Lineare Klassifikatoren, Kernel-Maschinen · your Email address has been picked online in this...
63
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Lineare Klassifikatoren Christoph Sawade, Blaine Nelson, Tobias Scheffer
Transcript of Lineare Klassifikatoren, Kernel-Maschinen · your Email address has been picked online in this...

Universität Potsdam Institut für Informatik
Lehrstuhl Maschinelles Lernen
Lineare Klassifikatoren
Christoph Sawade, Blaine Nelson, Tobias Scheffer

Maschin
elle
s L
ern
en
Inhalt Klassifikationsproblem
Bayes‘sche Klassenentscheidung
Lineare Klassifikator, MAP-Modell
Logistische Regression
Regularisierte Empirische Risikominimierung
Perzeptron, Support Vector Machine
Ridge Regression, LASSO
Kernel
Representer Theorem
Duales Perzeptron, Duale SVM
Mercer Map
Lernen mit strukturierter Ein- und Ausgabe
Taxonomie, Sequenzen, Ranking,…
Dekoder, Schnittebenenalgorithmus
2

Maschin
elle
s L
ern
en
Voraussetzungen
Statistik
Zufallsvariablen, Verteilungen
Bayes‘ Gleichung
Lineare Algebra
Vektoren und Matrizen
Transponierte, inverse Matrizen
Eigenwerte und Eigenvektoren
Analysis
Ableitung, partielle Ableitung
Gradient
3

Maschin
elle
s L
ern
en
4
Klassifikation
Eingabe: Instanz 𝐱 ∈ 𝑋
𝑋 kann z.B. Vektorraum über Attribute sein
Instanz ist in diesem Fall Belegung der Attribute.
𝐱 =
𝑥1⋮𝑥𝑚
Merkmalsvektor
Ausgabe: Klasse 𝑦 ∈ 𝑌; endliche Menge 𝑌.
Klasse wird auch als Zielattribut bezeichnet
𝑦 heißt auch (Klassen)Label
𝐱 ⟶ Klassifikator ⟶ 𝑦

Maschin
elle
s L
ern
en
5
Klassifikation: Beispiel
Eingabe: Instanz 𝐱 ∈ 𝑋
Ausgabe: 𝑦 ∈ 𝑌 = toxisch, ok
⟶ Klassifikator ⟶
𝑋 : Menge aller möglichen Kombinationen einer
Menge von Medikamenten
Medikament 1 enthalten?
Medikament 6 enthalten?
/
0
1
1
0
1
0
Attribute
Me
dik
am
en
ten-
ko
mb
ina
tion
Instanz 𝐱

Maschin
elle
s L
ern
en
6
Klassifikation: Beispiel
Eingabe: Instanz 𝐱 ∈ 𝑋
Ausgabe: 𝑦 ∈ 𝑌 = 0,1,2,3,4,5,6,7,8,9 : erkannte Ziffer
⟶ Klassifikator ⟶
𝑋 : Menge aller 16x16 Pixel Bitmaps
Grauwert Pixel 1
Grauwert Pixel 256 2
56
Pix
elw
erte
0.1
0.3
0.45
0.65
0.87
Attribute Instanz 𝐱
"6"

Maschin
elle
s L
ern
en
7
Klassifikation: Beispiel
Eingabe: Instanz 𝐱 ∈ 𝑋
Ausgabe: 𝑦 ∈ 𝑌 = spam, ok
⟶ Klassifikator ⟶
𝑋 : Menge aller möglichen Email-Texte
Wort 1 kommt vor?
Wort m kommt vor?
Address
Beneficiary
Sterling
Friend
Science …
0
1
0
1
0
Dear Beneficiary,
your Email address has been picked online in this
years MICROSOFT CONSUMER AWARD as a
Winner of One Hundred and Fifty Five Thousand
Pounds Sterling…
Dear Beneficiary,
We are pleased to notify you that your Email address
has been picked online in this second quarter's
MICROSOFT CONSUMER AWARD (MCA) as a
Winner of One Hundred and Fifty Five Thousand
Pounds Sterling…
„Spam“
Attribute Instanz 𝐱
𝑚 ≈ 1,000,000

Maschin
elle
s L
ern
en
Klassifikationslernen
Eingabe Lernproblem:
Trainingsdaten 𝑇𝑛.
𝐗 =
𝑥11 ⋯ 𝑥1𝑚⋮ ⋱ ⋮
𝑥𝑛1 ⋯ 𝑥𝑛𝑚
𝐲 =
𝑦1⋮𝑦𝑛
Trainingsdaten:
𝑇𝑛 = 𝐱1, 𝑦1 , … , 𝐱𝑛, 𝑦𝑛
8

Maschin
elle
s L
ern
en
Klassifikationslernen
Eingabe Lernproblem:
Trainingsdaten 𝑇𝑛.
𝐗 =
𝑥11 ⋯ 𝑥1𝑚⋮ ⋱ ⋮
𝑥𝑛1 ⋯ 𝑥𝑛𝑚
𝐲 =
𝑦1⋮𝑦𝑛
Trainingsdaten:
𝑇𝑛 = 𝐱1, 𝑦1 , … , 𝐱𝑛, 𝑦𝑛
9
Ausgabe: Modell
𝑦𝜃 ∶ 𝑋 → 𝑌
zum Beispiel
𝑦𝛉 𝐱 = if 𝜙 𝐱 T𝛉 ≥ 0
𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
Linearer Klassifikator mit
Parametervektor 𝛉.

