
Analyse zeitabhängiger Daten - eswf.uni-koeln.deeswf.uni-koeln.de/lehre/07/02/ss0702_03.pdf ·...
40
Analyse zeitabhängiger Daten Zeitreihenanalyse I
Transcript of Analyse zeitabhängiger Daten - eswf.uni-koeln.deeswf.uni-koeln.de/lehre/07/02/ss0702_03.pdf ·...

Analysezeitabhängiger Daten
Zeitreihenanalyse I

2
Warum geht es in den folgenden Sitzungen?
Pfingstferien06.06.07
Kumulierte Querschnittsdaten I18.04.07
Zusammenfassung, Klausurvorbereitung11.07.07
noch offen04.07.07
Ereignisdaten II27.06.07
Ereignisdaten I20.06.07
Paneldaten kategorialer Zielvariablen I13.06.07
Paneldaten kategorialer Zielvariablen I30.05.07
Paneldaten kontinuierlicher Zielvariablen II23.05.07
Paneldaten kontinuierlicher Zielvariablen I16.05.07
Zeitreihenanalyse II09.05.07
Zeitreihenanalyse I02.05.07
Kumulierte Querschnittsdaten II25.04.07
Schätzverfahren für Regressionsmodelle11.04.07
Einführung04.04.07
VorlesungDatum
Zeitreihen

