
PEΣO 12. Oktober 2001 - uni-giessen.deg31070/statistik2/bivariatVierfelderTafel.pdf ·...
21
Bivariater Zusammenhang in der Vierfeldertafel PEΣO 12. Oktober 2001
Transcript of PEΣO 12. Oktober 2001 - uni-giessen.deg31070/statistik2/bivariatVierfelderTafel.pdf ·...

Bivariater Zusammenhang in
der Vierfeldertafel
PEΣO
12. Oktober 2001

Zusammenhang zweier Variablen und bivaria-
te Haufigkeitsverteilung
• Die Bivariate Haufigkeitsverteilung gibt
Auskunft daruber, wie zwei verschiede-
ne Merkmale verteilt sind, wenn man sie
gemeinsam, d.h. in Relation zueinander
betrachtet.
• Falls ein Zusammenhang zwischen diesen
beiden Variablen besteht, muß er sich in
der bivariaten Haufigkeitsverteilung nie-
derschlagen. Aus diesem Grund untersucht
man die Haufigkeit der jeweiligen Aus-
pragungskombinationen.
1

Kreuztabelle
• Die Kreuztabelle eignet sich zur Darstel-
lung der bivariaten Verteilung zweier ka-
tegorialer Variablen.
• Die Auspragungen der einen Variablen wer-
den dabei in den Zeilen, die der anderen
Variablen in den Spalten angegeben. Man
spricht daher von Zeilen- und Spaltenva-
riablen.
• Die univariaten Verteilungen beider Va-
riablen werden hierbei hierbei am Rand
der Tabelle angegeben. Man spricht da-
her auch von der Randverteilung.
2

Haufigkeiten und Anteile in der Kreuztabelle
• absolute Haufigkeiten
• relative Haufigkeiten
bezogen auf die Gesamtfallzahl
3
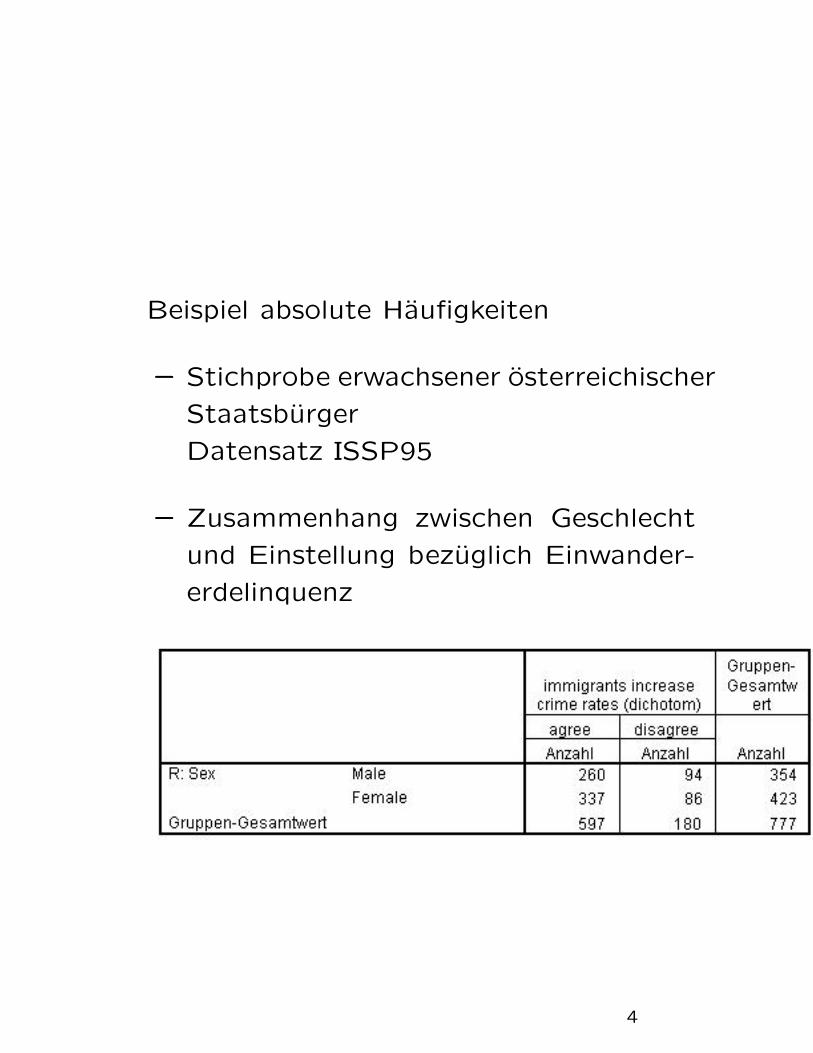
Beispiel absolute Haufigkeiten
– Stichprobe erwachsener osterreichischer
Staatsburger
Datensatz ISSP95
– Zusammenhang zwischen Geschlecht
und Einstellung bezuglich Einwander-
erdelinquenz
4

