Clusteranalyse - Technische Universität Chemnitz Multivariate Verfahren SS 2010 Seminarleiter: Dr....
42
23.06.2010 1 Seminar Multivariate Verfahren SS 2010 Seminarleiter: Dr. Thomas Schäfer Theresia Montag, Claudia Wendschuh & Anne Brantl Clusteranalyse Gliederung 1. Einführung 2. Vorgehensweise 1. Bestimmung der Ähnlichkeiten 2. Auswahl des Fusionierungsalgorithmus 3. Bestimmung der Clusteranzahl 3. Anwendungshinweise 4. Abgrenzung zu Faktorenanalyse 5. Fallbeispiel & SPSS
Transcript of Clusteranalyse - Technische Universität Chemnitz Multivariate Verfahren SS 2010 Seminarleiter: Dr....

23.06.2010
1
Seminar Multivariate Verfahren SS 2010
Seminarleiter: Dr. Thomas Schäfer
Theresia Montag, Claudia Wendschuh & Anne Brantl
Clusteranalyse
Gliederung
1. Einführung
2. Vorgehensweise
1. Bestimmung der Ähnlichkeiten
2. Auswahl des Fusionierungsalgorithmus
3. Bestimmung der Clusteranzahl
3. Anwendungshinweise
4. Abgrenzung zu Faktorenanalyse
5. Fallbeispiel & SPSS
23.06.2010
2
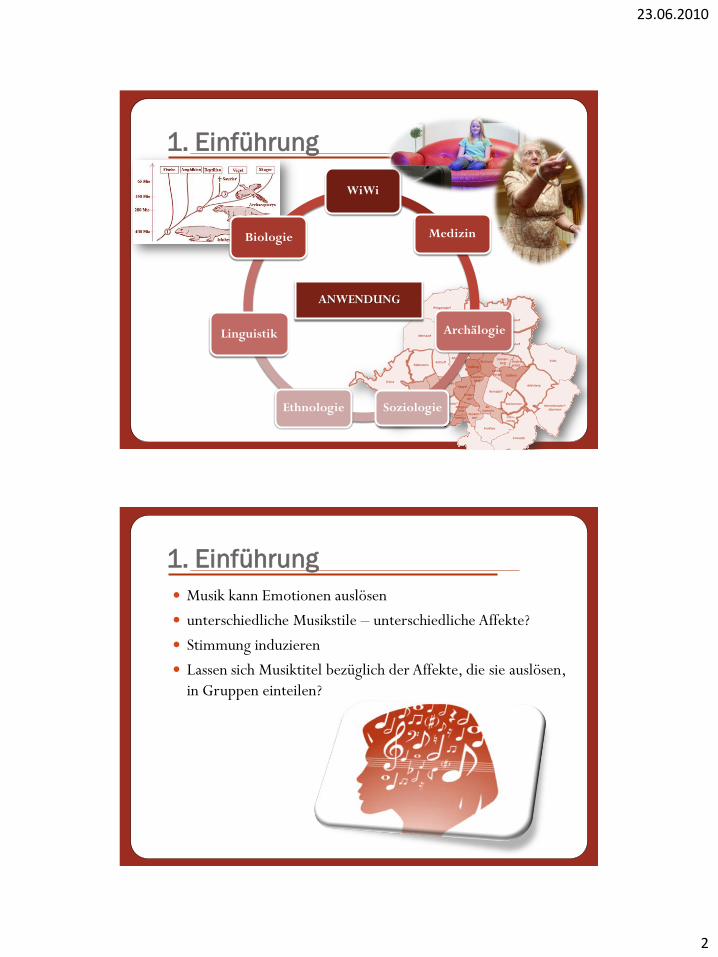
ANWENDUNG
WiWi
Medizin
Archälogie
SoziologieEthnologie
Linguistik
Biologie
1. Einführung
Musik kann Emotionen auslösen
unterschiedliche Musikstile – unterschiedliche Affekte?
Stimmung induzieren
Lassen sich Musiktitel bezüglich der Affekte, die sie auslösen,
in Gruppen einteilen?
1. Einführung
23.06.2010
3
1. Einführung
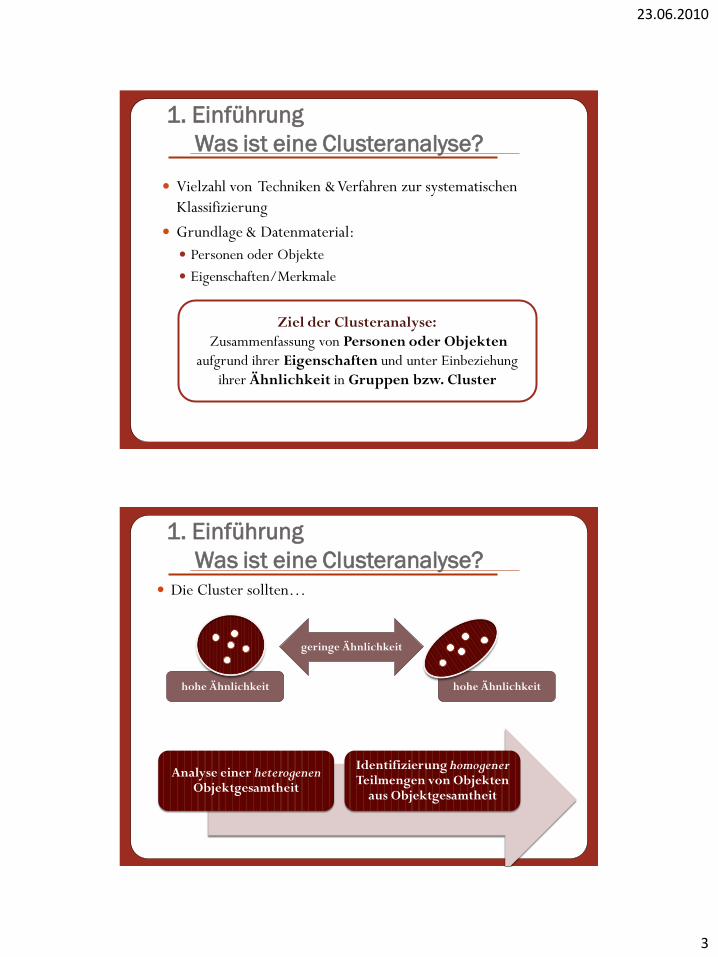
Was ist eine Clusteranalyse?
Vielzahl von Techniken & Verfahren zur systematischen
Klassifizierung
Grundlage & Datenmaterial:
Personen oder Objekte
Eigenschaften/Merkmale
Ziel der Clusteranalyse:
Zusammenfassung von Personen oder Objekten
aufgrund ihrer Eigenschaften und unter Einbeziehung
ihrer Ähnlichkeit in Gruppen bzw. Cluster
Die Cluster sollten…
Analyse einer heterogenenObjektgesamtheit
Identifizierung homogenerTeilmengen von Objekten
aus Objektgesamtheit
hohe Ähnlichkeit
geringe Ähnlichkeit
hohe Ähnlichkeit
1. Einführung
Was ist eine Clusteranalyse?
23.06.2010
4
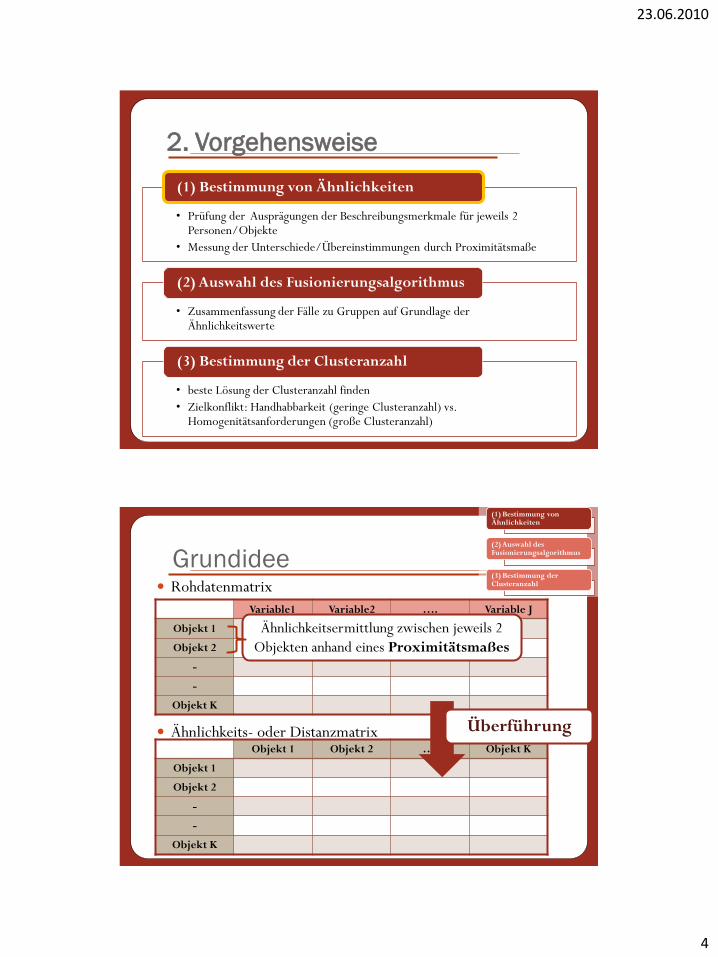
• Prüfung der Ausprägungen der Beschreibungsmerkmale für jeweils 2 Personen/Objekte
• Messung der Unterschiede/Übereinstimmungen durch Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
• Zusammenfassung der Fälle zu Gruppen auf Grundlage der Ähnlichkeitswerte
(2) Auswahl des Fusionierungsalgorithmus
• beste Lösung der Clusteranzahl finden
• Zielkonflikt: Handhabbarkeit (geringe Clusteranzahl) vs. Homogenitätsanforderungen (große Clusteranzahl)
(3) Bestimmung der Clusteranzahl
2. Vorgehensweise
Variable1 Variable2 …. Variable J
Objekt 1
Objekt 2
-
-
Objekt K
Ähnlichkeitsermittlung zwischen jeweils 2
Objekten anhand eines Proximitätsmaßes
Rohdatenmatrix
Ähnlichkeits- oder Distanzmatrix
Grundidee
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Objekt 1 Objekt 2 …. Objekt K
Objekt 1
Objekt 2
-
-
Objekt K
Überführung

23.06.2010
5
Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsmaße
• messen Ähnlichkeit zwischen 2 Objekten
• je größer Wert des Ähnlichkeitsmaßes, desto ähnlicher 2 Objekte
Distanzmaße
• messen Unähnlichkeit zwischen 2 Objekten
• je größer Distanz, desto unähnlicher 2 Objekte
… sind Maße, die eine Quantifizierung der
Ähnlichkeit oder Distanz zwischen den Objekten
ermöglichen
Proximitätsmaße
bei Nominal-Skalen
RR-Koeffizient
M-Koeffizient
Kulczynski-Koeffizent
bei metrischen Skalen
L1-Norm
L2-Norm
Mahalanobis-Distanz
Q-Korrelations-Koeffizient
Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Tanimoto-Koeffizient
Dice-Koeffizient

23.06.2010
6
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Spezialfall nominales Skalenniveau
Vergleich von jeweils 2 Objekten über alle
Merkmalsausprägungen hinweg
Unterscheidung von 4 Fällen:
Objekt 1
ZeilensummeEigenschaft
vorhanden (1)
Eigenschaft nicht
vorhanden (0)
Ob
jek
t 2 Eigenschaft
vorhanden (1)a c a+c
Eigenschaft nicht
vorhanden (0)b d b+d
Spaltensumme a+b c+d m
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
Var
iab
le 1
Var
iab
le 2
Var
iab
le 3
Var
iab
le 4
Var
iab
le 5
Var
iab
le 6
Var
iab
le 7
Var
iab
le 8
Objekt 1 1 1 1 1 0 0 1 0
Objekt 2 1 1 0 1 0 1 0 1
Objekt 3 1 0 1 1 0 0 1 03x beide vorhanden
a = 3
2x nur bei Objekt 1 vorhanden
b = 2
2x nur bei Objekt 2 vorhanden
c = 2
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Rohdatenmatrix
1x beide nicht vorhanden
d = 1

23.06.2010
7
misst den relativen Anteil gemeinsamer Eigenschaften
Berechnung:
Rohdatenmatrix
Ähnlichkeitsmaße
a) Tanimoto-Koeffizient (Jaccard-Koeffizient):
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
a
a + b + cV
aria
ble
1
Var
iab
le 2
Var
iab
le 3
Var
iab
le 4
Var
iab
le 5
Var
iab
le 6
Var
iab
le 7
Var
iab
le 8
Objekt 1 1 1 1 1 0 0 1 0
Objekt 2 1 1 0 1 0 1 0 1
Objekt 3 1 0 1 1 0 0 1 0
a = 3
b = 2 c = 2
3
+ + 0,429
3 2 2
Objekt 1 Objekt 2 … Objekt K
Objekt 1 1
Objekt 2 1
… 1
Objekt K 1
misst den relativen Anteil gemeinsamer Eigenschaften
Berechnung:
Ähnlichkeitsmatrix (Tanimoto-Koeffizient)
Ähnlichkeitsmaße
a) Tanimoto-Koeffizient (Jaccard-Koeffizient):
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
a
a + b + c
3
+ + 0,429
3 2 2
0,429

23.06.2010
8
Ähnlichkeitsmaße
a) Tanimoto-Koeffizient (Jaccard-Koeffizient)
b) RR-Koeffizient (Russel & Rao):
c) M-Koeffizient (Simple Matching):
+ Eigenschaft vorhanden
- Eigenschaft nicht vorhanden
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
Berechnung:a
a + b + c + d
Berechnung:a + d
a + b + c + d
Objekt 1
Objekt 2 + -
+ a c
- b d
Wann verwende ich welches Ähnlichkeitsmaß ?
