
Technische Grundlagen der Informatik - euk.cs.ovgu.deeuk.cs.ovgu.de/doc/scriptTGI.pdf · Ein...
131
Skript zur gleichnamigen Lehrveranstaltung Technische Grundlagen der Informatik Wickborn, Ihme, Gööck, Deutscher, Hoffmann 18. August 2011
-
Upload
nguyentruc -
Category
Documents
-
view
225 -
download
0
Transcript of Technische Grundlagen der Informatik - euk.cs.ovgu.deeuk.cs.ovgu.de/doc/scriptTGI.pdf · Ein...

Skript zur gleichnamigen Lehrveranstaltung
Technische Grundlagen der Informatik
Wickborn, Ihme, Gööck, Deutscher, Hoffmann
18. August 2011


Ausgabe 2008
Arbeitsgruppe Echtzeitsysteme und KommunikationOtto-von-Guericke-Universität Magdeburg
Technische Grundlagen der Informatik 3

4 Technische Grundlagen der Informatik

Technische Grundlagen der Informatik 5

Dieses Skript richtet sich im Wesentlichen an Studierende der Otto-von-Guericke-Universität, die an der Fakultätfür Informatik im ersten Semester Technische Grundlagen der Informatik als Pflicht- oder Wahlpflichtveranstaltunghören.An diesem Skript haben mitgearbeitet:
• Fabian Wickborn
• Thomas Ihme
• David Gööck
• Manfred Deutscher
• Jan Leif Hoffmann
Magdeburg, 2001–2008
6 Technische Grundlagen der Informatik

Inhaltsverzeichnis
1 Einführung 111.1 Der Transistor als analoges System . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.2 Das binäre System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3 Das Abstraktionsprinzip und seine Ebenen . . . . . . . . . . . . . . . . . . . . . . . 121.4 Hardware oder Software? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.5 Grobstruktur eines Rechners . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.6 Kommunikation zwischen den Komponenten . . . . . . . . . . . . . . . . . . . . . 15
2 Kombinatorische Schaltnetze 192.1 Die Basisgatter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2 Beispiele für kombinatorische Schaltnetze . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.1 Beispiel 1: Mehrheitsentscheider . . . . . . . . . . . . . . . . . . . . . . . . . 212.2.2 Beispiel 2: Multiplexer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.3 Beispiel 3: XOR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3 Äquivalenz von Schaltnetzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3 Boolesche Algebra 273.1 Einführung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.1 Beispiel: Entwurf eines 2-Bit-Multiplizierers . . . . . . . . . . . . . . . . . . 303.1.2 Assoziativität von NAND und NOR . . . . . . . . . . . . . . . . . . . . . . . . 343.1.3 Zusammenfassung boolesche Algebra . . . . . . . . . . . . . . . . . . . . . 35
3.2 Minimierung von Schaltfunktionen . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2.1 Karnaugh-Diagramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2.2 Don’t-care-Zustände . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4 Sequentielle Schaltungen 434.1 RS-Flipflop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.1.1 Beispiel Impulsfolgengenerator . . . . . . . . . . . . . . . . . . . . . . . . . 464.2 Getaktete Flipflops . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.3 Das D-Flipflop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3.1 Beispiel m-Bit-Datenbus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.4 Das JK-Flipflop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.5 Master-Slave-Flipflop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.6 Flankengesteuerte Flipflops . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.7 Zusammenfassung Flipflops . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.8 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.8.1 Register . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.8.2 Schiebe- und Rotationsregister . . . . . . . . . . . . . . . . . . . . . . . . . . 564.8.3 Frequenzteiler und Zähler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.9 Zustandsdiagramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.9.1 Beispiel Drei-Bit-Zähler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.10 Testen von digitalen Schaltungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
7

Inhaltsverzeichnis Inhaltsverzeichnis
4.10.1 Test durch Pfadsensitivierung . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.11 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5 Codes 655.1 Zeichencodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.1.1 ASCII oder „ISO 7-bit character code“ . . . . . . . . . . . . . . . . . . . . . . 665.1.2 ASCII-Fortentwicklung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 675.1.3 Unicode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.2 Bildcodierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.3 Ungewichtete Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 695.4 Huffman-Codierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.5 Fehler erkennende Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.5.1 Arbeitsweise Fehler erkennender Codes . . . . . . . . . . . . . . . . . . . . 755.5.2 Fehlererkennung durch Parität . . . . . . . . . . . . . . . . . . . . . . . . . . 765.5.3 Zyklische Redundanzcodes oder CRC . . . . . . . . . . . . . . . . . . . . . . 79
5.6 Fehlerkorrektur durch Hamming-Codierung . . . . . . . . . . . . . . . . . . . . . . 825.6.1 Weitere Eigenschaften von Hamming-Codes . . . . . . . . . . . . . . . . . . 84
6 Computerarithmetik 856.1 Zahlensysteme mit unterschiedlichen Basen . . . . . . . . . . . . . . . . . . . . . . 876.2 Zahlbasiswechsel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.2.1 Dezimal zu binär, oktal, hexadezimal . . . . . . . . . . . . . . . . . . . . . . 886.2.2 Binär zu dezimal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 896.2.3 Oktal zu dezimal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.2.4 Hexadezimal zu dezimal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
6.3 BCD – Binary Coded Decimal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.4 Darstellung ganzer Zahlen mit Vorzeichen . . . . . . . . . . . . . . . . . . . . . . . 91
6.4.1 Vorzeichen-/Betrag-Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . 916.4.2 Einerkomplement-Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . . 926.4.3 Zweierkomplement-Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.5 Überlauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 956.6 Addition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6.6.1 Halbaddierer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 956.6.2 Volladdierer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 966.6.3 Addition von Wörtern . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 986.6.4 Vorausschauende Addierer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.7 Multiplikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1036.7.1 Erste Version einer Multiplikations-Hardware . . . . . . . . . . . . . . . . . 1046.7.2 Zweite Version einer Multiplikations-Hardware . . . . . . . . . . . . . . . . 1056.7.3 Finale dritte Version einer Multiplikations-Hardware . . . . . . . . . . . . . 106
6.8 Der Booth-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1066.9 Schnelle Multiplikation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1126.10 Ganzzahldivision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
6.10.1 Erste Version einer Divisions-Hardware . . . . . . . . . . . . . . . . . . . . . 1146.10.2 Zweite Version einer Divisions-Hardware . . . . . . . . . . . . . . . . . . . . 1156.10.3 Finale dritte Version einer Divisions-Hardware . . . . . . . . . . . . . . . . 1176.10.4 Division mit Vorzeichen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.11 Festkommazahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1196.12 Gleitkommazahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
6.12.1 Mögliche Systeme für Gleitkommazahlen . . . . . . . . . . . . . . . . . . . 121
8 Technische Grundlagen der Informatik

Inhaltsverzeichnis Inhaltsverzeichnis
6.12.2 Akkurate Arithmetik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1246.12.3 Vereinfachte Algorithmen zur Berechnung von Gleitkommazahlen . . . . 126
6.13 Zusammenfassung Computerarithmetik . . . . . . . . . . . . . . . . . . . . . . . . 127
Technische Grundlagen der Informatik 9

Inhaltsverzeichnis Inhaltsverzeichnis
10 Technische Grundlagen der Informatik

1 Einführung
Heutzutage ist der Computer ein allgegenwärtiges Werkzeug geworden. Dass sich das so entwi-ckelt hat, ist zu einem großen Teil Verdienst der Entwicklung effizienter Nutzerschnittstellen:Ein Anwender bekommt nur noch das für ihn Wesentliche zu Gesicht; wie ein Rechner internfunktioniert, bleibt ihm dagegen verborgen. Dieses Verbergen von Detailinformationen nenntman Abstraktion.
Der Programmierer, der das Anwendungsprogramm des Nutzers geschrieben hat, benötigtauch kein ausgereiftes Detailwissen über die expliziten Vorgänge im Prozessor. Auch er ver-wendet eine Schnittstelle, die ihrerseits ein bereits abstrahiertes Bild der Vorgänge im Rechnerwiderspiegelt. Im Vergleich zum erstgenannten Anwender muss der Programmierer aber be-reits mehr über die Innereien eines Computers wissen.
Diese Abstraktionsunterteilung über das Wissen der Funktionsweise eines Computers ließesich entsprechend fortführen. Sie ist notwendig, da der Computer ein technisches Gerät ist,welches sich vom Vorgehen eines Menschen stark unterscheidet. Die Abstraktion ist der Weg,Mensch und Maschine „in einen Topf“ zu bekommen.
Sie als zukünftig programmierende Menschen erfahren in dieser Lehrveranstaltung die grund-legenden Dinge, die den Aufbau eines Computers ermöglichen: Ausgehend von elektronischenBauteilen wird auf deren Verknüpfung zu komplexen Schaltungen eingegangen und schließ-lich erklärt, wie Computer rechnen und es möglich ist, trotz der Beschränktheit auf die Dar-stellung von Null und Eins beliebige Daten abzuspeichern. Sie bekommen dadurch einen Blick„hinter die Kulissen“ und verstehen danach wahrscheinlich besser, warum sich ein Computerverhält, wie er sich verhält.
1.1 Der Transistor als analoges System
Ein Computer ist im Wesentlichen nichts anderes als ein Haufen elektronischer Schaltungen.Diese sorgsam verknüpften Bauelemente bestehen wiederum aus noch kleineren Bauelemen-ten.
Die Grundeinheit einer elektronischen Schaltung ist der Transistor. Als analoges Bauelementarbeitet er mit unendlich vielen Werten aus einem bestimmten Wertebereich (Betriebsspan-nung, Strom). In der Regel liegen Ein- und Ausgangsspannungen von wenigen Volt an. Für dieDarstellung von Informationen ist es sinnvoll, einen endlichen Wertebereich (Alphabet) miteiner bestimmten Anzahl von Elementen (Symbolen) zu nutzen. Dazu wird der Transistor alsSchalter betrieben. Die beiden Schaltzustände „offen“ und „geschlossen“ erlauben es, eine In-formation mit Hilfe des Alphabetes auf bestimmte Abschnitte des Wertebereiches (Symbole)abzubilden (siehe Abbildung 1.1).
Auffällig ist hierbei, dass jeweils der Eingabebereich größer als der Ausgabebereich ist. Da-durch kann ein „Rauschen“ (d. h. Spannungsschwankungen) auf dem Übertragungsweg vonder Ausgabe einer Schaltung zur Eingabe der folgenden toleriert werden. Die angegebenenGrenzen für die Spannungsbereiche H und L werden von den Herstellern garantiert. Die Dif-ferenz zwischen den Grenzen wird deshalb als garantierter statischer Störabstand bezeichnet.
11

1.2 Das binäre System 1 Einführung
Abbildung 1.1: Logik-Pegel am Beispiel von Standard-TTL
Bei realen Systemen führt jedoch nur ein sehr kleiner Teil des Wertebereiches im verbotenenBereich zu keiner definierten Zuordnung, sodass auch relativ stark verrauschte Signale (ver-zerrte Symbole) zugeordnet werden können.
Solche Eigenschaften machen sich so genannte Fehler korrigierende Codes, wie sie bei derNachrichtenübertragung eingesetzt werden, zunutze.
1.2 Das binäre System
In der Digitaltechnik bzw. in einem Computer umfasst das digitale Alphabet zwei Elemente:In Zahlen- und Sprachdarstellung 0 (Null) und 1 (Eins), in der Logik auch F(alse) und T(rue)genannt. Dieses Alphabet heißt Binärsystem, die Symbole sind binäre Ziffern (binary digits,kurz Bits). Ein Bit ist die kleinste Informationseinheit in einem Computer. Die Elemente desAlphabetes 0 und 1 werden auf die Spannungsbereiche für L (Low) und H (High) abgebildet.
Die Verwendung des Binärsystems resultiert aus folgenden Tatsachen:
• Die Symbole sind sich so unähnlich wie möglich; sie haben eine einheitliche Distanzund können somit nicht verwechselt werden.
• Das Prinzip der Zweiwertigkeit ist häufig anzutreffen: ja/nein, wahr/falsch, Strom fließt/fließtnicht (vgl. Aussagenlogik der Lehrveranstaltung Logik)
1.3 Das Abstraktionsprinzip und seine Ebenen
Ein Computer lässt sich als ein System, welches aus mehreren aufeinander aufbauenden Ebe-nen besteht, modellieren. Dabei baut jede Ebene auf der darunterliegenden Ebene auf, wases erlaubt, von den Details der unteren Ebene zu abstrahieren, d. h. sie in der Abstraktion zu„verstecken“.
Im Bereich der Hardware gibt es zwei wesentliche Ebenen:
12 Technische Grundlagen der Informatik

1 Einführung 1.3 Das Abstraktionsprinzip und seine Ebenen
Ebene Abstraktion Beispiel
4 Metasprache, Hochsprache graphische Programmierung
3 Hochsprache, problemorientiert C, Pascal, Fortran; C++, Java
2 Maschinensprache Assembler
1b komplexe Funktionseinheiten ALU, Steuerwerk, Speicher
1a einfache Funktionseinheiten Register
0 Gatter UND, ODER
-1 Transistoren CMOS, TTL
-2 Atome Elektronen-Loch-Modell
-3 Quanten Bänder / Quantenmodell
Tabelle 1.1: Abstraktionsebenen
• Logische oder Gatterebene (Gatter wie z. B. UND, ODER sind die kleinsten Komponen-ten einer logischen Schaltung)
• Physikalische oder Transistorebene (Transistor als kleinste Komponente von elektroni-schen Schaltungen)
Es bleibt die Frage, wie dem Computer beigebracht werden kann, Probleme zu lösen. Dazumuss der Hardware der Lösungsweg in kleinsten Schritten verständlich gemacht werden. Dasist Aufgabe der Software eines Rechners. Dazu müssen zunächst einmal die einzelnen Schrit-te formal beschrieben werden, d. h. es muss ein Algorithmus geschaffen werden. Dieser wirdanschließend in einer dem Computer verständlichen Sprache ausformuliert. Die Sprache wie-derum ist definiert durch den Befehlssatz, d. h. die Menge der Befehle, welche die Hardwareausführen kann.
Da die Sprache des Rechners nur aus Bitfolgen besteht, welche aus der Sicht des menschlichenBetrachters schwer verständlich ist, ist es notwendig, eine weitere Sprache mit einer definier-ten Menge von Befehlen zu entwerfen (Assemblersprache), welche durch den Computer (bzw.durch Software in Form eines Assemblers) in die Befehle seiner Maschinensprache übersetztwerden. Da auch das Schreiben von Assemblercode noch nicht optimal für den menschlichenProgrammierer ist, existieren aufbauend auf der Assemblersprache höhere Programmierspra-chen wie zum Beispiel C oder Pascal (das Übersetzungsprogramm heißt hierbei Compiler).
Diese Herangehensweise an eine Problemlösung ist eine wiederholte Anwendung des Abstrak-tionsprinzips. Eine detaillierte Darstellung der Ebenen könnte z. B. wie in Tabelle 1.1 aussehen.
Sowohl Hardware- als auch Softwaredesigner benutzen das Abstraktionsprinzip, um die Kom-plexität des Rechners besser zu beherrschen.
Für das Verständnis des Prinzips sei noch gesagt, dass es für die praktische Implementierungeiner Ebene ausreicht, die Ebene darunter zu kennen: Die Details der Implementierung wer-den in der nächsttieferen Ebene verborgen. Ein Beispiel: Wenn man versucht, Quellcode einerHochsprache in Assemblercode umzuwandeln, ist es überflüssig zu wissen, wie dieser Assem-blercode in Maschinensprache umgesetzt wird, solange man alle nötigen Assemblerbefehleund ihre Funktion kennt.
Für die Implementierung einer Abstraktion gibt es prinzipiell verschiedene Möglichkeiten. Inder Lehrveranstaltung Technische Grundlagen der Informatik und diesem (dazugehörigen)Skript werden die Ebenen 0 und 1a behandelt. Die Ebenen 1b und 2 sind Thema der Lehr-veranstaltung Rechnersysteme im zweiten Semester.
Die darüberliegenden Ebenen brauchen uns nicht zu interessieren, denn Hardware und Soft-ware sind zueinander logisch äquivalent, d. h. jeder Befehl, der von einer Softwareebene im-
Technische Grundlagen der Informatik 13

1.4 Hardware oder Software? 1 Einführung
plementiert wird, kann auch direkt durch Hardware ausgeführt werden und umgekehrt. Dabeiist die Hardwareimplementierung eines Befehls deutlich schneller.
Ein gutes Beispiel hierfür sind moderne Grafikkarten mit Chipsätzen, die Berechnungen vonkomplexen Bildern selbst durchführen, anstatt dies der langsameren Software zu überlassen.Die Implementierung wurde also „nach unten“ verlagert.
Auch der umgekehrte Weg ist möglich: In eingebetteten Systemen kommen zum Teil abge-speckte Prozessoren zum Einsatz, die keinen Gleitkommazahlen verarbeitenden Teil haben.Darum muss die Berechnung mit Kommazahlen vollständig in Software durchgeführt werden.Dies entspricht einer Verlagerung der Implementierung „nach oben“.
1.4 Hardware oder Software?
Eine der wichtigsten Entscheidungen beim Entwurf eines Rechners ist, was wird durch Hard-ware und was durch Software realisiert. Folgende Kriterien beeinflussen die Entscheidung:
• Kosten der Implementierung
• Geschwindigkeit
• Zuverlässigkeit
• Häufigkeit der unveränderten Nutzung
Eine direkte Ausführung in Hardware ist in der Regel der schnellste und zuverlässigste Weg,allerdings auch der teuerste (je zuverlässiger, desto teurer! Beispiel: militärische Anwendun-gen). Ein Programm für die existierende Hardware zu schreiben, welches denselben Befehlausführt, ist zwar billiger, dauert aber in der Programmausführung länger, da die Hardwarein diesem Fall nicht optimiert ist. Hierbei ist die Frage, wie häufig der Befehl voraussichtlichgenutzt wird, in die Überlegungen mit einzubeziehen.
Die Hardware definiert die Grenzen eines Rechners, insbesondere ihre Geschwindigkeit (z. B.muss der Navigationscomputer eines Flugzeuges Kurskorrekturen „schnell genug“ berechnenkönnen). Wie schnell ein Rechner nun ist, bestimmt die Hardware und ihre Einsatzsteuerung.Die Grenzen sind offensichtlich davon abhängig, wie ein Rechner eingesetzt wird:
• Workstation (Arbeitsplatzrechner, Bürorechner)
• Supercomputer (für naturwissenschaftliche Berechnungen in Gentechnik, Wetter- bzw.Klimaforschung, Urknallsimulation usw.)
• Server (zum Beispiel für Webseiten)
• Eingebettetes System (automatische Kontrolle in Autos, Waschmaschinen, Backöfen),eingebettet in ein Gesamtsystem und meist unsichtbar für den Benutzer, sogenannte„Konsumentenelektronik“
Letzterer Typ ist heutzutage mit Abstand der häufigste Einsatztyp für Rechner, speziell Mikro-prozessoren. Da meist bei diesen Anwendungen Interaktion mit der Außenwelt des zu kon-trollierenden Systems stattfindet, spielt Zeit neben der Korrektheit der Ausführung eine großeRolle; zeitliche (rechtzeitige) Ausführung zu garantieren ist implementierungsabhängig. Manmuss die Details kennen, Abstraktion hilft hier leider nicht weiter, da sie kein Mittel zur Garan-tie von zeitlicher, rechtzeitiger Ausführung ist (Ein Flugzeugpassagier braucht nicht zu wissen,wie die Instrumente im Cockpit funktionieren, der Pilot schon.).
14 Technische Grundlagen der Informatik

1 Einführung 1.5 Grobstruktur eines Rechners
Abbildung 1.2: Grobstruktur der Organisation eines Rechners
1.5 Grobstruktur eines Rechners
Grob betrachtet, arbeitet ein Rechner folgendermaßen (visualisiert in Abbildung 1.2):
• Die Daten werden von der Eingabe gelesen (z. B. von einem Terminal) und in den Spei-cher geschrieben.
• Der Hauptprozessor bekommt über den Datenpfad Daten aus dem Speicher.
• Die Kontrolleinheit steuert die Operationen (Befehle) aller anderen Komponenten undkoordiniert sie.
• Der Ausgang liest Daten aus dem Speicher und schreibt sie z. B. an einen Drucker, einTerminal oder einen Massenspeicher
Generell wird der Prozessor insgesamt als das Gehirn des Rechners bezeichnet.
1.6 Kommunikation zwischen den Komponenten
Die Komponenten kommunizieren über so genannte Busse (vgl. Abbildung 1.3). Dies Kommu-nikationsmedium ist meist bidirektional und geteilt, d. h. alle Komponenten können lesendund schreibend darauf zugreifen.
Auf dem Datenpfad im Prozessor befinden sich die ALU (Rechenwerk, engl. Arithmetic LogicUnit) und die Register. Die ALU ist eine komplexe Schalteinheit, in der die meisten Operatio-nen eines Rechners ausgeführt werden. Register (sowohl spezielle als auch allgemeine) sindsehr einfache und schnelle Speichereinheiten innerhalb der CPU. Jedes Register kann einenOperanden speichern. Die Wortlänge des Operanden ist dabei fest definiert. Sie werden zurkurzzeitigen Speicherung von häufig gebrauchten Operanden seitens der ALU genutzt. Auf-grund ihrer geringen Zugriffszeit (Register sind im Allgemeinen deutlich schneller als normaleSpeichereinheiten) erhöht sich somit die Geschwindigkeit der Ausführung der Operationen.
Insgesamt sind ALU und Kontrolleinheit sehr viel schneller als die anderen Komponenten desRechners. Die Kontrolleinheit versetzt den Prozessor in die Lage, alle Aktivitäten zu kontrol-lieren, zu koordinieren und zu organisieren, ähnlich wie ein Gehirn im menschlichen Körpergegenüber den anderen Organen.
Die Kontrolleinheit der CPU dekodiert den Inhalt des IR und bestimmt dabei die auszuführen-den Operationen. Wozu die allgemeinen Register und die ALU genutzt werden können, zeigtAbbildung 1.5.
Technische Grundlagen der Informatik 15
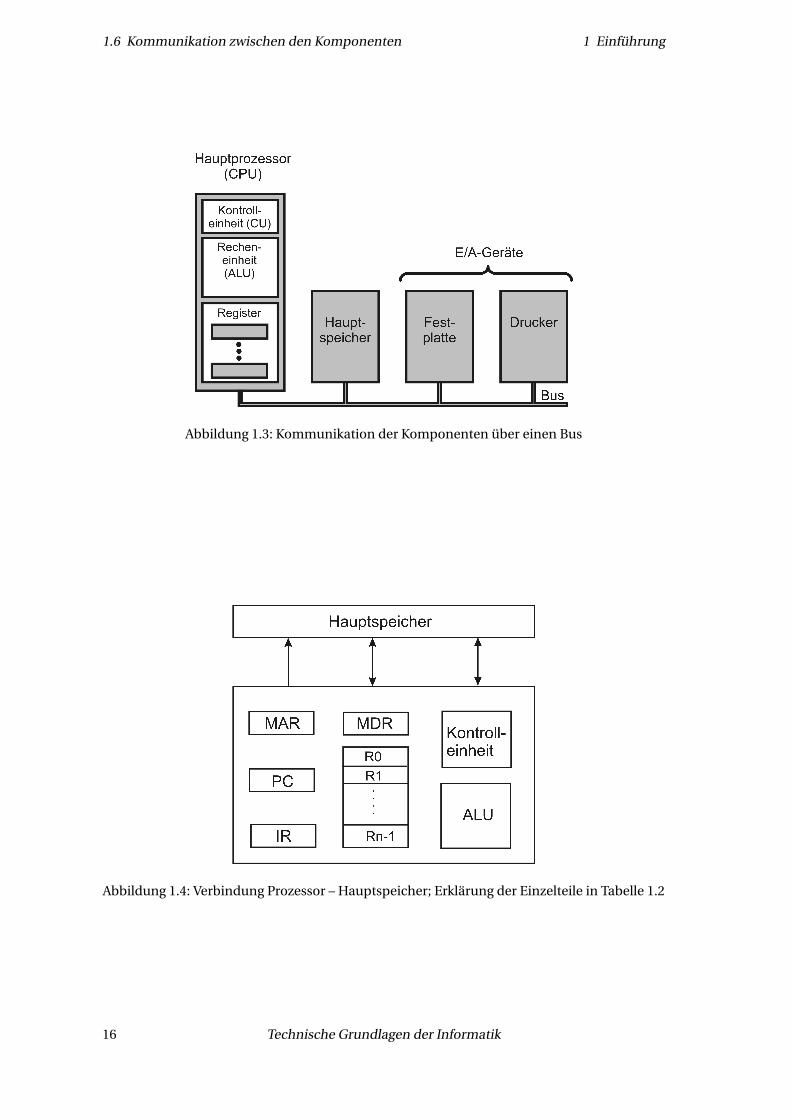
1.6 Kommunikation zwischen den Komponenten 1 Einführung
Abbildung 1.3: Kommunikation der Komponenten über einen Bus
Abbildung 1.4: Verbindung Prozessor – Hauptspeicher; Erklärung der Einzelteile in Tabelle 1.2
16 Technische Grundlagen der Informatik

1 Einführung 1.6 Kommunikation zwischen den Komponenten
CPU-Komponente Erklärung
MAR Memory Adress Register, Speicheradressregister: enthält Adresse, zu oder
von (je nachdem, ob Lesen oder Schreiben angeregt ist) der ein Wort
transferiert wird
MDR Memory Data Register, Speicherdatenregister: enthält das Datenwort,
welches geschrieben oder gelesen werden soll
IR Instruction Register, Befehlsregister: enthält den Befehl, der momentan
ausgeführt wird
PC Program Counter, Programmzähler: Der Programmzähler zeigt auf den
nächsten Befehl, der aus dem Speicher geholt wird, und heißt so, weil er die
Befehle hochzählt (er zählt also keine Befehle).
R0–Rn−1 n allgemeine Register
Tabelle 1.2: Aufgaben der CPU-Komponenten
Abbildung 1.5: Grobstruktur des Datenpfades
Der Datenpfad besteht aus den allgemeinen Registern (in der Regel 8–64) und der ALU. Die ty-pische Operation ist eine Register-Register-Operation: Zwei Registerinhalte (Operanden) wer-den nahezu gleichzeitig in die ALU geladen, diese führt eine Operation aus (in Abbildung 1.5eine Addition) und das Resultat wird in ein Register zurückgespeichert (welches auch ein Ope-randenregister sein könnte, das in diesem Fall überschrieben werden würde). Diese Proze-dur nennt man den Datenpfadzyklus; er ist das Herz des Prozessors. Je schneller er ist, destoschneller kann der gesamte Rechner werden (die tatsächliche Gesamtgeschwindigkeit hängtjedoch von vielen weiteren Faktoren ab).
Des Weiteren gibt es sogenannte Register-Speicher-Operationen: Bei diesen wird ein Operandüber MAR und MDR in ein ALU-Register geladen. Die Dateneinheiten, die zwischen Registerund Speicher hin- und herbewegt werden, nennt man Datenworte. Sie passen genau in einRegister, d. h. sie haben die gleiche Wortlänge.
Zum Ende der Einführung fassen wir die prinzipielle Arbeitsweise eines Rechners noch einmalzusammen:
• Der Rechner akzeptiert Informationen in der Form von Programmen und Daten durch
Technische Grundlagen der Informatik 17

1.6 Kommunikation zwischen den Komponenten 1 Einführung
Eingabeeinheit und speichert sie.
• Von da werden sie in der Regel in die ALU geladen.
• Verarbeitete Informationen verlassen den Rechner durch eine Ausgabeeinheit.
• Alle Aktivitäten innerhalb des Rechners werden gesteuert durch seine Kontrolleinheit.
Wie sind die Komponenten nun im Einzelnen entworfen (insbesondere Prozessor, Speicher,Ein- und Ausgabe) und wie funktionieren sie in sich und miteinander? Diese Fragen werdenzum Teil in dieser Lehrveranstaltung beantwortet, zum Teil im zweiten Semester in der Lehr-veranstaltung Rechnersysteme.
18 Technische Grundlagen der Informatik

2 Kombinatorische Schaltnetze
Ein kombinatorisches Schaltnetz ist die reale Umsetzung einer logischen oder mathematischenFunktion. Das kleinste Element eines solchen Schaltnetzes ist ein Gatter, eine Box (d. h. eineSchaltung) mit einem oder mehreren Eingängen und einem Ausgang, wobei der Ausgang dasErgebnis der Anwendung einer Funktion (realisiert durch das betreffende Gatter) auf die Ein-gangsbelegungen darstellt. Eingänge und Ausgang sind dabei zweiwertig, also 1 oder 0.
Abbildung 2.1: Beispiel für die Berechnung von y = f (x) = 2x2 +x +1 mit Gattern
In Abbildung 2.1 ist ein Beispiel dargestellt, wie man eine mathematische Funktion mit einemkombinatorischen Schaltnetz berechnen kann. Aus diesem Beispiel sind folgende Konventio-nen umgesetzt:
1. Schaltnetze werden in Richtung der Pfeilorientierung gelesen
2. Soll eine Variable an mehreren Eingängen angelegt werden (d. h. mit mehreren Eingän-gen verknüpft werden), dann wird dies durch einen Verknüpfungspunkt symbolisiert –im Gegensatz dazu, dass sich zwei Leitungen einfach im Design kreuzen, ohne mitein-ander verknüpft zu sein.
In sequentiellen Schaltungen hängen Ausgänge unter Umständen auch von früheren Ausgän-gen ab. Man braucht also so etwas wie Taktung, um die Schaltungen zu synchronisieren. Dazuspäter mehr.
2.1 Die Basisgatter
Es gibt eine Handvoll logischer Gatter, aus denen sich sämtliche kombinatorische Schaltnetzezusammensetzen lassen. Die grundlegenden davon (Abbildung 2.2) werden nachfolgend be-schrieben:
Die Gatter NICHT (NOT), UND (AND) und ODER (OR) repräsentieren die drei Grundoperatio-nen in der zweiwertigen Logik (boolesche Algebra). Mithilfe dieser drei Funktionen könnenalle anderen dargestellt werden. Die Gatter NAND (Not AND) und NOR (Not OR), die manauch als Reihenschaltung von UND und NICHT bzw. ODER und NICHT realisieren könnte,sind schneller und billiger als UND- bzw. ODER-Gatter. Ein weiterer Vorteil von NAND undNOR ist es, nur unter Verwendung einer dieser Gatterarten alle anderen Gattertypen realisie-ren zu können. Als letztes gibt es noch das Gatter XOR (gesprochen EX-OR, eXclusive OR); es
19

2.1 Die Basisgatter 2 Kombinatorische Schaltnetze
Abbildung 2.2: Symbole der logischen Gatter
entspricht einem “Entweder . . . oder . . .” und ist ein vielfach verwendetes logisches Elementbeim Vergleichen.
Die Kreise am Ausgang von NICHT, NAND und NOR werden Inversionsblasen (inversion bub-bles) genannt. Sie können zwischen Ein- oder Ausgangsleitung und Gattersymbol auftauchen.Ihre Funktion entspricht der eines NICHT-Gatters.
Die Funktion eines Gatters, also das Verhältnis von Eingangsvariablen zu Ausgangsvariablen,wird üblicherweise mit Wahrheitstabellen dargestellt. In ihnen wird für jede mögliche Kombi-nation von Eingaben (links des Doppelstrichs) der entsprechende Ausgaben (jeweils unterhalbeiner genannten Funktion, die sich aus den Eingaben kombiniert) angegeben. Tabelle 2.1 isteine solche Wahrheitstabelle; sie beschreibt die Basisgatter vollständig. Wie man sieht, lässtsich NAND als „Nicht beide“ und NOR als „Weder noch“ beschreiben.
A B NICHT(A) UND(A, B) ODER(A,B) NAND(A, B) NOR(A,B) XOR(A,B)
0 0 1 0 0 1 1 0
0 1 1 0 1 1 0 1
1 0 0 0 1 1 0 1
1 1 0 1 1 0 0 0
Tabelle 2.1: Wahrheitstabelle der in Abbildung 2.2 dargestellten Gatter
Wir können diese Gatter auch als Formel darstellen:
• NICHT(A) =¬A = A
• UND(A,B) = A∧B = A ·B = AB
• ODER(A,B) = A∨B = A+B
• XOR(A,B) = A⊕B
In dieser Lehrveranstaltung verwenden wir die jeweils am Zeilenende notierte Form.
In der Sprache der elektrischen Lehre ausgedrückt ist ein UND-Gatter die Serienschaltungzweier Schalter und ein ODER-Gatter die Parallelschaltung (Abbildung 2.3).
NICHT und XOR lassen sich als Öffner bzw. als Wechselschaltung implementieren (Abbildung 2.4).
Gatter mit zwei Eingängen lassen sich zur Steuerung der Informationsflusses einsetzen, wobeieiner der beiden Eingang die Funktion einer Steuerungsvariablen übernimmt. Dessen Bele-gung (0 oder 1) entscheidet über den Durchlass oder auch die Komplementierung des anderenEingangssignal (Abbildung 2.5).
20 Technische Grundlagen der Informatik

2 Kombinatorische Schaltnetze 2.2 Beispiele für kombinatorische Schaltnetze
Abbildung 2.3: Realisierung von UND und ODER mit elektrischen Schaltern
Abbildung 2.4: Realisierung von NICHT und XOR mit elektrischen Schaltern
2.2 Beispiele für kombinatorische Schaltnetze
In diesem Abschnitt werden drei Beispiele für einfache kombinatorische Schaltnetze gegeben,wie sie tatsächlich später anzutreffen sind.
2.2.1 Beispiel 1: Mehrheitsentscheider
In Abbildung 2.6 wird eine Schaltung mit drei Eingangsvariablen dargestellt, die aus drei UND-Gattern und einem ODER-Gatter besteht.
Man kann die drei Eingangsvariablen A, B und C, die jeweils die Werte 0 oder 1 annehmenkönnen, auf 23 = 8 verschiedene Weisen belegen. Um die Ausgabe F (Funktionswert) besserberechnen zu können, wurden für die Stellen P, Q und R jeweils zusätzlich Zwischenzuständeermittelt, die in der Wahrheitstabelle (Tabelle 2.2) mit aufgeführt werden.
Daraus ergibt sich die Ausgabefunktion F = P +Q +R = AB +BC + AC . F ist wahr (= 1, Stromfließt), wenn zwei der Eingänge auf wahr stehen. Solange aber nur maximal ein Eingang wahrist, ist der Ausgang falsch (= 0, kein Strom fließt). Die Ausgabe hat also denselben Wert wie dieMehrheit der Eingaben.
Eine solche Schaltung lässt sich verschiedentlich einsetzen. Beispielsweise kann sie als Mehr-heitsentscheider zu Fehlertoleranzzwecken eingesetzt werden. Dabei sollen Werte an den Ein-gängen stets den gleichen Wert haben. Ist dies nicht der Fall, weil bei einem der vorgeschalte-ten Geräte ein Fehler aufgetreten ist, ist das Ergebnis F der Schaltung trotzdem korrekt – bis zuein umgedrehtes Bit wird also korrigiert. Die Schaltung wird weiterhin in einer Addier-Einheiteingesetzt, auf die wir später eingehen werden.
Abbildung 2.5: Gatter als Steuerungseinheiten eines Informationsflusses X. Das Signal C steu-ert, ob und wie X weitergeleitet wird
Technische Grundlagen der Informatik 21

2.2 Beispiele für kombinatorische Schaltnetze 2 Kombinatorische Schaltnetze
Abbildung 2.6: Kombinatorisches Schaltnetz: Mehrheitsentscheider
A B C P = AB Q = BC R = AC F = P +Q +R0 0 0 0 0 0 0
0 0 1 0 0 0 0
0 1 0 0 0 0 0
0 1 1 0 1 0 1
1 0 0 0 0 0 0
1 0 1 0 0 1 1
1 1 0 1 0 0 1
1 1 1 1 1 1 1
Tabelle 2.2: Wahrheitstabelle für die Schaltung in Abbildung 2.6
2.2.2 Beispiel 2: Multiplexer
Eine nicht ganz so intuitiv verständliche Schaltung ist in Abbildung 2.7 dargestellt.
Auch diese Schaltung besitzt drei Eingaben, eine Ausgabe und drei Zwischenwerte. Daraus re-sultiert die Wahrheitstabelle, die in Tabelle 2.3 abgebildet ist.
Wie der Wahrheitstabelle zu entnehmen ist, gilt: Ist X Null, entspricht der Ausgang F dem Ein-gang Y . Ist aber X Eins, so entspricht F dem Eingang Z . Offenbar steuert in diesem SchaltnetzX also, welche der beiden Eingänge Y und Z zum Ausgang durchgeschaltet wird. Solch eineSchaltung nennt man Multiplexer mit zwei Eingängen. Man könnte die Schaltung auch Selek-tor nennen. Eine entsprechende elektrische Realisation ist in Abbildung 2.8 dargestellt.
Eine wichtige Anwendung für Multiplexer ist die Hardwareimplementierung einer If-Then-Else-Anweisung, d. h. die Durchführung einer zweiseitigen Auswahl. Eine Beispielschaltungwird in Abbildung 2.9 dargestellt.
Abhängig vom Inhalt einer Zelle des Condition-Code-Registers (ein Statusregister, welches Ei-genschaften des Ergebnisses einer vorausgegangenen Aktion des Rechners speichert), wirdder Programmzähler mit dem Inhalt des Registers X oder Y geladen. Diese Register enthaltenAdressen der entsprechend nächsten auszuführenden Instruktion.
22 Technische Grundlagen der Informatik

2 Kombinatorische Schaltnetze 2.2 Beispiele für kombinatorische Schaltnetze
Abbildung 2.7: Kombinatorisches Schaltnetz: Multiplexer
X Y Z P = X Q = Y P R = X Z F =QR0 0 0 1 1 1 0
0 0 1 1 1 1 0
0 1 0 1 0 1 1
0 1 1 1 0 1 1
1 0 0 0 1 1 0
1 0 1 0 1 0 1
1 1 0 0 1 1 0
1 1 1 0 1 0 1
Tabelle 2.3: Wahrheitstabelle für die Schaltung in Abbildung 2.7
2.2.3 Beispiel 3: XOR
Mit logischen Gattern lassen sich auch Schaltnetze erstellen, deren Funktion ein anderes logi-sches Gatter repräsentiert. Dies ist beispielsweise nötig, wenn nur bestimmte logische Gatterzur Verfügung stehen (zum Beispiel bei NAND-Flash, einer Speicherart). In diesem dritten Bei-spiel wird gezeigt, wie sich ein XOR-Gatter ohne die Verwendung eines XOR-Gatters erstellenlässt (Abbildung 2.10).
Dieses Schaltnetz stellt die folgende Funktion dar:
F = (A+B)AB = AB + AB
Der Wahrheitstabelle (Tabelle 2.4) lässt sich entnehmen, dass F genau dann Eins ist, wenngenau einer der Eingänge Eins ist; dies entspricht wie angekündigt dem XOR-Gatter.
Die Funktion F = AB + AB lässt sich auch in dieser Form in eine Schaltung umsetzen (Ab-bildung 2.11), wobei nur UND-, ODER- und NICHT-Gatter Verwendung finden. Ebenfalls ist
Abbildung 2.8: Schalterrepräsentation eines Multiplexers
Technische Grundlagen der Informatik 23
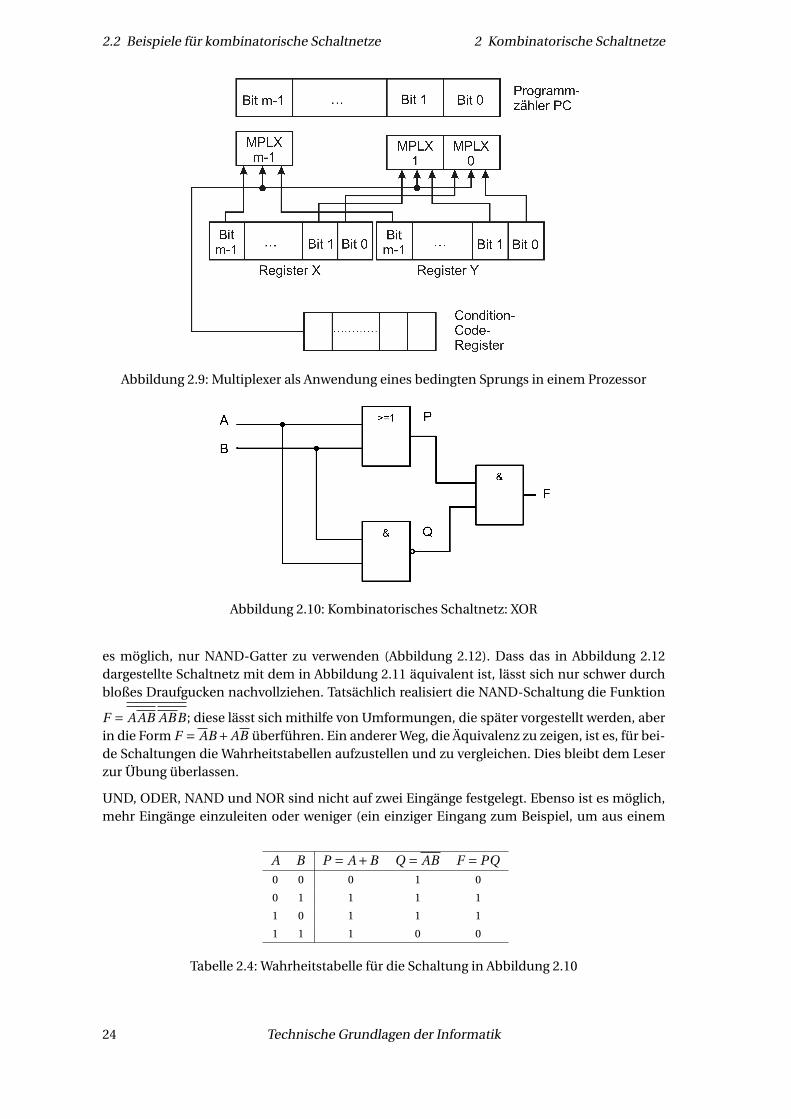
2.2 Beispiele für kombinatorische Schaltnetze 2 Kombinatorische Schaltnetze
Abbildung 2.9: Multiplexer als Anwendung eines bedingten Sprungs in einem Prozessor
Abbildung 2.10: Kombinatorisches Schaltnetz: XOR
es möglich, nur NAND-Gatter zu verwenden (Abbildung 2.12). Dass das in Abbildung 2.12dargestellte Schaltnetz mit dem in Abbildung 2.11 äquivalent ist, lässt sich nur schwer durchbloßes Draufgucken nachvollziehen. Tatsächlich realisiert die NAND-Schaltung die Funktion
F = A AB ABB ; diese lässt sich mithilfe von Umformungen, die später vorgestellt werden, aberin die Form F = AB +AB überführen. Ein anderer Weg, die Äquivalenz zu zeigen, ist es, für bei-de Schaltungen die Wahrheitstabellen aufzustellen und zu vergleichen. Dies bleibt dem Leserzur Übung überlassen.
UND, ODER, NAND und NOR sind nicht auf zwei Eingänge festgelegt. Ebenso ist es möglich,mehr Eingänge einzuleiten oder weniger (ein einziger Eingang zum Beispiel, um aus einem
A B P = A+B Q = AB F = PQ0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Tabelle 2.4: Wahrheitstabelle für die Schaltung in Abbildung 2.10
24 Technische Grundlagen der Informatik