Anteile bezogen auf die Gesamtfallzahl
– Formel Zellenanteile
pij =nij
n••
– Beispiel
5

Bedingte und Unbedingte Haufigkeitsver-
teilungen
– Bis jetzt wurden nur unbedingte Haufig-
keitsverteilungen betrachtet. Beding-
te Haufigkeitsverteilungen dienen zur
Untersuchung des Einflusses der be-
dingenden Variable auf die Verteilung
der jeweils Anderen.
– Beispiel:
Auf diese Art kann man den Anteil
der Personen, welche einen Krimina-
litatsanstieg durch Einwanderer erwar-
ten uber die Geschlechter (bedingende
Variable) vergleichen.
– Man erhalt bedingte Kreuztabellen, in-
dem man nicht uber die Gesamtfall-
zahl, sondern uber die Kategoriensum-
men der Kategorien der bedingenden
Variablen prozentuiert.
6

Bedingte Haufigkeitsverteilungen
• Bedingte Anteile
bezogen auf die Spaltensummen
• Bedingte Anteile
bezogen auf die Zeilensummen
7

Bedingte Anteile
• Formel bedingte Zellenanteile(Spaltenvariable
bedingend)
pi(j) =nij
n•j=
nij/n
n•j/n=
pij
p•j
• Beispiel
8

Zusammenhangsmaße
in der Vierfeldertabelle
• Asymmetrische Zusammenhangsmaße
unterscheiden zwischen unabhangiger (be-
dingender) und abhangiger (bedingter) Va-
riable. Dies wirkt sich bei Vertauschung
dieser Variablen in veranderten Auspragun-
gen der Maße aus.
• Symmetrische Zusammenhangsmaße
treffen die obengenannte Unterscheidung
nicht.
9

