht damit die Verschiebung nachverarbeiteter Daten auf einen anderen Tier überflüssig. Durch die Möglichkeit, gleichzeitige Hadoop-Datenstreams zu verarbeiten, ist der EMC Isilon-Scale-out-Data-Lake gut für virtualisierte Hadoop-Workloads geeignet.
Eine Enterprise-Data-Lake-Plattform sollte gegenüber einer Standard-DAS-Konfiguration eine enorm verbesserte Hadoop-Workload-Performance bereitstellen.
Wichtiges Ergebnis: Performance von Multiprotokoll-Workloads
Fähigkeit Warum ist das wichtig?
HDFS-Lese- und Schreibperformance in einer gemeinsamen Data-Lake-Plattform
NFS-Performance während der Multiprotokollaufnahme
Eine hervorragende Performance von Hadoop-Clustern, die an einen gemeinsamen Data Lake angebunden sind, bedeutet eine deutliche Verbesserung bei Zuordnungs-/Reduzierungsvorgängen und damit effizientere Big Data-Workflows. Unternehmen profitieren von einer schnelleren Fertigstellung von Aufgaben und minimieren damit die Latenz zwischen nachfolgenden Vorgängen. Die Performance verbessert sich, da die SmartFlash-L3-Zwischenspeicherung bedeutet, dass die Lese-/Schreibperformance während der Multiprotokollaufnahme gesteigert wird.

PG 8
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Funktion/Validierung – Zusammenfassung Der EMC Isilon-Scale-out-Data-Lake ist so ausgelegt, dass ein oder mehrere gleichzeitige Komponentenausfälle möglich sind, ohne dass sich dies auf die Datenbereitstellung durch das Cluster auswirkt. Er bietet eine verteilte RAID-Technologie (Reed-Solomon-Codierung oder Spiegelung nach Bedarf). Bei einem Komponentenausfall, beispielsweise einem Festplattenausfall, stellt OneFS nur File-basierte Daten wieder her, die von dem Ausfall betroffen sind, statt das gesamte Volume wiederherzustellen. Da Metadaten und Inodes nicht nur über alle Nodes im Cluster verteilt, sondern auch durch eine Spiegelung auf Node-Level geschützt sind, führt ein Ausfall auf Festplattenebene zudem nur selten zu einer Performanceverschlechterung.
Validiert: Hohe Verfügbarkeit von Isilon OneFS (Recovery nach Ausfall auf Festplattenebene)
IDC hat validiert, dass ein Festplattenausfall auf einem einzelnen Node keine merkbare Auswirkung auf das Cluster hat. Darüber hinaus ist das Austauschen des Laufwerks ein nahtloser Prozess mit wenig Verwaltungsoverhead, der sich nicht von Enterprise-Festplattenspeichersystemen unterscheidet. Im Gegensatz dazu ist das Austauschen eines Laufwerks bei DAS ein eher komplizierter und zeitaufwendiger Vorgang.
Fortsetzung auf der nächsten Seite
4

