
Datenbasierte Regelsuche f ur Fuzzy-Systeme mittels
15
Transcript of Datenbasierte Regelsuche f ur Fuzzy-Systeme mittels

Datenbasierte Regelsuche f�ur Fuzzy-Systeme
mittels baumorientierter Verfahren
Jens J�akel, Ralf Mikut, Hagen Malberg, Georg Bretthauer
Forschungszentrum Karlsruhe GmbH,Institut f�ur Angewandte InformatikPostfach 3640, D-76021 Karlsruhe
Tel.: 07247/82-5736, Fax: 07247/82-5785,E-Mail: [email protected]
Kurzfassung: Der Beitrag gibt zun�achst einen �Uberblick �uber Verfahren zur daten-gest�utzten Regelsuche. Dabei liegt der Schwerpunkt auf baumorientierten Methoden,die sich zur Generierung von Fuzzy-Regeln nutzen lassen. Im zweiten Teil wird ein Al-gorithmus n�aher vorgestellt. Dieser beinhaltet die Induktion eines Entscheidungsbaumsund seine Transformation in Fuzzy-Regeln. Er bildet den Ausgangspunkt f�ur die Generie-rung und Bewertung neuer, generalisierender Regelhypothesen, aus denen abschlie�endkooperierende Regeln zu einer Regelbasis zusammengestellt werden. Die Darstellung desAlgorithmus bezieht als Beispiel die Regelgenerierung f�ur eine medizinische Diagnoseauf-gabe ein.
1 Einf�uhrung
Fuzzy-Systeme werden { z. B. als Fuzzy-Modell oder Fuzzy-Regler { insbesondere bei kom-plexen, nichtlinearen Prozessen eingesetzt. Dabei besteht eine wesentliche Motivation dar-in, dem Anwender Einblick in die Probleml�osung zu geben. Dazu mu� die Regelbasis desFuzzy-Systems aus verst�andlichen und signi�kanten Regeln bestehen und eine bestimmteApproximations- bzw. Klassi�kationsg�ute aufweisen. Verfahren zum automatischen, da-tengest�utzten Generieren einer solchen Regelbasis stellen seit einigen Jahren einen intensivbearbeiteten Forschungsschwerpunkt dar [1].
Eine Regelbasis kann zum einen unmittelbar in der Menge m�oglicher Regelbasen ge-sucht werden. Ein alternatives Vorgehen besteht in der Suche von guten Regeln unddem Kombinieren geeigneter Regeln zu einer Regelbasis. Dabei besteht das Problem indem zweckm�a�igen Generieren von Hypothesen und ihrer Bewertung. Bei praktischenAufgabenstellungen ist das vollst�andige Durchsuchen des Hypothesenraums unm�oglich,weswegen verschiedene Suchstrategien zum Einsatz kommen. Diese k�onnen ihrem Wesennach heuristisch, probabilistisch (Evolution�are Algorithmen) oder systematisch (indukti-ves Lernen) sein. Dar�uber hinaus bilden Clustertechniken die Grundlage von Regelgene-rierungsverfahren [2, 3], auf die hier nicht weiter eingegangen wird.
Insbesondere die Methoden des Maschinellen Lernens [4] bilden eine Grundlage f�ur e�zien-te Suchstrategien. Sie haben deshalb, vor allem in Form der baumorientierten Verfahren,zunehmend Verbreitung bei der Fuzzy-Regelgenerierung gefunden. Innerhalb des Maschi-nellen Lernens wiederum hat die Theorie der Fuzzy-Mengen zur Behandlung der Unsch�arfelinguistischer Ausdr�ucke und der Unsicherheit von Daten Akzeptanz erlangt (s. z. B. [5, 6]).
Schwerpunkt dieses Beitrags bildet die Vorstellung eines Regelsuchverfahrens f�ur Fuzzy-Systeme, das die E�zienz der Induktion von Entscheidungsb�aumen zum Generieren vonRegelhypothesen nutzt. Diese dienen als Ausgangspunkt f�ur das Aufstellen generalisierterRegelhypothesen. Die Verallgemeinerungen betre�en die Struktur der Pr�amissen (auf-tretende Eingangsgr�o�en) und die linguistischen Terme (Bilden von modi�zierten Ter-men). Die Bewertung der Hypothesen ber�ucksichtigt die verschiedenen Anforderungen

(Modellg�ute, Transparenz, Signi�kanz). Ein Vorteil dieses Vorgehens gegen�uber dem Ge-neralisieren des Entscheidungsbaums besteht darin, nichtoptimale Entscheidungen �uberdie Aufteilung in einem Knoten aufheben zu k�onnen. Aus der Menge der generierter Re-geln werden schlie�lich diejenigen gew�ahlt, deren kooperatives Zusammenwirken in einerRegelbasis die beste Gesamtg�ute ergibt.
Ziel der Arbeit ist es,
� zun�achst einen �Uberblick �uber Verfahren zur Regelsuche zu geben, wobei eine Kon-zentration auf Verfahren des Maschinellen Lernens erfolgt, und
� ein baumorientiertes Verfahren vorzustellen, wozu eine Anwendung aus der medizi-nischen Diagnose herangezogen wird.
2 �Uberblick �uber Verfahren zur datenbasierten Regelsuche
Datenbasierte Regelsuchverfahren gehen von einer Menge von Beispielen B =fx[k]; y[k] j k = 1; : : : ; Ng aus, wobei vorausgesetzt wird, da� die Beispiele u.U. mitSt�orungen �uberlagerte Realisierungen einer unbekannten Funktion y = f(x) sind. DieEingangsgr�o�en x und die Ausgangsgr�o�e y k�onnen nominale (kategorische), ordinale odernumerische Variable sein. Die Aufgabe besteht darin, eine regelbasierte Beschreibung bzw.Approximation dieser Funktion f zu �nden.
Ist y eine nominale oder ordinale Variable, wird i. allg. von einem Klassi�kationspro-blem gesprochen. Anwendungen �nden sich z. B. bei Diagnose, der Entscheidungs�n-dung oder der Mustererkennung. Aufgabenstellungen mit numerischen y werden zumeistals Regressions- bzw. Approximationsprobleme bezeichnet. Entsprechende Anwendungensind z. B. Pr�adiktionsmodelle oder Reglerfunktionale.
Bei der o. g. Aufgabenstellung bestehen zus�atzlich bestimmte Anforderungen, zu denen
� die Verst�andlichkeit der Einzelregeln,
� die Transparenz ihres Zusammenwirkens,
� die Genauigkeit der Approximation von f ,
� ein niedriger Aufwand zur Speicherung und Auswertung der Regeln,
� ein niedriger Me�aufwand f�ur die in den Regelpr�amissen auftretenden Variablen
geh�oren. Diese Anforderungen schlagen sich zum einen in einem Vorzugskriterium bez. desSuchraums nieder, z. B. durch Beschr�ankung auf bestimmte Formen von Regeln oder aufRegeln mit einer festgelegten maximalen Anzahl von Partialpr�amissen und zum anderen inder Bewertung der Hypothesen. Dabei kann z. B. die Bevorzugung allgemeinerer Regeln,die Bevorzugung klarerer Regeln oder eine Kombination beider zugrunde liegen.
Stellen die Hypothesen komplette Regelbasen dar, wird im Kontext sog. Classi�er Systemsh�au�g vom Pittsburgh-Ansatz [7] gesprochen. Hier soll dieser Fall als direkter Zugangbezeichnet werden. Im Unterschied dazu bilden beim Michigan-Ansatz einzelne Regelndie Hypothesen [8]. Dieser Ansatz wird im folgenden indirekter Zugang genannt.
