Universität Osnabrück Studierenden-Statistik fileUniversität Osnabrück Studierenden-Statistik

Formelsammlungzur
Statistik I
Prof. Dr. Rolf HupenProf. Dr. Manfred Losch
Fakultat fur Wirtschaftswissenschaft

Inhaltsverzeichnis
1 Deskriptive Statistik 31.1 Datenlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Quantile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.3 Mittelwerte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.4 Streuungsmaße . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.5 Konzentrationsmaße . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.6 Korrelationskoeffizienten . . . . . . . . . . . . . . . . . . . . . . . . . 121.7 Lineare Einfachregression . . . . . . . . . . . . . . . . . . . . . . . . . 131.8 Grundbegriffe der Zeitreihenanalyse . . . . . . . . . . . . . . . . . . . 141.9 Zeitliche Veranderungszahlen . . . . . . . . . . . . . . . . . . . . . . . 161.10 Wachstumsmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.11 Elastizitaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.12 Indexzahlen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1

1 Deskriptive Statistik
1.1 Datenlagen
1.1.1 Datenlage A
n beobachtete Merkmalswerte liegen als Urliste x1, . . . , xn vor.
1.1.2 Datenlage B
Es liegen zu m von einander verschiedenen Merkmalsauspragungen x1, . . . , xm diezugehorigen absoluten Haufigkeiten h1, . . . , hm (hi ≥ 0) ihres Auftretens vor.
n := h1 + . . . + hm ist die Anzahl der Merkmalstrager, bei denen das Merkmalerhoben worden ist.
fi := hi
nheißt relative Haufigkeit der i-ten Auspragung xi.
Hi := h1 + . . . + hi heißt kumulierte absolute Haufigkeit und
Fi := f1 + . . . + fi = 1n(h1 + . . . + hi) = 1
nHi heißt kumulierte relative Haufigkeit.
Haufigkeitstabelle:
Merkmals- Haufigkeit kumulierte Haufigkeiti auspragung absolut relativ absolut relativ1 x1 h1 f1 = h1/n H1 F1
2 x2 h2 f2 = h2/n H2 F2...
......
......
...m xm hm fm = hm/n Hm = n Fm = 1
n =m∑
i=1hi 1 =
m∑i=1
fi
3

1 Deskriptive Statistik
Empirische Verteilungsfunktion:
F (x) :=
0 , x < x1
Fi , xi ≤ x < xi+1 , i = 1, . . . ,m− 11 , xm ≤ x
1.1.3 Datenlage C
Es liegen vor k Klassen G1 = [a0, a1), . . . , Gk = [ak−1, ak) mit der Breite ∆i :=ai−ai−1 > 0 fur alle i = 1, . . . , k, sowie die absoluten Haufigkeiten h1, . . . , hk in denk Klassen.
n := h1+. . .+hk ist die Anzahl der Merkmalstrager, bei denen das Merkmal erhobenworden ist.
fi := hi
nrelative Haufigkeit zur Klasse Gi,
Hi := h1 + . . . + hi kumulierte absolute Haufigkeit zur Klasse Gi und
Fi := f1 + . . . + fi = 1nHi kumulierte relative Haufigkeit
Haufigkeitstabelle:
Klasse Grenzen Mittel- Breite Haufigkeit kumuliertepunkt absolut relativ relative H.keit
G1 [a0, a1) x1 ∆1 = a1 − a0 h1 f1 = h1/n F1
G2 [a1, a2) x2 ∆2 = a2 − a1 h2 f2 = h2/n F2
......
......
......
...Gk [ak−1, ak) xk ∆k = ak − ak−1 hk fk = hk/n Fk = 1
n =k∑
i=1
hi 1 =k∑
i=1
fi
Approximierende empirische Verteilungsfunktion:
F (x) :=
0 , x < a0
Fi−1 + fi∆i
(x− ai−1) , ai−1 ≤ x < ai , i = 1, . . . , k
1 , ak ≤ x
Histogramm:
Darstellung der Haufigkeiten unter Beachtung der Flachenproportionalitat der Bal-ken.
Die Hohe des Rechtecks uber der Klasse Gi = [ai−1, ai) wird wie folgt bestimmt:
4