PG 9
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Validierungsprozess Für diese Validierung wurde ein Festplattenausfall mit dem Smartfail-Dienstprogramm auf dem EMC Isilon-Scale-out-Data-Lake simuliert. Der Smartfail-Prozess wurde ausgeführt, bis alle Daten auf dem „ausgefallenen“ Laufwerk sicher zu anderen Laufwerken im Cluster migriert waren. Nach Abschluss der Smartfail-Aktion änderte sich der Laufwerkstatus in REPLACE. Nun konnte das Laufwerk sicher entfernt werden. Diese Situation ähnelt einem ausgefallenen oder physisch ersetzten Laufwerk, mit der Ausnahme, dass in diesen beiden Fällen das System automatisch prüft, ob zu wenig replizierte Blöcke vorhanden sind, und einen Ausgleich zu anderen Ersatzfestplatten auf demselben Node im Cluster durchführt. Auf ähnliche Weise wurde ein Festplattenausfall mithilfe von Standard-UNIX-Befehlen (darunter das erzwungene Unmounten der Dateisystemkonfiguration auf diesem Laufwerk auf einem der Worker Nodes) im Hadoop-DAS-Cluster simuliert.
Unter Isilon OneFS kann die Datenredundanz auf Datei- oder Dateityp-, Verzeichnis- oder Festplattenpoolebene festgelegt werden (der Standardwert ist +2,1 – d. h. es können beliebige 2 Laufwerke oder 1 Node ausfallen). Der Administrator gibt das Schutzlevel eines Clusters an (d. h. die Anzahl gleichzeitiger Ausfälle von Festplatten und/oder Nodes, die das Cluster tolerieren kann, bevor Daten verloren gehen). OneFS reagiert auf diese Einstellung mit einem entsprechenden Daten-Striping. Wenn es zu einem Hardwareausfall kommt oder der Administrator das Schutzlevel ändert, führt der FlexProtect-Job nach Bedarf einen erneuten Stripe-Aufbau aus. (Die Priorität des FlexProtect-Jobs kann außerdem nach Bedarf geändert werden.) Bei Auswahl eines niedrigen Schutzlevels wird die Kapazität gesteigert, während gleichzeitig das Risiko eines Datenverlusts steigt.
Validiert: Hohe Verfügbarkeit von Isilon OneFS (Recovery nach Ausfall auf Festplattenebene)Fortsetzung von vorheriger Seite
4
PG 10
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
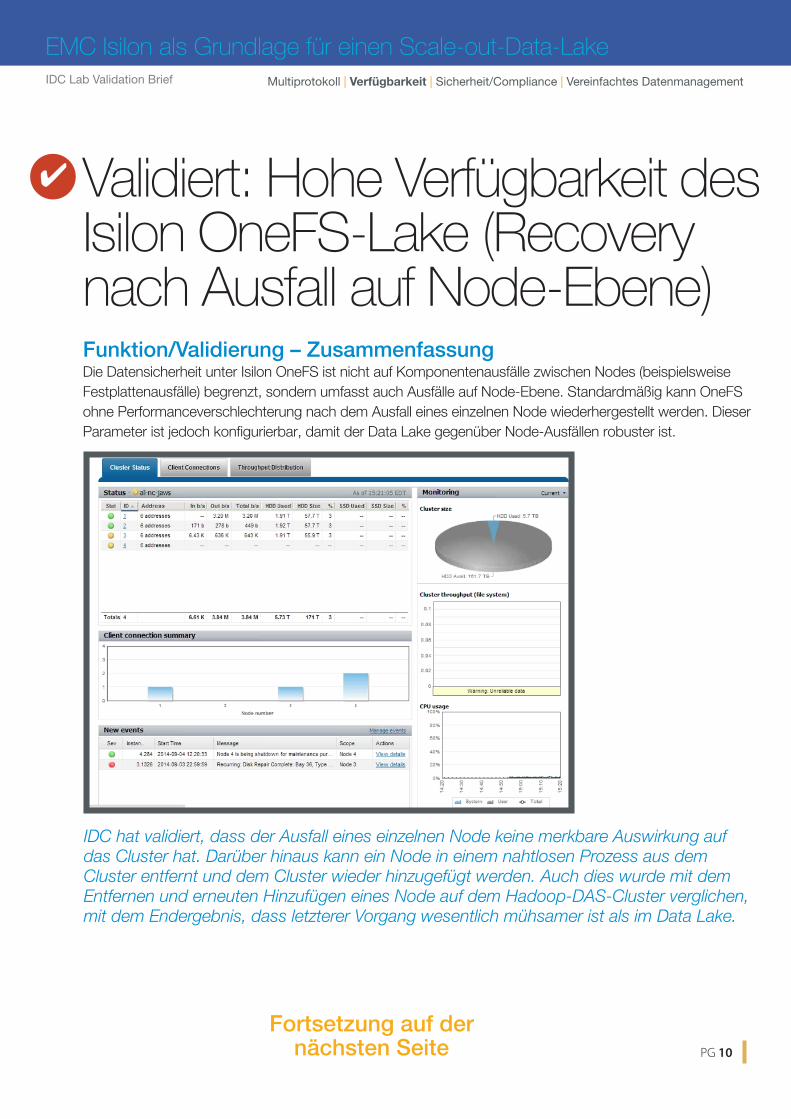
Funktion/Validierung – Zusammenfassung Die Datensicherheit unter Isilon OneFS ist nicht auf Komponentenausfälle zwischen Nodes (beispielsweise Festplattenausfälle) begrenzt, sondern umfasst auch Ausfälle auf Node-Ebene. Standardmäßig kann OneFS ohne Performanceverschlechterung nach dem Ausfall eines einzelnen Node wiederhergestellt werden. Dieser Parameter ist jedoch konfigurierbar, damit der Data Lake gegenüber Node-Ausfällen robuster ist.
Validiert: Hohe Verfügbarkeit des Isilon OneFS-Lake (Recovery nach Ausfall auf Node-Ebene)
IDC hat validiert, dass der Ausfall eines einzelnen Node keine merkbare Auswirkung auf das Cluster hat. Darüber hinaus kann ein Node in einem nahtlosen Prozess aus dem Cluster entfernt und dem Cluster wieder hinzugefügt werden. Auch dies wurde mit dem Entfernen und erneuten Hinzufügen eines Node auf dem Hadoop-DAS-Cluster verglichen, mit dem Endergebnis, dass letzterer Vorgang wesentlich mühsamer ist als im Data Lake.
Fortsetzung auf der nächsten Seite
4