Maschin
elle
s L
ern
en
BAYES‘SCHE KLASSENENTSCHEIDUNG
10

Maschin
elle
s L
ern
en
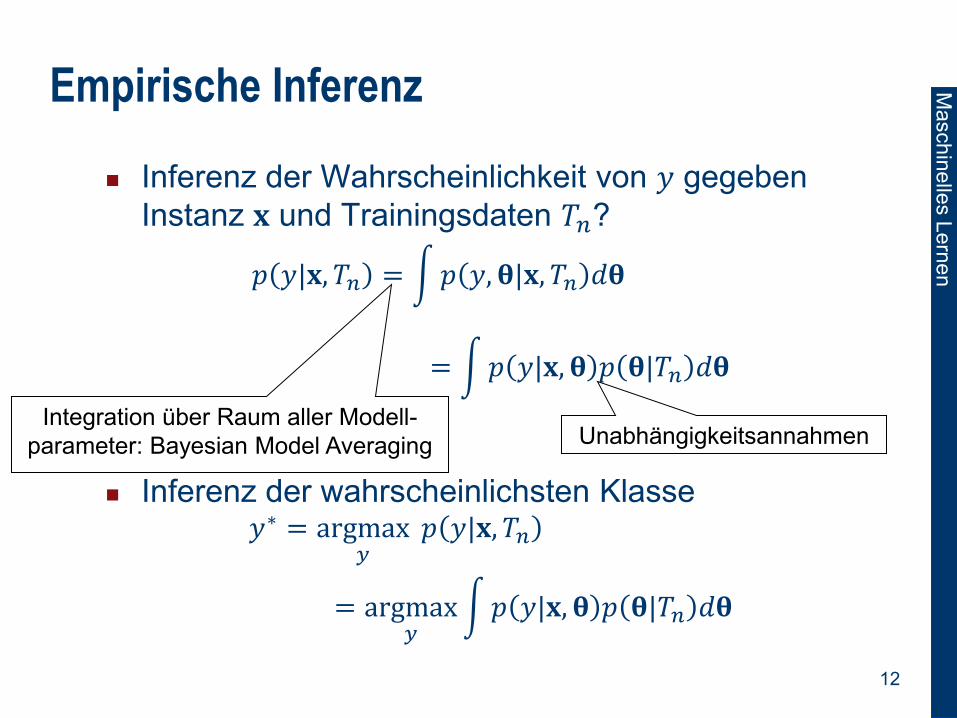
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛? 𝑝 𝑦|𝐱, 𝑇𝑛
Inferenz der wahrscheinlichsten Klasse
𝑦∗ = argmax𝑦
𝑝 𝑦|𝐱, 𝑇𝑛
Wir müssen jetzt Annahmen über den Prozess
treffen, durch den die Daten erzeugt werden, um
die wahrscheinlichste Klasse berechnen zu können.
Annahme: alle Daten sind unabhängig gegebenes
Modell 𝛉. 11
Maschin
elle
s L
ern
en
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛?
𝑝 𝑦|𝐱, 𝑇𝑛 = 𝑝 𝑦, 𝛉|𝐱, 𝑇𝑛 𝑑𝛉
= 𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
Inferenz der wahrscheinlichsten Klasse 𝑦∗ = argmax
𝑦 𝑝 𝑦|𝐱, 𝑇𝑛
= argmax𝑦
𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
12
Integration über Raum aller Modell-
parameter: Bayesian Model Averaging Unabhängigkeitsannahmen

Maschin
elle
s L
ern
en
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛?
𝑝 𝑦|𝐱, 𝑇𝑛 = 𝑝 𝑦, 𝛉|𝐱, 𝑇𝑛 𝑑𝛉
= 𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
Inferenz der wahrscheinlichsten Klasse 𝑦∗ = argmax
𝑦 𝑝 𝑦|𝐱, 𝑇𝑛
= argmax𝑦
𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
13
Klassenwahrscheinlichkeit
für x auf Grundlage von 𝛉. A-Posteriori-Wahrscheinlichkeit
(Posterior): Wahrscheinlichkeit des
Modells gegeben Trainingsdaten

Maschin
elle
s L
ern
en
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛?
𝑝 𝑦|𝐱, 𝑇𝑛 = 𝑝 𝑦, 𝛉|𝐱, 𝑇𝑛 𝑑𝛉
Keine geschlossene Lösung für Klassifikation.
Schwierig zu approximieren, da Raum aller
Parametervektoren 𝛉 zu groß ist.
14

Maschin
elle
s L
ern
en
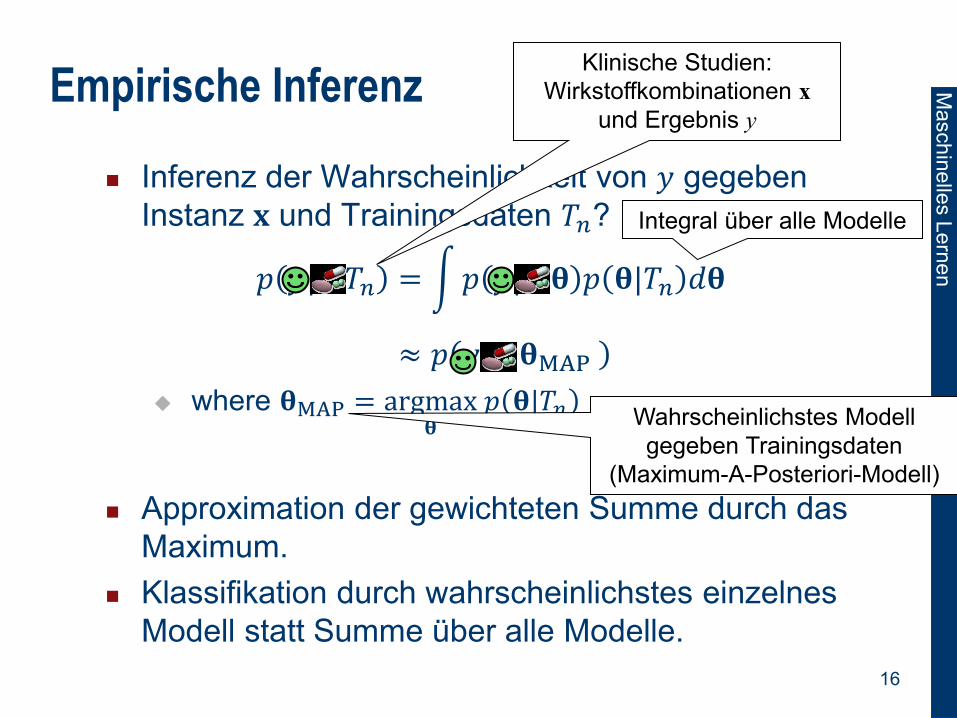
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛?
𝑝 𝑦|𝐱, 𝑇𝑛 = 𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
≈ 𝑝 𝑦|𝐱, 𝛉MAP
where 𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
Approximation der gewichteten Summe durch das
Maximum.
Klassifikation durch wahrscheinlichstes einzelnes
Modell statt Summe über alle Modelle.
15
Maschin
elle
s L
ern
en
Empirische Inferenz
Inferenz der Wahrscheinlichkeit von 𝑦 gegeben
Instanz 𝐱 und Trainingsdaten 𝑇𝑛?
𝑝 𝑦|𝐱, 𝑇𝑛 = 𝑝 𝑦|𝐱, 𝛉 𝑝 𝛉|𝑇𝑛 𝑑𝛉
≈ 𝑝 𝑦|𝐱, 𝛉MAP
where 𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
Approximation der gewichteten Summe durch das
Maximum.
Klassifikation durch wahrscheinlichstes einzelnes
Modell statt Summe über alle Modelle.
16
Klinische Studien:
Wirkstoffkombinationen x
und Ergebnis y
Integral über alle Modelle
Wahrscheinlichstes Modell
gegeben Trainingsdaten
(Maximum-A-Posteriori-Modell)

Maschin
elle
s L
ern
en
Graphisches Modell für Klassifikation
Graphisches Modell definiert
stochastischen Prozess
Bildet Modellannahme über
Erzeugung der Daten
Zuerst wird ein
Modellparameter 𝛉 gezogen
Dieses 𝛉 parametrisiert
Trainingsdaten p 𝑦𝑖|𝐱𝑖 , 𝛉
Die Verteilung der Daten 𝑝 𝐱𝑖
wird nicht weiter modelliert
17
θ
iy
nix
y
x

