
HPC in Unternehmen...LS-DYNA PAM-CRASH RADIOSS CFD Apps CFD++ ANSYS Fluent PowerFLOW STAR-CCM+...
35
science + computing ag IT-Dienstleistungen und Software für anspruchsvolle Rechnernetze Tübingen | München | Berlin | Düsseldorf HPC in Unternehmen Ein Überblick Harry Schlagenhauf
Transcript of HPC in Unternehmen...LS-DYNA PAM-CRASH RADIOSS CFD Apps CFD++ ANSYS Fluent PowerFLOW STAR-CCM+...

science + computing ag
IT-Dienstleistungen und Software für anspruchsvolle Rechnernetze
Tübingen | München | Berlin | Düsseldorf
HPC in Unternehmen Ein Überblick
Harry Schlagenhauf

Inhalt
1. Unternehmen Bull/science + computing
2. HPC in Unternehmen
3. Beispiele
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 2

Inhalt
1. Unternehmen Bull/science + computing
1. Bull – Extreme Computing
2. science + computing ag (s+c)
2. HPC in Unternehmen
3. Beispiele
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 3

© 2013 science + computing ag science + computing ag | 24.01.2013
Page 4
BCS
BIS
BSS
BIP
€1.35 – 1.45 billion
Maint. & PRS
Services
Hardw. & systems
Fulfillment
Critical systems
€1.2 billion
Direct
margin
Direct
margin
EBIT
Indirect
costs
EBIT
€50-60
million
Indirect
costs
2011 figures
Revenue €1,301 M + 4.6%
Gross margin +4.2%
EBIT +23%
Employees 9,000
Shareholders
Crescendo Ind. 20%
France Télécom 8%
FSI 5%
NEC 2%
Floating 65%
Total 100%
Revenue 2010 > 2013 Profitability 2010 > 2013

Extreme Computing (1/4)
© 2013 science + computing ag science + computing ag | 24.01.2013
Page 5
Group commitment since 2005
the largest HPC R&D effort in Europe 35M€ budget for HPC (65M€ total)
230 engineers
Certified ISO 9001 (quality)
the largest HPC pool of experts in Europe 370 engineers (600 inc. R&D)
BU certified ISO 9001
world-Class Factory in Angers certified ISO 9001 (quality), ISO 14001 (environment), OHSAS
18000 / ILO-OSH (security)
From mid-size to petascale HPC production systems:
bullx (R-B-S) launched 2009
bullx supercomputer suite launched 2010
new–generation bullx B blades launched 2011
bullx Direct Liquid Cooling Blades available 2012

Extreme Computing (2/4)
© 2013 science + computing ag science + computing ag | 24.01.2013
Page 6
180M€+ income in 2011 (w/o maintenance)
Three petaflop-scale systems 2010: Tera 100, the first petaflopic system ever designed
and developed in Europe, one of the most efficient in its
category (84% @ linpack)
2010-2011: Genci / Curie (France) - 2 Pflops
2011-2012: IFERC – 1.5 Pflops
Other recent key projects KNMI (Netherlands): meteo
Barcelona Supercomputing Center (Spain): 186 Tflops
(hybrid)
Société Générale (France) : 350 Tflops
Dassault Aviation (France) : 100 Tflops
AWE (UK) : 250 Tflops
Launch of Extreme Factory (HPC pay per use)
and Mobull (HPC mobile data center) Extreme Factory: Renault, Exa, LL Products, Classified
Mobull: U_Perpignan, Cenaero
0 50 100 150 200
2007
2008
2009
2010
2011
37
70
98
152
181

Extreme Computing (3/4) 3 petaflop-scale systems
© 2013 science + computing ag science + computing ag | 24.01.2013
Page 7
TERA 100 in figures
1.25 PetaFlops
140 000+ Xeon cores
256 TB memory
30 PB disk storage
500 GB/s IO throughput
580 m² footprint
CURIE in figures
2 PetaFlops
90 000+ Xeon cores
148 000 GPU cores
360 TB memory
10 PB disk storage
250 GB/s IO throughput
200 m² footprint
IFERC in figures
1,5 PetaFlops
70 000+ Xeon cores
280 TB memory
15 PB disk storage
120 GB/s IO throughput
200 m² footprint
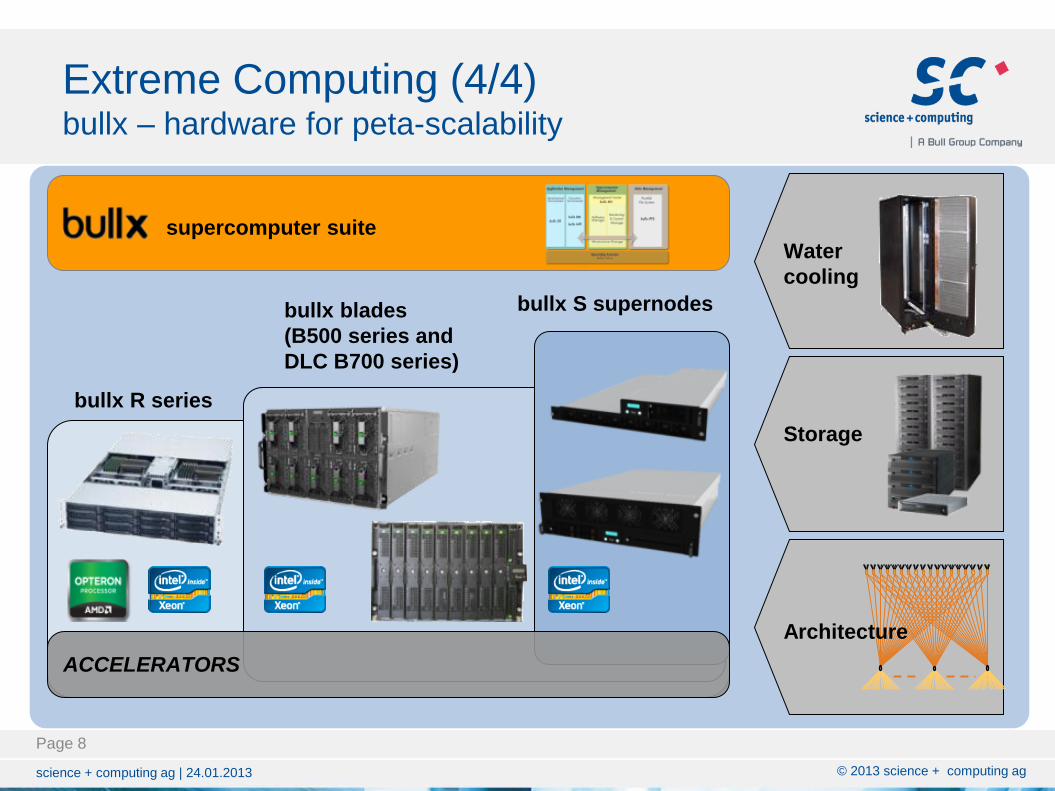
Extreme Computing (4/4) bullx – hardware for peta-scalability
© 2013 science + computing ag science + computing ag | 24.01.2013
Page 8
Water
cooling
bullx S supernodes bullx blades
(B500 series and
DLC B700 series)
bullx R series
Storage
ACCELERATORS
supercomputer suite
Architecture

