
Thema Modul 3 – Datenverarbeitung Datenbanken · FHTW–Berlin Technisches Gebäudemanagement...
52
FHTW–Berlin Technisches Gebäudemanagement Studienarbeit im Rahmen der Vorlesung Informatik I bei Dozentin Frau Dr. Antonova Thema Modul 3 – Datenverarbeitung Datenbanken • Modelle • Konzepte • Abfragesprachen • Marktübersicht und Beispiele Ihrer Anwendungen • Praktische Aufgabenstellung / Praktisches Beispiel: o Programmieren Sie eine Datenbank, die die Datenbasis für eine Self-Service-Anwendung speichern könnte. o Stellen Sie sicher, dass verschiedene Webanwendungen an die Datenbank andocken könnten und aus diesem Grund das Datenmanagement innerhalb der Datenbank abgewickelt wird. o Erstellen Sie ein ER-Modell der Datenbank. vorgelegt von: Martin Sowinski Matrikel-Nr.: 518833 [email protected]
Transcript of Thema Modul 3 – Datenverarbeitung Datenbanken · FHTW–Berlin Technisches Gebäudemanagement...

FHTW–Berlin Technisches Gebäudemanagement
Studienarbeit im Rahmen der Vorlesung
Informatik I bei Dozentin
Frau Dr. Antonova
Thema Modul 3 – Datenverarbeitung
Datenbanken
• Modelle
• Konzepte
• Abfragesprachen
• Marktübersicht und Beispiele Ihrer Anwendungen
• Praktische Aufgabenstellung / Praktisches Beispiel:
o Programmieren Sie eine Datenbank, die die Datenbasis für
eine Self-Service-Anwendung speichern könnte.
o Stellen Sie sicher, dass verschiedene Webanwendungen an
die Datenbank andocken könnten und aus diesem Grund das
Datenmanagement innerhalb der Datenbank abgewickelt
wird.
o Erstellen Sie ein ER-Modell der Datenbank.
vorgelegt von: Martin Sowinski Matrikel-Nr.: 518833 [email protected]


Informatik I - Datenbanken Inhaltsverzeichnis
INHALTSVERZEICHNIS
1 EINFÜHRUNG 6
2 DAS DBMS / DIE DATENBANKMODELLE 9
2.1 DAS DATENBANKMANAGEMENTSYSTEM - DBMS 10
2.2 EBENEN DER DATENBANKANWENDUNGEN 10
2.2.1 EINSCHICHTIGE ANWENDUNGEN 12
2.2.2 ZWEISCHICHTIGE ANWENDUNGEN 12
2.2.3 N-SCHICHTIGE ANWENDUNGEN 14
2.3 DATENMODELLE 16
2.3.1 HIERARCHISCHE DATENBANKEN 17
2.3.2 NETZWERKDATENBANKEN 19
2.3.3 RELATIONALE DATENBANKEN 21
2.3.4 OBJEKTORIENTIERTE DATENBANKSYSTEME 24
3 DIE DATENBANKSPRACHE SQL 28
3.1 SPRACHKOMPONENTEN VON SQL 29
4 ER-MODELLE 30
5 NORMALISIERUNG 31
5.1 DIE ERSTE NORMALFORM 31
5.2 DIE ZWEITE NORMALFORM 31
5.3 DIE DRITTE NORMALFORM 32
5.4 DIE VIERTE NORMALFORM 32

Informatik I - Datenbanken Inhaltsverzeichnis
4
5.5 DIE FÜNFTE NORMALFORM 32
5.6 DIE BOYCE-CODD-NORMALFORM 33
6 PRAKTISCHE AUFGABENSTELLUNG 34
6.1 EINFÜHRUNG IN DAS BEISPIEL 34
6.2 FINDUNGEN EINES GESCHÄFTSPROZESSES 35
6.3 DATENBANKENTWURF UND ENTWICKLUNG DES ER-MODELLS 38
6.4 ENTSCHEIDUNGSFINDUNG FÜR DATENBANKFABRIKAT 40
6.5 UMSETZUNG DER PROGRAMMIERUNG 42
6.5.1 VERWENDETE DATENTYPEN 42
6.5.2 VERWENDETER ZEICHENSATZ UND VERWENDET SORTIERORDNUNG 42
6.5.3 ERSTELLEN DER TABELLEN 42
7 ABKÜRZUNGSVERZEICHNIS 48
8 LITERATURVERZEICHNIS 49
Anlagen:
Anlage 1: CD
Anlage 2 Präsentation
Anlage 3 Relationen MySQL-Datenbank

Informatik I - Datenbanken Inhaltsverzeichnis
5
1 Agenda
• Introduction
• The DBMS / Types of Databases
o The Database Management System (DBMS)
o Database Applications
o Hierarchical Databases
o Network Databases
o Relational Databases
� Entity Relationship Model
� Normalisation of Databases
o Object Relational Databases
• Programming languages of Databases SQL
• The Example

Informatik I - Datenbanken Einführung
6
1 Einführung
Es gibt viele Gründe sich gerade im technischen Gebäudemanagement mit Daten-
banken und ihrer Arbeitsweise auseinanderzusetzen. Ein Grund ist die wachsende
Verbreitung von Datenbankanwendungen gerade bei intelligenten Gebäudemana-
gementsystemen.
Ein anderer Grund ist die ständig wachsende Datenmenge, die so gespeichert wer-
den sollte, dass wir als Nutzer dieser Daten sie auch beherrschen. Hierbei gibt es
verschiedene Techniken.
Fakt ist auch, dass die Menge der zu speichernden Daten in den vergangenen 20
Jahren stark zugenommen hat. Und dass die Perioden, in denen sich das Datenvo-
lumen verdoppelt, immer kürzer werden. Aus diesem Grund wurden geeignete Sys-
teme gesucht, um diese Datenmengen zu beherrschen. Die Entwicklung von leis-
tungsfähigen Datenbanken zur Steuerung dieser Daten bekam eine große Bedeu-
tung. So hat auch das Wissen über Datenbanken stark zugenommen.
In Datenbanken wird die Verwaltung der Daten so organisiert, dass die Nutzer
schnell und gezielt auf ihre Informationen zugreifen und diese auch auswerten kön-
nen.
Ein weiterer Aspekt ist die Speicherung von Daten aus Programmen. Die hat sich
gerade in den letzten 10 Jahren dahingehend verändert, dass früher zum Beispiel
Programmprozessdaten in Dateien ausgelagert oder direkt im jeweiligen Programm
gespeichert wurden, nun aber die meisten Anwendungsprogramme, die ein großes
Volumen an Prozessdaten erzeugen, diese Daten in Datenbanken speichern. Dies
hat unter anderem auch den Vorteil, dass Daten programmübergreifend genutzt wer-
den. Durch die Speicherung dieser Daten in einer Datenbank können verschiedene
Programme auf die gleichen Informationen zugreifen.
Im Technischen Gebäudemanagement wurden Datenbanken mit der Erweiterung
von Anlagen der Gebäude-Leit-Technik und der Einführung des CAFM (Computer
Aided Facility Management) etabliert.
Eine praktische Anwendung, wie Sie bei der Royal BAM Group im Einsatz ist, zeigt
die Abbildung 1. Im Zentrum der Anwendungen steht eine Oracle®-Datenbank, in der
die Daten der zwei Hauptanwendungen SAP® und FaMe® gespeichert werden. Da-
bei werden die kaufmännischen Prozesse der Bauunternehmung im SAP und die
Prozesse des Gebäudemanagements im FaMe abgebildet. Zusätzlich gibt es noch
für verschiedene Projekte ein SelfServicePortal, über das die Nutzer von Gebäuden