2 Kombinatorische Schaltnetze 2.3 Äquivalenz von Schaltnetzen
Abbildung 2.11: XOR-Schaltnetz, nur aus UND, ODER und NICHT erstellt
Abbildung 2.12: XOR-Schaltnetz, nur aus NAND-Gattern erstellt
NAND ein NICHT zu machen). In der Praxis setzen allerdings der beschränkte Raum und dieProduktionskosten Grenzen. Das XOR-Gatter ist im Gegensatz zu den genannten Gattern aufzwei Eingänge festgelegt.
XOR-Gatter werden verwendet, um Bits zu vergleichen. Immer, wenn die beiden Eingänge ver-schieden sind, signalisiert der XOR-Ausgang dies mit einer Eins. Mit vielen XOR-Gattern lassensich ganze binäre Wörter vergleichen. Führt man alle XOR-Ausgänge schließlich in einem NORzusammen (wie in Abbildung 2.13 dargestellt), so liegt am Ausgang F ein Signal an, das Aus-kunft darüber gibt, ob alle Bits gleich sind (Eins) oder mindestens ein Unterschied aufgetretenist (Null). Eine solche Schaltung wird in Prozessoren eingesetzt, um ein Kriterium für einenbedingten Sprung schnell zu ermitteln.
2.3 Äquivalenz von Schaltnetzen
Zwei Schaltnetz sind zueinander äquivalent, wenn sie identische Wahrheitstabellen (beste-hend aus Eingangs- und Ausgangsbelegungen) haben. Für den Hardware-Entwickler als In-genieur und Menschen der Praxis spielt aber auch die Wirtschaftlichkeit eine hohe Rolle. Sogibt es für den Vergleich äquivalenter Schaltnetze mehrere Kriterien: Die Geschwindigkeit, dieAnzahl der Verbindungen und die integrierende, allgemeine Kostenfunktion.
Geschwindigkeit heißt hierbei, wie lange es dauert, bis eine neue Eingabebelegung das ent-sprechende Ausgabesignal generiert. Das Maß hierfür ist die maximale Anzahl von Gattern,durch die ein Zustandswechsel der Eingabevariablen propagiert werden muss (längster Weg),d. h. die maximale Anzahl der in Serie geschalteten Gatter im Schaltnetz. Dieses Maß zu mini-mieren heißt, die Geschwindigkeit zu maximieren. In der Praxis wird dies dadurch erschwert,dass nicht alle Gatter die gleiche Propagierungsverzögerung haben. Wie schon erwähnt, sindNAND- bzw. NOR-Gatter schneller als andere Gatter.
Technische Grundlagen der Informatik 25

2.4 Zusammenfassung 2 Kombinatorische Schaltnetze
Abbildung 2.13: Test auf Gleichheit zweier Worte durch XOR-Gatter
Dass die Anzahl der Verbindungen mit in Betracht gezogen werden muss, hat mehrere Gründe.Es kostet Geld, die Gatter miteinander zu verbinden. Je mehr Verbindungen existieren, destokomplexer und teurer wird der Entwurf. Gleichzeitig wächst die Wahrscheinlichkeit einer feh-lerhaften Verbindung (was die Anzahl der Verbindungen auch zu einem Maß für die Zuverläs-sigkeit macht).
Die integrierte allgemeine Kostenfunktion enthält das komplette Verbindungsmaß und Aspek-te des Geschwindigkeitsmaßes. Generell ist es ausreichend, sich darunter die Summe der An-zahl der Gatter und der Anzahl der Verbindungen vorzustellen.
Ein Schaltnetz ist minimal, wenn es bzgl. eines vorgegebenen Maßes (Kostenfunktion) keinäquivalentes Schaltnetz mit geringeren Kosten gibt.
2.4 Zusammenfassung
Gatter sind die Basiseinheiten von Schaltnetzen. Ihr Verhalten wird beschrieben durch Wahr-heitstabellen. Für die Entwicklung sind minimale Schaltnetze interessant. So bedarf es nuneiner formalen, eleganten (d. h. weniger umständlichen als das Hantieren mit Wahrheitstabel-len) Methodik zu Beschreibung, Analyse und Synthese sowie Minimierung von Schaltnetzen.
Dies wird Aufgabe der booleschen (Schalt-)Algebra sein, die im nächsten Kapitel behandeltwird.
26 Technische Grundlagen der Informatik

3 Boolesche Algebra
In diesem Kapitel gehen wir näher auf die mathematische Grundlage von kombinatorischenSchaltnetzen ein, die in Kapitel 2 vorgestellt wurden. Außerdem zeigen wir mit Karnaugh-Diagrammen einen effektiven Weg, boolesche Funktionen zu minimieren.
3.1 Einführung
Zunächst definieren wir eine boolesche Algebra:
Sei B =∑2 = {0,1} das Alphabet mit den Elementen 0 und 1. Seien auf B die folgenden Opera-
tionen definiert für x, y ∈ B :
x + y = max(x, y
)x · y = min
(x, y
)¬x = x = 1−x
Dann ist (B ,+,¬, ·)eine boolesche Algebra. In dieser Algebra gelten folgende Gesetze:
• Kommutativgesetze: x + y = y +x, x y = y x
• Assoziativgesetze:(x + y
)+ z = x + (y + z
),(x y
)z = x
(y z
)• Distributivgesetze: x
(y + z
)= x y +xz, x + (y z
)= (x + y
)(x + z)
• Komplementgesetze: x +x = 1, xx = 0
• Idempotenzgesetze: x +x = x, xx = x
• Doppelnegationsgesetz: x = x
• Gesetze vom kleinsten und größten Element:
– Neutralitätsgesetze: x ·1 = x, x +0 = x
– Extremalgesetze: x ·0 = 0, x +1 = 1
• De Morgansche Gesetze: x + y = x y , x y = x + y
Dass diese Gesetze tatsächlich gelten, lässt sich über Wahrheitstabellen beweisen, d. h. Über-prüfung aller möglichen Kombination von Eingangsvariablen. Da hierbei alle Elemente desDefinitionsbereiches der Funktion betrachtet werden, entspricht dies einem mathematischenBeweis durch vollständige Induktion.
Als Beispiel wird in Tabelle 3.1 der Beweis der sehr wichtigen De Morganschen Gesetze geführtwerden. Diese Regeln dienen der Komplementierung von + durch · und umgekehrt sowie vonVariablen (x durch x) und Literalen (0 durch 1).
Weitere booleschen Algebren dürften aus der Mathematik (Mengen mit den Operationen∩,∪, ),sowie der Aussagenlogik (∨,∧,¬) bekannt sein.
27

3.1 Einführung 3 Boolesche Algebra
x y x + y x+y x x x y
0 0 0 1 1 1 1
0 1 1 0 1 0 0
1 0 1 0 0 1 0
1 1 1 0 0 0 0
Tabelle 3.1: Beweis des De Morgansches Gesetzes x + y = x y
Wichtig: Die Negation ¬ ist nicht distributiv! Weiterhin gibt es keine Subtraktion und Divisionin der booleschen Algebra.
Seien nun n,m ∈ N, m > 0. Dann heißt eine Funktion f = B n → B m Schaltfunktion. EineSchaltfunktion entspricht einem Schaltnetz als Black Box mit n Eingängen und m Ausgängen(Abbildung 3.1). Als Beispiel stelle man sich eine Schaltung vor, welche die Addition von zwei16-stelligen Dualzahlen realisiert. Die Eingabe ist ein Bitvektor der Länge 32 (n = 32), wobei je-weils 16 Bit einen Operanden enthalten. Die Ausgabe muss demzufolge ein Bitvektor der Längem = 17 (16+1 Bit für möglichen Übertrag) sein. Die Blackbox realisiert also eine Schaltfunktionf = B 32 → B 17.
Abbildung 3.1: Black Box mit n Eingängen und m Ausgängen
Eine Schaltfunktion f = B n → B heißt (n-stellige) boolesche Funktion. Sei x1, x2, . . . , xn ∈ B n .Dann heißt das Produkt x1x2 . . . xn der Elemente von (x1, x2, . . . , xn) ein Minterm von f . DerMinterm heißt einschlägig, wenn f (x1, x2, . . . , xn) = 1 . Jede boolesche Funktion lässt sich alsSumme (VerODERung) ihrer einschlägigen Minterme darstellen.
Dazu ein Beispiel: Eine Wahrheitstabelle beschreibe die boolesche Funktion f (x1, x2, x3) (Ta-belle 3.2).
Zeilenindex x1 x2 x3 f (x1, x2, x3)
0 0 0 0 0
1 0 0 1 0
2 0 1 0 0
3 0 1 1 1
4 1 0 0 0
5 1 0 1 1
6 1 1 0 0
7 1 1 1 1
Tabelle 3.2: Wahrheitstabelle zum Minterm-Beispiel
Die interessanten Zeilen sind die Zeilen 3, 5 und 7, da der Funktionswert dort 1 ist. Diese Zeilenkann man auch in Abhängigkeit von den Variablen xi beschreiben, was an Zeile 3 vorgeführtwerden soll: Es muss gelten x1 = 0 UND x2 = 1 UND x3 = 1. Negieren wir x1, sodass gilt x1 = 1,erhalten wir bei der VerUNDung x1x2x3 nur dann 1 als Ergebnis, wenn genau die Eingangsbe-legung von Zeile 3 gegeben ist.
28 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.1 Einführung
Dieses Verfahren ermöglicht es, in Abhängigkeit von allen Variablen genau die Terme zu be-schreiben, die 1 als Funktionswert ergeben. Wir ersetzen also 0 durch xi und 1 durch xi underhalten so die Minterme. Verknüpft man diese durch ein ODER (+), erhält man die oben er-wähnte Darstellung als Summe der Minterme: f = x1x2x3+x1x2x3+x1x2x3 (meint: Wenn eineder Eingangsbelegungen so ist, dass der Funktionswert 1 erzeugt wird, gib 1 aus, sonst 0). Siebeschreibt f vollständig und ersetzt somit die aufwendige Wahrheitstabelle. Es handelt sichbei dieser Darstellungsform um die (aus der Aussagenlogik bekannte) disjunktive Normalform.In diesem Fall liegt sogar die kanonische Form vor, da jeder Minterm in der Funktion alle xi
enthält, von denen f abhängig ist.
Jede n-stellige boolesche Funktion ist darstellbar als Kombination der zweistelligen boole-schen Funktionen + und · sowie der einstelligen booleschen Funktion ¬. Anders ausgedrückt:{+, ·,¬} ist funktional vollständig.
Aus dieser Tatsache, den Idempotenzgesetzen und den De Morganschen Gesetzen folgt, dassauch {+,¬} und {·,¬} funktional vollständig sind. Denn mithilfe der Negation lässt sich einODER auch als UND ausdrücken oder umgekehrt ein UND als ODER:
x y = x · y = x + y
x + y = x + y = x · y
Das wiederum bedeutet, dass NAND und NOR jeweils für sich funktional vollständig sind (Ab-bildung 3.2).
Abbildung 3.2: x + y nur mit NANDs (x y)
¬ ist nicht durch + oder · ersetzbar (ist also unverzichtbar), aber auch allein nicht vollständig.Zur An- und weiteren Verwendung leiten wir noch einige Theoreme her:
Absorptionsgesetze: Es gelten x +x y = x und x(x + y) = x; ersteres lässt sich so herleiten:
x +x y = x ·1+x y Neutralitätsgesetz
= x(1+ y) Distributivitätsgesetz
= x(1) Extremalgesetz
= x Extremalgesetz
Es gilt x +x y = x + y :
Technische Grundlagen der Informatik 29

3.1 Einführung 3 Boolesche Algebra
x +x y = (x +x
)(x + y
)Distributivitätsgesetz
= 1(x + y
)Komplementgesetz
= x + y Neutralitätsgesetz
Es gilt x y +xz + y z = x y +xz:
x y +xz + y z = x y +xz + y z ·1 Neutralitätsgesetz
= x y +xz + y z(x +x
)Komplementgesetz
= x y +xz + y zx + y zx Distributivitätsgesetz
= x y +x y z +xz +x y z 2x Kommutativitätsgesetz
= x y (1+ z)+xz(1+ y
)2x Distributivitätsgesetz
= x y ·1+xz ·1 2x Extremalgesetz
= x y +xz 2x Extremalgesetz
Es gilt(x + y
)(x + z
)= xz +x y :
(x + y
)(x + z
)= xx +xz + y x + y z Distributivitätsgesetz
= 0+xz +x y + y z Komplementgesetz, Kommutativgesetz
= xz +x y + y z Neutralitätsgesetz
= xz +x y Siehe vorheriges Theorem
Es gilt(x + y
)(x + z
)(y + z
)= (x + y
)(x + z
):
(x + y
)(x + z
)(y + z
)= (xz +x y
)(y + z
)Siehe vorheriges Theorem
= x y z +xzz +x y y +x y z Distributivgesetz, 2x Kommutativg.
= x y z +xz +x y +x y z 2x Idempotenzgesetz
= xz +x y 2x Absorptionsgesetz
= (x + y
)(x + z
)Siehe vorheriges Theorem
Bislang waren alle Anwendungen der booleschen Algebra rein theoretische Beispiele, die unsals Testbasis für die Gesetze dieser Algebra dienten. Im Gegensatz dazu ist das folgende Bei-spiel an ein praktisches Problem angelehnt.
3.1.1 Beispiel: Entwurf eines 2-Bit-Multiplizierers
Man stelle sich vor, ein Hardwareentwickler möchte einen Zwei-Bit-Multiplizierer entwickeln,also einen Baustein, der zwei Zwei-Bit-Zahlen entgegennimmt und ein Produkt von vier BitLänge ausgibt (Abbildung 3.3). Die beiden Zwei-Bit-Eingänge heißen X (aufgeteilt in die Bi-teingänge X1 und X0) und Y (aufgeteilt in die Biteingänge Y1 und Y0). Das Vier-Bit-Produktliegt am Ausgang Z (ebenfalls aufgeteilt in die Bitausgänge Z3, . . . Z0) an. Beginnen wir damit,die Wahrheitstabelle aufzustellen.
30 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.1 Einführung
Abbildung 3.3: Blockschaltbild eines Zwei-Bit-Multiplizierers
X ·Y = Z (dezimal) X1 X0 Y1 Y0 Z3 Z2 Z1 Z0
0 ·0 = 0 0 0 0 0 0 0 0 0
0 ·1 = 0 0 0 0 1 0 0 0 0
0 ·2 = 0 0 0 1 0 0 0 0 0
0 ·3 = 0 0 0 1 1 0 0 0 0
1 ·0 = 0 0 1 0 0 0 0 0 0
1 ·1 = 1 0 1 0 1 0 0 0 1
1 ·2 = 2 0 1 1 0 0 0 1 0
1 ·3 = 3 0 1 1 1 0 0 1 1
2 ·0 = 0 1 0 0 0 0 0 0 0
2 ·1 = 2 1 0 0 1 0 0 1 0
2 ·2 = 4 1 0 1 0 0 1 0 0
2 ·3 = 6 1 0 1 1 0 1 1 0
3 ·0 = 0 1 1 0 0 0 0 0 0
3 ·1 = 3 1 1 0 1 0 0 1 1
3 ·2 = 6 1 1 1 0 0 1 1 0
3 ·3 = 9 1 1 1 1 1 0 0 1
Tabelle 3.3: Wahrheitstabelle eines Zwei-Bit-Multiplizierers
Die Schaltung hat vier Eingänge, die in unserer binären Betrachtungsweise 24 = 16 verschie-dene Eingangsbelegungen entgegennehmen kann. Daraus ergibt sich direkt, dass bis zu 16verschiedene Ausgangsbelegungen an den vier Ausgangsleitungen möglich sind. Die Wahr-heitstabelle ist in Tabelle 3.3 abgebildet.
Jede 4-Bit-Eingabe repräsentiert das Produkt zweier Zwei-Bit-Zahlen, sodass zum Beispiel eineEingabe von X1X0Y1Y0 = 1110 das Produkt 112 ·102 (oder 310 ·210) darstellt. Die dazugehörigeAusgabe ist eine 4-Bit-Zahl, welche in diesem Fall den Wert 610 (oder 01102 in binärer Form)hat.
Aus der Tabelle lassen sich die Ausdrücke für die vier Ausgänge Z0–Z3 ableiten. Man beach-te, dass für eine Wahrheitstabelle mit m Ausgangsleitungen immer m boolesche Funktionenabgeleitet werden müssen. Eine Funktion ist mit jeweils einer der m Ausgangsspalten assozi-iert. Für das Ableiten nehmen wir die einschlägigen Minterme der einzelnen Ausgänge (alsodie Minterme, wo der entsprechende Ausgang den Wert Eins annimmt) und bringen sie durchODER-Verknüpfungen in die disjunktive Normalform.
Technische Grundlagen der Informatik 31

3.1 Einführung 3 Boolesche Algebra
Z0 = X1X0Y1Y0 +X1X0Y1Y0 +X1X0Y1Y0 +X1X0Y1Y0
= X1X0Y0
(Y1 +Y1
)+X1X0Y0
(Y1 +Y1
)= X1X0Y0 +X1X0Y0
= X0Y0
(X1 +X1
)= X0Y0
Z1 = X1X0Y1Y0 +X1X0Y1Y0 +X1X0 Y1Y0 +X1X0Y1Y0 +X1X0Y1Y0 +X1X0Y1Y0
= X1X0Y1
(Y0 +Y0
)+X1X0Y0
(Y1 +Y1
)+X1X0Y1Y0 +X1X0Y1Y0
= X1X0Y1 +X1X0Y0 +X1X0Y1Y0 +X1X0Y1Y0
= X1X0Y1 +X1X0Y1Y0 +X1X0Y0 +X1X0Y1Y0
= X0Y1
(X1 +X1Y0
)+X1Y0
(X0 +X0Y1
)= X0Y1
(X1 +Y0
)+X1Y0
(X0 +Y1
)= X1X0Y1 +X0Y1Y0 +X1X0Y0 +X1Y1Y0
Z2 = X1X0Y1Y0 +X1X0Y1Y0 +X1X0Y1Y0
= X1X0Y1
(Y0 +Y0
)+X1X0Y1Y0
= X1X0Y1 +X1X0Y1Y0
= X1Y1
(X0 +X0Y0
)= X1Y1
(X0 +Y0
)= X1X0Y1 +X1Y1Y0
Z3 = X1X0Y1Y0
Dadurch erhält man also diese vier vereinfachten disjunktiven Normalformen für Z3–Z0:
Z0 = X0Y0
Z1 = X1X0Y1 +X0Y1Y0 +X1X0Y0 +X1Y1Y0
Z2 = X1X0Y1 +X1Y1Y0
Z3 = X1X0Y1Y0
Die obigen Ausdrücke sind bezüglich X und Y symmetrisch, d. h. man kann X durch Y erset-zen und umgekehrt und kommt zu den gleichen Ergebnissen. Diese Eigenschaft entspricht derKommutativität der Aufgabe (z. B. 3 ·1 = 1 ·3).
Es gibt nun mehrere Wege, diese Ausdrücke in einem Schaltnetz zu realisieren. Abbildung 3.4illustriert einen davon.
32 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.1 Einführung
Abbildung 3.4: Schaltnetz eines 2-Bit-Multiplizierers
Wir haben bereits festgestellt, dass NAND und NOR jeweils funktional vollständig sind, d. h.alle Schaltnetze sind auch durch Schaltnetze ersetzt werden, die nur aus NAND- bzw. NOR-Gattern bestehen. Dadurch kann der bereits erwähnte Vorteil ausgenutzt werden, dass NAND-bzw. NOR-Gatter schneller und billiger als UND- oder ODER-Gatter.
Dies ist, wie ebenfalls bereits festgestellt, wichtig, da NAND bzw. (NOR)-Gatter schneller undbilliger sind als die entsprechenden UND- bzw. ODER-Gatter. In der Praxis gibt es deswegenviele verschiedene Gatter dieser Typen (von Formen mit zwei Eingängen bis hin zu 13), abernur wenige Typen von UND bzw. ODER-Gattern.
Um den oben entworfenen 2-Bit-Multiplizierer nur mit NAND-Gattern aufzubauen, sind nurwenige Umformungen nötig. Es genügt, auf eine disjunktive Normalform zunächst das Dop-pelnegationsgesetz und anschließend das De Morgansche Gesetz anzuwenden.
Z0 = X0Y0
= X0Y0
Z1 = X1X0Y1 +X0Y1Y0 +X1X0Y0 +X1Y1Y0
= X1X0Y1 +X0Y1Y0 +X1X0Y0 +X1Y1Y0
= X1X0Y1 ·X0Y1Y0 ·X1X0Y0 ·X1Y1Y0
Technische Grundlagen der Informatik 33

3.1 Einführung 3 Boolesche Algebra
Z2 = X1X0Y1 +X1Y1Y0
= X1X0Y1 +X1Y1Y0
= X1X0Y1 ·X1Y1Y0
Z3 = X1X0Y1Y0
= X1X0Y1Y0
Das entsprechende Schaltnetz zeigt die Abbildung 3.5. Analog könnte man die Schaltung auchnur aus NOR-Gattern bauen.
Abbildung 3.5: Schaltnetz eines 2-Bit-Multiplizierers aus NAND-Gattern
3.1.2 Assoziativität von NAND und NOR
Das Assoziativgesetz gilt bei NAND- und NOR-Operationen nicht, daher ist der Logikentwurfmit NAND und NOR nicht so intuitiv wie mit UND und ODER. Die Abbildungen 3.6 und 3.7zeigen diesen Sachverhalt anhand der bereits vorgestellten Symbole.
Formal ausgedrückt: Es gilt x y z = (x y
)z (Assoziativitätsgesetz). Bei NANDs gilt aber nicht
x y z = (x y
)z (formal betrachtet ist der Fehler offensichtlich), sondern x y z =
(x y
)z.
34 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.2 Minimierung von Schaltfunktionen
Abbildung 3.6: Mögliche Realisierung eines Drei-Eingänge-UND-Gatters mit Zwei-Eingänge-UND-Gattern
Abbildung 3.7: Mögliche Realisierung eines Drei-Eingänge-NAND-Gatters mit Zwei-Eingänge-NAND-Gattern
3.1.3 Zusammenfassung boolesche Algebra
Schaltfunktionen sind ein logischer Formalismus zur Beschreibung von Schaltnetzen. Schalt-netze sind einfacher und kostengünstiger zu implementieren, wenn sie aus weniger Gatternund Eingängen bestehen. Aus Effizienzgründen ist es daher geboten, Schaltfunktionen zu-nächst zu minimieren, bevor sie in Hardware umgesetzt werden. Ein Weg der Vereinfachungvon Schaltfunktionen ist die algebraische Minimierung mithilfe der booleschen Algebra.
3.2 Minimierung von Schaltfunktionen
Es ist nicht immer leicht ersichtlich, welches boolesche Gesetz als nächstes anzuwenden ist,um einen Ausdruck minimal werden zu lassen. Hinzu kommt, dass uninteressante Eingangs-belegungen nicht vernachlässigt werden und in das Minimierungsergebnis einfließen (selbstwenn sie beispielsweise nie auftreten).
Eine (gerade für den Menschen) einfache Alternative ist das nach seinem Entwickler benann-te Karnaugh-Diagramm. Dieses ist auch in der Lage, einen Nutzen aus nicht vorkommendenEingangsbelegungen zu ziehen.
Darüber existieren algorithmische Verfahren, die mit beliebig vielen Variablen auskommen,z. B. das Quine-McCluskey-Verfahren. Diese werden in diesem Skript jedoch nicht behandelt.
3.2.1 Karnaugh-Diagramme
Das Aufstellen von Karnaugh-Diagrammen ist eine grafische Technik zur Darstellung und Ver-einfachung von booleschen Funktionen, die höchstens vier unterschiedliche Variablen enthal-ten. Prinzipiell ist diese Diagrammform eine zweidimensionale Darstellung von Wahrheitsta-bellen, wobei jede Zelle des Diagramms genau einen Minterm repräsentiert.Karnaugh-Diagramme (eigentlich Karnaugh-Veitch-Diagramme) wurden 1952 von Edward W.Veitch entworfen. Ein Jahr darauf brachte Maurice Karnaugh sie in die aktuelle Form.
Technische Grundlagen der Informatik 35

3.2 Minimierung von Schaltfunktionen 3 Boolesche Algebra
Benachbarte Zellen eines Karnaugh-Diagramms unterscheiden sich in nur einer Variablen.Daher sind bei Diagrammen ab drei Eingangsvariablen die 11- und 10-Spalte bzw. -Zeile ver-tauscht. (Man könnte auch sagen: Es findet ein Zwei-Bit-Grey-Code Anwendung) Ein Beispieldazu ist in Abbildung 3.8 gegeben.
Abbildung 3.8: Karnaugh-Diagramm-Beispiele
Benachbarte Einsen lassen sich zu einem kleineren Produktterm vereinfachen. (Hierbei han-delt es sich um eine Anwendung des Distributiv- und des Komplementgesetzes). Man beach-te, dass Karnaugh-Diagramme geometrisch einen Torus repräsentieren, also auch die obersteZeile zur untersten benachbart ist, genauso wie die Spalte links außen zu der auf am rechtenAußenrand. Weiterhin kann eine Zelle aufgrund des Idempotenzgesetzes zu mehreren Termengehören. Man kann nur immer 2n (d. h. 1,2,4,8, . . .) Einsen zusammenfassen. In Abbildung 3.8rechts sind die möglichen Einser-Gruppen eingekreist. Dabei ist zu beachten, dass der ent-stehende Term dann minimal ist, wenn die größtmögliche Einsergruppe jeweils zusammen-gefasst wird und jede Eins am Ende erfasst ist. Es gelten folgende Zusammenhänge in einemKarnaugh-Diagramm mit vier Eingangsvariablen:
• Ein Produktterm mit 1 Variablen überdeckt 8 Zellen
• Ein Produktterm mit 2 Variablen überdeckt 4 Zellen
• Ein Produktterm mit 3 Variablen überdeckt 2 Zellen
• Ein Produktterm mit 4 Variablen überdeckt 1 Zelle
Wenn wir uns zum Beispiel die dritte Zeile des rechten Diagramms in Abbildung 3.8 ansehen,
lassen sich die beiden Einsen so zusammenfassen: A BC D + ABC D = AC D(B +B
)= AC D
Diese Formel braucht nicht aufgestellt zu werden, da man direkt im Diagramm sieht, dass dasErgebnis unabhängig vom Wert von B ist. Den vereinfachten Term kann man also direkt able-sen. Die anderen Terme, die man dem Beispiel entnehmen kann, sind AB und AB C D .
Bevor wir uns nun das Minimieren mit Karnaugh-Diagrammen näher ansehen werden, wer-fen wir einen Blick darauf, wie man boolesche Ausdrücke auf diese Diagramme überträgt. AlsBeispielfunktion verwenden wir F1 = x1 x2 + x3x4. Das dazugehörige Karnaugh-Diagramm istin Abbildung 3.9a) dargestellt.
Der einschlägige Minterm x1 x2x3x4 ist sowohl durch die Konjuktion x1 x2 als auch durch x3x4
erfasst. Die Überlappung führt aufgrund der Idempotenz aber zu keinerlei Auswirkungen.
Ein weiteres Beispiel stellt die Funktion F2 = x2 x4 + x1x3x4 dar, bei der die Toruseigenschaftdes Karnaugh-Diagramms eine Rolle spielt: Die vier Ecken können zusammengefasst werden,weil sie Nachbarn sind. Das Diagramm findet sich in Abbildung 3.9b).
36 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.2 Minimierung von Schaltfunktionen
a) b)
Abbildung 3.9: Beispiel-Karnaugh-Diagramm: a) Funktion F1, b) Funktion F2
Das Minimieren mit Karnaugh-Diagrammen gestaltet sich einfacher als die Verwendung derGesetze der booleschen Algebra. Betrachten wir die folgende boolesche Funktion: f = x1 x2 x3+x1 x2x3+x1x2x3+x1x2 x3+x1x2x3. Das entsprechende Karnaugh-Diagramm zeigt Abbildung 3.10.
Abbildung 3.10: Vereinfachung einer Funktion mittels Karnaugh
Aus der Abbildung lässt sich der minimierte Term f = x2 + x1 x3 ablesen. Die Funktion wirdalso dann 1, wenn x2 = 0, oder wenn x1 = 0 und x3 = 0. Wollte man diese Vereinfachung formalnachvollziehen, würde das etwa so aussehen (in der zweiten Zeile wurde der erste Mintermverdoppelt, was durch das Idempotenzgesetz möglich ist):
f = x1 x2 x3 +x1 x2x3 +x1x2x3 +x1x2 x3 +x1x2x3
= x1 x2 x3 +x1 x2 x3 +x1 x2x3 +x1x2x3 +x1x2 x3 +x1x2x3
= x1 x2(x3 +x3
)+x1 x2 x3 +x1x2x3 +x1x2(x3 +x3
)= x1 x2 +x1 x3
(x2 +x2
)+x1x2
= x1 x2 +x1x2 +x1 x3
= x2(x1 +x1
)+x1 x3
= x2 +x1 x3
An diesem Beispiel kann man gut sehen, dass mit Karnaugh-Diagrammen eine Vereinfachungerheblich einfacher ist als mit formalen Umformungen. In Abbildung 3.11 sind weitere Bei-spiele zum Verständnis abgebildet.
Beim Vereinfachen strebt man immer eine Überdeckung aller Einsen mit minimaler Anzahlvon Gruppen an. Weiterhin wählt man immer Gruppen maximaler Größe ( auch mit bereits
Technische Grundlagen der Informatik 37

3.2 Minimierung von Schaltfunktionen 3 Boolesche Algebra
Abbildung 3.11: Karnaugh-Beispiele
durch andere Gruppen involvierte Zellen). Es gilt, dass es mehrere minimale Lösungen gebenkann (vergleiche Abbildung 3.12).
Abbildung 3.12: Unterschiedliche minimale Ergebnisse der gleichen Funktion
3.2.2 Don’t-care-Zustände
Es gibt Schaltnetze, bei denen bestimmte Eingabebelegungen von vornherein ausgeschlos-sen werden können. Die entsprechenden Ausgabebelegungen sind in diesem Fall egal, manbraucht sich nicht um sie zu kümmern („Don’t care“). Besser noch: Man kann diese Zuständebei der Minimierung so verwenden, wie man sie gerade braucht: Steht in einem benachbartenFeld eine 1, so kann die Zelle mit dem Don’t-Care-Zustand wie eine 1 behandelt werden. Be-finden sich dagegen ein Don’t-Care-Zustand fern jeglicher Einsen, braucht man ihn nicht beider Minimierung zu berücksichtigen. In diesem Fall entspricht der zugemessene Inhalt einer0. Es wird ein drittes Symbol eingeführt, um diese Zustände im Karnaugh-Diagramm (und derentsprechenden Wahrheitstabelle) zu repräsentieren: d .
Der Sachverhalt wird an folgendem Beispiel vorgeführt: Es soll eine Schaltung für eine automa-tische Klimaanlagensteuerung entwickelt werden. Die Klimaanlage soll so gesteuert werden,dass auf die unabhängigen Außenparameter Temperatur und Luftfeuchtigkeit reagiert wird.
38 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.2 Minimierung von Schaltfunktionen
Dabei bekommt unsere Steuerung nur mitgeteilt, ob es heiß (H), kalt (K ), feucht (F ) oder tro-cken (T ) ist. Die genauen Parameter sind in Tabelle 3.4 abgebildet.
Eingabevariable wenn 0 wenn 1
Heiß < 22 °C > 22 °C
Kalt > 15 °C < 15 °C
Feucht < 75 % > 75 %
Trocken > 40 % < 40 %
Tabelle 3.4: Eingabeparameter der Klimaanlagensteuerung
Die Klimaanlage besteht aus vier Modulen: Einem Kaltlufterzeuger, einem Warmlufterzeuger,einem Ent- und einem Befeuchter. Diese können jeweils entweder ein- oder ausgeschaltet wer-den. Wir modellieren diese Schalter als P , Q, R und S (Tabelle 3.5).
Ausgabe wenn 0 wenn 1
P Kaltlufterzeuger aus Kaltlufterzeuger an
Q Warmlufterzeuger aus Warmlufterzeuger an
R Entfeuchter aus Entfeuchter an
S Befeuchter aus Befeuchter an
Tabelle 3.5: Ausgabeparameter der Klimaanlagensteuerung
In einer Wahrheitstabelle können wir nun die Abhängkeiten der Ausgabeparameter von denden Eingangsvariablen darstellen (Tabelle 3.6). Einige Eingangsbelegungen sind unmöglich(es kann z. B. nicht gleichzeitig heiß und kalt sein). Außerdem nimmt die relative Luftfeuchteab, wenn die Luft erwärmt wird. Deshalb muss kalte und feuchte Luft nicht extra entfeuchtetwerden. Umgekehrt muss heiße und trockene Luft zunächst nicht befeuchtet werden, da dierelative Feuchte beim Abkühlen steigt.
H K F T Bedeutung P Q R S
0 0 0 0 neutral 0 0 0 0
0 0 0 1 trocken 0 0 0 1
0 0 1 0 feucht 0 0 1 0
0 0 1 1 unmöglich d d d d
0 1 0 0 kalt 0 1 0 0
0 1 0 1 kalt/trocken 0 1 0 1
0 1 1 0 kalt/feucht 0 1 0 0
0 1 1 1 unmöglich d d d d
1 0 0 0 heiß 1 0 0 0
1 0 0 1 heiß/trocken 1 0 0 0
1 0 1 0 heiß/feucht 1 0 1 0
1 0 1 1 unmöglich d d d d
1 1 0 0 unmöglich d d d d
1 1 0 1 unmöglich d d d d
1 1 1 0 unmöglich d d d d
1 1 1 1 unmöglich d d d d
Tabelle 3.6: Wahrheitstabelle der Klimaanlagensteuerung
Beim Minimieren per Karnaugh-Diagramm (Abbildung 3.13 und 3.14) lassen sich die Don’t-
Technische Grundlagen der Informatik 39

3.3 Zusammenfassung 3 Boolesche Algebra
Care-Zustände dort wie Einsen behandeln, wo dadurch größere Gruppen ermöglicht werden,zu denen die Einsen zusammengefasst werden. Die Don’t-Care-Zustände werden so verwen-det, dass sich möglichst große und wenige Blöcke ergeben, die alle Einsen einschließen.
Kaltlufterzeuger P Warmlufterzeuger Q
P = H Q = KBei Hitze Kaltluft erzeugen Bei Kälte Warmluft erzeugen
Abbildung 3.13: Karnaugh-Diagramme zur Klimaanlagensteuerung (Temperatur)
Entfeuchter R Befeuchter S
R = K F S = HTWenn feucht und nicht kalt, entfeuchten Wenn trocken und nicht heiß, befeuchten
Abbildung 3.14: Karnaugh-Diagramme zur Klimaanlagensteuerung (Luftfeuchtigkeit)
3.3 Zusammenfassung
Es wurde gezeigt, wie sich kombinatorische Schaltnetze bzw. Schaltungen mit einem bestimm-ten gewünschten Verhalten auf der Basis von Gattern mit folgenden Schritten realisieren las-sen:
• Das gewünschte Verhalten wird in Form einer Wahrheitstabelle beschrieben.
• Aus dieser Tabelle wird durch Anwendung von algebraischen oder grafischen Methodeneine Schaltfunktion daraus abgeleitet.
• Schließlich wandelt man die Schaltfunktion in eine Schaltung um, indem die Operatorenin entsprechende Gatter abgebildet werden, deren Eingänge den Variablen entsprechen,
40 Technische Grundlagen der Informatik

3 Boolesche Algebra 3.3 Zusammenfassung
die die Operatoren verwenden.
Technische Grundlagen der Informatik 41

3.3 Zusammenfassung 3 Boolesche Algebra
42 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen
Jede Schaltung, die uns bis hierhin begegnet ist, war eine kombinatorische Schaltung, derenAusgabe nur eine Funktion ihrer Eingabewerte war. Das heißt, dass wir mit Kenntnis der Ein-gabewerte und der booleschen Funktion einer kombinatorischen Schaltung jederzeit ihre Aus-gabe berechnen können.
Schaltungen, deren Ausgaben nicht nur von ihren momentanen, sondern auch von seinen ver-gangenen Eingabewerten abhängen, nennt man sequentielle Schaltungen. Selbst wenn die be-rechnete boolesche Funktion einer solchen sequentiellen Schaltung bekannt ist, lassen sichihre Ausgabewerte ohne Kenntnis ihrer vorherigen Eingaben (d. h. der vorherigen internenZustände) nicht vorherbestimmen. Wesentliche Elemente einer CPU wie Register, Zähler oderSchieberegister werden durch sequentielle Schaltungen realisiert. In diesem Kapitel werdenwir uns ein paar einfache sequentielle Schaltungen ansehen.
Die Grundeinheit sequentieller Schaltungen ist ein Flipflop, so wie die Grundeinheit eineskombinatorischen Schaltnetzes das Gatter ist. Ein Flipflop ist eine bistabile Kippstufe, da derAusgangswert für eine bekannte Eingabe unbestimmt einen von zwei stabilen Zuständen hat.Das heißt, der Ausgangswert kann entweder den Wert 0 oder den Wert 1 annehmen, der ak-tuelle Zustand hängt dabei von den vorherigen Eingaben ab. Meist handelt es sich um zweiAusgänge, wobei der zweite in der Regel das Komplement des ersten ist, siehe schematischeDarstellung in Abbildung 4.1. Gewissermaßen hat eine solche Schaltung ein Gedächtnis undist somit eine Art von Speicherelement. Ein Flipflop ist die kleinstmögliche Speicherzelle undspeichert lediglich ein Bit.
Abbildung 4.1: Flipflop in Black-Box-Darstellung
Der Begriff Flipflop leitet sich aus dem Geräusch ab, das solche frühe Bauelemente – die al-lesamt durch elektromagnetische Relais realisiert wurden – beim Wechseln ihres Zustandesmachten.
4.1 RS-Flipflop
Beginnen wir die Betrachtung der Flipflops mit dem einfachsten Mitglied dieser Familie, demRS-Flipflop. Die Abbildung 4.2 zeigt ein solches Flipflop aus NOR-Gattern. Obwohl die Schal-tung nicht mehr umfasst als zwei NOR-Gatter mit jeweils zwei Eingängen, ist die Arbeitsweisenicht sofort ersichtlich. Aus diesem Grund soll sie im Folgenden schrittweise hergeleitet wer-den.
Die Schaltung besitzt zwei Eingänge (A und B) und zwei Ausgänge (X und Y ). Mit unserenKenntnissen der booleschen Algebra lassen sich für die Ausgänge schnell Ausdrücke mit Ter-men in Abhängigkeit von den Eingängen finden:
43

4.1 RS-Flipflop 4 Sequentielle Schaltungen
Abbildung 4.2: RS-Flipflop aus NOR-Gattern
X = A+Y
Y = B +X
Wenn wir die untere in die obere Gleichung einsetzen, erhalten wir:
X = A+B +X = A ·B +X = A (B +X ) = AB + AX
Da die boolesche Algebra keine Operationen der Division oder Subtraktion bietet, um X kom-plett auf eine Seite zu bringen, ist die Bedeutung der Formel nicht direkt klar. Wir müssenuns einen anderen Weg suchen, um das Verhalten so vernetzter Gatter zu untersuchen. Es isthilfreich, sich zunächst einen beliebigen Anfangswert für X und die Eingänge zu denken, vondenen ausgegangen wird. Wir wählen hier die folgende Werte: X = 1, A = B = 0. Die Eingängedes Gatters G2 sind X = 1, B = 0; sein Ausgang Y muss demzufolge 0 sein (vgl. Wahrheitswertefür NOR in Tabelle 2.1). Analog ist der Ausgang X des Gatters G1 mit Y = 0 und A = 0 berechen-bar, das Ergebnis ist 1. Offenbar sorgt die Eingangsbelegung dafür, dass die Ausgangsbelegungstabil ist. Diesen Zustand nennt man selbsterhaltend. Der Ausgang des Gatters G1 ist 1, wel-cher wieder als Eingang von G1 zurückgeführt wird, um X im Zustand 1 zu halten. Solch eineSchaltung wird kreuzweise gekoppelt (cross-coupled) genannt, da die Ausgänge gleichzeitigEingaben der ODER-Gatter sind. Damit erklärt sich auch, warum in der oben hergeleitetenFormel X auf beiden Seiten der Gleichung auftaucht.
Nehmen wir für X = 0 und für A = B = 0 an, ist der folgender Gedankenganz möglich: DieEingänge für G2 sind X = 0 und B = 0, woraus die Ausgabe Y = 1 resultiert. Die Eingänge für G1
wären somit Y = 1 und A = 0, was wieder X = 0 zur Folge hätte. Wir beobachten also, dass dieSchaltung auch mit dieser Eingangsbelegung selbsterhaltend ist. Interessant zu beobachtenist, dass die Eingabeparameter mit A = B = 0 offenbar keinen Einfluss auf die Ausgänge haben;X kann entweder 0 oder 1 sein und Y ist das entsprechende Komplement. Stattdessen sind Xund Y vom vorherigen internen Zustand abhängig.
Der nächste Schritt der Untersuchung ist es, das Verhalten bei der Änderung der EingängeA und B zu betrachten. Dafür nehmen wir wieder an, X habe zu Beginn den Zustand 1 undA = B = 0.
Nun schaltet der Eingang B des Gatters G2 auf 1. G2, welches nur eine 1 ausgibt, wenn keinEingang aktiv ist, gibt bereits eine 0 aus, da X = 1. Der Ausgang Y ändert sich also nicht. Damitändert sich auch nichts an der Eingangsbelegung des Gatters G1. Das Setzen des Eingangs Bändert also auf Ausgangsseite nichts.
Für den nächsten Gedankengang schalten wir B zunächst auf 0 zurück, sodass die alte Konfi-guration (X = 1, A = B = 0) wieder hergestellt ist.
44 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.1 RS-Flipflop
Wir setzen jetzt A auf 1 (B bleibt auf 0). G1, das wie G2 nur dann eine 1 ausgibt, wenn keinEingang aktiv ist, schaltet den Ausgang X von 1 auf 0. Dadurch werden beide Eingänge von G2
0, wodurch der Ausgang von G2, Y , 1 wird. G1 ändert sich dadurch nicht mehr, da ja bereits eine1 anliegt. Setzt man anschließend A zurück auf 0, bleibt der Ausgangszustand (Y = 1, X = 0)erhalten. Diesen Sachverhalt haben wir eingangs bereits betrachtet. Man kann das Setzen vonA folglich als Setzen von Y oder als Rücksetzen von X auffassen.
Es wurde bereits angemerkt, dass sich der Zustand des Flipflops als Funktion des aktuellenZustandes beschreiben lässt (X = AB + AX ). Die Zustandstabelle (Tabelle 4.1) umgeht diesesProblem, indem sie eine neue Variable X ∗ einführt, wobei X ∗ der neue Wert zur alten AusgabeX und den dazugehörigen Eingängen A und B ist. So lässt sich auch die Gleichung zu X ∗ =AB + AX umschreiben. Die Spalten der Wahrheitstabellen sind nun nicht mehr nur räumlich,sondern auch zeitlich getrennt. Die momentane Ausgabe X wird mit A und B kombiniert, umX ∗ zu generieren. Der Wert X wird damit überschrieben.
Wir haben bislang nur die Zeilen 1, 2, 3 und 5 der Tabelle Tabelle 4.1 beschrieben. Die übrigenZustände durchzugehen bleibt dem Leser als Übung überlassen.
A B X X ∗
0 0 0 00 0 1 10 1 0 10 1 1 11 0 0 01 0 1 01 1 0 01 1 1 0
Tabelle 4.1: Zustandstabelle für Abbildung 4.2
Die Schaltung wird RS-Flipflop genannt. RS steht dabei für Reset und Set (Rücksetzen und Set-zen). Das sind die Namen der Eingänge, wobei wir A als Reset-Eingang und B als Set-Eingangbetrachten. Der Ausgang eines RS-Flipflops heißt traditionell Q (vormals X ) und dessen Kom-plement Q (vormals Y ). Das Schaltzeichen eines RS-Flipflops ist in Abbildung 4.3 dargestellt.Tabelle 4.2 zeigt Tabelle 4.1 mit korrekten Eingangs- und Ausgangsbezeichnungen. Außerdemlassen sich die Eingangsbelegungen trotz unterschiedlichem Ausgang gruppieren.
Abbildung 4.3: Schaltzeichen für ein RS-Flipflop
Da der zweite Ausgang nur das Komplement des ersten ist, verzichten viele Hersteller auf dasAnbinden des zweiten Ausgangs an die Außenseite des Chips und überlassen dem Anwendernur Q.
Eine Sonderstellung hat die Eingangsbelegung R = S = 1 (bzw. A = B = 1) inne. Für die Spei-cherfähigkeit und Veränderbarkeit des Flipflops – der grundlegenden Eigenschaft – werdennur drei Zustände benötigt: Speichern (keine Änderung; R = S = 0), Setzen (R = 0, S = 1) undRücksetzen (R = 1, S = 0). Der vierte Zustand R = S = 1ist über (man kann nicht gleichzeitigsetzen und rücksetzen). Da sich in diesem Zustand ein RS-Flipflop aus NOR-Gattern anders
Technische Grundlagen der Informatik 45