science + computing auf einen Blick
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 9
Gründungsjahr 1989
Standorte Tübingen
München
Berlin
Düsseldorf
Mitarbeiter (Juni) 270
Hauptaktionär Bull S.A. (100%)
Umsatz 10/11 (12) 26,66 Mio. Euro (29,65 Mio. Euro)
Partner Daikin Industries, Japan
NICE srl, Italien
IBM Platform Computing, IBM Deutschland

Das Angebot auf einen Blick
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 10
s+c Kernkompetenzen für anspruchsvolle Rechnernetze
Software
System Management
Workload Management
Jobflow Management
Open Software
Softwareentwicklung Consulting
IT-Services
Outsourcing
IT-Sicherheit
Migration
Cluster Computing
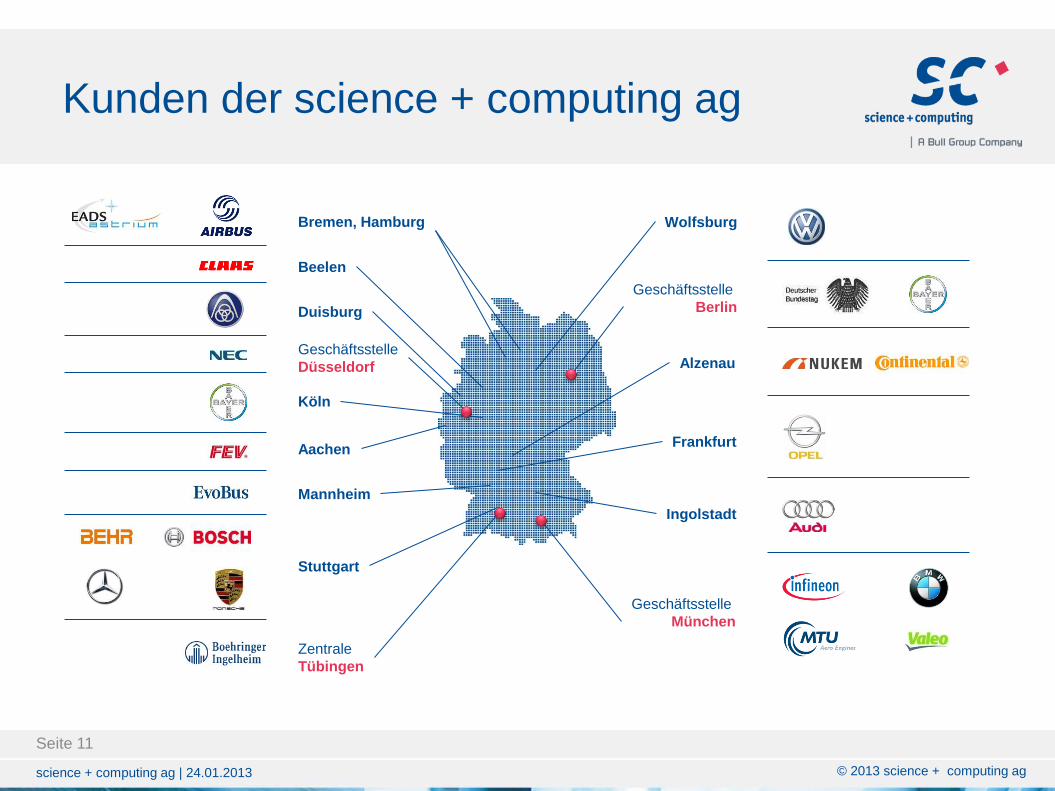
Kunden der science + computing ag
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 11
Geschäftsstelle
Berlin
Bremen, Hamburg
Beelen
Duisburg
Geschäftsstelle
Düsseldorf
Aachen
Alzenau
Zentrale
Tübingen
Stuttgart
Mannheim
Frankfurt
Ingolstadt
Wolfsburg
Geschäftsstelle
München
Köln

Inhalt
1. Unternehmen Bull/science + computing
2. HPC in Unternehmen
3. Beispiele
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 12

Einsatzgebiete von HPC-Cluster
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 13
Computat. Chemistry
Quantum Mechanics
Computational Fluid
Dynamics
Structural Mechanics
Explicit
Electro-Magnetics Computat. Chemistry
Molecular Dynamics
Computational
Biology
Rendering/Ray Tracing
Seismic Processing
Climate / Weather
Ocean Simulation Data Analytics
Structural Mechanics
Implicit
Reservoir Simulation