3
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!4. Zufall bei Zeitreihen

4
Beispiel 1: Verkehrsunfälle30
000
3500
040
000
4500
050
000
5500
0st
atew
ide
tota
l acc
iden
ts
Jul80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
Datum UnfälleJan. 81 40511Feb. 81 36034Mrz. 81 40328Apr. 81 37699Mai. 81 38816Jun. 81 38900Jul. 81 38625Aug. 81 39539Sep. 81 38070Okt. 81 40676Nov. 81 39270Dez. 81 39734Jan. 82 36672Feb. 82 32699
… …Dez. 89 47251
Daten: traffic2.dta, n=108, monatliche Anzahl der Verkehrsunfälle im US-Bundesstaat Kalifornien (1981-1989)
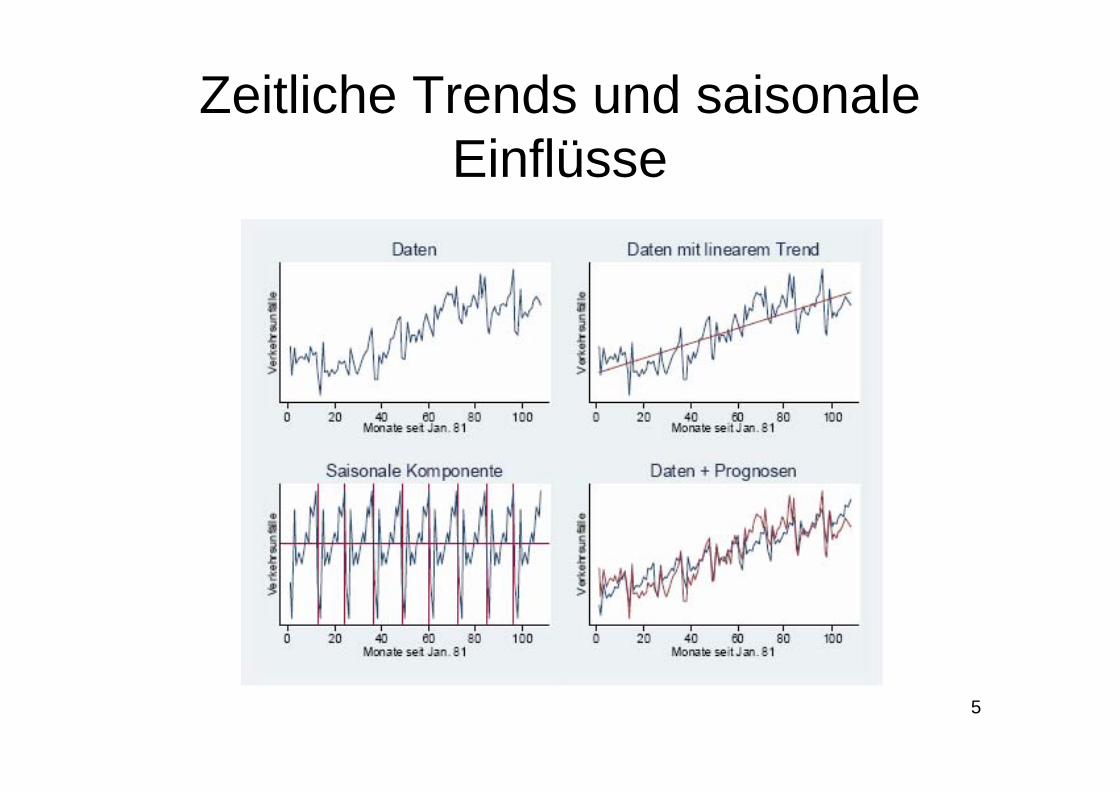
5
Zeitliche Trends und saisonale Einflüsse
6
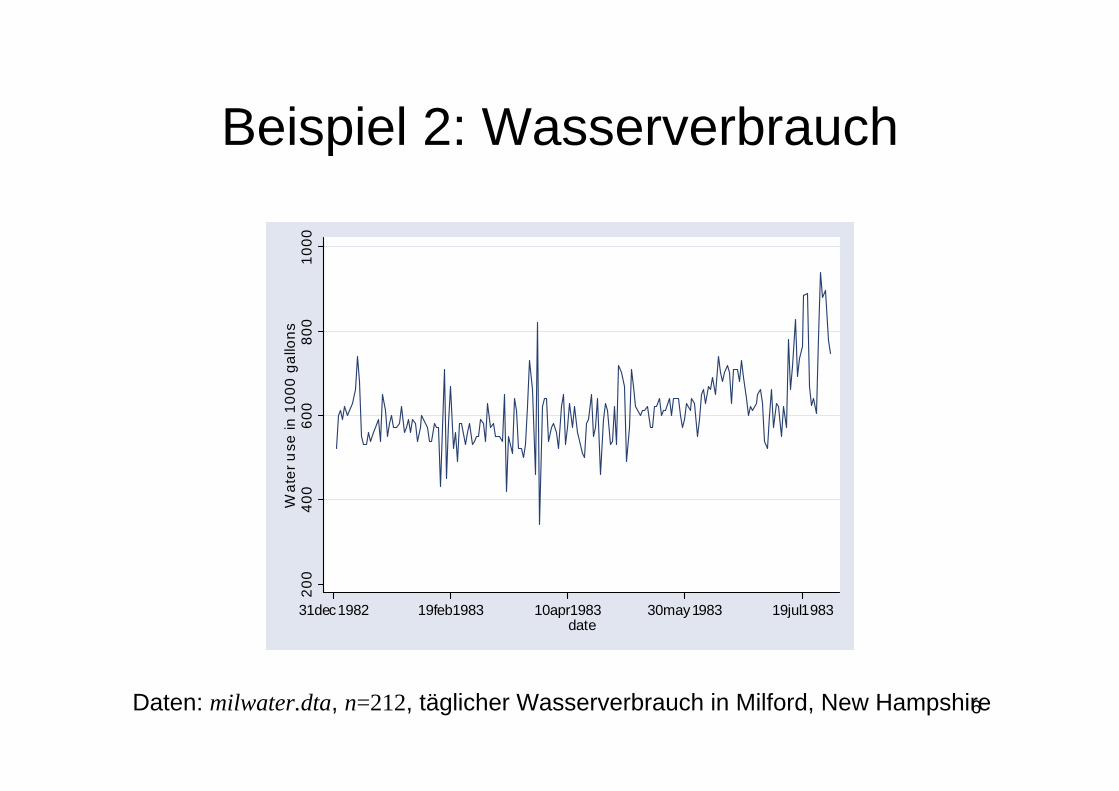
Beispiel 2: Wasserverbrauch
200
400
600
800
1000
Wat
er u
se in
100
0 ga
llons
31dec1982 19feb1983 10apr1983 30may1983 19jul1983date
Daten: milwater.dta, n=212, täglicher Wasserverbrauch in Milford, New Hampshire