4.1 RS-Flipflop 4 Sequentielle Schaltungen
R S Q Q∗
0 0 0 0 Keine Änderung0 0 1 10 1 0 1 Q setzen0 1 1 11 0 0 0 Q rücksetzen1 0 1 01 1 0 X verboten1 1 1 X
Tabelle 4.2: Zustandstabelle für RS-Flipflop, Q∗ ist das neue Ausgangssignal
verhält als eins aus NANDs, bezeichnen wir diese Eingangsbelegung als “verboten”. Bei NOR-Gattern fallen beide Ausgänge auf 0. Schalten beide Eingänge gleichzeitig auf 0, ist unklar, wel-chen Wert Q annimmt. Der Wert ist in diesem Fall sogar von den physikalischen Bauteilenabhängig. In der Praxis versucht man daher, den Zustand R = S = 1 zu vermeiden (zumal wennunbekannt ist, wie das Flipflop intern aufgebaut ist.
Die Wahrheitstabelle oben war insofern umständlich, dass jeweils zwei Zeilen für jede Bele-gung der Eingänge nötig waren, eine für Q = 0 und eine für Q = 1. Einen alternativen Ansatzzeigt Tabelle 4.3, die nur den algebraischen Wert zeigt. Hierbei bedeutet X als Symbol entweder„nicht definiert“ (d. h. kann nicht berechnet werden) oder das bekannte „Don’t care“.
R S Q Q
0 0 Q Q0 1 1 01 0 0 11 1 X X
Tabelle 4.3: Zustandsfolgetabelle für RS-Flipflop
RS-Flipflops lassen sich auch mit NAND-Gattern realisieren. Diese Version ist low-active, d. h.die logische 1 wird elektrisch durch einen niedrigen Spannungspegel dargestellt und die 0durch einen hohen Spannungspegel. In der Praxis ist dies ein häufig anzutreffender Modus(negative Logik), weshalb NAND-RS-Flipflops gängig sind.
4.1.1 Beispiel Impulsfolgengenerator
Eine einfache Anwendung von RS-Flipflops ist der Impulsfolgengenerator, wie ihn Abbildung 4.4zeigt. Er erzeugt bei jeder Triggerung (Aktivierung) eine Sequenz von n Impulsen. Der Wert vonn wird dabei vom Anwender festgelegt und durch Schalter in die Schaltung überführt. In dieserAnwendung des RS-Flipflop dient S dazu, die Ausgabe der Impulsfolge zu starten, und R dazu,sie zu stoppen. Nehmen wir zu Beginn an, dass die Eingänge des Flipflops R und S jeweils 0sind und dass der Ausgang Q im Zustand 0 ist.
Wenn eine 1 auf den Eingang S (d. h. Start) des Flipflops gelegt wird, steigt Q auf 1 und ak-tiviert das UND-Gatter G1. Eine Folge von Takt-Impulsen am zweiten Eingang von G1 wirdnun auf den Ausgang des UND abgebildet. Diese Impulsfolge dient nun als Eingabe eines Zäh-lers (den wir später noch betrachten werden), welcher die Impulse zählt und einen Drei-Bit-Ausgabewert (Wertebereich 0–7) entsprechend der gezählten Impulse an den Ausgängen Q A ,
46 Technische Grundlagen der Informatik
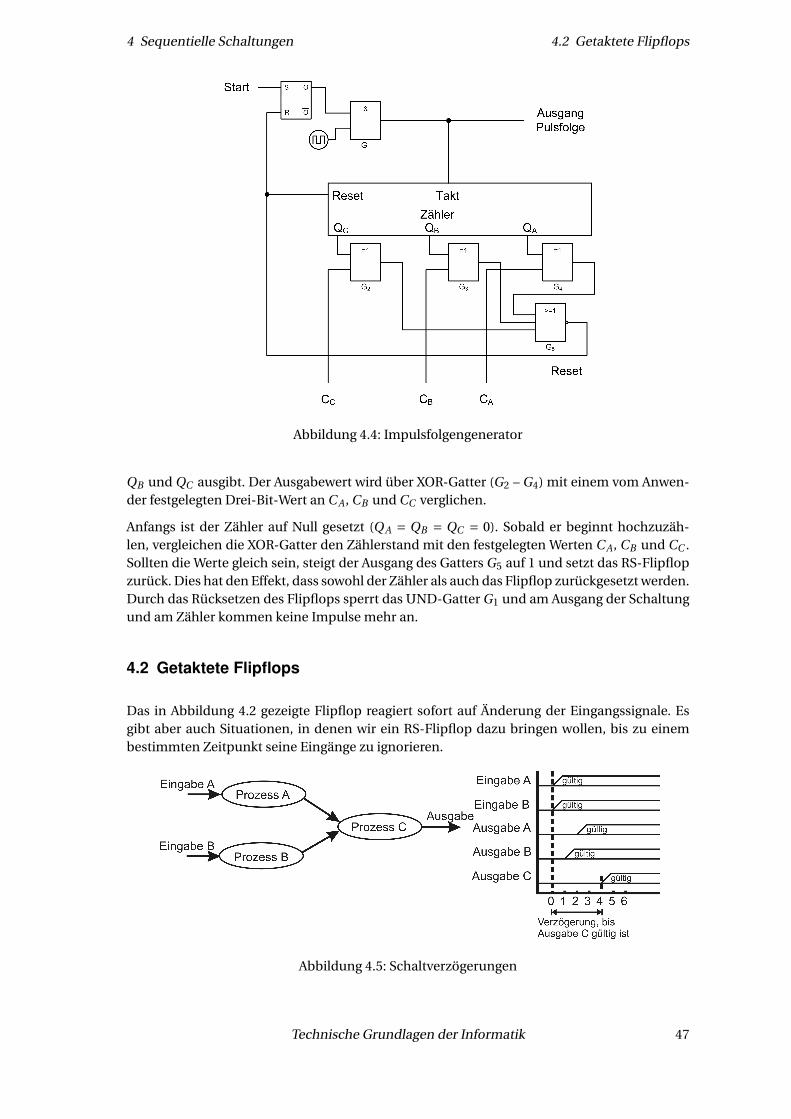
4 Sequentielle Schaltungen 4.2 Getaktete Flipflops
Abbildung 4.4: Impulsfolgengenerator
QB und QC ausgibt. Der Ausgabewert wird über XOR-Gatter (G2 – G4) mit einem vom Anwen-der festgelegten Drei-Bit-Wert an C A , CB und CC verglichen.
Anfangs ist der Zähler auf Null gesetzt (Q A = QB = QC = 0). Sobald er beginnt hochzuzäh-len, vergleichen die XOR-Gatter den Zählerstand mit den festgelegten Werten C A , CB und CC .Sollten die Werte gleich sein, steigt der Ausgang des Gatters G5 auf 1 und setzt das RS-Flipflopzurück. Dies hat den Effekt, dass sowohl der Zähler als auch das Flipflop zurückgesetzt werden.Durch das Rücksetzen des Flipflops sperrt das UND-Gatter G1 und am Ausgang der Schaltungund am Zähler kommen keine Impulse mehr an.
4.2 Getaktete Flipflops
Das in Abbildung 4.2 gezeigte Flipflop reagiert sofort auf Änderung der Eingangssignale. Esgibt aber auch Situationen, in denen wir ein RS-Flipflop dazu bringen wollen, bis zu einembestimmten Zeitpunkt seine Eingänge zu ignorieren.
Abbildung 4.5: Schaltverzögerungen
Technische Grundlagen der Informatik 47

4.3 Das D-Flipflop 4 Sequentielle Schaltungen
Abbildung 4.5 demonstriert den Effekt von Schaltverzögerungen eines Systems. Zwei EingängeA und B werden von zwei Prozessen A und B (der Begriff Prozess steht hier für eine sequentielleSchaltung) genutzt, um jeweils ein Signal zu erzeugen, welches als Eingabe Prozess C zugeführtwird. Die Art der Prozesse spielt im Moment keine Rolle, da wir nur daran interessiert sind,inwiefern sie die Signale verzögern. Stellen wir uns vor, dass zum Zeitpunkt t = 0 die Eingängeder Prozesse A und B gültig werden (d. h. es sind von da an die korrekten Werten, die durch denProzess verarbeitet werden). Nehmen wir weiterhin an, dass der Prozess A eine Verzögerungvon zwei Zeiteinheiten und der Prozess B eine Verzögerung von einer Zeiteinheit verursacht.Wie groß diese Zeiteinheit ist, spielt keine Rolle.
Die Ausgaben von A und B dienen Prozess C als Eingabe. Auch C verursacht eine Verzögerungvon zwei Zeiteinheiten. Offensichtlich ist die Ausgabe von C erst vier Zeiteinheiten nach t = 0gültig. Der Ausgabewert von C ändert sich in der Zeit von t = 0 bis t = 4 mindestens einmal,nämlich wenn der Prozess B bereits den korrekten Wert am Ausgang ausgibt, A aber noch nicht.Erst ab t = 4 können wir davon ausgehen, dass C den korrekten Wert ausgibt. Das stellt einProblem da: Wie weiß ein Anwender des Prozesses C, wann er mit den Ausgabewerten von Carbeiten kann?
Eine Problemlösung wäre es, den Zugriff auf das Ausgangssignal von Prozess C erst nach vierZeiteinheiten zuzulassen. Dies erreicht man, indem man das Signal zusammen mit einem „Er-laubnissignal“ als Eingabe in ein UND-Gatter leitet. Dessen Ausgabe ist das neue Ausgangs-signal des Prozesses C. Erst, wenn das „Erlaubnissignal“ auf 1 steht, wird das Ergebnis von Czum Ausgang durchgeschaltet. Wir werden auf dieses Anwendungsbeispiel zurückkommen.
Abbildung 4.6: Getaktetes RS-Flipflop
Die Schaltung der Abbildung 4.6 zeigt, wie man dieses Prinzip nutzen kann, um ungewollteÄnderungen in einem RS-Flipflop zu unterbinden. Die innere Box in der Abbildung enthält eingewöhnliches RS-Flipflop. Dessen Eingänge R ′ und S′ werden durch UND-Gatter beschaltet,die die externen Eingänge R und S mit einem Takt-Eingang C (Clock) verknüpfen. Solange C =0 gilt, bleiben beide Eingänge des RS-Flipflops auf 0. Dadurch speichert das (innere) Flipflop;der Ausgang des Flipflops bleibt also konstant.
Wann immer C = 1 gilt, werden die Eingänge R und S zum Flipflop „durchgestellt“, sodassR ′ = R und S′ = S gilt. Man kann sich als den Takt-Eingang als Hemmer vorstellen, der dasFlipflop daran hindert, vor einem bestimmten Zeitpunkt seinen Zustand zu verändern. Wennwir nachfolgend den Takt von 0 auf 1 ändern, sprechen wir vom Takten (z. B. des Flipflops).
4.3 Das D-Flipflop
Eine etwas andere Herangehensweise wurde mit dem D-Flipflop geschaffen: Es ist taktgesteu-ert und hat neben dem Takteingang C (clock input) nur einen Dateneingang (D). Solange C = 0ist, hat eine Änderung des Dateneingangs keine Auswirkung. Erst wenn C gesetzt wird, wird
48 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.3 Das D-Flipflop
der Dateneingang übernommen und zum Ausgangssignal Q „durchgestellt“. Das D-Flipflopgibt es folglich auch nur in der getakteten Version.
Das D-Flipflop wird verwendet, um ein Bit zu halten bzw. um eine Übernahme zu verzögern(delay). Es wird daher auch als Verzögerungselement bezeichnet, als „Zustandsbewahrer“ (sta-ticizer).
Das Verhalten des D-Flipflops lässt sich wieder durch Zustandstabelle (Tabelle 4.4) und Zu-standsfolgetabelle (Tabelle 4.5) darstellen.
C D Q Q∗
0 0 0 00 0 1 1 Q bleibt0 1 0 00 1 1 11 0 0 01 0 1 0 Q∗ = D1 1 0 11 1 1 1
Tabelle 4.4: Zustandstabelle des D-Flipflops
C D Q Q
0 0 Q Q0 1 Q Q1 0 0 11 1 1 0
Tabelle 4.5: Zustandsfolgetabelle des D-Flipflops
Eine Möglichkeit, wie ein D-Flipflop intern aufgebaut ist, zeigt Abbildung 4.7. Es besteht auseinem RS-Flipflop und einigen zusätzlichen Gattern. Die Aufgabe der UND-Gatter ist es, dasRS-Flipflop mit einer Taktung zu versehen. So lange C = 0 gilt, sind R und S ebenfalls 0 und Qverändert sich nicht. Wenn C auf 1 steigt, wird S zu D verbunden und R zu D .
Abbildung 4.7: Getaktetes D-Flipflop
4.3.1 Beispiel m-Bit-Datenbus
Eine typische Anwendung von D-Flipflops ist der Anschluss an einen m Bit breiten Datenbus,der zur Datenübertragung in einem digitalen System eingesetzt wird (Abbildung 4.8). Die Da-ten auf dem Bus ändern sich andauernd, da verschiedene Geräte ihn benutzen, um Daten voneinem Register ins nächste zu übermitteln.
Technische Grundlagen der Informatik 49

4.3 Das D-Flipflop 4 Sequentielle Schaltungen
Abbildung 4.8: Auslesen eines m-Bit-Datenbusses mit D-Flipflops
Die D-Eingänge einer Gruppe von m D-Flipflops sind mit den m Leitungen des Busses verbun-den. Die Takteingänge C hingegen sind alle miteinander verbunden, womit sich alle Flipflopsgleichzeitig takten lassen. So lange C = 0 gilt, ignorieren die Flipflops die Daten auf dem Busund ihre Ausgänge Q ändern ihre Werte nicht. Wenn nun Geräte ihre Daten zu den Flipflopsübermitteln wollen, legen sie diese auf den Bus und takten die Flipflops, wodurch die Daten insie überführt werden. C fällt danach auf 0 zurück und die Daten werden in den Flipflops „ein-gefroren“. Wie wir später sehen werden, besteht ein Computer eigentlich aus wenig mehr alsaus kombinatorischen Logikbausteinen, mehreren Bussystemen und Gruppen von Flipflops,welche Daten von und zu den Bussystemen lesen und schreiben.
Wenden wir uns wieder der Frage der zeitlichen Verzögerung zu (Abbildung 4.5). Wenn ein D-Flipflop am Ausgang von Prozess C angebracht und z. B. vier Zeiteinheiten nach dem Zeitpunktt = 0 getaktet wird, werden die gewünschten Daten in das Flipflop übertragen und bis zumnächsten Taktimpuls beibehalten. Getaktete Systeme halten also digitale Information mittelsFlipflops konstant, während mit der Information durch Gruppen logischer Bausteine gearbei-tet wird, analog zu den Prozessen in der Abbildung. Zwischen den einzelnen Taktimpulsenwerden die Ausgaben der Flipflops von den Logikelementen verarbeitet und die neuen Wertewerden den Eingängen der Flipflops zur Verfügung gestellt.
Nach einer gewissen Zeitverzögerung (mindestens länger, als der langsamste Prozess bis zuseinem Ende benötigt), werden die Flipflops getaktet. Die Ausgaben werden konstant gehalten,bis die Flipflops das nächste Mal getaktet werden. Ein getaktetes System heißt synchron (zeit-gesteuert, taktgesteuert), da alle Prozesse gleichzeitig bei jedem neuen Taktimpuls gestartetwerden. In einem asynchronen (eigengesteuerten) System ist das Ende des einen Prozesses derStart des nächsten. Wie man sich leicht denken kann, muss ein asynchrones System schnellerals seine synchrone Entsprechung sein. Asynchrone Systeme sind dabei aber auch viel kom-plexer und schwieriger zu entwerfen als synchrone Systeme. Aus der praktischen Erfahrungweiß man, dass man sie am besten vermeiden sollte, da sie in sich selbst weniger zuverlässigsind als synchrone Schaltungen.
Die Auswirkungen, eines D-Flipflop mit dem Ausgang des Prozesses C zu verbinden, zeigt Ab-
50 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.4 Das JK-Flipflop
bildung 4.9. Neue Daten werden dort nur bei einem Taktimpuls übernommen.
Abbildung 4.9: Getaktete Schaltverzögerung
Nun ist es natürlich auch möglich, jeden der Prozesse A, B und C mit einem D-Flipflop zu ver-sehen. Jedes dieser Flipflops wird gleichzeitig alle zwei Zeiteinheiten getaktet. In diesem Fallwird eine neue Eingabe alle zwei Zeiteinheiten übernommen, anstatt nur alle vier, wie oben.Das Geheimnis in der Steigerung unserer Durchsatzrate heißt Pipelining, da an den unter-schiedlichen Stufen der Verarbeitungskette auch mit unterschiedlichen Daten gearbeitet wird.So ist die Ausgabe am Ausgang des Prozesses C abhängig vom Datensatz i −2. Prozess C verar-beitet die Daten i −1 und Prozesse A und B verarbeiten die Daten i .
Man stelle sich dies vielleicht ähnlich wie ein Fließband vor. An den Punkten A und B wird einProdukt verpackt und in C ein bereits verpacktes Produkt mit einer Adresse versehen. Im Korbam Ende des Fließbandes liegen bereits verpackte und adressierte Waren, welche vor einigenMomenten noch auf dem Fließband die einzelnen Stationen durchliefen.
4.4 Das JK-Flipflop
Das JK-Flipflop ist das wahrscheinlich am häufigsten gebrauchte Flipflop. Es unterscheidetsich fast nicht vom getakteten RS-Flipflop. Der Eingang J entspricht dabei S und K entsprichtR. Als Eselbrücke mag man sich vorstellen, das J für „jump“ und K für „kill“ steht. Nur für J =K = 1 ist das Verhalten im Vergleich zum RS-Flipflop ein anderes: Die Ausgabewerte werdengetauscht (siehe Tabelle 4.6 und Tabelle 4.7), man spricht dabei auch vom Togglen.
J K Q Q∗
0 0 0 0 Keine Änderung0 0 1 10 1 0 0 Q rücksetzen0 1 1 01 0 0 1 Q setzen1 0 1 11 1 0 1 Q „kippt“1 1 1 0
Tabelle 4.6: Zustandstabelle für das JK-Flipflop
Das lässt sich z. B. mit einem RS-Flipflop bewerkstelligen, wobei S = JQ und R = KQ sind, wiein Abbildung 4.10 gezeigt.
Der Leser möge sich im Selbststudium von der korrekten, gewünschten Funktion dieser Schal-tung überzeugen. Bei den ersten drei Eingangsbelegungen der Zustandsfolgetabelle ist der re-sultierende Ausgang immer stabil, d. h. auch die eventuell resultierenden neuen Inputbelegun-gen durch ein verändertes Q führen nicht zu einem neuen (geänderten) Ausgangssignal.
Technische Grundlagen der Informatik 51

4.5 Master-Slave-Flipflop 4 Sequentielle Schaltungen
J K Q Q
0 0 Q Q0 1 0 11 0 1 01 1 Q Q
Tabelle 4.7: Zustandsfolgetabelle für das JK-Flipflop
Abbildung 4.10: Interner Aufbau eines JK-Flipflops
Bei der (beim RS-Flipflop verbotenen) Belegung J = K = 1 jedoch wird die Ausgabe des mo-mentanen Wertes während der Taktung, also wenn C = 1, fortlaufend komplementiert. DiesesPhänomen wird als Oszillationsproblem bezeichnet. Dabei ändert jede neue Ausgangsbele-gung sich auch wieder selbst: Das Flipflop oszilliert und erreicht keinen stabilen Zustand mehr.Es ist im Sinne der Definition streng genommen kein Flipflop (d. h. Speicherelement) mehr!
Dieses Problem kann man auf zwei voneinander unabhängige Arten lösen: Eine davon ist dieOrganisation des Flipflops in einer Master-Slave-Form, welches im nächsten Abschnitt am Bei-spiel des RS-Flipflops erläutert wird. Die andere ist die Taktflankensteuerung, auf die danacheingegangen wird.
4.5 Master-Slave-Flipflop
Das Master-Slave-Flipflop (MS-Flipflop) kommt nur in getakteter Fassung vor und entkoppeltdie Eingänge von den Ausgängen. Es hat die äußere Erscheinung eines einzelnen Flipflops,besteht im Inneren aber aus zwei in Reihe geschalteten Flipflops. Eins dieser Flipflops wird alsMaster, das andere als Slave bezeichnet (Abbildung 4.11). Der Master kann seinen Zustand nurändern, wenn der Takt 1 ist, der Slave dagegen nur, wenn der Takt 0 ist. Nur die Ausgänge desSlave-Flipflops werden nach außen geleitet.
Abbildung 4.11: RS-Master-Slave-Flipflop
52 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.6 Flankengesteuerte Flipflops
Im Detail funktioniert das so: Ist der Takt aktiv, werden die Eingabedaten (S und R) in dasMaster-Flipflop übernommen. Da die Ausgänge des Master-Flipflops nur mit den Eingängendes Slave-Flipflops verbunden sind und nicht an die Außenwelt weitergeleitet werden, än-dert sich der Zustand der Ausgänge des gesamten Master-Slave-Flipflops zu diesem Zeitpunktnicht.
Weil der Master ein pegelgesteuertes RS-Flipflop ist, übernimmt es Werte von R und S, solan-ge der Taktimpuls anhält (d. h. solange C = 1). Sobald C auf 0 fällt, wird der letzte Zustand derEingänge im Master gespeichert (eingefroren). Zugleich wird das Ausgangssignal des Master-Flipflops zu den Eingängen des Slave-Flipflops durchgestellt. Dadurch kann dieses seinen Zu-stand ändern und damit auch das Ausgangssignal des gesamten MS-Flipflops. Da sich die Aus-gänge des Slave-Flipflops erst ändern, wenn das Ausgangssignal des Master-Flipflops eingefro-ren ist, sind sie komplett von den Eingängen des gesamten MS-Flipflops entkoppelt.
Im vorhergehenden Abschnitt wurde bei „einfaches“ JK-Flipflops, die durch ein einzelnes RS-Flipflop realisiert sind, auf das Oszillationsproblem hingewiesen. Eine Lösungsmöglichkeitstellt das Master-Slave-Prinzip dar, da die Oszillation durch die direkte Rückkopplung der Aus-gänge mit den Eingängen zustande kommt und beim Master-Slave-Flipflop eine solche direkteRückkopplung keine Auswirkungen mehr haben kann.
Das Kippen (toggeln) bleibt aber insofern erhalten, als dass es jeweils bei einem neuen Tak-timpuls erfolgt. Dadurch ergibt sich die sehr nützliche Eigenschaft, dass in diesem Fall amAusgang genau halb so viele Impulse ausgegeben werden wie am Takteingang eingespeist.Diese Eigenschaft wird zum Aufbau von Zählern genutzt. Abbildung 4.12 zeigt ein getaktetesJK-Master-Slave Flipflop.
Abbildung 4.12: Getaktetes JK-Master-Slave-Flipflop (pegelgesteuert)
4.6 Flankengesteuerte Flipflops
Bislang waren alle Flipflops, die mit einem Takt verknüpft wurden, pegelgesteuert, d. h. solangeder Takt in einem bestimmten Zustand war (z. B. auf 1), wurden die Eingangsänderungen indas Flipflop übernommen. Die Taktung erfolgte also über den Pegel des Taktsignals. Beim JK-Flipflop führte das zum Oszillationsproblem.
Eine Alternative zu diesem Ansatz ist die Steuerung über die Flanken (edges) des Takts, alsoden Übergängen von 0 zu 1 oder 1 zu 0. Diese Übergänge sind nur augenscheinlich unmittel-bar; tatsächlich muss sich der Spannungspegel einschwingen. Die Einschwingzeit ist im Ver-gleich zum Takt sehr kurz. In der Regel dauert das Einschwingen weniger als fünf Nanosekun-den1. Man kann im Vergleich zu der Zeitlänge, die ein Pegel konstant ist (etwa einen halben
1eine Nanosekunde entspricht einem Milliardstel einer Sekunde; etwa 10−9 Sekunden
Technische Grundlagen der Informatik 53

4.6 Flankengesteuerte Flipflops 4 Sequentielle Schaltungen
Takt lang), eine Taktflanke wie einen Impuls von sehr kurzer Dauer betrachten, quasi als Zeit-punkt. Wenn man per Taktflanke steuern möchte, muss man darauf achten, dass die Bauteileentsprechend eine geringe Reaktionszeit haben, also schnell sind. Eine Taktflanke ist kurz ge-nug, um bei flankengesteuerten JK-Flipflops kein Oszillationsproblem entstehen zu lassen.
Man unterscheidet zwischen der positiven Flanke (auch: steigende Flanke; gemeint ist derÜbergang von 0 auf 1) und negativer Flanke (auch: fallende Flanke; gemeint ist der Übergangvon 1 auf 0). Entsprechend unterscheidet man zwischen positivflankengesteuerten und nega-tivflankengesteuerten Bauteilen.
Abbildung 4.13: Negativflankengesteuertes D-Flipflop
In Abbildung 4.13 ist ein negativflankengesteuertes D-Flipflop dargestellt. Es besteht aus sechsNOR-Gattern Gi , i ∈ {1, . . . ,6}. Diese kann man gruppieren zu drei NOR-Flipflops. Die Funkti-onsweise wird nachfolgend beschrieben:
Ist der Takt aktiv (C = 1), geben dadurch die Gatter G2 und G3 eine 0 aus (man erinnere sich,dass NOR-Gatter nur dann 1 ausgeben, wenn alle Eingänge auf 0 stehen). Dies führt dazu, dassdie Eingänge der Gatter G5 und G6 0 als Eingabe haben, was Speichern bedeutet. Die Ausgabedes gesamten Flipflops ist in diesem Zustand folglich stabil; Q und Q sind konstant.
Der Zustand des D-Eingangs hat in diesem Taktabschnitt nur Auswirkungen auf die Gatter G1
und G4: G1 hat als Eingangssignale den Ausgang von G2, also 0, und D . Es gibt bei D = 0 eine1 aus, sonst eine 0, und G4 gibt (da ja dessen zweiter Eingang gleich dem Ausgang von G3 ist,also 0) das Gegenteil davon aus. Man kann das auch so beschreiben: G1 gibt D aus und G4 gibtD aus.
In dem Moment, wenn der Takt auf 0 fällt, ändern sich die Ausgänge der Gatter G2 und G3 unddamit die Eingabewerte des “hinteren” Flipflops (G5 und G6). Ist C = 0, haben weitere Ände-rungen von D keine Auswirkungen mehr auf die Eingänge der Gatter G5 und G6. Wir betrachtendazu zwei Fälle:
• D = 0 während der fallenden Flanke: G3 invertiert den Ausgangswert von G4 und leitetdieses Signal als Eingabe an G6 (d. h. D = 1 liegt an diesem Punkt der Schaltung an). Wei-terhin wird diese 1 an G2 geleitet, wodurch dieses Gatter zunächst nur eine 0 ausgebenkann. Damit steht auch der Eingang von G5 fest auf 0. Zusammengefasst: G5 hat nun eine0 als Eingangssignal, G6 eine 1, das bedeutet, der Ausgang Q wird zurückgesetzt (wenner es noch nicht war).
54 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.7 Zusammenfassung Flipflops
• D = 1 während der fallenden Flanke: Gatter G2 ändert den Ausgabewert auf 1, wodurchzum Einen der zweite Eingang an Gatter G1 auf 1 gesetzt wird und weitere Änderungenvon D zunächst keine Auswirkungen auf den Rest der Schaltung mehr haben, zum An-deren ist damit der Eingang des Gatters G5 1, dessen Ausgang Q dadurch 0, wodurch derAusgang Q von G6 1 wird.
Wenn C danach zu Beginn des nächsten Impulses auf 1 steigt, werden die Eingabewerte des„hinteren“ Flipflops (G5 und G6) auf 0 gesetzt, wodurch sie von den Ausgängen der restlichenSchaltung isoliert werden.
4.7 Zusammenfassung Flipflops
Flipflops haben interne Zustände und externe Eingänge. Ihr Ausgang ist sowohl von den exter-nen Eingaben als auch von den internen Zuständen und damit auch von früheren Eingabenabhängig. Flipflops haben die Fähigkeit, einen Zustand beibehalten zu können und sind somitSpeicherelemente.
Unterschieden werden Flipflops durch die Art ihrer Eingaben und ihrer Taktung. Wir habendas RS-, D- und JK-Flipflop kennengelernt. Dabei sind alle Flipflops im Prinzip Variationenvon RS:
• Das RS-Flipflop (Reset/Set) löscht bzw. setzt den Ausgang bei einem Impuls auf einemder Eingänge.
• Beim D-Flipflop wird, wenn das Flipflop getaktet wird (d. h. der zweite Eingang C = 1),der Eingang D zum Ausgang durchgereicht.
• Das JK-Flipflop arbeitet weitgehend wie das RS-Flipflop, nur dass hier zusätzlich dervierte Zustand (beide Eingänge sind 1) zum Kippen des Ausgangs Q genutzt wird.
Es wird zwischen Taktzustandssteuerung (Taktpegelsteuerung) und Taktflankensteuerung un-terschieden. Dabei beschränkt die Taktflankensteuerung den Zeitbereich, in dem die Eingangs-signale übernommen werden.
Weiterhin wird zwischen „normalen“ und Master-Slave-Flipflops unterschieden. Gewöhnlichführt eine Zustandsänderung aufgrund einer veränderten Eingangsbelegung direkt zu einerveränderten Ausgangsbelegung (bzw. mit minimaler Verzögerung, die nur von der Implemen-tierung abhängt). Master-Slave-Flipflops dagegen entkoppeln die Eingänge von den Ausgän-gen; sie schalten in zwei zeitlich überlappungsfreien Stufen. Dadurch werden unerwünschteRückkopplungseffekte vermieden.
4.8 Beispiele für sequentielle Schaltnetzelemente
So wie Gatter mit anderen Gattern verbunden werden, um kombinatorische Schaltungen wieAddierer und Multiplexer zu schaffen, lassen sich Flipflops zu sequentiellen Schaltungen zu-sammenschließen (wie wir es schon bei dem taktflankengesteuerten D-Flipflop gesehen ha-ben). Nachfolgend beschäftigen wir uns mit zwei Arten dieser sequentiellen Schaltungen: DemSchieberegister und dem Zähler.
Technische Grundlagen der Informatik 55

4.8 Beispiele 4 Sequentielle Schaltungen
4.8.1 Register
In Computern wird zur Komplexitätsminderung nicht mit einzelnen Bits gearbeitet, sondernmit Wörtern. Das sind geordnete Bit-Gruppen, zum Beispiel Bytes (8-Bit-Wörter) oder Doppel-wörter (32-Bit-Wörter).
Ein solches Wort speichert man in einem Register; es umfasst mehrere Flipflops, die jeweilsein Bit speichern. Damit die Flipflops nicht beliebig ihren Zustand ändern, sondern unterein-ander abgestimmt sind, werden sie über ein gemeinsames Taktsignal synchronisiert. Damitübernimmt entweder kein Flipflop eine Eingangsbelegung oder alle gleichzeitig. Wie in Unter-abschnitt 4.3.1 gesehen, nimmt eine Gruppe von m D-Flipflops ein m-Bitwort auf.
4.8.2 Schiebe- und Rotationsregister
Bei der Programmierung werden häufig die Operationen Schieben und Rotieren verwendet.Schieben (shift) bedeutet ein Verrücken der Bits eines Wortes. Herausgeschobene Bits sind ver-loren. Die frei werdenden Stellen werden mit Nullen oder Einsen aufgefüllt; wir gehen an die-ser Stelle von einem logischen Schieben aus, bei dem Nullen eingeschoben werden. Schiebenkann man nach links (in Richtung des höchstwertigen Bits) oder rechts (in Richtung des nie-derwertigsten Bits). Mathematisch betrachtet entspricht ein Linksverschieben (left shift) einerVerdopplung der Zahl, ein Rechtsverschieben (right shift) einer Ganzzahldivision durch Zwei.
Betrachten wir beispielsweise drei Zustände eines (so genanntes logisches) Rechtsschiebere-gisters: Zu Beginn enthalten die Flipflops die Werte 01110101. Wird das Register getaktet,werden die alle Bits um eine Stelle nach rechts verschoben, das letzte Bit fallengelassen undin die freie linke Stelle eine Null geschrieben. Das Wort sieht danach so aus: 00111010. Nacheinem weiteren Impuls ändert sich das Binärmuster zu 00011101 usw.
Ähnlich funktioniert das Linksschieberegister, bei dem das Bitmuster nach links verrückt, daserste Bit fallengelassen und rechts eine Null angefügt wird.
Verwandt mit den Schieberegistern sind Rotationsregister: Diese lassen das herausgeschobeneBit nicht fallen, sondern fügen es in die frei werdende Stelle am anderen Wortende ein. Dies istebenfalls nach links oder rechts möglich.
Abbildung 4.14: Schieberegister aus D-Flipflops
Abbildung 4.14 zeigt ein aus D-Flipflops aufgebautes Schieberegister. Der Ausgang Q jedesFlipflops ist mit dem Eingang D des jeweils rechten Flipflops verbunden. Jedes Flipflop be-kommt das Taktsignal eines gemeinsamen Taktgebers. Wenn das Flipflop i getaktet wird, über-nimmt es den Zustand des vorherigen (linken) Flipflops i −1.
Wäre diese Schaltung taktpegelgesteuert und bestünde aus „normalen“ Flipflops, so würdeeine Eingabe an Di n sofort bis zum letzten Flipflop durchgereicht werden. Um dies zu verhin-dern, müssen die D-Flipflops flankengesteuert (wie in der Abbildung) oder als Master-Slave-Flipflop umgesetzt sein.
56 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.8 Beispiele
Abbildung 4.15: Schieberegister aus JK-Flipflops
Flipflops speichern Daten, unabhängig von der genaueren Ausgestaltung (RS, D, JK usw.). Da-her lassen sich sequentielle Schaltnetze mit ein paar kleineren Anpassungen auf die Verwen-dung einer anderen Flipflopart ändern. Dies wird gezeigt in Abbildung 4.15, in der die gleicheSchaltung wie in Abbildung 4.14 realisiert ist, jedoch nicht aus D-, sondern aus JK-Flipflops.Das Dateneingangssignal wird in den J-Eingang und als Komplement in den K-Eingang desersten Flipflops geleitet. Es ist also entweder J aktiv (Bit setzen) oder K (Bit rücksetzen), aberkeinesfalls beide gleichzeitig. Auch der Speicherzustand J = K = 0 wird nicht erreicht. Somitentspricht das Flipflop als Black Box betrachtet dem D-Flipflop.
Abbildung 4.16: Paralleles Schieberegister
Dementsprechend kann ein solches Register auch aus RS-Flipflops gebildet werden. Dies wirdals 4-Bit-Variante in Abbildung 4.16 gezeigt, in der durch ein paar zusätzliche Gatter ermöglichtwird, das Register entweder parallel oder seriell zu laden. Die Ausgabe erfolgt parallel.
Die Eingabe Schieben/Laden (SL) steuert, ob geschoben oder geladen wird: Ist SL = 1, so wirdgeschoben und seriell geladen (Schiebemodus); ist SL = 0, so wird parallel geladen (Parallella-demodus).
Intern sorgt ein Zwei-Eingabe-Multiplexer als zusätzliche Logik (additional gating) für die Um-setzung der Funktionalität. Pro Flipflop wird dabei ein solches Multiplexer verwendet, der aus
Technische Grundlagen der Informatik 57

4.8 Beispiele 4 Sequentielle Schaltungen
zwei UNDs, einem ODER und einem Inverter besteht. Je nach Zustand des Steuersignals SLwird an den Eingang des jeweiligen Flipflops entweder der Ausgang des Vorgängerflipflopsdurchgeleitet oder Signal am Paralleleingang. Wie in Abbildung 2.5 dargestellt, werden dieUND-Gatter zur Informationsflusssteuerung verwendet.
4.8.3 Frequenzteiler und Zähler
Genauso nützlich wie bei der Konstruktion von Registern sind Flipflops bei der Implementie-rung von Frequenzteilern und Zählern. Diese spielen in digitalen Geräten eine wichtige Rol-le. Dabei wird im Prinzip die gleiche Schaltung für beide Zwecke eingesetzt. Sie unterscheidetsich in ihrer Ausgangsanzahl: Ein Frequenzteiler, der ein Taktsignal quasi streckt, hat nur einenAusgang, ein Zähler dagegen mehrere.
Abbildung 4.17: 1:16-Frequenzteiler bzw. Vier-Bit-Rückwärts-Zähler aus JK-Flipflops
Abbildung 4.17 zeigt einen 4-Bit-Zähler/-Frequenzteiler aus JK-Flipflops, die in diesem Fall po-sitivflankengesteuert sind. Es wird die Eigenschaft ausgenutzt, dass bei J = K = 1 der Ausgangbei jedem Taktimpuls invertiert wird.
Interpretiert man am ersten Flipflop F1 den Ausgang Q1 als neues Taktsignal, so kann manbeim Vergleich mit dem Eingangstaktsignal erkennen, dass der Ausgang nur halb so schnelltaktet. Anders gesagt: Um an Q1 vom Zustand 1 über eine 0 wieder zum Zustand 1 zu gelangen,werden zwei Takte benötigt. Da Q1 ebenfalls als Taktsignal des zweiten Flipflops verwendetwird, hat dessen Ausgang Q2 nur noch ein Viertel der Frequenz des Systemtakts. Entsprechendgibt F3 ein Taktsignal von einem Achtel der Ursprungsfrequenz aus und an Q4 liegt nur nochein Sechzehntel der Frequenz an. Wenn wir also nur den letzten Ausgang Q4 abgreifen, ist dieseSchaltung für uns ein 1:16-Frequenzteiler.
Wenn wir dagegen alle Ausgänge gleichzeitig auslesen, können wir beobachten, wie die Schal-tung binär von 11112 bis 00002 herunterzählt. Im Anschluss daran beginnt sie wieder bei 11112;die Schaltung arbeitet also zyklisch. Man beachte, dass dabei Q4 das höchstwertige Bit und Q1
das niederwertigste Bit repräsentiert.
Allgemein definiert, ist ein Zähler eine spezielle sequentielle Schaltung mit einem einzelnenTakteingang und einer bestimmten Anzahl von Ausgängen. Jedes Mal, wenn der Zähler getak-tet wird, ändert sich einer oder mehrere der Ausgänge. Diese Ausgänge bilden eine Sequenzmit n unterschiedlichen und eindeutigen Werten. Nachdem der Wert n an den Ausgängen be-obachtet werden konnte, setzt der nächste Taktimpuls den Zähler wieder auf die Ausgangsbe-legung zurück, die zu Beginn der Sequenz vorlag. Daraus folgt, dass die Sequenz zyklisch ist.Dabei muss der Wert n nicht das Maximum sein, sondern kann – wie im Beispiel gesehen –auch das Minimum darstellen.
Einen Zähler wie in Abbildung 4.17 nennt man auch asynchron oder ripple counter (ripple –engl.: dahinplätschern, kleine Wellen schlagen), da der Ausgang des ersten Flipflops sofort daszweite Flipflop auslöst, welches sogleich das dritte Flipflop ändert usw. Das hat zur Folge, dass
58 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.9 Zustandsdiagramme
eine Zustandsänderung des ersten Flipflops sofort Auswirkungen auf das nächste Flipflop hat.Im Extremfall sind alle Flipflops betroffen.
Das wäre kein Problem, wenn alle Flipflops ohne Zeitverzögerung den neuen Ausgangswertanzeigen würden. Tatsächlich aber verursachen Flipflops eine gewisse Verzögerung d , die siebenötigen, bis das korrekte Ergebnis am Ausgang anliegt. Beim asynchronen Zähler summiertdiese Verzögerung sich auf. Im schlechtesten Fall steht bei unserem Vier-Bit-Zähler der neuekorrekte Wert an allen Ausgängen erst nach der Zeit 4d bereit. Nicht in jedem Fall ist ein Taktlang genug, um eine solche Verzögerung zu tolerieren.
Dem Problem kann man begegnen, indem man unter Hinzunahme einiger Logikgatter einensynchronen Zähler konstruiert. Bei diesem sind alle Flipflops durch einen gemeinsamen Taktgesteuert. Dadurch ändern sie gemeinsam ihren Zustand. Da die maximal mögliche Verzöge-rung durch diese Maßnahme stark reduziert ist, kann ein solcher Zähler erheblich schneller alsein asynchroner Zähler arbeiten.
Zähler finden in digitalen Rechnern vielfache Anwendung. Beispielsweise wird im Prozessorder als nächstes auszuführende Befehl durch den Programmzähler festgelegt. Das ist ein Re-gister, das die Adresse des jeweils nächsten Befehls enthält. Sobald der Befehl geladen ist, mussder Programmzähler um 1 erhöht werden und zeigt dann auf den nächsten Befehl.
4.9 Beschreibung durch Zustandsdiagramme
Wir haben bereits an den Beispielen gesehen, dass die Beschreibungen von sequentiellen Schal-tungen und deren Arbeitsweise recht umfangreich und komplex werden können. Es ist dahererstrebenswert, eine Darstellung zu finden, die sich leichter lesen lässt.
Eine häufig verwendete Form, die Arbeitsweise von sequentiellen Schaltungen zu beschreiben,sind die so genannten Zustandsdiagramme. Diese werden im Folgenden beschrieben.
Ein Zustand beschreibt dabei eine bestimmte innere Konfiguration und Ausgabebelegung. Zu-stände werden in einem Zustandsdiagramm durch bezeichnete Kreise symbolisiert. GleicheZustände werden zusammengefasst. Beispielsweise gibt es beim Flipflop zwei Zustände: Ent-weder Q ist 0 (Zustand S1) oder Q ist 1 (Zustand S2).
Weiterhin gibt es Übergänge, die einer Eingabekonfiguration entsprechen. Übergänge gehenvon einem Zustand aus und führen wieder in einen Zustand. Da in der Regel alle Eingabekon-figurationen ungeachtet des inneren Zustands möglich sind, müssen von einem Zustand ausalle möglichen Übergänge behandelt werden. Es handelt sich um gerichtete Kanten, die imZustandsdiagramm durch beschriftete Pfeile dargestellt werden.
Abbildung 4.18: Zustandsdiagramm eines JK-Flipflops
Um das obige Beispiel fortzuführen, nehmen wir an, dass es sich beim betrachteten Flipflopum ein JK-Flipflop handelt (Abbildung 4.18). Egal, ob dieses gerade 1 oder 0 ausgibt, kann
Technische Grundlagen der Informatik 59