Einsatzgebiete von HPC-Cluster
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 14
Computat. Chemistry
Quantum Mechanics
Computational Fluid
Dynamics
Structural Mechanics
Explicit
Electro-Magnetics Computat. Chemistry
Molecular Dynamics
Computational
Biology
Rendering/Ray Tracing
Seismic Processing
Climate / Weather
Ocean Simulation Data Analytics
Structural Mechanics
Implicit
Reservoir Simulation
Automobilindustrie
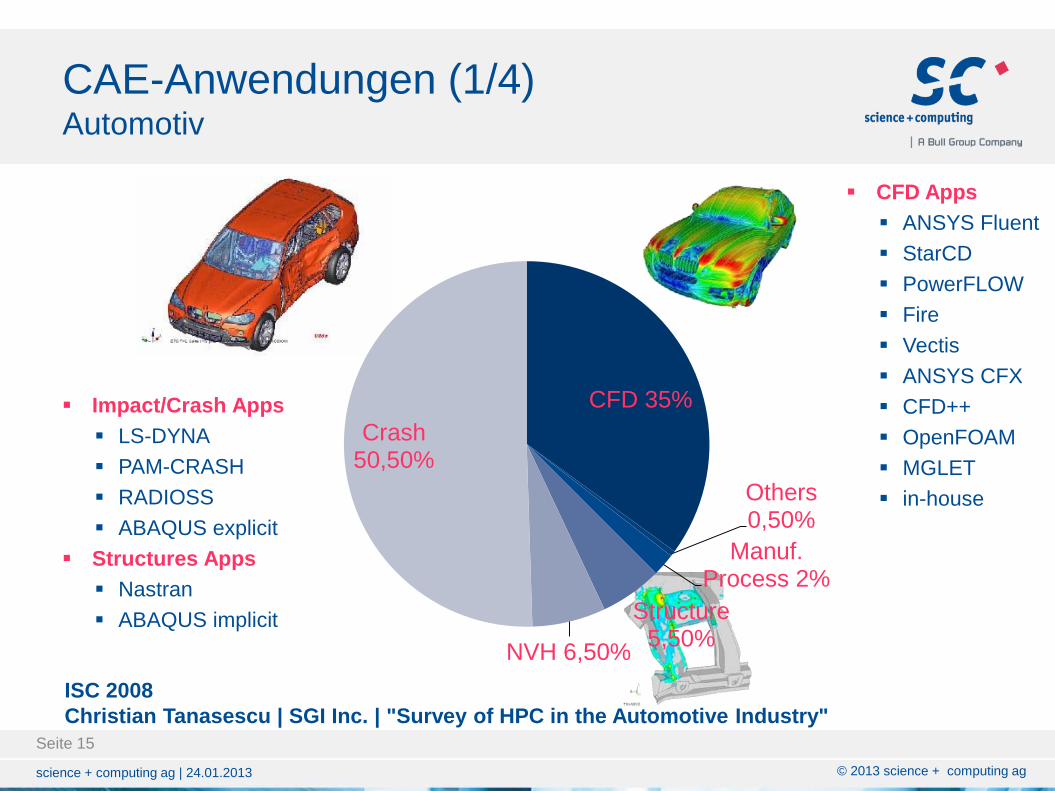
CFD Apps
ANSYS Fluent
StarCD
PowerFLOW
Fire
Vectis
ANSYS CFX
CFD++
OpenFOAM
MGLET
in-house
CFD 35%
Others 0,50%
Manuf. Process 2%
Structure 5,50%
NVH 6,50%
Crash 50,50%
CAE-Anwendungen (1/4) Automotiv
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 15
ISC 2008
Christian Tanasescu | SGI Inc. | "Survey of HPC in the Automotive Industry"
Impact/Crash Apps
LS-DYNA
PAM-CRASH
RADIOSS
ABAQUS explicit
Structures Apps
Nastran
ABAQUS implicit
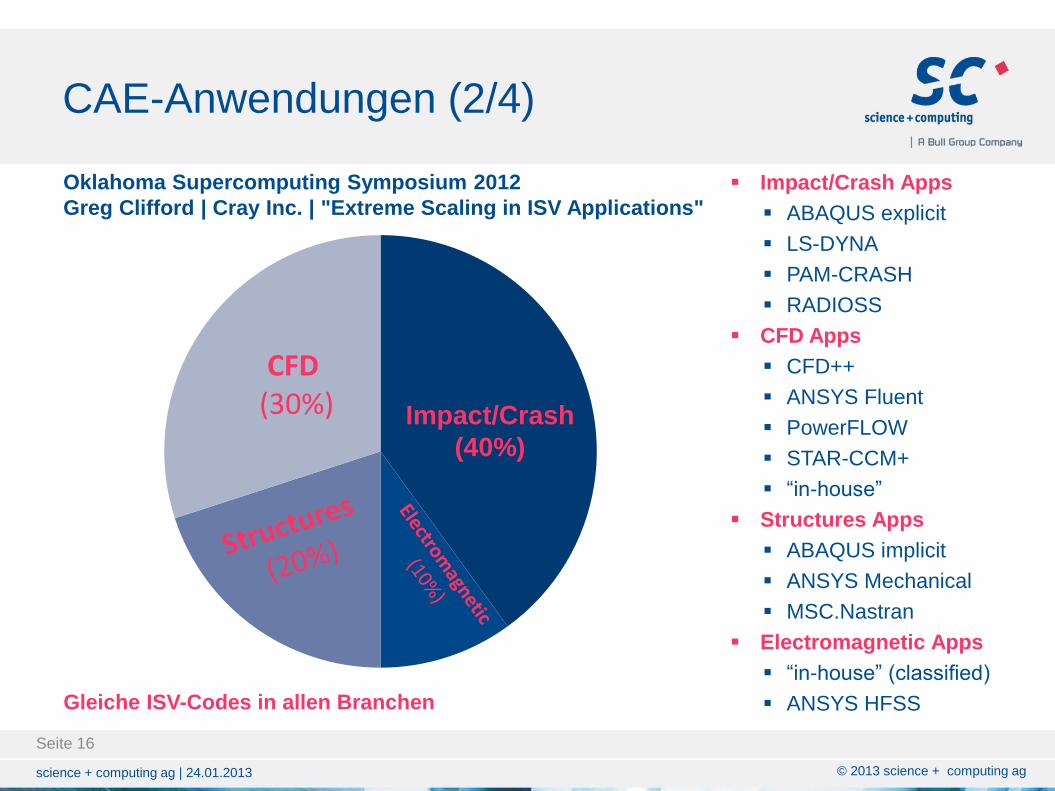
CAE-Anwendungen (2/4)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 16
CFD (30%) Impact/Crash
(40%)
Impact/Crash Apps
ABAQUS explicit
LS-DYNA
PAM-CRASH
RADIOSS
CFD Apps
CFD++
ANSYS Fluent
PowerFLOW
STAR-CCM+
“in-house”
Structures Apps
ABAQUS implicit
ANSYS Mechanical
MSC.Nastran
Electromagnetic Apps
“in-house” (classified)
ANSYS HFSS
Oklahoma Supercomputing Symposium 2012
Greg Clifford | Cray Inc. | "Extreme Scaling in ISV Applications"
Gleiche ISV-Codes in allen Branchen
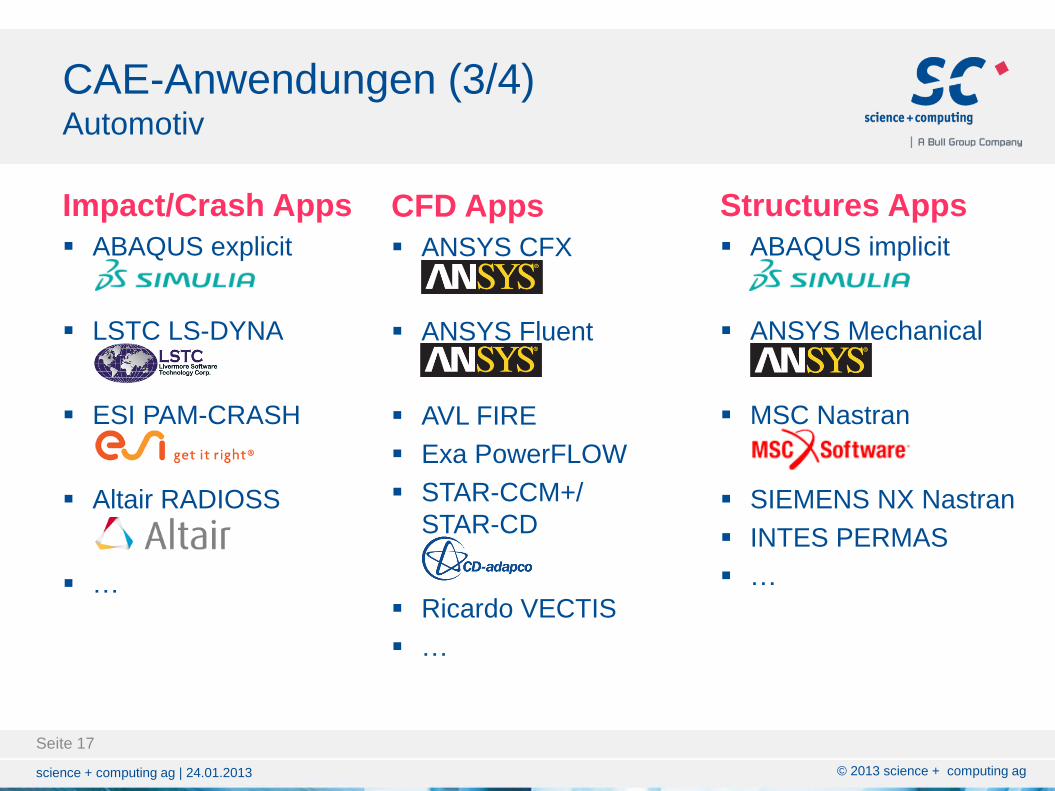
CAE-Anwendungen (3/4) Automotiv
Impact/Crash Apps
ABAQUS explicit
LSTC LS-DYNA
ESI PAM-CRASH
Altair RADIOSS
…
Structures Apps
ABAQUS implicit
ANSYS Mechanical
MSC Nastran
SIEMENS NX Nastran
INTES PERMAS
…
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 17
CFD Apps
ANSYS CFX
ANSYS Fluent
AVL FIRE
Exa PowerFLOW
STAR-CCM+/
STAR-CD
Ricardo VECTIS
…