1.2 Quantile
Hohe gi := hi∆i
bei absoluten Haufigkeiten
Hohe di := fi∆i
bei relativen Haufigkeiten
gi heißt absolute Haufigkeitsdichte
di heißt relative Haufigkeitsdichte
1.2 Quantile
1.2.1 Definition des p-Quantils
Zu 0 < p < 1 heißt xp p-Quantil, falls sich unterhalb von xp hochstens 100 · p %und oberhalb von xp hochstens 100 · (1− p) % der Beobachtungswerte befinden.
0.25-Quantil := Q1 := unteres Quartil
0.50-Quantil := Q2 := mittleres Quartil oder Median
0.75-Quantil := Q3 := oberes Quartil
1.2.2 Datenlage A:
xp =
{x([np+1]) , np nicht ganzzahlig12(x([np]) + x([np+1])) , np ganzzahlig
,
wobei
[α] := großte ganze Zahl, die kleiner oder gleich α ist
und
x(i) den i-ten Beobachtungswert in der geordneten Urliste x(1) ≤ x(2) ≤ . . . ≤ x(n)
bezeichnet.
1.2.3 Datenlage B:
xp =
{xi , falls Fi−1 < p < Fi
12(xi + xi+1) , falls p = Fi
,
wobei F0 := 0 gesetzt wird.
5

1 Deskriptive Statistik
1.2.4 Datenlage C:
xp wird angenahert als Losung der Gleichung F (xp) = p mit der approximierenden
empirischen Verteilungsfunktion F berechnet.
Man bestimme zunachst die Klasse Gi = [ai−1, ai) mit Fi−1 < p ≤ Fi, (F0 := 0),und setze dann
xp ≈ ai−1 +p− Fi−1
Fi − Fi−1
· (ai − ai−1) .
Liegen absolute Haufigkeiten vor, bestimme man die Klasse Gi = [ai−1, ai) mitHi−1 < n · p ≤ Hi, (H0 := 0), und setze dann
xp ≈ ai−1 +n · p−Hi−1
Hi −Hi−1
· (ai − ai−1) .
1.3 Mittelwerte
1.3.1 Datenlage A:
Modus := haufigster Beobachtungswert
Median := mittleres Quartil = 0.50-Quantil
arithmetisches Mittel (AM):
AM :=1
n
n∑i=1
xi
harmonisches Mittel (HM):
HM :=n
n∑i=1
1
xi
geometrisches Mittel (GM):
GM := n
√√√√ n∏i=1
xi
6

1.3 Mittelwerte
1.3.2 Datenlage B:
Modus := Merkmalsauspragung mit der großten absoluten oder relativen Haufigkeit
Median :=
xi , falls Fi−1 < 0.5 < Fi
12(xi + xi+1) , falls 0.5 = Fi
Gewichtetes arithmetisches Mittel (GAM):
GAM :=1
m∑i=1
hi
·m∑
i=1
hi · xi =m∑
i=1
fi · xi
Gewichtetes harmonisches Mittel (GHM):
GHM :=
m∑i=1
hi
m∑i=1
(hi
xi
) =1
m∑i=1
(fi
xi
)
Gewichtetes geometrisches Mittel (GGM):
GGM :=
(m∏
i=1
xhii
)1/m∑
i=1
hi
= n
√√√√ m∏i=1
xhii
1.3.3 Datenlage C:
Modus (Verfahren 1):
Quadratische Interpolation in der modalen (haufigsten) Gruppe.
Man bestimmt die modale Klasse Gi, d.h. die Klasse Gi = [ai−1, ai) mit der großtenHaufigkeitsdichte gi := hi/(ai − ai−1) und legt ein quadratisches Polynom
f(x) = ax2 + bx + c
durch die Punkte mit den Koordinaten (xi−1; gi−1), (xi; gi), (xi+1; gi+1), wobei xi−1,xi, xi+1 die Mittelpunkte der Klassen Gi−1, Gi, Gi+1 bezeichnen.
Die Stelle x0, fur die f(x) das Maximum annimmt, wird als Modus gewahlt.
7