4.9 Zustandsdiagramme 4 Sequentielle Schaltungen
bei einem Taktimpuls am Eingang eine der vier möglichen Eingangsbelegungen anliegen (Ta-belle 4.8). Die Übergänge müssen alle diese Möglichkeiten abdecken. Ist Q = 0 (Zustand S1),ändert ein Rücksetzen (C2) oder Speichern (C1) den Ausgangszustand des Flipflops nicht. DerÜbergang ist also eine Kante, die in den gleichen Zustand zurückführt. Die anderen beidenEingangsbelegungen (C3 und C4) dagegen ändern die Ausgabe des Flipflops und somit auchden internen Zustand. Daher führt die entsprechende Kante in den Zustand S2.
J K Eingangsbelegungen0 0 C1
0 1 C2
1 0 C3
1 1 C4
Tabelle 4.8: Eingabemöglichkeiten an einem JK-Flipflop
Analog dazu ändert sich die Ausgangsbelegung S2 nicht, wenn die Eingangsbelegung C1 oderC3 anliegen. Bei C2 und C4 dagegen wird der Zustand S2 in Zustand S1 überführt. Wie wir se-hen, ändert die Eingangsbelegung C4 den Zustand, egal, in welchem Zustand man sich vorherbefunden hat (JK-Flipflop-Eigenschaft).
4.9.1 Zustandsdiagrammdarstellung eines Drei-Bit-Zählers
Ein weiteres Beispiel zeigt Abbildung 4.19. Sie zeigt ein Zustandsdiagramm eines Drei-Bit-Zählers. Da ein Zähler wie oben erklärt nur einen Eingang hat (nämlich den Takt), hat jederZustand nur jeweils eine abgehende Kante, die in diesem Fall einer Taktung entspricht. Zwi-schen den einzelnen Taktungen verbleibt das System in dem entsprechenden Zustand.
Abbildung 4.19: Zustandsdiagramm eines Drei-Bit-Zählers
Wenn das System getaktet wird, rotiert es durch die Zustände S0 bis S7, welche in den Aus-gangsbelegungen den binären Ganzzahlen von 010 bis 710 entsprechen.
Alle acht Taktimpulse erreicht der Zähler wieder den Ausgangszustand. An dem Diagrammerkennt man gut die zyklische Form eines Zählers.
60 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.10 Testen von digitalen Schaltungen
4.10 Testen von digitalen Schaltungen
Gegenüber kombinatorischen Schaltnetzen bringen sequentielle Schaltnetze eine Komplexi-tätssteigerung mit sich. Dadurch ist es nun unter anderem möglich, Speicher oder Zähler zubauen. Nachteilig ist dagegen, dass es schwieriger wird, eine Schaltung auf korrekte Funkti-onsweise zu testen.
Ein Beispiel wird dies veranschaulichen: Wir möchten einen ein Kilobyte großen Speicher tes-ten. Er hat einen 10-Bit-Adress-Eingang, kann also über 210 verschiedene Adressen angespro-chen werden. Der Datentransfer erfolgt über eine 8-Bit-Datenschnittstelle; der Speicher kannalso entweder ein Byte empfangen, das an die entsprechende Adresse geschrieben wird, oderdas Byte ausgeben, welches durch die eingegebene Adresse angesprochen wird. Mögliche Funk-tionstests wären:
1. Trivialer Test: Schreiben eines (beliebigen) Testmusters in jede der 210 Speicherzellenund anschließendes Auslesen (210 Tests).Dieser Test überprüft zwar die prinzipielle Funktionsweise des Speichers, aber nicht, obin jeder Zelle auch jedes denkbare 8-Bit-Wort korrekt gespeichert wird. Besser wäre:
2. Überprüfen aller 28 Testmuster für jede der 210 Speicherzellen (28 ·210 = 218 Tests).Dieser Test überprüft zwar, ob jede Speicherzelle für sich sämtliche möglichen Bitbele-gungen korrekt speichert, aber nicht, ob diese auch stabil gespeichert sind, wenn irgend-ein anderer Wert auf dem Speicherchip geändert wird. Daher folgt die dritte Teststufe:
3. Überprüfung auf musterabhängige Fehler: 218 · [(210 −1) ·28
]≈ 236 Tests
Zur Überprüfung auf musterabhängige Fehler müssen wir also für jeden der 218 Testsfolgendes machen: In jede der 210−1 übrigen Zellen müssen jeweils zusätzlich sämtlichemögliche Wörter (jeweils 28) geschrieben werden, um zu sehen, ob sich das Wort in derzu testenden Zelle verändert hat.
Selbst bei einer Rate von 106 Tests pro Sekunde würde ein Speichertest nach Variante 3 ca.19 Stunden, 5 Minuten dauern – und es handelt sich nur um die Funktionsüberprüfung eineseinzelnen Kilobytes.
Diese Testkomplexität zeigt, dass vollständige Tests nur in Ausnahmefällen durchführbar sind.Bei einem Rechnerstart werden daher auch nur einfache Speichertests durchgeführt. DieseTests heißen Power-On Self-Test (POST). Es wird beispielsweise der gesamte Speicher mit 0 be-schrieben und anschließend getestet, ob im Speicher tatsächlich 0 steht (Test nach Variante 1).Damit sind nur sehr schwerwiegende Fehler wie defekte Speicherzellen zu entdecken. DieserTest dient mehr dazu herauszufinden, ob und wo Speicher vorhanden ist.
Weitaus wahrscheinlicher als eine kaputte Speicherzelle sind Überbrückungsfehler. Dabei be-einflusst eine Speicherzelle eine benachbarte oder es sind zwei Leitungen überbrückt. SolcheFehler lassen sich dadurch finden, indem ein Testmuster in eine Zelle geschrieben wird unddann getestet wird, ob dadurch eine andere Speicherzelle verändert wurde (Test ähnlich derVariante 3). Um nicht jedes Testmuster schreiben zu müssen, werden beispielsweise durch-laufende Einsen und anschließend das inverse Testmuster geschrieben (walking ones, movinginverse), was eine brauchbare Annäherung an den Test nach Variante 2 darstellt, wobei zu-sätzlich benachbarte Zellen gelesen werden. Da sich ein Überbrückungsfehler auf eine höhereoder niedrigere Adresse auswirkt, wird der Test einmal beginnend von der kleinsten und ein-mal beginnend von der größten Adresse ausgeführt. Dadurch wird eine gute Annäherung anTestvariante 3 erzielt.
Um aus diesem Dilemma herauszukommen, entwirft man Tests, die eine ausreichende Zuver-lässigkeit beim Aufspüren des größten Teils der möglichen Fehler bieten, ohne dabei zu lang zu
Technische Grundlagen der Informatik 61

4.10 Testen von digitalen Schaltungen 4 Sequentielle Schaltungen
dauern. Der erste Schritt bei der Planung solcher Tests ist die Unterscheidung zwischen einemDefekt (defect) und einer Störung (fault).
• Ein Defekt ein ein Fehler, der bereits bei der Herstellung in das System integriert wurde.Zum Beispiel kann ein Chip Fehler machen, wenn es einen Defekt auf der Komponente-nebene (ein defekter Kristall im Siliziumchip) oder auf der Systemebene (ein Lötspritzer,der zwei getrennte Leitungen auf einer Platine miteinander verbindet und so für einenKurzschluss sorgt).
• Den beobachteten Fehler, also das Symptom, nennt man Störung.
Obwohl es eine große Anzahl an möglichen Defekten gibt, ist die Menge der Symptome rechtklein (Bei einem Auto, das nicht anspringt, sind ebenfalls unterschiedliche Ursachen möglich).Digitale Systeme kann man deswegen in Störungsmodellen oder Fehlermodellen beschreiben.Typische Störungen sind:
1. Stuck-at-one (Auf Eins festgefahren) Der Eingang oder Ausgang einer Schaltung bleibt kon-stant bei Logisch 1, unabhängig von den anderen Schaltparametern. Eine Schreibweise dafürist s_a_1.
2. Stuck-at-zero (Auf Null festgefahren) In diesem Fall bleibt der Eingang oder Ausgang kon-stant auf Logisch 0.
3. Bridging Fault (Überbrückungsfehler) Zwei Eingänge oder Ausgänge sind anscheinend mit-einander verbunden und können keine unterschiedlichen Werte annehmen, das heißt sie sindentweder beide 0 oder beide 1.
Es ist möglich, eine längere Liste von Fehlermodellen aufzustellen. Interessant ist, dass das„stuck-at“-Modell in der Lage ist, eine überraschend hohe Anzahl von möglichen Defekten zuerkennen. Dies bedeutet, dass der Test auf alle möglichen „stuck at“-Fehler fast alle möglichenDefekte erkennen wird. Solche Fehler lassen sich mithilfe einer Pfadsensitivierung finden.
4.10.1 Test durch Pfadsensitivierung
Pfadsensitivierung bedeutet, dass Eingangsbelegungen so gewählt werden, dass sich bei Ände-rung einer Eingangsbelegung in eine andere der Ausgang ändern sollte. Man sensibilisiert denAusgang für einen bestimmten Fall.
Abbildung 4.20(a) zeigt einen zu testenden Pfad zwischen dem Eingang A und dem AusgangK. In Abbildung 4.20(b) haben wir den sensitivierten Pfad bereits ausgewählt, indem wir durchdas Setzen aller anderen Parameter auf 1 (UND) bzw. 0 (ODER) sichergestellt haben, dass derEingang A durch die Schaltung durchgereicht wird.
(a) (b)
Abbildung 4.20: Beispiel einer Pfadsensitivierung
62 Technische Grundlagen der Informatik

4 Sequentielle Schaltungen 4.11 Zusammenfassung
Dadurch ist nun K = A, sodass wir durch Setzen von A auf 0 oder 1 auf eine „A stuck at“-Störungtesten können.
Nun könnte man eine Störungsliste für die Schaltung anfertigen, welche in diesem Falle ausden Einträgen A s_a_0, A s_a_1, B s_a_0, B s_a_1,... bestehen würde. Eine übliche Notationdafür ist auch A/0, A/1, B/0, B/1 usw. Dabei bedeutet „/“ so viel wie „stuck at“.
Um auf A/0 zu testen, werden die anderen Ausgänge entsprechend belegt und überprüft, obsich der Ausgang K bei einer entsprechenden Änderung von A von 0 auf 1 ebenfalls ändert.Sollte dies der Fall sein, so hängt A nicht fest. Für den Test auf A/1 verfährt man analog dazu.
Störungstests werden von Ingenieuren (möglicherweise mit CAD-Systemen) entwickelt undkönnen entweder manuell oder durch eine computergesteuerte automatische Testausrüstung(ATE, automatic test equipment) durchgeführt werden. Diese setzt die entsprechenden Ein-gangssignale und vergleicht den Ausgang mit dem erwarteten Wert.
Es ist aufgrund des topologischen Aufbaus einer Schaltung nicht immer möglich, diese wieeben beschrieben zu testen. Zum Beispiel kann ein digitales Signal mehr als einen Weg durchdie Schaltung nehmen und mehrere Defekte können sich in einem bestimmten Knoten gegen-seitig eliminieren, sodass keine Störung beobachtet wird. Darüber hinaus können Schaltungenauch nicht erkennbare Fehler haben.
Abbildung 4.21: Beispiel für einen nicht erkennbaren Fehler
Ein Beispiel für eine solche Schaltung ist in Abbildung 4.21 dargestellt. Um hierbei einen sen-sitiven Pfad für den Knoten D zu schaffen, müssen die Punkte G und F auf 0 gesetzt werden,was aber nur möglich ist, wenn der Eingang A gleichzeitig 0 und 1 ist. Aufgrund dieses Wider-spruches lässt sich der Eingang D nicht auf einen „stuck at“-Fehler testen.
Man beachte, dass diese Art eines nicht erkennbaren Fehlers durch Redundanz auftritt, unddurch eine Neugestaltung der Schaltung behoben werden könnte. Alternativ dazu kann maneine Schaltung auch leichter testen, indem man bei der Konstruktion einige interne Knotenmit weiteren Ausgängen versieht, die sich dann direkt untersuchen ließen.
Viele Schaltungen auf einem Chip (d. h. hohe Integrationsdichte) bei einer konstanten Anzahlvon Pins (Ausgänge des Chips) resultieren in einer schlechten Testbarkeit. Aus diesem Grundwerden in kritischen Anwendungen in der Regel ältere, sehr gut erprobte Schaltkreise (soge-nannte good known dies) verwendet.
4.11 Zusammenfassung
In diesem Kapitel haben wir einige der grundlegenden Komponenten eingeführt, die bei derEntwicklung von digitalen Systemen angewendet werden. Aus der Sicht des Entwicklers sind
Technische Grundlagen der Informatik 63

4.11 Zusammenfassung 4 Sequentielle Schaltungen
die wichtigsten Parameter bei der Entwicklung eines Chips die Kosten und die Geschwindig-keit. Beide Parameter lassen sich verbessern, indem man die Komplexität einzelner Schaltun-gen so klein wie möglich hält. Bei großen Chips ist das möglich, da mehrere komplexere logi-sche Schaltungen auf einem einzelnen Chip Platz finden.
Zwei andere Prinzipien des Designs werden zunehmend wichtig. Die Fähigkeit, die Schaltungeinfach entwerfen zu können, vereinfacht die Aufgabe, die korrekte Funktion der neuen Hard-ware nachzuweisen und sie andernfalls leicht reparieren zu können. Weiterhin ist es meist er-strebenswert, die Zuverlässigkeit des Systems mit Hilfe von weiterer, auch überflüssiger, Logikzu erhöhen (z. B. manche Bestandteile doppelt zu integrieren). Beide dieser Prinzipien führenschnell zu erhöhten Kosten.
Es ist Aufgabe des Entwicklers, hier einen zufriedenstellenden Kompromiss zwischen den Über-legungen zu finden. Es gibt leider keine optimalen Wahrheiten wie in der Mathematik, weil eskeine widerspruchsfreien Randbedingungen gibt.
64 Technische Grundlagen der Informatik

5 Codes
In einem Computer findet man, sobald von den analogen Bausteinen auf die digitale Ebeneabstrahiert wurde, im Wesentlichen Nullen und Einsen vor. Diese steuern die internen Abläufeoder stellen Daten dar, je nachdem, wo sie im Rechner auftauchen und wie sie interpretiertwerden. Damit aber überhaupt aus Nullen und Einsen Daten oder Befehle werden, muss si-chergestellt werden, dass die entsprechenden Geräte der gleichen Interpretation der Bitmusterfolgen.
Ein n-Bit-Wort kann eins von 2n unterschiedliche Bitmustern beinhalten. Diese Bitmuster ha-ben von sich aus keine Bedeutung; diese bekommen sie erst durch eine entsprechende Pro-grammierung, die die Syntax (die Anordnung von Einsen und Nullen) mit einer Semantik A(die Bedeutung bestimmter Anordnungen) verknüpft. Die Abbildungsvorschrift C , die dieseVerknüpfung vornimmt, nennt man Code. C definiert sich also wie folgt: C : {0,1} → A.
Der Rechner selbst kann keine Aussage über die Bedeutung eines Wortes treffen; er behandeltes lediglich so, wie der Programmier es vorschreibt. Dadurch ist es möglich, Buchstaben zu„multiplizieren“, auch wenn dies in den meisten Fällen ohne Sinn ist.
Es gibt wohl unendlich viele Möglichkeiten, einem Bitmuster eine Bedeutung beizumessen.Zwei typische, häufig anzutreffende Vertreter sind:
1. Die Instruktion: Instruktionen sind Befehle eines Programms, die dem Prozessor mittei-len, was er als nächstes tun soll. Da Menschen besser mit Zeichenfolgen und Computerbesser mit Zahlen umgehen können, werden bestimmten Bitfolgen Befehle zugeordnet.Wie genau dies vonstatten geht, wird in der Lehrveranstaltung Rechnersysteme genauerbetrachtet.
2. Die Zahl: Zahlen können auf viele Arten im Computer auf Binärebene dargestellt werden.Dazu gehören binäre Ganzzahlen mit oder ohne Vorzeichen, Gleitkommazahlen, binärcodierte Dezimalzahlen (BCD) und andere, wie im Kapitel 6 gezeigt.
Die Zuordnung der Semantik ist auf dieser Ebene hardwareabhängig. In diesem Kapitel wirdauf verschiedene Arten der Interpretation eingegangen.
5.1 Zeichencodes
Jeder Rechner hat eine Menge von Zeichen (Alphabet genannt), mit der er arbeitet. Als eingrobes Minimum beinhaltet diese Menge die 26 Großbuchstaben, die 26 Kleinbuchstaben, diezehn Ziffern von 0 bis 9 und eine Menge von Sonderzeichen, wie z. B. Leerzeichen, Punkt, Mi-nus, Komma, Semikolon, und Steuerzeichen wie den Zeilenwechsel; also Zeichen, die man aufeiner Tastatur vorfindet.
Um diese Zeichen in einen Rechner zu übertragen, wird jedem von ihnen eine Zahl zugewie-sen:
Zum Beispiel: a = 1,b = 2, . . . z = 26,+= 27,−= 28
Die Zuweisung von Zeichen zu Ganzzahlen nennt man Zeichencode.
65
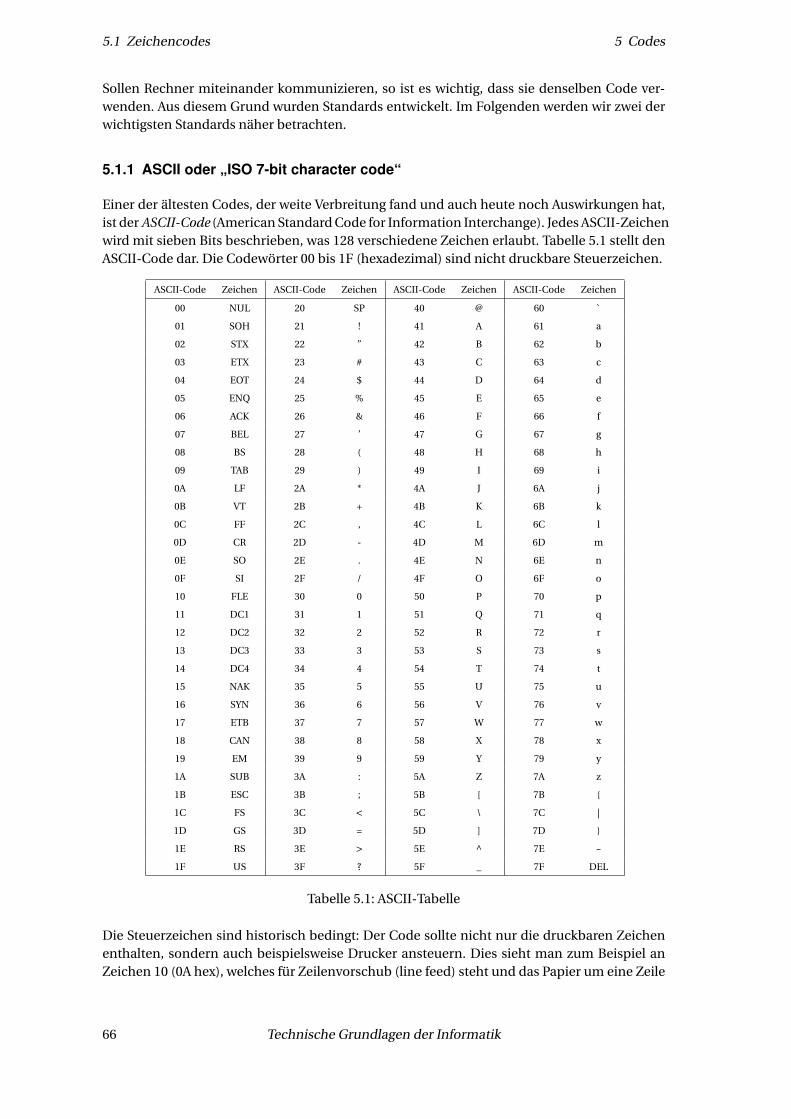
5.1 Zeichencodes 5 Codes
Sollen Rechner miteinander kommunizieren, so ist es wichtig, dass sie denselben Code ver-wenden. Aus diesem Grund wurden Standards entwickelt. Im Folgenden werden wir zwei derwichtigsten Standards näher betrachten.
5.1.1 ASCII oder „ISO 7-bit character code“
Einer der ältesten Codes, der weite Verbreitung fand und auch heute noch Auswirkungen hat,ist der ASCII-Code (American Standard Code for Information Interchange). Jedes ASCII-Zeichenwird mit sieben Bits beschrieben, was 128 verschiedene Zeichen erlaubt. Tabelle 5.1 stellt denASCII-Code dar. Die Codewörter 00 bis 1F (hexadezimal) sind nicht druckbare Steuerzeichen.
ASCII-Code Zeichen ASCII-Code Zeichen ASCII-Code Zeichen ASCII-Code Zeichen
00 NUL 20 SP 40 @ 60 `
01 SOH 21 ! 41 A 61 a
02 STX 22 ” 42 B 62 b
03 ETX 23 # 43 C 63 c
04 EOT 24 $ 44 D 64 d
05 ENQ 25 % 45 E 65 e
06 ACK 26 & 46 F 66 f
07 BEL 27 ’ 47 G 67 g
08 BS 28 ( 48 H 68 h
09 TAB 29 ) 49 I 69 i
0A LF 2A * 4A J 6A j
0B VT 2B + 4B K 6B k
0C FF 2C , 4C L 6C l
0D CR 2D - 4D M 6D m
0E SO 2E . 4E N 6E n
0F SI 2F / 4F O 6F o
10 FLE 30 0 50 P 70 p
11 DC1 31 1 51 Q 71 q
12 DC2 32 2 52 R 72 r
13 DC3 33 3 53 S 73 s
14 DC4 34 4 54 T 74 t
15 NAK 35 5 55 U 75 u
16 SYN 36 6 56 V 76 v
17 ETB 37 7 57 W 77 w
18 CAN 38 8 58 X 78 x
19 EM 39 9 59 Y 79 y
1A SUB 3A : 5A Z 7A z
1B ESC 3B ; 5B [ 7B {
1C FS 3C < 5C \ 7C |
1D GS 3D = 5D ] 7D }
1E RS 3E > 5E ^ 7E ~
1F US 3F ? 5F _ 7F DEL
Tabelle 5.1: ASCII-Tabelle
Die Steuerzeichen sind historisch bedingt: Der Code sollte nicht nur die druckbaren Zeichenenthalten, sondern auch beispielsweise Drucker ansteuern. Dies sieht man zum Beispiel anZeichen 10 (0A hex), welches für Zeilenvorschub (line feed) steht und das Papier um eine Zeile
66 Technische Grundlagen der Informatik

5 Codes 5.1 Zeichencodes
weiterschieben soll. Ein weiterer Einsatzzweck war die Datenfernübertragung, wie man an denZeichen 1–4 sehen kann (SOH=Start of Header, STX=Start of Text, ETX=End of Text, EOT=Endof Transmission). Steuerzeichen spielen heute nur noch eine Nebenrolle.
Zeichen werden normalerweise zu Zeichenketten (Strings) kombiniert, welche eine variableAnzahl von Zeichen beinhalten können. Es gibt drei Möglichkeiten, eine Zeichenkette darzu-stellen:
1. Die erste Position des Strings ist für eine Angabe der Länge der Zeichenkette reserviert.
2. Eine dazugehörige Variable beinhaltet die Länge der Zeichenkette.
3. Die letzte Position der Zeichenkette wird durch ein spezielles Zeichen angegeben, die Zei-chenkette wird also durch dieses Zeichen terminiert (beendet).
Die zweite Methode findet z. B. bei Headern von Netzwerkpaketen Anwendung, um anzuge-ben, wie lang das angehängte Datenfragment ist.
Die dritte Methode wird in der Programmiersprache C eingesetzt; ein String wird dabei durchein Byte mit dem Wert 0 terminiert. Demzufolge würde die Zeichenkette „Cal“ in C durch vierBytes mit den dezimalen Werten 67, 97, 108, 0 dargestellt werden (43, 61, 6C, 00 hexadezimal).
5.1.2 ASCII-Fortentwicklung
Als Code des amerikanischen Standardisierungsinstituts nimmt ASCII keine Rücksicht auf Son-derzeichen der Schriftsprache, die in nicht-englischen Sprachen anwendung finden. So fehlendie deutschen Umlaute und das Eszett, aber auch beispielsweise die französischen Zeichen mitAkzent. Schriftalphabete, die eine ganz andere Basis haben, wie zum Beispiel Russisch oderArabisch, werden ebenfalls nicht berücksichtigt.
Der erste Versuch, ASCII zu erweitern, war der ISO 646, welcher ASCII um ein Bit erweiterteund so weitere 128 Zeichen hinzufügte. Dieser Code wird auch Latin-1 genannt. Die zusätzli-chen Zeichen waren meist lateinische Buchstaben mit Akzent- oder Umlautmarkierungen. Dernächste Schritt war ISO 8859, welcher das Konzept der Codeseiten einführte. Eine Codeseiteist eine Menge von 256 Zeichen für eine bestimmte Sprache oder eine Gruppe von Sprachen.ISO 8859-1 ist Latin-1, ISO 8859-2 bedient slawische Sprachen mit lateinischen Buchstaben(z. B. Tschechisch, Polnisch und Ungarisch). ISO 8859-3 beinhaltet die Zeichen, die man fürTürkisch, Maltesisch, Esperanto oder Gälisch benötigt, usw.
An dieser Stelle war zwar das Problem mit den Akzenten und gelegentlichen Sonderzeichengelöst, allerdings wurde es dadurch notwendig, sich nicht nur auf einen bestimmten Code,sondern zusätzlich auf eine bestimmte Seite zueinigen, um fehlerfrei kommunizieren zu kön-nen. Das Problem komplett anderer Alphabetschemata wie Japanisch oder Chinesisch war andieser Stell noch gar nicht angegangen worden.
5.1.3 Unicode
Unicode entstand aus der Idee heraus, einen Code zu etablieren, der die meisten Schreibsys-teme der Welt enthält. Dadurch sollte es möglich werden, auf einem Rechner zugleich in meh-reren Sprachsystemen arbeiten zu können, zum Beispiel Deutsch und Koreanisch.
Die Grundidee hinter UNICODE war ursprünglich, jedem Zeichen und Symbol einen einzigar-tigen und dauerhaften 16-Bit-Wert zuzuweisen, der Codepunkt genannt wurde. Mit einer Sym-bolbreite von 16 Bits hat UNICODE 216 = 65536 mögliche Codepunkte. Um rückwärtskompa-
Technische Grundlagen der Informatik 67

5.2 Bildcodierung 5 Codes
tibel zu bleiben und die Akzeptanz zu steigern, wurde der Latin-1-Zeichensatz unverändert inden Anfang des Unicodes übernommen.
Es stellte sich aber schnell heraus, dass diese Codepunktkapazität zu gering für das Vorhabenist. Daher wurde mit Unicode 2.0 das Konzept der Planes (Ebenen) eingeführt, bei der jedesPlane 65536 enthält. Es wurden zunächst 17 Ebenen eingefügt, sodass insgesamt 1.114.112 Zei-chen speicherbar sind. Bei dem im April 2008 erschienenen Unicode 5.1 waren davon 100.713Codepunkte vergeben.
Jede Sprache bekommt mehr Codepunkte zugewiesen, als sie Buchstaben hat. Diese Entschei-dung beruht zum Teil auf der Tatsache, dass viele Sprachen mehrere Formen eines Buchstabenhaben. Zum Beispiel unterscheiden wir im lateinischen Alphabet zwischen GROSSBUCHSTA-BEN und kleinbuchstaben. Andere Sprachen haben drei oder mehr verschiedene Formen, jenachdem, ob ein Buchstabe am Anfang, in der Mitte oder am Ende eines Wortes steht.
Zusätzlich zu den Alphabeten wurden weitere Codepunkte zugewiesen; unter anderem fürUmlautzeichen, Satzzeichen, Hoch- und Tiefzeichen, Währungssymbole, geometrische For-men und mathematische und grafische Symbole.
5.2 Bildcodierung
Neben der Verwendung zur Zeichen- und Befehlscodierung können Bitfolgen auch Bilder re-präsentieren. Der einfachste Ansatz ist die direkte Umsetzung von Schwarzweißbildern in Bit-folgen: Ordnet man einer Null einem schwarzen Bildpunkt und einer Eins einen weißen Bild-punkt zu, so lassen sich zweifarbige Bilder recht einfach binär darstellen. Diese Art der Bild-codierung nennt sich Bitmap. Zusätzlich zu den reinen Bildinhalten müssen dabei Metadatenüber das Bild gespeichert werden, zum Beispiel die Höhe und Breite. Diese Darstellungsartbenötigt relativ viel Speicher im Verhältnis zu den dargestellten Informationen. Ein möglicherAusweg ist, anstatt von Bildrasterpunkten vordefinierte Symbole zu referenzieren, die größersind als die zur Referenzierung notwendigen Bits. Dieser Ansatz wird beispielsweise beim Vi-deotext verwendet. Auf diese Weise lassen sich jedoch nur grobe Bilder übertragen.
Bilder bestehen aber meistens nicht aus lediglich zwei Farben und sind – gerade bei Fotografi-en – aus sehr vielen Pixeln zusammengesetzt. Ein Beispiel: Ein Digitalfoto aus einer aktuellenDigitalkamera hat 10 Megapixel; das entspricht einer Auflösung von 3648×2736 Bildpunkten(Breite mal Höhe).1 Jeder Bildpunkt wird, da für die drei Grundfarben Rot, Grün und Blau jeacht Bit verwendet werden, mit einer Farbauflösung von 24 Bit gespeichert. Um die reinenBilddaten ohne Metadaten zu speichern, benötigt man folglich 3648×2736×24 = 239.542.272Bit, was umgerechnet etwa 28,5 Megabyte Speicherplatz entspricht. Dieser hohe Speicher-platzbedarf ist aber glücklicherweise reduzierbar.
Es gibt komplexe Techniken, um die Speichermenge zu komprimieren. Solche Techniken su-chen beispielsweise Felder mit konstanter Farbe und Intensität und speichern die Form undPosition dieses Feldes und seine Farbe. Dieses Prinzip wird beispielsweise beim GIF-Format(Graphics Interchange Format) genutzt und realisiert eine verlustfreie Komprimierung. Ande-re Kompressionsalgorithmen nutzen Transformationen, um Ähnlichkeiten in Bildteilen zu be-schreiben und weniger wichtige Details wegzulassen. Solche Kompressionsalgorithmen kön-nen verlustbehaftet ausgeführt sein, d. h. kleine Details werden ignoriert, um den Speicher-bedarf zu minimieren. Ein Beispiel hierzu ist das JPEG-Verfahren, bei dem die diskrete Kosi-
1eigentlich entsprechen 3648× 2736 = 9980928, aber das ist der Industrie nah genug an 10 Megapixel, dass sierundet
68 Technische Grundlagen der Informatik
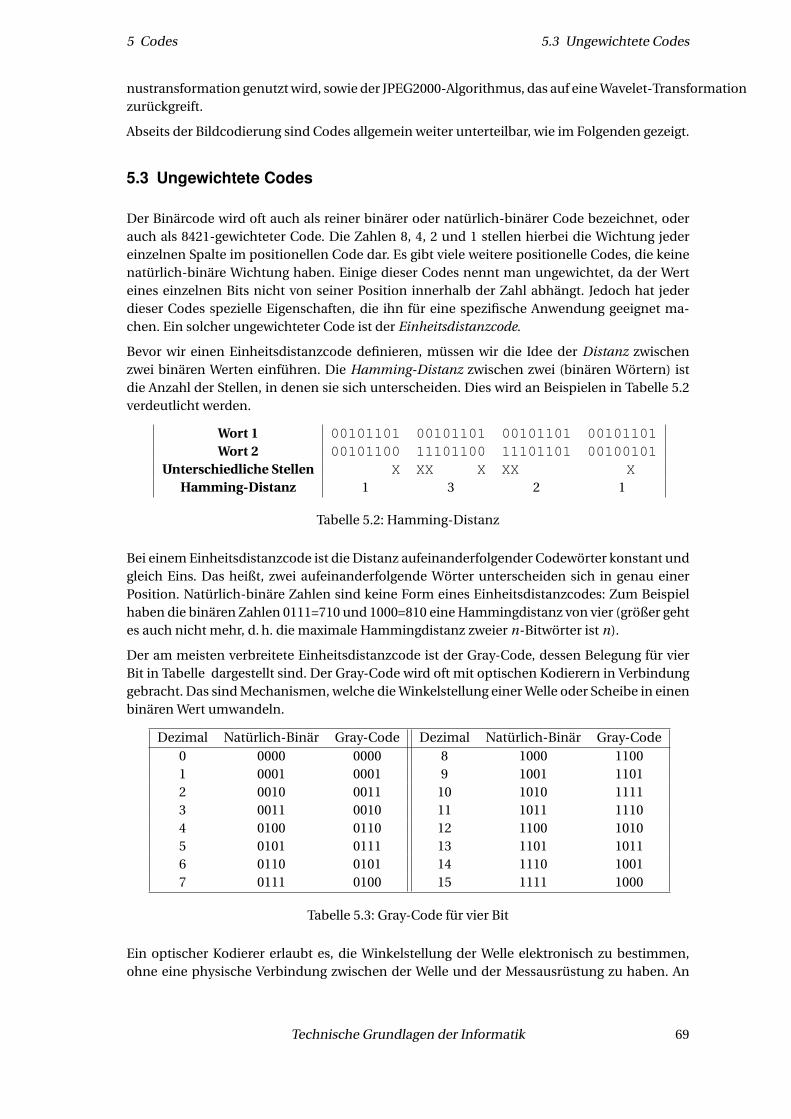
5 Codes 5.3 Ungewichtete Codes
nustransformation genutzt wird, sowie der JPEG2000-Algorithmus, das auf eine Wavelet-Transformationzurückgreift.
Abseits der Bildcodierung sind Codes allgemein weiter unterteilbar, wie im Folgenden gezeigt.
5.3 Ungewichtete Codes
Der Binärcode wird oft auch als reiner binärer oder natürlich-binärer Code bezeichnet, oderauch als 8421-gewichteter Code. Die Zahlen 8, 4, 2 und 1 stellen hierbei die Wichtung jedereinzelnen Spalte im positionellen Code dar. Es gibt viele weitere positionelle Codes, die keinenatürlich-binäre Wichtung haben. Einige dieser Codes nennt man ungewichtet, da der Werteines einzelnen Bits nicht von seiner Position innerhalb der Zahl abhängt. Jedoch hat jederdieser Codes spezielle Eigenschaften, die ihn für eine spezifische Anwendung geeignet ma-chen. Ein solcher ungewichteter Code ist der Einheitsdistanzcode.
Bevor wir einen Einheitsdistanzcode definieren, müssen wir die Idee der Distanz zwischenzwei binären Werten einführen. Die Hamming-Distanz zwischen zwei (binären Wörtern) istdie Anzahl der Stellen, in denen sie sich unterscheiden. Dies wird an Beispielen in Tabelle 5.2verdeutlicht werden.
Wort 1 00101101 00101101 00101101 00101101Wort 2 00101100 11101100 11101101 00100101
Unterschiedliche Stellen X XX X XX XHamming-Distanz 1 3 2 1
Tabelle 5.2: Hamming-Distanz
Bei einem Einheitsdistanzcode ist die Distanz aufeinanderfolgender Codewörter konstant undgleich Eins. Das heißt, zwei aufeinanderfolgende Wörter unterscheiden sich in genau einerPosition. Natürlich-binäre Zahlen sind keine Form eines Einheitsdistanzcodes: Zum Beispielhaben die binären Zahlen 0111=710 und 1000=810 eine Hammingdistanz von vier (größer gehtes auch nicht mehr, d. h. die maximale Hammingdistanz zweier n-Bitwörter ist n).
Der am meisten verbreitete Einheitsdistanzcode ist der Gray-Code, dessen Belegung für vierBit in Tabelle dargestellt sind. Der Gray-Code wird oft mit optischen Kodierern in Verbindunggebracht. Das sind Mechanismen, welche die Winkelstellung einer Welle oder Scheibe in einenbinären Wert umwandeln.
Dezimal Natürlich-Binär Gray-Code Dezimal Natürlich-Binär Gray-Code0 0000 0000 8 1000 11001 0001 0001 9 1001 11012 0010 0011 10 1010 11113 0011 0010 11 1011 11104 0100 0110 12 1100 10105 0101 0111 13 1101 10116 0110 0101 14 1110 10017 0111 0100 15 1111 1000
Tabelle 5.3: Gray-Code für vier Bit
Ein optischer Kodierer erlaubt es, die Winkelstellung der Welle elektronisch zu bestimmen,ohne eine physische Verbindung zwischen der Welle und der Messausrüstung zu haben. An
Technische Grundlagen der Informatik 69
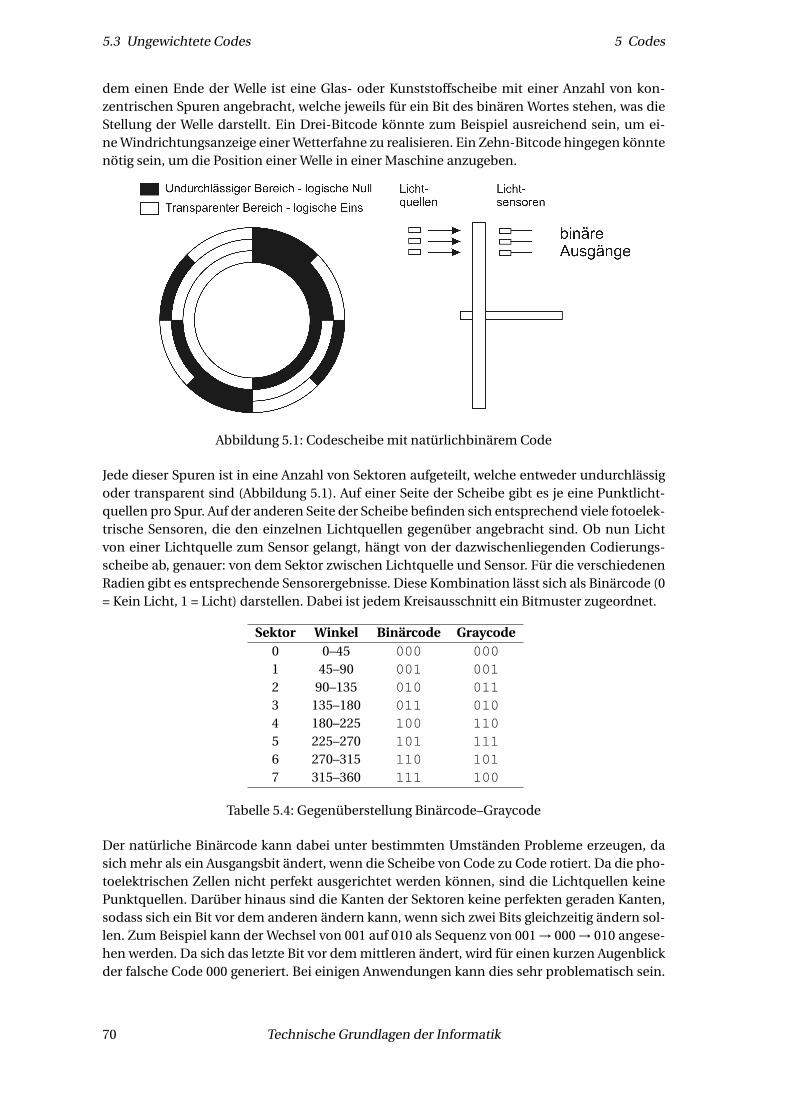
5.3 Ungewichtete Codes 5 Codes
dem einen Ende der Welle ist eine Glas- oder Kunststoffscheibe mit einer Anzahl von kon-zentrischen Spuren angebracht, welche jeweils für ein Bit des binären Wortes stehen, was dieStellung der Welle darstellt. Ein Drei-Bitcode könnte zum Beispiel ausreichend sein, um ei-ne Windrichtungsanzeige einer Wetterfahne zu realisieren. Ein Zehn-Bitcode hingegen könntenötig sein, um die Position einer Welle in einer Maschine anzugeben.
Abbildung 5.1: Codescheibe mit natürlichbinärem Code
Jede dieser Spuren ist in eine Anzahl von Sektoren aufgeteilt, welche entweder undurchlässigoder transparent sind (Abbildung 5.1). Auf einer Seite der Scheibe gibt es je eine Punktlicht-quellen pro Spur. Auf der anderen Seite der Scheibe befinden sich entsprechend viele fotoelek-trische Sensoren, die den einzelnen Lichtquellen gegenüber angebracht sind. Ob nun Lichtvon einer Lichtquelle zum Sensor gelangt, hängt von der dazwischenliegenden Codierungs-scheibe ab, genauer: von dem Sektor zwischen Lichtquelle und Sensor. Für die verschiedenenRadien gibt es entsprechende Sensorergebnisse. Diese Kombination lässt sich als Binärcode (0= Kein Licht, 1 = Licht) darstellen. Dabei ist jedem Kreisausschnitt ein Bitmuster zugeordnet.
Sektor Winkel Binärcode Graycode0 0–45 000 0001 45–90 001 0012 90–135 010 0113 135–180 011 0104 180–225 100 1105 225–270 101 1116 270–315 110 1017 315–360 111 100
Tabelle 5.4: Gegenüberstellung Binärcode–Graycode
Der natürliche Binärcode kann dabei unter bestimmten Umständen Probleme erzeugen, dasich mehr als ein Ausgangsbit ändert, wenn die Scheibe von Code zu Code rotiert. Da die pho-toelektrischen Zellen nicht perfekt ausgerichtet werden können, sind die Lichtquellen keinePunktquellen. Darüber hinaus sind die Kanten der Sektoren keine perfekten geraden Kanten,sodass sich ein Bit vor dem anderen ändern kann, wenn sich zwei Bits gleichzeitig ändern sol-len. Zum Beispiel kann der Wechsel von 001 auf 010 als Sequenz von 001 → 000 → 010 angese-hen werden. Da sich das letzte Bit vor dem mittleren ändert, wird für einen kurzen Augenblickder falsche Code 000 generiert. Bei einigen Anwendungen kann dies sehr problematisch sein.
70 Technische Grundlagen der Informatik

5 Codes 5.4 Huffman-Codierung
Aus Abbildung 5.2 ist ersichtlich, dass eine mit dem Gray-Code codierte Scheibe die Eigen-schaft hat, dass sich nur ein Bit gleichzeitig ändert, was das Problem in dem natürlich-binärenSystem löst (Tabelle 5.4). Nachdem der Gray-Code einmal in ein digitales System eingelesenwurde, kann er in den natürlich-binären Code umgewandelt werden, um die Daten normalweiterzuverarbeiten.
Abbildung 5.2: Codescheibe mit Gray-Code
Gray-Codes können in ein natürlich-binäres Format umgewandelt werden (und umgekehrt),indem man Schaltungen aus XOR-Gattern wie in Abbildung einsetzt. Die verwendete Logik isteinfach und regulär.
Abbildung 5.3: Schaltungen für die Umwandlung von natürlich-binärem Code in Gray-Codeund zurück
5.4 Huffman-Codierung
Nachdem mit dem Gray-Code ein ungewichteter Code vorgestellt wurde, soll nun auf gewich-tete Codes eingegangen werden.
Diese kurze Einführung in die Huffman-Codierung wurde in die Vorlesung mit aufgenommen,um zu zeigen, dass es nicht nur einen Weg gibt, Codierungen für Quellworte zu finden. DieHuffman-Codierung unterscheidet sich insofern von allen bisher erwähnten Kodierungstech-niken, weil sie eine variable Codewortlänge haben. Die Idee hinter der Huffman-Codierung
Technische Grundlagen der Informatik 71

5.4 Huffman-Codierung 5 Codes
hingegen ist nicht neu. Als Samuel Morse seinen Morse-Code entwickelte, schickte er seinenAssistenten zu Drucksetzern bei Zeitungen, um die Anzahl der Druckformen für die Buchsta-ben A bis Z zu bestimmen. Zu dieser Zeit wurden Zeitungsseiten noch per Hand zusammenge-stellt und Drucksetzer verfügten über einen Schrank mit jeweils einem Fach pro Buchstaben,die unterschiedlich stark gefüllt waren. Da zum Beispiel der Buchstabe E so häufig in der eng-lischen Sprache auftritt, war das Fach für den Buchstaben E recht voll. Gleichzeitig gab es nurwenige Q im entsprechenden Fach. So schuf Samuel Morse seinen Code, wobei häufig benutz-te Buchstaben kurze Codewörter (oder besser Symbole) hatten, während selten verwendeteBuchstaben durch lange Symbole dargestellt waren. Zum Beispiel hatte der Buchstaben E dasMorsesymbol ·, während Q das Symbol −−·− hatte.
Eine solche Vereinbarung kann auf binäre Codes erweitert werden. Dabei muss vorausgesetztwerden, dass die Huffman-Codierung nur auf Informationen angewendet wird, bei denen man-che Buchstaben oder Buchstabengruppen häufiger als andere auftreten. Normaler Text (egalob deutsch, englisch usw.) ist so ein Fall.
Der Huffman-Code wird nun an einem einfachen Beispiel demonstriert: Angenommen, es sol-len möglichst wenig Bit verwendet werden, um das Wort SALATBLATT abzuspeichern. Wieman sieht, kommen in diesem Wort fünf verschiedene Zeichen vor. Folglich müssen (mindes-tens) fünf verschiedene binäre Symbole (d. h. Bitreihen) definiert werden, die jeweils einemder Buchstaben entsprechen. Mit zwei Bit kann man vier unterschiedliche Symbole darstel-len, das ist zu wenig; drei Bit dagegen ermöglichen die Darstellung von acht verschiedenenSymbolen. Somit sind drei Bit notwendig und hinreichend für die Anforderung.
Zurück zum SALATBLATT-Beispiel: Ordnet man jedem Buchstaben ein Symbol aus drei Bit zu,zum Beispiel S = 000, A = 001 usw., so benötigt die Symboldarstellung des zehn Zeichen lan-gen Wortes 10×3 Bit Speicherplatz, also 30 Bit. Man bemerke, dass drei der möglichen Sym-bole nicht benötigt werden und quasi brach liegen. Dieser Überschuss wird hierbei in Kaufgenommen und treibt den Speicherbedarf in die Höhe. Zudem wird nicht berücksichtigt, dassZeichen wie das T oder das A viel häufiger vorkommen als zum Beispiel das S.
Der Huffman-Code reduziert den Speicherbedarf, indem er die relative Häufigkeit der Buch-staben in dem Wort berücksichtigt. Bei genauer Betrachtung ergeben sich die in Tabelle 5.5aufgeführten relativen Häufigkeiten.
Zeichen relative HäufigkeitS 1
10A 3
10L 2
10T 3
10B 1
10
Tabelle 5.5: Relative Zeichenhäufigkeiten im Wort SALATBLATT
Der Huffman-Code wird algorithmisch erstellt: Man zieht die beiden Elemente mit den ge-ringsten Werten der relativen Häufigkeit zusammen zu einem neuen Zwischensymbol, wel-ches als Wert die Summe der Elemente erhält. Zum Beispiel wird als erstes das S und das B,beide mit der relativen Häufigkeit 1
10 , zu einem Zwischensymbol zusammengezogen, welchesals Wert 2 · 1
10 = 210 erhält. Die Ursprungssymbole S und B werden damit ersetzt und der Algo-
rithmus so lange wiederholt, bis nur noch ein Symbol vorhanden ist, das die Häufigkeit 1010 = 1
haben muss. Als letztes werden nun die Kanten zwischen den Symbolen beliebig jeweils mit 0oder 1 bezeichnet. Das Ergebnis zeigt Abbildung 5.4.
72 Technische Grundlagen der Informatik

