
Vorlesung 8: Zeitreihenanalyse - eswf.uni-koeln.deeswf.uni-koeln.de/lehre/04/04_03/aswf2_08.pdf ·...
43
Vorlesung 8: Zeitreihenanalyse 1. Was ist besonders an Zeitreihen? 2. Unabhängige Beobachtungen bei Zeitreihen? 3. Regressionsmodelle für Zeitreihen 4. Zufall und Zeitreihen 5. Schätzung von Regressionsmodellen für Zeitreihen • Stil: Einführung in die Problematik von Zeitreihen, keine Vermittlung von Techniken
Transcript of Vorlesung 8: Zeitreihenanalyse - eswf.uni-koeln.deeswf.uni-koeln.de/lehre/04/04_03/aswf2_08.pdf ·...

Vorlesung 8: Zeitreihenanalyse
1. Was ist besonders an Zeitreihen?2. Unabhängige Beobachtungen bei Zeitreihen?3. Regressionsmodelle für Zeitreihen4. Zufall und Zeitreihen5. Schätzung von Regressionsmodellen für
Zeitreihen
• Stil: Einführung in die Problematik von Zeitreihen, keine Vermittlung von Techniken

Teil 1
Was ist besonders an Zeitreihen?
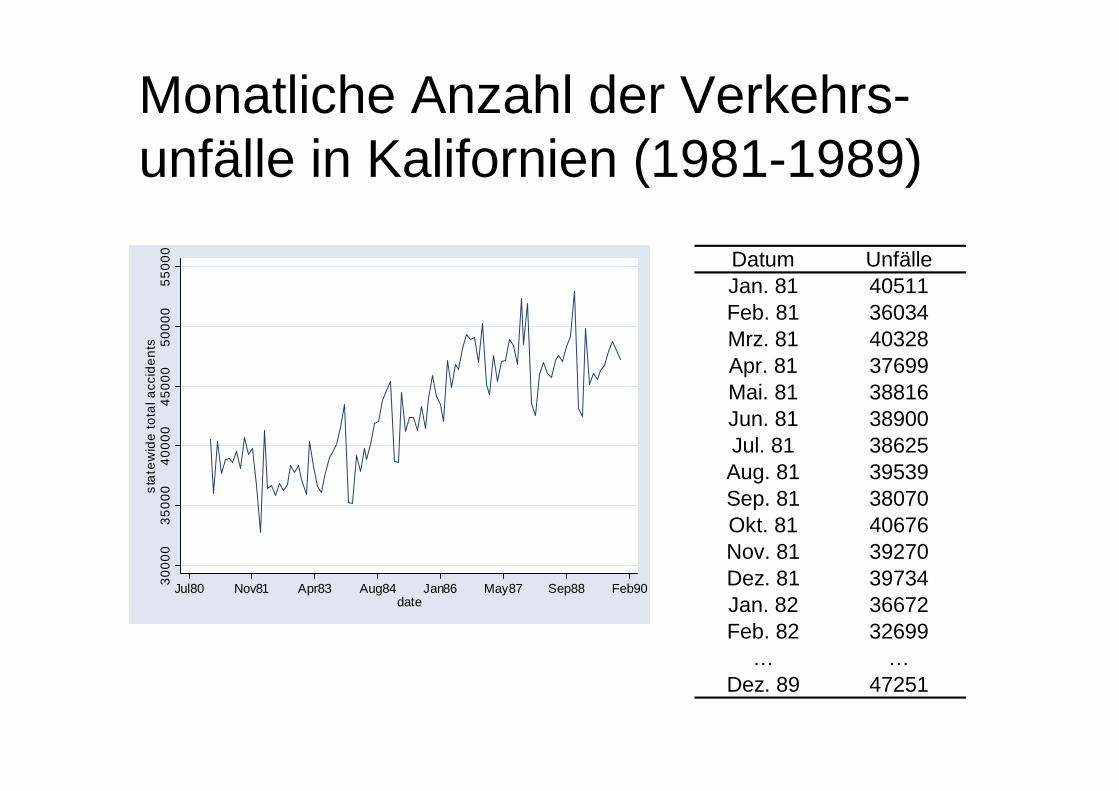
Monatliche Anzahl der Verkehrs-unfälle in Kalifornien (1981-1989)
3000
035
000
4000
045
000
5000
055
000
stat
ewid
e to
tal a
ccid
ents
Jul80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Datum UnfälleJan. 81 40511Feb. 81 36034Mrz. 81 40328Apr. 81 37699Mai. 81 38816Jun. 81 38900Jul. 81 38625Aug. 81 39539Sep. 81 38070Okt. 81 40676Nov. 81 39270Dez. 81 39734Jan. 82 36672Feb. 82 32699
… …Dez. 89 47251
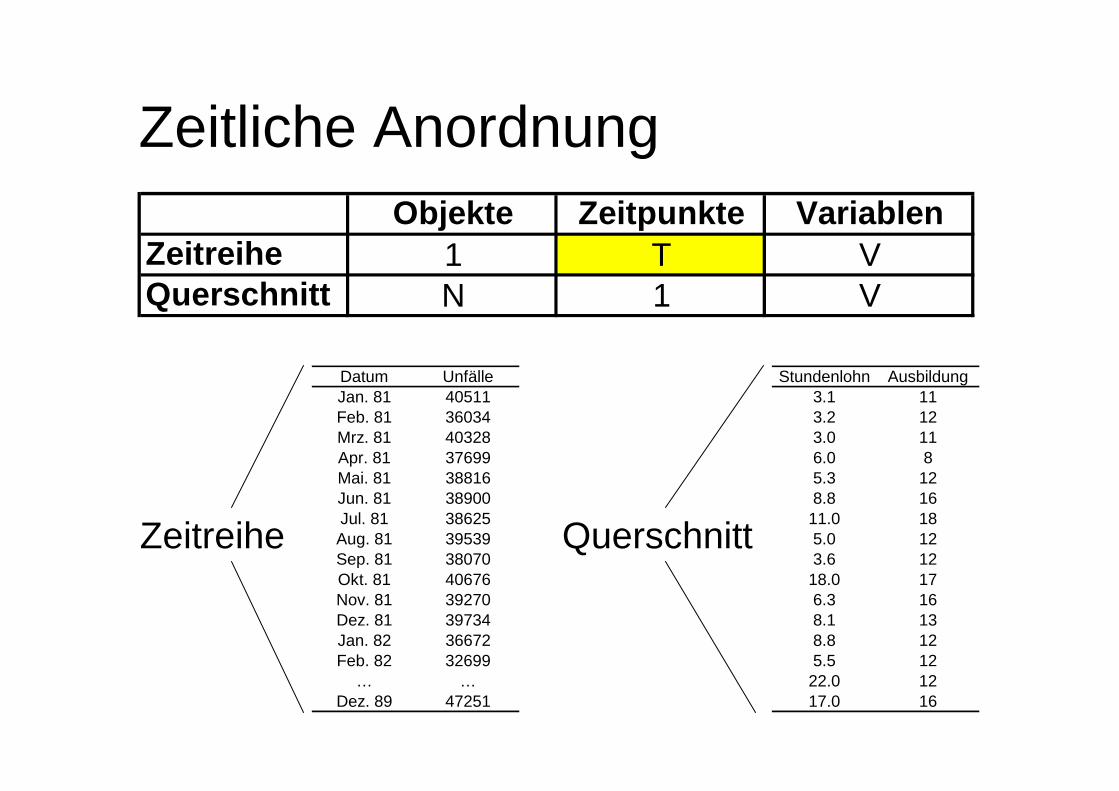
Zeitliche AnordnungObjekte Zeitpunkte Variablen