Beim direkten Zugang, bei dem i. allg. globale G�utema�e angewendet werden, besteht dasProblem, die Qualit�at einzelner Regeln nicht bewerten zu k�onnen. Das kann dazu f�uhren,da� sich fehlerhafte Einzelregeln in ihren Auswirkungen kompensieren und so trotzdem eingutes Approximationsverhalten ergeben, was die Interpretierbarkeit der Regeln reduziert.Au�erdem ist der Suchraum wegen der gro�en Anzahl m�oglicher Hypothesen sehr gro�.

Der Suchraum beim indirekten Zugang ist deutlich kleiner. Da sich die Bewertung beider Regelsuche zun�achst auf die einzelnen Regeln bezieht, besteht die Notwendigkeit, ihrZusammenwirken in der Regelbasis �ahnlich wie beim direkten Zugang zu bewerten. Zudemist meist nur ein Teil des Eingangsraums durch die Regeln abgedeckt.
Im Suchraum von Regelhypothesen besteht eine Halbordnung:
Eine Regelhypothese ist spezi�scher als eine andere, wenn aus der Erf�ulltheit der zweitenPr�amisse die der ersten folgt. Bei Regelbasen als Hypothesen l�a�t sich eine vergleichbareHalbordnung angeben.
Damit k�onnen zwei prinzipielle Suchrichtungen unterschieden werden:
Neue Hypothesen k�onnen Spezialisierungen oder Verallgemeinerungen zuvor akzeptierterHypothesen sein. Spezialisierung bedeutet, da� die Suche vom Allgemeinen zum Speziellenerfolgt, bei Verallgemeinerungen wird die umgekehrte Suchrichtung verfolgt.
Ausgehend von einer Menge von Anfangshypothesen, diese kann z. B. aus einer initialenRegelbasis (direkter Zugang), der allgemeinsten Regel mit
"leerer\ Pr�amisse oder aus den
speziellsten mittels der Beispiele aufstellbarer Regeln (indirekter Zugang) bestehen, wer-den sukzessive neue Hypothesen generiert, bewertet und entsprechend akzeptiert oder ver-worfen. F�ur das Aufstellen neuer Hypothesen kommen verschiedene heuristische, proba-bilistische und induktive Strategien in Frage. Tabelle 1 zeigt eine Einteilung ausgew�ahlterVerfahren zur Regelgenerierung f�ur Fuzzy-Systeme entsprechend der beiden Zug�ange sowieder Suchstrategien.
direkter Zugang indirekter Zugang
heuri-stisch
� ASMOD [9, 10]� Fuzzy-ROSA (explorative Standard-strategie) [11]
probabi-listisch
GA-basierter Entwurf
� von Fuzzy-Reglern [12]
� hierarchischer Fuzzy-Systeme [13]
� strukturierter Fuzzy-Systeme [14]
� von Neuro-Fuzzy-Systemen mitSMOG [15, 16]
� evolution�are Regelgenerierung [17]
� Fuzzy-ROSA (evolution�are Suchstrate-gie) [18]
� GA-basierte Regelgenerierung [19]
Induk-tion
� Fuzzy-CART [20]
� LOLIMOT [21]
� Fuzzy-Entscheidungsb�aume [22{27]
� baumbasierte Regelgenerierung [11,28{32]
� Fuzzy Version Space Learning [33, 34]
� induktives Lernen modularerFuzzy-Regeln [35]
� Induktion hierarchischer Fuzzy-Systeme [36]
Tabelle 1: Einteilung von Verfahren zur Regelgenerierung f�ur Fuzzy-Systeme
Nachfolgend werden die Verfahren der Induktion von Fuzzy-Entscheidungsb�aumen undRegeln n�aher betrachtet. Ein Entscheidungsbaum kann prinzipiell in einen Regelsatz
�uberf�uhrt werden. Darauf beruhen die baumorientierten Regelinduktionsverfahren. DieInduktion von Entscheidungsb�aumen, zur�uckgehend auf [37], erfolgt in Richtung der Spe-zialisierung. Daher wird der Begri� der Top-Down-Induktion gebraucht. Die Verfahren zurFuzzy-Regelgenerierung beruhen zumeist auf dem von Quinlan entwickelten AlgorithmenID3 [38], der nachfolgend vorgestellt wird.

Induktion eines Entscheidungsbaums mit ID3 Ein Entscheidungsbaum besteht ausKnoten und Zweigen und kann als gerichteter Graph interpretiert werden (vgl. Bild 4).Jeder Knoten weist der Ausgangsgr�o�e einen linguistischen Term zu, der f�ur die zugeh�origeBeispielmenge die beste Entscheidung darstellt. Wenn die Beispielmenge korrekt klassi-�ziert wird, ist ihre weitere Auftrennung nicht notwendig und der Knoten wird somit zueinem Endknoten. Weist die Beispielmenge noch Klassi�kationsfehler auf, so wird sie inAbh�angigkeit vom Wert einer Variablen xl in die entsprechende Zahl von Zweigen auf-gespalten. Von den m�oglichen Entscheidungsvariablen xl wird diejenige gew�ahlt, die dieTransinformation H(xl; y) maximiert [38]. Die Transinformation H(xl; y) stellt ein Ma�f�ur die wechselseitige Abh�angigkeit zwischen xl und y dar. Sie l�a�t sich mit
H(xl; y) = H(xl) +H(y)�H(xl; y) (1)
berechnen. Dabei istH(xl) die Eingangsentropie, H(y) die Ausgangsentropie undH(xl; y)die Gesamtentropie. Die Entropie einer Gr�o�e z mit einer disjunkten Einteilung in i =1; : : : ; c Klassen Ai ergibt sich zu
H(z) = �
cXi=1
p(z 2 Ai) ld p(z 2 Ai) (2)
mit den gesch�atzten Klassenwahrscheinlichkeiten p(z 2 Ai) = h(z 2 Ai) = n(z 2 Ai)=N .Die Verbundentropie H(z; w) zweier Gr�o�en z und w berechnet sich entsprechend alsDoppelsumme mit den gesch�atzten Wahrscheinlichkeiten p(z 2 Ai ^ w 2 Bj) = h(z 2Ai ^ w 2 Bj) = n(z 2 Ai ^ w 2 Bj)=N . h ist die H�au�gkeit, die sich als Quotient aus derAnzahl n und der Gesamtanzahl der Datens�atze N ergibt.
Die Berechnung der relativen H�au�gkeiten, also auch die Transinformation (1), beziehtsich dabei immer auf die verbliebene Beispieldatenmenge in einem Entscheidungsknotenund nicht auf den gesamten Lerndatensatz. Wenn keine weitere Entscheidungsvariableexistiert oder der Zuwachs der Transinformation zu gering ist, wird der Knoten zu einemEndknoten.
Eine Weiterentwicklung des Entscheidungskriteriums erfolgt im C4.5-Algorithmus [39],der die Transinformation (1) noch durch die Eingangsentropie teilt. Damit werden imGegensatz zum ID3-Verfahren Aufteilungen nach Variablen unterdr�uckt, die eine sehr hoheEingangsentropie (z. B. durch viele linguistische Terme) aufweisen. Bei gleicher Anzahllinguistischer Terme in den Eingangsvariablen und �ahnlichen Verteilungen sind hingegendie Ergebnisse beider Verfahren nahezu gleich.