Asymmetrischer Zusammenhang:
die Prozentsatzdifferenz
• Die Prozentsatzdifferenz dyx÷ ist ein Maß,
welches bei bedingten Kreuztabellen an-
gewendet wird.
Hierbei wird die Prozentsatzdifferenz (zwi-
schen den Kategorien der abhangigen Va-
riable) uber die Kategorien der unabhangi-
gen Variable verglichen.
• Formel
Prozentsatzdifferenz mit X als bedingen-
der Spaltenvariable
dyx÷ = 100∗(n11
n•1−n12
n•2) = 100∗(p1(1)−p1(2))
10
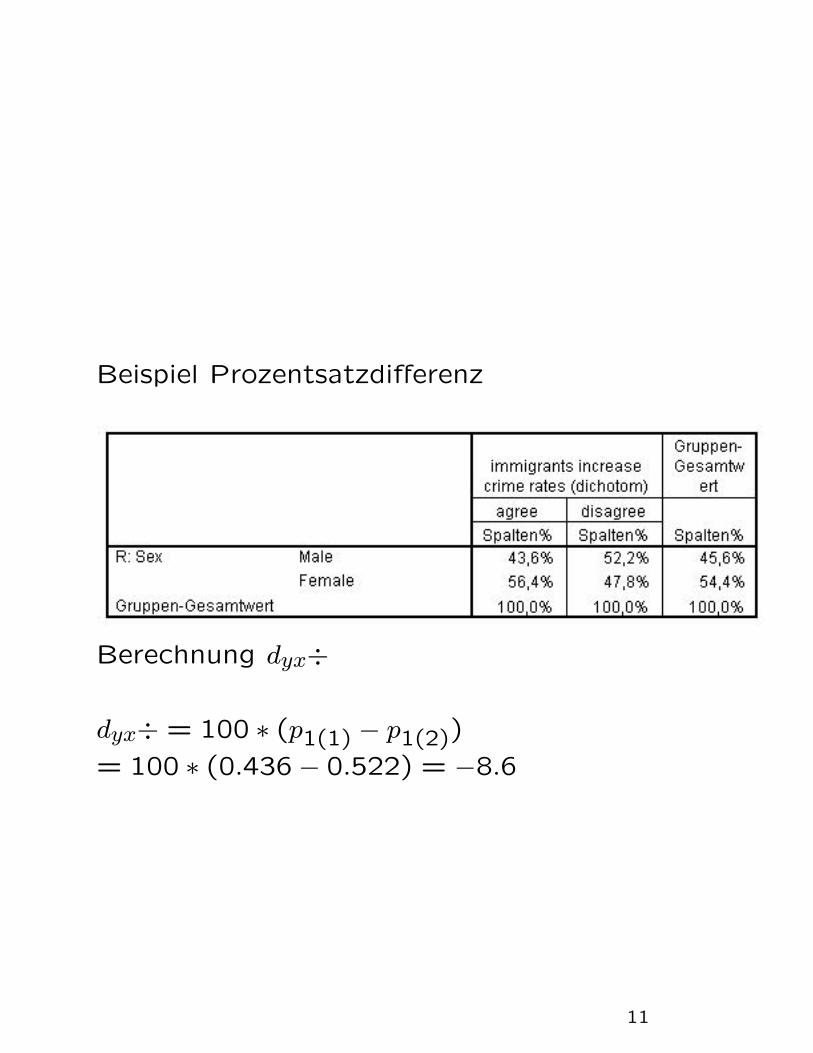
Beispiel Prozentsatzdifferenz
Berechnung dyx÷
dyx÷ = 100 ∗ (p1(1) − p1(2))
= 100 ∗ (0.436− 0.522) = −8.6
11

Hypothesenprufung der Prozentsatzdifferenz
• Als Testverteilung der Prozentsatzdiffe-
renz wird bei ausreichendem Stichprobe-
numfang (wie bei Anteilen generell) die
Normalverteilung und damit die Z-Statistik
herangezogen.
• Es lassen sich prinzipiell folgende Hypo-
thesenpaare formulieren:
H0 : δyx÷ = δhypo ÷ H1 : δyx÷ 6= δhypo ÷ (1)
H0 : δyx÷ ≤ δhypo ÷ H1 : δyx÷ > δhypo ÷ (2)
H0 : δyx÷ ≥ δhypo ÷ H1 : δyx÷ < δhypo÷ (3)
12

Berechnung der Z-Statistik fur δxy÷ bei un-
abhangigen Stichproben
• Formel
Z-Statistik fur δxy÷ aus Anteilen
Z = (p1−p2)−π√p1∗(1−p1)
n1+
p2∗(1−p2)n2
• Formel
Z-Statistik fur δxy÷ aus absoluten Haufig-
keiten (vermeidet Rundungsfehler)
Z =(
n11n11+n21
− n12n12+n22
)−δhypo÷100√
n11∗n21(n11+n21)3
+n12∗n22
(n12+n22)3
13

Berechnung der Z-Statistik fur δxy÷ bei abhangi-
gen Stichproben
• Diese Formel berechnet die Z-Statistik
fur den Test einer Populations-
Prozentsatzdifferenz von (minimal oder
maximal) null.
• Formel
Z-Statistik fur δhypo÷ = 0 bei abhangigen
Stichproben aus Anteilen
Z = p1−p2√πpooled∗(1−πpooled)∗( 1
n1+ 1
n2)
mit
πpooled = p1 ∗ n1n1+n2
+ p2 ∗ n2n1+n2
14

