
Statistik III - uni-goettingen.de...II Inhaltsverzeichnis 5.1.2 Bernoulli-Verteilung, Geometrische...
224
Statistik III Walter Zucchini Fred B ¨ oker Andreas Stadie 18. April 2006
Transcript of Statistik III - uni-goettingen.de...II Inhaltsverzeichnis 5.1.2 Bernoulli-Verteilung, Geometrische...

Statistik III
Walter ZucchiniFred Boker
Andreas Stadie
18. April 2006

Inhaltsverzeichnis
1 Zufallsvariablen und ihre Verteilung 1
1.1 Diskrete Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Stetige Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Die Verteilungsfunktion einer Zufallsvariablen . . . . . . . . . . . . . . . . 6
2 Erwartungswert 12
2.1 Erwartungswert einer Zufallsvariablen . . . . . . . . . . . . . . . . . . . . 12
2.2 Erwartungswert einer Funktion einer Zufallsvariablen . . . . . . . . . . . . 17
2.3 Momente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4 Die Varianz einer Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . 20
3 Stetige Verteilungen 23
3.1 Rechteckverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 Normalverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3 Gammaverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.4 Chiquadratverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.5 Exponentialverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.6 Betaverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4 Diskrete Verteilungen 60
4.1 Bernoulli-Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.2 Binomialverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.3 Geometrische Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.4 Die negative Binomialverteilung . . . . . . . . . . . . . . . . . . . . . . . 66
4.5 Poissonverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
5 Beziehungen zwischen Verteilungen 74
5.1 Diskrete Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.1.1 Bernoulli-Verteilung, Binomialverteilung . . . . . . . . . . . . . . 74
I

II Inhaltsverzeichnis
5.1.2 Bernoulli-Verteilung, Geometrische Verteilung . . . . . . . . . . . 75
5.1.3 Bernoulli-Verteilung, Negative Binomialverteilung . . . . . . . . . 75
5.1.4 Geometrische Verteilung, Negative Binomialverteilung . . . . . . . 75
5.1.5 Binomialverteilung, Poissonverteilung . . . . . . . . . . . . . . . . 76
5.1.6 Binomialverteilung, Normalverteilung . . . . . . . . . . . . . . . . 77
5.1.7 Negative Binomialverteilung, Normalverteilung . . . . . . . . . . . 77
5.1.8 Summen poissonverteilter Zufallsvariablen . . . . . . . . . . . . . 78
5.1.9 Poissonverteilung, Normalverteilung . . . . . . . . . . . . . . . . . 78
5.2 Stetige Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.2.1 Exponentialverteilung, Gammaverteilung, Normalverteilung . . . . 79
5.2.2 Summe von gammaverteilten Zufallsvariablen . . . . . . . . . . . . 79
5.2.3 Gammaverteilung, χ2-Verteilung, Normalverteilung . . . . . . . . 80
5.2.4 Summen normalverteilter Zufallsvariablen . . . . . . . . . . . . . 80
5.2.5 Normalverteilung, χ2-Verteilung . . . . . . . . . . . . . . . . . . . 81
5.2.6 Normalverteilung, t-Verteilung . . . . . . . . . . . . . . . . . . . . 82
5.2.7 Normalverteilung, F-Verteilung . . . . . . . . . . . . . . . . . . . 85
5.2.8 Normalverteilung, Lognormalverteilung . . . . . . . . . . . . . . . 87
6 Gemeinsame Verteilung von Zufallsvariablen 90
6.1 Gemeinsame Verteilungen zweier Zufallsvariablen . . . . . . . . . . . . . 90
6.1.1 Gemeinsame Verteilung zweier diskreter Zufallsvariablen . . . . . 91
6.1.2 Gemeinsame Verteilung zweier stetiger Zufallsvariablen . . . . . . 92
6.1.3 Die gemeinsame Verteilungsfunktion . . . . . . . . . . . . . . . . 98
6.2 Gemeinsame Momente . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
6.3 Bedingte Verteilungen, Unabhangigkeit . . . . . . . . . . . . . . . . . . . 110
6.3.1 Bedingte Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . 110
6.3.2 Unabhangigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.4 Die bivariate Normalverteilung . . . . . . . . . . . . . . . . . . . . . . . . 119
7 p-dimensionale Zufallsvariablen 125
7.1 Definitionen, Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . 125
7.2 Die p-dimensionale Normalverteilung . . . . . . . . . . . . . . . . . . . . 130
7.3 Summen und Linearkombinationen von Zufallsvariablen . . . . . . . . . . 134
7.4 Weiteres zur multivariaten Normalverteilung . . . . . . . . . . . . . . . . . 136
8 Schatzung von Parametern 142
8.1 Schatzmethoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142

Inhaltsverzeichnis III
8.1.1 Die Methode der Momente . . . . . . . . . . . . . . . . . . . . . . 142
8.1.2 Die Maximum-Likelihood-Methode . . . . . . . . . . . . . . . . . 144
8.2 Einige Eigenschaften von Schatzern . . . . . . . . . . . . . . . . . . . . . 150
8.2.1 Erwartungstreue, Bias . . . . . . . . . . . . . . . . . . . . . . . . 150
8.2.2 Standardfehler . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
8.2.3 Mittlerer quadratischer Fehler . . . . . . . . . . . . . . . . . . . . 154
8.2.4 Konsistenz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
8.2.5 Effizienz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
9 Mischverteilungen 160
9.1 Diskrete Mischung diskreter Verteilungen . . . . . . . . . . . . . . . . . . 160
9.2 Diskrete Mischung stetiger Verteilungen . . . . . . . . . . . . . . . . . . . 166
9.3 Stetige Mischungen diskreter Verteilungen . . . . . . . . . . . . . . . . . . 173
9.3.1 Die Beta-Binomialverteilung . . . . . . . . . . . . . . . . . . . . . 173
9.3.2 Die negative Binomialverteilung . . . . . . . . . . . . . . . . . . . 177
9.4 ML–Schatzung bei Mischverteilungen . . . . . . . . . . . . . . . . . . . . 179
9.4.1 Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
9.4.2 Die Likelihoodfunktion fur Mischverteilungen . . . . . . . . . . . 179
9.4.3 Parameterschatzung mit C.A.MAN . . . . . . . . . . . . . . . . . 182
10 Bayes’sche Verfahren 186
10.1 Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
10.2 Das Theorem von Bayes . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
10.3 Bayes’sche Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
10.4 Bemerkungen zu konjugierten Verteilungen . . . . . . . . . . . . . . . . . 205
Literatur 208
Index 210
Formeln 216

Kapitel 1
Zufallsvariablen und ihre Verteilung
1.1 Diskrete Zufallsvariablen
Definition 1.1 Eine Zufallsvariable X heißt diskret, wenn sie nur endlich viele oderhochstens abzahlbar unendlich viele Werte annehmen kann.
Beispiel 1.1 Wir betrachten drei Situationen, die sich in den Bereichen der m oglichen Werte unter-scheiden.
a) Eine M unze wird zweimal geworfen. Sei X die Anzahl der dabei geworfenen ,,K opfe”. Diem oglichen Werte dieser Zufallsvariablen sind: 0, 1, 2.
b) Eine M unze wird so lange geworfen, bis zum ersten mal ,,Zahl” erscheint. X sei die Anzahl derbis dahin geworfenen ,,K opfe”. Die m oglichen Werte dieser Zufallsvariablen sind: 0, 1, 2, . . . .
c) Sei X die Anzahl der Autos, die eine Firma im n achsten Jahr verkauft. Die m oglichen Wertedieser Zufallsvariablen sind: 0, 1, . . . , N. (Dabei sei N die Anzahl der maximal produzierbarenAutos.)
Definition 1.2 Sei X eine diskrete Zufallsvariable. Die Funktion PX mit
PX(x) = P (X = x)
heißt die Wahrscheinlichkeitsfunktion von X .
Wir wollen die Wahrscheinlichkeitsfunktionen fur die drei Situationen aus Beispiel 1.1 be-stimmen.
Beispiel 1.1 a:
Wir gehen von der Annahme aus, dass die M unze fair ist, d.h. beide Seiten der M unze, die wir mit Kf ur ,,Kopf” und Z f ur ,,Zahl” bezeichnen, haben die gleiche Chance aufzutreffen.
M oglichkeiten: (ZZ) (ZK) (KZ) (KK)Werte von X: 0 1 1 2Wahrscheinlichkeit: 1/4 1/4 1/4 1/4
1
2 KAPITEL 1. ZUFALLSVARIABLEN UND IHRE VERTEILUNG
Fasst man gleiche Werte von X zusammen, so ergibt sich:
x P (X = x)0 1/41 1/22 1/4
Daf ur schreibt man auch
PX(x) =
1/4 x = 01/2 x = 11/4 x = 20 sonst .
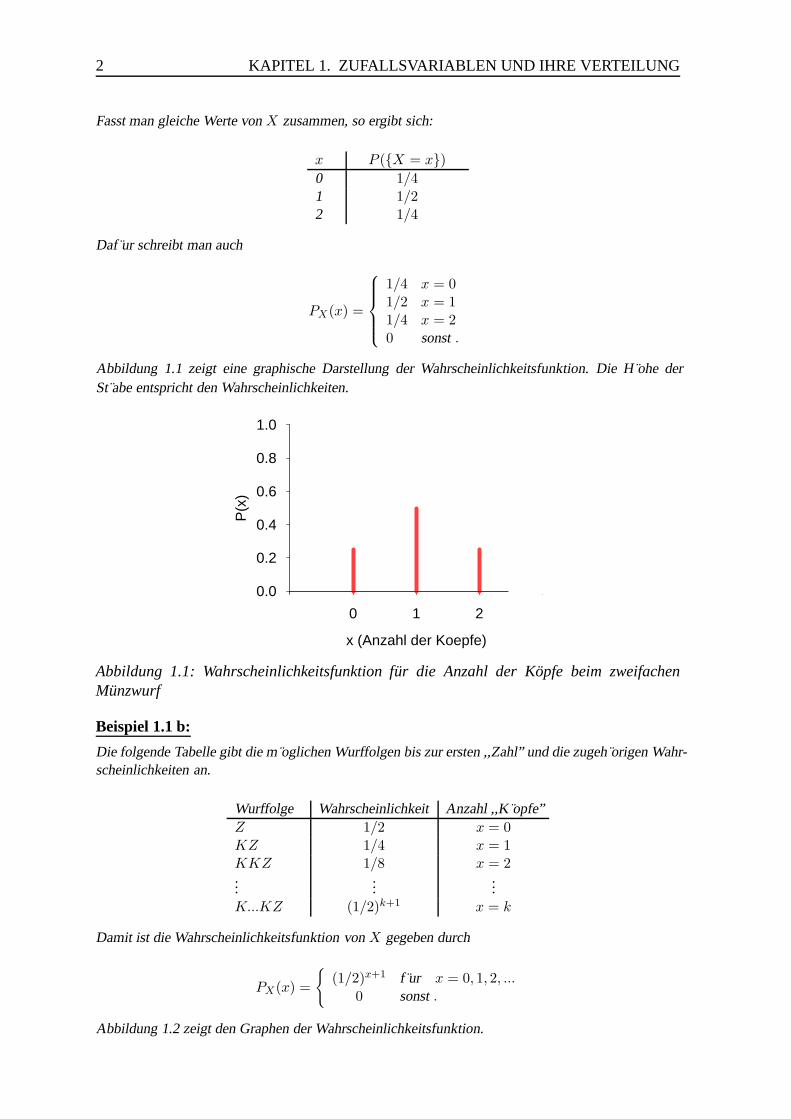
Abbildung 1.1 zeigt eine graphische Darstellung der Wahrscheinlichkeitsfunktion. Die H ohe derSt abe entspricht den Wahrscheinlichkeiten.
x (Anzahl der Koepfe)
P(x
)
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 1.1: Wahrscheinlichkeitsfunktion fur die Anzahl der Kopfe beim zweifachenMunzwurf
Beispiel 1.1 b:
Die folgende Tabelle gibt die m oglichen Wurffolgen bis zur ersten ,,Zahl” und die zugeh origen Wahr-scheinlichkeiten an.
Wurffolge Wahrscheinlichkeit Anzahl ,,K opfe”Z 1/2 x = 0KZ 1/4 x = 1KKZ 1/8 x = 2...
......
K...KZ (1/2)k+1 x = k
Damit ist die Wahrscheinlichkeitsfunktion von X gegeben durch
PX(x) =
(1/2)x+1 f ur x = 0, 1, 2, ...0 sonst .
Abbildung 1.2 zeigt den Graphen der Wahrscheinlichkeitsfunktion.

1.2. STETIGE ZUFALLSVARIABLEN 3
x (Anzahl der Koepfe vor Zahl)
P(x
)
-1 0 1 2 3 4 5 6 7 8 9 10
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 1.2: Wahrscheinlichkeitsfunktion fur die Anzahl der Kopfe vor der ersten Zahl
Beispiel 1.1 c:
In diesem Beispiel k onnen wir ohne zus atzliche Information keine Wahrscheinlichkeitsfunktion auf-stellen.
Satz 1.1 Eine Wahrscheinlichkeitsfunktion hat die Eigenschaften:
a) PX(x) ≥ 0 fur alle x ,
b) PX(x) > 0 fur hochstens abzahlbar unendlich viele x ,
c)∑
xPX(x) = 1 .
Bei diskreten Zufallsvariablen gibt es Lucken zwischen den einzelnen Werten, d.h. Werte,die die Zufallsvariable nicht annehmen kann.
1.2 Stetige Zufallsvariablen
Es gibt auch Zufallsvariablen, die im Prinzip jeden Zwischenwert annehmen konnen, z.B.
• Temperatur am Mittag
• Marktanteil
• Umsatz
Solche Zufallsvariablen heißen stetig. Man verwendet eine Dichtefunktion, um Wahrschein-lichkeiten zu beschreiben.
4 KAPITEL 1. ZUFALLSVARIABLEN UND IHRE VERTEILUNG
Definition 1.3 Die Dichtefunktion fX einer stetigen Zufallsvariablen X hat die Eigen-schaften
a) fX(x) ≥ 0 fur alle x,
b)∞∫
−∞fX(x)dx = 1,
c) P (a ≤ X ≤ b) =b∫
afX(x)dx fur alle a und b mit a ≤ b.
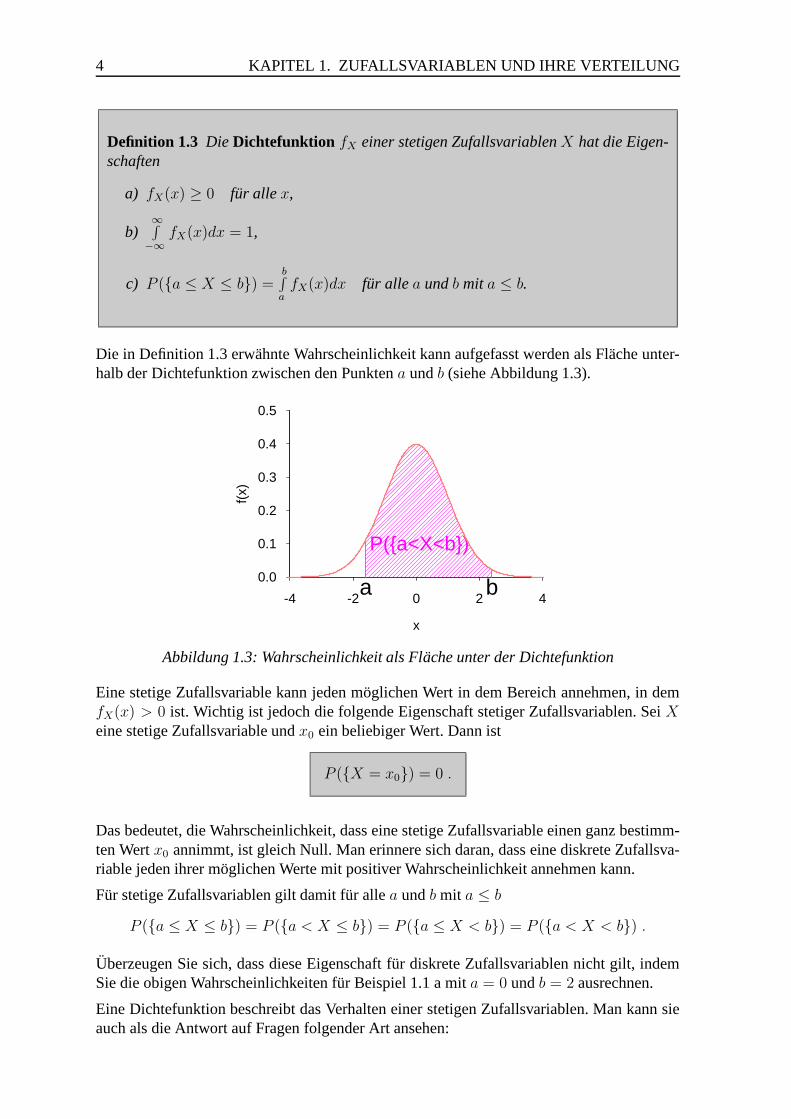
Die in Definition 1.3 erwahnte Wahrscheinlichkeit kann aufgefasst werden als Flache unter-halb der Dichtefunktion zwischen den Punkten a und b (siehe Abbildung 1.3).
x
f(x)
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
0.5
P(a<X<b)
a b
Abbildung 1.3: Wahrscheinlichkeit als Flache unter der Dichtefunktion
Eine stetige Zufallsvariable kann jeden moglichen Wert in dem Bereich annehmen, in demfX(x) > 0 ist. Wichtig ist jedoch die folgende Eigenschaft stetiger Zufallsvariablen. Sei Xeine stetige Zufallsvariable und x0 ein beliebiger Wert. Dann ist
P (X = x0) = 0 .
Das bedeutet, die Wahrscheinlichkeit, dass eine stetige Zufallsvariable einen ganz bestimm-ten Wert x0 annimmt, ist gleich Null. Man erinnere sich daran, dass eine diskrete Zufallsva-riable jeden ihrer moglichen Werte mit positiver Wahrscheinlichkeit annehmen kann.
Fur stetige Zufallsvariablen gilt damit fur alle a und b mit a ≤ b
P (a ≤ X ≤ b) = P (a < X ≤ b) = P (a ≤ X < b) = P (a < X < b) .
Uberzeugen Sie sich, dass diese Eigenschaft fur diskrete Zufallsvariablen nicht gilt, indemSie die obigen Wahrscheinlichkeiten fur Beispiel 1.1 a mit a = 0 und b = 2 ausrechnen.
Eine Dichtefunktion beschreibt das Verhalten einer stetigen Zufallsvariablen. Man kann sieauch als die Antwort auf Fragen folgender Art ansehen:
1.2. STETIGE ZUFALLSVARIABLEN 5
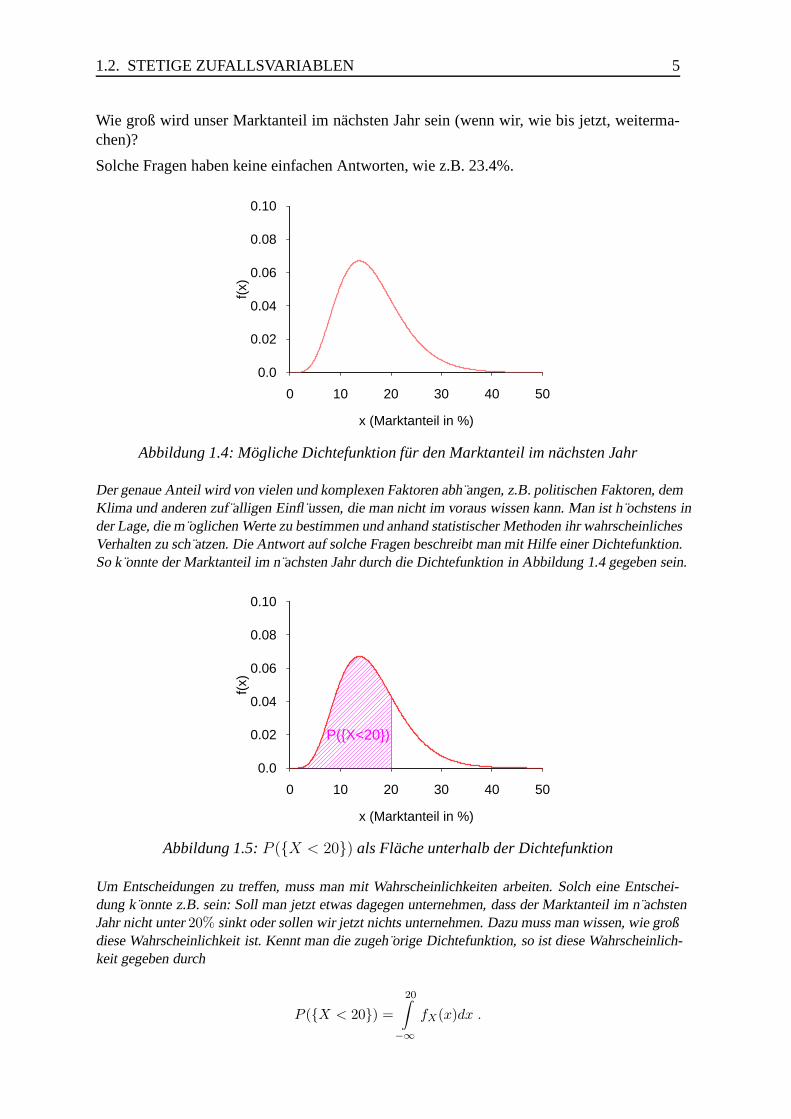
Wie groß wird unser Marktanteil im nachsten Jahr sein (wenn wir, wie bis jetzt, weiterma-chen)?
Solche Fragen haben keine einfachen Antworten, wie z.B. 23.4%.
x (Marktanteil in %)
f(x)
0 10 20 30 40 50
0.0
0.02
0.04
0.06
0.08
0.10
Abbildung 1.4: Mogliche Dichtefunktion fur den Marktanteil im nachsten Jahr
Der genaue Anteil wird von vielen und komplexen Faktoren abh angen, z.B. politischen Faktoren, demKlima und anderen zuf alligen Einfl ussen, die man nicht im voraus wissen kann. Man ist h ochstens inder Lage, die m oglichen Werte zu bestimmen und anhand statistischer Methoden ihr wahrscheinlichesVerhalten zu sch atzen. Die Antwort auf solche Fragen beschreibt man mit Hilfe einer Dichtefunktion.So k onnte der Marktanteil im n achsten Jahr durch die Dichtefunktion in Abbildung 1.4 gegeben sein.
x (Marktanteil in %)
f(x)
0 10 20 30 40 50
0.0
0.02
0.04
0.06
0.08
0.10
P(X<20)
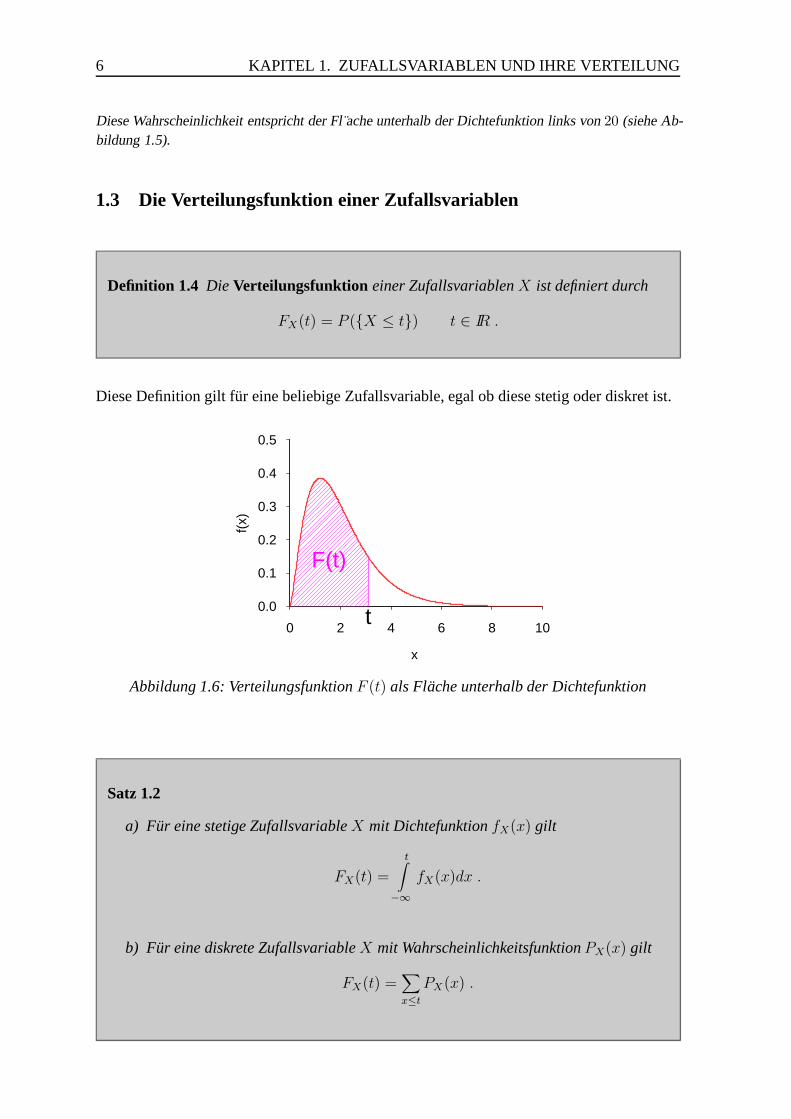
Abbildung 1.5: P (X < 20) als Flache unterhalb der Dichtefunktion
Um Entscheidungen zu treffen, muss man mit Wahrscheinlichkeiten arbeiten. Solch eine Entschei-dung k onnte z.B. sein: Soll man jetzt etwas dagegen unternehmen, dass der Marktanteil im n achstenJahr nicht unter 20% sinkt oder sollen wir jetzt nichts unternehmen. Dazu muss man wissen, wie großdiese Wahrscheinlichkeit ist. Kennt man die zugeh orige Dichtefunktion, so ist diese Wahrscheinlich-keit gegeben durch
P (X < 20) =
20∫
−∞fX(x)dx .
6 KAPITEL 1. ZUFALLSVARIABLEN UND IHRE VERTEILUNG
Diese Wahrscheinlichkeit entspricht der Fl ache unterhalb der Dichtefunktion links von 20 (siehe Ab-bildung 1.5).
1.3 Die Verteilungsfunktion einer Zufallsvariablen
Definition 1.4 Die Verteilungsfunktion einer Zufallsvariablen X ist definiert durch
FX(t) = P (X ≤ t) t ∈ IR .
Diese Definition gilt fur eine beliebige Zufallsvariable, egal ob diese stetig oder diskret ist.
x
f(x)
0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
0.5
F(t)
t
Abbildung 1.6: Verteilungsfunktion F (t) als Flache unterhalb der Dichtefunktion
Satz 1.2
a) Fur eine stetige Zufallsvariable X mit Dichtefunktion fX(x) gilt
FX(t) =
t∫
−∞fX(x)dx .
b) Fur eine diskrete Zufallsvariable X mit Wahrscheinlichkeitsfunktion PX(x) gilt
FX(t) =∑
x≤t
PX(x) .
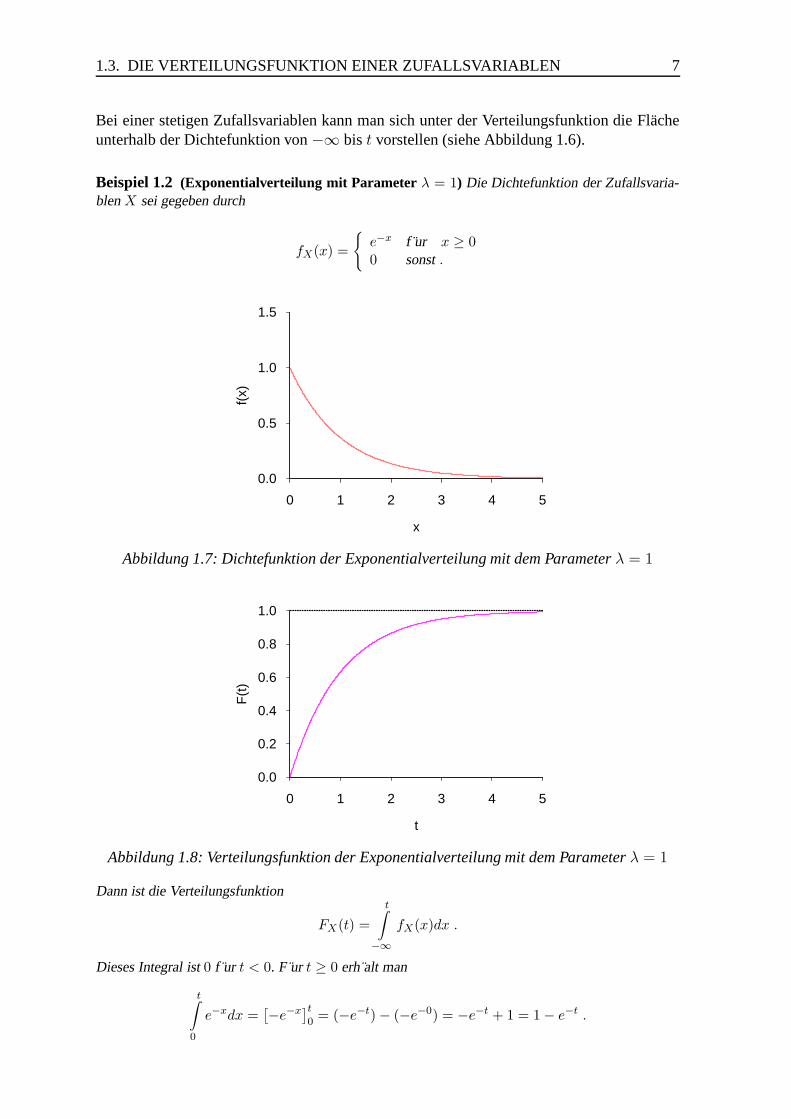
1.3. DIE VERTEILUNGSFUNKTION EINER ZUFALLSVARIABLEN 7
Bei einer stetigen Zufallsvariablen kann man sich unter der Verteilungsfunktion die Flacheunterhalb der Dichtefunktion von −∞ bis t vorstellen (siehe Abbildung 1.6).
Beispiel 1.2 (Exponentialverteilung mit Parameter λ = 1) Die Dichtefunktion der Zufallsvaria-blen X sei gegeben durch
fX(x) =
e−x f ur x ≥ 00 sonst .
x
f(x)
0 1 2 3 4 5
0.0
0.5
1.0
1.5
Abbildung 1.7: Dichtefunktion der Exponentialverteilung mit dem Parameter λ = 1
t
F(t
)
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 1.8: Verteilungsfunktion der Exponentialverteilung mit dem Parameter λ = 1
Dann ist die Verteilungsfunktion
FX(t) =
t∫
−∞fX(x)dx .
Dieses Integral ist 0 f ur t < 0. F ur t ≥ 0 erh alt man
t∫
0
e−xdx =[−e−x]t
0 = (−e−t) − (−e−0) = −e−t + 1 = 1 − e−t .
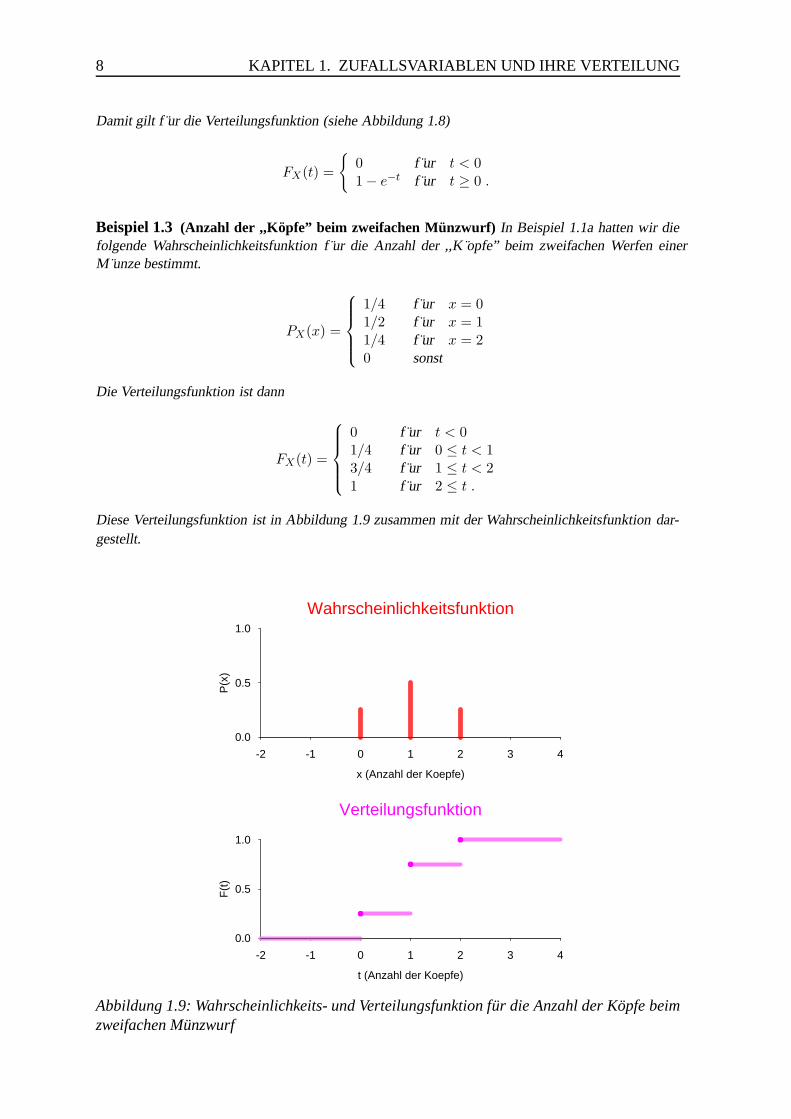
8 KAPITEL 1. ZUFALLSVARIABLEN UND IHRE VERTEILUNG
Damit gilt f ur die Verteilungsfunktion (siehe Abbildung 1.8)
FX(t) =
0 f ur t < 01 − e−t f ur t ≥ 0 .
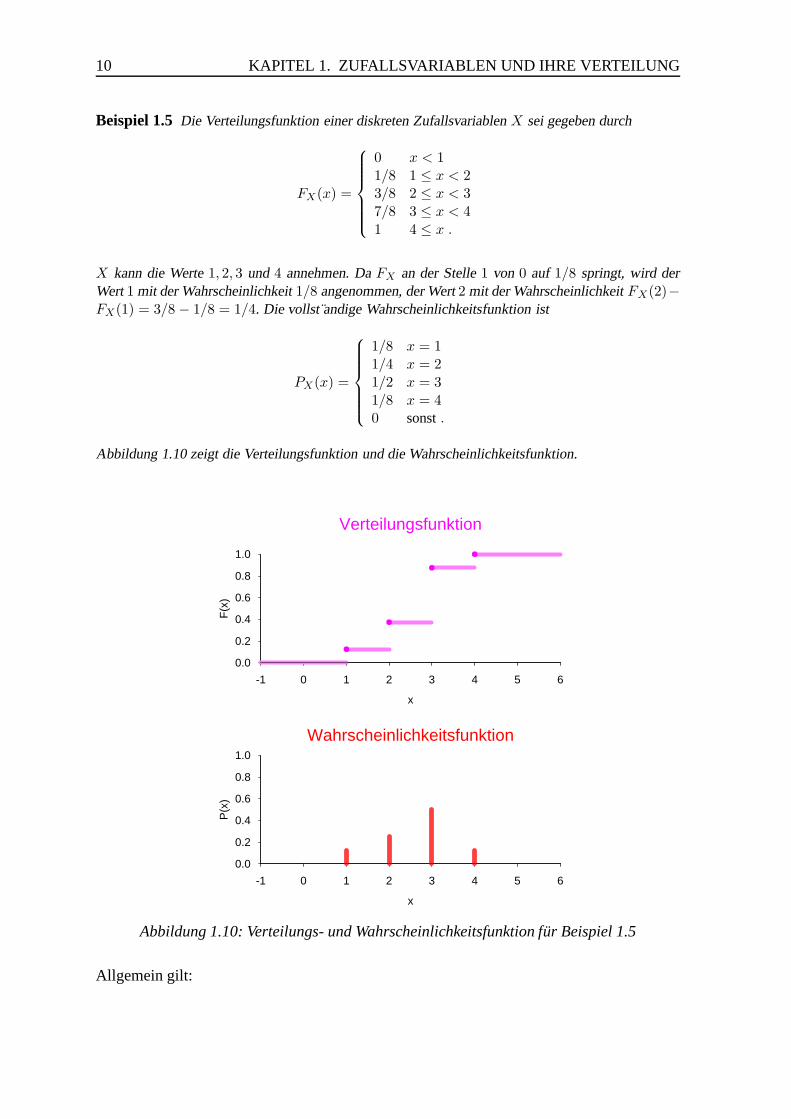
Beispiel 1.3 (Anzahl der ,,Kopfe” beim zweifachen Munzwurf) In Beispiel 1.1a hatten wir diefolgende Wahrscheinlichkeitsfunktion f ur die Anzahl der ,,K opfe” beim zweifachen Werfen einerM unze bestimmt.
PX(x) =
1/4 f ur x = 01/2 f ur x = 11/4 f ur x = 20 sonst
Die Verteilungsfunktion ist dann
FX(t) =
0 f ur t < 01/4 f ur 0 ≤ t < 13/4 f ur 1 ≤ t < 21 f ur 2 ≤ t .
Diese Verteilungsfunktion ist in Abbildung 1.9 zusammen mit der Wahrscheinlichkeitsfunktion dar-gestellt.
x (Anzahl der Koepfe)
P(x
)
-2 -1 0 1 2 3 4
0.0
0.5
1.0
Wahrscheinlichkeitsfunktion
t (Anzahl der Koepfe)
F(t
)
-2 -1 0 1 2 3 4
0.0
0.5
1.0
Verteilungsfunktion
Abbildung 1.9: Wahrscheinlichkeits- und Verteilungsfunktion fur die Anzahl der Kopfe beimzweifachen Munzwurf

1.3. DIE VERTEILUNGSFUNKTION EINER ZUFALLSVARIABLEN 9
Anschaulich ist die Verteilungsfunktion also die Summe der Hohen der Stabe bis einschließ-lich t. Beachten Sie, dass die Verteilungsfunktion an den Sprungstellen den oberen Wertannimmt. Die Verteilungsfunktion ist also stetig von rechts.
Satz 1.3 (Eigenschaften einer Verteilungsfunktion) Eine Verteilungsfunktion FX hatdie Eigenschaften:
a) 0 ≤ FX(t) ≤ 1 ,
b) FX(t1) ≤ FX(t2), falls t1 < t2 ,
c) limt→−∞
FX(t) = 0 ,
d) limt→∞
FX(t) = 1 ,
e) FX ist stetig von rechts.
Jetzt sei die Verteilungsfunktion einer Zufallsvariablen X gegeben, und wir wollen die Dichte-oder Wahrscheinlichkeitsfunktion von X bestimmen.
Satz 1.4 Sei X eine stetige Zufallsvariable mit der Verteilungsfunktion FX . Dann ist dieDichtefunktion von X gegeben durch
fX(x) = F ′X(x) .
Beispiel 1.4 (Exponentialverteilung mit dem Parameter λ = 1) Die Verteilungsfunktion einerstetigen Zufallsvariablen sei (vergleiche Beispiel 1.2)
FX(x) =
0 f ur x ≤ 01 − e−x f ur x > 0 .
Dann gilt
fX(x) =dFX (x)
dx=
0 f ur x ≤ 00 − (−e−x) = e−x f ur x > 0 .
Fur diskrete Zufallsvariablen erhalt man die Wahrscheinlichkeitsfunktion, indem man an denSprungstellen der Verteilungsfunktion die Differenz berechnet.
10 KAPITEL 1. ZUFALLSVARIABLEN UND IHRE VERTEILUNG
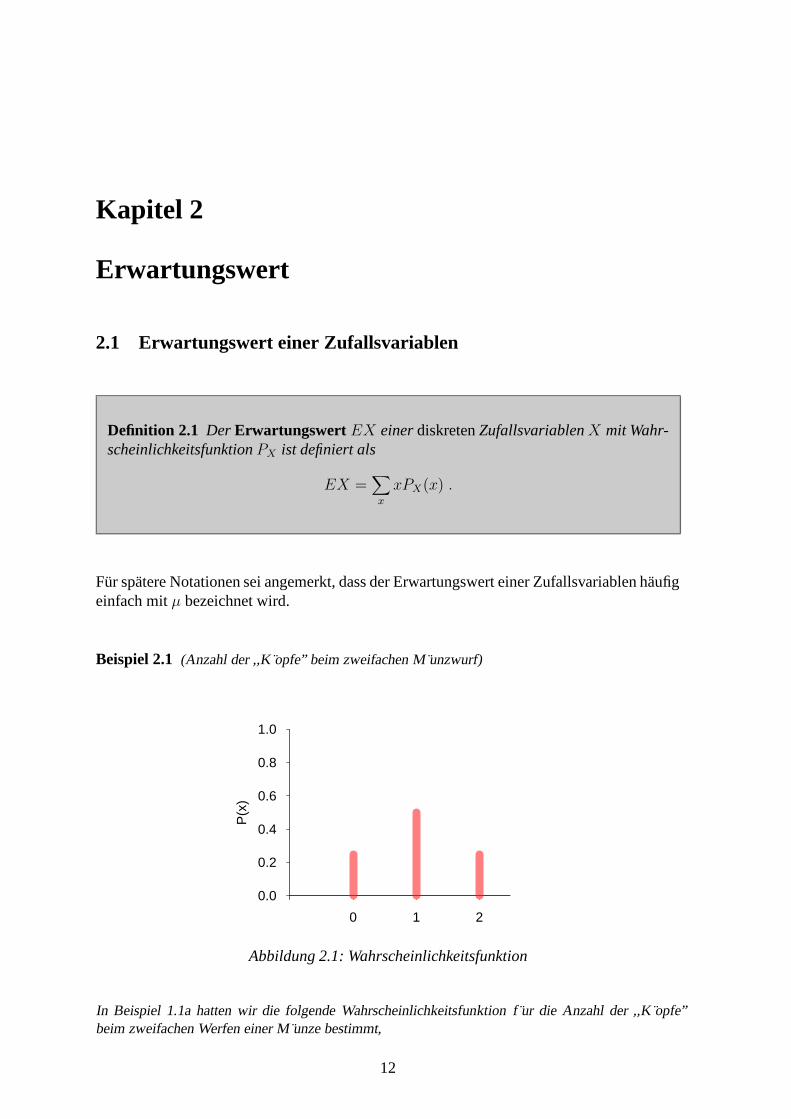
Beispiel 1.5 Die Verteilungsfunktion einer diskreten Zufallsvariablen X sei gegeben durch
FX(x) =
0 x < 11/8 1 ≤ x < 23/8 2 ≤ x < 37/8 3 ≤ x < 41 4 ≤ x .
X kann die Werte 1, 2, 3 und 4 annehmen. Da FX an der Stelle 1 von 0 auf 1/8 springt, wird derWert 1 mit der Wahrscheinlichkeit 1/8 angenommen, der Wert 2 mit der Wahrscheinlichkeit FX(2)−FX(1) = 3/8 − 1/8 = 1/4. Die vollst andige Wahrscheinlichkeitsfunktion ist
PX(x) =
1/8 x = 11/4 x = 21/2 x = 31/8 x = 40 sonst .
Abbildung 1.10 zeigt die Verteilungsfunktion und die Wahrscheinlichkeitsfunktion.
x
F(x
)
-1 0 1 2 3 4 5 6
0.0
0.2
0.4
0.6
0.8
1.0
Verteilungsfunktion
x
P(x
)
-1 0 1 2 3 4 5 6
0.0
0.2
0.4
0.6
0.8
1.0
Wahrscheinlichkeitsfunktion
Abbildung 1.10: Verteilungs- und Wahrscheinlichkeitsfunktion fur Beispiel 1.5
Allgemein gilt:

1.3. DIE VERTEILUNGSFUNKTION EINER ZUFALLSVARIABLEN 11
Satz 1.5 Sei X eine diskrete Zufallsvariable mit der Verteilungsfunktion FX . Dann istdie Wahrscheinlichkeitsfunktion von X gegeben durch
PX(x) = FX(x) − limh→0h>0
FX(x − h) .
Mit Hilfe der Verteilungsfunktion ist es besonders einfach, Wahrscheinlichkeiten auszurech-nen, dass eine Zufallsvariable Werte in einem Intervall (a, b] annimmt. Denn es gilt:
Satz 1.6 Sei X eine Zufallsvariable mit der Verteilungsfunktion FX . Dann gilt
P (a < X ≤ b) = FX(b) − FX(a) . (1.1)
Dieser Satz gilt sowohl fur stetige als auch fur diskrete Zufallsvariablen. Wie wir schongesehen haben (siehe S. 4), kommt es bei stetigen Zufallsvariablen nicht darauf an, ob es inder Gleichung (1.1) < oder ≤ heißt. Fur diskrete Zufallsvariablen gilt dieser Satz jedoch nurin dieser Form, wenn a und b mogliche Werte der Zufallsvariablen sind!
Beispiel 1.6 (Exponentialverteilung mit dem Parameter λ = 1) Die Verteilungsfunktion einerstetigen Zufallsvariablen sei (vergleiche Beispiel 1.2 und 1.4)
FX(x) =
0 f ur x ≤ 01 − e−x f ur x > 0 .
Dann gilt
P (1 < X ≤ 2) = FX(2) − FX(1) = (1 − e−2) − (1 − e−1)
= e−1 − e−2 = 0.3679 − 0.1353 = 0.2326 .
Beispiel 1.7 Die Zufallsvariable X besitze die Verteilungsfunktion aus Beispiel 1.5. Dann gilt
P (1 < X ≤ 3) = FX(3) − FX(1) = 7/8 − 1/8 = 3/4
P (1 < X < 3) = FX(2) − FX(1) = 3/8 − 1/8 = 1/4
P (1 ≤ X ≤ 3) = FX(3) = 7/8
undP (1 ≤ X < 3) = FX(2) = 3/8 .
Kapitel 2
Erwartungswert
2.1 Erwartungswert einer Zufallsvariablen
Definition 2.1 Der Erwartungswert EX einer diskreten Zufallsvariablen X mit Wahr-scheinlichkeitsfunktion PX ist definiert als
EX =∑
x
xPX(x) .
Fur spatere Notationen sei angemerkt, dass der Erwartungswert einer Zufallsvariablen haufigeinfach mit µ bezeichnet wird.
Beispiel 2.1 (Anzahl der ,,K opfe” beim zweifachen M unzwurf)
P(x
)
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 2.1: Wahrscheinlichkeitsfunktion
In Beispiel 1.1a hatten wir die folgende Wahrscheinlichkeitsfunktion f ur die Anzahl der ,,K opfe”beim zweifachen Werfen einer M unze bestimmt,
12
2.1. ERWARTUNGSWERT EINER ZUFALLSVARIABLEN 13
PX(x) =
14 f ur x = 012 f ur x = 114 f ur x = 20 sonst .
Damit erh alt man als Erwartungswert
EX =2∑
x=0
xPX(x) = 0(1/4) + 1(1/2) + 2(1/4) = 1 .
Wir werden jetzt zwei m ogliche Interpretationen des Erwartungswertes kennenlernen.
a) EX ist die x-Koordinate des Schwerpunktes der Wahrscheinlichkeitsfunktion von X .
Die Wahrscheinlichkeitsfunktion ist in Abbildung 2.1 graphisch dargestellt. Stellen Sie sich die dreiBalken in Abbildung 2.1 als Metallst abe vor, die an die x-Achse geklebt sind. Versuchen Sie dann,die Wahrscheinlichkeitsfunktion auf eine scharfe Kante zu legen und dort auszubalancieren.
Wenn Sie die Wahrscheinlichkeitsfunktion so, wie in Abbildung 2.2 dargestellt, auf die Kante legten,fiele die Funktion nach rechts, in Abbildung 2.3 w urde sie nach links fallen.
P(x
)
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 2.2: Kippt nach rechts
Wenn die Kante exakt unter dem Erwartungswert w are, wie in Abbildung 2.4, w urde die Funktion dieBalance halten.
In diesem Beispiel ist der Erwartungwert gerade 1.
Der Erwartungswert ist also der Schwerpunkt von PX .
b) Der Erwartungswert EX kann als Mittelwert sehr vieler Realisationen von X aufge-fasst werden.
14 KAPITEL 2. ERWARTUNGSWERT
P(x
)
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 2.3: Kippt nach links
P(x
)
-1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Abbildung 2.4: Gleichgewicht: Erwartungswert als Schwerpunkt
Stellen Sie sich dazu vor, dass Sie die zwei M unzen sehr oft werfen.
Eine typische Folge von Ergebnissen k onnte so aussehen:
Wurfspiel 1 2 3 4 5 . . . 10 000
Ergebnis x 0 1 1 0 2 . . . 0Summe 0 1 2 2 4 . . . 10 068
Mittelwert 0/1 1/2 2/3 2/4 4/5 . . . 1.0068
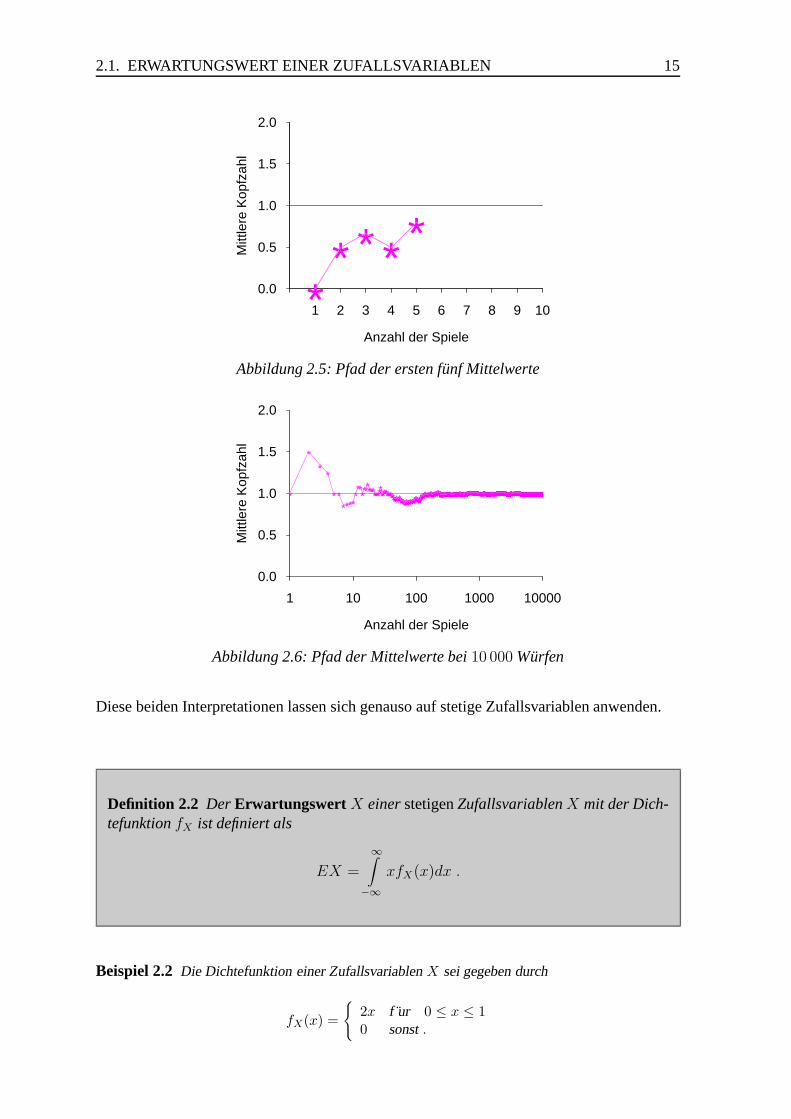
Abbildung 2.5 zeigt die ersten f unf Mittelwerte.
Abbildung 2.6 zeigt den Pfad der Mittelwerte bei 10 000 simulierten Wurfspielen. In jedem Wurfspielwird die M unze zweimal geworfen und die Anzahl der ,,K opfe” bestimmt. Nach jedem Wurfspiel wirdder Mittelwert der bisher erzeugten Realisationen von X berechnet. Abbildung 2.6 zeigt, dass der Pfadder Mittelwerte sich mit wachsender Anzahl der Realisationen stabilisiert, gegen einen endg ultigenWert konvergiert. Um zu zeigen, dass dies kein einmaliges Ergebnis war, sind in Abbildung 2.7 dreisolcher Mittelwertpfade dargestellt.
Wir folgern aus diesen Bildern, dass der Mittelwert mit zunehmender Anzahl von Spielen gegen denErwartungswert EX = 1 konvergiert. Diese Tatsache l asst sich nat urlich auch exakt beweisen.
2.1. ERWARTUNGSWERT EINER ZUFALLSVARIABLEN 15
Anzahl der Spiele
Mitt
lere
Kop
fzah
l
0 1 2 3 4 5 6 7 8 9 10
0.0
0.5
1.0
1.5
2.0
** * * *
Abbildung 2.5: Pfad der ersten funf Mittelwerte
Anzahl der Spiele
Mitt
lere
Kop
fzah
l
1 10 100 1000 10000
0.0
0.5
1.0
1.5
2.0
*
**
*
******
***********************************************************************************************************
*******************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
Abbildung 2.6: Pfad der Mittelwerte bei 10 000 Wurfen
Diese beiden Interpretationen lassen sich genauso auf stetige Zufallsvariablen anwenden.
Definition 2.2 Der Erwartungswert X einer stetigen Zufallsvariablen X mit der Dich-tefunktion fX ist definiert als
EX =
∞∫
−∞xfX(x)dx .
Beispiel 2.2 Die Dichtefunktion einer Zufallsvariablen X sei gegeben durch
fX(x) =
2x f ur 0 ≤ x ≤ 10 sonst .
16 KAPITEL 2. ERWARTUNGSWERT
Anzahl der Spiele
Mitt
lere
Kop
fzah
l
1 10 100 1000 10000
0.0
0.5
1.0
1.5
2.0 *
**
* **
**************************************************************************
********************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
*
* *
************
****************************************************************************************
**********************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
** *
***
***************
***************************************************************************************************************************
***************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
Abbildung 2.7: Drei Mittelwertpfade in je 10 000 Spielen
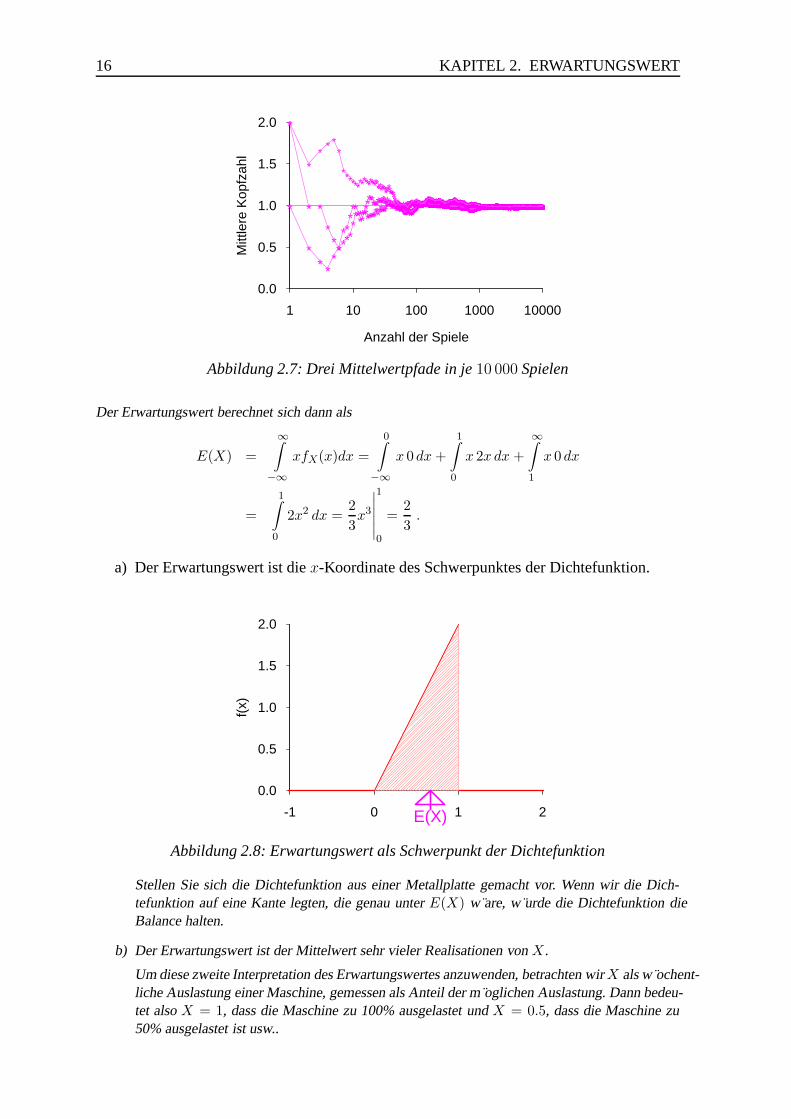
Der Erwartungswert berechnet sich dann als
E(X) =
∞∫
−∞xfX(x)dx =
0∫
−∞x 0 dx +
1∫
0
x 2x dx +
∞∫
1
x 0 dx
=
1∫
0
2x2 dx =2
3x3
∣∣∣∣∣∣
1
0
=2
3.
a) Der Erwartungswert ist die x-Koordinate des Schwerpunktes der Dichtefunktion.
f(x)
-1 0 1 2
0.0
0.5
1.0
1.5
2.0
E(X)
Abbildung 2.8: Erwartungswert als Schwerpunkt der Dichtefunktion
Stellen Sie sich die Dichtefunktion aus einer Metallplatte gemacht vor. Wenn wir die Dich-tefunktion auf eine Kante legten, die genau unter E(X) w are, w urde die Dichtefunktion dieBalance halten.
b) Der Erwartungswert ist der Mittelwert sehr vieler Realisationen von X .
Um diese zweite Interpretation des Erwartungswertes anzuwenden, betrachten wir X als w ochent-liche Auslastung einer Maschine, gemessen als Anteil der m oglichen Auslastung. Dann bedeu-tet also X = 1, dass die Maschine zu 100% ausgelastet und X = 0.5, dass die Maschine zu50% ausgelastet ist usw..
2.2. ERWARTUNGSWERT EINER FUNKTION EINER ZUFALLSVARIABLEN 17
Typische Beobachtungen uber mehrere Wochen k onnten so aussehen:
Werte: 0.80 0.59 0.39 0.65 0.37 usw.Summe: 0.80 1.39 1.78 2.43 2.80 usw.Mittelwert: 0.80 0.70 0.59 0.61 0.56 usw.
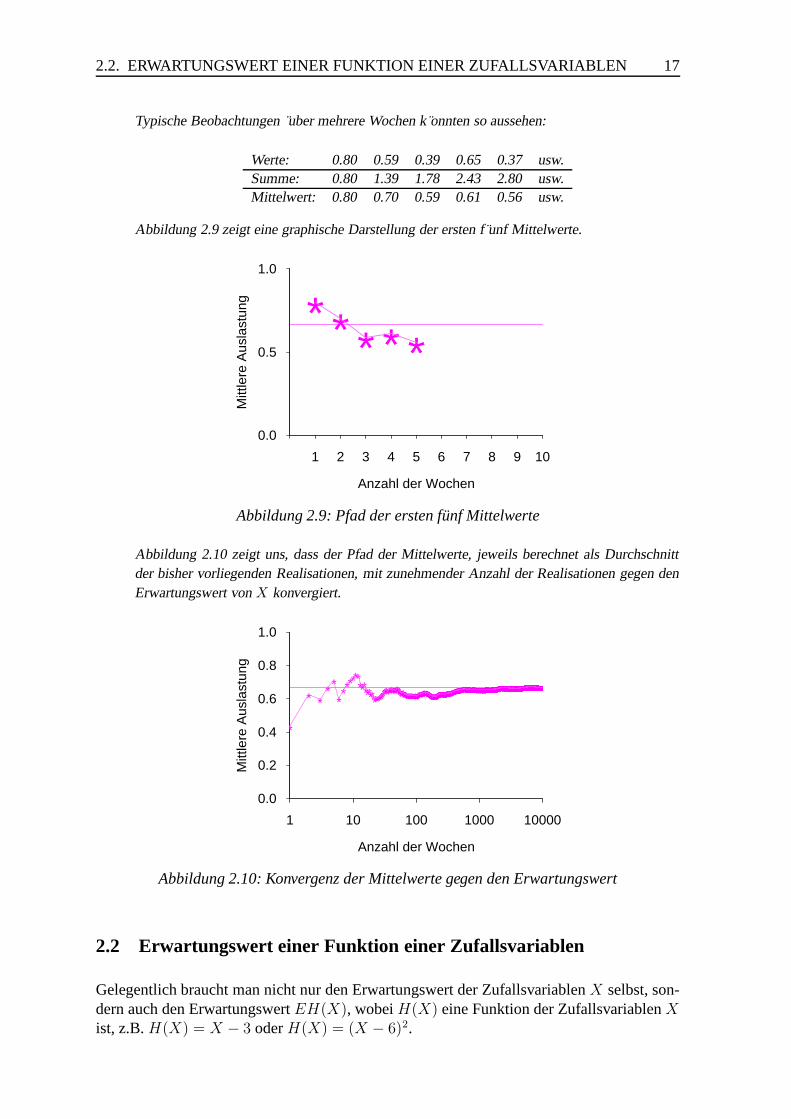
Abbildung 2.9 zeigt eine graphische Darstellung der ersten f unf Mittelwerte.
Anzahl der Wochen
Mitt
lere
Aus
last
ung
0 1 2 3 4 5 6 7 8 9 10
0.0
0.5
1.0
* * * * *
Abbildung 2.9: Pfad der ersten funf Mittelwerte
Abbildung 2.10 zeigt uns, dass der Pfad der Mittelwerte, jeweils berechnet als Durchschnittder bisher vorliegenden Realisationen, mit zunehmender Anzahl der Realisationen gegen denErwartungswert von X konvergiert.
Anzahl der Wochen
Mitt
lere
Aus
last
ung
1 10 100 1000 10000
0.0
0.2
0.4
0.6
0.8
1.0
*
* ***
*************************
**********************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
Abbildung 2.10: Konvergenz der Mittelwerte gegen den Erwartungswert
2.2 Erwartungswert einer Funktion einer Zufallsvariablen
Gelegentlich braucht man nicht nur den Erwartungswert der Zufallsvariablen X selbst, son-dern auch den Erwartungswert EH(X), wobei H(X) eine Funktion der Zufallsvariablen Xist, z.B. H(X) = X − 3 oder H(X) = (X − 6)2.

18 KAPITEL 2. ERWARTUNGSWERT
Beispiel 2.3 Betrachten Sie folgendes Spiel. Ich werfe zwei faire M unzen. X sei die Anzahl der,,K opfe”.
Die Spielregeln sind die folgenden:
• Sie zahlen 3 Euro, um zu spielen.
• Wenn
X = 0, verlieren Sie die 3 Euro.
X = 1, bekommen Sie 5 Euro (3+2).
X = 2, bekommen Sie 4 Euro (3+1).
Ihr Gewinn ist eine Funktion von X , die in der folgenden Tabelle aufgelistet ist:
X : 0 1 2H(X) : -3 +2 +1
Wenn Sie vor der Entscheidung stehen, ob Sie dieses Spielangebot annehmen oder nicht, ist es f ur Siewichtig, den Erwartungswert von H(X) zu kennen. Bevor wir dieses Beispiel fortsetzen k onnen, istder Erwartungswert einer Funktion H(X) einer Zufallsvariablen X zu definieren.
Definition 2.3 Sei H(X) eine Funktion der Zufallsvariablen X . Der ErwartungswertEH(X) ist definiert durch:
EH(X) =∑
x
H(x)PX(x) , falls Xdiskret ist,
EH(X) =
∞∫
−∞H(x)fX(x)dx , falls Xstetig ist.
F ur das obige Beispiel hatten wir die Wahrscheinlichkeitsfunktion schon in Beispiel 1.1a berechnet.Damit ist der Erwartungswert:
EH(X) =2∑
x=0
H(x)PX (x) = H(0)PX(0) + H(1)PX (1) + H(2)PX (2)
= (−3)(1/4) + (2)(1/2) + (1)(1/4) = 1/2 Euro (= 50Cent pro Spiel)
Im Mittel gewinnen Sie also 50 Cent pro Spiel. Auf lange Sicht lohnt sich also das Spiel f ur Sie.Wenn Sie dagegen nur ein einziges Mal spielen, ist die Wahrscheinlichkeit 1/4, dass Sie Ihre 3 Euroverlieren werden.
Beispiel 2.4 Die stetige Zufallsvariable X besitze die Dichtefunktion aus Beispiel 2.2, d.h.
fX(x) =
2x 0 ≤ x ≤ 10 sonst .

2.3. MOMENTE 19
Die Funktion H(X) sei gegeben durch
H(X) = X2 .
Dann ist der Erwartungswert von H(X)
EH(X) =
1∫
0
x2 2x dx =
1∫
0
2x3 dx =2
4x4
∣∣∣∣
1
0=
1
2.
Nutzlich sind die folgenden Rechenregeln fur Erwartungswerte, die sich aus den entspre-chenden Regeln fur Summen bzw. Integrale ergeben.
Satz 2.1 (Rechenregeln fur Erwartungswerte)
a) Ec = c, wenn c eine Konstante ist.
b) EcH(X) = cEH(X), insb. EcX = cEX .
c) E(H(X) + G(X)) = EH(X) + EG(X), wenn G(X) eine weitere Funktionvon X ist, insb. E(X + c) = EX + c.
Beweis:
H(X) = c, Ec =∞∫
−∞cf(x)dx = c
∞∫
−∞f(x)dx
︸ ︷︷ ︸
1
= c. ♦
Auf die weiteren Beweise verzichten wir hier.
2.3 Momente
Wichtige Funktionen einer Zufallsvariablen X sind die Potenzen Xk, d.h.
H(X) = Xk .
Definition 2.4 µ′k = EXk heißt das k-te Moment von X .
Es gilt:
• 1. Moment: µ′1 = EX . . . µ′
1 ≡ µ

20 KAPITEL 2. ERWARTUNGSWERT
• 2. Moment µ′2 = EX2
• 3. Moment µ′3 = EX3
Sind alle Momente einer Zufallsvariablen bekannt, so ist dadurch die Verteilung dieser Zu-fallsvariablen eindeutig bestimmt. Es ist
µ′k = EXk =
∑
x
xkPX(x), falls X diskret ist, (2.1)
µ′k = EXk =
∫ ∞
−∞xkfX(x)dx, falls X stetig ist. (2.2)
Eine weitere wichtige Funktion einer Zufallsvariablen ist
H(X) = (X − µ)k .
Definition 2.5 µk = E(X −µ)k heißt das k-te zentrale Moment von X , auch zentrier-tes Moment oder Moment um den Erwartungswert.
Erstes zentrales Moment:
µ1 = E(X − µ) = EX − Eµ = µ − µ = 0 .
Zweites zentrales Moment:
µ2 = E(X − µ)2 ≡ Var X ≡ σ2 .
Das zweite zentrale Moment stimmt also mit der Varianz uberein, die wir abkurzend auchmit σ2 bezeichnen.
Drittes zentrales Moment:µ3 = E(X − µ)3 .
2.4 Die Varianz einer Zufallsvariablen
Besonders wichtig ist das zweite zentrale Moment µ2 = E(X−µ)2, da es gleich der Varianzvon X ist:
µ2 = σ2X = E(X − EX)2 = V arX .
Nutzlich zur Berechnung von Varianzen ist die folgende Regel:
Satz 2.2µ2 = V arX = EX2 − (EX)2

2.4. DIE VARIANZ EINER ZUFALLSVARIABLEN 21
Beweis:
µ2 = E(X − µ)2 = E(X2 − 2µX + µ2) = EX2 − E(2µX) + Eµ2
= EX2 − 2µEX + µ2 = EX2 − 2(EX)2 + (EX)2 = EX2 − (EX)2
♦
Beispiel 2.5 In den Beispielen 2.2 und 2.4 hatten wir den Erwartungswert EX bzw. EX 2 einerstetigen Zufallsvariablen mit der Dichtefunktion
fX(x) =
2x 0 ≤ x ≤ 10 sonst
berechnet. Es warEX = 2/3 und EX2 = 1/2 .
Damit ist nach der Regel aus Satz 2.2
VarX = 1/2 − (2/3)2 = 1/18 .
Dies ist i.allg. einfacher als
1∫
0
(x − 2/3)22xdx = . . . = 1/18 .
Wichtig sind die folgenden Rechenregeln fur Varianzen, die aus den Rechenregeln fur Er-wartungwerte folgen.
Satz 2.3 (Rechenregeln fur Varianzen)Sei c eine Konstante. Dann gilt:
a) V ar(c) = 0
b) V ar(cX) = c2V arX
c) V ar(X + c) = V arX
Beweis:a) Es ist
Ec = c
undEc2 = c2 ,
d.h.V ar(c) = c2 − c2 = 0 .

22 KAPITEL 2. ERWARTUNGSWERT
b)
V ar(cX) = E(cX)2 − (E(cX))2 = E(c2X2) − c2(EX)2
= c2(EX2 − (EX)2) = c2V arX
c)
V ar(X + c) = E(X + c − E(X + c))2 = E(X + c − EX − c)2
= E(X − EX)2 = V arX
♦Diese Formeln kann man sich auch auf anschauliche Weise merken. Die Quadratwurzel ausder Varianz ist die Standardabweichung einer Zufallsvariablen und misst die Breite einerVerteilung oder die Streuung einer Zufallsvariablen. Die Varianz ist also das Quadrat einesStreuungsmaßes. Es ist doch nur vernunftig, dass
a) die Streuung einer Konstanten, d.h. einer Zufallsvariablen, die nur einen einzigen Wertannehmen kann, Null ist,
b) ein Streuungsmaß mit dem Faktor c, also das Quadrat eines Streuungsmaßes mit demFaktor c2 zu multiplizieren ist, wenn ich jeden moglichen Wert dieser Zufallsvariablenmit einem Faktor c multipliziere,
c) sich ein Streuungsmaß nicht andert, wenn ich den Wertebereich einer Zufallsvariablenum eine Konstante c verschiebe.

Kapitel 3
Stetige Verteilungen
3.1 Rechteckverteilung
Fur die Rechteckverteilung benutzen wir die Notation U(a; b). Der Buchstabe U ruhrt von derenglischen Bezeichnung Uniform her. Wir wollen aber nicht Gleichverteilung oder gleich-maßige Verteilung sagen, um keine Verwechslungen mit gleicher Verteilung zu provozieren.Statt gleicher Verteilung werden wir identische Verteilung sagen. Wir schreiben
X ∼ U(a; b) ,
wenn eine Zufallsvariable X eine Rechteckverteilung besitzt. Dabei sind a und b zwei Para-meter, fur die a < b gelten muss.
Definition 3.1 Die Dichtefunktion der Rechteckverteilung ist gegeben durch:
fX(x) =
1
b−afur a ≤ x ≤ b
0 sonst .
Der Verlauf der Dichtefunktion (siehe Abbildung 3.1) entspricht einem Rechteck uber demIntervall [a, b].
Die Standardform der Rechteckverteilung oder Standardrechteckverteilung U(0; 1), die großeBedeutung bei der Erzeugung von Zufallszahlen hat, hat die Parameter a = 0 und b = 1.
Satz 3.1 Die Verteilungsfunktion der Rechteckverteilung ist:
FX(t) =
0 fur t < at−ab−a
fur a ≤ t ≤ b
1 fur t > b .
23

24 KAPITEL 3. STETIGE VERTEILUNGEN
a b
1/(b-a)
Abbildung 3.1: Dichtefunktion der Rechteckverteilung
Beweis:
FX(t) =
t∫
−∞fX(x)dx =
0 fur t < at∫
a
1b−a
dx = t−ab−a
fur a ≤ t ≤ b
1 fur t > b .
♦Abbildung 3.2 zeigt die Verteilungsfunktion. Es handelt sich also um eine Gerade mit derSteigung 1/(b − a).
Wir wollen jetzt den Erwartungswert und die Varianz einer Rechteckverteilung bestimmen.
Satz 3.2 Sei X eine Zufallsvariable mit einer Rechteckverteilung mit den Parametern aund b. Dann gilt
EX =b + a
2und V arX =
(b − a)2
12.
Beweis:
EX =
∞∫
−∞xfX(x)dx =
a∫
−∞x · 0 dx +
b∫
a
x1
b − adx +
∞∫
b
x · 0 dx
=
[
x2
2
1
b − a
]b
a
=1
2
b2 − a2
b − a=
b + a
2.
EX2 =
b∫
a
x2 1
b − adx =
[
1
b − a
x3
3
]b
a
=1
3
b3 − a3
b − a=
1
3(a2 + ab + b2) .
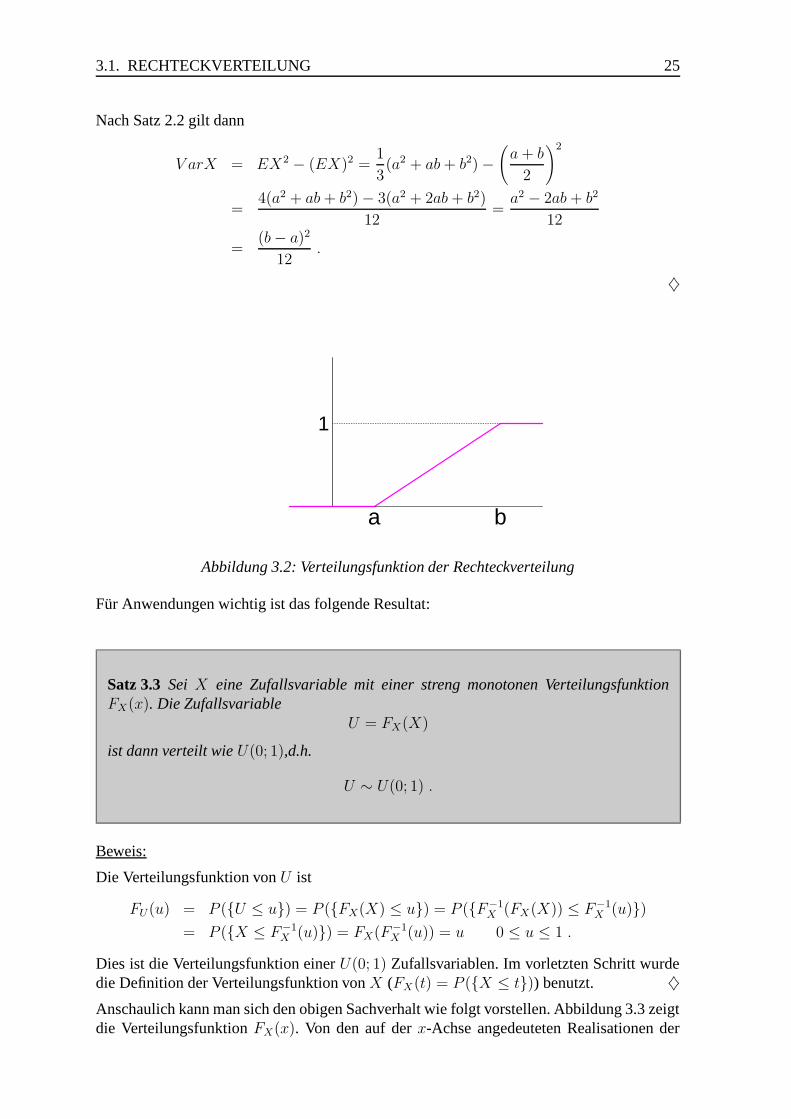
3.1. RECHTECKVERTEILUNG 25
Nach Satz 2.2 gilt dann
V arX = EX2 − (EX)2 =1
3(a2 + ab + b2) −
(
a + b
2
)2
=4(a2 + ab + b2) − 3(a2 + 2ab + b2)
12=
a2 − 2ab + b2
12
=(b − a)2
12.
♦
a b
1
Abbildung 3.2: Verteilungsfunktion der Rechteckverteilung
Fur Anwendungen wichtig ist das folgende Resultat:
Satz 3.3 Sei X eine Zufallsvariable mit einer streng monotonen VerteilungsfunktionFX(x). Die Zufallsvariable
U = FX(X)
ist dann verteilt wie U(0; 1),d.h.
U ∼ U(0; 1) .
Beweis:
Die Verteilungsfunktion von U ist
FU(u) = P (U ≤ u) = P (FX(X) ≤ u) = P (F−1X (FX(X)) ≤ F−1
X (u))= P (X ≤ F−1
X (u)) = FX(F−1X (u)) = u 0 ≤ u ≤ 1 .
Dies ist die Verteilungsfunktion einer U(0; 1) Zufallsvariablen. Im vorletzten Schritt wurdedie Definition der Verteilungsfunktion von X (FX(t) = P (X ≤ t)) benutzt. ♦Anschaulich kann man sich den obigen Sachverhalt wie folgt vorstellen. Abbildung 3.3 zeigtdie Verteilungsfunktion FX(x). Von den auf der x-Achse angedeuteten Realisationen der
26 KAPITEL 3. STETIGE VERTEILUNGEN
Zufallsvariablen X geht man dann in Pfeilrichtung zu den entsprechenden Werten der Ver-teilungsfunktion, die man an der u-Achse abliest. Dies sind dann die Realisationen der Zu-fallsvariablen U .
u
-4 -2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
x
Abbildung 3.3: Zur Konstruktion der Zufallsvariablen U
Angewendet wird der Satz wie folgt:
Wenn wir eine Verteilung FX(x) fur die Daten x1, x2, ..., xn postulieren, dann mussen u1 =FX(x1), u2 = FX(x2), ..., un = FX(xn) U(0; 1)-verteilt sein.
Wir konnen dies z.B. durch graphische Darstellungen (wie Histogramm) oder durch ande-re statistische Verfahren uberprufen. Ein Histogramm sollte etwa so aussehen, wie das inAbbildung 3.4 dargestellte Histogramm.
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
x
Abbildung 3.4: Histogramm der u1, u2, ..., un (n = 100)
Das Histogramm in Abbildung 3.4 wurde mit folgenden R-Befehlen erzeugt:
u<-runif(100) # erzeugt 100 U(0,1)-Zufallszahlen
hist(u, probability=T) # zeichnet Histogramm
Stellt man sich die empirische Verteilungsfunktion der u1, u2, . . . , un graphisch dar, so solltesich ungefahr eine Gerade mit der Steigung 1 wie in Abbildung 3.5 ergeben. Die Abbildung3.5 wurde mit den folgenden R-Befehlen erzeugt.
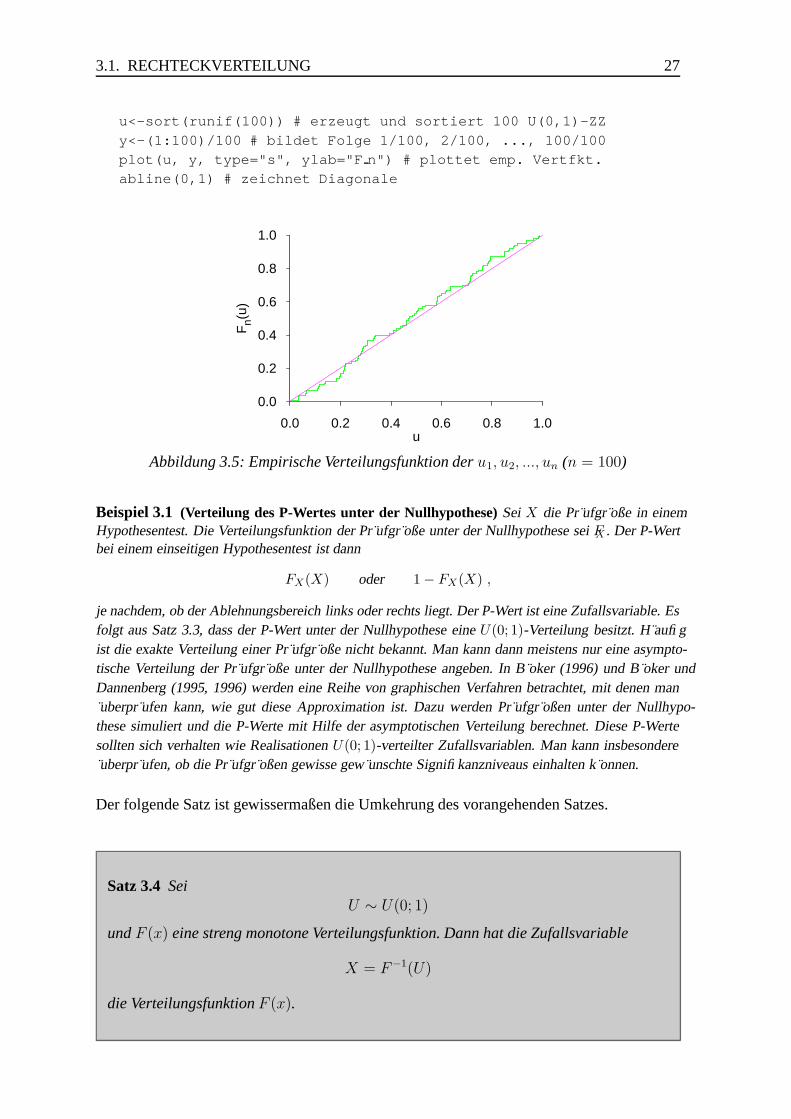
3.1. RECHTECKVERTEILUNG 27
u<-sort(runif(100)) # erzeugt und sortiert 100 U(0,1)-ZZ
y<-(1:100)/100 # bildet Folge 1/100, 2/100, ..., 100/100
plot(u, y, type="s", ylab="F n") # plottet emp. Vertfkt.
abline(0,1) # zeichnet Diagonale
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
Fn(
u)
Abbildung 3.5: Empirische Verteilungsfunktion der u1, u2, ..., un (n = 100)
Beispiel 3.1 (Verteilung des P-Wertes unter der Nullhypothese) Sei X die Pr ufgr oße in einemHypothesentest. Die Verteilungsfunktion der Pr ufgr oße unter der Nullhypothese sei FX . Der P-Wertbei einem einseitigen Hypothesentest ist dann
FX(X) oder 1 − FX(X) ,
je nachdem, ob der Ablehnungsbereich links oder rechts liegt. Der P-Wert ist eine Zufallsvariable. Esfolgt aus Satz 3.3, dass der P-Wert unter der Nullhypothese eine U(0; 1)-Verteilung besitzt. H aufigist die exakte Verteilung einer Pr ufgr oße nicht bekannt. Man kann dann meistens nur eine asympto-tische Verteilung der Pr ufgr oße unter der Nullhypothese angeben. In B oker (1996) und B oker undDannenberg (1995, 1996) werden eine Reihe von graphischen Verfahren betrachtet, mit denen manuberpr ufen kann, wie gut diese Approximation ist. Dazu werden Pr ufgr oßen unter der Nullhypo-
these simuliert und die P-Werte mit Hilfe der asymptotischen Verteilung berechnet. Diese P-Wertesollten sich verhalten wie Realisationen U(0; 1)-verteilter Zufallsvariablen. Man kann insbesondereuberpr ufen, ob die Pr ufgr oßen gewisse gew unschte Signifikanzniveaus einhalten k onnen.
Der folgende Satz ist gewissermaßen die Umkehrung des vorangehenden Satzes.
Satz 3.4 SeiU ∼ U(0; 1)
und F (x) eine streng monotone Verteilungsfunktion. Dann hat die Zufallsvariable
X = F−1(U)
die Verteilungsfunktion F (x).
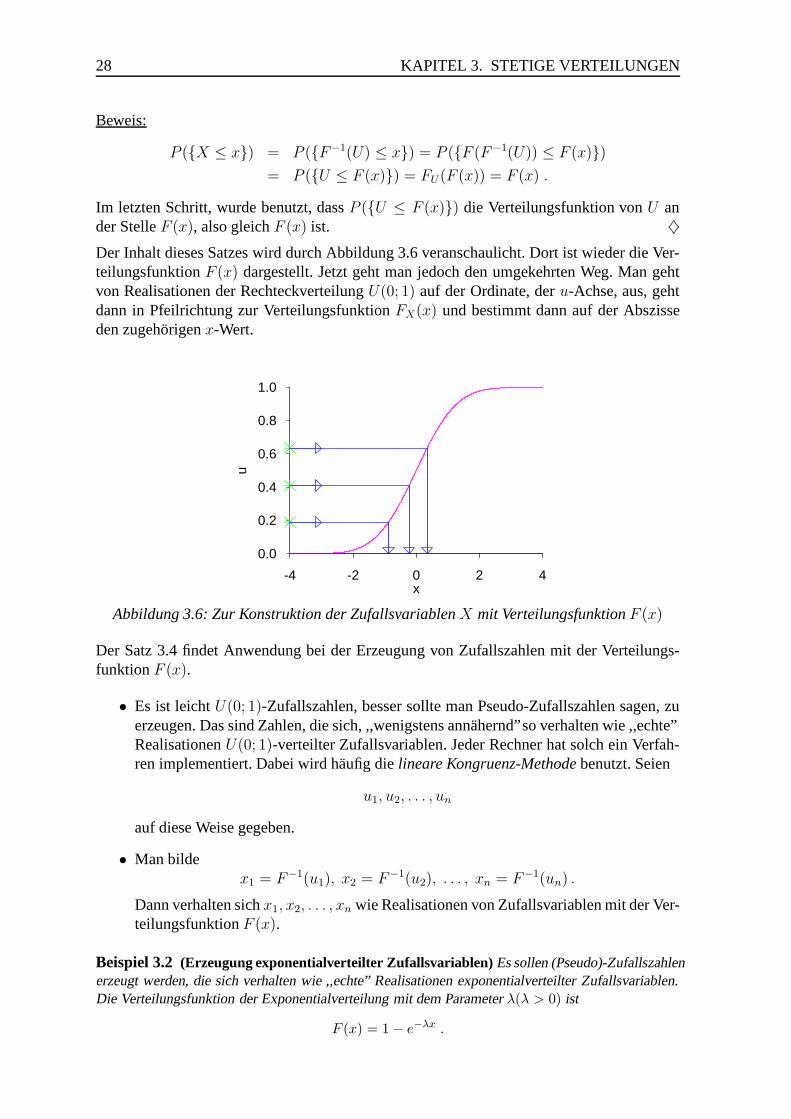
28 KAPITEL 3. STETIGE VERTEILUNGEN
Beweis:
P (X ≤ x) = P (F−1(U) ≤ x) = P (F (F−1(U)) ≤ F (x))= P (U ≤ F (x)) = FU(F (x)) = F (x) .
Im letzten Schritt, wurde benutzt, dass P (U ≤ F (x)) die Verteilungsfunktion von U ander Stelle F (x), also gleich F (x) ist. ♦Der Inhalt dieses Satzes wird durch Abbildung 3.6 veranschaulicht. Dort ist wieder die Ver-teilungsfunktion F (x) dargestellt. Jetzt geht man jedoch den umgekehrten Weg. Man gehtvon Realisationen der Rechteckverteilung U(0; 1) auf der Ordinate, der u-Achse, aus, gehtdann in Pfeilrichtung zur Verteilungsfunktion FX(x) und bestimmt dann auf der Abszisseden zugehorigen x-Wert.
u
-4 -2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
x
Abbildung 3.6: Zur Konstruktion der Zufallsvariablen X mit Verteilungsfunktion F (x)
Der Satz 3.4 findet Anwendung bei der Erzeugung von Zufallszahlen mit der Verteilungs-funktion F (x).
• Es ist leicht U(0; 1)-Zufallszahlen, besser sollte man Pseudo-Zufallszahlen sagen, zuerzeugen. Das sind Zahlen, die sich, ,,wenigstens annahernd” so verhalten wie ,,echte”Realisationen U(0; 1)-verteilter Zufallsvariablen. Jeder Rechner hat solch ein Verfah-ren implementiert. Dabei wird haufig die lineare Kongruenz-Methode benutzt. Seien
u1, u2, . . . , un
auf diese Weise gegeben.
• Man bildex1 = F−1(u1), x2 = F−1(u2), . . . , xn = F−1(un) .
Dann verhalten sich x1, x2, . . . , xn wie Realisationen von Zufallsvariablen mit der Ver-teilungsfunktion F (x).
Beispiel 3.2 (Erzeugung exponentialverteilter Zufallsvariablen) Es sollen (Pseudo)-Zufallszahlenerzeugt werden, die sich verhalten wie ,,echte” Realisationen exponentialverteilter Zufallsvariablen.Die Verteilungsfunktion der Exponentialverteilung mit dem Parameter λ(λ > 0) ist
F (x) = 1 − e−λx .

