
Vorlesungsagenda Übersicht -...
38
Informationsmanagement Vorlesung 10: Grundlagen der Datenmodellierung Univ.-Prof. Dr.-Ing. Wolfgang Maass Lehrstuhl für Betriebswirtschaftslehre, insb. Wirtschaftsinformatik im Dienstleistungsbereich (Information and Service Systems ISS) Universität des Saarlandes, Saarbrücken SS 2012 Donnerstags, 10:00 – 12:00 Uhr (s.t.) Audimax, B4 1
Transcript of Vorlesungsagenda Übersicht -...

Informationsmanagement Vorlesung 10: Grundlagen der Datenmodellierung
Univ.-Prof. Dr.-Ing. Wolfgang Maass Lehrstuhl für Betriebswirtschaftslehre, insb. Wirtschaftsinformatik im Dienstleistungsbereich (Information and Service Systems ISS) Universität des Saarlandes, Saarbrücken SS 2012 Donnerstags, 10:00 – 12:00 Uhr (s.t.) Audimax, B4 1

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 2
Vorlesungsagenda Übersicht
1. Einleitung Managementsicht des Informationsmanagement
2. Grundlagen des Informationsmanagement 3. Aufgaben des Informationsmanagement – Management der Informationswirtschaft (2-stündig!) 4. Aufgaben des Informationsmanagement – Management der Informationssysteme und
Führungsaufgaben (2-stündig!) 5. Aufgaben des Informationsmanagement – IT-Controlling
Unternehmensarchitekturen 6. Grundlagen der Unternehmensarchitekturen – Gastvortrag Dr. Steffen Roehn (2-stündig!)
Systemarchitekturen 7. Architekturen von Informationssystemen 8. Webarchitekturen (2-stündig!) 9. Mobile & Cloud Computing
Datenmodellierung 10. Grundlagen der Datenmodellierung (2-stündig!) 11. Semantische Datenrepräsentationen (2-stündig!)
Prozessmodellierung 12. Grundlagen der Prozessmodellierung

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 3
Rückblick
Presentation Business Logic Data User
Infrastructure
is provided by some
• Was versteht man unter Daten im Kontext von Informationssystemen?
• Wie werden Daten modelliert, so dass sie von Informationssystemen genutzt werden können?
• Wie können Daten gespeichert und verarbeitet werden?

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 4
Was sind Daten?
1. Wirtschaftstheorie: Bezeichnung für volkswirtschaftliche Gegebenheiten, die den Wirtschaftsablauf beeinflussen, ohne von diesem selbst - zumindest unmittelbar und kurzfristig - beeinflusst zu werden. 2. Wirtschaftsinformatik: Zum Zweck der Verarbeitung zusammengefasste Zeichen, die aufgrund bekannter oder unterstellter Abmachungen Informationen (d.h. Angaben über Sachverhalte und Vorgänge) darstellen.
(Gabler Wirtschaftslexikon)
“A reinterpretable representation of information in a formalized manner,
suitable for communication, interpretation or processing.“
(Technologiestandard ISO/IEC 2382-1)
Informatik und Datenverarbeitung: • Daten = (maschinen-) lesbare und (maschinen-) bearbeitbare, in
der Regel digitale Repräsentation von Information ① Kodierung des Inhalts in Zeichen -> Syntax, z.B. Zahlenfolge
„123456“ = Aneinanderreihung von Ziffern ② Interpretation der Daten in einem Bedeutungskontext, um aus
ihnen Informationen zu gewinnen, z.B. Zahlenfolge „123456“ kann in Abhängigkeit vom Kontext für Telefonnummer, Kontonummer o.ä.

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 5
Was sind Daten?
• Semiotik (Wissenschaft der Zeichensysteme) definiert Daten als potenzielle Information
• Semiotisches Dreieck à Beziehung zwischen einem Zeichen und dem entsprechenden Gegenstand ist indirekt à sie verläuft über eine mentale Repräsentation des Gegenstands
• Erst über geistiges Konzept ('Begriff' genannt) wird die Zuordnung von Zeichen zu Objekten ermöglicht (Peirce, 1907; de Saussure, 1916)
Zeichen
Begriff
Gegenstand
'Baum'

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 6
1,8 Zettabytes an Daten! (Stand: 2011)
• Weltweit 1,8 Zettabytes (1021 Byte = 1.000.000.000.000.000.000.000 Byte = 1,8 Billionen Gigabytes) an digitalen Informationen (Stand 2011)
• Wachstum des Gesamtvolumens in den letzten 5 Jahren um den Faktor 5 Trillion

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 7
Kategorisierung von Daten
o Strukturierte Daten • Daten unterliegen einer allgemeinen Struktur - Datenmodell liegt vor • z.B. relationales Datenbankmodell für Datenbanken
o Semistrukturierte Daten • Daten unterliegen keiner allgemeinen Struktur, sondern tragen einen Teil der
Strukturinformation mit sich • z.B. HTML, Extensible Markup Language (XML), Email
o Unstrukturierte Daten • Digitalisierte Informationen, die in einer nicht formalisierten Struktur vorliegen • Automatische Nutzbarkeit unstrukturierter Daten stark eingeschränkt, da kein
Datenmodell vorliegt -> um Daten zu strukturieren, ist Modellierung erforderlich
• z.B. Grafiken, Audio-Daten, natürliche Sprache
Beispiel: E-Mail • Semistrukturiert – E-Mail liegt in gewisser Struktur vor: Empfänger, Absender, Text der E-Mail und
eventuell Betreff • Text der E-Mail ist aber unstrukturiert
<?xml version="1.0" encoding="UTF-8"?> <rezept xmlns:lm="http://lebensmittel.org"> <zutaten anzahl="3"> <lm:zutat>Ei</lm:zutat> <lm:zutat>Mehl</lm:zutat> <lm:zutat>Salz</lm:zutat> </zutaten> <anleitung> Alles zusammenrühren und backen. </anleitung> <foto><![CDATA[BELIEBIGE DATEN]]> </foto> </rezept>