Die Berechnung von Klassenwahrscheinlichkeiten setzt die Disjunktheit der Werte einerVariablen voraus. Deshalb werden bei einem Teil der Verfahren [22, 24{26, 30] spezi�scheMa�e wie eine Fuzzy-Entropie oder Unsicherheits- und Unsch�arfema�e genutzt, wobei z. B.anstelle der Anzahl n die Summe der Zugeh�origkeitswerte zur Fuzzy-Mengen der Klasseverwendet wird und N sich als Summe der Zugeh�origkeitswerte der Beispiele zum betrach-teten Knoten ergibt. Die anderen Verfahren verwenden zun�achst gew�ohnliche Mengenanstelle der Fuzzy-Mengen.
Der E�zienz des Baum-Induktionsverfahrens stehen verschiedene Nachteile ge-gen�uber:
� Die Reihenfolge der Spezialisierungen, die von den Lerndaten abh�angt, entscheidetdar�uber, welcher Entscheidungsbaum entsteht. Mit anderen Worten, zwei unter-schiedliche Datens�atze desselben Prozesses k�onnen zu sehr unterschiedlichen Ent-scheidungsb�aumen f�uhren.

� Bei gest�orten und nicht eindeutigen Daten lernt der Entscheidungsbaum auch dieSt�orung auswendig und ist nicht in der Lage, befriedigend zu generalisieren.
� Abgeleitete Regeln sind i. allg. zu speziell, u. a. wegen der vergleichsweise geringerenRepr�asentationsf�ahigkeit eines Entscheidungsbaums.
Um die Generalisierungsf�ahigkeit zu gew�ahrleisten, wird die Entwicklung des Baumesvorzeitig gestoppt oder Spezialisierungen am vollst�andig entwickelten Baum werdenzur�uckgenommen (geprunt). Allerdings kann dieser Vorgang eine nichtoptimale Entwick-lung des Baums (Auswahl einer bestimmten Variablen in einem Knoten) i. allg. nicht behe-ben. Zudem k�onnen bestimmte Regels�atze nicht durch einen Baum repr�asentiert werden.Aus diesem Grund bringt es Vorteile, nicht den Baum, sondern die aus ihm abgeleitetenRegeln zu generalisieren (s. Abschnitt 3).
Die induktiven Verfahren, die unmittelbar Regeln generieren, beruhen auf dem Versi-on Space Learning [40] oder anderen Verfahren, z. B. PRSIM [41]. Beim Version SpaceLearning werden parallel beide Suchrichtungen, in Richtung Spezialisierung und Genera-lisierung, verfolgt. Zu spezielle und zu allgemeine Hypothesen werden sukzessive ausge-schlossen. Der PRSIM-Algorithmus sucht in Richtung der Spezialisierungen �ahnlich wiebei der Induktion eines Entscheidungsbaums, wobei getrennt nach Regeln f�ur jeden Wert(Term) der Ausgangsvariablen gesucht wird.
3 Ein baumorientiertes Verfahren zur Generierung von
Fuzzy-Regeln
3.1 Prinzip
Die Grundidee des nachfolgend beschrieben Verfahrens (s. Bild 1) besteht darin, zun�achstden Hypothesenraum in Richtung Spezialisierung systematisch zu durchsuchen. Dazudient ein Induktionsverfahren f�ur Entscheidungsb�aume. Anschlie�end wird ausgehend vonden i. allg. zu speziellen Regelhypothesen nach Verallgemeinerungen gesucht. Sowohl dieInduktion des Entscheidungsbaums als auch das anschlie�ende Generalisieren (Prunen)der Regeln nutzen spezielle Ma�e zur Bewertung der G�ute von Hypothesen.
Zur Darstellung des Verfahrens dient als Beispiel die Analyse der spontanen Barorezep-torsensitivit�at, eine Aufgabenstellung, die im folgenden Abschnitt eingef�uhrt wird.
Bild 1: Prinzip der Regelgenerierung
3.2 Analyse der spontanen Barorezeptorsensitivit�at bei Patienten mit
dilatativer Kardiomyopathie mit der Dualen Sequenzmethode
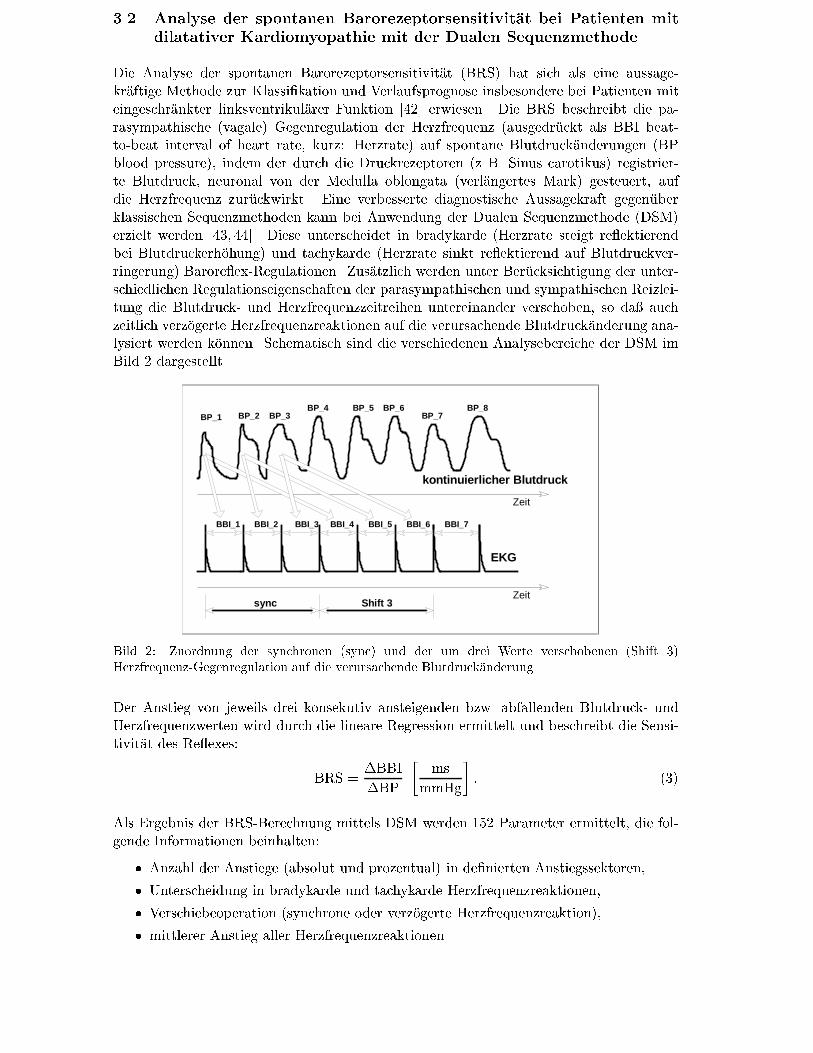
Die Analyse der spontanen Barorezeptorsensitivit�at (BRS) hat sich als eine aussage-kr�aftige Methode zur Klassi�kation und Verlaufsprognose insbesondere bei Patienten miteingeschr�ankter linksventrikul�arer Funktion [42] erwiesen. Die BRS beschreibt die pa-rasympathische (vagale) Gegenregulation der Herzfrequenz (ausgedr�uckt als BBI beat-to-beat interval of heart rate, kurz: Herzrate) auf spontane Blutdruck�anderungen (BPblood pressure), indem der durch die Druckrezeptoren (z. B. Sinus carotikus) registrier-te Blutdruck, neuronal von der Medulla oblongata (verl�angertes Mark) gesteuert, aufdie Herzfrequenz zur�uckwirkt. Eine verbesserte diagnostische Aussagekraft gegen�uberklassischen Sequenzmethoden kann bei Anwendung der Dualen Sequenzmethode (DSM)erzielt werden [43, 44]. Diese unterscheidet in bradykarde (Herzrate steigt re ektierendbei Blutdruckerh�ohung) und tachykarde (Herzrate sinkt re ektierend auf Blutdruckver-ringerung) Barore ex-Regulationen. Zus�atzlich werden unter Ber�ucksichtigung der unter-schiedlichen Regulationseigenschaften der parasympathischen und sympathischen Reizlei-tung die Blutdruck- und Herzfrequenzzeitreihen untereinander verschoben, so da� auchzeitlich verz�ogerte Herzfrequenzreaktionen auf die verursachende Blutdruck�anderung ana-lysiert werden k�onnen. Schematisch sind die verschiedenen Analysebereiche der DSM imBild 2 dargestellt.