Informatik I - Datenbanken Einführung
7
mit der Objektleitung kommunizieren können. Diese drei Elemente greifen direkt auf
eine Datenbank zu.
Ein weiteres System für die aktive Steuerung von Immobilien und Gebäuden ist die
GLT (Gebäudeleittechnik). Die verschiedenen Systeme in den einzelnen Gebäuden
sind nicht gleichartig. Sie funktionieren an den Einsatzorten autark. Die Anbindung
dieser Elemente an das CAFM geht nur über Schnittstellen zwischen den Datenban-
ken. Man nutzt die Datenbank der GLT um die Informationen für den Betrieb des Ge-
bäudes zu sammeln und vorzuhalten. Die Auswertung dieser Daten findet dann aber
in einem CAFM-System statt, da hierfür oft ergänzende Informationen benötigt wer-
den. So sagt der Energieverbrauch eines Gebäudes zum Beispiel nur etwas aus,
wenn man ihn auf die Nutzfläche bezieht. Erst mit der Koppelung von Gebäude- und
Gebäudeprozessdaten ist der Facility Manager in der Lage, eine Aussage über die
Wirtschaftlichkeit des Gebäudes zu treffen.
Abbildung 1 - Mehrere Anwendungen greifen auf eine Oracle®-Datenbank zu
Ein weiteres Beispiel für die Abbildung von kaufmännischen Prozessen in Unterneh-
men ist die Speicherung von Firmendaten. Wenn wir allein die Abteilungen Einkauf,
Kreditoren und Debitoren betrachten, stellen wir fest, dass diese Abteilungen im Be-
reich der Firmendatenverwaltung (Geschäftspartnerdaten) zum größten Teil auf den
gleichen Datenstamm zugreifen. Das sind im Detail Lieferantenadressen, die in allen
Abteilungen gleichzeitig gepflegt werden. Durch Zusammenführung dieser Daten
werden Redundanzen bei der Datenhaltung vermieden.

Informatik I - Datenbanken Einführung
8
Die Vermeidung von Redundanzen war ein Hauptanliegen bei der Einführung der
Datenbanken.
In dieser Arbeit werden ich zuerst auf die verschiedenen Datenbankmodelle einge-
hen, wobei der Schwerpunkt bei den zukunftorientierten Modellen der relationalen
und objektorientierten Datenbanken liegt. Anschließend sind die verschiedenen Da-
tenbankanwendungen Thema der Betrachtung, bevor ich zu dem überaus wichtigen
Thema der Programmier- und Abfragesprache SQL für Datenbanken komme. Im An-
schluss an die Einführung der Grundbegriffe und Konzepte werde ich das praktische
Beispiel umsetzen. Hierbei wird ein Anliegen der Bezug zum Fachgebiet Techni-
sches Gebäudemanagement sein.

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
9
2 Das DBMS / Die Datenbankmodelle
Die verwendeten Datenbanken können sich beträchtlich in ihrer Organisation und
ihrem Aufbau unterscheiden. Schon beim Ansatz zur Lösung von Datenbanksystem-
aufgaben sollte dies berücksichtigt werden. Die Entwicklung von Datenbanken hatte
ihren Ursprung mit den hierarchischen Datenbanken. Eine Weiterentwicklung dieser
waren dann die Netzwerkdatenbanken, aus denen schließlich die relationalen Da-
tenbanken hervorgingen.
Abbildung 2 - Aufgaben eines Datenbankmanagementsys tems (DBMS) 1
Die vorerst letzte marktfähige Weiterentwicklung stellen die objektbezogenen Daten-
banken dar. Diese sind aber heute noch relativ selten anzutreffen, da die relationalen
Datenbanken sehr weit verbreitet sind und eine Umstrukturierung dieser Daten sehr
aufwendig erscheint.
1 [2], S.51

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
10
2.1 Das Datenbankmanagementsystem - DBMS
Dem Datenbankmanagementsystem kommen ganz verschiedene Aufgaben zu, die
sich von DBMS zu DBMS unterscheiden. Die Leistungsfähigkeit dieser Systeme ent-
scheidet grundlegend über die Leistungsfähigkeit der Datenbanken an sich.
Der Unterschied zwischen einem DBMS und der Datenbank liegt in der Funktion.
Das DBMS stellt einen Funktionsrahmen zur Verfügung, der für die Nutzung der Da-
tenbanken in Anspruch genommen wird. Innerhalb eines DBMS können mehrere Da-
tenbanken angelegt werden. In der Datenbank selbst werden die Daten gespeichert
und organisiert abgelegt. Hier können auch Programme und Prozesse gespeichert
sein, aber die Organisation der Daten übernimmt das DBMS.
Innerhalb des DBMS sind z.B. die Sicherheits- und Sicherungsfunktionen sowie die
Benutzerverwaltung angesiedelt. Unter Sicherungsfunktionen versteht man zum Bei-
spiel Abläufe die ein Recovery (Wiederherstellen) der Datenbank ermöglichen.
Das DBMS kann aber auch mit Hilfe von Zusatzprogrammen umgangen werden.
Zum Beispiel können die in die Datenbank gesendeten Daten durch externe Pro-
gramme speziell aufbereitet werden. Man spricht dann von der Auslagerung des Da-
tenmanagements.
Das DBMS ist der große Rahmen, der das Handling mit den Datenbanken vorgibt.
2.2 Ebenen der Datenbankanwendungen 23
Die Betrachtung der Datenbankanwendungen entsprechen nicht im Gesamten der
Betrachtung der DBMS. Hier sind die Managementsysteme Bestandteil einer An-
wendung die über die Datenbank an sich hinaus geht. Es wird der Einsatz der Da-
tenbanken in den Vordergrund gestellt.
Die Speicherung der Daten, der Umgang mit den Daten und die Anzeige der Daten
werden über drei Ebenen gesteuert. Wie in Abbildung 3 gezeigt, heißt die erste Ebe-
ne „Physische Ebene“. Hier werden die Daten gespeichert. Dazu dienen in der Regel
die handelsüblichen Speichermedien, wie zum Beispiel Plattenlaufwerke. Die zweite
Ebene ist die logische Ebene. Hier sind bestimmte Regeln und Kriterien zum Hand-
ling der Daten gespeichert.
2 [2] 3 [3]

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
11
Eine weitere Ebene sind die Sichten. Als Sichten können Sie sich einen Ausschnitt
aus der Gesamtheit der Daten vorstellen. Beim professionellen Einsatz von Daten-
banken in Firmen werden den einzelnen Nutzern oder Benutzergruppen bestimmte
Rechte übertragen, die die Sichtbarkeit der Daten steuern. Nicht jeder Nutzer wird
alle Daten sehen können. Die meisten werden nur einen bestimmten Ausschnitt se-
hen dürfen z.B. nur die Daten, die für die Abteilung des Benutzers relevant sind.
Die wenigsten Nutzer werden direkt auf die Daten in der Datenbank zugreifen. Hier
werden sogenannte GUI Graphical User Interfaces verwendet, die den Umgang mit
den Daten erleichtern. Typische Anwendungen dieser Art sind zum Beispiel Baulogis,
FaMe, SAP oder pro27. Die als Beispiel aufgeführten Anwendungen sind professio-
nelle Anwendungen, die gerade in der 2. Ebene, der Geschäftsebene, sehr komplex
strukturiert sind. Aus diesem Grund sind diese Anwendungen auch vorwiegend als
Application-Server-Anwendungen oder Web-Server-Anwendungen umgesetzt. Die
Form, in der die Anwendung angeboten wird, ergibt sich aus der IT-Organisation der
einzelnen Komponenten.
In der IT-Struktur unterscheidet man nun einschichtige, zweischichtige und n-
schichtige Systeme.
Abbildung 3 - Ebenen eines DBMS 4
4 [3]