Maschin
elle
s L
ern
en
Beispiel
Die Evolution legt physiologische
Parameter des Menschen fest
Gegeben diese Parameter und
die Wirkstoffkombination würfelt
die Natur, ob wir die Einnahme
einer Wirkstoffkombination
überleben.
Für jede Einnahme einer
Wirkstoffkombination wird neu
nach p 𝑦𝑖|𝐱𝑖 , 𝛉 gewürfelt
18
nix
?
x

Maschin
elle
s L
ern
en
Empirische Inferenz
Berechnung von 𝛉MAP:
𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝛉,𝑇𝑛
𝑝 𝑇𝑛
19
θ
iy
nix

Maschin
elle
s L
ern
en
Empirische Inferenz
Berechnung von 𝛉MAP:
𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝛉,𝑇𝑛
𝑝 𝑇𝑛
= argmax𝛉
𝑝 𝛉 𝑝 𝐗 𝑝 𝐲 𝐗,𝛉
𝑝 𝑇𝑛
20
θ
iy
nix
(Datenmodell)

Maschin
elle
s L
ern
en
Empirische Inferenz
Berechnung von 𝛉MAP:
𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝛉,𝑇𝑛
𝑝 𝑇𝑛
= argmax𝛉
𝑝 𝛉 𝑝 𝐗 𝑝 𝐲 𝐗,𝛉
𝑝 𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
21
θ
iy
nix
(Konstante für 𝛉)

Maschin
elle
s L
ern
en
Empirische Inferenz
Berechnung von 𝑝 𝐲|𝐗, 𝛉 .
Unabhängigkeit der Trainingsdaten
(aus graphischem Modell)
𝑝 𝐲|𝐗, 𝛉 = 𝑝 𝑦𝑖|𝐱𝑖 , 𝛉
𝑛
𝑖=1
Diskriminitive Klassenwahrscheinlichkeiten
𝑝 𝑦𝑖|𝐱𝑖 , 𝛉 werden direkt durch das Modell
festgelegt.
22
θ
iy
nix

Maschin
elle
s L
ern
en
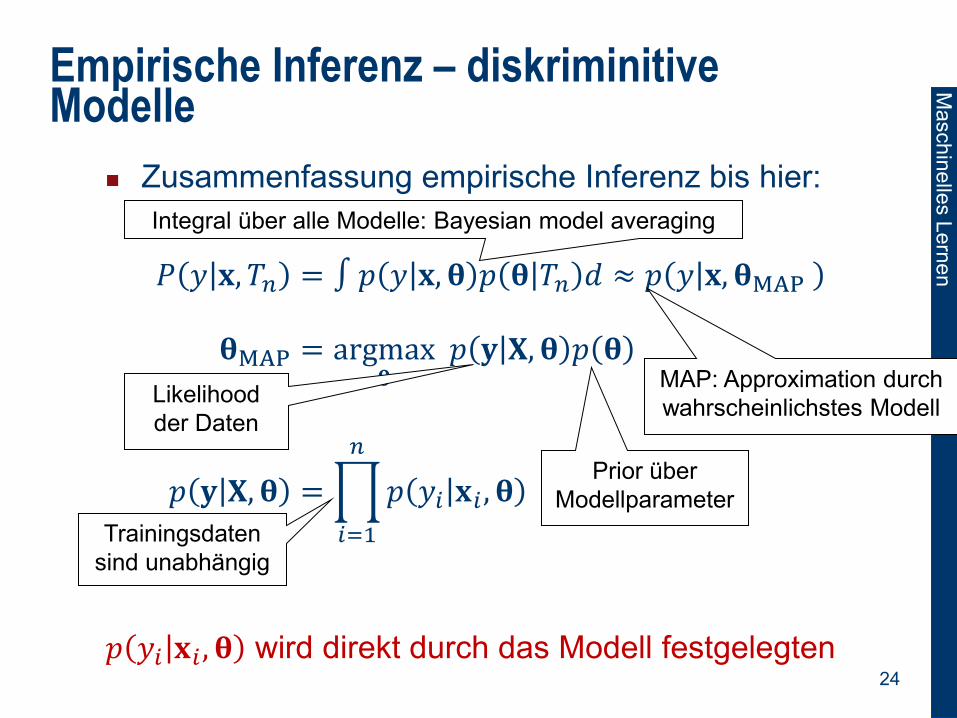
Empirische Inferenz – diskriminitive Modelle
Zusammenfassung empirische Inferenz bis hier:
𝑃 𝑦 𝐱, 𝑇𝑛 = ∫ 𝑝 𝑦 𝐱, 𝛉 𝑝 𝛉 𝑇𝑛 𝑑 ≈ 𝑝 𝑦 𝐱, 𝛉MAP
𝛉MAP = argmax𝛉
𝑝 𝐲 𝐗, 𝛉 𝑝 𝛉
𝑝 𝐲 𝐗, 𝛉 = 𝑝 𝑦𝑖 𝐱𝑖 , 𝛉
𝑛
𝑖=1
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 wird direkt durch das Modell festgelegten 23
Maschin
elle
s L
ern
en
Empirische Inferenz – diskriminitive Modelle
Zusammenfassung empirische Inferenz bis hier:
𝑃 𝑦 𝐱, 𝑇𝑛 = ∫ 𝑝 𝑦 𝐱, 𝛉 𝑝 𝛉 𝑇𝑛 𝑑 ≈ 𝑝 𝑦 𝐱, 𝛉MAP
𝛉MAP = argmax𝛉
𝑝 𝐲 𝐗, 𝛉 𝑝 𝛉
𝑝 𝐲 𝐗, 𝛉 = 𝑝 𝑦𝑖 𝐱𝑖 , 𝛉
𝑛
𝑖=1
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 wird direkt durch das Modell festgelegten 24
Integral über alle Modelle: Bayesian model averaging
MAP: Approximation durch
wahrscheinlichstes Modell Likelihood
der Daten
Prior über
Modellparameter
Trainingsdaten
sind unabhängig

Maschin
elle
s L
ern
en
DISKRIMINITIVER ANSATZ
25

Maschin
elle
s L
ern
en
Klassenwahrscheinlichkeiten: diskriminitive Modelle
Wie sollen wir 𝑝 𝑦 𝐱, 𝛉 modellieren?
Einfacher Ansatz: angenommen 𝑝 hängt von 𝐱T𝛉 ab
𝑝 𝑦 𝐱, 𝛉 = 𝑞 𝑦 𝐱T𝛉
lineares Modell:
z.B. binäre logistische Regression:
𝑝 𝑦 = +1 𝐱, 𝛉 =1
1 + exp − 𝐱T𝛉 + 𝑏
𝑝 𝑦 = −1 𝐱, 𝛉 = 1 − 𝑝 𝑦 = +1 𝐱, 𝛉 =1
1 + exp 𝐱T𝛉 + 𝑏
Später betrachten wir andere Frameworks für
lineare Modelle 26