Zeitreihe 1 T VQuerschnitt N 1 V
Datum UnfälleJan. 81 40511Feb. 81 36034Mrz. 81 40328Apr. 81 37699Mai. 81 38816Jun. 81 38900Jul. 81 38625Aug. 81 39539Sep. 81 38070Okt. 81 40676Nov. 81 39270Dez. 81 39734Jan. 82 36672Feb. 82 32699
… …Dez. 89 47251
Stundenlohn Ausbildung3.1 113.2 123.0 116.0 85.3 128.8 16
11.0 185.0 123.6 12
18.0 176.3 168.1 138.8 125.5 12
22.0 1217.0 16
Zeitreihe Querschnitt
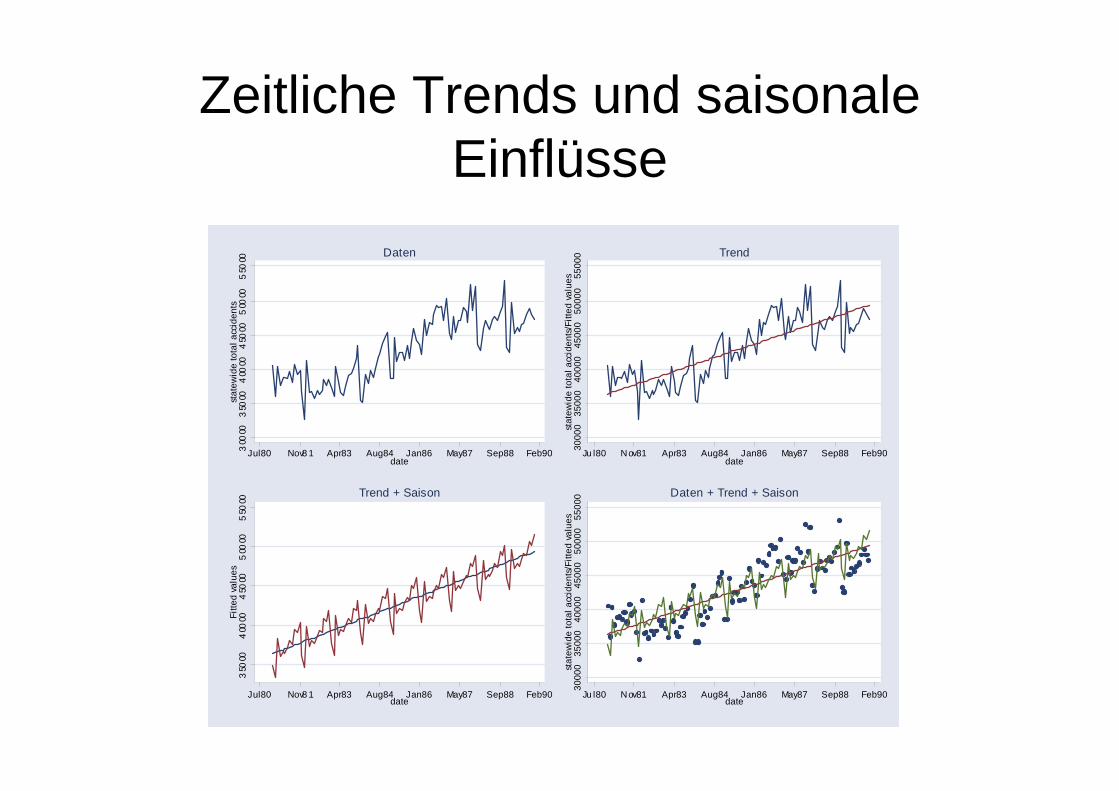
Zeitliche Trends und saisonale Einflüsse
300
003
5000
400
004
5000
500
005
5000
stat
ewid
e to
tal a
ccid
ents
Jul80 Nov8 1 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Daten
3000
035
000
4000
045
000
5000
055
000
stat
ewid
e to
tal a
ccid
ents
/Fitt
ed v
alue
s
Ju l80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Trend3
5000
400
004
5000
500
005
5000
Fitte
d va
lues
Jul80 Nov8 1 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Trend + Saison
3000
035
000
4000
045
000
5000
055
000
stat
ewid
e to
tal a
ccid
ents
/Fitt
ed v
alue
s
Ju l80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Daten + Trend + Saison
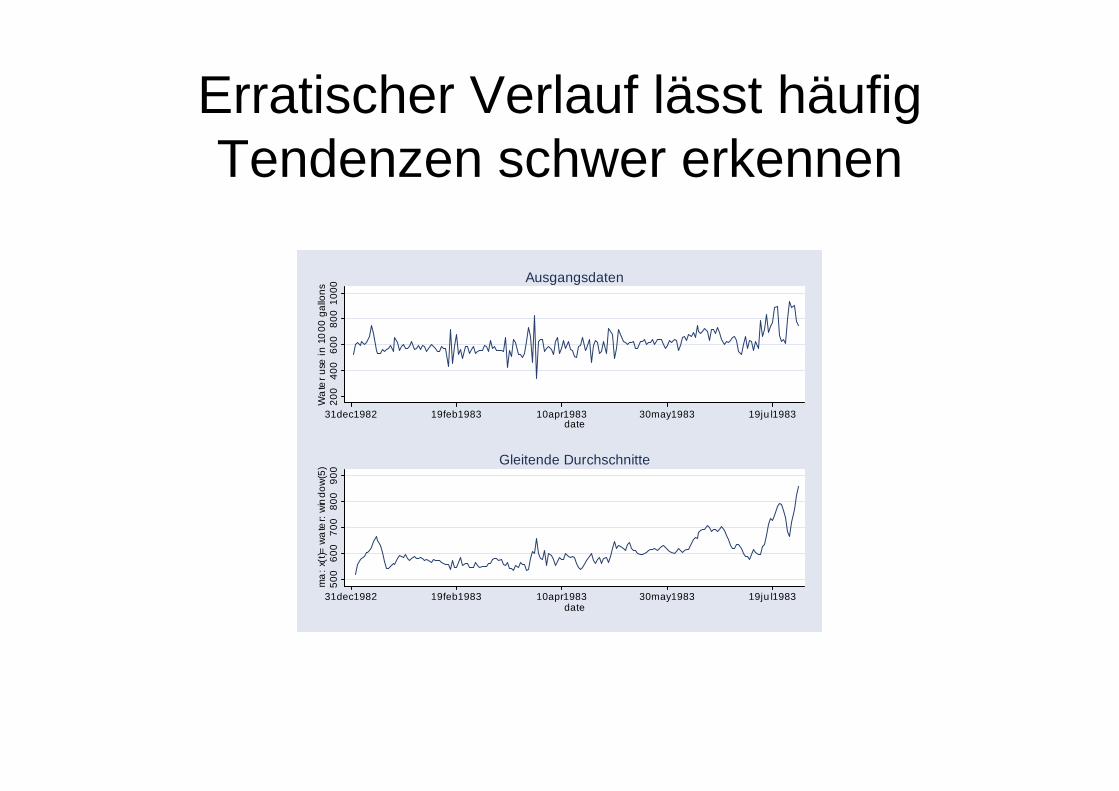
Erratischer Verlauf lässt häufig Tendenzen schwer erkennen
200
400
600
800
1000
Wa
ter u
se in
10
00 g
allo
ns
31dec1982 19feb1983 10apr1983 30may1983 19ju l1983date
Ausgangsdaten
500
600
700
800
900
ma
: x(t
)= w
ate
r: w
indo
w(5
)
31dec1982 19feb1983 10apr1983 30may1983 19ju l1983date
Gleitende Durchschnitte