3.2. NORMALVERTEILUNG 29
Um die Umkehrfunktion F−1 zu bestimmen, setzen wir
u = 1 − e−λx .
Diese Gleichung ist nach x aufzul osen:
x = − log(1 − u)/λ = F−1(u) .
Speziell f ur λ = 1 istx = − log (1 − u) . (3.1)
In der folgenden Tabelle stehen einige Werte von u, die mit dem R-Befehl
runif(5)
erzeugt wurden. Die x-Werte wurden nach Gleichung (3.1) erzeugt.
u 0.42 0.31 0.87 0.17 0.69x 0.54 0.37 2.04 0.19 1.17
R-Befehle zur Rechteckverteilung
dunif(x, min=0, max=1) berechnet die Dichtefunktion der Rechteckverteilungan der Stelle x, wobei x ein Vektor ist. Defaultmaßig (min=0, max=1) wird dieDichte der Standardrechteckverteilung berechnet. Durch Veranderung der optionalenArgumente min und max kann die Dichtefunktion fur beliebige Parameter a und bberechnet werden.
punif(q, min=0, max=1) berechnet die Verteilungsfunktion der Rechteckver-teilung mit den Parametern a =min und b =max an der Stelle q, wobei q ein Vektorist.
qunif(p, min=0, max=1) berechnet die Umkehrfunktion der Verteilungsfunk-tion der Rechteckverteilung mit den Parametern a =min und b =max an der Stelle p,wobei p ein Vektor von Wahrscheinlichkeiten, also Zahlen zwischen 0 und 1, ist.
runif(n, min=0, max=1) erzeugt n rechteckverteilte Zufallszahlen im Inter-vall [0, 1].
3.2 Normalverteilung
Definition 3.2 Die Dichtefunktion der Normalverteilung ist gegeben durch
fX(x) =1√
2πσ2e−(x−µ)2/2σ2
fur −∞ < x < ∞ .
Dabei sind µ und σ2 Parameter, fur die gelten muss
−∞ < µ < ∞ und σ2 > 0 .
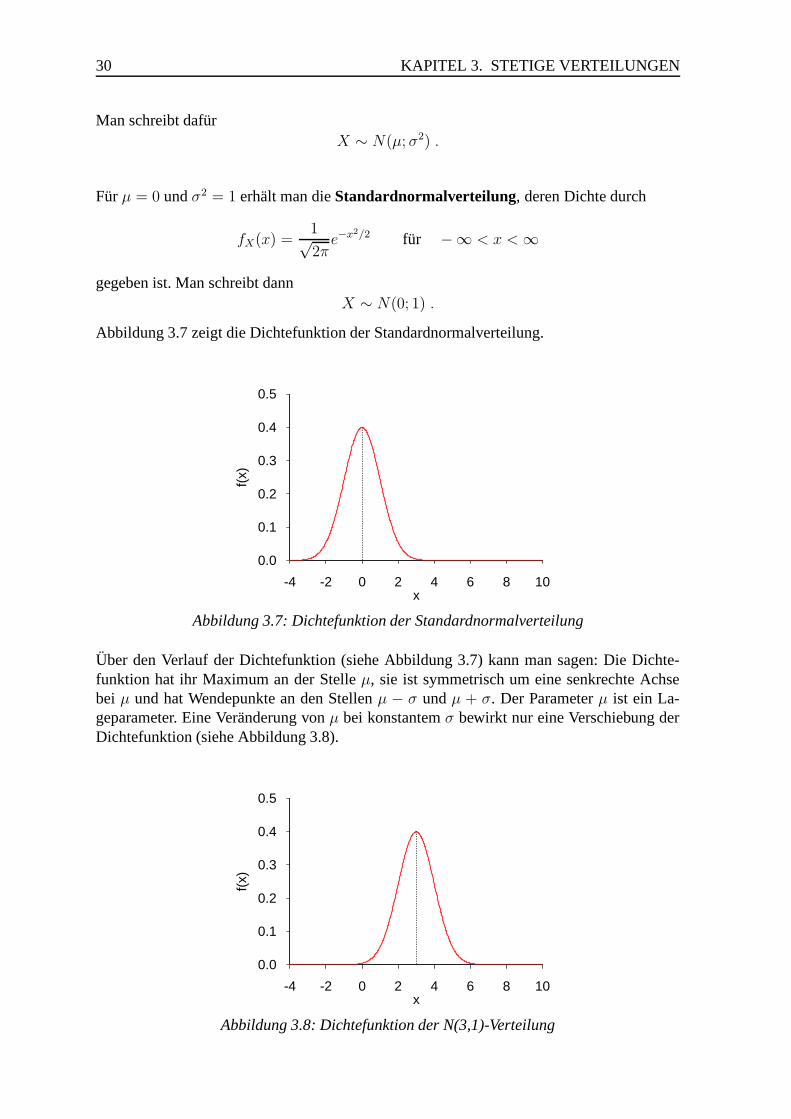
30 KAPITEL 3. STETIGE VERTEILUNGEN
Man schreibt dafurX ∼ N(µ; σ2) .
Fur µ = 0 und σ2 = 1 erhalt man die Standardnormalverteilung, deren Dichte durch
fX(x) =1√2π
e−x2/2 fur −∞ < x < ∞
gegeben ist. Man schreibt dannX ∼ N(0; 1) .
Abbildung 3.7 zeigt die Dichtefunktion der Standardnormalverteilung.
f(x)
-4 -2 0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
0.5
x
Abbildung 3.7: Dichtefunktion der Standardnormalverteilung
Uber den Verlauf der Dichtefunktion (siehe Abbildung 3.7) kann man sagen: Die Dichte-funktion hat ihr Maximum an der Stelle µ, sie ist symmetrisch um eine senkrechte Achsebei µ und hat Wendepunkte an den Stellen µ − σ und µ + σ. Der Parameter µ ist ein La-geparameter. Eine Veranderung von µ bei konstantem σ bewirkt nur eine Verschiebung derDichtefunktion (siehe Abbildung 3.8).
f(x)
-4 -2 0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
0.5
x
Abbildung 3.8: Dichtefunktion der N(3,1)-Verteilung
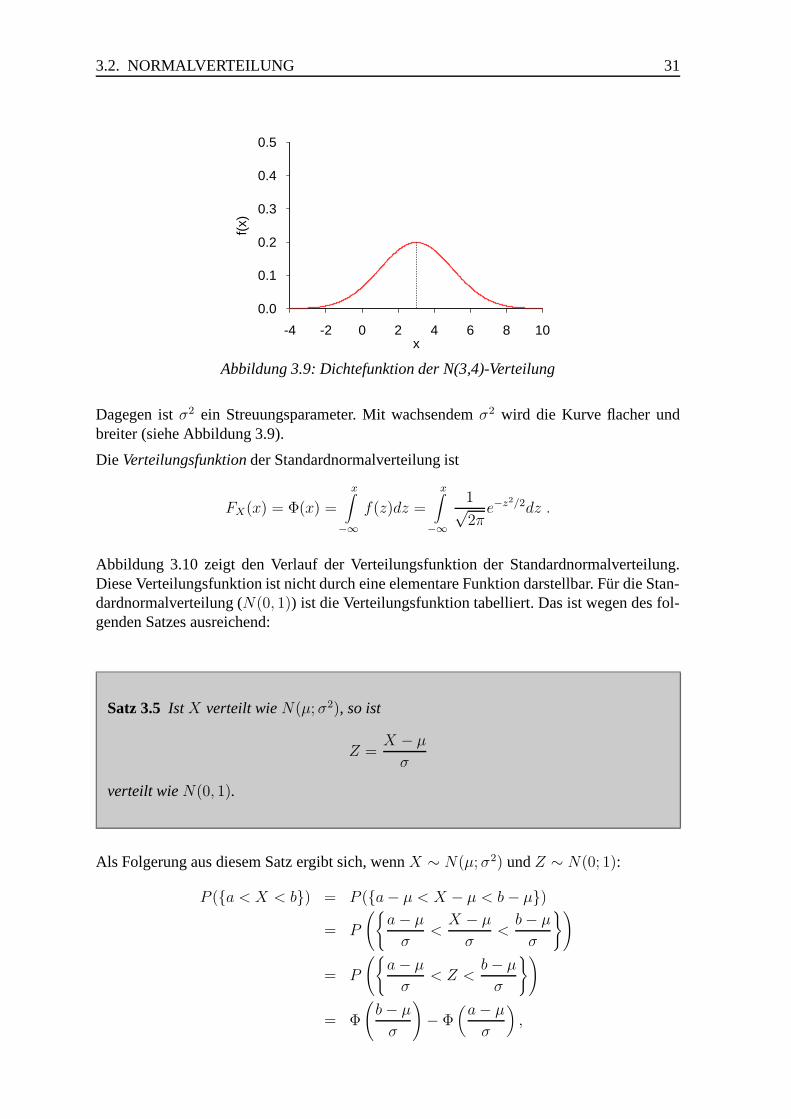
3.2. NORMALVERTEILUNG 31
f(x)
-4 -2 0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
0.5
x
Abbildung 3.9: Dichtefunktion der N(3,4)-Verteilung
Dagegen ist σ2 ein Streuungsparameter. Mit wachsendem σ2 wird die Kurve flacher undbreiter (siehe Abbildung 3.9).
Die Verteilungsfunktion der Standardnormalverteilung ist
FX(x) = Φ(x) =
x∫
−∞f(z)dz =
x∫
−∞
1√2π
e−z2/2dz .
Abbildung 3.10 zeigt den Verlauf der Verteilungsfunktion der Standardnormalverteilung.Diese Verteilungsfunktion ist nicht durch eine elementare Funktion darstellbar. Fur die Stan-dardnormalverteilung (N(0, 1)) ist die Verteilungsfunktion tabelliert. Das ist wegen des fol-genden Satzes ausreichend:
Satz 3.5 Ist X verteilt wie N(µ; σ2), so ist
Z =X − µ
σ
verteilt wie N(0, 1).
Als Folgerung aus diesem Satz ergibt sich, wenn X ∼ N(µ; σ2) und Z ∼ N(0; 1):
P (a < X < b) = P (a − µ < X − µ < b − µ)
= P
(
a − µ
σ<
X − µ
σ<
b − µ
σ
)
= P
(
a − µ
σ< Z <
b − µ
σ
)
= Φ
(
b − µ
σ
)
− Φ(
a − µ
σ
)
,
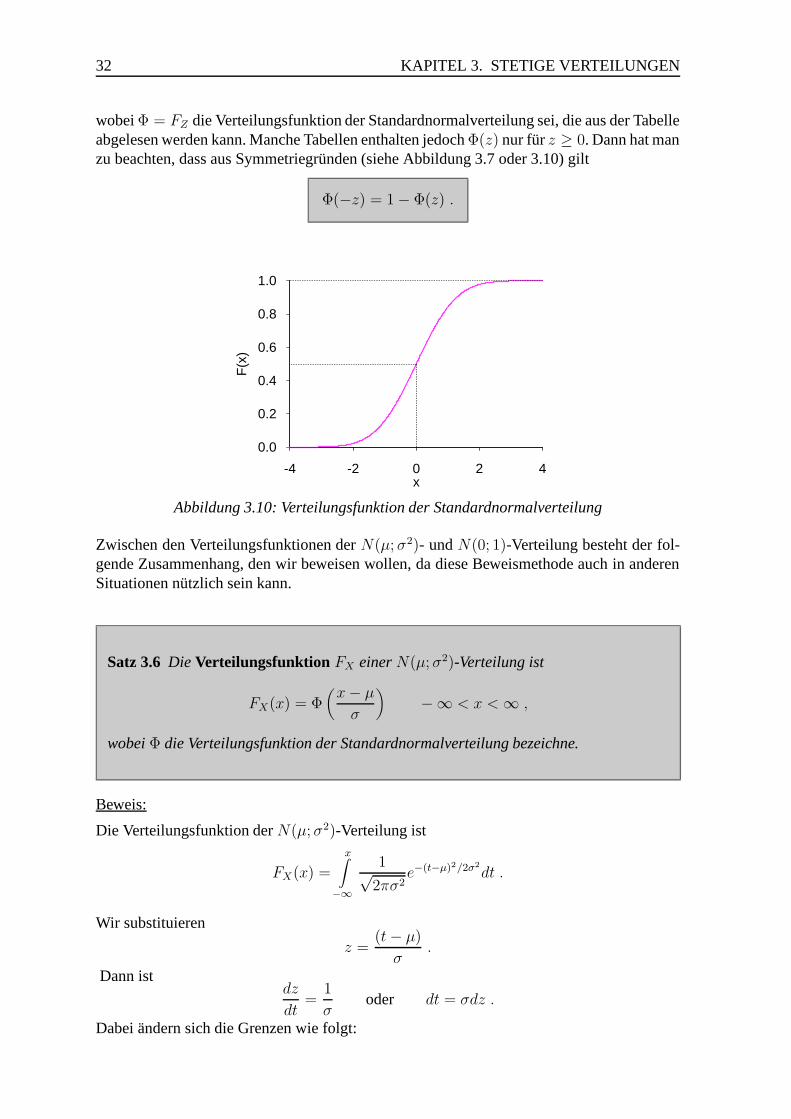
32 KAPITEL 3. STETIGE VERTEILUNGEN
wobei Φ = FZ die Verteilungsfunktion der Standardnormalverteilung sei, die aus der Tabelleabgelesen werden kann. Manche Tabellen enthalten jedoch Φ(z) nur fur z ≥ 0. Dann hat manzu beachten, dass aus Symmetriegrunden (siehe Abbildung 3.7 oder 3.10) gilt
Φ(−z) = 1 − Φ(z) .
F(x
)
-4 -2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
x
Abbildung 3.10: Verteilungsfunktion der Standardnormalverteilung
Zwischen den Verteilungsfunktionen der N(µ; σ2)- und N(0; 1)-Verteilung besteht der fol-gende Zusammenhang, den wir beweisen wollen, da diese Beweismethode auch in anderenSituationen nutzlich sein kann.
Satz 3.6 Die Verteilungsfunktion FX einer N(µ; σ2)-Verteilung ist
FX(x) = Φ(
x − µ
σ
)
−∞ < x < ∞ ,
wobei Φ die Verteilungsfunktion der Standardnormalverteilung bezeichne.
Beweis:
Die Verteilungsfunktion der N(µ; σ2)-Verteilung ist
FX(x) =
x∫
−∞
1√2πσ2
e−(t−µ)2/2σ2
dt .
Wir substituieren
z =(t − µ)
σ.
Dann istdz
dt=
1
σoder dt = σdz .
Dabei andern sich die Grenzen wie folgt:
3.2. NORMALVERTEILUNG 33
• Wenn t = −∞, ist z = −∞ .
• Wenn t = x, ist z = x−µσ
.
Damit ist
FX(x) =
x−µσ∫
−∞
1√2π
e−z2/2dz = Φ(
x − µ
σ
)
.
♦
Beispiel 3.3 Sei X ∼ N(10; 32). Die zugeh orige Dichtefunktion ist in Abbildung 3.11 dargestellt.
f(x)
0 5 10 15 20
0.0
0.1
0.2
0.3
x
Abbildung 3.11: Dichtefunktion der N(10,9)-Verteilung
Die Verteilungsfunktion ist dann
FX(x) = Φ
(x − 10
3
)
.
Die Wahrscheinlichkeit P (13 ≤ X ≤ 16), die in Abbildung 3.12 als Fl ache unterhalb der Dichte-funktion zwischen 13 und 16 dargestellt ist, berechnet sich dann zu:
P (13 ≤ X ≤ 16) = FX(16) − FX(13) = Φ
(16 − 10
3
)
− Φ
(13 − 10
3
)
= Φ(2) − Φ(1) = 0.977 − 0.841 = 0.136 .
Satz 3.7 Fur eine normalverteilte Zufallsvariable X ∼ N(µ; σ2) gilt
EX = µ und Var(X) = σ2 .
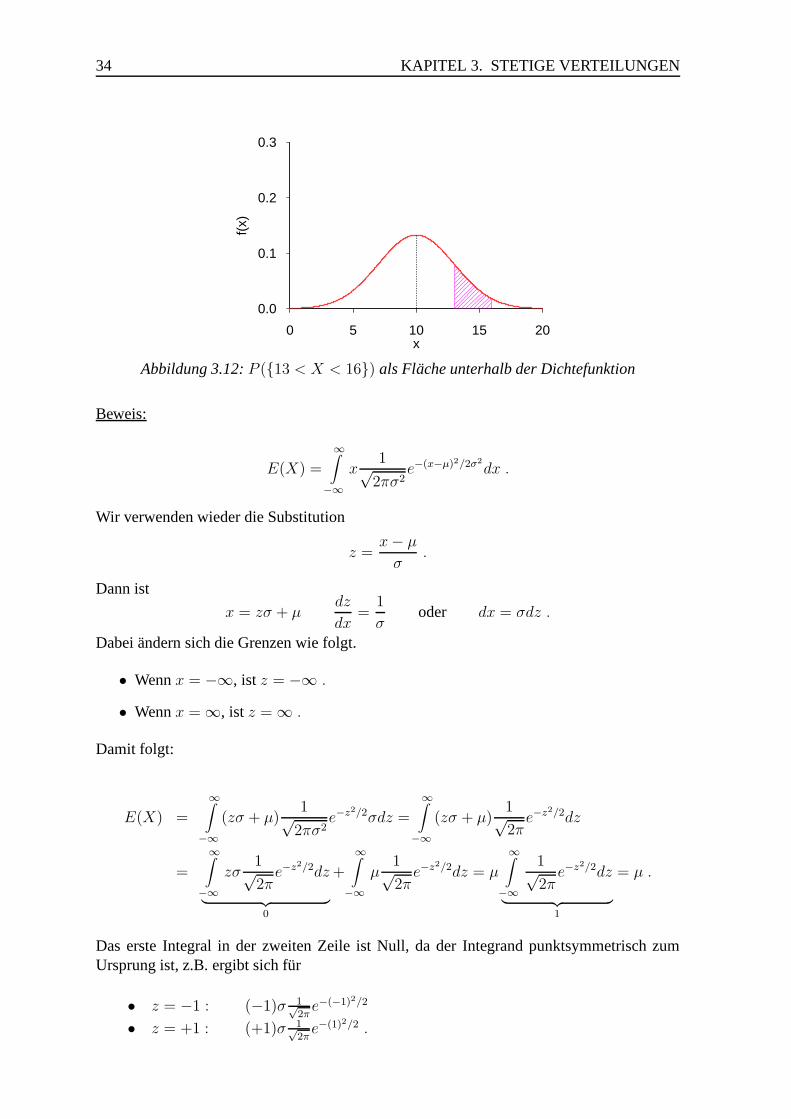
34 KAPITEL 3. STETIGE VERTEILUNGEN
f(x)
0 5 10 15 20
0.0
0.1
0.2
0.3
x
Abbildung 3.12: P (13 < X < 16) als Flache unterhalb der Dichtefunktion
Beweis:
E(X) =
∞∫
−∞x
1√2πσ2
e−(x−µ)2/2σ2
dx .
Wir verwenden wieder die Substitution
z =x − µ
σ.
Dann ist
x = zσ + µdz
dx=
1
σoder dx = σdz .
Dabei andern sich die Grenzen wie folgt.
• Wenn x = −∞, ist z = −∞ .
• Wenn x = ∞, ist z = ∞ .
Damit folgt:
E(X) =
∞∫
−∞(zσ + µ)
1√2πσ2
e−z2/2σdz =
∞∫
−∞(zσ + µ)
1√2π
e−z2/2dz
=
∞∫
−∞zσ
1√2π
e−z2/2dz
︸ ︷︷ ︸
0
+
∞∫
−∞µ
1√2π
e−z2/2dz = µ
∞∫
−∞
1√2π
e−z2/2dz
︸ ︷︷ ︸
1
= µ .
Das erste Integral in der zweiten Zeile ist Null, da der Integrand punktsymmetrisch zumUrsprung ist, z.B. ergibt sich fur
• z = −1 : (−1)σ 1√2π
e−(−1)2/2
• z = +1 : (+1)σ 1√2π
e−(1)2/2 .
3.2. NORMALVERTEILUNG 35
Es gilt alsog(z) = −g(−z) ,
wenn wir den Integranden, dessen Graph in Abbildung 3.13 dargestellt ist, mit g bezeich-nen. Das letzte Integral in dieser Zeile ist 1, da es das Integral uber die Dichtefunktion derStandardnormalverteilung ist.
g(z)
-4 -2 0 2 4
-0.4
-0.2
0.0
0.2
0.4
z
Abbildung 3.13: Graph der Funktion zσ 1√2π
e−z2/2 fur σ = 1
Bei der Bestimmung der Varianz verwenden wir wieder die gleiche Substitution wie oben.Zur Berechnung des Integrals in der zweiten Zeile verwenden wir die Regel der partiellenIntegration, die hier zur Erinnerung noch einmal aufgeschrieben sei:
b∫
a
v(x)w′
(x)dx = v(x)w(x)
∣∣∣∣∣∣
b
a
−b∫
a
v′
(x)w(x)dx . (3.2)
Var(X) =
∞∫
−∞(x − µ)2 1√
2πσ2e−(x−µ)2/2σ2
dx =
∞∫
−∞z2σ2 1√
2πσ2e−z2/2σdz
= σ2
∞∫
−∞z · z 1√
2πe−z2/2dz = σ2
[
− z√2π
e−z2/2
]∞
−∞︸ ︷︷ ︸
0
+σ2
∞∫
−∞
1√2π
e−z2/2dz
︸ ︷︷ ︸
1
= σ2
Bei der partiellen Integration wurde
• v(z) = z =⇒ v′(z) = 1
• w′(z) = z 1√2π
e−z2/2 =⇒ w(z) = − 1√2π
e−z2/2
benutzt. Ferner wurde wiederum benutzt, dass das Integral uber eine Dichtefunktion (hier dieStandardnormalverteilung) Null ist und dass ze−z2/2 → 0, wenn z → ∞. (Dies lasst sich mitden Regeln von L‘Hospital (Theorem 7.11.1 in Sydsæter und Hammond (2003)) beweisen.Siehe dort auch Formel 7.11.4.) ♦
Die große Bedeutung der Normalverteilung beruht auf folgenden Tatsachen:
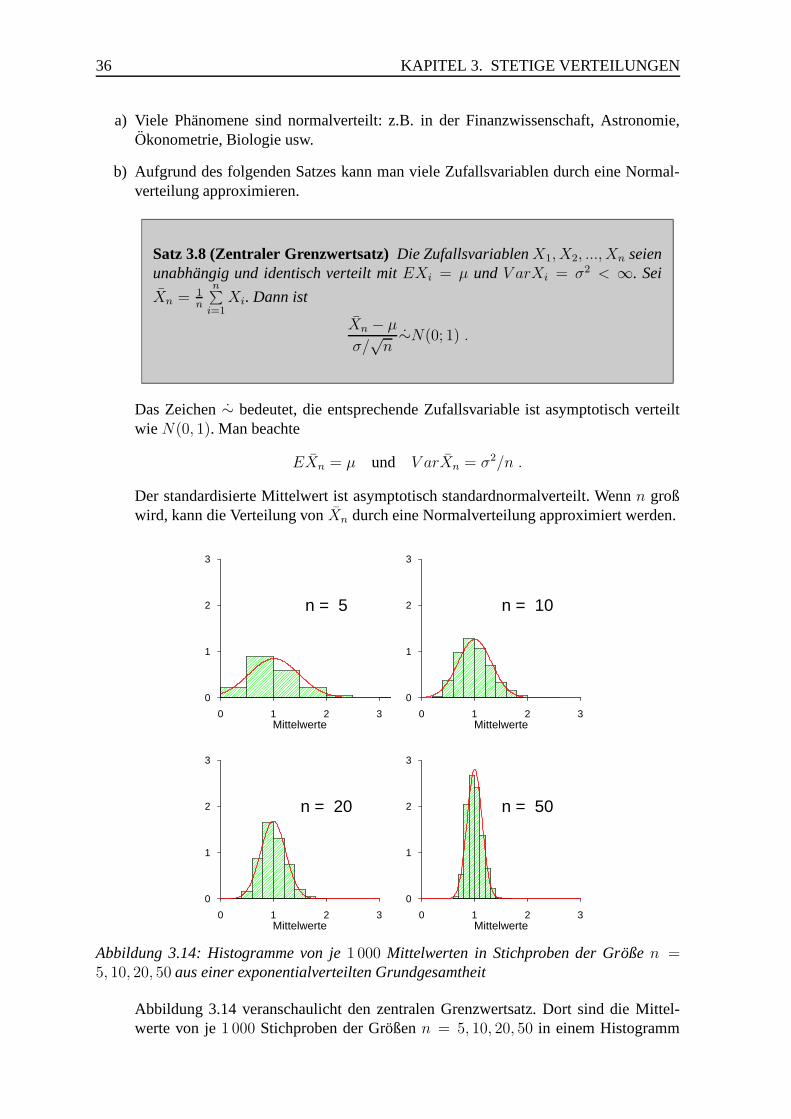
36 KAPITEL 3. STETIGE VERTEILUNGEN
a) Viele Phanomene sind normalverteilt: z.B. in der Finanzwissenschaft, Astronomie,Okonometrie, Biologie usw.
b) Aufgrund des folgenden Satzes kann man viele Zufallsvariablen durch eine Normal-verteilung approximieren.
Satz 3.8 (Zentraler Grenzwertsatz) Die Zufallsvariablen X1, X2, ..., Xn seienunabhangig und identisch verteilt mit EXi = µ und V arXi = σ2 < ∞. Sei
Xn = 1n
n∑
i=1Xi. Dann ist
Xn − µ
σ/√
n∼N(0; 1) .
Das Zeichen ∼ bedeutet, die entsprechende Zufallsvariable ist asymptotisch verteiltwie N(0, 1). Man beachte
EXn = µ und V arXn = σ2/n .
Der standardisierte Mittelwert ist asymptotisch standardnormalverteilt. Wenn n großwird, kann die Verteilung von Xn durch eine Normalverteilung approximiert werden.
0 1 2 3
0
1
2
3
Mittelwerte
n = 5
0 1 2 3
0
1
2
3
Mittelwerte
n = 10
0 1 2 3
0
1
2
3
Mittelwerte
n = 20
0 1 2 3
0
1
2
3
Mittelwerte
n = 50
Abbildung 3.14: Histogramme von je 1 000 Mittelwerten in Stichproben der Große n =5, 10, 20, 50 aus einer exponentialverteilten Grundgesamtheit
Abbildung 3.14 veranschaulicht den zentralen Grenzwertsatz. Dort sind die Mittel-werte von je 1 000 Stichproben der Großen n = 5, 10, 20, 50 in einem Histogramm

3.2. NORMALVERTEILUNG 37
dargestellt. Je großer der Stichprobenumfang, desto mehr nahert sich die Form desHistogramms der Dichtefunktion einer Normalverteilung an.
c) Oft ist eine Variable die Summe unterschiedlicher Zufallseinflusse. In solchen Fallenist die Normalverteilung haufig ein gutes Modell.
d) Die theoretischen Eigenschaften sind einfach zu bestimmen. Daher ist die Theorie derNormalverteilung sehr weit entwickelt.
e) Die Normalverteilung hat viele angenehme Eigenschaften. So sind Linearkombinatio-nen und insbesondere Summen unabhangiger normalverteilter Zufallsvariablen wiedernormalverteilt.
f) Abgesehen von einigen Ausnahmen sind Maximum-Likelihood-Schatzer von Parame-tern asymptotisch normalverteilt. Man benutzt dann diese Eigenschaft bei der Kon-struktion von Konfidenzintervallen.
g) Die Normalverteilung tritt im Zusammenhang mit sogenannten Wiener-Prozessen auf.Ein Wiener-Prozess ist ein stochastischer Prozess X(t), t ≥ 0 mit stetiger Zeit, d.h. furjedes t gibt es eine Zufallsvariable X(t). Eine der Annahmen des Wiener-Prozesses ist,dass die Zuwachse X(t) − X(s) fur s < t normalverteilt sind. Wiener-Prozesse fan-den zunachst Anwendung in der Physik, wo die Bewegung eines kleinen Teilchensbeschrieben wurde, das einer großen Anzahl kleiner Stoße ausgesetzt ist. In diesemZusammenhang spricht man von einer Brownschen Bewegung. Wiener-Prozesse wer-den aber auch als Modell fur Aktienkurse angewendet und wurden z.B. bei der Her-leitung der Black-Scholes-Formel verwendet, deren Erfinder 1997 mit dem Nobelpreisfur Wirtschaftswissenschaften ausgezeichnet wurden.
Aufgrund ihrer angenehmen Eigenschaften und der weit entwickelten Theorie wird die An-nahme einer Normalverteilung in vielen statistischen Verfahren, wie Varianzanalyse, Regres-sionsanalyse, Zeitreihenanalyse, Diskriminanzanalyse usw. verwendet. Ein weiterer Vorteilist es, dass die unter der Annahme der Normalverteilung entwickelten Test- und Schatzver-fahren relativ unempfindlich gegenuber Abweichungen von dieser Annahme sind. Man sagt,dass solche Verfahren robust sind. So kommt es z.B. beim t-Test zur Prufung der Hypothese,dass der Erwartungswert einen bestimmten Wert besitzt, nicht so sehr darauf an, dass dieeinzelnen Beobachtungen einer Normalverteilung entstammen, sondern mehr, dass der Mit-telwert normalverteilt ist, was aufgrund des zentralen Grenzwertsatzes zumindest fur großen gewahrleistet ist.
R-Befehle zur Normalverteilung
dnorm(x, mean=0, sd=1) berechnet die Dichtefunktion der Normalverteilungan der Stelle x, wobei x ein Vektor ist. Defaultmaßig (mean=0, sd=1) wird dieDichte der Standardnormalverteilung berechnet. Durch Veranderung der optionalenArgumente mean und sd kann die Dichtefunktion fur beliebige Parameter µ und σ2
berechnet werden. Dabei ist zu beachten, dass sd die Standardabweichung, also dieQuadratwurzel aus der Varianz σ2 ist. Der Erwartungswert µ ist durch mean anzuge-ben.

38 KAPITEL 3. STETIGE VERTEILUNGEN
pnorm(q, mean=0, sd=1) berechnet die Verteilungsfunktion der Normalvertei-lung mit dem Erwartungswert µ =mean und der Standardabweichung sd an der Stelleq, wobei q ein Vektor ist. Standardmaßig wird P (X ≤ q) berechnet. Mit dem zusatz-lichen Argument lower.tail=Fwird die Wahrscheinlichkeit P (X > q) berechnet.
qnorm(p, mean=0, sd=1) berechnet die Umkehrfunktion der Verteilungsfunk-tion der Normalverteilung mit dem Erwartungswert µ =mean und der Standardabwei-chung sd an der Stelle p, wobei p ein Vektor von Wahrscheinlichkeiten, also Zahlenzwischen 0 und 1, ist. Auch hier kann das Argument lower.tail verwendet wer-den.
rnorm(n, mean=0, sd=1)] erzeugt n normalverteilte Zufallszahlen mit demErwartungswert µ =mean und der Standardabweichung sd.
3.3 Gammaverteilung
Definition 3.3 Die Gammafunktion ist fur ν > 0 definiert durch das Integral
Γ(ν) =
∞∫
0
tν−1e−tdt . (3.3)
Fur ν = 1 ergibt sich
Γ(1) =
∞∫
0
e−tdt = 1 .
Wir wenden fur ν > 1 auf das Integral in Gleichung (3.3) die Regel der partiellen Integration(siehe Gleichung (3.2)) an. Dabei setzen wir
v(t) = tν−1 =⇒ v′(t) = (ν − 1)tν−2
und
w′(t) = e−t =⇒ w(t) = −e−t .
Damit folgt
Γ(ν) = −tν−1e−t |∞0︸ ︷︷ ︸
0
−
−∞∫
0
(ν − 1)tν−2e−tdt
= (ν − 1)
∞∫
0
tν−2e−tdt
︸ ︷︷ ︸
Γ(ν−1)
.
Das bedeutet
Γ(ν) = (ν − 1)Γ(ν − 1) .
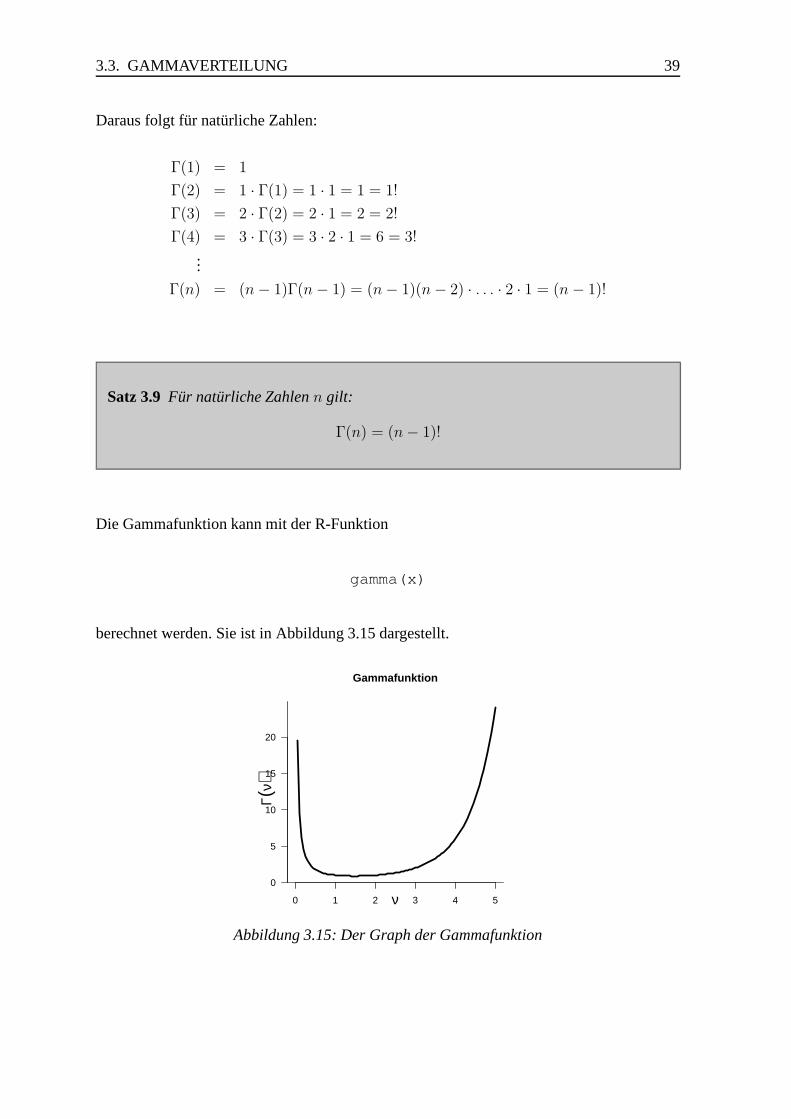
3.3. GAMMAVERTEILUNG 39
Daraus folgt fur naturliche Zahlen:
Γ(1) = 1
Γ(2) = 1 · Γ(1) = 1 · 1 = 1 = 1!
Γ(3) = 2 · Γ(2) = 2 · 1 = 2 = 2!
Γ(4) = 3 · Γ(3) = 3 · 2 · 1 = 6 = 3!...
Γ(n) = (n − 1)Γ(n − 1) = (n − 1)(n − 2) · . . . · 2 · 1 = (n − 1)!
Satz 3.9 Fur naturliche Zahlen n gilt:
Γ(n) = (n − 1)!
Die Gammafunktion kann mit der R-Funktion
gamma(x)
berechnet werden. Sie ist in Abbildung 3.15 dargestellt.
0 1 2 3 4 5
0
5
10
15
20
ν
Γ(ν)
Gammafunktion
Abbildung 3.15: Der Graph der Gammafunktion

40 KAPITEL 3. STETIGE VERTEILUNGEN
Definition 3.4 Die Dichtefunktion der Gammaverteilung ist gegeben durch
fX(x) =
λνxν−1e−λx
Γ(ν)x ≥ 0
0 sonst .(3.4)
Dabei sind ν und λ Parameter, fur die gelten muss
ν > 0 und λ > 0 .
Wir schreibenX ∼ G(ν; λ) ,
wenn eine Zufallsvariable X eine Gammaverteilung besitzt.
Wir wollen nachweisen, dass durch Gleichung (3.7) tatsachlich eine Dichtefunktion definiertwird, d.h. dass das Integral
∞∫
0
λνxν−1e−λx
Γ(ν)dx =
1
Γ(ν)
∞∫
0
λνxν−1e−λxdx =1
Γ(ν)
∞∫
0
(λx)ν−1e−λxλdx (3.5)
den Wert 1 hat, d.h. das ganz rechts stehende Integral muss Γ(ν) ergeben.
Wir verwenden die Substitution
t = λx =⇒ dt = λdx .
Die Grenzen andern sich wie folgt:
• Wenn x = 0, ist t = 0 .
• Wenn x → ∞, gilt auch t → ∞ .
Damit ergibt sich fur das obige Integral in Gleichung (3.5)
1
Γ(ν)
∞∫
0
tν−1e−tdt
︸ ︷︷ ︸
Γ(ν)
= 1 .
♦Einen wichtigen Spezialfall der Gammaverteilung erhalten wir, wenn der Parameter ν denWert 1 hat. Dann ist
fX(x) =λ1x1−1e−λx
Γ(1)= λe−λx fur x ≥ 0 .
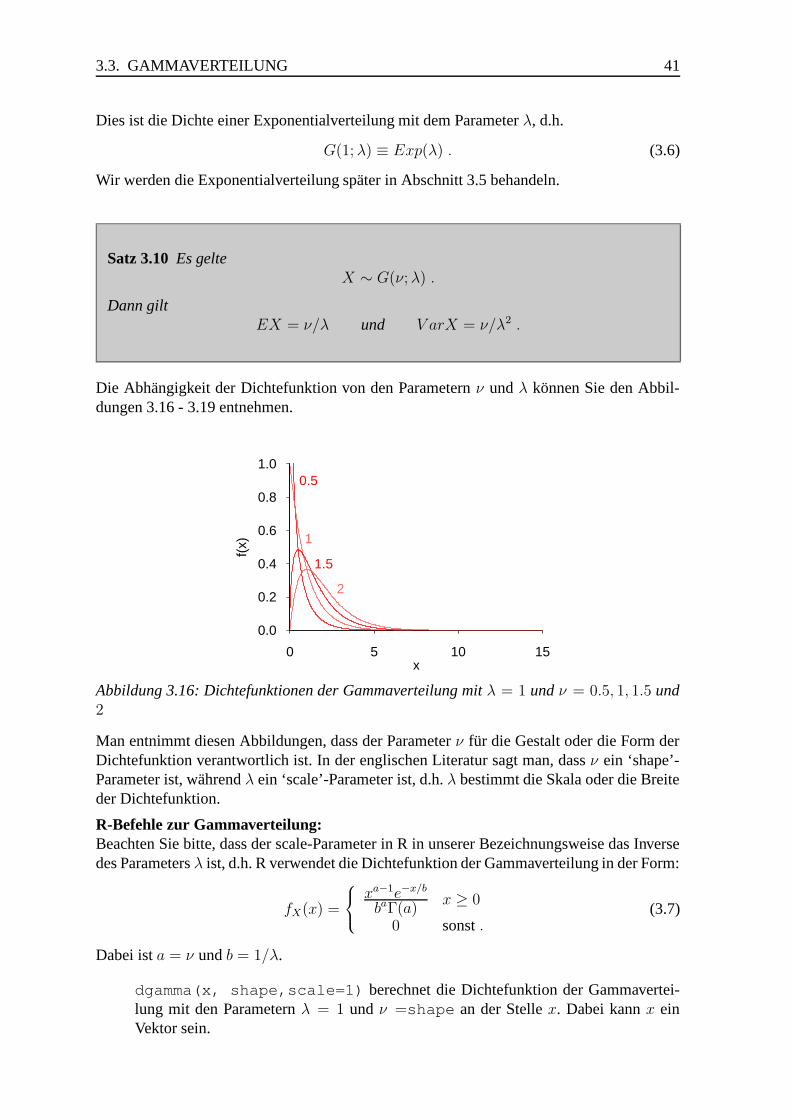
3.3. GAMMAVERTEILUNG 41
Dies ist die Dichte einer Exponentialverteilung mit dem Parameter λ, d.h.
G(1; λ) ≡ Exp(λ) . (3.6)
Wir werden die Exponentialverteilung spater in Abschnitt 3.5 behandeln.
Satz 3.10 Es gelteX ∼ G(ν; λ) .
Dann giltEX = ν/λ und V arX = ν/λ2 .
Die Abhangigkeit der Dichtefunktion von den Parametern ν und λ konnen Sie den Abbil-dungen 3.16 - 3.19 entnehmen.
f(x)
0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
x
0.5
1
1.5
2
Abbildung 3.16: Dichtefunktionen der Gammaverteilung mit λ = 1 und ν = 0.5, 1, 1.5 und2
Man entnimmt diesen Abbildungen, dass der Parameter ν fur die Gestalt oder die Form derDichtefunktion verantwortlich ist. In der englischen Literatur sagt man, dass ν ein ‘shape’-Parameter ist, wahrend λ ein ‘scale’-Parameter ist, d.h. λ bestimmt die Skala oder die Breiteder Dichtefunktion.
R-Befehle zur Gammaverteilung:Beachten Sie bitte, dass der scale-Parameter in R in unserer Bezeichnungsweise das Inversedes Parameters λ ist, d.h. R verwendet die Dichtefunktion der Gammaverteilung in der Form:
fX(x) =
xa−1e−x/b
baΓ(a)x ≥ 0
0 sonst .(3.7)
Dabei ist a = ν und b = 1/λ.
dgamma(x, shape,scale=1) berechnet die Dichtefunktion der Gammavertei-lung mit den Parametern λ = 1 und ν =shape an der Stelle x. Dabei kann x einVektor sein.
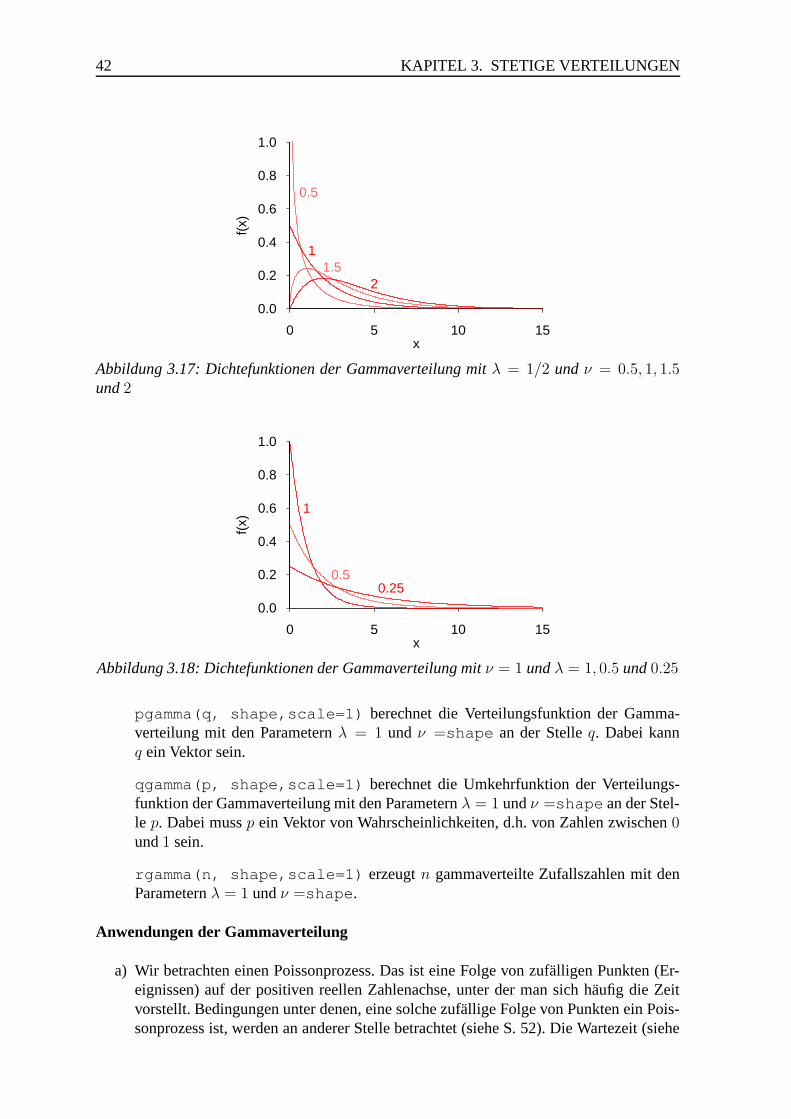
42 KAPITEL 3. STETIGE VERTEILUNGEN
f(x)
0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
x
0.5
11.5
2
Abbildung 3.17: Dichtefunktionen der Gammaverteilung mit λ = 1/2 und ν = 0.5, 1, 1.5und 2
f(x)
0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
x
1
0.50.25
Abbildung 3.18: Dichtefunktionen der Gammaverteilung mit ν = 1 und λ = 1, 0.5 und 0.25
pgamma(q, shape,scale=1) berechnet die Verteilungsfunktion der Gamma-verteilung mit den Parametern λ = 1 und ν =shape an der Stelle q. Dabei kannq ein Vektor sein.
qgamma(p, shape,scale=1) berechnet die Umkehrfunktion der Verteilungs-funktion der Gammaverteilung mit den Parametern λ = 1 und ν =shape an der Stel-le p. Dabei muss p ein Vektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0und 1 sein.
rgamma(n, shape,scale=1) erzeugt n gammaverteilte Zufallszahlen mit denParametern λ = 1 und ν =shape.
Anwendungen der Gammaverteilung
a) Wir betrachten einen Poissonprozess. Das ist eine Folge von zufalligen Punkten (Er-eignissen) auf der positiven reellen Zahlenachse, unter der man sich haufig die Zeitvorstellt. Bedingungen unter denen, eine solche zufallige Folge von Punkten ein Pois-sonprozess ist, werden an anderer Stelle betrachtet (siehe S. 52). Die Wartezeit (siehe
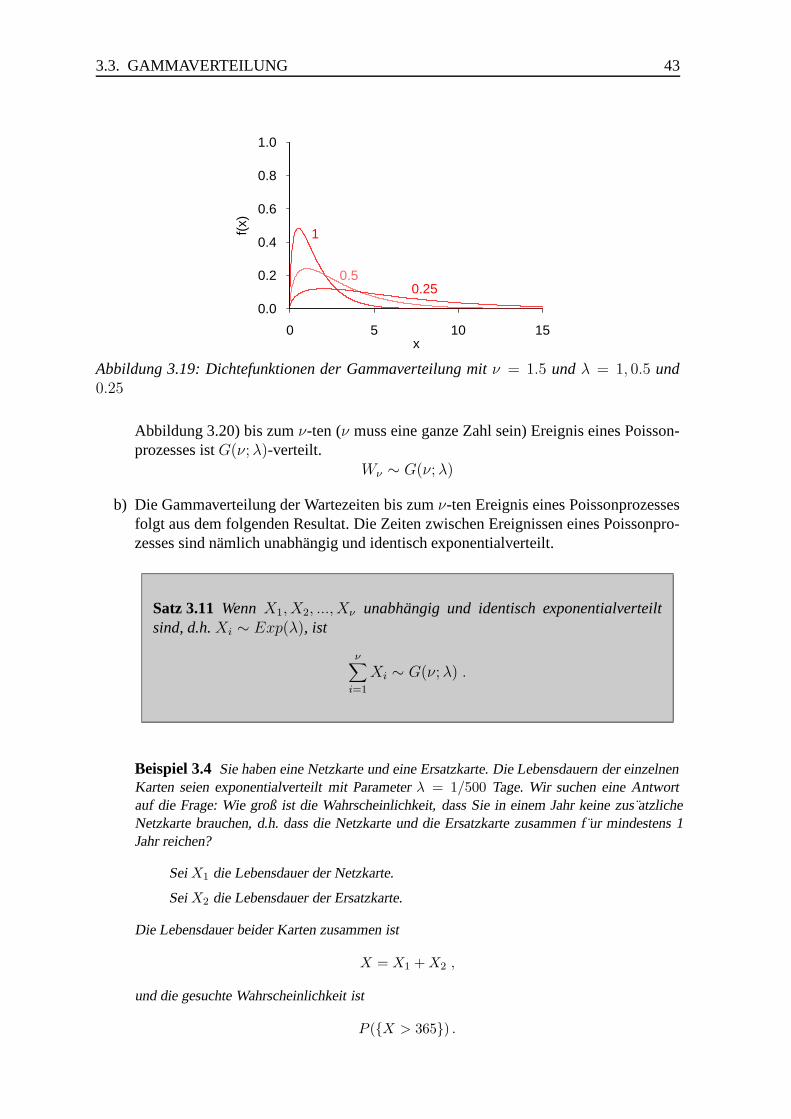
3.3. GAMMAVERTEILUNG 43
f(x)
0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
x
1
0.50.25
Abbildung 3.19: Dichtefunktionen der Gammaverteilung mit ν = 1.5 und λ = 1, 0.5 und0.25
Abbildung 3.20) bis zum ν-ten (ν muss eine ganze Zahl sein) Ereignis eines Poisson-prozesses ist G(ν; λ)-verteilt.
Wν ∼ G(ν; λ)
b) Die Gammaverteilung der Wartezeiten bis zum ν-ten Ereignis eines Poissonprozessesfolgt aus dem folgenden Resultat. Die Zeiten zwischen Ereignissen eines Poissonpro-zesses sind namlich unabhangig und identisch exponentialverteilt.
Satz 3.11 Wenn X1, X2, ..., Xν unabhangig und identisch exponentialverteiltsind, d.h. Xi ∼ Exp(λ), ist
ν∑
i=1
Xi ∼ G(ν; λ) .
Beispiel 3.4 Sie haben eine Netzkarte und eine Ersatzkarte. Die Lebensdauern der einzelnenKarten seien exponentialverteilt mit Parameter λ = 1/500 Tage. Wir suchen eine Antwortauf die Frage: Wie groß ist die Wahrscheinlichkeit, dass Sie in einem Jahr keine zus atzlicheNetzkarte brauchen, d.h. dass die Netzkarte und die Ersatzkarte zusammen f ur mindestens 1Jahr reichen?
Sei X1 die Lebensdauer der Netzkarte.
Sei X2 die Lebensdauer der Ersatzkarte.
Die Lebensdauer beider Karten zusammen ist
X = X1 + X2 ,
und die gesuchte Wahrscheinlichkeit ist
P (X > 365) .

44 KAPITEL 3. STETIGE VERTEILUNGEN
Zeit
W1
W2
W3
Poissonprozess
Abbildung 3.20: Wartezeiten bei einem Poissonprozess
Aufgrund unserer Annahmen uber die Verteilungen von X1 und X2 und des Satzes 3.11 gilt
X ∼ G(2; 1/500) .
Abbildung 3.21 zeigt die Dichtefunktion von X und die gesuchte Wahrscheinlichkeit als schraf-fierte Fl ache unterhalb der Dichtefunktion. Sie k onnen diese Wahrscheinlichkeit mit dem R-Befehl
1-pgamma (365, 2, 500)
oder
pgamma(365,2,500,lower.tail=F)
berechnen.
Es giltP (X > 365) = 0.8337 .
c) Fur ganzzahliges ν wird die Gammaverteilung (G(ν; λ)) auch als Erlangverteilungbezeichnet.
3.4 Chiquadratverteilung
Die aus der Grundvorlesung bekannte Chiquadratverteilung ist ein Spezialfall der Gamma-verteilung.
Satz 3.12 Die Gammaverteilung mit den Parametern ν = n/2 und λ = 1/2 stimmt mitder χ2-Verteilung mit dem Parameter n uberein. Dabei ist n eine positive ganze Zahl.

3.4. CHIQUADRATVERTEILUNG 45
10 0
00*f
(x)
0 1000 2000 3000 4000 5000
0
1
2
3
4
5
6
7
8
x
P(X>365)
Abbildung 3.21: P (X > 365) als Flache unterhalb der Dichtefunktion
Die χ2-Verteilung hat einen Parameter n. Wir schreiben
X ∼ χ2n oder X ∼ χ2(n) ,
wenn X eine χ2-Verteilung mit dem Parameter n besitzt und sagen: X hat eine χ2-Verteilungmit n Freiheitsgraden.
Die Dichtefunktion der χ2-Verteilung mit n Freiheitsgraden ist
f(x) =
xn/2−1e−x/2
2n/2Γ(n/2)x ≥ 0
0 sonst .
Aus Satz 3.10 erhalten wir sofort:
Satz 3.13 SeiX ∼ χ2
n .
Dann giltEX = n und V arX = 2n .
Beweis:
Nach Satz 3.12 giltχ2
n ≡ G(n/2; 1/2) .
Erwartungswert und Varianz einer Gammaverteilung waren in Satz 3.10 angegeben. Mitν = n/2 und λ = 1/2 folgt
EX =ν
λ=
n/2
1/2= n
und
V arX =ν
λ2=
n/2
(1/2)2= 2n .
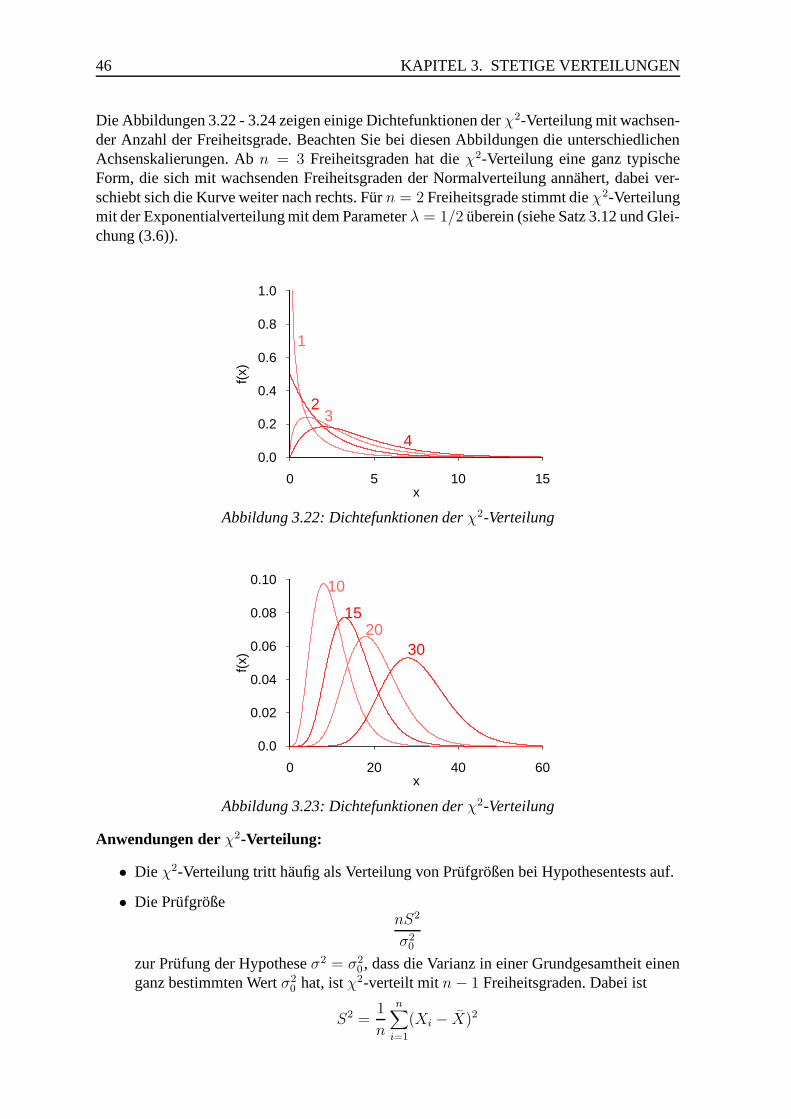
46 KAPITEL 3. STETIGE VERTEILUNGEN
Die Abbildungen 3.22 - 3.24 zeigen einige Dichtefunktionen der χ2-Verteilung mit wachsen-der Anzahl der Freiheitsgrade. Beachten Sie bei diesen Abbildungen die unterschiedlichenAchsenskalierungen. Ab n = 3 Freiheitsgraden hat die χ2-Verteilung eine ganz typischeForm, die sich mit wachsenden Freiheitsgraden der Normalverteilung annahert, dabei ver-schiebt sich die Kurve weiter nach rechts. Fur n = 2 Freiheitsgrade stimmt die χ2-Verteilungmit der Exponentialverteilung mit dem Parameter λ = 1/2 uberein (siehe Satz 3.12 und Glei-chung (3.6)).
f(x)
0 5 10 15
0.0
0.2
0.4
0.6
0.8
1.0
x
1
23
4
Abbildung 3.22: Dichtefunktionen der χ2-Verteilung
f(x)
0 20 40 60
0.0
0.02
0.04
0.06
0.08
0.10
x
10
1520
30
Abbildung 3.23: Dichtefunktionen der χ2-Verteilung
Anwendungen der χ2-Verteilung:
• Die χ2-Verteilung tritt haufig als Verteilung von Prufgroßen bei Hypothesentests auf.
• Die PrufgroßenS2
σ20
zur Prufung der Hypothese σ2 = σ20 , dass die Varianz in einer Grundgesamtheit einen
ganz bestimmten Wert σ20 hat, ist χ2-verteilt mit n − 1 Freiheitsgraden. Dabei ist
S2 =1
n
n∑
i=1
(Xi − X)2
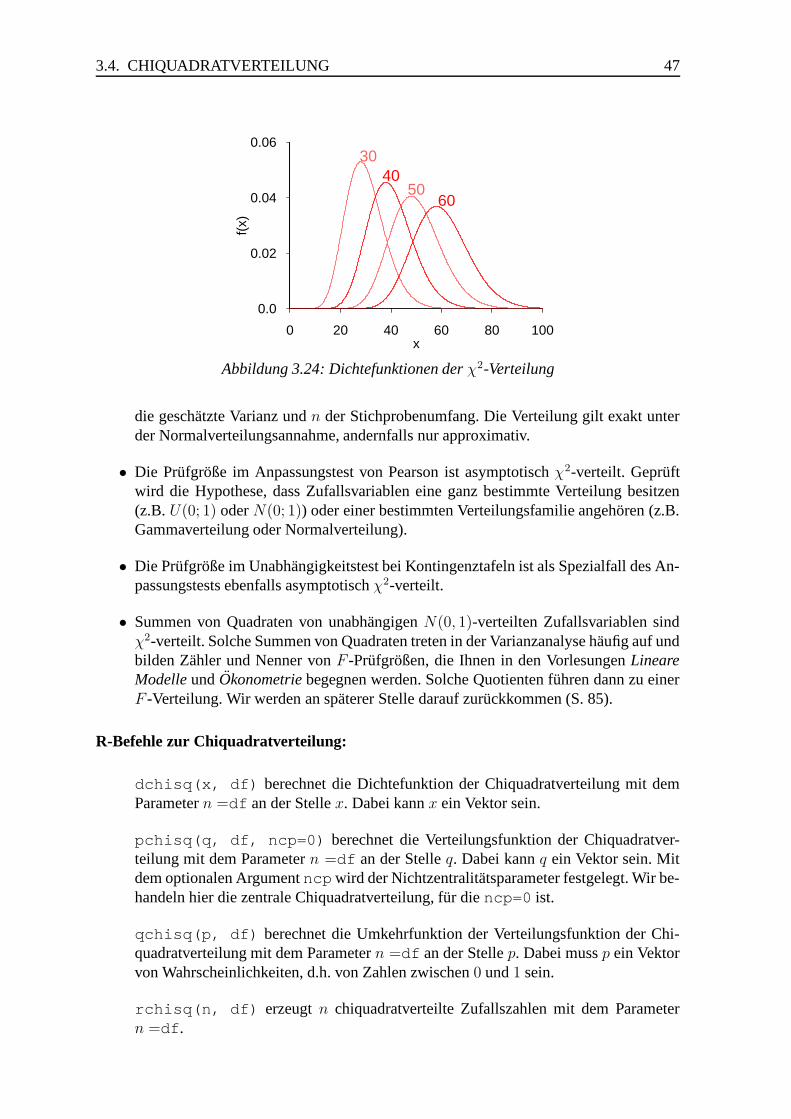
3.4. CHIQUADRATVERTEILUNG 47
f(x)
0 20 40 60 80 100
0.0
0.02
0.04
0.06
x
3040
5060
Abbildung 3.24: Dichtefunktionen der χ2-Verteilung
die geschatzte Varianz und n der Stichprobenumfang. Die Verteilung gilt exakt unterder Normalverteilungsannahme, andernfalls nur approximativ.
• Die Prufgroße im Anpassungstest von Pearson ist asymptotisch χ2-verteilt. Gepruftwird die Hypothese, dass Zufallsvariablen eine ganz bestimmte Verteilung besitzen(z.B. U(0; 1) oder N(0; 1)) oder einer bestimmten Verteilungsfamilie angehoren (z.B.Gammaverteilung oder Normalverteilung).
• Die Prufgroße im Unabhangigkeitstest bei Kontingenztafeln ist als Spezialfall des An-passungstests ebenfalls asymptotisch χ2-verteilt.
• Summen von Quadraten von unabhangigen N(0, 1)-verteilten Zufallsvariablen sindχ2-verteilt. Solche Summen von Quadraten treten in der Varianzanalyse haufig auf undbilden Zahler und Nenner von F -Prufgroßen, die Ihnen in den Vorlesungen LineareModelle und Okonometrie begegnen werden. Solche Quotienten fuhren dann zu einerF -Verteilung. Wir werden an spaterer Stelle darauf zuruckkommen (S. 85).
R-Befehle zur Chiquadratverteilung:
dchisq(x, df) berechnet die Dichtefunktion der Chiquadratverteilung mit demParameter n =df an der Stelle x. Dabei kann x ein Vektor sein.
pchisq(q, df, ncp=0) berechnet die Verteilungsfunktion der Chiquadratver-teilung mit dem Parameter n =df an der Stelle q. Dabei kann q ein Vektor sein. Mitdem optionalen Argument ncpwird der Nichtzentralitatsparameter festgelegt. Wir be-handeln hier die zentrale Chiquadratverteilung, fur die ncp=0 ist.
qchisq(p, df) berechnet die Umkehrfunktion der Verteilungsfunktion der Chi-quadratverteilung mit dem Parameter n =df an der Stelle p. Dabei muss p ein Vektorvon Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rchisq(n, df) erzeugt n chiquadratverteilte Zufallszahlen mit dem Parametern =df.
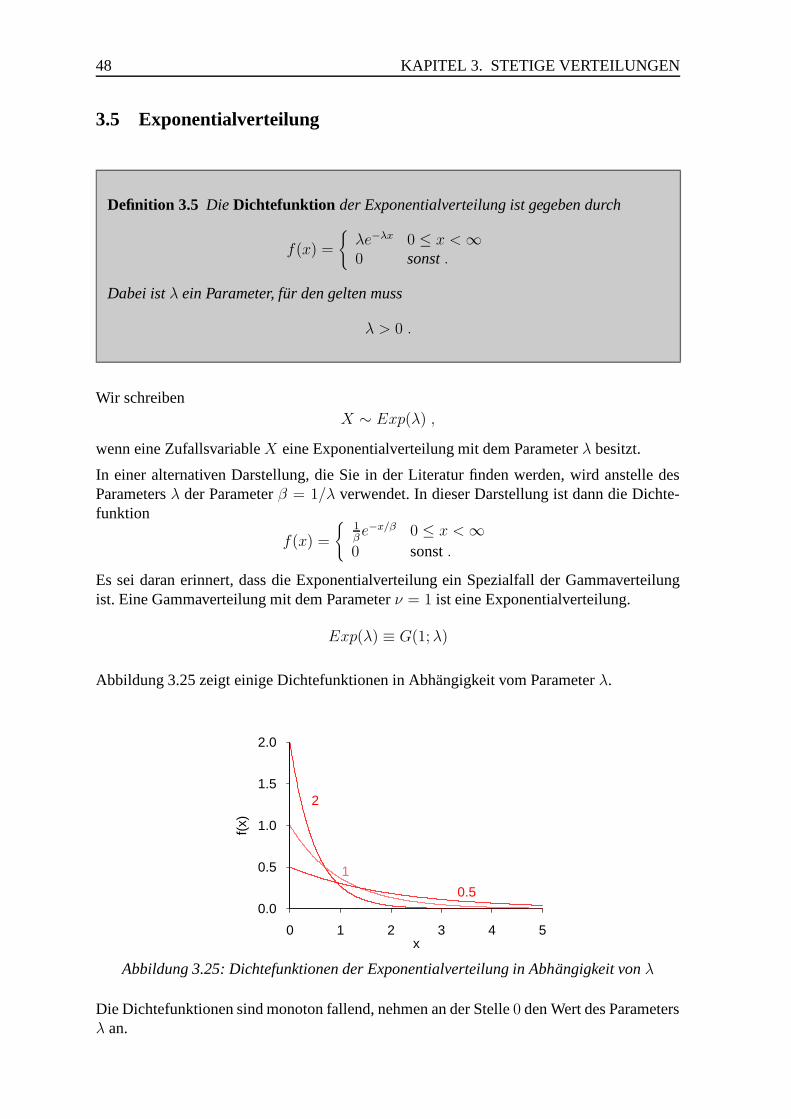
48 KAPITEL 3. STETIGE VERTEILUNGEN
3.5 Exponentialverteilung
Definition 3.5 Die Dichtefunktion der Exponentialverteilung ist gegeben durch
f(x) =
λe−λx 0 ≤ x < ∞0 sonst .
Dabei ist λ ein Parameter, fur den gelten muss
λ > 0 .
Wir schreibenX ∼ Exp(λ) ,
wenn eine Zufallsvariable X eine Exponentialverteilung mit dem Parameter λ besitzt.
In einer alternativen Darstellung, die Sie in der Literatur finden werden, wird anstelle desParameters λ der Parameter β = 1/λ verwendet. In dieser Darstellung ist dann die Dichte-funktion
f(x) =
1βe−x/β 0 ≤ x < ∞
0 sonst .
Es sei daran erinnert, dass die Exponentialverteilung ein Spezialfall der Gammaverteilungist. Eine Gammaverteilung mit dem Parameter ν = 1 ist eine Exponentialverteilung.
Exp(λ) ≡ G(1; λ)
Abbildung 3.25 zeigt einige Dichtefunktionen in Abhangigkeit vom Parameter λ.
f(x)
0 1 2 3 4 5
0.0
0.5
1.0
1.5
2.0
x
2
1
0.5
Abbildung 3.25: Dichtefunktionen der Exponentialverteilung in Abhangigkeit von λ
Die Dichtefunktionen sind monoton fallend, nehmen an der Stelle 0 den Wert des Parametersλ an.
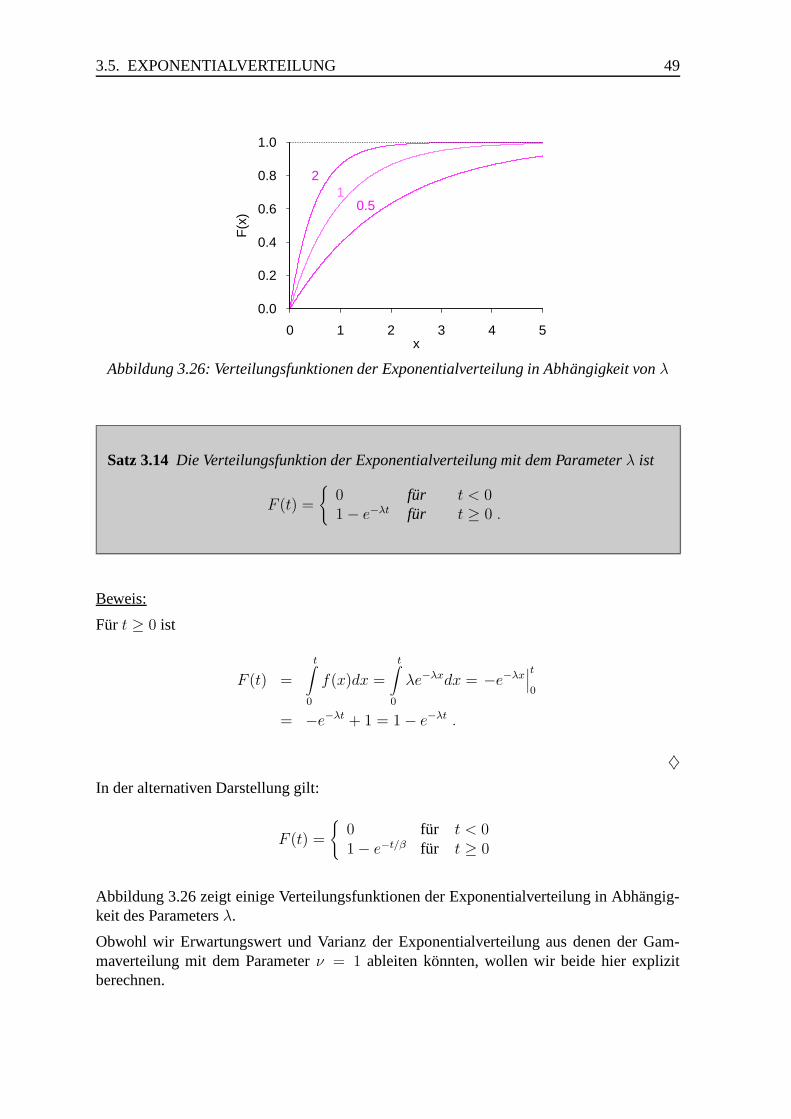
3.5. EXPONENTIALVERTEILUNG 49
F(x
)
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
x
21
0.5
Abbildung 3.26: Verteilungsfunktionen der Exponentialverteilung in Abhangigkeit von λ
Satz 3.14 Die Verteilungsfunktion der Exponentialverteilung mit dem Parameter λ ist
F (t) =
0 fur t < 01 − e−λt fur t ≥ 0 .
Beweis:
Fur t ≥ 0 ist
F (t) =
t∫
0
f(x)dx =
t∫
0
λe−λxdx = −e−λx∣∣∣
t
0
= −e−λt + 1 = 1 − e−λt .
♦In der alternativen Darstellung gilt:
F (t) =
0 fur t < 01 − e−t/β fur t ≥ 0
Abbildung 3.26 zeigt einige Verteilungsfunktionen der Exponentialverteilung in Abhangig-keit des Parameters λ.
Obwohl wir Erwartungswert und Varianz der Exponentialverteilung aus denen der Gam-maverteilung mit dem Parameter ν = 1 ableiten konnten, wollen wir beide hier explizitberechnen.

50 KAPITEL 3. STETIGE VERTEILUNGEN
Satz 3.15 Es gelteX ∼ Exp(λ) .
Dann gilt
EX =1
λund V arX =
1
λ2.
Beweis:
EX =
∞∫
−∞xfX(x)dx =
∞∫
0
xλe−λxdx
Wir verwenden die Regel der partiellen Integration (siehe Gleichung (3.2) und setzen dabei
• v(x) = x =⇒ v′(x) = 1
• w′(x) = λe−λx =⇒ w(x) = −e−λx
Damit gilt
EX = −xe−λx∣∣∣
∞
0︸ ︷︷ ︸
=0
−∞∫
0
(−e−λx)dx
=1
λ
∞∫
0
λe−λxdx
︸ ︷︷ ︸
=1
=1
λ.
Dabei wurde benutzt (siehe Formel (7.11.4) in Sydsæter und Hammond (2003)) , dass
limx→∞
xe−λx = 0
und dass das Integral uber eine Dichtefunktion 1 ergibt.
Durch zweimalige Anwendung der partiellen Integration erhalt man
EX2 =
∞∫
0
x2λe−λxdx = 2/λ2
und damit nach Satz 2.2
V arX = EX2 − (EX)2 = 2/λ2 − (1/λ)2 = 1/λ2
♦In der alternativen Darstellung gilt
EX = β und V arX = β2 .
Anwendungen der Exponentialverteilung:

3.5. EXPONENTIALVERTEILUNG 51
a) Die Exponentialverteilung ist ein nutzliches Modell fur die Lebensdauer von Teilen,die nicht wesentlich ,,altern”, wie elektronische Komponenten oder Fensterscheiben.In diesem Zusammenhang ist die Exponentialverteilung durch die folgende Eigen-schaft charakterisiert:
Satz 3.16 (Markoffsche Eigenschaft) Sei X die Lebensdauer eines Teiles. DieZufallsvariable X ist genau dann exponentialverteilt, wenn fur alle x und x0
P (X > x + x0|X > x0) = P (X > x) (3.8)
gilt.
Dieser Satz besagt, dass man Individuen (Teilen), deren Lebensdauer einer Exponenti-alverteilung folgt, ihr Alter nicht anmerkt. Gleichung (3.8) bedeutet, dass die bedingteWahrscheinlichkeit, den Zeitpunkt x + x0 zu uberleben, wenn man weiß, dass derZeitpunkt x0 bereits uberlebt wurde, genau so groß ist wie die Wahrscheinlichkeit, denZeitpunkt x (von 0 ausgehend) zu uberleben. Das bisher erreichte Alter des Individu-ums hat also keinen Einfluss auf die weiteren Uberlebenswahrscheinlichkeiten, z.B.gilt
P (X > (3 + 2) Jahre|X > 2 Jahre) = P (X > 3 Jahre) .
Das bedeutet die Wahrscheinlichkeit
P (Ein zwei Jahre altes Teil halt sich noch drei weitere Jahre )
ist gleich der Wahrscheinlichkeit
P (Ein neues Teil halt sich drei Jahre ) .
Die Exponentialverteilung ist also eine Verteilung ohne Gedachtnis.
Auch Gegenstande, die sich wenig verandern, z. B. Teller, haben eine exponentialver-teilte Lebensdauer.
b) Die Zeitintervalle zwischen Ereignissen eines Poissonprozesses sind exponentialver-teilt. Typischerweise sind dies die folgenden Ereignisse: Unfalle, Nachfrage bestimm-ter Produkte, Sturme, Fluten, Telefonanrufe, radioaktiver Zerfall, usw..
Wir wollen die fur einen Poissonprozess charakteristischen Eigenschaften in der fol-genden Definition zusammenfassen.