kontinuierlicher Blutdruck
BP_1 BP_2 BP_3 BP_4 BP_5 BP_6
BP_7 BP_8
BBI_1 BBI_2 BBI_3 BBI_4 BBI_5 BBI_6 BBI_7
EKG
sync Shift 3
Zeit
Zeit
Bild 2: Zuordnung der synchronen (sync) und der um drei Werte verschobenen (Shift 3)Herzfrequenz-Gegenregulation auf die verursachende Blutdruck�anderung
Der Anstieg von jeweils drei konsekutiv ansteigenden bzw. abfallenden Blutdruck- undHerzfrequenzwerten wird durch die lineare Regression ermittelt und beschreibt die Sensi-tivit�at des Re exes:
BRS =�BBI
�BP
�ms
mmHg
�: (3)
Als Ergebnis der BRS-Berechnung mittels DSM werden 152 Parameter ermittelt, die fol-gende Informationen beinhalten:
� Anzahl der Anstiege (absolut und prozentual) in de�nierten Anstiegssektoren,
� Unterscheidung in bradykarde und tachykarde Herzfrequenzreaktionen,
� Verschiebeoperation (synchrone oder verz�ogerte Herzfrequenzreaktion),
� mittlerer Anstieg aller Herzfrequenzreaktionen.

In einer klinischen Studie [44] wurde untersucht, ob mittels DSM bei Patienten mit dilatati-ver Kardiomyopathie (DCM) Parameter zur Hochrisikostrati�zierung und Verlaufsprogno-se ermittelt werden k�onnen. Die dilatative Kardiomyopathie ist eine sehr schwerwiegendeMyokarderkrankung, bei welcher der Herzmuskel bei einer Ejektionsfraktion unter 30%bereits so insu�zient ist, da� eine Herztransplantation notwendig wird.
In dieser Studie wurden 26 Patienten (20 m�annlich und sechs weiblich) und ein Proban-denkollektiv mit 23 Personen untersucht, das hinsichtlich des Alters und des Geschlechtsvergleichbar ist. Unter vergleichbaren Zeit- und Umgebungsbedingungen wurden mit demphotoplethysmographischen Blutdruckme�ger�at PORTAPRES Mod. 2 (Fa. BMI-TNO)halbst�undige kontinuierliche Blutdruckverl�aufe aufgezeichnet. Die entsprechende Klas-si�kation im Datensatz entstammt hier den routinem�a�igen klinischen Untersuchungen(Ultraschall, Dopplersonographie).
Mit dem Einsatz eines Fuzzy-Klassi�kators sollen diejenigen Parameter der DSM ermit-telt werden, mit denen einerseits die DCM-Patienten von den Gesunden getrennt (dia-gnostiziert) werden k�onnen und andererseits auch eine physiologische Aussage �uber dascharakteristische BRS-Regulationsverhalten bei DCM-Patienten m�oglich ist.
Die mittels der DSM bestimmten Parameter beruhen auf medizinischen Erfahrungen undErwartungen �uber ein typisches Regulationsverhalten. Dabei stehen systematische Un-tersuchungen, inwieweit durch Modi�kation oder Kombination dieser Parameter weitereaussagekr�aftige Merkmale f�ur die Klassi�kation gewonnen werden k�onnen, noch aus.
Das vorgestellte Problem ist insofern typisch f�ur medizinische Klassi�kationsaufgaben, weilaufgrund der geringen Anzahl von Datens�atzen eine statistische Absicherung schwierig ist.Dar�uber hinaus ist eine eindeutige Trennung zwischen Kranken und Gesunden h�au�g nichtm�oglich.
3.3 Wahl der Zugeh�origkeitsfunktionen
Um den Entscheidungsbaum in linguistische Regeln �uberf�uhren zu k�onnen, werden f�urdie Ein- und Ausgangsvariablen entsprechende linguistische Variablen, Terme und Zu-geh�origkeitsfunktionen de�niert.
Die Induktion eines Entscheidungsbaums setzt eine disjunkte Partitionierung der Ein-gangsvariablen voraus. Daher werden den linguistischen Termen sowohl gew�ohnliche alsauch Fuzzy-Mengen zugeordnet. Die Zugeh�origkeitsfunktionen der gew�ohnlichen Mengensind rechteckf�ormig und nicht �uberlappend, die der Fuzzy-Mengen dreieckf�ormig und ein-fach �uberlappend. Dabei soll hier gelten, da� die Summe der Zugeh�origkeitswerte stetsEins ist.
Zur Festlegung der Zugeh�origkeitsfunktionen k�onnen sowohl Expertenwissen als auch Da-ten herangezogen werden. Bei der datenbasierten Bestimmung der Zugeh�origkeitsfunktio-nen wird neben Clustertechniken auch das nachfolgend skizzierte heuristische Verfahrenangewendet.
Ausgehend von zwei Zugeh�origkeitsfunktionen mit Maxima an den Grundbereichsgrenzenwird schrittweise je eine weitere Zugeh�origkeitsfunktion eingef�uhrt, bis die zul�assige An-zahl erreicht wird. Deren Maximum liegt an der Stelle xl[k], ein im Datensatz enthaltenerWert, f�ur den ein Kriterium maximal wird. Das Kriterium ist hier die gewichtete Summeder Eingangsentropie H(xl) und der Transinformation H(xl; y) (Abschnitt 2). Im Un-terschied zu Clustertechniken wird damit auch Information bez. der Ausgangsgr�o�en zurFestlegung der Zugeh�origkeitsfunktionen der Eingangsgr�o�en genutzt. Dieses Verfahren

ist insbesondere bei der Regelgenerierung mittels ID3 bzw. C4.5 vorteilhaft, da die Zu-geh�origkeitsfunktionen so festgelegt werden, da� mit ihnen eine gute Trennung nach denAusgangsklassen durch den Entscheidungsbaum erfolgen kann.
F�ur das Anwendungsbeispiel wird die Anzahl der Zugeh�origkeitsfunktionen zu f�unf festge-legt, die mit sehr klein (SK), klein (K),mittel (M), gro� (G) und sehr gro� (SG) bezeichnetwerden. Bild 3 zeigt beispielhaft die f�ur ein Merkmal ermittelten Zugeh�origkeitsfunktionenund Histogramme �uber die beiden Ausgangsklassen.