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
12
2.2.1 Einschichtige Anwendungen
Als einschichtiges System kann man zum Beispiel eine ACCESS-Anwendung sehen,
die auf einem Rechner installiert und nicht netzwerkfähig ist. In der praktischen An-
wendung kann das eine Datenbank sein, die zur Inventarisierung in einem neuem
Objekt genutzt wird.
Abbildung 4 - Schematische Darstellung einer einsch ichtigen Anwendung 5
In dem auf dem Rechner installierten System liegt die physische Ebene, in diesem
Fall die Festplatte des Rechners, die logische Ebene, hier die Definition der Formula-
re und Abfragen und die Präsentationsebene, die von dem Formular und Abfrageer-
gebnis selbst dargestellt wird.
2.2.2 Zweischichtige Anwendungen
Bei zweischichtigen Anwendungen werden die Ebenen voneinander getrennt. Dabei
gibt es zwei Herangehensweisen. Bei der ersten Variante wird die Präsentationsebe-
ne von der Geschäfts- und der physischen Ebene getrennt. Dabei übernimmt der
Client-Rechner nur die Präsentation der Daten. Die eigentliche Leistung vollbringt ein
Server auf dem die Geschäftslogik und auch die Datenbank selbst gespeichert sind.
Der Vorteil einer solchen Anwendung ist die leistungsmäßig schwache Auslegung
der Client-Rechner. Das wirkt sich positiv auf die Kosten einer Arbeitsplatzausstat-
5 [3], S.76

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
13
tung aus. Wegen der schwachen Auslegung der Client-Rechner werden diese An-
wendungen auch als Thin-Client bezeichnet.
Abbildung 5 - Schematische Darstellung einer zweisc hichtigen Anwendung (Thin Client) 6
Ein Nachteil dieser Konstruktion ist der vermehrt auftretenden bidirektionale Daten-
verkehr. Die Daten werden bei allen Abfragen immer vom Client zum Server und
wieder zurück übertragen. Dies muss bei der Planung des Netzwerkes beachtet wer-
den.
Abbildung 6 - Schematische Darstellung einer zweisc hichtigen Anwendung (Fat Client) 7
Eine andere Möglichkeit stellen die sogenannten Fat-Client-Anwendungen dar. Hier
beinhaltet der Client neben der Präsentationsebene auch die Businessebene. Aus
diesem Grund muss dieser leistungsmäßig entsprechend stärker ausgeprägt sein,
was zur Bezeichnung Fat-Client führte.
6 [3] S.77 7 [3] S.77

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
14
Die Daten der Anwendungen werden auch in der physischen Ebene auf einem ex-
ternen Server gespeichert, aber es entfällt der Traffic zwischen der Präsentations-
und der Businessebene. Die Operationen oder auch Prozesse mit den Daten der
Anwendung werden auf dem Client ausgeführt.
Bei entsprechender Auslegung der Clients können diese Anwendungen sehr schnel-
le Antwortzeiten vorweisen.
2.2.3 N-schichtige Anwendungen
Diese Art der Ebenenverteilung ist die, die zur Zeit am häufigsten im professionellen
Bereich Verwendung findet und die auch in Zukunft noch weiter ausgebaut wird. Hier
werden die Ebenen auch über mehrere Rechner verteilt, aber mit fortschreitender
Leistungsnachfrage wächst auch die Verteilung.
Für die Abarbeitung der Aufgabe sind hier immer zwei Gruppen von Servern notwen-
dig. Die eine Gruppe ist mit der Datenhaltung betraut. Hier laufen die Datenbankser-
ver. Die andere Gruppe erledigt die Anwendungsaufgaben. Um die heute geforderten
Geschäftsprozesse in ihrer Komplexität zu bewältigen, wird gerade die Gruppe der
Anwendungsserver sehr stark gerüstet. Häufig werden die Anwendungen schon bei
der ersten Implementierung solcher Systeme über mehrere Server verteilt, um im
täglichen Geschäftsbetrieb die nötige Performance zu erreichen.
Abbildung 7 - N-schichtige Datenbankanwendung 8
8 [3], S.78

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
15
Neben der grundlegenden Trennung von Anwendung und Datenbank gibt es nun
mehrere Möglichkeiten der weiteren Verteilung. Ich möchte an dieser Stelle auf zwei
eingehen. Zum Einen sind das die Intranetanwendungen und zum Anderen die Web-
anwendungen.
Bei den Intranetanwendungen wird die Präsentationsebene bei den Client-Rechnern
angesiedelt, die Geschäftslogik bei den Anwendungsservern hinterlegt und die Da-
tenspeicherung wird von der physischen Ebene sichergestellt.
Ein Nachteil dieser Methode ist die dezentrale Speicherung der Client-Software. Als
Client-Programme werden häufig keine Standardsoftwareprodukte, wie etwa ein In-
ternetbrowser, genutzt. Hier wird spezielle Clientsoftware verwendet, die auf jedem
Client installiert und gewartet werden muss. Das erhöht den administrativen Aufwand
bei Release-Wechseln und der Nutzerbetreuung.
Abbildung 8 - Schematische Darstellung ein N-schich tigen Webanwendung 9
Eine andere Methode, die seit einigen Jahren einen starken Aufwind erfährt, sind die
Internettechnologien. Hier wird die Präsentationsebene auf dem Anwendungsserver
dargestellt. Die Präsentation der Daten im eigentlichen Sinne erfolgt aber in einem
9 [3] S.79

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
16
normalen Webbrowser. Gerade diese Verteilung birgt große Vorteile. Zum Einen sind
auf den Client-Rechnern nur das Betriebssystem und ein Browser nötig und keine
aufwendigen lokalen Installationen.
Zum Anderen kann man auch mit firmenfremden Rechnern auf die Systeme von au-
ßen zugreifen. Das bringt den Mitarbeitern eine gewisse Unabhängigkeit und es er-
laubt Kunden, Geschäftspartnern und Auftragnehmern das System mit zu nutzen,
dies natürlich nur in einem begrenzten Rahmen. Der Vorteil den solche Systeme mit
sich bringen ist klar. Sie sparen Arbeit, weil zum Beispiel Doppeleingaben vermieden
werden. Ein auf den Geschäftsprozess abgestimmter Workflow kann somit für die
Vorgangsbearbeitung die Zeit, die für die Verwaltungsaufgaben anfallen, stark mini-
mieren.
Gerade die Internetanwendungen werden in den nächsten Jahren weiter an Bedeu-
tung gewinnen.
2.3 Datenmodelle
Datenmodelle bezeichnen die Art der Datenstrukturierung. Sie geben den Rahmen
für die Organisation der Daten in der Datenbank vor. Datenmodelle kann man sich
ähnlich einer Programmiersprache vorstellen. Hier werden die generischen Struktu-
ren und Operatoren definiert, die dann für das Datenmanagement benötigt werden.10
Für die Definition des Datenmodells betrachtet man zwei Bereiche. Auf der einen
Seite muss die Struktur der Daten definiert werden, auf der anderen Seite betrachtet
man das Handling der Daten. Das heißt, das Ändern der Daten in der Datenbank und
das Auswerten der Informationen. Den ersten Teil bezeichnet man als Datendefiniti-
onssprache und den zweiten Teil als Datenmanipulationssprache. In modernen Da-
tenbanksprachen sind diese beiden Sprachteile zusammengefasst.11
Das Thema Datenbanksprachen ist so umfangreich, dass es im Rahmen dieser Ar-
beit nur zu einem geringen Teil Beachtung findet. Ich werde in einem späteren Ab-
schnitt konkret auf die Datenbanksprache SQL und deren Aufteilung der verschiede-
nen Sprachelemente eingehen.
10 [3] S.20-26 11 [2] S.21-40 und [3] S.20-26