52 KAPITEL 3. STETIGE VERTEILUNGEN
Definition 3.6 Ein Poissonprozess liegt vor, wenn die folgenden Eigenschaftenerfullt sind
i) Die Wahrscheinlichkeit, dass ein Ereignis in einem Intervall der Lange ∆tvorkommt, ist λ∆t, wobei λ eine Konstante ist.
ii) Die Wahrscheinlichkeit, dass zwei oder mehr Ereignisse in einem Intervallder Lange ∆t vorkommen, ist klein im Vergleich zu λ∆t.
lim∆t→0
P (2 oder mehr Ereignisse in ∆t)P (1 Ereignis in ∆t) = 0
iii) Die Ereignisse treten unabhangig auf.
Satz 3.17 Die Zeit zwischen zwei Ereignissen in einem Poissonprozess ist expo-nentialverteilt mit dem Parameter λ.
Beweis:
Betrachten Sie die Abbildung 3.27. Dort sind zwei Ereignisse durch das Zeichen ∗dargestellt.
| | | | | | | | | | | | | | | | | | | | |
123 n
X
Abbildung 3.27: Zeitintervall zwischen zwei Ereignissen in einem Poissonprozess
Sei X das Zeitintervall zwischen diesen beiden Ereignissen. Die Zeitachse ist in klei-ne Intervalle der Lange ∆t aufgeteilt. Die Anzahl der Teilintervalle zwischen diesenbeiden Ereignissen sei n. Wir mussen zeigen, dass die Verteilungsfunktion von X dieeiner Exponentialverteilung ist (siehe Satz 3.14). Aquivalent dazu ist der Nachweis,dass P (X > x), diese Funktion bezeichnet man auch als Uberlebenszeitfunktion,gegeben ist durch
P (X > x) =
0 fur x < 0e−λx fur x ≥ 0
Fur x > 0 gilt
P (X > x) = P (kein Ereignis in Intervall 1 und
kein Ereignis in Intervall 2 und...
kein Ereignis in Intervall n)

3.6. BETAVERTEILUNG 53
= P (kein Ereignis in Intervall 1) ·P (kein Ereignis in Intervall 2) ·
...
P (kein Ereignis in Intervall n)= (1 − λ∆t) · (1 − λ∆t) · . . . · (1 − λ∆t)
︸ ︷︷ ︸
n
= (1 − λ∆t)n = (1 − λ∆t)x/∆t .
Nun gilt (siehe z.B. Sydsæter und Hammond (2003), Formel (6.11.4) oder (7.10.1))
lim∆t→0
(1 − λ∆t)x/∆t = e−λx .
Damit gilt fur x > 0
F (x) = P (X ≤ x) = 1 − P (X > x) = 1 − e−λx .
♦
R-Befehle zur Exponentialverteilung:
dexp(x, rate=1) berechnet die Dichtefunktion der Exponentialverteilung mit demParameter λ =rate=1 an der Stelle x. Dabei kann x ein Vektor sein.
pexp(q, rate=1) berechnet die Verteilungsfunktion der Exponentialverteilungmit dem Parameter λ =rate an der Stelle q. Dabei kann q ein Vektor sein.
qexp(p, rate=1) berechnet die Umkehrfunktion der Verteilungsfunktion der Ex-ponentialverteilung mit dem Parameter λ =rate an der Stelle p. Dabei muss p einVektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rexp(n, rate=1) erzeugt n exponentialverteilte Zufallszahlen mit dem Parameterλ =rate.
3.6 Betaverteilung
Definition 3.7 Die Betafunktion ist definiert durch
B(α, β) =
1∫
0
tα−1(1 − t)β−1dt α > 0 β > 0
=Γ(α)Γ(β)
Γ(α + β).
Es gibt eine R-Funktion beta(a,b), die die Betafunktion nach der obigen Formel berech-net.

54 KAPITEL 3. STETIGE VERTEILUNGEN
Definition 3.8 Die Dichtefunktion der Betaverteilung ist gegeben durch
fX(x) =
xα−1(1−x)β−1
B(α,β)0 ≤ x ≤ 1
0 sonst .
Die Betaverteilung hat zwei Parameter, fur die gelten muss
α > 0 und β > 0 .
Wir schreiben
X ∼ Be(α; β) ,
wenn X eine Betaverteilung mit den Parametern α und β besitzt.
Die Verteilungsfunktion ist fur 0 < x < 1 gleich
FX(x) =1
B(α, β)
x∫
0
tα−1(1 − t)β−1dt .
Das Integral auf der rechten Seite der obigen Gleichung ist auch als unvollstandiger Beta-funktions-Quotient (,,incomplete beta function ratio”) bekannt. Wir werden die Verteilungs-funktion bei Bedarf mit R berechnen (siehe unten).
Satz 3.18 Die Zufallsvariable X sei betaverteilt mit den Parametern α und β. Dann gilt
E(X) =α
α + βund V arX =
αβ
(α + β)2(α + β + 1).
Beweis:
Im folgenden Beweis benutzen wir den Zusammenhang zwischen der Betafunktion und derGammafunktion (siehe Definition 3.7).
EX =
1∫
0
xf(x)dx =
1∫
0
xα−1+1(1 − x)β−1
B(α, β)dx =
B(α + 1, β)
B(α, β)
=Γ(α + 1)Γ(β)
Γ(α + 1 + β)· Γ(α + β)
Γ(α)Γ(β)=
αΓ(α)Γ(α + β)
Γ(α)Γ(α + β)(α + β)
=α
α + β

3.6. BETAVERTEILUNG 55
EX2 =
1∫
0
x2f(x)dx =
1∫
0
xα−1+2(1 − x)β−1
B(α, β)dx =
B(α + 2, β)
B(α, β)
=Γ(α + 2)Γ(β)
Γ(α + 2 + β)· Γ(α + β)
Γ(α)Γ(β)=
(α + 1)αΓ(α)Γ(α + β)
Γ(α)Γ(α + β)(α + 1 + β)(α + β)
=(α + 1)α
(α + 1 + β)(α + β)
Mit Satz 2.2 folgt
V arX = EX2 − (EX)2 =(α + 1)α
(α + 1 + β)(α + β)−(
α
α + β
)2
=(α + 1)α(α + β) − α2(α + 1 + β)
(α + 1 + β)(α + β)2
=α3 + α2 + α2β + αβ − α3 − α2 − α2β
(α + β)2(α + β + 1)=
αβ
(α + β)2(α + β + 1).
♦Abbildung 3.28 zeigt einige Dichtefunktionen der Betaverteilung. Diese Abbildung machtdeutlich, wie verschieden die Gestalt der Dichtefunktion in Abhangigkeit der beiden Para-meter sein kann. Fur α = 1 und β = 1 ergibt sich als Spezialfall die RechteckverteilungU(0; 1). Fur α = β ist die Dichtefunktion symmetrisch zu einer senkrechten Achse durchx = 0.5. Vertauscht man α und β, so wird die Dichtefunktion an der gleichen Achse gespie-gelt.
Die Betaverteilung kann auch in Abhangigkeit von den Parametern µ und θ dargestellt wer-den, wobei
µ = E(X) und θ =1
α + β.
Da die Betaverteilung nur Werte im Intervall [0, 1] annehmen kann, α > 0 und β > 0 sind,gilt
0 < µ < 1 und θ > 0 .
Da E(X) = α/(α + β) ist, gilt
µ =α
α + βund θ =
1
α + β.
Umgekehrt gilt:α = µ/θ und β = (1 − µ)/θ .
Mit diesen neuen Parametern gilt
E(X) = µ und Var(X) = µ(1 − µ)θ/(1 + θ) .
Der Parameter θ ist ein Formparameter. Er bestimmt die Gestalt der Dichtefunktion.
Abbildung 3.29 zeigt Dichtefunktionen der Betaverteilung in Abhangigkeit von diesen Para-metern.
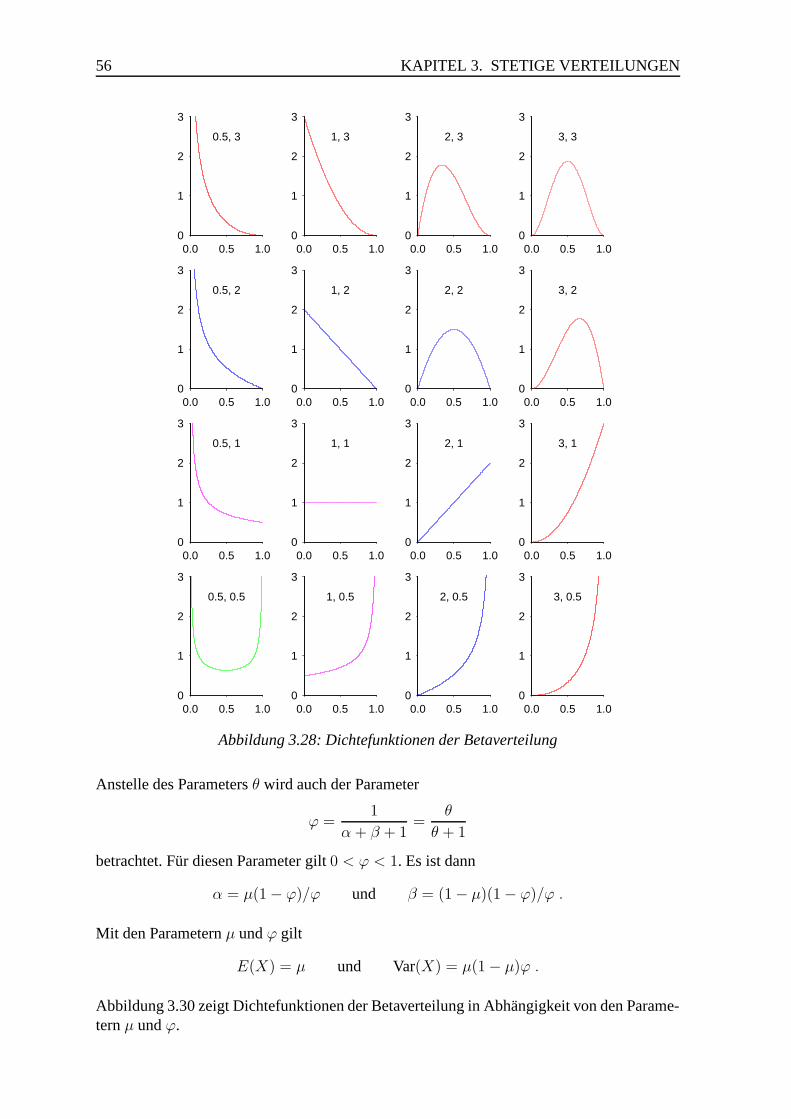
56 KAPITEL 3. STETIGE VERTEILUNGEN
0.0 0.5 1.00
1
2
3
0.5, 3
0.0 0.5 1.00
1
2
3
1, 3
0.0 0.5 1.00
1
2
3
2, 3
0.0 0.5 1.00
1
2
3
3, 3
0.0 0.5 1.00
1
2
3
0.5, 2
0.0 0.5 1.00
1
2
3
1, 2
0.0 0.5 1.00
1
2
3
2, 2
0.0 0.5 1.00
1
2
3
3, 2
0.0 0.5 1.00
1
2
3
0.5, 1
0.0 0.5 1.00
1
2
3
1, 1
0.0 0.5 1.00
1
2
3
2, 1
0.0 0.5 1.00
1
2
3
3, 1
0.0 0.5 1.00
1
2
3
0.5, 0.5
0.0 0.5 1.00
1
2
3
1, 0.5
0.0 0.5 1.00
1
2
3
2, 0.5
0.0 0.5 1.00
1
2
3
3, 0.5
Abbildung 3.28: Dichtefunktionen der Betaverteilung
Anstelle des Parameters θ wird auch der Parameter
ϕ =1
α + β + 1=
θ
θ + 1
betrachtet. Fur diesen Parameter gilt 0 < ϕ < 1. Es ist dann
α = µ(1 − ϕ)/ϕ und β = (1 − µ)(1 − ϕ)/ϕ .
Mit den Parametern µ und ϕ gilt
E(X) = µ und Var(X) = µ(1 − µ)ϕ .
Abbildung 3.30 zeigt Dichtefunktionen der Betaverteilung in Abhangigkeit von den Parame-tern µ und ϕ.
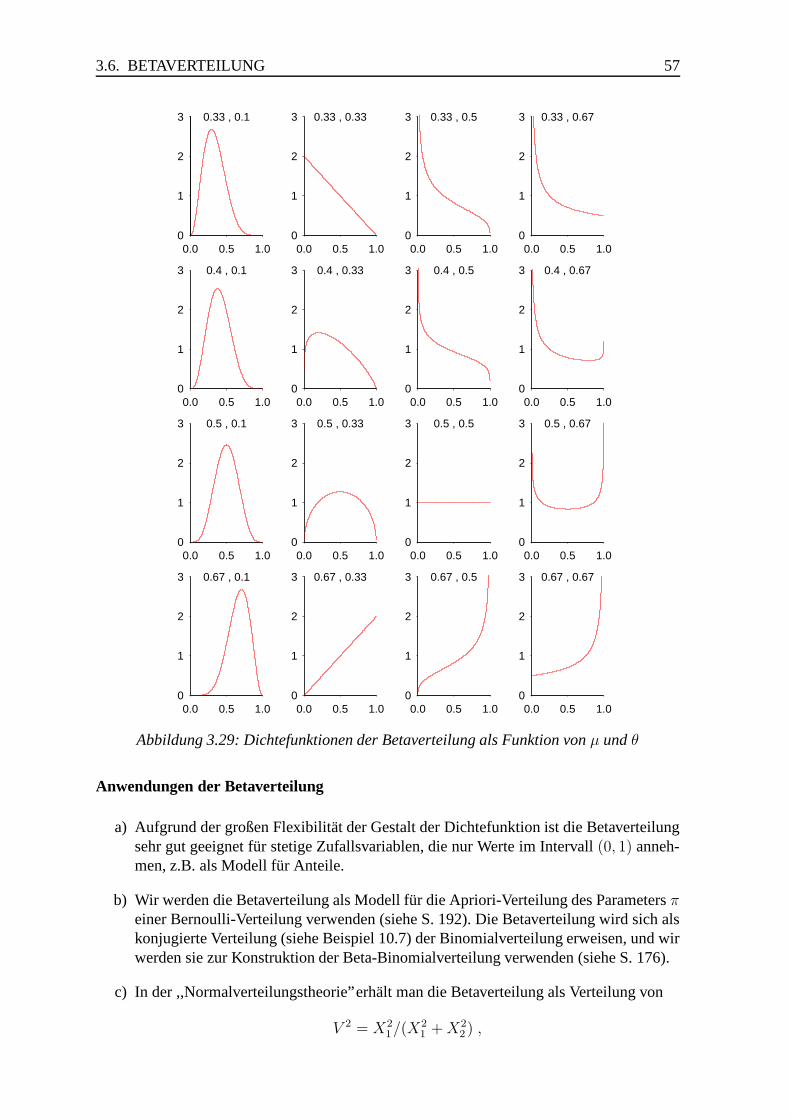
3.6. BETAVERTEILUNG 57
0.0 0.5 1.00
1
2
3 0.33 , 0.1
0.0 0.5 1.00
1
2
3 0.33 , 0.33
0.0 0.5 1.00
1
2
3 0.33 , 0.5
0.0 0.5 1.00
1
2
3 0.33 , 0.67
0.0 0.5 1.00
1
2
3 0.4 , 0.1
0.0 0.5 1.00
1
2
3 0.4 , 0.33
0.0 0.5 1.00
1
2
3 0.4 , 0.5
0.0 0.5 1.00
1
2
3 0.4 , 0.67
0.0 0.5 1.00
1
2
3 0.5 , 0.1
0.0 0.5 1.00
1
2
3 0.5 , 0.33
0.0 0.5 1.00
1
2
3 0.5 , 0.5
0.0 0.5 1.00
1
2
3 0.5 , 0.67
0.0 0.5 1.00
1
2
3 0.67 , 0.1
0.0 0.5 1.00
1
2
3 0.67 , 0.33
0.0 0.5 1.00
1
2
3 0.67 , 0.5
0.0 0.5 1.00
1
2
3 0.67 , 0.67
Abbildung 3.29: Dichtefunktionen der Betaverteilung als Funktion von µ und θ
Anwendungen der Betaverteilung
a) Aufgrund der großen Flexibilitat der Gestalt der Dichtefunktion ist die Betaverteilungsehr gut geeignet fur stetige Zufallsvariablen, die nur Werte im Intervall (0, 1) anneh-men, z.B. als Modell fur Anteile.
b) Wir werden die Betaverteilung als Modell fur die Apriori-Verteilung des Parameters πeiner Bernoulli-Verteilung verwenden (siehe S. 192). Die Betaverteilung wird sich alskonjugierte Verteilung (siehe Beispiel 10.7) der Binomialverteilung erweisen, und wirwerden sie zur Konstruktion der Beta-Binomialverteilung verwenden (siehe S. 176).
c) In der ,,Normalverteilungstheorie” erhalt man die Betaverteilung als Verteilung von
V 2 = X21/(X2
1 + X22 ) ,
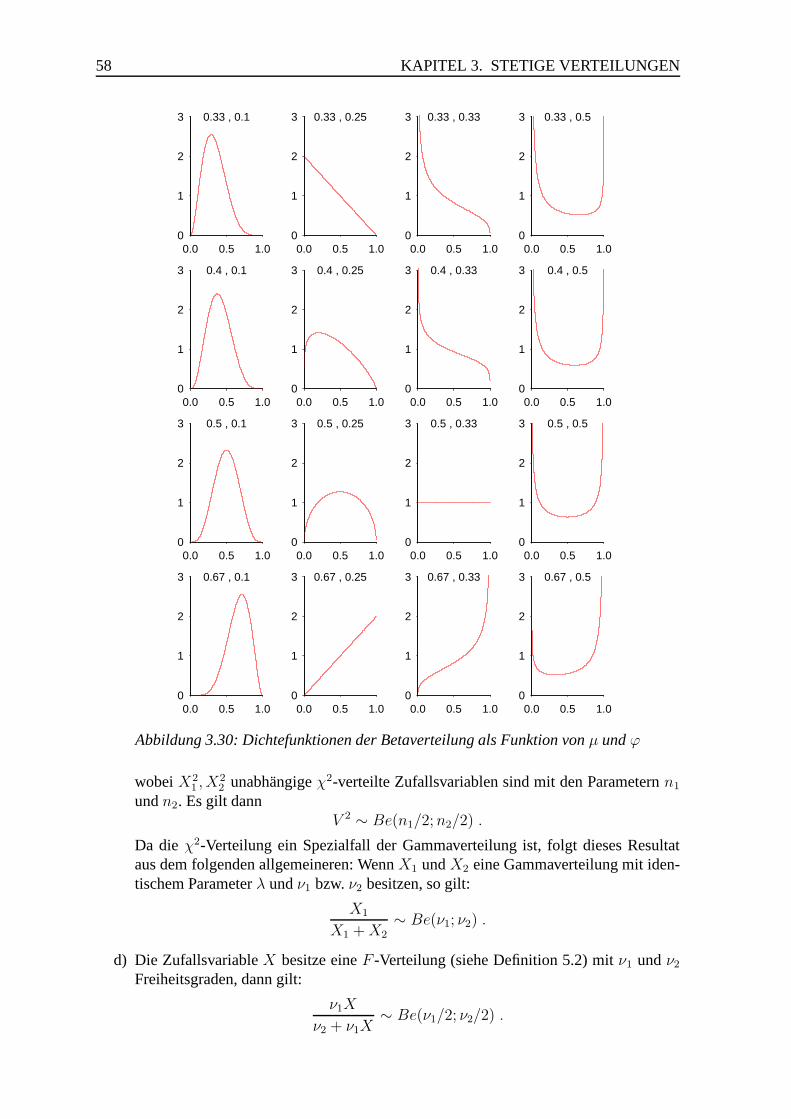
58 KAPITEL 3. STETIGE VERTEILUNGEN
0.0 0.5 1.00
1
2
3 0.33 , 0.1
0.0 0.5 1.00
1
2
3 0.33 , 0.25
0.0 0.5 1.00
1
2
3 0.33 , 0.33
0.0 0.5 1.00
1
2
3 0.33 , 0.5
0.0 0.5 1.00
1
2
3 0.4 , 0.1
0.0 0.5 1.00
1
2
3 0.4 , 0.25
0.0 0.5 1.00
1
2
3 0.4 , 0.33
0.0 0.5 1.00
1
2
3 0.4 , 0.5
0.0 0.5 1.00
1
2
3 0.5 , 0.1
0.0 0.5 1.00
1
2
3 0.5 , 0.25
0.0 0.5 1.00
1
2
3 0.5 , 0.33
0.0 0.5 1.00
1
2
3 0.5 , 0.5
0.0 0.5 1.00
1
2
3 0.67 , 0.1
0.0 0.5 1.00
1
2
3 0.67 , 0.25
0.0 0.5 1.00
1
2
3 0.67 , 0.33
0.0 0.5 1.00
1
2
3 0.67 , 0.5
Abbildung 3.30: Dichtefunktionen der Betaverteilung als Funktion von µ und ϕ
wobei X21 , X
22 unabhangige χ2-verteilte Zufallsvariablen sind mit den Parametern n1
und n2. Es gilt dannV 2 ∼ Be(n1/2; n2/2) .
Da die χ2-Verteilung ein Spezialfall der Gammaverteilung ist, folgt dieses Resultataus dem folgenden allgemeineren: Wenn X1 und X2 eine Gammaverteilung mit iden-tischem Parameter λ und ν1 bzw. ν2 besitzen, so gilt:
X1
X1 + X2∼ Be(ν1; ν2) .
d) Die Zufallsvariable X besitze eine F -Verteilung (siehe Definition 5.2) mit ν1 und ν2
Freiheitsgraden, dann gilt:
ν1X
ν2 + ν1X∼ Be(ν1/2; ν2/2) .

3.6. BETAVERTEILUNG 59
e) Fur α = β = 1/2 ergibt sich als Spezialfall die Arcus-Sinus-Verteilung, die in derTheorie der ,,random walks” Anwendung findet. Erfullen die Parameter α + β = 1(jedoch α 6= 1/2), so spricht man auch von einer verallgemeinerten Arcus-Sinus-Verteilung.
f) Seien U1, U2, . . . Un unabhangig und identisch U(0, 1)-verteilt. Ordnet man die Reali-sationen u1, u2, . . . , un der Große nach, so dass
u(1) ≤ u(2) ≤ u(3) ≤ . . . ≤ u(n) ,
so nennt man die durch diese Umordnung neu entstehenden Zufallsvariablen
U(i), i = 1, 2, . . . , n
die i-ten Ordnungsstatistiken, die ganz allgemein bei der Konstruktion verteilungsfrei-er Verfahren Anwendung finden. Unter der obigen Annahme der Rechteckverteilungfur Ui gilt
U(i) ∼ Be(i; n − i + 1) .
R-Befehle zur Betaverteilung:
dbeta(x, shape1, shape2) berechnet die Dichtefunktion der Betaverteilungmit den Parametern α =shape1 und β =shape2 an der Stelle x. Dabei kann x einVektor sein.
pbeta(q, shape1, shape2) berechnet die Verteilungsfunktion der Betavertei-lung mit den Parametern α =shape1 und β =shape2 an der Stelle q. Dabei kann qein Vektor sein.
qbeta(p, shape1, shape2) berechnet die Umkehrfunktion der Verteilungs-funktion der Betaverteilung mit den Parametern α =shape1 und β =shape2 an derStelle p. Dabei muss p ein Vektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen0 und 1 sein.
rbeta(n, shape1, shape2) erzeugt n betaverteilte Zufallszahlen mit den Pa-rametern α =shape1 und β =shape2.

Kapitel 4
Diskrete Verteilungen
4.1 Bernoulli-Verteilung
Definition 4.1 Die Wahrscheinlichkeitsfunktion der Bernoulli-Verteilung ist gegebendurch
PX(x) =
1 − π fur x = 0π fur x = 10 sonst .
Die Bernoulli-Verteilung hat einen Parameter π, fur den gelten muss
0 < π < 1 .
Wir schreiben
X ∼ Ber(π) ,
wenn eine Zufallsvariable X eine Bernoulli-Verteilung besitzt. Eine Bernoulli-verteilte Zu-fallsvariable X nimmt nur die zwei Werte 0 und 1 an. Dabei spricht man von einem Erfolg,wenn X = 1 ist und von einem Misserfolg, wenn X = 0 ist, wobei mit Erfolg nicht immerein ,,positives” Ereignis im gewohnlichen Sprachgebrauch gemeint ist.
1ErfolgMisserfolg
0
1−ππ
Abbildung 4.1: Wahrscheinlichkeitsfunktion der Bernoulli-Verteilung
60

4.2. BINOMIALVERTEILUNG 61
Satz 4.1 Es gelteX ∼ Ber(π) .
Dann gilt fur den Erwartungswert und die Varianz
EX = π und V ar(X) = π − π2 = π(1 − π) .
In Anwendungen der Bernoulli-Verteilung ist die Erfolgswahrscheinlichkeit π gleich einemAnteil in einer Grundgesamtheit (z.B. Besitzt einen Fernseher, kauft ein Produkt, ist krank,wahlt ,,Ja” usw.).
4.2 Binomialverteilung
Definition 4.2 Die Wahrscheinlichkeitsfunktion der Binomialverteilung ist gegebendurch
PX(x) =
(nx
)
πx(1 − π)n−x x = 0, 1, 2, ..., n
0 sonst .
Die Binomialverteilung hat zwei Parameter n und π, fur die gelten muss
n ∈ IN und 0 < π < 1 .
Wir schreibenX ∼ b(n; π) ,
wenn die Zufallsvariable X eine Binomialverteilung besitzt.
Satz 4.2 Es gelteX ∼ b(n; π) .
Dann gilt fur den Erwartungswert und die Varianz
EX = nπ und V arX = nπ(1 − π) .
Die Abbildungen 4.2 - 4.4 zeigen einige Wahrscheinlichkeitsfunktionen der Binomialver-teilung. Achten Sie auf die Symmetrie und die Annaherung an die Normalverteilung mitwachsendem n.
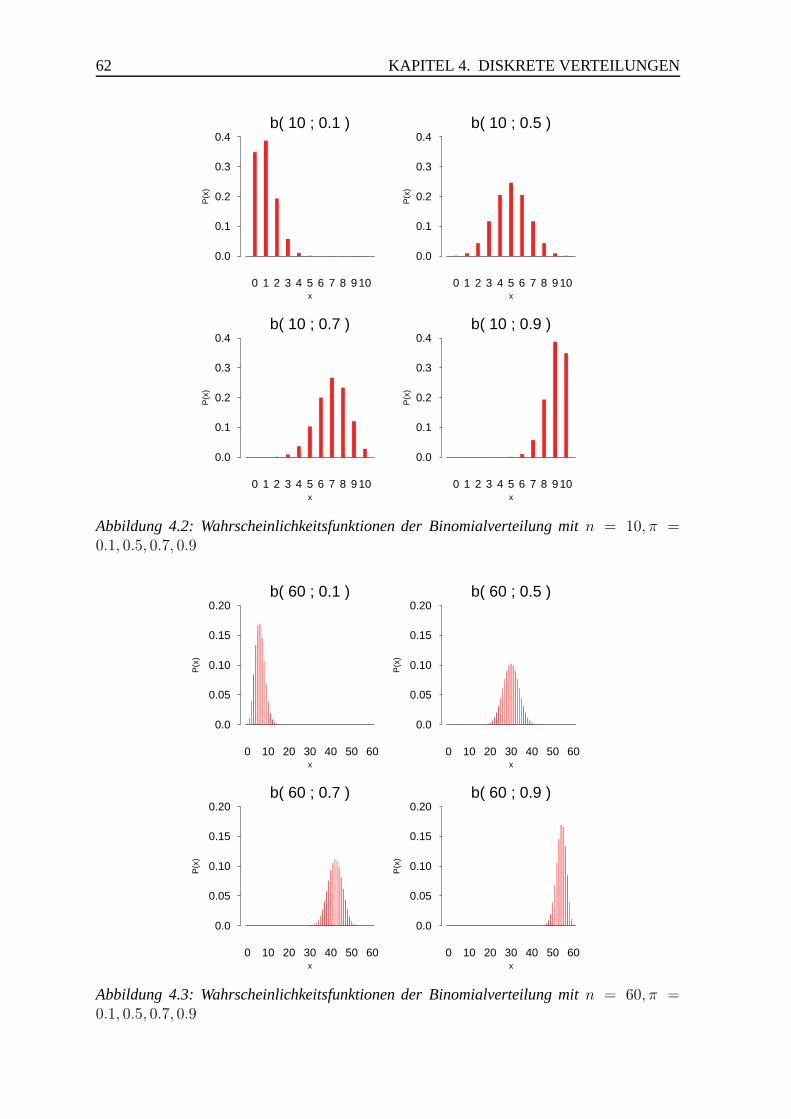
62 KAPITEL 4. DISKRETE VERTEILUNGEN
0 1 2 3 4 5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4
P
(x)
x
b( 10 ; 0.1 )
0 1 2 3 4 5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4
b( 10 ; 0.5 )
P(x
)
x
0 1 2 3 4 5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4
b( 10 ; 0.7 )
P(x
)
x
0 1 2 3 4 5 6 7 8 9 10
0.0
0.1
0.2
0.3
0.4
b( 10 ; 0.9 )
P(x
)
x
Abbildung 4.2: Wahrscheinlichkeitsfunktionen der Binomialverteilung mit n = 10, π =0.1, 0.5, 0.7, 0.9
0 10 20 30 40 50 60
0.0
0.05
0.10
0.15
0.20
P
(x)
x
b( 60 ; 0.1 )
0 10 20 30 40 50 60
0.0
0.05
0.10
0.15
0.20
P
(x)
x
b( 60 ; 0.5 )
0 10 20 30 40 50 60
0.0
0.05
0.10
0.15
0.20
P
(x)
x
b( 60 ; 0.7 )
0 10 20 30 40 50 60
0.0
0.05
0.10
0.15
0.20
P
(x)
x
b( 60 ; 0.9 )
Abbildung 4.3: Wahrscheinlichkeitsfunktionen der Binomialverteilung mit n = 60, π =0.1, 0.5, 0.7, 0.9
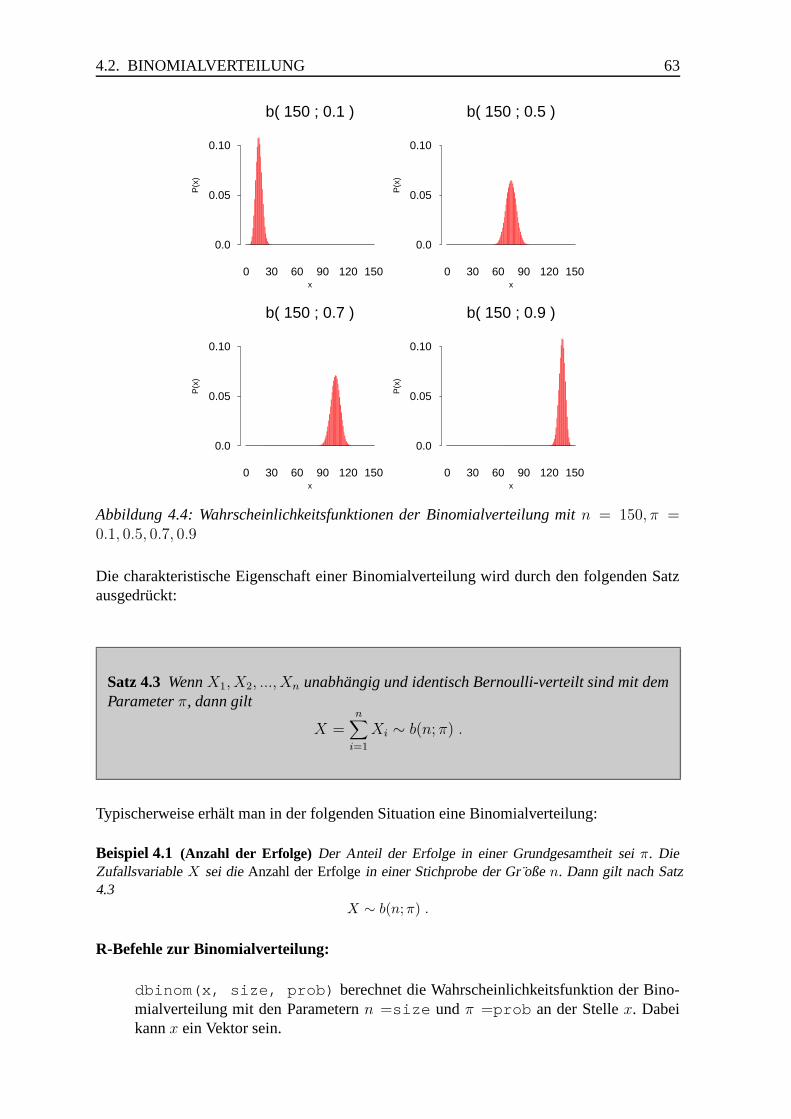
4.2. BINOMIALVERTEILUNG 63
0 30 60 90 120 150
0.0
0.05
0.10
P
(x)
x
b( 150 ; 0.1 )
0 30 60 90 120 150
0.0
0.05
0.10
P
(x)
x
b( 150 ; 0.5 )
0 30 60 90 120 150
0.0
0.05
0.10
P
(x)
x
b( 150 ; 0.7 )
0 30 60 90 120 150
0.0
0.05
0.10
P
(x)
x
b( 150 ; 0.9 )
Abbildung 4.4: Wahrscheinlichkeitsfunktionen der Binomialverteilung mit n = 150, π =0.1, 0.5, 0.7, 0.9
Die charakteristische Eigenschaft einer Binomialverteilung wird durch den folgenden Satzausgedruckt:
Satz 4.3 Wenn X1, X2, ..., Xn unabhangig und identisch Bernoulli-verteilt sind mit demParameter π, dann gilt
X =n∑
i=1
Xi ∼ b(n; π) .
Typischerweise erhalt man in der folgenden Situation eine Binomialverteilung:
Beispiel 4.1 (Anzahl der Erfolge) Der Anteil der Erfolge in einer Grundgesamtheit sei π. DieZufallsvariable X sei die Anzahl der Erfolge in einer Stichprobe der Gr oße n. Dann gilt nach Satz4.3
X ∼ b(n;π) .
R-Befehle zur Binomialverteilung:
dbinom(x, size, prob) berechnet die Wahrscheinlichkeitsfunktion der Bino-mialverteilung mit den Parametern n =size und π =prob an der Stelle x. Dabeikann x ein Vektor sein.

64 KAPITEL 4. DISKRETE VERTEILUNGEN
pbinom(q, size, prob) berechnet die Verteilungsfunktion der Binomialvertei-lung mit den Parametern n =size und π =prob an der Stelle q. Dabei kann q einVektor sein.
qbinom(p, size, prob) berechnet die Umkehrfunktion der Verteilungsfunkti-on der Binomialverteilung mit den Parametern n =size und π =prob an der Stellep. Dabei muss p ein Vektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und1 sein.
rbinom(n, size, prob) erzeugt n binomialverteilte Zufallszahlen mit den Pa-rametern n =size und π =prob.
choose(n,k) berechnet den Binomialkoeffizienten(
nx
)
.
4.3 Geometrische Verteilung
Definition 4.3 Die Wahrscheinlichkeitsfunktion der geometrischen Verteilung ist gege-ben durch
PX(x) =
(1 − π)xπ x = 0, 1, 2, ...0 sonst .
Die geometrische Verteilung hat einen Parameter π, fur den gelten muss 0 < π < 1.
Wir schreibenX ∼ Ge(π) ,
wenn die Zufallsvariable X eine geometrische Verteilung besitzt.
Satz 4.4 Es gelte X ∼ Ge(π) . Dann gilt fur den Erwartungswert und die Varianz
EX =1 − π
πund V arX =
1 − π
π2.
Beispiel 4.2 (Anzahl der Misserfolge vor dem ersten Erfolg) Unabh angige Bernoulli-Experimentewerden solange durchgef uhrt, bis der erste Erfolg eintritt. Die Zufallsvariable X sei die Anzahl derMisserfolge vor dem ersten Erfolg bei diesen Bernoulli-Experimenten. Dann gilt
X ∼ Ge(π) .
In der anschließenden Berechnung der Wahrscheinlichkeitsfunktion werde ein Erfolg mit ,,E” und einMisserfolg mit ,,M” bezeichnet.
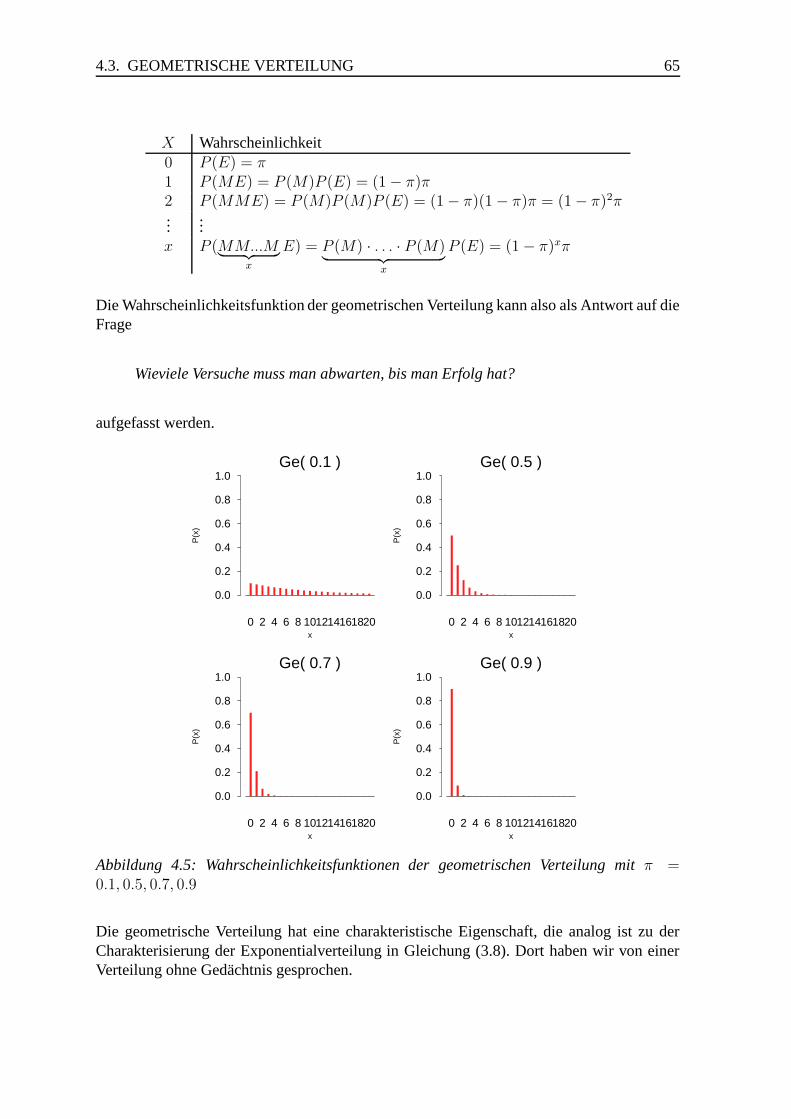
4.3. GEOMETRISCHE VERTEILUNG 65
X Wahrscheinlichkeit0 P (E) = π1 P (ME) = P (M)P (E) = (1 − π)π2 P (MME) = P (M)P (M)P (E) = (1 − π)(1 − π)π = (1 − π)2π...
...x P (MM...M
︸ ︷︷ ︸
x
E) = P (M) · . . . · P (M)︸ ︷︷ ︸
x
P (E) = (1 − π)xπ
Die Wahrscheinlichkeitsfunktion der geometrischen Verteilung kann also als Antwort auf dieFrage
Wieviele Versuche muss man abwarten, bis man Erfolg hat?
aufgefasst werden.
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
0.8
1.0
P
(x)
x
Ge( 0.1 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
0.8
1.0
P
(x)
x
Ge( 0.5 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
0.8
1.0
P
(x)
x
Ge( 0.7 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
0.8
1.0
P
(x)
x
Ge( 0.9 )
Abbildung 4.5: Wahrscheinlichkeitsfunktionen der geometrischen Verteilung mit π =0.1, 0.5, 0.7, 0.9
Die geometrische Verteilung hat eine charakteristische Eigenschaft, die analog ist zu derCharakterisierung der Exponentialverteilung in Gleichung (3.8). Dort haben wir von einerVerteilung ohne Gedachtnis gesprochen.

66 KAPITEL 4. DISKRETE VERTEILUNGEN
Satz 4.5 (Markoffsche Eigenschaft) Die geometrische Verteilung ist charakterisiertdurch die Eigenschaft
P (X = x + x0|X ≥ x0) = P (X = x) .
Egal, wie viele Misserfolge man beim Warten auf den ersten Erfolg schon erlebt hat, dieVerteilung der noch folgenden Misserfolge vor dem ersten Erfolg andert sich dadurch nicht.
R-Befehle zur geometrischen Verteilung:
dgeom(x, prob) berechnet die Wahrscheinlichkeitsfunktion der geometrischen Ver-teilung mit dem Parameter π =prob an der Stelle x. Dabei kann x ein Vektor sein.
pgeom(q, prob) berechnet die Verteilungsfunktion der geometrischen Verteilungmit dem Parameter π =prob an der Stelle q. Dabei kann q ein Vektor sein.
qgeom(p, prob) berechnet die Umkehrfunktion der Verteilungsfunktion der geo-metrischen Verteilung mit dem Parameter π =prob an der Stelle p. Dabei muss p einVektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rgeom(n, prob) erzeugt n geometrisch verteilte Zufallszahlen mit dem Parameterπ =prob.
4.4 Die negative Binomialverteilung
Definition 4.4 Die Wahrscheinlichkeitsfunktion der negativen Binomialverteilung istgegeben durch
PX(x) =
(x+r−1
r−1
)
πr(1 − π)x x = 0, 1, 2, . . .
0 sonst .
Die negative Binomialverteilung hat zwei Parameter r und π, fur die gelten muss
r ∈ IN und 0 < π < 1 .
Wir schreiben
X ∼ NB(r; π) ,
wenn X eine negative Binomialverteilung mit den Parametern r und π besitzt.
Die negative Binomialverteilung tritt typischerweise in der folgenden Situation auf.
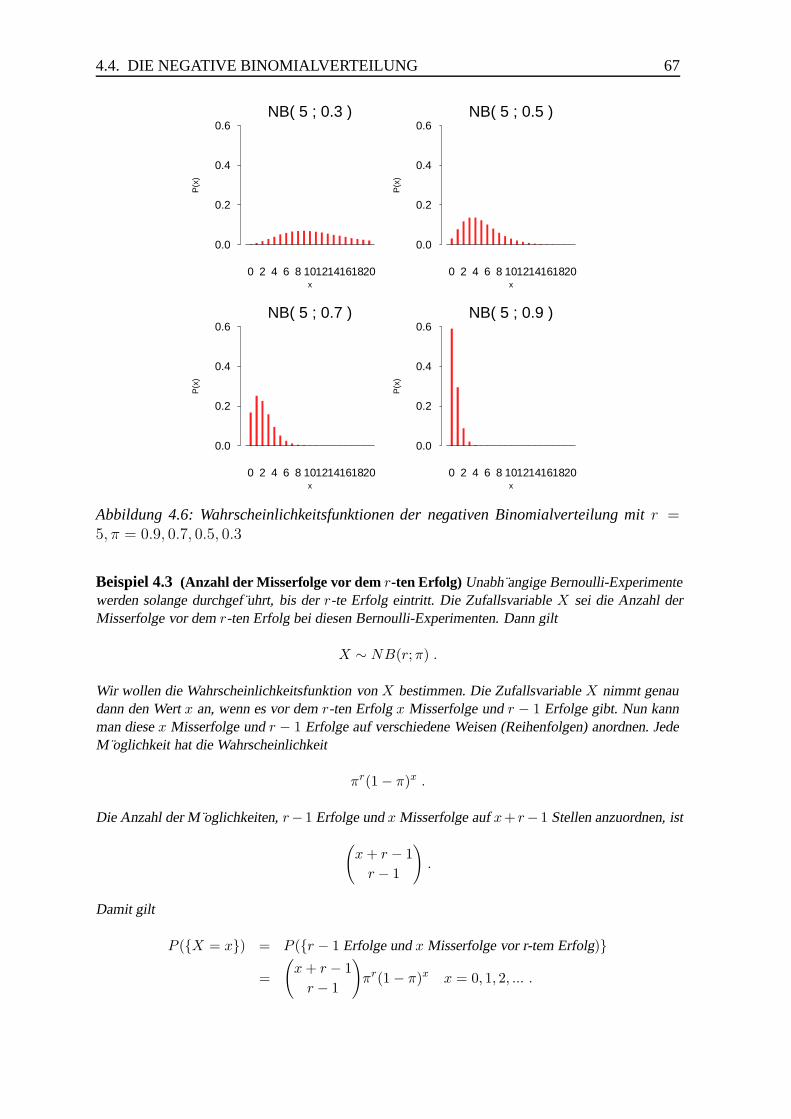
4.4. DIE NEGATIVE BINOMIALVERTEILUNG 67
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
P
(x)
x
NB( 5 ; 0.3 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
P
(x)
x
NB( 5 ; 0.5 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
P
(x)
x
NB( 5 ; 0.7 )
0 2 4 6 8 10 12 14 16 18 20
0.0
0.2
0.4
0.6
P
(x)
x
NB( 5 ; 0.9 )
Abbildung 4.6: Wahrscheinlichkeitsfunktionen der negativen Binomialverteilung mit r =5, π = 0.9, 0.7, 0.5, 0.3
Beispiel 4.3 (Anzahl der Misserfolge vor dem r-ten Erfolg) Unabh angige Bernoulli-Experimentewerden solange durchgef uhrt, bis der r-te Erfolg eintritt. Die Zufallsvariable X sei die Anzahl derMisserfolge vor dem r-ten Erfolg bei diesen Bernoulli-Experimenten. Dann gilt
X ∼ NB(r;π) .
Wir wollen die Wahrscheinlichkeitsfunktion von X bestimmen. Die Zufallsvariable X nimmt genaudann den Wert x an, wenn es vor dem r-ten Erfolg x Misserfolge und r − 1 Erfolge gibt. Nun kannman diese x Misserfolge und r − 1 Erfolge auf verschiedene Weisen (Reihenfolgen) anordnen. JedeM oglichkeit hat die Wahrscheinlichkeit
πr(1 − π)x .
Die Anzahl der M oglichkeiten, r− 1 Erfolge und x Misserfolge auf x+ r− 1 Stellen anzuordnen, ist
(
x + r − 1
r − 1
)
.
Damit gilt
P (X = x) = P (r − 1 Erfolge und x Misserfolge vor r-tem Erfolg)
=
(
x + r − 1
r − 1
)
πr(1 − π)x x = 0, 1, 2, ... .
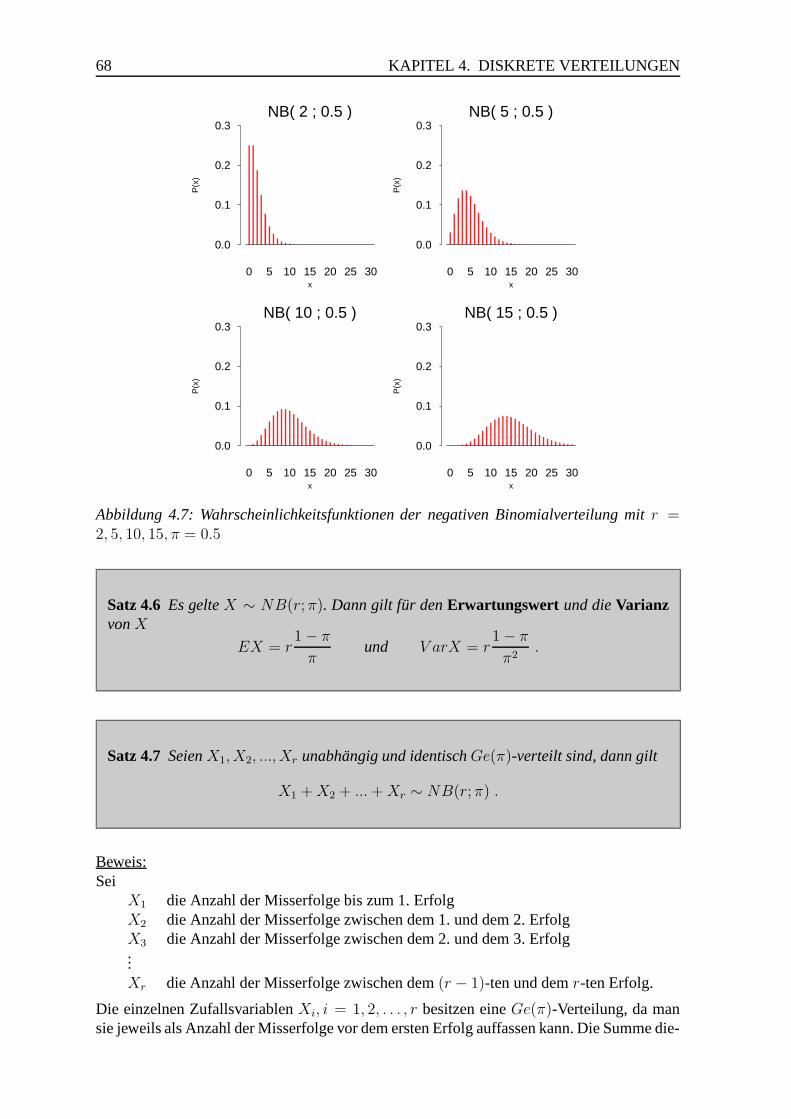
68 KAPITEL 4. DISKRETE VERTEILUNGEN
0 5 10 15 20 25 30
0.0
0.1
0.2
0.3
P
(x)
x
NB( 2 ; 0.5 )
0 5 10 15 20 25 30
0.0
0.1
0.2
0.3
P
(x)
x
NB( 5 ; 0.5 )
0 5 10 15 20 25 30
0.0
0.1
0.2
0.3
P
(x)
x
NB( 10 ; 0.5 )
0 5 10 15 20 25 30
0.0
0.1
0.2
0.3
P
(x)
x
NB( 15 ; 0.5 )
Abbildung 4.7: Wahrscheinlichkeitsfunktionen der negativen Binomialverteilung mit r =2, 5, 10, 15, π = 0.5
Satz 4.6 Es gelte X ∼ NB(r; π). Dann gilt fur den Erwartungswert und die Varianzvon X
EX = r1 − π
πund V arX = r
1 − π
π2.
Satz 4.7 Seien X1, X2, ..., Xr unabhangig und identisch Ge(π)-verteilt sind, dann gilt
X1 + X2 + ... + Xr ∼ NB(r; π) .
Beweis:Sei
X1 die Anzahl der Misserfolge bis zum 1. ErfolgX2 die Anzahl der Misserfolge zwischen dem 1. und dem 2. ErfolgX3 die Anzahl der Misserfolge zwischen dem 2. und dem 3. Erfolg...Xr die Anzahl der Misserfolge zwischen dem (r − 1)-ten und dem r-ten Erfolg.
Die einzelnen Zufallsvariablen Xi, i = 1, 2, . . . , r besitzen eine Ge(π)-Verteilung, da mansie jeweils als Anzahl der Misserfolge vor dem ersten Erfolg auffassen kann. Die Summe die-

4.4. DIE NEGATIVE BINOMIALVERTEILUNG 69
ser Zufallsvariablen ist die Anzahl der Misserfolge bis zum r-ten Erfolg und besitzt demnacheine NB(r; π)-Verteilung. ♦
Beispiel 4.4 Sei r = 3. Vor dem dritten Erfolg gebe es die folgende Anordnung von Erfolgen undMisserfolgen.
000︸︷︷︸
X1
1 0000︸ ︷︷ ︸
X2
1 0︸︷︷︸
X3
1
Dann ist die Anzahl der Misserfolge bis zum dritten Erfolg
X = 3 + 4 + 1 = 8 .
Die Abbildungen 4.6 und 4.7 zeigen die Vielseitigkeit der Gestalt der negativen Binomial-verteilung, die sich daher in Anwendungen gut zum Anpassen an gegebene Daten eignet(siehe Johnson, Kotz und Kemp (1992), dort werden auch Literaturangaben zu Anwendun-gen aus dem okonomischen Bereich gegeben). Sie weist im Vergleich zur Poissonverteilunggroßere Flexibilitat auf. Dabei braucht r keine naturliche Zahl zu sein. Man kann die ne-gative Binomialverteilung fur beliebiges positives reelles r definieren. Dazu muss man diein der Definition der Binomialkoeffizienten auftretenden Fakultaten durch die Gammaver-teilung definieren. Wenn n keine naturliche Zahl ist, so definiert man aufgrund des Satzes3.9
n! = Γ(n + 1) .
Als weitere Anwendung werden wir die negative Binomialverteilung im Zusammenhangmit Mischverteilungen (siehe Kapitel 9.3.2) und Bayes’schen Verfahren kennenlernen, dennsie ist die pradiktive Verteilung einer Poissonverteilung, deren Parameter gammaverteilt ist(siehe Satz 10.8).
R-Befehle zur negativen Binomialverteilung:
dnbinom(x, size, prob) berechnet die Wahrscheinlichkeitsfunktion der nega-tiven Binomialverteilung mit den Parametern r =size und π =prob an der Stelle x.Dabei kann x ein Vektor sein.
pnbinom(q, size, prob) berechnet die Verteilungsfunktion der negativen Bi-nomialverteilung mit den Parametern r =size und π =prob an der Stelle q. Dabeikann q ein Vektor sein.
qnbinom(p, size, prob) berechnet die Umkehrfunktion der Verteilungsfunk-tion der negativen Binomialverteilung mit den Parametern r =size und π =proban der Stelle p. Dabei muss p ein Vektor von Wahrscheinlichkeiten, d.h. von Zahlenzwischen 0 und 1 sein.
rnbinom(n, size, prob) erzeugt n binomialverteilte Zufallszahlen mit denParametern r =size und π =prob.

70 KAPITEL 4. DISKRETE VERTEILUNGEN
4.5 Poissonverteilung
Definition 4.5 Die Wahrscheinlichkeitsfunktion der Poissonverteilung ist definiertdurch
PX(x) =
λxe−λ
x!x = 0, 1, 2, ...
0 sonst.
Die Poissonverteilung hat einen Parameter λ, fur den gelten muss λ > 0.
Wir schreiben
X ∼ Po(λ) ,
wenn X eine Poissonverteilung mit dem Parameter λ besitzt.
Abbildung 4.8 zeigt einige Wahrscheinlichkeitsfunktionen der Poissonverteilung. Man be-achte, dass die Poissonverteilung mit wachsendem Parameter λ immer mehr die Gestalt derDichte einer Normalverteilung annimmt. Daher hat man in der Vorcomputerzeit die Poisson-verteilung fur große λ durch eine Normalverteilung approximiert.
Satz 4.8 Es gelte X ∼ Po(λ). Dann gilt fur den Erwartungswert und die Varianz vonX
EX = λ und V arX = λ .
Der Poissonverteilung kommt in Anwendungen eine ahnliche Bedeutung unter den dis-kreten Verteilungen zu wie der Normalverteilung unter den stetigen Verteilungen. Sie wirdgebraucht als
• Approximation der Binomialverteilung (siehe Satz 4.9) und anderer Verteilungen,
• wenn Ereignisse zufallig in der Zeit oder allgemeiner auf der reellen Zahlenachse(Poissonprozess) oder im Raum (raumliche Poissonprozesse) auftreten (siehe Beispiel4.6),
• in Modellen fur die Analyse von Haufigkeitstabellen,
• in der empirischen Analyse von Zahldaten.
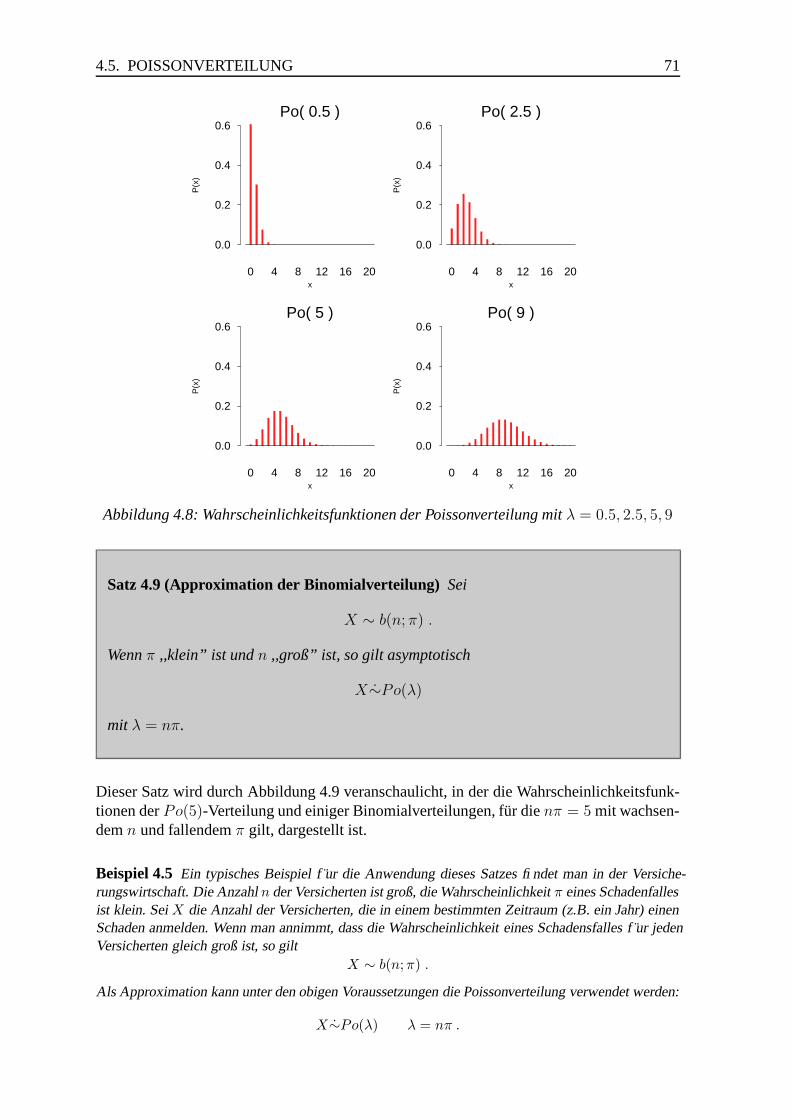
4.5. POISSONVERTEILUNG 71
0 4 8 12 16 20
0.0
0.2
0.4
0.6
P
(x)
x
Po( 0.5 )
0 4 8 12 16 20
0.0
0.2
0.4
0.6
P
(x)
x
Po( 2.5 )
0 4 8 12 16 20
0.0
0.2
0.4
0.6
P
(x)
x
Po( 5 )
0 4 8 12 16 20
0.0
0.2
0.4
0.6
P
(x)
x
Po( 9 )
Abbildung 4.8: Wahrscheinlichkeitsfunktionen der Poissonverteilung mit λ = 0.5, 2.5, 5, 9
Satz 4.9 (Approximation der Binomialverteilung) Sei
X ∼ b(n; π) .
Wenn π ,,klein” ist und n ,,groß” ist, so gilt asymptotisch
X∼Po(λ)
mit λ = nπ.
Dieser Satz wird durch Abbildung 4.9 veranschaulicht, in der die Wahrscheinlichkeitsfunk-tionen der Po(5)-Verteilung und einiger Binomialverteilungen, fur die nπ = 5 mit wachsen-dem n und fallendem π gilt, dargestellt ist.
Beispiel 4.5 Ein typisches Beispiel f ur die Anwendung dieses Satzes findet man in der Versiche-rungswirtschaft. Die Anzahl n der Versicherten ist groß, die Wahrscheinlichkeit π eines Schadenfallesist klein. Sei X die Anzahl der Versicherten, die in einem bestimmten Zeitraum (z.B. ein Jahr) einenSchaden anmelden. Wenn man annimmt, dass die Wahrscheinlichkeit eines Schadensfalles f ur jedenVersicherten gleich groß ist, so gilt
X ∼ b(n;π) .
Als Approximation kann unter den obigen Voraussetzungen die Poissonverteilung verwendet werden:
X∼Po(λ) λ = nπ .
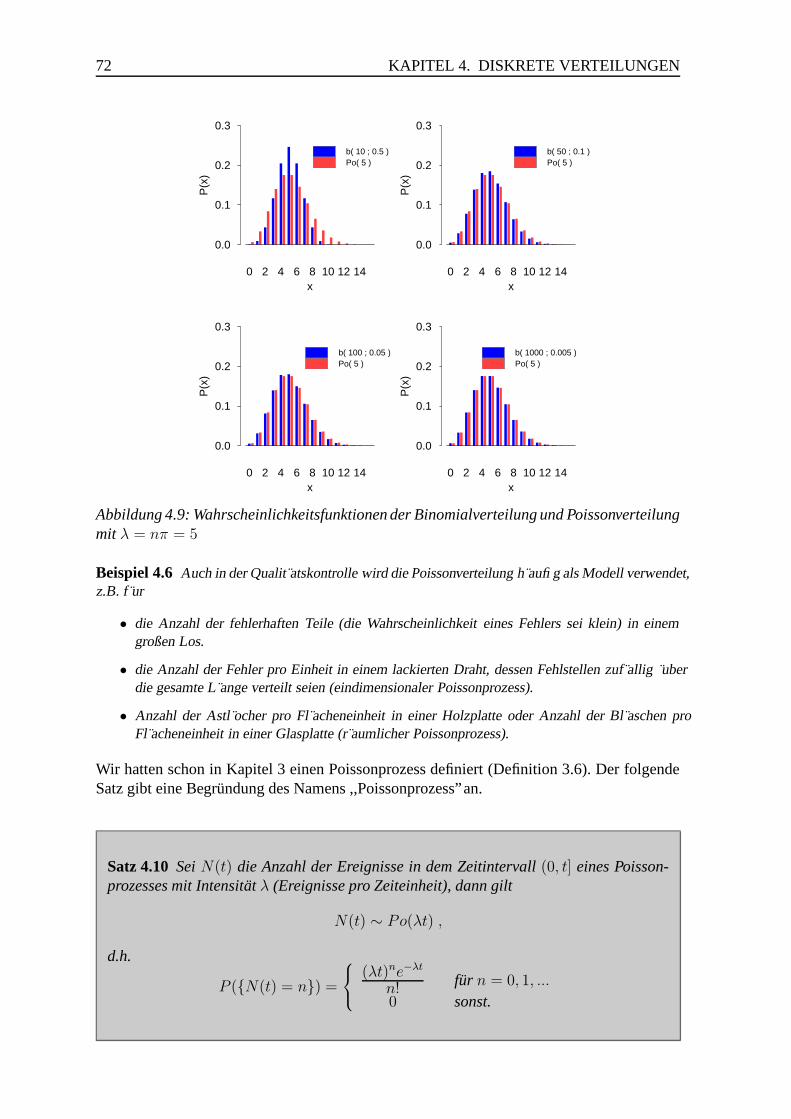
72 KAPITEL 4. DISKRETE VERTEILUNGEN
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
P(x
)
x
b( 10 ; 0.5 )Po( 5 )
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
P(x
)
x
b( 50 ; 0.1 )Po( 5 )
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
P(x
)
x
b( 100 ; 0.05 )Po( 5 )
0 2 4 6 8 10 12 14
0.0
0.1
0.2
0.3
P(x
)
x
b( 1000 ; 0.005 )Po( 5 )
Abbildung 4.9: Wahrscheinlichkeitsfunktionen der Binomialverteilung und Poissonverteilungmit λ = nπ = 5
Beispiel 4.6 Auch in der Qualit atskontrolle wird die Poissonverteilung h aufig als Modell verwendet,z.B. f ur
• die Anzahl der fehlerhaften Teile (die Wahrscheinlichkeit eines Fehlers sei klein) in einemgroßen Los.
• die Anzahl der Fehler pro Einheit in einem lackierten Draht, dessen Fehlstellen zuf allig uberdie gesamte L ange verteilt seien (eindimensionaler Poissonprozess).
• Anzahl der Astl ocher pro Fl acheneinheit in einer Holzplatte oder Anzahl der Bl aschen proFl acheneinheit in einer Glasplatte (r aumlicher Poissonprozess).
Wir hatten schon in Kapitel 3 einen Poissonprozess definiert (Definition 3.6). Der folgendeSatz gibt eine Begrundung des Namens ,,Poissonprozess” an.
Satz 4.10 Sei N(t) die Anzahl der Ereignisse in dem Zeitintervall (0, t] eines Poisson-prozesses mit Intensitat λ (Ereignisse pro Zeiteinheit), dann gilt
N(t) ∼ Po(λt) ,
d.h.
P (N(t) = n) =
(λt)ne−λt
n!fur n = 0, 1, ...
0 sonst.

4.5. POISSONVERTEILUNG 73
Beispiel 4.7 Unterbrechungen am Fließband tauchen wie ein Poissonprozess N(t) auf mit Intensit atλ = 0.1 pro Stunde. Sei X = N(8) die Anzahl der Unterbrechungen in 8 Stunden. Dann gilt:
X ∼ Po((0.1) · 8) = Po(0.8)
Dann gilt z.B.
P (X = 0) = (0.8)0e−0.8
0! = e−0.8 = 0.449 ,
P (X = 1) = (0.8)1e−0.8
1! = ... = 0.359 ,
P (X = 2) = (0.8)2e−0.8
2! = ... = 0.144 ,
P (X = 3) = (0.8)3e−0.8
3! = ... = 0.038 .
R-Befehle zur Poissonverteilung:
dpois(x, lambda) berechnet die Wahrscheinlichkeitsfunktion der Poissonvertei-lung mit dem Parameter λ =lambda an der Stelle x. Dabei kann x ein Vektor sein.
ppois(q, lambda) berechnet die Verteilungsfunktion der Poissonverteilung mitdem Parameter λ =lambda an der Stelle q. Dabei kann q ein Vektor sein.
qpois(p, lambda) berechnet die Umkehrfunktion der Verteilungsfunktion derPoissonverteilung mit dem Parameter λ =lambda an der Stelle p. Dabei muss p einVektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rpois(n, lambda) erzeugt n poissonverteilte Zufallszahlen mit dem Parameterλ =lambda.

Kapitel 5
Beziehungen zwischen Verteilungen
In diesem Kapitel wollen wir Beziehungen zwischen Verteilungen betrachten, die wir z.T.schon bei den einzelnen Verteilungen betrachtet haben. So wissen Sie schon, dass die Ex-ponentialverteilung und die χ2-Verteilung spezielle Gammaverteilungen sind oder dass dieSumme geometrisch verteilter Zufallsvariablen negativ binomialverteilt ist. All diese Zusam-menhange sollen hier noch einmal zusammenfassend betrachtet werden. Dabei werden wirauch einige neue Verteilungen kennenlernen.
5.1 Diskrete Verteilungen
5.1.1 Bernoulli-Verteilung, Binomialverteilung
Der Zusammenhang zwischen der Bernoulli- und der Binomialverteilung wurde schon inSatz 4.3 behandelt.
Satz 5.1 Seien X1, X2, . . . , Xn unabhangig und identisch Ber(π)-verteilt. Dann gilt:
X =n∑
i=1
Xi ∼ b(n; π) .
Beweis:
P (X = x) = P (X1 + X2 + ... + Xn = x)= P (x Erfolge und (n − x) Misserfolge )
Die Erfolge und Misserfolge konnen in verschiedenen Reihenfolgen angeordnet werden. DieAnzahl der Moglichkeiten, x Erfolge und (n − x) Misserfolge in n Positionen anzuordnen,ist (
n
x
)
.
Jede einzelne dieser Moglichkeiten hat die Wahrscheinlichkeit
πx(1 − π)n−x .
74

5.1. DISKRETE VERTEILUNGEN 75
Demnach gilt:
P (X = x) =
(nx
)
πx(1 − π)n−x x = 0, 1, 2, ..., n
0 sonst .
♦Als Folgerung aus diesem Satz ergibt sich:
Satz 5.2 Die Zufallsvariablen X1 und X2 seien unabhangig und binomialverteilt mit denParametern n1 bzw. n2 und identischem Parameter π. Dann gilt:
X1 + X2 ∼ b(n1 + n2; π) .
Beweis:Die Summe lasst sich auffassen als die Anzahl der Erfolge in n1+n2 unabhangigen Bernoulli-Experimenten mit Erfolgswahrscheinlichkeit π. ♦
5.1.2 Bernoulli-Verteilung, Geometrische Verteilung
Eine Folge von Bernoulli-Experimenten mit Erfolgswahrscheinlichkeit π werde solange durch-gefuhrt, bis der erste Erfolg eintritt. Die Zufallsvariable X sei die Anzahl der Misserfolge biszum ersten Erfolg. Dann gilt (siehe Beispiel 4.2):
X ∼ Ge(π) .
5.1.3 Bernoulli-Verteilung, Negative Binomialverteilung
Wir betrachten weiterhin eine Folge von Bernoulli-Experimenten mit Erfolgswahrschein-lichkeit π. Die Zufallsvariable X sei die Anzahl der Misserfolge vor dem r-ten Erfolg (r >0). Dann gilt:
X ∼ NB(r; π) .
5.1.4 Geometrische Verteilung, Negative Binomialverteilung
Die geometrische Verteilung ist ein Spezialfall der negativen Binomialverteilung, denn esgilt offensichtlich
Ge(π) ≡ NB(1; π) .
Daruberhinaus kann man fur r ∈ IN jede negativ binomialverteilte Zufallsvariable als Sum-me von geometrisch verteilten Zufallsvariablen auffassen (vergleiche Satz 4.7).

76 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Satz 5.3 Seien X1, X2, . . . , Xr unabhangig und identisch Ge(π)–verteilt. Dann gilt:
X =r∑
i=1
Xi ∼ NB(r; π) .
Es folgt aus Satz 5.3, dass der Erwartungswert und die Varianz einer negativ binomialver-teilten Zufallsvariablen r mal so groß sind wie die entsprechenden Werte der geometrischenVerteilung. Zur Warnung sei aber gesagt, dass die Unabhangigkeit der Zufallsvariablen einewesentliche Voraussetzung ist. Bei nicht unabhangigen Zufallsvariablen darf man die Vari-anzen nicht einfach addieren. Ein ahnlicher Zusammenhang bestand zwischen den Erwar-tungswerten und Varianzen der Bernoulli- und Binomialverteilung.
Als weitere Folgerung aus Satz 5.3 ergibt sich:
Satz 5.4 Die Zufallsvariablen X1 und X2 seien unabhangig und negativ binomialverteiltmit den Parametern r1 bzw. r2 und identischem Parameter π. Dann gilt:
X1 + X2 ∼ NB(r1 + r2; π) .
Beweis:Man fasse beide Zufallsvariablen als Summe von r1 bzw. r2 unabhangig und identisch geo-metrisch verteilten Zufallsvariablen auf. Die Summe dieser r1 + r2 unabhangig geometrischverteilten Zufallsvariablen ist dann negativ binomialverteilt mit den Parametern r1 + r2 undπ. ♦
5.1.5 Binomialverteilung, Poissonverteilung
Die Binomialverteilung hatten wir als Anzahl der Erfolge in n unabhangigen Bernoulli-Experimenten mit Erfolgswahrscheinlichkeit π kennengelernt (siehe Beispiel 4.1). Ist dieAnzahl der Experimente sehr groß und die Erfolgswahrscheinlichkeit klein, so kann man dieBinomialverteilung durch eine Poissonverteilung approximieren (siehe Satz 4.9).

5.1. DISKRETE VERTEILUNGEN 77
Satz 5.5 SeiX ∼ b(n; π) .
Wenn π ,,klein” ist und n ,,groß” ist, so gilt asymptotisch
X∼Po(λ)
mitλ = nπ .
Aufgrund dieses Satzes spricht man bei der Poissonverteilung auch als der Verteilung selte-ner Ereignisse.
5.1.6 Binomialverteilung, Normalverteilung
Aufgrund des zentralen Grenzwertsatzes (siehe Satz 3.8) kann man eine binomialverteilteZufallsvariable fur große n durch eine Normalverteilung approximieren.
Satz 5.6 SeiX ∼ b(n; π) .
Wenn n ,,groß” ist, so gilt asymptotisch:
X∼N(µ; σ2)
mitµ = nπ und σ2 = nπ(1 − π) .
In diesem Satz wird nur verlangt, dass n groß sein muss. Uber π wird nichts gesagt. In derTat gilt dieser Satz schließlich fur jedes π. Nur fur sehr kleine oder sehr große π (d.h. π nahebei 1), dauert es sehr lange, bis die Wahrscheinlichkeitsfunktion der Binomialverteilung mitwachsendem n allmahlich eine symmetrische glockenformige Gestalt annimmt. Fur solcheπ muss dann n eben noch großer sein, bis die Approximation durch die Normalverteilunghinreichend genau ist.
5.1.7 Negative Binomialverteilung, Normalverteilung
Aufgrund des zentralen Grenzwertsatzes (siehe Satz 3.8) kann man auch eine negativ bino-mialverteilte Zufallsvariable fur große r durch eine Normalverteilung approximieren. Auchhier werden nur Voraussetzungen uber r gemacht. Der Parameter π bestimmt aber, wie großr sein muss, damit man von einer guten Approximation sprechen kann.

78 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Satz 5.7 SeiX ∼ NB(r; π) .
Wenn r ,,groß” ist, so gilt asymptotisch:
X∼N(µ; σ2)
mitµ = r(1 − π)/π und σ2 = r(1 − π)/π2 .
5.1.8 Summen poissonverteilter Zufallsvariablen
Satz 5.8 Die Zufallsvariablen X1 und X2 seien unabhangig und poissonverteilt mit denParametern λ1 bzw. λ2. Dann gilt:
X1 + X2 ∼ Po(λ1 + λ2) .
Die Summe von zwei und damit von beliebig vielen unabhangigen poissonverteilten Zu-fallsvariablen ist also wieder poissonverteilt. Die Parameter sind zu addieren. Damit kannman sich die Poissonverteilung fur großes λ auch als Verteilung der Summe von vielen un-abhangig und identisch verteilten Zufallsvariablen vorstellen und den zentralen Grenzwert-satz (siehe Satz 3.8) anwenden.
5.1.9 Poissonverteilung, Normalverteilung
Die Poissonverteilung kann fur große λ bekanntlich (siehe S. 70) durch eine Normalvertei-lung approximiert werden.
Satz 5.9 SeiX ∼ Po(λ) .
Wenn λ ,,groß” ist, so gilt asymptotisch:
X∼N(µ; σ2)
mitµ = λ und σ2 = λ .

5.2. STETIGE VERTEILUNGEN 79
5.2 Stetige Verteilungen
5.2.1 Exponentialverteilung, Gammaverteilung, Normalverteilung
Die Exponentialverteilung ist ein Spezialfall der Gammaverteilung, denn es gilt nach Glei-chung (3.6):
Exp(λ) ≡ G(1; λ) .
Wir erhalten also eine Exponentialverteilung, wenn der Parameter ν der Gammaverteilung 1ist. Daruberhinaus erhalten wir eine Gammaverteilung als Summe unabhangiger exponenti-alverteilter Zufallsvariablen (siehe Satz 3.11).
Satz 5.10 Wenn X1, X2, ..., Xν unabhangig und identisch exponentialverteilt sind, d.h.Xi ∼ Exp(λ), so gilt:
ν∑
i=1
Xi ∼ G(ν; λ) .
Nun kann man wieder den zentralen Grenzwertsatz (Satz 3.8) anwenden, um zu folgern:
Satz 5.11 SeiX ∼ G(ν; λ) .
Wenn ν ,,groß” ist, so gilt asymptotisch:
X∼N(µ; σ2)
mitµ =
ν
λund σ2 =
ν
λ2.
5.2.2 Summe von gammaverteilten Zufallsvariablen
Satz 5.12 Die Zufallsvariablen X1 und X2 seien unabhangig und gammaverteilt mit denParametern ν1 bzw. ν2 und identischem Parameter λ. Dann gilt:
X1 + X2 ∼ G(ν1 + ν2; λ) .
Die Summe von zwei und damit beliebig vielen gammaverteilten Zufallsvariablen mit iden-tischem Parameter λ ist wieder gammaverteilt. Der Parameter ν ist die Summe der beidenParameter ν1 und ν2.

80 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
5.2.3 Gammaverteilung, χ2-Verteilung, Normalverteilung
Die χ2-Verteilung ist ein Spezialfall der Gammaverteilung. Nach Satz 3.12 gilt:
χ2n ≡ G(n/2; 1/2) .
Es folgt aus Satz 5.12, dass die Summe unabhangiger χ2-verteilter Zufallsvariablen wiederχ2-verteilt ist, wobei die Freiheitsgrade zu addieren sind.
Satz 5.13 Die Zufallsvariablen X1 und X2 seien unabhangig und χ2-verteilt mit denParametern n1 bzw. n2. Dann gilt:
X1 + X2 ∼ χ2n1+n2
.
Mit dem zentralen Grenzwertsatz (Satz 3.8) oder aus Satz 5.11 folgt wieder:
Satz 5.14 SeiX ∼ χ2
n .
Wenn n ,,groß” ist, so gilt asymptotisch:
X∼N(µ; σ2)
mitµ = n und σ2 = 2n .
5.2.4 Summen normalverteilter Zufallsvariablen
Satz 5.15 Seien X1, X2, . . . , Xn unabhangig und identisch N(µ; σ2)-verteilt. Dann gilt:
X =n∑
i=1
Xi ∼ N(nµ; nσ2) .
Fur nicht identisch normalverteilte Zufallsvariablen gilt:

5.2. STETIGE VERTEILUNGEN 81
Satz 5.16 Seien X1, X2, . . . , Xn unabhangig N(µi; σ2i )-verteilt. Dann gilt:
X =n∑
i=1
Xi ∼ N(n∑
i=1
µi;n∑
i=1
σ2i ) .
5.2.5 Normalverteilung, χ2-Verteilung
Satz 5.17 Es gelteX ∼ N(0; 1) .
Dann gilt:X2 ∼ χ2
1 .
Das Quadrat einer standarnormalverteilten Zufallsvariablen ist also χ2-verteilt mit einemFreiheitsgrad. Mit Satz 5.13 folgt, dass auch die Summe der Quadrate unabhangiger N(0; 1)-verteilter Zufallsvariablen χ2-verteilt ist.
Satz 5.18 Seien X1, X2, ..., Xn unabhangig und identisch N(0; 1)-verteilt. Dann gilt:
X =n∑
i=1
X2i ∼ χ2
n .
Fur praktische Anwendungen wichtig ist der folgende Satz:
Satz 5.19 Seien X1, X2, ..., Xn unabhangig und identisch N(µ; σ2)-verteilt. Sei
X =1
n
n∑
i=1
Xi und S2 =1
n
n∑
i=1
(Xi − X)2 .
Dann gilt:nS2
σ2∼ χ2(n − 1) .

82 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Man benutzt dieses Resultat, um Hypothesen uber die Varianz in einer normalverteiltenGrundgesamtheit zu testen. Um die Nullhypothese
H0 : σ2 = σ20
gegen die AlternativeH1 : σ2 6= σ2
0
zu testen, verwendet man die Prufgroße
nS2
σ20
,
die nach Satz 5.19 unter der Hypothese eine χ2-Verteilung mit n− 1 Freiheitsgraden besitzt.
Die χ2-Verteilung ist eine wichtige Verteilung in der Varianzanalyse. Die dort berechnetenSummen der Quadrate von normalverteilten Zufallsvariablen sind verteilt wie σ2 · χ2, wobeiσ2 die Varianz ist (siehe Beispiel 5.1).
5.2.6 Normalverteilung, t-Verteilung
Definition 5.1 Die Dichtefunktion der t-Verteilung ist gegeben durch
fX(x) =Γ(ν+1
2)(1 + x2/ν)−(ν+1)/2
√νπΓ(ν/2)
−∞ < x < ∞ ..
Die t-Verteilung besitzt einen Parameter ν, fur den gilt ν ∈ IN .
Wir schreibenX ∼ tν ,
wenn eine Zufallsvariable eine t-Verteilung besitzt. Wir sagen dann auch, dass X eine t-Verteilung mit ν Freiheitsgraden besitzt.
Abbildung 5.1 zeigt einige Dichtefunktionen der t-Verteilung. Sie ist wie die Normalvertei-lung symmetrisch um eine senkrechte Achse bei 0 und nahert sich mit wachsender Zahl derFreiheitsgrade der Dichtefunktion der Standardnormalverteilung.
Aufgrund der Symmetrie der Dichtefunktion folgt:
Satz 5.20 Es gelteX ∼ tν .
Dann gilt fur den Erwartungswert:
EX = 0 .
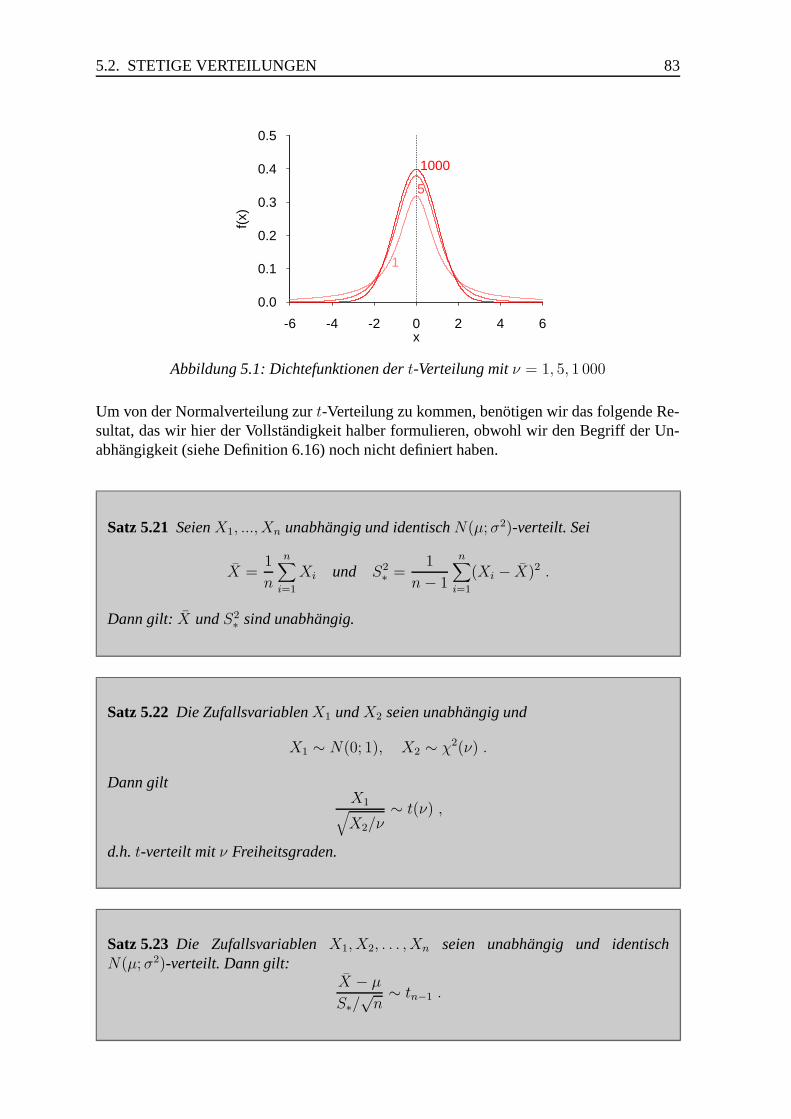
5.2. STETIGE VERTEILUNGEN 83
f(x)
-6 -4 -2 0 2 4 6
0.0
0.1
0.2
0.3
0.4
0.5
x
1
5
1000
Abbildung 5.1: Dichtefunktionen der t-Verteilung mit ν = 1, 5, 1 000
Um von der Normalverteilung zur t-Verteilung zu kommen, benotigen wir das folgende Re-sultat, das wir hier der Vollstandigkeit halber formulieren, obwohl wir den Begriff der Un-abhangigkeit (siehe Definition 6.16) noch nicht definiert haben.
Satz 5.21 Seien X1, ..., Xn unabhangig und identisch N(µ; σ2)-verteilt. Sei
X =1
n
n∑
i=1
Xi und S2∗ =
1
n − 1
n∑
i=1
(Xi − X)2 .
Dann gilt: X und S2∗ sind unabhangig.
Satz 5.22 Die Zufallsvariablen X1 und X2 seien unabhangig und
X1 ∼ N(0; 1), X2 ∼ χ2(ν) .
Dann giltX1
√
X2/ν∼ t(ν) ,
d.h. t-verteilt mit ν Freiheitsgraden.
Satz 5.23 Die Zufallsvariablen X1, X2, . . . , Xn seien unabhangig und identischN(µ; σ2)-verteilt. Dann gilt:
X − µ
S∗/√
n∼ tn−1 .