Maschin
elle
s L
ern
en
Binäre Logistische Regression
Binäre Klassifikation: Klassen +1 und -1
𝑝 𝑦 = +1 𝐱, 𝛉 =1
1 + exp − 𝐱T𝛉 + 𝑏
Entscheidungsgrenze: 𝑝 𝑦 = +1 𝐱, 𝛉 = 𝑝 𝑦 = −1 𝐱, 𝛉 1
2=
1
1 + exp − 𝐱T𝛉 + 𝑏 ⟺ 𝐱T𝛉 + 𝑏 = 0
Punktmenge 𝐱 | 𝐱T𝛉 + 𝑏 = 0 bildet eine
Trennebene zwischen den Klassen -1 und +1.
27

Maschin
elle
s L
ern
en
28
Lineare Modelle
Hyperebene durch Normalenvektor und
Verschiebung gegeben:
𝐻𝛉 = 𝐱|𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏
Klassifikator:
𝑦 𝐱 = sign 𝑓𝛉 𝐱
Klassenwahrscheinlichkeit:
𝑃 𝑦 = +1|𝐱, 𝛉 =1
1+exp − 𝐱T𝛉+𝑏
𝐱2
𝐱1
𝑓𝛉 𝐱 > 𝟎
𝑓𝛉 𝐱 = 𝟎
𝑓𝛉 𝐱 < 𝟎
𝛉
𝑏
𝛉

Maschin
elle
s L
ern
en
29
Lineare Modelle
Hyperebene durch Normalenvektor und
Verschiebung gegeben:
𝐻𝛉 = 𝐱|𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏
Klassifikator:
𝑦 𝐱 = sign 𝑓𝛉 𝐱
Klassenwahrscheinlichkeit:
𝑃 𝑦 = +1|𝐱, 𝛉 =1
1+exp − 𝐱T𝛉+𝑏
𝑝 𝐱|𝑦 = +1,𝛉
𝑝 𝐱|𝑦 = −1,𝛉
𝑥1
𝑥2

Maschin
elle
s L
ern
en
30
Lineare Modelle
Hyperebene durch Normalenvektor und
Verschiebung gegeben:
𝐻𝛉 = 𝐱|𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏
Klassifikator:
𝑦 𝐱 = sign 𝑓𝛉 𝐱
Klassenwahrscheinlichkeit:
𝑃 𝑦 = +1|𝐱, 𝛉 =1
1+exp − 𝐱T𝛉+𝑏
𝑝 𝐱|𝑦 = −1,𝛉
𝑥1
𝑥2
𝑓𝛉 𝐱 = 𝟎

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz von 𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
Weitere Annahme: Prior normalverteilt mit
Mittelwert 0:
𝑝 𝛉 = 𝑁 𝛉; 𝟎, 𝚺
31

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter : 𝛉MAP = argmax
𝛉𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
= argmax𝛉
log 𝑝 𝐲|𝐗, 𝛉 + log 𝑝 𝛉
= argmax𝛉
log𝑝 𝑦𝑖|𝐱𝑖 , 𝛉𝑛
𝑖=1+ log𝑁 𝛉; 𝟎, 𝚺
= argmax𝛉
log1
1 + exp − 𝐱T𝛉 + 𝑏𝑦𝑖=+1
+ log1
1 + exp + 𝐱T𝛉 + 𝑏𝑦𝑖=−1+⋯
= argmax𝛉
log1
1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏
𝑛
𝑖=1+ log
𝑒−12𝛉T𝚺−1𝛉
2𝜋 𝑚 𝚺
= argmin𝛉
log 1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏 +
1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
32

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter: 𝛉MAP = argmax
𝛉𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
= argmax𝛉
log 𝑝 𝐲|𝐗, 𝛉 + log 𝑝 𝛉
= argmax𝛉
log𝑝 𝑦𝑖|𝐱𝑖 , 𝛉𝑛
𝑖=1+ log𝑁 𝛉; 𝟎, 𝚺
= argmax𝛉
log1
1 + exp − 𝐱T𝛉 + 𝑏𝑦𝑖=+1
+ log1
1 + exp + 𝐱T𝛉 + 𝑏𝑦𝑖=−1+⋯
= argmax𝛉
log1
1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏
𝑛
𝑖=1+ log
𝑒−12𝛉T𝚺−1𝛉
2𝜋 𝑚 𝚺
= argmin𝛉
log 1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏 +
1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
33

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter: 𝛉MAP = argmax
𝛉𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
= argmax𝛉
log 𝑝 𝐲|𝐗, 𝛉 + log 𝑝 𝛉
= argmax𝛉
log𝑝 𝑦𝑖|𝐱𝑖 , 𝛉𝑛
𝑖=1+ log𝑁 𝛉; 𝟎, 𝚺
= argmax𝛉
log1
1 + exp − 𝐱T𝛉 + 𝑏𝑦𝑖=+1
+ log1
1 + exp + 𝐱T𝛉 + 𝑏𝑦𝑖=−1+⋯
= argmax𝛉
log1
1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏
𝑛
𝑖=1+ log
𝑒−12𝛉T𝚺−1𝛉
2𝜋 𝑚 𝚺
= argmin𝛉
log 1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏 +
1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
34

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter: 𝛉MAP = argmax
𝛉𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
= argmax𝛉
log 𝑝 𝐲|𝐗, 𝛉 + log 𝑝 𝛉
= argmax𝛉
log𝑝 𝑦𝑖|𝐱𝑖 , 𝛉𝑛
𝑖=1+ log𝑁 𝛉; 𝟎, 𝚺
= argmax𝛉
log1
1 + exp − 𝐱T𝛉 + 𝑏𝑦𝑖=+1
+ log1
1 + exp + 𝐱T𝛉 + 𝑏𝑦𝑖=−1+⋯
= argmax𝛉
log1
1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏
𝑛
𝑖=1+ log
𝑒−12𝛉T𝚺−1𝛉
2𝜋 𝑚 𝚺
= argmin𝛉
log 1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏 +
1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
35

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter
Binäre logistische Regression: Klassen +1 und -1
𝛉MAP = argmin𝛉
log 1 + exp −𝑦𝑖 𝐱T𝛉 + 𝑏 +1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
Wie kann 𝛉MAP berechnet werden?
Fortsetzung folgt…
36
𝑦𝑖 ∈ −1, +1