5 Codes 5.4 Huffman-Codierung
Abbildung 5.4: SALATBLATT als Huffman-Baum
Geht man nun vom Schlussknoten (Symbol) an den Kanten entlang zu den Zeichen, so er-hält man die Bitfolgen, die den einzelnen Buchstaben zugeordnet werden. Das T erreicht manbeispielsweise mit der Zeichenfolge 11, es ist auch eines der häufigsten Zeichen im Wort. Umdagegen zum B zu kommen, muss man die Kanten 001 durchlaufen; das Zeichen kommt abernur einmal vor. Tabelle 5.6 zeigt alle im Beispiel zugeordneten Codewörter.
Zeichen relative Häufigkeit Huffman-CodewortS 1
10 000A 3
10 10L 2
10 01T 3
10 11B 1
10 001
Tabelle 5.6: Huffman-Symbole für die Buchstaben in SALATBLATT
Multipliziert man die Häufigkeit mit der Codewortlänge und summiert das Ergebnis aller Buch-staben auf, so erhält man den so benötigten Speicherbedarf:
1 ·3︸︷︷︸S
+ 3 ·2︸︷︷︸A
+ 2 ·2︸︷︷︸L
+ 3 ·2︸︷︷︸T
+ 1 ·3︸︷︷︸B
= 22
Das bedeutet, dass pro Zeichen 2,2 Bit benötigt werden – gegenüber den drei Bit pro Zeichen,die der ungewichtete Code benötigt, eine echte Verbesserung. Wenn man noch größere Un-gleichheiten im zu kodierenden Material hat, so wird die benötigte Menge an Bits pro Zeichenweiter sinken.
Das Salatblatt sieht huffmancodiert so aus: 0001001101100101101111. Zur besseren Lesbar-keit wurden hier Leerzeichen gesetzt, die im Computer natürlich nicht existieren.
Jemand, der das so codierte Wort und die Tabelle (oder den Baum) erhält, kann es auslesen:Er startet im Baum beim obersten Knoten und geht entsprechend der Bits zu den Blattknotenhinunter. Wie man leicht nachvollziehen kann, ist ein versehentlich gekipptes Bit ein Problem:alles darauf folgende kann nicht mehr ausgelesen werden. Beim ungewichteten Code ist dasanders!
Technische Grundlagen der Informatik 73

5.5 Fehler erkennende Codes 5 Codes
5.5 Fehler erkennende Codes
Wann immer digitale Signale über große Entfernungen durch ein Kabel übertragen werden,wird ihre Signalstärke schwächer, was es möglich macht, dass äußere Störsignale die digita-len Signale beeinträchtigen oder sogar vernichten. Der Effekt von elektro-magnetischem Rau-schen ist den meisten Menschen bekannt, da sie wissen, wenn sie Fernseher oder Radios ein-schalten, der Empfang von entfernteren Sendern von schlechterer Qualität als der von loka-len Sendern ist. Es handelt sich also um einen Fehler bei der Kommunikation (Informations-übermittlung) und Informationsspeicherung. Wann immer ein Fehler beim Empfang von di-gitalen Signalen auftritt, ist es wichtig, dass dieser erkannt werden kann, damit eine Anfragenach erneuter Versendung der vernichteten Daten gemacht werden oder der Fehler gleich vorOrt behoben werden kann (Was in militärischen Anwendungen sehr sinnvoll sein kann, wennder Empfänger nicht lokalisiert werden will.) Fehlererkennende Codes (error detection codes =EDC) und fehlerkorrigierende Codes (error correction codes = ECC) werden auch in der Daten-sicherungstechnologie benötigt. Viele der Techniken, um digitale Daten zu sichern, sind sehranfällig für Fehler (obwohl die Fehlerwahrscheinlichkeit sehr klein ist). Folglich werden EDCsund ECCs häufig zur Entscheidung verwendet, ob Daten während des Prozesses der Sicherungund Rückholung vernichtet wurden.
Die Korrektur-Algorithmen sind sehr rechenaufwendig, sodass heute vorzugsweise spezielleintegrierte Schaltkreise eingesetzt werden. Anwendungsgebiete sind:
• stark gestörte Übertragungswege, auf denen die effektive Übertragungsrate durch zu ho-he Blockwiederholraten zu sehr gesenkt würde,
• militärische Datenübertragungen auf Funkwegen, bei denen sich ein Quittungs- undWiederholdialog aus Gründen der Peilung verbietet,
• Arbeitsspeicher und Plattenspeicher in Rechenanlagen, um Lesefehler zunächst ohneWiederholvorgang zu beheben.
Eine weit verbreitete Methode zur Fehlererkennung ist die Implementierung, bei der mandie Übertragung der gewünschten digitalen Informationen (d. h. dem Quellwort) um ein odermehrere Prüfbits erweitert, die sich aus einer Funktion über den Informationsbits errechnen.
Da Prüfbits keine zusätzliche Information beinhalten, nennt man sie redundante (überflüssi-ge) Bits. Am Empfänger-Ende einer Datenverbindung werden die Informationsbits verwendet,um die Prüfbits lokal zu berechnen. Wenn die empfangenen Prüfbits gleich denen der lokalgenerierten sind, kann die Übertragung als fehlerfrei angesehen werden, ansonsten muss derEmpfänger dem Sender eine Nachricht zukommen lassen, in der er um wiederholte Zusen-dung der Daten bittet. Wenn der Fehler in einem gespeicherten Wort auftritt, kann es nichtkorrigiert werden, in dem der Rechner gefragt wird, was es war, da es keine weitere Kopie desWortes gibt. Folglich muss das Betriebssystem über den Fehler informiert werden, um an-schließend entsprechende Aktionen einzuleiten (üblicherweise die momentane Aufgabe ab-brechen). Glücklicherweise setzen einige Speicher fehlerkorrigierende Codes ein und sind so-mit in der Lage, den durch den Fehler entstandenen Schaden zu beheben, bevor das Daten-wort zum Rechner übertragen wird.
Als Beispiel für eine Anwendung von Prüfbits denke man sich eine einfache zweistellige Dezi-malzahl, mit einer einzelnen dezimalen Prüfziffer. Diese Prüfziffer errechnet sich aus der Sum-me der beiden Quellziffern modulo zehn (was hierbei einfach nur bedeutet, dass wir eineneventuellen Übertrag bei der Addition der Ziffern ignorieren – der „modulo zehn“-Wert von6+7 = 3). Wen die beiden Quellziffern 4 und 9 sind, wäre das Codewort 493 (3 ist die Prüfzif-fer). Nehmen wir an, dass bei der Übertragung das Codewort verstümmelt und zu 463 wurde.
74 Technische Grundlagen der Informatik

5 Codes 5.5 Fehler erkennende Codes
Wenn wir die Prüfziffer nun erneut ausrechnen, erhalten wir 4+6 = 10 und 10 mod 10 = 0. Dadie empfangene Prüfziffer aber 3 ist, wissen wir, dass ein Fehler aufgetreten sein muss.
5.5.1 Arbeitsweise Fehler erkennender Codes
Die Idee hinter EDCs ist, dass ein m-Bit-Quellcode 2m einzigartige Nachrichten übermittelnkann. Wenn r Prüfbits zu den m Nachrichtenziffern hinzuaddiert werden, um ein n-Bit-Codewortzu schaffen, dann gibt es 2n = 2m+r mögliche Codewörter. Von diesen Codewörtern sind nur2m gültig. Sollte ein Codewort empfangen werden, welches nicht eins dieser 2m Werte ist, soist ein Fehler aufgetreten.
Nachdem wir die Hamming-Distanz bereits erklärt haben, soll nun eine genaue Definition fol-gen. Seien x und y Codewörter im R2
n (Die Menge aller n-Bit-Codewörter, wobei ein Bit aus{0,1} ist).
Dann heißt die Funktion
d(x, y) := Anzahl der Bitstellen, an denen sich x und y unterscheiden
Hamming-Distanz von x und y . Die Hamming-Distanz des gesamten Codes (Menge aller Co-dewörter) ist gleich der minimalen Hamming-Distanz zwischen zwei Codewörtern dieses Co-des.
Seien x und y Elemente der Menge O, und d : O×O → R eine Funktion auf O. das heißt Metrik,wenn für alle x, y, z ∈O gilt:
• d(x, y) = 0 genau dann, wenn x = y
• d(x, y) = d(y, x)
• d(x, y) ≤ d(x, z)+d(z, y) (Dreiecksungleichung)
→ Die Hamming-Distanz ist also eine Metrik auf R2n .
Abbildung 5.5: Ein Fehler erkennender Code mit zwei Nutzbits
Abbildung 5.5 zeigt einen fehlererkennenden Code mit n = 3. Jedes der 23 = 8 möglichen Code-wörter wird durch eine Ecke des dreidimensionalen Würfels dargestellt. Von diesen acht mögli-chen Codewörtern wurden nun vier als gültig markiert (schwarz eingefärbt: 000, 011, 101, 110).Wenn wir ein Codewort aus diesem Raum aussuchen, können wir sofort entscheiden, ob es eingültiges Wort ist oder nicht. Es ist gültig, wenn es eine gerade Anzahl von Einsen enthält. Keinbenachbartes Wort (Hamming-Distanz = 1) eines Codewortes ist wieder ein Codewort, weildie Hamming-Distanz zwischen zwei Codewörtern 2 ist. Ein 1-Bit-Fehler resultiert in einemunkorrekten Codewort und kann erkannt werden.
Technische Grundlagen der Informatik 75

5.5 Fehler erkennende Codes 5 Codes
Abbildung 5.6: Ein Fehler erkennender Code mit einem Nutzbit
In Abbildung 5.6 haben wir einen anderen dreidimensionalen Würfel gezeichnet, allerdingswird in diesem Fall nur ein Bit mit Nutzinformation genutzt (m = 1 und r = 2). Hier gibt esnur zwei gültige Codeworte, 000 und 111. Man beachte, dass jedes gültige Codewort vom an-deren durch eine Hamming-Distanz von drei getrennt ist. Wenn ein ungültiges Codewort er-kannt wurde, können wir versuchen, den Fehler zu korrigieren, indem wir das zum fehlerhaf-ten Wort nächstgelegene gültige Codewort nehmen. Wenn also das ungültige empfangene Co-dewort 001 wäre, würden wir annehmen, dass der korrekte Code 000 wäre (da 001 dichter an000 als an 111 liegt). Alle fehlererkennenden Codes arbeiteten nach diesem Prinzip, bei demgültige Codewörter durch eine Hamming-Distanz von mindestens drei getrennt sind. Folglichkönnen wir eine Strategie zur Fehlerkorrektur entwickeln: Wenn wir ein ungültiges Codewortentdecken, korrigieren wir den Fehler, indem wir das fehlerhafte Wort durch das nächstgelege-ne gültige Wort ersetzen. Da gültige Codewörter voneinander durch mindestens drei Einheitenvoneinander getrennt sind, bewegt ein einzelner Fehler ein Codewort um eine Einheit von sei-nem korrekten Wert weg, aber es bleibt so mindestens zwei Einheiten zu anderen korrektenWörtern entfernt.
Man sieht leicht den erhöhten Aufwand (d. h. erhöhte Redundanz), denn nur noch zwei derinsgesamt acht möglichen Wörter sind wirklich Codewörter, es werden also drei Bits verbraucht,wo nur eins notwendig wäre.
Sei C ⊆ R2n ein Code. C heißt auf p-Bit-Fehler prüfbar (erkennbar), wenn für jedes x ∈C gilt:
K (x, p)∩C = {x}, wobei K (x, p) := x|d(y, x) = p
C heißt auf p-Bit-Fehler korrigierbar, wenn für alle x, y ∈C gilt:
K (x, p)∩K (y, p) = {}
→C ist genau dann auf p-Bit-Fehler prüfbar, wenn für alle x, y ∈C gilt:
d(x, y) = p +1
→C ist genau dann auf p-Bit-Fehler korrigierbar, wenn für alle x, y ∈C gilt:
d(x, y) = 2p +1
Wollen wir nun einen konkreten Code definieren, müssen wir angeben, wie die Kontrollbitsbestimmt werden.
5.5.2 Fehlererkennung durch Parität
Einer der einfachsten Fehler erkennenden Codes prüft, ob in einem binären Wort fester Län-ge die Anzahl der Einsen gerade oder ungerade ist, und fügt ein Paritätsbit genanntes Bit mit
76 Technische Grundlagen der Informatik

5 Codes 5.5 Fehler erkennende Codes
dieser Information an: Eine 1, wenn die Anzahl der Einsen ungerade ist, oder eine 0, wenn dieEinzenmenge gerade ist. Hierbei spricht man übrigens von einer geraden Parität, da das ur-sprüngliche Wort zusammen mit dem Paritätsbit immer eine gerade Anzahl an Einsen enthält.Ebenso ist aber auch eine ungerade Parität möglich. Dabei wird eine 0 angefügt, wenn die An-zahl der Einsen ungerade ist, oder eine 1, wenn die Einzenmenge gerade ist. Ein Beispiel dazuwird in Tabelle 5.7 dargestellt. An welcher Position das Paritätsbit eingefügt wird, ist unerheb-lich für die Fehlererkennung; es muss jedoch beim Codieren und Dekodieren an gleicher Stelleverwendet werden.
Quellwort Gerade Parität Ungerade Parität000 0000 0001001 0011 0010010 0101 0100011 0110 0111100 1001 1000101 1010 1011110 1100 1101111 1111 1110
Tabelle 5.7: Paritätscodes mit drei Nutzbits (Paritätsbit rechts angefügt)
Nehmen wir an, dass das Codewort 0101101 versendet und verstümmelt als 00101100 emp-fangen wird, weil sich das letzte Bit von 1 auf 0 geändert hat. Die Parität des Wortes, die aufder Empfängerseite berechnet wurde, ist ungerade (es gibt drei Einsen); da gerade Parität aus-gemacht war, ist anscheinend ein Fehler aufgetreten. Wir können aus dem empfangenen Wortnicht schließen, in welchem Bit der Fehler auftrat und können ihn somit auch nicht korrigie-ren. Man beachte, dass, wenn es zwei Fehler gegeben hätte, keine Paritätsverletzung erkanntworden wäre und die Fehler somit unbemerkt geblieben wären. Einzelne Paritätsprüfbits sindfolglich nur zweckmäßig, wenn die Fehler relativ selten und vereinzelt auftreten.
Wie beschrieben können mit dem Paritätsbit nur Fehler erkannt, aber nicht korrigiert wer-den. Um diesen Ansatz um Fehlerkorrektur zu erweitern, geht man in die zweite Dimension:Bei den so genannten Block-EDCs (Matrix-EDCs) wird jede Spalte (also jede Bitposition) umein Paritätsbit ergänzt, zusätzlich zu dem Paritätsbit des Wortes. In diesem Zustand hätte manmehr Paritätsbits als Nutzbits. Um die ganze Sache etwas effizienter zu machen, wird die Spal-tenparität über mehrere Worte gebildet. Tabelle 5.8 zeigt ein Beispiel mit sechs Wörtern, dieum Paritätsbits ergänzt werden sollen.
D2 D1 D0
Wort 1 1 1 0Wort 2 1 0 1Wort 3 0 0 1Wort 4 1 1 0Wort 5 1 0 1Wort 6 0 1 0
Tabelle 5.8: Sechs Quellwörter, die als Eingabe für das Paritätsbeispiel dienen
Nun werden zunächst die einzelnen Wörter um Paritätsbits ergänzt (Tabelle 5.9). Danach wer-den die Spalten um Paritätsbits ergänzt, auch die Paritätsspalte des ersten Schritts (Tabel-le 5.10).
Technische Grundlagen der Informatik 77

5.5 Fehler erkennende Codes 5 Codes
D2 D1 D0 ParitätWort 1 1 1 0 0Wort 2 1 0 1 0Wort 3 0 0 1 1Wort 4 1 1 0 0Wort 5 1 0 1 0Wort 6 0 1 0 1
Tabelle 5.9: Die sechs Quellwörter, die mit Paritäten ergänzt wurden.
D2 D1 D0 ParitätWort 1 1 1 0 0Wort 2 1 0 1 0Wort 3 0 0 1 1Wort 4 1 1 0 0Wort 5 1 0 1 0Wort 6 0 1 0 1Parität 0 1 1 0
Tabelle 5.10: Vertikale Paritäten an den sechs Beispielquellwörtern
Wenn nun ein einzelne Fehler in einem bestimmten Wort auftritt, können wir über das hori-zontale Paritätsbit erkennen, welches Wort fehlerhaft ist. Weiterhin sagt uns das vertikale Pa-ritätsbit, welches Bit im Wort fehlerhaft ist (d. h. ein Fehler in D0 oder D1 etc.). Nun, da wir dieSpalte und die Zeile kennen, in welcher der Fehler auftritt, können wir die exakte Position desFehlers bestimmen (Tabelle 5.11). Und da wir wissen, welches Bit verstümmelt wurde, könnenwir es kippen und somit den Fehler korrigieren.
D2 D1 D0 Parität PrüfungWort 1 1 1 0 0
pWort 2 1 0 1 0
pWort 3 0 1 1 1 ×Wort 4 1 1 0 0
pWort 5 1 0 1 0
pWort 6 0 1 0 1
pParität 0 1 1 0
p
Prüfungp × p p
Tabelle 5.11: Fehlererkennung im Beispiel: Ein Haken zeigt, dass gerade Parität vorgefundenwurde, ein Kreuz zeigt die ungerade Parität (ein Fehler)
Der Redundanzaufwand bei diesem Verfahren ist sehr hoch: Ein Block von m Worten der Län-ge n benötigt m +n + 1 Paritätsbits. In unserem Beispiel brauchten unsere sechs Wörter derLänge drei insgesamt zehn Paritätsbits, d. h. 10 von 28 Bits waren redundant und somit keineNutzinformation.
Der Paritätsblockcode kann einzelne Fehler erkennen und korrigieren und er kann bestim-me Kombinationen von Fehlern erkennen – diese dann aber nicht korrigieren. Solche feh-lererkennenden und -korrigierenden Codes findet man in Datenübertragungssystemen oder-speicherungssystemen.
78 Technische Grundlagen der Informatik
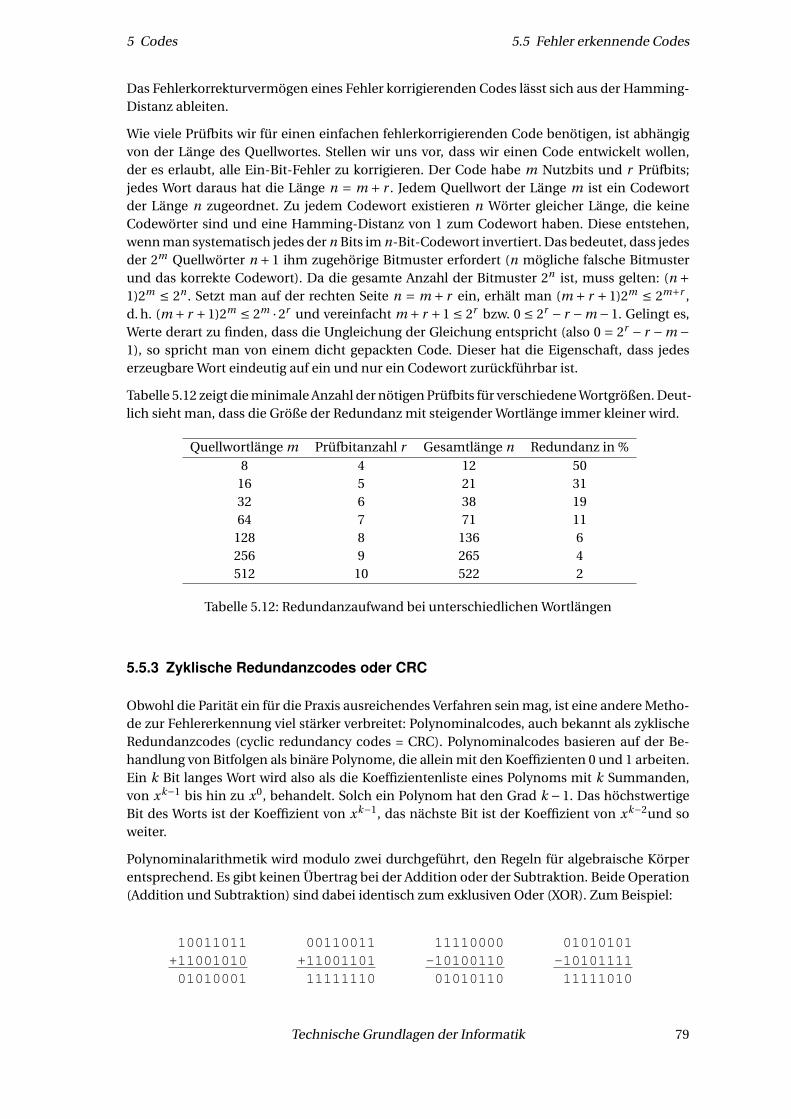
5 Codes 5.5 Fehler erkennende Codes
Das Fehlerkorrekturvermögen eines Fehler korrigierenden Codes lässt sich aus der Hamming-Distanz ableiten.
Wie viele Prüfbits wir für einen einfachen fehlerkorrigierenden Code benötigen, ist abhängigvon der Länge des Quellwortes. Stellen wir uns vor, dass wir einen Code entwickelt wollen,der es erlaubt, alle Ein-Bit-Fehler zu korrigieren. Der Code habe m Nutzbits und r Prüfbits;jedes Wort daraus hat die Länge n = m + r . Jedem Quellwort der Länge m ist ein Codewortder Länge n zugeordnet. Zu jedem Codewort existieren n Wörter gleicher Länge, die keineCodewörter sind und eine Hamming-Distanz von 1 zum Codewort haben. Diese entstehen,wenn man systematisch jedes der n Bits im n-Bit-Codewort invertiert. Das bedeutet, dass jedesder 2m Quellwörter n + 1 ihm zugehörige Bitmuster erfordert (n mögliche falsche Bitmusterund das korrekte Codewort). Da die gesamte Anzahl der Bitmuster 2n ist, muss gelten: (n +1)2m ≤ 2n . Setzt man auf der rechten Seite n = m + r ein, erhält man (m + r + 1)2m ≤ 2m+r ,d. h. (m + r +1)2m ≤ 2m ·2r und vereinfacht m + r +1 ≤ 2r bzw. 0 ≤ 2r − r −m −1. Gelingt es,Werte derart zu finden, dass die Ungleichung der Gleichung entspricht (also 0 = 2r − r −m −1), so spricht man von einem dicht gepackten Code. Dieser hat die Eigenschaft, dass jedeserzeugbare Wort eindeutig auf ein und nur ein Codewort zurückführbar ist.
Tabelle 5.12 zeigt die minimale Anzahl der nötigen Prüfbits für verschiedene Wortgrößen. Deut-lich sieht man, dass die Größe der Redundanz mit steigender Wortlänge immer kleiner wird.
Quellwortlänge m Prüfbitanzahl r Gesamtlänge n Redundanz in %8 4 12 50
16 5 21 3132 6 38 1964 7 71 11
128 8 136 6256 9 265 4512 10 522 2
Tabelle 5.12: Redundanzaufwand bei unterschiedlichen Wortlängen
5.5.3 Zyklische Redundanzcodes oder CRC
Obwohl die Parität ein für die Praxis ausreichendes Verfahren sein mag, ist eine andere Metho-de zur Fehlererkennung viel stärker verbreitet: Polynominalcodes, auch bekannt als zyklischeRedundanzcodes (cyclic redundancy codes = CRC). Polynominalcodes basieren auf der Be-handlung von Bitfolgen als binäre Polynome, die allein mit den Koeffizienten 0 und 1 arbeiten.Ein k Bit langes Wort wird also als die Koeffizientenliste eines Polynoms mit k Summanden,von xk−1 bis hin zu x0, behandelt. Solch ein Polynom hat den Grad k −1. Das höchstwertigeBit des Worts ist der Koeffizient von xk−1, das nächste Bit ist der Koeffizient von xk−2und soweiter.
Polynominalarithmetik wird modulo zwei durchgeführt, den Regeln für algebraische Körperentsprechend. Es gibt keinen Übertrag bei der Addition oder der Subtraktion. Beide Operation(Addition und Subtraktion) sind dabei identisch zum exklusiven Oder (XOR). Zum Beispiel:
10011011+1100101001010001
00110011+1100110111111110
11110000-1010011001010110
01010101-1010111111111010
Technische Grundlagen der Informatik 79

5.5 Fehler erkennende Codes 5 Codes
Die Division auf solchen Polynomen wird genauso ausgeführt wie bei den binären Entspre-chungen (siehe Division im Kapitel 6). Man sagt, dass der Divisor in den Dividenden übergeht,wenn der Dividend genauso viele Bits wie der Divisor hat.
Wenn der Polynominalcode verwendet wird, müssen sich Sender und Empfänger vorher aufeinen Generatorpolynom G(x) einigen. Bei diesem müssen sowohl das höchstwertige als auchdas niederwertigste Bit 1 sein. Um eine Prüfsumme für ein m-Bit-Quellwort zu berechnen(welches zu dem Polynom M(x) gehört), muss das Wort länger als das Generatorpolynom sein(m > g ). Die Idee ist, eine Prüfsumme in der Weise an das Quellwort anzuhängen, dass dasdadurch erzeugte Bitmuster (d. h. das dazugehörige Polynom) durch G(x) teilbar ist. Wenn derEmpfänger das neue Bitmuster erhält, versucht er, es durch G(x) zu teilen. Wenn es dabei einenRest ungleich 0 gibt, trat ein Übertragungsfehler auf; ist der Rest dagegen 0, verlief die Über-tragung mit hoher Wahrscheinlichkeit fehlerfrei.
Der Algorithmus für die Berechnung der Prüfsumme ist wie folgt:
1. Sei r der Grad von G(x). Hänge r Nullbits an das Bitmuster des Quellwortes an, sodasses nun m + r Bits lang ist und zu dem Polynom xr M(x) gehört. Damit ist sichergestellt,dass das Wort nun länger als G(x) ist (andernfalls wäre eine Division nicht möglich).
2. Teile das Wort, welches xr M(x) entspricht, per modulo-2-Division durch das Bitmustervon G(x)
3. Subtrahiere den Rest (welcher immer höchstens r bit lang ist) von dem Bitmuster, wel-ches xr M(x) entspricht mittels modulo-2-Subtraktion. Das Ergebnis ist die zu übertra-gende, mit einer Prüfsumme versehende Bitfolge T (x)
Abbildung 5.7: CRC-Berechnungsbeispiel
Abbildung 5.7 illustriert das Verfahren für ein Wort 1101011011 und den Generator 10011 (G(x) =x4 +x +1).
Es sollte klar sein, dass T (x) durch G(x) teilbar ist (modulo 2). Bei jeder Division ist zu fordern,dass der „Dividend minus Rest“ durch den Divisor teilbar ist. Ein Beispiel mit Zahlen zur Basis10: Der ganzzahlige Rest der Division von 210278 durch 10941 ist 2399. Subtrahiert man von210278 diesen Rest 2399, so ist der Ergebnis (207879) durch 10941 teilbar.
80 Technische Grundlagen der Informatik

5 Codes 5.5 Fehler erkennende Codes
Betrachten wir nun die Mächtigkeit dieser Methode. Welche Arten von Fehlern werden er-kannt? Stellen wir uns vor, dass ein Übertragungsfehler auftritt, sodass statt der Bitfolge fürT (x) die Bitfolge für T (x)+E(x) eintrifft. Jedes Bit in E(x), welches 1 ist, gehört zu einem Bit,dass sich umgedreht hat. Wenn es k Bits mit dem Wert 1 in E(x) gibt, dann sind k Einzelbitfeh-ler aufgetreten. Man spricht von einem Impulsfehler, wenn er mit einer 1 beginnt, gefolgt voneinem Mix von 0 und 1, und mit einer letzten 1 endet, wobei die verbleibenden Bits alle 0 sind.
Der Empfänger erhält nun die mit der Prüfsumme versehende Bitfolge und teilt sie durch G(x),d. h. er berechnet
T (x)+E(x)
G(x)
T (x)/G(x) ist gleich Null, sodass das Ergebnis der Berechnung einfach E(x)/G(x) ist. Die Feh-ler, die zu Polynomen gehören, welche G(x) als Faktor beinhalten, gehen dabei durch, alle an-deren Fehler werden erkannt.
Wenn es einen Einbitfehler gab, ist E(x) = xi , wobei i bestimmt, welches Bit fehlerhaft ist.Wenn G(x) zwei oder mehr Terme beinhaltet, wird es niemals E(x) teilen können. Somit wer-den alle Einbitfehler erkannt.
Wenn es zwei getrennte Einbitfehler gab, ist E(x) = xi + x j , wobei i > j . Alternativ kann mandies als E(x) = x j (xi− j + 1) schreiben. Wenn wir annehmen, dass G(x) nicht durch x teilbarist, ist es eine hinreichende Bedingung für die Erkennung aller Doppelfehler, dass xk +1 nichtdurch G(x) teilbar ist für jedes k ≤ i − j (d. h. bis zur maximalen Wortlänge). Es sind Polynomemit kleinem Grad bekannt, die Sicherheit für große Wortlängen geben. Zum Beispiel wird x15+x14 +1 kein xk +1 bis zu einem Wert k = 32768 teilen.
Wenn es eine ungerade Anzahl von fehlerhaften Bits gibt, besteht E(x) aus einer ungeradenAnzahl von Summanden (z. B. x5 + x2 +1, aber nicht x2 +1). Interessant ist dabei, dass es keinPolynom mit einer ungerade Anzahl von Summanden gibt, welche x+1 als Faktor im modulo-2-System haben. Indem wir x + 1 zu einem Faktor von G(x) machen, können wir alle Fehlerabfangen, die aus einer ungeraden Zahl von verdrehten Bits bestehen.
Um zu verstehen, dass kein Polynom mit einer ungeraden Anzahl von Summanden durch x+1teilbar ist, nehmen wir vorerst an, dass dem so wäre, alsodass E(x) eine ungerade Anzahl vonSummanden hat und durch x+1 teilbar ist. Zerlegen wir E(x) in die Faktoren (x +1)·Q(x). Nunberechnen wir E(1) = (1+1)·Q(1). Da 1+1 = 0 (modulo 2) ist, muss E(1) immer Null sein. WennE(x) eine ungerade Anzahl von Summanden hat, wird die Substitution der Variablen x durch1 immer auch 1 als Ergebnis liefern. Dies ist offensichtlich ein Widerspruch. Also kann es keinPolynom mit ungerader Summandenzahl geben, welches durch x +1 teilbar ist.
Die wichtigste Eigenschaft ist aber, dass ein Polynominalcode mit r Prüfbits alle Impulsfehlerder Länge kleiner/gleich r erkennen wird. Ein Impulsfehler der Länge k kann durch xi
(xk−1 +1. . .+1
)dargestellt werden, wobei i bestimmt, wie weit der Impuls vom hinteren Ende des Wortes ent-fernt ist. Wenn G(x) den Summanden x0 enthält, wird es nicht xi als Faktor haben können. DerRest kann also, wenn der Grad des geklammerten Ausdrucks kleiner als der Grad von G(x) ist,nie Null sein.
Wenn die Länge des Impulses r +1 ist, wird der Rest der Division durch G(x) genau dann Nullsein, wenn der Impuls identisch zu G(x) ist. Laut der Definition des Impulses muss das ersteund das letzte Bit jeweils 1 sein, also ist die Identität mit G(x) abhängig von den r −1 mittlerenBits. Wenn alle Kombination als gleichverteilt angesehen werden, ist die Wahrscheinlichkeit,dass ein solches Bitmuster akzeptiert wird (d. h. durch den CRC nicht als Fehler erkannt wird),gleich 1
2r−1 .
Technische Grundlagen der Informatik 81

5.6 Fehlerkorrektur durch Hamming-Codierung 5 Codes
Ebenso kann man zeigen: Die Wahrscheinlichkeit eines nicht als fehlerhaft erkannten Bitmus-ters 1
2r ist, wenn ein Fehlerimpuls der Länge r +1 auftritt oder mehrere kürzere Impulse auf-treten (wobei man annimmt, dass alle Kombinationen gleichverteilt sind).
Drei Polynome haben sich u.a. als internationale Standards etabliert. Alle drei beinhalten x+1als einen Primfaktor. CRC-12 wird benutzt, wenn die Zeichenlänge 6 Bits ist (d. h. der entspre-chende Code benötigt 6 Bits zur Codierung eines Zeichens). Die anderen beiden sind für 8-Bit-Zeichen. Eine 16-Bit-Prüfsumme wie bei CRC-16 oder CRC-CCITT erkennt alle Einzel- undDoppelfehler, alle Fehler mit einer ungeraden Anzahl von Bits, alle Impulsfehler mit einer Im-pulslänge von bis zu 16 Bits, 99,997% aller 17-Bit-Impulse und 99,998% aller Impulse von 18Bits oder mehr.
1961 wurde gezeigt, dass sich Prüfsummen unter Einsatz eines einfachen Schieberegisterschalt-kreises berechnen lassen.
Jahrzehntelang nahm man an, dass mit Prüfsummen versehende Bitmuster zufällige Bits ent-halten. Alle Analysen von Prüfsummenalgorithmen wurden basierend auf dieser Annahmedurchgeführt. Eine erst vor kurzem erfolgte Inspektion von realen Daten hat gezeigt, dass dieAnnahme gänzlich falsch ist. Daraus folgt, dass unter bestimmten Umständen unerkannteFehler gewöhnlicher sind, als man bisher dachte.
5.6 Fehlerkorrektur durch Hamming-Codierung
Die bei der Parität in Abschnitt 5.5.2 erwähnte theoretische untere Grenze für die Anzahl vonPrüfbits kann durch eine Methode erreicht werden, die auf Richard Hamming (1950) zurück-geht.
Wir erinnern uns, dass die Hamming-Distanz zwischen zwei gültigen Codewörtern mindes-tens drei ist, damit man die Metrikeigenschaften ausnutzen kann. Eine in nur einem Bit ge-störte Übertragung erzeugt dann aus einem Codewort x ein fehlerhaftes Wort w , das sich innur einer Stelle von x unterscheidet, also die Hamming-Distanz d(x, w) = 1 hat, während derAbstand zu allen anderen Codewörtern mindestens zwei beträgt, d. h. d(y, w) ≥ 2. Die Korrek-tur erfolgt nun so, dass w in das – unter den gemachten Voraussetzungen eindeutig bestimmte– Codewort x mit überführt wird.
Für ein 4-Bit-Wort sieht das Hamming-Verfahren (Hamming-Codierung) demnach drei Kon-trollbits vor (m = 4, r = 3). Die Nutzinformation (in Beispiel sei sie 1011) wird in dem Verfahrenum Kontrollinformation ergänzt ergeben. Die Prüfbits stehen dabei an den Stellen j ( j ist eineZweierpotenz, also 1, 2, 4, 8 usw.) und bilden die Parität über die Bits, welche an Positionenk (das j -te Bit von k in Binärdarstellung ist gleich 1) stehen. Man könnte auch anders herumsagen, dass das Bit b von den Bits b1,b2, . . . ,bi geprüft wird, sodass b = b1 +b2 + . . .+bi . DieseParität ergibt sich aus einem schrittweise ausgeführtem XOR über diese Bits.
Die Prüfbits errechnen sich also wie folgt:
r0 = m3 ⊕−−⊕m1 ⊕m0
r1 = m3 ⊕m2 ⊕−−⊕m0
r2 = m3 ⊕m2 ⊕m1 ⊕−−
rx entspricht dadurch dem geraden Paritätsbit zu den drei berücksichtigten Quellwortstellen.
82 Technische Grundlagen der Informatik

5 Codes 5.6 Fehlerkorrektur durch Hamming-Codierung
Im Beispiel mit m3m2m1m0 = 1011:
r0 = 1⊕−−⊕1⊕1 = 1
r1 = 1⊕0⊕−−⊕1 = 0
r2 = 1⊕0⊕1⊕−−= 0
Da die Prüfbits sich an den Stellen j = 2x (mit x als Index des Prüfbits) befinden, wird das Co-dewort also nach der Vorschrift m3m2m1r2m0r1r0 gebildet. Diese Vorschrift ist bei der Codie-rung und Dekodierung notwendig, um festzustellen, welches die eigentlichen Quellwortbitssind und in welcher Reihenfolge sie angeordnet sind.
Es ergibt sich das Codewort c = 1010101. Dieses kann zum Beispiel versendet werden. Auf derEmpfängerseite werden die Prüfbits über die Nutzbits neu errechnet; es werden dabei also nurdie ersten drei und das fünfte Bit berücksichtigt. Ergibt sich dabei ein Unterschied an den Prüf-bitstellen, ist ein Fehler aufgetreten. Unter der Annahme, dass maximal ein Fehler aufgetretenist, kann man aus diesem Unterschied die Stelle des gekippten Bits errechnen und den Fehlerso korrigieren. Dabei ist es unerheblich, ob ein Nutzbit oder ein Prüfbit gekippt ist.
Nehmen wir an, dass statt unserem korrekten Codewort das Wort 1000101 empfangen wurde,dass also das Nutzbit m1 gestört wurde. Es ergibt sich bei der Neubildung der Prüfbits folglichdas Bitmuster r2r1r0 = 100 anstatt 001. Um den Fehler zu lokalisieren, führt man ein bitweisesXOR dieser Muster durch. Es ergibt sich 101. Dies entspricht der binären 5 – und genau diefünfte Stelle von rechts ist im Wort m3m2m1r2m0r1r0 gekippt worden (m1). Kippt man diesesBit zurück auf 1, so ergibt sich das ursprüngliche Codewort, aus dem nun die eigentlichenNutzbits, nämlich 1011, ausgelesen werden können.
Es sei darauf hingewiesen, dass der hier beobachte Redundanzaufwand von 75% (3 Prüfbitsfür 4 Nutzbits) deutlich niedriger wird, wenn größere Codewortlängen vorliegen. So ist er bei16 + 5 Bits bzw. 64 + 7 Bits nur noch 32% bzw. 11%.
Betrachten wir zum Verständnis noch ein zweites Beispiel mit 16 Nutzbits und 5 Prüfbits. DieBits 1, 2, 4 8 und 16 sind hierin Prüf- oder Paritätsbits, der Rest die Nutzbits. Ingesamt ist dasWort also 21 Bits lang. Wir werden im Beispiel durchgängig gerade Parität verwenden.
Jedes Paritätsbit prüft bestimmte Bits, das Paritätsbit selber wird dann so gesetzt, dass die An-zahl der Einsen in den geprüften Positionen gerade ist. Tabelle 5.13 gibt an, welche Prüfbits indiesem Beispiel welche Bits prüfen.
Bit . . . kontrolliert die Bits20 = 1 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 2121 = 2 2, 3, 6, 7, 10, 11, 14, 15, 18, 1922 = 4 4, 5, 6, 7, 12, 13, 14, 15, 20, 2123 = 8 8, 9, 10, 11, 12, 13, 14, 15
24 = 16 16, 17, 18, 19, 20, 21
Tabelle 5.13: Prüfbits an Binärpositionen bis 21
Auch hier kann wieder allgemein gesagt werden, dass das Bit b von den Bits b1,b2, . . . ,bi geprüftwird, sodass b = b1 +b2 + . . .+bi . Zum Beispiel wird das Bit 5 durch die Bits 1 und 4 geprüft, da1+4 = 5 ist. Man beachte, dass die Kontrollbits sich immer selber prüfen: 1 = 1, 2 = 2, usw. DasWort und die Prüfbits sind in Abbildung 5.8 dargestellt.
Technische Grundlagen der Informatik 83

5.6 Fehlerkorrektur durch Hamming-Codierung 5 Codes
Abbildung 5.8: Beispiel zur Hamming-Codierung mit 21 Stellen, darin 5 Prüfbits
Nehmen wir nun an, dass Bit 5 umgedreht wurde: 001001100000101101110. Wir können derTabelle 5.13 entnehmen, dass das fünfte Bit für die Prüfbits 1 und 4 relevant ist. Auf Empfänger-seite wird man folglich feststellen, dass diese beiden Bits nicht korrekt sind. Die Schnittmen-ge von geprüften Nutzbits dieser beiden Prüfbits besteht jedoch nicht nur aus der 5, sondernebenfalls aus 7, 13, 15 und 21. Letztere sind jedoch ebenfalls unter Kontrolle anderer Prüfbits,z. B. prüft Bit 2 ebenfalls die 7 und 15, wird aber korrekt berechnet. Geht man alle Möglich-keiten durch, ergibt sich, dass der Fehler nur an Position 5 aufgetreten sein kann. Wird das Bitdort gekippt, ergibt sich ein fehlerfreies Codewort.
Eine einfachere Art, den Fehler zu lokalisieren, ist die bereits besprochene Art, die Paritätsbitsneu zu berechnen, um anschließend die Addition modulo zwei mit den empfangenen Paritäts-bits durchzuführen. Die Summe gibt, als (binäre) Zahl gelesen, die Position des Fehlers an.
5.6.1 Weitere Eigenschaften von Hamming-Codes
• Die komponentenweise gebildete Summe (modulo zwei) zweier Codewörter ist wiederein Codewort. Damit kann man den der Code als einen Vektorraum über einem Körpermit zwei Elementen auffassen. Dafür gibt es mit der „Linearen Codetheorie“ eine ma-thematische Theorie.
• Die Kugeln mit Radius n um Codewörter sind nicht nur disjunkt, sondern enthalten allemöglichen Wörter der Länge n. → Jedes Wort der Länge n kann decodiert werden. EinCode mit dieser Eigenschaft heißt perfekt.
• Geht man von x1x2 . . . xn über zu x2 . . . xn x1 (Rotation), erhält man wieder ein Codewort.Ein Code mit dieser Eigenschaft heißt zyklisch.
84 Technische Grundlagen der Informatik

6 Computerarithmetik
Im folgenden Kapitel werden wir uns im Wesentlichen mit den folgenden vier, scheinbar tri-vialen, Fragen auseinandersetzen:
1. Wie werden Zahlen repräsentiert und konvertiert?
2. Wie werden negative Zahlen und Brüche repräsentiert?
3. Wie werden die Grundrechenarten ausgeführt?
4. Was ist, wenn das Ergebnis einer Operation größer ist als die größte darzustellende Zahl?
Die Antwort erhält man, wenn man sich fragt: Was sind die wesentlichen Unterschiede zwi-schen der Arithmetik, wie sie vom Rechner ausgeführt wird, und der menschlichen Rechen-weise? Die Antwort lautet im Wesentlichen, dass im Rechner die Genauigkeit der Zahlen undihr Platzbedarf für die Darstellung endlich und begrenzt ist.
Wenn man selbst rechnet, denkt man wenig über die Frage nach, wie viele Ziffern man braucht,um eine Zahl darzustellen. Physiker können berechnen, dass es 1078 Elektronen im Universumgibt, ohne sich davon stören zu lassen, dass man 79 Ziffern brauchen würde, um diese Zahlganz aufzuschreiben. Wenn jemand das Ergebnis einer Funktion auf sechs Stellen genau be-rechnen möchte, behält er einfach Zwischenergebnisse mit einer Genauigkeit von sieben oderacht Stellen. Das Problem, dass es kein Papier gibt, welches nicht breit genug für siebenstelligeZahlen ist, tritt niemals auf.
In Computern sieht dies nun ganz anders aus. Bei den meisten Rechnern wird die Speicher-menge, die für das Speichern einer Zahl zur Verfügung steht, bereits festgelegt, wenn der Rech-ner entworfen wird. Mit einem bestimmten Aufwand kann ein Programmierer damit auch Zah-len darstellen, die doppelt oder dreifach so groß sind, was das Problem an sich aber nicht ausder Welt schafft. Die endliche Natur der Computerarithmetik zwingt uns, uns lediglich auf Zah-len, die durch eine endliche Anzahl von Ziffern dargestellt werden können, zu beschränken.Solche Zahlen heißen Zahlen mit endlicher Genauigkeit (finite precision numbers).
Rechner speichern solche Zahlen in Einheiten festgelegter Länge, die man Worte nennt. EinigeBeispiele für reale Wortlängen sind in Tabelle 6.1 aufgelistet.
Mikroprozessor Wortlänge in Bit8085, Z80, 6809, AVR 8
8085, 68000 1680386, 68020 32
Pentium, Athlon, PowerPC (Sun SPARC, IBM AIX) 32Xeon, Athlon 64 64
typische Mikrocontroller (4), 8, 16, (32)Cray-1 (Supercomputer) 64
Tabelle 6.1: Wortlängen in verschiedenen Computersystemen
Eine Gruppe von acht Bits nennt man auch Byte. Oft sagt man auch, ein Wort ist zwei oder vierBytes lang, da die Anzahl der Bits ein Vielfaches von Acht ist. Mikroprozessoren und Kleincom-puter sind normalerweise byte-orientiert mit Wortlängen und Adressen der Länge 8, 16 oder32 Bits.
85