Teil 2
Unabhängige Beobachtungen bei Zeitreihen?

Zeitreihe: Statistische Abhängigkeit zwischen Beobachtungen
• tsset t• corr zeit L.zeit
• Korrelation 0,8040
Datum Unfälle(t-1) Unfälle(t)Jan. 81 … 40511Feb. 81 40511 36034Mrz. 81 36034 40328Apr. 81 40328 37699Mai. 81 37699 38816Jun. 81 38816 38900Jul. 81 38900 38625Aug. 81 38625 39539Sep. 81 39539 38070Okt. 81 38070 40676Nov. 81 40676 39270Dez. 81 39270 39734Jan. 82 39734 36672Feb. 82 36672 32699
… … …Dez. 89 47971 47251
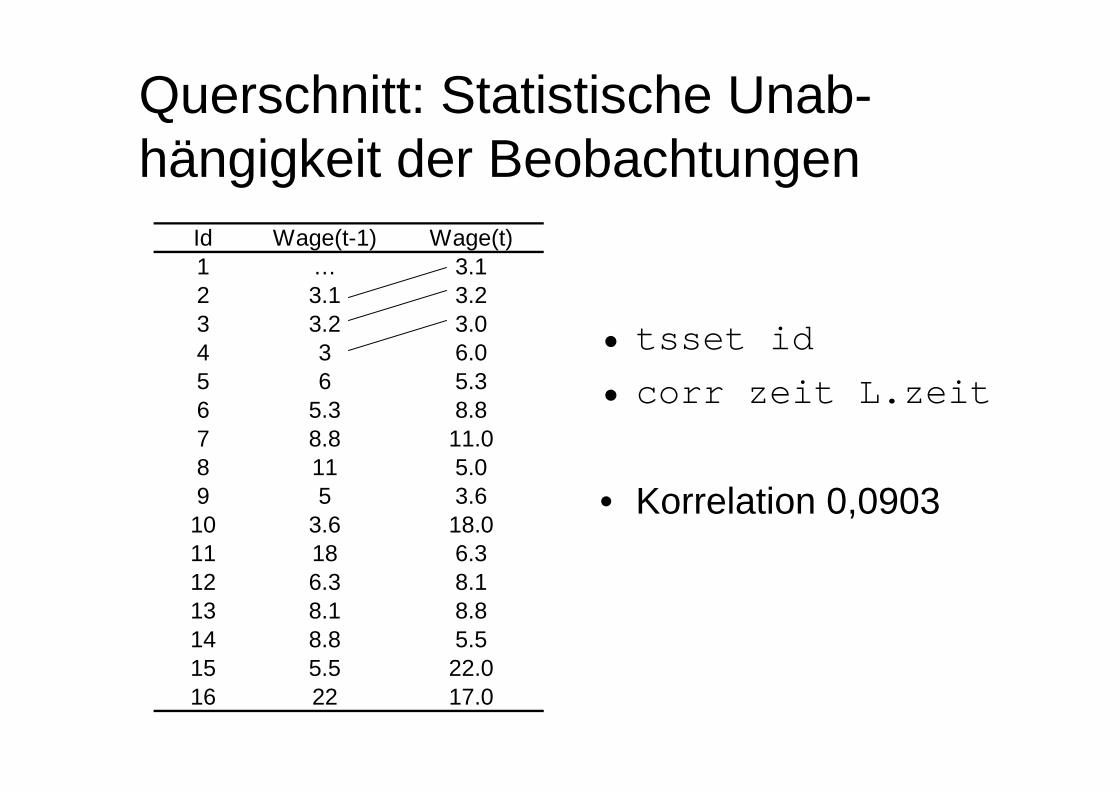
Querschnitt: Statistische Unab-hängigkeit der Beobachtungen
• tsset id• corr zeit L.zeit
• Korrelation 0,0903
Id Wage(t-1) Wage(t)1 … 3.12 3.1 3.23 3.2 3.04 3 6.05 6 5.36 5.3 8.87 8.8 11.08 11 5.09 5 3.610 3.6 18.011 18 6.312 6.3 8.113 8.1 8.814 8.8 5.515 5.5 22.016 22 17.0

Zur Erinnerung: Annahmen

Einflüsse im Zeitablauf
Der Fehlerterm erfasst Messfehler und vor allem nicht berücksichtigte Einflüsse von Drittvariablen. Bei Zeitreihen können solche Einflüsse zeitlich vorhergehende und nachfolgende Drittvariablen sein.
Es muss daher zusätzlich gefordert werden, dass die Fehlerterme nicht nur von den aktuellen x-Werten, sondern auch von allen zeitlich vorhergehenden und nachfolgenden x-Werten unabhängig sind. Dies ist eine sehr restriktive Annahme, die häufig nicht angemessen ist.

Unabhängige Beobachtungen
Auch wenn die Fehlerterme von allen zeitlich vorhergehenden und nachfolgenden x-Werten unabhängig sind, ist nicht davon auszugehen, dass die nicht berücksichtigten Drittvariablen selbst (und damit die Fehlerterme) im Zeitablauf zusammenhängen.
Die Annahme der Unkorreliertheit der Fehlerterme ist daher bei Zeitreihen in der Regel nicht gegeben. Man spricht auch von Autokorrelation.

Querschnitt: immer statistische unabhängige Beobachtungen?
Fakultät Studierende Anteil Frauen Anteil Zeit Std Miete StdBiologie 1054 5.45% 604 57.31% 43 0.500 230.25 € 30.097Chemie 533 2.76% 186 34.90% 43 0.500 230.23 € 29.784Geschichte 1274 6.59% 588 46.15% 34 0.500 230.80 € 29.875Gesundheitswissenschaften 524 2.71% 326 62.21% 44 0.500 230.11 € 27.475Literaturwissenschaft 3358 17.38% 2495 74.30% 34 0.500 229.78 € 30.298Mathematik 752 3.89% 343 45.61% 35 0.500 230.21 € 30.688Paedagogik 2487 12.87% 1807 72.66% 30 0.500 229.58 € 30.069Physik 375 1.94% 57 15.20% 36 0.500 227.64 € 28.260Psychologie 1498 7.75% 887 59.21% 33 0.500 230.07 € 30.023Rechtswissenschaft 2485 12.86% 1193 48.01% 37 0.500 230.58 € 29.828Soziologie 1813 9.38% 1014 55.93% 30 0.500 229.73 € 29.897Technische Fakultaet 1089 5.64% 256 23.51% 35 0.500 230.80 € 29.791Wirtschaftswissenschaften 2080 10.76% 789 37.93% 36 0.500 229.62 € 29.918Insgesamt 19322 100.00% 10545 54.58% 34.78 3.796 230.00 € 29.926
Beispiel: Untersuchung Bielefelder Studierender
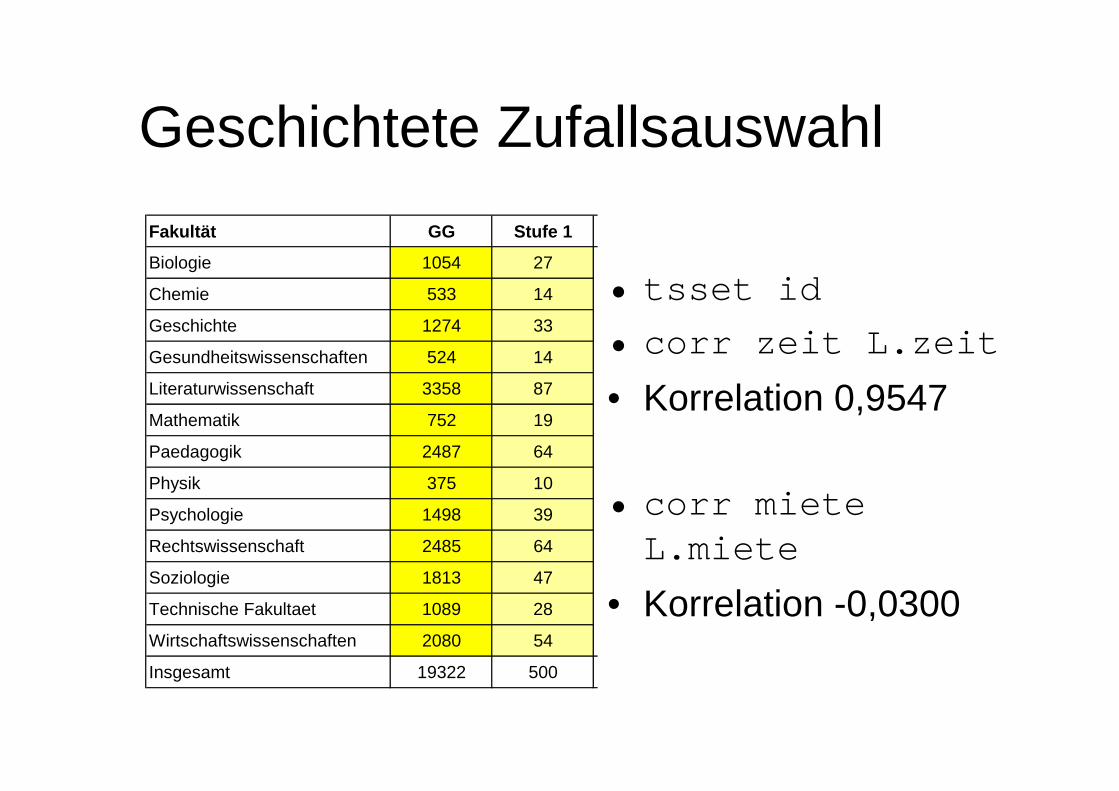
Geschichtete ZufallsauswahlFakultät GG Stufe 1 Stufe 2
Biologie 1054 27
Chemie 533 14
Geschichte 1274 33
Gesundheitswissenschaften 524 14
Literaturwissenschaft 3358 87
Mathematik 752 19
Paedagogik 2487 64
Physik 375 10
Psychologie 1498 39
Rechtswissenschaft 2485 64
Soziologie 1813 47
Technische Fakultaet 1089 28
Wirtschaftswissenschaften 2080 54
Insgesamt 19322 500
• tsset id• corr zeit L.zeit
• Korrelation 0,9547
• corr miete L.miete
• Korrelation -0,0300