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
binärer Variablenstruktur
Vorhandensein eines Merkmals besitzt dieselbe
Aussagekraft für die Gruppierung wie das
Nichtvorhandensein
z.B. Verwendung des M- Koeffizienten
Vorhandensein eines Merkmals besitzt höhere
Aussagekraft für die Gruppierung wie das
Nichtvorhandensein
Verwendung des Tanimoto-Koeffizienten
a
a + b + c
a + d
a + b + c + d

23.06.2010
9
Proximitätsmaße
bei Nominal-Skalen
RR-Koeffizient
M-Koeffizient
Kulczynski-Koeffizent
bei metrischen Skalen
L1-Norm
L2-Norm
Mahalanobis-Distanz
Q-Korrelations-Koeffizient
Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Tanimoto-Koeffizient
Dice-Koeffizient
Voraussetzung: vergleichbare Maßeinheiten
Berechnung:
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
metrischer Variablenstruktur
Betrachtung der „Distanz“ zur Beschreibung der Beziehung zwischen 2 Objekten 2 Objekte sind ähnlich, wenn Distanz sehr klein ist
2 Objekte sind unähnlich, wenn Distanz sehr groß ist
Distanzmaße
a) Minkowski-Metriken (L-Normen):
d = Σ x - x k, l
J
j=1 kj lj
r
1
r
Distanz der
Objekte k und l
Wert der Variablen j bei
Objekt k, l (j=1,2,…J)
r > 1 : Minkowski-Konstante
r = 1
City-Block-Metrik (L1-Norm)
r = 2
Euklidische Distanz (L2-Norm)
23.06.2010
10
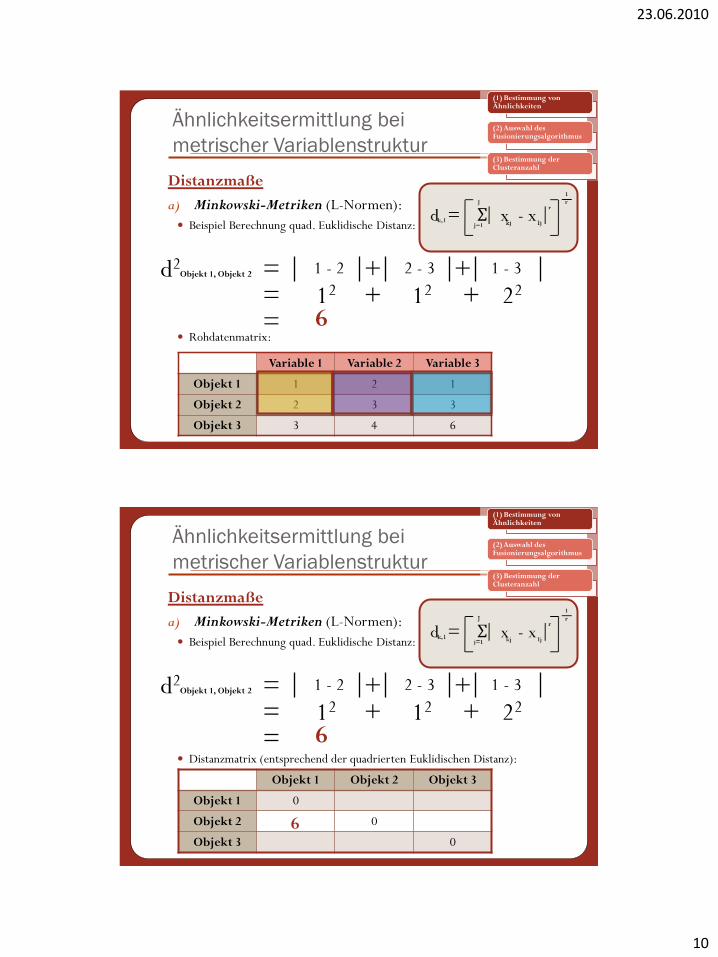
Variable 1 Variable 2 Variable 3
Objekt 1 1 2 1
Objekt 2 2 3 3
Objekt 3 3 4 6
d2 = + +
Beispiel Berechnung quad. Euklidische Distanz:
Rohdatenmatrix:
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
metrischer Variablenstruktur
Distanzmaße
a) Minkowski-Metriken (L-Normen):
Objekt 1, Objekt 2 1 - 2 2 - 3 1 - 3
= 12 + 12 + 22
= 6
Objekt 1 Objekt 2 Objekt 3
Objekt 1 0
Objekt 2 0
Objekt 3 0
d2 = + +
Beispiel Berechnung quad. Euklidische Distanz:
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsermittlung bei
metrischer Variablenstruktur
Distanzmaße
a) Minkowski-Metriken (L-Normen):
Objekt 1, Objekt 2 1 - 2 2 - 3 1 - 3
= 12 + 12 + 22
= Distanzmatrix (entsprechend der quadrierten Euklidischen Distanz):
6
6

23.06.2010
11
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ähnlichkeitsmaß
b) Q – Korrelationskoeffizient:
r = Σ (x - x ) (x - x )
J
j=1
jk
k jl l.
Σ (x - x ) Σ(x - x )
jk
k jl.
2 2 ½k, l
j=1 j=1
Ausprägung der Eigenschaft j bei Objekt
(Cluster) k (bzw. 1), wobei: j = 1,2,…,J
Durchschnittswerte aller Eigenschaften
bei Objekt (Cluster) k (bzw. 1)
Ähnlichkeitsermittlung bei
metrischer Variablenstruktur
l
Anwendung der
Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Person A Person B
Ausprägung
Big Five
V
O
G
E
N
Distanzmaße
• absolute Abstand zwischen Objekte von Interesse
• Unähnlichkeit dann als größer anzusehen, wenn 2 Objekte weit entfernt voneinander liegen
Ähnlichkeitsmaße
• primärer Ähnlichkeitsaspekt im Gleichverlauf zweier Profile ersichtlich
• unabhängig vom Niveau der Objekte
23.06.2010
12
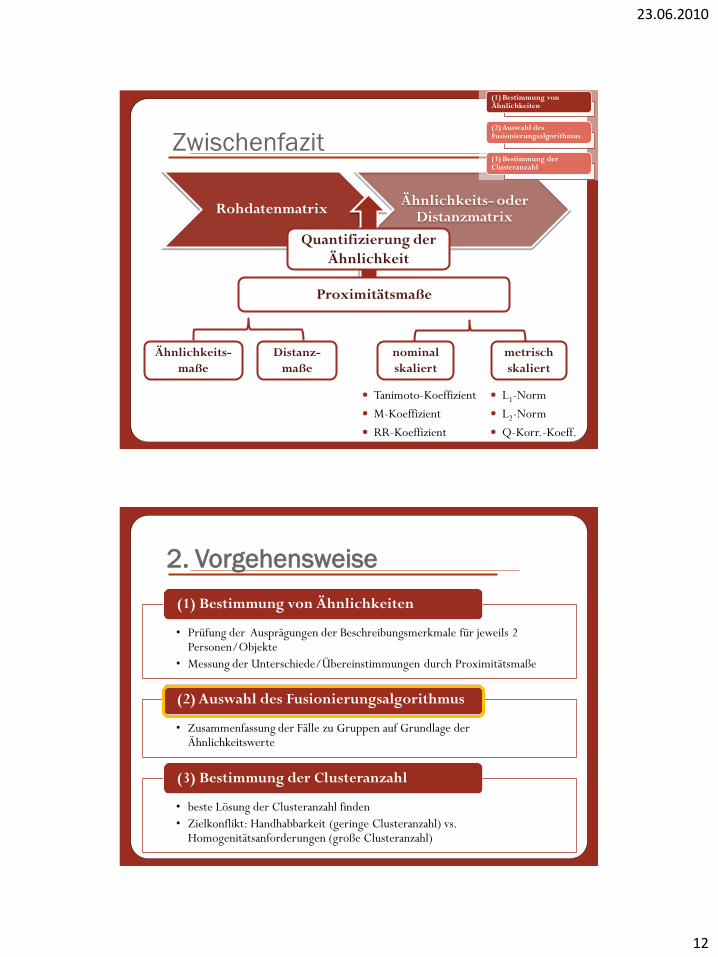
Zwischenfazit
RohdatenmatrixÄhnlichkeits- oder
Distanzmatrix
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Quantifizierung der
Ähnlichkeit
Proximitätsmaße
Ähnlichkeits-
maße
Distanz-
maße
nominal
skaliert
metrisch
skaliert
Tanimoto-Koeffizient
M-Koeffizient
RR-Koeffizient
L1-Norm
L2-Norm
Q-Korr.-Koeff.