6 Computerarithmetik
Um die Eigenschaften von Zahlen mit endlicher Genauigkeit kennen zu lernen, untersuchenwir die Menge aller positiven Ganzzahlen mit drei Ziffern. Die Menge hat genau 1000 Elemente:000, 001, 002, 003, ..., 999; es sei darauf hingewiesen, dass die führenden Nullen normalerweisenicht hingeschrieben werden, da das Weglassen den Wert der Zahl nicht beeinflusst.
Eine wichtige Eigenschaft der Arithmetik auf der Menge von Ganzzahlen ist die Abgeschlos-senheit bezüglich der Operationen Addition, Subtraktion und Multiplikation (vgl. Lehrveran-staltung Mathematik I „Algebra“). Das heißt, dass für jedes Paar der Ganzzahlen i und j auchi + j , i − j und i · j Ganzzahlen sein müssen. Abgeschlossenheit bezüglich der Division existiertnicht, da es Werte für i und j gibt, sodass i / j nicht mehr durch eine Ganzzahl darstellbar ist(z. B. 7/2).
Unsere Ganzzahlmenge ist nicht abgeschlossen bezüglich der anderen drei Grundrechenope-rationen:
600+600 = 1200 Resultat ist zu groß (Überlauf)
3−5 = −2 Resultat ist zu klein (negativer Überlauf)
50 ·50 = 2500 Resultat ist zu groß (Überlauf)
Daraus folgt, dass alle Zahlen mit endlicher Genauigkeit nicht abgeschlossen bezüglich denGrundrechenoperationen sind, da es immer ein Paar gibt, dessen Operationsergebnis außer-halb der Grundmenge liegt.
Das hat wiederum zur Folge, dass das Ergebnis bestimmter Berechnungen aus der Sicht derklassischen Mathematik einfach falsch sind! Ein Rechengerät, das die falsche Antwort gibt, ob-wohl es korrekt arbeitet, mag auf den ersten Blick ungewöhnlich erscheinen. Aber der Fehlerist eine logische Konsequenz der endlichen Natur des Gerätes. Einige Rechner haben spezielleHardware, welche Überlauffehler erkennt.
Es gibt noch weitere Unterschiede zwischen der Algebra in einem Rechner und der normalenAlgebra. Sehen wir uns zum Beispiel das Assoziativgesetz bei unseren dreistelligen, positivenGanzzahlen an:
a + (b − c) = (a +b)− c
Berechnen wir beide Seiten mit a = 700, b = 400 und c = 300. Zum Errechnen der linken Seite,berechnen wir zunächst (b − c), mit dem Ergebnis 100, und addieren diesen Wert zu a, sodassdas Gesamtergebnis 800 ist. Für die rechte Seite berechnen wir anfangs (a +b), was uns soforteinen Überlauf in dieser algebraischen Struktur liefert. Das exakte Ergebnis hängt von der ge-nauen Implementierung des Rechners ab, aber es wird nicht 1100 sein. Das Assoziativgesetzgilt also nicht. Die Reihenfolge der Operationen ist also wichtig.
Als ein weiteres Beispiel betrachten wir das Distributivgesetz:
a · (b − c) = a ·b −a · c
Wenn wir für a = 5, b = 210 und c = 192 annehmen, ist der Wert der linken Seite 5 ·15, also 75.Das Ergebnis der rechten Seite ist aber nicht 75, da a ·b bereits überläuft.
Aus diesen Beispielen kann man schließen, dass Computer, obwohl sie Mehrzweckgeräte sind,durch ihre endliche Natur nur unzureichend für Arithmetik geeignet sind. (Und das, obwohl
86 Technische Grundlagen der Informatik

6 Computerarithmetik 6.1 Zahlensysteme mit unterschiedlichen Basen
sie genau dafür eigentlich erfunden wurden: Das Rechnen). Der Schluss ist natürlich so auchnicht ganz richtig, aber er dient zur Illustration der enormen Wichtigkeit, zu verstehen, wieRechner arbeiten und welche Einschränkungen sie haben.
6.1 Zahlensysteme mit unterschiedlichen Basen
Eine normale Dezimalzahl, wie sie jedermann geläufig sein sollte, besteht aus einer Folge ausZiffern und möglicherweise einem Dezimalkomma (oder einem Dezimalpunkt, wie er im eng-lischsprachigen Raum gebräuchlich ist). Diese Notation ist positionell. Positionell heißt hier-bei, dass der Wert oder die Wichtung einer Ziffer von ihrer Position innerhalb der Zahl abhängt.Wenn eine Ziffer um eine Stelle nach links verschoben wird, wird sie mit dem Wert zehn (derBasis dieses Zahlensystems) multipliziert. Analog dazu entspricht einer Verschiebung um eineStelle nach rechts einer Division durch zehn. Also ist die Ziffer 9 in der Zahl 95 zehnmal so vielwert wie die 9 in einer 59.
Das mag nun offensichtlich und nicht der Rede wert erscheinen. Allerdings ist es für uns nurdeshalb so trivial, da wir täglich damit arbeiten. Betrachten wir zum Beispiel der Kultur deralten Römer: Während sie die halbe Welt eroberten und die lateinischer Grammatik erfanden,hatten sie dennoch eine sehr schwerfällige Mathematik. Da sie kein direktes positionelles Sys-tem verwendeten, musste jede große Zahl ein eigenes spezielles Symbol haben. Ihr Zahlensys-tem war indirekt abhängig von der Position, d. h. wenn X = 10 und I = 1, so war X I = 11 (10+1)und I X = 9 (10−1). Den Nachteil dieses Systems erkennt man beispielsweise bei der Multipli-kation. Bekanntlich ist die Fläche eines Rechteckes das Produkt der Seitenlängen. VersuchenSie einmal, die Fläche eines rechteckigen Feldes mit den Seitenlängen von 35 und 45 Längen-einheiten mit Hilfe von römischen Zahlen zu berechnen! Ein scheinbar triviales Problem, dochdas war damals nur von Experten lösbar.
Eine Zahl N , die in einer positionellen Notation mit der Basis b dargestellt wird, wird als an an−1an−2 . . . a1a0a−1 . . . a−m
dargestellt und ist definiert als
anbn +an−1bn−1 +an−2bn−2 +·· ·+a1b1 +a0b0 +a−1b−1 +·· ·+a−mb−m =n∑
i=−mai bi
Die ai der obigen Gleichung werden Ziffern genannt und können einen von b verschiedenenWerten annehmen. Die positionelle Darstellung verwendet das Komma, um ganzzahlige undgebrochene Teile der Zahl zu trennen.
Die Wahl der Basis für das menschliche Zahlensystem fällt auf zehn, da wir dezimale Zahlen(also mit der Basis zehn) nutzen. Wenn man mit Computern zu tun hat, werden gewöhnlicher-weise andere Basen als zehn verwendet. Die wichtigsten davon sind die Basen 2, 8 und 16. Diedarauf aufbauenden Zahlensysteme nennt man demzufolge binär, oktal, und hexdezimal. Daalle diese Basen Zweierpotenzen sind, lassen sie sich leicht ineinander konvertieren.
Wenn es notwendig ist, die Basis einer Zahl mit anzugeben, so geschieht dies für gewöhnlichdurch einen Index. So bedeutet 12310 auch 123 dezimal und 1238 folglich 123 oktal.
Menschen arbeiten normalerweise dezimal und Rechner binär. Wir werden später sehen, dassder Zweck des oktalen und des hexadezimalen Systems als eine Hilfe für das menschliche Ge-dächnis dient. Es ist nahezu unmöglich, sich lange Folgen von binären Ziffern zu merken.Wenn man diese in das oktale oder hexadezimale System umwandelt (eine sehr einfach Aufga-be), lassen sich die kürzeren oktalen bzw. hexadezimalen Zahlen besser im Gedächtnis behal-ten (8916 ist einfacher zu merken als 100010012). Diese Eigenschaft macht sich auch das ein-gangs erläuterte Abstraktionsprinzip zu nutze: Bei der Assemblerprogrammierung wird das
Technische Grundlagen der Informatik 87

6.2 Zahlbasiswechsel 6 Computerarithmetik
hexadezimale System sehr häufig verwendet. Darüberhinaus sind Oktal- und Hexadezimal-zahlen kompakter als ihre binären Entsprechungen (1 Oktalziffer = 3 Binärziffern, 1 Hexziffer= 4 Binärziffern), weswegen sie häufig in Computertexten und core dumps (Kernspeicheraus-züge, wie sie beim Debuggen systemnaher Programme üblich sind) benutzt werden.
6.2 Zahlbasiswechsel
Die Umwandlung von Oktal- oder Hexadezimalzahlen und Binärzahlen ist einfach. Um eineBinärzahl in eine oktale umzuwandeln, teilt man sie in Gruppen zu drei Bits auf, mit den 3Bits direkt links oder rechts vom Dezimalpunkt als jeweils ein Gruppe und dann jeweils fort-schreitend nach links oder rechts. Jede Dreiergruppe lässt sich direkt in eine einzelne Oktal-ziffer (0...7) umwandeln. Es kann nötig sein, eine oder zwei führende oder folgende Nullenanzufügen, damit eine vollständige Dreiergruppe entsteht. Die Rücktransformation ist ebensotrivial. Jede oktale Ziffer wird lediglich durch die entsprechende Dreibitbinärzahl ersetzt. EineUmwandlung zwischen hexadezimalem und binärem System wird nach dem gleichen grund-legenden Prinzip vorgenommen, nur das hier statt Dreiergruppen jeweils vier Bit zusammen-gefasst werden (Abbildung 6.2).
Hexadezimal Binär Hexadezimal Binär0 0000 8 10001 0001 9 10012 0010 a 10103 0011 b 10114 0100 c 11005 0101 d 11016 0110 e 11107 0111 f 1111
Tabelle 6.2: Umrechnung zwischen Hexadezimal und Binär
In der Abbildung sind in der Binärdarstellung die führenden Nullen, die man normalerweisenicht mitschreibt, enthalten. Dies hat den Hintergrund, dass man gewöhnlich Hexzahlen ausmehreren Stellen auf einmal umwandelt und jede Hex-Ziffer für vier Binärstellen steht.
Zahlen des Dezimalsystems umzuwandeln, ist etwas schwieriger. Stellvertretend für den bi-nären Block (binär, oktal, hexadezimal) betrachten wir nur die Umwandlung zwischen bi-närem und dezimalem System.
6.2.1 Dezimal zu binär, oktal, hexadezimal
Die Umwandlung von dezimalen Zahlen in Binärzahlen kann über zwei unterschiedliche We-ge erfolgen. Die erste Methode folgt direkt aus der Definition binärer Zahlen. Die größte Zwei-erpotenz, die kleiner als die umzuwandelnde Zahl ist, wird von eben dieser abgezogen. DasVerfahren wird mit der Differenz wiederholt. Sobald die Zahl in Zweierpotenzen zerlegt wurde,kann die Binärzahl aus Einsen, wenn die entsprechende Potenz ein Summand der zerlegtenZahl ist, und Nullen sonst zusammengesetzt werden. Ein Beispiel für die Zahl 1500:
88 Technische Grundlagen der Informatik

6 Computerarithmetik 6.2 Zahlbasiswechsel
1500− 1024 = 476 1024 = 210
476− 256 = 220 256 = 28
220− 128 = 92 128 = 27
92− 64 = 28 64 = 26
28− 16 = 12 16 = 24
12− 8 = 4 8 = 23
4− 4 = 0 4 = 22
Setzt man in einer Binärzahl 21029282726252423222120 nun alle Zweierpotenzstellen, die in die-ser Rechnung auftauchen, auf 1 und die übrigen auf 0, so erhält man 1500 als Binärzahl, näm-lich 10111011100.
Die andere Methode, die allerdings nur bei Ganzzahlen anwendbar ist, besteht darin, die Zahljeweils direkt durch Zwei zu dividieren. Der Quotient wird dabei direkt unter die Originalzahlgeschrieben und der Rest, 0 oder 1, daneben. Dann wird dieser Quotient betrachtet und dasVerfahren so lange erneut angewendet, bis die Zahl Null erreicht ist. Als Ergebnis erhält manzwei Spalten mit Zahlen: Die Quotienten und die Reste.
1500 : 2 = 750 Rest 0
750 : 2 = 375 Rest 0
375 : 2 = 187 Rest 1
187 : 2 = 93 Rest 1
93 : 2 = 46 Rest 1
46 : 2 = 23 Rest 0
23 : 2 = 11 Rest 1
11 : 2 = 5 Rest 1
5 : 2 = 2 Rest 1
2 : 2 = 1 Rest 0
1 : 2 = 0 Rest 1
Die Binärzahl lässt sich nun direkt aus der Restwertspalte auslesen, nämlich von unten nachoben.
Dezimal-zu-oktal- und Dezimal-zu-hexadezimal-Umwandlungen lassen sich leicht bewerk-stelligen, indem man die Zahl erst binär darstellt und anschließend wie oben beschriebenumwandelt. Andererseits kann man auch gleich durch 8 bzw. 16 dividieren (nach dem ebenerläuterten Verfahren).
6.2.2 Binär zu dezimal
Auch für den umgekehrten Weg gibt es auch wieder zwei Möglichkeiten. Die erste besteht dar-in, einfach die Zweierpotenzen, denen die Einsen in der Binärzahl entsprechen, aufzuaddie-ren. Zum Beispiel ist 101102 = 24 +22 +21 = 16+4+2 = 22.
Technische Grundlagen der Informatik 89

6.3 BCD – Binary Coded Decimal 6 Computerarithmetik
Eine methodischere Technik basiert auf dem folgenden rekursiven Algorithmus. Man nimmtdas am weitesten links stehende (höchstwertige) Bit, das nicht Null ist. Dieses verdoppelt manund addiert es zum Bit rechts daneben. Dieses Ergebnis nimmt man, verdoppelt es und addiertes wieder zum nächstrechten Bit. Dies wiederholt man, bis das kleinste Bit auch hinzuaddiertwurde. Diese rekursive Prozedur ließe sich mathematisch durch
(a0 +2(a1 +2(a2 + . . .)))
beschreiben, wobei a0 das kleinste Bit der Binärzahl ist.
6.2.3 Oktal zu dezimal
Man erinnere sich, dass jede Regel, die auf ein System mit Basis X zutrifft, ebenfalls in einemSystem mit Basis Y gilt. Wenn wir also Binärzahlen in Dezimalzahlen umwandeln, indem wir2ai zu ai−1 addieren, so können wir Oktalzahlen zu Dezimalzahlen machen, wenn wir durch-gängig 8ai zu ai−1 hinzuaddieren. Eine Oktalzahl lässt sich mathematisch als
(a0 +8(a1 +8(a2 + . . .)))
beschreiben. Wir nehmen uns die am weitesten links stehende Ziffer, multiplizieren sie mitAcht und addieren sie zur Ziffer zu ihrer Rechten. Dieses Zwischenergebnis verachtfachen wirwieder und addieren es wieder zur rechten Ziffer. Das Verfahren endet, wenn wir bei der kleins-ten Ziffer rechts außen angekommen sind.
6.2.4 Hexadezimal zu dezimal
Die Methode ist identisch zu der für oktale und binäre Zahlen, wie sie oben beschrieben ist.Allerdings verwenden wir hier die 16 als Faktor.
6.3 BCD – Binary Coded Decimal
Binary-Coded Decimal (binärkodierte Dezimalzahl) ist eine weitere Möglichkeit der Zahlen-darstellung in Binärform. Der Name deutet hierbei schon das Prinzip an: So wird hierbei nichtdie gesamte Dezimalzahl in eine Binärzahl umgewandelt, sondern jede einzelne Dezimalzif-fer für sich (473910 entspricht 01000111001110012 in der BCD-Darstellung). Wie man sieht, istBCD auch nur eine Form der Dezimaldarstellung, die sich von der klassischen Form nur inder Weise unterscheidet, wie die zehn Ziffern dargestellt werden. Um der Logik mit ihrer Zwei-wertigkeit (0 und 1) Rechnung zu tragen, werden hier für jede Dezimalziffer binäre 4-Tupelverwendet. Diese Darstellung ist für uns Menschen, die an Dezimalzahlen gewohnt sind, ameinfachsten. Der größte Vorteil des BCD-Codes ist die einfache Umwandlung von dezimaler inbinäre Darstellung. Das Konvertierungsprinzip ist praktisch identisch zu dem der Unwandlungzwischen hexadezimalen und binären Zahlen, allerdings werden hier nur zehn der 16 mögli-chen Bitmuster genutzt. Daraus resultiert auch der größte Nachteil dieser Zahlendarstellung,und zwar in zweierlei Hinsicht. Zum ersten verkompliziert sich die Arithmetik.
Wie man im Beispiel in Tabelle 6.3 sieht, treten bei der Addition der 4-Tupel undefinierte Werteauf, die letzte Ziffer geht sogar ganz verloren (7+9 = 16). Dies liegt daran, dass der Übertragdort erst bei 16, und nicht bei zehn erfolgt. Es muss eine sogenannte Dezimalanpassung erfol-gen, sodass man – von rechts beginnend – die Dualkodierung der „verlorenen“ Sechs (01102)
90 Technische Grundlagen der Informatik

6 Computerarithmetik 6.4 Darstellung ganzer Zahlen mit Vorzeichen
473910 0100 0111 0011 1001+128710 +0001 0010 1000 0111602610 0101 1001 1100 0000 = 59?010
510 910 1210 010
Tabelle 6.3: Neue Rechenprobleme bei einer BCD-Addition
bei jedem Übertrag und bei jeder ungültigen BCD-Ziffer (die durch einen Übertrag korrigiertwerden muss) nachträglich addiert.
Für das Beispiel bedeutet dies, dass wir bei der letzten Stelle des offenbar falschen Ergebnis-ses 0101 1001 1100 0000, bei der es ja einen Übertrag gab, eine 6 (binär 110) addieren. Beider zweitletzten Stelle gab es zwar keinen Übertrag, aber als Ergebnis eine Zahl, die nicht imZahlenbereich 0–9 liegt. Auch hier wird eine 6 addiert (1100+ 110 = 0010), wobei wieder einÜbertrag entsteht. Dieser wird der nächsthöheren Stelle hinzugefügt. Dadurch gerät die Zahlaber aus dem gültigen Zahlenbereich (1001 + 1 = 1010, dezimal 11); es muss eine 6 addiertwerden. Dadurch entsteht wieder ein Übertrag (1010+110 = 0000). Der Übertrag wird auf diehöchstwertige Hex-Ziffer addiert. Das Ergebnis lautet folglich 602610.
Grundsätzlich hat die BCD-Darstellung einen schwer wiegenden Nachteil: Sie geht aufgrundder nicht verwendeten Binärbelegungsmöglichkeiten (hex A, B, C, D, E, F) verschwenderischmit Speicherplatz um. Dadurch ist sie vergleichsweise ineffizient. In Zahlen sieht dies folgen-dermaßen aus: Um eine Dezimalzahl binär darzustellen, erhöht sich die Stellenanzahl (also dieLänge der Zahl) um Faktor 3,3. Die Umwandlung einer Dezimalzahl in die BCD-Repräsentationverursacht jedoch immer eine Vervierfachung der Länge. Mit anderen Worten: BCD-Zahlenbrauchen etwa 20 % mehr Speicher als „natürliche“ Binärzahlen.
6.4 Darstellung ganzer Zahlen mit Vorzeichen
Die Darstellung positiver Ganzzahlen im Binärsystem ist vergleichsweise einfach, da es ein imVergleich zum Dezimalsystem entsprechendes System zur Bildung der Zahlen anbietet: DieZahl ist rechts ausgerichtet und man beginnt damit, die letzte Stelle so lange zu erhöhen, bisder Zeichenvorrat aufgebraucht ist. Beim Dezimalsystem durchläuft die Stelle dabei die Zah-len von 0–9, beim Dualsystem dagegen ist nach der 1 schon Schluss. Um die nachfolgende Zahldarzustellen, muss die Stelle links der erhöhten Stelle um 1 erhöht werden und die ursprüng-lich betrachtete Stelle wird zurück auf 0 gesetzt. Beispielsweise muss beim Übergang von der9 zur 10 die Stelle links der 9 (eine implizite 0) um 1 erhöht werden und die 9 zurück auf 0 ge-setzt werden. Im Binärsystem sieht es ähnlich aus: Um von der 1 zur 10 zu kommen, wird dieStelle links der 1 (auch hier eine implizite 0) um 1 erhöht und die ursprüngliche 1 zurück auf 0gesetzt.
Die Darstellung negativer Zahlen dagegen stellt ein Problem dar: Wie wir sehen werden, ist diebei Dezimalzahlen verwendete Darstellungsart nicht sehr effizient. Es lässt sich nämlich rechtschwer damit rechnen. Diese Darstellungsart heißt Vorzeichen-/Betrag-Darstellung.
6.4.1 Vorzeichen-/Betrag-Darstellung
Bei der Darstellung einer Zahl durch Vorzeichen und Betrag wird links der Zahl ein Vorzeichengesetzt: Ein + für positive Zahlen, ein− für negative Zahlen und kein Vorzeichen für die 0. DieseKonvention stellt das Binärsystem vor ein Problem, da sich drei Zustände nicht mit einem Bit,
Technische Grundlagen der Informatik 91

6.4 Darstellung ganzer Zahlen mit Vorzeichen 6 Computerarithmetik
sondern nur (mindestens) mit zwei Bit darstellen lassen. Pragmatischerweise ordnet man der0 daher ein Vorzeichen zu – denn zwei Zustände lassen sich mit genau einem Bit darstellen.
Bei der typischen Vorzeichen-/Betrag-Darstellung wird das höchstwertige Bit eines Wortes ex-klusiv für die Angabe des Vorzeichens genutzt. Eine Zahl Z lässt sich durch Z = (−1)S ·M be-zeichnen, wobei S das Vorzeichen (sign) und M der Betrag (magnitude) ist. Wenn das Vor-zeichenbit gleich 0 ist, gilt (−1)0 = 1 und die Z ist positiv, andererseits gilt (−1)1 = −1 und Zist negativ. Betrachten wir als Beispiel ein Wort der Länge acht Bit: Bei Ganzzahlen ohne Vor-zeichen ist der Wertebereich [0,255]. Verwendet man die Vorzeichen-/Betrag-Darstellung, sorepräsentieren sieben Bit den Betrag der Zahl und ein Bit das Vorzeichen. Der Wertebereich istdamit [−127,127] oder [111111112,011111112].
Wer genau nachzählt, wird feststellen, dass damit nur 255 verschiedene Werte möglich sind.Prinzipiell kann man mit acht Bit aber 28 = 256 verschiedene Zustände realisieren. Der „feh-lende“ Zustand liegt in der Darstellung der 0 begründet: Diese gibt es sowohl mit positivem alsauch mit negativem Vorzeichen, also doppelt. Ein Standardvergleicher (siehe Abbildung 2.13)würde diese beiden Zahlen (000000002 und 100000002) naturgemäß als ungleich ansehen, ob-wohl sie den gleichen Wert meinen.
Bei Additionen und Subtraktionen muss entschieden werden, ob addiert oder subtrahiert wer-den muss, in welcher Operandenreihenfolge und welches Vorzeichen das Ergebnis haben wird.Die möglichen Fälle sind in Tabelle 6.4 dargestellt. Wohlgemerkt: Dieser Aufwand kommt zureigentlichen Rechnung hinzu!
Operanden Auszuführende Operation+x,+y +(
x + y)
Addition−x,−y −(
x + y)
Addition+x,−y mit |x| ≥ ∣∣y
∣∣ oder +(x − y
)Subtraktion
−x,+y mit |x| ≤ ∣∣y∣∣ +(
y −x)
+x,−y mit |x| < ∣∣y∣∣ oder −(
x − y)
Subtraktion−x,+y mit |x| > ∣∣y
∣∣ oder −(y −x
)Tabelle 6.4: Fallunterscheidung in der Vorzeichen-/Betrag-Darstellung bei
Addition/Subtraktion
Bei Binärzahlen bietet sich aufgrund der Zweiwertigkeit der Zahlen ein anderer Ansatz an: DieKomplementdarstellung, bei der negative Zahlen den invertierten positiven Zahlen gleichenBetrags entsprechen (evtl. mit weiteren Modifikationen).
6.4.2 Einerkomplement-Darstellung
Wie bei der Vorzeichen/Betrag-Darstellung dient auch bei der Komplement-Darstellung daserste Bit zur Darstellung des Vorzeichens. Der Wert wird allerdings anders dargestellt: Mankippt sämtliche Bits des Betrags in posiver Darstellung.
Das Vorzeichenbit ist Teil des Summanden und wird in eine arithmetische Operation mit ein-geschlossen. Die Subtraktion wird auf die Addition zurückgeführt (x − y = x + (−y
)); somit be-
steht keine Notwendigkeit für ein zusätzliches Subtrahierwerk.
Beim Einerkomplement wird eine Zahl N aus dem Wertebereich[0,2n−1 −1
]durch bitweises
Invertieren in die Zahl −N aus dem Wertebereich[−2n−1 −1,0
]umgewandelt. Wie man sieht,
ist auch hier die Null doppelt vorhanden.
92 Technische Grundlagen der Informatik

6 Computerarithmetik 6.4 Darstellung ganzer Zahlen mit Vorzeichen
Da N eine bestimmte Länge besitzt (nämlich n), kann man die negative Entsprechung einerZahl auch rechnerisch bestimmen: −N = 2n −N −1. Mit dieser Formel erhält man die positi-ve Ganzzahl, die als Einerkomplement interpretiert die gewünschte Zahl −N ergibt. Beispiel:Nehmen wir an, wir haben eine Fünf-Bit-Zahl (also n = 5) und interessieren uns für die Dar-stellung der Zahl −9 (also N = 9). Das Einerkomplement ist folglich −910 = 25−9−1 = 22. N istbinär 010012. 2210 = 101102, was genau dem Inversen von 010012 = 910 entspricht.
Die Subtraktion ist dabei gleich der Addition plus einem end-around-carry bzw. Carry-Out (imNachfolgenden durch 1 gekennzeichnet), d. h. zu der Summe wird das am weitesten links ste-hende Bit der Summanden aufaddiert. Sehen wir uns dies näher an:
1. x − y mit x > yx = 9 = 010012
y =−410 =−001002 = 1011001001+11011 =1 0010000100+1 = 001012 = 510
Das Carry-Out ist bei x > y immer 1. x − y = x + (2n − y −1
)= 2n + (x − y
)−1Dies ist genau x − y , wenn man das Carry-Out streicht und den Wert 1 hinzuaddiert.
2. x − y mit x < yx = 4 = 001002 = 00100y =−910 =−010012 = 1011000100+10110 = 1101011010 =−001012 =−510
Das Carry-Out ist bei x > y immer 0. Offenbar gilt somit, dass auch ohne diesen letztenSchritt des Carry-Out-Addierens das korrekte Ergebnis berechnet wird.
3. (−x)+ (−y)
x =−410 =−001002 = 11011y =−910 =−010012 = 1011011011+10110 =1 1000110001+1 = 1001010010 =−011012 =−1310
Das Carry-Out ist bei zwei negativen Zahlen immer 1.
Wie man sieht, ist für das Rechnen mit dem Einerkomplement kein zusätzliches Subtrahier-werk nötig. Allerdings gibt es immer noch keine eindeutige Darstellung der Null. Außerdemmuss ein eventuelles Übertragsbit in einem anschließenden Rechenschritt addiert werden. Mitdem Zweierkomplement entfällt dieser und es gibt nur noch eine 0.
6.4.3 Zweierkomplement-Darstellung
In der Zweierkomplement-Darstellung ist −N = 2n − N . Bestimmen kann man die negativeEntsprechung der Zahl N im Zweierkomplement durch Zuhilfenahme des Einerkomplements:−N = Einerkomplement+ 1. Man invertiert also die Zahl N bitweise und addiert schließlicheine 1. −N ist dabei aus dem Wertebereich [−2n −1,−1]. Die Darstellung der Null ist eindeutig.Der Wertebereich des Zweierkomplements ist
[−2n−1,2n−1 −1].
Die Zweierkomplement-Darstellung lässt sich an einem Zahlenkreis veranschaulichen, wie erin Abbildung 6.1 gezeigt wird. Additionen entsprechen einer schrittweisen Bewegung im Uhr-zeigersinn und Subtraktionen der entgegengesetzten Richtung. Ein Beispiel: −4+3 soll berech-net werden. Binär entspricht dies der Rechnung von 1100+0011, was offensichtlich 1111 ergibt,genau der Darstellung von −1 im Zweierkomplement.
Technische Grundlagen der Informatik 93

6.4 Darstellung ganzer Zahlen mit Vorzeichen 6 Computerarithmetik
Abbildung 6.1: Zweierkomplement-Darstellung am Zahlenkreis
Nehmen wir nun die Beispiele, bei denen wir beim Einer-Komplement aufgrund des Carry-outnoch die Korrekturoperation (+1) machen mussten:
1. x − y mit x > yx = 510 = 1012
y =−310 =−00112 +1 = 1100+1 = 11010101+1101 =1 001000102 = 210
Wie man sieht, kann man das Carry-Out ignorieren. Es ist keine Korrekturaddition not-wendig.
2. −x − yx =−310 = 11012
y =−410 = 11002
1101+1100 =1 100110012 =−710
Hier ist ebenfalls keine Korrekturaddition notwendig
Generell gilt: Additionen mit Zahlen in Zweierkomplement-Darstellung bedürfen wie in denBeispielen oben gezeigt nur eines einzigen Rechenschrittes. Solange das Ergebnis der Additionden Wertebereich nicht überschreitet, ist die Berechnung damit abgeschlossen.
Die Subtraktion lässt sich einfach in die Addition überführen: Man negiert die Zahl, die abge-zogen werden soll, und addiert im Anschluss.
Aufgrund dieser für Berechnungen günstigen Eigenschaften wird in Computern bei Ganzzah-len mit Vorzeichen die Zweierkomplementdarstellung verwendet.
Es sei darauf hingewiesen, dass auch das Zweierkomplement nachteilige Aspekte hat: Nichtjeder Betrag kann sowohl positiv als auch negativ dargestellt werden. Das untere Extremumdes Wertebereichs hat nämlich keine mögliche positive Entsprechung. Beispiel: Mit sieben Bitskann man die Zahl −128 darstellen, aber nicht die Zahl +128, sondern höchstens +127. Diesliegt daran, dass die Null den positiven Zahlen zugeordnet wurde.
94 Technische Grundlagen der Informatik

6 Computerarithmetik 6.5 Überlauf
6.5 Überlauf
Als Überlauf (Overflow) bezeichnet man das Ergebnis einer Operation, deren Summe außer-halb des Wertebereiches liegt. Eine Erkennung des Überlaufs ist wesentlich für den korrektenAblauf einer Berechnung. Bei Addition von natürlichen Zahlen kann das Carry-Out-Bit als In-dikator für einen Überlauf dienen. Bei Addition ganzer Zahlen gilt dies nicht.
Weiterhin ergibt die Addition von Summanden mit unterschiedlichen Vorzeichen nie einenÜberlauf, da der absolute Wert ihrer Summe immer kleiner als der absolute Wert eines derbeiden Summanden ist. Demzufolge tritt ein Überlauf nur genau dann auf, wenn beide Sum-manden das gleiche Vorzeichen haben. Dies soll an den folgenden 4-Bit-Beispielen verdeutlichwerden:
01112 +710
+01002 +410
= 010112 −510 Falsches Ergebnis, aber Carry-Out ist 0
11002 −410
+10102 −610
= 101102 +610 Falsches Ergebnis und Carry-Out ist 1
Günstigerweise gibt es eine Schaltfunktion, mit der man auf einen Überlauf schließen kann:
O = an−1bn−1sn−1 +an−1 bn−1sn−1
Die Faktoren repräsentieren hier die Vorzeichenbits der Summanden a und b sowie der Sum-me s. Diese Schaltfunktion kann in ein Rechenwerk integriert werden. Über sie wird ein Signal(ein so genanntes flag) im Condition Code Register (CCR) gesetzt, in dem bestimmte Eigen-schaften von Operationsergebnissen hinterlegt werden. Das Überlaufsignal (meistens mit Vbezeichnet) wird oft zur Erzeugung eines Interrupts genutzt, welcher auf eine Fehlerbehand-lung (exception handling) auf Programmebene hinausläuft, d. h. der Programmierer entschei-det über den weiteren Verlauf der Ausführung.
6.6 Addition
Mit Gattern, der booleschen Algebra und den Grundlagen der Binärarithmetik haben wir dieDinge kennengelernt, die für die Entwicklung einer Addierschaltung für binäre Zahlen not-wendig sind. Im Folgenden werden verschiedene Konzepte vorgestellt.
6.6.1 Halbaddierer
Die einfachste Schaltung, die zur Binäraddition genutzt wird, nennt sich Halbaddierer (halfadder). Er addiert zwei Bits A und B zu einer Summe S und einem Übertrag (carry) C (Tabel-le 6.5).
Wie man aus der Tabelle erkennen kann, ist S = AB + AB = A ⊕B , also A XOR B , berechenbar.Der Übertrag C berechnet sich als A UND B , also C = AB . Aus dem früheren Kapitel zu Gattern
Technische Grundlagen der Informatik 95

6.6 Addition 6 Computerarithmetik
A B S C0 0 0 00 1 1 01 0 1 01 1 0 1
Tabelle 6.5: Wahrheitstabelle eines Halbaddierers
wissen wir bereits, dass sich diese Funktion durch mindestens drei verschiedene Schaltun-gen realisieren lässt. Aus Abstraktionsgründen wird die Schaltung daher unabhängig von dereigentlichen Implementierung durch ein Symbol symbolisiert, wie es in Abbildung 6.2 darge-stellt ist.
Abbildung 6.2: Symbol eines Halbaddierers
6.6.2 Volladdierer
Ein Halbaddierer genügt so lange, wie nur das Ergebnis einer Addition zweier Bits berechnetwerden soll. Normalerweise werden jedoch ganze Bitketten addiert, wobei zusätzlich ein Über-trag als Eingabe berücksichtigt werden muss. Aus der Addition der Zahlen A und B wird alsodie Addition dieser beiden Zahlen und des Übertrags.
an−1 . . . a2a1a0
+bn−1 . . .b2b1b0
+cn−1 . . .c2c1c0
c1 entspricht dabei beispielsweise dem Übertrag, der sich aus der Addition a0 +b0 + c0 ergibt.Wie man sieht, kann der Berechnung mit c0 von außen mitgeteilt werden, ob eine vorherigeBerechnung einen Übertrag verursacht hat. So lassen sich Additionen von Zahlen realisieren,die länger als die n Bits sind, wobei n beispielsweise eine Hardwarebeschränkung ist.Außerdem stellt diese zusätzliche Eingabe eine einfache Möglichkeit dar, die Zahl um 1 zu er-höhen. Dies kann beispielsweise bei der Bildung einer negativen Ganzzahl in Zweierkomple-ment-Darstellung nach Bildung des Einerkomplements praktisch sein.
Ein Volladdierer entspricht der Wahrheitstabelle, die in Tabelle 6.6 abgebildet ist. Eine einfacheMöglichkeit, einen Volladdierer zu implementieren, ist, zwei Halbaddierer in Reihe zu schalten(siehe Abbildung 6.3). Im Prinzip bedeutet dies, dass man die beiden Bits von A und B mitein-ander addiert, um wiederum das daraus entstehende Ergebnis mit dem Carry-In zu addieren.Der Ausgang S des Volladdierers wird durch den Summenausgang des zweiten Halbaddierersbestimmt, während der Übertrag Cout durch ODER-Verknüpfung der beiden Überträge derHalbaddierer bestimmt wird.
96 Technische Grundlagen der Informatik

6 Computerarithmetik 6.6 Addition
cin a b s cout0 0 0 0 00 0 1 1 00 1 0 1 00 1 1 0 11 0 0 1 01 0 1 0 11 1 0 0 11 1 1 1 1
Tabelle 6.6: Wahrheitstabelle eines Volladdierers
a) b)
Abbildung 6.3: Volladdierer aus Halbaddierern
In der Praxis wird man eine solche Implementierung nur selten finden, da der Pfad der Berech-nung durch die beiden Halbaddierer eine Verzögerung von sechs Zeiteinheiten hervorruft. Ei-ne alternative Volladdiererschaltung kann direkt aus den Gleichungen für die Summe und demÜbertrag aus der Wahrheitstabelle abgeleitet werden:
s = c ab + cab + ca b + cab
und
cout = cab + cab + cab + cab
= cab + cab + ca(b +b
)= cab + cab + ca
= cab + c(ab +a
)= cab + c (b +a) = cab + cb + ca
= a(cb + c
)+ cb = a (b + c)+ cb
= ca + cb +ab
Das Übertragsbit entspricht also genau dem in Abschnitt 2.2.1 kennengelernten Mehrheitsent-scheider. Es ist also 1, wenn mindestens zwei Eingänge 1 sind. Abbildung 6.4 zeigt einen Schalt-
Technische Grundlagen der Informatik 97
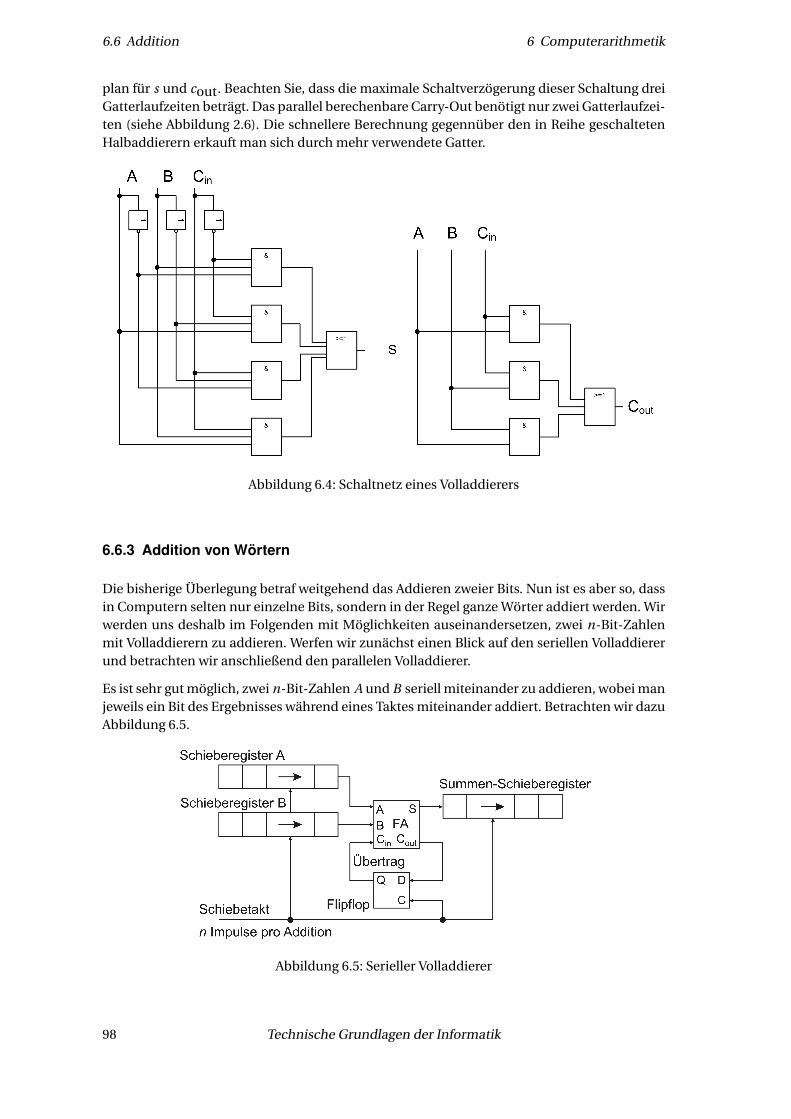
6.6 Addition 6 Computerarithmetik
plan für s und cout. Beachten Sie, dass die maximale Schaltverzögerung dieser Schaltung dreiGatterlaufzeiten beträgt. Das parallel berechenbare Carry-Out benötigt nur zwei Gatterlaufzei-ten (siehe Abbildung 2.6). Die schnellere Berechnung gegennüber den in Reihe geschaltetenHalbaddierern erkauft man sich durch mehr verwendete Gatter.
Abbildung 6.4: Schaltnetz eines Volladdierers
6.6.3 Addition von Wörtern
Die bisherige Überlegung betraf weitgehend das Addieren zweier Bits. Nun ist es aber so, dassin Computern selten nur einzelne Bits, sondern in der Regel ganze Wörter addiert werden. Wirwerden uns deshalb im Folgenden mit Möglichkeiten auseinandersetzen, zwei n-Bit-Zahlenmit Volladdierern zu addieren. Werfen wir zunächst einen Blick auf den seriellen Volladdiererund betrachten wir anschließend den parallelen Volladdierer.
Es ist sehr gut möglich, zwei n-Bit-Zahlen A und B seriell miteinander zu addieren, wobei manjeweils ein Bit des Ergebnisses während eines Taktes miteinander addiert. Betrachten wir dazuAbbildung 6.5.
Abbildung 6.5: Serieller Volladdierer
98 Technische Grundlagen der Informatik

6 Computerarithmetik 6.6 Addition
Die Inhalte der Schieberegister, in welchen die n-Bit-Zahlen A und B stehen, werden jeweilsmit einem Bit pro Takt in den Volladdierer geschoben. Das Ergebnis jeder Addition wird dannweiter in ein Ergebnisregister geschoben. Ein einzelnes Flipflop nimmt sich des Carry-Bits, alsodes Übertrages an, sodass das alte Carry-Out jeweils zum neuen Carry-In wird.
Nach n Taktimpulsen beinhaltet das Summenregister S die Summe von A und B . Serielle Ad-dierer finden sich häufig in älteren Lehrbüchern mit der Bemerkung, dass sie aufgrund der Tat-sache, dass sie nur einen Volladdierer benötigen, günstiger als Paralleladdierer sind. SolcherleiÜberlegungen mögen in der Vergangenheit richtig gewesen sein, nicht aber mehr heute. Mitder heutigen Möglichkeit, mehrere hunderttausend Transistoren auf einem einzigen Chip un-terzubringen, kann eine Schaltung auf Höchstleistung anstatt auf minimale Gatteranzahl hinentwickelt werden. In diesem Skript findet sich der serielle Volladdierer dennoch, damit derKontrast zwischen seriellen (Bit für Bit) und parallelen Operationen, bei denen alle Bits gleich-zeitig verarbeitet werden, deutlich wird.
Wenn das Carry-out des höchstwertigen Bits gleich 1 ist, tritt ein Überlauf während der Opera-tion auf, was zur Folge hat, dass n Bits nicht ausreichen, um das Ergebnis darzustellen.
Die praktischere Variante der Addierer ist der parallele Volladdierer, welcher sich n Volladdie-rern bedient, um zwei n-Bit-Zahlen miteinander zu addieren. Das Carry-Out jedes Volladdie-rers wird dabei als Carry-In des nächsten verwendet. Die n Bits von Zahl A und die n Bits vonZahl B werden dabei in einem gleichzeitigen Schritt addiert. Der Begriff „parallel“ weist auchdarauf hin, dass alle n Additionen zur gleichen Zeit stattfinden. Man ist sicherlich geneigt an-zunehmen, dass der parallele Addierer n-mal so schnell wie sein serielles Gegenstück ist. Inder Praxis wird ein paralleler Addierer jedoch dadurch verlangsamt, dass der Übertrag durchalle Stufen hindurchgereicht werden muss. Darauf kommen wir gleich noch einmal zurück.
Abbildung 6.6: Paralleler Volladdierer
Das erste Carry-In, welches bei der Addition von a0 und b0 (die niederwertigsten Bits der Zah-len A und B) verwendet wird, lässt sich auch beim parallelen Volladdierer wieder dazu nutzen,zwischen einer normalen Addition (Carry-In = 0) oder zur Erzeugung von A+B +1 zu wählen.Letzteres ist z. B. bei der Erzeugung des Zweier-Komplements oder zu Inkrementierung von A(wenn man für B einfach den Wert 010 annimmt) von Nutzen.
Das Carry-Out des höchstwertigen Bits lässt sich an ein Flipflop weiterreichen, dass z. B. Teildes Condition Code Registers sein könnte. Wenn die Addition durch Software als Teil einesProgramms durchgeführt wird, testet der Programmierer für gewöhnlich das Carry-Bit, ob dasErgebnis der Addition außerhalb des Wertebereiches liegt (Überlauf-Erkennung).
Eine letzte Bemerkung zum parallelen Volladdierer betrifft die Bedeutung des Begriffes par-allel. Es muss klar sein, dass, während a0 und b0 zu s0 in der ersten Stufe zusammenaddiertwerden, sobald die Zahlen A und B an den Eingängen des Volladdierers anliegen, die zwei-te Stufe stattdessen auf den Übertrag der ersten warten muss, bevor dieser bei der Additionvon a1 und b1 berücksichtigt werden kann und somit s0 einen gültigen Wert annimmt. Derschlechteste Fall ist die Addition der Zahlen 11. . .12 und 12. Bei diesem muss der Übertrag sich
Technische Grundlagen der Informatik 99