Teil 3
Regressionsmodelle für Zeitreihen

Alle bekannten Modelle verwendbar
• lineare (zj = xj)• nicht-lineare (z.B. z2 = ln(x2))• additive (zj = xj und Effekte additiv
verknüpft)• nicht-additive (z.B. z4 = x2 ⋅ d mit Dummy-
Variablen d)
uzzzzzy kk +++++++= ββββββ K443322110

Statische und „dynamische“ Modelle
• Querschnitt
• Zeitreihe: statisches Modell
• Zeitreihe: „dynamisches Modell“
• Ein „dynamisches“ Modell enthält zeitverzögerte x-Variablen und/oder zeitverzögerte y-Variablen
ikikiii uxxxy +++++= ββββ K22110
tktkttt uxxxy +++++= ββββ K22110
ttttt uyxxy +++++= −− K131,12110 ββββ

Zeitliche Trends und saisonale Einflüsse
Beispiel: Dummies für Monatesaisonale Effekte
exponentieller Trend
quadratischer Trend
linearer Trend tt uty +⋅+= 10 ββ
tt utty +⋅+⋅+= 2210 βββ
tt uty +⋅+= 10ln ββ
ttttt udddy +++++= ,121232210 ββββ K
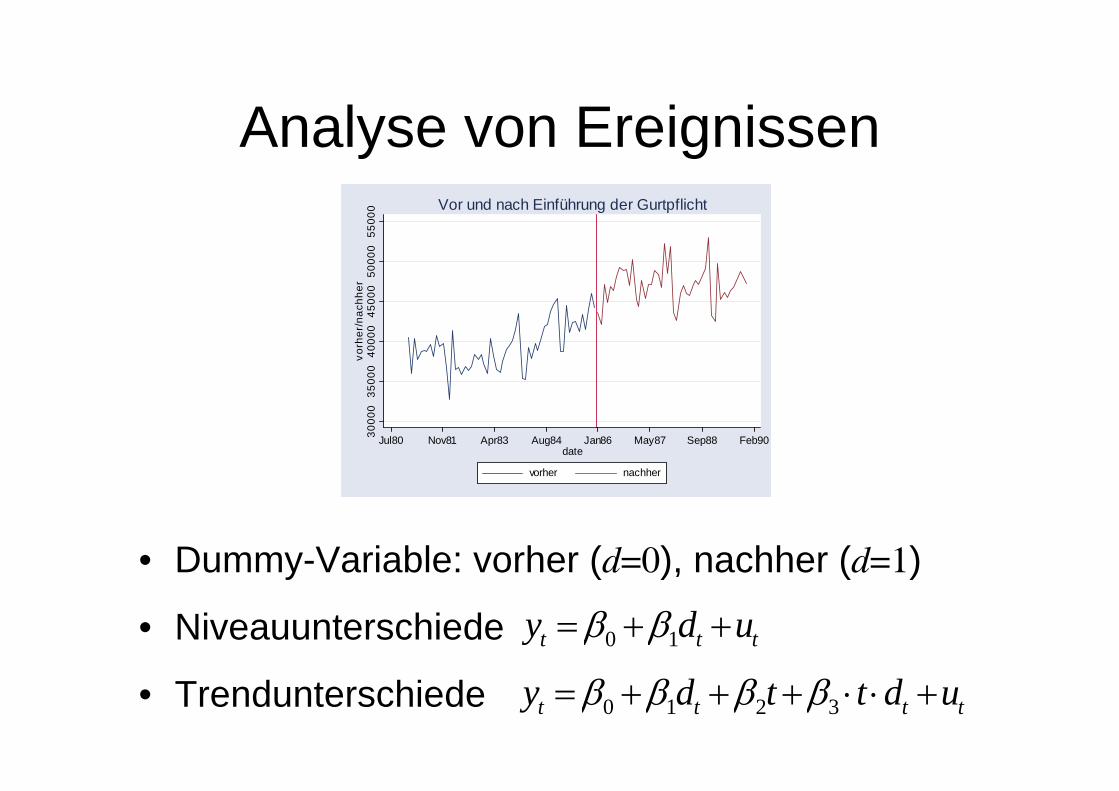
Analyse von Ereignissen
• Dummy-Variable: vorher (d=0), nachher (d=1)
• Niveauunterschiede
• Trendunterschiede
3000
035
000
4000
045
000
5000
055
000
vorh
er/n
achh
er
Jul80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
vorher nachher
Vor und nach Einführung der Gurtpflicht
ttt udy ++= 10 ββ
tttt udttdy +⋅⋅+++= 3210 ββββ
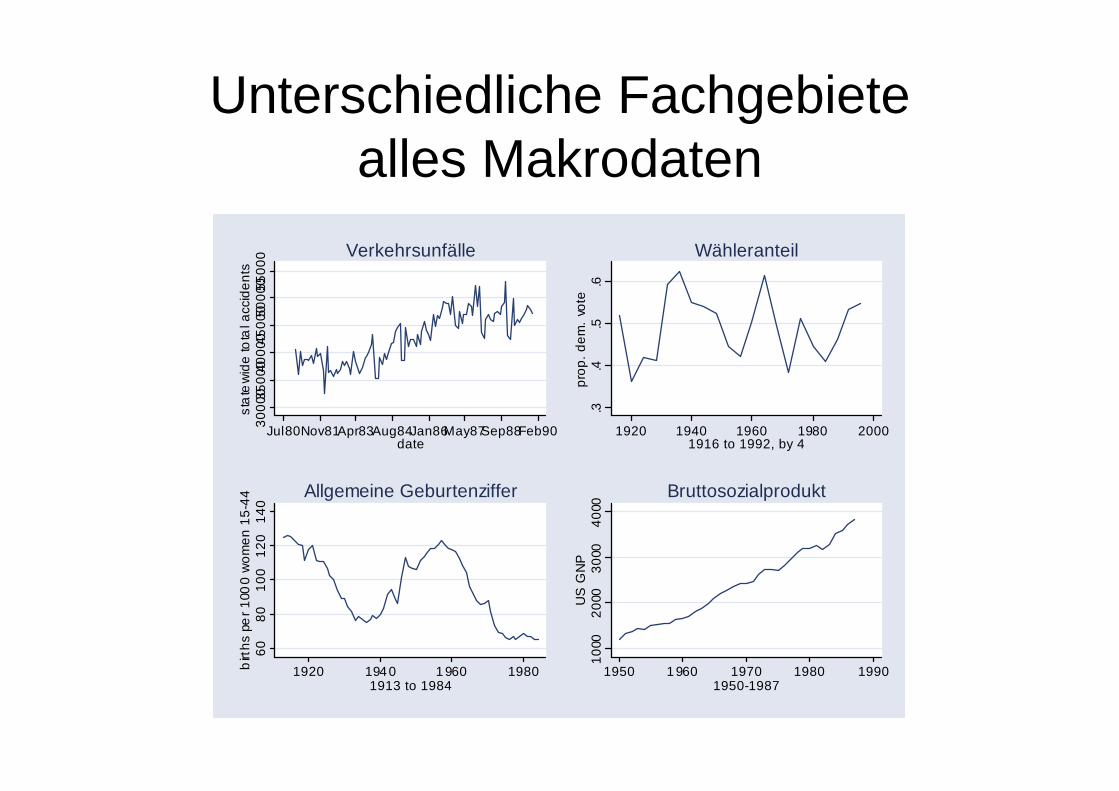
Unterschiedliche Fachgebietealles Makrodaten30
00035
00040
00045
00050
00055
000
sta
tew
ide
tota
l acc
iden
ts
Jul80Nov81Apr83Aug84Jan86May87Sep88Feb90date
Verkehrsunfälle
.3.4
.5.6
prop
. dem
. vo
te
1920 1940 1960 1980 20001916 to 1992, by 4
Wähleranteil60
8010
012
014
0b
irths
pe
r 100
0 w
omen
15-
44
1920 194 0 1 960 19801913 to 1984
Allgemeine Geburtenziffer
1000
2000
3000
4000
US
GN
P
1950 1 960 1970 1980 19901950-1987
Bruttosozialprodukt