• Prüfung der Ausprägungen der Beschreibungsmerkmale für jeweils 2 Personen/Objekte
• Messung der Unterschiede/Übereinstimmungen durch Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
• Zusammenfassung der Fälle zu Gruppen auf Grundlage der Ähnlichkeitswerte
(2) Auswahl des Fusionierungsalgorithmus
• beste Lösung der Clusteranzahl finden
• Zielkonflikt: Handhabbarkeit (geringe Clusteranzahl) vs. Homogenitätsanforderungen (große Clusteranzahl)
(3) Bestimmung der Clusteranzahl
2. Vorgehensweise

23.06.2010
13
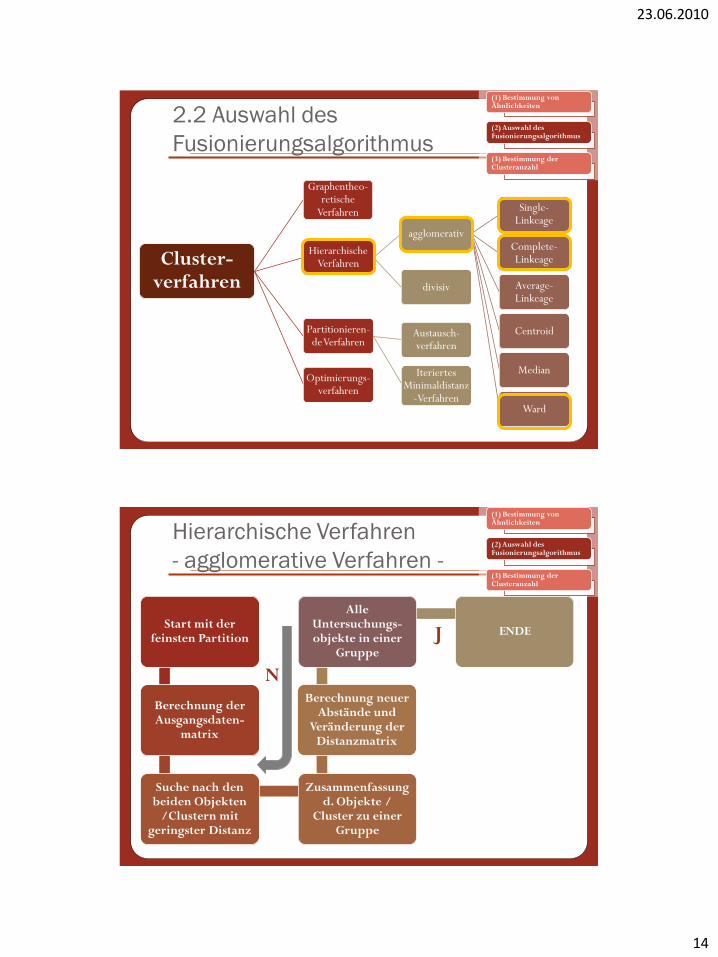
2.2 Auswahl des
Fusionierungsalgorithmus
Cluster-verfahren
Graphentheo-retische
Verfahren
Hierarchische Verfahren
agglomerativ
Single-Linkeage
Complete-Linkeage
Average-Linkeage
Centroid
Median
Ward
divisiv
Partitionieren-de Verfahren
Austausch-verfahren
Iteriertes Minimaldistanz
-Verfahren
Optimierungs-verfahren
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Partitionierende Verfahren
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Versuch besserer Lösung durch Objektverlagerung zwischen
Gruppen auf Basis vorgegebener Gruppeneinteilung
Ende der Clusterung
wenn alle Objekte bzgl. Verlagerung untersucht wurden und
keine Verbesserung des Varianzkriteriums mehr möglich ist
• Objekt 1
• Objekt 2
Gruppe A
• Objekt 2
• Objekt 3
Gruppe B
23.06.2010
14
2.2 Auswahl des
Fusionierungsalgorithmus
Cluster-verfahren
Graphentheo-retische
Verfahren
Hierarchische Verfahren
agglomerativ
Single-Linkeage
Complete-Linkeage
Average-Linkeage
Centroid
Median
Ward
divisiv
Partitionieren-de Verfahren
Austausch-verfahren
Iteriertes Minimaldistanz
-Verfahren
Optimierungs-verfahren
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
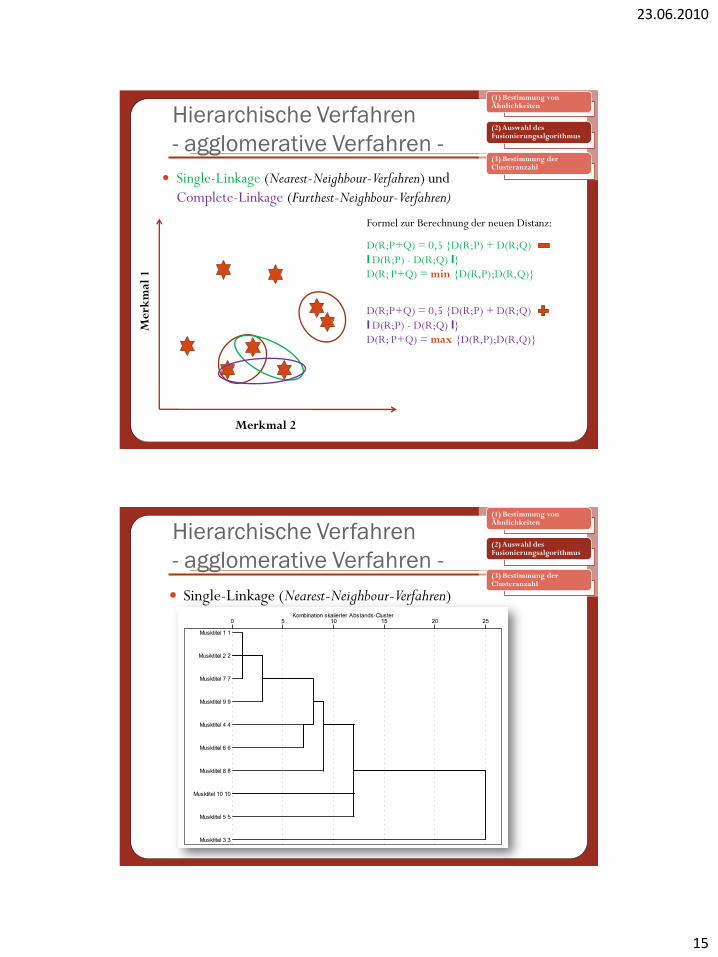
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Start mit der feinsten Partition
Berechnung der Ausgangsdaten-
matrix
Suche nach den beiden Objekten
/Clustern mitgeringster Distanz
Zusammenfassung d. Objekte /
Cluster zu einerGruppe
Berechnung neuer Abstände und
Veränderung der Distanzmatrix
Alle Untersuchungs-objekte in einer
Gruppe
ENDE
N
J
23.06.2010
15
Single-Linkage (Nearest-Neighbour-Verfahren) und
Complete-Linkage (Furthest-Neighbour-Verfahren)
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Formel zur Berechnung der neuen Distanz:
D(R;P+Q) = 0,5 {D(R;P) + D(R;Q)
I D(R;P) - D(R;Q) I}
D(R; P+Q) = min {D(R,P);D(R,Q)}
D(R;P+Q) = 0,5 {D(R;P) + D(R;Q)
I D(R;P) - D(R;Q) I}
D(R; P+Q) = max {D(R,P);D(R,Q)}
Mer
km
al 1
Merkmal 2
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Single-Linkage (Nearest-Neighbour-Verfahren)
23.06.2010
16
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
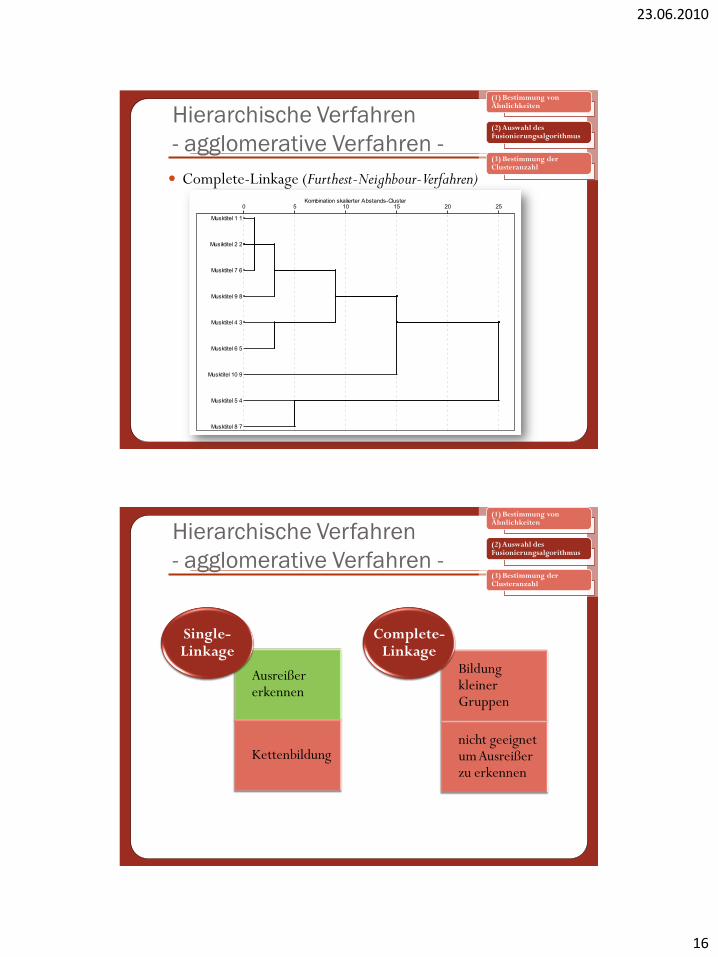
Complete-Linkage (Furthest-Neighbour-Verfahren)
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ausreißer erkennen
Kettenbildung
Single-Linkage
Bildung kleiner Gruppen
nicht geeignet um Ausreißer zu erkennen
Complete-Linkage
23.06.2010
17
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
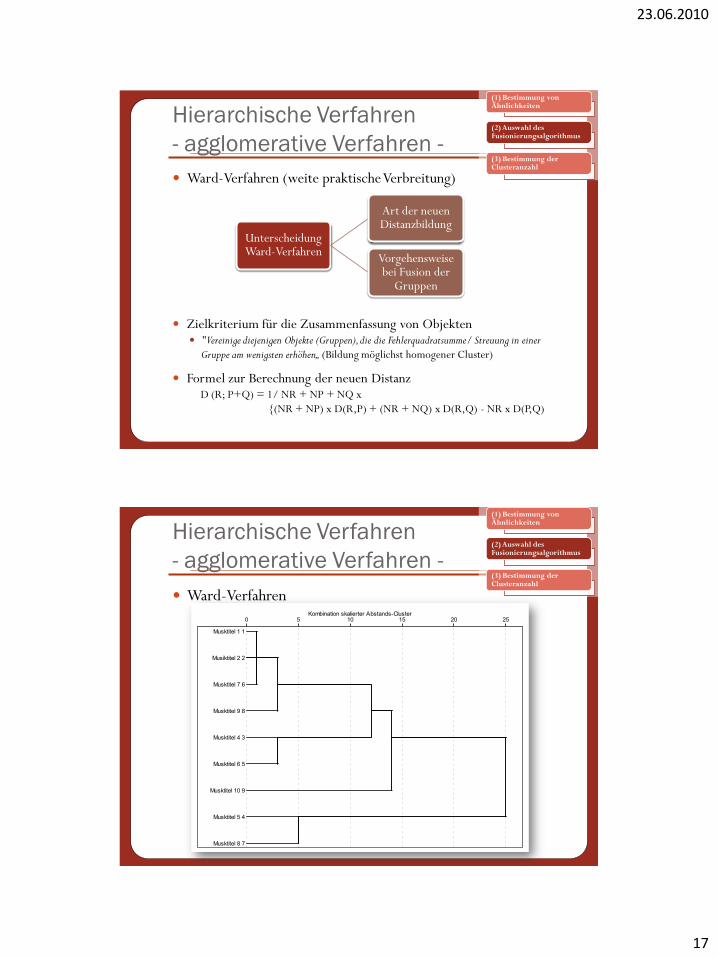
Ward-Verfahren (weite praktische Verbreitung)
Zielkriterium für die Zusammenfassung von Objekten "Vereinige diejenigen Objekte (Gruppen), die die Fehlerquadratsumme/ Streuung in einer
Gruppe am wenigsten erhöhen„ (Bildung möglichst homogener Cluster)
Formel zur Berechnung der neuen DistanzD (R; P+Q) = 1/ NR + NP + NQ x
{(NR + NP) x D(R,P) + (NR + NQ) x D(R,Q) - NR x D(P,Q)
Unterscheidung Ward-Verfahren
Art der neuen Distanzbildung
Vorgehensweise bei Fusion der
Gruppen
Hierarchische Verfahren
- agglomerative Verfahren -
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