6.6 Addition 6 Computerarithmetik
durch alle Stufen fortpflanzen (hier könnte man wieder den Begriff „ripple-through“ – „durch-plätschern“ verwenden). Der hier beschriebene Volladdierer heißt deswegen parallel, weil alleBits von A in einem Schritt zu den Bits von B addiert werden, ohne dass die Notwendigkeit füreine gewissen Anzahl Taktzyklen besteht. Wenn die Werte von A und B an die Eingänge desVolladdierers angelegt wurden, muss das System warten, bis die Schaltung diese verarbeitethat und alle Überträge durchgereicht wurden, bevor die nächste Operation erfolgen kann.
6.6.4 Vorausschauende Addierer
Es wird davon ausgegangen, dass eine arithmetische Operation in einem Taktzyklus vom Re-chenwerk durchgeführt werden kann. Dies bedeutet, dass ein Prozessor, der mit einer Taktratevon 100 MHz arbeitet, eine Addition in 10−8 s (10 ns) abgeschlossen haben muss (100MHz =108 s−1). Die Verzögerung eines n-Bit-Addierers kann dabei wie folgt bestimmt werden: Neh-men wir an, dass die Verzögerung von einem Übertrag ci zum nächsten Übertrag ci+1 jederAddiererstufe in der prozessorinternen Schaltung 1 ns beträgt. Eine n-Bit-Addition kann alsoin der Zeit ausgeführt werden, die nötig ist, damit der Übertrag die Position cn−1 erreicht, plusder Zeit, um die letzte Volladdiererstufe sn−1 zu errechnen. Wenn für Letzteres eine Verzöge-rung von 1,5ns annehmen, würde eine 32-Bit-Addition (31 ·1ns)+1,5ns = 32,5ns benötigen(Die Überlegungen gehen von einer Gatterverzögerung von 0,5ns aus und eine Addition hatdrei Gatter in Serie).
Die Taktgeschwindigkeit hat mithin den größten Einfluss auf die Leistung eines Prozessors.Es ist sehr wichtig, die arithmetischen Operationen in möglichst wenigen Taktzyklen (optimaleinem) abschließen zu können. Die Zeit, die nötig ist, um eine arithmetische Operation durch-zuführen, hat einen dominanten Effekt auf die zu erzielende Taktrate.
Es gibt zwei Ansätze, um die Verzögerung unter die gewünschten 10 ns zu bringen. Der ersteAnsatz ist die Nutzung von schnelleren Schaltungstechnologien, mit denen man die Logik derÜbertragweitergabe implementiert. Der zweite Ansatz besteht darin, ein andere Struktur derLogik als der oben verwendeten zu entwerfen.
Die logischen Strukturen für die Entwicklung schneller Addierer müssen die Erzeugung derÜberträge beschleunigen. Die logischen Ausdrücke für si (Summe) und ci+1 (Carry-Out) derStufe i sind si = xi yi ci + xi yi ci + xi yi ci + xi yi ci und ci+1 = yi ci + xi ci + xi yi . Dabei lässt sichdie zweite Gleichung auch als ci+1 = xi yi +
(xi + yi
)ci schreiben. Diesen Term kann man unter-
teilen: Der erste Teil erzeugt auf dieser Stufe ggf. einen Übertrag; man nennt ihn darum auchGenerierungsfunktion (gi = xi yi ). Der hintere Teil pflanzt, falls ci = 1 ist, möglicherweise denÜbertrag fort und heißt daher Fortpflanzungsfunktion (pi =
(xi + yi
); p steht für propagate).
Man kann also auch ci+1 = gi +pi ci schreiben. Offensichtlich lassen sich gi und pi berechnen,sobald X und Y anliegen, und zwar innerhalb einer Gatterlaufzeit. Sobald ci bekannt ist, dau-ert es eine weiter Gatterlaufzeit, bis pi ci berechnet ist, und noch eine Gatterlaufzeit, bis derÜbertrag ci+1 = gi +pi ci berechnet ist.
So betrachtet ist es von wesentlichem Interesse, die Berechnung von ci zu beschleunigen. An-sonsten hätte man wieder den Effekt des parallelen Addierers, dass höherwertige Stellen aufdie Überträge der niederwertigen Stellen warten müssen.
Für i = 0, also das niederwertigste Bit, ist der Übertrag c0 vorgegeben: Es gehört zu den Ein-gaben, die von außen kommen. Dadurch lässt sich c1 = g0 + p0c0 direkt, das heißt in dreiGatterlaufzeiten, berechnen. Um die Stelle links davon (i = 1) schnell berechnen zu können,setzt man in c2 = g1 + p1c1 für den Übertrag c1 entsprechend g0 + p0c0 ein und erhält c2 =g1 + p1
(g0 +p0c0
) = g1 + g0p1 + p1p0c0. Der Übertrag c2 lässt sich somit auch in drei Gatter-laufzeiten berechnen. Auch für c3 lässt sich dieses Einsetzungsverfahren fortführen, was zu
100 Technische Grundlagen der Informatik

6 Computerarithmetik 6.6 Addition
c3 = g2 + g1p2 + g0p2p1 +p2p1p0c0 führt. Für die übrigen Stellen des zu addierenden Worteslassen sich ebenfalls derlei Formeln aufstellen, die dafür sorgen, dass alle Überträge nach dreiGatterlaufzeiten bekannt sind.
Die allgemeine Gleichung lautet
ci+1 = gi +pi gi−1 +pi pi−1gi−2 +·· ·+pi pi−1 . . . p1g0 +pi pi−1 . . . p1p0c0
Dadurch lassen sich alle Überträge mit der Verzögerung von drei Logikgattern bestimmen,nachdem die Eingangswerte X , Y und c0 verfügbar sind (eine Gatterverzögerung , um allepi - und gi -Signale zu entwickeln, gefolgt von zwei Gatterverzögerungen durch die AND/OR-Schaltung zur Bestimmung von ci+1). Nach drei weiteren Gatterverzögerungen, die ein Vollad-dierer zur Berechnung des Ergebnisses benötigt, sind alle Summenbits verfügbar. Deswegenbenötigt die n-Bit-Addition unabhängig von n nur sechs Logikebenen bzw. Gatterlaufzeiten.
Ein solcher Addierer ist ziemlich schnell. Leider bringt er praktische Probleme mit sich, diein einem Beispiel veranschaulicht werden. Es soll ein vorausschauender Addierer für n = 4entworfen werden. Die Überträge berechnen sich nach den folgenden Formeln:
c1 = g0 +p0c0
c2 = g1 + g0p1 +p1p0c0
c3 = g2 + g1p2 + g0p2p1 +p2p1p0c0
c4 = g3 + g2p3 + g1p3p2 + g0p3p2p1 +p3p2p1p0c0
Abbildung 6.7: Vorausschauender Addierer mit n = 4
Eine Schaltung des entsprechenden Addierers ist in Abbildung 6.7 dargestellt. Da die eigent-lichen Additionen in den Volladdierern stattfindet, die in der Schaltungsgrafik symbolisch ge-kapselt sind, zeigt sich, dass die Übertragsberechnung einen großen Überbau verursacht. Wohl-gemerkt: Die Schaltung berechnet nur die Addition von vier Bits! Man stelle sich vor, wie großder Überbau bei der Berechnung von acht, sechzehn oder zweiunddreißig Bit breiten Wör-tern sein mag. Aus diesem Grund beschränkt zum Einen die bloße Machbarkeit die beliebige
Technische Grundlagen der Informatik 101

6.6 Addition 6 Computerarithmetik
Verbreiterung des Addierers, andererseits lassen sich auch mehrere vorausschauende Addiererhintereinander schalten, um die Wortbreite zu erhöhen. Dadurch leidet die Geschwindigkeitetwas, aber nicht in dem Maße, dass es diese Art der Addierer unattraktiv werden ließe.
Ein weiteres Problem sind die Eingänge an den Gattern: Das letzte ODER-Gatter zur Berech-nung von c4 benötigt fünf Eingänge; generell benötigt es zur Berechnung von ci genau i + 1Eingänge. Auch hier beschränkt das hardwareseitig machbare die beliebige Wortverlängerung.Die meisten auf dem Markt verfügbaren Gatter haben nicht mehr als 8, meistens erheblichweniger Eingänge.
Mit acht vorausschauenden 4-Bit-Addierern lässt sich ein 32-Bit-Addierer erstellen, der eineAddition in nur 20 Gatterlaufzeiten durchführt. Bei einer Gatterlaufzeitdauer von 0,5ns be-deutet das, dass die Summe nach 10 ns bereitsteht. Das ist viel besser als die 32,5 ns, die manmit einem parallelen Addierer erzielen würde. Man beachte, dass bei dem zusammengesetztenvorausschauenden Addierer nur innerhalb der 4-Bit-Addierer vorausschauend addiert wird.Zwischen diesen Blöcken „plätschert“ das Übertragsbit wie zuvor durch.
Für längere Wörter mag es notwendig sein, die Addition noch weiter zu beschleunigen. Dieskann dadurch erreicht werden, indem man die Vorschau-Technik auf die Überträge zwischenden Blöcken anwendet und so eine zweite Ebene der Vorschau und der Abstraktion schafft.
Zunächst einmal denken wir uns wieder einen 4-Bit-Addierer mit seiner vorausschauendenLogik als eine Blackbox. Wenn wir nun vier davon in Reihe zusammenschalten, um einen 16-Bit-Addierer zu schaffen, wird die Addition mit nur wenig mehr Hardware deutlich schnellerals ein normaler 16-Bit-Addierer sein.
Um schneller zu sein, benötigen wir eine Übertragsvorschau auf einer höheren Ebene. Alsobrauchen wir auch Übertrags- und Fortpflanzungssignale und -funktionen auf dieser höherenEbene, wie sie unten für jeden der vier 4-Bit-Addierer aufgeführt sind.
P0 = p3p2p1p0
P1 = p7p6p5p4
P2 = p11p10p9p8
P3 = p15p14p13p12
Diese übergeordneten Fortpflanzungsfunktionen Pi für die 4-Bit-Abstraktion sind nur dannwahr, wenn jedes der Bits innerhalb der Gruppe einen Übertrag durchreicht.
Für die übergeordneten Generierungsfunktionen braucht es uns nur zu interessieren, ob eseinen Übertrag durch das niederwertigste Bit der 4-Bit-Gruppe gibt. Dies ist offensichtlichdann der Fall, wenn die Generierungsfunktion für das niederwertigste Bit wahr ist, oder wenneine noch frühere Generierungsfunktion einen Übertrag erzeugt hat, welcher von allen zwi-schenliegenden Stufen durchgereicht wurde.
G0 = g3 +p3g2 +p3p2g1 +p3p2p1g0
G1 = g7 +p7g6 +p7p6g5 +p7p6p5g4
G2 = g11 +p11g10 +p11p10g9 +p11p10p9g8
G3 = g15 +p15g14 +p15p14g13 +p15p14p13g12
102 Technische Grundlagen der Informatik

6 Computerarithmetik 6.7 Multiplikation
Dann sind die Gleichungen für die vier Carry-Ins der Blöcke auf dieser höheren Abstraktions-ebene ähnlich denen für die Carry-Outs innerhalb jeder 4-Bit-Gruppe.
C1 =G0 +P0c0
C2 =G1 +P1G0 +P1P0c0
C3 =G2 +P2G1 +P2P1G0 +P2P1P0c0
C4 =G3 +P3G2 +P3P2G1 +P3P2P1G0 +P3P2P1P0c0
C4 = c16 ist hierbei bereits fünf Gatterlaufzeiten, nachdem X , Y und c0 angelegt wurden, ver-fügbar. Bei der reinen Verwendung von gi - und pi -Funktionen brauchten wir dafür noch zwölfGatterlaufzeiten. Größere Addierer lassen sich wieder entwickeln, indem man solche 16-Bit-Addierer und eine weitere Abstraktion zugrunde legt. Dadurch lässt sich die Gesamtverzöge-rung auf die Hälfte gegenüber der direkten Nutzung der 4-Bit-Addierer reduzieren.
Die vorausschauenden Addierer sind ein gutes Beispiel für eine Anwendung des Abstraktions-prinzips. Das Vorschau-Prinzip selbst wird im Rechner durchgehend angewendet, um mög-licherweise seriell ablaufende Vorgänge durch Parallelisierung zu beschleunigen. Dies ist z. B.auch bei der Adressenberechnung für zukünftige Speicherzugriffe, bei Eingangsberechnungenfür einzelne Stufen des Pipelinings (wird in der Lehrveranstaltung Rechnersysteme behandelt)und bei der Compiler-Optimierung der Fall.
6.7 Multiplikation
Mit der Konstruktion der ALU und der Erläuterung von Addition, Subtraktion und Verschie-bungen (shifts) sind wir nun bereit, die nächsthöhere Operation des Multiplizierens anzuge-hen. Betrachten wir jedoch vorher die schriftliche Multiplikation von Dezimalzahlen, um unsan den dort zugrundegelegten Algorithmus und die Bezeichnungen der Operanden zu erin-nern. Wir werden dieses Dezimalbeispiel auch auf die Ziffern 0 und 1 beschränken, da uns imBinärsystem auch nicht mehr zur Verfügung stehen. Multiplizieren wir also 100010 mit 100110.Diese Faktoren kann man auch unterschiedlich bezeichnen: Der erste Operand heißt der Mul-tiplikand (der Wert, der vervielfacht wird) und der zweite der Multiplikator (wie oft vervielfachtwird).
Multiplikand 1 0 0 010
Multiplikator × 1 0 0 110
1 0 0 00 0 0 0
0 0 0 01 0 0 0
Produkt 1 0 0 1 0 0 010
Wie man sich vielleicht erinnert, multipliziert man laut dem Grundschulalgorithmus die Zif-fern des Multiplikators von rechts nach links einzeln mit dem Multiplikanden und verschiebtjedes Zwischenergebnis eine Stelle weiter nach rechts als das vorherige Zwischenresultat.
Eine wichtige Feststellung ist, dass die Anzahl der Ziffern des Produktes beträchtlich größer istals die Anzahl der Ziffern des Multiplikanden oder des Multiplikators. Tatsächlich ist das Er-gebnis der Multiplikation einer n-Bit-Zahl und einer m-Bit-Zahl – die Vorzeichenbits beiseite
Technische Grundlagen der Informatik 103

6.7 Multiplikation 6 Computerarithmetik
gelassen – n+m Bits lang. Das bedeutet, dass man n+m Bits braucht, um alle möglichen Pro-dukte darzustellen. Folglich muss die Multiplikation wie beim Addieren ebenfalls mit Überläu-fen fertig werden, da man häufig ein 32-Bit-Produkt als Ergebnis zweier 32-Bit-Faktoren habenmöchte.
In diesem Beispiel beschränkten wir die Dezimalziffern auf 0 und 1. Mit diesen beiden Alter-nativen allein ist jeder Schritt der Multiplikation simpel:
1. Nimm eine Kopie der Multiplikanden als aktuelles Zwischenergebnis, wenn die aktuelleMultiplikatorziffer 1 ist (1·Multiplikand)
2. Nimm ansonsten 0 als Zwischenergebnis (0·Multiplikand), wenn die Ziffer des Multipli-kators 0 ist.
Dies ist der Algorithmus. Sehen wir uns nun die Hardware an, die diesen ausführen soll. Im Restdieses Abschnitts betrachten wird aufeinanderfolgende Verfeinerungen der Hardware und desAlgorithmus, bis wir zu einer in realen Rechnern verwendeten Version kommen. Nehmen wirvorerst an, dass wir nur positive Ganzzahlen miteinander multiplizieren.
6.7.1 Erste Version einer Multiplikations-Hardware
Das ursprüngliche Design spiegelt den Grundschulalgorithmus wieder.
Nehmen wir an, dass sich der Multiplikator im 32-Bit-Multiplikatorregister befindet (Abbil-dung 6.8) und dass das 64-Bit-Produktregister auf 0 initialisiert wurde. Von der manuellenschriftlichen Multiplikation wissen wir, dass wir den Multiplikanden bei jedem Schritt um eineZiffer nach links bewegen müssen, bevor er zu den Zwischenprodukten addiert werden kann.Bei 32 Schritten bewegt sich der 32-Bit-Multiplikand dabei um 32 Bits nach links. Folglich brau-chen wir ein 64-Bit-Multiplikandenregister, welches in der rechten Hälfte mit den 32 Bits desMultiplikanden initialisiert werden muss, während in der linken Hälfte nur Nullen stehen. Die-ses Register wird dann bei jedem Schritt jeweils um ein Bit nach links verschoben, um denMultiplikanden an der Summe, die im 64-Bit-Produktregister steht, auszurichten. Der Algo-rithmus in der Abbildung 6.9 zeigt die drei Grundschritte, die für jedes Bit auszuführen sind.Das niederwertigste Bit des Multiplikators bestimmt dabei, ob der Multiplikand zum Produkt-register hinzuaddiert wird. Die Linksverschiebung im zweiten Schritt verschiebt die Zwischen-ergebnisse jeweils nach links, analog der manuellen schriftlichen Multiplikation. Die Rechts-verschiebung in Schritt 3 hingegen liefert uns das nächste Bit des Multiplikators, welches imnächsten Schleifendurchlauf untersucht wird. Diese drei Schritte werden 32-mal wiederholt,um das Produkt zu erhalten.
Abbildung 6.8: Erste Version einer Multiplikationshardware
104 Technische Grundlagen der Informatik

6 Computerarithmetik 6.7 Multiplikation
Abbildung 6.9: Algorithmus zur ersten Version einer Multiplikationshardware
Als Beispiel multiplizieren wir 210 mit 310, also 00102 mit 00112. Tabelle 6.7 zeigt die Wertejedes Registers nach jedem der besprochenen Schritte, mit dem Endwert 000001102 = 610. Diefettgedruckten Bits des Multiplikators sind dabei diejenigen, die untersucht werden.
Die Wichtigkeit von arithmetischen Operationen wie der Multiplikation variiert von Programmzu Programm, aber die Addition und die Subtraktion sind überall 5 bis 100 mal wichtiger alsdas Multiplizieren. Deswegen kann das Multiplizieren in den meisten Anwendungen mehre-re Taktzyklen benötigen, ohne die Geschwindigkeit spürbar zu beeinträchtigen. Man beachteaber, dass selbst eine mittlere Häufigkeit für eine langsame Operation die Geschwindigkeit si-gnifikant verringern kann.
Fast alle modernen Rechner bieten die Multiplikation in ihrem Maschinenbefehlssatz. Dieneuesten Hochleistungsprozessoren nutzen einen beträchtlichen Anteil der Chipfläche, umarithmetische Operationen auf Ganzzahl- und Gleitkommaoperanden auszuführen.
6.7.2 Zweite Version einer Multiplikations-Hardware
Die zweite Version unterscheidet sich im Wesentlichen nur im Schritt 1a von der ersten. ImGegensatz dazu wird hier nicht ein 64-Bit-Multiplikand zum Produkt addiert, sondern nur ein32 Bit breites Wort (welches den Multiplikanden beinhaltet) zu der linken Hälfte des Produktes(Abbildung 6.10 und Abbildung 6.11).
Auch dies soll wieder am Beispiel der Multiplikation von 00102 mit 00112 verdeutlicht werden(Tabelle 6.8). Das Ergebnis ist ebenfalls 01102 = 610.
Technische Grundlagen der Informatik 105

6.8 Der Booth-Algorithmus 6 Computerarithmetik
Schleife Schritt Multiplikator Multiplikand Produkt0 Anfangswerte 0011 0000 0010 0000 0000
1 1a: 1 ⇒ Prod = Prod+Mkand 0011 0000 0010 0000 0010
2: Schiebe Multiplikand nach links 0011 0000 0100 0000 0010
3: Schiebe Multiplikator nach links 000h 0000 0100 0000 0010
2 1a: 1 ⇒ Prod = Prod+Mkand 0001 0000 0100 0000 0110
2: Schiebe Multiplikand nach links 0001 0000 1000 0000 0110
3: Schiebe Multiplikator nach links 0000 0000 1000 0000 0110
3 1: 0 ⇒ keine Operation 0000 0000 1000 0000 0110
2: Schiebe Multiplikand nach links 0000 0001 0000 0000 0110
3: Schiebe Multiplikator nach links 0000 0001 0000 0000 0110
4 1: 0 ⇒ keine Operation 0000 0001 0000 0000 0110
2: Schiebe Multiplikand nach links 0000 0010 0000 0000 0110
3: Schiebe Multiplikator nach links 0000 0010 0000 0000 0110
Tabelle 6.7: Multiplikation Version 1 in Registern
Abbildung 6.10: Zweite Version einer Multiplikationshardware
6.7.3 Finale dritte Version einer Multiplikations-Hardware
Die letzte Beobachtung der sparsamen Rechnerpioniere war, dass das Produktregister Platzin der Größe des Multiplikators verschwendete: Wenn der verschwendete Platz verschwindet,dann verschwinden auch die Bits des Multiplikators. In der Folge verbindet die dritte Versi-on der Multiplikation die rechte Hälfte des Produktes mit dem Multiplikator (Abbildung 6.12).Dadurch entfällt zusätzlich die Notwendigkeit für ein eigenes Multiplikatorregister (und so-mit auch der Schritt 3) (Abbildung 6.13). Beim Test wird also nun das niederwertigste Bit desProdukts überprüft. Auch hierzu wieder unser Beispiel: 00102 mal 00112 (Tabelle 6.9).
6.8 Der Booth-Algorithmus
Bisher haben wir ausschließlich die Multiplikation von positiven Ganzzahlen betrachtet unddie Hardware darauf optimiert. Nun gilt es, dass Vorzeichen zu berücksichtigen und dann dieAlgorithmen anzupassen und schneller zu machen.
Ein mächtiger Algorithmus für die Multiplikation vorzeichenbehafteter ganzer Zahlen ist derBooth-Algorithmus. Er generiert ein 2n-Bit-Produkt und behandelt positive und negative Zah-len gleich. Man denke sich eine Multiplikation, bei welcher der Multiplikator positiv ist undeine einfache Folge von Einsen beinhalte, zum Beispiel 0011110. Um das Produkt zu erhalten,könnte man vier entsprechend verschobene Versionen des Multiplikanden aufsummieren:
106 Technische Grundlagen der Informatik
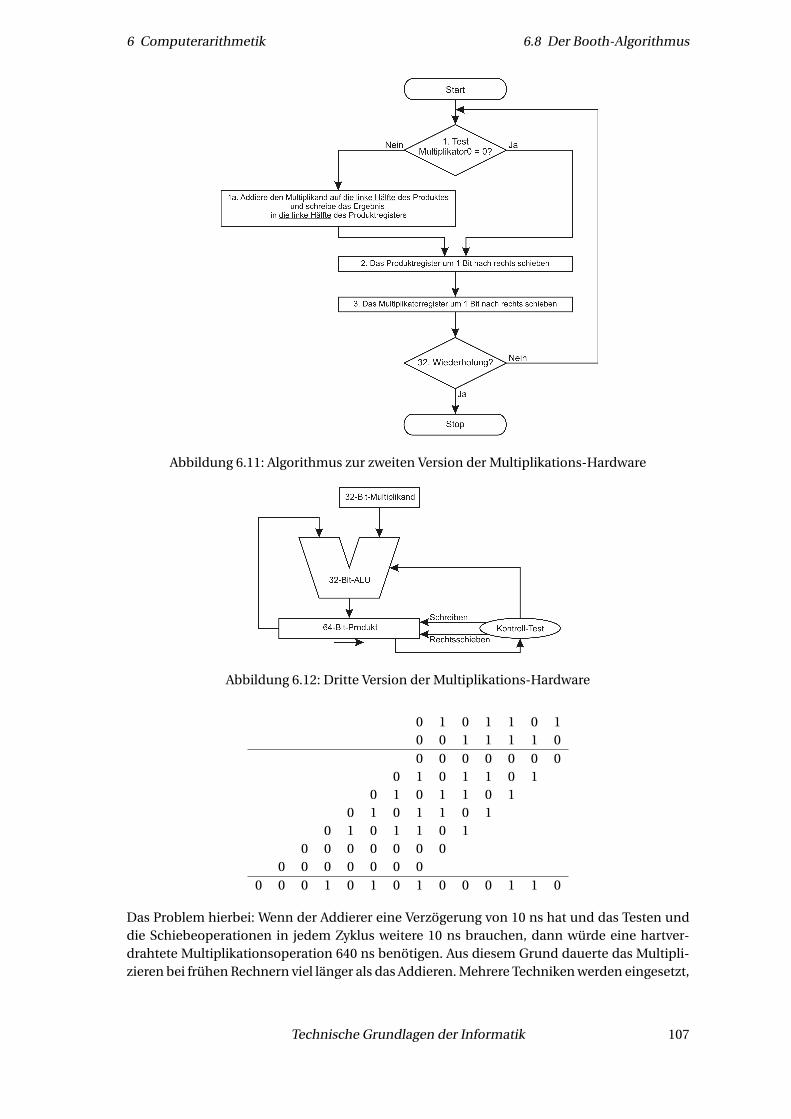
6 Computerarithmetik 6.8 Der Booth-Algorithmus
Abbildung 6.11: Algorithmus zur zweiten Version der Multiplikations-Hardware
Abbildung 6.12: Dritte Version der Multiplikations-Hardware
0 1 0 1 1 0 10 0 1 1 1 1 00 0 0 0 0 0 0
0 1 0 1 1 0 10 1 0 1 1 0 1
0 1 0 1 1 0 10 1 0 1 1 0 1
0 0 0 0 0 0 00 0 0 0 0 0 0
0 0 0 1 0 1 0 1 0 0 0 1 1 0
Das Problem hierbei: Wenn der Addierer eine Verzögerung von 10 ns hat und das Testen unddie Schiebeoperationen in jedem Zyklus weitere 10 ns brauchen, dann würde eine hartver-drahtete Multiplikationsoperation 640 ns benötigen. Aus diesem Grund dauerte das Multipli-zieren bei frühen Rechnern viel länger als das Addieren. Mehrere Techniken werden eingesetzt,
Technische Grundlagen der Informatik 107

6.8 Der Booth-Algorithmus 6 Computerarithmetik
Schleife Schritt Multiplikator Multiplikand Produkt0 Anfangswerte 0011 0010 0000 0000
1 1a: 1 ⇒ Prod = Prod+Mkand 0011 0010 0010 0000
2: Schiebe Produkt nach rechts 0011 0010 0001 0000
3: Schiebe Multiplikator nach rechts 0001 0010 0001 0000
2 1a: 1 ⇒ Prod = Prod+Mkand 0001 0010 0011 0000
2: Schiebe Produkt nach rechts 0001 0010 0001 1000
3: Schiebe Multiplikator nach rechts 0000 0010 0001 1000
3 1: 0 ⇒keine Operation 0000 0010 0001 1000
2: Schiebe Produkt nach rechts 0000 0010 0000 1100
3: Schiebe Multiplikator nach rechts 0000 0010 0000 1100
4 1: 0 ⇒keine Operation 0000 0010 0000 1100
2: Schiebe Produkt nach rechts 0000 0010 0000 0110
3: Schiebe Multiplikator nach rechts 0000 0010 0000 0110
Tabelle 6.8: Multiplikation Version 2 in Registern
Schleife Schritt Multiplikand Produkt0 Anfangswerte 0010 0000 0011
1 1a: 1 ⇒ Prod = Prod+Mkand 0010 0010 0011
2: Schiebe Produkt nach rechts 0010 0001 0001
2 1a: 1 ⇒ Prod = Prod+Mkand 0010 0011 0001
2: Schiebe Produkt nach rechts 0010 0001 1000
3 1: 0 ⇒ keine Operation 0010 0001 1000
2: Schiebe Produkt nach rechts 0010 0000 1100
4 1: 0 ⇒ keine Operation 0010 0000 1100
2: Schiebe Produkt nach rechts 0010 0000 0110
Tabelle 6.9: Multiplikation Version 3 in Registern
um die Multiplikation in modernen Prozessoren zu beschleunigen, einige davon werden wir inden nächsten Abschnitten besprechen.
Wie auch immer, wir können die Anzahl der benötigten Operationen verringern, indem wirdiesen Multiplikator als Differenz zweier Zahlen ansehen:
0100000 = 3210
−0000010 = 210
0011110 = 3010
Dadurch ist leicht ersichtlich, dass das Produkt generiert werden kann, indem man „25 malden Multiplikand“ zum Zweierkomplement von „21 mal dem Multiplikanden“ addiert. AusBequemlichkeit können wir die Sequenz der benötigten Operationen beim Umschreiben dervorangegangenen Multiplikators als
0 +1 0 0 0 -1 0
beschreiben.
Im Allgemeinen wird im Booth-Schema „−1 mal dem verschobenen Multiplikanden“ benutzt,wenn sich der aktuelle Prüfwert von 0 auf 1 ändert. Analog addiert man „+1 mal dem geshifte-
108 Technische Grundlagen der Informatik

6 Computerarithmetik 6.8 Der Booth-Algorithmus
Abbildung 6.13: Algorithmus zur dritten Version der Multiplikations-Hardware
ten Multiplikanden“, wenn sich der Wert von 1 auf 0 ändert. Dabei wird der Multiplikator vonrechts nach links untersucht. Für das Beispiel von vorhin bedeutet das:
0 1 0 1 1 0 10 +1 0 0 0 −1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 01 1 1 1 1 1 0 1 0 1 1 0 10 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 01 1 0 1 0 1 1 0 10 0 0 0 0 0 0 00 0 0 1 0 1 0 1 0 0 0 1 1 0
Und tatsächlich erhalten wir das gleiche Ergebnis wie oben. Allein in diesem Beispiel werdenschon zwei Additionen eingespart. Wovon nun die Größe der Einsparung abhängt, werden wirspäter noch betrachten.
Der Trick bei der Arbeit des Booth-Algorithmus ist seine Einteilung der Bits in Gruppen desBeginns, der Mitte und des Endes einer Folge von Einsen. Klar ist, dass eine Folge von Nullenuns Arithmetik erspart und somit ignoriert werden kann.
Der Booth-Algorithmus ändert den ersten Schritt der zuletzt besprochenen Multiplikations-Hardware, indem hier nicht mehr nur ein Bit genutzt wird, um zu entscheiden, ob der Multipli-kand zum Produkt hinzuaddiert wird. Stattdessen werden hierbei zwei Bits des Multiplikatorsüberprüft. Dieser neue erste Schritt hat dann also vier verschiedene Fälle zu unterscheiden,welche von den Werten dieser zwei Bits abhängen. Nehmen wir an, dass das untersuchte Bit-paar aus dem momentanen Bit und dem rechts daneben (welches im vorherigen Schritt das
Technische Grundlagen der Informatik 109

6.8 Der Booth-Algorithmus 6 Computerarithmetik
momentane Bit war) besteht. Der zweite Schritt besteht immer noch darin, dass Produkt umeine Stelle nach rechts zu verschieben. Der neue Algorithmus sieht dann folgendermaßen aus:
1. 1. Abhängig vom momentanen und dem vorherigen Bit mache folgendes:
• 00: Innenraum in einer Folge von Nullen, also keine Arithmetik nötig
• 01: Ende einer Folge von Einsen, also addiere den Multiplikanden zur linken Hälftedes Produkts
• 10: Beginn einer Folge von Einsen, also subtrahiere den Multiplikanden von derlinken Hälfte des Produkts
• 11: Innenraum in einer Folge von Einsen, also keine Arithmetik nötig
2. Verschiebe wie im vorherigen Algorithmus das Produktregister um ein Bit nach rechts
Zum Vergleich betrachten wir die beiden Algorithmen am Beispiel (Tabelle 6.10). Dabei neh-men wir für den Booth-Algorithmus zu Beginn immer eine Null herausgeschobenes Bit an.Man beachte, dass der Booth-Algorithmus immer durch zwei Bits entscheidet, welche Opera-tion auszuführen ist. Nach dem vierten Schritt haben die beiden Algorithmen den selben Wertin ihren Produktregistern.
Schleife Multi- Urspr. Algorithmus Booth-Algorithmus
plikant Schritt Produkt Schritt Produkt
0 0010 Anfangswerte 0000 0110 Anfangswerte 0000 0110 0
1 0010 1: 0 ⇒ keine Operation 0000 0110 1d: 00 ⇒ keine Operation 0000 0110 0
0010 2: Schiebe Produkt nach rechts 0000 0011 2: Schiebe Produkt nach rechts 0000 0011 0
2 0010 1a: 1 ⇒ Prod = Prod+Mkand 0010 0011 1c: 10 ⇒ Prod = Prod−Mkand 1110 0011 0
0010 2: Schiebe Produkt nach rechts 0001 0001 2: Schiebe Produkt nach rechts 1111 0001 1
3 0010 1a: 1 ⇒ Prod = Prod+Mkand 0011 0001 1d: 11 ⇒ keine Operation 1111 0001 1
0010 2: Schiebe Produkt nach rechts 0001 1000 2: Schiebe Produkt nach rechts 1111 1000 1
4 0010 1: 0 ⇒ keine Operation 0001 1000 1b: 01 ⇒ Prod = Prod+Mkand 0001 1000 1
0010 2: Schiebe Produkt nach rechts 0000 1100 2: Schiebe Produkt nach rechts 0000 1100 0
Tabelle 6.10: Vergleich normale Multiplikation und Multiplikation mit Booth
Die einzige weitere Voraussetzung ist, dass – da wir es mit vorzeichenbehafteten Zahlen zu tunhaben – die Zwischenergebnisse trotz Rechtsverschiebung im Produkt das Vorzeichen beibe-halten. Dafür wird das Vorzeichen schlicht erweitert, d. h. der Wert des ersten Bits wird bei-behalten. Dadurch erzeugt der zweite Schritt des zweiten Schleifendurchlaufs aus 1110001102
den Wert 1111000112 (anstatt 0111000112). Diese Art der Verschiebung heißt arithmetischeRechtsverschiebung (arithmetic shift right), um sie von der logischen Rechtsverschiebung zuunterscheiden, die immer Nullen anfügt.
Nachfolgendend noch ein Beispiel für einen negativen Multiplikator: 210 · (−310) = −610 bzw.00102 ·11012 = 111110102 (Tabelle 6.11).
Jetzt, da wir gesehen haben, dass der Booth-Algorithmus funktioniert, können wir uns anse-hen, warum er für vorzeichenbehaftete Ganzzahlen in Zweierkomplementdarstellung funktio-niert. Lassen wir a den Multiplikator und b den Multiplikanden sein. Wir werden weiterhin ai
für das i -te Bit von a schreiben.Gestaltet man den Booth-Algorithmus so um, dass man nach den Werten der zu überprüfen-den Bits unterscheidet, erhält man Tabelle 6.12.
110 Technische Grundlagen der Informatik

6 Computerarithmetik 6.8 Der Booth-Algorithmus
Schleife Schritt Multiplikand Produkt0 Anfangswerte 0010 0000 1101 0
1 1c: 10 ⇒ Prod = Prod−Mkand 0010 1110 1101 0
2: Schiebe Produkt nach rechts 0010 1111 0110 1
2 1b: 01 ⇒ Prod = Prod+Mkand 0010 0001 0110 1
2: Schiebe Produkt nach rechts 0010 0000 1011 0
3 1c: 10 ⇒ Prod = Prod−Mkand 0010 1110 1011 0
2: Schiebe Produkt nach rechts 0010 1111 0101 1
4 1d: 11 ⇒ keine Operation 0010 1111 0101 1
2: Schiebe Produkt nach rechts 0010 1111 1010 1
Tabelle 6.11: Beispiel negative Multiplikation
ai ai−1 Auszuführende Operation0 0 Nichts0 1 Addiere b1 0 Subtrahiere b1 1 Nichts
Tabelle 6.12: Bitgesteuerte Boothbelegungen
Anstatt dies in tabellarischer Form darzustellen, lässt sich der Booth-Algorithmus durch denAusdruck (ai−1 −ai ) beschreiben. Ist das Ergebnis 0, so wird mit dem nächsten Schritt im Al-gorithmus fortgefahren. Bei +1 wird zuvor b addiert und bei −1 subtrahiert.
Da wir wissen, dass eine Linksverschiebung des Multiplikanden als eine Multiplikation um denFaktor Zwei angesehen werden kann, können wir den Booth-Algorithmus als folgende Summeaufschreiben:
(a−1 −a0)×b ×20
+ (a0 −a1)×b ×21
+ (a1 −a2)×b ×22
· · ·+ (a30 −a31)×b ×231
Wir können diese Summe vereinfachen, da
−ai ×2i +ai ×2i+1 = (−ai +2ai )×2i
= (2ai −ai )×2i
= ai ×2i
Wir erinnern uns, dass a−1 = 0 und klammern b aus jedem Term aus:
b × ((a31 ×−231)+ (
a30 ×−230)+·· ·+ (a1 ×−21)+ (
a0 ×−20))
Technische Grundlagen der Informatik 111

6.9 Schnelle Multiplikation 6 Computerarithmetik
Die lange Formel in Klammern auf der rechten Seite der ersten Multiplikation ist einfach dieZweierkomplementdarstellung von a, wie wir sie bereits behandelt haben. Dass a31 mit −231
multipliziert wird, hat zur Folge, dass a negativ ist, wenn das höchstwertige Bit (a31) gesetztist, und positiv, falls a31 = 0. Folglich führt der Booth-Algorithmus in der Tat die Zweierkom-plementmultiplikation von a und b aus.
Der Booth-Algorithmus hat zwei attraktive Vorteile. Erstens behandelt er positive und negativeMultiplikatoren gleich. Zweitens ist der Booth-Algorithmus im Mittel genauso langsam wie dieherkömmliche Multiplikation, begünstigt aber Multiplikationen von Daten, die lange Einser-oder Nullerketten haben. Dies ist in Computern häufig der Fall.
In jedem Fall ist es hilfreich, vor der Multiplikation zu überprüfen, welcher Faktor sich auf-grund wenigeren 0-1- oder 1-0-Wechseln besser als Multiplikator eignet. Will man als Beispiel01012 und 11112 miteinander multiplizieren, so wäre eine ungünstige Zuordnung von Multi-plikand und Multiplikator folgende:
1 1 1 10 1 0 1
(umcodiert) +1 −1 +1 −10 0 0 0 0 0 0 11 1 1 1 1 1 10 0 0 0 0 11 1 1 1 11 1 1 1 1 0 1 1
Günstig wäre dagegen folgende Zuordnung:
0 1 0 11 1 1 1
(umcodiert) 0 0 0 −11 1 1 1 1 0 1 10 0 0 0 0 0 00 0 0 0 0 00 0 0 0 01 1 1 1 1 0 1 1
6.9 Schnelle Multiplikation
Wir beschreiben nun zwei Techniken, mit denen man die Multiplikationsoperation beschleu-nigen kann. Die erste Technik reduziert die maximale Anzahl von Summanden (Versionendes Multiplikanden), die addiert werden müssen, unter Umständen auf die Hälfte. Die zweiteTechnik verringert die zum Addieren der Summanden notwendige Zeit.
Eine Technik namens bit-pair recoding (Neucodierung eines Bitpaares) kann die Anzahl derSummanden gegebenenfalls halbieren. Die Technik kann direkt aus dem Booth-Algorithmusabgeleitet werden und wird deshalb oft auch als Booth-2-Algorithmus bezeichnet.
Das Bit-Pair-Verfahren nutzt die Tatsache, dass in der binären Darstellung eine Ziffer a linkseiner Ziffer b für den Wert a = 2 ·b steht. Zum Beispiel steht das niederwertigste Bit für 20 = 1und das links davon stehende Bit für 21 = 2. Offensichtlich gilt 2 = 2 ·1.
112 Technische Grundlagen der Informatik

6 Computerarithmetik 6.9 Schnelle Multiplikation
Wenn man gemäß der Booth-Algorithmus-Vorverarbeitung einen der Faktoren umcodiert, be-kommt man Folgen aus +1, −1 und 0. Ist ein Ausschnitt daraus das Paar {+1,−1}, so entsprichtdas nach obiger Definition (+1) · 2b + (−1) · b = 2b − b = b. Folglich genügt es, nur die rech-te Stelle einmal zu addieren; das Bitpaar lässt sich also in {0,+1} umcodieren. Das bedeutet,dass wir an dieser Stelle eine Addition sparen können. Die Umcodierungsmöglichkeiten sindin Tabelle 6.13 dargestellt.
Ursprüngliches Bitpaar Umcodiertes Bitpaar{+1,−1} {0,+1}{−1,+1} 0,−1
Tabelle 6.13: Varianten des Bit-Pair-Recoding
Der umgeschriebene Multiplikator wird jeweils auf zwei Bits zugleich geprüft wird (von rechtsbeginnend). Bei Zahlwörtern mit vielen 1-0- oder 0-1-Wechseln kann die tatsächliche Anzahlan Operationen dadurch erheblich reduziert werden.
Die Multiplikation bedient sich der Addition mehrerer Summanden. Eine Technik namenscarry-save addition (Übertragssichernde Addition) beschleunigt den Additionsvorgang. Bei derAddition der drei Summanden A, B und C wird gleich A +B +C errechnet (wobei ansonstenja zwei mal Übertragsdurchreichung stattfinden müsste), anstatt erst das ZwischenergebnisA +B = S zu berechnen. Eine mögliche Schaltung finden Sie in Abbildung 6.14. Einzelheitenentnehme man der weiterführenden Literatur.
Abbildung 6.14: Carry-Save-Addierer
Dabei werden aus drei Summanden immer wieder die Vektoren S und C generiert. Die verblie-benen S und C werden wieder zu Dreiergruppen zusammengefasst und das Verfahren wirderneut angewendet. Am Ende ist das ganze System auf zwei Vektoren S und C reduziert. Hiermuss eine Addition mit Carry durchgeführt werden. Sie kann mit Hilfe eines Carry-Lookahead-Addierers realisiert werden.
Fassen wir die Anwendung dieser Techniken bei der Hochgeschwindigkeitsmultiplikation zu-sammen. Neucodierung der Bitpaare des Multiplikators, abgeleitet aus dem Booth-Algorith-mus, reduziert die Anzahl der Summanden um die Hälfte. Diese Summanden lassen sich dannauf nur zwei reduzieren, wenn man eine verhältnismäßig kleine Anzahl von übertragssichern-den Operationen anwendet. Das Endprodukt kann durch eine einzige Addition generiert wer-den und diese letzte Operation kann durch vorausschauende Addierer weiter beschleunigtwerden. Alle diese drei Grundtechniken sind in vielen Variationen durch Entwickler von Hoch-
Technische Grundlagen der Informatik 113

6.10 Ganzzahldivision 6 Computerarithmetik
leistungsprozessoren angewendet worden, um die für eine Multiplikation nötige Zeit zu redu-zieren.
6.10 Ganzzahldivision
Im vorhergehenden Abschnitt besprachen wir die Multiplikation positiver Zahlen, indem wirdie Operation, wie sie durch eine Logikschaltung ausgeführt wird, an die manuelle Rechnunganlehnten. Bei der Division gehen jetzt wir denselben Weg. Wir besprechen zunächst nur diepositiven Ganzzahlen und machen später ein paar allgemeine Bemerkungen zu vorzeichen-behafteten Operanden.
Abbildung 6.15 zeigt dezimale Division und die binär-codierte Division mit denselben Werten.
2 7 4 : 13 = 212 6
1 41 3
1
1 0 0 0 1 0 0 1 0 : 1101 = 101011 1 0 1
1 0 0 0 01 1 0 1
1 1 1 01 1 0 1
1
Abbildung 6.15: Schriftliche Division in dezimaler und binärer Darstellung
Betrachten wir zunächst nur die dezimale Version. Die 2 im Quotienten wird folgendermaßenbestimmt: Zuerst versuchen wir, 2 durch 13 zu teilen, was natürlich nicht geht. Darauf teilenwir 27 durch 13 (mit dem Ergebnis 2). Wir machen die Probe und erhalten 13 ·2 = 26. DiesesErgebnis ist kleiner als 27, es bleibt also ein Rest von 1. Also tragen wir 2 als erstes Ergebnis einund vollführen die benötigte Subtraktion. Die nächste Ziffer des Dividenden (4) holen wir run-ter und beenden die Division mit der Entscheidung, dass 13 genau einmal in 14 passt, wobeiein Rest von 1 bleibt. Wir können die binäre Division durch die gleiche Methode durchführen,mit der Vereinfachung, dass die Quotientenbits nur 0 oder 1 sein können. Es kann also längerdauern, bis wieder eine Teil-Division durchführbar ist (z. B. lässt sich 1 nicht durch 1101 teilen,ebenso wenig 10, 100 oder gar 1000 – erst mit 10001 ist die Operation durchführbar).
6.10.1 Erste Version einer Divisions-Hardware
Nehmen wir nun an, die Operanden sowie das Ergebnis der Division sind 32-Bit-Werte undpositiv. Die erste Version der Divisionshardware hält sich komplett an den Grundschulalgo-rithmus (Abbildung 6.16).
Wir beginnen mit einem 32-Bit-Quotientenregister, welches komplett auf 0 gesetzt ist. Bei je-dem Schritt des Algorithmus muss der Divisor um eine Ziffer nach rechts bewegt werden, alsobefindet er sich zu Beginn in der linken Hälfte des 64-Bit-Divisorregisters und wird bei jedemSchritt um ein Bit nach rechts verschoben, um ihn am Dividenden ausrichten. Das Restregisterwird mit dem Dividenden initialisiert.
Im Gegensatz zu einem Menschen ist ein Rechner nicht schlau genug, um im Voraus zu wissen,ob der Divisor kleiner als der Dividend ist. Also muss er im ersten Schritt den Divisor subtra-hieren. Ist das Ergebnis positiv, dann ist der Divisor kleiner oder gleich dem Dividenden, alsoerzeugen wir eine 1 im Quotienten (Schritt 2a) in Abbildung 6.17. Wenn das Ergebnis negativ
114 Technische Grundlagen der Informatik