84 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Beweis:Es gilt (ohne kompletten Beweis, den Erwartungswert und die Varianz von X werden wirspater berechnen)
X − µ
σ/√
n∼ N(0; 1) .
Nach Satz 5.19 gilt:
(n − 1)S2∗
σ2∼ χ2(n − 1) .
Ferner sind X und S2∗ nach Satz 5.21 unabhangig. Damit gilt nach Satz 5.22:
X−µσ/
√n
√
(n−1)S2∗
σ2(n−1)
=X − µ
S∗/√
n∼ t(n − 1) .
♦Man verwendet
T =X − µ
S∗/√
n∼ tn−1
als Prufgroße im t-Test zur Prufung von Hypothesen uber den Erwartungswert in einer nor-malverteilten Grundgesamtheit, z.B.
H0 : µ = µ0
gegen die Alternative
H1 : µ 6= µ0 .
Unter der Nullhypothese H0 besitzt die Prufgroße T dann die in Satz 5.23 angegebene Ver-teilung. Dieses Resultat wird ferner bei der Konstruktion von Konfidenzintervallen fur denParameter µ der Normalverteilung benutzt.
R-Befehle zur t-Verteilung:
dt(x, df) berechnet die Dichtefunktion der t-Verteilung mit dem Parameter ν =dfan der Stelle x. Dabei kann x ein Vektor sein.
pt(q, df, ncp=0) berechnet die Verteilungsfunktion der t-Verteilung mit demParameter ν =df an der Stelle q. Dabei kann q ein Vektor sein. Mit dem optionalenArgument ncp wird der Nichtzentralitatsparameter festgelegt. Wir behandeln hier diezentrale t-Verteilung, fur die ncp=0 ist.
qt(p, df) berechnet die Umkehrfunktion der Verteilungsfunktion der t-Verteilungmit dem Parameter ν =df an der Stelle p. Dabei muss p ein Vektor von Wahrschein-lichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rt(n, df) erzeugt n t-verteilte Zufallszahlen mit dem Parameter ν =df.
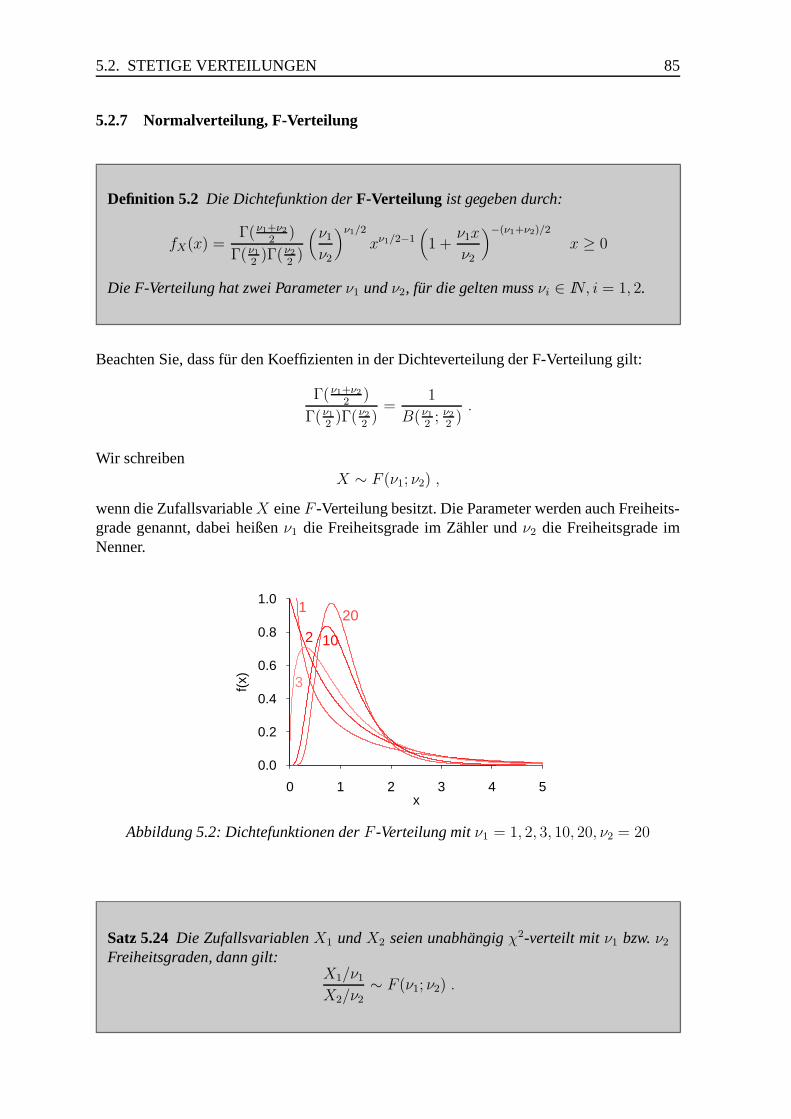
5.2. STETIGE VERTEILUNGEN 85
5.2.7 Normalverteilung, F-Verteilung
Definition 5.2 Die Dichtefunktion der F-Verteilung ist gegeben durch:
fX(x) =Γ(ν1+ν2
2)
Γ(ν1
2)Γ(ν2
2)
(ν1
ν2
)ν1/2
xν1/2−1(
1 +ν1x
ν2
)−(ν1+ν2)/2
x ≥ 0
Die F-Verteilung hat zwei Parameter ν1 und ν2, fur die gelten muss νi ∈ IN, i = 1, 2.
Beachten Sie, dass fur den Koeffizienten in der Dichteverteilung der F-Verteilung gilt:
Γ(ν1+ν2
2)
Γ(ν1
2)Γ(ν2
2)
=1
B(ν1
2; ν2
2)
.
Wir schreibenX ∼ F (ν1; ν2) ,
wenn die Zufallsvariable X eine F -Verteilung besitzt. Die Parameter werden auch Freiheits-grade genannt, dabei heißen ν1 die Freiheitsgrade im Zahler und ν2 die Freiheitsgrade imNenner.
f(x)
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
x
1
2
3
10
20
Abbildung 5.2: Dichtefunktionen der F -Verteilung mit ν1 = 1, 2, 3, 10, 20, ν2 = 20
Satz 5.24 Die Zufallsvariablen X1 und X2 seien unabhangig χ2-verteilt mit ν1 bzw. ν2
Freiheitsgraden, dann gilt:X1/ν1
X2/ν2∼ F (ν1; ν2) .

86 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Beispiel 5.1 (Varianzanalyse) In der Grundvorlesung haben Sie bereits einen F -Test kennenge-lernt. Die Situation kann wie folgt beschrieben werden. Es liegen Beobachtungen in I Gruppen vor.
Yij = µi + eij i = 1, 2, . . . , I; j = 1, 2, . . . , J.
Dabei seien µi Konstante, die eij seien normalverteilte unabh angige Zufallsvariablen mit E(eij) = 0und V ar(eij) = σ2. Es soll die Hypothese
H0 : µ1 = µ2 = . . . = µI
gepr uft werden. Die Pr ufgr oße ist dann
PG =
1I−1
I∑
i=1J(Yi. − Y..
)2
1I(J−1)
I∑
i=1
J∑
j=1
(
Yij − Yi.
)2
Diese Pr ufgr oße ist typisch f ur viele F -Pr ufgr oßen, die Ihnen in Regressionsanalysen (z.B. in derVorlesung Okonometrie) oder in Varianzanalysen (in der Vorlesung Lineare Modelle) oder bei derAnalyse von Daten mit Statistikprogrammpaketen begegnen werden. Die Summen der Quadrate inZ ahler und Nenner der Pr ufgr oße
•I∑
i=1J(Yi. − Y..
)2 Summe der Quadrate Gruppen
•I∑
i=1
J∑
j=1
(Yij − Yi.
)2 Summe der Quadrate Rest
sind jeweils verteilt wie σ2 · χ2 mit I − 1 bzw. I(J − 1) Freiheitsgraden. Außerdem sind die beidenSummen der Quadrate unabh angig. Es folgt dann aus Satz 5.24, dass der Quotient eine F -Verteilungmit I − 1 und I(J − 1) Freiheitsgraden besitzt.
Beispiel 5.2 Auch den fogenden F -Test haben Sie in der Grundvorlesung im Zusammenhang mitder Regressionsanalyse kennengelernt. Das Modell M2 bezeichne eine Vereinfachung des ModellsM1, d.h. einige der Parameter aus M1 fehlen in M2. Zur Pr ufung der Hypothese, dass die Modellver-einfachung gilt, d.h. die in M2 fehlenden Parameter aus M1 null sind, wird die Pr ufgr oße
PG =(SQ(Res;M2) − SQ(Res;M1))/(FG(M2) − FG(M1))
SQ(Res;M1)/FG(M1)
verwendet, die unter der Nullhypothese eine F -Verteilung mit FG(M2) − FG(M1) und FG(M1)
Freiheitsgraden hat. Dabei sind SQ(Res;M1) und SQ(Res;M2) die Summe der Quadrate der Resi-duale unter den Modellen M1 und M2 und FG bezeichnen die jeweiligen Freiheitsgrade.
R-Befehle zur F-Verteilung:
df(x, df1, df2) berechnet die Dichtefunktion der F-Verteilung mit den Parame-tern ν1 =df1 und ν2 =df2 an der Stelle x. Dabei kann x ein Vektor sein.
pf(q, df1, df2, ncp=0) berechnet die Verteilungsfunktion der F-Verteilungmit den Parametern ν1 =df1 und ν2 =df2 an der Stelle q. Dabei kann q ein Vektorsein. Mit dem optionalen Argument ncp wird der Nichtzentralitatsparameter festge-legt. Wir behandeln hier die zentrale F-Verteilung, fur die ncp=0 ist.

5.2. STETIGE VERTEILUNGEN 87
qf(p, df1, df2) berechnet die Umkehrfunktion der Verteilungsfunktion der F-Verteilung mit den Parametern ν1 =df1 und ν2 =df2 an der Stelle p. Dabei muss pein Vektor von Wahrscheinlichkeiten, d.h. von Zahlen zwischen 0 und 1 sein.
rf(n, df1, df2) erzeugt n F-verteilte Zufallszahlen mit den Parametern ν1 =df1und ν2 =df2 .
5.2.8 Normalverteilung, Lognormalverteilung
Definition 5.3 Die Dichtefunktion der Lognormalverteilung ist gegeben durch
f(x) =
1
x√
2πσ2e−(log x−µ)2/2σ2
x > 0
0 sonst .
Die Lognormalverteilung hat zwei Parameter µ und σ2, fur die gelten muss
−∞ < µ < ∞ und σ2 > 0 .
Wir schreiben
X ∼ Λ(µ; σ2) ,
wenn die Zufallsvariable X eine Lognormalverteilung besitzt. Der folgende Satz erklart denNamen Lognormalverteilung. Die Zufallsvariable log X besitzt namlich eine Normalvertei-lung, wenn X eine Lognormalverteilung besitzt.
Satz 5.25a) Es gelte X ∼ Λ(µ; σ2), dann gilt:
log X ∼ N(µ; σ2) .
b) Es gelte Y ∼ N(µ; σ2), dann gilt:
eY ∼ Λ(µ; σ2) .
Die Verteilungsfunktion der Lognormalnormalverteilung kann man auf die der Standardnor-malverteilung zuruckfuhren.

88 KAPITEL 5. BEZIEHUNGEN ZWISCHEN VERTEILUNGEN
Satz 5.26 Fur die Verteilungsfunktion FX einer lognormalverteilten ZufallsvariablenX gilt
FX(x) = Φ
(
log x − µ
σ
)
,
wobei Φ die Verteilungsfunktion der Standardnormalverteilung bezeichne.
Beweis:Fur x ≥ 0 gilt:
FX(x) = P (X ≤ x)
=
x∫
0
1
t√
2πσ2e−(log t−µ)2/2σ2
dt .
Wir substituierens = log t .
Dann istds
dt=
1
tds =
1
tdt .
Dabei andern sich die Grenzen wie folgt:
• Wenn t −→ 0, gilt s −→ −∞ .
• Wenn t = x, ist s = log x .
Damit folgt, wenn man beachtet, dass der folgende Integrand die Dichtefunktion einer Nor-malverteilung mit den Parametern µ und σ2 ist, unter Anwendung von Satz 3.6
FX(x) =
log x∫
−∞
1√2πσ2
e−(s−µ)2/2σ2
ds
= Φ
(
log x − µ
σ
)
.
♦
Satz 5.27 Es gelteX ∼ Λ(µ; σ2) .
Dann gilt fur den Erwartungswert und die Varianz von X:
EX = eµ+σ2/2 und V arX = e2µeσ2
(eσ2 − 1) .
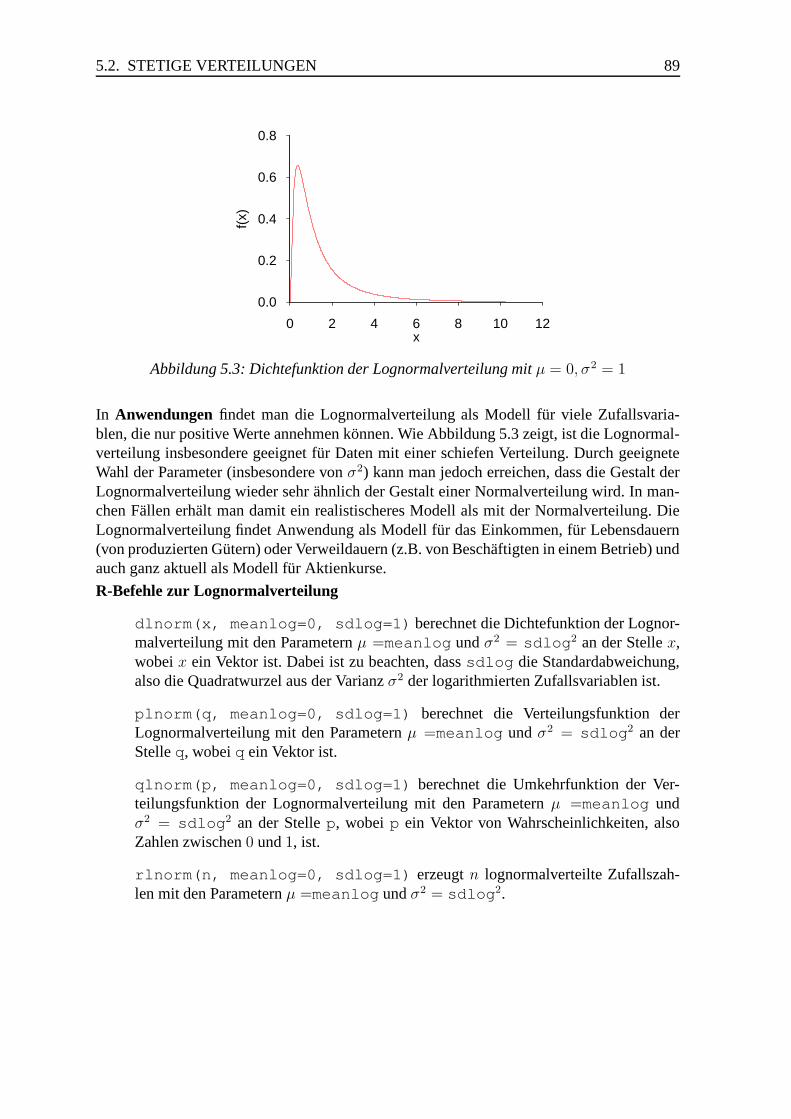
5.2. STETIGE VERTEILUNGEN 89
f(x)
0 2 4 6 8 10 12
0.0
0.2
0.4
0.6
0.8
x
Abbildung 5.3: Dichtefunktion der Lognormalverteilung mit µ = 0, σ2 = 1
In Anwendungen findet man die Lognormalverteilung als Modell fur viele Zufallsvaria-blen, die nur positive Werte annehmen konnen. Wie Abbildung 5.3 zeigt, ist die Lognormal-verteilung insbesondere geeignet fur Daten mit einer schiefen Verteilung. Durch geeigneteWahl der Parameter (insbesondere von σ2) kann man jedoch erreichen, dass die Gestalt derLognormalverteilung wieder sehr ahnlich der Gestalt einer Normalverteilung wird. In man-chen Fallen erhalt man damit ein realistischeres Modell als mit der Normalverteilung. DieLognormalverteilung findet Anwendung als Modell fur das Einkommen, fur Lebensdauern(von produzierten Gutern) oder Verweildauern (z.B. von Beschaftigten in einem Betrieb) undauch ganz aktuell als Modell fur Aktienkurse.
R-Befehle zur Lognormalverteilung
dlnorm(x, meanlog=0, sdlog=1) berechnet die Dichtefunktion der Lognor-malverteilung mit den Parametern µ =meanlog und σ2 = sdlog2 an der Stelle x,wobei x ein Vektor ist. Dabei ist zu beachten, dass sdlog die Standardabweichung,also die Quadratwurzel aus der Varianz σ2 der logarithmierten Zufallsvariablen ist.
plnorm(q, meanlog=0, sdlog=1) berechnet die Verteilungsfunktion derLognormalverteilung mit den Parametern µ =meanlog und σ2 = sdlog2 an derStelle q, wobei q ein Vektor ist.
qlnorm(p, meanlog=0, sdlog=1) berechnet die Umkehrfunktion der Ver-teilungsfunktion der Lognormalverteilung mit den Parametern µ =meanlog undσ2 = sdlog2 an der Stelle p, wobei p ein Vektor von Wahrscheinlichkeiten, alsoZahlen zwischen 0 und 1, ist.
rlnorm(n, meanlog=0, sdlog=1) erzeugt n lognormalverteilte Zufallszah-len mit den Parametern µ =meanlog und σ2 = sdlog2.

Kapitel 6
Gemeinsame Verteilung von Zufallsvariablen
6.1 Gemeinsame Verteilungen zweier Zufallsvariablen
Bisher haben wir nur die Verteilung einer Zufallsvariablen betrachtet. Zur Beschreibung desstochastischen Verhaltens einer Zufallsvariablen haben wir die Begriffe Wahrscheinlichkeits-funktion, Dichtefunktion und Verteilungsfunktion kennengelernt. Jetzt werden wir analogeBegriffe kennenlernen, um das gemeinsame Verhalten zweier Zufallsvariablen X und Y zubetrachten.
X YEinkommen Ausgaben fur LebensmittelEinkommen Ausgaben fur VersicherungenHaushaltsgroße Anzahl der AutosAutotyp Anzahl der SchadensfalleAutotyp SchadenshoheSchulbildung Durchschnittliche Fernsehzeit pro TagDAX heute DAX morgenWerbungsausgaben UmsatzGeschlecht EinkommenNote Vordiplom Note Hauptdiplom
Bei der Behandlung einer Zufallsvariablen haben wir zwischen diskreten und stetigen Zu-fallsvariablen unterschieden. Jetzt sind die folgenden drei Falle zu unterscheiden:
a) Beide Zufallsvariablen sind diskret.
b) Beide Zufallsvariablen sind stetig.
c) Eine Zufallsvariable ist diskret, die andere ist stetig.
Wir werden nur die beiden ersten Falle behandeln.
90
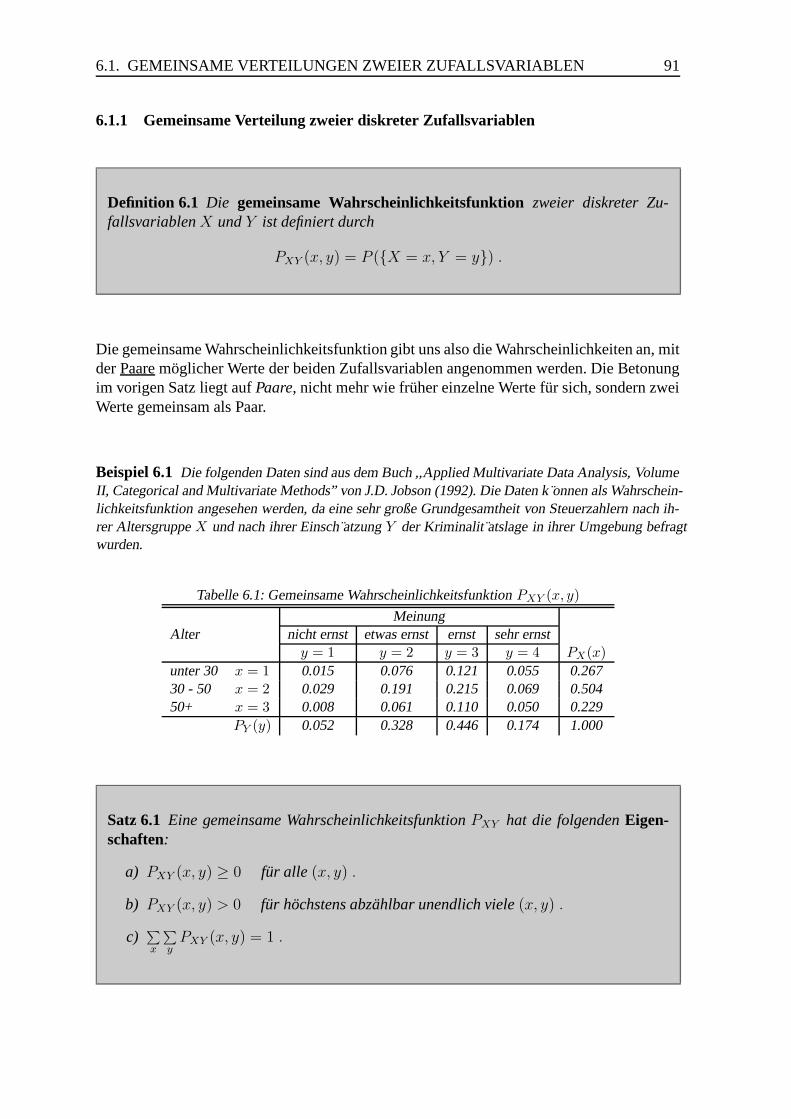
6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 91
6.1.1 Gemeinsame Verteilung zweier diskreter Zufallsvariablen
Definition 6.1 Die gemeinsame Wahrscheinlichkeitsfunktion zweier diskreter Zu-fallsvariablen X und Y ist definiert durch
PXY (x, y) = P (X = x, Y = y) .
Die gemeinsame Wahrscheinlichkeitsfunktion gibt uns also die Wahrscheinlichkeiten an, mitder Paare moglicher Werte der beiden Zufallsvariablen angenommen werden. Die Betonungim vorigen Satz liegt auf Paare, nicht mehr wie fruher einzelne Werte fur sich, sondern zweiWerte gemeinsam als Paar.
Beispiel 6.1 Die folgenden Daten sind aus dem Buch ,,Applied Multivariate Data Analysis, VolumeII, Categorical and Multivariate Methods” von J.D. Jobson (1992). Die Daten k onnen als Wahrschein-lichkeitsfunktion angesehen werden, da eine sehr große Grundgesamtheit von Steuerzahlern nach ih-rer Altersgruppe X und nach ihrer Einsch atzung Y der Kriminalit atslage in ihrer Umgebung befragtwurden.
Tabelle 6.1: Gemeinsame Wahrscheinlichkeitsfunktion PXY (x, y)
MeinungAlter nicht ernst etwas ernst ernst sehr ernst
y = 1 y = 2 y = 3 y = 4 PX(x)
unter 30 x = 1 0.015 0.076 0.121 0.055 0.26730 - 50 x = 2 0.029 0.191 0.215 0.069 0.50450+ x = 3 0.008 0.061 0.110 0.050 0.229
PY (y) 0.052 0.328 0.446 0.174 1.000
Satz 6.1 Eine gemeinsame Wahrscheinlichkeitsfunktion PXY hat die folgenden Eigen-schaften:
a) PXY (x, y) ≥ 0 fur alle (x, y) .
b) PXY (x, y) > 0 fur hochstens abzahlbar unendlich viele (x, y) .
c)∑
x
∑
yPXY (x, y) = 1 .

92 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
Definition 6.2 Die Randwahrscheinlichkeitsfunktionen von X und Y sind definiertdurch
a) PX(x) = P (X = x) =∑
yP (X = x; Y = y) =
∑
yPXY (x, y)
b) PY (y) = P (Y = y) =∑
xP (X = x; Y = y) =
∑
xPXY (x, y)
In Tabelle 6.1 sind die Randwahrscheinlichkeitsfunktionen ausgerechnet und an den Rand(daher der Name!) geschrieben worden. Es sind einfach die Summen der gemeinsamenWahrscheinlichkeiten uber die einzelnen Zeilen bzw. Spalten zu bilden. Die Randwahr-scheinlichkeiten sind gewohnliche Wahrscheinlichkeitsfunktionen einer Zufallsvariablen, wiewir sie in Kapitel 1 kennengelernt haben.
6.1.2 Gemeinsame Verteilung zweier stetiger Zufallsvariablen
Definition 6.3 Die gemeinsame Dichtefunktion fXY (x, y) zweier ZufallsvariablenX, Y hat die Eigenschaften
a) fXY (x, y) ≥ 0 fur alle x, y ,
b)∞∫
−∞
∞∫
−∞fXY (x, y)dx dy = 1 ,
c) P (a ≤ X ≤ b; c ≤ Y ≤ d) =b∫
a
d∫
cfXY (x, y)dy dx fur alle Paare (a, b) und
(c, d) mit a ≤ b und c ≤ d.
Beispiel 6.2 Die Funktion f sei definiert durch
f(x, y) =
125 x(2 − x − y) 0 ≤ x ≤ 1, 0 ≤ y ≤ 10 sonst.
.
Es soll gezeigt werden, dass f eine gemeinsame Dichtefunktion ist. Es ist f(x, y) ≥ 0 und∫ 1
0
∫ 1
0f(x, y)dydx =
12
5
∫ 1
0
∫ 1
0(2x − x2 − xy)dydx
=12
5
∫ 1
0(2xy − x2y − 1
2xy2)
∣∣∣∣
1
0dx
=12
5
∫ 1
0(2x − x2 − 1
2x)dx
=12
5(x2 − 1
3x3 − 1
4x2)
∣∣∣∣
1
0
=12
5(1 − 1
3− 1
4) =
12
5
5
12= 1 .
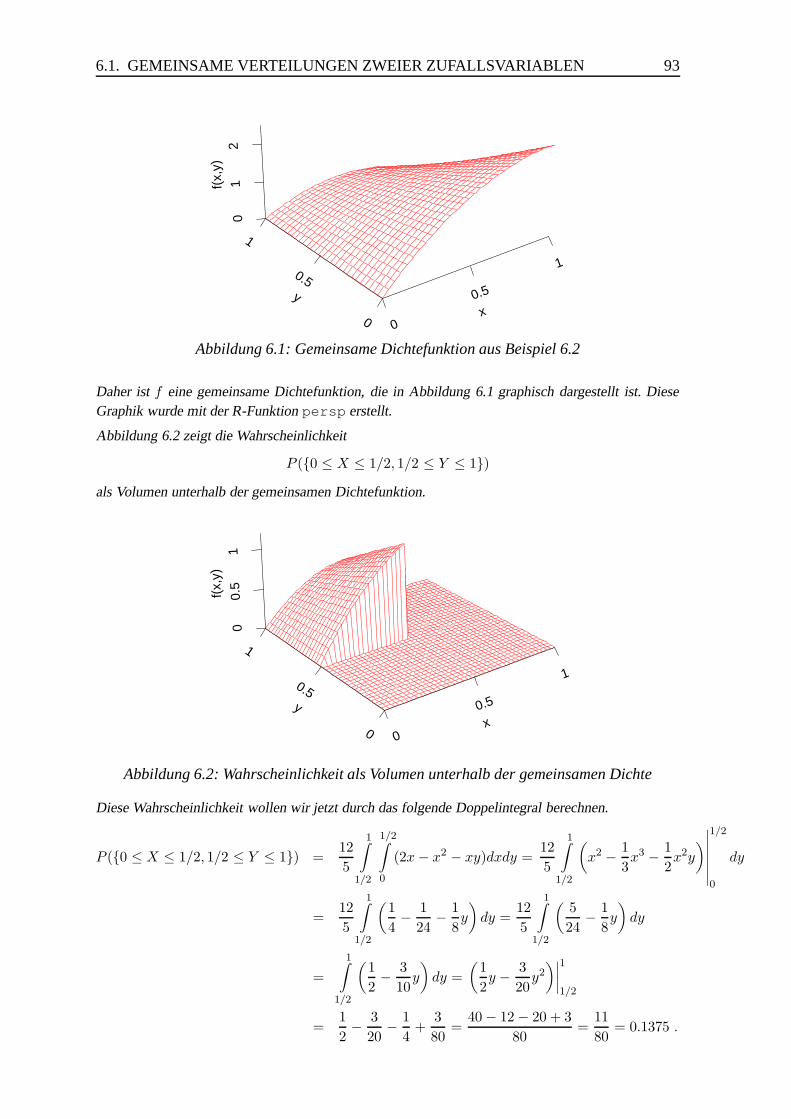
6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 93
0
0.5
1
x 0
0.5
1
y
01
2f(
x,y)
Abbildung 6.1: Gemeinsame Dichtefunktion aus Beispiel 6.2
Daher ist f eine gemeinsame Dichtefunktion, die in Abbildung 6.1 graphisch dargestellt ist. DieseGraphik wurde mit der R-Funktion persp erstellt.
Abbildung 6.2 zeigt die Wahrscheinlichkeit
P (0 ≤ X ≤ 1/2, 1/2 ≤ Y ≤ 1)
als Volumen unterhalb der gemeinsamen Dichtefunktion.
0
0.5
1
x 0
0.5
1
y
00.
51
f(x,
y)
Abbildung 6.2: Wahrscheinlichkeit als Volumen unterhalb der gemeinsamen Dichte
Diese Wahrscheinlichkeit wollen wir jetzt durch das folgende Doppelintegral berechnen.
P (0 ≤ X ≤ 1/2, 1/2 ≤ Y ≤ 1) =12
5
1∫
1/2
1/2∫
0
(2x − x2 − xy)dxdy =12
5
1∫
1/2
(
x2 − 1
3x3 − 1
2x2y
)
∣∣∣∣∣∣∣
1/2
0
dy
=12
5
1∫
1/2
(1
4− 1
24− 1
8y
)
dy =12
5
1∫
1/2
(5
24− 1
8y
)
dy
=
1∫
1/2
(1
2− 3
10y
)
dy =
(1
2y − 3
20y2)∣∣∣∣
1
1/2
=1
2− 3
20− 1
4+
3
80=
40 − 12 − 20 + 3
80=
11
80= 0.1375 .
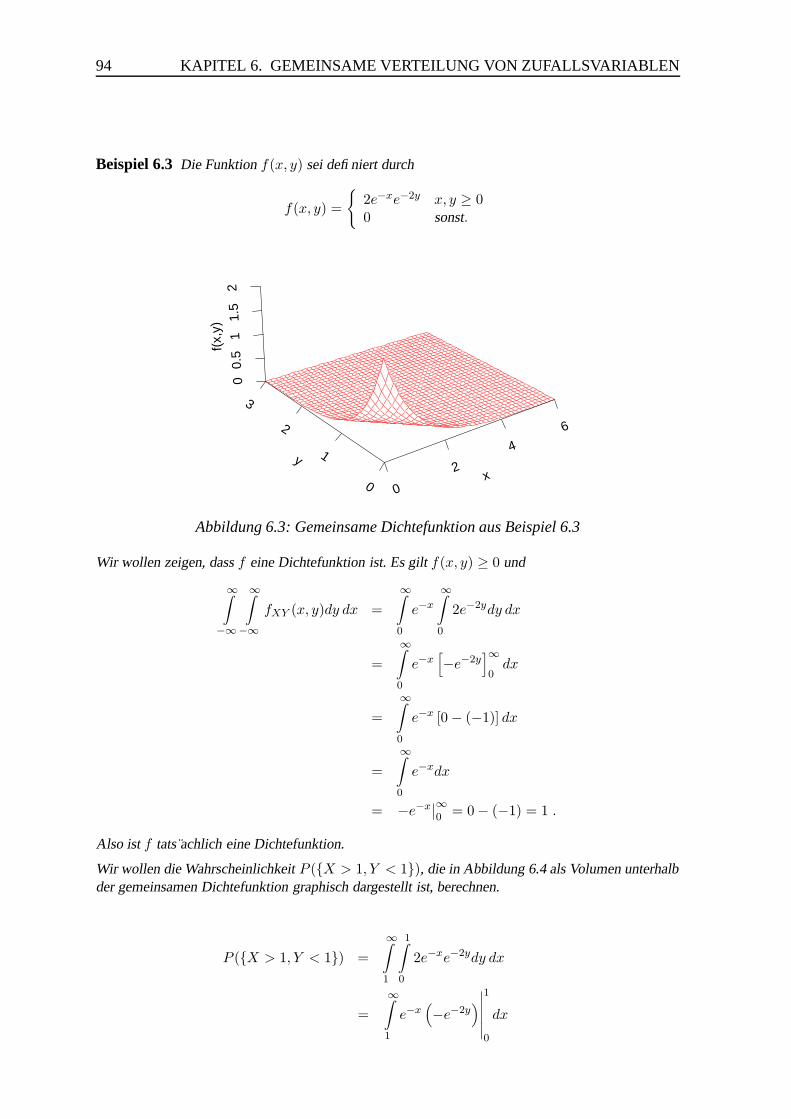
94 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
Beispiel 6.3 Die Funktion f(x, y) sei definiert durch
f(x, y) =
2e−xe−2y x, y ≥ 00 sonst.
0
2
4
6
x 0
1
2
3
y
00.
51
1.5
2f(
x,y)
Abbildung 6.3: Gemeinsame Dichtefunktion aus Beispiel 6.3
Wir wollen zeigen, dass f eine Dichtefunktion ist. Es gilt f(x, y) ≥ 0 und
∞∫
−∞
∞∫
−∞fXY (x, y)dy dx =
∞∫
0
e−x
∞∫
0
2e−2ydy dx
=
∞∫
0
e−x[
−e−2y]∞
0dx
=
∞∫
0
e−x [0 − (−1)] dx
=
∞∫
0
e−xdx
= −e−x∣∣∞0 = 0 − (−1) = 1 .
Also ist f tats achlich eine Dichtefunktion.
Wir wollen die Wahrscheinlichkeit P (X > 1, Y < 1), die in Abbildung 6.4 als Volumen unterhalbder gemeinsamen Dichtefunktion graphisch dargestellt ist, berechnen.
P (X > 1, Y < 1) =
∞∫
1
1∫
0
2e−xe−2ydy dx
=
∞∫
1
e−x(
−e−2y)
∣∣∣∣∣∣
1
0
dx
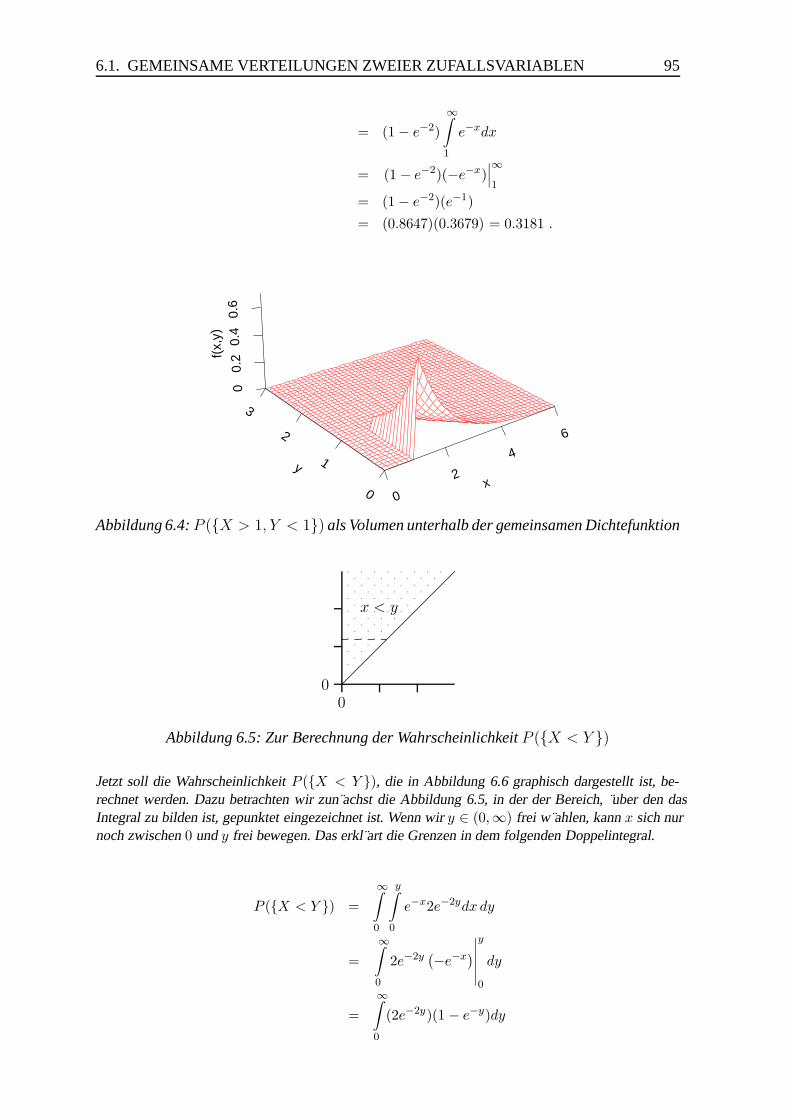
6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 95
= (1 − e−2)
∞∫
1
e−xdx
= (1 − e−2)(−e−x)∣∣∣
∞
1
= (1 − e−2)(e−1)
= (0.8647)(0.3679) = 0.3181 .
0
2
4
6
x 0
1
2
3
y
00.
20.
40.
6f(
x,y)
Abbildung 6.4: P (X > 1, Y < 1) als Volumen unterhalb der gemeinsamen Dichtefunktion
00
.
.............................................................................................................................................................................................................................................................................................................
............. ............. ............. ...........
x < y
.
.
. .
. .
. . .
. . .
. . . .
. . . .
. . . . .
. . . . .
. . . . . .
. . . . . .
. . . . . . .
. . . . . . .
. . . . . . . .
Abbildung 6.5: Zur Berechnung der Wahrscheinlichkeit P (X < Y )
Jetzt soll die Wahrscheinlichkeit P (X < Y ), die in Abbildung 6.6 graphisch dargestellt ist, be-rechnet werden. Dazu betrachten wir zun achst die Abbildung 6.5, in der der Bereich, uber den dasIntegral zu bilden ist, gepunktet eingezeichnet ist. Wenn wir y ∈ (0,∞) frei w ahlen, kann x sich nurnoch zwischen 0 und y frei bewegen. Das erkl art die Grenzen in dem folgenden Doppelintegral.
P (X < Y ) =
∞∫
0
y∫
0
e−x2e−2ydx dy
=
∞∫
0
2e−2y (−e−x)
∣∣∣∣∣∣
y
0
dy
=
∞∫
0
(2e−2y)(1 − e−y)dy
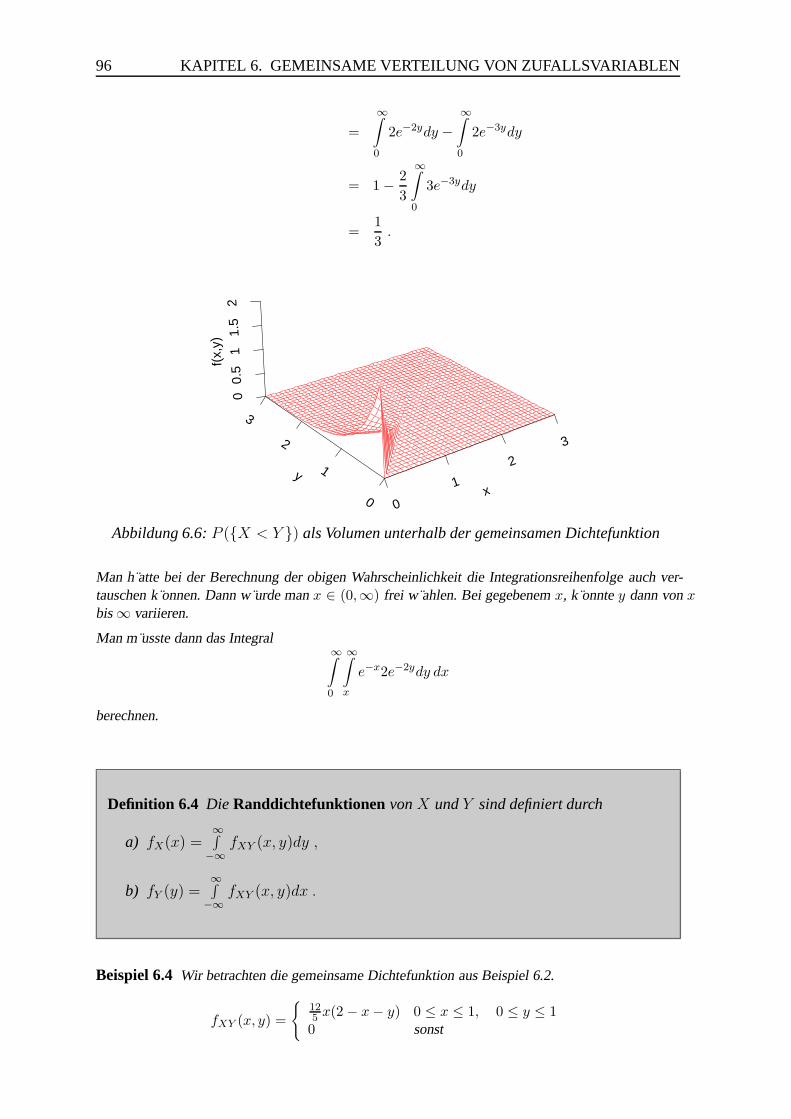
96 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
=
∞∫
0
2e−2ydy −∞∫
0
2e−3ydy
= 1 − 2
3
∞∫
0
3e−3ydy
=1
3.
0
1
2
3
x 0
1
2
3
y
00.
51
1.5
2f(
x,y)
Abbildung 6.6: P (X < Y ) als Volumen unterhalb der gemeinsamen Dichtefunktion
Man h atte bei der Berechnung der obigen Wahrscheinlichkeit die Integrationsreihenfolge auch ver-tauschen k onnen. Dann w urde man x ∈ (0,∞) frei w ahlen. Bei gegebenem x, k onnte y dann von xbis ∞ variieren.
Man m usste dann das Integral∞∫
0
∞∫
x
e−x2e−2ydy dx
berechnen.
Definition 6.4 Die Randdichtefunktionen von X und Y sind definiert durch
a) fX(x) =∞∫
−∞fXY (x, y)dy ,
b) fY (y) =∞∫
−∞fXY (x, y)dx .
Beispiel 6.4 Wir betrachten die gemeinsame Dichtefunktion aus Beispiel 6.2.
fXY (x, y) =
125 x(2 − x − y) 0 ≤ x ≤ 1, 0 ≤ y ≤ 10 sonst

6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 97
fX(x) =12
5
1∫
0
(2x − x2 − xy)dy
=12
5
(
2xy − x2y − 1
2xy2
)∣∣∣∣
1
0
=12
5
(
2x − x2 − 1
2x
)
=12
5
(3
2x − x2
)
,
d.h.
fX(x) =
125
(32x − x2
)
0 ≤ x ≤ 1
0 sonst .
fY (y) =12
5
1∫
0
(2x − x2 − xy)dx =12
5(x2 − 1
3x3 − 1
2x2y)
∣∣∣∣
1
0
=12
5(1 − 1
3− 1
2y) =
12
5(2
3− 1
2y) ,
d.h.
fY (y) =
125 (2
3 − 12y) 0 ≤ y ≤ 1
0 sonst .
Man beachte, dass die Randdichten nicht die gemeinsame Dichtefunktion bestimmen. Imvorangehenden Beispiel ist das Produkt der Randdichten fX(x)fY (y) wieder eine gemeinsa-me Dichtefunktion, die jedoch nicht mit der anfangs gegebenen gemeinsamen Dichtefunkti-on fXY (x, y) ubereinstimmt.
Beispiel 6.5 Wir betrachten die gemeinsame Dichtefunktion aus Beispiel 6.3, d.h.
fXY (x, y) =
2e−xe−2y 0 ≤ x < ∞, 0 ≤ y < ∞0 sonst ,
fX(x) =
e−x∞∫
02e−2ydy = e−x 0 ≤ x < ∞
0 sonst ,
fY (y) =
2e−2y∞∫
0e−xdx = 2e−2y 0 ≤ y < ∞
0 sonst .
In diesem Beispiel ist die gemeinsame Dichtefunktion das Produkt der Randdichten. Wir werdensp ater sehen (Beispiel 6.14), dass X und Y in diesem Fall unabh angig sind.
Bildlich ist die Randdichtefunktion von X an der Stelle x der Flacheninhalt der in Abbildung6.7 dargestellten Schnittflache der gemeinsamen Dichtefunktion. Genauso ist die Randdich-tefunktion von Y an der Stelle y der Flacheninhalt der in Abbildung 6.8 dargestellten Schnitt-flache der gemeinsamen Dichtefunktion.
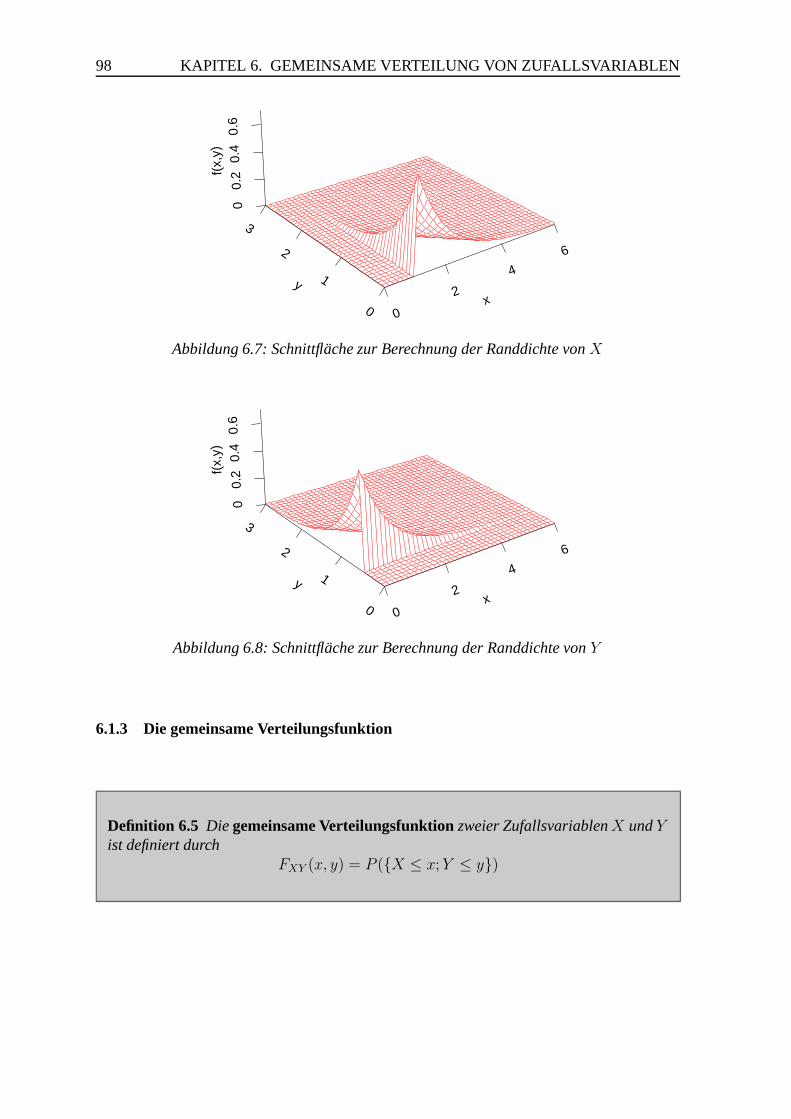
98 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
0
2
4
6
x 0
1
2
3
y
00.
20.
40.
6f(
x,y)
Abbildung 6.7: Schnittflache zur Berechnung der Randdichte von X
0
2
4
6
x 0
1
2
3
y
00.
20.
40.
6f(
x,y)
Abbildung 6.8: Schnittflache zur Berechnung der Randdichte von Y
6.1.3 Die gemeinsame Verteilungsfunktion
Definition 6.5 Die gemeinsame Verteilungsfunktion zweier Zufallsvariablen X und Yist definiert durch
FXY (x, y) = P (X ≤ x; Y ≤ y)
6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 99
Satz 6.2 Fur zwei diskrete Zufallsvariablen X und Y mit der gemeinsamen Wahrschein-lichkeitsfunktion PXY gilt
FXY (x, y) =∑
s≤x
∑
t≤y
PXY (s, t) .
Fur zwei stetige Zufallsvariablen mit der gemeinsamen Dichtefunktion fXY gilt
FXY (x, y) =
x∫
−∞
y∫
−∞fXY (s, t)dt ds .
Beispiel 6.6 Wir betrachten die gemeinsame Wahrscheinlichkeitsfunktion aus dem Beispiel 6.1, indem eine große Grundgesamtheit von Steuerzahlern nach ihrer Altersgruppe und zu ihrer Einsch at-zung der Kriminalit atslage befragt wurde. Aus Tabelle 6.1 erhalten wir die folgende gemeinsameVerteilungsfunktion.
Tabelle 6.2: Gemeinsame Verteilungsfunktion FXY (x, y)
y = 1 y = 2 y = 3 y = 4
x = 1 0.015 0.091 0.212 0.267x = 2 0.044 0.311 0.647 0.771x = 3 0.052 0.380 0.826 1.000
Beispiel 6.7 Die gemeinsame Dichtefunktion zweier Zufallsvariablen X und Y sei
fXY (x, y) =
4(1 − x)y 0 ≤ x ≤ 1 0 ≤ y ≤ 10 sonst.
0
0.5
1
x 0
0.5
1
y
01
23
4f(
x,y)
Abbildung 6.9: Gemeinsame Dichtefunktion f(x, y) = 4(1 − x)y
Dann giltFXY (x, y) = 0
100 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
f ur x < 0 oder y < 0, w ahrend f ur 0 ≤ x ≤ 1 und 0 ≤ y ≤ 1 gilt
FXY (x, y) =
x∫
0
y∫
0
4(1 − s)t dt ds
= 2x(1 − 1
2x)y2 .
Zusammenfassend gilt
FXY (x, y) =
0 f ur x < 0 oder y < 02x(1 − 1
2x)y2 f ur 0 ≤ x ≤ 1, 0 ≤ y ≤ 12x(1 − 1
2x) f ur 0 ≤ x ≤ 1, y > 1y2 f ur x > 1, 0 ≤ y ≤ 11 f ur x > 1, y > 1 .
Die einzelnen Bereiche der Verteilungsfunktion sind in Abbildung 6.10 dargestellt, w ahrend Abbil-dung 6.11 die Verteilungsfunktion zeigt.
0
1
0 1
..............................................................................................................................................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
............. ............. ............. ............. ............. ............. ............. ............. ............. ............. ............. ............. ............. ............. ......
x > 1 0 ≤ y ≤ 1
x > 1 y > 10 ≤ x ≤ 1
y > 1
Abbildung 6.10: Definitionsbereich der obigen Verteilungsfunktion
0
0.5
1
x 0
0.5
1
y
00.
51
F(x
,y)
Abbildung 6.11: Gemeinsame Verteilungsfunktion FXY (x, y) = 2x(1 − x/2)y2
Die Randverteilungsfunktionen erh alt man wie folgt
FX(x) = P (X ≤ x) = P (X ≤ x; Y < ∞)= FXY (x;∞)

6.1. GEMEINSAME VERTEILUNGEN ZWEIER ZUFALLSVARIABLEN 101
FX(x) =
0 f ur x < 02x(1 − 1
2x) f ur 0 ≤ x ≤ 11 f ur x > 1
FY (y) = P (Y ≤ y) = P (X < ∞; Y ≤ y)= FXY (∞; y)
FY (y) =
0 f ur y < 0y2 f ur 0 ≤ y ≤ 11 f ur y > 1
Wir wollen jetzt die gemeinsame Dichtefunktion zweier stetiger Zufallsvariablen bestimmen,wenn die gemeinsame Verteilungsfunktion gegeben ist.
Satz 6.3 Seien X und Y zwei stetige Zufallsvariablen mit der gemeinsamen Verteilungs-funktion FXY (x, y). Dann erhalt man die gemeinsame Dichtefunktion durch Differentia-tion:
fXY (x, y) =∂2
∂x∂yFXY (x, y) .
Beispiel 6.8 Wir betrachten die Verteilungsfunktion, die wir in Beispiel 6.6 aus der gemeinsamenDichtefunktion bestimmt hatten. Wir m ussten also jetzt durch Differentiation zu der uspr unglichenDichtefunktion zur uckkommen. Die Verteilungsfunktion war:
FXY (x, y) =
0 f ur x < 0 oder y < 02x(1 − 1
2x)y2 f ur 0 ≤ x ≤ 1, 0 ≤ y ≤ 12x(1 − 1
2x) f ur 0 ≤ x ≤ 1, y > 1y2 f ur x > 1, 0 ≤ y ≤ 11 sonst
F ur 0 ≤ x ≤ 1, 0 ≤ y ≤ 1 gilt
∂
∂x
∂
∂yF (x, y) =
∂
∂x2x(1 − 1
2x)2y
=∂
∂x(4x − 2x2)y
= (4 − 4x)y
= 4(1 − x)y
F ur alle ubrigen Bereiche ist∂
∂x
∂
∂yF (x, y) = 0 .
Damit gilt
fXY (x, y) =
4(1 − x)y 0 ≤ x ≤ 1 0 ≤ y ≤ 10 sonst.

102 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
Dies ist die gemeinsame Dichtefunktion, von der wir in Beispiel 6.6 ausgegangen waren.
R-Befehl zur graphischen Darstellung gemeinsamer Dichtefunktionen
• persp(x,y,z) erstellt einen 3D-Plot. Dabei sind x und y Vektoren, die das Gitter-netz bilden, uber dem die Funktion gezeichnet werden soll. Und z ist eine Matrix, diedie Funktionswerte angibt. In der Hilfe finden Sie weitere optionale Argumente.
6.2 Gemeinsame Momente
Wir betrachten jetzt Erwartungswerte von Funktionen H(X, Y ) von zwei ZufallsvariablenX und Y .
Definition 6.6 Sei H(X, Y ) eine Funktion der Zufallsvariablen (X, Y ). Der Erwar-tungswert EH(X, Y ) ist definiert durch
EH(X, Y ) =
∑
x
∑
yH(x, y)PXY (x, y) falls X und Y diskret sind,
∞∫
−∞
∞∫
−∞H(x, y)fXY (x, y)dydx falls X und Y stetig sind.
Fur das Rechnen mit Erwartungswerten gelten die folgenden Regeln (vergleiche Satz 2.1).
Satz 6.4 Seien H(X, Y ) und G(X, Y ) Funktionen der beiden Zufallsvariablen X undY , dann gilt:
a) E(cH(X, Y )) = cEH(X, Y ), wenn c eine Konstante ist,
b) E[(H(X, Y ) + G(X, Y )] = EH(X, Y ) + EG(X, Y ), insb.E(H(X, Y ) + c) = EH(X, Y ) + c .
Man beachte jedoch, dass im allgemeinen:
E[H(X, Y ) · G(X, Y )] 6= EH(X, Y ) · EG(X, Y ) .
Definition 6.7 Das (r, s)-te gemeinsame Moment zweier Zufallsvariablen X und Y istdefiniert als
µ′rs = EXrY s .
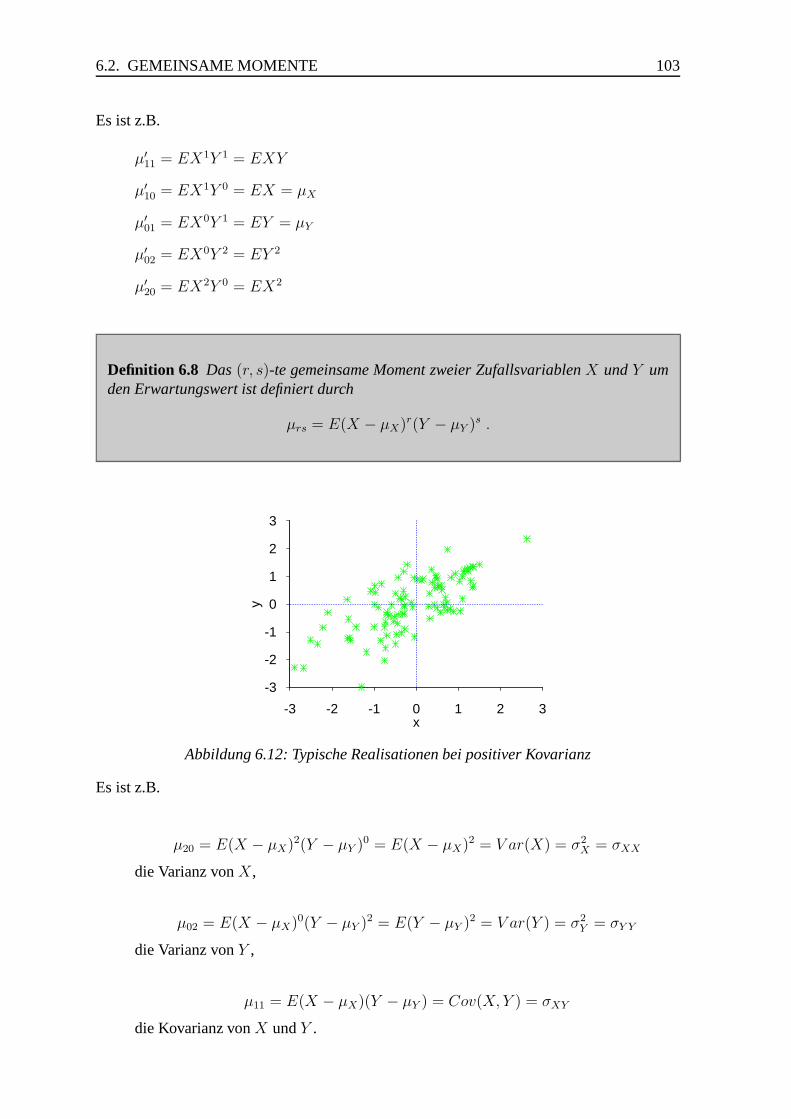
6.2. GEMEINSAME MOMENTE 103
Es ist z.B.
µ′11 = EX1Y 1 = EXY
µ′10 = EX1Y 0 = EX = µX
µ′01 = EX0Y 1 = EY = µY
µ′02 = EX0Y 2 = EY 2
µ′20 = EX2Y 0 = EX2
Definition 6.8 Das (r, s)-te gemeinsame Moment zweier Zufallsvariablen X und Y umden Erwartungswert ist definiert durch
µrs = E(X − µX)r(Y − µY )s .
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
x
y
Abbildung 6.12: Typische Realisationen bei positiver Kovarianz
Es ist z.B.
µ20 = E(X − µX)2(Y − µY )0 = E(X − µX)2 = V ar(X) = σ2X = σXX
die Varianz von X ,
µ02 = E(X − µX)0(Y − µY )2 = E(Y − µY )2 = V ar(Y ) = σ2Y = σY Y
die Varianz von Y ,
µ11 = E(X − µX)(Y − µY ) = Cov(X, Y ) = σXY
die Kovarianz von X und Y .
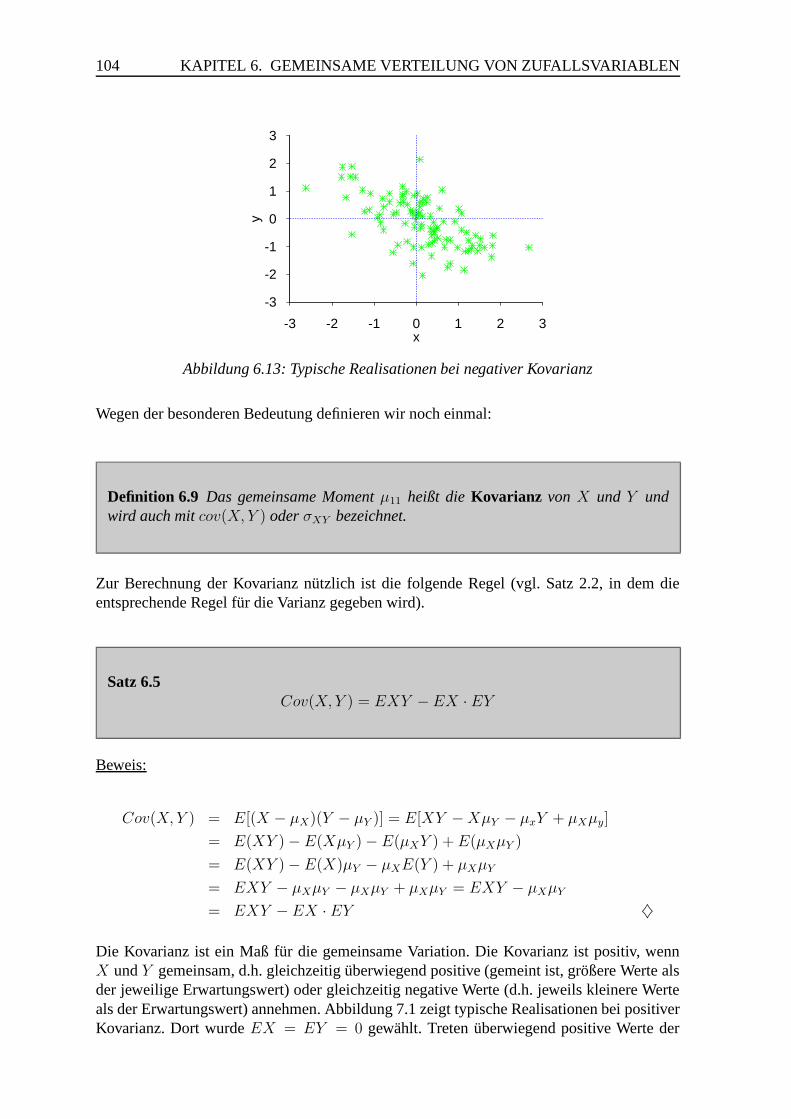
104 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
x
y
Abbildung 6.13: Typische Realisationen bei negativer Kovarianz
Wegen der besonderen Bedeutung definieren wir noch einmal:
Definition 6.9 Das gemeinsame Moment µ11 heißt die Kovarianz von X und Y undwird auch mit cov(X, Y ) oder σXY bezeichnet.
Zur Berechnung der Kovarianz nutzlich ist die folgende Regel (vgl. Satz 2.2, in dem dieentsprechende Regel fur die Varianz gegeben wird).
Satz 6.5Cov(X, Y ) = EXY − EX · EY
Beweis:
Cov(X, Y ) = E[(X − µX)(Y − µY )] = E[XY − XµY − µxY + µXµy]
= E(XY ) − E(XµY ) − E(µXY ) + E(µXµY )
= E(XY ) − E(X)µY − µXE(Y ) + µXµY
= EXY − µXµY − µXµY + µXµY = EXY − µXµY
= EXY − EX · EY ♦
Die Kovarianz ist ein Maß fur die gemeinsame Variation. Die Kovarianz ist positiv, wennX und Y gemeinsam, d.h. gleichzeitig uberwiegend positive (gemeint ist, großere Werte alsder jeweilige Erwartungswert) oder gleichzeitig negative Werte (d.h. jeweils kleinere Werteals der Erwartungswert) annehmen. Abbildung 7.1 zeigt typische Realisationen bei positiverKovarianz. Dort wurde EX = EY = 0 gewahlt. Treten uberwiegend positive Werte der
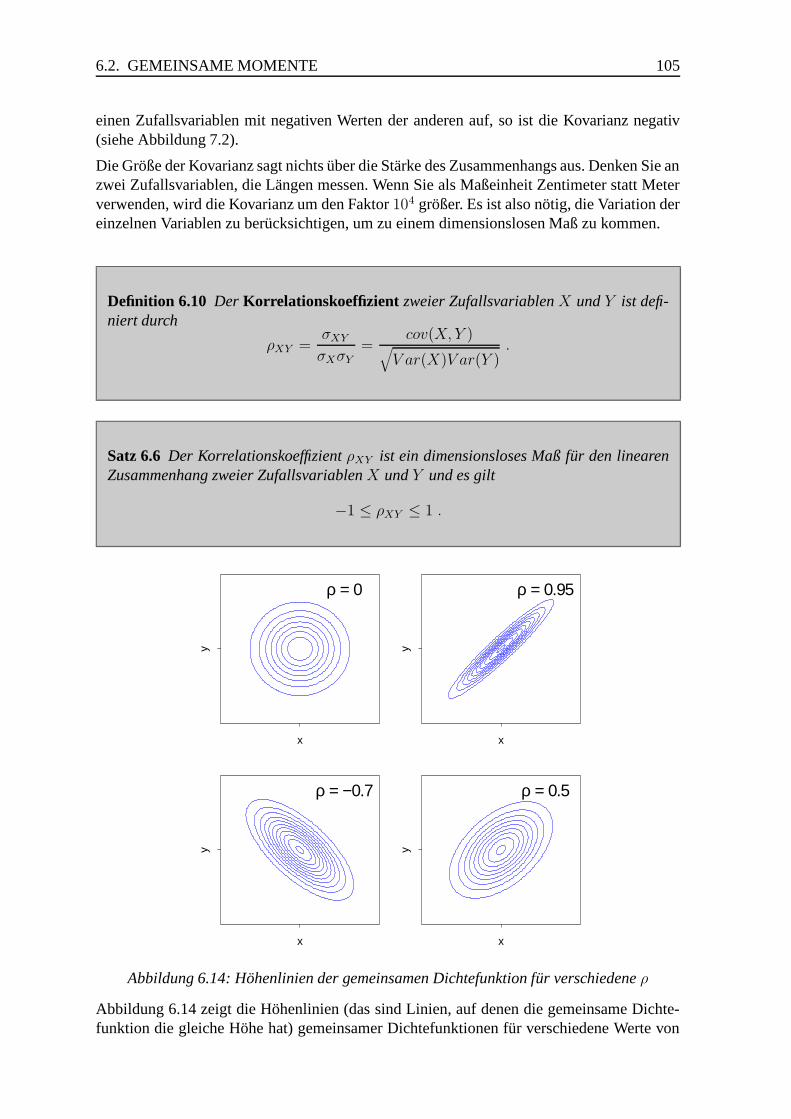
6.2. GEMEINSAME MOMENTE 105
einen Zufallsvariablen mit negativen Werten der anderen auf, so ist die Kovarianz negativ(siehe Abbildung 7.2).
Die Große der Kovarianz sagt nichts uber die Starke des Zusammenhangs aus. Denken Sie anzwei Zufallsvariablen, die Langen messen. Wenn Sie als Maßeinheit Zentimeter statt Meterverwenden, wird die Kovarianz um den Faktor 104 großer. Es ist also notig, die Variation dereinzelnen Variablen zu berucksichtigen, um zu einem dimensionslosen Maß zu kommen.
Definition 6.10 Der Korrelationskoeffizient zweier Zufallsvariablen X und Y ist defi-niert durch
ρXY =σXY
σXσY=
cov(X, Y )√
V ar(X)V ar(Y ).
Satz 6.6 Der Korrelationskoeffizient ρXY ist ein dimensionsloses Maß fur den linearenZusammenhang zweier Zufallsvariablen X und Y und es gilt
−1 ≤ ρXY ≤ 1 .
x
y
ρ = 0
x
y
ρ = 0.95
x
y
ρ = −0.7
x
y
ρ = 0.5
Abbildung 6.14: Hohenlinien der gemeinsamen Dichtefunktion fur verschiedene ρ
Abbildung 6.14 zeigt die Hohenlinien (das sind Linien, auf denen die gemeinsame Dichte-funktion die gleiche Hohe hat) gemeinsamer Dichtefunktionen fur verschiedene Werte von
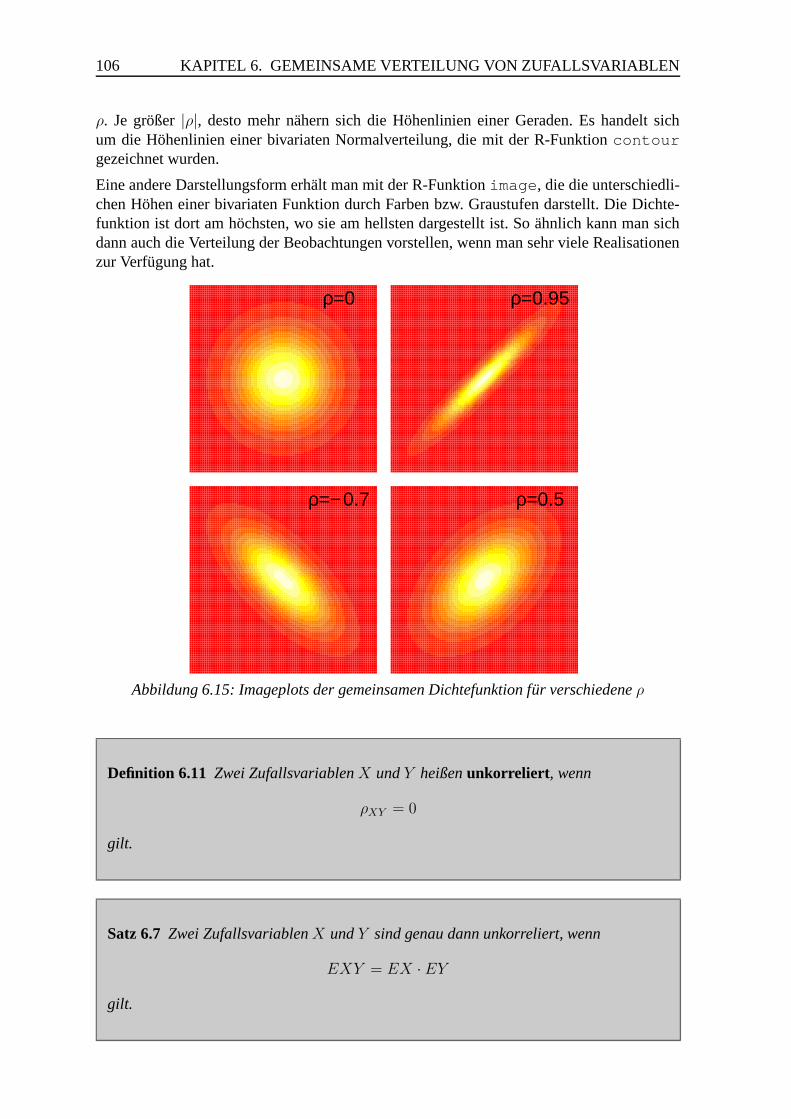
106 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
ρ. Je großer |ρ|, desto mehr nahern sich die Hohenlinien einer Geraden. Es handelt sichum die Hohenlinien einer bivariaten Normalverteilung, die mit der R-Funktion contourgezeichnet wurden.
Eine andere Darstellungsform erhalt man mit der R-Funktion image, die die unterschiedli-chen Hohen einer bivariaten Funktion durch Farben bzw. Graustufen darstellt. Die Dichte-funktion ist dort am hochsten, wo sie am hellsten dargestellt ist. So ahnlich kann man sichdann auch die Verteilung der Beobachtungen vorstellen, wenn man sehr viele Realisationenzur Verfugung hat.
ρ=0 ρ=0.95
ρ=− 0.7 ρ=0.5
Abbildung 6.15: Imageplots der gemeinsamen Dichtefunktion fur verschiedene ρ
Definition 6.11 Zwei Zufallsvariablen X und Y heißen unkorreliert, wenn
ρXY = 0
gilt.
Satz 6.7 Zwei Zufallsvariablen X und Y sind genau dann unkorreliert, wenn
EXY = EX · EY
gilt.
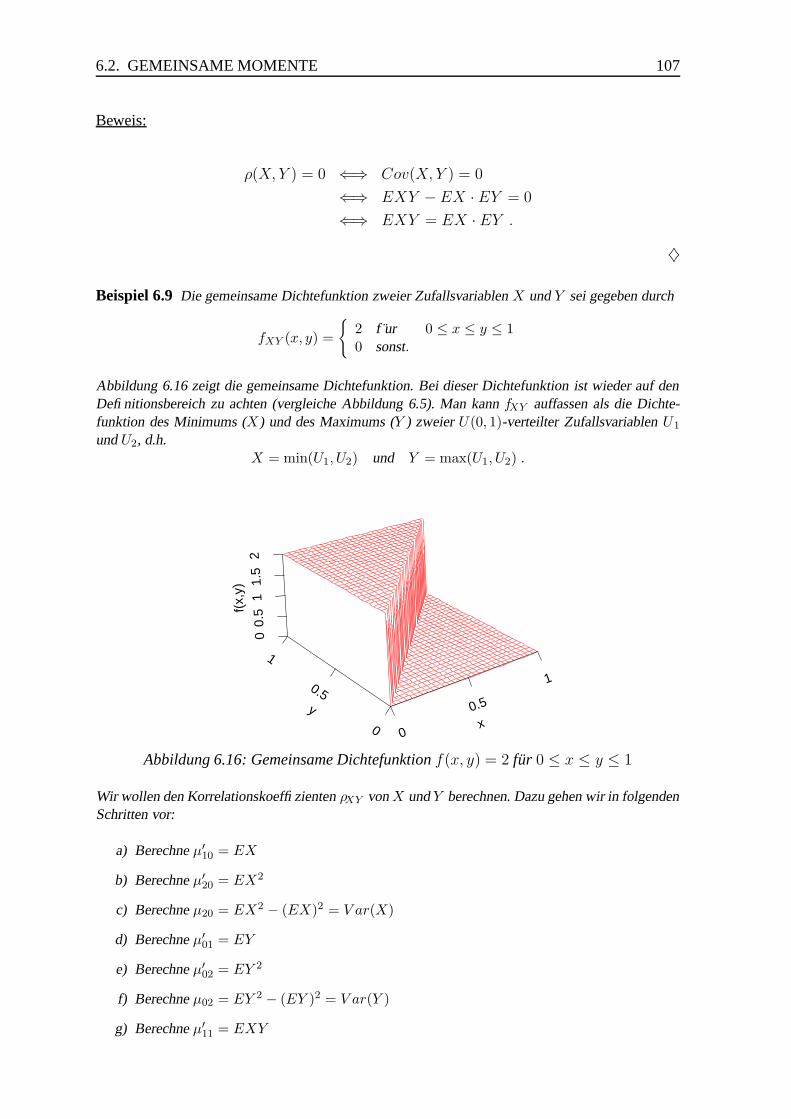
6.2. GEMEINSAME MOMENTE 107
Beweis:
ρ(X, Y ) = 0 ⇐⇒ Cov(X, Y ) = 0
⇐⇒ EXY − EX · EY = 0
⇐⇒ EXY = EX · EY .
♦
Beispiel 6.9 Die gemeinsame Dichtefunktion zweier Zufallsvariablen X und Y sei gegeben durch
fXY (x, y) =
2 f ur 0 ≤ x ≤ y ≤ 10 sonst.
Abbildung 6.16 zeigt die gemeinsame Dichtefunktion. Bei dieser Dichtefunktion ist wieder auf denDefinitionsbereich zu achten (vergleiche Abbildung 6.5). Man kann fXY auffassen als die Dichte-funktion des Minimums (X) und des Maximums (Y ) zweier U(0, 1)-verteilter Zufallsvariablen U1
und U2, d.h.X = min(U1, U2) und Y = max(U1, U2) .
0
0.5
1
x 0
0.5
1
y
00.
51
1.5
2f(
x,y)
Abbildung 6.16: Gemeinsame Dichtefunktion f(x, y) = 2 fur 0 ≤ x ≤ y ≤ 1
Wir wollen den Korrelationskoeffizienten ρXY von X und Y berechnen. Dazu gehen wir in folgendenSchritten vor:
a) Berechne µ′10 = EX
b) Berechne µ′20 = EX2
c) Berechne µ20 = EX2 − (EX)2 = V ar(X)
d) Berechne µ′01 = EY
e) Berechne µ′02 = EY 2
f) Berechne µ02 = EY 2 − (EY )2 = V ar(Y )
g) Berechne µ′11 = EXY

108 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
h) Berechne µ11 = EXY − EXEY = Cov(X,Y )
i) Berechne ρXY = Cov(X,Y )√V ar(X)V ar(Y )
Bevor wir mit den einzelnen Schritten beginnen, bestimmen wir zun achst die Randdichten von X undY , da wir die ersten und zweiten Momente von X und Y einfacher mit den Randdichtefunktionen alsmit der gemeinsamen Dichtefunktion berechnen k onnen.
fX(x) =
∞∫
−∞fXY (x, y)dy
=
1∫
x
2 dy
= 2y|1x
=
2(1 − x) f ur 0 ≤ x ≤ 10 sonst
fY (y) =
∞∫
−∞fXY (x, y)dx
=
y∫
0
2 dx
= 2x|y0
=
2y f ur 0 ≤ y ≤ 10 sonst
Jetzt gehen wir in den obigen Schritten vor:
a)
µ′10 = EX =
1∫
0
x2(1 − x)dx
=
1∫
0
2x − 2x2dx
= x2 − 2
3x3
∣∣∣∣
1
0
=1
3
b)
µ′20 = EX2 =
1∫
0
x22(1 − x)dx

6.2. GEMEINSAME MOMENTE 109
=
1∫
0
2x2 − 2x3dx
=2
3x3 − 1
2x4
∣∣∣∣
1
0
=1
6
c)
V arX = µ20 = E(X2) − (EX)2
=1
6−(
1
3
)2
=1
6− 1
9=
1
18
d)
µ′01 = EY =
1∫
0
y2ydy =2
3y3
∣∣∣∣∣∣
1
0
=2
3
e)
µ′02 = EY 2 =
1∫
0
y22ydy =1
2y4
∣∣∣∣∣∣
1
0
=1
2
f)
V arY = µ02 = E(Y 2) − (EY )2
=1
2−(
2
3
)2
=1
2− 4
9=
1
18
g)
µ′11 = EXY =
1∫
0
y∫
0
xy · 2dxdy
=
1∫
0
x2y∣∣∣
y
0dy
=
1∫
0
y3dy
=1
4y4
∣∣∣∣
1
0=
1
4
h)
µ11 = Cov(X,Y ) = EXY − EXEY
=1
4− 1
3· 2
3
=1
4− 2
9=
1
36

110 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
i)
ρXY =Cov(X,Y )
√
V ar(X)V ar(Y )
=136
√118
118
=18
36=
1
2
R-Befehle zur graphischen Darstellung gemeinsamer Dichtefunktionen
• contour(x, y, z) zeichnet die Hohenlinien der durch die Matrix z einzugeben-den Funktion. Die Vektoren x und y bestimmen das Gitternetz, uber dem die Funktionberechnet werden soll. In der Hilfe finden Sie weitere optionale Argumente, mit denenSie z.B. die Anzahl der Hohenlinien bestimmen konnen.
• image(x, y, z) zeichnet die Hohenlinien durch Farbabstufungen oder durch Grau-stufen. Die Argumente sind wie bei der Funktion contour.
6.3 Bedingte Verteilungen, Unabhangigkeit
6.3.1 Bedingte Verteilungen
Definition 6.12 Seien X und Y diskrete Zufallsvariablen. Die bedingte Wahrschein-lichkeitsfunktion von Y gegeben X = x ist definiert als
PY |X(y|x) =PXY (x, y)
PX(x),
und die bedingte Wahrscheinichkeitsfunktion von X gegeben Y = y ist definiert als
PX|Y (x|y) =PXY (x, y)
PY (y).
Beispiel 6.10 Wir betrachten die Situation aus Beispiel 6.1. Dort wurde eine große Grundgesamtheitvon Steuerzahlern nach ihrer Altersgruppe und nach ihrer Meinung zur Kriminalit atslage in ihrerUmgebung befragt. Die gemeinsame Wahrscheinlichkeitsfunktion PXY ist in Tabelle 6.1 gegeben.
Nehmen Sie an, dass wir eine Person aus der Grundgesamtheit zuf allig ausw ahlen. Wir stellen diebeiden folgenden Fragen:
• FRAGE 1: Wie hoch ist die Wahrscheinlichkeit, dass er oder sie die Kriminalit atslage als ,,sehrernst” einsch atzt?
ANTWORT:
P (Y = 4) = PY (4) = 0.055 + 0.069 + 0.050 = 0.174

6.3. BEDINGTE VERTEILUNGEN, UNABHANGIGKEIT 111
• FRAGE 2: Wie hoch ist die Wahrscheinlichkeit, dass er oder sie die Kriminalit atslage als ,,sehrernst” betrachtet, gegeben, dass er oder sie zwischen 30 und 50 Jahre alt ist?
ANTWORT:
P (Y = 4|X = 2) =PXY (2, 4)
PX(2)=
0.069
0.504= 0.137
Wir wollen die komplette bedingte Wahrscheinlichkeitsfunktion von Y , gegeben X = 2 bestimmen.
PY |X(y|2) =PXY (2, y)
PX(2)=
0.029/0.504 = 0.058 y = 10.191/0.504 = 0.379 y = 20.215/0.504 = 0.427 y = 30.069/0.504 = 0.137 y = 4
0 sonst .
Schließlich bestimmen wir noch die bedingte Wahrscheinlichkeitsfunktion von X , gegeben Y = 4.Diese Wahrscheinlichkeitsfunktion gibt uns die Antwort auf die
• FRAGE: Wie groß ist die Wahrscheinlichkeit, dass eine zuf allig ausgew ahlte Person einer be-stimmten Altersgruppe angeh ort, gegeben, dass diese Person die Kriminalit atslage als ,,sehrernst” einsch atzt?
ANTWORT:
PX|Y (x|4) =PXY (x, 4)
PY (4)=
0.055/0.174 = 0.316 x = 10.069/0.174 = 0.397 x = 20.050/0.174 = 0.287 x = 3
0 sonst .
Definition 6.13 Seien X und Y stetige Zufallsvariablen. Die bedingte Dichtefunktionvon Y gegeben X = x ist definiert durch
fY |X(y|x) =fXY (x, y)
fX(x),
und die bedingte Dichtefunktion von X gegeben Y = y ist definiert durch
fX|Y (x|y) =fXY (x, y)
fY (y).
Beispiel 6.11 Wir betrachten die gemeinsame Dichtefunktion aus Beispiel 6.2, die in Abbildung 6.1graphisch dargestellt ist.
fXY (x, y) =
125 x(2 − x − y) 0 ≤ x ≤ 1, 0 ≤ y ≤ 10 sonst
In Beispiel 6.4 hatten wir auch schon die Randdichtefunktionen bestimmt. Es war
fX(x) =
125
(32x − x2
)
0 ≤ x ≤ 1
0 sonst
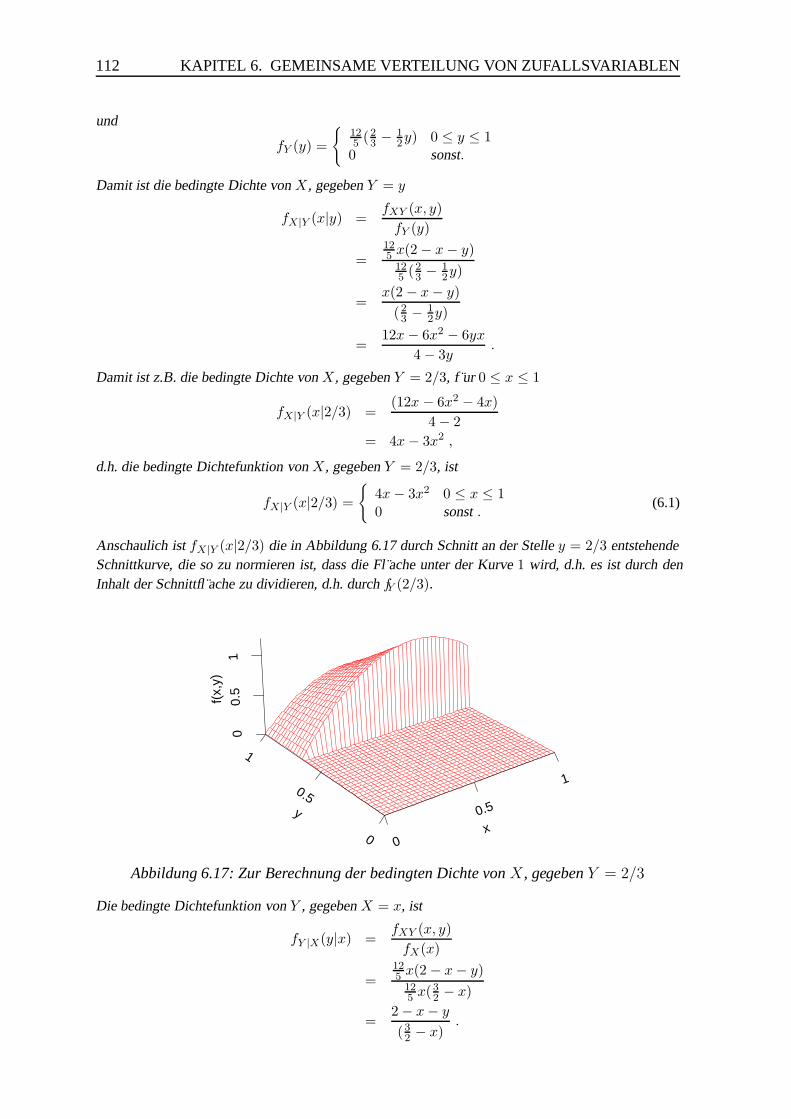
112 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
und
fY (y) =
125 (2
3 − 12y) 0 ≤ y ≤ 1
0 sonst.
Damit ist die bedingte Dichte von X , gegeben Y = y
fX|Y (x|y) =fXY (x, y)
fY (y)
=125 x(2 − x − y)
125 (2
3 − 12y)
=x(2 − x − y)
(23 − 1
2y)
=12x − 6x2 − 6yx
4 − 3y.
Damit ist z.B. die bedingte Dichte von X , gegeben Y = 2/3, f ur 0 ≤ x ≤ 1
fX|Y (x|2/3) =(12x − 6x2 − 4x)
4 − 2
= 4x − 3x2 ,
d.h. die bedingte Dichtefunktion von X , gegeben Y = 2/3, ist
fX|Y (x|2/3) =
4x − 3x2 0 ≤ x ≤ 10 sonst .
(6.1)
Anschaulich ist fX|Y (x|2/3) die in Abbildung 6.17 durch Schnitt an der Stelle y = 2/3 entstehendeSchnittkurve, die so zu normieren ist, dass die Fl ache unter der Kurve 1 wird, d.h. es ist durch denInhalt der Schnittfl ache zu dividieren, d.h. durch fY (2/3).
0
0.5
1
x 0
0.5
1
y
00.
51
f(x,
y)
Abbildung 6.17: Zur Berechnung der bedingten Dichte von X , gegeben Y = 2/3
Die bedingte Dichtefunktion von Y , gegeben X = x, ist
fY |X(y|x) =fXY (x, y)
fX(x)
=125 x(2 − x − y)
125 x(3
2 − x)
=2 − x − y
(32 − x)
.
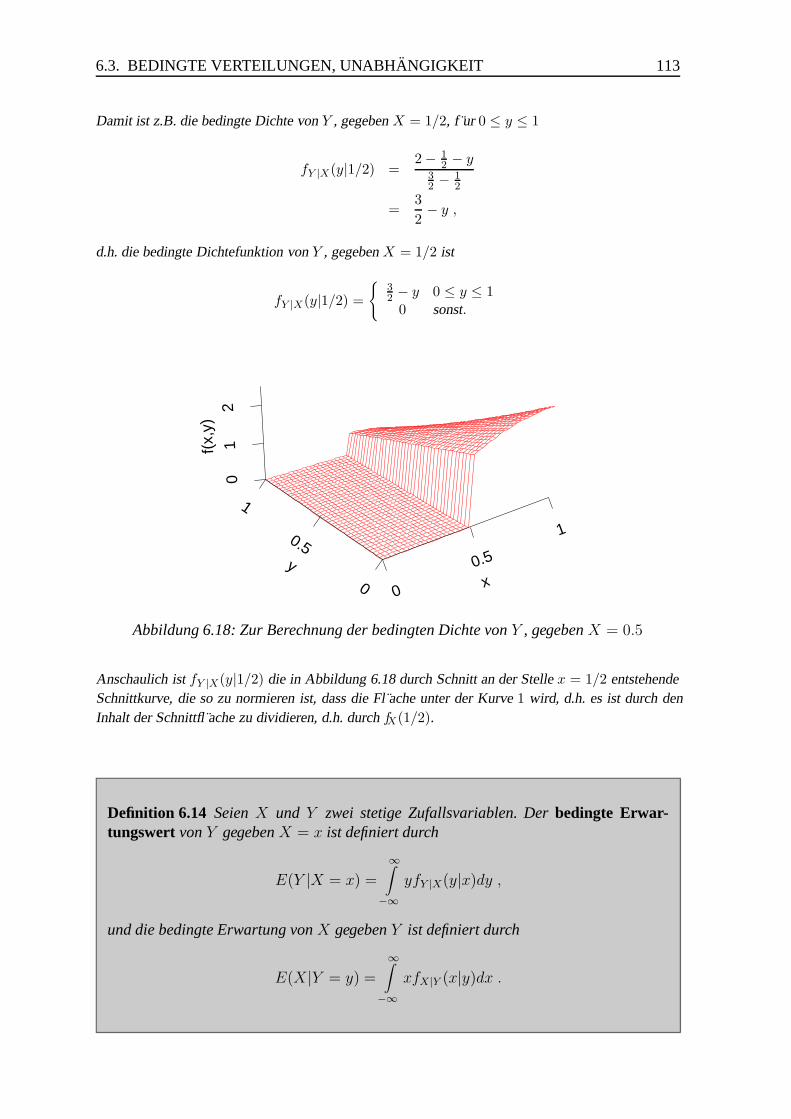
6.3. BEDINGTE VERTEILUNGEN, UNABHANGIGKEIT 113
Damit ist z.B. die bedingte Dichte von Y , gegeben X = 1/2, f ur 0 ≤ y ≤ 1
fY |X(y|1/2) =2 − 1
2 − y32 − 1
2
=3
2− y ,
d.h. die bedingte Dichtefunktion von Y , gegeben X = 1/2 ist
fY |X(y|1/2) =
32 − y 0 ≤ y ≤ 1
0 sonst.
0
0.5
1
x 0
0.5
1
y
01
2f(
x,y)
Abbildung 6.18: Zur Berechnung der bedingten Dichte von Y , gegeben X = 0.5
Anschaulich ist fY |X(y|1/2) die in Abbildung 6.18 durch Schnitt an der Stelle x = 1/2 entstehendeSchnittkurve, die so zu normieren ist, dass die Fl ache unter der Kurve 1 wird, d.h. es ist durch denInhalt der Schnittfl ache zu dividieren, d.h. durch fX(1/2).
Definition 6.14 Seien X und Y zwei stetige Zufallsvariablen. Der bedingte Erwar-tungswert von Y gegeben X = x ist definiert durch
E(Y |X = x) =
∞∫
−∞yfY |X(y|x)dy ,
und die bedingte Erwartung von X gegeben Y ist definiert durch
E(X|Y = y) =
∞∫
−∞xfX|Y (x|y)dx .