1 Deskriptive Statistik
Modus (Verfahren 2):
Naherungslosung fur Verfahren 1
Man bestimmt wie beim Verfahren 1 die modale Klasse Gi und berechnet
Modus =ai(hi − hi−1) + ai−1(hi − hi+1)
(hi − hi−1) + (hi − hi+1)
Bei unterschiedlichen Klassenbreiten sind in der obigen Formel die absoluten Haufig-keitsdichten gi anstelle von hi zu verwenden.
Median:
Man bestimme die Klasse Gi = [ai−1, ai) mit Fi−1 < 0.5 ≤ Fi. In diese Klasse Gi
fallt der Median.
Eine Feinberechnung x des Medians laßt sich unter der Annahme der Gleichvertei-lung in den Klassen wie folgt durchfuhren:
x = ai−1 +0.5− Fi−1
Fi − Fi−1
· (ai − ai−1) = ai−1 + (0.5− Fi−1) ·∆i
fi
Liegen absolute Haufigkeiten vor, bestimmt man die Klasse Gi = [ai−1, ai) mitHi−1 < n
2≤ Hi und approximiert den Median mit
x = ai−1 +0.5 · n−Hi−1
Hi −Hi−1
· (ai − ai−1) = ai−1 + (0.5 · n−Hi−1) ·∆i
hi
.
Arithmetisches, harmonisches und geometrisches Mittel werden wie bei derDatenlage B in Form der gewichteten Mittel GAM, GHM und GGM mit Hilfe derKlassenmitten berechnet.
1.3.4 Allgemeine Aussagen fur Mittelwerte
• xi = c fur alle i = 1, . . . , n ⇒ Modus = Median = AM = HM = GM
• HM < GM < AM, falls xi nicht konstant
• Lageregel von Fechner:
Modus ≤ Median ≤ AM bei einer linkssteilen Verteilung
Modus ≥ Median ≥ AM bei einer rechtssteilen Verteilung
Modus = Median = AM bei einer symmetrischen Verteilung
8

1.4 Streuungsmaße
1.4 Streuungsmaße
Normierte Entropie (ENorm) fur Datenlage B:
ENorm =1
log(m)
{log(n)− 1
n
m∑i=1
[ hi log(hi) ]
}=
m∑i=1
fi · log
(1
fi
)log(m)
mit hi log hi = fi log( 1fi
) := 0 fur hi = fi = 0
Spannweite R:= Max - Min
Quartilsabstand := Q3 −Q1
Mittlere Spannweite (MSP):
MSP :=
(− Q2 −Min
Q2
· 100 ;Max−Q2
Q2
· 100
)
Mittlerer Quartilsabstand (MQA):
MQA :=
(− Q2 −Q1
Q2
· 100 ;Q3 −Q2
Q2
· 100
)
Mittlere quadratische Abweichung (s2):
Datenlage A: s2 := 1n
n∑i=1
(xi − AM)2
Datenlage B: s2 := 1n
m∑i=1
hi · (xi −GAM)2
Datenlage C: s2 := 1n
k∑i=1
hi · (xi −GAM)2
Standardabweichung (s):
s := +√
s2
Variationskoeffizient (V):
V :=s
AM· 100 (in %)
9

1 Deskriptive Statistik
1.5 Konzentrationsmaße
1.5.1 Lorenzkurve
1.5.1.1 Datenlage A
• Gegeben: geordnete Urliste der n Beobachtungswerte: x(1) ≤ x(2) ≤ . . . ≤ x(n)
• Merkmalssumme: S =n∑
i=1x(i)
• Kumulierte relative Haufigkeit: Fi = in
• Kumulierter Anteil an der Merkmalssumme: Gi =
i∑j=1
x(j)
S
Dann entsteht die Lorenzkurve in einem F-G-Koordinatensystem als Streckenzug,der die Punkte (0, 0), (F1, G1), (F2, G2), . . . , (Fn−1, Gn−1), (1, 1) miteinander verbin-det.
1.5.1.2 Datenlage B
• Gegeben: m voneinander verschiedene mogliche Merkmalsauspragungen x1 <x2 < . . . < xm mit den absoluten Haufigkeiten h1, h2, . . . , hm.
• Anzahl der Merkmalstrager: n =m∑
i=1hi mit m ≤ n
• Kumulierte relative Haufigkeiten: Fi =
i∑j=1
hj
n
• Merkmalssumme: S =m∑
i=1(hi · xi)
• Kumulierter Anteil an der Merkmalssumme: Gi =
i∑j=1
(hj · xj)
S
Dann entsteht die Lorenzkurve in einem F-G-Koordinatensystem als Streckenzug,der die Punkte (0, 0), (F1, G1), (F2, G2), . . . , (Fm−1, Gm−1), (1, 1) miteinander verbin-det.
10