CAE-Anwendungen (4/4) Typische Konfigurationen
Impact/Crash Apps
Processors: 2x x64 (2x 8 Cores), z.B.
Intel Xeon E5-2670 CPU
(20M Cache, 2.60 GHz,
8.00 GT/s Intel QPI)
Memory: 2GB/Core (32 GB), z.B.
8x 4GB DDR3-1600 ECC
SDRam (1x 4GB)
Storage: 1-2 local Disks, z.B.
1x 500 GB 7.2krpm SATA
or
shared file-system, low IO
Network: InfiniBand
Structures Apps
Processors: 2x x64 (2x 8 Cores), z.B.
Intel Xeon E5-2670 CPU
(20M Cache, 2.60 GHz,
8.00 GT/s Intel QPI)
Memory: 4-8GB/Core (128 GB), z.B.
8x 16GB DDR3-1600 ECC
SDRam (1x 16GB)
Storage: 5-6 local Disks, z.B.
6x 600 GB 15krpm SAS
or
shared file-system, very
high in IO
Network: InfiniBand
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 18
CFD Apps
Processors: 2x x64 (2x 8 Cores), z.B.
Intel Xeon E5-2670 CPU
(20M Cache, 2.60 GHz,
8.00 GT/s Intel QPI)
Memory: 2-4GB/Core (64 GB), z.B.
8x 8GB DDR3-1600 ECC
SDRam (1x 8GB)
Storage: 1-2 local Disks, z.B.
1x 500 GB 10krpm SATA
or
shared file-system, low IO
(steady-state), high IO
(transient)
Network: InfiniBand
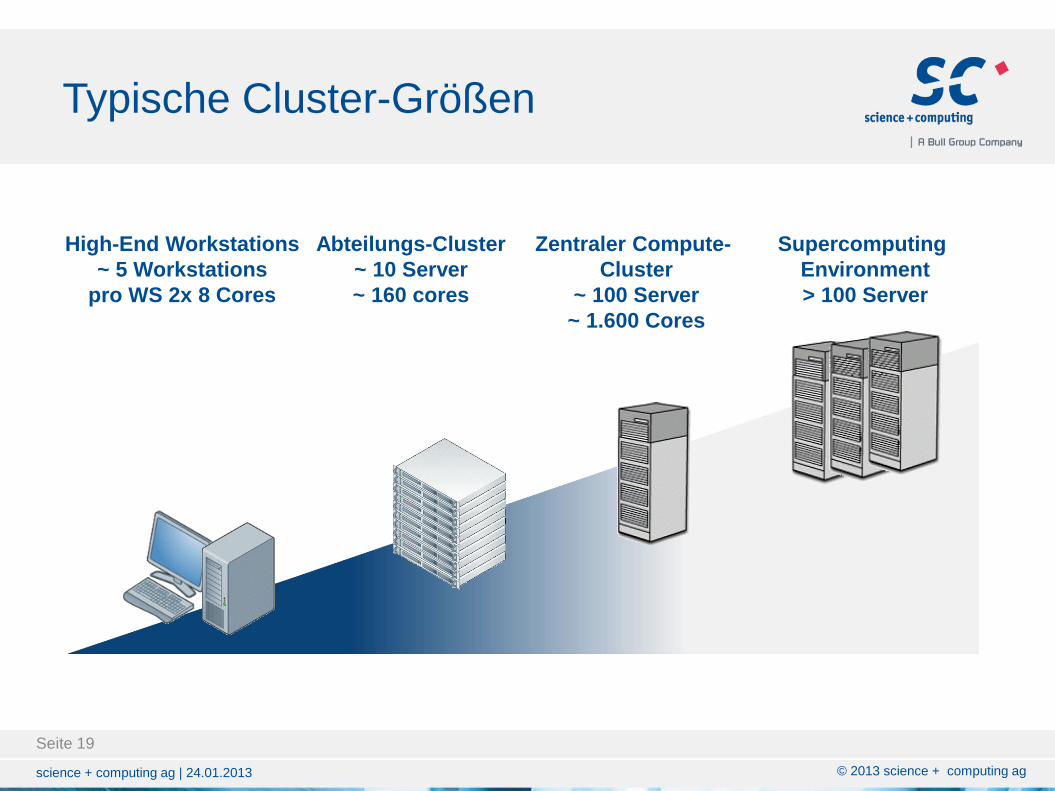
Typische Cluster-Größen
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 19
High-End Workstations
~ 5 Workstations
pro WS 2x 8 Cores
Abteilungs-Cluster
~ 10 Server
~ 160 cores
Zentraler Compute-
Cluster
~ 100 Server
~ 1.600 Cores
Supercomputing
Environment
> 100 Server
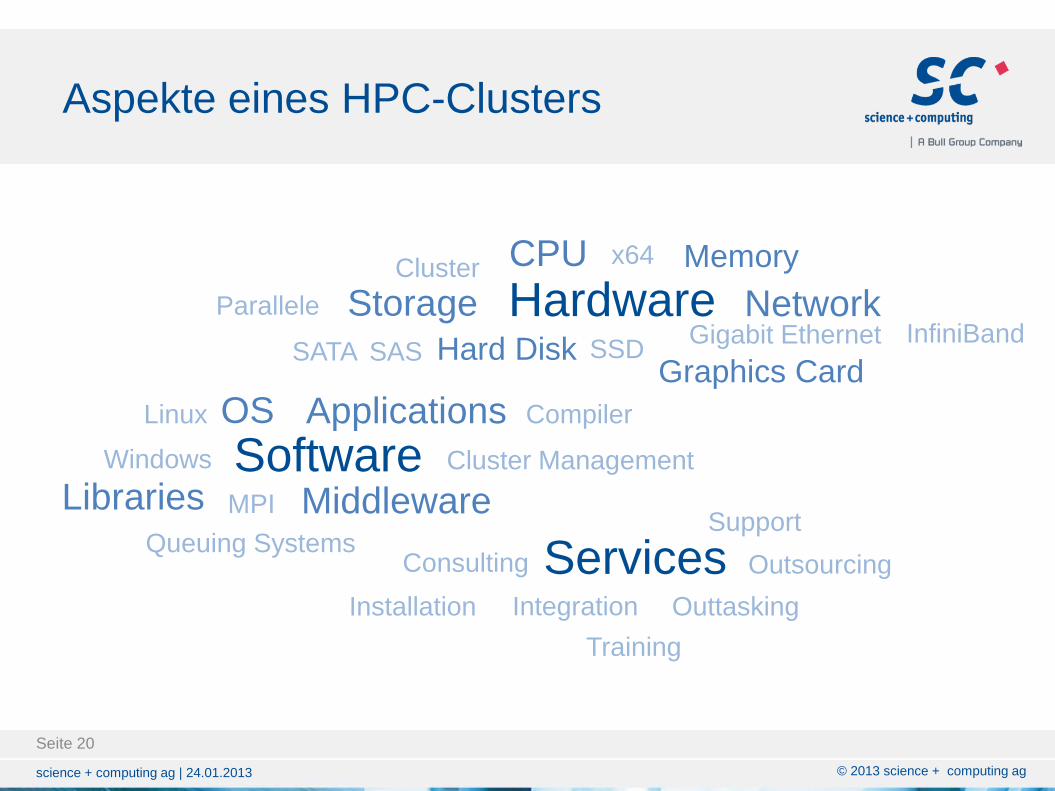
Aspekte eines HPC-Clusters
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 20
Software OS
Libraries Middleware
Applications
Windows
Linux
MPI
Compiler
Queuing Systems
Cluster Management
Services Installation Integration
Training
Consulting
Outtasking
Support
Outsourcing
Hardware CPU Memory
Hard Disk
Network
Graphics Card
Gigabit Ethernet InfiniBand SATA SSD SAS
Storage Parallele
Cluster x64