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 8
Semi-strukturierte Daten Beispiel Email

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 9
Datenmodellierung
• Datenmodellierung = Verfahren der Informatik zur formalen Abbildung der in einem definierten Kontext relevanten Objekte mittels ihrer Attribute und Beziehungen
• Ziel: eindeutige Definition und Spezifikation der in einem Informationssystem zu verwaltenden Objekte, ihrer erforderlichen Attribute und der Zusammenhänge zwischen den Informationsobjekten
• Vorteil: Überblick über die Datensicht des Informationssystems
• Ergebnis: Datenmodelle, die nach dem Durchlauf mehrerer Modellierungsstufen zu einsatzfähigen Datenbanken bzw. Datenbeständen führen
(Maass & Janzen, 2011; Ferstl & Sinz, 2006)
• Datenmodelle -> längere Lebensdauer als Funktionen und Prozesse (Software) - "Data is stable – functions are not."
• "Daten sind Allgemeingut." -> sollten den Anwendungen zur Verfügung stehen, die sie benötigen und nicht (ausschließlich) einer bestimmten IT-Anwendung gehören
Abstract Information System Model (AISM)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 10
Relevante Objekte der “realen Welt” im Kontext
des Informationssystems, z.B. Personen
Vorgehen bei der Datenmodellierung
(1)
Konzeptueller Entwurf
(2)
Logischer Entwurf
(3)
Physischer Entwurf
Konzeptuelles Modell Fachliches Abbild durch
Typisierung und Beschreibung, z.B. Entity-
Relationship-Modell
Logisches Datenbankschema
Datentechnische Festlegung des
Datenbankmodells, z.B. Schlüssel
Physisches Datenbankschema
Script zur Erstellung der Datenbank gemäß
Datenbank Management System (DBMS)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 11
(1) Konzeptioneller Entwurf
• ERM … • … besteht aus Grafik – ER-Diagramm (ERD) – und
textueller Beschreibung der darin verwendeten Elemente
• … behandelt das “Was” (Sachlogik) und nicht das “Wie” (Technik)
• … stellt Datenstrukturen vereinfacht dar -> erleichtert interdisziplinäre Arbeit am Datenbestand des Informationssystems
• ... erfasst Informationsobjekte der realen Welt (z.B. Angestellter, Projekte) und verbindet diese mittels Beziehungen (z.B. Angestellter – leitet -Projekt)
• Betrachtung eines Ausschnitts der realen Welt -> Analyse sowie grafische und textuelle Beschreibung der Objekte mit allen relevanten Eigenschaften
• De-facto Standard für den konzeptuellen Entwurf im Rahmen der Datenmodellierung = Entity Relationship Modell (ERM) (Chen, 1976)
(Bildquelle: wikipedia.de)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 12
Entitätstyp (Entity): Typisierung gleichartiger Entitäten, d.h. Dinge / Objekte der Wirklichkeit, die eindeutig identifizierbar sind, z.B. Student, Unternehmen, Projekt
Entity-Relationship-Modell Komponenten des ERD (Chen-Notation)
Student
N
Student Veranstaltung
Vorname
besucht
Student Veranstaltung besucht
M
Beziehungstyp (Relationship): Typisierung gleichartiger Beziehungen zwischen zwei oder mehreren Entitäten, z.B. Student besucht Veranstaltung
1:N – Beziehung: 1 Geschäftsstelle : N Mitarbeiter M:N –Beziehung: M Projekte : N Projektarbeiter 1:1 – Beziehung: 1 Geschäftsführer : 1 Person
Attribut (Value): Typisierung gleichartiger Eigenschaften von Entitäten, z.B. Nachname, Vorname für Entitätstyp Student -> Attribute, die Entität eindeutig beschreiben, werden identifizierende Attribute genannt, z.B. Projektnummer für Entitätstyp Projekt
Kardinalität (Cardinality): Festlegung der Anzahl der beteiligten Entitäten bei Beziehungstypen, z.B. Student besucht M Veranstaltungen