Bild 3: Automatisch generierte Zugeh�origkeitsfunktionen f�ur das Merkmal x141 und Histogrammef�ur die beiden Ausgangsklassen (schwarz: Proband, wei�: Patient)
3.4 Induktion eines Entscheidungsbaums und Ableiten der Regeln
Mit dem ID3- bzw. C4.5-Algorithmus wird wie in Abschnitt 2 ein Entscheidungsbaumgeneriert. F�ur jeden Endknoten des Entscheidungsbaums wird eine Regel gebildet. DerenPr�amisse besteht aus einer konjunktiven Verkn�upfung aller Variablen und ihrer lingui-stischen Terme in den Entscheidungsknoten, die auf dem Pfad zwischen der Wurzel desBaumes und dem jeweiligen Endknoten durchlaufen werden. Wegen der vollst�andigen Par-titionierung des Eingangsraums durch den ID3-Algorithmus ergibt sich eine Regelbasis,die den Eingangsraum redundanzfrei abdeckt. Die Zuweisung von Fuzzy-Mengen anstelleder gew�ohnlichen Menge erfolgt rein formal.
Bild 4 zeigt den besten mit dem ID3-Algorithmus erzeugten Entscheidungsbaum, wobeialle 152 Merkmale zur Verf�ugung standen. Aus diesem Baum lassen sich 17 Regeln bilden,wobei lediglich vier Merkmale verwendet werden. Allerdings entstehen so auch einigeRegeln, f�ur die nur ein oder gar kein Beispiel im Lerndatensatz existiert (vgl. Bild 4, z. B.x141=1, x18=1).
Zur Gewinnung weiterer Regelhypothesen erweist sich die Induktion verschiedener Ent-scheidungsb�aume, z. B. durch Herausstreichen dominanter Eingangsvariablen aus dem Da-tensatz, als sinnvoll. Damit wird der abgesuchte Hypothesenraum beim Generalisierengr�o�er (112 Regeln bei f�unf verschiedenen Entscheidungsb�aumen).
Als zus�atzliches Ergebnis bei der Generierung von Entscheidungsb�aumen entstehen heu-ristische Merkmalsrelevanzen, die aus einer gewichteten Addition der Transinformation

Bild 4: Mit ID3 generierter Entscheidungsbaum zur BRS-Analyse (oben im Knoten Entschei-dungsvariable xl, unten im Knoten Entscheidung y, y = 1 Patient, y = 2 Proband, in KlammernBeispielanzahl, Terme: 1=SK, : : : , 5=SG)
zwischen dem jeweiligen Merkmal und der Ausgangsgr�o�e entstehen. Der Wichtungs-faktor ergibt sich als Quotient der Beispielanzahl je Knoten und der Beispielanzahl alleruntersuchten Knoten.
F�ur die BRS-Analyse ergeben sich die folgenden heuristischen Merkmalsrelevanzen:
1. Merkmal : x141 ( 10-15_brady_3_a) - Guete 0.370
2. Merkmal : x113 ( alle_tachy_3_a) - Guete 0.292
3. Merkmal : x151 ( alle_brady_3_a) - Guete 0.193
4. Merkmal : x95 ( 7.5-10_tachy_3_a) - Guete 0.181
5. Merkmal : x85 ( 4-5_tachy_3_a) - Guete 0.176
...
31. Merkmal : x12 ( 0-2.5_tachy_1_p) - Guete 0.106
...
49. Merkmal : x18 ( 5-7.5_tachy_1_p) - Guete 0.082
50. Merkmal : x100 ( 10-12.5_tachy_3_p) - Guete 0.082
...
80. Merkmal : x33 ( 50-75_tachy_1_a) - Guete 0.058
...
151. Merkmal : x69 ( 25-50_brady_1_a) - Guete 0.008
152. Merkmal : x71 ( 50-75_brady_1_a) - Guete 0.002
3.5 Generalisieren und logische Reduktion von Regeln
Modulare Bewertung von Fuzzy-Regeln Die Bewertung der Regeln mu� die An-forderungen Relevanz, Verst�andlichkeit und statistische Absicherung in geeigneter Weiseber�ucksichtigen. Dazu dient hier das Kriterium [32, 45]
Q = (1�FPF 0
P
)�(1� FK)�; �; � > 0 (4)
dessen erster Term die relative Verbesserung der Prognoseg�ute im Vergleich zur Trivi-alsch�atzung (Regel mit stets wahrer Pr�amisse und h�au�gstem Term in der Konklusion)angibt. Indirekt wird hierbei die statistische Absicherung bewertet, da nur Regeln, diehinreichend durch Beispiele abgedeckt sind, eine wesentliche Verbesserung der Progno-seg�ute bewirken k�onnen. Der zweite Term, die Bewertung der Klarheit der Pr�amissen-Konklusionszuordnung, ist um so gr�o�er, je geringer der Anteil von Gegenbeispielen in derMenge der abgedeckten Beispiele ist. Die Exponenten � und � erlauben eine Gewichtung

beider Bewertungen. Die in (4) verwendeten Gr�o�en berechnen sich wie folgt:
FP = kY � Y kF = kRP � Y kF ! MinR
; mit 1TnR = 1Tq und R � 0n�q (5)
Y =
0@�B1
(y[1]) : : : �B1(y[N ])
: : : : : : : : : : : : : : : : : : : : : : : : : :�Bn
(y[1]) : : : �Bn(y[N ])
1A ; P =
��Pr(x[1]) : : : �Pr(x[N ])
1� �Pr(x[1]) : : : 1� �Pr(x[N ])
�(6)
FK = 1� kR�1k1 = 1� maxi=1;::: ;n
ri1 (7)
Hierbei ist P die Matrix der korrigierten Regelaktivierungen, Y die Matrix der fuzzi�zier-ten Ausgangsgr�o�e, Y ihre Sch�atzung und F 0
P der Prognosefehler der Trivialsch�atzung.
Generalisieren Als Generalisierungsm�oglichkeiten in den Regelpr�amissen werden zuge-lassen:
1. Streichen einer beliebigen Variable und ihrer linguistischen Terme und
2. Hinzuf�ugen eines benachbarten ODER-verkn�upften linguistischen Terms f�ur einelinguistische Variable.
Das Generalisieren geht damit �uber identische Umformungen der Regeln, z. B. mit demQuine-McCluskey-Algorithmus wie in [46] beschrieben, hinaus.
Mit der zweiten Generalisierungsm�oglichkeit entstehen abgeleitete Terme, die durch dieBeschr�ankung auf benachbarte Terme interpretierbar bleiben.
F�ur jede Regel werden nun alle bildbaren Hypothesen mittels (4) bewertet und die besteals neue Regel �ubernommen. Diese Prozedur wird solange durchgef�uhrt, bis alle Genera-lisierungen einer Regel auf schlechter bewertete Hypothesen f�uhren.
Beim Generalisieren der Regel
Q=0.136 ( 0 Feh./ 9 Bsp.): WENN x100=SG UND x141=K DANN Patient
f�ur die BRS-Analyse ergeben sich die folgenden Hypothesen und Bewertungen (Anzahlder Beispiele bzw. Fehler durch Rundung der Zugeh�origkeitswerte):
Q=0.157 ( 0 Feh./10 Bsp.): WENN x100=(G [ SG) UND x141=K DANN Patient
Q=0.051 ( 2 Feh./11 Bsp.): WENN x100=SG UND x141=(K [ M) DANN Patient
Q=0.213 ( 0 Feh./15 Bsp.): WENN x100=SG UND x141=(SK [ K) DANN Patient
Q=0.084 ( 4 Feh./14 Bsp.): WENN x141=K DANN Patient
Q=0.050 (10 Feh./27 Bsp.): WENN x100=SG DANN Patient
Die dritte Hypothese wird akzeptiert und weiter generalisiert. Dabei entsteht die Regel:
Q=0.287 ( 0 Feh./18 Bsp.): WENN x100=(G [ SG) UND x141=(SK [ K) DANN Patient
Bild 5 stellt die angegebene Regel dar (umrahmt). Die Gitterlinien f�ur die Merkmale x100und x141 kennzeichnen die Maxima der Zugeh�origkeitsfunktionen. Hierbei zeigt sich, dasein Gro�teil der Beispiele der Klasse
"Patient\ (
"*\) durch diese Regel erkl�art wird.