Ward-Verfahren
23.06.2010
18
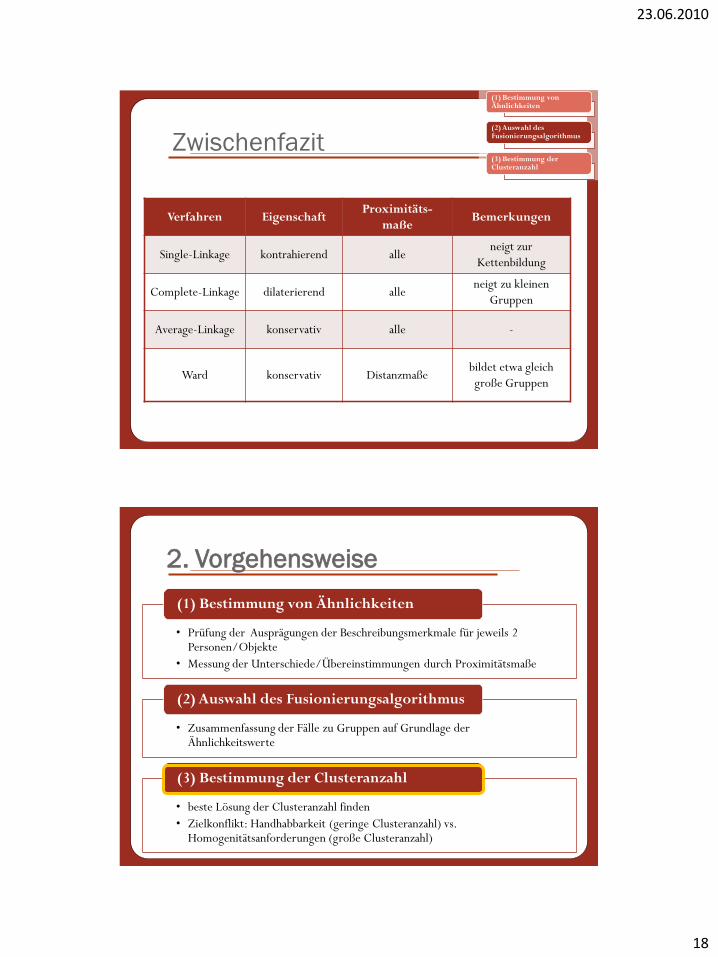
Zwischenfazit
Verfahren EigenschaftProximitäts-
maßeBemerkungen
Single-Linkage kontrahierend alleneigt zur
Kettenbildung
Complete-Linkage dilaterierend alleneigt zu kleinen
Gruppen
Average-Linkage konservativ alle -
Ward konservativ Distanzmaßebildet etwa gleich
große Gruppen
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
• Prüfung der Ausprägungen der Beschreibungsmerkmale für jeweils 2 Personen/Objekte
• Messung der Unterschiede/Übereinstimmungen durch Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
• Zusammenfassung der Fälle zu Gruppen auf Grundlage der Ähnlichkeitswerte
(2) Auswahl des Fusionierungsalgorithmus
• beste Lösung der Clusteranzahl finden
• Zielkonflikt: Handhabbarkeit (geringe Clusteranzahl) vs. Homogenitätsanforderungen (große Clusteranzahl)
(3) Bestimmung der Clusteranzahl
2. Vorgehensweise

23.06.2010
19
Entscheidung, welche Clusterlösung zu wählen ist
zumeist keine sachlogisch begründbare Vorstellungen
statistische Kriterien
Entwicklung des Heterogenitätsmaßes (z.B. Fehlerquadratsumme)
graphische Verdeutlichung: Dendrogramm
Elbow-Kriterium
sachlogische Kriterien
Homogenitätsanforderung an die Clusterlösung vs.
Handhabbarkeit der Clusterlösung
Auswahl Anzahl der Cluster, nicht Auswahl von Fällen
Bestimmung der Clusteranzahl
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
statistische Kriterien
Entwicklung des Heterogenitätsmaßes (z.B.
Fehlerquadratsumme)
Bestimmung der Clusteranzahl
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
„Sprünge“
23.06.2010
20
statistische Kriterien
graphische Verdeutlichung: Dendrogramm
Bestimmung der Clusteranzahl
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
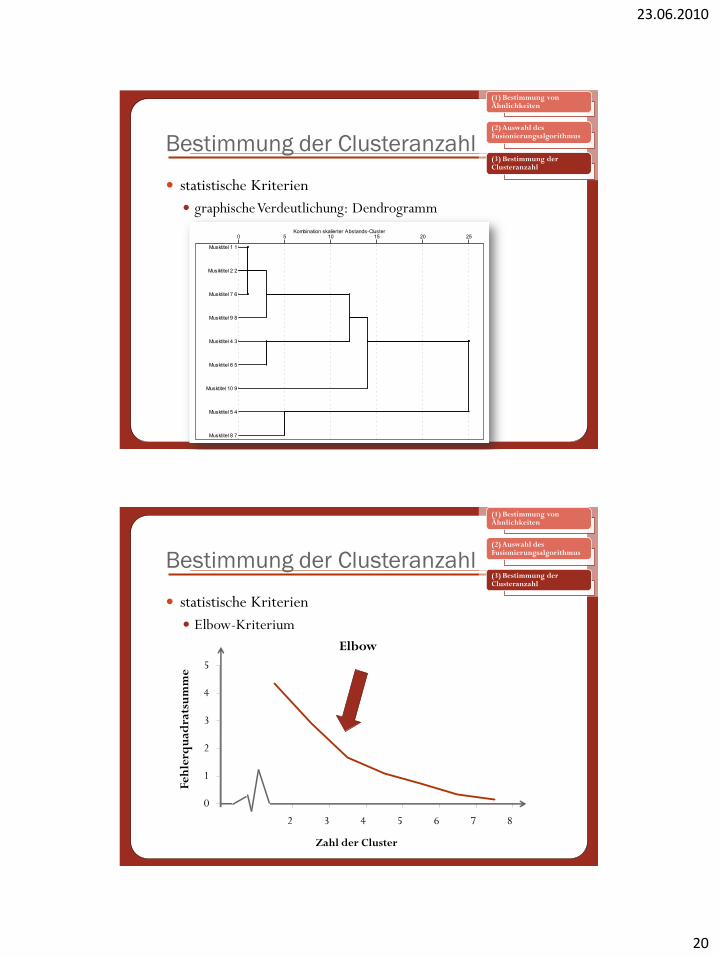
statistische Kriterien
Elbow-Kriterium
0
1
2
3
4
5
1 2 3 4 5 6 7 8
Elbow
Feh
lerq
uad
rats
um
me
Zahl der Cluster
Bestimmung der Clusteranzahl
(1) Bestimmung von Ähnlichkeiten
(2) Auswahl des Fusionierungsalgorithmus
(3) Bestimmung der Clusteranzahl
23.06.2010
21
• Prüfung der Ausprägungen der Beschreibungsmerkmale für jeweils 2 Personen/Objekte
• Messung der Unterschiede/Übereinstimmungen durch Proximitätsmaße
(1) Bestimmung von Ähnlichkeiten
• Zusammenfassung der Fälle zu Gruppen auf Grundlage der Ähnlichkeitswerte
(2) Auswahl des Fusionierungsalgorithmus
• beste Lösung der Clusteranzahl finden
• Zielkonflikt: Handhabbarkeit (geringe Clusteranzahl) vs. Homogenitätsanforderungen (große Clusteranzahl)
(3) Bestimmung der Clusteranzahl
2. Vorgehensweise
Ausreißer
relevante Merkmale
Gewichtung der Merkmale
Korrelation der Merkmale
unterschiedliches Skalenniveau
Gütemaße
3. AnwendungshinweiseSingle-Linkage
Vorschalten
Faktorenanalyse
Mahalanobis-
Distanz
Ausschluss
korrelierter Variable
Standardisierung
23.06.2010
22
Konkretisierung der
Problemstellung
Bestimmung der zu
klassifizierenden Objekte
Auswahl der Variablen
Festlegung eines Proximitätsmaßes
Auswahl eines Algorithmus
zur Gruppierung
Bestimmung der
Gruppenzahl
Durchführung des Gruppierungs-
vorganges
Analyse & Interpretation der Ergebnisse
3. Anwendungshinweise
Gemeinsamkeiten
Aufspüren „versteckter“ Größen
Datenreduktion
gleicher Ausgangspunkt/ Datenmatrix
Unterschiede
Clusteranalyse: Reduzierung der Objekte/ Personen
Faktorenanalyse: Reduzierung der Variablen/ Merkmale
4. Abgrenzung zu Faktorenanalyse
Variable1 Variable2 …. Variable J
Objekt 1
Objekt 2
-
-
Objekt K

23.06.2010
23
Unsere Studie:
Fragestellung:
Lassen sich Musikstile bezüglich der Affekte, die sie auslösen, ihrer Bekanntheit und ihrer Beliebtheit in Gruppen einordnen?