PG 11
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Validierungsprozess Für diese Validierung wurde ein Node-Ausfall simuliert, indem einfach einer der fehlerfreien Nodes des EMC Isilon-Scale-out-Data-Lake heruntergefahren wurde. Nach Herunterfahren des Node beobachtete IDC, dass für die IP-Adresse des ausgefallenen Node ein Failover zu einem anderen Node erfolgte. Des Weiteren beobachtete IDC, dass OneFS standardmäßig nach dem Herunterfahren eines Node nicht den Prozess mit Replikation/Ausgleich des Clusters durchführt in der Annahme, dass ein Offline-Node eine temporäre Wartungssituation ist. Dennoch wurde der erneute Aufbau des Clusters (d. h. Replikation/Ausgleich des Clusters) durch Initiieren von Smartfail auf dem Node simuliert. Ein ähnlicher Ausfall wurde durch Ausschalten eines der Nodes auf dem Hadoop-DAS-Cluster simuliert. Im Vergleich zum EMC Isilon-Scale-out-Data-Lake benötigte das Hadoop-Cluster länger (10 Minuten, bis der Daten-Node als ausgefallen deklariert wurde). Während dieser Zeit sendete das Cluster weiterhin Jobs an den ausgefallenen Node, gab aber Fehler zurück. Nachdem der Node als „ausgefallen“ gekennzeichnet war, begann das Hadoop-Cluster automatisch, das Cluster erneut aufzubauen/auszugleichen.
In beiden Simulationen wurde der TeraSort-Job während und nach dem Node-Ausfall im Hadoop-Data-Lake und auf den Hadoop-DAS-Clustern ausgeführt (TeraGen wurde zuvor verwendet, um das Dataset für die Sortierung zu füllen). Die Ergebnisse wurden notiert und sind in der Tabelle unten zusammengefasst.
Validiert: Hohe Verfügbarkeit des Isilon OneFS-Lake (Recovery nach Ausfall auf Node-Ebene)Fortsetzung von vorheriger Seite
TeraSort (MB/Sek.) % der Baseline
Baseline (4 Isilon-Nodes) 642 100 %Während Smartfail von 1 Node 429 67 %Nach Smartfail von 1 Node 507 79 %Baseline (6 DAS-Nodes) 416 100 %Während Ausgleich von 1 Node-Ausfall 123 29 %Nach Ausgleich von 1 Node-Ausfall 356 86 %
4

PG 12
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
IDC-Schlussfolgerung Der EMC Isilon-Scale-out-Data-Lake bietet eine robuste Datenverfügbarkeit und -sicherheit im Einklang mit den meisten Unternehmensspeicherplattformen. Darüber hinaus führen Ausfälle von Komponenten und auf Node-Ebene nicht zu einer merkbaren Verschlechterung der Performance, insbesondere während und nach dem erneuten Aufbau. Die Wiederherstellung nach solchen Ausfällen erfolgt nahtlos und ressourcenfreundlich. Das steht in starkem Kontrast zu den Begrenzungen und dem Overhead eines Standard-Hadoop-Clusters, das mit handelsüblichen Komponenten aufgebaut ist.
Hinweis: IDC hat die Schutz- und Ausfallsicherheitsfunktionen des EMC Isilon-Scale-out-Data-Lake auf Standortebene nicht validiert, räumt aber ein, dass solche Funktionen für einen Data Lake essenziell sind.
Policy-basierte Hochverfügbarkeitsfunktionen sind eine Voraussetzung für die Einführung von Data Lakes in Unternehmen.
Wichtiges Ergebnis: Hohe Verfügbarkeit
Fähigkeit Hauptvorteile Warum ist das wichtig?Recovery nach Ausfall von Festplatten Recovery nach Ausfall auf Node-Ebene
Keine Unterbrechung des normalen Betriebs während des Ausfalls einer innerhalb des Node verwendeten Komponente Keine Unterbrechung des normalen Betriebs während des Ausfalls eines einzelnen Node Begrenzte Verschlechterung der Performance während des erneuten Aufbaus
Höhere operative Ausfallsicherheit des EMC Isilon-Scale-out-Data-Lake Integrierter Schutz für eine Recovery innerhalb von Sekunden bei gleichzeitiger Beibehaltung von Datenintegrität, Aufnahmefähigkeit und Zugriff

PG 13
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• Die Validierung wurde mithilfe einer lokalen Authentifizierung durchgeführt, die Zugriffszonen funktionieren
jedoch auch mit anderen Mechanismen wie NIS, LDAP und Active Directory.• Da Zugriffszonen eine Isolierung auf der Benutzerebene bieten, ist es wichtig, über eindeutige UIDs/GIDs
für jeden Benutzer in jedem Cluster zu verfügen, das isoliert werden muss. Auch die Systemzone kann zum Isolieren von Benutzern verwendet werden. Aus Konsistenz- und Symmetriegründen wurden jedoch separate Zugriffszonen für jede Isolierungsdomain erstellt.
• Der einzige legitime Mechanismus für die Freigabe von Daten zwischen 2 Zugriffszonen erfolgt über symbolische Links, die einen referenziellen Pfad zu einem freigegebenen Zielverzeichnis in einer anderen Zone als der initiierenden Zugriffszone bereitstellen.
• Dateiberechtigungen sind wichtig, um sicherzustellen, dass Benutzer aus einer anderen Zugriffszone über die entsprechenden Lese-, Schreib- und Ausführungsberechtigungen verfügen.
Funktion/Validierung – Zusammenfassung Zugriffszonen bieten eine Meth-ode zur logischen Partitionierung des Clusterzugriffs und zum Zuweisen von Ressourcen zu eigenständigen Einheiten. Sie sind ein wichtiger Teil der Mehrman-dantenfähigkeitsfunktionen von Isilon OneFS. Sie bieten logische Isolierung und einen Mechanis-mus, der das OneFS-Cluster in mehrere Authentifizierungs- und Zugriffszonen partitioniert.
Validierungsprozess Für diese Validierung wurde das Isilon-Cluster mit 2 zusätzlichen Zugriffszonen (zusätzlich zur Systemzone) konfiguriert. Jede Zugriffszone wurde mit 2 separaten Benutzerlisten (mit nicht in Konflikt stehenden UIDs/GIDs) und Datasets konfiguriert, auf die über HDFS zugegriffen werden kann. Dann wurden 2 unabhängige Hadoop-Cluster konfiguriert, um jeweils auf die einzelnen Zonen zuzugreifen. IDC hat auch die Freigabe von Daten zwischen Zugriffszonen durch die Erstellung eines Softlinks (symbolischer UNIX-Link) von einer Zugriffszone zu einer anderen validiert.
Validiert: Zugriffszonen und Zugriffskontrolllisten
IDC hat validiert, dass Zugriffszonen tatsächlich eine nicht übergehende Isolierung zwischen 2 separaten Hadoop-Clustern bereitstellen – mit unterschiedlichen (lokalen) Authentifizierungsdomains und Datasets. IDC hat außerdem die Freigabe von Daten über Zugriffszonen hinweg validiert.
4