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
17
2.3.1 Hierarchische Datenbanken
Die Entwicklung der Datenbanken begann mit den hierarchischen Datenbanken. Ei-
nige der hier verankerten Grundkonzepte werden auch noch bei späteren Evoluti-
onsstufen verwendet.
Bei der Entwicklung wollte man reale Einheiten hierarchisch zerteilen und so eine
Speicherstruktur für die Datenbankanwendung finden. Deutlich wird das in Abbildung
9. Hier wird die Aufteilung von der Liegenschaft, als größte reale Einheit, zu den Räu-
men, als kleinste Bestandteile dieser Einheit, vorgenommen. Bei dieser Anordnung
werden die einzelnen Verzweigungspunkte als Knoten bezeichnet. Der Wurzelknoten
ist die Liegenschaft und alle der Liegenschaft nachgeordneten Knoten werden Kind-
knoten genannt. Jeder einem Kindknoten vorgeordneter Knoten wird als Elternknoten
dieses Kindknotens dargestellt. In der Abbildung 9 wird die Beziehung im Bereich der
„Freiflächen“ dargestellt. Hier ist der Knoten „Freiflächen“ der Elternknoten für „Natür-
liche Oberflächen“. Die einzelnen Hierarchieebenen werden graduiert, d.h. nach je-
dem Knotensprung erhält die der aktuellen Ebene folgende Kindebene einen um eins
erhöhten Grad.
Das revolutionäre an diesen Systemen war unter anderem die Mehrbenutzerfähig-
keit. Während Dateien immer nur von einer Person geöffnet und bearbeitet werden
konnten, erlaubten die Datenbanken mehreren Benutzern gleichzeitig den Zugriff auf
die Datenbasis. Die Daten konnten mit Hilfe von Schnittstellen zwischen den ver-
schiedenen Anwendungsprogrammen zum ersten Mal programmunabhängig gespei-
chert werden.
Die Daten wurden mit Hilfe von Knotenangaben in das System gebracht. Hierin lag
jedoch auch ein Nachteil, weil alle in der Datenbank liegenden Knoten nacheinander
von der Wurzel und danach von links nach rechts zur Prüfung angefahren wurden.
Das machte das System sehr langsam.
Ein anderer Schwachpunkt war die strukturelle Abhängigkeit der Anwendungspro-
gramme von der Datenbank. Die Abgrifftechnik, wie sie schon oben beschrieben
wurde, legte nahe, Daten, die besonders häufig angegriffen wurden, links anzuord-
nen, da diese Seite zuerst bei der Suche nach einer Entsprechung für den Daten-
punkt abgegriffen wurde. So kam es, dass man hierarchische Datenbanken zur Per-
formanceoptimierung häufig umstrukturierte. Da die Anwendungsprogramme aber
fest auf die Äste dieses Datenbaumes zugriffen, mussten auch sie bei derartigen Än-
derungen angepasst werden. Das war häufig sehr aufwendig und kostenintensiv.

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
18
Abbildung 9 - Struktur einer hierarchischen Datenba nk
Auch die baumartige Struktur provozierte Fehler durch die Administratoren. Daten
wurden durch falsches Löschen von Knoten vernichtet. Löschte man nämlich einen
Elternknoten, so wurden alle ihm nachgeordneten Kinderknoten auch bereinigt.
Die beiden nächsten Punkte besiegelten das Schicksal dieser Konstruktion
endgültig und waren gleichzeitig für die Konzeption der nachfolgenden Strukturen
von entscheidender Bedeutung. In der Phase als die hierarchischen Datenbanken
eingesetzt wurden, gab es noch keine Standards für den Datenaustausch. Ein Frabri-
kationswechsel von einer Datenbank zu einer anderen brachte enorme Schwierigkei-
ten mit sich, so dass der Aufwand für eine Portierung häufig einer Neuentwicklung
glich.
Aus diesen Schwierigkeiten lernten die Entwickler und schufen verschiedene Stan-
dardschnittstellen für den Datenaustausch zwischen den jeweiligen Datenbanken.
Auch aus den letzten Punkten wurde ein großes Potential für weitere Entwick-
lungen gewonnen. Wenn wir die Entity Relations, die Beziehungen zwischen den
Datensätzen betrachten, fällt auf, dass ein Elternknoten zwar beliebig viele Kindkno-

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
19
ten haben darf, aber dass umgekehrt ein Kindknoten nur ein Elternknoten haben
darf. Datenbanktechnisch ausgedrückt, kann diese Art von Datenbanken zwar 1:n-
Beziehungen darstellen, aber nicht n:m-Beziehungen. Das schränkte die Leistungs-
fähigkeit gegenüber den nachfolgenden Konzepten stark ein. Auf diese Beziehungen
werden ich genau im Abschnitt zur ER-Modellierung (Entity Relationship Model) ein-
gehen.
Das hierarchische Modell wurde abgelöst von den Netzwerkdatenbanken.
2.3.2 Netzwerkdatenbanken
Die Probleme, die aus der Anwendung des hierarchischen Datenbankmodells resul-
tierten, sollten mit der Schaffung der Netzwerkdatenbanken beseitigt werden. Wenn
wir auf die hierarchischen Systeme blicken, waren die größten Hindernisse in der
Portierungsfähigkeit der Datenbanken und in der mangelnden Fähigkeit der Darstel-
lung von m:n Beziehungen zu sehen.
Zur Umsetzung dieser Anliegen gab es einen freiwilligen Zusammenschluss von
Computerherstellern, -anwendern und staatlichen Einrichtungen.12
Dieser Zusammenschluss wurde CODASYL (Conference on Data System Langua-
ges) genannt. Die Verbindung entstand bereits im Jahre 1959 in den USA und ein
Ergebnis der Arbeit war die Weiterentwicklung der Programmiersprache COBOL.
Erst 1973 wurde dann mit dem Bericht CODA73 der Grundstein für die Netzwerkter-
minologie gelegt.
Die beiden elementaren Anforderungen an die Netzwerkdatenbanken wurden er-
reicht. Die Einführung der Standardsprache COBOL trug dazu bei, dass es bessere
Voraussetzungen für die Portierung gab.
Außerdem änderte man die Beziehungsfähigkeit der Datensätze. Wenn Sie sich zu-
erst die Abbildung 9 ansehen und anschließend die Abbildung 10, werden Sie einen
fundamentalen Unterschied erkennen. Die Redundanzen aus der Kindebene 6. Gra-
des wurden abgebaut.
Die Reinigungsklassen werden nun nur noch ein Mal gespeichert und können belie-
big oft anderen Elementen zugeordnet werden. Das sparte für die Zukunft enorme
Speicherkapazität durch Verhinderung von Redundanzen
12 [2], S.59-70

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
20
Abbildung 10 - Struktur einer Netzwerkdatenbank
Eine andere Errungenschaft stellt die Einführung der Subschemas dar. Innerhalb der
Benutzerebene wurde es nun ermöglicht jedem Nutzer eine eigene Sicht auf die
Summe aller Daten zu geben. Dies war nicht nur für Nutzer im eigentlichen Sinne
wichtig, sondern auch für bestimmte Anwendungsprogramme, die auf die Daten
zugreifen. Die Programmierer befassten sich jetzt nur noch mit dem Teil der Daten-
bank, der wirklich die benötigten Daten für die Anwendung betrifft. Dies stellt eine
enorme Erleichterung im Gegensatz zu den hierarchischen Datenbanken dar, bei der
sich die Anwendungsprogrammierer noch mit der gesamten Datenbankstruktur aus-
einandersetzten.13
Diese Art der Datendarstellung wurde bis in die heutigen Systeme mitgenommen und
weiterentwickelt. Das heute als View bekannte Konzept, ist fester Bestandteil von
Methoden vieler moderne DBMS. So hat Oracle Praktiken entwickelt, bei denen
Views zur Speicherung und Zwischenspeicherung von Daten genutzt werden kön-
nen.
Das Problem der Portierung, welches das hierarchische System mit sich brachte,
konnte jedoch noch einige Zeit nicht gelöst werden. Obwohl 1971 auf der CODASYL
eindeutige Regeln zur Verbesserung der Portierbarkeit von Datenbanken gefunden
wurden, fanden diese Vorschriften bei den Herstellern keine Akzeptanz. Sie wollten
verhindern, dass Kunden zu schnell zu anderen Anbietern wechseln könnten. Die 13 [5], S.842