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 13
Entity-Relationship-Modell Komponenten des ERD
Eine Person ist in maximal einem Ort geboren. Ein Ort ist Geburtsort von beliebig vielen Personen. Ein Ort kann ein Geburtsort sein, muss es aber nicht sein.
Beispiel in Chen- und UML-Notation
(Bildquelle: wikipedia.de)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 14
① Erkennen und Zusammenfassen von Entitäten zu Entitätstypen durch Abstraktion (z.B. Studenten Fritz Maier und Paul Lehmann -> Entitätstyp Student)
② Erkennen und Zusammenfassen von Beziehungen zwischen je zwei Objekten zu Beziehungstyp (z.B. Student Paul Lehmann besucht Vorlesung “Informationsmanagement” und Student Fritz Maier besucht Vorlesung “Web Technologien” -> Beziehungstyp „Student besucht Vorlesung“
③ Bestimmung der Kardinalitäten -> Darf ein Student mehrere Vorlesungen besuchen? Von wie vielen Studenten kann eine Vorlesung besucht werden?
④ Bestimmung relevanter Attribute für Entitätstypen, z.B. Vorname, Nachname bei Typ Student
Entity-Relationship-Modell Vorgehen
Darstellung von Details zu Entitäten, Attributen und Beziehungen - Ziel: einheitliche und klare Kommunikation der detaillierten Sachverhalte • Beschreibung der Attribute, Entitätstypen und Beziehungen, z.B. Beispiele für Entitäten,
Aussagen von Beziehungen (Mitarbeiter leitet Projekt), Wertebereiche für Attribute (Alter: 1-99)
• Bestimmen geeigneter Attribute eines Entitätstyps als identifizierende(s) Attribut(e), z.B. Matrikelnummer für Typ Student
Dokum
entation des ER
D
Erstellung des ERD

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 15
Relevante Objekte der “realen Welt” im Kontext des
Informationssystems, z.B. Personen
Vorgehen bei der Datenmodellierung
(1)
Konzeptueller Entwurf
(2)
Logischer Entwurf
(3)
Physischer Entwurf
Konzeptuelles Modell Fachliches Abbild durch
Typisierung und Beschreibung, z.B. Entity-
Relationship-Modell
Logisches Datenbankschema
Datentechnische Festlegung des
Datenbankmodells, z.B. Schlüssel
Physisches Datenbankschema
Script zur Erstellung der Datenbank gemäß
Datenbank Management System (DBMS)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 16
(2) Logischer Entwurf
• Überführung eines konzeptuellen Modells in ein logisches Datenbankschema • Diverse Datenbankmodelle, z.B. relational, objektorientiert, graphenbasiert • Bekanntestes Datenbankmodell -> Relationales Datenbankmodell (Codd, 1983):
Speicherung von Daten auf Basis von teilweise untereinander verknüpften Tabellen Datenbankmodell hat drei Eigenschaften (Codd, 1980) ① Generische Datenstruktur, die die Struktur von Daten in einer Datenbank beschreibt
• Beispiel: relationale Datenbank besteht aus Relationen (Tabellen) mit eindeutigen Namen • Relation = Menge von Tupeln (Datensätzen) gleichen Typs • Relationen und ihre Attribute (Spalten) können beliebig gewählt werden
② Menge von generischen Operatoren, die man auf die Datenstrukturen (siehe 1) anwenden kann, um Daten einzutragen, zu ändern, abzufragen oder abzuleiten
③ Menge von Integritätsbedingungen, mit denen die zulässigen Datenbankinhalte über die Datenstrukturen (siehe 1) weiter einschränken kann
• Beispiel: im relationalen Datenbankmodell kann jedes Attribut einer Relation als eindeutig bestimmt werden -> zwei Tupel dieser Relation dürfen dann nicht den gleichen Wert in diesem Attribut haben, ansonsten Verletzung der Integritätsbedingungen

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 17
(2) Logischer Entwurf Relationales Datenbankmodell
Kernfragen: • Welche Tabellen benötige ich? • Welche Spalten in den Tabellen benötige ich? • Wie sehen die möglichen Beziehungen zwischen den verschiedenen Datensätzen aus?
Kundennummer Name
10000 Max Müller
10001 Franziska Maier
10002 Schmid und Söhne GmbH
Tabelle Kunden
AdressID Kundennummer Straße ...
0 10000 Hauptstraße
1 10000 Bahnhofsstraße
Tabelle Adressen
Kunde
KN
Name
...
Adresse hat 1 n
Straße
Stadt
...
Aufgaben des logischen Entwurfs u.a.: • Überführung des ERM in relationales Datenschema • Festlegung der identifizierenden Schlüssel • Festlegungen zur technischen Umsetzung von
Beziehungen • Methodische Überprüfung der modellierten Ansätze
durch Normalisierung

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 18
(2) Logischer Entwurf Relationales Datenbankmodell - Terminologie
• Datenbank/Database: Ein Behältnis zum Speichern von Daten
Relationales Datenbankmodell: • Tabelle/Table:
Der Teil einer Datenbank, welche die Daten enthält. Eine Tabelle hat Spalten/Columns zur Speicherung der zeilenweise abgelegten Daten.
Kundennummer Name Kundentyp
10000 Max Müller 0
10001 Franziska Maier 0
10002 Schmid und Söhne GmbH 1
Tabelle Kunden
TypID Typbezeichnung
0 Privatkunde
1 Geschäftskunde
Tabelle Kundentypen • Spalten/Columns: Jede Spalte enthält ein Attribut eines Datensatzes in einem festgelegten Datentyp (z.B. string (Text), integer (Zahl), date)
• Zeile/Row: Der Datensatz in einer Tabelle
• Primärschlüssel/Primary Key: Eine oder mehrere Spalten, welche eindeutige Werte zur Referenzierung eines Datensatzes enthalten, z.B. Kundennummer