PG 14
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
IDC-Schlussfolgerung Der EMC Isilon-Scale-out-Data-Lake bietet einen umfassenden, einheitlichen und skalierbaren Speicher für Big Data-Workloads. Er stellt außerdem einen effizienten Mechanismus für die Optimierung der Anzahl von Datenkopien bereit, indem mehrere Big Data-Workloads (Hadoop-Cluster) mit demselben Dataset betrieben werden können, während gleichzeitig Isolierungsfunktionen bereitgestellt werden, um den Zugriff zwischen logisch separaten Datasets und Benutzern einzuschränken.
Der EMC Isilon-Scale-out-Data-Lake bietet eine sichere Mehrmandantenumgebung für mehrere Big Data-Workloads (Hadoop). Das Shared-Storage-Modell bietet eine fein granulierte Kontrolle und Freigabefunktionen.
Wichtiges Ergebnis: Sichere Mehrmandantenfähigkeit
Fähigkeit Besondere Funktionen Warum ist das wichtig?
Zugriffszonen und Zugriffskontrolllisten
Zugriff durch unabhängige Hadoop-Cluster auf verschiedene Ressourcen auf demselben Isilon-Cluster (partitionierte Benutzer und Datasets)
Logische Trennung von Daten in einem freigegebenen/einheitlichen Data Lake
Selektive Freigabe von Daten zwischen 2 oder mehr Zugriffszonen, die auf referenziellen Links und Datei-/Verzeichnisberechtigungen basieren
Ein zwischen 2 oder mehreren Clustern freigegebenes Dataset

PG 15
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• Für eine große Installation wird ein Verzeichnisservice wie LDAP und Active Directory empfohlen, um
potenzielle UID/GID-Konflikte zu vermeiden und ein zentrales Sicherheits- und Identitätsmanagement bereitzustellen.
• Lokale SMB-Benutzer können Dateiberechtigungen ändern, nicht authentifizierte Benutzer können jedoch nicht geändert werden, da keine Benutzersuche in einem Verzeichnis durchgeführt werden kann.
• Zur Erhöhung der Sicherheit kann Kerberos aktiviert werden.
• Isilon unterstützt Authentifizierungsanbieter wie NIS, Active Directory und LDAP zusammen mit lokalen Konten.
Funktion/Validierung – Zusammenfassung Der EMC Isilon-Scale-out-Data-Lake stellt mehrere lokale und verzeichnisbasierte Authentifizierungs- und Autorisierungsschemata bereit. Eine Kernkomponente der sicheren Mehrmandantenfähigkeit ist die Fähigkeit, einen sicheren Authentifizierungs- und Autorisierungsmechanismus für lokale und verzeichnisbasierte Benutzer und Gruppen bereitzustellen.
ValidierungsprozessDiese Validierung ist eine Erweiterung des zuvor dargestellten Validierungsprozesses für die Mehrmandantenfähigkeit. Für diese Validierung wurden 4 separate Benutzer und Gruppen in jeder der Zugriffszonen erstellt. UIDs und GIDs wurden im EMC Isilon-Scale-out-Data-Lake zugeordnet, damit NFS ordnungsgemäß funktioniert (SMB und HDFS verwenden eine Kombination aus Benutzername und Passwort). Dann wurden Dateien vom Benutzerkonto in NFS erstellt, auf die mithilfe desselben und anderer Benutzerkonten über SMB und HDFS zugegriffen wurde. Die Schritte wurden für den Lese- und Schreibzugriff über verschiedene Protokolle wiederholt.
Validiert: Authentifizierung und Autorisierung auf Benutzerebene
IDC hat validiert, dass der EMC Isilon-Scale-out-Data-Lake eine Verbundauthentifizierung und -autorisierung auf Benutzerebene bereitstellt. Berechtigungen auf Benutzerebene werden über Protokolle wie NFS, SMB und HDFS hinweg beibehalten.
4