Teil 4
Zufall und Zeitreihen
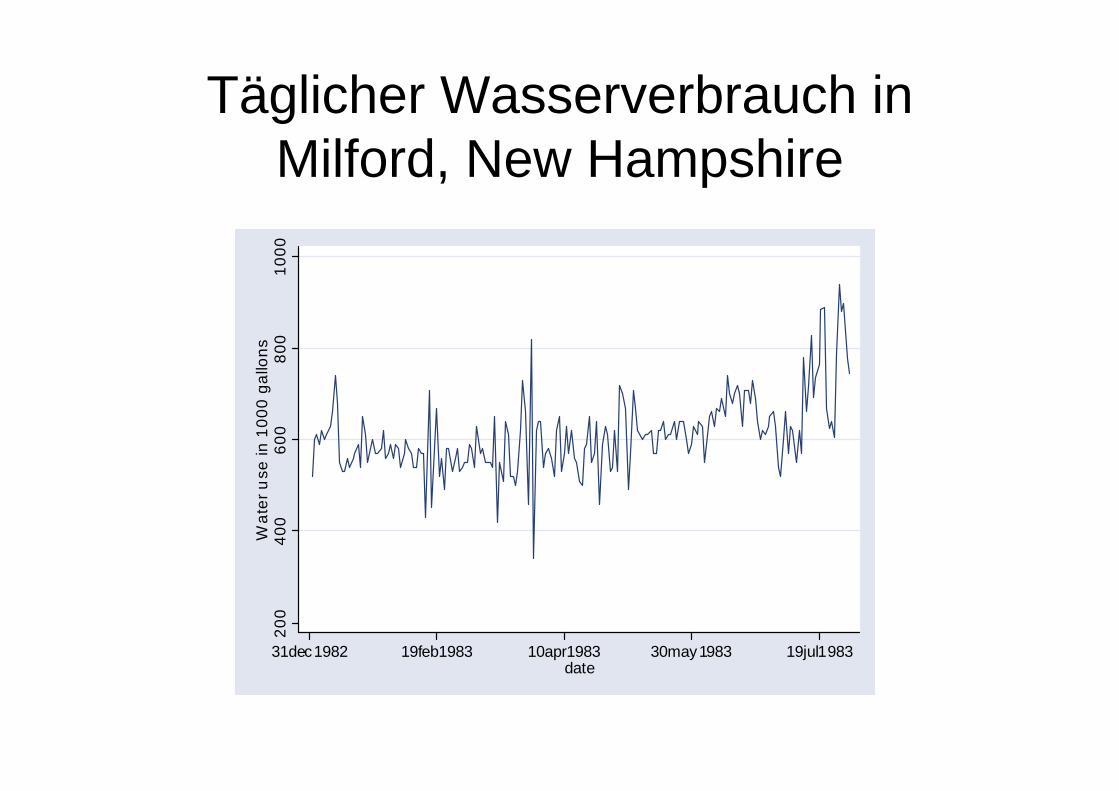
Täglicher Wasserverbrauch in Milford, New Hampshire
200
400
600
800
1000
Wat
er u
se in
100
0 ga
llons
31dec1982 19feb1983 10apr1983 30may1983 19jul1983date
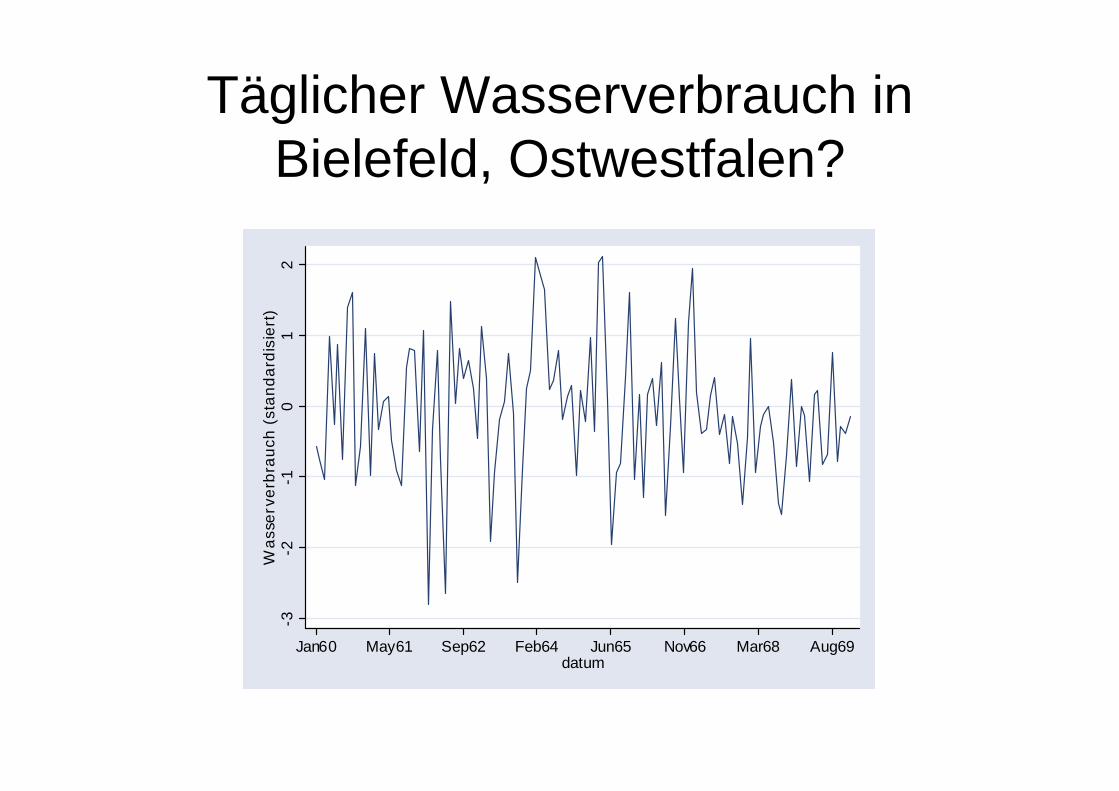
Täglicher Wasserverbrauch in Bielefeld, Ostwestfalen?
-3-2
-10
12
Was
serv
erbr
auch
(st
anda
rdis
iert
)
Jan60 May61 Sep62 Feb64 Jun65 Nov66 Mar68 Aug69datum