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 19
(2) Logischer Entwurf Vorgehen - Normalisierung
• Minimierung von Redundanzen und inneren Abhängigkeiten Normalisierung eines relationalen Datenschemas = Zerlegung von Relationen (Tabellen) gemäß Normalisierungsregeln -> 4 Normalformen (Codd, 1970) (Normalform 1-3 sind Gegenstand dieser VL)
• Datenredundanzen können zu inkonsistenten Datenbeständen führen, da der Fall eintreten kann, dass mehrfach enthaltene Daten nur teilweise geändert werden -> zudem unnötig Speicherplatz
• Vorgehen um ein relationales Datenschema in eine Normalform zu bringen -> fortschreitend Tabellen in einfachere Tabellen zerlegen bis keine weitere Zerlegung mehr möglich ist ohne Verlust von Daten
• Essentiell: das Schlüsselkonzept -> ein Schlüssel ist eine Menge von Attributen (eines oder mehrere), die eine Datenzeile einer Tabelle eindeutig identifiziert, z.B. Kunden-ID

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 20
(2) Logischer Entwurf Vorgehen - Normalisierung
1. Normalform (1NF): Jedes Attribut der Relation muss einen atomaren Wertebereich haben. • Zusammengesetzte Wertebereiche sind nicht erlaubt • Ziel: kein Attributwertebereich kann in weitere (sinnvolle) Teilbereiche aufgespalten werden, z.B.
Adresse wird aufgeteilt in PLZ, Ort, Straße, Hausnummer • Nutzen: Abfragen der Datenbank werden erleichtert bzw. überhaupt erst ermöglicht, da die
Attributwertebereiche atomar sind; Felder, die einen ganzen Text aus Titel, Vorname und Nachname enthalten, kann man nicht nach dem Nachnamen sortieren
(Bildquelle: wikipedia.de)
Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 21
(2) Logischer Entwurf Vorgehen - Normalisierung
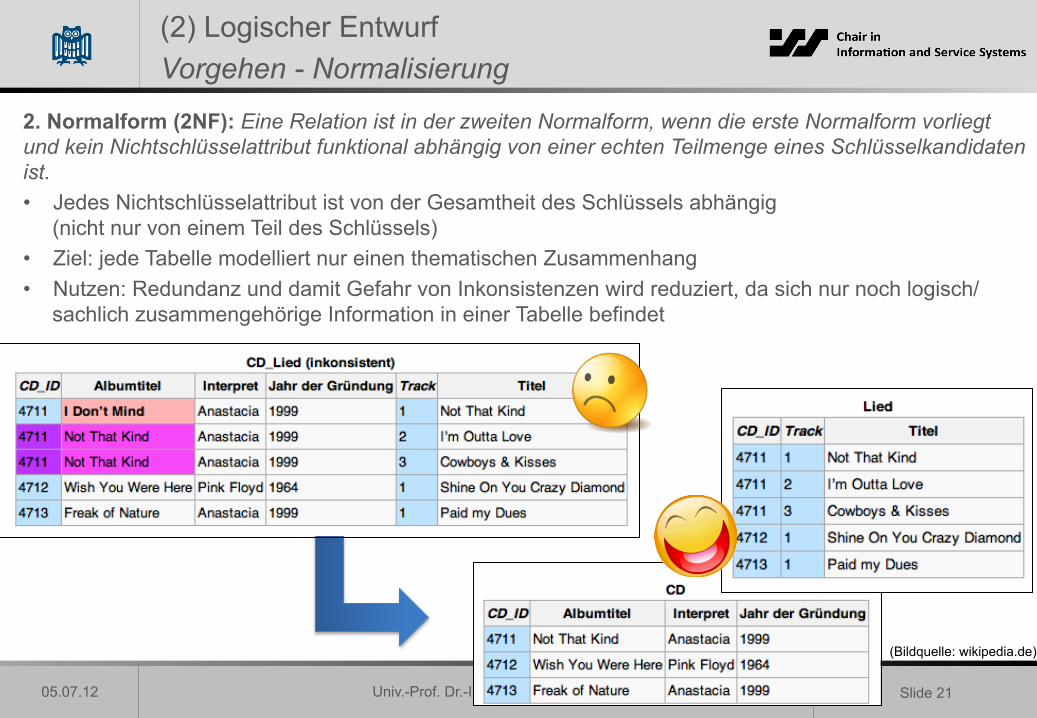
2. Normalform (2NF): Eine Relation ist in der zweiten Normalform, wenn die erste Normalform vorliegt und kein Nichtschlüsselattribut funktional abhängig von einer echten Teilmenge eines Schlüsselkandidaten ist. • Jedes Nichtschlüsselattribut ist von der Gesamtheit des Schlüssels abhängig
(nicht nur von einem Teil des Schlüssels) • Ziel: jede Tabelle modelliert nur einen thematischen Zusammenhang • Nutzen: Redundanz und damit Gefahr von Inkonsistenzen wird reduziert, da sich nur noch logisch/
sachlich zusammengehörige Information in einer Tabelle befindet
(Bildquelle: wikipedia.de)
Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 22
(2) Logischer Entwurf Vorgehen - Normalisierung
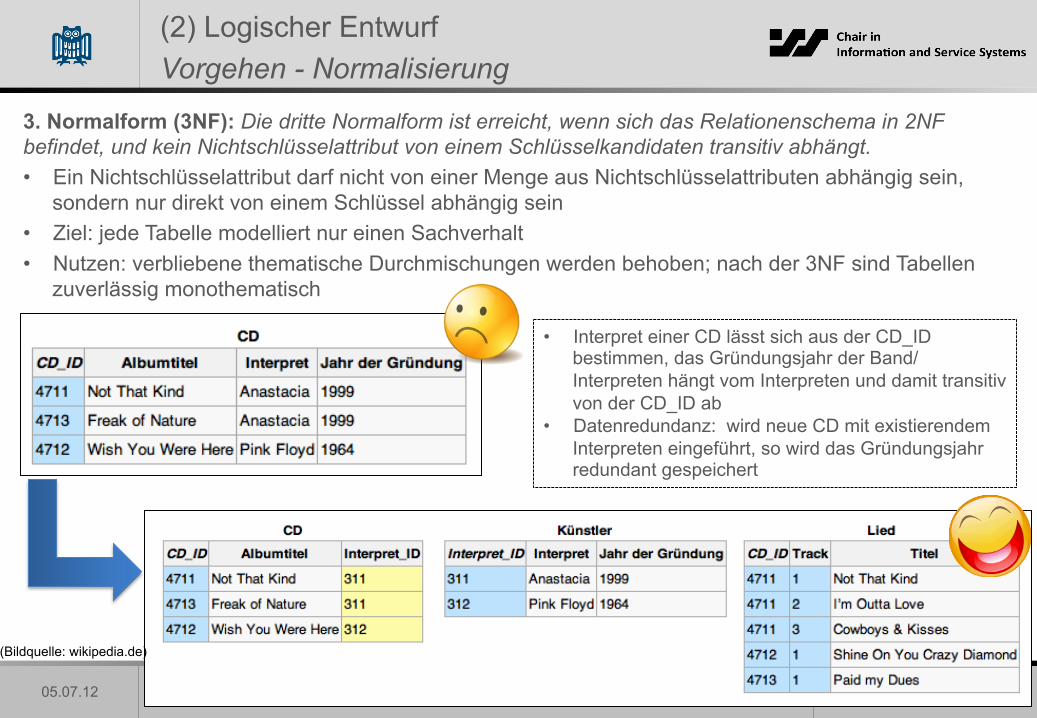
3. Normalform (3NF): Die dritte Normalform ist erreicht, wenn sich das Relationenschema in 2NF befindet, und kein Nichtschlüsselattribut von einem Schlüsselkandidaten transitiv abhängt. • Ein Nichtschlüsselattribut darf nicht von einer Menge aus Nichtschlüsselattributen abhängig sein,
sondern nur direkt von einem Schlüssel abhängig sein • Ziel: jede Tabelle modelliert nur einen Sachverhalt • Nutzen: verbliebene thematische Durchmischungen werden behoben; nach der 3NF sind Tabellen
zuverlässig monothematisch
• Interpret einer CD lässt sich aus der CD_ID bestimmen, das Gründungsjahr der Band/Interpreten hängt vom Interpreten und damit transitiv von der CD_ID ab
• Datenredundanz: wird neue CD mit existierendem Interpreten eingeführt, so wird das Gründungsjahr redundant gespeichert
(Bildquelle: wikipedia.de)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 23
Relevante Objekte der “realen Welt” im Kontext des Informations-systems, z.B.
Personen
Vorgehen bei der Datenmodellierung
(1)
Konzeptueller Entwurf
(2)
Logischer Entwurf
(3)
Physischer Entwurf
Konzeptuelles Modell Fachliches Abbild durch
Typisierung und Beschreibung, z.B. Entity-
Relationship-Modell
Logisches Datenbankschema
Datentechnische Festlegung des
Datenbankmodells, z.B. Schlüssel
Physisches Datenbankschema
Script zur Erstellung der Datenbank gemäß
Datenbank Management System (DBMS)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 24
(3) Physischer Entwurf
• Umsetzung des logischen Datenbankschemas in ein physisches Datenbankschema: Formulierung aller Angaben in der Syntax des Datenbank-Management-System (DBMS) zur Datenbankgenerierung
• DBMS = Menge aus Komponenten zur Definition, Erstellung und Verwaltung von Datenbanken
• Abfrage und Manipulation der Daten überwiegend durch Datenbanksprache SQL (Structured Query Language)
• Beispiel: Anlegen einer Datenbank “Shop” sowie einer Tabelle “Kunden”, die anschließend wieder gelöscht werden mittels SQL (im Rahmen eines relationalen DBMS)
���mysql> create database `Shop`; Query OK, 1 row affected (0.00 sec) mysql> use `Shop`; Database changed ���mysql> create table `Kunden` (`Kundennummer` INT NOT NULL AUTO_INCREMENT, `Name` VARCHAR(45), PRIMARY KEY (`Kundennummer`)); Query OK, 0 rows affected (0.02 sec) ���mysql> drop table `Kunden`; Query OK, 0 rows affected (0.00 sec) mysql> drop database `Shop`; Query OK, 0 rows affected (0.04 sec)
SQL Kommandozeile
Datenbanksystem
Anwendung DBMS Datenbank-‐
Dateien