Aufbau eines Abteilungs-Cluster (1/4) Hardware
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 21
Management-/File-Server
Login-/Visuali.-Server
Compute-Server
Gigabit Ethernet-Switch
InfiniBand-Switch
1. Management-/File-Server
Bull R423-E3 Server mit:
- 2x Intel Xeon E5-2670 8c (2.6GHz - 8.0GT - 20MB - 115W)
- 8x 4GB DDR3-1600 ECC SDRam (1x 4GB) DR (32GB Hauptspeicher)
- 2x 500GB 7.2krpm 3.5’’ SATA3 HDD 64MB (System)
- 1x RAID Controller
- 1x SAS Adapter
- 1x QDR IB + IB-Kabel, 2 m
Storage-System
CDE 2600 Snowmass (12 Slots - SingleController - 2x6Gb SAS) mit:
- 12-Pack: 3TB NL-SAS - 7.2K - PI/FDE (brutto 36TB) 3
1
2
4
IB GE
2. Login-/Visualisierungs-Server
Bull R425-E3 Server mit:
- 2x Intel Xeon E5-2690 8c (2.9GHz - 8.0GT - 20MB - 135W)
- 8x 8GB DDR3-1600 ECC SDRam (1x 8GB) DR (64GB Hauptspeicher)
- 2x 500GB 7.2krpm 3.5’’ SATA3 HDD 64MB (System)
- 1x RAID Controller
- 1x Nvidia Quadro 5000 Graphikkarte
- 1x QDR IB + IB-Kabel, 2 m
- 1x DVD Rom