Im Ergebnis des Prunings entstehen aus den 112 Regeln des Baums 34 generalisierteRegeln, z. B.:

Bild 5: Gra�sche Darstellung der generalisierten Regel
1. Q=0.318: WENN x12=(M [ G [ SG) UND x141=(M [ G [ SG) DANN Proband
2. Q=0.292: WENN x67=(K [ M [ G) UND x103=(M [ G [ SG) UND x151=SG DANN Proband
3. Q=0.287: WENN x100=(G [ SG) UND x141=(SK [ K) DANN Patient
4. Q=0.227: WENN x33=SK UND x113=SG DANN Proband
5. Q=0.221: WENN x83=(SK [ K) UND x151=(SK [ K [ M) DANN Patient
...
20. Q=0.114: WENN x100=(NICHT SG) UND x141=(NICHT SK) DANN Proband
...
Logische Reduktion In Folge der Generalisierung k�onnen identische Regeln entstehen.Von diesen werden alle bis auf eine gestrichen. Weiterhin k�onnen Pr�amissen speziellererRegeln durch die allgemeinerer (mit derselben Konklusion) vollst�andig abgedeckt werden.In diesem Fall werden die speziellen Regeln gel�oscht, wenn ihre Bewertung nicht besserals die der allgemeineren ist.
3.6 Aufstellen der Regelbasis
Die Problematik der Auswahl von Regeln h�angt wiederum eng mit den hier verwendetenMethoden zur Generalisierung zusammen. Allgemeine Regeln, die aus unterschiedlichenspeziellen Regeln hervorgehen, unterscheiden sich h�au�g nur in den linguistischen Termender gleichen linguistischen Variablen oder in jeweils einer anderen linguistischen Variablen.Mit anderen Worten, es besteht ein hohes Ma� an Redundanz in der Regelmenge.
Die wichtigste Aufgabe der Regelauswahl besteht darin, das Zusammenwirken der Regelnin einer Regelbasis zu betrachten und partiell redundante Regeln zu reduzieren. Deswegenwerden in der Menge zuvor generierter Regeln gute Einzelregeln gesucht, die miteinanderkooperieren und sich erg�anzen. Hierbei mu� das anzuwendende Inferenzverfahren beachtetwerden, da verschiedene Inferenzverfahren bei logisch �aquivalenten Regelbasen auf unter-schiedliche Ergebnisse f�uhren k�onnen [47].
Durch die Auswahl von Regeln wird der Eingangsraum i. allg. nicht mehr vollst�andig abge-deckt. Deswegen wird der Regelbasis eine Regel zugef�ugt, deren Pr�amisse das Komplementzur Vereinigung der Pr�amissen aller �ubrigen Regeln der Regelbasis ist.

Als Ma� zur Bewertung wird der relative Prognosefehler herangezogen. Da nunmehr dieKonklusionen festgesetzt sind, ist in (5) anstelle von R die Matrix C1 zu setzen, die dieZuordnung einer Konklusion
"y = Bi\ zur Pr�amisse Pj mit cij = 1 kodiert [45].
Im Beispiel werden die Regeln Nr. 1, 3, 4 und 20 f�ur die Regelbasis ausgew�ahlt und miteiner Defaultregel
"SONST Patient\ erg�anzt (urspr�ungliche Regelnummer in Klammern):
1. (1.) Q=0.318: WENN x12=(M [ G [ SG) UND x141=(M [ G [ SG) DANN Proband
2. (3.) Q=0.287: WENN x100=(G [ SG) UND x141=(SK [ K) DANN Patient
3. (4.) Q=0.227: WENN x33=SK UND x113=SG DANN Proband
4. (20.) Q=0.114: WENN x100=(NICHT SG) UND x141=(NICHT SK) DANN Proband
5. SONST Patient
Die Verwendung der Defaultregel bewirkt eine erhebliche Reduktion der Regelbasis, dai. allg. nur Ausnahmen von der h�au�gsten Klasse (hier: Klasse
"Patient\) erkl�art werden
m�ussen.
Aus medizinischer Sicht sind diese Regeln nun zu diskutieren:
Regel 1:
Der Parameter x141 (10-15 brady 3 a) beschreibt gro�e (10-15 ms/mmHg) und langanhaltende (Shift 3) Reaktionen der Herzfrequenz auf Blutdruck�anderungen. Die verursa-chenden Blutdruckschwankungen scheint das Herz der Patienten nicht mehr ausgleichenzu k�onnen, so da� der Klassi�kator bei gro�en Werten dieses Parameters auf Probandenschlie�t. Der Parameter x12 (0-2.5 tachy 1 p) beschreibt die niedrigsten Variabilit�atender Herzrate, d. h. das Herz reagiert nur minimal auf Blutdruckschwankungen. Sicher-lich wird dieser Parameter auch von Me�fehlern �uberlagert, da� die Interpretation desParameters schwerf�allt.
Regel 2:
Der Parameter x100 (10-12.5 tachy 3 p) kennzeichnet die prozentuale Anzahl der ta-chykarden Anstiege im Bereich 10-12.5 ms/mmHg. O�ensichtlich liegt in diesem Bereichdie maximale Gegenregulation bei Patienten, was sich in dem h�oheren Prozentsatz in demAnstiegsbereich manifestiert. Bei Probanden hingegen k�onnen noch weitaus intensivereGegenregulationen (>12 ms/mmHg) vorkommen, so da� deren anstiegsbezogene prozen-tuale Verteilung ausgeglichener ist. Der verminderte Parameter x141 (10-15 brady 3 a)beschreibt die bei Patienten eingeschr�ankte und o�enbar ine�ektive Gegenregulation aufhohe Blutdruck�anderungen.
Diese Regel, die einzige au�er der Defaultregel mit einer Konklusion Patient, dient einerbesseren Approximation einer nichtachsenparalellen Klassengrenze (vgl. Bild 5) durch einegeringf�ugige �Uberdeckung mit Regel Nr. 20, die zu einem lokalen Widerspruch f�uhrt.
Regel 3:
Der erste Parameter (x33 { 50-75 tachy 1 a) der Regel ist schwierig zu interpretieren,da in diesem Regulationsbereich vermutlich aphysiologische Extremwerte, gegebenenfallsExtrasystolen liegen k�onnten. Die Gesamtanzahl von Herzfrequenzreaktionen auf ver-ursachende Blutdruck uktuationen (x113 { alle tachy 3 a) ist dagegen ein wichtigerParameter zur Klassi�kation, deren Gr�o�e Hinweise auf Regulationsabweichungen gestat-tet. Eine gro�e Anzahl von bradykarden Fluktuationen l�a�t auf eine gesunde Regulationschlie�en.