Nein: ein einfacher Zufallsprozess!
• Die systematische Komponente ist null und die Fehlerterme sind standardnormal-verteilt. Die Fehlerterme zu den einzelnen Zeitpunkten sind unabhängig voneinander (keine Autokorrelation).
stuuu
uy
st
t
tt
≠=
=
0),Corr()1,0N(~
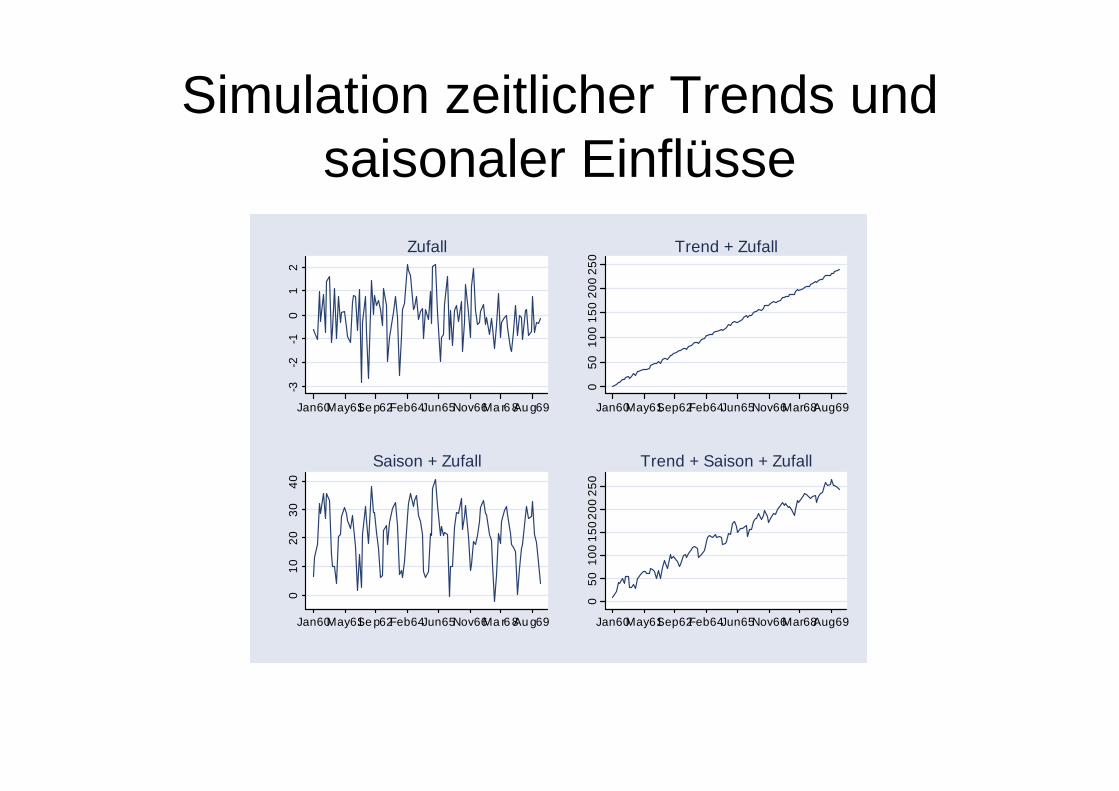
Simulation zeitlicher Trends und saisonaler Einflüsse
-3-2
-10
12
Jan60May61Se p62Feb64Jun65Nov66Ma r68Au g69
Zufall
050
100
150
200
250
Jan60May61Sep62Feb64Jun65Nov66Mar68Aug69
Trend + Zufall
010
2030
40
Jan60May61Se p62Feb64Jun65Nov66Ma r68Au g69
Saison + Zufall
050
100
150
200
250
Jan60May61Sep62Feb64Jun65Nov66Mar68Aug69
Trend + Saison + Zufall
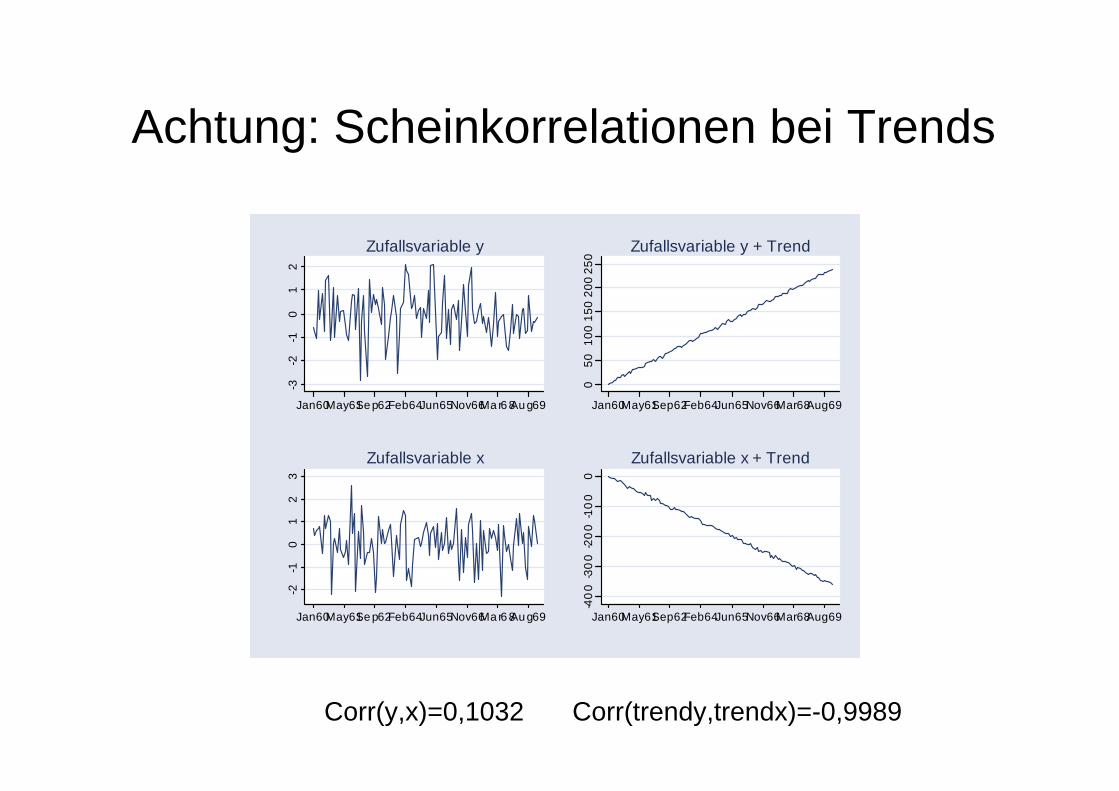
Achtung: Scheinkorrelationen bei Trends
-3-2
-10
12
Jan60May61Se p62Feb64Jun65Nov66Ma r6 8Au g69
Zufallsvariable y
050
100
150
200
250
Jan60May61Sep62Feb64Jun65Nov66Mar68Aug69
Zufallsvariable y + Trend
-2-1
01
23
Jan60May61Se p62Feb64Jun65Nov66Ma r6 8Au g69
Zufallsvariable x
-40
0-3
00
-20
0-1
00
0
Jan60May61Sep62Feb64Jun65Nov66Mar68Aug69
Zufallsvariable x + Trend
Corr(y,x)=0,1032 Corr(trendy,trendx)=-0,9989
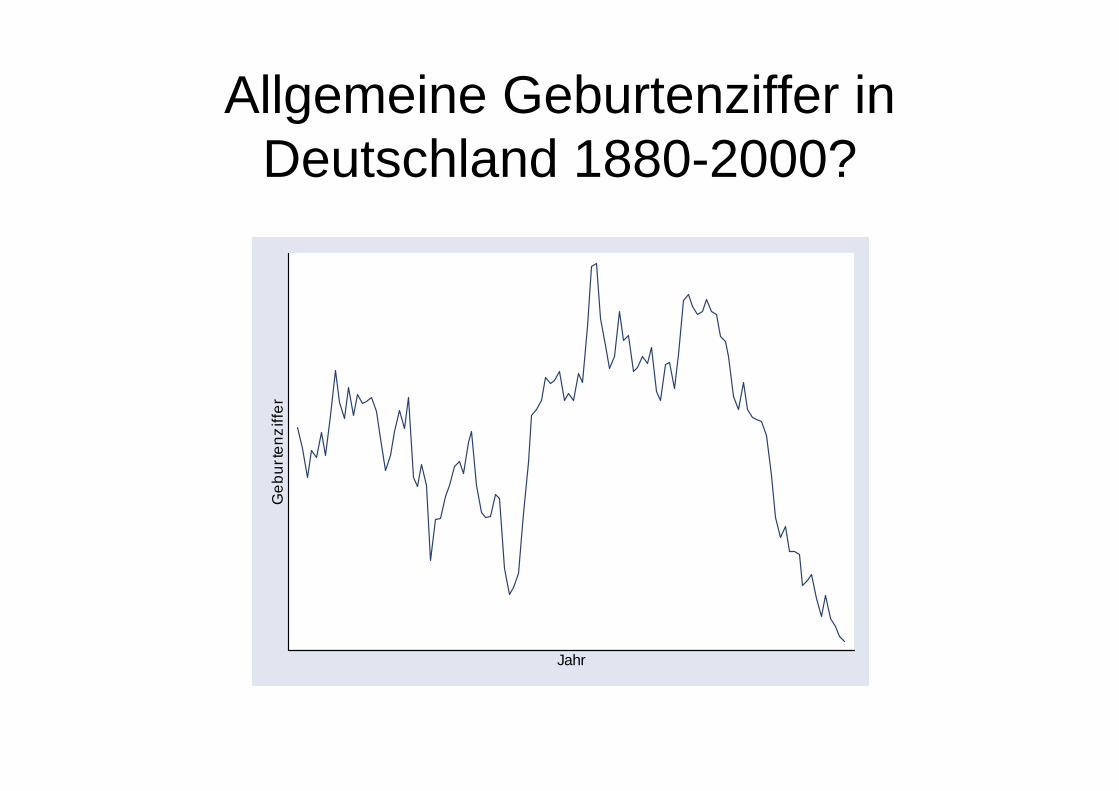
Allgemeine Geburtenziffer in Deutschland 1880-2000?
Geb
urte
nziff
er
Jahr