114 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
Fur zwei diskrete Zufallsvariablen gilt entsprechend
E(Y |X = x) =∑
y
yPY |X(y|x) ,
undE(X|Y = y) =
∑
x
xPX|Y (x|y) .
Beispiel 6.12 Wir betrachten wieder die gemeinsame Dichtefunktion aus dem Beispiel 6.11 undwollen die bedingte Erwartung von
E(X|Y = y)
bestimmen. Dabei wollen wir f ur y zun achst keinen bestimmten Wert festlegen. Dann gilt
E(X|Y = y) =
∞∫
−∞xfX|Y (x|y)dx
=
1∫
0
x12x − 6x2 − 6yx
4 − 3ydx
=
1∫
0
12x2 − 6x3 − 6yx2
4 − 3ydx
=4x3 − (3/2)x4 − 2yx3
4 − 3y
∣∣∣∣∣
1
0
=5 − 4y
8 − 6y.
Zum Beispiel f ur y = 2/3 ergibt sich die bedingte Erwartung
E(X|Y = 2/3) = 7/12 . (6.2)
Definition 6.15 Seien X und Y zwei stetige Zufallsvariablen. Die bedingte Varianz vonY , gegeben X = x, ist definiert durch
V ar(Y |X = x) =
∞∫
−∞(y − E(Y |X = x))2fY |X(y|x)dy ,
und die bedingte Varianz von X , gegeben Y = y, ist definiert durch
V ar(X|Y = y) =
∞∫
−∞(x − E(X|Y = y))2fX|Y (x|y)dx .

6.3. BEDINGTE VERTEILUNGEN, UNABHANGIGKEIT 115
Fur zwei diskrete Zufallsvariablen gilt entsprechend
V ar(Y |X = x) =∑
y
(y − E(Y |X = x))2PY |X(y|x) ,
undV ar(X|Y = y) =
∑
x
(x − E(X|Y = y))2PX|Y (x|y) .
Beispiel 6.13 Wir benutzen die gemeinsame Dichtefunktion aus den beiden vorigen Beispielen undwollen jetzt die bedingte Varianz von X , gegeben Y = 2/3, berechnen. Die bedingte Erwartung istnach Gleichung 6.2
E(X|Y = 2/3) = 7/12 .
Wir wollen jetzt E(X2|Y = 2/3) bestimmen und benutzen dazu die bedingte Dichtefunktion von X ,gegeben Y = 2/3, die wir in Gleichung 6.1 bestimmt hatten.
E(X2|Y = 2/3) =
1∫
0
x2(4x − 3x2)dx
=
1∫
0
(4x3 − 3x4)dx
= x4 − 3
5x5
∣∣∣∣
1
0
= 1 − 3/5 = 2/5 .
Damit ist die bedingte Varianz
V ar(X|Y = 2/3) = E(X2|Y = 2/3) − [E(X|Y = 2/3)]2
=2
5−(
7
12
)2
=288 − 245
720=
43
720.
Man rechnet also bedingte Erwartungswerte und bedingte Varianzen genauso aus wie gewohn-liche Erwartungswerte und Varianzen. Man muss nur die bedingten Dichtefunktionen bzw.Wahrscheinlichkeitsfunktionen verwenden.

116 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
6.3.2 Unabhangigkeit
Definition 6.16 Zwei Zufallsvariablen X und Y heißen unabhangig, wenn im Falle dis-kreter Zufallsvariablen fur die gemeinsame Wahrscheinlichkeitsfunktion
PXY (x, y) = PX(x)PY (y)
fur alle x, y gilt, bzw. im Falle stetiger Zufallsvariablen fur die gemeinsame Dichtefunk-tion
fXY (x, y) = fX(x)fY (y)
fur alle x, y gilt.
Beispiel 6.14 In Beispiel 6.5 hatten wir gesehen, dass die gemeinsame Dichtefunktion
fXY (x, y) =
2e−xe−2y 0 < x < ∞, 0 < y < ∞0 sonst
das Produkt ihrer Randdichten
fX(x) =
e−x 0 < x < ∞0 sonst
und
fY (y) =
2e−2y 0 < y < ∞0 sonst
ist. Die Zufallsvariablen X und Y sind also unabh angig.
Satz 6.8 Wenn die beiden Zufallsvariablen X und Y unabhangig sind, so gilt fur diskreteZufallsvariablen
PY |X(y|x) = PY (y) und PX|Y (x|y) = PX(x) .
Fur stetige Zufallsvariablen gilt
fY |X(y|x) = fY (y) und fX|Y (x|y) = fX(x) .
Beweis:Fur diskrete Zufallsvariablen gilt im Falle der Unabhangigkeit
PY |X(y|x) =PXY (x, y)
PX(x)=
PX(x)PY (y)
PX(x)= PY (y) .
Fur stetige Zufallsvariablen ersetze man P durch f . ♦

6.3. BEDINGTE VERTEILUNGEN, UNABHANGIGKEIT 117
Beispiel 6.15 Wir betrachten die gemeinsame Wahrscheinlichkeitsfunktion aus dem Beispiel 6.1(Einsch atzung der Kriminalit atslage). Dort war
PXY (1, 1) = 0.015, PX(1) = 0.267 und PY (1) = 0.052 .
Offensichtlich gilt
PX(1)PY (1) = 0.267 · 0.052 = 0.013884 6= 0.015 = PXY (1, 1) .
Damit sind X und Y nicht unabh angig. In dieser Grundgesamtheit ist also die Einsch atzung derKriminalit atslage nicht unabh angig vom Alter.
Beispiel 6.16 In Beispiel 6.9 hatten wir die folgende gemeinsame Dichtefunktion zweier stetigerZufallsvariablen X und Y betrachtet.
fXY (x, y) =
2 f ur 0 < x < y < 10 sonst.
Die Randdichten waren
fX(x) =
2(1 − x) f ur 0 < x < 10 sonst
und
fY (y) =
2y f ur 0 < y < 10 sonst .
DafX(x)fY (y) = 4y(1 − x) 6= 2 = fXY (x, y) ,
sind die beiden Zufallsvariablen X und Y nicht unabh angig.
Beispiel 6.17 In Beispiel 6.11 hatten wir die bedingten Dichtefunktionen ausgerechnet. Es galt
fX|Y (x|y) =
12x−6x2−6yx
4−3y f ur 0 < x < 1
0 sonst
und
fY |X(y|x) =
2−x−y( 32−x)
f ur 0 < y < 1
0 sonst .
Offensichtlich h angt die bedingte Dichtefunktion von X , gegeben Y = y von y und die bedingteDichte von Y , gegeben X = x von x ab, so dass die beiden Zufallsvariablen X und Y nach Satz 6.8nicht unabh angig sein k onnen.
Satz 6.9 Wenn die beiden Zufallsvariablen X und Y unabhangig sind, so sind sie unkor-reliert, d.h. es gilt
EXY = EX · EY .

118 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
Beweis:Wir fuhren den Beweis nur fur stetige Zufallsvariablen, fur diskrete ist der Beweis analog,wenn man die Integrale durch Summen ersetzt.
EXY =
∞∫
−∞
∞∫
−∞xyfXY (x, y)dxdy
=
∞∫
−∞
∞∫
−∞xyfX(x)fY (y)dxdy
=
∞∫
−∞yfY (y)
∞∫
−∞xfX(x)dx
︸ ︷︷ ︸
EX
dy
= EX
∞∫
−∞yfY (y)dy
︸ ︷︷ ︸
EY
= EXEY .
Die Umkehrung dieses Satzes gilt jedoch i. allg. nicht, wie das folgende Beispiel zeigt.
Beispiel 6.18 Wir betrachten die gemeinsame Wahrscheinlichkeitsfunktion
PXY (x, y) =
1/4 (x, y) = (−2, 4), (−1, 1), (1, 1), (2, 4)0 sonst .
Die Randwahrscheinlichkeitsfunktionen sind
PX(x) =
1/4 x = −2,−1, 1, 20 sonst ,
PY (y) =
1/2 y = 1, 40 sonst .
Es gilt
EXY = 0 und EX = 0 ,
d.h.
EXY = EX · EY .
Die Zufallsvariablen X und Y sind also nach Satz 6.7 unkorreliert. Sie sind jedoch nicht unabh angig,da z.B.
PXY (1, 1) = 1/4 6= 1/8 = PX(1)PY (1) .
Das ist auch anschaulich klar, da Y = X2 gilt.
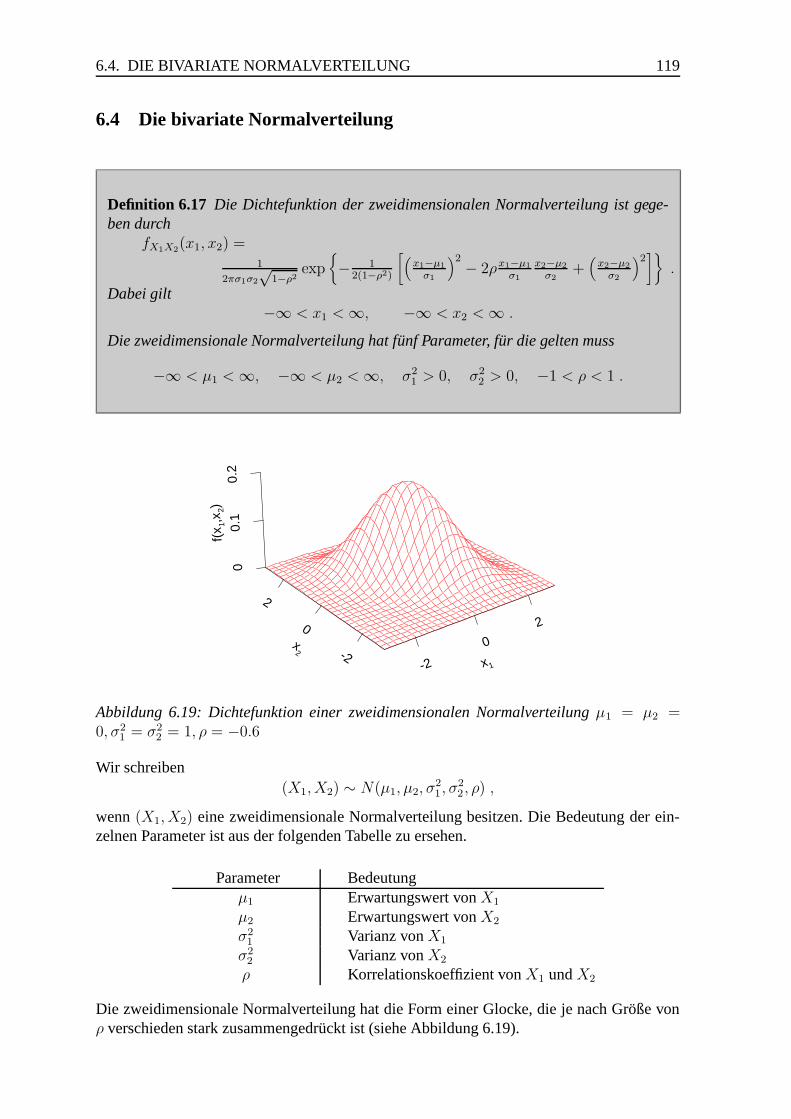
6.4. DIE BIVARIATE NORMALVERTEILUNG 119
6.4 Die bivariate Normalverteilung
Definition 6.17 Die Dichtefunktion der zweidimensionalen Normalverteilung ist gege-ben durch
fX1X2(x1, x2) =1
2πσ1σ2
√1−ρ2
exp
− 12(1−ρ2)
[(x1−µ1
σ1
)2 − 2ρx1−µ1
σ1
x2−µ2
σ2+(
x2−µ2
σ2
)2]
.
Dabei gilt−∞ < x1 < ∞, −∞ < x2 < ∞ .
Die zweidimensionale Normalverteilung hat funf Parameter, fur die gelten muss
−∞ < µ1 < ∞, −∞ < µ2 < ∞, σ21 > 0, σ2
2 > 0, −1 < ρ < 1 .
-2
0
2
x 1-2
0
2
x2
00.
10.
2f(
x 1,x
2)
Abbildung 6.19: Dichtefunktion einer zweidimensionalen Normalverteilung µ1 = µ2 =0, σ2
1 = σ22 = 1, ρ = −0.6
Wir schreiben(X1, X2) ∼ N(µ1, µ2, σ
21, σ
22, ρ) ,
wenn (X1, X2) eine zweidimensionale Normalverteilung besitzen. Die Bedeutung der ein-zelnen Parameter ist aus der folgenden Tabelle zu ersehen.
Parameter Bedeutungµ1 Erwartungswert von X1
µ2 Erwartungswert von X2
σ21 Varianz von X1
σ22 Varianz von X2
ρ Korrelationskoeffizient von X1 und X2
Die zweidimensionale Normalverteilung hat die Form einer Glocke, die je nach Große vonρ verschieden stark zusammengedruckt ist (siehe Abbildung 6.19).
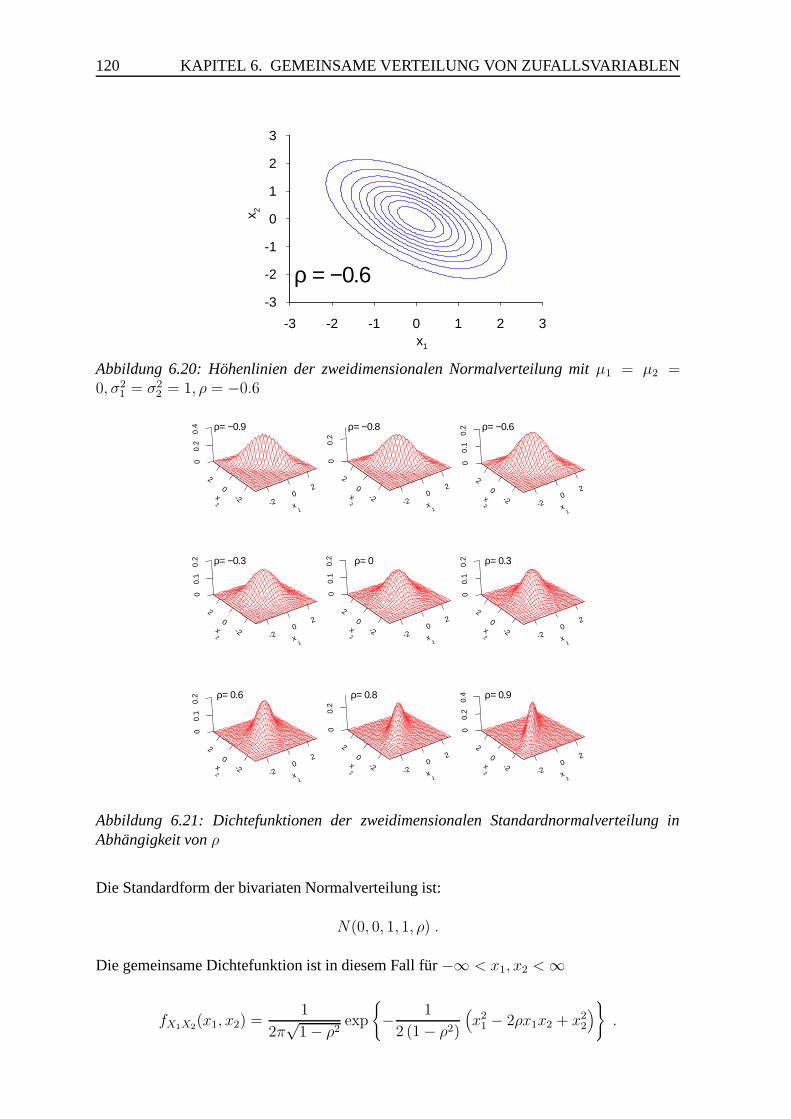
120 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
x1
x 2
ρ = −0.6
Abbildung 6.20: Hohenlinien der zweidimensionalen Normalverteilung mit µ1 = µ2 =0, σ2
1 = σ22 = 1, ρ = −0.6
-2 0
2
x1
-2
02
x2
00.
20.
4
ρ= −0.9
-2 0
2
x1
-2
02
x2
00.
2
ρ= −0.8
-2 0
2
x1
-2
02
x2
00.
10.
2
ρ= −0.6
-2 0
2
x1
-2
02
x2
00.
10.
2
ρ= −0.3
-2 0
2
x1
-2
02
x2
00.
10.
2
ρ= 0
-2 0
2
x1
-2
02
x2
00.
10.
2
ρ= 0.3
-2 0
2
x1
-2
02
x2
00.
10.
2
ρ= 0.6
-2 0
2
x1
-2
02
x2
00.
2
ρ= 0.8
-2 0
2
x1
-2
02
x2
00.
20.
4
ρ= 0.9
Abbildung 6.21: Dichtefunktionen der zweidimensionalen Standardnormalverteilung inAbhangigkeit von ρ
Die Standardform der bivariaten Normalverteilung ist:
N(0, 0, 1, 1, ρ) .
Die gemeinsame Dichtefunktion ist in diesem Fall fur −∞ < x1, x2 < ∞
fX1X2(x1, x2) =1
2π√
1 − ρ2exp
− 1
2 (1 − ρ2)
(
x21 − 2ρx1x2 + x2
2
)
.
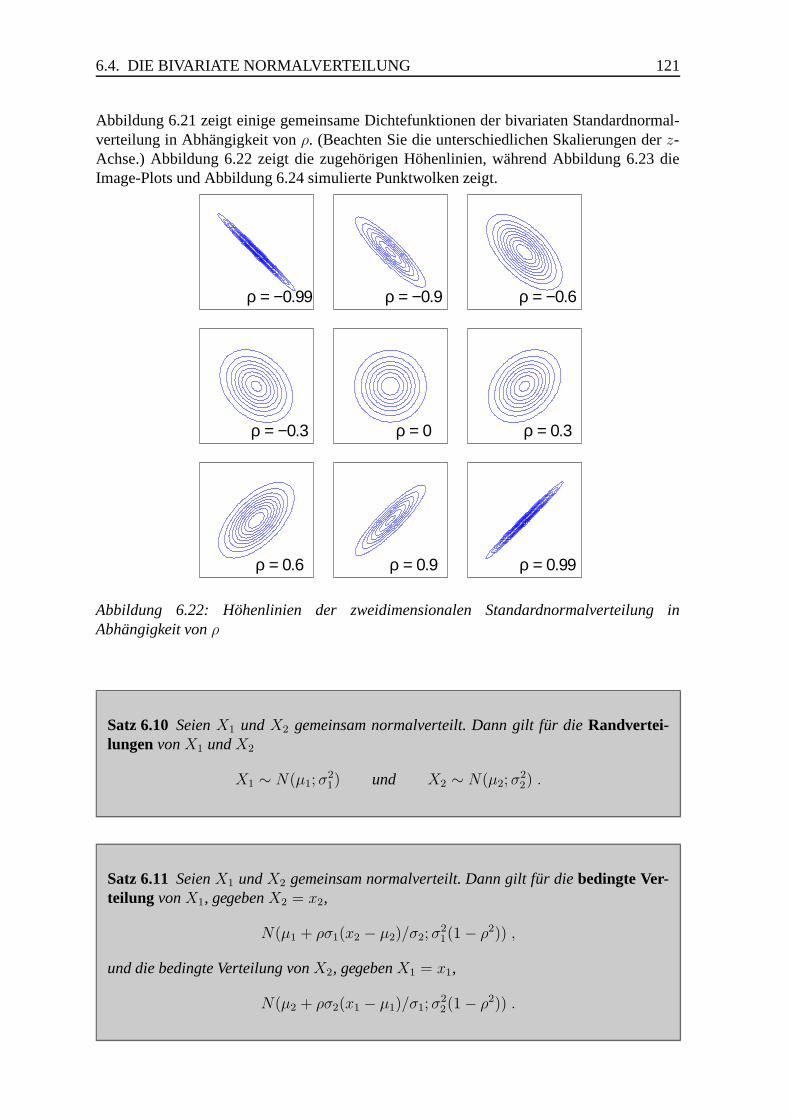
6.4. DIE BIVARIATE NORMALVERTEILUNG 121
Abbildung 6.21 zeigt einige gemeinsame Dichtefunktionen der bivariaten Standardnormal-verteilung in Abhangigkeit von ρ. (Beachten Sie die unterschiedlichen Skalierungen der z-Achse.) Abbildung 6.22 zeigt die zugehorigen Hohenlinien, wahrend Abbildung 6.23 dieImage-Plots und Abbildung 6.24 simulierte Punktwolken zeigt.
ρ = −0.99 ρ = −0.9 ρ = −0.6
ρ = −0.3 ρ = 0 ρ = 0.3
ρ = 0.6 ρ = 0.9 ρ = 0.99
Abbildung 6.22: Hohenlinien der zweidimensionalen Standardnormalverteilung inAbhangigkeit von ρ
Satz 6.10 Seien X1 und X2 gemeinsam normalverteilt. Dann gilt fur die Randvertei-lungen von X1 und X2
X1 ∼ N(µ1; σ21) und X2 ∼ N(µ2; σ
22) .
Satz 6.11 Seien X1 und X2 gemeinsam normalverteilt. Dann gilt fur die bedingte Ver-teilung von X1, gegeben X2 = x2,
N(µ1 + ρσ1(x2 − µ2)/σ2; σ21(1 − ρ2)) ,
und die bedingte Verteilung von X2, gegeben X1 = x1,
N(µ2 + ρσ2(x1 − µ1)/σ1; σ22(1 − ρ2)) .

122 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
ρ=− 0.99 ρ=− 0.9 ρ=− 0.6
ρ=− 0.3 ρ=0 ρ=0.3
ρ=0.6 ρ=0.9 ρ=0.99
Abbildung 6.23: Image-Plots der zweidimensionalen Standardnormalverteilung inAbhangigkeit von ρ
Die Abbildungen 6.25 und 6.26 veranschaulichen die bedingten Dichtefunktionen (verglei-che Seite 112). Die Schnittkurven sind so zu normieren, dass die Flache unterhalb der Dich-tefunktion den Wert 1 erhalt.
R-Befehle zur bivariaten Normalverteilung Zur bivariaten Normalverteilung gibt es keineinternen R-Funktionen. Es gibt jedoch die selbstgeschriebenen Funktionen:
dbnorm(x1=0, x2=0, mu1=0, mu2=0, sigma1=1, sigma2=1, rho=0)berechnet die Dichtefunktion an der Stelle (x1, x2).
rbnorm(n=1, mu1=0, mu2=0, sigma1=1, sigma2=1, rho=0) erzeugtn Paare bivariat normalverteilter Zufallszahlen.
Weitere selbstgeschriebene R-Funktionen zur bivariaten Normalverteilung sind:
• s3bnormpersp.fun(mu1=0, mu2=0, sigma1=1, sigma2=1, rho=0, nx=30, ax=1,
bx=nx, ay=1, by=nx, ...)
zeichnet einen 3D-Plot der gemeinsamen Dichtefunktion. Dabei ist nx die Anzahl derGitterpunkte in x1- und x2-Richtung, fur die die Dichtefunktion berechnet werden soll.Die Berechnung der Dichtefunktion kann auf den Bereich von ax bis bx und ay bisby (in Gitterpunkten gemessen) beschrankt werden, um Schnitte durch die gemeinsa-me Dichtefunktion zu erhalten (siehe Abbildung 9.7 oder 9.8). Es konnen optionaleArgumente der R-Funktion persp und graphische Parameter als weitere Argumenteangegeben werden.
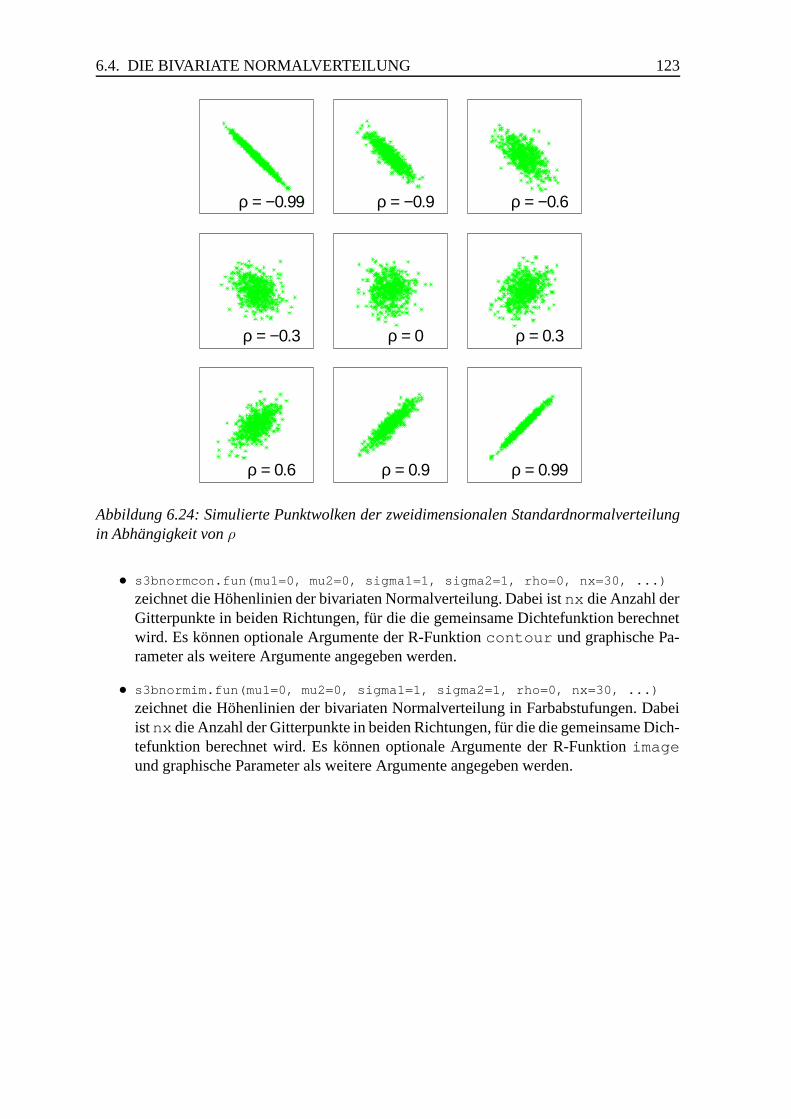
6.4. DIE BIVARIATE NORMALVERTEILUNG 123
ρ = −0.99 ρ = −0.9 ρ = −0.6
ρ = −0.3 ρ = 0 ρ = 0.3
ρ = 0.6 ρ = 0.9 ρ = 0.99
Abbildung 6.24: Simulierte Punktwolken der zweidimensionalen Standardnormalverteilungin Abhangigkeit von ρ
• s3bnormcon.fun(mu1=0, mu2=0, sigma1=1, sigma2=1, rho=0, nx=30, ...)
zeichnet die Hohenlinien der bivariaten Normalverteilung. Dabei ist nx die Anzahl derGitterpunkte in beiden Richtungen, fur die die gemeinsame Dichtefunktion berechnetwird. Es konnen optionale Argumente der R-Funktion contour und graphische Pa-rameter als weitere Argumente angegeben werden.
• s3bnormim.fun(mu1=0, mu2=0, sigma1=1, sigma2=1, rho=0, nx=30, ...)
zeichnet die Hohenlinien der bivariaten Normalverteilung in Farbabstufungen. Dabeiist nx die Anzahl der Gitterpunkte in beiden Richtungen, fur die die gemeinsame Dich-tefunktion berechnet wird. Es konnen optionale Argumente der R-Funktion imageund graphische Parameter als weitere Argumente angegeben werden.
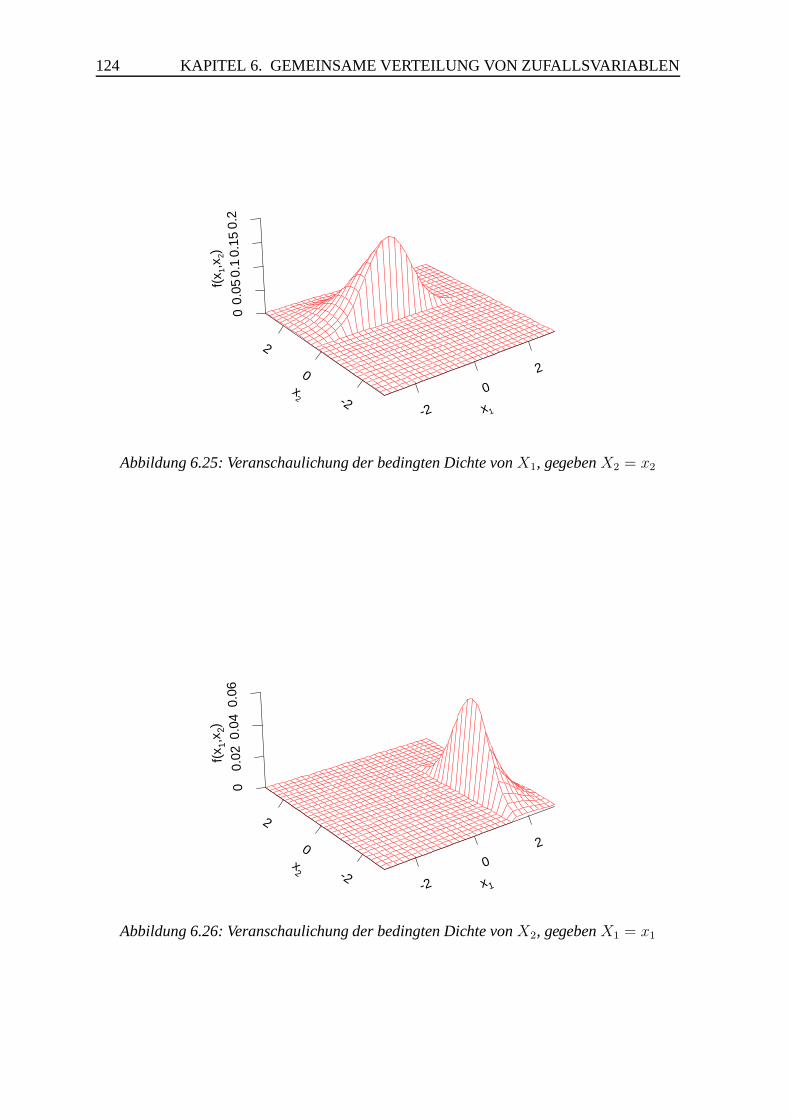
124 KAPITEL 6. GEMEINSAME VERTEILUNG VON ZUFALLSVARIABLEN
-2
0
2
x 1-2
0
2
x2
00.
050.
10.
150.
2f(
x 1,x
2)
Abbildung 6.25: Veranschaulichung der bedingten Dichte von X1, gegeben X2 = x2
-2
0
2
x 1-2
0
2
x2
00.
020.
040.
06f(
x 1,x
2)
Abbildung 6.26: Veranschaulichung der bedingten Dichte von X2, gegeben X1 = x1

Kapitel 7
p-dimensionale Zufallsvariablen
7.1 Definitionen, Eigenschaften
Wir betrachten jetzt p Zufallsvariablen X1, X2, . . . , Xp. Alle Definitionen, Notationen undEigenschaften sind analog zum 2-dimensionalen Fall.
Definition 7.1 Die Zufallsvariablen X1, X2, . . . , Xp seien diskret. Die gemeinsameWahrscheinlichkeitsfunktion ist dann definiert durch
PX1X2...Xp(x1, x2, . . . , xp) = P (X1 = x1, X2 = x2, . . . , Xp = xp) .
Definition 7.2 Eine Funktion f : IRp −→ IR heißt eine gemeinsame Dichtefunktion,wenn gilt
a) f(x1, x2 . . . , xp) ≥ 0 fur alle (x1, x2 . . . , xp) ,
b)∞∫
−∞. . .
∞∫
−∞
∞∫
−∞f(x1, x2, . . . , xp)dx1dx2 . . . dxp = 1 .
Definition 7.3 Die Zufallsvariablen (X1, X2, . . .Xp) heißen stetig, wenn es eine ge-meinsame Dichtefunktion fX1X2...Xp gibt, so dass fur alle ai, bi; i = 1, 2, . . . , p mit ai ≤ bi
giltP (a1 ≤ X1 ≤ b1, a2 ≤ X2 ≤ b2, . . . , ap ≤ Xp ≤ bp) =
bp∫
ap
. . .
b2∫
a2
b1∫
a1
fX1X2...Xp(x1, x2, . . . , xp)dx1dx2 . . . dxp .
125

126 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
Satz 7.1 Fur diskrete Zufallsvariablen (X1, X2, . . . , Xp) gilt
P (a1 ≤ X1 ≤ b1, a2 ≤ X2 ≤ b2, . . . , ap ≤ Xp ≤ bp) =
∑
ap≤xp≤bp
. . .∑
a2≤x2≤b2
∑
a1≤x1≤b1
PX1X2...Xp(x1, x2, . . . , xp) .
Definition 7.4 Die gemeinsame Verteilungsfunktion der p ZufallsvariablenX1, X2, . . . , Xp ist definiert als
FX1X2...,Xp(x1, x2, . . . , xp) = P (X1 ≤ x1, X2 ≤ x2, . . . , Xp ≤ xp) .
Satz 7.2 Fur stetige Zufallsvariablen X1, X2, . . . , Xp mit der gemeinsamen Verteilungs-funktion FX1X2...,Xp erhalt man die gemeinsame Dichtefunktion durch Differentiation:
fX1X2...,Xp(x1, x2, . . . , xp) =∂p
∂x1∂x2 . . . ∂xpFX1X2...Xp(x1, x2, . . . , xp) .
Definition 7.5 Der Erwartungswert einer Funktion H(X1, X2, . . . , Xp) ist im stetigenFall definiert durch
EH(X1, X2, . . . , Xp) =
∞∫
−∞. . .
∞∫
−∞
∞∫
−∞H(x1, x2, . . . , xp)fX1X2...Xp(x1, x2, . . . , xp)dx1dx2 . . . dxp
und im diskreten Fall durch
EH(X1, X2, . . . , Xp) =
∑
x1
∑
x2
. . .∑
xp
H(x1, x2, . . . , xp)PX1X2...Xp(x1, x2, . . . , xp) .
Seien H1(X1, X2, . . . , Xp) und H2(X1, X2, . . . , Xp) jeweils Funktionen von(X1, X2, . . . , Xp). Dann folgt sofort aus der Definition des Erwartungswertes
E(H1(X1, X2, . . . , Xp) + H2(X1, X2, . . . , Xp)) =
EH1(X1, X2, . . . , Xp) + EH2(X1, X2, . . . , Xp) .

7.1. DEFINITIONEN, EIGENSCHAFTEN 127
So ist z.B.E(X1 + X2 + . . . + Xp) = EX1 + EX2 + . . . + EXp .
Definition 7.6 Die gemeinsamen Momente von p Zufallsvariablen sind definiert durch
µ′r1r2...rp
= E(Xr11 Xr2
2 . . .Xrpp ) .
So ist z.B.µ′
100...0 = EX1
undµ′
1100...0 = EX1X2 .
Die Randverteilungsfunktion einer Teilmenge von X1, X2, . . . , Xp erhalt man, indem mandie nicht in dieser Teilmenge enthaltenen Argumente gegen ∞ konvergieren lasst. Seien z.B.X1, X2, . . . , X5 Zufallsvariablen mit der Verteilungsfunktion FX1X2...X5(x1, x2, . . . , x5). DieRandverteilungsfunktion von X1, X2 und X4 ist
FX1X2X4(x1, x2, x4) = limx3→∞
limx5→∞
FX1X2X3X4X5(x1, x2, x3, x4, x5)
Um die Randdichtefunktion (Randwahrscheinlichkeitsfunktion) einer Teilmenge von
X1, X2, . . . , Xp
zu bestimmen, integriert (summiert) man uber die nicht in der Teilmenge enthaltenen Argu-mente. So ist z.B. im stetigen Fall
fX1X2X4(x1, x2, x4) =
∞∫
−∞
∞∫
−∞fX1X2X3X4X5(x1, x2, x3, x4, x5)dx3dx5
und im diskreten Fall
PX1X2X4(x1, x2, x4) =∑
x3
∑
x5
PX1X2X3X4X5(x1, x2, x3, x4, x5) .
Definition 7.7 Die p Zufallsvariablen X1, X2, . . . , Xp sind unabhangig, wenn die fol-gende Bedingung fur stetige Zufallsvariablen erfullt ist
fX1X2...Xp(x1, x2, . . . , xp) = fX1(x1)fX2(x2) . . . fXp(xp) ,
bzw. fur diskrete Zufallsvariablen
PX1X2...Xp(x1, x2, . . . , xp) = PX1(x1)PX2(x2) . . . PXp(xp) .

128 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
Unabhangigkeit kann auch mit Hilfe der Verteilungsfunktionen nachgewiesen werden.
Satz 7.3 Die p Zufallsvariablen X1, X2, . . . , Xp sind genau dann unabhangig, wenn diefolgende Bedingung erfullt ist:
FX1X2...Xp(x1, x2, . . . , xp) = FX1(x1)FX2(x2) . . . FXp(xp) .
Bedingte Dichtefunktionen (Wahrscheinlichkeitsfunktionen) werden auf die ubliche Weisedefiniert. So ist z.B.
fX1X3|X2X4(x1, x3|x2, x4) =fX1X2X3X4(x1, x2, x3, x4)
fX2X4(x2, x4),
bzw.
PX1X3|X2X4(x1, x3|x2, x4) =
PX1X2X3X4(x1, x2, x3, x4)
PX2X4(x2, x4).
Wir wollen jetzt die p Zufallsvariablen X1, X2, . . . , Xp als Vektor betrachten, den wir mitdem Symbol X bezeichnen, also mit einem fettgedruckten X , d.h.
X =
X1
X2...
Xp
oder X t = (X1, . . . , Xp)
Ist µi = EXi der Erwartungswert von Xi, so bezeichnen wir mit µ den Vektor der Erwar-tungswerte.
µ =
µ1
µ2...
µp
oder µt = (µ1, . . . , µp)
Die Varianz-Kovarianzmatrix oder einfach Kovarianzmatrix wird mit Σ bezeichnet und enthaltin der i-ten Zeile und j-ten Spalte die Kovarianz zwischen Xi und Xj:
Σ =
V ar(X1) Kov(X1, X2) Kov(X1, X3) . . . Kov(X1, Xp)Kov(X2, X1) V ar(X2) Kov(X2, X3) . . . Kov(X2, Xp)Kov(X3, X1) Kov(X3, X2) V ar(X3) . . . Kov(X3, Xp)
.... . .
Kov(Xp, X1) Kov(Xp, X2) Kov(Xp, X3) . . . V ar(Xp)
=
σ11 σ12 σ13 . . . σ1p
σ21 σ22 σ23 . . . σ2p
σ31 σ32 σ33 . . . σ3p...
σp1 σp2 σp3 . . . σpp

7.1. DEFINITIONEN, EIGENSCHAFTEN 129
Falls j = i ist, so ist Kov(Xi, Xj) = Kov(Xi, Xi) = V ar(Xi), d.h. in der Diagonalen derKovarianzmatrix stehen die Varianzen der Variablen X1, X2, . . . , Xp.
Da
σij = E(Xi − µi)(Xj − µj) = E(Xj − µj)(Xi − µi) = σji ,
ist Σ eine symmetrische p × p Matrix.
Die Korrelationsmatrix wird mit einem großen griechischen Rho bezeichnet, das wie einlateinisches P aussieht. Sie enthalt in der i-ten Zeile und j-ten Spalte den Korrelationskoeffi-zienten zwischen Xi und Xj.
P =
ρ11 ρ12 ρ13 . . . ρ1p
ρ21 ρ22 ρ23 . . . ρ2p
ρ31 ρ32 ρ33 . . . ρ3p...
ρp1 ρp2 ρp3 . . . ρpp
Dabei ist
ρij =σij√σiiσjj
=σij
σiσj
und offensichtlich
ρii =σii√σiiσii
= 1 ,
d.h.
P =
1 ρ12 ρ13 . . . ρ1p
ρ21 1 ρ23 . . . ρ2p
ρ31 ρ32 1 . . . ρ3p...
ρp1 ρp2 ρp3 . . . 1
Die Korrelationsmatrix ist wie die Kovarianzmatrix eine symmetrische Matrix und enthaltin der Diagonalen jeweils Einsen. Der Zusammenhang zwischen der Kovarianzmatrix Σ undder Korrelationsmatrix P kann mithilfe der Diagonalmatrix D beschrieben werden, die inder Diagonalen die Standardabweichungen σi =
√σii enthalt. Fur den umgekehrten Zu-
sammenhang zwischen P und Σ benotigt man die Inverse D−1, die in der Diagonalen diereziproken Werte der Standardabweichungen enthalt.
D =
σ1 0 . . . 00 σ2 . . . 0...0 0 . . . σp
D−1 =
1σ1
0 . . . 0
0 1σ2
. . . 0...0 0 . . . 1
σp
Dann gilt:
Σ = DPD
P = D−1ΣD−1

130 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
7.2 Die p-dimensionale Normalverteilung
Wir schreibenX ∼ N(µ; Σ) ,
wenn der Vektor X t = (X1, X2, . . . , Xp) eine p-dimensionale Normalverteilung besitzt.
Definition 7.8 Die Dichtefunktion einer p-dimensionalen Normalverteilung ist
fX1X2...Xp(x1, x2, . . . , xp) =1
(2π)p/2√
det (Σ)e−(x−µ)
tΣ−1(x−µ)/2 .
Dabei ist det (Σ) die Determinante der symmetrischen und positiv definiten Matrix Σ,Σ−1 die Inverse der Matrix Σ und xt = (x1, x2, . . . , xp). Der Wertebereich ist
−∞ < x1, x2, . . . , xp < ∞ .
Die p-dimensionale Normalverteilung hat die Parameter µ und Σ, d.h. die Parameter
a) µ1, µ2, . . . , µp, d.h. die p Erwartungswerte und
b) p(p + 1)/2 Kovarianzen und Varianzen
σ11 σ12 σ13 . . . σ1p
σ22 σ23 . . . σ2p
σ33 . . . σ3p...
σpp
Wegen der Symmetrie wurden die Elemente unterhalb der Diagonalen weggelassen.
Beispiel 7.1 F ur die 2-dimensionale Normalverteilung ist
x =
(
x1
x2
)
µ =
(
µ1
µ2
)
Σ =
(
σ11 σ12
σ21 σ22
)
=
(
σ21 σ1σ2ρ
σ1σ2ρ σ22
)
det (Σ) =
∣∣∣∣∣
σ11 σ12
σ21 σ22
∣∣∣∣∣= σ11σ22 − σ12σ21 = σ2
1σ22 − σ2
1σ22ρ
2 = σ21σ
22(1 − ρ2)
Σ−1 =1
det (Σ)
(
σ22 −σ12
−σ21 σ11
)
=1
σ21σ
22(1 − ρ2)
(
σ22 −ρσ1σ2
−ρσ1σ2 σ21
)
.
Leiten Sie daraus die bekannte gemeinsame Dichtefunktion (siehe Definition 6.17) der bivariatenNormalverteilung her.
Wir betrachten jetzt den Spezialfall, dass in der Kovarianzmatrix Σ
σij = 0 fur alle i 6= j ,

7.2. DIE P-DIMENSIONALE NORMALVERTEILUNG 131
d.h.
Σ =
σ11 0 · · · · · · 00 σ22 0 · · · 0
0 0. . . · · · ...
... · · · . . . 00 0 · · · 0 σpp
. (7.1)
Dann ist auchρij =
σij√σiiσjj
= 0 fur i 6= j .
Die Zufallsvariablen X1, ..., Xp sind dann nach Definition 6.11 unkorreliert.
Wir hatten in Beispiel 6.18 gesehen, dass aus der Unkorreliertheit nicht notwendig die Un-abhangigkeit folgen muss. Fur gemeinsam normalverteilte Zufallsvariablen ist das jedochanders.
Satz 7.4 Die Zufallsvariablen X1, X2, . . . , Xp seien gemeinsam normalverteilt und un-korreliert. Dann sind X1, X2, . . . , Xp auch unabhangig verteilt.
Beweis:Da die Kovarianzmatrix eine Diagonalmatrix ist, folgt nach Gleichung (7.1)
det(Σ) = σ11σ22...σpp .
Damit ist die gemeinsame Dichtefunktion
fX1,...,Xp(x1, x2, . . . , xp) =1
(2π)p/2√σ11σ22...σppe−(x−µ)t
∑−1(x−µ)/2
Nun ist die Inverse der Kovarianzmatrix
Σ−1 =
1σ11
0 · · · · · · 0
0 1σ22
0 · · · 0... · · · . . . · · · ...... · · · . . . 00 · · · · · · 0 1
σpp
und damit
(x − µ)tΣ−1(x − µ) =(x1 − µ1)
2
σ11
+(x2 − µ2)
2
σ22
+ . . . +(xp − µp)
2
σpp
.
Daraus folgt
fX1,...,Xp(x1, x2, . . . , xp) =1√
2πσ11
e− 1
2(x1−µ1)2
σ111√
2πσ22
e− 1
2(x2−µ2)2
σ22 ...1√
2πσppe− 1
2
(xp−µp)2
σpp
= fX1(x1)fX2(x2), ..., fXp(xp) ,

132 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
d.h. X1, X2, . . . , Xp sind unabhangig verteilt. ♦Wir geben jetzt die Schatzer der Parameter einer multivariaten Normalverteilung an. Wirgehen davon aus, dass n unabhangige Wiederholungen eines p-dimensionalen normalverteil-ten Vektors beobachtet werden. Wir haben also eine Matrix von Zufallsvariablen:
X11 X21 . . . Xp1
X12 X22 . . . Xp2
X13 X23 . . . Xp3...
......
...X1n X2n . . . Xpn
Jede Zeile besitzt eine p-dimensionale Normalverteilung. Die Zeilenvektoren sind unabhangig.Man kann sich das so vorstellen, dass man an n Objekten (Personen, Merkmalstragern) jep Merkmale beobachtet hat. Die Beobachtungen der p Merkmale fur das i-te Objekt stehenin der i-ten Zeile. In der j-ten Spalte stehen alle Beobachtungen fur die j-te Zufallsvariable.Etwas unublich ist also Xji die i-te Beobachtung der j-ten Variable und steht in der i-tenZeile und j-ten Spalte.
Die Schatzer der Erwartungswerte sind dann
µ1 =n∑
j=1
X1j/n = X1, µ2 =n∑
j=1
X2j/n = X2, . . . , µp =n∑
j=1
Xpj/n = Xp .
Die Maximum-Likelihood-Schatzer der Kovarianzen sind
Sij = σij =1
n
n∑
k=1
(Xik − µi)(Xjk − µj) =1
n
n∑
k=1
(Xik − Xi)(Xjk − Xj) i, j = 1, 2, ..., p .
Diese Schatzer sind nicht erwartungstreu. Erwartungstreue Schatzer sind
S∗ij = σij =
1
n − 1
n∑
k=1
(Xik−µi)(Xjk−µj) =1
n − 1
n∑
k=1
(Xik−Xi)(Xjk−Xj) i, j = 1, 2, ..., p .
Die geschatzte Kovarianzmatrix ist dann
Σ = S =
S11 S12 . . . S1p
S21 S22 . . . S2p...
Sp1 Sp2 . . . Spp
oder
Σ = S∗ =
S∗11 S∗
12 . . . S∗1p
S∗21 S∗
22 . . . S∗2p
...S∗
p1 S∗p2 . . . S∗
pp
Schatzer der Korrelationskoeffizienten ρij erhalt man durch
ρij = rij =σij
√
σiiσjj
i, j = 1, 2, ..., p .
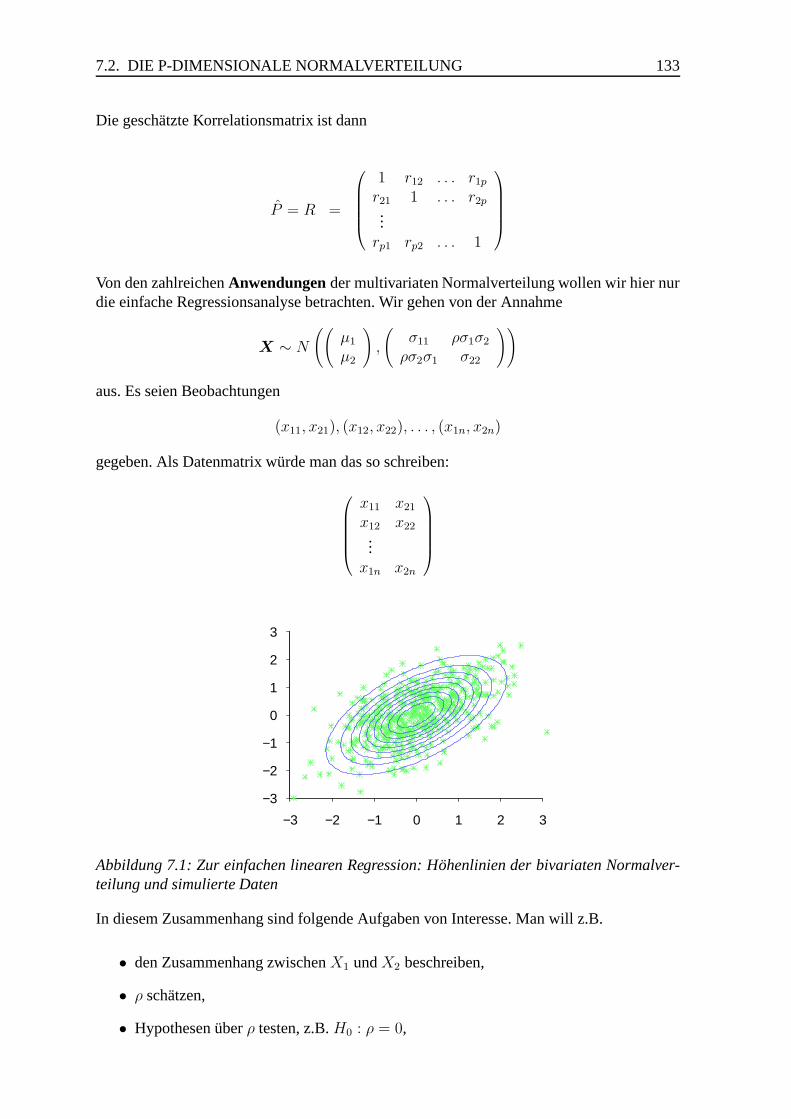
7.2. DIE P-DIMENSIONALE NORMALVERTEILUNG 133
Die geschatzte Korrelationsmatrix ist dann
P = R =
1 r12 . . . r1p
r21 1 . . . r2p...
rp1 rp2 . . . 1
Von den zahlreichen Anwendungen der multivariaten Normalverteilung wollen wir hier nurdie einfache Regressionsanalyse betrachten. Wir gehen von der Annahme
X ∼ N
((
µ1
µ2
)
,
(
σ11 ρσ1σ2
ρσ2σ1 σ22
))
aus. Es seien Beobachtungen
(x11, x21), (x12, x22), . . . , (x1n, x2n)
gegeben. Als Datenmatrix wurde man das so schreiben:
x11 x21
x12 x22...
x1n x2n
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
Abbildung 7.1: Zur einfachen linearen Regression: Hohenlinien der bivariaten Normalver-teilung und simulierte Daten
In diesem Zusammenhang sind folgende Aufgaben von Interesse. Man will z.B.
• den Zusammenhang zwischen X1 und X2 beschreiben,
• ρ schatzen,
• Hypothesen uber ρ testen, z.B. H0 : ρ = 0,

134 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
• X2 anhand einer Beobachtung von X1 vorhersagen,
• die bedingte Erwartung von X2 gegeben X1 = 2 berechnen,
• den 95%-Punkt der bedingten Verteilung von X2, gegeben X1 schatzen.
7.3 Summen und Linearkombinationen von Zufallsvariablen
Eine Linearkombination von n Zufallsvariablen X1, X2, . . . , Xn ist definiert durch:
L = a1X1 + a2X2 + . . . anXn ai ∈ IR
Wir wollen dieselbe Gleichung mit Vektoren schreiben. Dazu sei X t = (X1, X2, . . . , Xn)und at = (a1, a2, . . . , an). Dann ist
L = atX
Eine Linearkombination von Zufallsvariablen ist selbst wieder eine Zufallsvariable, die sehrhaufig in Anwendungen erscheint (z.B. Mittelwerte, gewichtete Durchschnitte, Summenusw.). Schaut man sich die Vektorschreibweise an, so wird durch die Bildung einer Linear-kombination aus dem zufalligen Vektor X mit einer multivariaten Verteilung ein zufalligerSkalar L mit einer univariaten Verteilung. Wir wollen die Eigenschaften der Verteilung einerLinearkombination, insbesondere Erwartungswert und Varianz untersuchen. Wir verwendendie folgenden Bezeichnungen:
EXi = µi µt = (µ1, µ2, . . . , µn)V arXi = E(Xi − µi)
2 = σ2i = σii
Kov(Xi, Xj) = E(Xi − µi)(Xj − µj) = σij
Σ bezeichnet die Varianz-Kovarianzmatrix von X .
Bei identisch verteilten Zufallsvariablen verwenden wir die Bezeichnungen µ, σ2 statt µi, σ2i .
Wir betrachten zunachst nur Summen:
S = X1 + X2 + . . .Xn = 1tX ,
wobei 1t = (1, 1, . . . , 1) sei.
Es ist:
ES = E(X1 + X2 + . . . + Xn) = EX1 + EX2 + . . . + EXn
= µ1 + µ2 + . . . + µn
= nµ falls Xi identisch verteilt
V arS = E(S − ES)2 = E(n∑
i=1
Xi −n∑
i=1
µi)2 = E(
n∑
i=1
(Xi − µi))2
= En∑
i=1
n∑
j=1
(Xi − µi)(Xj − µj) =n∑
i=1
n∑
j=1
E(Xi − µi)(Xj − µj)
=n∑
i=1
E(Xi − µi)2 +
n∑
i=1i6=j
n∑
j=1
E(Xi − µi)(Xj − µj)

7.3. SUMMEN UND LINEARKOMBINATIONEN VON ZUFALLSVARIABLEN 135
=n∑
i=1
σ2i +
n∑
i=1i6=j
n∑
j=1
σij
=n∑
i=1
σ2i falls Xi unabhangig
= nσ2 falls Xi unabhangig und identisch verteilt
Jetzt betrachten wir Linearkombinationen
L = atX = a1X1 + a2X2 + . . . anXn ai ∈ IR
Die entsprechenden Formeln sind dann:
EL = E(a1X1 + a2X2 + . . . + anXn) = Ea1X1 + Ea2X2 + . . . + EanXn
= a1EX1 + a2EX2 + . . . + anEXn = a1µ1 + a2µ2 + . . . + anµn
=n∑
i=1
aiµi
= µn∑
i=1
ai falls Xi identisch verteilt
In vektorieller Notation haben wir
E(L) = E(atX) = atµ
Var(L) = E(L − EL)2 = E(n∑
i=1
aiXi −n∑
i=1
aiµi)2 = E(
n∑
i=1
ai(Xi − µi))2
= En∑
i=1
n∑
j=1
aiaj(Xi − µi)(Xj − µj) =n∑
i=1
n∑
j=1
aiajE(Xi − µi)(Xj − µj)
=n∑
i=1
a2i E(Xi − µi)
2 +n∑
i=1i6=j
n∑
j=1
aiajE(Xi − µi)(Xj − µj)
=n∑
i=1
a2i σ
2i +
n∑
i=1i6=j
n∑
j=1
aiajσij
=n∑
i=1
a2i σ
2i falls Xi unabhangig
= σ2n∑
i=1
a2i falls Xi unabhangig und identisch verteilt
In vektorieller Notation haben wir das allgemeine Resultat:
Var(L) = Var(atX) = atΣa
Eine spezielle, besonders wichtige Linearkombination ist der Durchschnitt, d.h. das arith-metische Mittel:
Xn =1
n
n∑
i=1
Xi =1
nX1 +
1
nX2 + . . . +
1
nXn =
1
n1tX

136 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
Es ist also ai = 1/n fur i = 1, 2, . . . , n. Damit folgt aus den allgemeinen Formeln fur diesenSpezialfall:
EXn =1
n
n∑
i=1
µi
= µ falls Xi identisch verteilt
V arXn = E(Xn − EXn)2
=1
n2
n∑
i=1
σ2i +
1
n2
n∑
i=1i6=j
n∑
j=1
σij
=1
n2
n∑
i=1
σ2i falls Xi unabhangig
= σ2/n falls Xi unabh. und identisch verteilt
Die Verteilung einer Summe oder einer Linearkombination von Zufallsvariablen ist oft schwerzu bestimmen, auch wenn die Zufallsvariablen unabhangig sind. Einige Ausnahmen habenwir im Laufe der Vorlesung bzw. in den Ubungen kennengelernt. So wissen wir, dass dieSumme von unabhangig und identisch Bernoulli-verteilten Zufallsvariablen binomialverteilt,die Summe von unabhangig und identisch geometrisch verteilten Zufallsvariablen negativ bi-nomialverteilt, die Summe von unabhangig poissonverteilten Zufallsvariablen wieder Pois-sonverteilt ist, wobei sich die Parameter addieren. Die Summe von unabhangig und iden-tisch exponentialverteilten Zufallsvariablen ist gammaverteilt. Die Summe von unabhangi-gen gammaverteilten Zufallsvariablen ist (bei gleichem Parameter λ) wieder gammaverteilt,wobei die Parameter ν zu addieren sind. Die Summe von unabhangigen χ2-verteilten Zu-fallsvariablen ist wieder χ2-verteilt. Die Freiheitsgrade addieren sich. Schließlich ist jedeLinearkombination von normalverteilten Zufallsvariablen wieder normalverteilt. Die Para-meter µ und σ2 bestimmen sich aus den Formeln fur den Erwartungswert und die Varianz,die in diesem Kapitel hergeleitet wurden. Fur den Durchschnitt nutzlich ist oft der zentraleGrenzwertsatz, der Aussagen uber die asymptotische Verteilung von Xn macht.
Satz 7.5 (Zentraler Grenzwertsatz)Die Zufallsvariablen X1, X2, . . . , Xn seien unabhangig und identisch verteilt mitV arXi = σ2 < ∞. Dann besitzt
√n(Xn − µ)/σ
asymptotisch eine N(0, 1)-Verteilung.
Man kann dann die Verteilung von Xn durch eine N(µ, σ2/n)-Verteilung approximieren.
7.4 Weiteres zur multivariaten Normalverteilung
Wir haben weiter oben gesagt, dass jede Linearkombination normalverteilter Zufallsvaria-blen wieder normalverteilt ist. Nun besagt ein Resultat von Cramer und Wold, dass die

7.4. WEITERES ZUR MULTIVARIATEN NORMALVERTEILUNG 137
Verteilung eines p-dimensionalen zufalligen Vektors X vollstandig bestimmt ist durch dieunivariaten Verteilungen aller Linearkombinationen. Damit ist es moglich die multivariateNormalverteilung auf die folgende Weise zu definieren.
Definition 7.9 Eine p-dimensionale Zufallsvariable X hat eine multivariate Normalver-teilung, wenn alle Linearkombinationen von X eine univariate Normalverteilung besit-zen.
Jede Komponente des Vektors X ist eine Linearkombination von X und somit normalver-teilt. Eine Linearkombination atX ist eine univariate Zufallsvariable und die Varianz einerunivariaten Zufallsvariablen ist großer oder gleich 0, d.h. Var(atX) ≥ 0. Andererseits giltVar(atX) = atΣa, wenn Σ die Varianz-Kovarianzmatrix von X bezeichnet. Damit habenwir
atΣa ≥ 0 ∀a
Dieses Resultat bedeutet, dass die Varianz-Kovarianzmatrix Σ positiv semidefinit ist. In derfruheren Definition der multivariaten Normalverteilung mithilfe der gemeinsamen Dichte-funktion hatten wir verlangt, dass die Kovarianzmatrix Σ positiv definit und invertierbar ist.Die Kovarianzmatrix ist positiv definit, wenn atΣa > 0 fur alle a 6= 0. Eine multivariateNormalverteilung, fur die Σ−1 nicht existiert, heißt singulare oder degenerierte Normalver-teilung und besitzt keine Dichtefunktion.
Nicht nur jede Linearkombination von normalverteilten Zufallsvariablen ist wieder normal-verteilt. Die Normalverteilung bleibt auch bei linearen Transformationen erhalten. Sei X ∼N(µ, Σ) p-dimensional normalverteilt. Sei A eine p × m-Matrix. Dann ist W = AtX einm-dimensionaler Vektor und es gilt
W ∼ N(Atµ; AtΣA) (7.2)
Im univariaten Fall konnten wir jede beliebige Normalverteilung auf die Standardnormalver-teilung transformieren. Wir geben jetzt eine aquivalente Transformation zwischen einem Zu-fallsvektor X ∼ N(µ; Σ) und einem zufalligen Vektor U , dessen Komponenten unabhangigund standardnormalverteilt sind, so dass U ∼ N(0; Ip), wobei Ip eine p-dimensionale Ein-heitsmatrix ist. Wir beschranken uns auf den Fall, in dem Σ nichtsingular ist. Dann gibtes eine nichtsingulare Matrix p × p-Matrix B, so dass Σ = BB t. Betrachten wir jetzt dieTransformation (X − µ) = BU . Wenn U ∼ Np(0; I), dann gilt nach Gleichung 7.2(X − µ) ∼ N(0; BBt) und daher X ∼ N(µ; Σ).Da B−1 existiert, ist die inverse Transformation gegeben durch: U = B−1(X − µ). WennX ∼ N(µ; Σ), dann gilt
E(U) = 0
Var(U) = B−1Σ(B−1)t nach Gleichung 7.2
= B−1(BBt)(Bt)−1 = Ip
Damit gilt U ∼ N(0; Ip). Es sei angemerkt, dass die Matrix B nicht eindeutig ist, so dasses viele solche Transformationen gibt. Eine Moglichkeit, die Matrix B zu bestimmen ist:

138 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
B = CΛ1/2. Dabei ist C die Matrix der Eigenvektoren von Σ (in jeder Spalte steht einEigenvektor) und Λ ist die Diagonalmatrix der Eigenwerte.
Wir schieben kurz einige Bemerkungen zu Eigenwerten und Eigenvektoren ein. Sei Σ einep×p-Matrix. Die Eigenwerte (charakteristischen Wurzeln) sind die Losungen der Gleichung
det(Σ − λI) = 0 (7.3)
Diese Gleichung ist ein Polynom der Ordnung p in λ. Die der Große nach geordneten Eigen-werte werden mit λ1, λ2, . . . , λp (λ1 ≥ λ2 ≥ . . . ≥ λp) bezeichnet.
Wir betrachten die Matrix
Σ =
(
1 1/21/2 1
)
Dann gilt
det(Σ − λI) = det
(
1 − λ 1/21/2 1 − λ
)
= (1 − λ)2 − 1/4 = λ2 − 2λ + 3/4
Diese Gleichung hat die beiden Losungen λ1,2 = 1±√
1 − 3/4, d.h. λ1 = 3/2 und λ2 = 1/2.Zu jedem Eigenwert λi gehort ein Vektor ci, der Eigenvektor genannt wird, fur den gilt:
Σci = λici (7.4)
In unserem Beispiel ist also fur λ1 = 3/2 das Gleichungssystem (Σ − 3/2I)c = 0 zu losen,d.h.
−0.5c11 + 0.5c12 = 0
0.5c11 − 0.5c12 = 0
Das bedeutet c11 = c12, d.h jeder Vektor ct1 = (c11, c11) ist eine Losung.
Fur λ2 = 1/2 das Gleichungssystem Σ − 1/2I = 0 zu losen, d.h.
0.5c21 + 0.5c22 = 0
0.5c21 + 0.5c22 = 0
Das bedeutet c21 = −c22, d.h jeder Vektor ct2 = (c21,−c21) ist eine Losung.
Die Eigenvektoren sind nur bis auf einen konstanten Faktor eindeutig bestimmt. Daher wer-den sie gewohnlich so normiert, dass ct
ici = 1 gilt. In unserem Beispiel waren also ct1 =
(1/√
2, 1/√
2) und ct2 = (1/
√2,−1/
√2) normierte Losungen. Wenn es gleiche Eigenwerte
gibt, konnen die Eigenvektoren so gewahlt werden, dass sie orthonormiert sind (orthogonalund normiert).
In R konnen die Eigenwerte mit der Funktion eigen bestimmt werden.
Sigma<-matrix(c(1,0.5,0.5,1),nrow=2)eigen(Sigma)

7.4. WEITERES ZUR MULTIVARIATEN NORMALVERTEILUNG 139
$values1.5 0.5
$vectors0.7071068 0.70710680.7071068 -0.7071068
Die Matrix C der Eigenvektoren ist also:
C =
(
1/√
2 1/√
2
1/√
2 −1/√
2
)
=
(
0.7071 0.70710.7071 −0.7071
)
Die Diagonalmatrix der Eigenwerte ist
Λ =
(
3/2 00 1/2
)
Damit ist
Λ1/2 =
√
3/2 0
0√
1/2
=
(
1.2247 00 0.7071
)
und schließlich
B = CΛ1/2 =
( √3/2 1/2√3/2 −1/2
)
=
(
0.8660 0.50.8660 −0.5
)
Die Inverse einer quadratischen Matrix B bestimmt man in R mit dem Befehl solve(B).In diesem Fall ist
B−1 =
(
0.5774 0.57741.0000 −1.0000
)
Wir fassen das Ergebnis in folgendem Satz zusammen:
Satz 7.6 Sei Σ nichtsingular. Dann gilt X ∼ N(µ; Σ) genau dann, wenn X = µ+BU ,wobei U ∼ N(0; I), BBt = Σ und B ist eine p× p-Matrix vom Rang p und es gilt dannU = B−1(X − µ).
Wir hatten vorhin von einer degenerierten oder auch ausgearteten Verteilung gesprochen undwollen jetzt dafur ein Beispiel bringen: Betrachten Sie einen Vektor X , dessen Komponen-ten aus der Lange, Breite und dem Umfang eines zufalligen Rechtecks bestehen. Dann giltzwischen den drei Komponenten dieses Vektors die lineare Beziehung 2X1 +2X2−X3 = 0.Obwohl wir einen dreidimensionalen Vektor haben, ist die Variation in Wirklichkeit zweidi-mensional und Rang(Σ) = 2. Hatten wir Radius, Durchmesser und Umfang eines zufalligenKreises, so gabe es zwei lineare Beziehungen zwischen den Komponenten und die effektiveDimension dieses dreidimensionalen Vektors ware 1.

140 KAPITEL 7. P-DIMENSIONALE ZUFALLSVARIABLEN
Eigenschaften der multivariaten Normalverteilung:
a) Wenn X ∼ N(µ, Σ) mit nichtsingularem Σ, so gilt:
(X − µ)tΣ−1(X − µ) ∼ χ2p (7.5)
Dies ist eine Verallgemeinerung der bekannten Tatsache, dass das Quadrat einer stan-dardnormalverteilten Zufallsvariablen χ2
1-verteilt ist. Insbesondere gilt fur p = 1, dass[(Y − µ)/σ]2 ∼ χ2
1. Nach Satz 7.6 konnen wir schreiben: U = B−1(X − µ) mit
BBt = Σ und U ∼ N(0; I). Dann ist U tU =p∑
j=1U2
j , wobei die Uj unabhangige
standardnormalverteilte Zufallsvariablen sind. Folglich ist U tU ∼ χ2p-verteilt. Ande-
rerseits gilt aber:
U tU = (X − µ)t(B−1)tB−1(X − µ) = (X − µ)tΣ−1(X − µ)
Damit folgt das obige Resultat.
Subtrahiert man in Gleichung 7.5 nicht den Erwartungswertvektor µ, sondern z.B.µ0 6= µ, so erhalt man anstelle der zentralen χ2-Verteilung eine nichtzentrale χ2-Verteilung mit Nichtzentralitatsparameter δ2 = (µ − µ0)
tΣ−1(µ − µ0).
Wir werden jetzt zeigen, dass die Randverteilungen und die bedingten Verteilungen einermultivariaten Normalverteilung wieder Normalverteilungen sind. Zur Vereinfachung neh-men wir an, dass X folgendermaßen aufgeteilt ist (evtl. muß man vorher die Variablen um-ordnen):
X =
(
X1
X2
)
mit X1 ein (q × 1) − Vektor q < p
Entsprechende Aufteilungen gelten fur den Erwartungswertvektor und die Kovarianzmatrix:
µ =
(
µ1
µ2
)
Σ =
(
Σ11 Σ12
Σ21 Σ22
)
Dabei sind Σ11 und Σ22 symmetrische positiv semidefinite q × q bzw. (p − q) × (p − q)-Matrizen und Σ12 = Σt
21 sind q × (p − q)-Matrizen.
b) Die Randverteilung von X1 ist Nq(µ1; Σ11).
Die multivariate Normalverteilung von X1 folgt aus der Tatsache, dass Linearkombi-nationen von X1 auch Linearkombinationen von X sind und damit univariate Nor-malverteilungen haben.
c) X1 und X2 sind genau dann unabhangig verteilt, wenn Σ12 = 0.
d) Wenn Σ22 vollen Rang hat, so dass Σ−122 existiert, ist die bedingte Verteilung von X1,
gegeben X2 = x2 eine multivariate Normalverteilung mit:
E(X1|X2 = x2) = µ1 + Σ12Σ−122 (x2 − µ2)
Var(X1|X2 = x2) = Σ11 − Σ12Σ−122 Σ21

7.4. WEITERES ZUR MULTIVARIATEN NORMALVERTEILUNG 141
Wir betrachten den Spezialfall q = 1. Dann ist X 1 = X1 die erste Komponente vonX , also eine univariate Zufallsvariable. Dann ist
E(X1|X2 = x2) = µ1 + Σ12Σ−122 (x2 − µ2) (7.6)
Nun ist aber Σ12Σ−122 eine 1× (p−1)-Matrix, also ein Zeilenvektor, d.h. Gleichung 7.6
hat die Gestalt
E(X1|X2 = x2) = µ1 + β2(x2 − µ2) + . . . + βm(xp − µp) (7.7)
wenn wir die Elemente dieses Vektors mit β2, . . . , βp bezeichnen. Gleichung 7.7 istdie Regressionsfunktion von X1 auf X2, . . . , Xm. Fur die bedingte Varianz haben wirdann
Var(X1|X2 = x2) = σ11 − Σ12Σ−122 Σ21
Fur die bedingte Varianz kann man zeigen, dass
Var(X1|X2 = x2) =1
σ11
gilt. Dabei ist σ11 das (1, 1)-te Element der Inversen Σ−1. Das bedeutet: die bedingteVarianz ist eine Konstante, die nicht von x2 abhangt.

Kapitel 8
Schatzung von Parametern
8.1 Schatzmethoden
Gegeben seien Beobachtungenx1, x2, . . . , xn ,
die wir als Realisationen von unabhangig und identisch verteilten Zufallsvariablen
X1, X2, . . . , Xn
auffassen. Die Verteilung der Xi hange von einem oder mehreren unbekannten Parameternab. Die Parameter sollen aufgrund der vorliegenden Beobachtungen geschatzt werden. Wirwerden zwei allgemeine Schatzmethoden besprechen.
8.1.1 Die Methode der Momente
Definition 8.1Das k-te Stichprobenmoment ist definiert als
m′k =
1
n
n∑
i=1
xki .
Das erste Stichprobenmoment ist z.B.
m′1 =
1
n
n∑
i=1
xi = x .
Die Methode der Momente beruht darauf, dass man
a) zunachst die Parameter einer Verteilung durch die Momente µ′k der Verteilung aus-
druckt.
b) anschließend in dem in a) entstandenen Ausdruck die Momente µ′k durch die entspre-
chenden Stichprobenmomente m′k ersetzt.
142

8.1. SCHATZMETHODEN 143
Beispiel 8.1 Die Exponentialverteilung hat einen Parameter λ und es gilt
µ′1 = 1/λ oder λ = 1/µ′
1 .
Daher sch atzt man λ durchλ = 1/m′
1 = 1/x .
Beispiel 8.2 F ur eine normalverteilte Zufallsvariable
X ∼ N(µ;σ2)
giltEX = µ = µ′
1 .
Daher verwendet man
µ = m′1 = x =
1
n
n∑
i=1
xi
als Sch atzer von µ. F ur die Varianz von X gilt
VarX = σ2 = EX2 − (EX)2 = µ′2 − (µ′
1)2 .
Daher sch atzt man σ2 durchσ2 = m′
2 − (m′1)
2 .
Es gilt
σ2 = m′2 − (m′
1)2 =
1
n
n∑
i=1
x2i − (x)2
=1
n
n∑
i=1
(xi − x)2 = s2 .
Beispiel 8.3 Die Gammaverteilung hat zwei Parameter ν und λ, und es gilt
EX = ν/λ und VarX = ν/λ2 .
Daraus folgt
λ =EX
VarX=
µ′1
µ′2 − (µ′
1)2
und
ν = λEX =(EX)2
VarX=
(µ′1)
2
µ′2 − (µ′
1)2
.
Daher sind die Sch atzer von ν und λ nach der Methode der Momente
ν =(m′
1)2
m′2 − (m′
1)2
=x2
s2
und
λ =m′
1
m′2 − (m′
1)2
=x
s2.
Beispiel 8.4 Die Poissonverteilung hat einen Parameter λ und es gilt
µ′1 = EX = λ .
Daher sch atzt man λ durchλ = m′
1 = x .