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 25
(3) Physischer Entwurf
Physischer Entwurf unter Einsatz von Generatoren automatisch oder halbautomatisch möglich, z.B. MySQL DBMS
Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 26
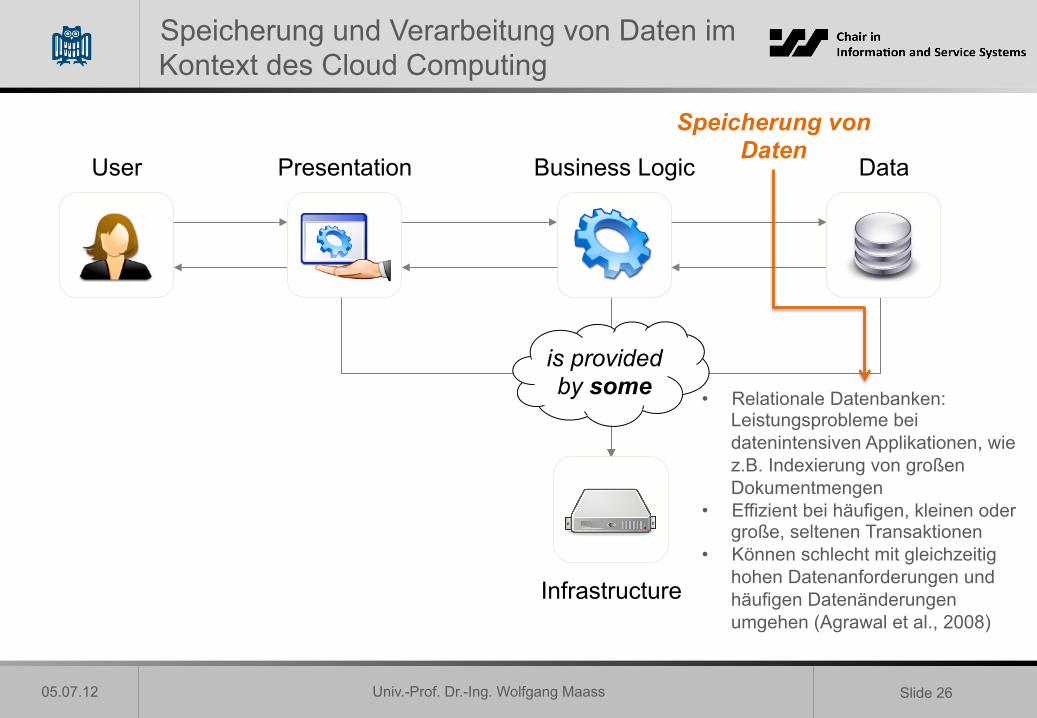
Speicherung und Verarbeitung von Daten im Kontext des Cloud Computing
Presentation Business Logic Data User
Speicherung von Daten
• Relationale Datenbanken: Leistungsprobleme bei datenintensiven Applikationen, wie z.B. Indexierung von großen Dokumentmengen
• Effizient bei häufigen, kleinen oder große, seltenen Transaktionen
• Können schlecht mit gleichzeitig hohen Datenanforderungen und häufigen Datenänderungen umgehen (Agrawal et al., 2008)
Infrastructure
is provided by some