1.5 Konzentrationsmaße
1.5.1.3 Datenlage C
• Die Merkmalsauspragungen sind in k Klassen i = 1, 2, . . . , k eingeteilt.
• Grenzen der Klasse i: [ ai−1, ai)
• Mittelpunkt der Klasse i: xi =ai−1 + ai
2
• Anzahl der Merkmalstrager in Klasse i: hi
• Gesamtzahl der Merkmalstrager: n =k∑
i=1hi mit k < n
• Kumulierte relative Haufigkeiten: Fi =
i∑j=1
hj
n
• Naherungswert fur die Merkmalssumme: S =k∑
i=1(hi · xi)
• Naherungswert fur den kumulierten Anteil an der Merkmalssumme:
Gi =
i∑j=1
(hj · xj)
S
Dann entsteht die Lorenzkurve in einem F-G-Koordinatensystem als Streckenzug,der die Punkte (0, 0), (F1, G1), (F2, G2), . . . , (Fk−1, Gk−1), (1, 1) miteinander verbin-det.
1.5.2 Gini-Koeffizient
Berechnung der Flache L unter der Lorenzkurve:
• Datenlage A: L = 12n·
n∑i=1
(Gi−1 + Gi), wobei G0 = 0 gesetzt wird.
• Datenlage B: L = 12n·
m∑i=1
(Gi−1 + Gi) · hi, wobei G0 = 0 gesetzt wird.
• Datenlage C: L = 12n·
k∑i=1
(Gi−1 + Gi) · hi, wobei G0 = 0 gesetzt wird.
Daraus erhalt man den Gini-Koeffizienten: CG = 1− 2 · L
11

1 Deskriptive Statistik
1.6 Korrelationskoeffizienten
Es liegen n Beobachtungen (xi, yi), i = 1, . . . , n, vor.
1.6.1 Korrelationskoeffizient von Fechner
rF =U −N
U + N
wobei
U : Anzahl der in den Vorzeichen ubereinstimmenden Paare (xi − x, yi − y)
N : Anzahl der in den Vorzeichen nicht ubereinstimmenden Paare (xi − x, yi − y)
1.6.2 Korrelationskoeffizient von Bravais-Pearson
r =
n∑i=1
(xi − x)(yi − y)√n∑
i=1(xi − x)2
n∑i=1
(yi − y)2
=n
n∑i=1
xiyi −n∑
i=1xi
n∑i=1
yi√[n
n∑i=1
x2i − (
n∑i=1
xi)2] · [nn∑
i=1y2
i − (n∑
i=1yi)2]
1.6.3 Korrelationskoeffizient von Spearman(Rangkorrelationskoeffizient)
rSp = 1−6
n∑i=1
d2i
n(n2 − 1)
mit
di := Differenz der Rangzahlen der Beobachtungen xi und yi
12

1.7 Lineare Einfachregression
1.7 Lineare Einfachregression
Bei Vorliegen der Werte (xi, yi), i = 1, . . . , n, mit xi 6= c fur alle i = 1, ..., n lautendie Regressionskoeffizienten a und b fur die Regressionsgleichung y∗
i = a + bxi:
b =
n∑i=1
(xi − x)(yi − y)
n∑i=1
(xi − x)2=
nn∑
i=1xiyi −
n∑i=1
xi
n∑i=1
yi
nn∑
i=1x2
i − (n∑
i=1xi)2
unda = y − bx.
mit x := 1n
n∑i=1
xi und y := 1n
n∑i=1
yi.
Der Quotient
d :=
n∑i=1
(y∗i − y)2
n∑i=1
(yi − y)2
heißt Determinationskoeffizient.
Es gilt:
• d = r2
• r = b · sxsy
, wobei sx :=
√1n
n∑i=1
(xi − x)2 und sy =
√1n
n∑i=1
(yi − y)2
13

1 Deskriptive Statistik
1.8 Grundbegriffe der Zeitreihenanalyse
Es liegen n Zeitreihenwerte x1, . . . , xn vor. Fur die den Zeitindizes t zugeordnetenBeobachtungswerte xt soll gelten
xt = Tt + Zt + St + Rt (additive Verknupfung)
wobei
Tt : Trendkomponente (beschreibt die monotone langfristige Entwicklung)
Zt : zyklische Komponente (beschreibt den Konjunkturverlauf)
Gt = Tt + Zt : glatte Komponente (Zusammenfassung von Trend und zyklischerKomponente)
St : Saisonkomponente (beschreibt die saisonale Abweichung von Trendkompo-nente und zyklischer Komponente)
Rt : irregulare Komponente (Restkomponente; beschreibt den Teil der Beobach-tungen, den Tt, Zt und St nicht beschreiben)
1.8.1 Trendbestimmung mit der Methode der kleinstenQuadrate
Nach der Methode der kleinsten Quadrate ergibt sich fur die Trendkomponente dieSchatzung
T ∗t = a + b · t
mit
b =n
n∑t=1
txt −n∑
t=1t
n∑t=1
xt
nn∑
t=1t2 − (
n∑t=1
t)2und a =
1
n
n∑t=1
xt − b · 1
n
n∑t=1
t
n∑t=1
t =1
2n(n + 1) und
n∑t=1
t2 =1
6n(n + 1)(2n + 1)
14