Maschin
elle
s L
ern
en
FEATURE MAPPINGS
37

Maschin
elle
s L
ern
en
38
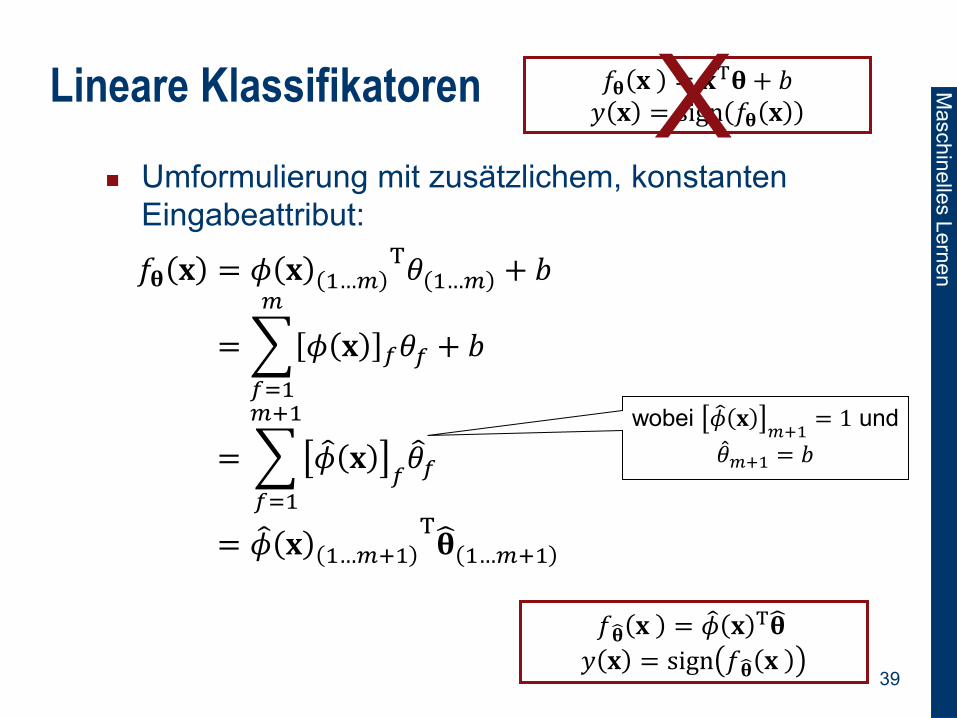
Lineare Klassifikatoren
Umformulierung mit zusätzlichem, konstanten
Eingabeattribut:
𝑓𝛉 𝐱 = 𝜙 𝐱 1…𝑚T𝜃 1…𝑚 + 𝑏
= 𝜙 𝐱 𝑓𝜃𝑓
𝑚
𝑓=1
+ 𝑏
= 𝜙 𝐱𝑓𝜃 𝑓
𝑚+1
𝑓=1
= 𝜙 𝐱 1…𝑚+1
T𝛉 1…𝑚+1
𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏
𝑦 𝐱 = sign 𝑓𝛉 𝐱
wobei 𝜙 𝐱𝑚+1
= 1 und
𝜃 𝑚+1 = 𝑏
Maschin
elle
s L
ern
en
39
Lineare Klassifikatoren
Umformulierung mit zusätzlichem, konstanten
Eingabeattribut:
𝑓𝛉 𝐱 = 𝜙 𝐱 1…𝑚T𝜃 1…𝑚 + 𝑏
= 𝜙 𝐱 𝑓𝜃𝑓
𝑚
𝑓=1
+ 𝑏
= 𝜙 𝐱𝑓𝜃 𝑓
𝑚+1
𝑓=1
= 𝜙 𝐱 1…𝑚+1
T𝛉 1…𝑚+1
wobei 𝜙 𝐱𝑚+1
= 1 und
𝜃 𝑚+1 = 𝑏
𝑓𝛉 𝐱 = 𝐱T𝛉 + 𝑏
𝑦 𝐱 = sign 𝑓𝛉 𝐱 X
𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉
𝑦 𝐱 = sign 𝑓𝛉 𝐱

Maschin
elle
s L
ern
en
Weitere Feature-Mappings
Wegen der Abstraktion 𝜙 𝐱 können wir in
allgemeineren Merkmalsräume lernen.
Wir können 𝐱 durch 𝜙 𝐱 ersetzen und danach lernen
wir 𝛉MAP gleich.
𝛉MAP = argmin𝛉
log 1 + exp −𝑦𝑖 𝜙 𝐱 T𝛉 + 𝑏 +1
2𝛉T𝚺−1𝛉
𝑛
𝑖=1
Tensorprodukt zwischen einem 𝑛- und einem 𝑚-
dimensionalen Vektor liefert einen 𝑛𝑚-
dimensionalen Vektor aller Produkte der Elemente:
𝐱⨂𝐲 =
𝑥1⋮𝑥𝑛
⨂
𝑦1⋮𝑦𝑚
=
𝑥1𝑦1⋮
𝑥1𝑦𝑚⋯
𝑥𝑛𝑦1⋮
𝑥𝑛𝑦𝑚
40

Maschin
elle
s L
ern
en
Feature Mapping
Lineares Mapping: 𝜙 𝐱𝑖 = 𝐱𝑖
Quadratisches Mapping: 𝜙 𝐱𝑖 =1𝐱𝑖
𝐱𝑖⨂𝐱𝑖
Polynomielles Mapping: 𝜙 𝐱𝑖 =
1𝐱𝑖
𝐱𝑖⨂𝐱𝑖𝐱𝑖⨂…⨂𝐱𝑖𝑝 𝑓𝑎𝑐𝑡𝑜𝑟𝑠
Häufig verwendet man auch Mappings, die keine
geschlossene Form haben, für die sich aber innere
Produkte bestimmen lassen
Z.B. RBF-Kerne, Hash-Kerne
41
Tensorprodukt