7
Glättung durch gleitende Mittelwerte
200
400
600
800
1000
Wa
ter u
se in
10
00 g
allo
ns
31dec1982 19feb1983 10apr1983 30may1983 19ju l1983date
Ausgangsdaten
500
600
700
800
900
ma
: x(t
)= w
ate
r: w
indo
w(5
)
31dec1982 19feb1983 10apr1983 30may1983 19ju l1983date
Gleitende Durchschnitte

8
Autokorrelationsfunktion
-0.2
00.
000.
200.
400.
60A
utoc
orre
latio
ns o
f wat
er
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands

9
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!4. Zufall bei Zeitreihen

10
Alle bekannten Modelle verwendbar
• lineare (zj = xj)• nicht-lineare (z.B. z2 = ln(x2))• additive (zj = xj und Effekte additiv
verknüpft)• nicht-additive (z.B. z4 = x2 ⋅ d mit Dummy-
Variablen d)
uzzzzzy kk +++++++= ββββββ K443322110

11
Statische und „dynamische“ Modelle
• Querschnitt
• Zeitreihe: statisches Modell
• Zeitreihe: „dynamisches Modell“
• Ein „dynamisches“ Modell enthält zeitverzögerte x-Variablen und/oder zeitverzögerte y-Variablen
ikikiii uxxxy +++++= ββββ K22110
tktkttt uxxxy +++++= ββββ K22110
ttttt uyxxy +++++= −− K131,12110 ββββ

12
Wozu dynamische Modelle?
• zeitverzögerte x-Variablen– Eine Variable x entfaltet ihre Wirkung nicht
unmittelbar, sondern mit zeitlicher Verzögerung.– Arbeitssparende Investitionen erhöhen die
Arbeitsproduktivität im nächsten Jahr.• zeitverzögerte y-Variablen
– bürokratische Beharrungsprozesse– Die Staatsausgaben des folgenden Jahres können
nur bedingt verändert werden, weil viele Ausgabepositionen gesetzlich festgelegt sind.

13
Zeitliche Trends und saisonale Einflüsse
Beispiel: Dummies für Monatesaisonale Effekte
exponentieller Trend
quadratischer Trend
linearer Trend tt uty +⋅+= 10 ββ
tt utty +⋅+⋅+= 2210 βββ
tt uty +⋅+= 10ln ββ
ttttt udddy +++++= ,121232210 ββββ K

14
Analyse von Ereignissen
• Dummy-Variable: vorher (d=0), nachher (d=1)
• Niveauunterschiede
• Trendunterschiede
3000
035
000
4000
045
000
5000
055
000
vorh
er/n
achh
er
Jul80 Nov81 Apr83 Aug84 Jan86 May87 Sep88 Feb90date
vorher nachher
Vor und nach Einführung der Gurtpflicht
ttt udy ++= 10 ββ
tttt udttdy +⋅⋅+++= 3210 ββββ

15
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!
a. Variablen mit Trendb. Stark abhängige Prozessec. Gegenmaßnahmen (mit Beispiel)
4. Zufall bei Zeitreihen

16
Scheinkorrelation durch Trends
-3-2
-10
12
e
01jan196001jan196201jan196401jan196601jan196801jan1970
Normalverteilte Zufallsvariable e
050
100
150
200
250
y
01jan196001jan196201jan196401jan196601jan196801jan1970
Trend: y = 2*t + 10*e
-4-2
02
4a
01jan196001jan196201jan196401jan196601jan196801jan1970
Normalverteilte Zufallsvariable a
-400
-300
-200
-100
0x
01jan196001jan196201jan196401jan196601jan196801jan1970
Trend: x = -3*t + 10*a
120,968,0)011,0()323,2(
660,0386,0ˆ
2 ==
−=
nR
xy
120,013,0)085,0()088,0(
104,0066,0ˆ
2 ==
−−=
nR
ae