Objekte: 10 Musiktitel unterschiedlicher Musikrichtungen
Merkmalsausprägungen: Affekte, Beliebtheit & Bekanntheit
Affekt: PANAS
Beliebtheit
Bekanntheit
23 Versuchspersonen, 15-53 Jahre (M=27.7, SD=11.55)
5. Fallbeispiel & SPSS
fünfstufige Lickert-Skala (gar nicht - äußerst
nominal, ja/nein
Praktische Schritte
1. Single-Linkage-Verfahren
2. Ward-Verfahren
3. Bestimmung Clusteranzahl
1. Dendrogramm
2. Elbow-Kriterium
4. Interpretation
23.06.2010
24
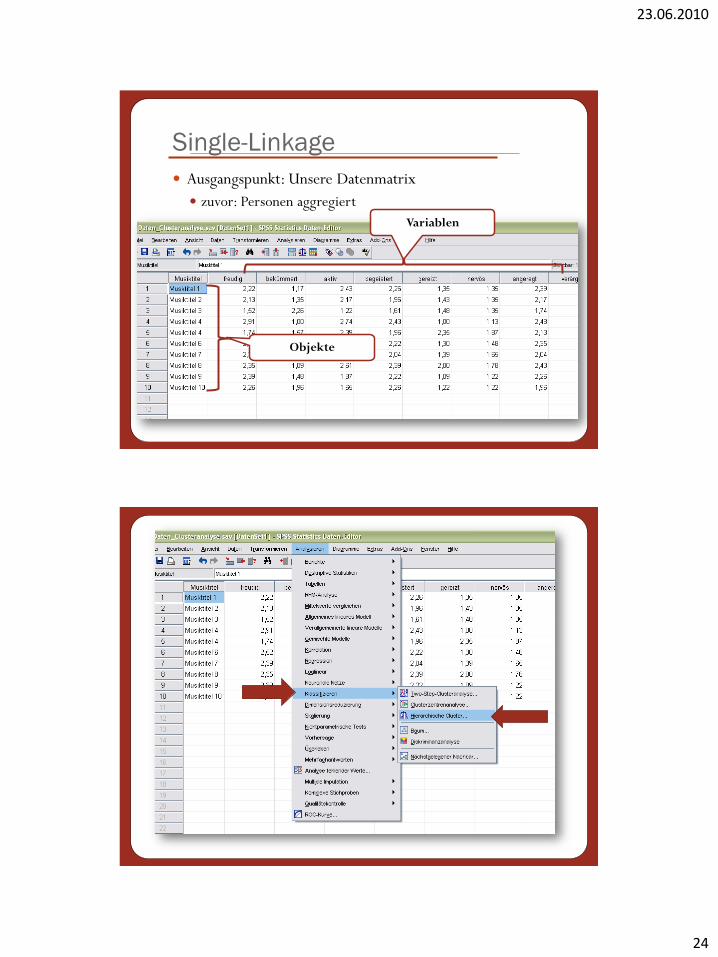
Single-Linkage
Ausgangspunkt: Unsere Datenmatrix
zuvor: Personen aggregiert
Variablen
Objekte
Single-Linkage
23.06.2010
25
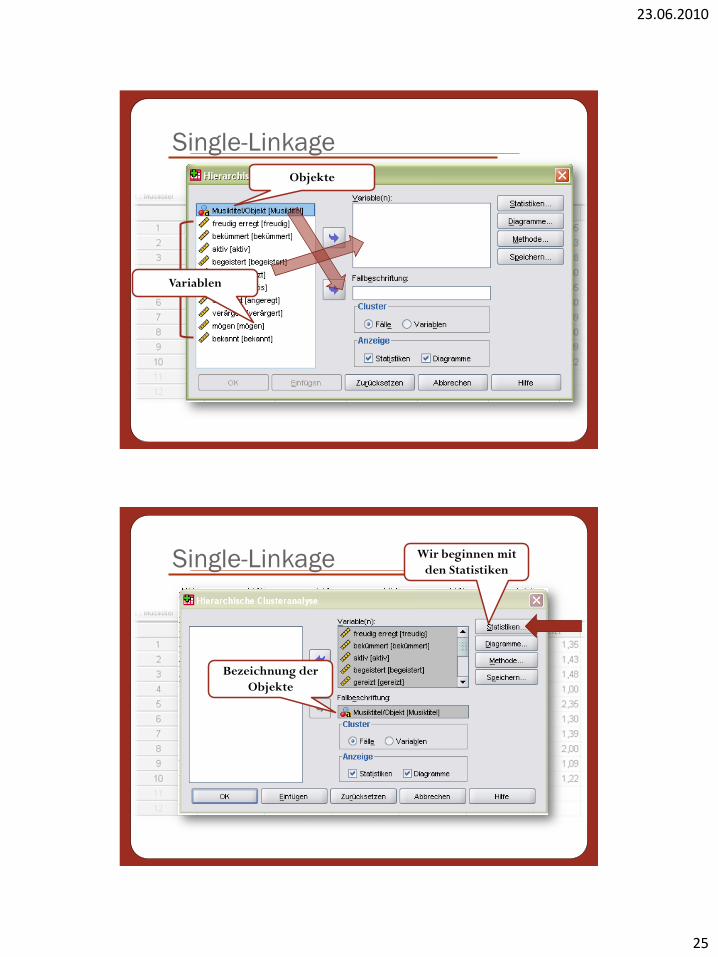
Single-Linkage
Objekte
Variablen
Single-Linkage
Bezeichnung der
Objekte
Wir beginnen mit
den Statistiken
23.06.2010
26
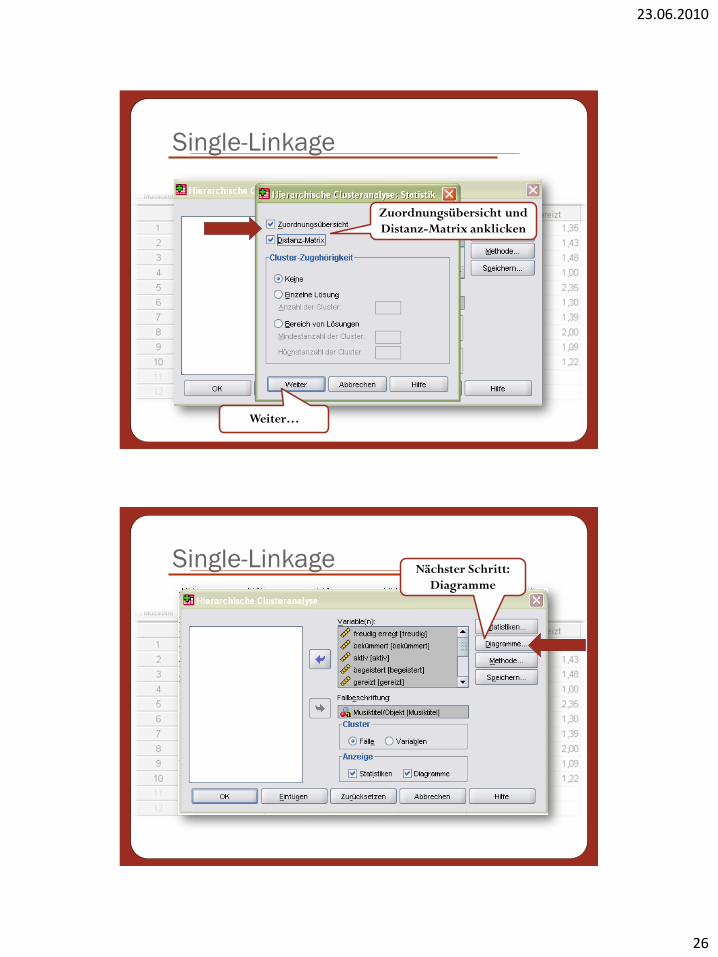
Single-Linkage
Zuordnungsübersicht und
Distanz-Matrix anklicken
Weiter…
Single-Linkage Nächster Schritt:
Diagramme
23.06.2010
27
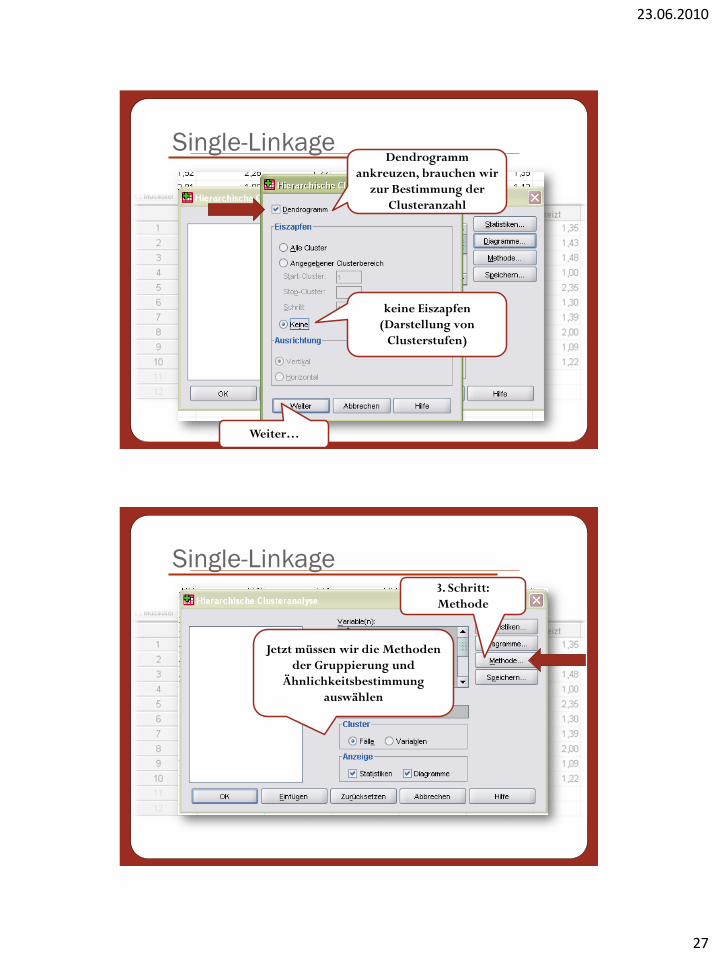
Single-LinkageDendrogramm
ankreuzen, brauchen wir
zur Bestimmung der
Clusteranzahl
keine Eiszapfen
(Darstellung von
Clusterstufen)
Weiter…
Single-Linkage3. Schritt:
Methode
Jetzt müssen wir die Methoden
der Gruppierung und