Maschin
elle
s L
ern
en
Suffiziente Statistik, Feature Mapping
Lineares Mappings:
Lineares Mapping 𝜙 𝐱𝑖 = 𝐱𝑖 ist suffiziente Statistik,
wenn 𝑝 𝐱|𝑦, 𝛉 = 𝑁 𝐱; 𝛍𝑦, 𝚺 und die
Kovarianzmatrix der Klassen gleich ist
Ein lineares Mapping 𝜙 𝐱𝑖 = 𝐱𝑖 genügt dann für die
Berechnung der Klassenwahrscheinlichkeit.
Quadratisches Mapping:
Allgemein ist eine quadratische Mapping die
suffiziente Statistik, wenn Klassen haben
unterschiedliche Kovarianzmatrizen.
42
Maschin
elle
s L
ern
en
43
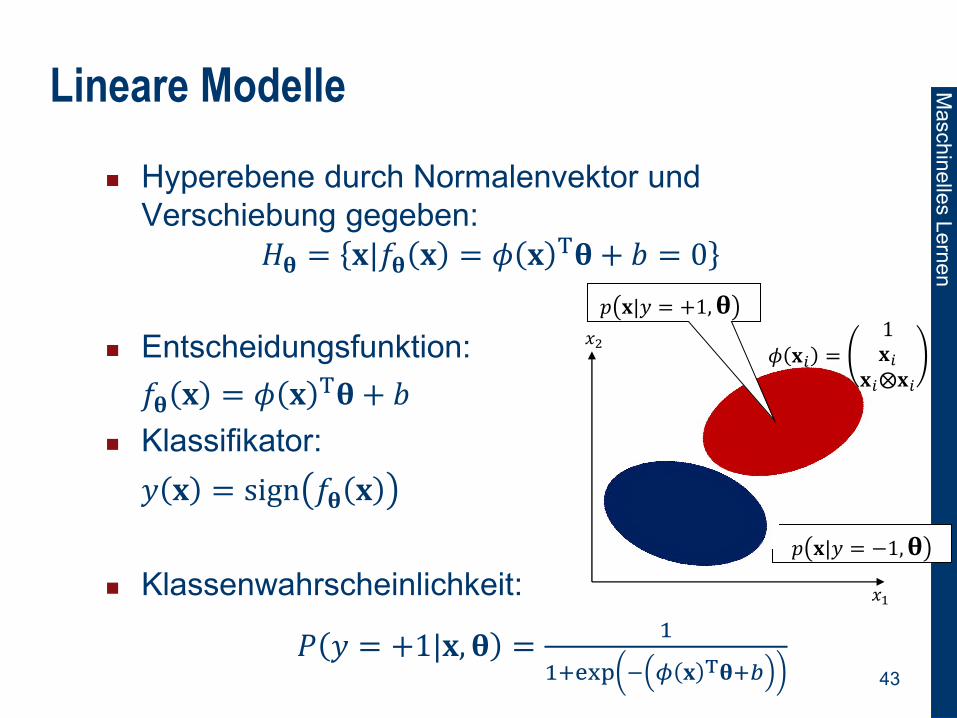
Lineare Modelle
Hyperebene durch Normalenvektor und
Verschiebung gegeben:
𝐻𝛉 = 𝐱|𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉 + 𝑏 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉 + 𝑏
Klassifikator:
𝑦 𝐱 = sign 𝑓𝛉 𝐱
Klassenwahrscheinlichkeit:
𝑃 𝑦 = +1|𝐱, 𝛉 =1
1+exp − 𝜙 𝐱 T𝛉+𝑏
𝑝 𝐱|𝑦 = −1,𝛉
𝑥1
𝑥2
𝑝 𝐱|𝑦 = +1,𝛉
𝜙 𝐱𝑖 =1𝐱𝑖
𝐱𝑖⨂𝐱𝑖

Maschin
elle
s L
ern
en
44
Lineare Modelle
Hyperebene durch Normalenvektor und
Verschiebung gegeben:
𝐻𝛉 = 𝐱|𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉 + 𝑏 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉 + 𝑏
Klassifikator:
𝑦 𝐱 = sign 𝑓𝛉 𝐱
Klassenwahrscheinlichkeit:
𝑃 𝑦 = +1|𝐱, 𝛉 =1
1+exp − 𝜙 𝐱 T𝛉+𝑏
𝑥1
𝑥2
𝑓𝛉 𝐱 = 𝟎
𝜙 𝐱𝑖 =1𝐱𝑖
𝐱𝑖⨂𝐱𝑖
𝑝 𝐱|𝑦 = −1,𝛉

Maschin
elle
s L
ern
en
MULTI-KLASSEN KLASSIFIKATION
45

Maschin
elle
s L
ern
en
Multi-Klassen Klassifikation
Motivation: wir wollen Multi-Klassen Klassifikation
mit ähnlichen Verfahren implementieren.
𝑌 = 1,… , 𝑘
Problem: Wir können nicht 𝑘 Klassen mit einer
einzigen Hyperebene trennen.
Idee: Jede Klasse 𝑦 bekommt eine eigene
Funktion 𝑓𝛉 𝐱, 𝑦 . Diese modelliert die
Wahrscheinlichkeit, dass 𝐱 das Label 𝑦 bekommt.
Jede Funktion wird linear modelliert.
Die Klasse 𝑦 mit der höchsten Bewertungsfunktion
𝑓𝛉 𝐱, 𝑦 ist unsere Wahl für 𝐱. 46

Maschin
elle
s L
ern
en
Logistische Regression
Wahrscheinlichkeit für Klasse 𝑦:
𝑝 𝑦|𝐱, 𝛉 =exp 𝜙 𝐱 T𝛉𝑦+𝑏𝑦
exp 𝜙 𝐱 T𝛉𝑧+𝑏𝑧𝑧∈𝑌
Klasse 𝑦∗ ist wahrscheinlichste Klasse wenn
𝑦∗ ∈ argmax𝑧∈𝑌
𝜙 𝐱 T𝛉𝑧 + 𝑏𝑧
Lineare (+offset) Entscheidungsfunktion
47
Exponent ist affin in
𝜙 𝐱 (linear + offset)
Nenner ist konstant bezüglich 𝑦

Maschin
elle
s L
ern
en
48
Lineare Modelle – Mehrklassenfall
Hyperebenen durch Normalenvektoren und
Verschiebung gegeben:
𝐻𝛉,𝑦 = 𝐱|𝑓𝛉 𝐱, 𝑦 = 𝜙 𝐱 T𝛉𝑦 + 𝑏𝑦 = 0
Entscheidungsfunktion:
𝑓𝛉 𝐱, 𝑦 = 𝜙 𝐱 T𝛉𝑦 + 𝑏𝑦
Klassifikator:
𝑦 𝐱 = argmax𝑧∈𝑌
𝑓𝛉 𝐱, 𝑧
Klassenwahrscheinlichkeit:
𝑃 𝑦|𝐱, 𝛉 =exp 𝜙 𝐱 T𝛉𝑦 + 𝑏𝑦
exp 𝜙 𝐱 T𝛉𝑧 + 𝑏𝑧𝑧∈𝑌
𝑓𝛉 𝐱, 𝑦1 > 𝟎
𝑓𝛉 𝐱, 𝑦3 > 𝟎
𝑓𝛉 𝐱, 𝑦2 > 𝟎
𝑥1
𝑥2
𝛉𝑦1
𝛉𝑦2
𝛉𝑦3

Maschin
elle
s L
ern
en
Logistische Regression: Lernproblem
Inferenz der MAP-Parameter: 𝛉 = 𝛉1, ⋯ , 𝛉𝑘 T
𝛉MAP = argmax𝛉
𝑝 𝛉|𝑇𝑛
= argmax𝛉
𝑝 𝐲|𝐗, 𝛉 𝑝 𝛉
= argmax𝛉
log 𝑝 𝐲|𝐗, 𝛉 + log 𝑝 𝛉
= argmax𝛉
log𝑝 𝑦𝑖|𝐱𝑖 , 𝛉𝑛
𝑖=1+ log𝑁 𝛉; 𝟎, 𝚺
= argmin𝛉
−logexp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 + 𝑏𝑦𝑖
exp 𝜙 𝐱𝑖T𝛉𝑧 + 𝑏𝑧
𝑧∈𝑌
− log𝑒−12𝛉T𝚺−1𝛉
2𝜋 𝑚 𝚺
𝑛
𝑖=1
= argmin𝛉
log Σ𝑧∈𝑌exp 𝜙 𝐱𝑖T𝛉𝑧 + 𝑏𝑧
𝑛
𝑖=1
− 𝜙 𝐱𝑖T𝛉𝑦𝑖 + 𝑏𝑦𝑖 +
𝛉T𝚺−1𝛉
2
49