1.8 Grundbegriffe der Zeitreihenanalyse
1.8.2 Trendbestimmung mit der Methode der Reihenhalften
Fall 1: Die Anzahl der vorhandenen Zeitreihenwerte ist gerade n = 2n′.
• Reihenhalften x1, . . . , xn′ und xn′+1, . . . , xn
• x(1) = 1n′ ·
n′∑t=1
xt und x(2) = 1n′ ·
n∑t=n′+1
xt
• Tt = a + b · tmit
b =x(2) − x(1)
n′ und a = x(1) − b · n′ + 12
Fall 2: Die Anzahl der vorhandenen Zeitreihenwerte ist ungerade n = 2n′ + 1.
• Mittleren Wert xn′+1 weglassen.
• Weiteres Vorgehen analog zu Fall 1.
1.8.3 Reihenglattung mit Hilfe gleitender Durchschnitte
Fur die Berechnung der gleitenden Durchschnitte werden die Beobachtungen desStutzbereichs [t−m; t + m] herangezogen.
1. Anzahl der herangezogenen Beobachtungen: 2m + 1
xt =1
2m + 1·
t+m∑i=t−m
xi
2. Anzahl der herangezogenen Beobachtungen: 5
xt =1
4
(1
2xt−2 + xt−1 + xt + xt+1 +
1
2xt+2
)
3. Anzahl der herangezogenen Beobachtungen: 13
xt =1
12
(1
2xt−6 + xt−5 + . . . + xt + . . . + xt+5 +
1
2xt+6
)
15

1 Deskriptive Statistik
1.9 Zeitliche Veranderungszahlen
Gegeben sind Zeitreihenwerte x0, x1, . . . , xn, die in zeitlich gleichen Abstanden er-hoben worden sind.
1.9.1 Messzahlen
mb,t :=xt
xb
=Wert im Berichtsjahr t
Wert im Basisjahr b
Messzahlen genugen folgenden Bedingungen:
Identitatsprobe : mt,t = 1
Zeitumkehrprobe : mb,t ·mt,b = 1
Rundprobe : m1,2 ·m2,3 · · ·mt−1,t = m1,t
Proportionalitatsprobe : r ·mb,t = r · xtxb
Sind mxb,t, m
yb,t und mz
b,t Messzahlen zu den Zeitreihenwerten xi, yi, zi, i = 0, . . . , n,dann genugen die obigen Messzahlen der Faktorumkehrprobe, falls
mxb,t ·m
yb,t = mz
b,t .
Umbasierung von Messzahlen
Messzahl mb,t wird auf eine neue Basis s umgestellt:
ms,t =mb,t
mb,s
Verkettung von Messzahlen
Zwei Reihen von Messzahlen zur Basis b und zur Basis s werden zu einer langenReihe zur Basis b zusammengefugt:
mb,t = mb,s ·ms,t
16

1.9 Zeitliche Veranderungszahlen
1.9.2 Erste Differenzen
∆xt = xt − xt−1
• xt = xt−1 + ∆xt
•n∑
t=1∆xt = xn − x0
• Genugen die xt-Werte dem linearen Wachstumsmodell xt = a + b · xt−1, danngilt b = ∆xt
1.9.3 Gliedzahlen (Wachstumsfaktoren)
qt := mt−1,t :=xt
xt−1
• xt = qt · xt−1
•n∏
t=1qt = m0,n = xn
x0
1.9.4 Wachstumsraten in diskreter Zeit
pt :=xt − xt−1
xt−1
• qt =xt
xt−1
= 1 + pt
• pt = qt − 1
• xt = qt · xt−1 = xt−1 + pt · xt−1
• Fur q := n
√n∏
t=1qt gilt: xn = qn · x0
• p := q − 1 ist die mittlere Wachstumsrate der n Wachstumsraten p1, . . . , pn.
• Genugen die xt-Werte dem exponentiellen Wachstumsmodell in diskreter Zeit
xt = a · qt , t = 0, . . . , n ,
dann gilt: qt = q und pt = p = q − 1 fur alle t = 1, . . . , n.
17

1 Deskriptive Statistik
1.9.5 Wachstumsraten in stetiger Zeit
bt := ln
(xt
xt−1
)
• xt = ebt · xt−1
• b = 1n·
n∑t=1
bt ist die mittlere Wachstumsrate der n stetigen Wachstumsraten
b1, . . . , bn.
• Fur b gilt: xn = eb·n · x0
• Genugen die xt-Werte dem exponentiellen Wachstumsmodell in stetiger Zeit
xt = a · eb·t , t = 0, 1, . . . , n ,
dann gilt bt = b fur alle t = 1, . . . , n.
18