17
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!
a. Variablen mit Trendb. Stark abhängige Prozessec. Gegenmaßnahmen (mit Beispiel)
4. Zufall bei Zeitreihen

18
Stark abhängige Prozesse
120,087,0)069,0()530,0(
230,03912ˆ
2 ==
−−=
nR
x.y
-15
-10
-50
x
01jan196001jan196201jan196401jan196601jan196801jan1970
x_t = x_t-1 + a_t
-10
-50
5y
01jan196001jan196201jan196401jan196601jan196801jan1970
y_t = y_t-1 + e_t
-1.0
0-0.
500.
000.
501.
00A
utoc
orre
latio
n
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands
Autocorrelations of x
-0.5
00.
000.
501.
00Au
toco
rrel
atio
n
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands
Autocorrelations of y
ttt axxax
+==
−1
11
ttt eyyey
+==
−1
11
Obwohl beide Zeitreihen aus Zufallszahlen generiert wurden, zeigen sie in bestimmten Phasen einen Trend.

19
Aber Ergebnis vielleicht Zufall?
• beide Zeitreihen (yt, xt) sind unabhängig voneinander
• deshalb sollte der Regressionskoeffizient β1 inyt = β0 + β1xt gleich Null sein (H0)
• β1=0,230 (Handout) zufällig ungleich Null?• Simulationsstudie Davidson / MacKinnon (1993)
– 10,000 Zeitreihen aus jeweils n=50 Werten simuliert– jeweils T-Test von β1 mit α=0,05 durchgeführt– 66,2% der Zeitreihen wird H0 verworfen

20
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!
a. Variablen mit Trendb. Stark abhängige Prozessec. Gegenmaßnahmen (mit Beispiel)
4. Zufall bei Zeitreihen

21
Zusammenfassung
• Zusammenhang zwischen y und x immer dann groß, wenn– y und x jeweils einen Trend aufweisen.– y und x jeweils ein stark abhängiger Prozess
zugrundeliegt (zeigt in einzelnen Phasen Trend).• In beiden Fällen kann der Zusammenhang nicht
kausal erklärt werden.• Er ist durch eine dritte Variable (Trend) zu
erklären (Scheinkorrelation)!

22
Gegenmaßnahmen
• Wie erkennt man?– Trends: graphische Darstellung der Zeitreihen– stark abhängige Prozesse: schwieriger, siehe
nächste Vorlesung• Was macht man bei
– Trends: Trendbereinigung– stark abhängigen Prozessen: Differenzierung
der Zeitreihe, siehe nächste Vorlesung
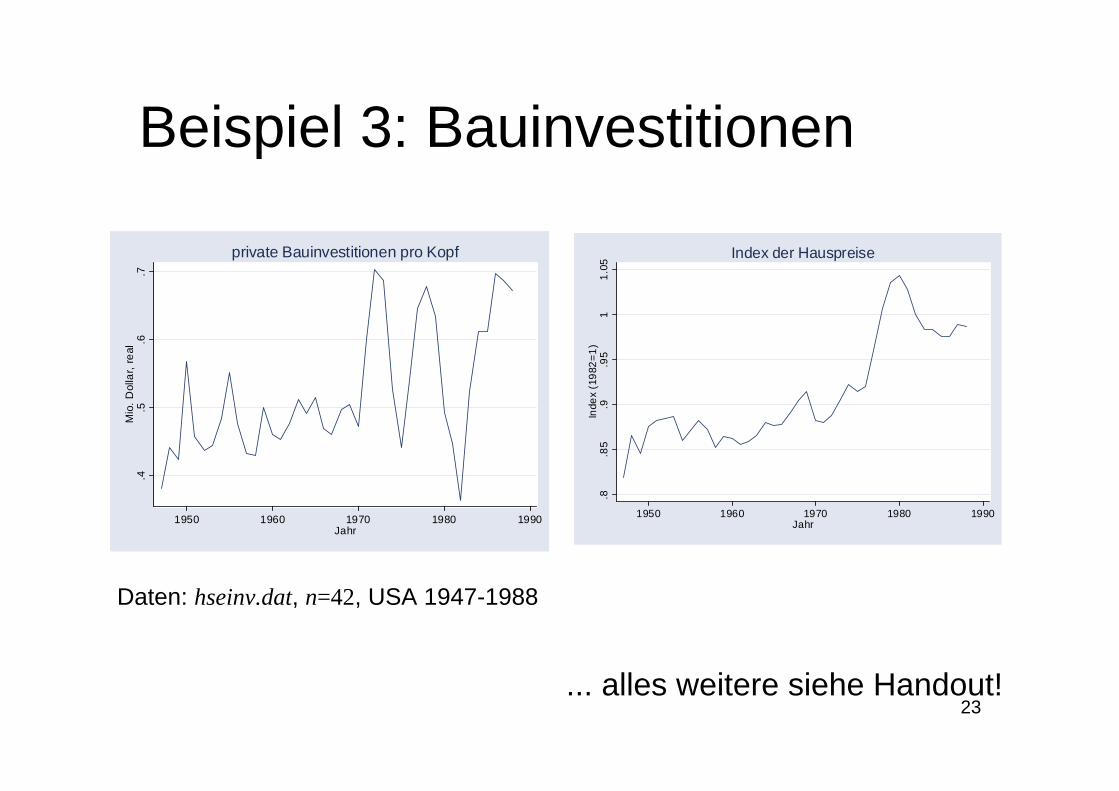
23
Beispiel 3: Bauinvestitionen.4
.5.6
.7M
io. D
olla
r, re
al
1950 1960 1970 1980 1990Jahr
private Bauinvestitionen pro Kopf
Daten: hseinv.dat, n=42, USA 1947-1988.8
.85
.9.9
51
1.05
Inde
x (1
982=
1)
1950 1960 1970 1980 1990Jahr
Index der Hauspreise
... alles weitere siehe Handout!