Das Verfahren verwendet die Variable x33, da damit die Fehleranzahl der Regel auf Nullreduziert wird. Bei einer relativ gleichm�a�igen Verteilung der Werte der Variablen wirdsich die Anzahl der Beispiele, f�ur die die Regel aktiviert wird, soweit verringern, da� die

speziellere Regel nicht besser bewertet wird. Im gegebenen Fall, bei dem diese Varia-ble fast immer sehr kleine Werte annimmt, verringert sich die abgedeckte Beispielanzahlkaum. Eine M�oglichkeit, solche Probleme zu l�osen, besteht darin, die Verteilung oder dieheuristische Bewertung der Variablen beim Generalisieren zu ber�ucksichtigen.
Regel 4:
Diese Regel ist au�er einer �Uberschneidung reziprok zur Regel 2.
Die Regelbasis erreicht auf dem Lerndatensatz eine Klassi�kationsg�ute von 98%, wenndie Fuzzy-Entscheidung wieder in eine scharfe Entscheidung umgewandelt wird. Bei ei-ner mehrfach durchgef�uhrten 10-fachen Crossvalidierung mit einer zuf�alligen Auswahl derLerndaten f�allt diese Quote f�ur den Testdatensatz allerdings auf 74.1%. Sie liegt damitim Bereich einer schwerer interpretierbaren linearen Diskriminanzanalyse (74.3%) [43], beider sechs Merkmale mit speziellen Verfahren ausgew�ahlt wurden. Interessanterweise sinddie geeignetsten Merkmale f�ur eine lineare Diskriminanzanalyse und f�ur eine nichtlineareFuzzy-Klassi�kation nahezu vollst�andig disjunkt. Nur ein f�ur die Diskriminanzanalyse aus-gew�ahltes Merkmal ist unter den besten sechs heuristischen Merkmalen vertreten, w�ahrenddie ausgew�ahlte Regelbasis generell mit anderen Merkmalen arbeitet.
4 Zusammenfassung und Ausblick
Die vorliegende Arbeit gibt zun�achst einen �Uberblick �uber Verfahren zur datenbasiertenGenerierung von Fuzzy-Regeln, wobei der Schwerpunkt auf baumorientierten Verfahrenliegt. Das hier vorgestellte Verfahren zeichnet sich durch das Generalisieren der mittelsEntscheidungsbaum gewonnen Regeln aus. Dabei werden spezielle Ma�e verwendet, diedie Erf�ullung bestimmter Anforderungen an die Regeln bewerten. Eine weitere Beson-derheit des Verfahrens besteht in der Auswahl von Regeln zur Bildung einer Regelbasis,die ihr Zusammenwirken ber�ucksichtigt. Dar�uber hinaus ist das Verfahren in der Lage,die Auswahl von relevanten Merkmalen sowie die Festlegung der Zugeh�origkeitsfunktionenautomatisch vorzunehmen bzw. zu unterst�utzen.
Als Beispiel zur Beschreibung der Regelgenerierung dient die Analyse der Barorezeptor-sensitivit�at bei dilativer Kardiomyopathie. Dieses medizinische Diagnoseproblem stelltaufgrund geringer Datensatz- und gro�er Merkmalsanzahl eine gro�e Herausforderung f�urautomatische Verfahren dar. Die erzielten Ergebnisse sind mit den Resultaten einer li-nearen Diskriminanzanalyse hinsichtlich der Klassi�kationsg�ute vergleichbar, aber besserinterpretierbar.
In zuk�unftigen Arbeiten soll der Nutzen von mehrfachen aufeinanderfolgenden Speziali-sierungen und Generalisierungen untersucht werden. Weiterhin wird eine st�arkere Ver-bindung zwischen dem Entwurf der Zugeh�origkeitsfunktionen und der Regelgenerierungangestrebt. Au�erdem soll das Verfahren dahingehend erweitert werden, da� bei der Re-gelgenerierung gleichzeitig Regelplausibilit�aten bestimmt und geeignet verarbeitet werden.
Literatur
[1] Kiendl, H. et al. (Hg.) Berichtsb�ande Workshop Fuzzy Control d. GMA-FA 5.22 , Forschungs-berichte der Fak. Elektrotechnik der Uni Dortmund. 1994-1998.
[2] Kruse, R.; Nauck, D. Learning Methods for Fuzzy Systems. In: Proc. Fuzzy-Neuro-Systeme'95, Darmstadt , S. 7{22. 1995.
[3] Babu�ska, R. Fuzzy Modelling for Control . Boston: Kluwer. 1998.
[4] Wysotzki, F. Maschinelles Lernen. Automatisierungstechnik 45 (1997) 11, S. 526{536.

[5] Koch, M.; Kuhn, T.; Wernstedt, J. Fuzzy Control: optimale Nachbildung und Entwurf opti-
maler Entscheidungen. M�unchen: Oldenbourg. 1996.
[6] Wehenkel, L. A. Automatic Learning Techniques in Power Systems . Boston: Kluwer. 1998.
[7] Smith, S. F. A Learning System Based on Genetic Adaptive Systems . Dissertation, Univ. ofPittsburgh. 1980.
[8] Holland, J. H.; Holyoak, K. J.; Nisbett, K. J.; Thagard, P. R. Induction: Processes Of
Inference. Cambridge, MA: MIT Press. 1986.
[9] Kavli, T. ASMOD{An Algorithm for Adaptive Spline Modelling of Observation Data. In:Advances in Intelligent Control (Harris, C. J., Hg.), S. 141{161. London: Taylor and Francis.1994.
[10] Lines, G. T.; Kavli, T. The Equivalence of Spline Models and Fuzzy Logic Applied to ModelConstruction and Interpretation. In: Neural Adaptive Control Technology (Zbikowski, R.;Hunt, K. J., Hg.). Singapore: World Scienti�c. 1996.
[11] Fritsch, M. Baumorientierte Regel-Induktionsstrategie f�ur das ROSA-Verfahren zur Modellie-
rung komplexer dynamischer Systeme. Fortschritt-Bericht VDI, Reihe 8, Nr. 565. D�usseldorf:VDI-Verlag. 1996.
[12] Karr, C. L. Design of an Adaptive Fuzzy Logic Controller Using a Genetic Algorithm. In:Proc. Int. Conf. on Genetic Algorithms , S. 450{457. San Mateo. 1991.
[13] Ho�mann, F.; P�ster, G. Optimierung hierarchischer Fuzzy-Regler mit Genetischen Algo-rithmen. In: Fuzzy Logik: Theorie und Praxis, Proc. 4. Dortmunder Fuzzy-Tage (Reusch, B.,Hg.), S. 97{89. Berlin: Springer. 1994.
[14] J�akel, J. Linguistische Fuzzy-Systeme mit verallgemeinerten Konklusionen und ihre Anwen-
dung zur Modellbildung und Regelung . Fortschritt-Berichte VDI, Reihe 8, Nr. 793. D�usseldorf:VDI-Verlag. 1999.
[15] Marenbach, P.; Brown, M. Evolutionary versus Inductive Construction of Neurofuzzy Systemsfor Bioprocess Modelling. In: Proc. 2nd Int. Conf. Genetic Algorithms in Engineering Systems:
Innovations and Applications GALESIA'97 . University of Strathclyde, Glasgow, UK. 1997.
[16] Bettenhausen, K. D. Automatische Struktursuche f�ur Regler und Strecke. Beitr�age zur daten-
getriebenen Analyse und optimierenden F�uhrung komplexer Prozesse mit Hilfe evolution�arer
Methoden und lernf�ahiger Fuzzy-Systeme. Dissertation, TH Darmstadt. 1995.