Maschin
elle
s L
ern
en
Zusammenfassung – Logistische Regression
Wenn die Modellannahmen erfüllt sind:
Datengenerierungsmodell von Folie 17.
𝑝 𝛉 = 𝑁 𝛉; 𝟎, 𝚺 ; das heißt, der Verteilung normal
verteilt ist.
Dann verwenden wir
𝑃 𝑦|𝐱, 𝛉 =exp 𝜙 𝐱 T𝛉𝑦 + 𝑏𝑦
exp 𝜙 𝐱 T𝛉𝑧 + 𝑏𝑧𝑧∈𝑌
Und der Maximum-A-Posteriori-Parameter ist
𝛉MAP = argmin𝛉
log Σ𝑧∈𝑌exp 𝜙 𝐱𝑖T𝛉𝑧 + 𝑏𝑧
𝑛
𝑖=1
− 𝜙 𝐱𝑖T𝛉𝑦𝑖 + 𝑏𝑦𝑖 +
𝛉T𝚺−1𝛉
2
Wie kann 𝛉MAP berechnet werden?
Fortsetzung folgt… 50

Maschin
elle
s L
ern
en
GENERATIVER ANSATZ
51
Maschin
elle
s L
ern
en
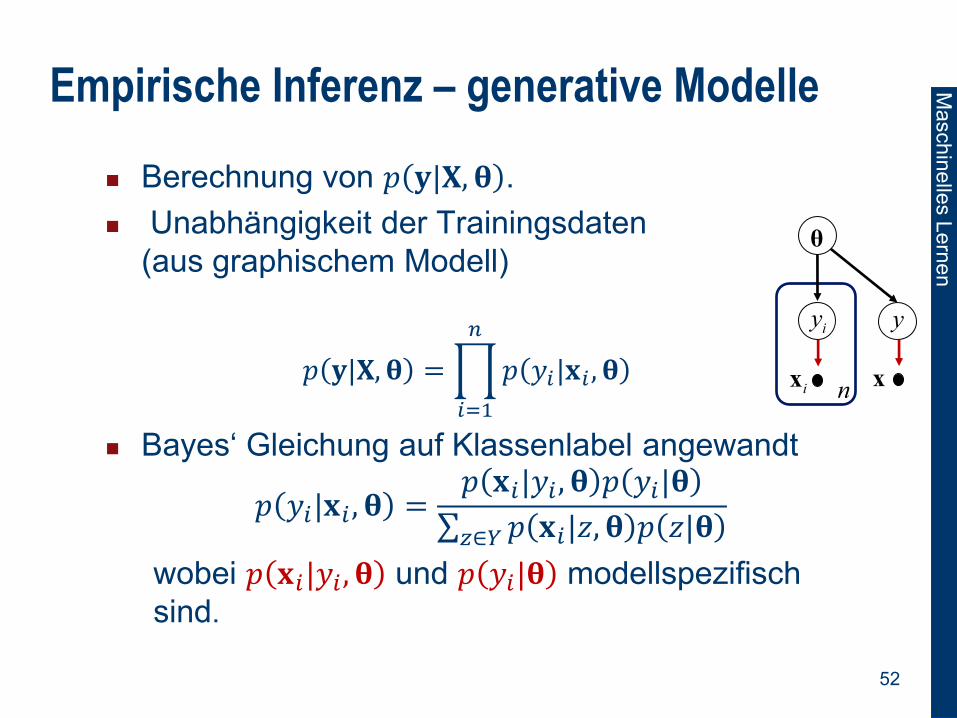
Empirische Inferenz – generative Modelle
Berechnung von 𝑝 𝐲|𝐗, 𝛉 .
Unabhängigkeit der Trainingsdaten
(aus graphischem Modell)
𝑝 𝐲|𝐗, 𝛉 = 𝑝 𝑦𝑖|𝐱𝑖 , 𝛉
𝑛
𝑖=1
Bayes‘ Gleichung auf Klassenlabel angewandt
𝑝 𝑦𝑖|𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖|𝑦𝑖 , 𝛉 𝑝 𝑦𝑖|𝛉
𝑝 𝐱𝑖|𝑧, 𝛉 𝑝 𝑧|𝛉𝑧∈𝑌
wobei 𝑝 𝐱𝑖|𝑦𝑖 , 𝛉 und 𝑝 𝑦𝑖|𝛉 modellspezifisch
sind.
52
θ
iy
nix
y
x

Maschin
elle
s L
ern
en
Exponentielle Familien
Wahrscheinlichkeit für Klassenlabel
ist Teil des Parametervektors
𝑝 𝑦|𝛉 = 𝜋𝑦
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Bei Klassen 1 … k zerfällt Parametervektor 𝛉 in
𝛉 =
𝛉1
⋮𝛉𝑘
𝜋1
⋮𝜋𝑘
53
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖 𝑦𝑖 , 𝛉 𝑝 𝑦𝑖 𝛉
𝑝 𝐱𝑖 𝑧, 𝛉 𝑝 𝑧 𝛉𝑦∈𝑌
𝛉
𝛑

Maschin
elle
s L
ern
en
Exponentielle Familien
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Abbildung 𝜙 𝐱 ist die suffiziente Statistik.
Abbildung, die alle Informationen über die zu Grunde
liegende Wahrscheinlichkeitsverteilung erhält.
Partitionierungsfunktion 1
𝑔 𝛉𝑦 normiert die
Verteilung
Base Measure ℎ 𝐱 .
Verteilung wird durch ℎ 𝐱 , 𝜙 𝐱 , 𝛉 und 𝑔
festgelegt.
Viele Verteilungen liegen in der exponentiellen
Familie. 54

Maschin
elle
s L
ern
en
Exponentielle Familien: Normalverteilung
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Beispiel: Normalverteilung
𝑁 𝐱; 𝛍, 𝚺 =1
2𝜋 𝑚 𝚺𝑒−
1
2𝐱−𝛍 T𝚺−1 𝐱−𝛍
Kann als exponentielle Familie
dargestellt werden
55 x1
x2
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
𝑁𝑥1𝑥2
;00
,0.5 0.60.6 1