24
Gliederung
1. Deskriptive Analyse von Zeitreihen2. Regressionsmodelle für Zeitreihen3. Achtung Scheinkorrelation!4. Zufall bei Zeitreihen

25
Analyse der Lebenszufriedenheit
• St. Regression: eine kleine Insel im Südpazifik mit 665 Einwohnern
• Lebenszufriedenheit (Index 1-20)• Determinanten: Haushaltseinkommen, Berufsprestige,
Ausbildungsdauer, Kirchgangshäufigkeit, Ortsgröße• Messfehler und weitere Einflüsse sind unabhängig von
diesen Determinanten: u korreliert mit keiner der fünf Variablen
• Frage: Ist der folgende in der „Grundgesamtheit“ gültige Zusammenhang zwischen Lebenszufriedenheit und Einkommen, Prestige usw. auch in einer Zufallsstichprobe beobachtbar?
uxxxxxy +−++++= 54321 056.0265.0116.0011.0065.051.10

26
Annahme: Zufallsauswahl
Einfache Zufallsstichprobe (n=300)
Urnenmodell:
Grundgesamtheit (N=665)

27
Simulation der Stichprobenverteilung des geschätzten Einkommenseffektes
1000 Stichproben (Replikationen) jeweils mit n=300
01
23
4D
ensi
ty
-.4 -.2 0 .2 .4_b[income]
Std.abw. = 0,110
Arithm. Mittel = 0,061(Bias = 0,061 – 0,065)

28
Schätzverfahren notwendig bei Totalerhebungen?• Beispiele für Totalerhebungen
– Verkehrsunfälle in Kalifornien 1981-1989– Kindersterblichkeit 1990 für jeden
Bundesstaat der USA• Wie kann es einen vom Parameter der
Grundgesamtheit abweichenden Schätzwert geben, wenn man Daten über alle Elemente der Grundgesamtheit hat?

29
Schätzverfahren bei Totalerhebungen?
• Gedankenexperiment– Daten zur Kindersterblichkeit
(Verkehrsunfälle) werden nach Abschluss erneut überprüft.
• Ergebnis– Wegen Erfassungsproblemen ergeben sich
leicht abweichende Werte der Zielvariablen.• Schlussfolgerung
– Messfehler gibt es auch bei Totalerhebungen.