PG 16
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Funktion/Validierung – Zusammenfassung SmartLock ist eine wichtige Sicherheitsfunktion der OneFS-Plattform. Sie wurde speziell für die Bereitstellung sicherer und vorgabenkonformer (SEC 17a/4) Enterprise-Data-Lake-Plattformen entwickelt. SmartLock bietet die Sicherheitsabstufungen Enterprise (sicher) und Compliance (gesperrt). Die Lösung stellt 2 Betriebskomponenten bereit:
• Die Möglichkeit, den Administratorzugriff clusterweit einzuschränken
• Die Möglichkeit, WORM-Attribute (Write Once Read Many) für Dateien und Verzeichnisse zu steuern
Der SmartLock Compliance-Modus ist eine clusterweite Einstellung und bei Aktivierung dieses Modus wird das Root-Benutzerkonto gesperrt (das kann während der Erstkonfiguration eingerichtet werden). Alle Aufgaben werden nur von einem speziellen Benutzerkonto namens „Compadmin“ (Abkürzung für Complianceadministrator) durchgeführt, bei dem Befehle für Auditingzwecke protokolliert werden. Dieser Benutzer kann nur eine vorab festgelegte Liste von Befehlen, die als vorgabenkonform betrachtet werden, als privilegierter Benutzer ausführen.
Die WORM-Funktionen können in 2 Modi auf Ressourcenebene festgelegt werden. Das WORM-Flag für den Enterprise-Modus stellt eine Einstellung mit WORM-Attributen pro Verzeichnis bereit, ermöglicht dem Compadmin jedoch, Dateien zu löschen, bevor die Aufbewahrungsfrist abläuft. Wenn das WORM-Flag für den Compliancemodus festgelegt wird, können Dateien und Verzeichnisse nicht vor Ablauf der Aufbewahrungsfrist gelöscht werden. WORM-Modi sind über Protokolle hinweg vorgabenkonform und können nicht übergangen werden. Dateien können über ein beliebiges Protokoll oder lokal auf den OneFS-Cluster-Nodes eingetragen werden.
Validiert – SmartLock (SEC 17a/4-Compliance)
IDC hat sowohl den Enterprise- als auch den Compliance-Modus der OneFS-Plattform validiert. IDC hat die Einschränkungen validiert, die für den Compadmin-Benutzer gelten, wenn der clusterweite Compliancemodus festgelegt wurde. Darüber hinaus hat IDC die Enterprise- und Compliance-WORM-Modi für Hadoop-Workloads validiert.
Fortsetzung auf der nächsten Seite
4

PG 17
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• SmartLock-Flags können auf Verzeichnisebene festgelegt werden. Jedes Verzeichnis verfügt über
einen eigenen eindeutigen Satz von SmartLock-Berechtigungen.
• Die Aufbewahrung der Dateien kann auf dreierlei Weise festgelegt werden. Dateien können gesperrt werden, wenn für einen bestimmten Zeitraum nicht darauf zugegriffen wurde. Jeder Benutzer mit dem Recht zum Ändern von Berechtigungen kann gezielt alle Schreibberechtigungen entfernen. Und schließlich kann der Benutzer auch die Zugriffszeit (UNIX atime) für die Datei festlegen, um das WORM-Flag manuell auszulösen.
• Standardmäßige Aufbewahrungsfrist: Der Administrator kann angeben, wie lange die Datei gesperrt bleibt. Nach Ablauf der Aufbewahrungsfrist kann die Datei nur gelöscht werden – die Berechtigungen können nicht geändert werden.
• Für das Deaktivieren von SmartLock nach der Aktivierung muss das Cluster neu formatiert werden.
ValidierungsprozessFür diese Validierung wurde eine virtuelle Instanz des OneFS-Clusters verwendet (siehe Hinweise). Während des Initialisierungsprozesses wurde die Complianceoption ausgewählt und damit die Verwendung von Compadmin für die Durchführung aller genehmigten Aufgaben (über die sudoers-Dateien) erzwungen. Der 2. Schritt im Prozess war die Festlegung eines Compliancedatums – ein einmaliger Vorgang, der eine hardwarebasierte Complianceuhr auf den Cluster-Nodes aktiviert. Danach folgte die Erstellung eines Benutzerkontos, das zum Validieren der schreibgeschützten Berechtigungen verwendet wird. Der nächste Schritt war die Erstellung eines Verzeichnisses, für das WORM-Attribute festgelegt wurden (dafür wurde die Option „WORM Domain“ verwendet, das Flag „Compliance“ aktiviert und das Flag „default-retention“ auf 1 Tag festgelegt). Für den SmartLock-Compliancetest hat IDC validiert, dass die Datei durch Entfernen der Schreibberechtigungen für alle Benutzer gesperrt wurde. Das Festlegen der UNIX-Zugriffszeit (Zugriffszeit vor Entfernen der Schreibberechtigungen) ermöglicht jedoch eine ausdrückliche Ablaufzeit für die Schreibsperre, die in diesem Fall standardmäßig auf 1 Tag festgelegt wird. Während dieser Zeit war das Lesen (aber nicht das Schreiben) über NFS oder HDFS möglich.
Validiert – SmartLock (SEC 17a/4-Compliance)Fortsetzung von vorheriger Seite
4