1.10 Wachstumsmodelle
1.10 Wachstumsmodelle
1.10.1 Lineares Wachstumsmodell
xt = a + b · t , t = 0, 1, . . . , n
xn : Endwert, Prognosewert
x0 : Anfangswert, Startwert
b = xt − xt−1 = ∆xt : Erste Differenz
Konstante a = x0
• Prognosewert: xn = x0 + b · n
• Startwert: x0 = xn − b · n
• Durchschnittswachstum (absolut): b = xn − x0n
• Zeitraum: n = xn − x0b fur b 6= 0
• Sind zwei Werte xt1 und xt2 , t1 6= t2, gegeben, dann konnen a und b wie folgtberechnet werden:
a =t2 · xt1 − t1 · xt2
t2 − t1und b =
xt2 − xt1
t2 − t1
• Vervielfachungszeit tα (xtα = α · x0, α > 0):
tα =(α− 1) · x0
bfur b 6= 0
• Verdoppelungszeit: t2 = x0b fur b 6= 0
• Schnittpunkt S = (tS; xS) zweier linearer Wachstumsfunktionen a1 + b1 · t unda2 + b2 · t, b1 6= b2:
tS =a2 − a1
b1 − b2
und xS = a1 + b1 · tS = a2 + b2 · tS
19

1 Deskriptive Statistik
1.10.2 Exponentielles Wachstumsmodell in diskreter Zeit
xt = a · qt , t = 0, 1, . . . , n
Wachstumsrate:=xt − xt−1
xt−1=: p fur alle t ≥ 1
Wachstumsfaktor xtxt−1
=: q fur alle t ≥ 1
Konstante a = x0
• Es gilt q = 1 + p und p = q − 1
• Prognosewert: xn = x0 · qn
• Barwert: x0 =xn
qn
• Durchschnittlicher Wachstumsfaktor q: q = n√ xn
x0
• Durchschnittswachstum p = n√ xn
x0− 1
• Zeitraum: n = ln xn − ln x0ln q fur q 6= 1
• Sind zwei Werte xt1 und xt2 , t1 6= t2, gegeben, dann konnen a und q wie folgtberechnet werden:
a = xt1 ·(
xt1
xt2
) t1t2−t1
und q =
(xt2
xt1
) 1t2−t1
• Vervielfachungszeit tα (xtα = α · x0, α > 0):
tα =ln α
ln qfur q 6= 1
• Schnittpunkt S = (tS; xS) zweier Wachstumsfunktionen a1 · qt1 und a2 · qt
2,q1 6= q2:
tS =ln(a2/a1)
ln(q1/q2)und xS = a1 · qtS
1 = a2 · qtS2
20