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
21
Vorteile wurden von den Herstellern erst später bemerkt, danach versuchten die An-
bieter aber sich durchgängig an diese Regeln zu halten.14
Aus eigener Erfahrung kann ich aber sagen, das es auch heute noch zu einer der
spannendsten Aufgaben gehören kann, große Datenbanken zusammenzuführen.
Dies ist zum Beispiel notwendig, wenn Firmen fusionieren. Auch wenn bestimmte
Regeln heute eingehalten werden und es bestimmte Schnittstellen zwischen den
verschiedenen DBMS gibt, so ist doch der Inhalt der Datenbank und deren Struktur
sehr inkonsistent.
2.3.3 Relationale Datenbanken
Die relationalen Datenbanken sind in den heutigen Anwendungen am weitesten ver-
breitet. Viele der modernen Anwendungsprogramme in der Wirtschaft arbeiten auf
der Basis von relationalen Datenbanken. Beispiele hierfür sind SAP, FaMe 6.0, Bau-
logis, M24 oder Build-Online.
Erstmals vorgestellt wurde der Begriff des relationalen Datenbankmodells 1970 von
E.F. Codd. In der Zeitschrift „Communications of the ACM“ wurde damals dieser Arti-
kel veröffentlicht. Die Ansichten zu Datenbanken und Datenmodellen waren sehr
modern und das relationale Modell wurde gerade wegen seiner Einfachheit zu einem
waren Erfolgsmodell.15
Während bei den Netzwerkdatenbanken in Bezug auf die hierarchischen Systeme,
die Struktur lediglich ergänzt wurde, stellt die Schaffung der relationalen Datenban-
ken einen völlig neuen Schritt in der Technologie dar. Dieses Datenbankmodell löste
eine „sprunghafte Entwicklung“ im Bereich der Datenbanken aus.16
Visuell kann man sich die relationalen Datenbanken als ein Sammelwerk von Tabel-
len vorstellen, wobei die einzelnen Datensätze auf mehrere Tabellen verteilt wurden.
Die Verteilung der Daten nimmt man nach den sechs Normalisierungsregeln vor.
Ein Hauptanliegen der relationalen Datenbanken ist die Vermeidung von Redundan-
zen. Hierauf kann man seit der Existenz der Netzwerkdatenbanken gezielt Einfluss
nehmen. Das Konzept zur Vermeidung der Datendoppelung ist durch Schaffung des
14 [2], S.59-61 15 [4], S.51-55 16 [4], S.51-55

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
22
relationalen Konzeptes sehr verbessert worden. Zur Erklärung möchte ich das Bei-
spiel der Speicherung von Raumdaten einführen. Wie in Abbildung 11 zu sehen ist,
habe ich dazu die vier Tabellen „Liegenschaft“, „Gebäude“, „Ebene“ und „Raum“ er-
stellt. Die Daten, die zur Charakterisierung der Räume in einem Gebäude notwendig
sind, werden auf die genannten Tabellen verteilt und miteinander verknüpft. Der Sinn
dieser Vorgehensweise wird deutlich, wenn wir als Gegenbeispiel die Daten in einer
Tabelle speichern.
Abbildung 11 - Relationale Struktur zur Speicherung von Raumdaten
Zuvor möchte ich jedoch die Vorteile erläutern, die die Vermeidung von Redundan-
zen mit sich bringt. Die beiden Hauptargumente sind die Garantie auf durchgängige
Datenintegrität und das Einsparen von Speicherplatz.
Durchgängige Datenintegrität heißt, dass der User nur an einer Stelle Daten ändert
und diese Änderung durch das ganze System geführt wird.
Diese Vorgehensweise möchte ich an einem Beispiel erläutern. Wir wollen Daten für
700 Räume in einem Gebäude mit 7 Ebenen abspeichern. Bei einer Speicherung in
einer einzigen Tabelle, würden sich die Daten der Liegenschaft und des Gebäudes in
jedem Datensatz ganz und die Daten zu den Ebenen teilweise wiederholen. Das be-
deutet, das diese Tabelle 26 Spalten enthalten würde.

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
23
Abbildung 11 - Alle
Daten in einer Tabelle
In den Daten würden Redundanzen auftreten. Bei einer Hochrechnung würden wir
für jeden Datensatz 26 Datenfelder und somit bei der
Erstellung der 700 Datensätze 18200 Datenfelder erzeugen.
Bei einer relationalen Speicherung, wie es in der Abbildung
11 dargestellt wurde, werden die Daten über mehrere
Tabellen verteilt und dadurch Redundanzen vermieden. Das
heißt, dass die Daten, die nur die Liegenschaft betreffen
auch nur in der Tabelle für die Liegenschaften gespeichert
werden und in den Tabellen, in denen sich die Daten auf die
Liegenschaftsdaten beziehen, eine Art Verlinkung eingebaut
wird. In unserem konkreten Beispiel wird die Verknüpfung
der Daten durch das Abspeichern der Primary–Keys in den
Bezugstabellen als Foreign–Key geschaffen. In dem
gewählten Beispiel beginnen die Spaltennamen, welche die
Foreign–Keys abspeichern mit dem Kürzel „FK“. So
speichert man die Daten in der Tabelle „Gebäude“ von der
Liegenschaft in der Spalte „FK_Liegenschaft“. Hier wird nur
eine Spalte reserviert, die den Primary Key der Tabelle
Liegenschaft fasst. Ähnlich wird der Bezug zwischen den
Tabellen „Gebäude“ und „Ebene“ und zwischen den
Tabellen „Ebene“ und „Raum“ geknüpft. Für das Speichern
des gleichen Informationsgehaltes wird somit jeweils ein
Datensatz in den Tabellen „Liegenschaft“ und „Gebäude“, sieben Datensätze in der
Tabelle „Ebene“ und 700 Datensätze in der Tabelle Raum erstellt. Das ergibt folgen-
de Anzahl von Attributen in den Tabellen:
Liegenschaft 7 Attribute
Gebäude 9 Attribute
Ebene 4 Attribute
Raum 12 Attribute
Daraus folgt eine Datenfeldanzahl von:
1 DS * 7 ATT + 1 DS * 9 ATT + 7 DS * 4
ATT + 700 DS * 12 ATT=
8444 DF (Datenfelder)
Der Unterschied ist sehr deutlich. In der ersten Variante benötigten wir 18200 Daten-
felder in der zweiten Variante nur noch 8444 Datenfelder. An dieser Stelle wird auch

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
24
deutlich was mit der Durchgängigkeit der Datenintegrität gemeint ist. Ändert sich zum
Beispiel durch einen Umbau oder Umnutzung die Gebäudebezeichnung, nimmt man
die Änderung bei dem relationalen Modell nur in einem Datensatz der Tabelle „Ge-
bäude“ vor. Alle anderen Datensätze, die mit dem betreffenden Datensatz verbunden
sind, erhalten nun immer die richtigen Informationen. Bei einer Speicherung aller Da-
ten in einer Tabelle müssten hier im Beispiel alle 700 Datensätze geändert werden.
Bei 700 Datensätzen, die alle zu einem Gebäude gehören, mag das noch übersicht-
lich sein, aber wenn von verschiedenen Gebäuden hier die Daten abgelegt werden,
ist das System in dieser Hinsicht sehr störungsanfällig. Fehler am Informationsgehalt
einer Datenbank führen zur Inakzeptanz der Systeme. Gerade bei der Einführung
von Systemen kann das äußerst hinderlich sein.
Wer relationale Datenbanken verstehen will, muss sich mit den Themen SQL und
auch ER-Modell beschäftigen. SQL ist die unverzichtbare Abfragesprache für Daten-
banken. SQL, ausgeschrieben structured query language, ist eine logische Abfrage-
sprache, die es ermöglicht, die entsprechenden Daten aus den jeweiligen Tabellen
zu ziehen.
In einem ER-Modell (Entity Relation Modell) werden die einzelnen Beziehungen zwi-
schen den Tabellen geplant und auch nachgehalten. Das ER-Modell ist der techni-
sche Fahrplan durch die relationalen Datenbanken. Das oben gewählte Einführungs-
beispiel zeigt, dass der Vorteil, den die Verteilung der Informationen auf mehrere Ta-
bellen in Hinsicht aus Datenqualität und –quantität existiert, den Nachteil induziert,
dass die Datenbanken sehr groß und unübersichtlich werden können. Hier ist das
ER-Modell unverzichtbar. Es zeigt wo die Daten der Zieltabellen herkommen.
Relationale Datenbanken werden auch in Zukunft eine große Anwendung finden,
weil sie bereits sehr stark verbreitet sind. Eine Umstellung dieser Systeme kostet
sehr viel Zeit und auch Geld. Aus diesem Grund scheuen sehr viele Unternehmen
die Umstellung der Systeme. Das ist auch ein Grund, für die weitere Existenz von
hierarchischen oder netzwerktechnischen Datenbanken.
2.3.4 Objektorientierte Datenbanksysteme
Die objektorientierten Datenbanken stellen einen neuen Schritt in der Entwicklung
der Datenbanken dar. Die Konzeption dieser Datenbanken stammt schon aus dem
Jahr 1981. Dieser Ansatz hat es zur Zeit sehr schwer sich durchzusetzen, weil die