144 KAPITEL 8. SCHATZUNG VON PARAMETERN
Beispiel 8.5 Die Bernoulli-Verteilung hat einen Parameter π und es gilt
µ′1 = EX = π .
Daher sch atzt man π durchπ = m′
1 = x .
8.1.2 Die Maximum-Likelihood-Methode
Von dem Philosophen Rudolph Hermann Lotze (1817 - 1881), der von 1844 - 1880 in Gottin-gen lebte und nach dem die Lotzestraße benannt ist, stammt das folgende Zitat:
Wenn gegebene Thatsachen aus mehreren verschiedenen Ursachen ableitbar sind, so ist die-jenige Ursache die wahrscheinlichste, unter deren Voraussetzung die aus ihr berechneteWahrscheinlichkeit der gegebenen Thatsachen die großte ist.
Das ist eine sehr treffende Beschreibung der Maximum-Likelihood-Schatzmethode, die all-gemein Fisher (1912) zugeschrieben wird, obwohl es sogar Quellen aus dem 18. Jahrhundertfur diese Methode gibt.
Definition 8.2 Der Maximum-Likelihood-Schatzer eines Parameters ist der Wert desParameters, der den Beobachtungen die großte Wahrscheinlichkeit zuordnet.
Beispiel 8.6 Es soll die Wahrscheinlichkeit
π = P (Kopf) ,
mit der eine M unze mit ,,Kopf” auftrifft, gesch atzt werden. Dazu werde die M unze sechsmal gewor-fen.
Sei
Xi =
1 wenn das Ergebnis im i-ten Wurf ,,Kopf” ist,0 wenn das Ergebnis im i-ten Wurf ,,Zahl” ist.
Die gemeinsame Wahrscheinlichkeitsfunktion von X1, X2, . . . , X6 ist
PX1X2...X6(x1, x2, . . . , x6;π) = P (X1 = x1, X2 = x2, . . . , X6 = x6) .
Wenn man annimmt, dass die Versuche unabh angig sind, gilt
PX1X2...X6(x1, x2, . . . , x6;π) = P (X1 = x1) · P (X2 = x2) · . . . · P (X6 = x6) .
Die Beobachtungen in 6 W urfen seien
1 1 0 1 0 1 .
Die Wahrscheinlichkeit dieser Beobachtungen ist
PX1X2...X6(1, 1, 0, 1, 0, 1) = π · π · (1 − π) · π · (1 − π) · π= π4(1 − π)2 .
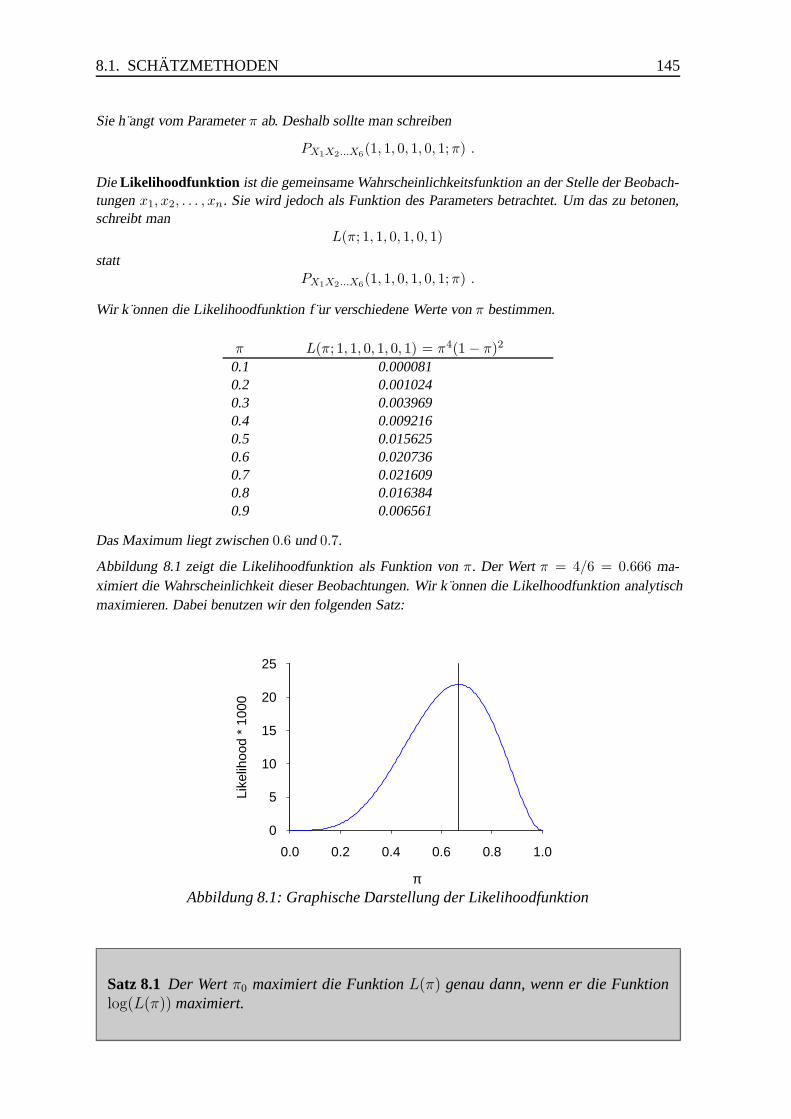
8.1. SCHATZMETHODEN 145
Sie h angt vom Parameter π ab. Deshalb sollte man schreiben
PX1X2...X6(1, 1, 0, 1, 0, 1;π) .
Die Likelihoodfunktion ist die gemeinsame Wahrscheinlichkeitsfunktion an der Stelle der Beobach-tungen x1, x2, . . . , xn. Sie wird jedoch als Funktion des Parameters betrachtet. Um das zu betonen,schreibt man
L(π; 1, 1, 0, 1, 0, 1)
stattPX1X2...X6(1, 1, 0, 1, 0, 1;π) .
Wir k onnen die Likelihoodfunktion f ur verschiedene Werte von π bestimmen.
π L(π; 1, 1, 0, 1, 0, 1) = π4(1 − π)2
0.1 0.0000810.2 0.0010240.3 0.0039690.4 0.0092160.5 0.0156250.6 0.0207360.7 0.0216090.8 0.0163840.9 0.006561
Das Maximum liegt zwischen 0.6 und 0.7.
Abbildung 8.1 zeigt die Likelihoodfunktion als Funktion von π. Der Wert π = 4/6 = 0.666 ma-ximiert die Wahrscheinlichkeit dieser Beobachtungen. Wir k onnen die Likelhoodfunktion analytischmaximieren. Dabei benutzen wir den folgenden Satz:
Like
lihoo
d *
1000
0.0 0.2 0.4 0.6 0.8 1.0
0
5
10
15
20
25
πAbbildung 8.1: Graphische Darstellung der Likelihoodfunktion
Satz 8.1 Der Wert π0 maximiert die Funktion L(π) genau dann, wenn er die Funktionlog(L(π)) maximiert.
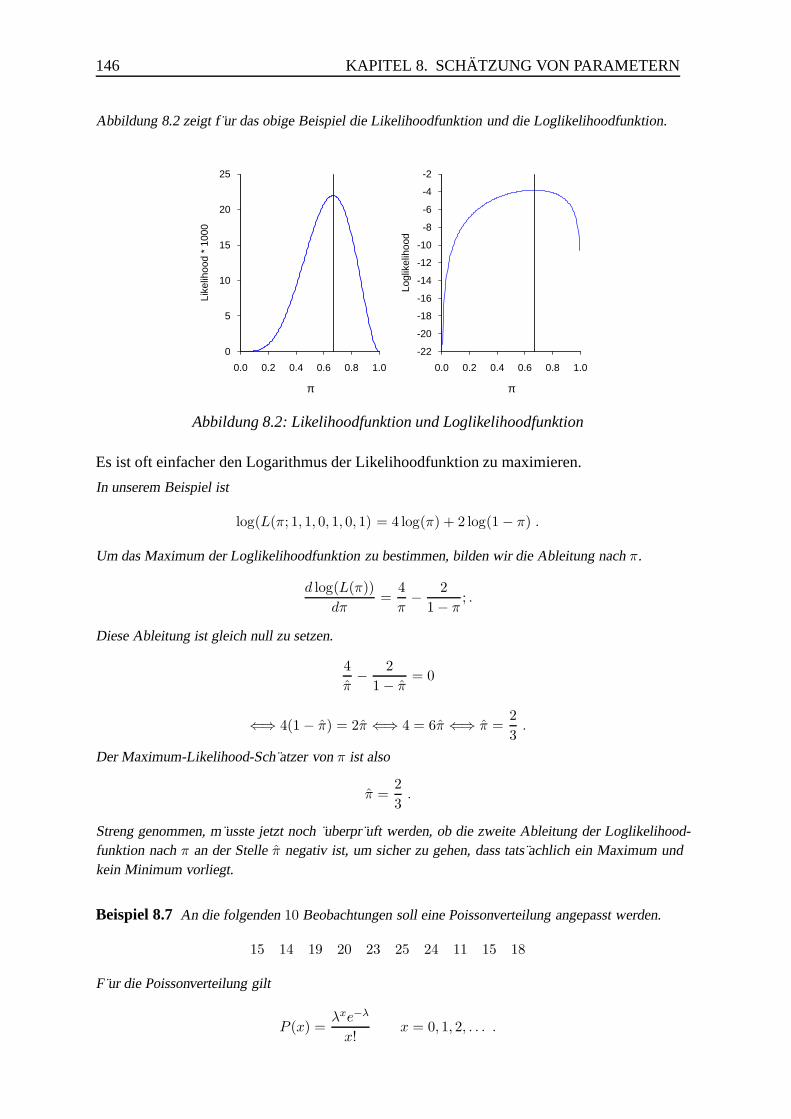
146 KAPITEL 8. SCHATZUNG VON PARAMETERN
Abbildung 8.2 zeigt f ur das obige Beispiel die Likelihoodfunktion und die Loglikelihoodfunktion.
Like
lihoo
d *
1000
0.0 0.2 0.4 0.6 0.8 1.0
0
5
10
15
20
25
πLo
glik
elih
ood
0.0 0.2 0.4 0.6 0.8 1.0
-22
-20
-18
-16
-14
-12
-10
-8
-6
-4
-2
π
Abbildung 8.2: Likelihoodfunktion und Loglikelihoodfunktion
Es ist oft einfacher den Logarithmus der Likelihoodfunktion zu maximieren.
In unserem Beispiel ist
log(L(π; 1, 1, 0, 1, 0, 1) = 4 log(π) + 2 log(1 − π) .
Um das Maximum der Loglikelihoodfunktion zu bestimmen, bilden wir die Ableitung nach π.
d log(L(π))
dπ=
4
π− 2
1 − π; .
Diese Ableitung ist gleich null zu setzen.
4
π− 2
1 − π= 0
⇐⇒ 4(1 − π) = 2π ⇐⇒ 4 = 6π ⇐⇒ π =2
3.
Der Maximum-Likelihood-Sch atzer von π ist also
π =2
3.
Streng genommen, m usste jetzt noch uberpr uft werden, ob die zweite Ableitung der Loglikelihood-funktion nach π an der Stelle π negativ ist, um sicher zu gehen, dass tats achlich ein Maximum undkein Minimum vorliegt.
Beispiel 8.7 An die folgenden 10 Beobachtungen soll eine Poissonverteilung angepasst werden.
15 14 19 20 23 25 24 11 15 18
F ur die Poissonverteilung gilt
P (x) =λxe−λ
x!x = 0, 1, 2, . . . .
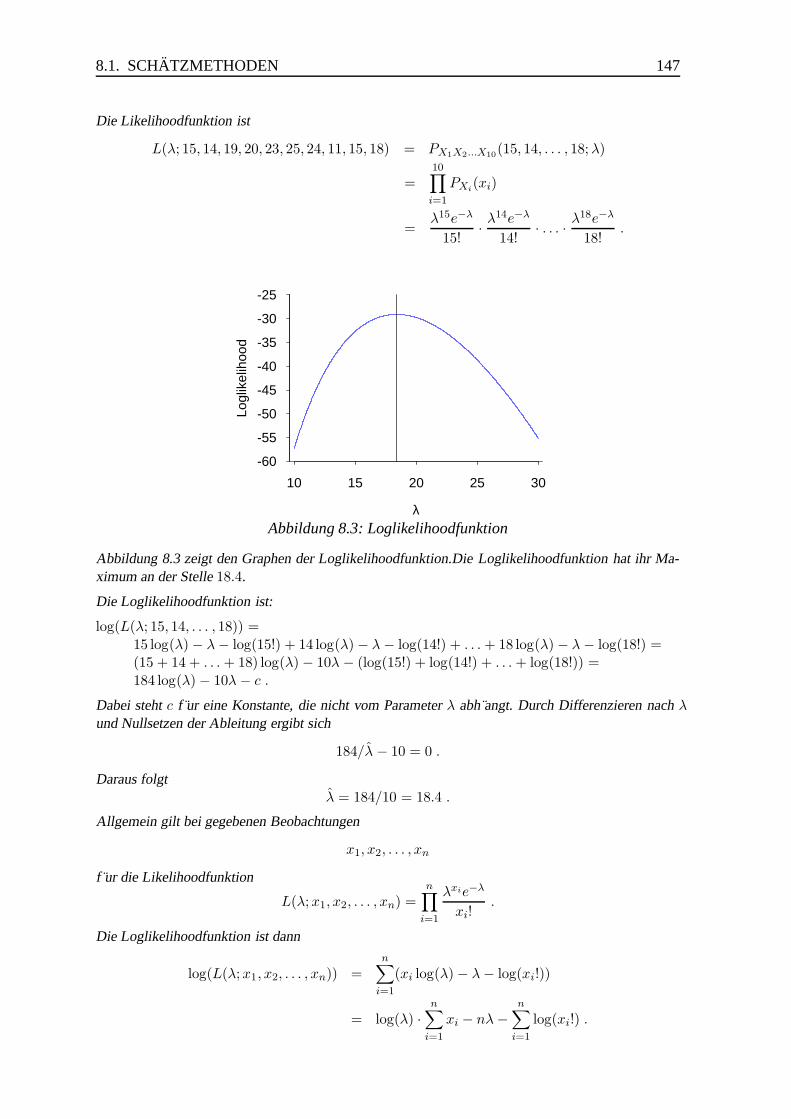
8.1. SCHATZMETHODEN 147
Die Likelihoodfunktion ist
L(λ; 15, 14, 19, 20, 23, 25, 24, 11, 15, 18) = PX1X2...X10(15, 14, . . . , 18;λ)
=10∏
i=1
PXi(xi)
=λ15e−λ
15!· λ14e−λ
14!· . . . · λ18e−λ
18!.
Logl
ikel
ihoo
d
10 15 20 25 30
-60
-55
-50
-45
-40
-35
-30
-25
λAbbildung 8.3: Loglikelihoodfunktion
Abbildung 8.3 zeigt den Graphen der Loglikelihoodfunktion.Die Loglikelihoodfunktion hat ihr Ma-ximum an der Stelle 18.4.
Die Loglikelihoodfunktion ist:
log(L(λ; 15, 14, . . . , 18)) =15 log(λ) − λ − log(15!) + 14 log(λ) − λ − log(14!) + . . . + 18 log(λ) − λ − log(18!) =(15 + 14 + . . . + 18) log(λ) − 10λ − (log(15!) + log(14!) + . . . + log(18!)) =184 log(λ) − 10λ − c .
Dabei steht c f ur eine Konstante, die nicht vom Parameter λ abh angt. Durch Differenzieren nach λund Nullsetzen der Ableitung ergibt sich
184/λ − 10 = 0 .
Daraus folgtλ = 184/10 = 18.4 .
Allgemein gilt bei gegebenen Beobachtungen
x1, x2, . . . , xn
f ur die Likelihoodfunktion
L(λ;x1, x2, . . . , xn) =n∏
i=1
λxie−λ
xi!.
Die Loglikelihoodfunktion ist dann
log(L(λ;x1, x2, . . . , xn)) =n∑
i=1
(xi log(λ) − λ − log(xi!))
= log(λ) ·n∑
i=1
xi − nλ −n∑
i=1
log(xi!) .

148 KAPITEL 8. SCHATZUNG VON PARAMETERN
Die Ableitung der Loglikelihoodfunktion nach λ ist
d log(L(λ; . . .))
dλ=
n∑
i=1xi
λ− n .
Nullsetzen ergibtn∑
i=1xi
λ= n .
Daraus folgt als Maximum-Likelihood-Sch atzer des Parameters λ der Poissonverteilung
λ =
n∑
i=1xi
n= x .
Beispiel 8.8 Die Zufallsvariable X sei normalverteilt mit dem Parameter µ und σ2 d.h.
f(x) =1√
2πσ2exp
(
−(x − µ)2
2σ2
)
−∞ < x < ∞ .
Dann ist die Likelihoodfunktion
L(µ, σ2) =n∏
i=1
1√2πσ2
exp
(
−(xi − µ)2
2σ2
)
= (2π)−n/2(σ2)−n/2 exp
(
− 1
2σ2
n∑
i=1
(xi − µ)2)
,
und die Loglikelihoodfunktion ist
log L(µ, σ2) = −(n/2) log(2π) − (n/2) log σ2 − 1
2σ2
n∑
i=1
(xi − µ)2 .
Die partiellen Ableitungen sind
∂ log L(µ, σ2)
∂µ=
1
σ2
n∑
i=1
(xi − µ)
und∂ log L(µ, σ2)
∂σ2= − n
2σ2+
1
2(σ2)2
n∑
i=1
(xi − µ)2 .
Nullsetzen der partiellen Ableitungen und Multiplikation mit σ2 bzw. 2σ2 ergibt
n∑
i=1
(xi − µ) = 0
und
−n +1
σ2
n∑
i=1
(xi − µ)2 = 0 .
Die L osungen der beiden Gleichungen sind
µ = x
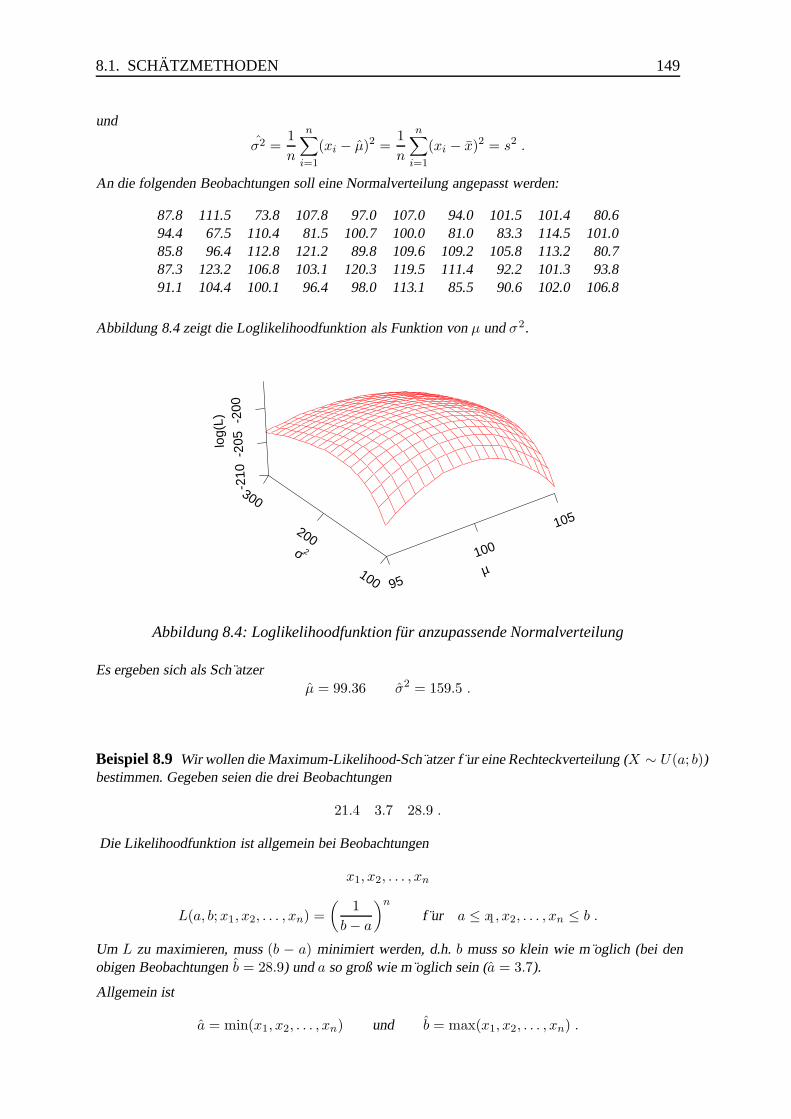
8.1. SCHATZMETHODEN 149
und
σ2 =1
n
n∑
i=1
(xi − µ)2 =1
n
n∑
i=1
(xi − x)2 = s2 .
An die folgenden Beobachtungen soll eine Normalverteilung angepasst werden:
87.8 111.5 73.8 107.8 97.0 107.0 94.0 101.5 101.4 80.694.4 67.5 110.4 81.5 100.7 100.0 81.0 83.3 114.5 101.085.8 96.4 112.8 121.2 89.8 109.6 109.2 105.8 113.2 80.787.3 123.2 106.8 103.1 120.3 119.5 111.4 92.2 101.3 93.891.1 104.4 100.1 96.4 98.0 113.1 85.5 90.6 102.0 106.8
Abbildung 8.4 zeigt die Loglikelihoodfunktion als Funktion von µ und σ2.
95
100
105
µ100
200
300
σ 2
-210
-205
-200
log(
L)
Abbildung 8.4: Loglikelihoodfunktion fur anzupassende Normalverteilung
Es ergeben sich als Sch atzerµ = 99.36 σ2 = 159.5 .
Beispiel 8.9 Wir wollen die Maximum-Likelihood-Sch atzer f ur eine Rechteckverteilung (X ∼ U(a; b))bestimmen. Gegeben seien die drei Beobachtungen
21.4 3.7 28.9 .
Die Likelihoodfunktion ist allgemein bei Beobachtungen
x1, x2, . . . , xn
L(a, b;x1, x2, . . . , xn) =
(1
b − a
)n
f ur a ≤ x1, x2, . . . , xn ≤ b .
Um L zu maximieren, muss (b − a) minimiert werden, d.h. b muss so klein wie m oglich (bei denobigen Beobachtungen b = 28.9) und a so groß wie m oglich sein (a = 3.7).
Allgemein ist
a = min(x1, x2, . . . , xn) und b = max(x1, x2, . . . , xn) .

150 KAPITEL 8. SCHATZUNG VON PARAMETERN
8.2 Einige Eigenschaften von Schatzern
Meistens gibt es mehrere Moglichkeiten, um einen Parameter zu schatzen, und man musssich zwischen verschiedenen Schatzern (oder auch Schatzfunktionen) entscheiden. Um dieWahl zu erleichtern, geben wir einige Eigenschaften von Schatzern an, die wir zur Beurtei-lung ihrer Qualitat heranziehen werden. Man wahlt dann den Schatzer aus, der die
”besten“
Eigenschaften hat oder der die Eigenschaften hat, die in der jeweiligen praktischen Situa-tion von Bedeutung sind. Zunachst ist festzustellen, dass ein Schatzer eine Zufallsvariableist, also eine Verteilung hat und insbesondere Momente, die wir gleich zur Beurteilung derGute des Schatzers heranziehen werden. Mit θ wollen wir den zu schatzenden Parameterbezeichnen, mit θ den Schatzer (oder die Schatzfunktion).
8.2.1 Erwartungstreue, Bias
Die Abbildungen 8.5 - 8.7 sollen jeweils zehn Realisationen von verschiedenen Schatzernθ1, θ2 und θ3 zeigen. Der Schatzer θ1 uberschatzt in den meisten Fallen, θ2 unterschatzt denzu schatzenden Parameter θ, wahrend θ3 im Mittel θ weder uberschatzt noch unterschatzt.Solch ein Schatzer heißt erwartungstreu.
θ×× ×× × ××× × ×
Abbildung 8.5: Typische Realisationen des Schatzers θ1
θ× ××××× ××× ×
Abbildung 8.6: Typische Realisationen des Schatzers θ2
θ× × ×× ×× ××× ×
Abbildung 8.7: Typische Realisationen des Schatzers θ3
Definition 8.3 Ein Schatzer θ heißt erwartungstreu, wenn gilt
Eθ = θ .

8.2. EINIGE EIGENSCHAFTEN VON SCHATZERN 151
Definition 8.4 Der Bias eines Schatzers θ ist definiert als
Bias(θ) = Eθ − θ .
Offensichtlich ist ein Schatzer θ genau dann erwartungstreu, wenn Bias(θ) = 0 gilt.
Beispiel 8.10 Die Beobachtungenx1, x2, . . . , xn
seien Realisierungen von unabh angigen N(µ;σ2)-verteilten Zufallsvariablen. Als Sch atzer von µbetrachten wir
µ =1
n
n∑
i=1
Xi .
Es ist
Eµ = E1
n
n∑
i=1
Xi =1
n
n∑
i=1
EXi = µ ,
d.h. µ ist ein erwartungstreuer Sch atzer von µ.
Eine abgeschwachte Forderung an den Schatzer ist die asymptotische Erwartungstreue:
Definition 8.5 Ein Schatzer θ heißt asymptotisch erwartungstreu, wenn gilt
limn→∞
Eθ = θ .
Asymptotische Erwartungstreue ist gleichbedeutend damit, dass der Bias (auch Verzerrunggenannt), mit wachsendem Stichprobenumfang n → ∞ verschwindet.
Beispiel 8.11 Die Beobachtungenx1, x2, . . . , xn
seien wieder Realisierungen von unabh angigen N(µ;σ2)-verteilten Zufallsvariablen. Wir betrachtenden Sch atzer der Varianz σ2,
σ2 = S2 =1
n
n∑
i=1
(Xi − X)2 .
Es ist bekannt, dassnS2
σ2∼ χ2(n − 1) .
Dann gilt nach Satz 3.13
ES2 =σ2
nE(χ2(n − 1)) =
σ2
n(n − 1) .

152 KAPITEL 8. SCHATZUNG VON PARAMETERN
Somit ist S2 kein erwartungstreuer Sch atzer von σ2. F ur den Bias gilt
Bias(S2) =σ2
n(n − 1) − σ2 = −σ2/n .
W urde man anstelle S2 den Sch atzer
S2∗ =
n
n − 1S2 =
1
n − 1
n∑
i=1
(Xi − X)2
verwenden, so h atte man wegen
ES2∗ =
n
n − 1ES2 = σ2
einen erwartungstreuen Sch atzer. Das ist der Grund, weshalb S2∗ h aufig als Sch atzer der Varianz σ2
verwendet wird. F ur den Bias von S2 gilt
Bias(S2) = −σ2/n −→n→∞ 0
Damit ist S2 asymptotisch erwartungstreu.
Asymptotische Erwartungstreue ist eine Eigenschaft des Schatzers fur große Stichprobe-numfange n. Ein asymptotisch erwartungstreuer Schatzer kann fur kleine Stichprobenum-fange erhebliche Verzerrungen liefern. So gilt z.B. fur n = 2 fur den Schatzer S2 : E(S2) =σ2/2, d.h. σ2 wird im Durchschnitt erheblich unterschatzt.
8.2.2 Standardfehler
Definition 8.6 Der Fehler eines Schatzers θ ist definiert als
θ − θ .
Die Abbildungen 8.8 und 8.9 zeigen typische Realisationen von zwei jeweils erwartungstreu-en Schatzern. Der Schatzer θ1 zeichnet sich durch eine kleinere Streuung aus und ist deshalbvorzuziehen. Das entsprechende Maß fur die Streuung eines Schatzers ist seine Standardab-weichung, d.h. die Wurzel aus seiner Varianz.
Definition 8.7 Der Standardfehler eines Schatzers θ ist seine Standardabweichung, d.h.
SF(θ) =√
Var(θ) .

8.2. EINIGE EIGENSCHAFTEN VON SCHATZERN 153
θ× × ×× ×× ××
Abbildung 8.8: Typische Realisationen des Schatzers θ1
θ× × ×× ×× × ×
Abbildung 8.9: Typische Realisationen des Schatzers θ2
Beispiel 8.12 Wie in Beispiel 8.10 seien die Beobachtungen
x1, x2, . . . , xn
Realisierungen von unabh angigen N(µ;σ2)-verteilten Zufallsvariablen, und wir betrachten wiederden Sch atzer
µ =1
n
n∑
i=1
Xi .
Es ist
Var(µ) = Var
(
1
n
n∑
i=1
Xi
)
= σ2/n
und damit
SF(µ) = σ/√
n .
Beispiel 8.13 Wir beziehen uns auf Beispiel 8.11 und die dort betrachteten Sch atzer S2 und S2∗ .
Der Sch atzer S2 war nicht erwartungstreu, sondern nur asymptotisch erwartungstreu, w ahrend S2∗
erwartungstreu ist. Es ist die Frage offen, was f ur die Verwendung von S2, also eines nicht erwar-tungstreuen Sch atzers spricht. Aus diesem Grunde untersuchen wir jetzt, wie sich beide Sch atzerhinsichtlich ihres Standardfehlers verhalten. Es gilt
VarS2 = Var
(
σ2
nχ2(n − 1)
)
=σ4
n22(n − 1)
und damit
SF (S2) =σ2
n
√
2(n − 1) .
F ur S2∗ gilt
VarS2∗ = Var
(n
n − 1S2)
=n2
(n − 1)2VarS2 = 2 · σ4
n − 1
und damit
SF (S2∗) = σ2
√
2
n − 1=
n
n − 1SF (S2) > SF (S2) .
Die Erwartungstreue wird also mit einem gr oßeren Standardfehler erkauft.

154 KAPITEL 8. SCHATZUNG VON PARAMETERN
8.2.3 Mittlerer quadratischer Fehler
Zur Beurteilung der Gute eines Schatzers muss man sowohl den Bias als auch den Standard-fehler berucksichtigen. Wir definieren jetzt ein Maß, das beide Großen zusammenfasst.
Definition 8.8 Der mittlere quadratische Fehler eines Schatzers θ ist definiert als
MQF(θ) = E(θ − θ)2 .
Der mittlere quadratische Fehler misst also die zu erwartende quadratische Abweichung zwi-schen dem Schatzer und dem zu schatzenden Parameter.
Satz 8.2 Fur den mittleren quadratischen Fehler eines Schatzers θ gilt
MQF(θ) = Var(θ) + (Bias(θ))2 .
Beweis:
MQF(θ) = E(θ − θ)2 = E(θ − Eθ + Eθ − θ)2
= E((θ − Eθ) + (Eθ − θ))2
= E((θ − Eθ)2 + 2(θ − Eθ)(Eθ − θ) + (Eθ − θ)2)
= E(θ − Eθ)2 + 2E(θ − Eθ)(Eθ − θ) + E(Eθ − θ)2
= V ar(θ) + 2(Eθ − Eθ︸ ︷︷ ︸
=0
)(Eθ − θ) + (Eθ − θ)2
︸ ︷︷ ︸
=(Bias(θ))2
= Var(θ) + (Bias(θ))2
♦Die zu erwartende quadratische Abweichung ist somit die Summe aus der Varianz von θ unddem quadrierten Bias von θ.
Beispiel 8.14 Wie in den fr uheren Beispielen seien die Beobachtungen
x1, x2, . . . , xn
Realisierungen von unabh angigen N(µ;σ2)-verteilten Zufallsvariablen. Wir betrachten zun achst denSch atzer
µ =1
n
n∑
i=1
Xi .

8.2. EINIGE EIGENSCHAFTEN VON SCHATZERN 155
Da µ erwartungstreu ist, giltMQF(µ) = Var(µ) = σ2/n .
F ur den Sch atzer S2 gilt
MQF(S2) = Var(S2) + (Bias(S2))2 =σ4
n22(n − 1) +
(
−σ2
n
)2
=σ4
n2(2n − 1) .
Der Sch atzer S2∗ ist erwartungstreu. Daher gilt
MQF(S2∗) = Var(S2
∗) = σ4 2
n − 1.
Es ist
MQF(S2) = σ4(
2
n− 1
n2
)
< σ4 2
n< σ4 2
n − 1= MQF (S2
∗) .
Beurteilt man also einen Sch atzer nach dem mittleren quadratischen Fehler, so ist S2 gegen uber S2∗vorzuziehen.
Satz 8.3 Fur einen erwartungstreuen Schatzer θ gilt
MQF(θ) = Var(θ) .
Beweis: Fur einen erwartungstreuen Schatzer θ gilt Bias(θ) = 0 und daher
MQF(θ) = Var(θ) + (Bias(θ))2 = Var(θ) .
♦
8.2.4 Konsistenz
Die Varianz eines Schatzers als alleiniges Kriterium ist also nur fur erwartungstreue Schatzersinnvoll. Bei asymptotisch erwartungstreuen Schatzern geht mit wachsendem Stichproben-umfang der Bias gegen Null. Geht gleichzeitig auch die Varianz gegen Null, so konvergiertauch der mittlere quadratische Fehler gegen Null. Man spricht dann von Konsistenz, genauer:Konsistenz im quadratischen Mittel.
Definition 8.9 Ein Schatzer θ heißt konsistent im quadratischen Mittel, wenn gilt
limn→∞
MQF (θ) = 0

156 KAPITEL 8. SCHATZUNG VON PARAMETERN
Die Konsistenz ist eine asymptotische Eigenschaft, die nur fur große Stichprobenumfangegilt. Eine konsistente Schatzfunktion kann fur endliche Stichprobenumfange eine große Va-rianz und eine erhebliche Verzerrung besitzen.
Die Konsistenz im quadratischen Mittel wird auch als starke Konsistenz bezeichnet. Einealternative Form der Konsistenz ist die schwache Konsistenz, bei der verlangt wird, dass dieWahrscheinlichkeit, mit der die Schatzfunktion Werte in einem beliebig kleinen Intervall umden wahren Parameter annimmt, mit wachsendem Stichprobenumfang gegen Eins konver-giert. Anschaulich bedeutet dies, dass der Schatzwert fur große n in unmittelbarer Nahe deswahren Parameters liegt.
Definition 8.10 Ein Schatzer θ heißt schwach konsistent, wenn fur beliebiges ε > 0 gilt
limn→∞
P (|θ − θ| < ε) = 1
oder gleichbedeutendlim
n→∞P (|θ − θ| ≥ ε) = 0
Aus der Konsistenz im quadratischen Mittel (oder der starken Konsistenz) folgt die schwacheKonsistenz.
Beispiel 8.15 Wie im vorigen Beispiel seien die Beobachtungen
x1, x2, . . . , xn
Realisierungen von unabh angigen N(µ;σ2)-verteilten Zufallsvariablen. Wir wissen, dass der Sch atzer
µ =1
n
n∑
i=1
Xi
erwartungstreu ist und den folgenden mittleren quadratischen Fehler besitzt:
MQF(µ) = Var(µ) = σ2/n
Der mittlere quadratische Fehler konvergiert offensichtlich gegen Null, d.h. der Sch atzer ist konsistentim quadratischen Mittel. Die schwache Konsistenz folgt aus der starken. Man k onnte sie auch sobeweisen:
P (|X − µ| ≤ ε) = P
(∣∣∣∣∣
X − µ
σ/√
n
∣∣∣∣∣≤ ε
σ√
n
)
= Φ
(ε
σ
√n
)
− Φ
(
− ε
σ
√n
)n→∞−→ 1 − 0 = 1
Diese Wahrscheinlichkeit ist in Abbildung 8.10 grafisch dargestellt. Mit wachsendem Stichproben-umfang liegt die gesamte Verteilung innerhalb der senkrechten Striche bei µ − ε und µ + ε.

8.2. EINIGE EIGENSCHAFTEN VON SCHATZERN 157
µ − ε µ + εµ
n1 = 2
n2 = 10
n3 = 20
Abbildung 8.10: Wahrscheinlichkeiten P (|X − µ| ≤ ε) fur ε = 3/4, σ = 1 bei Stichprobe-numfangen n1 = 2, n2 = 10, n3 = 20
Ein erwartungstreuer Schatzer ist offensichtlich genau dann konsistent im quadratischen Mit-tel, wenn die Varianz gegen Null konvergiert. Dasselbe laßt sich auch fur die schwache Kon-sistenz zeigen. Dazu brauchen wir die Tschebyscheffsche Ungleichung:
Satz 8.4 (Ungleichung von Tschebyscheff)Sei X eine Zufallsvariable mit E(X) = µ und Var(X) = σ2. Dann gilt die folgende
Ungleichung fur beliebiges c > 0:
P (|X − µ| ≥ c) ≤ σ2
c2
Diese Ungleichung besagt, dass bei festem c die Wahrscheinlichkeit, dass X um mindestensc von µ abweicht desto geringer ist, je kleiner die Varianz ist.
Da P (|X − µ| < c) = 1 − P (|X − µ| ≥ c) folgt daraus sofort eine zweite Ungleichung:
P (|X − µ| < c) ≥ 1 − σ2
c2
Die Tschebyscheffsche Ungleichung lasst sich so beweisen: Wir definieren eine diskreteZufallsvariable Y durch
Y =
0 falls |X − µ| < cc2 falls |X − µ| ≥ c
Dann gilt: P (Y = 0) = P (|X − µ| < c) und P (Y = c2) = P (|X − µ| ≥ c). Also ist:
E(Y ) = c2P (|X − µ| ≥ c)
Nach Definition von Y gilt immer Y ≤ |X − µ|2 und somit
E(Y ) ≤ E(X − µ)2 = Var(X) = σ2

158 KAPITEL 8. SCHATZUNG VON PARAMETERN
Also haben wirc2P (|X − µ| ≥ c) ≤ σ2
und damit P (|X − µ| ≥ c) ≤ σ2
c2.
Fur einen Schatzer θ folgt aus der Tschebyscheffschen Ungleichung
P (|θ − θ| ≥ ε) ≤ Var(θ)ε2
Daraus folgt, dass jeder erwartungstreue Schatzer schwach konsistent ist, wenn Var(θ) n→∞−→0.
Beispiel 8.16 Der Erwartungswert µ = E(X) einer Zufallsvariablen X mit Var(X) = σ2 wirddurch das arithmetische Mittel X gesch atzt. Da E(X) = E(X) ist X ein erwartungstreuer Sch atzer.F ur die Varianz vonX gilt Var(X) = σ2
nn→∞−→ 0. Demnach ist X konsistent im quadratischen Mittel
und auch schwach konsistent.
8.2.5 Effizienz
Der mittlere quadratische Fehler (MQF) ist ein Maß fur die Gute eines Schatzers, das sowohldie Verzerrung als auch die Varianz des Schatzers berucksichtigt. Demnach ist von zweiSchatzern θ1 und θ2 derjenige vorzuziehen, der den kleineren mittleren quadratischen Fehlerbesitzt. Man sagt dann, dass θ1 MQF-wirksamer ist als θ2, wenn
MQF (θ1) ≤ MQF (θ2)
Hierbei muss man jedoch den Bereich der zugelassenen Verteilungen einschranken, z.B. aufalle Poissonverteilungen, wenn es um die Schatzung des Parameters λ der Poissonvertei-lung geht oder auf alle Verteilungen mit endlicher Varianz, wenn es um die Schatzung desErwartungswertes geht.
Betrachtet man nur erwartungstreue Schatzer, d.h. Schatzer ohne Bias, so reduziert sich dieBetrachtung der Wirksamkeit auf den Vergleich der Varianzen:
Definition 8.11 Ein erwartungstreuer Schatzer θ1 heißt wirksamer oder effizienter alsder ebenfalls erwartungstreue Schatzer θ2, wenn
Var(θ1) ≤ Var(θ2)
fur alle zugelassenen Verteilungen gilt.Ein erwartungstreuer Schatzer θ heißt wirksamst oder effizient, wenn seine Varianz furalle zugelassenen Verteilungen den kleinsten moglichen Wert annimmt, d.h. wenn fur alleanderen erwartungstreuen Schatzer θ∗ gilt:
Var(θ) ≤ Var(θ∗)

8.2. EINIGE EIGENSCHAFTEN VON SCHATZERN 159
Es gibt eine untere Schranke fur die Varianz einer erwartungstreuen Schatzfunktion, die so-genannte Cramer-Rao-Schranke, die wir jedoch im Rahmen dieser Vorlesung nicht angebenkonnen. Diese Schranke wird von wirksamsten Schatzern angenommen.
Effiziente Schatzfunktionen sind u.a.
• X fur den Erwartungswert, wenn alle Verteilungen mit endlicher Varianz zugelassensind,
• X fur den Erwartungswert, wenn alle Normalverteilungen zugelassen sind,
• X fur den Anteilswert π, wenn alle Bernoulli-Verteilungen zugelassen sind,
• X fur den Parameter λ, wenn alle Poisson-Verteilungen Po(λ) zugelassen sind,
• X fur g(λ) = 1/λ, wenn alle Exponentialverteilungen Exp(λ) zugelassen sind,
• die mittlere quadratische Abweichung bzgl. µ, d.h. 1n
n∑
i=1(Xi − µ)2 fur die Varianz σ2,
wenn alle Normalverteilungen mit Erwartungswert µ zugelassen sind,
• die Stichprobenvarianz S2∗ = 1
n−1
n∑
i=1(Xi − X)2 fur die Varianz σ2 einer N(µ, σ2)-
verteilten Grundgesamtheit, wenn µ unbekannt ist.
Als Literatur zu diesem Kapitel sei Fahrmeir u.a. (1997), Bamberg und Baur (1996), Schlitt-gen (1996a, 1996b) genannt.

Kapitel 9
Mischverteilungen
Bei der Modellanpassung versucht man in der Regel ein einfaches Modell (beispielsweisedie Poissonverteilung) zur Beschreibung der Daten zu verwenden. Haufig zeigt sich jedoch,dass ein vermutetes Modell dazu nicht in der Lage ist. Beispielsweise kann die grafischeDarstellung der Haufigkeiten einer Stichprobe multimodal sein, was nicht zur unimodalenGestalt der Poissonverteilung passt. Eine mogliche Erklarung fur die Multimodalitat ist, dassdie Population, aus der die Daten stammen, heterogen ist. Damit ist gemeint, dass die Popu-lation aus verschiedenen Gruppen (Subpopulationen) besteht, bei denen sich die Verteilungdes betrachteten Merkmals unterscheidet und so zu der Multimodaltat fuhrt. Betrachtet manbeispielsweise die Anzahl von Zigarettenpackungen, die von einzelnen Kunden eines Super-markts gekauft werden, so ware ein Histogramm der Daten wahrscheinlich nicht unimodalund somit das zugehorige Modell keine Poissonverteilung. Es ist offensichtlich, dass die be-trachtete Grundgesamtheit aus zwei Gruppen besteht, den Rauchern und den Nichtrauchernund es ist auch offensichtlich, dass sich die Verteilung des Merkmals in den beiden Gruppenunterscheidet. Es ist gut moglich, dass die (bedingte, d.h. gegeben Raucher bzw. Nichtrau-cher) Verteilung jeweils vom Typ Poisson ist, die unbedingte Verteilung des Merkmals istjedoch eine Mischverteilung.
Wir wollen in diesem Kapitel die grundlegenden Eigenschaften von Mischverteilungen be-sprechen, die Sie in der englischen Literatur unter den Begriffen ,,Mixture Models”, ,,Mix-ture Distributions” (siehe z.B. Kotz und Johnson (1985), Band 5, wo Sie viele interessanteAnwendungsbeispiele finden) oder ,,Compound Distributions” finden (siehe auch Everitt undHand (1981)). Als wesentliche Literaturquelle sei das Buch ,,Computer–Assisted Analysis ofMixtures and Applications” (Bohning D., 1999) erwahnt. Die in diesem Buch beschriebeneSoftware C.A.MAN kann kostenlos von der Hompage des Autors (http://www.medizin.fu-berlin.de/sozmed/bo1.html) heruntergeladen werden.
9.1 Diskrete Mischung diskreter Verteilungen
Definition 9.1 Seien P1(x) und P2(x) Wahrscheinlichkeitsfunktionen und sei 0 ≤ r ≤1 . Dann heißt
P (x) = r · P1(x) + (1 − r)P2(x)
die Mischverteilung von P1 und P2.
160
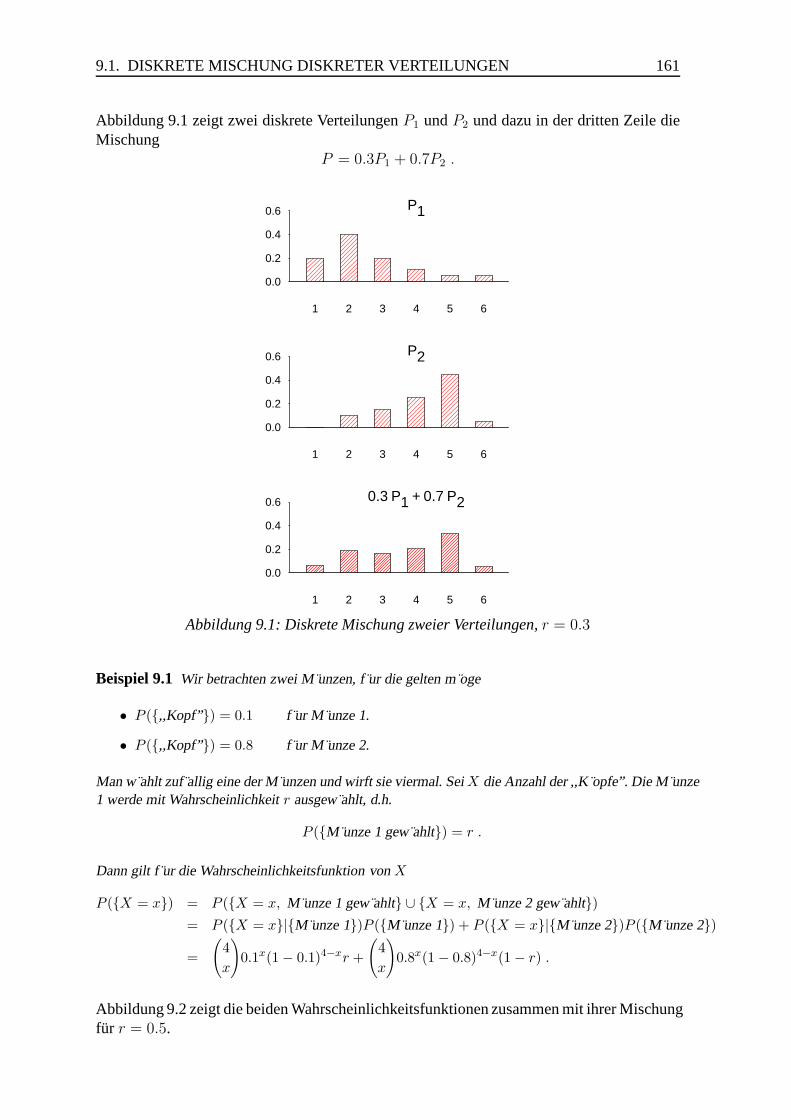
9.1. DISKRETE MISCHUNG DISKRETER VERTEILUNGEN 161
Abbildung 9.1 zeigt zwei diskrete Verteilungen P1 und P2 und dazu in der dritten Zeile dieMischung
P = 0.3P1 + 0.7P2 .
1 2 3 4 5 6
0.0
0.2
0.4
0.6 P1
1 2 3 4 5 6
0.0
0.2
0.4
0.6 P2
1 2 3 4 5 6
0.0
0.2
0.4
0.6 0.3 P1 + 0.7 P2
Abbildung 9.1: Diskrete Mischung zweier Verteilungen, r = 0.3
Beispiel 9.1 Wir betrachten zwei M unzen, f ur die gelten m oge
• P (,,Kopf”) = 0.1 f ur M unze 1.
• P (,,Kopf”) = 0.8 f ur M unze 2.
Man w ahlt zuf allig eine der M unzen und wirft sie viermal. Sei X die Anzahl der ,,K opfe”. Die M unze1 werde mit Wahrscheinlichkeit r ausgew ahlt, d.h.
P (M unze 1 gew ahlt) = r .
Dann gilt f ur die Wahrscheinlichkeitsfunktion von X
P (X = x) = P (X = x, M unze 1 gew ahlt ∪ X = x, M unze 2 gew ahlt)= P (X = x|M unze 1)P (M unze 1) + P (X = x|M unze 2)P (M unze 2)
=
(
4
x
)
0.1x(1 − 0.1)4−xr +
(
4
x
)
0.8x(1 − 0.8)4−x(1 − r) .
Abbildung 9.2 zeigt die beiden Wahrscheinlichkeitsfunktionen zusammen mit ihrer Mischungfur r = 0.5.
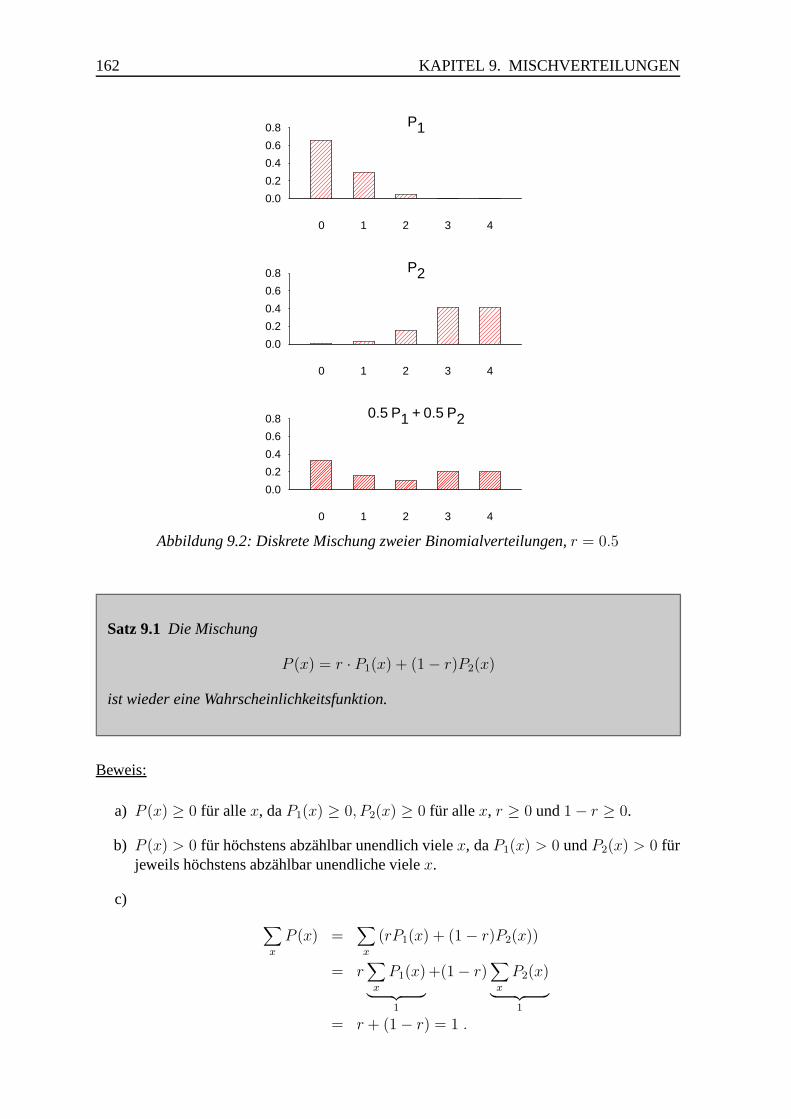
162 KAPITEL 9. MISCHVERTEILUNGEN
0 1 2 3 4
0.0
0.2
0.4
0.6
0.8 P1
0 1 2 3 4
0.0
0.2
0.4
0.6
0.8 P2
0 1 2 3 4
0.0
0.2
0.4
0.6
0.8 0.5 P1 + 0.5 P2
Abbildung 9.2: Diskrete Mischung zweier Binomialverteilungen, r = 0.5
Satz 9.1 Die Mischung
P (x) = r · P1(x) + (1 − r)P2(x)
ist wieder eine Wahrscheinlichkeitsfunktion.
Beweis:
a) P (x) ≥ 0 fur alle x, da P1(x) ≥ 0, P2(x) ≥ 0 fur alle x, r ≥ 0 und 1 − r ≥ 0.
b) P (x) > 0 fur hochstens abzahlbar unendlich viele x, da P1(x) > 0 und P2(x) > 0 furjeweils hochstens abzahlbar unendliche viele x.
c)
∑
x
P (x) =∑
x
(rP1(x) + (1 − r)P2(x))
= r∑
x
P1(x)
︸ ︷︷ ︸
1
+(1 − r)∑
x
P2(x)
︸ ︷︷ ︸
1
= r + (1 − r) = 1 .

9.1. DISKRETE MISCHUNG DISKRETER VERTEILUNGEN 163
Beispiel 9.2 Die Verteilung des Geschlechts von Zwillingen ist eine Mischverteilung (siehe Blisch-ke (1978)). Es gibt drei Klassen von Zwillingen:
WW WM MM .
Das f uhrt zu einer Trinomialverteilung. Dabei steht W f ur weiblich und M f ur m annlich. Ferner gibtes zweieiige und eineiige Zwillinge. Die Geschlechter zweieiiger Zwillinge sind unabh angig vonein-ander. Daher ist die Verteilung:
π2 2 · π · (1 − π) (1 − π)2 .
Eineiige Zwillinge haben jedoch das gleiche Geschlecht. Daher ist die Verteilung des Geschlechts f ureineiige Zwillinge:
π 0 (1 − π) ,
wobei π die Wahrscheinlichkeit einer M adchengeburt ist. Das Geschlecht von Zwillingen ist eineMischung dieser beiden Verteilungen, wobei der Mischungsparameter r bzw. 1 − r durch den Anteilder zweieiigen Zwillinge bzw. eineiigen Zwillinge bestimmt wird.
Definition 9.2 (Diskrete Mischung mit I Komponenten) Seien
P1(x), P2(x), . . . , PI(x)
jeweils Wahrscheinlichkeitsfunktionen. Eine diskrete Mischung dieser Wahrscheinlich-keitsfunktionen ist dann definiert durch
P (x) = r1P1(x) + r2P2(x) + · · ·+ rIPI(x)
=I∑
i=1
riPi(x) ,
wobei 0 ≤ ri ≤ 1 fur alle i undI∑
i=1ri = 1 .
Satz 9.2 Seien P1(x), P2(x), . . . , PI(x) jeweils Wahrscheinlichkeitsfunktionen und seiP (x) die Mischverteilung bezuglich der Mischungsparameter r1, r2, . . . , rI . Das k-teMoment der i-ten Verteilung sei mit µ′
k(i) bezeichnet. Dann gilt fur das k-te Momentder Mischverteilung
µ′k = r1µ
′k(1) + r2µ
′k(2) + · · ·+ rIµ
′k(I)
=I∑
i=1
riµ′k(i) .
Insbesondere gilt fur den Erwartungswert bezuglich einer Mischverteilung
E(X) = r1µ(1) + r2µ(2) + · · · rIµ(I) ,

164 KAPITEL 9. MISCHVERTEILUNGEN
wobei µ(i) der Erwartungswert bezuglich der i-ten Komponente ist. Auch fur die Varianzenkann man ein ahnliches Resultat herleiten, das jedoch komplizierter wird. Wir formulierenes nur fur die Mischung mit zwei Komponenten.
Satz 9.3 Seien P1 und P2 zwei Wahrscheinlichkeitsfunktionen mit Erwartungswertenµ(1) und µ(2) und Varianzen σ2(1) und σ2(2). Dann gilt fur die Varianz σ2 der Misch-verteilung mit den Mischungsparametern r1 und r2
σ2 = r1σ2(1) + r2σ
2(2) + r1r2(µ(1) − µ(2))2 .
Beweis:Wenn man im folgenden beachtet, dass µ′
2 = EX2 = Var(X) + (E(X))2 = σ2 + (µ′1)
2 undr2 = 1 − r1 gilt, so folgt:
σ2 = µ′2 − (µ′
1)2 = r1µ
′2(1) + r2µ
′2(2) − (µ′
1)2
= r1(σ2(1) + µ(1)2) + r2(σ
2(2) + µ(2)2) − (r1µ(1) + r2µ(2))2
= r1σ2(1) + r2σ
2(2) + r1µ(1)2 + r2µ(2)2 − r21µ(1)2 − 2r1r2µ(1)µ(2) − r2
2µ(2)2
= r1σ2(1) + r2σ
2(2) + r1(1 − r1)µ(1)2 + r2(1 − r2)µ(2)2 − 2r1r2µ(1)µ(2)
= r1σ2(1) + r2σ
2(2) + r1r2(µ(1)2 − 2µ(1)µ(2) + µ(2)2)
= r1σ2(1) + r2σ
2(2) + r1r2(µ(1) − µ(2))2
Beispiel 9.3 Das folgende Beispiel ist von B ohning, D. (1999, S. 3–5) ubernommen. Untersuchtwird die Einf uhrung eines neuen S ußwarenprodukts. Im Rahmen der Markteinf uhrung wird die An-zahl verkaufter Packungen (im folgenden mit X bezeichnet) in verschiedenen Gesch aften erhoben.Die nachfolgende Tabelle zeigt die Ergebnisse der Datenerhebung.
Anzahl verkaufter Packungen 0 1 2 3 4 5 6 7 8 9Haufigkeit 102 54 49 62 44 25 26 15 15 10
Anzahl verkaufter Packungen 10 11 12 13 14 15 16 17 18 19 20Haufigkeit 10 10 10 3 3 5 5 4 1 2 1
Typischerweise verwendet man zur Beschreibung von Z ahldaten unter homogenen Bedingungen inder Population die Poissonverteilung, d.h. P (x) = e−λλx/x!. Abbildung 9.3 zeigt jedoch eine bi-modale Verteilung der Daten. Mit anderen Worten ist die Population heterogen, sie besteht aus unter-schiedlichen Subpopulationen.
Sch atzt man die Anzahl der Komponenten, die Parameter der einzelnen Poissonverteilungen sowie dieMischungsparameter mit Hilfe des Programms C.A.MAN (zur Parametersch atzung siehe Abschnitt9.4.3), erh alt man f unf Komponenten:
r1 = 0.01 r2 = 0.24 r3 = 0.50 r4 = 0.15 r5 = 0.10λ1 = 0.00 λ2 = 0.21 λ3 = 3.00 λ4 = 7.39 λ5 = 12.86
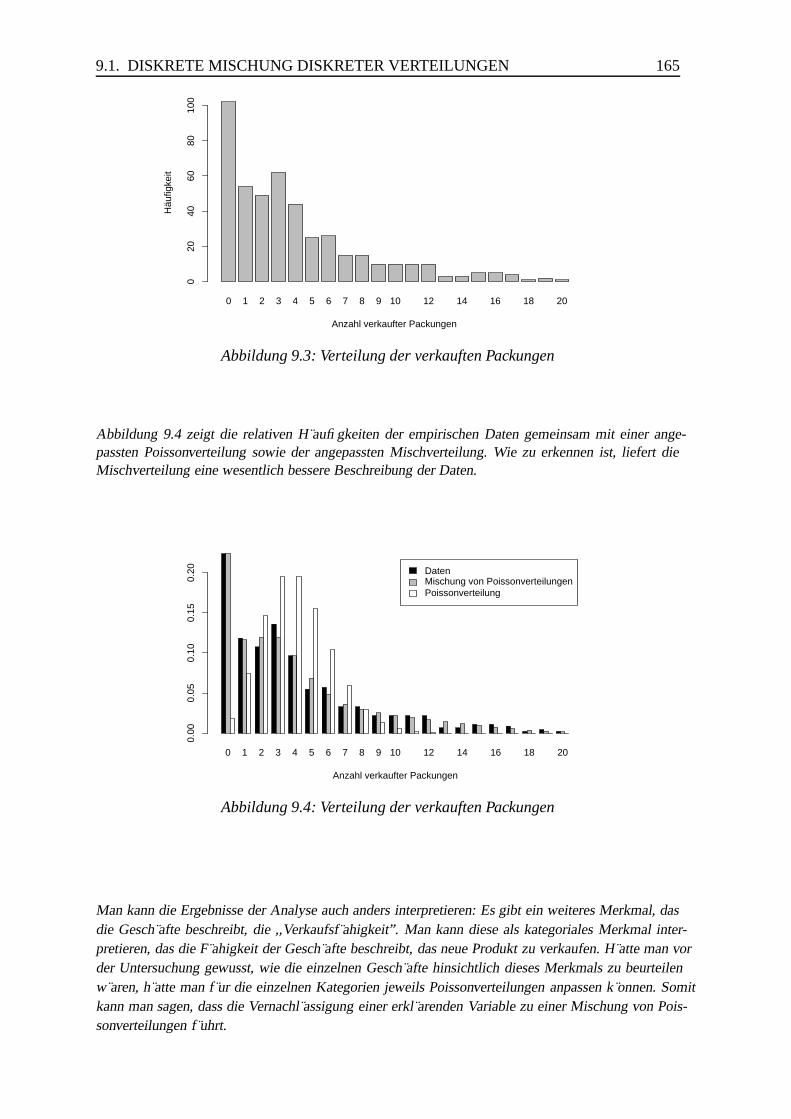
9.1. DISKRETE MISCHUNG DISKRETER VERTEILUNGEN 165
0 1 2 3 4 5 6 7 8 9 10 12 14 16 18 20
Anzahl verkaufter Packungen
Häu
figke
it
020
4060
8010
0
Abbildung 9.3: Verteilung der verkauften Packungen
Abbildung 9.4 zeigt die relativen H aufigkeiten der empirischen Daten gemeinsam mit einer ange-passten Poissonverteilung sowie der angepassten Mischverteilung. Wie zu erkennen ist, liefert dieMischverteilung eine wesentlich bessere Beschreibung der Daten.
0 1 2 3 4 5 6 7 8 9 10 12 14 16 18 20
DatenMischung von PoissonverteilungenPoissonverteilung
Anzahl verkaufter Packungen
0.00
0.05
0.10
0.15
0.20
Abbildung 9.4: Verteilung der verkauften Packungen
Man kann die Ergebnisse der Analyse auch anders interpretieren: Es gibt ein weiteres Merkmal, dasdie Gesch afte beschreibt, die ,,Verkaufsf ahigkeit”. Man kann diese als kategoriales Merkmal inter-pretieren, das die F ahigkeit der Gesch afte beschreibt, das neue Produkt zu verkaufen. H atte man vorder Untersuchung gewusst, wie die einzelnen Gesch afte hinsichtlich dieses Merkmals zu beurteilenw aren, h atte man f ur die einzelnen Kategorien jeweils Poissonverteilungen anpassen k onnen. Somitkann man sagen, dass die Vernachl assigung einer erkl arenden Variable zu einer Mischung von Pois-sonverteilungen f uhrt.