PG 18
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Sicherheit im Verbund ist ein wichtiges Attribut einer Enterprise Data Lake Platform mit der Möglichkeit, die Vertraulichkeit und Integrität der Daten unabhängig von den verwendeten Protokollen beizubehalten.
Wichtiges Ergebnis: Sicherheit und Compliance
IDC-Schlussfolgerung Der EMC Isilon-Scale-out-Data-Lake bietet eine Sicherheits-Fabric im Verbund über den gesamten Data Lake. Dadurch werden in Big Data-Umgebungen GRC-Funktionen (Governance, Regulatory and Compliance) der Enterprise-Klasse bereitgestellt.
Fähigkeit Besondere Funktionen Warum ist das wichtig?
Identitätsbasierte Berechtigungen
SmartLock (SEC 17/a4-Compliance)
Zugriff im Verbund über „einen Benutzer, eine Identität“ über mehrere Protokolle hinweg (SMB, HDFS und NFS)
Logische Trennung, berechtigungsbasierte Trennung
Einschränken von Administrator/privilegiertem Benutzer in einer vorgabenkonformen Umgebung
Festlegen von WORM-Attributen für Dateien und Verzeichnisse, damit diese nicht von Hadoop-Benutzern gelöscht und/oder aktualisiert werden können
Multiprotokoll-ACLs (Access Control Lists, Zugriffskontrolllisten), die mit HDFS, NFS und SMB funktionieren Aufrechterhaltung der Sicherheit/Datenintegrität auf Dateiebene in vorgabenkonformen Umgebungen
Begrenzen der Anzahl von Befehlen, die von einem privilegierten Benutzer in einer vorgabenkonformen Umgebung ausgeführt werden können
Aufrechterhaltung der WORM-Sicherheit/-Datenintegrität auf Dateiebene in vorgabenkonformen Umgebungen

PG 19
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Hinweise:• Für Cloud Pools ist keine zusätzliche Hardware erforderlich, da es sich um eine lizenzierte Funktion
handelt.
• CloudPools und SmartPools verwenden dieselbe Policy Engine.
• Für in der Cloud gespeicherte Dateien werden lokale Stub-Dateien erstellt, sodass sie dem Benutzer als Onlinedateien angezeigt werden.
• SmartPools ist eine erforderliche Lizenz für CloudPools.
Funktion/Validierung – Zusammenfassung Isilon OneFS ermöglicht das Managen von Daten innerhalb des Clusters und erweitert dies auf die Cloud (mit OneFS 8.0). Diese als Speicherpools bekannte Funktion ermöglicht Administratoren die Anwendung allgemeiner Datei-Policies im gesamten lokalen Cluster und darüber hinaus.
Validiert: Speicherpools
Speicherpools bestehen aus drei Komponenten:
1. SmartPools – Daten-Tiering innerhalb des Clusters
2. CloudPools – Daten-Tiering zwischen Cluster und Cloud
3. Dateipool-Policies – Policy Engine für das lokale und externe Datenmanagement
SmartPools und CloudPools sind zwei Tiering Engines, während Dateipool-Policies die Policy Engine sind, die Daten zwischen den Tiers managt.
4

PG 20
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Funktion/Validierung – Zusammenfassung SmartPools vereinfacht das Datenmanagement innerhalb des Clusters, indem es das Verschieben von Dateien zwischen „performanceoptimierten“ und „kapazitätsoptimierten“ Cluster-Nodes ermöglicht. Dadurch wird der Managementoverhead deutlich reduziert, da das Verschieben über Policies automatisiert wird.
Mit CloudPools kann das Isilon-Cluster in einem Public Tier, einem Private Cloud Tier (über eine Objekt-API) oder ein Isilon-Remotecluster gespeichert werden. CloudPools unterstützt EMC ECS, Amazon S3, Azure und ein Isilon-Remotecluster (Remotezugriffs-Node).
Validiert – Speicherpools Schritt 1/2: SmartPools und CloudPools (Policy-basierte Datenplatzierung innerhalb des Isilon-Clusters und der Cloud)
4
Hinweise:• CloudPools and SmartPools verwenden dieselbe Policy Engine.
• Für in der Cloud gespeicherte Dateien werden lokale Stub-Dateien erstellt, sodass sie dem Benutzer als Onlinedateien angezeigt werden.
• Im Fall einer Public Cloud ist es essenziell wichtig, dass der Kunde in irgendeiner Weise mit einem Public-Cloud-IaaS-Anbieter wie Amazon oder Microsoft zusammenarbeitet.
• Dateien, die an einer beliebigen Stelle im Cluster abgelegt werden, werden dem Benutzer als lokale Dateien und Onlinedateien angezeigt, da sie demselben globalen Namespace angehören.
IDC hat die Implementierung von SmartPools in OneFS validiert. IDC hat zudem den Prozess der CloudPools-Erstellung validiert. Die Schritte des Prozesses waren: (1) Erstellung eines Cloudbenutzerkontos und (2) Auswahl eines logischen Containers (Erstellung eines „Cloudpools“).