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
25
meisten Datenbankanwendungen auf der Basis von relationalen Strukturen arbeiten.
Anwendungen, die schon implementiert wurden und sich in der Betriebsphase befin-
den, sind sehr schwer auf das neue System anzuheben. Aus diesem Grund scheuen
Anwender diesen Schritt. Diese Rahmenbedingungen beeinflussen die Einführung
dieser Systeme. Es gibt aber auch weitere Gründe die gegen den Einsatz von
OODBMS sprechen. Während die oben bereits genannten Argumente jedes System
betreffen, das sich in einem professionellen Einsatz befindet, treffen diese speziell
auf das OODBMS zu. Auch wenn die Konzeption dieser Art der Datenspeicherung
schon mehr als zwanzig Jahre zurückliegt, haben es die Hersteller der Software noch
nicht geschafft, Definitionen von Standards für Datenübernahme, Datenim- oder ex-
port festzulegen. Das führt zu Problemen, wenn Daten einer Datenbank auf die eines
anderen Herstellers umgesetzt werden sollen. Des Weiteren sind ein Großteil der
OODBMS nicht plattformunabhängig.
Bei einem Vergleich der Performance zwischen relationalen und objektorientierten
Modellen schneiden die objektorientierten Systeme schlechter ab. Relationale Da-
tenbanken belasten die Hardware bei gleicher Output-Leistung geringer als die ob-
jektorientierten. Das ist besonders für große Business-Anwendungen zum Nachteil.
Trotzdem gibt es hier Anwendungen, die erfolgreich auf dieser Basis arbeiten.
Ein großer Vorteil dieser Software ist die Wiederverwendbarkeit der Programmie-
rung. Hier hat Microsoft® eine sehr richtungsweisende Technologie Namens „dot-
NET®“ auf den Markt gebracht, die es ermöglicht, die objektorientierten Ansätze fa-
belhaft umzusetzen. Die dot-NET-Technologie stellt einen Pool von objektorientierten
Programmiersprachen mit dem inzwischen weit verbreiteten Datenbankserver MS-
SQL zur Verfügung.
Der Ansatz zu einer Objektorientierung wird in der Mehrzahl als Mischform gestaltet.
Man spricht hier von objektrelationalen Datenbanken. Damit reagiert man aktiv auf
die Schwächen der OODBMS. Während die Anwendungsprogramme in einer objekt-
orientierten Programmiersprache geschrieben werden, bleiben die Daten aber streng
relational organisiert. Als Beispiel ist hier Oracle® zu nennen. Durch Einführung der
objektorientierten Programmiersprache PL-SQL in der Version 8i hat Oracle® die
Datenbanken objektrelational ausgestattet. Der PL-SQL-Code wird den Tabellen bei-
gefügt. Somit werden den Datensätzen Methoden und Prozesse in Form von Trig-
gern und Procs mitgegeben.

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
26
Dennoch gibt es reine OODBMS. Bei den herkömmlichen RDBMS ist man bisher von
einem inaktiven Datenbestand ausgegangen. Dies ändert sich grundlegend bei den
objektorientierten Datenbanken. Wie die Abbildung 12 zeigt, sind die Objekte die
zentralen Elemente der objektorientierten Systeme. In den Datenbanken werden die
Klassen definiert. Die Objekte sind die datentragenden Elemente dieser Klassen. So
besteht eine Klasse aus einer beliebigen Menge von Objekten. In der Klasse sind
auch die Eigenschaften der Objekte in Form von Attributen und Methoden definiert.
So setzt sich eine Klasse aus Objekten, Attributdefinitionen und Methoden zusam-
men. Methoden sind eine Art von Miniprogrammen, die die Eigenschaften oder auch
das Verhalten der Objekte umstandsabhängig beeinflussen. Auf der anderen Seite,
in Abbildung 12 als grüner und roter Strang dargestellt, gehören die in der Klasse
definierten Attribute und Methoden mit den jeweils spezifischen Werten zu den jewei-
ligen Objekten. Jedes Objekt ist erst sinnvoll definiert mit der Speicherung der ob-
jektspezifischen Daten.
Abbildung 12 - Innere Struktur von objektorientiert en Datenbanken
In dieser Klassendarstellung kann, wie bei der Objektorientierung üblich, zwischen
den Klassen eine Vererbung stattfinden. D.h. es gibt sogenannte Mutter- und Kind-
klassen. Dabei sind die Grunddaten durch die Mutterklasse vorgegeben und in den
Kindklassen wird eine weitere Spezifikation durchgeführt.

Informatik I - Datenbanken 2 Das DBMS / Die Datenbankmodelle
27
In dem Beispiel in Abbildung 13 nach Geißler [2] geht man davon aus, dass die
Grundattribute in der Klasse Person erstellt wurden. Die beiden nun folgenden Kind-
klassen Kunde und Berater sind zwar auch als Personen zu charakterisieren. Sie
unterschieden sich jedoch grundlegend in ihrer realen Funktion. Es werden die bei-
den Kindklassen Kunde und Berater geschaffen, die die Attribute Vorname, Name
und Telefonnummer von der Mutterklasse übernehmen. Dann wird ihnen ein weiteres
Attribut hinzu gegeben. Mit Methoden ist die Verfahrensweise ähnlich.
Das Nutzen der Vererbungspraktiken ist in der Weise von Vorteil, dass der Pro-
grammcode nicht doppelt eingebracht werden muss.
Abbildung 13 - Vererbung in Kindklassen 17
Die oben genannten Probleme bei der Anwendung von OODBMS wurden mit der
Verbreitung der von Microsoft® eingeführten Dot-net-Technologie® herstellerspezi-
fisch weitestgehend gelöst. Für die Zunkunft bleibt die Schaffung herstellerübergrei-
fender Standards eine Herausforderung, um die objektorientierten Systeme stärker
am Markt zu positionieren.
17 Nach [2], S.74

Informatik I - Datenbanken 4 ER-Modelle
28
3 Die Datenbanksprache SQL 18
SQL ist eine standardisierte Sprache mit der es ermöglicht wird Datenbanken zu be-
einflussen. Sie wurde anfangs von IBM grundlegend entwickelt, bevor dann die Be-
deutung der relationalen Datenbanken erkannt wurde. Ihren Ursprung hatte die
Sprache schon Anfang der 70er Jahre. IBM hat damit das erste relationale Daten-
bankprojekt bearbeitet.
Die Standardisierung wurde dann vom American National Standards Institute (ANSI)
vorgenommen. In Deutschland werden diese Standards vom Deutschen Institute für
Normung bereitgestellt. Die Standardisierung begann Anfang der 80er Jahre.
Im Laufe der Zeit wurden verschiedene Versionen dieser Standardisierung veröffent-
licht. Die erste Veröffentlichung wurde 1986 vorgenommen. Die Version wurde unter
dem Namen SQL1 eingeführt. Es folgten dann Aktualisierungen in den Jahren 1989,
1992 und 1995. Einen großen Entwicklungsschritt brachte die Version SQL99 (aus
dem Jahr 1999), da hier bereits objektorientierte Elemente berücksichtigt wurden.
Heute ist SQL aus der Datenbanklandschaft nicht mehr wegzudenken, aber
auch SQL hat ein Problem. Mit der Entwicklung der Datenbanken gibt es eine Beglei-
terscheinung, die auch schon oben beschrieben wurde und die sich durch die Evolu-
tion der Datenbanken wie eine roter Faden zieht. Es ist die fehlende Standardisie-
rung, die auch in der Datenbankentwicklung zuletzt die Einführung der objektorien-
tierten Datenbanken stark behinderte. Die späte Standardisierung von SQL durch
das ANSI hat hier eine allgemein auftretende Verunreinigung von SQL bei den jewei-
ligen Datenbankanbietern zur Folge. Man spricht von SQL-Dialekten. Das wohl sau-
berste SQL wird zur Zeit von der Open-Source-Datenbank MySQL verwendet. Hier
gibt es nur ganz geringe Abweichungen vom Standard. Jeder Anbieter von Daten-
banken hält seinen Dialekt bereit. Die bekanntesten sind Jet-SQL® von Microsoft®
und Oracle-SQL® von Oracle®.
Einen einheitlichen Standard wieder in die Datenbanklandschaft zu bringen, wird
auch in Zukunft daran scheitern, dass die Funktionen und das Handling der ver-
schiedenen Produkte sich sehr stark unterscheiden und auf im Laufe der Zeit entwi-
ckelt haben.
18 [10]