Ähnlichkeitsbestimmung
auswählen
23.06.2010
28
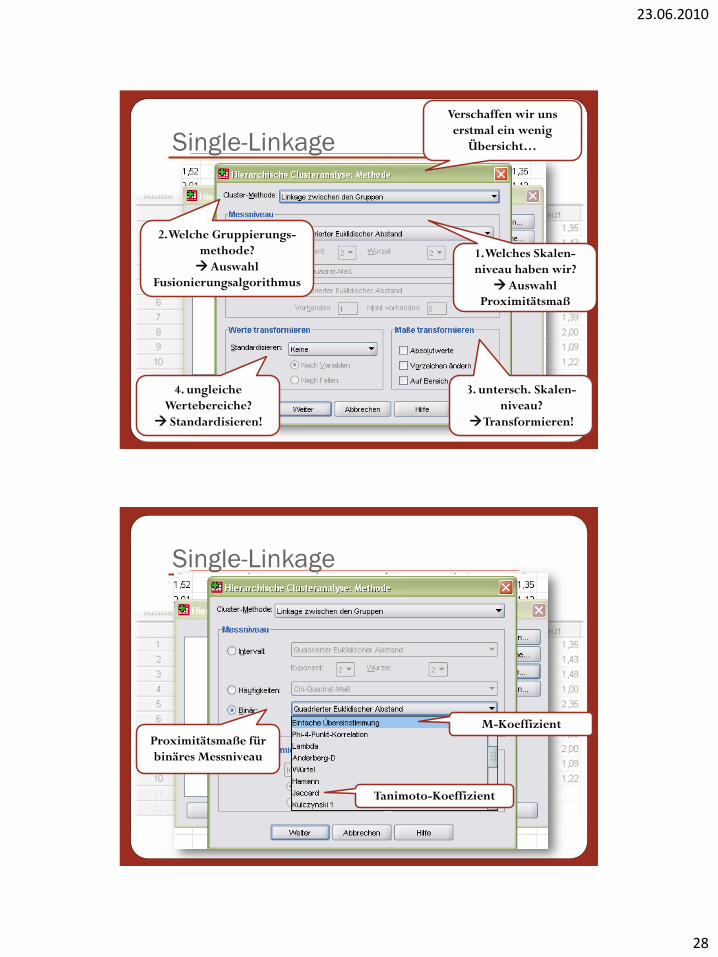
Single-Linkage
1. Welches Skalen-
niveau haben wir?
Auswahl
Proximitätsmaß
Verschaffen wir uns
erstmal ein wenig
Übersicht…
2. Welche Gruppierungs-
methode?
Auswahl
Fusionierungsalgorithmus
3. untersch. Skalen-
niveau?
Transformieren!
4. ungleiche
Wertebereiche?
Standardisieren!
Single-Linkage
Proximitätsmaße für
binäres Messniveau
M-Koeffizient
Tanimoto-Koeffizient

23.06.2010
29
Single-Linkage
Wir brauchen aber
Intervall-Skalierung
City-Block-Metrik (L1-Norm)
(L2-Norm)
Quadrierte
Euklidische Distanz
Auswählen!
Single-Linkage
City-Block-Metrik (L1-Norm)
nächstg. Nachbar =
Single-Linkage
Auswählen!
Complete-Linkage
Average-Linkage
Zuletzt wählen wir
unseren
Fusionierungsalgorithmus
Weiter…
23.06.2010
30
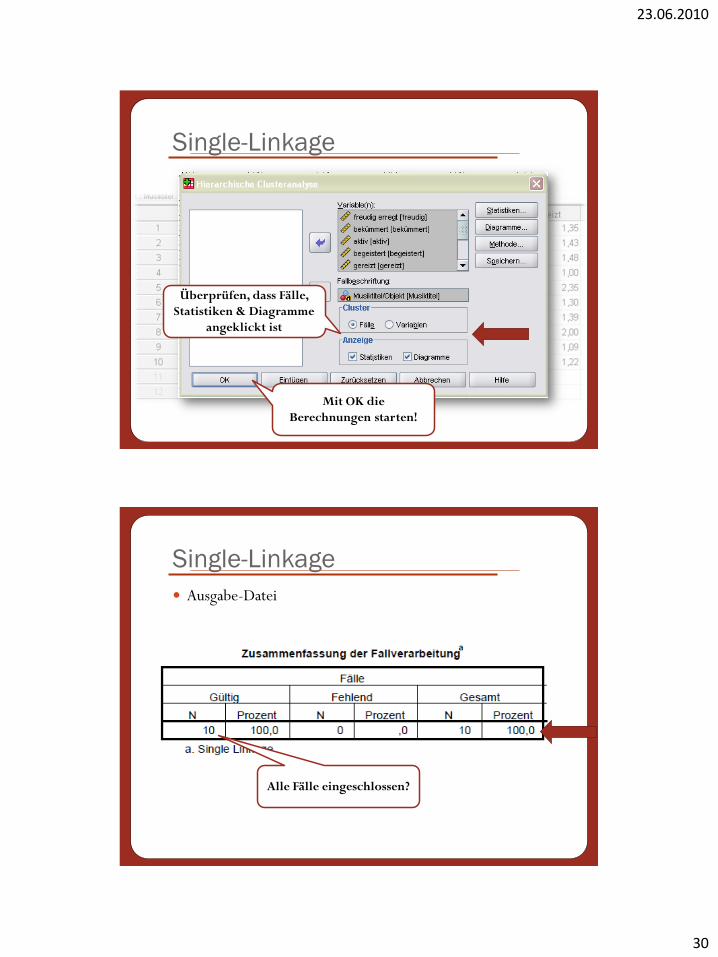
Single-Linkage
Überprüfen, dass Fälle,
Statistiken & Diagramme
angeklickt ist
Mit OK die
Berechnungen starten!
Ausgabe-Datei
Single-Linkage
Alle Fälle eingeschlossen?
23.06.2010
31
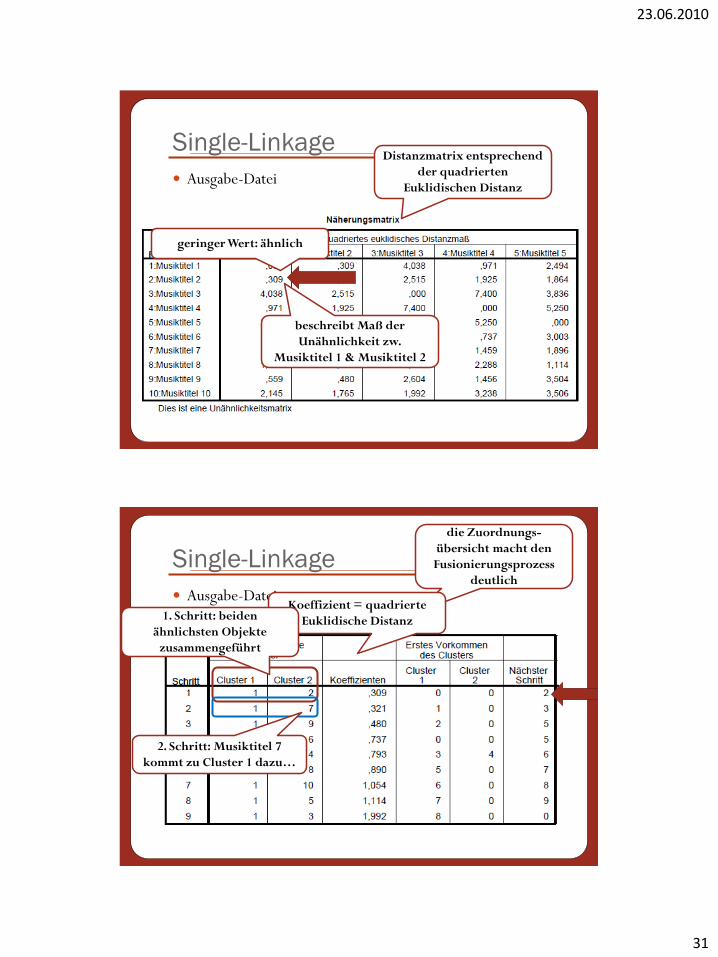
Ausgabe-Datei
Single-LinkageDistanzmatrix entsprechend
der quadrierten
Euklidischen Distanz
beschreibt Maß der
Unähnlichkeit zw.