[17] Bonarini, A. Evolutionary Learning of General Fuzzy Rules with Biased Evaluation Functions:Competition and Cooperation. In: Proc. 1st IEEE Conf. on Evolutionary Computation, Bd. 1,S. 51{56. Piscataway, NJ: IEEE Press. 1994.
[18] Krone, A.; B�ack, T.; Teuber, P. Evolution�ares Suchkonzept zum Aufstellen signi�kanterFuzzy-Regeln. Automatisierungstechnik 44 (1996) 8, S. 405{411.
[19] Herrera, F.; Lozano, M.; Verdegay, J. L. A Learning Process for Fuzzy Control Rules UsingGenetic Algorithms. Fuzzy Sets and Systems 100 (1998), S. 143{158.
[20] Jang, J.-S. R. Structure Determination in Fuzzy Modeling: A Fuzzy CART Approach. In:Proc. IEEE Int. Conf. on Fuzzy Systems , S. 480{485. Orlando, Florida. 1994.
[21] Nelles, O.; Fischer, M. Local Linear Model Trees (LOLIMOT) for Nonlinear System Identi-�cation of a Cooling Blast. In: Proc. 4th Europ. Congr. on Intelligent Techniques and Soft
Computing EUFIT'96 , S. 1187{1191. Aachen. 1996.
[22] Rives, J. FID3: Fuzzy Induction Decision Tree. In: Proc. 1st Int. Symp. Uncertainty, Model-
ling and Analysis , S. 457{462. 1990.
[23] Maher, P. E.; St. Clair, D. Uncertain Reasoning in an ID3 Machine Learning Framework. In:Proc. 2nd IEEE Int. Conf. on Fuzzy Systems , S. 7{12. San Francisco. 1993.
[24] Janikow, C. Z. Fuzzy Processing in Decision Trees. In: Proc. Int. Symp. On Arti�cial
Intelligence, S. 360{367. Monterrey. 1993.
[25] Yuan, Y.; Shaw, M. J. Induction of Fuzzy Decision Trees. Fuzzy Sets and Systems 69 (1995)2, S. 125{139.
[26] Boyen, X.; Wehenkel, L. Automatic Induction of Fuzzy Decision Trees and its Application toPower System Security Assessment. Fuzzy Sets and Systems 102 (1999), S. 3{19.

[27] Runkler, T.; Roychowdhury, S. Generating Decision Trees and Membership Functions byFuzzy Clustering. In: Proc. 7th Europ. Congr. on Intelligent Techniques and Soft Computing
EUFIT'99 . Aachen. 1999.
[28] Keller, H. B. Learning Rules for Modelling Dynamic Systems Behaviour. In: EUROSIM'95
(Breitenecker, F.; Husinsky, I., Hg.), S. 1205{1210. Amsterdam: Elsevier Science. 1995.
[29] Dung, L. T.; Otto, P. Fuzzy-Modellbildung mit maschinell gelernten Regeln. In: Proc. 42.
Int. Wissensch. Kolloquium, S. 209{215. TU Ilmenau. 1997.
[30] Hayashi, I.; Maeda, T.; Bastian, A.; Jain, L. C. Generation of Fuzzy Decision Trees by FuzzyID3 with Adjusting Mechanism of AND/OR Operators. In: Proc. IEEE Int. Conf. Fuzzy
Systems , S. 681{685. Piscataway, NJ. 1998.
[31] Otto, P.; Malberg, H. Fuzzy-Modellbildung zur Analyse von Wechselwirkungen bei Biosigna-len des Herz-Kreislaufsystems. In: Kiendl und Knicker [48], S. 82{95. 1998.
[32] J�akel, J.; Gr�oll, L.; Mikut, R. Tree-Oriented Hypothesis Generation for Interpretable FuzzyRules. In: Proc. 7th Europ. Congr. on Intelligent Techniques and Soft Computing EUFIT'99 .Aachen. 1999.
[33] Wang, C.-H.; Hong, T.-P.; Tseng, S.-S. Inductive Learning From Fuzzy Examples. In: Proc.the 5th IEEE Int. Conf. on Fuzzy Systems , S. 13{18. New Orleans, LA, USA. 1996.
[34] Hong, T. P.; Tseng, S. S. A Generalised Version Space Learning Algorithm for Noisy andUncertain Data. IEEE Trans. Knowledge Data Engng. 9 (1997), S. 336{340.
[35] Wang, C.-H.; Liu, J.-F.; Hong, T.-P.; Tseng, S.-S. A Fuzzy Inductive Learning Strategy forModular Rules. Fuzzy Sets and Systems 103 (1999), S. 91{105.
[36] Holve, R. \The curse of Dimensionality" { und was man dagegen tun kann : : : HierarchischeFuzzy Systeme zur Musterklassi�kation. In: Kiendl und Knicker [48], S. 195{208. 1998.
[37] Hunt, E. B.; Marin, J.; Stone, P. T. Experiments in Induction. New York: Academic Press.1966.
[38] Quinlan, J. R. Induction of Decision Trees. Machine Learning 1 (1986), S. 81{106.
[39] Quinlan, J. R. C4.5:Programs for Machine Learning . San Mateo, Ca: Morgan Kaufmann.1993.
[40] Mitchell, T. M. Version Spaces: An Approach to Concept Learning. Techn. Ber. HPP-79-2,Stanford University, Palo Alto, CA. 1978.
[41] Cendrowska, J. PRSIM: An Algorithm for Inducing Modular Rules. Int. J. Man-Machine
Studies 27 (1987), S. 349{370.
[42] La Rovere, M. T.; Bigger, J. T. J.; Marcus, F. I.; Mortara, A.; Schwartz, P. J. Barore ex Sen-sitivity and Heart-Rate Variability in Prediction of Total Cardiac Mortality After MyocardialInfarction. ATRAMI (Autonomic Tone and Re exes After Myocardial Infarction). Lancet 351(1998) 9101, S. 478{484.
[43] Malberg, H.; Wessel, N.; Schirdewan, A.; Osterziel, K. J.; Voss, A. Duale Sequenzmethode zurAnalyse der spontanen Barore exsensitivit�at bei Patienten mit dilatativer Kardiomyopathie.Z. Kardiologie 88 (1999) 5, S. 331{337.
[44] Malberg, H. Analyse und Klassi�kation der Wechselwirkungen der autonomen Regulation des
Herz-Kreislaufsystems . Dissertation, TU Ilmenau. 1999.
[45] J�akel, J.; Gr�oll, L.; Mikut, R. Bewertungsma�e zum Generieren von Fuzzy-Regeln unterBeachtung linguistisch motivierter Restriktionen. In: Kiendl und Knicker [48], S. 15{28.1998.
[46] Klose, A.; N�urnberger, A. Applying Boolean Transformations to Fuzzy Rule Bases. In: Proc.7th Europ. Congr. on Intelligent Techniques and Soft Computing EUFIT'99 . Aachen. 1999.
[47] Mikut, R.; J�akel, J.; Gr�oll, L. Inference Methods for Partial Redundant Rule Bases. In: Proc.7th Zittau Fuzzy Colloquium, S. 245{251. 1999.
[48] Kiendl, H.; Knicker, R. (Hg.) Berichtsband 8. Workshop Fuzzy Control d. GMA-FA 5.22 ,Forschungsbericht 0298 der Fak. Elektrotechnik der Uni Dortmund. 1998.


