PG 21
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
ValidierungsprozessDie SmartPools-Funktion ermöglicht Administratoren die Anwendung allgemeiner Datei-Policies (Dateipool-Policies) für die Verschiebung von Daten innerhalb des Clusters (über SmartPools) und zwischen Cluster und Cloud (über CloudPools).
Dateipool-Policies für die Verschiebung von Daten innerhalb des Clusters (über SmartPools) und zwischen Cluster und Cloud (über CloudPools).
Validiert – Speicherpools Schritt 2/2: Dateipool-Policies
4
Hinweise:• Dateipool-Policies werden immer auf dieselbe Weise ausgeführt, unabhängig davon, ob es sich um
SmartPool-Policies oder CloudPool-Policies handelt.
• Dateipool-Policies können auf einen Plan oder manuell über die Befehlszeile (entweder durch Ausführung der Policy oder durch Archivierung einer einzigen Datei) angewendet werden.
• Wenn eine Datei im Cloud-Tier gespeichert wird, wird eine Stub-Datei aus ihr erzeugt. Wird sie hingegen im Cluster-Tier gespeichert, wird sie innerhalb des Namespace verlagert.
• Das Tiering in oder aus einer Cloud kann granular kontrolliert werden.
IDC hat die Erstellung von Dateipool-Policies validiert – die Policy Engine, die das Daten-Tiering zwischen verschiedenen Clusterkonfigurationen und dem Cluster und der Cloud ermöglicht.

PG 22
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-LakeMultiprotokoll | Verfügbarkeit | Sicherheit/Compliance | Vereinfachtes Datenmanagement
Das vereinfachte Datenmanagement innerhalb eines Clusters und in/aus einer Cloud ist eine essenzielle Funktion einer Enterprise Data Lake Platform.
Wichtiges Ergebnis: Verein-fachtes Datenmanagement
IDC-Schlussfolgerung Der EMC Isilon-Scale-out-Data-Lake bietet ein Daten-Tiering-Schema im Verbund über den gesamten Data Lake. Mit dieser Funktion können IT-Administratoren die Infrastruktur durch Automatisierung der Datenplatzierung auf dem richtigen Tier korrekt dimensionieren.
Fähigkeit Besondere Funktionen Warum ist das wichtig?
SmartPools
CloudPools
Dateipool-Policies
Datenmanagement-Tiering innerhalb des Clusters
Datenmanagement-Tiering zwischen Cluster und Cloud
Policy Engine für das lokale Datenmanagement (innerhalb des Clusters) und das Datenmanagement zwischen Cluster und Cloud
Essenziell für das Tiering zwischen performanceoptimierten und kapazitätsoptimierten Cluster-Nodes
Essenziell für die Implementierung einer Hybrid Cloud und Platzierung von Archivdaten auf einen Low-Cost Tier (Cloud)
Essenziell für die Automatisierung der Datenverschiebung innerhalb des Clusters und der Cloud

PG 23
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-Lake
ValidierungstestsIDC hat die Validierung in den Laboren von EMC in North Carolina durchgeführt. Die Speichertestumgebung bestand aus Isilon- und Hadoop-Clustern. Die nachfolgende Tabelle enthält eine Übersicht über die Testumgebung.
Hinweise: • Alle Hadoop-Rechner-Nodes wurden auf einem vSphere-Cluster virtualisiert.
• Eine virtuelle Maschine pro physischem Server (vSphere-Host) wurde eingerichtet, um Nebeneffekte der Virtualisierung zu minimieren.
• Alle Hadoop-Nodes konnten auf interne Festplattenressourcen im physischen Server (vSphere-Host) oder über eine 10-GbE-Netzwerkverbindung auf den Data Lake zugreifen.
• VMware Big Data Extensions wurde für Hadoop-Nodes verwendet. VMware Big Data Extensions ist eine automatisierte Big Data-Provisioning- und -Managementlösung. Sie ermöglicht Administratoren die Bereitstellung und das zentrale Management von Hadoop- und HBase-Clustern.
• Master-Node-Rollen: HDFS Balancer, HDFS Secondary Name Node, Hive Gateway, Hive MetaStore Server, YARN Resource Manager, Zookeeper Server, Hive Server2.
• Isilon-Clusterkonfiguration mit eigener DNS-Zone, delegiert von dem auf einem Windows-Server ausgeführten Master.
Enterprise Data Lake Platform (EDLP)
Cluster für reinen Hadoop-Data-Lake-Rechner
Hadoop-DAS-Cluster
SMB-Zugriff
Skriptserver
Isilon X410-Cluster mit 4 Nodes
Hadoop-Cluster mit 7 Nodes
Hadoop-Cluster mit 7 Nodes
Windows 2008 R2 Server
Linux
Konfiguration jedes 4-HE-X410-Node mit Dual Intel Xeon-CPUs, 64 GB RAM, 57,7 TB Rohspeicher (Gesamtclustergröße ist 231 TB), 3,2-TB-SSD, 2 x 1GbE und 2 x 10GbE-SFP
1 Master-Node und 6 Worker Nodes (Konfiguration jedes Worker Node mit 16 Xeon-CPUs mit 2,8 GHz, 32 logischen CPUs, 64 GB RAM, 8 HDDs mit 10.000 U/min und 300 GB) mit Cloudera Hadoop-Distribution (CDH5)
1 Master-Node und 6 Worker Nodes (Konfiguration jedes Worker Node mit 16 Xeon-CPUs mit 2,8 GHz, 32 logischen CPUs, 64 GB RAM, 8 HDDs mit 10.000 U/min und 300 GB) mit Cloudera Hadoop-Distribution (CDH5)
Für Testzwecke wurden 2 integrierte 10-GbE-NICs verwendet. 2 Zugriffszonen wurden 2 Subnetzpools zugeordnet, um eine IP-basierte Isolierung bereitzustellen.
Einrichtung von Name Nodes für den Zugriff auf einen NFS-Datenspeicher. Verwendung von YARN für Benchmarktests
Einrichtung von Name Nodes für den Zugriff auf einen NFS-Datenspeicher. Verwendung von YARN für Benchmarktests
Konfiguriert mit demselben Benutzernamen wie dem von Hadoop für die Zugriffszone verwendeten Namen
Konfiguriert mit demselben Benutzernamen wie dem von Hadoop für die Zugriffszone verwendeten Namen
Funktion Komponenten Konfiguration Validierungseinzelheiten
(falls vorhanden)