Informatik I - Datenbanken 4 ER-Modelle
29
3.1 Sprachkomponenten von SQL
Die Sprache SQL gliedert sich in drei Komponenten. Die erste befasst sich mit der
Organisation der Datenbank, sie wird Data-Definition-Language kurz DDL bezeich-
net.
Die DDL beinhaltet alle Befehle und Sprachelemente, die es ermöglichen eine Da-
tenbank aufzubauen. Das sind zum Beispiel „create database“ oder „create table“,
um eine Datenbank oder eine Tabelle in einer Datenbank zu erstellen. Aber auch
Befehle um einzelne Elemente oder Objekten wieder zu löschen oder zu ändern sind
enthalten.
Die Daten werden über die zweite Komponente angesteuert. Sie heißt Data-
Manipulation-Language (DML). Mit Hilfe dieser Sprachelemente werden Daten in die
Tabellen gefüllt oder geändert. Der umfassendste Befehl in dieser Gruppe ist die Se-
lectanweisung. Dieser Befehl sorgt dafür, dass wir uns die Daten, die wir abspeichern
auch wieder anzeigen lassen können. Die Möglichkeiten, die der jeweilig verwendete
SQL-Akzent in dieser Phase mit sich bringt, ist sehr entscheidend dafür, wie die
Struktur der Datenbank gestaltet werden muss, um entsprechende Informationen aus
den Daten zu gewinnen.
Die dritte Komponente ist die Data-Control-Language (DCL). In der DCL sind alle
Sprachkonstrukte enthalten, die die Sicherheit der Daten bestimmen. Hier ist das
Vorgehen für Backups oder Exporte beschrieben. Diese Komponente enthält aber
auch alle Befehle zur Benutzerverwaltung und Sichten- oder Datenzugriffssteuerung.
Hierfür werden beispielsweise die Befehle „grant" oder „dany“ verwendet. Bei der
Benutzerverwaltung von Datenbanken werden häufig Rollen verwendet. Mehreren
Benutzern wird eine Rolle zugewiesen. Die Zugriffssteuerung erfolgt dann über die
Rechtevergabe zu einer Rolle. Das vereinfacht die Administration besonders bei sehr
vielen Nutzern, weil die Rechte dann nicht dem einzelnen Nutzer zugewiesen wer-
den, sondern einer Rolle. Die Rolle kann man sich auch als Benutzergruppe vorstel-
len.

Informatik I - Datenbanken 4 ER-Modelle
30
4 ER-Modelle 19
Mit Hilfe eines Entity-Relationship-Modells werden bei der Erstellung des Daten-
bankentwurf die verschiedenen Beziehung der Entitäten dargestellt. In unserem Fall
sind die Entitäten die Datenbanktabellen. Bei der Umsetzung des praktischen Bei-
spiels ist das ER-Modell für die Datenbank abgebildet.
Entwickelt wurde diese Herangehensweise von Chen 1976. Mit der Anwendung die-
ser Methode wurde sie über die Jahre weiterentwickelt. Die Detailtiefe des Modelles
kann stark differieren. Man unterscheidet die reine Darstellung der Entitäten, die Dar-
stellung der Entitäten mit Attributen, mit Beziehungen, das ER-Diagramm und die
Darstellung von Aggregationen und Gruppierungen in einem ER-Modell.
Bei der Umsetzung der praktischen Aufgabe habe ich ein ER-Modell entwickelt, das
die Tabellen mit ihren Attributen und den Beziehungen zwischen den einzelnen Ta-
bellen darstellt.
Bei der Darstellung der Tabellen mit den Attributen ist es wichtig, die primären und
die fremden Schlüssel zu berücksichtigen. Erst hierdurch werden die Beziehungen
zwischen den Tabellen sichtbar.
19 [6], S.35-48

Informatik I - Datenbanken 5 Normalisierung
31
5 Normalisierung
Für die gleichwertige Strukturierung der Tabellen in den Datenbanken wurden die
Normalisierungsregeln vereinbart. Bei der strikten Anwendung dieser Regeln ist ga-
rantiert, dass Redundanzen vermieden werden und die Datenkonsistenz gewährleis-
tet ist. Die Normalisierung besteht zur Zeit aus den fünf Normalformen und der Boy-
ce-Codd-Normalform (BCNF). Dabei stellen die erste bis zweite Normalform die
Grundformen dar. Die anderen Normalformen sind als Ergänzungen anzusehen.
Bei der Anwendung der Normalisierung besteht die Gefahr, dass man die Datenbank
zu stark strukturiert und dadurch die Abfragezeiten sehr lang werden. Aus diesem
Grund sollte man das Ziel, das hinter einer Datenbankanwendung steht nicht aus
den Augen verlieren.
5.1 Die erste Normalform
Die erste Normalform dient der Vermeidung von Redundanzen innerhalb der Tabel-
len. Sie lautet:
„Eine Tabelle befindet sich in der Ersten Normalform, wenn jedes Attribut nur einmal
in einer Tabelle vorkommt.“20
Das bedeutet für den Datenbankentwurf, dass alle Spalten aus der Tabelle ausge-
gliedert werden müssen, deren Sinn in der Tabelle mehrfach vorkommt. Wenn in ei-
ner Tabelle mehrfach eine Spalte mit der Bezeichnung „Name“ vorkommen würde,
so dass es zum „Name1“, „Name2“ usw. kommen würde, so müssten diese Spalten
in eine andere Tabelle ausgegliedert werden. Damit würde man zwar die Redundan-
zen nicht ganz vermeiden, weil man die Schlüssel zu diesen Namen in den gleichen
Spalten in der Haupttabelle speichern müsste, aber diese Vorgehensweise würde die
Daten besser kontrollierbar machen.
5.2 Die zweite Normalform
Bei der eindeutigen Bestimmung von Datensätzen ist es möglich den Primärschlüs-
sel in einer Tabelle zu splitten und über mehrere Spalten zu verteilen. Der Primär-
schlüssel ergibt sich dann aus der Kombination dieser Teilschlüssel. Hier setzt die
zweiten Normalform an:
20 [9], S.52