1.10 Wachstumsmodelle
1.10.3 Exponentielles Wachstumsmodell in stetiger Zeit
xt = a · eb·t , t = 0, 1, . . . , n
Wachstumsrate:=ln(
xtxt−1
)= b fur alle t ≥ 1
Wachstumsfaktor xtxt−1
= eb fur alle t ≥ 1
Konstante a = x0
• Prognosewert: xn = x0 · eb·n
• Startwert: x0 = xn · e−b·n
• Durchschnittswachstum b = ln xn − ln x0n
• Zeitraum: n = ln xn − ln x0b fur b 6= 0
• Sind zwei Werte xt1 und xt2 , t1 6= t2, gegeben, dann konnen a und b wie folgtberechnet werden:
a = et2 · ln xt1 − t1 · ln xt2
t2 − t1 und b =ln xt2 − ln xt1
t2 − t1
• Vervielfachungszeit tα (xtα = α · x0, α > 0):
tα =ln α
bfur b 6= 0
• Schnittpunkt S = (tS; xS) zweier Wachstumsfunktionen a1 · eb1·t und a2 · eb2·t,b1 6= b2:
tS =ln a2 − ln a1
b1 − b2
und xS = a1 · eb1·tS = a2 · eb2·tS
• Falls xt = a · eb·t = aqt, dann
ln
(xt
xt−1
)= b = ln q und q = eb
undxt − xt−1
xt−1
= p = q − 1 = eb − 1
21
1 Deskriptive Statistik
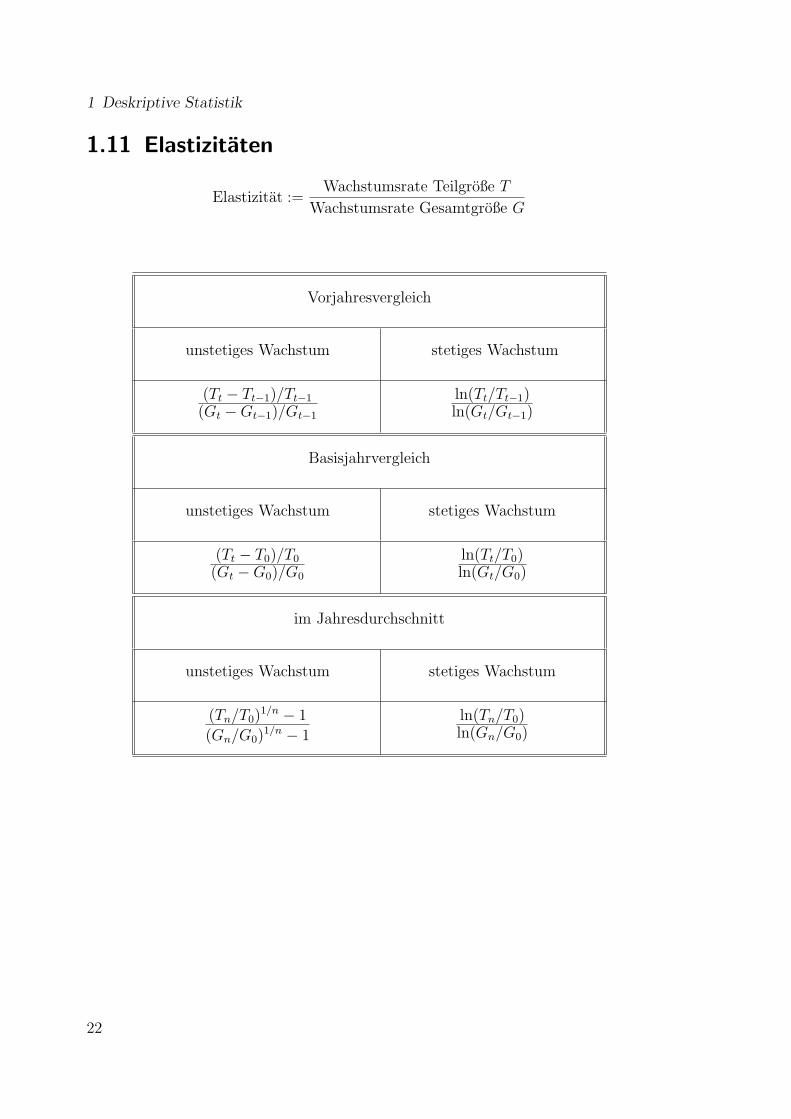
1.11 Elastizitaten
Elastizitat :=Wachstumsrate Teilgroße T
Wachstumsrate Gesamtgroße G
Vorjahresvergleich
unstetiges Wachstum stetiges Wachstum
(Tt − Tt−1)/Tt−1
(Gt −Gt−1)/Gt−1
ln(Tt/Tt−1)ln(Gt/Gt−1)
Basisjahrvergleich
unstetiges Wachstum stetiges Wachstum
(Tt − T0)/T0
(Gt −G0)/G0
ln(Tt/T0)ln(Gt/G0)
im Jahresdurchschnitt
unstetiges Wachstum stetiges Wachstum
(Tn/T0)1/n − 1
(Gn/G0)1/n − 1
ln(Tn/T0)ln(Gn/G0)
22

1.12 Indexzahlen
1.12 Indexzahlen
1.12.1 Notation
t : Berichtsjahr
0 : Basisjahr
n : Anzahl Guter
pi(t) : Preis des Gutes i zum Zeitpunkt t
qi(t) : umgesetzte Menge des Gutes i zum Zeitpunkt t
1.12.2 Preisindex von Laspeyres PL(0, t):
Drei Darstellungsmoglichkeiten:
1. Mit Hilfe der allgemeinen Gewichte wi := pi(0) · qi(0):
PL(0, t) =1
n∑i=1
wi
·n∑
i=1
wi ·pi(t)
pi(0)
2. Mit Hilfe der normierten Gewichte gi := wi/n∑
j=1wj:
PL(0, t) =n∑
i=1
gi ·pi(t)
pi(0)
3. Aggregatform (Summenform):
PL(0, t) =
n∑i=1
pi(t) · qi(0)
n∑i=1
pi(0) · qi(0)
Interpretation des Preisindexes von Laspeyres:
• Preisanderungsrate vom Basisjahr 0 zum Berichtsjahr t in Prozent:
(PL(0, t)− 1) · 100
23