Aufbau eines Abteilungs-Cluster (2/4) Hardware
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 22
Management-/File-Server
Login-/Visuali.-Server
Compute-Server
Gigabit Ethernet-Switch
InfiniBand-Switch
3
1
2
4
IB GE
3. Cluster-Knoten
2x Bull R424-E3 DualTwin-Server (2x 4 Server = 128 Cores) mit je:
- 2x Intel Xeon E5-2670 8c (2.6GHz - 8.0GT - 20MB - 115W)
- 8x 8GB DDR3-1600 ECC SDRam (1x 8GB) DR (64 GB Hauptspeicher)
- 1x 500GB 7.2krpm 3.5’’ SATA3 HDD 64MB (System)
- 1x 512GB 2,5" 10mm SATA3 SSD W/Tray 3.5" (Scratch)
- 1x QDR IB + IB-Kabel 2m
4.1 Gigabit Ethernet-Switch
Cisco Catalyst 2960G-24TC-L 20 ports 10/100/1000 - 4 SFP -
LAN Base Image
4.2 InfiniBand-Switch
Mellanox IS5023 QDR IB-Switch mit:
- 18 QSFP ports
- 1 power supply
- Unmanaged

Aufbau eines Abteilungs-Cluster (3/4) Software
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 23
Management-/File-Server
Login-/Visuali.-Server
Compute-Server
Gigabit Ethernet-Switch
InfiniBand-Switch
IB GE
OS: Red Hat Enterprise Linux 6.x
Application: ANSYS CFX
Middleware:
Cluster-Management: scVENUS
Queuing-System: IBM Platform LSF
Remote-Visualisierung: NICE DCV

Aufbau eines Abteilungs-Cluster (4/4) Services
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 24
Management-/File-Server
Login-/Visuali.-Server
Compute-Server
Gigabit Ethernet-Switch
InfiniBand-Switch
IB GE
Initialprojekt:
Grundinstallation des Berechnungs-Clusters
Installation + Konfiguration der Middleware
Installation + Konfiguration der CAE-Anwendungen
Installation + Konfiguration Submit-Umgebung
Betrieb:
Service-Desk (CAE-Hotline)
CAE-Applikationssupport
CAE-Server
Anwender-Support

Inhalt
1. Unternehmen Bull/science + computing
2. HPC in Unternehmen
3. Beispiele
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 25
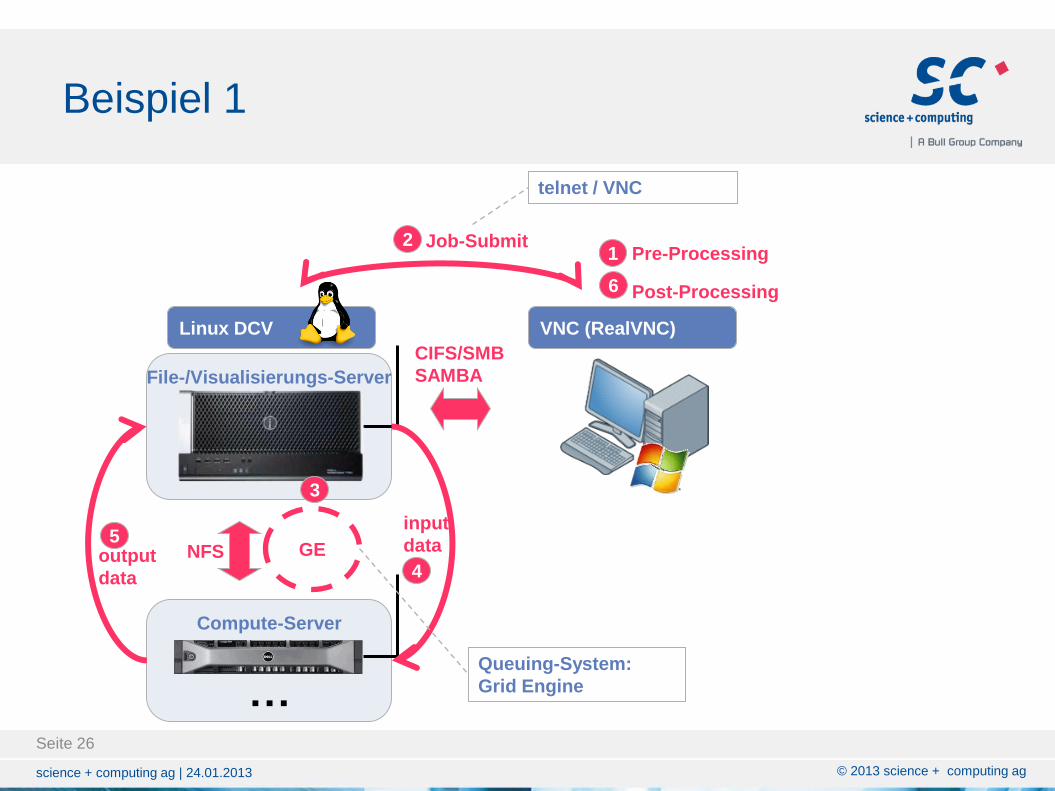
Beispiel 1
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 26
File-/Visualisierungs-Server
Compute-Server
…
GE NFS
VNC (RealVNC)
CIFS/SMB
SAMBA
Job-Submit 2
Linux DCV
Queuing-System:
Grid Engine
input
data
4 output
data
5
1
6
Pre-Processing
Post-Processing
telnet / VNC
3
File-Server File-Server
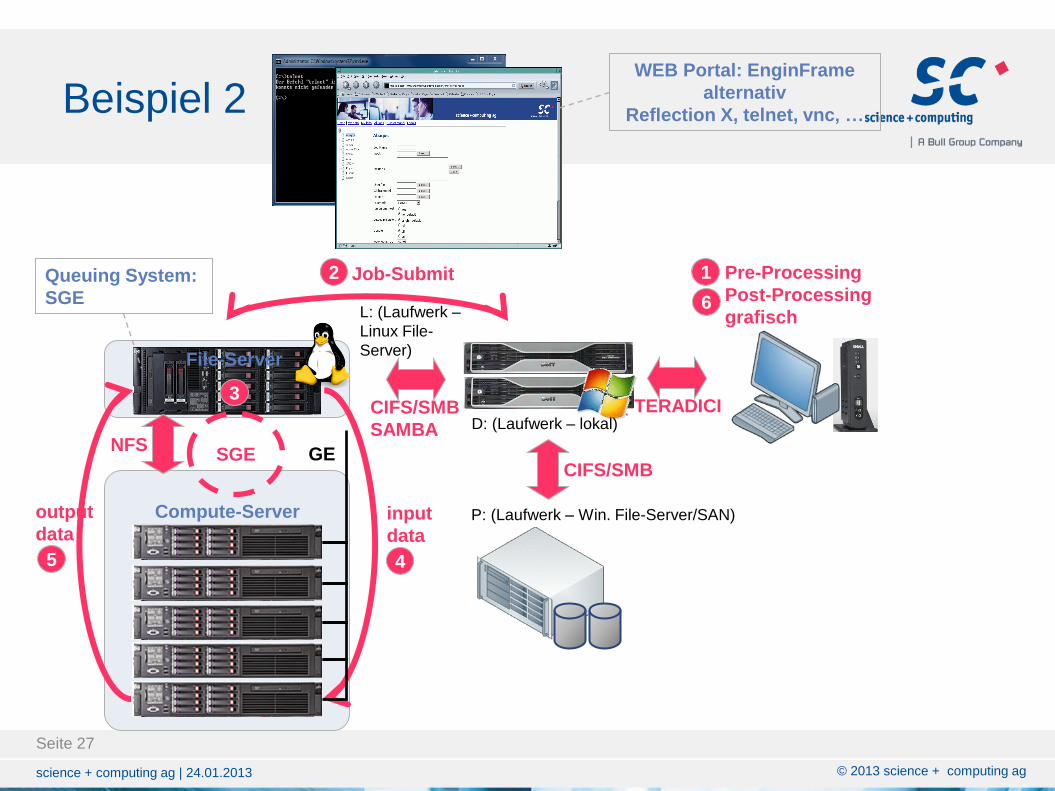
Beispiel 2
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 27
Compute-Server
Job-Submit 2
CIFS/SMB
SAMBA
input
data
output
data
4 5
Queuing System:
SGE
TERADICI
GE
D: (Laufwerk – lokal)
P: (Laufwerk – Win. File-Server/SAN)
CIFS/SMB
L: (Laufwerk –
Linux File-
Server)
WEB Portal: EnginFrame
alternativ
Reflection X, telnet, vnc, …
1
6
Pre-Processing
Post-Processing
grafisch
NFS SGE
3