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 27
Alternative Ansätze zur Datenspeicherung NoSQL
• NoSQL = not only SQL (SQL = Sprache zur Definition, Abfrage und Manipulation von relationalen Datenbanken) -> Datenbanken, die einen nicht-relationalen Ansatz verfolgen
• Merkmale: - kein festgelegtes Datenbankschema - Nicht relational - Kann mit vielen Schreib-/Leseanfragen umgehen - Schwache Garantien hinsichtlich Konsistenz oder auf einzelne
Datensätze eingeschränkte Transaktionen - Unterstützung von verteilten Datenbanken mit redundanter
Datenhaltung auf vielen Servern -> Systeme können einfach skalieren und Ausfälle einzelner Server überstehen
• Bekannte Implementierungen, z.B. Google BigTable, Amazon Dynamo; Open-Source-Implementierungen, z.B. CouchDB, Apache Cassandra, MongoDB
• Anwendung von NoSQL-Ansatz z.B. bei Facebook, eBay
Vertiefung in Veranstaltung “Web Technologien” im
WS12/13

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 28
Alternative Ansätze zur Datenspeicherung NoSQL-Typen
• Graphendatenbank, z.B. Neo4j: Speichern von komplexen Baum- und Netzwerkstrukturen, z.B. bei Twitter um Follower-Beziehungen zwischen den Mitgliedern abzulegen
• Objektorientierte Datenbanken, z.B. db4objects: Speicherung von Daten als Objekte; Einbettung in Anwendungen, die ojektorientiert programmiert sind
• Spaltenorientierte Datenbanken, z.B. HBase: Inhalte werden spaltenweise statt zeilenweise abspeichert; Vorteile beim Festplattenzugriff
• Dokumentorientierte Datenbanken, z.B. CouchDB: Dokumente bilden Grundeinheit zur Speicherung der Daten, z.B. JSON-formatierte Dokumente (XML-basiert)
• Key/Value-Stores, z.B. memcached: Einfache schlüsselbasierende Zugriffe auf Daten, die als Schlüssel-Wert-Paare abgelegt sind

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 29
Speicherung und Verarbeitung von Daten im Kontext des Cloud Computing
Presentation Business Logic Data User
Verarbeitung von Daten
Speicherung von Daten
• Relationale Datenbanken: Leistungsprobleme bei datenintensiven Applikationen, wie z.B. Indexierung von großen Dokumentmengen
• Effizient bei häufigen, kleinen oder große, seltenen Transaktionen
• Können schlecht mit gleichzeitig hohen Datenanforderungen und häufigen Datenänderungen umgehen (Agrawal et al., 2008)
• Verarbeitung vieler Datensätze (Big Data) • schneller Import großer Datenmengen • sofortige Abfrage importierter Daten (Realtime-
Processing) • kurze Antwortzeiten auch bei komplexen
Abfragen • Möglichkeit zur Verarbeitung vieler gleichzeitiger
Abfragen (Concurrent Queries)
Infrastructure
is provided by some