Maschin
elle
s L
ern
en
Exponentielle Familien: Normalverteilung
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Beispiel: Normalverteilung
𝑁 𝐱; 𝛍, 𝚺 =1
2𝜋 𝑚 𝚺𝑒−
1
2𝐱−𝛍 T𝚺−1 𝐱−𝛍
Als exponentielle Familie:
𝜙 𝐱 =𝐱
𝐱⨂𝐱 , 𝛉 =𝚺−1𝛍
−1
2𝑣𝑒𝑐 𝚺−1
ℎ 𝐱 = 2𝜋 −𝑚/2, 𝑔 𝛉 = 𝚺 exp 𝛍T𝚺−1𝛍
56 x1
x2
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
𝑁𝑥1𝑥2
;00
,0.5 0.60.6 1

Maschin
elle
s L
ern
en
Exponentielle Familien: Normalverteilung
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Beispiel: Normalverteilung
𝑁 𝑥; 𝜇, 𝜎 =1
𝜎 2𝜋𝑒−
1
2𝜎2𝑥−𝜇 2
Als exponentielle Familie:
𝜙 𝐱 =𝑥𝑥2 , 𝛉 =
𝜇
𝜎2
−1
2𝜎2
ℎ 𝐱 = 2𝜋 −1/2, 𝑔 𝛉 = 𝜎exp𝜇2
2𝜎2
57
x
N(0,1)
-3 -2 -1 0 1 2 3-0.1
0
0.1
0.2
0.3
0.4
0,1 xN

Maschin
elle
s L
ern
en
Exponentielle Familien
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Einsetzen in
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖 𝑦𝑖 , 𝛉 𝑝 𝑦𝑖 𝛉
𝑝 𝐱𝑖 𝑧, 𝛉 𝑝 𝑧 𝛉𝑧∈𝑌
=ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 − ln𝑔 𝛉𝑦𝑖 𝜋𝑦𝑖
ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖T𝛉𝑧 − ln𝑔 𝛉𝑧 𝜋𝑧
𝑧∈𝑌
58

Maschin
elle
s L
ern
en
Exponentielle Familien
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Einsetzen in
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖 𝑦𝑖 , 𝛉 𝑝 𝑦𝑖 𝛉
𝑝 𝐱𝑖 𝑧, 𝛉 𝑝 𝑧 𝛉𝑧∈𝑌
=ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 − ln𝑔 𝛉𝑦𝑖 𝜋𝑦𝑖
ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖T𝛉𝑧 − ln𝑔 𝛉𝑧 𝜋𝑧
𝑧∈𝑌
=exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 + 𝑏𝑦𝑖
exp 𝜙 𝐱𝑖T𝛉𝑧 + 𝑏𝑧𝑧∈𝑌
59
𝛉
𝛑
𝛉 =
𝛉1
⋮𝛉𝑘
𝜋1
⋮𝜋𝑘

Maschin
elle
s L
ern
en
Exponentielle Familien
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Einsetzen in
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖 𝑦𝑖 , 𝛉 𝑝 𝑦𝑖 𝛉
𝑝 𝐱𝑖 𝑧, 𝛉 𝑝 𝑧 𝛉𝑧∈𝑌
=ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 − ln𝑔 𝛉𝑦𝑖 𝜋𝑦𝑖
ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖T𝛉𝑧 − ln𝑔 𝛉𝑧 𝜋𝑧
𝑧∈𝑌
=exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 + 𝑏𝑦𝑖
exp 𝜙 𝐱𝑖T𝛉𝑧 + 𝑏𝑧𝑧∈𝑌
60
𝑏𝑦𝑖 = ln𝜋𝑦𝑖 − ln𝑔 𝛉𝑦𝑖
𝛉 =
𝛉1
𝑏1
⋮𝛉𝑘
𝑏𝑘

Maschin
elle
s L
ern
en
Exponentielle Familien
Bedingte Wahrscheinlichkeit für 𝐱 folgt:
𝑝 𝐱|𝑦, 𝛉 = ℎ 𝐱 exp 𝜙 𝐱 T𝛉𝑦 − ln𝑔 𝛉𝑦
Einsetzen in
𝑝 𝑦𝑖 𝐱𝑖 , 𝛉 =𝑝 𝐱𝑖 𝑦𝑖 , 𝛉 𝑝 𝑦𝑖 𝛉
𝑝 𝐱𝑖 𝑧, 𝛉 𝑝 𝑧 𝛉𝑧∈𝑌
=ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖
T𝛉𝑦𝑖 − ln𝑔 𝛉𝑦𝑖 𝜋𝑦𝑖
ℎ 𝐱𝑖 exp 𝜙 𝐱𝑖T𝛉𝑧 − ln𝑔 𝛉𝑧 𝜋𝑧
𝑧∈𝑌
=exp 𝜙 𝐱𝑖
T𝛉 𝑦𝑖
exp 𝜙 𝐱𝑖T𝛉 𝑧
𝑧∈𝑌
61
𝑓𝛉 𝐱, 𝑦 = 𝜙 𝐱 T𝛉 𝑦
𝑦 𝐱 = argmax𝑧∈𝑌
𝑓𝛉 𝐱, 𝑧
𝛉 =
𝛉1
𝑏1
⋮𝛉𝑘
𝑏𝑘

Maschin
elle
s L
ern
en
Logistische Regression
Aus den Annahmen
Datengenerierungsmodell von Folie 52.
𝑝 𝐱𝑖|𝑦𝑖 , 𝛉 ist eine exponentielle Familie
ergibt sich die Form der bedingten Verteilung der
Zielvariable:
𝑝 𝑦𝑖|𝐱𝑖 , 𝛉 =exp 𝜙 𝐱𝑖
T𝛉 𝑦𝑖
exp 𝜙 𝐱𝑖T𝛉 𝑧
𝑧∈𝑌
Wir kennen die Parameter 𝛉 𝑦𝑖 nicht.
Wir werden bald die MAP- (Maximum-A-Posteriori-)
Parameter inferieren.
62

Maschin
elle
s L
ern
en
Lineare Klassifikatoren
Im Zweiklassenfall ist für lineare Klassifikatoren
die Entscheidungsfunktion: 𝑓𝛉 𝐱 = 𝜙 𝐱 T𝛉 + 𝑏
der Klassifikator: 𝑦 𝐱 = sign 𝑓𝛉 𝐱
Im Mehrklassenfall ist für lineare Klassifikatoren
die Entscheidungsfunktion: 𝑓𝛉 𝐱, 𝑦 = 𝜙 𝐱 T𝛉𝑦 + 𝑏𝑦
Der Klassifikator: 𝑦 𝐱 = argmax𝑦
𝑓𝛉 𝐱, 𝑦
Die Daten werden durch 𝜙 𝐱 in den Merkmalsraum
abgebildet.
Die Offsets 𝑏𝑦 lassen sich ans Ende des Vektors 𝛉𝑦
hängen, ans Ende von 𝜙 𝐱𝑖 wird dafür eine 1 gehängt.
Parametervektor 𝛉𝑦 ist Normalenvektor einer
Trennebene.
63