166 KAPITEL 9. MISCHVERTEILUNGEN
9.2 Diskrete Mischung stetiger Verteilungen
Definition 9.3 Seien f1(x) und f2(x) zwei Dichtefunktionen und sei 0 ≤ r ≤ 1. Dannheißt
f(x) = rf1(x) + (1 − r)f2(x)
die Dichtefunktion der Mischverteilung.
Satz 9.4 Die Mischungf(x) = rf1(x) + (1 − r)f2(x)
ist wieder eine Dichtefunktion.
Beweis:Da f1 und f2 Dichtefunktionen sind, gilt
a) f(x) = rf1(x) + (1 − r)f2(x) ≥ 0 fur alle x, da f1(x) ≥ 0, f2(x) ≥ 0 fur alle x undr ≥ 0.
b)∞∫
−∞f(x)dx = r
∞∫
−∞f1(x)dx
︸ ︷︷ ︸
=1
+(1 − r)
∞∫
−∞f2(x)dx
︸ ︷︷ ︸
=1
= r + (1 − r) = 1.
c) Da f1(x) und f2(x) bis auf endlich viele Stellen stetig sind, ist f(x) auch stetig bis aufendlich viele Stellen. ♦
Mischverteilungen kommen oft vor, wenn man ein unbeobachtetes Merkmal hat. Stellen Siesich vor, Sie haben eine zufallige Stichprobe aus der Grundgesamtheit aller Gottinger Stu-denten genommen und deren Korpergoße gemessen. Wie wird ein vernunftiges Modell furdie Korpergroße der Gottinger Studenten aussehen? Zunachst gibt es unter den Studieren-den in Gottingen Frauen und Manner. Es ist allgemein bekannt, dass die Korpergroße derFrauen im Durchschnitt kleiner ist als die Korpergroße der Manner. Weiterhin ist es vernunf-tig anzunehmen, dass die Korpergroße von Frauen und von Mannern, jeweils fur sich alleingenommen, normalverteilt ist. Dies fuhrt zu dem folgenden Modell
f(x) = rf1(x; µF , σ2F ) + (1 − r)f2(x; µM , σ2
M),
wobei r der Anteil der Frauen in der Grundgesamtheit der Studierenden in Gottingen istund f1 bzw. f2 Dichten der Normalverteilung mit den Parametern µF und σ2
F bzw. µM undσ2
M fur Frauen bzw. Manner sind. (Dieses Beispiel wurde nach einem Beispiel von Everittin Johnson und Kotz (1985) abgeandert.) In diesem Beispiel hatte man das Geschlecht der
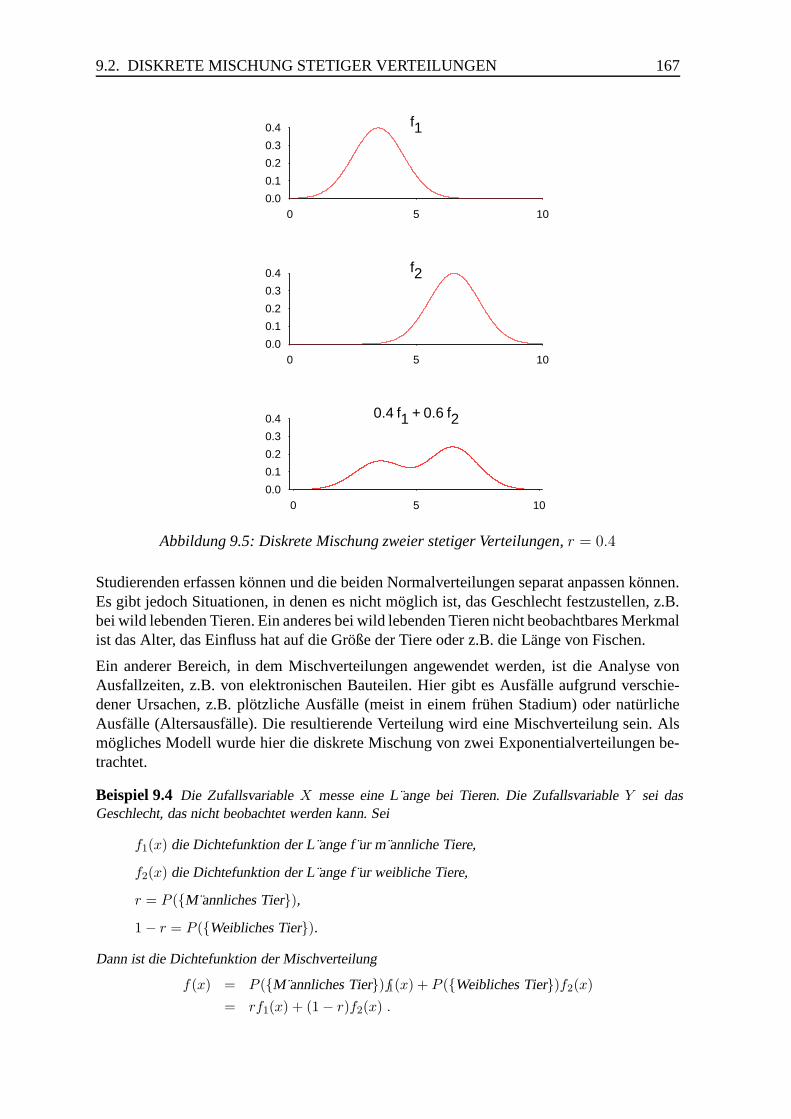
9.2. DISKRETE MISCHUNG STETIGER VERTEILUNGEN 167
0 5 100.0
0.1
0.2
0.3
0.4 f1
0 5 100.0
0.1
0.2
0.3
0.4 f2
0 5 100.0
0.1
0.2
0.3
0.4 0.4 f1 + 0.6 f2
Abbildung 9.5: Diskrete Mischung zweier stetiger Verteilungen, r = 0.4
Studierenden erfassen konnen und die beiden Normalverteilungen separat anpassen konnen.Es gibt jedoch Situationen, in denen es nicht moglich ist, das Geschlecht festzustellen, z.B.bei wild lebenden Tieren. Ein anderes bei wild lebenden Tieren nicht beobachtbares Merkmalist das Alter, das Einfluss hat auf die Große der Tiere oder z.B. die Lange von Fischen.
Ein anderer Bereich, in dem Mischverteilungen angewendet werden, ist die Analyse vonAusfallzeiten, z.B. von elektronischen Bauteilen. Hier gibt es Ausfalle aufgrund verschie-dener Ursachen, z.B. plotzliche Ausfalle (meist in einem fruhen Stadium) oder naturlicheAusfalle (Altersausfalle). Die resultierende Verteilung wird eine Mischverteilung sein. Alsmogliches Modell wurde hier die diskrete Mischung von zwei Exponentialverteilungen be-trachtet.
Beispiel 9.4 Die Zufallsvariable X messe eine L ange bei Tieren. Die Zufallsvariable Y sei dasGeschlecht, das nicht beobachtet werden kann. Sei
f1(x) die Dichtefunktion der L ange f ur m annliche Tiere,
f2(x) die Dichtefunktion der L ange f ur weibliche Tiere,
r = P (M annliches Tier),1 − r = P (Weibliches Tier).
Dann ist die Dichtefunktion der Mischverteilung
f(x) = P (M annliches Tier)f1(x) + P (Weibliches Tier)f2(x)
= rf1(x) + (1 − r)f2(x) .
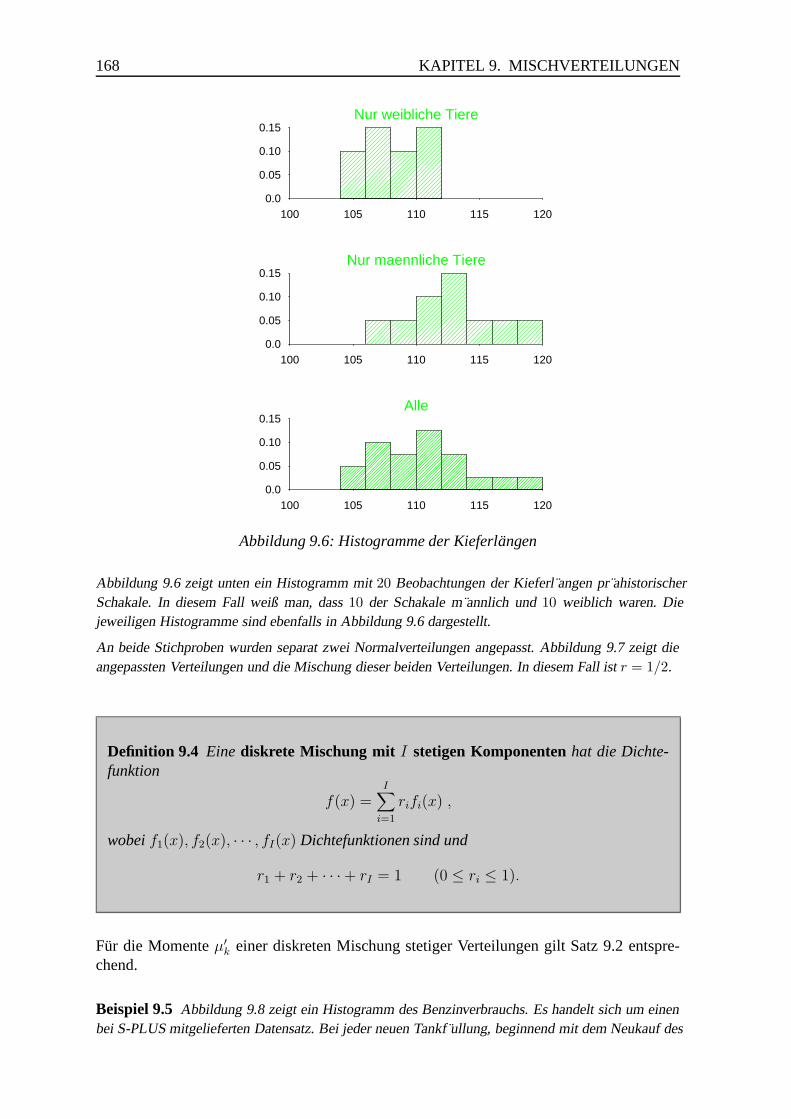
168 KAPITEL 9. MISCHVERTEILUNGEN
100 105 110 115 1200.0
0.05
0.10
0.15
Nur weibliche Tiere
100 105 110 115 1200.0
0.05
0.10
0.15
Nur maennliche Tiere
100 105 110 115 1200.0
0.05
0.10
0.15
Alle
Abbildung 9.6: Histogramme der Kieferlangen
Abbildung 9.6 zeigt unten ein Histogramm mit 20 Beobachtungen der Kieferl angen pr ahistorischerSchakale. In diesem Fall weiß man, dass 10 der Schakale m annlich und 10 weiblich waren. Diejeweiligen Histogramme sind ebenfalls in Abbildung 9.6 dargestellt.
An beide Stichproben wurden separat zwei Normalverteilungen angepasst. Abbildung 9.7 zeigt dieangepassten Verteilungen und die Mischung dieser beiden Verteilungen. In diesem Fall ist r = 1/2.
Definition 9.4 Eine diskrete Mischung mit I stetigen Komponenten hat die Dichte-funktion
f(x) =I∑
i=1
rifi(x) ,
wobei f1(x), f2(x), · · · , fI(x) Dichtefunktionen sind und
r1 + r2 + · · ·+ rI = 1 (0 ≤ ri ≤ 1).
Fur die Momente µ′k einer diskreten Mischung stetiger Verteilungen gilt Satz 9.2 entspre-
chend.
Beispiel 9.5 Abbildung 9.8 zeigt ein Histogramm des Benzinverbrauchs. Es handelt sich um einenbei S-PLUS mitgelieferten Datensatz. Bei jeder neuen Tankf ullung, beginnend mit dem Neukauf des
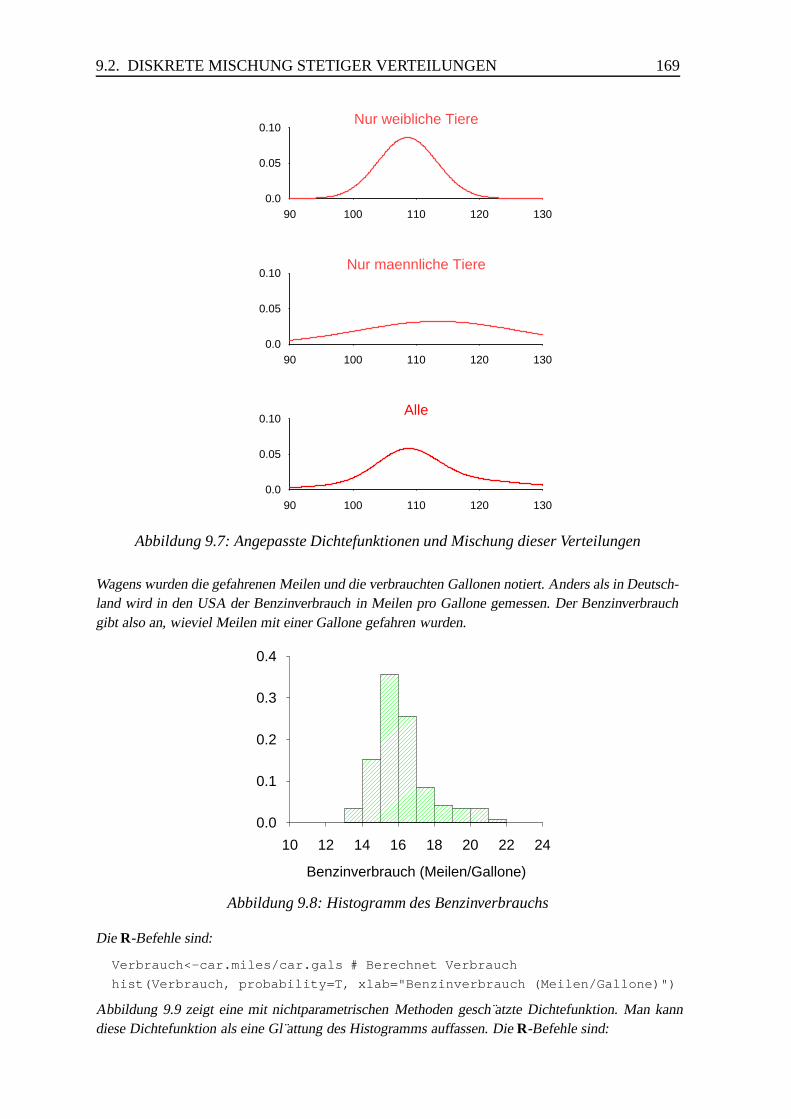
9.2. DISKRETE MISCHUNG STETIGER VERTEILUNGEN 169
90 100 110 120 1300.0
0.05
0.10Nur weibliche Tiere
90 100 110 120 1300.0
0.05
0.10Nur maennliche Tiere
90 100 110 120 1300.0
0.05
0.10Alle
Abbildung 9.7: Angepasste Dichtefunktionen und Mischung dieser Verteilungen
Wagens wurden die gefahrenen Meilen und die verbrauchten Gallonen notiert. Anders als in Deutsch-land wird in den USA der Benzinverbrauch in Meilen pro Gallone gemessen. Der Benzinverbrauchgibt also an, wieviel Meilen mit einer Gallone gefahren wurden.
10 12 14 16 18 20 22 24
0.0
0.1
0.2
0.3
0.4
Benzinverbrauch (Meilen/Gallone)
Abbildung 9.8: Histogramm des Benzinverbrauchs
Die R-Befehle sind:
Verbrauch<-car.miles/car.gals # Berechnet Verbrauch
hist(Verbrauch, probability=T, xlab="Benzinverbrauch (Meilen/Gallone)")
Abbildung 9.9 zeigt eine mit nichtparametrischen Methoden gesch atzte Dichtefunktion. Man kanndiese Dichtefunktion als eine Gl attung des Histogramms auffassen. Die R-Befehle sind:
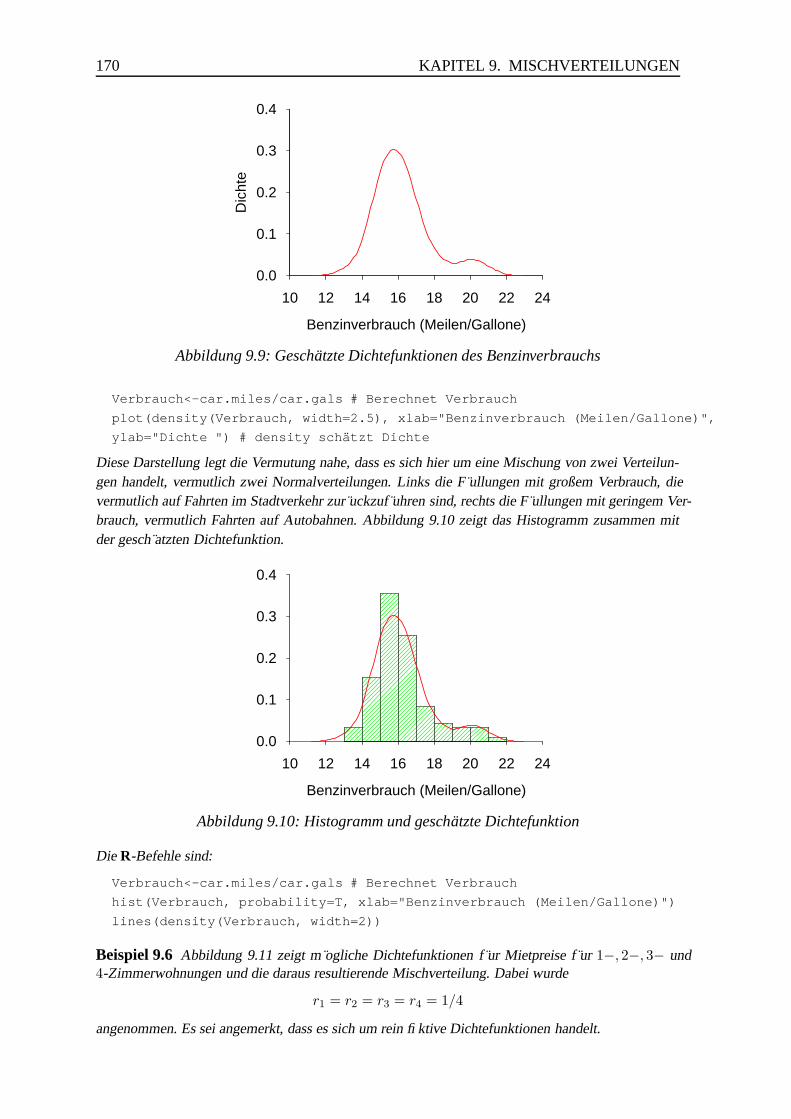
170 KAPITEL 9. MISCHVERTEILUNGEN
Benzinverbrauch (Meilen/Gallone)
Dic
hte
10 12 14 16 18 20 22 24
0.0
0.1
0.2
0.3
0.4
Abbildung 9.9: Geschatzte Dichtefunktionen des Benzinverbrauchs
Verbrauch<-car.miles/car.gals # Berechnet Verbrauch
plot(density(Verbrauch, width=2.5), xlab="Benzinverbrauch (Meilen/Gallone)",
ylab="Dichte ") # density schatzt Dichte
Diese Darstellung legt die Vermutung nahe, dass es sich hier um eine Mischung von zwei Verteilun-gen handelt, vermutlich zwei Normalverteilungen. Links die F ullungen mit großem Verbrauch, dievermutlich auf Fahrten im Stadtverkehr zur uckzuf uhren sind, rechts die F ullungen mit geringem Ver-brauch, vermutlich Fahrten auf Autobahnen. Abbildung 9.10 zeigt das Histogramm zusammen mitder gesch atzten Dichtefunktion.
10 12 14 16 18 20 22 24
0.0
0.1
0.2
0.3
0.4
Benzinverbrauch (Meilen/Gallone)
Abbildung 9.10: Histogramm und geschatzte Dichtefunktion
Die R-Befehle sind:
Verbrauch<-car.miles/car.gals # Berechnet Verbrauch
hist(Verbrauch, probability=T, xlab="Benzinverbrauch (Meilen/Gallone)")
lines(density(Verbrauch, width=2))
Beispiel 9.6 Abbildung 9.11 zeigt m ogliche Dichtefunktionen f ur Mietpreise f ur 1−, 2−, 3− und4-Zimmerwohnungen und die daraus resultierende Mischverteilung. Dabei wurde
r1 = r2 = r3 = r4 = 1/4
angenommen. Es sei angemerkt, dass es sich um rein fiktive Dichtefunktionen handelt.
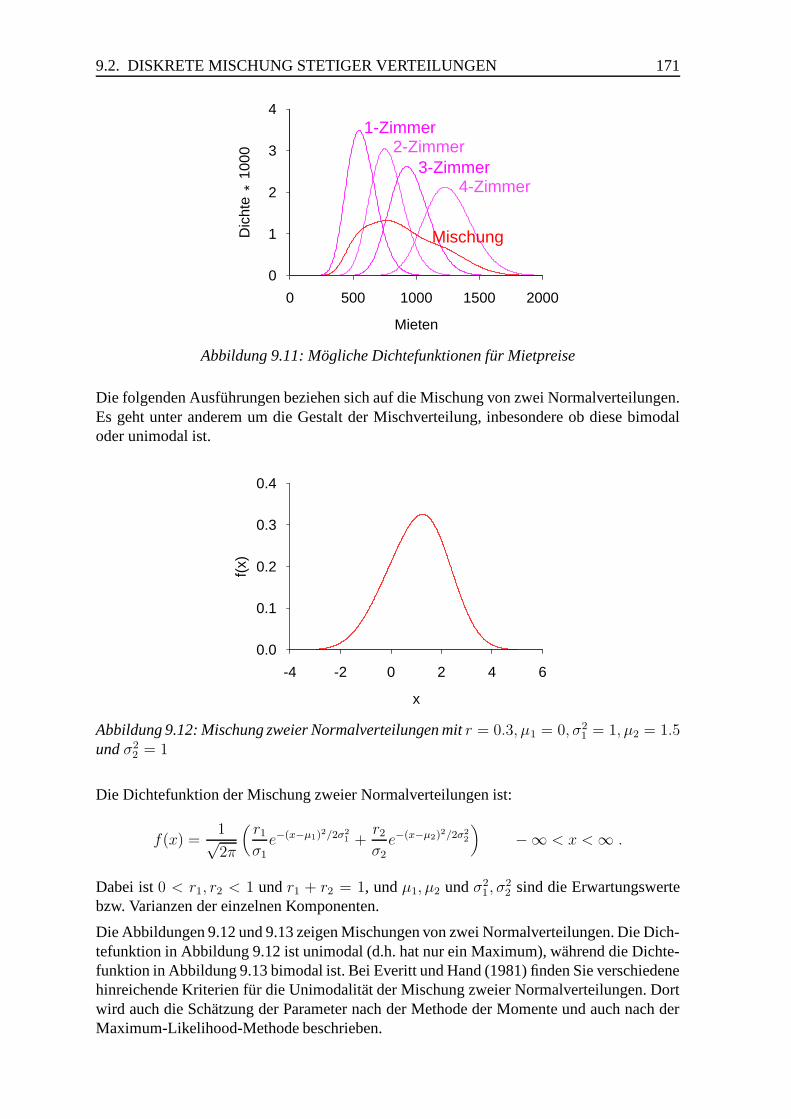
9.2. DISKRETE MISCHUNG STETIGER VERTEILUNGEN 171
Mieten
0 500 1000 1500 2000
0
1
2
3
4
Dic
hte
*10
00
1-Zimmer2-Zimmer
3-Zimmer4-Zimmer
Mischung
Abbildung 9.11: Mogliche Dichtefunktionen fur Mietpreise
Die folgenden Ausfuhrungen beziehen sich auf die Mischung von zwei Normalverteilungen.Es geht unter anderem um die Gestalt der Mischverteilung, inbesondere ob diese bimodaloder unimodal ist.
x
f(x)
-4 -2 0 2 4 6
0.0
0.1
0.2
0.3
0.4
Abbildung 9.12: Mischung zweier Normalverteilungen mit r = 0.3, µ1 = 0, σ21 = 1, µ2 = 1.5
und σ22 = 1
Die Dichtefunktion der Mischung zweier Normalverteilungen ist:
f(x) =1√2π
(r1
σ1e−(x−µ1)2/2σ2
1 +r2
σ2e−(x−µ2)2/2σ2
2
)
−∞ < x < ∞ .
Dabei ist 0 < r1, r2 < 1 und r1 + r2 = 1, und µ1, µ2 und σ21 , σ
22 sind die Erwartungswerte
bzw. Varianzen der einzelnen Komponenten.
Die Abbildungen 9.12 und 9.13 zeigen Mischungen von zwei Normalverteilungen. Die Dich-tefunktion in Abbildung 9.12 ist unimodal (d.h. hat nur ein Maximum), wahrend die Dichte-funktion in Abbildung 9.13 bimodal ist. Bei Everitt und Hand (1981) finden Sie verschiedenehinreichende Kriterien fur die Unimodalitat der Mischung zweier Normalverteilungen. Dortwird auch die Schatzung der Parameter nach der Methode der Momente und auch nach derMaximum-Likelihood-Methode beschrieben.
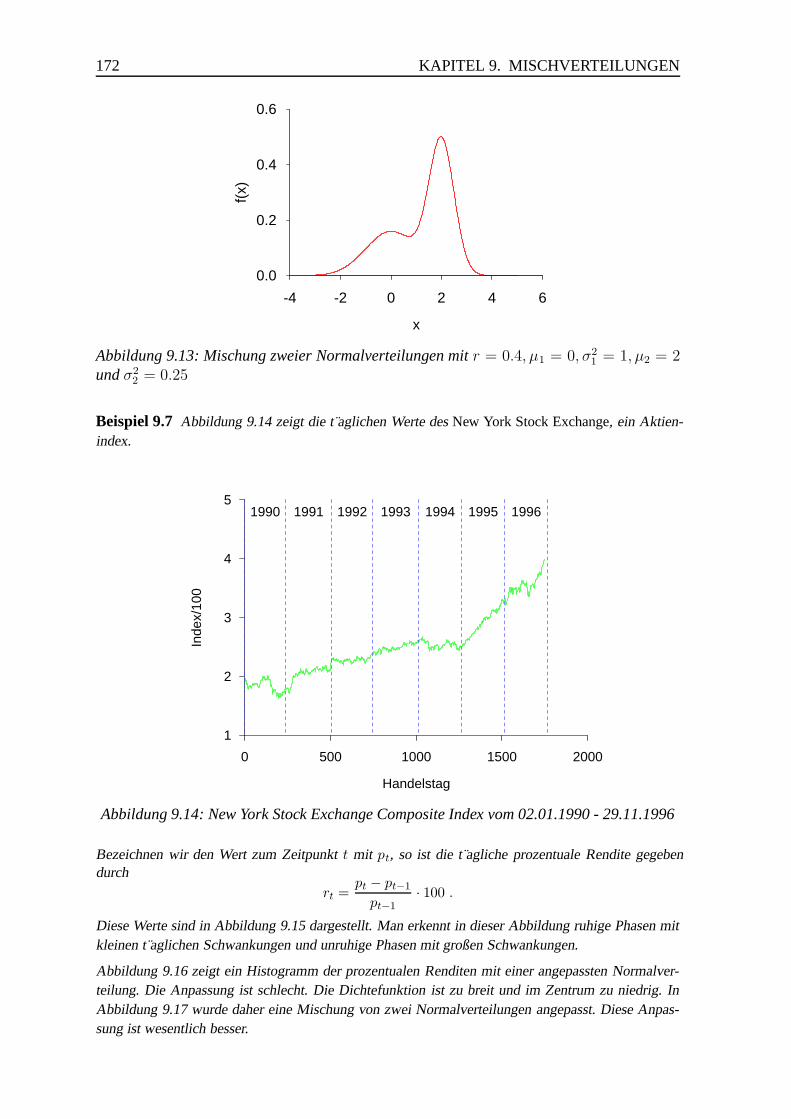
172 KAPITEL 9. MISCHVERTEILUNGEN
x
f(x)
-4 -2 0 2 4 6
0.0
0.2
0.4
0.6
Abbildung 9.13: Mischung zweier Normalverteilungen mit r = 0.4, µ1 = 0, σ21 = 1, µ2 = 2
und σ22 = 0.25
Beispiel 9.7 Abbildung 9.14 zeigt die t aglichen Werte des New York Stock Exchange, ein Aktien-index.
Handelstag
Inde
x/10
0
0 500 1000 1500 2000
1
2
3
4
51990 1991 1992 1993 1994 1995 1996
Abbildung 9.14: New York Stock Exchange Composite Index vom 02.01.1990 - 29.11.1996
Bezeichnen wir den Wert zum Zeitpunkt t mit pt, so ist die t agliche prozentuale Rendite gegebendurch
rt =pt − pt−1
pt−1· 100 .
Diese Werte sind in Abbildung 9.15 dargestellt. Man erkennt in dieser Abbildung ruhige Phasen mitkleinen t aglichen Schwankungen und unruhige Phasen mit großen Schwankungen.
Abbildung 9.16 zeigt ein Histogramm der prozentualen Renditen mit einer angepassten Normalver-teilung. Die Anpassung ist schlecht. Die Dichtefunktion ist zu breit und im Zentrum zu niedrig. InAbbildung 9.17 wurde daher eine Mischung von zwei Normalverteilungen angepasst. Diese Anpas-sung ist wesentlich besser.
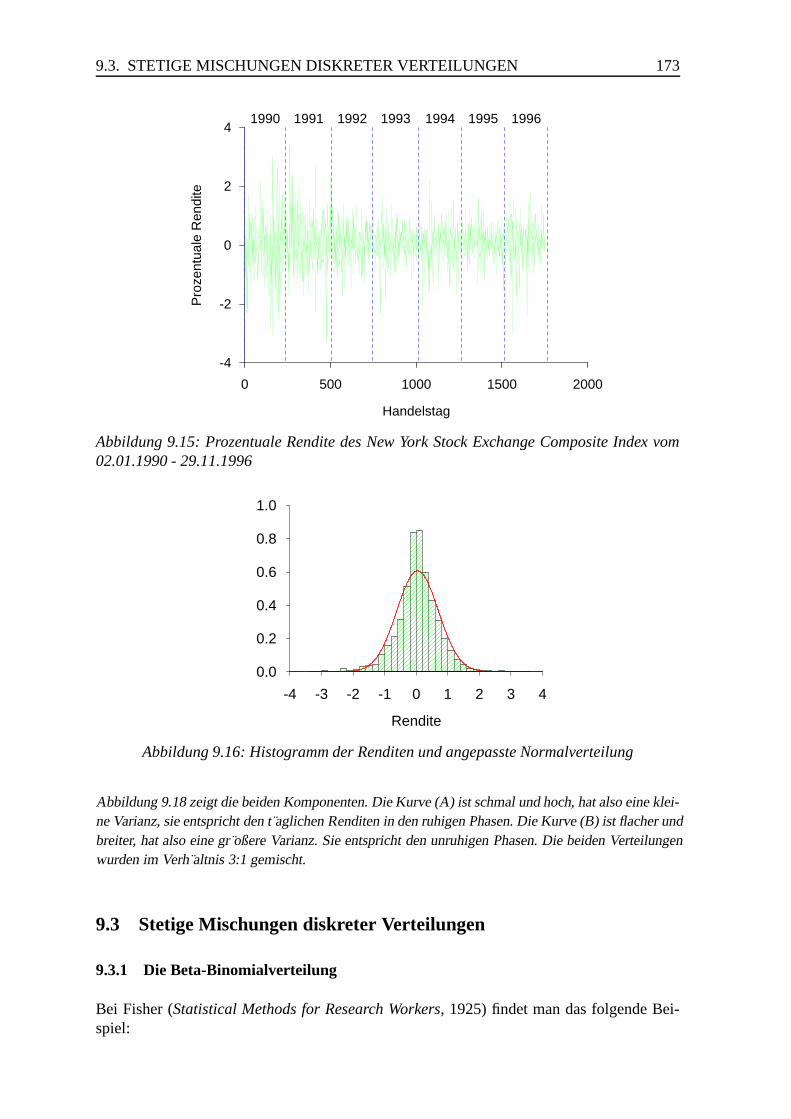
9.3. STETIGE MISCHUNGEN DISKRETER VERTEILUNGEN 173
Handelstag
Pro
zent
uale
Ren
dite
0 500 1000 1500 2000
-4
-2
0
2
41990 1991 1992 1993 1994 1995 1996
Abbildung 9.15: Prozentuale Rendite des New York Stock Exchange Composite Index vom02.01.1990 - 29.11.1996
-4 -3 -2 -1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
Rendite
Abbildung 9.16: Histogramm der Renditen und angepasste Normalverteilung
Abbildung 9.18 zeigt die beiden Komponenten. Die Kurve (A) ist schmal und hoch, hat also eine klei-ne Varianz, sie entspricht den t aglichen Renditen in den ruhigen Phasen. Die Kurve (B) ist flacher undbreiter, hat also eine gr oßere Varianz. Sie entspricht den unruhigen Phasen. Die beiden Verteilungenwurden im Verh altnis 3:1 gemischt.
9.3 Stetige Mischungen diskreter Verteilungen
9.3.1 Die Beta-Binomialverteilung
Bei Fisher (Statistical Methods for Research Workers, 1925) findet man das folgende Bei-spiel:
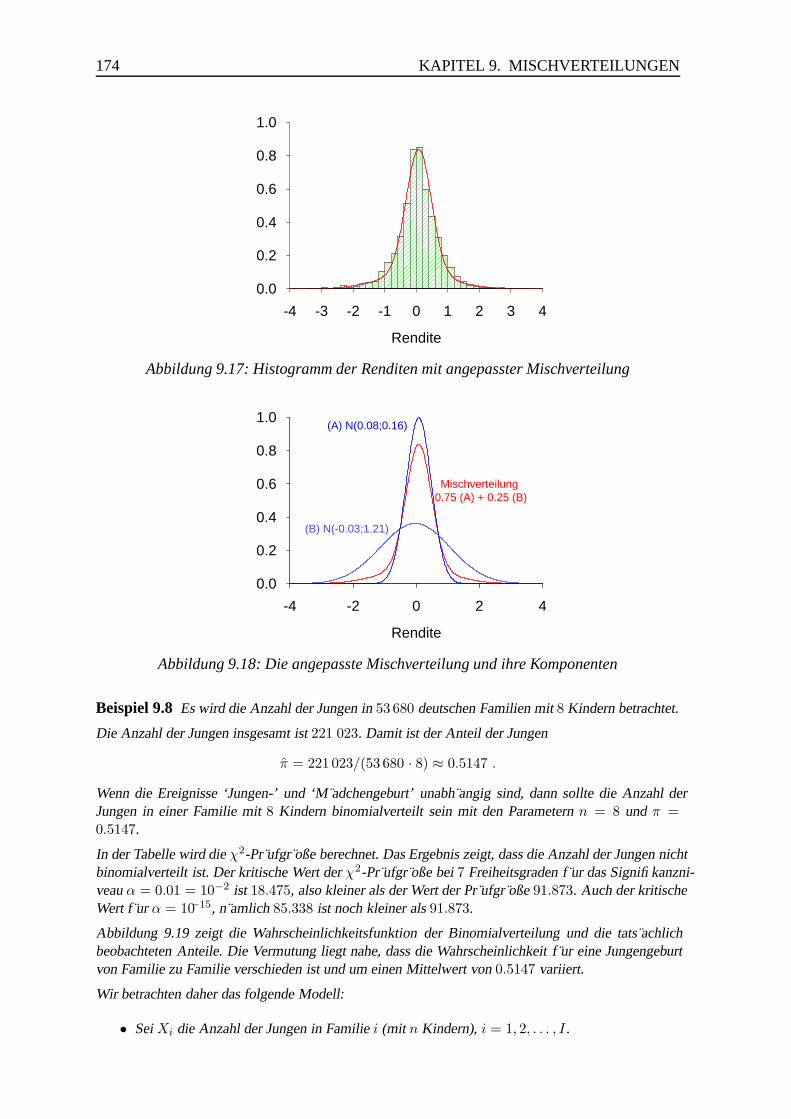
174 KAPITEL 9. MISCHVERTEILUNGEN
-4 -3 -2 -1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
Rendite
Abbildung 9.17: Histogramm der Renditen mit angepasster Mischverteilung
Rendite
-4 -2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0(A) N(0.08;0.16)
(B) N(-0.03;1.21)
Mischverteilung 0.75 (A) + 0.25 (B)
Abbildung 9.18: Die angepasste Mischverteilung und ihre Komponenten
Beispiel 9.8 Es wird die Anzahl der Jungen in 53 680 deutschen Familien mit 8 Kindern betrachtet.
Die Anzahl der Jungen insgesamt ist 221 023. Damit ist der Anteil der Jungen
π = 221 023/(53 680 · 8) ≈ 0.5147 .
Wenn die Ereignisse ‘Jungen-’ und ‘M adchengeburt’ unabh angig sind, dann sollte die Anzahl derJungen in einer Familie mit 8 Kindern binomialverteilt sein mit den Parametern n = 8 und π =0.5147.
In der Tabelle wird die χ2-Pr ufgr oße berechnet. Das Ergebnis zeigt, dass die Anzahl der Jungen nichtbinomialverteilt ist. Der kritische Wert der χ2-Pr ufgr oße bei 7 Freiheitsgraden f ur das Signifikanzni-veau α = 0.01 = 10−2 ist 18.475, also kleiner als der Wert der Pr ufgr oße 91.873. Auch der kritischeWert f ur α = 10−15, n amlich 85.338 ist noch kleiner als 91.873.
Abbildung 9.19 zeigt die Wahrscheinlichkeitsfunktion der Binomialverteilung und die tats achlichbeobachteten Anteile. Die Vermutung liegt nahe, dass die Wahrscheinlichkeit f ur eine Jungengeburtvon Familie zu Familie verschieden ist und um einen Mittelwert von 0.5147 variiert.
Wir betrachten daher das folgende Modell:
• Sei Xi die Anzahl der Jungen in Familie i (mit n Kindern), i = 1, 2, . . . , I .
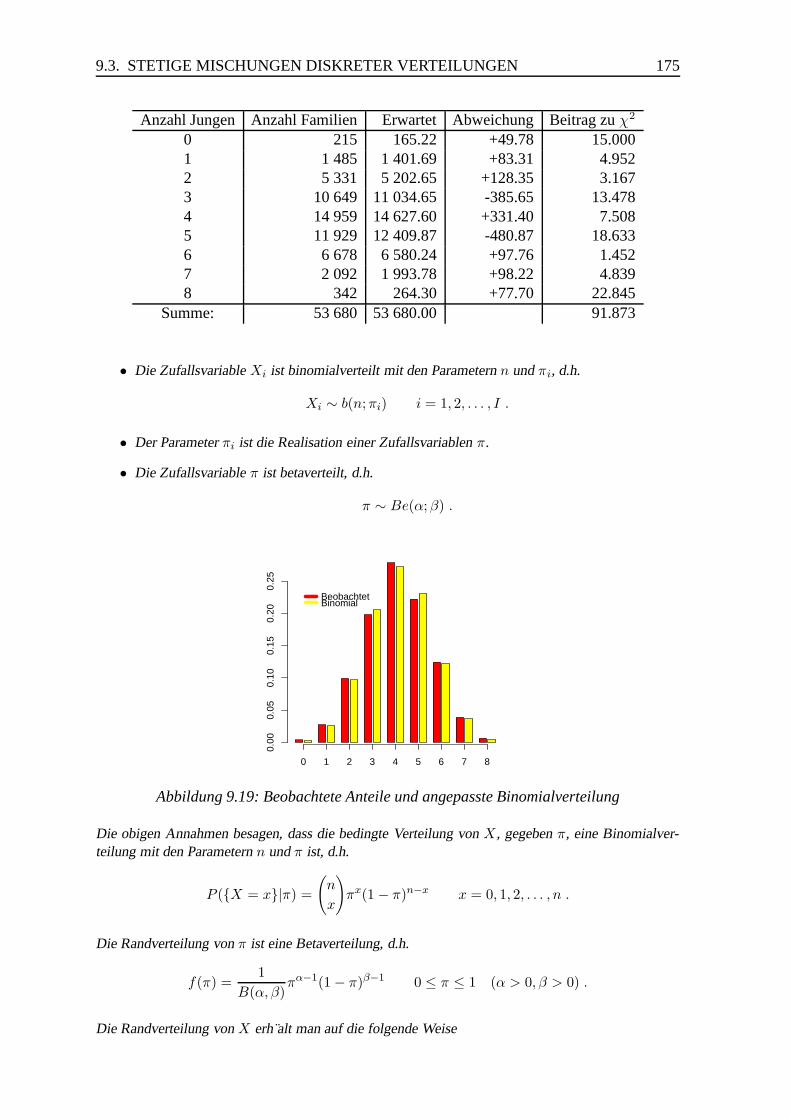
9.3. STETIGE MISCHUNGEN DISKRETER VERTEILUNGEN 175
Anzahl Jungen Anzahl Familien Erwartet Abweichung Beitrag zu χ2
0 215 165.22 +49.78 15.0001 1 485 1 401.69 +83.31 4.9522 5 331 5 202.65 +128.35 3.1673 10 649 11 034.65 -385.65 13.4784 14 959 14 627.60 +331.40 7.5085 11 929 12 409.87 -480.87 18.6336 6 678 6 580.24 +97.76 1.4527 2 092 1 993.78 +98.22 4.8398 342 264.30 +77.70 22.845
Summe: 53 680 53 680.00 91.873
• Die Zufallsvariable Xi ist binomialverteilt mit den Parametern n und πi, d.h.
Xi ∼ b(n;πi) i = 1, 2, . . . , I .
• Der Parameter πi ist die Realisation einer Zufallsvariablen π.
• Die Zufallsvariable π ist betaverteilt, d.h.
π ∼ Be(α;β) .
0 1 2 3 4 5 6 7 8
0.00
0.05
0.10
0.15
0.20
0.25
BeobachtetBinomial
Abbildung 9.19: Beobachtete Anteile und angepasste Binomialverteilung
Die obigen Annahmen besagen, dass die bedingte Verteilung von X , gegeben π, eine Binomialver-teilung mit den Parametern n und π ist, d.h.
P (X = x|π) =
(
n
x
)
πx(1 − π)n−x x = 0, 1, 2, . . . , n .
Die Randverteilung von π ist eine Betaverteilung, d.h.
f(π) =1
B(α, β)πα−1(1 − π)β−1 0 ≤ π ≤ 1 (α > 0, β > 0) .
Die Randverteilung von X erh alt man auf die folgende Weise
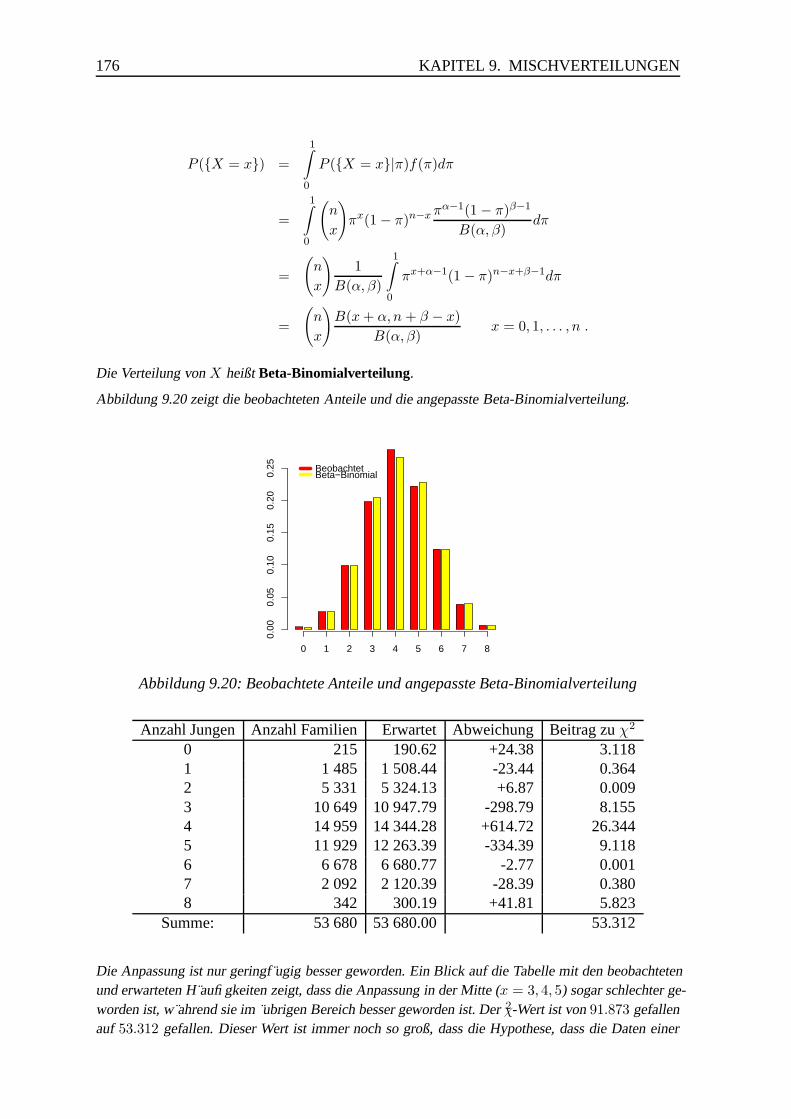
176 KAPITEL 9. MISCHVERTEILUNGEN
P (X = x) =
1∫
0
P (X = x|π)f(π)dπ
=
1∫
0
(
n
x
)
πx(1 − π)n−x πα−1(1 − π)β−1
B(α, β)dπ
=
(
n
x
)
1
B(α, β)
1∫
0
πx+α−1(1 − π)n−x+β−1dπ
=
(
n
x
)
B(x + α, n + β − x)
B(α, β)x = 0, 1, . . . , n .
Die Verteilung von X heißt Beta-Binomialverteilung.
Abbildung 9.20 zeigt die beobachteten Anteile und die angepasste Beta-Binomialverteilung.
0 1 2 3 4 5 6 7 8
0.00
0.05
0.10
0.15
0.20
0.25 Beobachtet
Beta−Binomial
Abbildung 9.20: Beobachtete Anteile und angepasste Beta-Binomialverteilung
Anzahl Jungen Anzahl Familien Erwartet Abweichung Beitrag zu χ2
0 215 190.62 +24.38 3.1181 1 485 1 508.44 -23.44 0.3642 5 331 5 324.13 +6.87 0.0093 10 649 10 947.79 -298.79 8.1554 14 959 14 344.28 +614.72 26.3445 11 929 12 263.39 -334.39 9.1186 6 678 6 680.77 -2.77 0.0017 2 092 2 120.39 -28.39 0.3808 342 300.19 +41.81 5.823
Summe: 53 680 53 680.00 53.312
Die Anpassung ist nur geringf ugig besser geworden. Ein Blick auf die Tabelle mit den beobachtetenund erwarteten H aufigkeiten zeigt, dass die Anpassung in der Mitte (x = 3, 4, 5) sogar schlechter ge-worden ist, w ahrend sie im ubrigen Bereich besser geworden ist. Der χ2-Wert ist von 91.873 gefallenauf 53.312 gefallen. Dieser Wert ist immer noch so groß, dass die Hypothese, dass die Daten einer

9.3. STETIGE MISCHUNGEN DISKRETER VERTEILUNGEN 177
Betabinomialverteilung gen ugen, abzulehnen ist. Der kritische Wert der χ2-Verteilung bei 6 Frei-heitsgraden f ur α = 0.01 ist 10.645. Die Parameter α und beta der Betabinomialverteilung wurdennach der Maximum-Likelihood-Methode gesch atzt zu α = 102.935 und β = 97.064. Es w are alsoeine weitere Analyse dieser Daten n otig.
Definition 9.5 Die Wahrscheinlichkeitsfunktion der Beta-Binomialverteilung ist defi-niert durch
P (X = x) =
(nx
)B(x+α,n+β−x)
B(α,β)x = 0, 1, . . . , n
0 sonst .
Die Beta-Binomialverteilung hat drei Parameter, fur die gelten muss
n ∈ IN, α > 0, und β > 0 .
Nach dem vorangehenden Beispiel kann die Beta-Binomialverteilung als stetige Mischungder Binomialverteilung aufgefasst werden, wenn der Parameter π eine Betaverteilung besitzt.
Fur die Wahrscheinlichkeitsfunktion und die Verteilungsfunktion der Beta-Binomialverteilungkann man auf die folgende Weise R-Funktionen schreiben.
dbbinom<-function(x, n, a, b)
# Wahrscheinlichkeitsfunktion der Beta-Binomialverteilung
# Parameter n, a, b; x Vektor
# Verwendete Funktion beta siehe Seite 53
f1<-gamma(n+1)/(gamma(x+1)*gamma(n-x+1)) # Binomialkoeffizient
f2<-beta(x+a,n+b-x) # Betafunktion im Zahler
f3<-beta(a,b) # Betafunktion im Nenner
f1*f2/f3
pbbinom<-function(x, n, a, b)
# Verteilungsfunktion der Beta-Binomialverteilung
# Parameter n, a, b; x Zahl
sum(dbbinom(0:x, n, a, b)
9.3.2 Die negative Binomialverteilung
Die negative Binomialverteilung kann als stetige Mischung der Poissonverteilung aufgefasstwerden, wenn man annimmt, dass der Parameter µ der Poissonverteilung eine Zufallsvaria-ble mit einer Gammaverteilung ist. (Entgegen der sonst verwendeten Notation bezeichnenwir den Parameter der Poissonverteilung hier mit µ, da λ auch in der Gammaverteilung auf-taucht.) Wir nehmen also an:

178 KAPITEL 9. MISCHVERTEILUNGEN
• Die bedingte Verteilung von X , gegeben µ, ist eine Poissonverteilung mit dem Para-meter µ.
• Die Zufallsvariable µ besitzt eine Gammaverteilung mit den Parametern ν und λ.
Die obigen Annahmen besagen, dass die bedingte Verteilung von X , gegeben µ, eine Pois-sonverteilung mit dem Parameter µ ist, d.h.
P (X = x|µ) =µx
x!e−µ x = 0, 1, 2, . . . .
Die Randverteilung von µ ist eine Gammaverteilung, d.h.
f(µ) =
λνµν−1e−λµ
Γ(ν)µ ≥ 0
0 sonst .
Die Randverteilung von X erhalt man auf die folgende Weise
P (X = x) =
∞∫
0
P (X = x|µ)f(µ)dµ =
∞∫
0
µx
x!e−µ λνµν−1e−λµ
Γ(ν)dµ
=λν
x!Γ(ν)
∞∫
0
µx+ν−1e−µ(1+λ)dµ
Wir verwenden die Substitutionz = µ(1 + λ) .
Dann istdz
dµ= 1 + λ
oder
µ =z
1 + λund dµ =
dz
(1 + λ).
Die Grenzen andern sich wie folgt:
• Wenn µ = 0, ist z = 0.
• Wenn µ → ∞, dann auch z → ∞.
Damit erhalten wir
P (X = x) =λν
x!Γ(ν)
∞∫
0
zx+ν−1
(1 + λ)x+ν−1e−z dz
(1 + λ)
=λν
x!Γ(ν)(1 + λ)x+ν
∞∫
0
zx+ν−1e−zdz
=λν
x!Γ(ν)(1 + λ)x+νΓ(x + ν) =
(x + ν − 1)!
x!(ν − 1)!
λν
(1 + λ)x+ν
=
(
x + ν − 1
ν − 1
)(
λ
1 + λ
)ν (1
1 + λ
)x

9.4. ML–SCHATZUNG BEI MISCHVERTEILUNGEN 179
Im vorletzten Schritt wurde
Γ(ν) = (ν − 1)! und Γ(x + ν) = (x + ν − 1)!
verwendet (siehe Satz 3.9) und schließlich
(
x + ν − 1
ν − 1
)
=(x + ν − 1)!
x!(ν − 1)!.
Wir haben also die Wahrscheinlichkeitsfunktion der negativen Binomialverteilung mit denParametern r = ν und π = λ/(1 + λ) erhalten.
Die negative Binomialverteilung mit den Parametern r und π hatte die Wahrscheinlichkeits-funktion
P (x) =
(
x + r − 1
r − 1
)
πr(1 − π)x , x = 0, 1, 2, . . . .
In Analogie zum Namen Beta-Binomialverteilung findet man fur die negative Binomialver-teilung auch den Namen Gamma-Poissonverteilung.
Die negative Bimomialverteilung hat gegenuber der Beta-Binomialverteilung den Vorteil,dass sie nur zwei statt drei Parameter hat.
9.4 ML–Schatzung bei Mischverteilungen
9.4.1 Einfuhrung
Bei den nachfolgenden Erlauterungen zur Parameterschatzung werden zwei Falle unterschie-den. Zum einen wird der Fall betrachtet, in dem die Anzahl der Mischungskomponentenbekannt ist und zum anderen der Fall, in dem die Anzahl der Subpopulationen unbekanntist. Die Falle unterscheiden sich nur unwesentlich, wenn man die Likelihoodfunktionen be-trachtet. Inhaltlich sind die Falle aber unterschiedlich zu interpretieren. Im ersten Fall hatman eine klare Vorstellung aus welchen unterschiedlichen Gruppen die Population besteht.Im zweiten Fall hingegen ist die Anzahl der Subpopulationen ein Ergebnis der Datenanalyse.Erst nach der Parameterschatzung erhalt man Informationen daruber, aus welchen Gruppensich die Population zusammensetzen konnte.
Alle folgenden Ausfuhrungen beziehen sich auf diskrete Mischungen.
9.4.2 Die Likelihoodfunktion fur Mischverteilungen
Zunachst wird der Fall betrachtet, bei der die Anzahl der Mischungskomponenten als gege-ben betrachtet wird. Sei P (x; θ) =
∑Ii=1 riPi(x; θi) die Wahrscheinlichkeitsfunktion einer
diskreten Mischung von einparametrigen diskreten Zufallsvariablen mit den Parametern θi
und seien x = (x1, x2, . . . , xn) die Beobachtungen, an die die Mischverteilung angepasstwerden soll. Dann gilt:

180 KAPITEL 9. MISCHVERTEILUNGEN
Satz 9.5
L(θ1, . . . , θI , r1, . . . , rI ; x) =n∏
j=1
I∑
i=1
riPi(xj; θi)
ist die Likelihoodfunktion der Mischverteilung.
Um die die Likelihoodfunktion uber die Parameter der einzelnen Mischungskomponentenθi, i = 1, . . . , I , sowie uber die Mischungsparameter ri, i = 1, . . . , I , zu maximieren. Insge-samt sind also 2I−1 Parameter zu schatzenSchatzer zu erhalten, ist . (Der letzte Mischungs-parameter ergibt sich aus den ubrigen, da die Summe eins betragen muss.) Leider ist esnicht moglich, das Problem analytisch zu losen, d.h. das gewohnte Vorgehen (Ableiten undNullsetzen) versagt. In diesem Fall muss die Maximierung numerisch mit entsprechenderSoftware durchgefuhrt werden (siehe ubernachster Abschnitt).
Die vorgestellte Likelihoodfunktion gilt fur diskrete Zufallsvariablen. Das analoge Ergebnisfur stetige Zufallsvariablen erhalt man, wenn man in der Likelihoodfunktion die Wahrschein-lichkeitsfunktionen durch Dichtefunktionen ersetzt:
∑Ii=1 rifi(xj, θi).
Beispiel 9.9 Im folgenden Beispiel wird gezeigt, wie die Likelihoodfunktion aufzustellen ist, wennan gegebene Daten eine Mischverteilung angepasst werden soll und die Anzahl der Mischungskompo-nenten bekannt ist. An die folgenden zehn Beobachtungen soll eine aus zwei Exponentialverteilungenbestehende Mischverteilung angepasst werden:
2.65 11.67 9.59 0.30 21.03 0.45 1.45 0.17 1.27 0.13
Die anzupassende Dichtefunktion lautet
f(x) = rλ1e−λ1x + (1 − r)λ2e
−λ2x
und man erh alt f ur die gemeinsame Verteilung der Beobachtungen als Funktion der Parameter, alsof ur die Likelihoodfunktion:
L(λ1, λ2, r) =10∏
j=1
(
rλ1e−λ1xj + (1 − r)λ2e
−λ2xj
)
Um die Parametersch atzer zu erhalten, ist die Funktion uber λ1, λ2 und r zu maximieren. Das Ma-ximierungsproblem ist analytisch nicht zu l osen. Die numerische L osung erh alt man beispielsweisemit dem Programm C.A.MAN. Die Sch atzwerte sind: r = 0.56, λ1 = 1/0.71 und λ2 = 1/10.07.Tats achlich sind die Daten aus einer Mischverteilung mit r = 0.5, λ1 = 1 und λ2 = 1/10 simuliertworden.
Wenn die Anzahl der Mischungskomponenten unbekannt ist, erfolgt die Konstruktion derLikelihoodfunktion analog zum oben dargestellten Vorgehen. Der Unterschied zwischen denFallen liegt darin, dass die Funktion uber einen weiteren Parameter, namlich I , zu maximie-ren ist. Man konnte zunachst vermuten, dass die Likelihoodfunktion ein Maximum annimmt,wenn fur jede (unterschiedliche) Beobachtung eine Mischungskomponente verwendet wird.Dies ist jedoch nicht der Fall, was anhand des nachfolgenden Beispiels verdeutlicht wird.
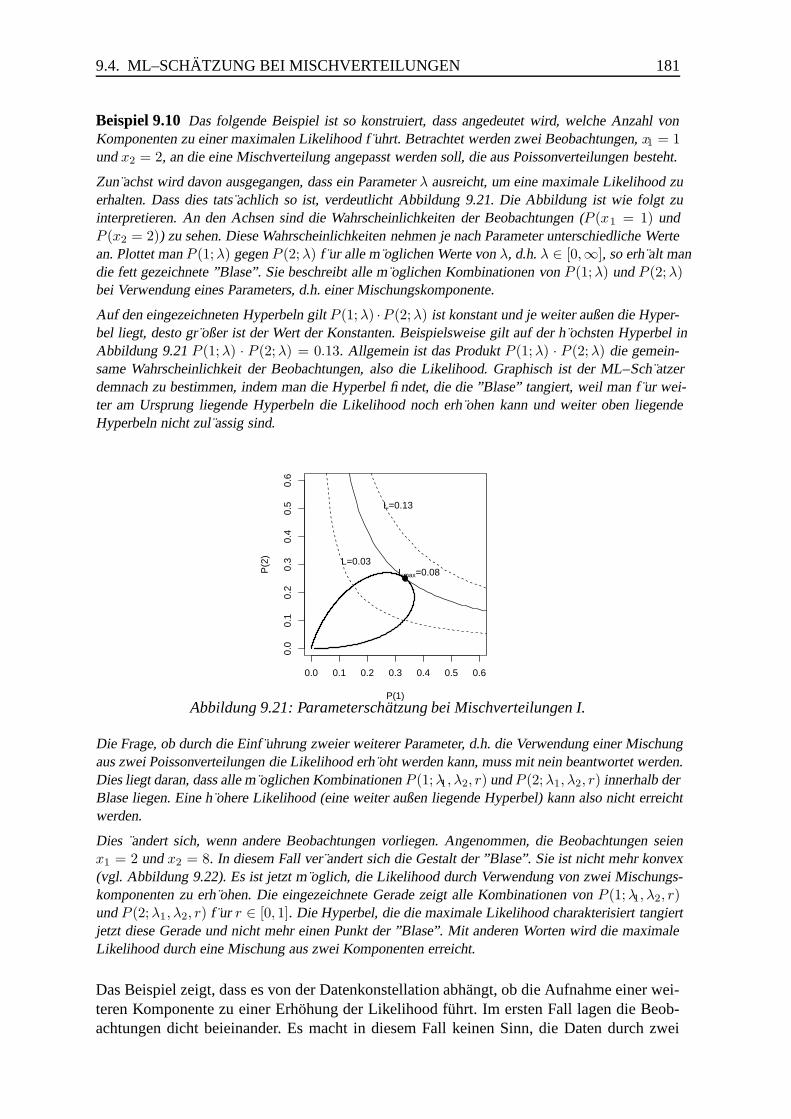
9.4. ML–SCHATZUNG BEI MISCHVERTEILUNGEN 181
Beispiel 9.10 Das folgende Beispiel ist so konstruiert, dass angedeutet wird, welche Anzahl vonKomponenten zu einer maximalen Likelihood f uhrt. Betrachtet werden zwei Beobachtungen, x1 = 1und x2 = 2, an die eine Mischverteilung angepasst werden soll, die aus Poissonverteilungen besteht.
Zun achst wird davon ausgegangen, dass ein Parameter λ ausreicht, um eine maximale Likelihood zuerhalten. Dass dies tats achlich so ist, verdeutlicht Abbildung 9.21. Die Abbildung ist wie folgt zuinterpretieren. An den Achsen sind die Wahrscheinlichkeiten der Beobachtungen (P (x1 = 1) undP (x2 = 2)) zu sehen. Diese Wahrscheinlichkeiten nehmen je nach Parameter unterschiedliche Wertean. Plottet man P (1;λ) gegen P (2;λ) f ur alle m oglichen Werte von λ, d.h. λ ∈ [0,∞], so erh alt mandie fett gezeichnete ”Blase”. Sie beschreibt alle m oglichen Kombinationen von P (1;λ) und P (2;λ)bei Verwendung eines Parameters, d.h. einer Mischungskomponente.
Auf den eingezeichneten Hyperbeln gilt P (1;λ) ·P (2;λ) ist konstant und je weiter außen die Hyper-bel liegt, desto gr oßer ist der Wert der Konstanten. Beispielsweise gilt auf der h ochsten Hyperbel inAbbildung 9.21 P (1;λ) · P (2;λ) = 0.13. Allgemein ist das Produkt P (1;λ) · P (2;λ) die gemein-same Wahrscheinlichkeit der Beobachtungen, also die Likelihood. Graphisch ist der ML–Sch atzerdemnach zu bestimmen, indem man die Hyperbel findet, die die ”Blase” tangiert, weil man f ur wei-ter am Ursprung liegende Hyperbeln die Likelihood noch erh ohen kann und weiter oben liegendeHyperbeln nicht zul assig sind.
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
P(1)
P(2
)
Lmax=0.08
L=0.13
L=0.03
Abbildung 9.21: Parameterschatzung bei Mischverteilungen I.
Die Frage, ob durch die Einf uhrung zweier weiterer Parameter, d.h. die Verwendung einer Mischungaus zwei Poissonverteilungen die Likelihood erh oht werden kann, muss mit nein beantwortet werden.Dies liegt daran, dass alle m oglichen Kombinationen P (1;λ1, λ2, r) und P (2;λ1, λ2, r) innerhalb derBlase liegen. Eine h ohere Likelihood (eine weiter außen liegende Hyperbel) kann also nicht erreichtwerden.
Dies andert sich, wenn andere Beobachtungen vorliegen. Angenommen, die Beobachtungen seienx1 = 2 und x2 = 8. In diesem Fall ver andert sich die Gestalt der ”Blase”. Sie ist nicht mehr konvex(vgl. Abbildung 9.22). Es ist jetzt m oglich, die Likelihood durch Verwendung von zwei Mischungs-komponenten zu erh ohen. Die eingezeichnete Gerade zeigt alle Kombinationen von P (1;λ1, λ2, r)und P (2;λ1, λ2, r) f ur r ∈ [0, 1]. Die Hyperbel, die die maximale Likelihood charakterisiert tangiertjetzt diese Gerade und nicht mehr einen Punkt der ”Blase”. Mit anderen Worten wird die maximaleLikelihood durch eine Mischung aus zwei Komponenten erreicht.
Das Beispiel zeigt, dass es von der Datenkonstellation abhangt, ob die Aufnahme einer wei-teren Komponente zu einer Erhohung der Likelihood fuhrt. Im ersten Fall lagen die Beob-achtungen dicht beieinander. Es macht in diesem Fall keinen Sinn, die Daten durch zwei
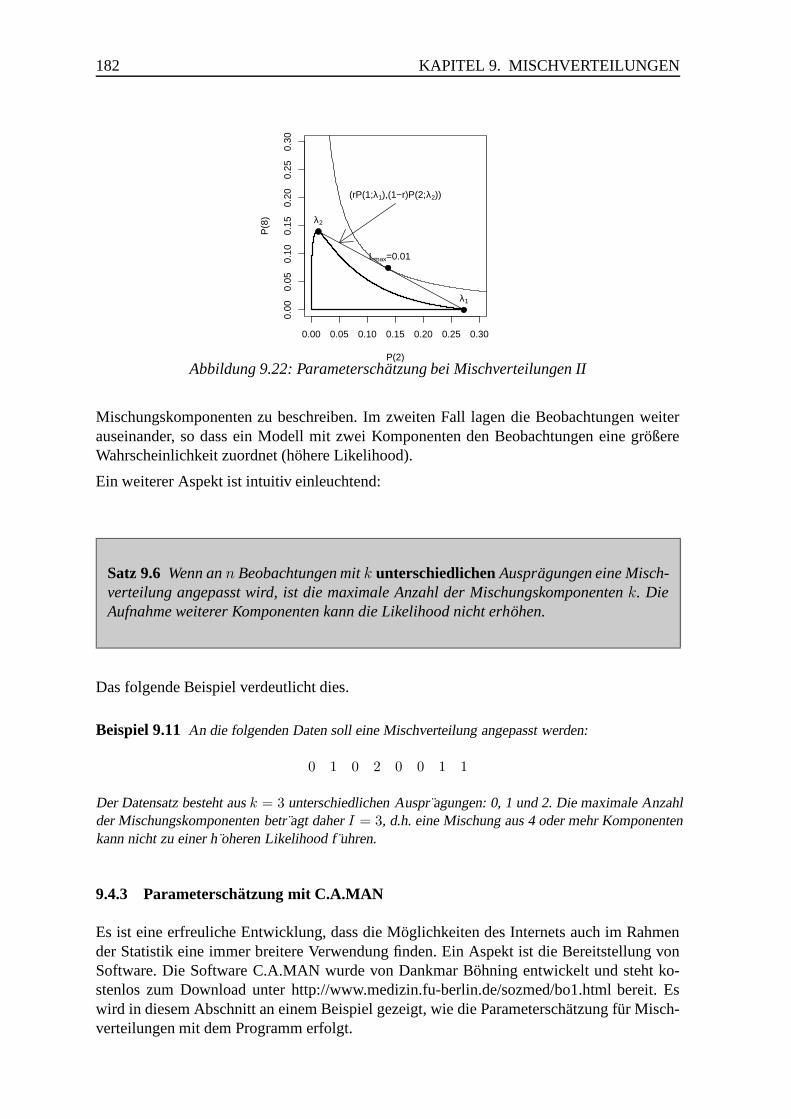
182 KAPITEL 9. MISCHVERTEILUNGEN
0.00 0.05 0.10 0.15 0.20 0.25 0.30
0.00
0.05
0.10
0.15
0.20
0.25
0.30
P(2)
P(8
)Lmax=0.01
λ2
λ1
(rP(1;λ1),(1−r)P(2; λ2))
Abbildung 9.22: Parameterschatzung bei Mischverteilungen II
Mischungskomponenten zu beschreiben. Im zweiten Fall lagen die Beobachtungen weiterauseinander, so dass ein Modell mit zwei Komponenten den Beobachtungen eine großereWahrscheinlichkeit zuordnet (hohere Likelihood).
Ein weiterer Aspekt ist intuitiv einleuchtend:
Satz 9.6 Wenn an n Beobachtungen mit k unterschiedlichen Auspragungen eine Misch-verteilung angepasst wird, ist die maximale Anzahl der Mischungskomponenten k. DieAufnahme weiterer Komponenten kann die Likelihood nicht erhohen.
Das folgende Beispiel verdeutlicht dies.
Beispiel 9.11 An die folgenden Daten soll eine Mischverteilung angepasst werden:
0 1 0 2 0 0 1 1
Der Datensatz besteht aus k = 3 unterschiedlichen Auspr agungen: 0, 1 und 2. Die maximale Anzahlder Mischungskomponenten betr agt daher I = 3, d.h. eine Mischung aus 4 oder mehr Komponentenkann nicht zu einer h oheren Likelihood f uhren.
9.4.3 Parameterschatzung mit C.A.MAN
Es ist eine erfreuliche Entwicklung, dass die Moglichkeiten des Internets auch im Rahmender Statistik eine immer breitere Verwendung finden. Ein Aspekt ist die Bereitstellung vonSoftware. Die Software C.A.MAN wurde von Dankmar Bohning entwickelt und steht ko-stenlos zum Download unter http://www.medizin.fu-berlin.de/sozmed/bo1.html bereit. Eswird in diesem Abschnitt an einem Beispiel gezeigt, wie die Parameterschatzung fur Misch-verteilungen mit dem Programm erfolgt.

9.4. ML–SCHATZUNG BEI MISCHVERTEILUNGEN 183
Anzahl verkaufter Packungen 0 1 2 3 4 5 6 7 8 9Haufigkeit 102 54 49 62 44 25 26 15 15 10
Anzahl verkaufter Packungen 10 11 12 13 14 15 16 17 18 19 20Haufigkeit 10 10 10 3 3 5 5 4 1 2 1
Beispiel 9.12 Betrachtet werden noch einmal die Daten zur Einf uhrung des S ußwarenprodukts, diebereits in Beispiel 9.3 betrachtet worden sind. Diese sind in der folgenden Tabelle nochmals darge-stellt.
Es wird im folgenden an einem Beispiel dargestellt, welche Schritte durchzuf uhren sind, um den Pa-rametersch atzer zu erhalten. Eine allgemeine Beschreibung der Anwendung findet sich bei B ohning,D. (1999, S. 201–209).
a) Erstellung der Inputdatei:
Zun achst ist eine Datei zu erstellen, die die Daten enth alt. Dazu werden in eine Textdateidie Auspr agungen und die H aufigkeiten der Auspr agungen geschrieben. Auspr agungen undH aufigkeiten werden durch ein Leerzeichen getrennt, und verschiedene Auspr agungen werdendurch einen Absatz getrennt. F ur das Beispiel also:
0 1021 542 49...
Anschließend ist die Datei (zum Beispiel unter der Bezeichnung candy.dat) in dem Verzeichniszu speichern, in dem das Programm liegt.
b) Start des Programms:
Als n achstes ist das Programm (Caman.exe) zu starten und so lange Return zu dr ucken, bisman im Hauptmen u angekommen ist.
c) Bestimmung von Inputdatei und Outputdatei:
Im Hauptmen u ist der Punkt ”INPUT DATA” zu w ahlen, indem eine 1 eingetippt wird undanschließend Return gedr uckt wird. Im erscheinenden Untermen u erneut der Punkt 1 (Specifydata–file) zu w ahlen. Anschließend ist der Name der Datei einzutippen, in der die Beobach-tungen stehen, also candy.dat. Danach kann die Bezeichnung der Ausgabedatei (candy.out)best atigt werden oder eine selbsgew ahlte Bezeichnung eingegeben werden. Die Ausgabedateienth alt die Ergebnisse der Parametersch atzung.
d) Bestimmung des Datenformats:
Nach Best atigung der Ausgabedatei befindet man sich weiterhim im Untermen u ”INPUT DA-TA”. Jetzt ist das Datenformat anzugeben. Da die Daten in der Form [Auspr agung, H aufigkeitder Auspr agung] vorliegen, ist die Alternative 3 (”VARIABLE REPLICATION FACTOR”)zu w ahlen. Daraufhin wird angezeigt, wieviele unterschiedliche Beobachtungen in den Datenenthalten sind, und durch erneutes Dr ucken der Returntaste gelangt man wieder in das Haupt-men u.

184 KAPITEL 9. MISCHVERTEILUNGEN
e) Wahl der Verteilung:
Als n achstes ist der Punkt 3 ”CHOISE OF DISTRIBUTION” zu w ahlen. Da die Mischungs-komponenten hier vom Typ Poisson sind, ist in diesem Untermen u der Punkt 2 ”Poisson-distribution” zu best atigen.
f) Durchfuhrung der Schatzung:
Mit dem Schritt d sind die minimal notwendigen Daten eingegeben, so dass mit der Parame-tersch atzung begonnen werden kann. Diese beginnt mit der Wahl des Men upunktes 7 ”COM-PUTE NPMLE” (NPMLE steht f ur Nonparametric Maximum–Likelihood–Estimator). NachAuswahl dieser Option fasst das Programm noch einmal die Voraussetzungen der Optimierungzusammen und fragt, ob noch Anderungen vorgenommen werden sollen. Durch Eingabe vonN(o) beginnt die Parametersch atzung. Jetzt ist die Returntaste so h aufig zu bet atigen, bis derfolgende Output erscheint:
The NPMLE consists of 5 support pointsResult after combining equal estimates:weight: .0068 parameter: .000000weight: .2373 parameter: .211226weight: .5019 parameter: 2.998342weight: .1516 parameter: 7.388325weight: .1024 parameter: 12.858300Log-Likelihood at iterate: -1130.13700
Dies ist das Ergebnis der Parametersch atzung. Eine Mischverteilung mit f unf Komponenten besitztdie h ochste Likelihood. Diese Werte der Sch atzer sind bereits weiter oben (bei der erstmaligen Be-trachtung der Daten) angegeben worden. Ferner ist die Likelihood der L osung angegeben.
Das letzte Beispiel betrachtet einen Fall, bei dem die Anzahl der Komponenten nicht be-kannt ist. Man erhalt als Resultat das Modell das zu der hochstmoglichen Likelihood fuhrt.Es ist jedoch denkbar, dass ein Modell mit weniger Komponenten (und somit weniger Para-meteren) die Daten ebenfalls angemessen beschreibt. Mochte man ein Modell mit wenigerParametern anpassen, so ist die Parameterschatzung fur eine bekannte Anzahl von Kompo-nenten durchzufuhren.
Beispiel 9.13 Es wird jetzt gezeigt, wie man mit C.A.MAN an die Daten des vorangegangenenBeispiels ein Modell mit einer bekannten Anzahl von Komponenten anpassen kann.
a) Es sind die Schritte a) bis e) aus dem letzten Beispiel durchzuf uhren.
b) Bestimmung der Anzahl von Komponenten und der Startwerte:
Es ist jetzt das Untermen u 2 ”CHOICE OF PARAMETER GRID” aufzurufen und der Punkt3 (If you want to use fixed support size and if you want to enter starting values) zu w ahlen.Anschließend wird man aufgefordert, die Anzahl der Komponenten einzugeben. Dies k onntebeispielsweise der Wert 4 sein. Danach ist es notwendig, die Startwerte f ur die numerische Ma-ximierung anzugeben. Beispielsweise k onnte man einfach die Komponente mit dem kleinstenMischungsparameter aus der vorangegangenen Sch atzung entfernen und die ubrigen vier (evtl.gerundet) als Startwerte verwenden. Eine m ogliche Eingabe w are also (der jeweils erste Wertsteht f ur den Parameter und der jeweils zweite Wert f ur das entsprechende Gewicht):
0.2 0.253 0.57.4 0.1512.9 0.1

9.4. ML–SCHATZUNG BEI MISCHVERTEILUNGEN 185
c) Wahl des Algorithmus:
Als n achstes ist im Untermen u ”CHOICE OF ALGORITHM” (Men upunkt 4) die Option 5(Fixed support size) zu setzen. Die anschließend angeforderten Eingaben sind nicht unbedingtnotwendig, d.h. man kann durch die Wahl von Punkt 6 (Back to Main Menu) zum Haupt-men u zur uckkehren.
d) Durchfuhrung der Parameterschatzung:
Dieser Schritt entspricht dem Schritt 6 aus dem letzten Beispiel. Man erh alt jetzt die folgendenErgebnisse:
The NPMLE consists of 5 support pointsResult after combining equal estimates:weight: .244 parameter: .204273weight: .5022 parameter: 2.998540weight: .1515 parameter: 7.391778weight: .1023 parameter: 12.859990Log-Likelihood at iterate: -1130.13100
Man sieht, dass die Likelihood des Modell mit vier Komponenten nur um 0.006 kleinerist als fur das Modell mit funf Komponenten. Eine weitergehende Frage ist jetzt, welchesModell man zur Beschreibung der Daten verwenden sollte: Sollte man das Modell mit funfKomponenten verwenden, weil die Beobachtungen unter diesem Modell eine hohere Wahr-scheinlichkeit besitzen oder sollte man das Modell mit vier Komponenten wahlen, weilman dadurch den Fehler durch Schatzung verringern konnte? Bohning verwendet in prakti-schen Situationen einen Signifikanztest zur Modellauswahl. Er weist aber gleichzeitig dar-auf hin, dass die Voraussetzungen zur Durchfuhrung des Tests nur approximativ erfullt sind(Bohning, D., 1999, S. 77). Eine weitere Moglichkeit ware eine Analyse der Modelle mitHilfe von Pseudo–Residuen (vgl. Verallgemeinerte Lineare Modelle, 1999, S. 54–63).

Kapitel 10
Bayes’sche Verfahren
10.1 Einf uhrung
Alle bislang besprochenen Konzepte und Methoden (einschließlich der Grundstudiumsin-halte), konnen unter der Uberschrift ”Klassische Methoden” eingeordnet werden. Es exi-stiert ferner eine alternative Idee statistische Analysen durchzufuhren. Diese Idee ist in densogenannten ”Bayes’schen Methoden” verankert, die eine andere Art des Denkens verfol-gen, wenn es um die Gewinnung von Informationen aus Daten geht. Insbesondere ist mitden Bayes’schen Methoden das Konzept der Apriori–Informationen verbunden, d.h. in dieDatenanalyse werden Informationen einbezogen, die bereits vor der Erhebung von Datenvorliegen. Das Ziel der Bayes’schen Methoden ist die Kombination der beiden Informati-onsquellen, d.h. der Apriori–Informationen und der Daten.
Ziel dieses Abschnitts ist es, einen Einblick in die elementaren Konzepte und Vorgehenswei-sen der Bayes’schen Verfahren zu geben. Ein unter praktischen Gesichtspunkten bedeutenderAspekt der Verfahren ist die Notwendigkeit der Anwendung anspruchsvoller numerischerVerfahren. Es gibt jedoch auch einige einfache Beispiele, in denen auf rechenintensive Ver-fahren verzichtet werden kann, weil einfache Losungen vorliegen. Die folgenden Ausfuhrun-gen konzentrieren sich in erster Linie auf diese einfachen Falle. Auf die komplizierteren Fallewerden im letzten Abschnitt des Kapitel kurz angesprochen.
Eine tiefere Diskussion der Bayes’schen Idee findet man bei Lee (1997), Gelman et al. (1995)oder Wickmann (1990). French and Smith (1997) zeigen eine Auswahl umfangreicher Fall-studien, in denen die Bayes’schen Verfahren angewendet werden.
10.2 Das Theorem von Bayes
Definition 10.1 Die Ereignisse B1, B2, . . . , Bk heißen eine Zerlegung der Ergebnis-menge Ω, wenn sie
a) disjunkt sind, d.h. Bi ∩ Bj = ∅ fur alle i 6= j,
b) die ganze Ergebnismenge ausschopfen, d.h. B1 ∪ B2 ∪ . . . ∪ Bk = Ω.
186

10.2. DAS THEOREM VON BAYES 187
Beispiel 10.1 Sei Ω = 1, 2, . . . , 6 die Ergebnismenge beim W urfel.
a) B1 = 1 B2 = 2, 3, 4 B3 = 5, 6 ist eine Zerlegung.
b) B1 = 1, 2, 3 B2 = 4, 5 ist keine Zerlegung, da B1 ∪ B2 6= Ω .
c) B1 = 1, 2, 3 B2 = 3, 4, 5, 6 ist keine Zerlegung, da B1 ∩ B2 6= ∅ .
Satz 10.1 (Formel der totalen Wahrscheinlichkeit) Sei A ⊂ Ω ein Ereignis undB1, B2, . . . , Bk eine Zerlegung der Ergebnismenge Ω mit P (Bi) > 0 fur i = 1, 2, . . . k.Dann gilt
P (A) =k∑
i=1
P (A|Bi) · P (Bi) .
Beweis:Es gilt
A = A ∩ Ω
= A ∩ (B1 ∪ B2 ∪ . . . ∪ Bk)
= (A ∩ B1) ∪ (A ∩ B2) ∪ . . . ∪ (A ∩ Bk) .
Da die Ereignisse Bi; i = 1, 2, . . . , k disjunkt sind, sind auch die Ereignisse A ∩ Bi; i =1, 2, . . . , k disjunkt. Damit gilt
P (A) = P (A ∩ B1) + P (A ∩ B2) + . . . + P (A ∩ Bk)
= P (A|B1)P (B1) + P (A|B2)P (B2) + . . . + P (A|Bk)P (Bk)
=k∑
i=1
P (A|Bi) · P (Bi) .
Dabei wurde die Definition der bedingten Wahrscheinlichkeiten
P (A|Bi) =P (A ∩ Bi)
P (Bi)
und die FolgerungP (A ∩ Bi) = P (A|Bi)P (Bi)
benutzt. ♦
Satz 10.2 (Theorem von Bayes) Sei A ⊂ Ω ein Ereignis und B1, B2, . . . , Bk eine Zer-legung der Ergebnismenge Ω mit P (Bi) > 0 fur i = 1, 2, . . . k. Dann gilt
P (Bj|A) =P (A|Bj)P (Bj)k∑
i=1P (A|Bi)P (Bi)
.

188 KAPITEL 10. BAYES’SCHE VERFAHREN
Beweis:Durch zweimalige Anwendung der Definition der bedingten Wahrscheinlichkeit und des Sat-zes der totalen Wahrscheinlichkeit erhalt man
P (Bj|A) =P (Bj ∩ A)
P (A)
=P (A|Bj)P (Bj)k∑
i=1P (A|Bi)P (Bi)
.
♦
Beispiel 10.2 (Aus Hartung u.a., 1993)Durch einen zu sp at erkannten Fabrikationsfehler sind in einer Automobilproduktion genau 20 de-fekte Lenkgetriebe eingebaut worden. In einer R uckrufaktion wurden 200 000 Wagen dieser Serieuberpr uft und alle als fehlerhaft identifizierten Lenkgetriebe wurden ausgetauscht. Dabei wird die
Uberpr ufung mit 99%-iger Sicherheit zu einem korrekten Ergebnis f uhren. Wie groß ist die Wahr-scheinlichkeit, dass ein ausgewechseltes Lenkgetriebe auch defekt war? Wir verwenden die folgendenBezeichnungen:
B1 sei das Ereignis eines defekten Lenkgetriebes.
B2 sei das Ereignis eines nicht defekten Lenkgetriebes.
A sei das Ereignis eines ausgewechselten Lenkgetriebes.
Die folgenden Informationen sind uns gegeben:
P (B1) =20
200 000= 0.0001 P (A|B1) = 0.99 P (A|B2) = 0.01
Gesucht ist die Wahrscheinlichkeit
P (B1|A) = P (Lenkgetriebe defekt|Lenkgetriebe ausgewechselt) .
Mit dem Theorem von Bayes folgt
P (B1|A) =P (A|B1)P (B1)2∑
i=1P (A|Bi)P (Bi)
=0.99 · 0.0001
0.99 · 0.0001 + 0.01 · 0.9999 ≈ 0.0098 .
Fast alle ausgewechselten Lenkgetriebe waren demnach nicht defekt.
Beispiel 10.3 Es sei bekannt, dass in einer Familie die Großmutter und ein Sohn der Großmutter dieBluterkrankheit (H amophilie) haben. Die Großmutter habe auch eine Tochter, von der es unbekanntist, ob sie die Bluterkrankheit hat.
Wir betrachten dann die Ereignisse
B1 = Tochter hat H amophilie,
B2 = Tochter hat nicht H amophilie.

10.2. DAS THEOREM VON BAYES 189
Es gilt dannP (B1) = 0.5 und P (B2) = 0.5 .
Nun gebe es die zus atzliche Information, dass die Tochter zwei S ohne hat, die nicht eineiige Zwillingesind. Beide S ohne haben keine H amophilie.
Wir betrachten die Ereignisse
a) A1 = Sohn 1 hat nicht H amopholie,
b) A2 = Sohn 2 hat nicht H amopholie,
c) A = A1 ∩ A2 = Kein Sohn hat H amopholie.
Es gilt
P (A1|B1) = 0.5 ,
P (A2|B1) = 0.5 .
Da die S ohne nicht eineiige Zwillinge sind, gilt
P (A|B1) = P (A1|B1) · P (A2|B1) = 0.5 · 0.5 = 0.25
undP (A|B2) = 1 .
Wie hoch ist die Wahrscheinlichkeit, dass die Tochter (die Mutter der beiden S ohne) H amophilie hat(gegeben, dass beide S ohne keine H amophilie haben)?
Gesucht ist die WahrscheinlichkeitP (B1|A) .
Nach dem Theorem von Bayes gilt
P (B1|A) =P (A|B1)P (B1)
P (A|B1)P (B1) + P (A|B2)P (B2)
=(0.25)(0.5)
(0.25)(0.5) + 1 · (0.5)
=0.125
0.625= 0.2 .
Fur Dichtefunktion gibt es eine zum Bayes-Theorem analoge Formel. Man kann dabei aneine stetige Zerlegung des Ergebnisraums denken.
Satz 10.3 Die gemeinsame Dichtefunktion der Zufallsvariablen X und Y sei f(x, y).Dann gilt
f(y|x) =f(x|y)f(y)
∞∫
−∞f(x|y)f(y)dy
.

190 KAPITEL 10. BAYES’SCHE VERFAHREN
Beweis:Durch zweimalige Anwendung der Definition einer bedingten Dichtefunktion (siehe Defini-tion 6.13) erhalt man
f(y|x) =f(x, y)
f(x)=
f(x|y)f(y)
f(x).
Nun gilt fur die Randdichtefunktion im Nenner
f(x) =
∞∫
−∞f(x, y)dy =
∞∫
−∞f(x|y)f(y)dy .
Damit hat man das gewunschte Ergebnis. ♦Wir werden das Bayes-Theorem auch in dem Fall benutzen, in dem eine Zufallsvariable, z.B.Y , stetig und die andere diskret ist. Es gilt dann
f(y|X = x) =P (X = x|y)f(y)
∞∫
−∞P (X = x|y)f(y)dy
. (10.1)
10.3 Bayes’sche Verfahren
Beispiel 10.4 Man m ochte f ur eine M unze die Wahrscheinlichkeit sch atzen, mit der sie beim Wurfmit ,,Kopf” auftrifft, d.h.
π = P (,,Kopf”) .
FRAGE: Wie interpretiert man diese Wahrscheinlichkeit π?
Wir betrachten zwei m ogliche Interpretationen.
a) Das klassische Verfahren interpretiert diese Wahrscheinlichkeit als relative Haufig-keit.
Die Wahrscheinlichkeit eines Ereignisses ist der Wert, gegen den die relative Haufig-keit des Ereignisses konvergiert, wenn man das Experiment unendlich oft unter glei-chen Bedingungen ausfuhrte. Diese Interpretation wird nicht von allen akzeptiert. Andieser Vorstellung wird kritisiert, dass man solche Experimente nicht unendlich oftdurchfuhren kann.
b) Bei der subjektiven Interpretation von Wahrscheinlichkeiten wird ,,Wahrscheinlich-keit” als ein subjektiver Begriff aufgefasst. Er beschreibt quantitativ unsere Vorstel-lung, dass ein Ereignis vorkommen wird.
Man kann die Ergebnisse eines Experiments verwenden, um die bisherige Vorstellungder Wahrscheinlichkeit eines gegebenen Ereignisses zu andern oder zu prazisieren.
Wir betrachten das folgende EXPERIMENT:
Wir werfen dreimal eine M unze. Sei X die Anzahl der ,,K opfe”. Wenn die drei Versuche unabh angigsind, ist die Wahrscheinlichkeitsfunktion von X (gegeben π)
P (x|π) =
(3x
)
πx(1 − π)3−x x = 0, 1, 2, 30 sonst .
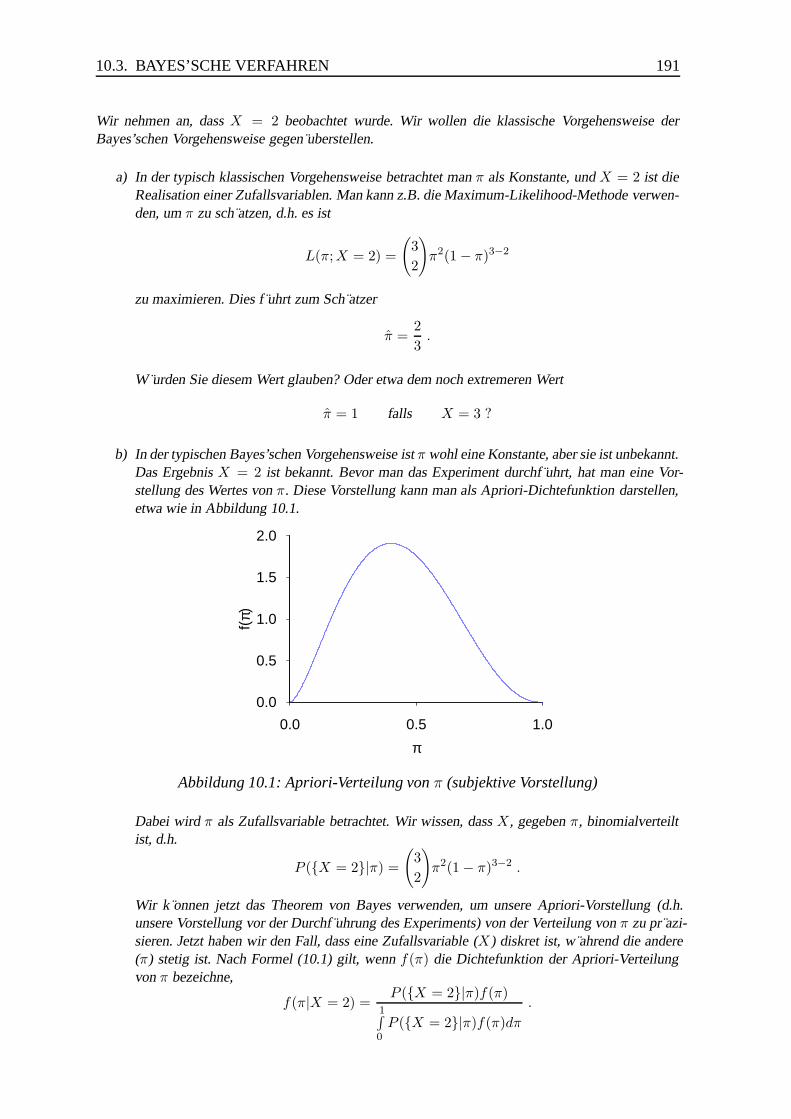
10.3. BAYES’SCHE VERFAHREN 191
Wir nehmen an, dass X = 2 beobachtet wurde. Wir wollen die klassische Vorgehensweise derBayes’schen Vorgehensweise gegen uberstellen.
a) In der typisch klassischen Vorgehensweise betrachtet man π als Konstante, und X = 2 ist dieRealisation einer Zufallsvariablen. Man kann z.B. die Maximum-Likelihood-Methode verwen-den, um π zu sch atzen, d.h. es ist
L(π;X = 2) =
(
3
2
)
π2(1 − π)3−2
zu maximieren. Dies f uhrt zum Sch atzer
π =2
3.
W urden Sie diesem Wert glauben? Oder etwa dem noch extremeren Wert
π = 1 falls X = 3 ?
b) In der typischen Bayes’schen Vorgehensweise ist π wohl eine Konstante, aber sie ist unbekannt.Das Ergebnis X = 2 ist bekannt. Bevor man das Experiment durchf uhrt, hat man eine Vor-stellung des Wertes von π. Diese Vorstellung kann man als Apriori-Dichtefunktion darstellen,etwa wie in Abbildung 10.1.
0.0 0.5 1.0
0.0
0.5
1.0
1.5
2.0
π
f(π)
Abbildung 10.1: Apriori-Verteilung von π (subjektive Vorstellung)
Dabei wird π als Zufallsvariable betrachtet. Wir wissen, dass X , gegeben π, binomialverteiltist, d.h.
P (X = 2|π) =
(
3
2
)
π2(1 − π)3−2 .
Wir k onnen jetzt das Theorem von Bayes verwenden, um unsere Apriori-Vorstellung (d.h.unsere Vorstellung vor der Durchf uhrung des Experiments) von der Verteilung von π zu pr azi-sieren. Jetzt haben wir den Fall, dass eine Zufallsvariable (X) diskret ist, w ahrend die andere(π) stetig ist. Nach Formel (10.1) gilt, wenn f(π) die Dichtefunktion der Apriori-Verteilungvon π bezeichne,
f(π|X = 2) =P (X = 2|π)f(π)
1∫
0P (X = 2|π)f(π)dπ
.
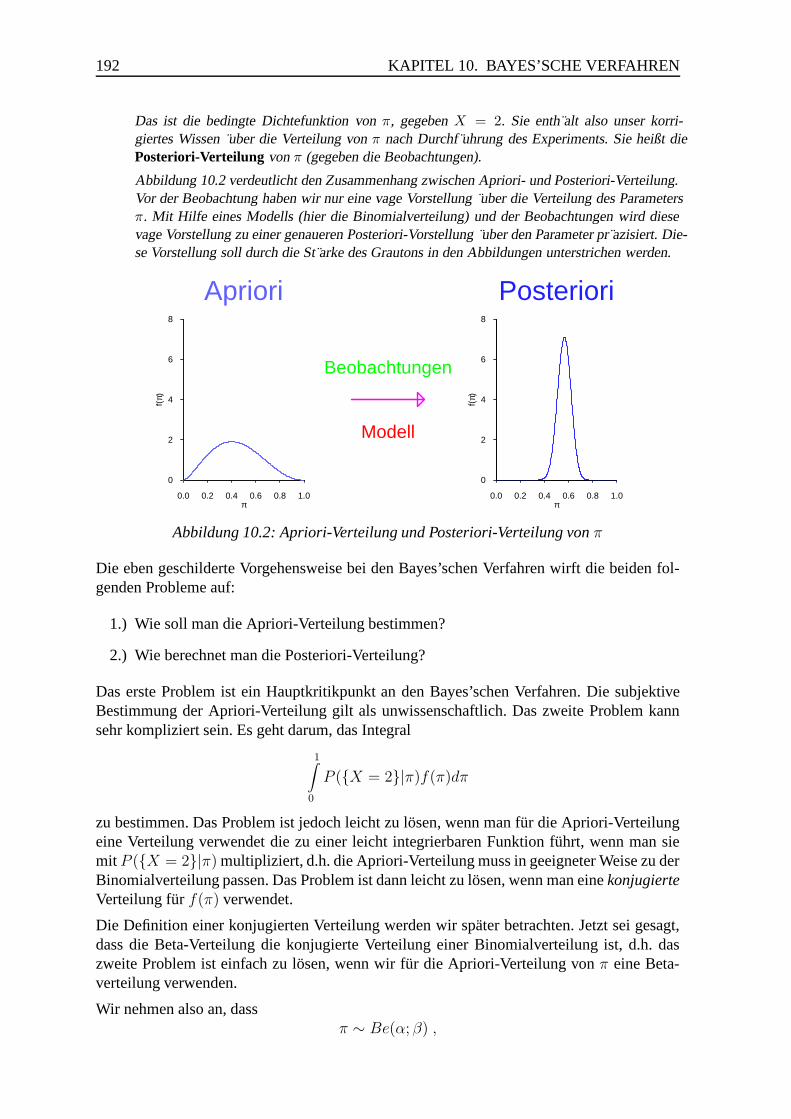
192 KAPITEL 10. BAYES’SCHE VERFAHREN
Das ist die bedingte Dichtefunktion von π, gegeben X = 2. Sie enth alt also unser korri-giertes Wissen uber die Verteilung von π nach Durchf uhrung des Experiments. Sie heißt diePosteriori-Verteilung von π (gegeben die Beobachtungen).
Abbildung 10.2 verdeutlicht den Zusammenhang zwischen Apriori- und Posteriori-Verteilung.Vor der Beobachtung haben wir nur eine vage Vorstellung uber die Verteilung des Parametersπ. Mit Hilfe eines Modells (hier die Binomialverteilung) und der Beobachtungen wird diesevage Vorstellung zu einer genaueren Posteriori-Vorstellung uber den Parameter pr azisiert. Die-se Vorstellung soll durch die St arke des Grautons in den Abbildungen unterstrichen werden.
0.0 0.2 0.4 0.6 0.8 1.0
0
2
4
6
8
π
f(π)
Apriori
Beobachtungen
Modell
0.0 0.2 0.4 0.6 0.8 1.0
0
2
4
6
8
π
f(π)
Posteriori
Abbildung 10.2: Apriori-Verteilung und Posteriori-Verteilung von π
Die eben geschilderte Vorgehensweise bei den Bayes’schen Verfahren wirft die beiden fol-genden Probleme auf:
1.) Wie soll man die Apriori-Verteilung bestimmen?
2.) Wie berechnet man die Posteriori-Verteilung?
Das erste Problem ist ein Hauptkritikpunkt an den Bayes’schen Verfahren. Die subjektiveBestimmung der Apriori-Verteilung gilt als unwissenschaftlich. Das zweite Problem kannsehr kompliziert sein. Es geht darum, das Integral
1∫
0
P (X = 2|π)f(π)dπ
zu bestimmen. Das Problem ist jedoch leicht zu losen, wenn man fur die Apriori-Verteilungeine Verteilung verwendet die zu einer leicht integrierbaren Funktion fuhrt, wenn man siemit P (X = 2|π) multipliziert, d.h. die Apriori-Verteilung muss in geeigneter Weise zu derBinomialverteilung passen. Das Problem ist dann leicht zu losen, wenn man eine konjugierteVerteilung fur f(π) verwendet.
Die Definition einer konjugierten Verteilung werden wir spater betrachten. Jetzt sei gesagt,dass die Beta-Verteilung die konjugierte Verteilung einer Binomialverteilung ist, d.h. daszweite Problem ist einfach zu losen, wenn wir fur die Apriori-Verteilung von π eine Beta-verteilung verwenden.
Wir nehmen also an, dassπ ∼ Be(α; β) ,
10.3. BAYES’SCHE VERFAHREN 193
d.h.
f(π) =
1
B(α,β)πα−1(1 − π)β−1 0 < π < 1
0 sonst .
Abbildung 10.3 zeigt einige Beta-Apriori-Verteilungen.
0.0 0.2 0.4 0.6 0.8 1.0
0
2
4
6
8
10
12
π
f(π)
Be(100,100)
Be(50,20)
Be(10,10)
Abbildung 10.3: Einige Beta-Apriori-Verteilungen
Wir nehmen auch weiterhin an, dass
X|π ∼ b(n; π) .
Dann ist
f(π|X = x) =P (X = x|π)f(π)
1∫
0P (X = x|π)f(π)dπ
.
Das Integral im Nenner ist
1∫
0
P (X = x|π)f(π)dπ =
1∫
0
(
n
x
)
πx(1 − π)n−x πα−1(1 − π)β−1
B(α, β)dπ
=
(
n
x
)
1
B(α, β)
1∫
0
πx+α−1(1 − π)n−x+β−1dπ
︸ ︷︷ ︸
B(α+x; β+n−x)
=
(
n
x
)
B(α + x; β + n − x)
B(α, β).
(Beachten Sie, dass wir dieses Integral schon in Kapitel 12 bei der Herleitung der Beta-Binomial-Verteilung berechnet haben. Es handelt sich um die Bestimmung einer Mischver-teilung. Die Binomialverteilung wird gemaß einer Betaverteilung gemischt.)
Damit ist die Posteriori-Dichte
f(π|X = x) =
(nx
)
πx(1 − π)n−xπα−1(1 − π)β−1/B(α; β)(
nx
)
B(α + x; β + n − x)/B(α; β)
=πx+α−1(1 − π)n−x+β−1
B(α + x; β + n − x),
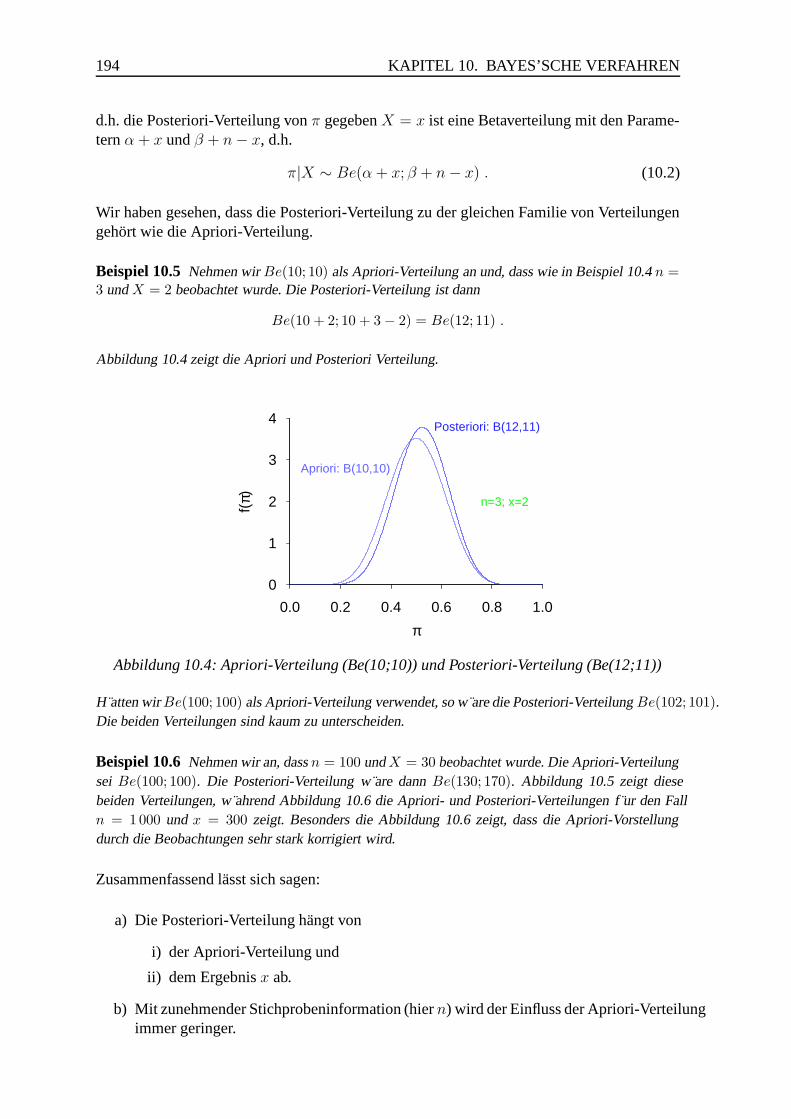
194 KAPITEL 10. BAYES’SCHE VERFAHREN
d.h. die Posteriori-Verteilung von π gegeben X = x ist eine Betaverteilung mit den Parame-tern α + x und β + n − x, d.h.
π|X ∼ Be(α + x; β + n − x) . (10.2)
Wir haben gesehen, dass die Posteriori-Verteilung zu der gleichen Familie von Verteilungengehort wie die Apriori-Verteilung.
Beispiel 10.5 Nehmen wir Be(10; 10) als Apriori-Verteilung an und, dass wie in Beispiel 10.4 n =3 und X = 2 beobachtet wurde. Die Posteriori-Verteilung ist dann
Be(10 + 2; 10 + 3 − 2) = Be(12; 11) .
Abbildung 10.4 zeigt die Apriori und Posteriori Verteilung.
0.0 0.2 0.4 0.6 0.8 1.0
0
1
2
3
4
π
f(π)
Posteriori: B(12,11)
Apriori: B(10,10)
n=3; x=2
Abbildung 10.4: Apriori-Verteilung (Be(10;10)) und Posteriori-Verteilung (Be(12;11))
H atten wir Be(100; 100) als Apriori-Verteilung verwendet, so w are die Posteriori-Verteilung Be(102; 101).Die beiden Verteilungen sind kaum zu unterscheiden.
Beispiel 10.6 Nehmen wir an, dass n = 100 und X = 30 beobachtet wurde. Die Apriori-Verteilungsei Be(100; 100). Die Posteriori-Verteilung w are dann Be(130; 170). Abbildung 10.5 zeigt diesebeiden Verteilungen, w ahrend Abbildung 10.6 die Apriori- und Posteriori-Verteilungen f ur den Falln = 1000 und x = 300 zeigt. Besonders die Abbildung 10.6 zeigt, dass die Apriori-Vorstellungdurch die Beobachtungen sehr stark korrigiert wird.
Zusammenfassend lasst sich sagen:
a) Die Posteriori-Verteilung hangt von
i) der Apriori-Verteilung und
ii) dem Ergebnis x ab.
b) Mit zunehmender Stichprobeninformation (hier n) wird der Einfluss der Apriori-Verteilungimmer geringer.
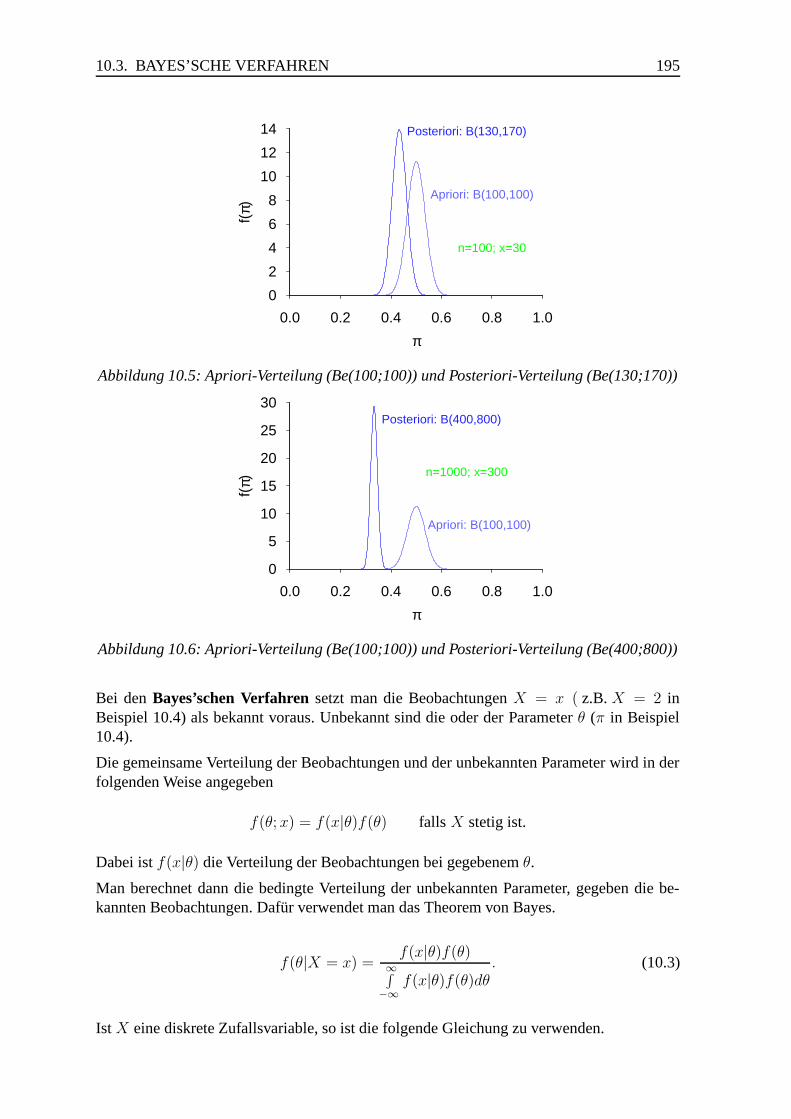
10.3. BAYES’SCHE VERFAHREN 195
0.0 0.2 0.4 0.6 0.8 1.0
0
2
4
6
8
10
12
14
π
f(π)
Posteriori: B(130,170)
Apriori: B(100,100)
n=100; x=30
Abbildung 10.5: Apriori-Verteilung (Be(100;100)) und Posteriori-Verteilung (Be(130;170))
0.0 0.2 0.4 0.6 0.8 1.0
0
5
10
15
20
25
30
π
f(π)
Posteriori: B(400,800)
Apriori: B(100,100)
n=1000; x=300
Abbildung 10.6: Apriori-Verteilung (Be(100;100)) und Posteriori-Verteilung (Be(400;800))
Bei den Bayes’schen Verfahren setzt man die Beobachtungen X = x ( z.B. X = 2 inBeispiel 10.4) als bekannt voraus. Unbekannt sind die oder der Parameter θ (π in Beispiel10.4).
Die gemeinsame Verteilung der Beobachtungen und der unbekannten Parameter wird in derfolgenden Weise angegeben
f(θ; x) = f(x|θ)f(θ) falls X stetig ist.
Dabei ist f(x|θ) die Verteilung der Beobachtungen bei gegebenem θ.
Man berechnet dann die bedingte Verteilung der unbekannten Parameter, gegeben die be-kannten Beobachtungen. Dafur verwendet man das Theorem von Bayes.
f(θ|X = x) =f(x|θ)f(θ)
∞∫
−∞f(x|θ)f(θ)dθ
. (10.3)
Ist X eine diskrete Zufallsvariable, so ist die folgende Gleichung zu verwenden.