30
Schätzverfahren bei Totalerhebungen?
• Gedankenexperiment– Erhebung zur Lebenszufriedenheit wird eine Woche
später wiederholt. Messfehler seien ausgeschlossen.• Ergebnis
– Sonstige Determinanten der Lebenszufriedenheit (z.B. subjektive Stimmungen), die man wegen ihrer Zufälligkeit zunächst vernachlässigt hat, können andere Werte aufweisen.
• Schlussfolgerung– Auch bei Totalerhebungen ist von weiteren Einflüssen
auszugehen, die man jedoch nicht weiter modelliert und statt dessen als Zufallsvariable betrachtet.

31
Universum der sonstigen Einflüsse und Messfehler
Totalerhebung als stochastischer Prozess
systematischeKomponente
µi
stochastischeKomponente
ui
Zielvariableyi
+
=
54
321
056.0265.0116.0011.0065.051.10
xxxxx
−++++
),0N(~orlengeneratZufallszah
σiu
immer gleiche Werte, wenn ui=0verschiedene Werte, wenn ui≠0

32
Schlussfolgerungen• Analysiere die stochastischen Eigenschaften
des datengenerierenden Prozesses• Zufallsstichprobe
– u: Messfehler und unbekannte Determinanten– Auswahl einer Teilstichprobe aus einer endlichen
Grundgesamtheit• Totalerhebung
– u: Messfehler und unbekannte Determinanten– Auswahl einer Teilstichprobe aus einer
hypothetischen Grundgesamtheit• Auch bei Totalerhebungen ist Schätzen (und
Testen) sinnvoll!

33
Zeitreihe als stochastischer Prozess
systematischeKomponente
µt
stochastischeKomponente
ut
Zielvariableyt
+
=
KK ,,,,,,Einflüsse ertezeitverzög und ezeitgleich
2121 −−−− ttttt yyxxx
),0N(~
orlengeneratZufallszah
σtu
je nach Modell: Determinante der Zielvariablen in nächster Periode

34
Abhängige Beobachtungen
• weil die Werte der x-Variablen, die hier als gegeben betrachtet werden, im Zeitablauf miteinander zusammenhängen.
• weil die Vergangenheit des Prozesses(yt-1, yt-2, ...) in die aktuellen Werte yt eingeht.
• weil die stochastische Komponente nicht nur aus der aktuellen ut, sondern auch aus früheren Zufallszahlen ut-1, ut-2, ... zusammengesetzt ist (Verallgemeinerung der vorherigen Folie).

35
Zufall bei Querschnitt und bei Zeitreihe
janeinneinAbhängig?
Fehlerterm
n Elemente
einmaln Elemente
Universum ui∞ Elemente
Total-erhebung
FehlertermAuswahlZufall
t Elementen ElementeStichprobe
t-malein Element
einmaln Elemente
Stichproben-entnahme
Zufallsprozess∞ Elemente
UrneN Elemente
Grund-gesamtheit
ZeitreiheQuerschnitt