PG 24
IDC Lab Validation Brief
EMC Isilon als Grundlage für einen Scale-out-Data-Lake
Ein Data Lake sollte ein Teil jedes Big Data-Workflows im Unternehmen sein. Durch die Konsolidierung von Speicher für mehrere Workloads auf einer einzigen gemeinsamen Speicherplattform können Käufer Kosten und Komplexität in ihrer Umgebung reduzieren und ihre Big Data-Lösung effizient, flexibel und skalierbar gestalten. Darüber hinaus sollte ein Data Lake nicht nur die Anforderungen an die Hadoop-Workload-Performance, sondern auch die Anforderungen anderer Workloads erfüllen, die den Data Lake als einen zuverlässigen Speicher der Enterprise-Klasse verwenden.
IDC ist der Meinung, dass EDLPs eine Kernkomponente jeder Strategie für die Unternehmensspeicherinfrastruktur sein sollten. „Während Unternehmen sich damit auseinandersetzen, wie sie Daten aus verschiedenen Quellen einander zuordnen und in nutzbare Informationsbestandteile für ihre unterschiedlichen Unternehmensbereiche umwandeln, wird es sicherlich erforderlich werden, unternehmensweite Data Lakes einzuführen, in denen verschiedene Workloads gleichzeitig ausgeführt werden können. Diese Data Lakes ermöglichen die Handhabung von bereits vorhandenen Workloads und bieten gleichzeitig eine zukunftssichere, nahtlose Unterstützung neuer Anwendungen und Workloads.“
IDC kommt zu dem Ergebnis, dass EMC Isilon die erforderlichen Attribute wie Multiprotokollzugriff, Verfügbarkeit und Sicherheit besitzt, um die Grundlage für den Aufbau eines Big Data Lake der Enterprise-Klasse für die meisten Big Data-Hadoop-Workloads bereitzustellen.
IDC-ValidierungsmethodologieDiese Übersicht (Lab Validation Brief) bietet eine Zusammenfassung eines umfassenden Validierungsprozesses, der von IDC in Zusammenarbeit mit den Teams des Anbieters durchgeführt wurde. IDC hat für die Durchführung dieser Validierung die Ausrüstung, Einrichtungen und Konfiguration des Anbieters verwendet. Alle Tests wurden in Anwesenheit mindestens eines IDC-Analysten durchgeführt.
Diese Zusammenfassung soll einen schnellen Überblick über Schlussfolgerungen und Einblicke für IT-Mitarbeiter und Entscheidungsträger in Unternehmen bereitstellen, die Funktionen des Produkts und/oder der Services sorgfältig auswerten möchten, die in dieser Zusammenfassung validiert wurden. Das Ziel dieser Zusammenfassung liegt jedoch nicht darin, detaillierte praktische Testpläne und Validierungsjobs bereitzustellen. Sie soll nicht den Evaluierungsprozess ersetzen, den die meisten Unternehmen durchführen, bevor sie eine Kaufentscheidung für das Produkt und/oder die Services treffen.
Aus diesem Grund ist diese Zusammenfassung nicht als allumfassendes Dokument zu allen Funktionen des Produkts konzipiert, sondern als ein kurz gefasstes Dokument, in dem die Funktionen/Merkmale von Produkten, ihre relative Performance im Vergleich zu einer herkömmlichen Umgebung und der Wert dieser Funktionen für Unternehmen hervorgehoben werden, die bestimmte Probleme bei Hadoop-Workloads beheben sollen.
Und schließlich ist diese Übersicht zwar ein gesponsertes Dokument, das aber nicht als IDC-Empfehlung für das Produkt, den Service oder den sponsernden Anbieter zu verstehen ist. IDC vertritt eigene Meinungen, die nicht von der Erstellung dieses Dokuments beeinflusst werden.
Wichtige Hinweise: Rat für Käufer


