6 Computerarithmetik 6.10 Ganzzahldivision
Abbildung 6.16: Hardware zur Division (Erste Version)
ist, besteht der nächste Schritt darin, den Originalwert durch Addition des Divisors zum Restwiederherzustellen und eine 0 im Quotienten zu erzeugen (Schritt 2b). Der Divisor wird nachrechts verschoben und wir wiederholen die Schleife. Der Rest und der Quotient sind dann inden entsprechenden Registern zu finden, nachdem alle Iterationen abgeschlossen sind.
Sehen wir uns dies am Beispiel einer 4-Bit-Division an, indem wir 710 durch 210 teilen, also000001112 durch 00102 (Tabelle 6.14). Auch hierbei stellen die fettgedruckten Stellen die zuuntersuchenden Bits dar. Das Ergebnis ist 310 mit dem Rest 110. Man beachte, dass der Testauf positiven oder negativen Rest im zweiten Schritt lediglich das Vorzeichenbit des Restesüberprüft. Eine überraschende Eigenschaft des Algorithmus ist, dass er n+1 (bei Wortlänge n)Durchläufe benötigt, um das entsprechende Ergebnis zu liefern.
Schleife Schritt Quotient Divisor Rest0 Anfangswerte 0000 0010 0000 0000 0111
1 1: Rest = Rest−Div 0000 0010 0000 1110 0111
2b: Rest < 0 ⇒+Div, Quotient linksschieben, Q0 = 0 0000 0010 0000 0000 0111
3: Div rechtschieben 0000 0001 0000 0000 0111
2 1: Rest = Rest−Div 0000 0001 0000 1111 0111
2b: Rest < 0 ⇒+Div, Quotient linksschieben, Q0 = 0 0000 0001 0000 0000 0111
3: Div rechtschieben 0000 0000 1000 0000 0111
3 1: Rest = Rest−Div 0000 0000 1000 1111 1111
2b: Rest < 0 ⇒+Div, Quotient linksschieben, Q0 = 0 0000 0000 1000 0000 0111
3: Div rechtschieben 0000 0000 0100 0000 0111
4 1: Rest = Rest−Div 0000 0000 0100 0000 0011
2a: Rest ≥ 0 ⇒Quotient linksschieben, Q0 = 0 0001 0000 0100 0000 0011
3: Div rechtschieben 0001 0000 0010 0000 0011
5 1: Rest = Rest−Div 0001 0000 0010 0000 0001
2a: Rest ≥ 0 ⇒Quotient linksschieben, Q0 = 0 0011 0000 0010 0000 0001
3: Div rechtschieben 0011 0000 0001 0000 0001
Tabelle 6.14: Beispiel Division (Erste Version)
6.10.2 Zweite Version einer Divisions-Hardware
Wieder einmal erkannten die sparsamen Rechnerpioniere, dass höchstens die Hälfte des Di-visors nützliche Information war und dass man deswegen den Divisor und die ALU mögli-
Technische Grundlagen der Informatik 115
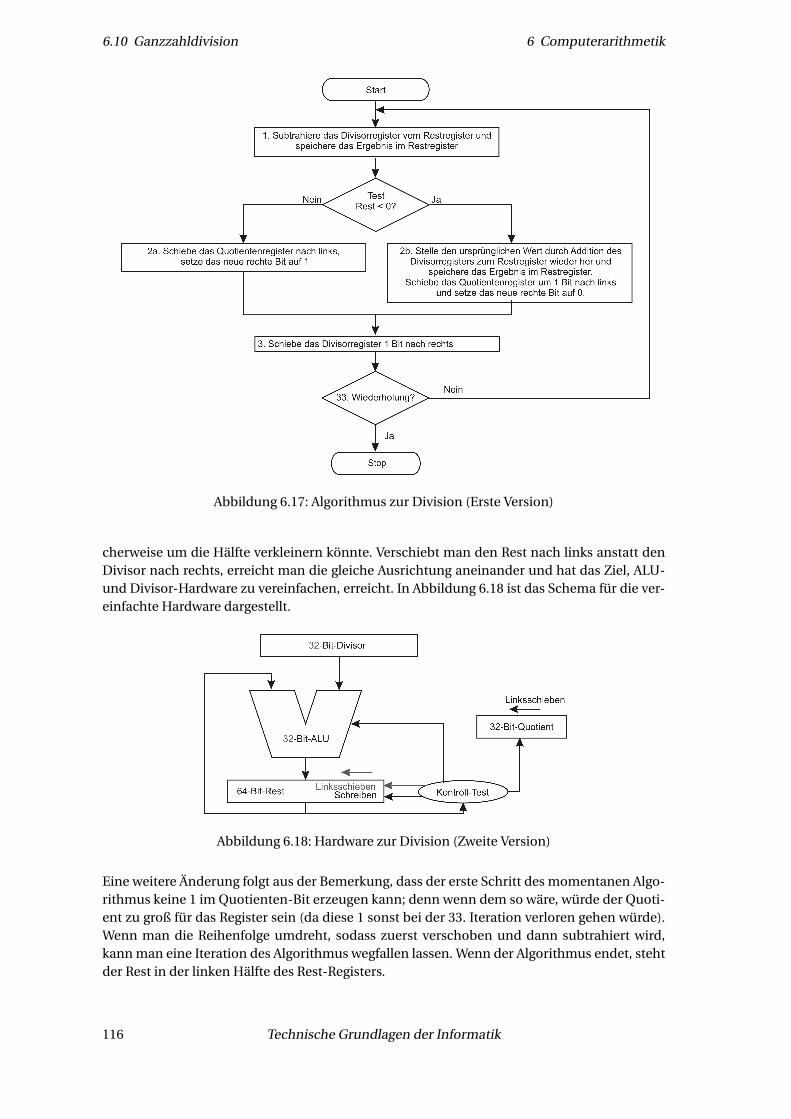
6.10 Ganzzahldivision 6 Computerarithmetik
Abbildung 6.17: Algorithmus zur Division (Erste Version)
cherweise um die Hälfte verkleinern könnte. Verschiebt man den Rest nach links anstatt denDivisor nach rechts, erreicht man die gleiche Ausrichtung aneinander und hat das Ziel, ALU-und Divisor-Hardware zu vereinfachen, erreicht. In Abbildung 6.18 ist das Schema für die ver-einfachte Hardware dargestellt.
Abbildung 6.18: Hardware zur Division (Zweite Version)
Eine weitere Änderung folgt aus der Bemerkung, dass der erste Schritt des momentanen Algo-rithmus keine 1 im Quotienten-Bit erzeugen kann; denn wenn dem so wäre, würde der Quoti-ent zu groß für das Register sein (da diese 1 sonst bei der 33. Iteration verloren gehen würde).Wenn man die Reihenfolge umdreht, sodass zuerst verschoben und dann subtrahiert wird,kann man eine Iteration des Algorithmus wegfallen lassen. Wenn der Algorithmus endet, stehtder Rest in der linken Hälfte des Rest-Registers.
116 Technische Grundlagen der Informatik

6 Computerarithmetik 6.10 Ganzzahldivision
6.10.3 Finale dritte Version einer Divisions-Hardware
Mit der gleichen Einsicht und Motivation wie bei der dritten Version des Multiplikationsal-gorithmus sahen die Rechnerpioniere, dass das Quotientenregister abgeschafft werden kann,wenn man die Bits des Quotienten anstatt der in den vorherigen Versionen verwendeten Nul-len in das Restregister verschiebt (Abbildung 6.19).
Abbildung 6.19: Hardware zur Division (dritte Version)
Wir beginnen den Algorithmus (Abbildung 6.20) wie üblich mit dem Linksschieben des Re-stregisters. Daraufhin besteht die Schleife nur noch aus zwei Schritten, da das Verschiebendes Restregisters den Rest in die linke Hälfte und den Quotient in die rechte Hälfte bewegt.Die Konsequenz aus der Zusammenlegung der beiden Register und der neuen Reihenfolge derOperationen in der Schleife ist, dass der Rest einmal zu oft nach links verschoben wird. Deswe-gen muss ein letzter Korrekturschritt daraus bestehen, dass nur die linke Hälfte des Registersum eine Ziffer nach rechts zurückzuverschieben ist. Zeigen wir auch dies am Beispiel der Di-vision von 710 durch 210 (Tabelle 6.15).
Schleife Schritt Divisor Rest0 Anfangswerte 0010 0000 0111
Rest um 1 nach links schieben 0010 0000 1110
1 2: Rest = Rest−Divisor 0010 1110 1110
3b: Rest < 0 ⇒+Divisor
Rest nach links schieben, R0 = 0 0010 0001 1100
2 2: Rest = Rest−Divisor 0010 1111 1100
3b: Rest < 0 ⇒+Divisor,
Rest nach links schieben, R0 = 0 0010 0011 1000
3 2: Rest = Rest−Divisor 0010 0001 1000
3a: Rest ≥ 0 ⇒Rest nach links schieben, R0 = 1 0010 0011 0001
4 2: Rest = Rest−Divisor 0010 0001 0001
3a: Rest ≥ 0 ⇒Rest nach links schieben, R0 = 1 0010 0010 0011
5 Linke Resthälfte um 1 nach links schieben 0010 0001 0011
Tabelle 6.15: Beispiel zur Division (dritte Version)
Ist der Rest negativ, wird der Algorithmus schneller, indem der Dividend nicht sofort zurückaddiert wird, sondern zum verschobenen Rest im folgenden Schritt, da
Technische Grundlagen der Informatik 117

6.10 Ganzzahldivision 6 Computerarithmetik
Abbildung 6.20: Algorithmus zur Division (dritte Version)
(r +d) ·2−d = 2r +2d −d
= 2r +d
Dieser Algorithmus heißt nicht-wiederherstellender Divisionsalgorithmus.
6.10.4 Division mit Vorzeichen
Es gibt keine einfachen Algorithmen, um Division mit Vorzeichen so auszuführen, wie wir sievon der Multiplikation mit Vorzeichen kennen (z. B. Booth). Bei der Division können die Ope-randen jedoch vorverarbeitet werden, indem man sie in positive Werte umwandelt. Nachdemman dann einen der besprochenen Algorithmen angewandt hat, wandelt man das Ergebnis ineinen korrekten vorzeichenbehafteten Wert um, falls nötig.
Dabei gilt folgende Regel: Der Dividend und der Rest müssen das gleiche Vorzeichen haben,unabhängig von den Vorzeichen von Divisor und Quotient. Dazu ein Beispiel:
+7÷ (−2) =−3 (Quotient),+1 (Rest)
−7÷ (−2) =+3 (Quotient),−1 (Rest)
Also muss ein korrekter Algorithmus für die Division mit Vorzeichen den Quotienten negieren,falls die Vorzeichen der Operanden unterschiedlich sind und weiterhin das Vorzeichen des vonNull verschiedenen Restes an den Dividenden anpassen.
118 Technische Grundlagen der Informatik

6 Computerarithmetik 6.11 Festkommazahlen
6.11 Festkommazahlen
Bevor wir Gleitkommazahlen einführen, wollen wir untersuchen, wie Festkommazahlen (fixedpoint numbers) von einem Rechner behandelt werden. Wir haben bereits demonstriert, dassman Wörter miteinander verkettet, wenn man große Zahlen auf einer Maschine mit kleinerWortlänge darstellen will. Allerdings haben wir uns noch nicht angesehen, wie ein Rechnermit binären Brüchen umgeht. Glücklicherweise stellt ein binärer (oder ein dezimaler) Bruchkein Problem dar. Man stelle sich die folgenden zwei Rechnungen in der Dezimalarithmetikvor:
1. Fall: Ganzzahlarithmetik7632135
+ 17948219426956
2. Fall: Festkommaarithmetik763,2135
+ 179,4821942,6956
Obwohl Fall 1 Ganzzahlarithmetik und Fall 2 Brucharithmetik verwendet, sind die Rechnungengänzlich identisch. Wir können dieses Prinzip auf die Rechnerarithmetik ausweiten. Alles, wasder Programmierer zu tun hat, ist sich zu erinnern, wo das Binärkomma liegt. Jegliche Einga-ben des Rechners werden skaliert, damit sie dieser Vereinbarung nachkommen – genauso wiedie Ausgaben. Die internen Operationen werden weiterhin so ausgeführt, als handele es sichum ganze Zahlen. Dieses Arrangement nennt man Festkommaarithmetik, da das Binärkommaimmer an derselben Position angenommen wird. Das heißt, es gibt immer gleich viele Ziffernvor und nach dem Binärkomma. Der Vorteil der Festkommaarithmetik: Es wird keine speziellekomplexe Soft- oder Hardware benötigt, um sie zu implementieren.
Ein einfaches Beispiel soll die Idee hinter der Festkommaarithmetik verdeutlichen. Man stellesich eine 8 Bit lange Festkommazahl vor, deren vier vordere Bits den Ganzzahlteil realisierenund die vier hinteren den gebrochenen Teil.
Was passiert nun, wenn wir die beiden Zahlen 3,625 und 6,5 addieren und das Ergebnis aus-geben lassen möchten? Ein Eingabeprogramm konvertiert dieses Zahlen zunächst in binäreForm.
3,62510 = 11,1012 → 0011,10102
6,510 = 110,12 → 0110,10002
Rechts sind die Zahlen wie im Rechner in Acht-Bit-Darstellung dargestellt. Der Rechner spei-chert diese Zahlen als 00111010 und 01101000. Das Binärkomma wird nur implizit gespeichert;in diesem Fall legt man vorher fest, dass die acht Bit sich zu gleichen Teilen auf Vor- und Nach-kommastellen aufteilen.Diese Zahlen addiert man nun wie gehabt.
00111010
+01101000
=10100010 (= 16210)
Technische Grundlagen der Informatik 119

6.12 Gleitkommazahlen 6 Computerarithmetik
Das Ausgabeprogramm nimmt nun dieses Ergebnis und teilt es in einen Ganzzahlteil 1010 undeinen gebrochenen Teil ,0010 auf und gibt damit das dezimal korrekte Ergebnis 10,125 aus.Man beachte, dass eine Festkommazahl über mehrere Wörter verteilt werden kann um einengrößeren Wertebereich als bei Nutzung eines einzelnen Wortes zu ermöglichen.
Festkommazahlen haben ihre Einschränkungen. Denken wir nur an den Astrophysiker, der dasVerhalten der Sonne untersucht. Solch ein Astrophysiker wird mit Größen wie der Masse derSonne konfrontiert (1 990 000 000 000 000 000 000 000 000 000 000 g), ebenso wie mit der Masseeines Elektrons (0,000 000 000 000 000 000 000 000 000 910 956 g). Wenn Astrophysiker anFestkommazahlen gebunden wären, würden sie eine riesig große Anzahl von Bytes benötigen,um einen großen Bereich von Zahlen darzustellen. Ein einzelnes Byte kann Werte zwischen 0und 255 annehmen, also rund von 0 bis 1
4 Tausend. Wenn unser Physiker nun mit astronomischgroßen und mikroskopisch kleinen Zahlen arbeiten will, würde er grob geschätzt 14 Bytes fürden Ganzzahlteil und 12 Bytes für den gebrochenen Teil brauchen – ein 26-Byte-Wort (208 Bit).
Nun gibt es aber zwei wichtige Parameter für die Güte einer Zahlendarstellung:
1. Der Wertebereich (range) einer Zahl sagt uns, wie klein oder wie groß sie sein kann.Im Falle des Astrophysikers würde es sich dabei um Zahlen in der Größenordnung von2 ·1033 bis hin zu winzigen Werten wie 9 ·10−28 handeln. Dies sind 61 Dekaden, also einWertebereich von 1061. Der Wertebereich von Zahlen, die in digitalen Rechnern darge-stellt werden, muss ausreichend für die riesige Mehrheit von möglichen Berechnungensein. Wenn der Rechner in einer bestimmten Anwendung eingesetzt wird, ist der Werte-bereich der zu behandelnden Daten bekannt und meistens klein, sodass sich der Wer-tebereich der gültigen Zahlen beschränken lässt. Dadurch vereinfachen sich auch dieAnforderungen an Hard- und Software.
2. Die Präzision (precision) einer Zahl ist ein Maß ihrer Exaktheit oder Genauigkeit undhängt mit der Anzahl der zur Darstellung notwendigen signifikanten Ziffern zusammen.Zum Beispiel lässt sich die Konstante π als 3,142 oder 3,141592 schreiben. Letztere Formist präziser als die erste, da mehr Ziffern von π angegeben sind.
Diese beiden Parameter sollten unabhängig voneinander sein. Natürlich lässt sich durch dieVerkettung von Worten ein genügend großer Wertebereich schaffen. Aber dieser enorme Auf-wand wäre in diesem Fall extrem ineffizient, da mit diesem Mittel automatisch auch eine Er-höhung der Präzision einhergeht, die gar nicht zu erreichen ist.
Die Masse der Sonne ist nicht nur mir einer Genauigkeit von fünf Ziffern bekannt, sondern mit57 Ziffern. In der Praxis lassen sich nur wenige Messungen jeglicher Art auf 62 Stellen genaumachen (meist ist dies auch überhaupt nicht nötig). Obwohl es möglich ist, alle Zwischener-gebnisse auf 62 Stellen genau zu behalten und bei der Ausgabe 50 oder 60 Stellen zu ignorieren,ist dies eine Verschwendung von CPU-Zeit und Speicher.
6.12 Gleitkommazahlen
Was wir brauchen, ist ein System zur Zahlendarstellung, in dem der Wertebereich der Zahlenunabhängig von der Anzahl der signifikanten Ziffern (sprich: der Genauigkeit) ist. Im Folgen-den wollen wir so ein System besprechen. Es basiert auf einer wissenschaftlichen Notation, wiesie in der Physik, der Chemie und den Ingenieurswissenschaften üblich ist. Die computerarith-metische Entsprechung der wissenschaftlichen Notation sind Gleitkommazahlen (floating-pointnumbers). Zahlen werden dabei als
n = a × r e
120 Technische Grundlagen der Informatik

6 Computerarithmetik 6.12 Gleitkommazahlen
geschrieben, wobei a die Mantisse (oder Argument), r die Basis (oder Radix) und e der Expo-nent ist. Ein Rechner speichert gebrochene Zahlen in solch einer Form, indem er die binäreSequenz in zwei Felder aufteilt:
Exponent e Mantisse a
Dies repräsentiert n = a ×2e . Es wird aufgrund des binären Zahlensystems immer die Basis 2verwendet und muss deshalb nicht explizit gespeichert werden.
Durch diese explizite Trennung in zwei Felder wird nun auch erreicht, dass das Komma nichtmehr starr an einer bestimmten Stelle steht, sondern gleitet, je nach Definition des Exponen-ten.
Die normalisierte Darstellung ist n = 1, xx . . . x2 × 2y y ...y . Mantissen werden dabei einheitlichmit dem Binärkomma hinter dem ersten von 0 verschiedenen Bit dargestellt. Zum Beispielwird so aus 0,00001010×20 die Darstellung 1,010×2−5. Da das höchstwertige Bit per Definition1 ist, kann es bei der Darstellung eingespart werden. Das frei werdende Bit ermöglicht, eineStelle mehr von der Mantisse abzuspeichern. Dadurch wird die Genauigkeit erhöht. Weiterhinist ein Vorzeichenbit notwendig. Gleitkommazahlen werden also folgendermaßen dargestellt:
(−1)s ×a ×2e mit 110 ≤ a ≤ 210
6.12.1 Mögliche Systeme für Gleitkommazahlen
Um eine Darstellungsform für Gleitkommazahlen in einem bestehenden Rechner zu schaffen,muss ein Entwickler die folgenden fünf Entscheidungen treffen:
1. Die Anzahl der benutzen Wörter (und damit auch die Gesamtanzahl der Bits)
2. Die Art der Darstellung der Mantisse (Zweierkomplement etc.)
3. Die Art der Darstellung des Exponenten
4. Die Anzahl der Bits, die für Mantisse und Exponent aufgewendet werden
5. Die Anordnung von Mantisse und Exponent im Wort (Mantisse zuerst oder Exponentzuerst)
Der vierte Punkt ist einige weitere Gedanken wert. Sobald der Entwickler sich für eine Ge-samtanzahl von Bits für die Darstellung der Gleitkommazahl entschieden hat (ein ganzzahli-ges Vielfaches der einzelnen Wortlänge), muss er diese Darstellung in Mantisse und Exponentaufteilen. Wenn er sich entscheidet, viele Bits dem Exponenten zu widmen, resultiert daraus ei-ne Gleitkommazahl mit einem großen Wertebereich. Diese Exponentenbits wurden allerdingsauf Kosten der Mantisse gewonnen, sodass die Präzision der Gleitkommazahl reduziert wird.Andersherum reduziert eine große Mantisse den Wertebereich, sorgt aber für eine höhere Prä-zision.
Aufgrund der oben genannten fünf Kriterien hatten Rechnerhersteller bis ungefähr 1980 je-weils ein eigenes Gleitkomma-Zahlenformat. Es ist wohl unnötig hinzuzufügen, dass dieseFormate alle verschieden waren. Weitaus schlimmer war, dass manche dieser Formate einefehlerhafte Arithmetik besaßen, da die Gleitkommaarithmetik manche Tücke besitzt, die demdurchschnittlichen Hardwareentwickler nicht bekannt ist.
Um diesen Missstand zu beseitigen, setzte das IEEE (Institute of Electrical and ElectronicsEngineers) in den späten Siebzigern des zwanzigsten Jahrhunderts ein Komitee zusammen,
Technische Grundlagen der Informatik 121

6.12 Gleitkommazahlen 6 Computerarithmetik
welches die Gleitkommaarithmetik standardisieren sollte. Das Ziel war nicht nur, dass Gleit-kommadaten zwischen verschiedenen Rechnern ausgetauscht werden können, sondern auch,Hardwareentwicklern ein Modell zu liefern, dass man als korrekt kennt. Das Ergebnis führ-te zum IEEE-Standard 754 (IEEE, 1985). Die meisten der heutigen CPUs (inklusive Intel undSPARC) beinhalten Gleitkommainstruktionen, die dem Gleitkomma-Standard der IEEE ent-sprechen. Dieser Standard hat sowohl die Einfachheit der Portierung von Gleitkommapro-grammen als auch die Qualität der Rechnerarithmetik entscheidend verbessert.
Die Entwickler von IEEE 754 wollten auch eine Gleitkommadarstellung, die schnell und ein-fach Ganzzahlvergleiche ausführen konnte, was z. B. ein allgemeines Kriterium beim Sortierenist. Dieser Drang erklärt die Position des Vorzeichenbits (an höchstwertiger Stelle im Wort),durch die ein Test auf „größer gleich“, „kleiner gleich“ oder „gleich Null“ schnell ausgeführtwerden kann.
Die Platzierung des Exponenten vor der Mantisse vereinfacht auch das Sortieren von Gleit-kommazahlen mit Instruktionen zum Ganzzahlvergleich, da Zahlen mit höheren Exponentenauch immer größer als Zahlen mit kleinerem Exponenten sind – solange beide Zahlen das glei-che Vorzeichen haben (es ist jedoch ein wenig komplizierter als ein einfacher Ganzzahlver-gleich, da diese Notation im Wesentlichen aus Vorzeichen und Mantisse besteht anstatt ausdem Zweierkomplement).
Eine Gleitkommazahlendarstellung muss positive und negative Exponenten und Mantisseneinschließen. Die Mantisse kann hierbei problemlos durch das Zweierkomplementverfahrendargestellt werden. Negative Exponenten stellen hingegen eine Herausforderung für verein-fachtes Sortieren dar. Wenn wir das Zweierkomplement oder eine andere Notation nutzen, inder negative Zahlen eine 1 im höchstwertigen Bit haben, sieht ein negativer Exponent wie einegroße Zahl aus. Eine +110 wäre als 8-Bit-Exponent 000000012, der negierte Wert −110 dagegenewürde als 111111112 dargestellt.
Als Ausweg wurde die so genannte Exzess-Darstellung gewählt. Bei dieser addiert man einenkonstanten Wert, der der Hälfte des Wertebereichs entspricht, auf den Exponenten (der so ge-nannte „bias“). Dadurch wird selbst die kleinste darstellbare Zahl positiv (oder 0). Sind aberalle Zahlen positiv, ist der Größenvergleich trivial, da hierbei die gleich Ordnung gilt wie beipositiven Ganzzahlen.
Hinter „Exzess“ wird üblicherweise der Verschiebungsbetrag notiert. Bei acht verfügbaren Bitsbedeutet das, dass 256 Werte darstellbar sind. Die Hälfte minus Eins (warum, wird gleich ge-zeigt) ist der Verschiebungsbetrag, also 127. Folglich würde die Darstellung Exzess-127 heißen.
IEEE 754 benutzt eine Verschiebung um den Wert 127 für die Darstellung mit einfacher Ge-nauigkeit, sodass −1 im Binärmuster durch den Wert −1+ 127 = 12610 = 011111102 und +1durch den Wert +1+127 = 12810 = 100000002 dargestellt wird. Die Extremwerte in der Exzess-Darstellung, also bei acht Bit die 000000002 und die 111111112, haben Spezialbedeutungenund stehen deshalb für die Wertebelegung des Exponenten nicht zur Verfügung. Der Exponente liegt daher im Wertebereich ]0,255[. Dies bedeutet, dass der reale Exponent aus dem Bereich−126 ≤ e ≤ 127 sein muss.
Abbildung 6.21 zeigt die 32-Bit-Darstellung der Gleitkommazahl im IEEE-754-Format.
Das Vorzeichen der Zahl wird durch das erste Bit gegeben, gefolgt von der Darstellung des Ex-ponenten (zur Basis 2) in Exzess-127-Darstellung. Die letzten 23 Bit repräsentieren die Mantis-se. Wie in der Einleitung dieses Abschnitts beschrieben, wird sie normalisiert, wodurch immergenau eine 1 vor dem Komma steht. Diese Eins kann man dadurch weglassen und das freiwerdende Bit für eine höhere Genauigkeit bei den Nachkommastellen verwenden. Die 23 ge-speicherten Bits sind also der gebrochene Teil der Mantisse (den man auch Signifikant nennt).
122 Technische Grundlagen der Informatik

6 Computerarithmetik 6.12 Gleitkommazahlen
Darstellung entspricht: (−1)S ·1, M ·2E−127
Abbildung 6.21: Gleitkommazahl einfacher Genauigkeit nach dem IEEE-Standard 754
Die Mantisse ist somit eigentlich 24 Bits lang. Ein Beispiel für eine solche Gleitkommazahl zeigtAbbildung 6.22.
0 00101000 0010100. . .0
Darstellung entspricht: (−1)0 ·1,0010100. . .0 ·2−87
Abbildung 6.22: Beispiel für eine Gleitkommazahl einfacher Genauigkeit
Der eben besprochene 32-Bit-Standard wird als einfache Genauigkeit bezeichnet, da er sichdurch ein einzelnes 32-Bit-Wort darstellen lässt. Der Wertebereich ist
[2−126,2127
], was un-
gefähr 10±38 entspricht. Die 24-Bit-Mantisse bietet ungefähr die gleiche Genauigkeit wie ein7-stelliger Dezimalwert. Um mehr Präzision und einen größeren Wertebereich zu bieten, spe-zifiziert der IEEE-Standard auch ein Format mit doppelter Genauigkeit (Abbildung 6.23).
Darstellung entspricht: (−1)S ·1, M ·2E−1023
Abbildung 6.23: Gleitkommazahl doppelter Genauigkeit nach dem IEEE-Standard 754
Diese doppelte Genauigkeit hat vergrößerte Exponent- und Mantissenbereiche. Der 11-Bit-Exponent (mit einer Verschiebung von 1023) liegt im Intervall 0 < E < 2047 für normale Wer-te, wobei 0 und 2047 selbst wie zuvor Spezialfällen vorbehalten sind. Dadurch liegt der echteExponent e im Bereich [−1022,1023] und bietet damit einen Wertebereich von
[2−1022,21023
](ungefähr 10±308). Die 53-Bit-Mantisse bietet eine Genauigkeit wie etwa 16 Dezimalziffern.
Es gibt vier Spezialfälle, die durch die Extremwerte im Exponenten und einer Mantissenbele-gung, die gleich oder ungleich Null ist, signalisiert werden. Diese vier Fälle sind:
1. DenormalisierungSobald der kleinste Exponent, also zum Beispiel 2−126 bei einfacher Genauigkeit, zu großist für eine Zahl, die dargestellt werden soll, würde diese Zahl auf Null gerundet werden.Die Entwickler des IEEE-754-Standards drückten diese Grenze weiter gegen Null, indemsie als Spezialfall eine denormalisierte Mantisse zuließen; diese wird durch eine Null imExponenten signalisiert. Der Signifikant ist in dem Fall ein Bitmuster ungleich Null undhat statt der implizieten 1 links des Kommas in dem Fall eine 0.
Technische Grundlagen der Informatik 123

6.12 Gleitkommazahlen 6 Computerarithmetik
2. NullDie Null wird durch eine Null im Exponenten und eine Null im gesamten Signifikantendargestellt. Bitte beachten Sie, dass es eine positive und eine negative Null gibt.
3. UnendlichkeitDer „Nichtwert“ Unendlichkeit wird signalisiert, indem der Exponent auf den Maximal-wert und der Signifikant auf 0 gesetzt wird.
4. keine Zahl (NaN)Dividiert man beispielsweise „Unendlich“ durch „Unendlich“, so ist das Ergebnis unde-finiert. Für diesen Fall ist die Bitbelegung „Exponent auf Maximalwert, Signifikant un-gleich Null“ vorgesehen und signalisiert Not a Number (NaN).
Jede kommerzielle Implementierung eines Rechners muss mindestens die Darstellung miteinfacher Genauigkeit beherrschen, um dem IEEE-Standard zu entsprechen. Die Darstellungmit doppelter Genauigkeit ist optional. Sie kann aber auch für die Darstellung von Zwischen-werten in einer Serie von Berechnungen benutzt werden. Zum Beispiel kann das Kreuzproduktzweier Zahlenvektoren ausgerechnet werden, indem man die Summen der Produkte mit er-weiterter Genauigkeit zusammenrechnet. Die Eingaben werden dabei mit einfacher Genauig-keit erfolgen und das Endergebnis wird auf genau diese einfache Genauigkeit zurechtgestutzt.Die Verwendung von erweiterten Formaten reduziert die Größe der Rundungsfehler in einerSequenz von Berechnungen.
6.12.2 Akkurate Arithmetik
Im Gegensatz zu Ganzzahlen, welche jede Zahl in ihrem Wertebereich exakt darstellen können,sind Gleitkommazahlen normalerweise nur Annäherungen an eine Zahl, die sie nicht wirklichdarstellen können. Der Grund dafür ist, dass zwischen – zum Beispiel – 010 und 110 unendlichviele reelle Zahlen existieren, aber nicht mehr als 253 davon (bei doppelter Genauigkeit) exaktdargestellt werden können. Man quantisiert daher die gewünschte Zahl so, dass sie auf die ihram nahe kommenste Gleitkommazahl abgebildet wird. Im Mittel sollte eine solche Operationfehlerneutral sein, d. h. die Abweichung von der tatsächlichen Zahl sollte im Mittel Null sein.Diesen Vorgang des Quantisierens nennt man Runden. Da sich verschiedene Rundungsme-thoden gibt, die unterschiedliche Stärken und Schwächen besitzen, bietet IEEE 754 mehrereRundungsschemata an, um dem Programmierer die gewünschte Annäherung wählen zu las-sen.
In den vorangegangenen Beispielen waren unsere Aussagen über die Anzahl der Bits, die einZwischenergebnis einnehmen kann, nur sehr ungenau. Es sollte jedoch klar sein, dass es keineMöglichkeit zum Runden gäbe, wenn jedes Zwischenergebnis auf die exakte Anzahl von Zif-fern gerundet würde. IEEE 754 nutzt deswegen zwei zusätzliche Bits während der Zwischen-rechnungen, die man guard und round nennt.
Addieren wir beispielsweise 2,99·100 zu 2,34·102 und nehmen wir dazu an, dass wir drei signi-fikante Dezimalziffern haben. Es können jedoch nur Zahlen mit gleichem Exponenten addiertwerden. Daher muss zunächst das Komma der kleineren Zahl zuerst nach links verschobenwerden, um die Exponenten anzugleichen. So wird aus 2,99 ·100 die Zahl 0,0299 ·102. Da wirdie Zusatzstellen für guard und round haben, brauchen wir die entstandene Zahl nicht zu run-den. Die Summe berechnet sich wie folgt:
124 Technische Grundlagen der Informatik

6 Computerarithmetik 6.12 Gleitkommazahlen
2,3400
+0,0299
=2,3699
Das Aufrunden auf 2,37 liegt nahe. Ohne die zwei zusätzlichen Ziffern wäre 0,0299 auf 0,02gerundet worden, bevor das Ergebnis 2,36 berechnet worden wäre:
2,34
+0,02
=2,36
Wie man sieht, verursacht dieses vorzeitige Runden also einen Fehler, der wie im Beipiel sehrgroß sein kann.
Das Entfernen der zusätzlichen Bits beim Erzeugen des Endergebnisses wirft ein wichtigesThema auf. Ein Binärbruch muss gerundet werden, damit er im Computer darstellbar bleibt.Wie erwähnt, ist das Rundungsergebnis eine mehr oder weniger schlechtere Annäherung deslängeren Wertes. Dieses Problem tritt auch anderswo auf, zum Beispiel beim Konvertieren vonDezimalbrüchen in eine binäre Darstellung.
Das Runden kann auf mehreren Wegen erfolgen. Der einfachste Weg ist, die zusätzlichen Bitseinfach zu entfernen und keine Änderungen in den verbleibenden Bits zu machen. Diese Me-thode wird als Abrunden bzw. Abschneiden (truncation oder chopping) bezeichnet. Nehmenwir an, wir wollen einen Bruch mit sechs Bits auf drei Bits runden. Alle Brüche im Bereich0,b−1b−2b−3000 bis 0,b−1b−2b−3111 werden dabei auf 0,b−1b−2b−3 reduziert. Der Fehler im3-Bit-Ergebnis hat eine Größe von 0 bis 0,000111. In anderen Worten: Der Fehler beim Run-den reicht von 0 bis fast 1 in der niederwertigsten Position der verbleibenden Bits. In unseremBeispiel ist das die Position b−3. Das Abschneiden ist eine nicht erwartungstreue Funktion:Die Abweichung führt zu einer verzerrten Schätzung der eigentlichen Zahl; die verursachtenFehler verteilen sich nicht gleichmäßig und symmetrisch um Null. Haben wir eine arithmeti-sche Operation, bedeutet das Abrunden das gleiche, als wenn man auf die zusätzlichen Bitsverzichtet.
Die nächste Rundungsmethode ist das so genannte Von-Neumann-Runden. Wenn die zu ent-fernenden Bits alle gleich Null sind, werden sie einfach ohne weitere Änderungen an den ver-bleibenden Bits verworfen. Wenn aber nur ein Bit der zu entfernenden gleich 1 ist, wird dasniederwertigste der verbleibenden Bits auf 1 gesetzt. In unserem Beispiel würden also alle 6-Bit-Brüche mit b−4b−5b−6 6= 000 auf 0,b−1b−21 gerundet werden. Der Fehler bei dieser Me-thode reicht von −1 bis +1 in der niederwertigsten Position der verbleibenden Bits. Das Von-Neumann-Runden ist erwartungstreu, d. h. verzerrt den Erwartungswert nicht, da sich Auf-und Abrunden im Mittel aufhebt.
Die dritte Methode ist das kaufmännische Runden. Kaufmännisches Runden rundet, indem es0,5 auf die zu rundende Stelle addiert, also die die Hälfte der letzten stehenbleibenden Stel-le. Für Binärzahlen bedeutet das, dass (um beim Beispiel zu bleiben) auf die Stelle b4 eine 1addiert und danach abgeschnitten wird, sodass nur noch 0,b−1b−2b−3 stehen bleiben. Mit an-deren Worten: 0,b−1b−2b−31. . . wird auf 0,b−1b−2b−3+0,001 gerundet und 0,b−1b−2b−30. . . auf
Technische Grundlagen der Informatik 125

6.12 Gleitkommazahlen 6 Computerarithmetik
0,b−1b−2b−3. Sind die Nachkommastellen b4b5b6 . . . = 100. . ., so ist die zu rundende Zahl ge-nau gleich weit entfernt von zwei gerundeten Zahlen. In diesem Fall wird immer aufgerundet;darum ist das kaufmännische Runden leicht positiv verzerrt, was jedoch nur bei sehr vielenaufeinander aufbauenden Rundungen feststellbar ist.
Der Ausweg ist das so genannte mathematische Runden, bei dem immer zur nächsten geradenZahl gerundet wird. Dieses Runden ist unverzerrt und wird im IEEE-754-Standard standard-mäßig verwendet.
6.12.3 Vereinfachte Algorithmen zur Berechnung von Gleitkommazahlen
Die folgenden Algorithmen beschreiben grob das Vorgehen beim Rechnen mit Gleitkomma-zahlen.
• Addition und Subtraktion
– Rechtsverschiebung auf der Mantisse des kleineren Operanden zur Angleichungder Exponenten
– Exponent der Summe (bzw. Differenz) := Exponent des größeren Operanden
– Addition (bzw. Subtraktion) der Mantissen und Bestimmung des Vorzeichens
– Wenn nötig, Normalisierung des Ergebnisses
• Multiplikation und Division
– Addiere (bzw. Subtrahiere) die Exponenten und subtrahiere (bzw. addiere) 12710
– Multipliziere (bzw. Dividiere) die Mantissen und bestimme das Vorzeichen
– Wenn nötig, normalisiere das Vorzeichen
Die explizite Addition (bzw. Subtraktion) von 127 bei der Multiplikation und Division trifft beiGleitkommazahlen einfacher Genauigkeit zu; bei doppelter Genauigkeit muss entsprechend102310 addiert oder subtrahiert werden. Dies ist notwendig, weil der Exponent in Exzess-Darstellunggespeichert wird, d. h. der kleinstmögliche (negative) Wert wird um den Exzess-Wert (127 oder1023) verschoben, sodass er nichtnegativ wird. Addiert man zwei Zahlen in dieser Darstellung,so fließt der Exzess-Wert doppelt in die Summe ein und muss dementsprechend einmal sub-trahiert werden. Ist der Exzess x und die (eigentlichen) Exponenten a und b sollen addiert wer-den, so lautet die Rechnung (a +x)+ (b +x) = a+b+2x. Entsprechendes gilt für die Subtrakti-on ((a +x)− (b +x) = a −b), bei der der Exzess mit subtrahiert wird und dementsprechend imAnschluss wieder addiert werden muss, damit auch das Ergebnis in Exzessdarstellung steht.In Abbildung 6.24 ist ein Schaltplan für die Hardware-Implementierung einer Gleitkomma-Additions-Subtraktions-Einheit dargestellt.
Ohne sich in Einzelheiten zu verlieren, sieht man die Komplexität und erkennt in den einzel-nen Blöcken als die Aktionen wieder, die schon diskutiert wurden.
Es wird jedenfalls einleuchtend, dass in Hochleistungsprozessoren ein maßgebender Teil derverfügbaren Chipfläche für Gleitkommzahlenoperationen verwendet wird. Bevor es möglichwar, diese Fähigkeiten im Prozessorchip zu implementieren, beinhalteten frühere Rechnereinen speziellen Gleitkomma-Koprozessor. Dieser hatte die gleiche Komplexität wie der Haupt-prozessor.
126 Technische Grundlagen der Informatik

6 Computerarithmetik 6.13 Zusammenfassung Computerarithmetik
Abbildung 6.24: Hardware für die Addition und Subtraktion von Gleitkommazahlen
6.13 Zusammenfassung Computerarithmetik
Ein Computer kann nur mit endlichen Zahlen rechnen. Dies beschränkt seine Möglichkeiten.Selbst der IEEE-754-Standard für die Darstellung von Gleitkommazahlen ist wie jede andereDarstellung fast immer nur eine Approximation der realen Zahlen. Daher müssen Rechnersys-teme dafür sorgen, den Unterschied zwischen menschlicher und Rechnerarithmetik zu mini-mieren. In dem vorangegangenen Abschnitt wurden verschiedene Techniken vorgestellt, diedabei eingesetzt werden sollen:
• Carry-lookahead-Techniken für Addierer mit großer Leistungsfähigkeit und Geschwin-digkeit
• Für schnelle Multiplizierer: Booth-Algorithmus und Bitpaar-Recoding zur Reduzierungder Anzahl der für die Erzeugung des Produkts benötigten Rechenschritte, Carry-save-Addition zur nochmaligen substantiellen Reduzierung auf letztlich zwei zu addierendenSummanden (mittels Carry-Lookahead)
Programmierer eines Rechners sollten sich dieser Zusammenhänge bewusst sein.
Technische Grundlagen der Informatik 127

6.13 Zusammenfassung Computerarithmetik 6 Computerarithmetik
128 Technische Grundlagen der Informatik

Index
Äquivalenz von Schaltnetzen, 25Überlauf, 95
Alphabet, 11ALU, 15AND, 19ASCII-Code, 66asynchron, 50
Binary-Coded Decimal, 90Bit, 12bit-pair recoding, 112Bitmap, 68boolesche Funktion, 28Booth-Algorithmus, 106Bridging Fault, 62Bus, 15
carry-save addition, 113Code, 65
Datenpfadzyklus, 17Datenworte, 17Defekt, 62disjunktive Normalform, 29Distanz (Code), 69
einfache Genauigkeit, 123Einheitsdistanzcode, 69end-around-carry, 93error correction codes, 74error detection codes, 74
Festkommaarithmetik, 119Festkommazahlen, 119Flipflop, 43funktionale Vollständigkeit, 29
Gatter, 13Gleitkommazahlen, 120
Halbaddierer, 95Hamming-Distanz, 69
Inversionsblase, 20
kanonische disjunktive Normalform, 29kombinatorisches Schaltnetz, 19
Linksschieberegister, 56low-active, 46
Master-Slave-Flipflop, 52minimal, Schaltnetz, 26Minterm, 28Minterm, einschlägig, 28Multiplexer, 22
NAND, 19NICHT, 19NOR, 19NOT, 19
ODER, 19OR, 19Oszillationsproblem, 52
p-Bit-Fehler prüfbar, 76Pfadsensitivierung, 62Power-On Self-Test (POST), 61
Rechtsschieberegister, 56Register, 15, 56Register-Register-Operation, 17Register-Speicher-Operation, 17ripple counter, 58RS-Flipflop, 45RS-Flipflop, getaktet, 48
Schaltfunktion, 28Schieben, 56selbsterhaltend, 44Semantik, 65sequentielle Schaltung, 43Signifikant, 122Störung, 62Stuck-at-one, 62Stuck-at-zero, 62Symbol, 11synchron, 50Syntax, 65
129

Index Index
Taktflanke, 53
UND, 19
Von-Neumann-Runden, 125
Wahrheitstabelle, 20Wort, 56
XOR, 19
130 Technische Grundlagen der Informatik

Schlussbemerkung
Dieses Skript stellt kein Lehrbuch im Sinne eines vollständigen Kompendiums dar, welchesden Vorlesungsstoff komplett abbildet, sondern ist nur eine Grundlage, ein Startpunkt. Es kanngut verwendet werden, um mit Informationen während der Vorlesung ergänzt zu werden.
131


