Zum Schluss

37
Zusammenfassung
• bei Trends• bei stark abhängigen Prozessen
Schein-korrelation
• Zeitreihen sind stochastische ProzesseZufall
• haben zeitliche Ordnung• keine unabhängigen Beobachtungen
Zeitreihen
• zeitverzögerte Variablen• Trend & saisonale Effekte• Ereignisse
Modelle
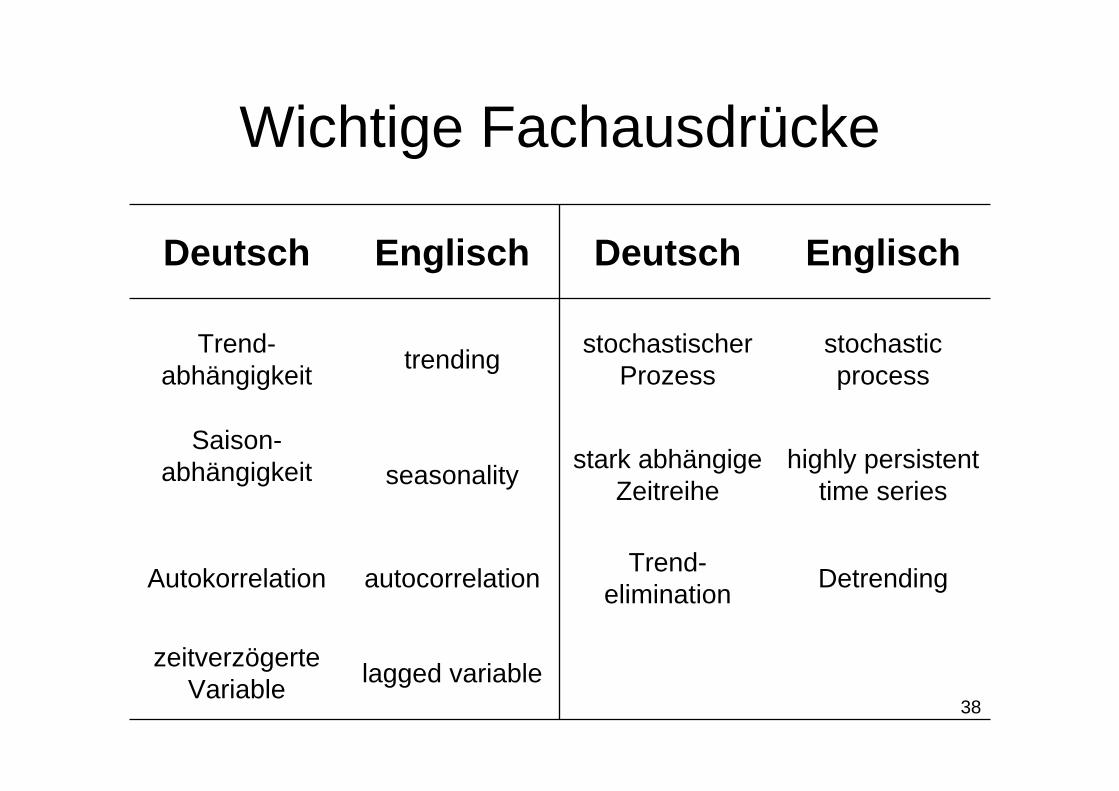
38
Wichtige Fachausdrücke
DetrendingTrend-eliminationautocorrelationAutokorrelation
lagged variablezeitverzögerte Variable
highly persistent time series
stark abhängige Zeitreiheseasonality
Saison-abhängigkeit
stochasticprocess
stochastischer ProzesstrendingTrend-
abhängigkeit
EnglischDeutschEnglischDeutsch

39
Weiterführende Literatur
• Wooldridge (2003)– Kapitel 10 (WO 323-359) gibt eine Einführung
in verschiedene Regressionsmodelle für Zeitreihen. Außerdem wird diskutiert, unter welchen restriktiven Bedingungen die Annahmen des klassischen linearen Modells auf Zeitreihen übertragbar sind. Scheinkorrelationen durch Trends werden besprochen, nicht aber durch stark abhängige Prozesse. Die werden erst in Kapitel 11 eingeführt. Das kommt nächste Woche dran.

40
Stata-Befehle
Berechnung der Residuen (trendbereinigte Werte)predict y_detrended, resid
Kleinste-Quadrate-Schätzung (z.B. eines linearen Trends)
reg y t
Berechnung mit zeitverzögerten Variablen (um einen Zeitpunkt verschoben: L.x oder L1.x, zwei Zeitpunkte L2.x)
generate y=L.x + egenerate y=L2.x + e
Graphik der Autokorrelationsfunktionac y, lags(15)
Berechnung der Autokorrelationsfunktioncorrgram y, lags(15)
Berechnung ungewichteter gleitender Mittelwerte aus den Datenwerten von t-2 bis t+2
tssmooth ma glatt=y, window(5)
Liniendiagrammgraph twoway line y t
Deklaration der Zeitreihenstrukturtsset t


