Beispiel 3 (1/4)
Beratung/Aufbau/Betrieb eines Engineering Centers im
CAE-Umfeld in Pune/Indien:
Zeitraum 2010 bis 2013
Geplanter Starttermin: Juni/Juli 2010
Admin-Server: 1 (FlexLM-, Backup-Server)
File-Server: 1 (NetApp)
Compute-Server: 2 (2010) – ~5 (2013)
CAE-Arbeitsplatzrechner: 10 (2010) – ~20 (2013)
CAE-Anwender: 10 (2010) – ~20 (2013)
Applikationen: Middleware (4), Compiler (2),
CAE-Applikationen (5)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 28
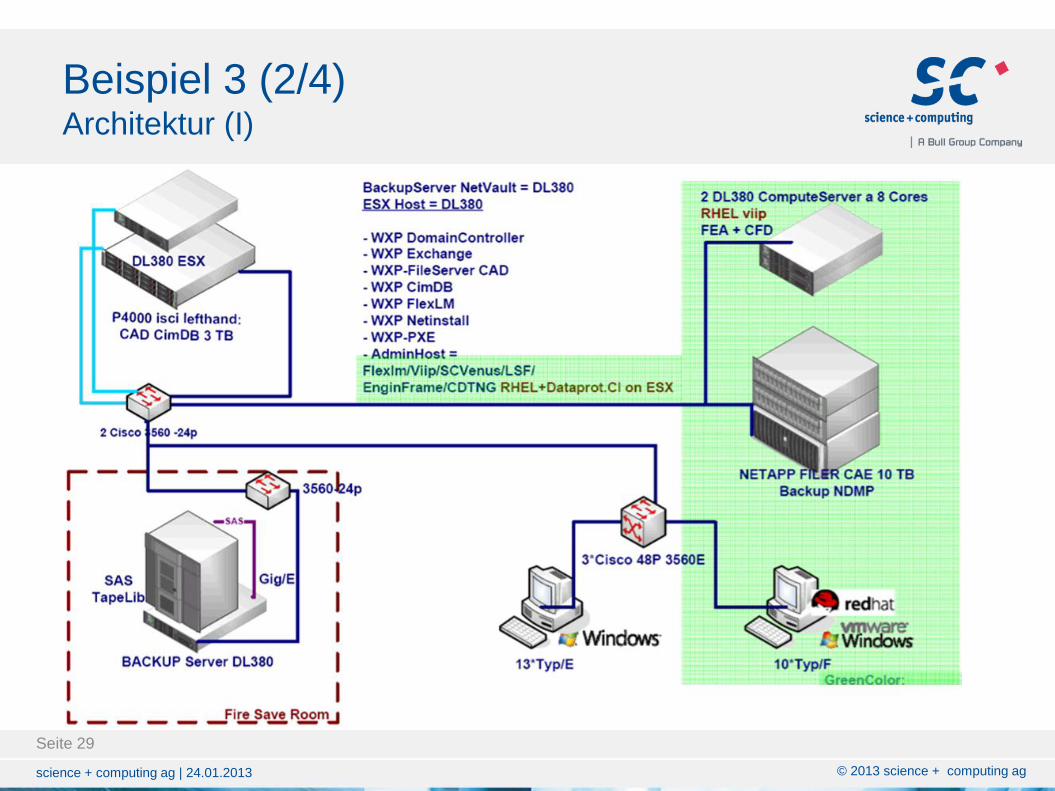
Beispiel 3 (2/4) Architektur (I)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 29
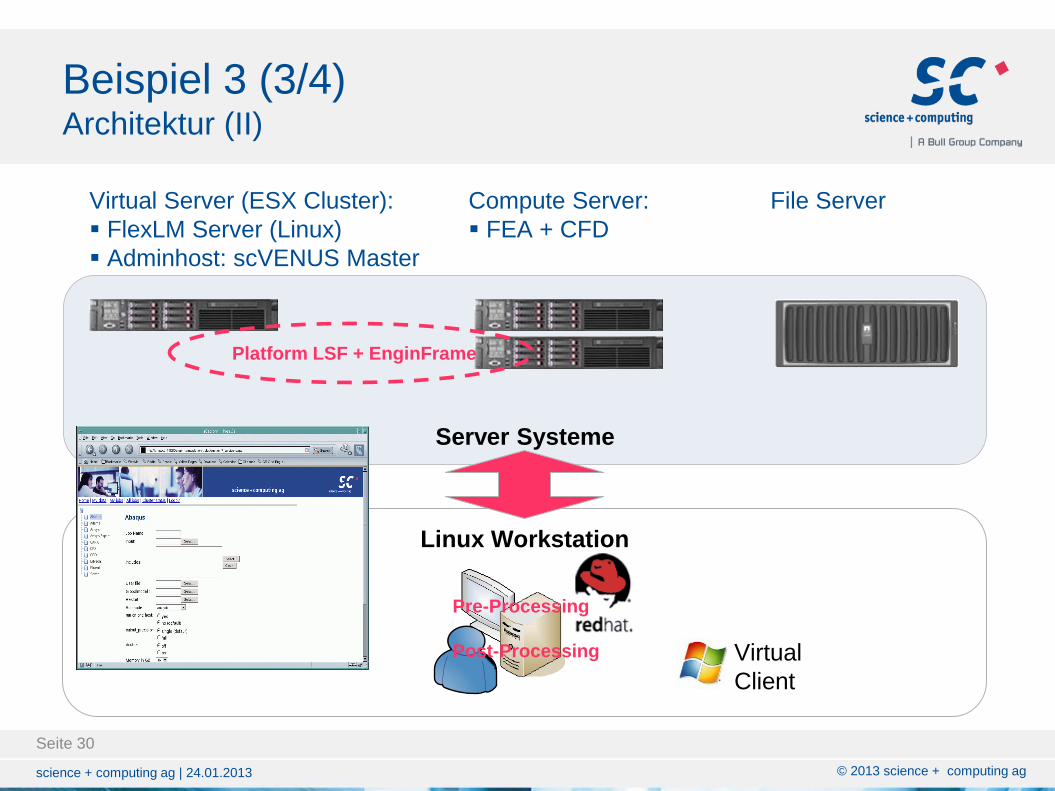
Beispiel 3 (3/4) Architektur (II)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 30
Server Systeme
Virtual Server (ESX Cluster):
FlexLM Server (Linux)
Adminhost: scVENUS Master
Compute Server:
FEA + CFD
File Server
Linux Workstation
Pre-Processing
Post-Processing Virtual
Client
Platform LSF + EnginFrame