1 Deskriptive Statistik
• Inflationsrate in % im Vorjahresvergleich:
PL(0, t)− PL(0, t− 1)
PL(0, t− 1)· 100
• Jahresdurchschnittliche Inflationsrate in % im Zeitraum t1 bis t2 (t1 < t2):[PL(0, t2)
PL(0, t1)
] 1t2−t1
− 1
· 100
• Kaufkraft, Binnenwert des Geldes:
1
PL(0, t)
• Kaufkraftanderungsrate in % im Vorjahresvergleich:
PL(0, t− 1)− PL(0, t)
PL(0, t)· 100
• Jahresdurchschnittliche Kaufkraftanderungsrate in % im Zeitraum t1 bis t2(t1 < t2): [PL(0, t1)
PL(0, t2)
] 1t2−t1
− 1
· 100
• Aggregation und Zerlegung des Preisindexes von Laspeyres:
n Guter, 2 Gruppen: i = 1, . . . , k, k + 1, . . . , n
PL1(0, t) =
k∑i=1
pi(t)qi(0)
k∑i=1
pi(0)qi(0)
, PL2(0, t) =
n∑i=k+1
pi(t)qi(0)
n∑i=k+1
pi(0)qi(0)
Normierte Gewichte der Gruppen im Basisjahr:
w1 =
k∑i=1
pi(0)qi(0)
n∑i=1
pi(0)qi(0)
, w2 =
n∑i=k+1
pi(0)qi(0)
n∑i=1
pi(0)qi(0)
Dann gilt fur den Gesamtindex PL(0, t):
PL(0, t) = w1 · PL1(0, t) + w2 · PL2(0, t)
24

1.12 Indexzahlen
1.12.3 Preisindex von Paasche PP (0, t):
Funf Darstellungsmoglichkeiten:
• Mit Hilfe der fiktiven Gewichte fi(t) := pi(0) · qi(t):
PP (0, t) =1
n∑i=1
fi(t)
·n∑
i=1
fi(t) ·pi(t)
pi(0)
• Mit Hilfe der normierten fiktiven Gewichte hi(t) := fi(t)/n∑
j=1fj(t):
PP (0, t) =n∑
i=1
hi(t) ·pi(t)
pi(0)
• Aggregatform (Summenform):
PP (0, t) =
n∑i=1
pi(t) · qi(t)
n∑i=1
pi(0) · qi(t)
• Mit Hilfe der allgemeinen Gewichte wi(t) := pi(t)qi(t):
PP (0, t) =
n∑i=1
wi(t)
n∑i=1
wi(t) ·[pi(0)
pi(t)
]
• Mit Hilfe der normierten allgemeinen Gewichte gi(t) := wi(t)/n∑
j=1wj(t):
PP (0, t) =1
n∑i=1
gi(t) ·[pi(0)
pi(t)
]
25

1 Deskriptive Statistik
1.12.4 Mengen- und Wertindizes und Reaktionsindex
Mengenindex nach Laspeyres ML(0, t):
ML(0, t) :=
n∑i=1
pi(0) · qi(t)
n∑i=1
pi(0) · qi(0)
Mengenindex nach Paasche MP (0, t):
MP (0, t) :=
n∑i=1
pi(t) · qi(t)
n∑i=1
pi(t) · qi(0)
Wertindex W (0, t):
W (0, t) :=
n∑i=1
pi(t) · qi(t)
n∑i=1
pi(0) · qi(0)
Reaktionsindex R(0, t):
R(0, t) := W (0, t)
[1− PL(0, t)
PP (0, t)
]
= W (0, t)
[1− ML(0, t)
MP (0, t)
]
26

1.12 Indexzahlen
1.12.5 Allgemeine Aussagen fur Indizes
• W (0, t) = PL(0, t) ·MP (0, t) = PP (0, t) ·ML(0, t)
• PL(0, t) > PP (0, t) ⇔ ML(0, t) > MP (0, t)
• W (0, t) = ML(0, t) · PL(0, t) + R(0, t)
• Umbasierung und Verkettung von Indizes erfolgt wie bei den Messzahlen.
• Werden beim Preis- bzw. Mengenindex die Mengen qi bzw. Preise pi un-abhangig vom Berichts- und Basisjahr gewahlt, so erhalt man den Preis- bzw.Mengenindex von Lowe:
PLo(0, t) :=
n∑i=1
pi(t)qi
n∑i=1
pi(0)qi
MLo(0, t) :=
n∑i=1
piqi(t)
n∑i=1
piqi(0)
• Die geometrischen Mittel
PF (0, t) :=√
PL(0, t) · PP (0, t)
undMF (0, t) :=
√ML(0, t) ·MP (0, t)
heißen Idealindizes von Fisher.
27