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 30
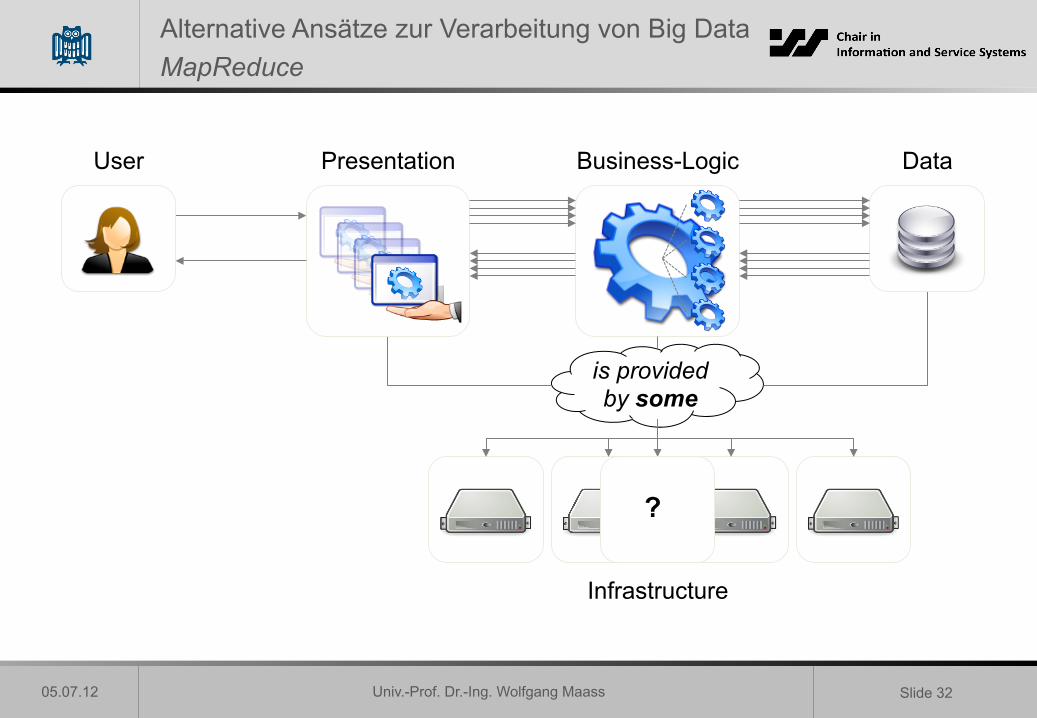
Alternative Ansätze zur Verarbeitung von Big Data MapReduce
• MapReduce = von Google eingeführtes Framework für nebenläufige Berechnungen über große (mehrere Petabyte) Datenmengen auf Computerclustern (US-Patent 2010)
• Für große Datenmengen • Für Datenverarbeitung ohne viel
Synchronisation • Keine schnellen Antwortzeiten • Keine komplexen
Rechenoperationen
Performance: Speedup with respect to sequential execution
1 - Workers:
(Ranger et al., 2007)

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 31
Alternative Ansätze zur Verarbeitung von Big Data MapReduce
2 - Datasize
(Ranger et al., 2007)
Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 32
Alternative Ansätze zur Verarbeitung von Big Data MapReduce
is provided by some
Infrastructure
Presentation Business-Logic Data User
?

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 33
Alternative Ansätze zur Verarbeitung von Big Data MapReduce
MapReduce Schritte: (1) Daten in Arbeitspakete aufteilen
(2) Arbeitspakete an die Knoten verteilen
(3) Map: Jeder Knoten wendet die Arbeitslogik auf sein eigenes Arbeitspaket an
Ergebnis: Liste aus Schlüssel/Wert-Paaren mit z.T. Schlüssel-Duplikaten
(4) Reduce: Zueinander gehörende Teilergebnisse (gleicher Schlüssel) werden aggregiert Ergebnis: Liste aus Schlüssel/Wert-Paaren mit einzigartigen Schlüsseln
(5) Weitere Zusammenführung zu Endergebnis

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 34
Alternative Ansätze zur Verarbeitung von Big Data MapReduce - Beispiel
Quelle: http://blog.jteam.nl/2009/08/04/introduction-to-hadoop/
Weiteres Beispiel zu MapReduce in der Übung am 12. Juli !

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 35
Alternative Ansätze zur Verarbeitung von Big Data MapReduce - Beispielimplementation
Apache Hadoop Distributed File System (HDFS) = Key-Value-Store (Hbase) + MapReduce Framework
Quelle: http://en.wikipedia.org/wiki/Hadoop

Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 36
Literatur
Bücher: • Ferstl, O. K. & Sinz, E. J. (2006), Grundlagen der Wirtschaftsinformatik, Oldenbourg Wissenschaftsverlag. • Peirce, C. S. (1907), Pragmatism. • de Saussure, F. (1995), Cours de linguistique générale, PAYOT. • Embley, D. W. & Thalheim, B., ed. (2011), Handbook of Conceptual Modeling: Theory, Practice, and Research Challenges, Springer.
Paper: • Agrawal, R.; Ailamaki, A.; Bernstein, P. A.; Brewer, E. A.; Carey, M. J.; Chaudhuri, S.; Doan, A.; Florescu, D.; Franklin, M. J.; Garcia-Molina, H.;
Gehrke, J.; Gruenwald, L.; Haas, L. M.; Halevy, A. Y.; Hellerstein, J. M.; Ioannidis, Y. E.; Korth, H. F.; Kossmann, D.; Madden, S.; Magoulas, R.; Ooi, B. C.; O'Reilly, T.; Ramakrishnan, R.; Sarawagi, S.; Stonebraker, M.; Szalay, A. S. & Weikum, G. (2008), 'The Claremont report on database research', SIGMOD Rec. 37(3), 9—19.
• Chen, P. P.-S. (1976), 'The Entity-Relationship Model–Toward a Unified View of Data', ACM Transactions on Database Systems 1(1). • Codd, E. F. (1983), 'A relational model of data for large shared data banks', Commun. ACM 26(1), 64—69. • Codd, E. F. (1980): Data models in database management, Proceedings of the 1980 Workshop on Data Abstraction, Databases and Conceptual
Modeling, • Maass, W. & Janzen, S. (2011), Pattern-Based Approach for Designing with Diagrammatic and Propositional Conceptual Models, in '6th Int. Conf.
on Design Science Research in Information Systems and Technology (DESRIST 2011), Milwaukee, Wisconsin, USA’. • Ranger, C.; Raghuraman, R.; Penmetsa, A.; Bradski, G. & Kozyrakis, C. (2007), Evaluating MapReduce for Multi-core and Multiprocessor
Systems, in 'Proceedings of the 2007 IEEE 13th International Symposium on High Performance Computer Architecture', IEEE Computer Society, Washington, DC, USA, pp. 13—24.
Web: • http://wirtschaftslexikon.gabler.de/ • http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=7229 • http://blog.jteam.nl/2009/08/04/introduction-to-hadoop/
Univ.-Prof. Dr.-Ing. Wolfgang Maass
05.07.12 Slide 37
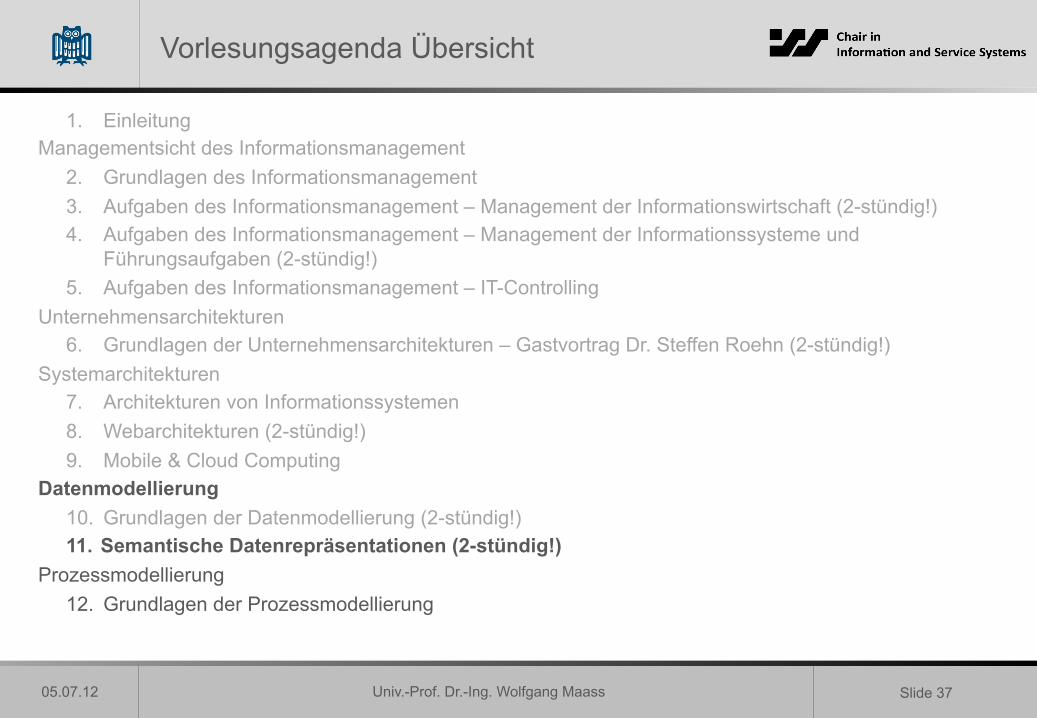
Vorlesungsagenda Übersicht
1. Einleitung Managementsicht des Informationsmanagement
2. Grundlagen des Informationsmanagement 3. Aufgaben des Informationsmanagement – Management der Informationswirtschaft (2-stündig!) 4. Aufgaben des Informationsmanagement – Management der Informationssysteme und
Führungsaufgaben (2-stündig!) 5. Aufgaben des Informationsmanagement – IT-Controlling
Unternehmensarchitekturen 6. Grundlagen der Unternehmensarchitekturen – Gastvortrag Dr. Steffen Roehn (2-stündig!)
Systemarchitekturen 7. Architekturen von Informationssystemen 8. Webarchitekturen (2-stündig!) 9. Mobile & Cloud Computing
Datenmodellierung 10. Grundlagen der Datenmodellierung (2-stündig!) 11. Semantische Datenrepräsentationen (2-stündig!)
Prozessmodellierung 12. Grundlagen der Prozessmodellierung

Univ.-Prof. Dr.-Ing. Wolfgang Maass
Univ.-Prof. Dr.-Ing. Wolfgang Maass Lehrstuhl für Betriebswirtschaftslehre, insb. Wirtschaftsinformatik im Dienstleistungsbereich (Information and Service Systems ISS) Universität des Saarlandes, Saarbrücken


