Beispiel 3 (4/4) Leistungen
Service-Desk (CAE-Hotline):
Service-Desk (CAE-Hotline) generell durch s+c
Themen, die nicht im Verantwortungsbereich von s+c liegen werden
weitergeleitet
Zugang über Telefon oder E-Mail
Supportzeiten Hotline: 7:00 bis 18:00 Uhr, MEZ (direkt erreichbar)
Hotline-Meldung: jederzeit über Band bzw. E-Mail (remote)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 31

Beispiel 4 (1/3)
Ersatzbeschaffung Crash- + NVH-Cluster
Crash: 768 Server
NVH: 25 Server, teilweise mit GPGPUs
(Lustre-Storage optional)
Inklusive QDR-InfiniBand + Gigabit Ethernet
Anwendungen: LS-DYNA, NASTRAN, AMLS
Betriebssystem: CentOS
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 32

Compute-Nodes NVH
25x Nodes
- 2x Intel Xeon E5-2680 8c (2.7GHz)
- 128 GB Hauptspeicher
- 1x 300GB 15krpm SAS HDD (System)
- 6x 600GB 15krpm SAS HDD (Scratch)
- Raid-Controller
- 1x QDR IB
8 Nodes mit GPGPU
- Nvidia Tesla 2090 / Nvidia Tesla K20)
Rack 1
…
…
Beispiel 4 (2/3) Crash- + NVH-Cluster
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 33
Rack 19
…
Rack 3
…
Rack 2
…
Rack 1
… Compute-Nodes Crash
192x Quad-Nodes (768 Server)
- 2x Intel Xeon E5-2670 8c (2.6GHz)
- 64 GB Hauptspeicher
- 1x 1000GB HDD
- 1x QDR IB

Beispiel 4 (3/3) Lustre Storage System 360/1080 TB raw (optional)
© 2013 science + computing ag science + computing ag | 24.01.2013
Seite 34
Meta-Daten-Storage
2x Nodes
- 2x Intel Xeon E5-2650 8c (2.0GHz)
- 64 GB Hauptspeicher
- 2x 500GB 7.2krpm SATA3 HDD (System)
- Raid-Controller
- 1x QDR IB
1x CDE 5400 PikesPeak (60Slots - DualController - Turbo –
24GB Cache - 8x FC8 ) mit:
- 2x Kit: 10-Pack Box: 900 GB Compass 10K - PI/FDE SAS
Object-Daten-Storage
6x Nodes
- 2x Intel Xeon E5-2650 8c (2.0GHz)
- 64 GB Hauptspeicher
- 2x 500GB 7.2krpm SATA3 HDD (System)
- Raid-Controller
- 1x QDR IB
6x CDE 5400 PikesPeak (60Slots - DualController - Turbo –
24GB Cache - 8x FC8 ) mit:
- 6x Kit: 10-Pack Muskie+ 1TB/3TB 3.5” 6Gb SAS PI/FDE
Object-Daten-Storage
Meta-Daten-Storage

Vielen Dank für Ihre Aufmerksamkeit.
science + computing ag
www.science-computing.de
Vortrag von: Harry Schlagenhauf
Telefon: 07071 9457-404
E-Mail: [email protected]




![Test Drive CFD · 2019. 11. 8. · CFD-Analyse –grundsätzliche Vorgehensweise Aufgabenstellung erfassen und Preprozessing: [SpaceClaim & ANSYS- oder Fluent-Meshing] 1. Ziel der](https://static.fdokument.com/doc/165x107/60d8c5c9c6a9f4410d421b1b/test-drive-cfd-2019-11-8-cfd-analyse-agrundstzliche-vorgehensweise-aufgabenstellung.jpg)