Nein: auch ein einfacher Zufallsprozess!
• Der Wert zum Zeitpunkt t entspricht dem Wert der Vorperiode plus einem standard-normalverteilten Fehler (random walk). Die Fehlerterme zu den einzelnen Zeitpunkten sind unabhängig voneinander, nicht aber die Messwerte y.
styyuuu
uyy
stst
t
ttt
≠≠=
=+= −
,0),Corr(,0),Corr()1,0N(~
1,1 ρρ
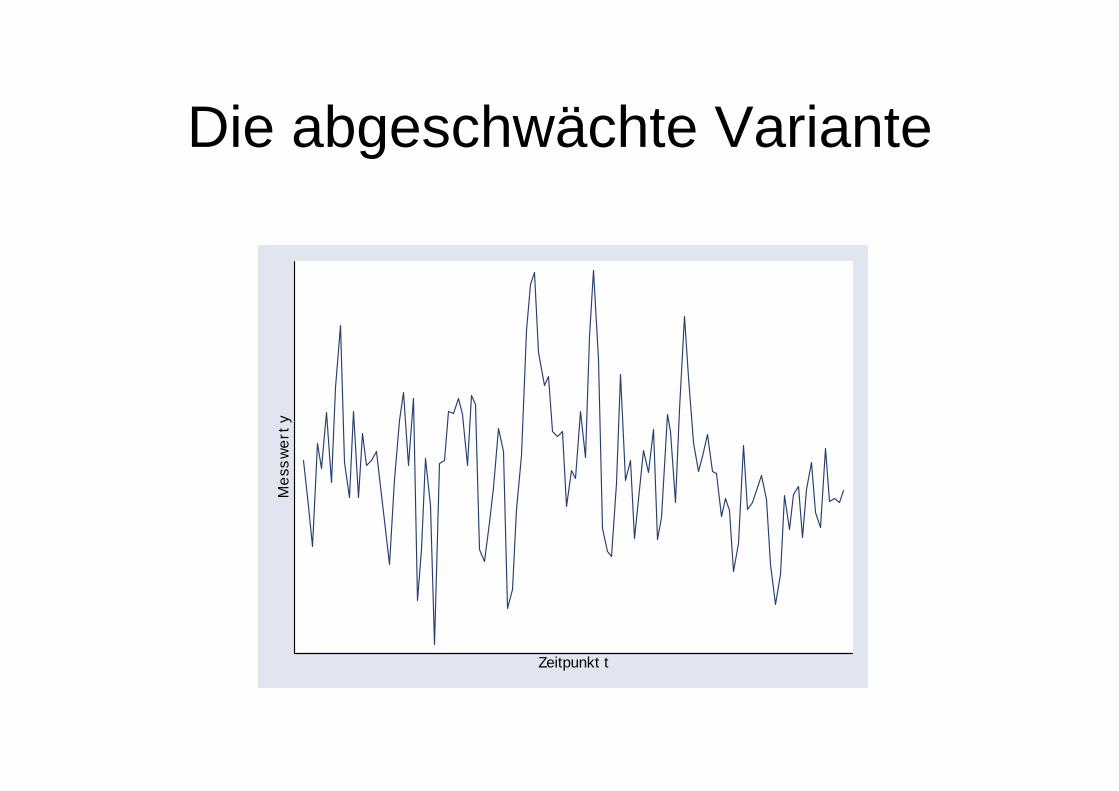
Die abgeschwächte Variante
Mes
swer
t y
Zeitpunkt t

Ein autoregressiver Prozess 1. Ordnung
• Ähnlich Random Walk, nur wird jetzt nicht der gesamte Wert der Vorperiode übernommen (der entsprechende Parameter ρ ist kleiner als 1).
styyuuu
uyy
stst
t
ttt
≠≠=
<+= −
,0),Corr(,0),Corr()1,0N(~
1,1 ρρ
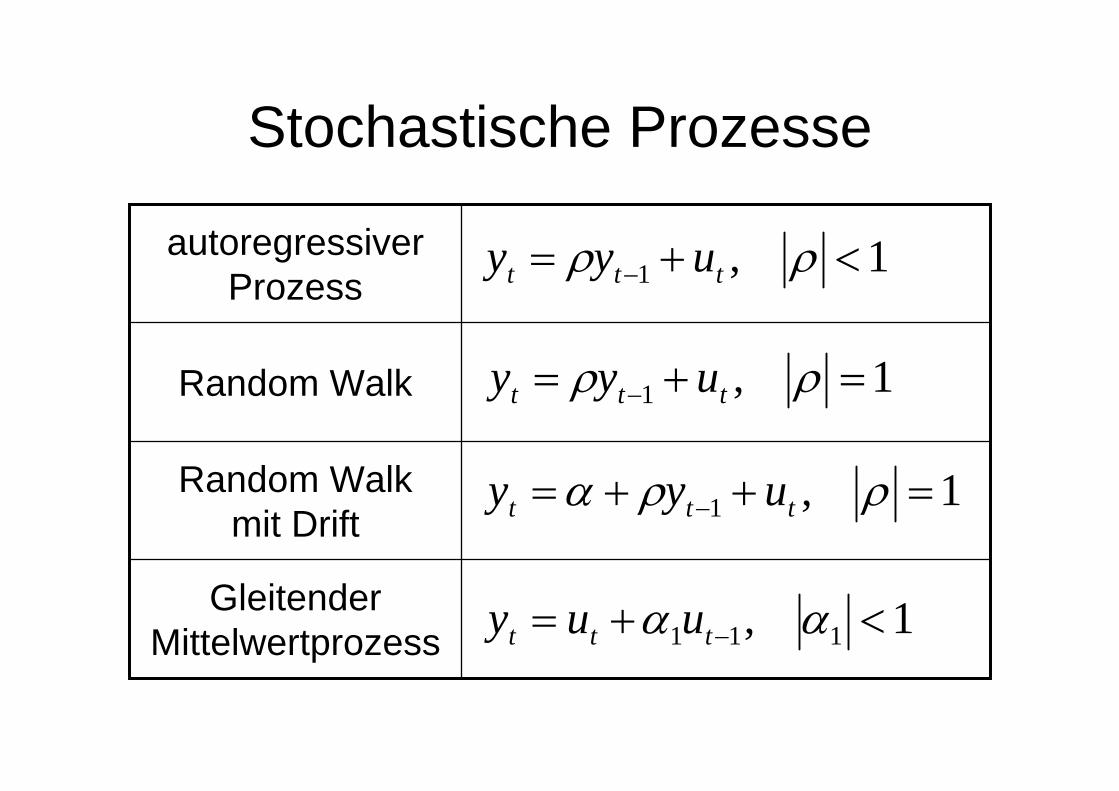
Stochastische Prozesse
Gleitender Mittelwertprozess
Random Walkmit Drift
Random Walk
autoregressiver Prozess
1,1 <+= − ρρ ttt uyy
1,1 =+= − ρρ ttt uyy
1,1 =++= − ρρα ttt uyy
1, 111 <+= − αα ttt uuy
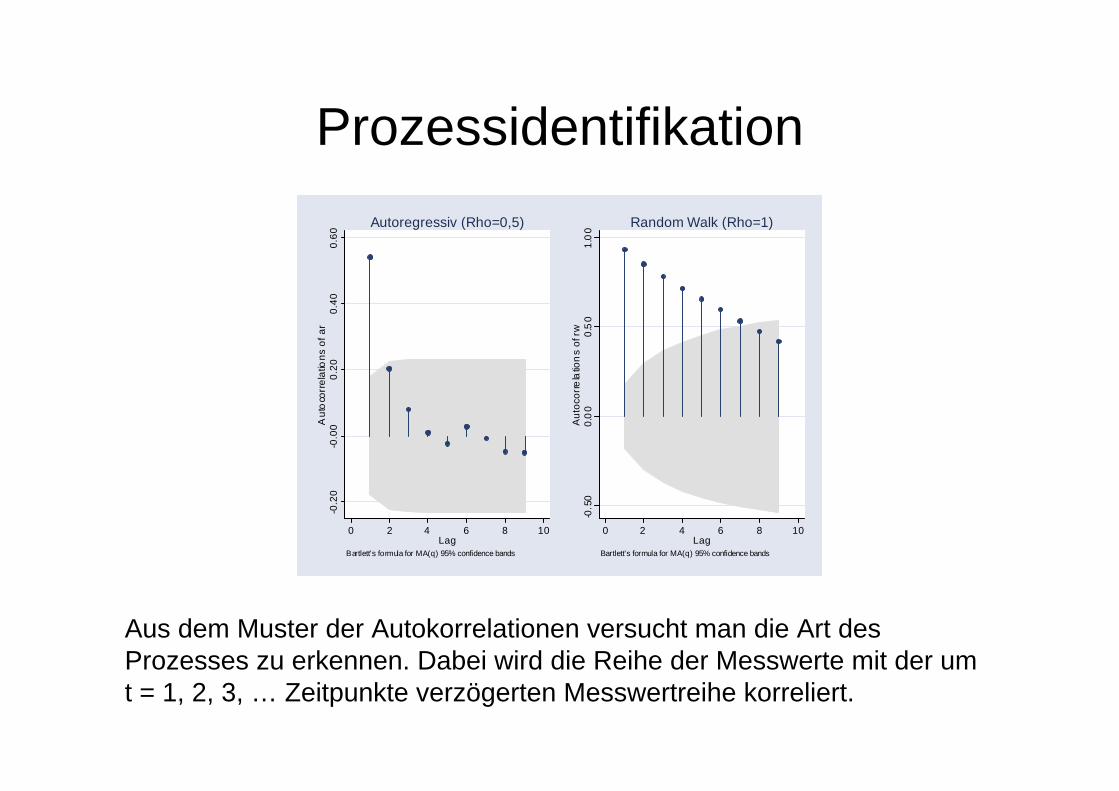
Prozessidentifikation
-0.2
0-0
.00
0.20
0.40
0.60
Aut
oco
rrel
atio
ns o
f ar
0 2 4 6 8 10Lag
Bartlett's formula for MA(q) 95% confidence bands
Autoregressiv (Rho=0,5)
-0.5
00.
00
0.5
01.
00
Aut
ocor
rela
tion
s of
rw
0 2 4 6 8 10Lag
Bartlett's formula for MA(q) 95% confidence bands
Random Walk (Rho=1)
Aus dem Muster der Autokorrelationen versucht man die Art des Prozesses zu erkennen. Dabei wird die Reihe der Messwerte mit der umt = 1, 2, 3, … Zeitpunkte verzögerten Messwertreihe korreliert.