Musiktitel 1 & Musiktitel 2
geringer Wert: ähnlich
Ausgabe-Datei
Single-Linkage
die Zuordnungs-
übersicht macht den
Fusionierungsprozess
deutlich
Koeffizient = quadrierte
Euklidische Distanz1. Schritt: beiden
ähnlichsten Objekte
zusammengeführt
2. Schritt: Musiktitel 7
kommt zu Cluster 1 dazu…
23.06.2010
32
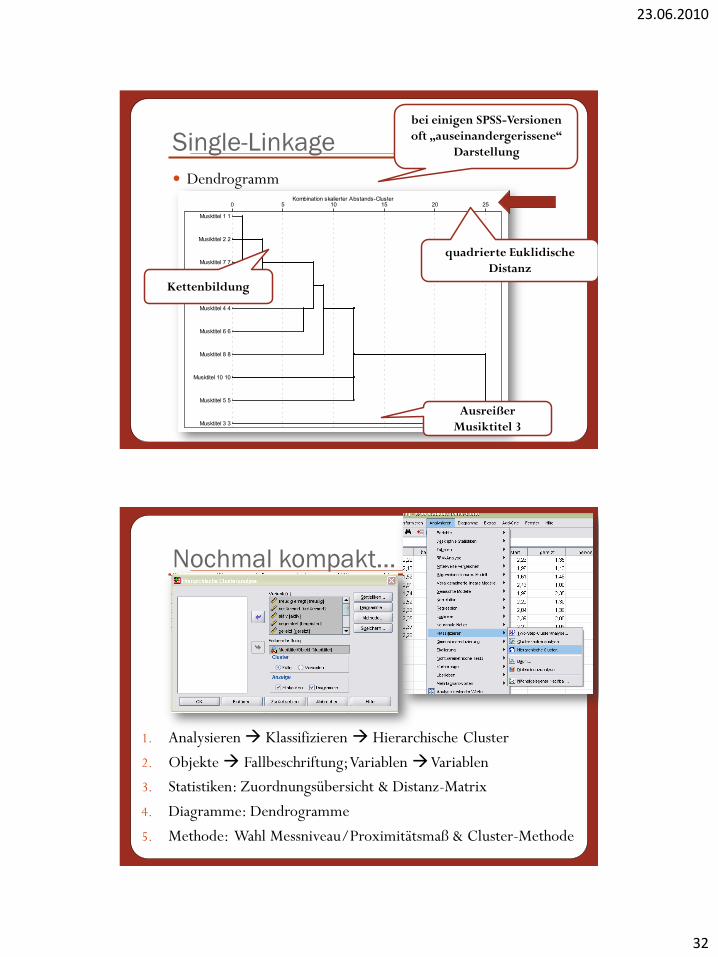
Dendrogramm
Single-Linkagebei einigen SPSS-Versionen
oft „auseinandergerissene“
Darstellung
quadrierte Euklidische
Distanz
Kettenbildung
Ausreißer
Musiktitel 3
Nochmal kompakt…
1. Analysieren Klassifizieren Hierarchische Cluster
2. Objekte Fallbeschriftung; Variablen Variablen
3. Statistiken: Zuordnungsübersicht & Distanz-Matrix
4. Diagramme: Dendrogramme
5. Methode: Wahl Messniveau/Proximitätsmaß & Cluster-Methode

23.06.2010
33
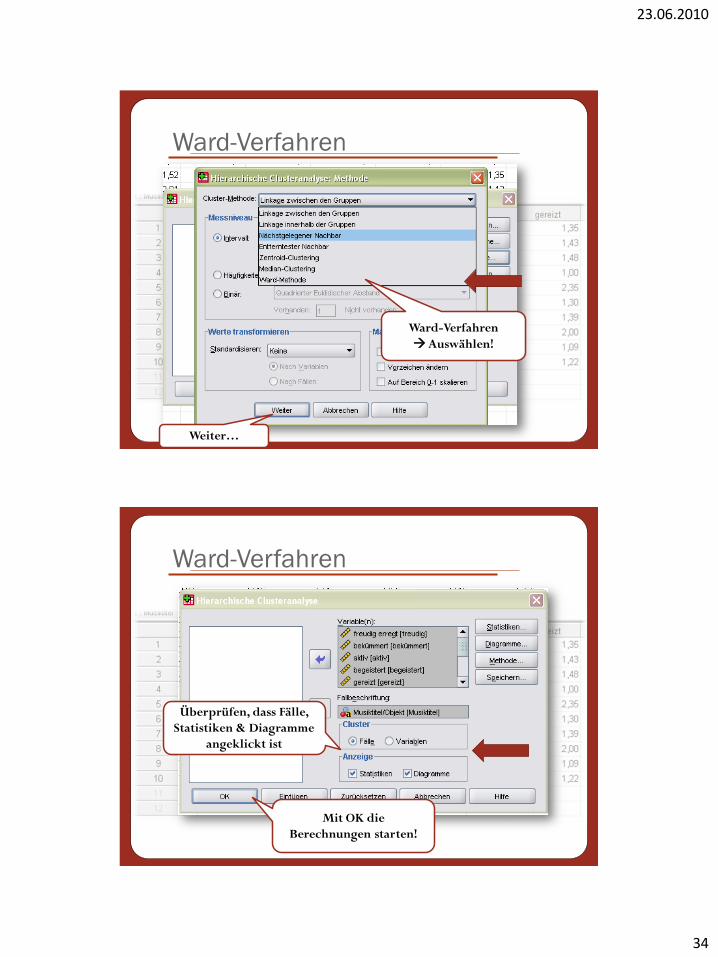
Ward-Verfahren
Musiktitel 3 ausschließen (Ausreißer)
Ward-Verfahren
Quadrierte
Euklidische Distanz
Auswählen!
23.06.2010
34
Ward-Verfahren
City-Block-Metrik (L1-Norm)
Ward-Verfahren
Auswählen!
Weiter…
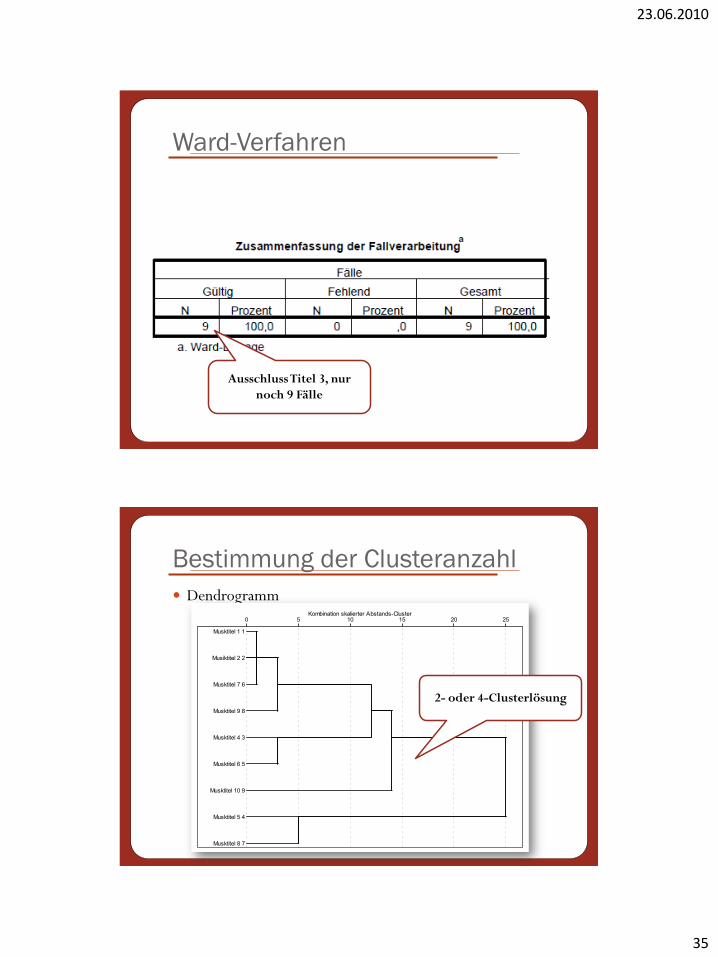
Ward-Verfahren
Überprüfen, dass Fälle,
Statistiken & Diagramme
angeklickt ist
Mit OK die
Berechnungen starten!
23.06.2010
35
Ausschluss Titel 3, nur
noch 9 Fälle
Ward-Verfahren
Bestimmung der Clusteranzahl
Dendrogramm
2- oder 4-Clusterlösung
23.06.2010
36
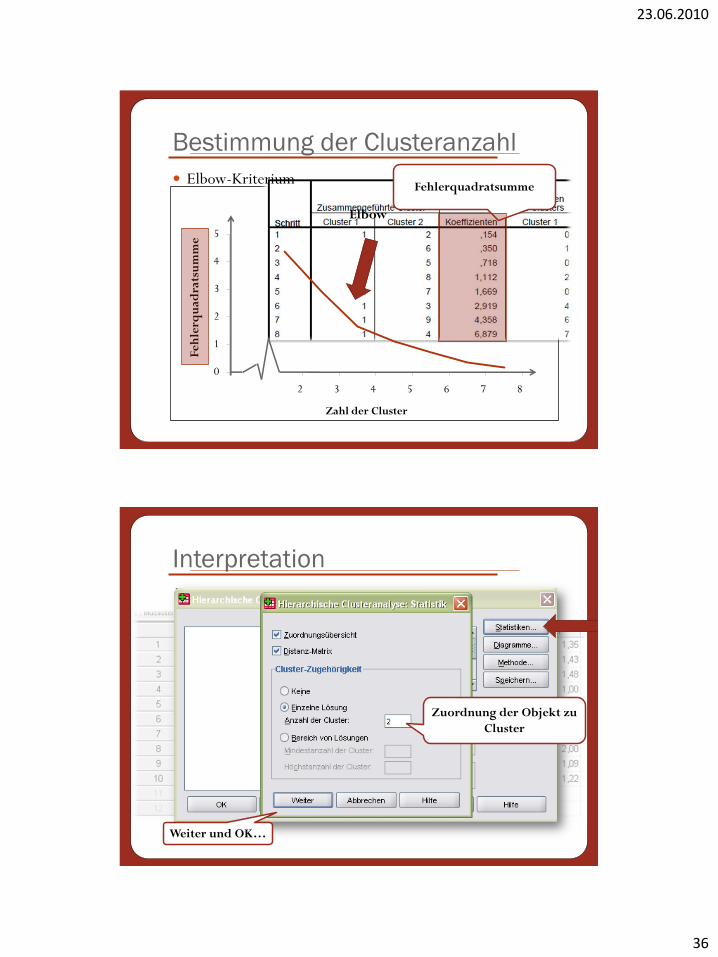
Fehlerquadratsumme
0
1
2
3
4
5
1 2 3 4 5 6 7 8
Elbow
Feh
lerq
uad
rats
um
me
Zahl der Cluster
Bestimmung der Clusteranzahl
Elbow-Kriterium
Interpretation
Zuordnung der Objekt zu
Cluster
Weiter und OK…
23.06.2010
37
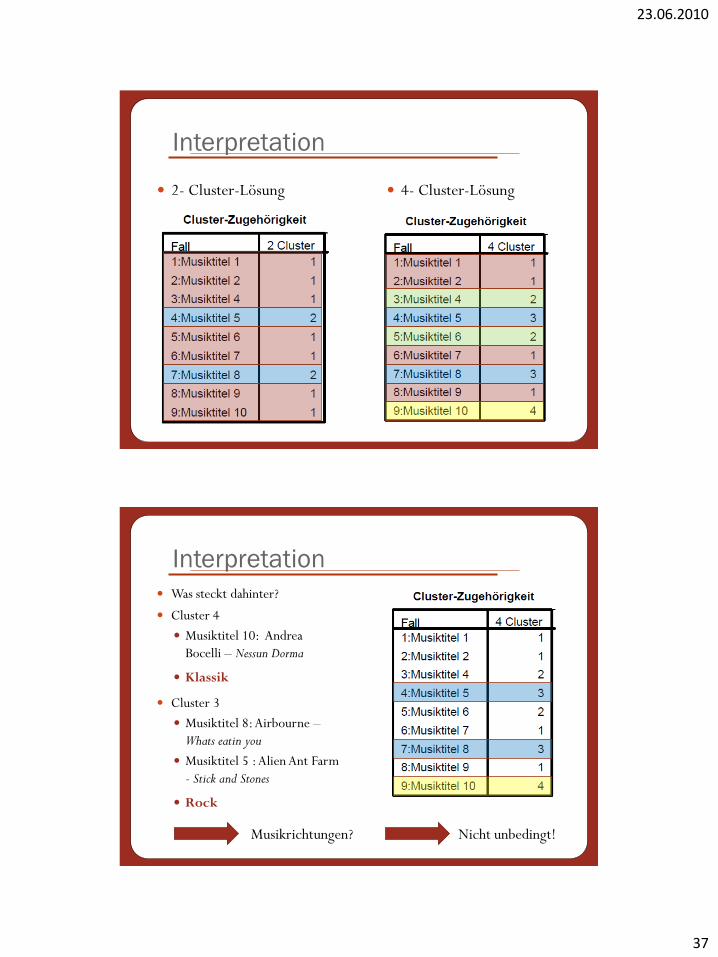
Interpretation
2- Cluster-Lösung 4- Cluster-Lösung
Interpretation
Was steckt dahinter?