196 KAPITEL 10. BAYES’SCHE VERFAHREN
f(θ|X = x) =P (x|θ)f(θ)
∞∫
−∞P (x|θ)f(θ)dθ
. (10.4)
Definition 10.2 Sei f(x|θ) die bedingte Dichtefunktion der Zufallsvariablen X bei ge-gebenem Parameter θ und f(θ) die Apriori-Verteilung des Parameters θ. Die Posteriori-Verteilung von θ, gegeben X = x ist dann durch Gleichung (10.3) gegeben. Ist X einediskrete Zufallsvariable mit der Wahrscheinlichkeitsfunktion P (x|θ), so ist die Posteriori-Verteilung von θ, gegeben X = x durch Gleichung (10.4) gegeben.
Wir wollen jetzt besprechen, wie man die Posteriori-Verteilung einfach bestimmen kann,wenn man konjugierte Verteilungen verwendet.
Definition 10.3 Die Verteilung f(θ) heißt die (naturliche) konjugierte Verteilung furf(x|θ), wenn f(θ|x) und f(θ) dieselbe Form haben, d.h. wenn die Apriori- undPosteriori-Verteilung zu derselben Familie von Verteilungen gehoren.
Beispiel 10.7 Die Betaverteilung ist die konjugierte Verteilung f ur den Parameter θ = π einer Bi-nomialverteilung. Wir hatten weiter oben angenommen, dass die bedingte Verteilung von X gegebenπ eine Binomialverteilung ist, d.h.
X|π ∼ b(n;π) .
Als Apriori-Verteilung von π hatten wir eine Betaverteilung angenommen, d.h.
π ∼ Be(α;β) .
Wir konnten zeigen, dass die bedingte Verteilung von π gegeben X eine Betaverteilung ist, genauer(siehe Gleichung (10.2)
π|X = x ∼ Be(α + x;β + n − x) .
Die Apriori-Dichte f(π) und die Posteriori-Dichte f(π|X = x) sind jeweils Betaverteilungen.
Wie verwendet man die Posteriori-Verteilung? Der Modalwert kann als Schatzer des Pa-rameters aufgefasst werden. Mit Hilfe der Verteilung kann ein Vertrauensbereich fur denParameter angegeben werden.
Betrachten wir die Situation in Abbildung 10.5. Die Posteriori-Verteilung ist die Betaverteilung mitden Parametern 130 und 170. Sie hat den Modalwert an der Stelle (130 − 1)/(300 − 2) = 0.43, d.h.man w urde π durch π = 0.43 sch atzen. Um einen 90%-Vertrauensbereich zu bestimmen, berechnetman mit Hilfe der Umkehrfunktion der Verteilungsfunktion den 5%- und 95%-Punkt der Betavertei-lung. In diesem Fall ergibt sich das Intervall (0.387, 0.481).

10.3. BAYES’SCHE VERFAHREN 197
Beispiel 10.8 Die Gammaverteilung ist die konjugierte Verteilung f ur den Parameter einer Poisson-verteilung.
Sei X|µ poissonverteilt mit dem Parameter µ, d.h.
P (X = x|µ) =
µxe−µ
x! f ur x = 0, 1, 2, . . .0 sonst .
Die Apriori-Verteilung von µ sei eine Gammaverteilung, d.h.
µ ∼ G(ν;λ) ,
d.h.
f(µ) =
λνµν−1e−λµ
Γ(ν)µ ≥ 0
0 sonst .
Dann ist die Posteriori-Verteilung von µ, gegeben X = x
f(µ|X = x) =P (X = x|µ)f(µ)
∞∫
0P (X = x|µ)f(µ)dµ
.
Wir bestimmen zun achst den Z ahler dieses Ausdrucks und bemerken, dass der Nenner das Integraluber den Ausdruck im Z ahler ist.
P (X = x|µ)f(µ) =µxe−µ
x!· λνµν−1e−λµ
Γ(ν)=
λν
x!Γ(ν)µx+ν−1e−µ(1+λ) (10.5)
Den Nenner hatten wir bereits in Kapitel 9 bestimmt, als wir die Mischung der Poissonverteilungbez uglich der Gammaverteilung betrachtet haben (siehe Seite 178). Als Zwischenergebnis hatten wirdort erhalten:
∞∫
0
P (X = x|µ)f(µ)dµ =Γ(x + ν)λν
x!Γ(ν)(1 + λ)x+ν. (10.6)
Dividieren wir Gleichung (10.5) durch Gleichung 10.6, so erhalten wir:
f(µ|X = x) =(λ + 1)ν+xµν+x−1e−(λ+1)µ
Γ(ν + x),
d.h. die Dichtefunktion einer Gammaverteilung mit den Parametern ν + x und λ + 1.
Wir fassen das Ergebnis des letzten Beispiels in folgendem Satz zusammen.
Satz 10.4 Die Zufallsvariable X sei bei gegebenem µ poissonverteilt mit dem Parameterµ (d.h. X|µ ∼ Po(µ)). Die Aprioriverteilung von µ sei G(ν; λ). Dann ist die Posteriori-Verteilung von µ, gegeben die Beobachtung x
µ ∼ G(ν + x; λ + 1) .
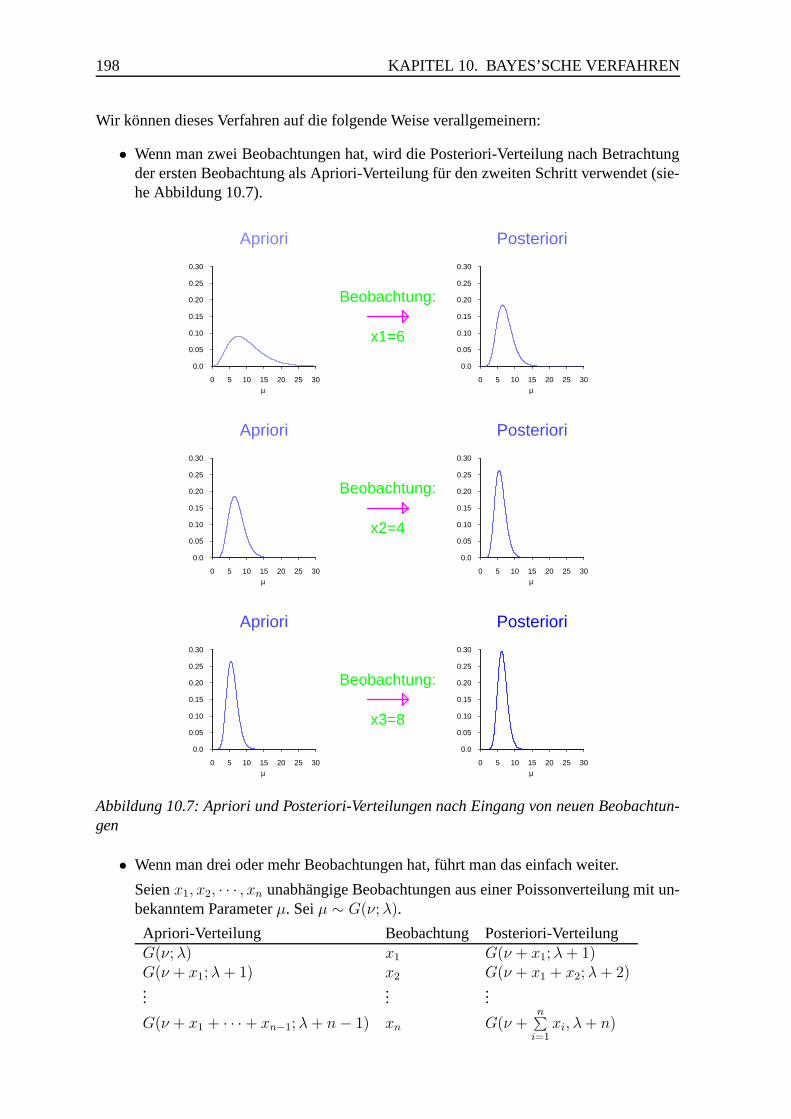
198 KAPITEL 10. BAYES’SCHE VERFAHREN
Wir konnen dieses Verfahren auf die folgende Weise verallgemeinern:
• Wenn man zwei Beobachtungen hat, wird die Posteriori-Verteilung nach Betrachtungder ersten Beobachtung als Apriori-Verteilung fur den zweiten Schritt verwendet (sie-he Abbildung 10.7).
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Apriori
Beobachtung:
x1=6
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Posteriori
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Apriori
Beobachtung:
x2=4
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Posteriori
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Apriori
Beobachtung:
x3=8
0 5 10 15 20 25 30
0.0
0.05
0.10
0.15
0.20
0.25
0.30
µ
Posteriori
Abbildung 10.7: Apriori und Posteriori-Verteilungen nach Eingang von neuen Beobachtun-gen
• Wenn man drei oder mehr Beobachtungen hat, fuhrt man das einfach weiter.
Seien x1, x2, · · · , xn unabhangige Beobachtungen aus einer Poissonverteilung mit un-bekanntem Parameter µ. Sei µ ∼ G(ν; λ).
Apriori-Verteilung Beobachtung Posteriori-VerteilungG(ν; λ) x1 G(ν + x1; λ + 1)G(ν + x1; λ + 1) x2 G(ν + x1 + x2; λ + 2)...
......
G(ν + x1 + · · · + xn−1; λ + n − 1) xn G(ν +n∑
i=1xi, λ + n)
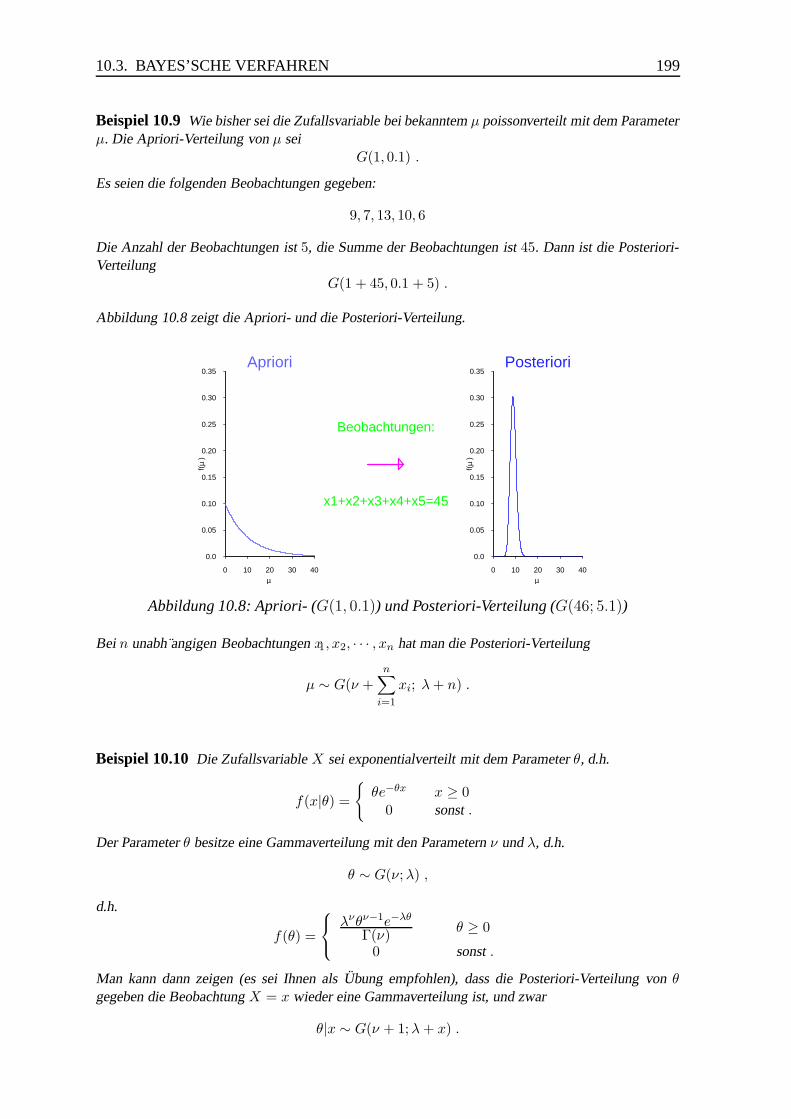
10.3. BAYES’SCHE VERFAHREN 199
Beispiel 10.9 Wie bisher sei die Zufallsvariable bei bekanntem µ poissonverteilt mit dem Parameterµ. Die Apriori-Verteilung von µ sei
G(1, 0.1) .
Es seien die folgenden Beobachtungen gegeben:
9, 7, 13, 10, 6
Die Anzahl der Beobachtungen ist 5, die Summe der Beobachtungen ist 45. Dann ist die Posteriori-Verteilung
G(1 + 45, 0.1 + 5) .
Abbildung 10.8 zeigt die Apriori- und die Posteriori-Verteilung.
0 10 20 30 40
0.0
0.05
0.10
0.15
0.20
0.25
0.30
0.35
µ
f(µ
)
Apriori
Beobachtungen:
x1+x2+x3+x4+x5=45
0 10 20 30 40
0.0
0.05
0.10
0.15
0.20
0.25
0.30
0.35
µ
f(µ
)
Posteriori
Abbildung 10.8: Apriori- (G(1, 0.1)) und Posteriori-Verteilung (G(46; 5.1))
Bei n unabh angigen Beobachtungen x1, x2, · · · , xn hat man die Posteriori-Verteilung
µ ∼ G(ν +n∑
i=1
xi; λ + n) .
Beispiel 10.10 Die Zufallsvariable X sei exponentialverteilt mit dem Parameter θ, d.h.
f(x|θ) =
θe−θx x ≥ 00 sonst .
Der Parameter θ besitze eine Gammaverteilung mit den Parametern ν und λ, d.h.
θ ∼ G(ν;λ) ,
d.h.
f(θ) =
λνθν−1e−λθ
Γ(ν)θ ≥ 0
0 sonst .
Man kann dann zeigen (es sei Ihnen als Ubung empfohlen), dass die Posteriori-Verteilung von θgegeben die Beobachtung X = x wieder eine Gammaverteilung ist, und zwar
θ|x ∼ G(ν + 1;λ + x) .

200 KAPITEL 10. BAYES’SCHE VERFAHREN
Die Gammaverteilung ist also die konjugierte Verteilung f ur die Exponentialverteilung. Nach Eingangder Beobachtungen x1, x2, . . . , xn ist die Posterioriverteilung
G(ν + n;λ +n∑
i=1
xi) .
In der Zuverl assigkeitstheorie bezeichnet man den Parameter θ als Hazardrate und T =n∑
i=1xi als
total time on test. Die Dichtefunktion von θ, gegeben die Beobachtungen x1, x2, . . . , xn ist dann
f(θ|x1, x2, ..., xn) =
1
Γ(ν) (λ + T )ν+nθν+n−1e−(λ+T )θ θ ≥ 0
0 sonst .
Man kann θ dann sch atzen durch den Erwartungswert dieser Verteilung, d.h durch
(ν + n)/(λ + T ) .
In der Zuverl assigkeitstheorie wird es h aufig als gef ahrlich angesehen, wenn die Hazardrate einenbestimmten Wert θ0 ubersteigt. Diese Wahrscheinlichkeit kann durch Integation der Posteriori-Dich-tefunktion von θ bestimmt werden.
Unsere bisherigen Resultate konnen wir so zusammenfassen:
a) Die Betaverteilung ist die konjugierte Verteilung fur die Binomialverteilung.
Apriori-Vert. Modell Beobacht. Posteriori-Vert.π ∼ Be(α; β) X|π ∼ b(n; π) X=x π|X = x ∼ Be(α + x; β + n − x)
b) Die Gammaverteilung ist die konjugierte Verteilung fur die Poisson-Verteilung.
Apriori-Vert. Modell Beobacht. Posteriori-Vert.µ ∼ G(ν; λ) X|µ ∼ P0(µ) X = x µ|X ∼ G(ν + x; λ + 1)
c) Die Gammaverteilung ist die konjugierte Verteilung fur die Exponentialverteilung.
Apriori-Vert. Modell Beobacht. Posteriori-Vert.θ ∼ G(ν; λ) X|θ ∼ Exp(θ) X = x θ|X ∼ G(ν + 1; λ + x)
Nachdem wir unsere Verteilung uber den Parameter θ durch die Posteriori-Verteilung korri-giert haben, wollen wir uns fragen:
Wie sind weitere zukunftige Werte der Zufallsvariablen X verteilt?
Definition 10.4Die pradiktive Verteilung von X ist die Randverteilung eines zukunftigen Wertes vonX .

10.3. BAYES’SCHE VERFAHREN 201
Satz 10.5Die pradiktive Verteilung einer binomialverteilten Zufallsvariablen (X ∼ b(n; π)), derenParameter betaverteilt (Be(α; β)) ist, ist die Beta-Binomialverteilung mit den Parame-tern n, α + x und β + n− x. Dabei ist x der zuvor beobachtete Wert von X und n ist dieAnzahl der weiteren Bernoulli-Experimente.
Bevor wir diesen Satz beweisen, wollen wir die Situation in der folgenden Ubersicht zusam-menfassen:
Apriori π ∼ Be(α; β)Modell X|π ∼ b(n; π)Posteriori π|X ∼ Be(α + x; β + n − x)
Die Apriori-Vorstellungen uber den Parameter π seien in einer Betaverteilung ausgedruckt.Das Modell fur die Beobachtungen bei gegebenem Parameter sei eine Binomialverteilung.Nach Eingang von Beobachtungen wird die Apriori-Vorstellung uber π in eine Posteriori-Vorstellung uber π modifiziert. Dies ist wieder eine Betaverteilung. Die Frage, die Satz 10.5beantwortet, ist die nach der Verteilung weiterer zukunftiger Werte unter Berucksichtigungder bisher gewonnenen Erkenntnisse.
Es werden weitere n Bernoulli-Versuche durchgefuhrt. Sei X die Anzahl der Erfolge indiesen weiteren Versuchen. Die Behauptung des Satzes ist
X ∼ Beta-Binomial(n; α + x; β + n − x) .
Beispiel 10.11 Wir betrachten das M unzwurfexperiment aus Beispiel 10.4.
Apriori-Verteilung π ∼ Be(α;β) z.B. Be(5; 5)Modell X|π ∼ b(n;π) z.B. b(3;π)Posteriori-Verteilung π|X ∼ Be(α + x;n − x + β) Be(7; 6) (falls x = 2)
Wir werfen die M unze noch n-mal. SeiX die Anzahl der ,,K opfe” in diesen weiteren Versuchen.
Gesucht ist die Verteilung von X . Sie heißt die pr adiktive Verteilung.
Wie groß ist z.B.P (X = x|x = 2) ?
Es istX|π ∼ b(n;π) .
Aber π ist nicht bekannt.
Beweis des Satzes:
P (X = x|X = x) =
1∫
0
P (X = x|X = x; π)f(π|x)dπ
=
1∫
0
(
n
x
)
πx(1 − π)n−x πα+x−1(1 − π)β+n−x−1
B(α + x; β + n − x)dπ
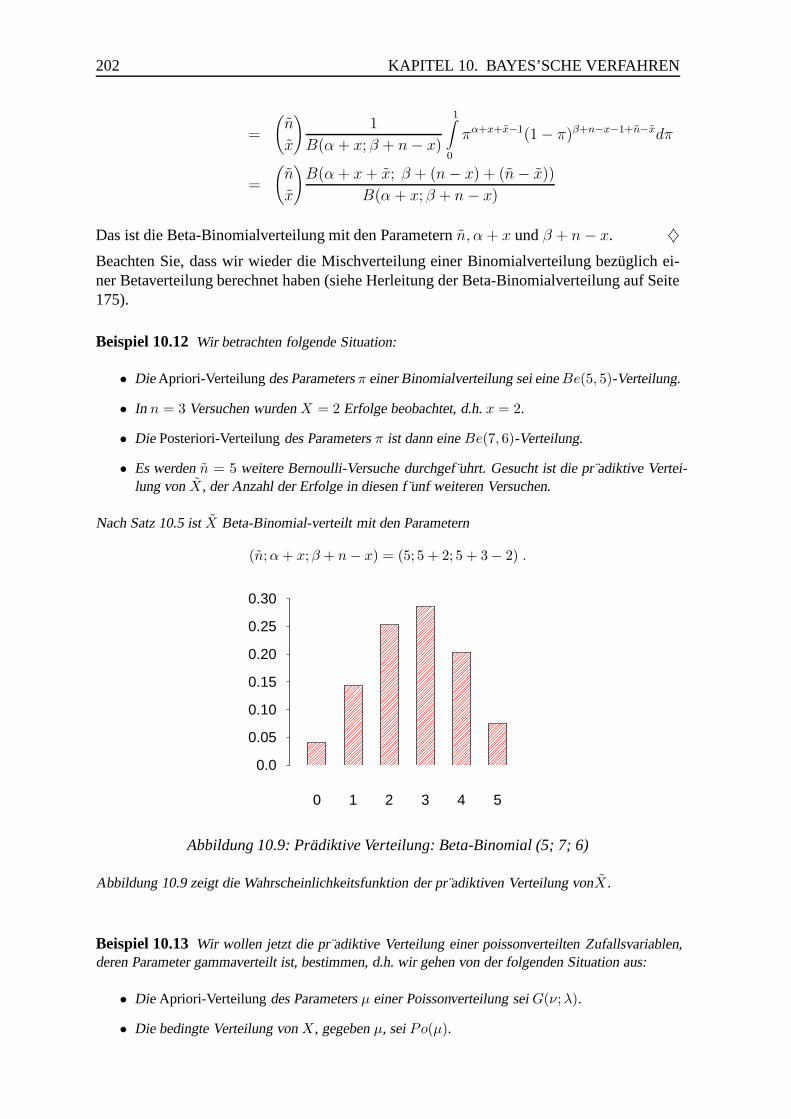
202 KAPITEL 10. BAYES’SCHE VERFAHREN
=
(
n
x
)
1
B(α + x; β + n − x)
1∫
0
πα+x+x−1(1 − π)β+n−x−1+n−xdπ
=
(
n
x
)
B(α + x + x; β + (n − x) + (n − x))
B(α + x; β + n − x)
Das ist die Beta-Binomialverteilung mit den Parametern n, α + x und β + n − x. ♦Beachten Sie, dass wir wieder die Mischverteilung einer Binomialverteilung bezuglich ei-ner Betaverteilung berechnet haben (siehe Herleitung der Beta-Binomialverteilung auf Seite175).
Beispiel 10.12 Wir betrachten folgende Situation:
• Die Apriori-Verteilung des Parameters π einer Binomialverteilung sei eine Be(5, 5)-Verteilung.
• In n = 3 Versuchen wurden X = 2 Erfolge beobachtet, d.h. x = 2.
• Die Posteriori-Verteilung des Parameters π ist dann eine Be(7, 6)-Verteilung.
• Es werden n = 5 weitere Bernoulli-Versuche durchgef uhrt. Gesucht ist die pr adiktive Vertei-lung von X , der Anzahl der Erfolge in diesen f unf weiteren Versuchen.
Nach Satz 10.5 ist X Beta-Binomial-verteilt mit den Parametern
(n;α + x;β + n − x) = (5; 5 + 2; 5 + 3 − 2) .
0 1 2 3 4 5
0.0
0.05
0.10
0.15
0.20
0.25
0.30
Abbildung 10.9: Pradiktive Verteilung: Beta-Binomial (5; 7; 6)
Abbildung 10.9 zeigt die Wahrscheinlichkeitsfunktion der pr adiktiven Verteilung vonX .
Beispiel 10.13 Wir wollen jetzt die pr adiktive Verteilung einer poissonverteilten Zufallsvariablen,deren Parameter gammaverteilt ist, bestimmen, d.h. wir gehen von der folgenden Situation aus:
• Die Apriori-Verteilung des Parameters µ einer Poissonverteilung sei G(ν;λ).
• Die bedingte Verteilung von X , gegeben µ, sei Po(µ).
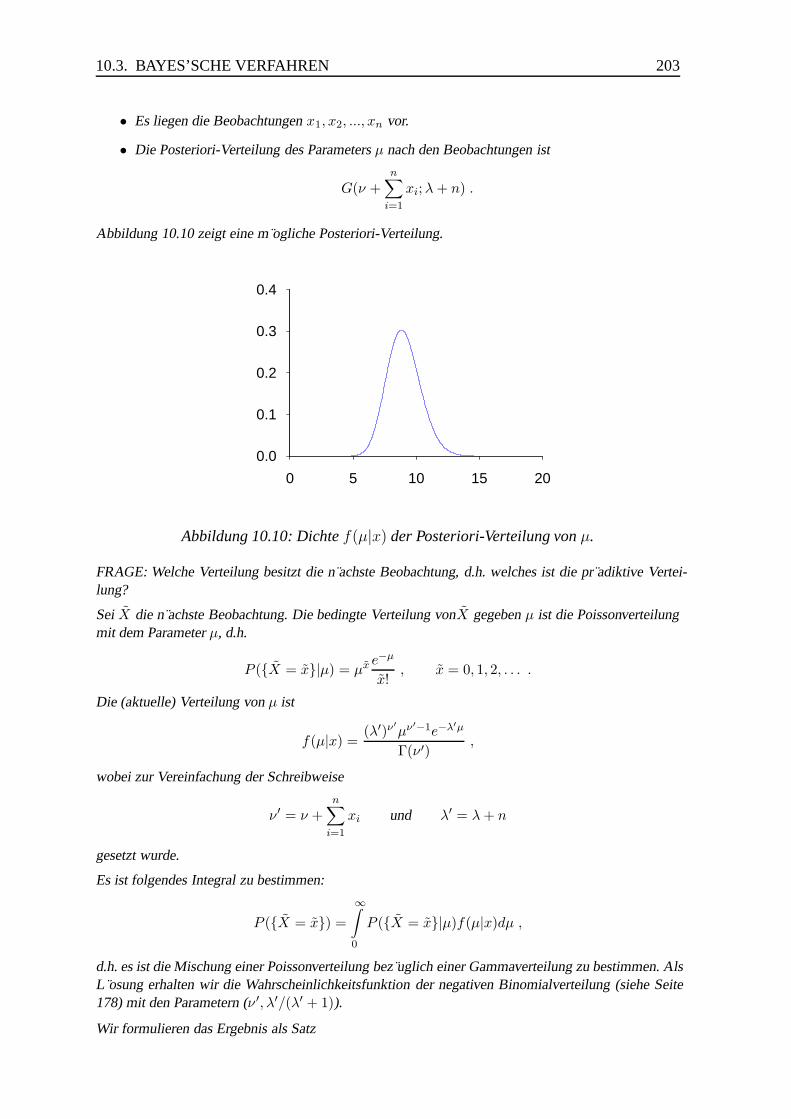
10.3. BAYES’SCHE VERFAHREN 203
• Es liegen die Beobachtungen x1, x2, ..., xn vor.
• Die Posteriori-Verteilung des Parameters µ nach den Beobachtungen ist
G(ν +n∑
i=1
xi;λ + n) .
Abbildung 10.10 zeigt eine m ogliche Posteriori-Verteilung.
0 5 10 15 20
0.0
0.1
0.2
0.3
0.4
Abbildung 10.10: Dichte f(µ|x) der Posteriori-Verteilung von µ.
FRAGE: Welche Verteilung besitzt die n achste Beobachtung, d.h. welches ist die pr adiktive Vertei-lung?
Sei X die n achste Beobachtung. Die bedingte Verteilung vonX gegeben µ ist die Poissonverteilungmit dem Parameter µ, d.h.
P (X = x|µ) = µx e−µ
x!, x = 0, 1, 2, . . . .
Die (aktuelle) Verteilung von µ ist
f(µ|x) =(λ′)ν
′µν′−1e−λ′µ
Γ(ν ′),
wobei zur Vereinfachung der Schreibweise
ν ′ = ν +n∑
i=1
xi und λ′ = λ + n
gesetzt wurde.
Es ist folgendes Integral zu bestimmen:
P (X = x) =
∞∫
0
P (X = x|µ)f(µ|x)dµ ,
d.h. es ist die Mischung einer Poissonverteilung bez uglich einer Gammaverteilung zu bestimmen. AlsL osung erhalten wir die Wahrscheinlichkeitsfunktion der negativen Binomialverteilung (siehe Seite178) mit den Parametern (ν ′, λ′/(λ′ + 1)).
Wir formulieren das Ergebnis als Satz

204 KAPITEL 10. BAYES’SCHE VERFAHREN
Satz 10.6 Die pradiktive Verteilung der Poissonverteilung, deren Parameter µ gamma-verteilt ist, ist eine negative Binomialverteilung.
Wir betrachten abschließend in diesem Abschnitt die Normalverteilung fur den Fall, dassdie Varianz σ2 bekannt ist. Der unbekannte Parameter ist der Erwartungswert µ, so dass einModell fur die Beobachtungen durch
X|µ ∼ N(µ; σ2) .
beschrieben werden kann. Es gilt dann:
Satz 10.7 Die konjugierte Verteilung fur den Parameter µ der Normalverteilung ist dieNormalverteilung.
Zunachst wird der Fall betrachtet, bei dem eine Apriori–Verteilung durch eine Beobachtungprazisiert wird. Sei µ ∼ N(µ0; τ
20 ) die Apriori–Verteilung und x die Beobachtung, dann ist
die Posteriori–Verteilung durch µ|x ∼ N(µ1; τ21 ) mit
µ1 = µ0 + (x − µ0)τ 20
σ2 + τ 20
und1
τ 21
=1
τ 20
+1
σ2
gegeben.
Zunachst wird der Erwartungswert µ1 der Posteriori–Verteilung betrachtet. Dieser stellt einenKompromiss zwischen dem Erwartungswert der Apriori–Verteilung und der Beobachtungdar: Das Ausmaß der Aktualisierung hangt davon ab, wie weit der ursprunglich angenom-mene Erwartungswert und die Beobachtung auseinander liegen. Ferner ist zu erkennen, dassdie Varianz der Posteriori–Verteilung in jedem Fall kleiner ist als die der Apriori–Verteilung.In der oben gegebenen Formel wird der Kehrwert der Varianz verwendet, der als Prazisi-on der Verteilung interpretiert werden kann. Wie zu sehen ist, steigt die Prazision um denSummanden 1/σ2
Beispiel 10.14 Angenommen es liegt eine Apriori–Verteilung µ ∼ N(1; 4) vor und es wird eineBeobachtung x = 10 gemacht. Sei ferner σ2 = 8, dann erh alt man durch Anwendung der obengegebenen Formeln f ur die Posteriori–Verteilung:
µ|x ∼ N(4; 8/3)
Vergleicht man dieses Ergebnis mit dem Fall, in dem eine Beobachtung gemacht wird, die n aher amErwartungswert der Apriori–Verteilung liegt, erkennt man dass die Posteriori– Verteilung im erstenFall st arker von der Apriori–Verteilung abweicht. W are beispielsweise x = 2 beobachtet worden, solautete die Posterioriverteilung µ|x ∼ N(4/3; 8/3).
Bemerkenswert ist auch, dass die Verringerung der Varianz unabh angig von der Beobachtung ist. Diesgilt allerdings nur f ur den hier betrachteten Fall einer bekannten Varianz.

10.4. BEMERKUNGEN ZU KONJUGIERTEN VERTEILUNGEN 205
Es wird jetzt der Fall betrachtet, bei dem eine Apriori–Verteilung durch n Beobachtungenprazisiert wird. Sei µ ∼ N(µ0; τ
20 ) die Apriori–Verteilung und x1, . . . , xn die Beobachtun-
gen, dann ist Posteriori–Verteilung durch µ|x1, . . . , xn ∼ N(µn; τ 2n) mit
µn = µ0 + (x − µ0)τ 20
σ2/n + τ 20
und1
τ 2n
=1
τ 20
+n
σ2
gegeben. Der Erwartungswert der Posteriori–Verteilung ist jetzt ein Kompromiss zwischendem Erwartungswert der Apriori–Verteilung und dem Mittelwert der Beobachtungen. Fernerist zu sehen, dass die Varianz mit zunehmender Anzahl von Beobachtungen kleiner wird.
Mit Hilfe der Posteriori–Verteilung kann jetzt die pradiktive Verteilung beschrieben werden:
Satz 10.8 Die pradiktive Verteilung einer Normalverteilung, deren Parameter µ eben-falls normalverteilt ist, lautet:
X ∼ N(µn; σ2 + τ 2n) .
Beispiel 10.15 Angenommen es liegt eine Apriori–Verteilung µ ∼ N(1; 4) vor und es werden zweiBeobachtungen gemacht: Beobachtung x1 = 11 und x2 = −1. Sei ferner σ2 = 8, dann erh alt mandurch Berechnung der oben gegebenen Formeln f ur die Posteriori–Verteilung:
µ|x ∼ N(3; 2)
und die pr adiktive Verteilung ist:X ∼ N(3; 10) .
Im Fall der Normalverteilung ist es auch denkbar, dass der Parameter µ bekannt ist und dieVarianz durch eine Verteilung beschrieben wird. Die konjugierte Verteilung der Varianz einerNormalverteilung (bei bekanntem Erwartungswert) ist die inverse χ2–Verteilung (siehe dazuLee, 1997, Appendix A.5). Der Fall unbekannter Varianz ist kompliziert und wird daher imRahmen dieser Veranstaltung nicht naher diskutiert. Fur Interessierte sei auf Lee (1997, Kap.2.7) oder Gelman et al. (1996, S. 46–48) verwiesen.
10.4 Bemerkungen zu konjugierten Verteilungen
Bei den Bayes’schen Verfahren beschreibt die Apriori–Verteilung das Wissen eines ”Exper-ten” uber den Parameter. Die Verwendung der konjugierten Verteilung (wegen der einfachenmathematischen Handhabbarkeit) schrankt die Freiheit, seine Vorstellungen uber den Para-meter zu quantifizieren, ein. Somit ist es beispielsweise moglich, dass man weiß, dass einAnteil π einer Grundgesamtheit großer ist als 0.1. Die konjugierte Verteilung fur die Bi-nomialverteilung ist die Betaverteilung, fur die aber in jedem Fall P (π < 0.1) > 0 gilt.Mit anderen Worten gibt es keine Betaverteilung, die in der Lage ist, das Wissen uber denParameter korrekt wiederzugeben.

206 KAPITEL 10. BAYES’SCHE VERFAHREN
Auf der anderen Seite sind die in der Praxis verwendeten konjugierten Verteilungen flexibelgenug um eine Verteilung zu bestimmen, die sehr nah an den Apriori–Vorstellungen liegt.Findet man aber keine Verteilung zur Beschreibung des Parameterwissens, kann man dieBayes’schen Verfahren trotzdem anwenden, wenngleich damit ein hoherer Rechenaufwand(Einsatz numerischer Verfahren) erforderlich wird. Im folgenden Beispiel wird das Vorgehenfur diesen Fall erlautert.
Beispiel 10.16 Betrachtet wird eine Binomialverteilung mit unbekannter Erfolgswahrscheinlichkeitπ (beispielsweise ”Kauft ein Produkt”, ”besitzt ein Auto”,. . . ). Sei die Apriori–Verteilung durch
f(π) =
100(π − 0.4) 0.4 ≤ π < 0.5100(0.6 − π) 0.5 ≤ π ≤ 0.60 sonst
gegeben. Die Dichte ist in Abbildung 10.11 dargestellt.
0.40 0.45 0.50 0.55 0.60
02
46
810
π
f(π)
Abbildung 10.11: Apriori-Verteilung von π (subjektive Vorstellung)
Zur Pr azisierung der Apriorivorstellung wird nun eine Stichprobe der Gr oße n gezogen und die An-zahl der Erfolge sei mit x bezeichnet. (Die Stichprobe wurde mit Zur ucklegen gezogen, so dass xals binomialverteilt betrachtet werden kann.) Unter diesen Bedingungen ist die Posteriori–Verteilungdurch
f(π|x) = c ·(
n
x
)
πx(1 − π)n−xf(π)
gegeben, wobei c eine Normierungskonstante darstellt, die gew ahrleistet, das die Fl ache unter derPosteriori–Verteilung eins ist. Man erh alt die Konstante durch Berechnung des Integrals
1/c =0.5∫
0.4
(nx
)πx(1 − π)n−x100(π − 0.4)dπ
+0.6∫
0.5
(nx
)πx(1 − π)n−x100(0.6 − π)dπ
Die Berechnung des komplizierten Ausdrucks mit Hilfe der Standardregeln ist sehr aufwendig. Esgibt auch Situationen, in denen das entsprechende Integral gar nicht analytisch zu l osen ist. Man kannaber die L osung mit Hilfe numerischer Methoden immer approximieren und somit die Posteriori–Verteilung bestimmen. Abbildung 10.12 zeigt die Posteriori–Verteilung f ur n = 100 und verschiedene
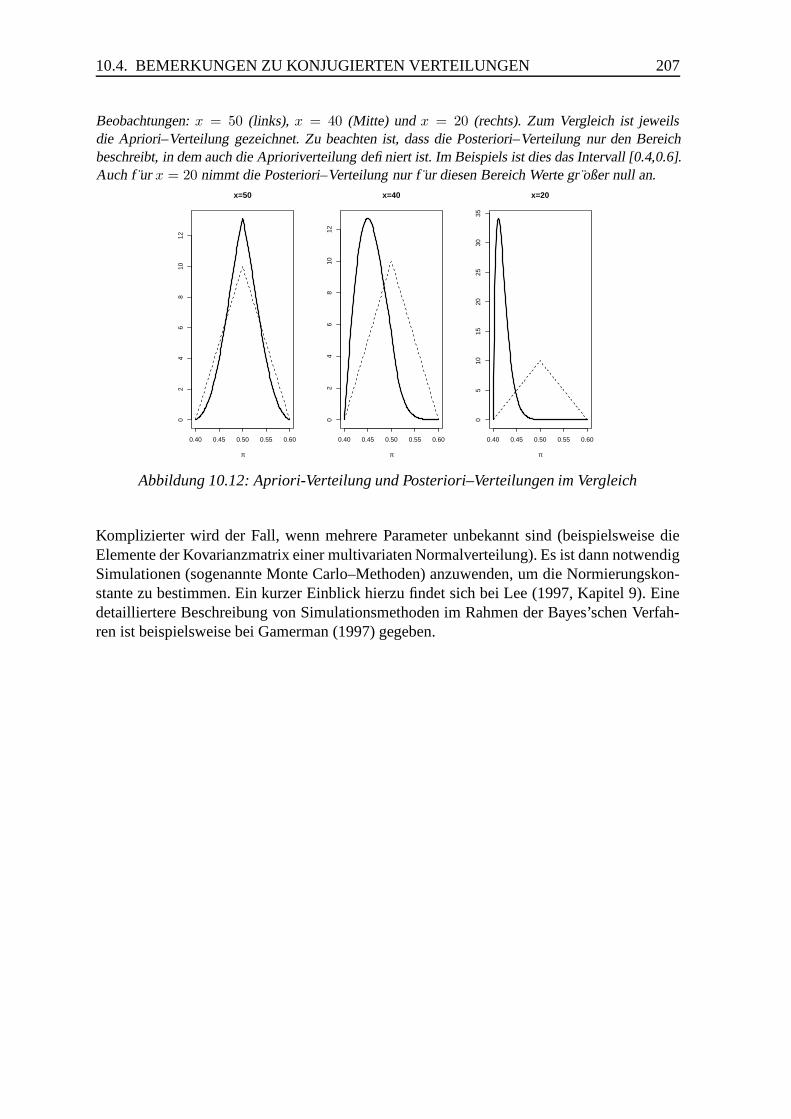
10.4. BEMERKUNGEN ZU KONJUGIERTEN VERTEILUNGEN 207
Beobachtungen: x = 50 (links), x = 40 (Mitte) und x = 20 (rechts). Zum Vergleich ist jeweilsdie Apriori–Verteilung gezeichnet. Zu beachten ist, dass die Posteriori–Verteilung nur den Bereichbeschreibt, in dem auch die Aprioriverteilung definiert ist. Im Beispiels ist dies das Intervall [0.4,0.6].Auch f ur x = 20 nimmt die Posteriori–Verteilung nur f ur diesen Bereich Werte gr oßer null an.
0.40 0.45 0.50 0.55 0.60
02
46
810
12
x=50
π
0.40 0.45 0.50 0.55 0.60
02
46
810
12
x=40
π
0.40 0.45 0.50 0.55 0.60
05
1015
2025
3035
x=20
π
Abbildung 10.12: Apriori-Verteilung und Posteriori–Verteilungen im Vergleich
Komplizierter wird der Fall, wenn mehrere Parameter unbekannt sind (beispielsweise dieElemente der Kovarianzmatrix einer multivariaten Normalverteilung). Es ist dann notwendigSimulationen (sogenannte Monte Carlo–Methoden) anzuwenden, um die Normierungskon-stante zu bestimmen. Ein kurzer Einblick hierzu findet sich bei Lee (1997, Kapitel 9). Einedetailliertere Beschreibung von Simulationsmethoden im Rahmen der Bayes’schen Verfah-ren ist beispielsweise bei Gamerman (1997) gegeben.

Literatur
BAMBERG, G. und BAUR, F. (1996): Statistik, 9. Auflage, Oldenbourg Verlag, M unchen.
BLISCHKE, W. R. (1978): Mixtures of Distributions. International Encyclopedia of Statistics. Her-ausgeber Kruskal und Tanur. The Free Press, New York.
BOHNING, D. (1999:) Computer–Assisted Assisted Analysis of Mixtures and Applications, Chap-man & Hall, Boca Raton et al.
BOKER, F. (1998): P-values and Power of Tests. Erscheint im Erg anzungsband der Enyclopedia ofStatistical Sciences, Herausgeber Johnson und Kotz.
BOKER, F. und DANNENBERG, O. (1995): Was k onnnen P-Werte uber die G ute von Pr ufgr oßen invergleichenden Simulationsstudien aussagen? Allg. Statistisches Archiv 79, 233-251.
BOKER, F. und DANNENBERG, O. (1996): Explorative Data Analysis for a Comparison of Statisti-cal Test Procedures. In SoftStat’95, Advances in Statistical Software 5, Herausgeber F. Faulbaumund W. Bandilla, Lucius & Lucius, Stuttgart, 97-104.
BOKER, F. (1997): S-PLUS, Learning by Doing, Eine Anleitung zum Arbeiten mit S-PLUS. Lucius& Lucius, Stuttgart.
EVERITT, B. S. und HAND, D. J. (1981): Finite Mixture Distribution. Chapman and Hall, London.
FAHRMEIR, L., KUNSTLER, R., PIGEOT, I. und TUTZ, G. (1997): Statistik, Der Weg zur Datenana-lyse, Springer, Berlin, Heidelberg.
FRENCH, S. und SMITH, J.Q. (1997): The Practice of Bayesian Analysis, Arnold, London.
GAMERMAN D. (1997): Markov Chain Monte Carlo, Chapman & Hall, London.
GELMAN A. et al. (1995): Bayesian Data Analysis, Chapman & Hall, London.
HARTUNG, J. (1993): Statistik, 9. Auflage, Oldenbourg Verlag, M unchen.
JOBSON, J. D. (1992): Applied Multivariate Data Analysis, Volume II: Categorical and MultivariateMethods, Springer Verlag, New York.
JOHNSON, N. L., KOTZ, S. und KEMP, A. W. (1992): Univariate Discrete Distributions, Second Edi-tion, Wiley, New York.
JOHNSON, N. L., KOTZ, S. und BALAKRISHNAN, N. (1994): Continuous Univariate Distributions,Volume 1, Second Edition, Wiley, New York.
JOHNSON, N. L., KOTZ, S. und BALAKRISHNAN, N. (1995): Continuous Univariate Distributions,Volume 2, Second Edition, Wiley, New York.
208

Literatur 209
KOTZ, S. und JOHNSON, N. L. (1982-88): Encyclopedia of Statistical Sciences, Volumes 1-9, Wi-ley, New York.
KRAUSE, A. (1997): Einf uhrung in S und S-PLUS, Springer Verlag, Berlin.
LEE, M.L.. (1997): Bayesian Statistics — An Introduction, second edition, Arnold, London.
SCHLITTGEN, R. (1996a): Einf uhrung in die Statistik, Analyse und Modellierung von Daten, 6. Auf-lage, Oldenbourg, M unchen.
SCHLITTGEN, R. (1996b): Statistische Inferenz, Oldenbourg, M unchen.
SPECTOR, P. (1994): An Introduction to S and S-Plus. Duxberry-Press, Belmont.
STUART, A. und ORD, J. K. (1994): Kendalls Advanced Theory of Statistics, Volume 1, Sixth Edi-tion, Arnold, London.
SUSELBECK, B. (1993): S und S-PLUS, Gustav Fischer, Stuttgart.
SYDSÆTER, K. und HAMMOND, P. (2003): Mathematik f ur Wirtschaftswissenschaftler, Basiswis-sen mit Praxisbezug, Pearson Studium, M unchen.
VENABLES, W. N. und RIPLEY, B. D. (1994): Modern Applied Statistics with S-Plus. Springer Ver-lag, New York
WICKMANN D. (1990): Bayes–Statistik — Einsicht gewinnen und Entscheiden bei Unsicherheit, BI Wissenschaftsverlag, Mannheim.
ZUCCHINI, W., NEUMANN, K. und STADIE, A. (2000): Einf uhrung in R, Institut f ur Statistik undOkonometrie, G ottingen.
ZUCCHINI, W. und STADIE, A. (1999): Verallgemeinerte Lineare Modelle, Skript zur Vorlesung ”Ei-nige Methoden der angewandten Statistik”, Institut f ur Statistik und Okonometrie, G ottingen.

Index
B(α, β), 53Be(α; β), 53Ber(π), 60Exp(λ), 48F (ν1, ν2), 85G(ν; λ), 39Ge(π), 64N(0, 1), 30N(µ; σ2), 30NB(r; π), 66Po(λ), 70U(a; b), 23Γ(ν), 38Λ(µ; σ2), 87χ2
n, 45∼, 36∼, 23b(n; π), 61tν , 82
Anpassungstest, 46Anzahl der Erfolge, 63Apriori-Dichtefunktion, 191Apriori-Verteilung, 58, 191Arcus-Sinus-Verteilung, 58
verallgemeinerte, 58Ausfallzeit, 167
BayesTheorem von, 186, 187
Bayes’sche Verfahren, 69, 186, 190bedingte Verteilung, 110bedingte Wahrscheinlichkeit, 187Bernoulli-Verteilung, 60, 74, 75
Anwendungen, 61Erwartungswert, 61Parameter, 60
Schatzung, 144Varianz, 61Wahrscheinlichkeitsfunktion, 60
Beta-Binomialverteilung, 58, 173, 201
Parameter, 176Verteilungsfunktion, 177Wahrscheinlichkeitsfunktion, 176, 177
Betafunktion, 53Betaverteilung, 53, 192, 201
Anwendungen, 58Dichtefunktion, 53Erwartungswert, 54Parameter, 53R-Befehle, 58Varianz, 54
Bias, 151Binomialkoeffizient, 64Binomialverteilung, 58, 61, 74, 76, 77, 201
Erwartungswert, 61Parameter, 61R-Befehle, 63Varianz, 61Wahrscheinlichkeitsfunktion, 61
Black-Scholes-Formel, 37Brownsche Bewegung, 37
Chiquadratverteilung, 44, 80, 81, 86Anwendungen, 45Dichtefunktion, 45Erwartungswert, 45Freiheitsgrade, 45Gestalt, 45Parameter, 45R-Befehle, 47Varianz, 45zentrale, 47
Cramer-rao-Schranke, 159
Dichtefunktion, 3, 9bedingte, 111, 128gemeinsame, 92, 111, 125
diskret, 1, 90diskrete Mischung
diskreter Verteilungen, 160stetiger Verteilungen, 166
210

Index 211
effizient, 158effizienter, 158Effizienz, 158Eigenvektor, 138Eigenwert, 138Erfolg, 60, 74Erfolgswahrscheinlichkeit, 61Ergebnismenge
Zerlegung, 186Erlangverteilung, 44erwartungstreu, 132, 150
asymptotisch, 151Erwartungswert, 12, 102, 126
als endgultiger Mittelwert, 14, 17als Schwerpunkt, 13, 16bedingter, 114einer diskreten ZV, 12einer Funktion der ZV, 17, 18einer Konstanten, 19einer stetigen ZV, 15einer Summe, 19Interpretation, 13Rechenregeln, 19, 102
Exponentialverteilung, 7, 9, 11, 40, 47, 79Anwendungen, 50Dichtefunktion, 47
alternative Darstellung, 48Erwartungswert, 49Parameter, 47
Schatzung, 143R-Befehle, 52Varianz, 49Verteilungsfunktion, 28, 49
Umkehrfunktion, 29
F-Test, 86Prufgroße, 47, 86
F-Verteilung, 47, 85, 86Dichtefunktion, 85Parameter, 85R-Befehle, 86zentrale, 86
fair, 1Fehler, 152Fisher, 144Formel
der totalen Wahrscheinlichkeit, 187Freiheitsgrade, 82, 85
Gammafunktion, 38, 39Gammaverteilung, 38, 79, 80, 197, 202
Anwendungen, 42Dichtefunktion, 39Erwartungswert, 40Gestalt, 41Parameter, 39
Schatzung, 143R-Befehle, 41Varianz, 40
Gemeinsame Verteilung, 902 Zufallsvariablen , 90
Geometrische Verteilung, 64, 75Parameter, 64R-Befehle, 66Varianz, 64Wahrscheinlichkeitsfunktion, 64
Glattung, 169Gleichverteilung, 23
Haufigkeitstabellen, 70Hohenlinien, 105Hypothese
uber Erwartungswert, 84uber Erwartungswerte
in Gruppen, 86uber Varianz, 45, 82
Hypothesentest, 27
Jungengeburten, 174
Konfidenzintervall, 84konjugierte Verteilung, 58, 192, 196, 205Konsistenz, 155
im quadratischen Mittel, 155schwache, 156starke, 156
Kontingenztafeln, 46Korrelationskoeffizient, 105, 119Korrelationsmatrix, 129Kovarianz, 104
Interpretation, 105Rechenregel, 104
Kovarianzmatrix, 128, 131
Lageparameter, 30Lebensdauer, 50Likelihoodfunktion, 145
fur Mischverteilungen, 179

212 Index
Lineare Kongruenz-Methode, 28Lineare Modelle, 47Linearkombinationen, 134Loglikelihoodfunktion, 146
Maximum, 146Lognormalverteilung, 87
Anwendungen, 89Dichtefunktion, 87Erwartungswert, 89R-Befehle, 89Varianz, 89Verteilungsfunktion, 87
Lotze, R. H., 144
Munzwurf, 1, 12, 144Wahrscheinlichkeitsfunktion, 1
Markoffsche Eigenschaft, 50, 66Maximum-Likelihood-Methode, 144Maximum-Likelihood-Schatzer, 37, 144Methode der Momente, 142Mischverteilungen, 69, 160
Erwartungswert, 163Momente, 163Negative Binomialverteilung, 177Varianz, 164
Misserfolg, 60, 74Mittelwertpfad, 14mittlerer quadratischer Fehler, 154Moment
um den Erwartungswert, 20gemeinsames, 102, 103
um Erwartungswert, 103k-tes, 19zentrales, 20zentriertes, 20
Momente, 19gemeinsame, 127
MQF-wiksamer, 158
negative Binomialverteilung, 66, 75, 77, 203Erwartungswert, 68Parameter, 66R-Befehle, 69Varianz, 68Wahrscheinlichkeitsfunktion, 66
Nichtzentralitatsparameter, 47, 84, 86Normalverteilung, 29, 77–80, 82, 85, 87,
204Bedeutung, 35
bivariate, 105, 119, 130bedingte Verteilungen, 121Dichtefunktion, 119Hohenlinien, 120Parameter, 119R-Befehle, 122Randverteilungen, 121Standardform, 120
Dichtefunktion, 29Erwartungswert, 33Likelihoodfunktion, 148Loglikelihoodfunktion, 148multivariate
bedingte Vert., 140Randverteilungen, 140
p-dimensionale, 130Definition, 137Dichtefunktion, 130Parameter, 130Schatzer, 132
Parameter, 29Schatzung, 143, 148
R-Befehle, 37singulare, 137Standard, 30, 137Varianz, 33Verteilungsfunktion, 32
Okonometrie, 47orthonormiert, 138
P-Wert, 27Verteilung unter der Nullhypothese, 27
Parameterscale, 41Schatzung, 142Schatzung fur Mischungen, 179Schatzung mit C.A.MAN, 182shape, 41
partielle Integration, 35Poissonprozess, 42, 51, 70, 72
Definition, 51Intensitat, 73raumlicher, 70Wartezeit, 42Zeit zwischen Ereignissen, 51
Poissonverteilung, 69, 70, 76, 78, 197, 202Anwendungen, 70Approximation

Index 213
der Binomialverteilung, 70durch Normalverteilung, 70
Erwartungswert, 70Likelihoodfunktion, 147Loglikelihoodfunktion, 147Parameter, 70
Schatzung, 143, 146R-Befehle, 73Varianz, 70Wahrscheinlichkeitsfunktion, 70
positiv definit, 137Posteriori-Verteilung, 192pradiktive Verteilung, 69, 200Prufgroße, 27
asymptotische Verteilung, 27Pseudo-Zufallszahlen, 28
R-Befehlbeta, 53choose, 64contour, 105, 123dbbinom, 177dbeta, 59dbinom, 63dbnorm, 122dchisq, 47density, 170dexp, 52df, 86dgamma, 41dgeom, 66dlnorm, 89dnbinom, 69dnorm, 37dpois, 73dt, 84dunif, 29gamma, 39image, 105, 123pbbinom, 177pbeta, 59pbinom, 64pchisq, 47persp, 122pexp, 53pf, 86pgamma, 42, 44pgeom, 66
plnorm, 89pnbinom, 69pnorm, 37ppois, 73pt, 84punif, 29qbeta, 59qbinom, 64qchisq, 47qexp, 53qf, 87qgamma, 42qgeom, 66qlnorm, 89qnbinom, 69qnorm, 38qpois, 73qt, 84qunif, 29rbeta, 59rbinom, 64rbnorm, 122rchisq, 47rexp, 53rf, 87rgamma, 42rgeom, 66rlnorm, 89rnbinom, 69rnorm, 38rpois, 73rt, 84runif, 29s3bnormpersp.fun, 122s3bormcon.fun, 123
Randdichtefunktion, 97, 108, 112, 127random walk, 58Randverteilungsfunktion, 127Randwahrscheinlichkeitsfunktion, 92, 127Rechenregeln
fur Erwartungswerte, 19Rechteckverteilung, 23
Dichtefunktion, 23empirische Verteilungsfunktion, 26Erwartungswert, 24Histogramm, 26Likelihoodfunktion, 149Parameter, 23

214 Index
Schatzung, 149R-Befehle, 29Standardform, 23Varianz, 24Verteilungsfunktion, 23
Regressionsanalyse, 86, 133relative Haufigkeit, 190Rendite, 172robust, 37
scale-Parameter, 41Schatzer
Bias, 151Eigenschaften, 150erwartungstreuer, 150Fehler, 152Standardabweichung, 152Standardfehler, 152Streuung, 152
Schatzfunktion, 150Schatzmethoden, 142shape-Parameter, 41Siginifikanzniveau
Einhaltung des, 27Standardabweichung, 22, 152Standardfehler, 152Standardnormalverteilung, 30
Verteilungsfunktion, 31Standardrechteckverteilung, 23stetig, 3, 90stetige Mischung, 177
diskreter Verteilungen, 173Stichprobenmoment, 142Stochastischer Prozess, 37Streuung, 22
einer Konstanten, 22Streuungsmaß, 22Streuungsparameter, 31Substitution, 32, 34Summe der Quadrate, 82, 86Summe der Quadrate Gruppen, 86Summe der Quadrate Rest, 86Summe von Quadraten, 46Summen und Linearkombinationen, 134
t-TestPrufgroße, 84
t-Verteilung, 82Dichtefunktion, 82
Erwartungswert, 82Parameter, 82R-Befehle, 84zentrale, 84
totale Wahrscheinlichkeit, 187Tschebyscheffsche Ungleichung, 157
Uberlebenszeitfunktion, 52uberschatzen, 150unabhangig, 127Unabhangigkeit, 98, 110, 116, 131Unabhangigkeitstest, 46Uniform, 23unkorreliert, 105Unkorreliertheit, 131unterschatzen, 150
Varianz, 20, 103bedingte, 115Berechnung, 20Rechenregeln, 21Schatzer, 46
Varianzanalyse, 46, 82, 86Verteilung
χ2-nichtzentrale, 140
identische, 23konjugierte, 192, 196, 205ohne Gedachtnis, 51, 65pradiktive, 200seltener Ereignisse, 77
Verteilungendiskrete, 60stetige, 23
Verteilungsfunktion, 6Eigenschaften, 9einer diskreten ZV, 6, 8einer stetigenm ZV, 6gemeinsame, 99, 126
Wahrscheinlichkeit, 3bedingte, 187Interpretation
klassisch, 190subjektive, 190
totale, 187Wahrscheinlichkeitsfunktion, 1, 9
bedingte, 110, 128Eigenschaften, 3

Index 215
gemeinsame, 91, 110, 125Eigenschaften, 91
Wiener-Prozess, 37wirksamer, 158wirksamst, 158
Zahldaten, 70Zentraler Grenzwertsatz, 36, 77, 79, 80zentrales Moment, 20zentriertes Moment, 20Zerlegung, 186Zufallsvariable
diskrete, 1Erwartungswert, 12Standardabweichung, 22stetige, 3, 125Streuung, 22Varianz, 20Verteilung, 1Verteilungsfunktion, 6
Zufallsvariablenp-dimensionale, 125
ZufallszahlenErzeugung, 28
exponentialverteilter, 28Erzeugung von, 23

Formeln
Kapitel 1: Zufallsvariablen und ihre Verteilung
Diskret: PX(x) = P (X = x) Stetig: P (a ≤ X ≤ b) =b∫
afX(x)dx a ≤ b
FX(t) = P (X ≤ t) t ∈ IR
Diskret: FX(t) =∑
x≤tPX(x) Stetig: FX(t) =
t∫
−∞fX(x)dx
Diskret: PX(x) = FX(x) − limh→0h>0
FX(x − h) Stetig: fX(x) = F ′X(x)
P (a < X ≤ b) = FX(b) − FX(a)
Kapitel 2: Erwartungswert
Diskret: EX =∑
xxPX(x) Stetig EX =
∞∫
−∞xfX(x)dx
Diskret: EH(X) =∑
xH(x)PX(x) Stetig: EH(X) =
∞∫
−∞H(x)fX(x)dx
Ec = c EcH(X) = cEH(X) E(H(X) + G(X)) = EH(X) + EG(X)µ′
k = EXk µk = E(X − µ)k
µ2 = σ2X = E(X − EX)2 = V ar(X) = EX2 − (EX)2
V ar(c) = 0 V ar(cX) = c2V arX V ar(X + c) = V arX
Kapitel 3: Stetige VerteilungenRechteckverteilung: X ∼ U(a; b)
fX(x) =
1
b−afur a ≤ x ≤ b
0 sonst .FX(t) =
0 fur t < at−ab−a
fur a ≤ t ≤ b
1 fur t > b .
EX = b+a2
V ar(X) = (b−a)2
12
dunif(x, min=0, max=1) punif(q, min=0, max=1)qunif(p, min=0, max=1) runif(n, min=0, max=1)Normalverteilung: X ∼ N(µ; σ2) −∞ < µ < ∞ σ2 > 0fX(x) = 1√
2πσ2e−(x−µ)2/2σ2 −∞ < x < ∞
X ∼ N(0; 1) FX(x) = Φ(x) =x∫
−∞f(z)dz =
x∫
−∞1√2π
e−z2/2dz
X ∼ N(µ; σ2) =⇒ Z = X−µσ
∼ N(0, 1) FX(x) = Φ(
x−µσ
)
−∞ < x < ∞EX = µ V ar(X) = σ2
Xn−µσ/
√n∼N(0; 1) EXn = µ und V arXn = σ2/n
dnorm(x, mean=0, sd=1) pnorm(q, mean=0, sd=1)qnorm(p, mean=0, sd=1) rnorm(n, mean=0, sd=1)]
Gammaverteilung: Γ(ν) =∞∫
0tν−1e−tdt Γ(1) = 1 Γ(n) = (n − 1)!
216

Formeln 217
X ∼ G(ν; λ) ν > 0 und λ > 0 G(1; λ) ≡ Exp(λ)
fX(x) =
λνxν−1e−λx
Γ(ν)x ≥ 0
0 sonst .EX = ν/λ V ar(X) = ν/λ2
dgamma(x, shape,scale=1) pgamma(q, shape,scale=1)qgamma(p, shape,scale=1) rgamma(n, shape,scale=1) scale= 1/λ
Xi ∼ Exp(λ) =⇒ν∑
i=1Xi ∼ G(ν; λ)
Chiquadratverteilung: X ∼ χ2n n ∈ IN χ2
n ≡ G(n/2; 1/2)EX = n V ar(X) = 2n
Xi ∼ N(µ; σ2) S2 = 1n
n∑
i=1(Xi − X)2 =⇒ nS2
σ2 ∼ χ2n−1
dchisq(x, df) pchisq(q, df, ncp=0)qchisq(p, df) rchisq(n, df)Exponentialverteilung: X ∼ Exp(λ) λ > 0 Exp(λ) ≡ G(1; λ)
f(x) =
λe−λx 0 ≤ x < ∞0 sonst
F (t) =
0 fur t < 01 − e−λt fur t ≥ 0 .
EX = 1λ
V ar(X) = 1λ2
dexp(x, rate=1) pexp(q, rate=1) qexp(p, rate=1) rexp(n, rate=1)Betaverteilung: X ∼ Be(α; β) α > 0 und β > 0
fX(x) =
xα−1(1−x)β−1
B(α,β)0 ≤ x ≤ 1
0 sonstB(α, β) =
1∫
0tα−1(1 − t)β−1dt = Γ(α)Γ(β)
Γ(α+β)
E(X) = αα+β
V arX = αβ(α+β)2(α+β+1)
dbeta(x, shape1, shape2) pbeta(q, shape1, shape2)qbeta(p, shape1, shape2) rbeta(n, shape1, shape2)
Kapitel 4: Diskrete VerteilungenBernoulli-Verteilung: X ∼ Ber(π) 0 < π < 1
PX(x) =
1 − π fur x = 0π fur x = 10 sonst .
EX = π V ar(X) = π(1 − π)
Binomialverteilung: X ∼ b(n; π) n ∈ IN 0 < π < 1
PX(x) =
(nx
)
πx(1 − π)n−x x = 0, 1, 2, ..., n
0 sonstEX = nπ V ar(X) = nπ(1 − π)
dbinom(x, size, prob) pbinom(q, size, prob)qbinom(p, size, prob) rbinom(n, size, prob)Geometrische Verteilung: X ∼ Ge(π) 0 < π < 1
PX(x) =
(1 − π)xπ x = 0, 1, 2, ...0 sonst
EX = 1−ππ
V arX = 1−ππ2
dgeom(x, prob) pgeom(q, prob)qgeom(p, prob) rgeom(n, prob)Negative Binomialverteilung: X ∼ NB(r; π) r ∈ IN 0 < π < 1
PX(x) =
(x+r−1
r−1
)
πr(1 − π)x x = 0, 1, 2, . . .
0 sonstEX = r 1−π
πV ar(X) = r 1−π
π2
dnbinom(x, size, prob) pnbinom(q, size, prob)qnbinom(p, size, prob) rnbinom(n, size, prob)Poissonverteilung: X ∼ Po(λ) λ > 0
PX(x) =
λxe−λ
x!x = 0, 1, 2, ...
0 sonst.EX = λ V arX = λ

218 Formeln
dpois(x, lambda) ppois(q, lambda)qpois(p, lambda) rpois(n, lambda)
Kapitel 5: Beziehungen zwischen Verteilungen
Xi ∼ Ber(π) unabhangig =⇒ X =n∑
i=1Xi ∼ b(n; π)
Xi ∼ b(ni; π) i = 1, 2 unabhangig =⇒ X1 + X2 ∼ b(n1 + n2; π)Ge(π) ≡ NB(1; π)
Xi ∼ Ge(π) unabhangig =⇒ X =r∑
i=1Xi ∼ NB(r; π)
Xi ∼ NB(ri; π) i = 1, 2 unabhangig =⇒ X1 + X2 ∼ NB(r1 + r2; π)X ∼ b(n; π) mit π ,,klein” und n ,,groß” =⇒ X∼Po(λ) mit λ = nπX ∼ b(n; π) mit n ,,groß” =⇒ X∼N(µ; σ 2) mit µ = nπ σ2 = nπ(1 − π)X ∼ NB(r; π) mit r ,,groß” =⇒ X∼N(µ; σ 2) mit µ = r(1 − π)/π σ2 = r(1 − π)/π2
Xi ∼ Po(λi) unabhangig =⇒ X1 + X2 ∼ Po(λ1 + λ2)X ∼ Po(λ) mit λ ,,groß” =⇒ X∼N(µ; σ 2) mit µ = λ σ2 = λ
Xi ∼ Exp(λ) =⇒ν∑
i=1Xi ∼ G(ν; λ)
X ∼ G(ν; λ) mit ν ,,groß” =⇒ X∼N(µ; σ 2) mit µ = ν/λ σ2 = ν/λ2
Xi ∼ G(νi; λ) unabhangig =⇒ X1 + X2 ∼ G(ν1 + ν2; λ)Xi ∼ χ2
niunabhangig =⇒ X1 + X2 ∼ χ2
n1+n2
X ∼ χ2n mit n ,,groß” =⇒ X∼N(µ; σ 2) mit µ = n σ2 = 2n
Xi ∼ N(µ; σ2) unabhangig =⇒ X =n∑
i=1Xi ∼ N(nµ; nσ2)
Xi ∼ N(µi; σ2i ) unabhangig =⇒ X =
n∑
i=1Xi ∼ N(
n∑
i=1µi;
n∑
i=1σ2
i )
Xi ∼ N(0, 1) unabhangig =⇒ X =n∑
i=1X2
i ∼ χ2n
Xi ∼ N(µ; σ2) unabhangig X = 1n
n∑
i=1Xi S2 = 1
n
n∑
i=1(Xi−X)2 =⇒ nS2
σ2 ∼ χ2(n−1)
t-Verteilung: X ∼ tν ν ∈ IN EX = 0X1 ∼ N(0; 1), X2 ∼ χ2(ν) unabhangig =⇒ X1√
X2/ν∼ t(ν)
Xi ∼ N(µ; σ2) unabhangig S2∗ = 1
n−1
n∑
i=1(Xi − X)2 X−µ
S∗/√
n∼ tn−1
dt(x, df) pt(q, df, ncp=0) qt(p, df) rt(n, df)F-Verteilung: X ∼ F (ν1; ν2) νi ∈ IN, i = 1, 2
Xi ∼ χ2νi
=⇒ X1/ν1
X2/ν2∼ F (ν1; ν2)
df(x, df1, df2) pf(q, df1, df2, ncp=0)qf(p, df1, df2) rf(n, df1, df2)Lognormalverteilung:: X ∼ Λ(µ; σ2) ∞ < µ < ∞ σ2 > 0
f(x) =
1
x√
2πσ2e−(log x−µ)2/2σ2
x > 0
0 sonstFX(x) = Φ
(log x−µ
σ
)
X ∼ Λ(µ; σ2) =⇒ log X ∼ N(µ; σ2) Y ∼ N(µ; σ2) =⇒ eY ∼ Λ(µ; σ2)EX = eµ+σ2/2 V ar(X) = e2µeσ2
(eσ2 − 1)dlnorm(x, meanlog=0, sdlog=1) plnorm(q, meanlog=0, sdlog=1)qlnorm(p, meanlog=0, sdlog=1) rlnorm(n, meanlog=0, sdlog=1)
Kapitel 6: Gemeinsame Verteilung von ZufallsvariablenPXY (x, y) = P (X = x, Y = y) PX(x) =
∑
yPXY (x, y) PY (y) =
∑
xPXY (x, y)

Formeln 219
P (a ≤ X ≤ b; c ≤ Y ≤ d) =b∫
a
d∫
cfXY (x, y)dy dx a ≤ b c ≤ d
fX(x) =∞∫
−∞fXY (x, y)dy fY (y) =
∞∫
−∞fXY (x, y)dx FXY (x, y) = P (X ≤ x; Y ≤ y)
Diskret: FXY (x, y) =∑
s≤x
∑
t≤yPXY (s, t) Stetig: FXY (x, y) =
x∫
−∞
y∫
−∞fXY (s, t)dt ds
fXY (x, y) = ∂2
∂x∂yFXY (x, y)
EH(X, Y ) =
∑
x
∑
yH(x, y)PXY (x, y) X und Y diskret
∞∫
−∞
∞∫
−∞H(x, y)fXY (x, y)dydx Xund Y stetig
E(cH(X, Y )) = cEH(X, Y ) E[(H(X, Y ) + G(X, Y )] = EH(X, Y ) + EG(X, Y )µ′
rs = EXrY s µrs = E(X − µX)r(Y − µY )s
µ11 = Cov(X, Y ) = σXY = E(X − µX)(Y − µY ) = EXY − EX · EY
ρXY = σXY
σXσY= cov(X,Y )√
V ar(X)V ar(Y )−1 ≤ ρXY ≤ 1
PY |X(y|x) = PXY (x,y)PX(x)
PX|Y (x|y) = PXY (x,y)PY (y)
fY |X(y|x) = fXY (x,y)fX(x)
fX|Y (x|y) = fXY (x,y)fY (y)
Unabhangigkeit: PXY (x, y) = PX(x)PY (y) fXY (x, y) = fX(x)fY (y)Bivariate Normalverteilung: (X1, X2) ∼ N(µ1, µ2, σ
21, σ
22, ρ)
fX1X2(x1, x2) = 1
2πσ1σ2
√1−ρ2
exp
− 12(1−ρ2)
[(x1−µ1
σ1
)2 − 2ρx1−µ1
σ1
x2−µ2
σ2+(
x2−µ2
σ2
)2]
X1 ∼ N(µ1; σ21) X2 ∼ N(µ2; σ
22)
X1|X2 = x2 ∼ N(µ1 + ρσ1(x2 − µ2)/σ2; σ21(1 − ρ2))
X2|X1 = x1 ∼ N(µ2 + ρσ2(x1 − µ1)/σ1; σ22(1 − ρ2))
Kapitel 7: P-dimensionale ZufallsvariablenDie p-dimensionale Normalverteilung: X ∼ N(µ; Σ)
fX1X2...Xp(x1, x2, . . . , xp) = 1
(2π)p/2√
det (Σ)e−(x−µ)
tΣ−1(x−µ)/2
Summen und Linearkombinationen von Zufallsvariablen:S = X1 + X2 + . . .Xn = 1tX L = a1X1 + a2X2 + . . . anXn = atX ai ∈ IR
E(S) =n∑
i=1µi V ar(S) =
n∑
i=1σ2
i +n∑
i=1i6=j
n∑
j=1σij
E(L) =n∑
i=1aiµi = atµ V ar(L) =
n∑
i=1a2
i σ2i +
n∑
i=1i6=j
n∑
j=1aiajσij = atΣa
Xn = 1n
n∑
i=1Xi = 1
n1tX EXn = 1
n
n∑
i=1µi = µ falls Xi identisch verteilt
V arXn = 1n2
n∑
i=1σ2
i + 1n2
n∑
i=1i6=j
n∑
j=1σij = 1
n2
n∑
i=1σ2
i falls Xi unabhangig
= σ2/n falls Xi unabh. und identisch verteilt
Kapitel 8: Schatzung von Parametern
m′k = 1
n
n∑
i=1xk
i L(θ) =n∏
i=1f(xi; θ) bzw. =
n∏
i=1P (xi; θ)
Bias(θ) = Eθ − θ SF(θ) =√
Var(θ) MQF(θ) = E(θ − θ)2 = Var(θ) + (Bias(θ))2
Konsistenz im quadratischen Mittel: limn→∞
MQF (θ) = 0
Schwache Konsistenz: limn→∞
P (|θ − θ| < ε) = 1
Ungleichung von Tschebyscheff: P (|X − µ| ≥ c) ≤ σ2
c2
Kapitel 9: Mischverteilungen

220 Formeln
P (x) =I∑
i=1riPi(x) 0 ≤ ri ≤ 1
I∑
i=1ri = 1 f(x) =
I∑
i=1rifi(x)
µ′k =
I∑
i=1riµ
′k(i) I = 2 : σ2 = r1σ
2(1) + r2σ2(2) + r1r2(µ(1) − µ(2))2
Beta-Binomialverteilung: n ∈ IN α > 0 β > 0
P (X = x) =
(nx
)B(x+α,n+β−x)
B(α,β)x = 0, 1, . . . , n
0 sonst .
Kapitel 10: Bayes’sche Verfahren
P (A) =k∑
i=1P (A|Bi) · P (Bi)
P (Bj|A) =P (A|Bj)P (Bj )k∑
i=1
P (A|Bi)P (Bi)
f(y|x) = f(x|y)f(y)∞∫
−∞
f(x|y)f(y)dy
f(y|X = x) = P (X=x|y)f(y)∞∫
−∞
P (X=x|y)f(y)dy
f(θ; x) = f(x|θ)f(θ) f(θ|X = x) = f(x|θ)f(θ)∞∫
−∞
f(x|θ)f(θ)dθ
(X stetig)
f(θ|X = x) = P (x|θ)f(θ)∞∫
−∞
P (x|θ)f(θ)dθ
(X diskret)


