ARIMA-Modelle• Modell: Die abhängige Variable besteht aus
einer systematischen Komponente und einem Fehlerterm
• Identifikation des den Fehlertermen zugrunde liegenden stochastischen Prozesses (linear autoregressive integrated moving averageprocess: ARIMA).
• Schätzung der Parameter der systematischen Komponente unter Kontrolle des zuvor identifizierten ARIMA-Prozesses.
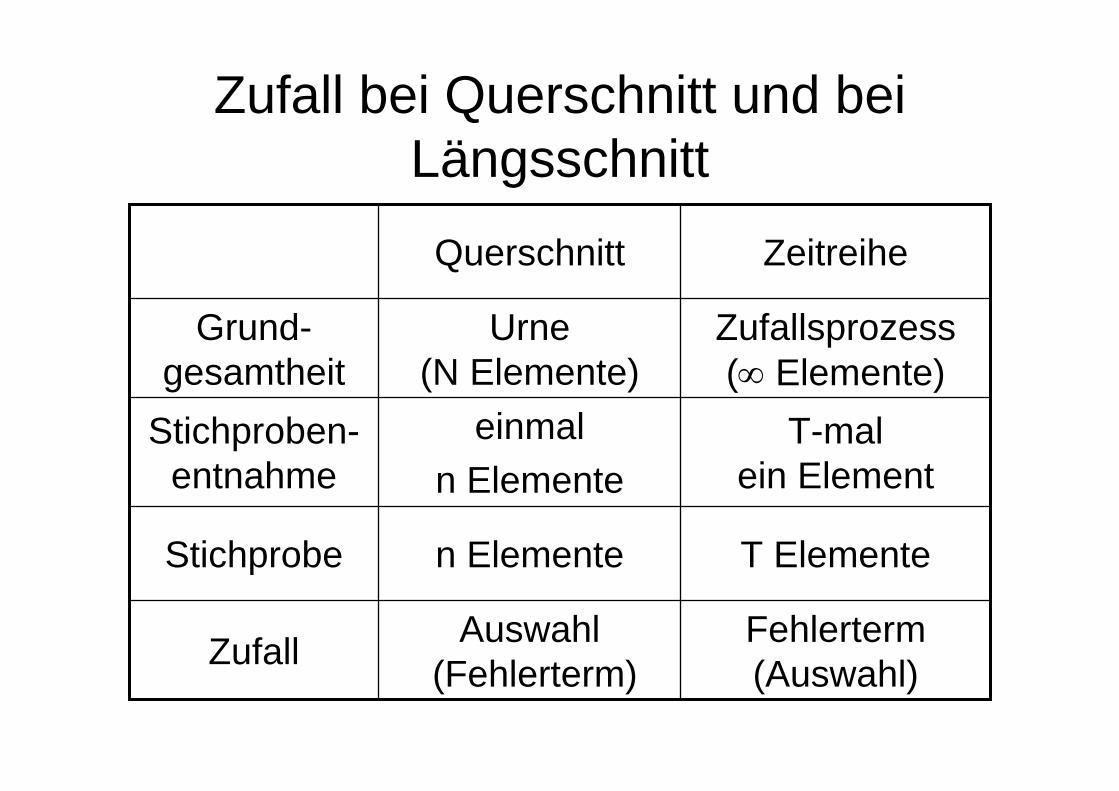
Zufall bei Querschnitt und bei Längsschnitt
Fehlerterm(Auswahl)
Auswahl(Fehlerterm)Zufall
T Elementen ElementeStichprobe
T-malein Element
einmaln Elemente
Stichproben-entnahme
Zufallsprozess(∞ Elemente)
Urne(N Elemente)
Grund-gesamtheit
ZeitreiheQuerschnitt

Statistische Eigenschaften von Regressionsverfahren bei Zeitreihen• Um die statistischen Eigenschaften
(Erwartungstreue, Effizienz, Konsistenz) von Regressionsverfahren für Querschnittsdatennachzuweisen, wird auf verschiedene Hilfsmittel zurückgegriffen (Verteilungsannahmen, zentraler Grenzwertsatz usw.).
• Um ähnliche Überlegungen für Zeitreihen anstellen zu können, darf sich der Zufallsprozess nicht von Zeitpunkt zu Zeitpunkt verändern. Wichtig ist daher, dass es sich um stationäre und schwach abhängige Prozesse handelt.

Teil 5
Schätzung von Regressionsmodellen für
Zeitreihen

Fall 1: statisches Modell (x1t, x2t, …)
• Problem– autokorrelierte Fehlerterme
• Folgen– verzerrte Standardfehler: in der Regel
unterschätzt– Fehlentscheidungen: eher gegen H0

Fall 1: Was tun?
• Tests auf Autokorrelation– Durbin-Watson Test– T-Test– Verallgemeinerung: Breusch-Godfrey-Test
• Kontrolle der Autokorrelation mit entsprechend verallgemeinertem Schätzverfahren– GLS bei bekannter Autokorrelation– Differenzenbildung– Feasible GLS: Prais-Winsten, Cochrane-Orcutt– Robuste Standardfehler: Newey-West

Fall 2: dynamisches Modell
nur zeitverzögerte x-Variablen (x1,t-1, x2,t-1, …)• siehe Fall 1auch zeitverzögerte y-Variablen (yt-1, yt-2, …)• Problem: autokorrelierte Fehlerterme• Folgen
- verzerrte Parameterschätzer: in der Regel überschätzt- verzerrte Schätzung der Autokorrelation: in der Regel
unterschätzt- verzerrte Standardfehler: in der Regel unterschätzt- Fehlentscheidungen: eher gegen H0

Fall 2: Was tun?
• Die entsprechenden Schätz- und Testverfahren übersteigen im Moment unsere Kenntnisse und Fähigkeiten.

Zum Schluss

Zusammenfassung
• Autokorrelation– verzerrte Standardfehler
• Autokorrelation & zeitverzögerte y-Variablen– verzerrte Standardfehler– verzerrte Parameterschätzer
Schätzung
• haben zeitliche Ordnung• keine unabhängigen Beobachtungen
Zeitreihen
• des zugrunde liegenden Prozesses• der Autokorrelation
Identifikation
• zeitverzögerte Variablen• Trend & saisonale Effekte• Ereignisse
Modelle

Weiterführende Literatur• Ostrom, C.W. (1978): Time series analysis:
regression techniques. Quantitative applicationsin the social sciences 9. Beverly Hills: Sage– Das Skript von Ostrom aus der Sage-Reihe ist bereits älteren
Datums, reicht aber als Einstieg in Probleme und TechnikenZeitreihenanalyse vollkommen aus.
• Wooldridge (2003)– Kapitel 10-12 (WO 323-423) behandeln Regressionsmodelle für
Zeitreihen. Da sie ausführlich die Schätzannahmen für Zeitreihen diskutieren, sind sie jedoch für die Erstanwender schwer zugänglich, die sich noch nie mit stochastischen Prozessen beschäftigt haben. Man sollte beim ersten Lesen über die entsprechenden Passagen „hinweglesen“. Es ist dann allerdings nicht einfach einzuordnen, wann welches Schätz- und Testverfahren verwendet werden sollte.


