Cluster 4
Musiktitel 10: Andrea
Bocelli – Nessun Dorma
Klassik
Cluster 3
Musiktitel 8: Airbourne –
Whats eatin you
Musiktitel 5 : Alien Ant Farm
- Stick and Stones
Rock
Musikrichtungen? Nicht unbedingt!
23.06.2010
38
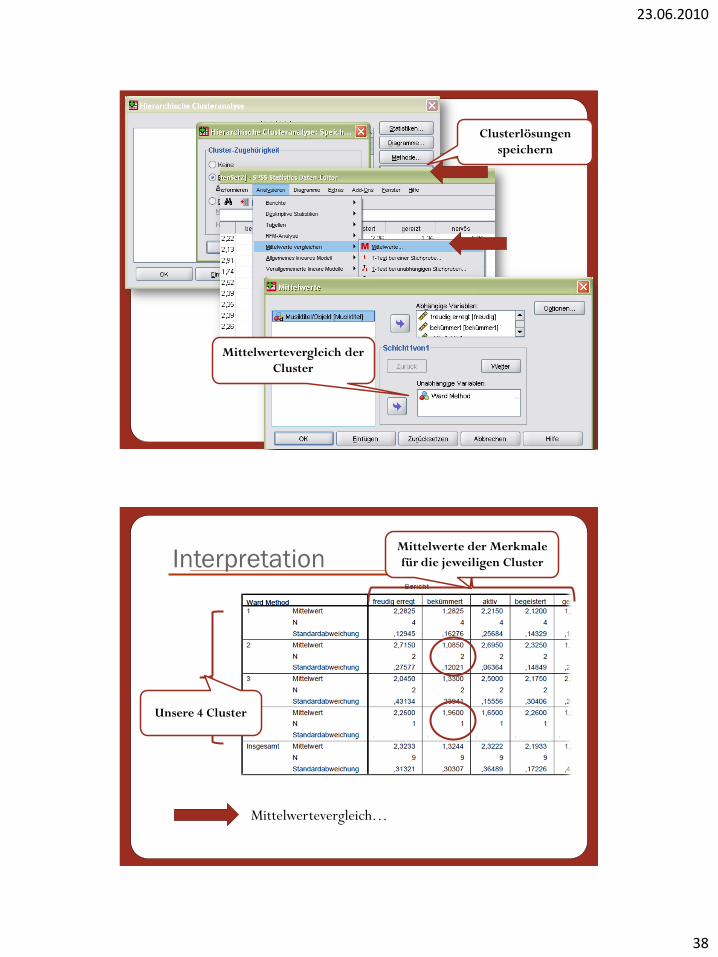
Interpretation
Mittelwertevergleich der
Cluster
Clusterlösungen
speichern
Interpretation
Unsere 4 Cluster
Mittelwerte der Merkmale
für die jeweiligen Cluster
Mittelwertevergleich…
23.06.2010
39
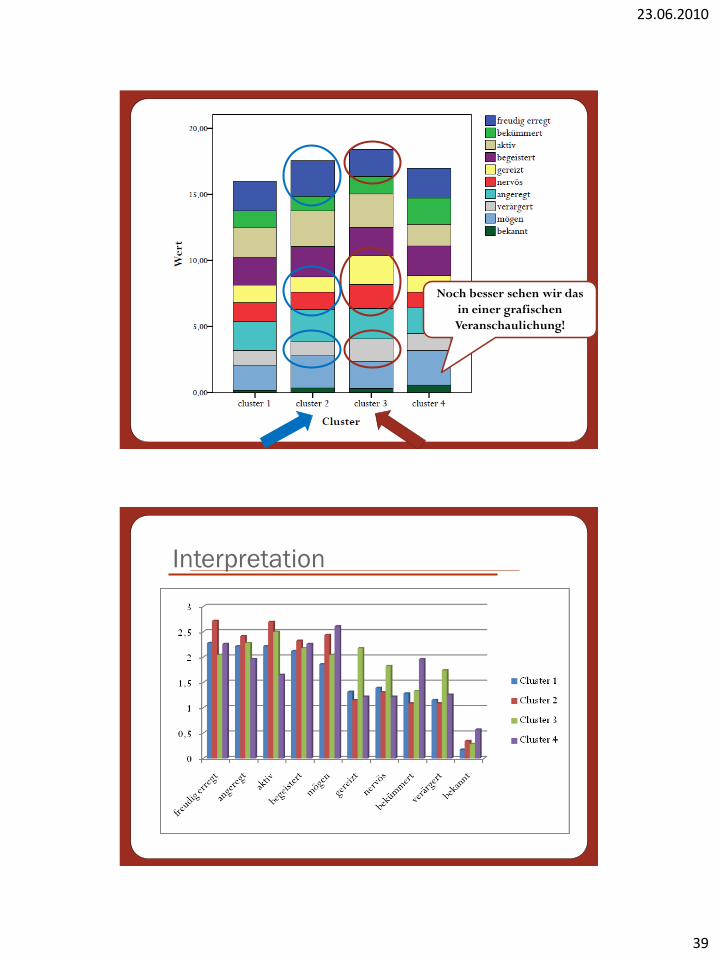
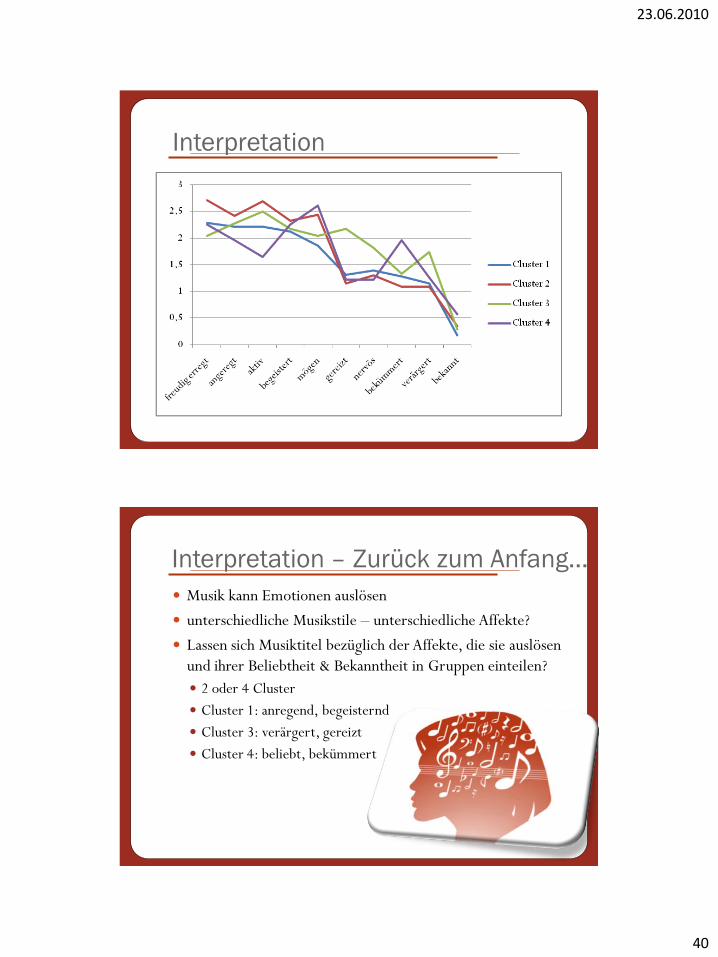
Interpretation
Noch besser sehen wir das
in einer grafischen
Veranschaulichung!
Interpretation
23.06.2010
40
Interpretation
Musik kann Emotionen auslösen
unterschiedliche Musikstile – unterschiedliche Affekte?
Lassen sich Musiktitel bezüglich der Affekte, die sie auslösen
und ihrer Beliebtheit & Bekanntheit in Gruppen einteilen?
2 oder 4 Cluster
Cluster 1: anregend, begeisternd
Cluster 3: verärgert, gereizt
Cluster 4: beliebt, bekümmert
Interpretation – Zurück zum Anfang…

23.06.2010
41
FAZIT – Die Clusteranalyse…
…umfasst eine Vielzahl von Verfahren zur Klassifizierung
…zielt darauf Personen oder Objekt aufgrund ihrer Merkmale zusammenzufassen
…besteht aus drei essentiellen Schritten:
1. Bestimmen von Ähnlichkeiten Proximitätsmaße
2. Zusammenfassen zu Gruppen aufgrund Ähnlichkeit Fusionierungsalgorithmus
3. Bestimmung der Clusterzahl Dendrogramm, Elbow, Fehlerquadrate
…sollte auf ihrer Güte überprüft werden
…kann weitläufig interpretiert werden
…kann Grundlage für weitere zahlreiche Analysen sein
Backhaus, K., Erichson, B., Plinke, W., & Weiber, R. (2006). Multivariate Analysemethoden. Berlin, Heidelberg: Springer.
Berekoven, L., Eckert, W., & Ellenrieder, P. (2006). Marktforschung: Methodische Grundlagen und praktische Anwendung. Wiesbaden: Gabler.
Bortz, J. (1999). Statistik für Sozialwissenschaftler. Berlin, Heidelberg: Springer.
Bortz, J., & Döring, N. (2006). Forschungsmethoden und Evaluation für Sozialwissenschaftler . Berlin, Heidelberg: Springer.
Janssen, J., & Laatz, W. (2007). Statistische Datenanalyse mit SPSS für Windows. Berlin, Heidelberg: Springer.
Lehnert, U. (2000). Datenanalysesystem SPSS Version 9. München: Oldenbourg
Voß, W. (2003). Taschenbuch der Statistik. München: Hanser.
Literatur

23.06.2010
42
VIELEN DANK
FÜR EURE
AUFMERK-
SAMKEIT UND
MITARBEIT!