Beispiel Hypothesentest der Prozentsatzdif-
ferenz
• Als Beispiel verwenden wir die Prozent-
satzdifferenz von -8,6 zwischen Zustim-
mung (43.6÷;n = 597) und Ablehnung(52.2÷;n =
180) der Aussage”Einwanderer erhohen
die Kriminalitat“ bei Mannern und Frau-
en in der osterreichischen ISSP Teilstich-
probe.
• Mogliche Hypothese:
H0 : δyx÷ = 0 H1 : δyx÷ 6= 0
• Z-Statistik fur unabhangige Stichproben
Z = −0.086−0√0.436∗0.574
597 +0.522∗0.478180
= −2.32
15

• Dieser Z-Wert entspricht einem empiri-
schen Signifikanzniveau von 0.01 . Daher
muß die Nullhypothese verworfen werden.
Man kann davon ausgehen, daß eine Pro-
zentsatzdifferenz in der Population vor-
liegt.

Konfidenzintervall fur Prozentsatzdifferenzen
• Formel
Konfidenzintervall
c.i.(δyx÷) =
dyx÷±z1−α/2∗100∗√
n11∗n21(n11∗n21)3
+ n12∗n22(n12∗n22)3
• Das 95÷Konfidenzintervall fur die Bie-
spieldifferenz von −8.6÷ betragt somit:
c.i.(δyx÷) =
− 8.6± 1.96 ∗ 100 ∗√
260∗3375973 + 94∗86
1803
c.i.(δyx÷) = −8.6± 8.08
16

Statistische Unabhangigkeit
• Symmetrische Zusammenhangsmaße ba-sieren auf der Uberprufung der Statisti-schen Unabhangigkeit der Tabelle. Die-se liegt dann vor, wenn die Anteile derbedingten Verteilung gleich den Anteilender Randverteilungen sind.
• Es ist moglich, bei gegebenen Randver-teilungen die relativen Zellenhaufigkeitenpeij anzugeben, die bei statistischer Un-abhangigkeit zu erwarten waren. Dies ge-schieht uber Multiplikation der Randan-teile der jeweiligen Zelle:
pe11 = π1• ∗ π•1pe12 = π1• ∗ π•2pe21 = π2• ∗ π•1pe22 = π2• ∗ π•2
Die bei Unabhangigkeit erwarteten abso-luten Haufigkeiten eij errechnen sich durchdie Multiplikation von peij mit der Ge-samtfallzahl n.
17

Die Chiquadrat χ2 Teststatistik
• Die χ2-Statistik kann zur Uberprufung der
Statistischen Unabhangigkeit einer Tabel-
le verwendet werden. Der Hypothesen-
test, der mit Hilfe der χ2-Statistik durch-
gefuhrt wird, heißt Chiquadrattest. Je großer
dei Abweichung zwischen beobachteten
und bei Unabhangigkeit erwarteten Haufig-
keiten, desto großer χ2.
• Formel:
χ2 =∑2
i=1∑2
i=j(nij−eij)
2
eij
bzw. in der Vierfeldertabelle:
χ2 = n ∗ (n11∗n22−n12∗n21)2
n1•∗n2•∗n•1∗n•2
18

Symmetrische Zusammenhangsmaße in derVierfeldertabelle
• SymmetrischesZusammenhangsmaß Phi ΦDa der Wert von χ2 mit der Fallzahl n
variiert, ist es als Maß fur die Starke ei-nes statistischen Zusammenhangs unge-eignet. Dies korrigiert der Phi-Koeffizient,der nur zwischen -1 und 1 variieren kann.Ein Φ von null bedeutet hier keinen Zu-sammenhang, ein negatives einen umge-kehrt proportionalen und ein positives einenproportionalen Zusammenhang. bei 1 und-1 sind die Zusammenhange jeweils per-fekt.
• Formel:
φ2 = χ2
n
Φ =
√χ2
n
19


