Informatik I - Datenbanken 5 Normalisierung
32
„Eine Datei ist in der Zweiten Normalform, wenn sie der Ersten Normalform entspricht
und die Nichtschlüsselfelder ausschließlich vom Gesamtschlüssel, nicht von einem
Teilschlüssel abhängen.“21
Die Verteilung über mehrere Spalten hat den Vorteil, dass man die Vermeidung einer
Datenfeldkombination innerhalb eines Datensatzes sicherstellen kann. Auch wenn
dadurch ein Datensatz eindeutig identifiziert werden kann, sollte man nicht auf einen
Hauptschlüssel für den Datensatz verzichten.
5.3 Die dritte Normalform
Die dritte Normalform zielt auf die Folgebeziehung zwischen den einzelnen Daten-
sätzen ab. Wenn aus einem Wert in der Spalte g ein Wert in einer anderen Spalte
folgt, sollten beide Spalten ausgegliedert werden. Die Spalte g verbleibt zusätzlich in
der Quelltabelle und bildet somit die Relation zwischen den beiden Tabellen.
Die dritte Normalform lautet: „Eine Datei ist in der Dritten Normalform, wenn sie der
Zweiten Normalform entspricht und die Nichtschlüsselfelder nicht von anderen Nicht-
schlüsselfeldern abhängen.“22
5.4 Die vierte Normalform 23
Die vierte Normalform beschäftigt sich mit mehrwertigen Abhängigkeiten. Mehrwerti-
ge Abhängigkeiten stellen sich so dar, dass es Elemente gibt, die durch mehrere Att-
ribute definiert sind. Durch die unterschiedliche Besetzung dieser Attribute wird das
Attribut nun in der gleichen Tabelle mehrfach beschrieben. Hier setzt die vierte Nor-
malform an und fordert die Aufteilung der Quelltabelle in eine Tabelle je beschrei-
bendes Element.
5.5 Die fünfte Normalform
„Die Relation ist in der 5. Normalform, wenn sie sich nicht weiter aufspalten lässt,
ohne dass Informationen verloren gehen.“24
21 [9], S.60 22 [9], S.62 23 [10], S.24-31

Informatik I - Datenbanken 5 Normalisierung
33
Der Kern der fünften Normalform liegt in der Aussage der Informationen. Wichtig ist
was die Daten in der Tabelle für Informationen liefern sollen. Ich will hier Bezug auf
das praktische Beispiel nehmen. Für die schnelle Beseitigung von Servicemeldungen
speichern wir in einer Tabelle Dienstleister mit ihrem Aufgabenspektrum und den
geographischen Bereichen, in den sie ihre Leistungen zur Verfügung stellen. Würden
wir eine solche Tabelle zerteilen, könnte die Information zerstört werden. Nehmen wir
an wir splitten die Tabelle in eine, in der die Lieferanten und ihre Einsatzbereiche de-
finiert werden. Dazu legen wir eine Tabelle an, in der die Leistungen der einzelnen
Dienstleister verankert wird. In der Realität gibt es nun die Möglichkeit, dass der An-
bieter A die Leistung A auch nur im Bereich A liefern kann. Es besteht also eine Ab-
hängigkeit in der Information zwischen dem Lieferante, der Lokalität und der Leis-
tung. Reist man diese Information auseinander, so kann es sein, dass bei einer Ab-
frage, ein Lieferant geliefert wird, der die Leistung gar nicht in diesem Gebiet anbie-
tet. So würde die Information durch Verteilung der Daten auf weitere Tabellen zer-
stört wird.
5.6 Die Boyce-Codd-Normalform 25
Diese Normalform soll die Abhängigkeit von verteilten Schlüsseln untereinander ver-
hindern. Die Voraussetzung für die Anwendung ist die Erfüllung der 3. Normalform,
da die BCNF auf dieser aufbaut und sie verschärft.
Der Datensatz befindet sich in der BCNF, wenn er die dritte Normalform erfüllt und
keine Redundanzen innerhalb der Teilschlüssel auftreten.
24 http://de.wikipedia.org/wiki/Normalisierung_(Datenbank) 25 http://de.wikipedia.org/wiki/Normalisierung_(Datenbank)

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
34
6 Praktische Aufgabenstellung
• Programmieren Sie eine Datenbank, die die Datenbasis für eine Self-Service-
Anwendung speichern könnte.
• Stellen Sie sicher, dass verschiedene Webanwendungen an die Datenbank
andocken könnten und aus diesem Grund das Datenmanagement innerhalb
der Datenbank abgewickelt wird.
• Erstellen Sie ein ER-Modell der Datenbank.
6.1 Einführung in das Beispiel
In der heutigen Kundenbetreuung werden sehr oft Self Service Portal verwendet.
Hierfür werden Internetseiten erstellt, die eine Art Dialog zwischen den Auftragneh-
mern und Auftraggebern erlauben. Dem Kunden (Auftraggeber) soll es hierüber er-
möglicht werden schnell und unkompliziert eine Supportmeldung an den Auftrag-
nehmer zu senden. Anwendung findet dies nicht nur im Gebäudemanagement, son-
dern überall dort, wo Dienstleistungen erbracht werden. Mit Self Service Portal ist der
Eingabe- und Bewertungsterminal bezeichnet, mit dem der Kunde Störungen oder
Dienstleitungsaufträge übermittelt und diese nach deren Fertigstellung bewertet. Ein
SSP wird sehr selten als alleinstehende Anwendung implementiert. Vielmehr ist sie
im Gebäudemanagement ein Modul eines CAFM-Systems (Computer Aided Facility
Management). CAFM-Anwendungen dienen zur Unterstützung von Prozessen im
FM. Sie ermöglichen eine flächenbezogene Auswertung von Immobilien und die Vi-
sualisierung des Auswertungsergebnisses. Viele dieser Systeme haben eine Schnitt-
stelle zu grafischen CAD-Anwendungen.
Bei der Umsetzung dieses Beispiels werde ich die Anwendung auf den Einsatz im
Facility Management abstimmen. Als Programmierung wird ausschließlich der Teil
der Datenbankprogrammierung umgesetzt. Der Teil der Webanwendung wird im
Rahmen dieser Arbeit nicht realisiert.
Im Gebäudemanagement werden diese Prozesse genutzt, um die Einhaltung be-
stimmter Service Levels zu überwachen. Häufig ist die Einhaltung dieser Level an
eine Bonus-Malus-Regelung gekoppelt. D.h., je nachdem wie gut der Dienstleister
seine Aufgaben erfüllt, fällt die Entlohnung am Ende der Leistungsperiode aus. Aus
diesem Grunde werden die Bereiche definiert, in denen eine Leistungsstörung auftre-

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
35
ten kann. Zu diesen werden die entsprechenden Reaktionszeiten vereinbart, um die
Störung zu beseitigen.
Mit Hilfe von modernen Datenbankanwendungen ist es möglich, die Störungsauf-
nahme sehr komplex zu gestalten und trotzdem den reinen Verwaltungsaufwand auf
ein Minimum zu beschränken. In der Realität können neben dem Eingabeterminal
der Kunden auch automatische Störungsermittlungssysteme auf eine solche Anwen-
dung aufgeschaltet sein. Zum Beispiel kann über eine moderne GLT-Anlage (Ge-
bäudeleittechnik) eine Überwachung der technischen Anlagen und Geräte im Ge-
bäude durchgeführt werden. Das Ergebnis dieser Überwachung wird dann an das
CAFM übermittelt und hier erfolgt dann die eigentliche Verarbeitung dieser Informati-
onen.
Der Lösungsansatz dieser Problemstellung zielt auf eine Teilbereichslösung hin. Es
gibt einen Bereich, in dem die Stammdaten gesammelt werden, die bei einer Erweite-
rung der Anwendung auch weiteren Bereichen zur Verfügung gestellt werden kön-
nen. Neben den Stammdaten gibt es dann einen weiteren Bereich, der den eigentli-
chen Prozess der Vorgangsbearbeitung wiederspiegelt.
6.2 Findungen eines Geschäftsprozesses
Wie oben schon beschrieben bringt eine Anfrage eines Kunden an seinen Auftrag-
nehmer den Workflow zum Anspringen. Der Kunde oder sein Beauftragter gibt eine
Serviceanfrage auf, die an den Auftragnehmer, in diesem Falle die Objektleitung ei-
ner Immobilie, gerichtet ist. Eine Serviceanfrage kann eine Störungsmeldung, ein
Zusatz- oder Kleinauftrag oder eine Information sein. Sobald die Meldung in der Da-
tenbank gespeichert ist, wird die Objektleitung informiert, dass eine neue Anfrage
eingegangen ist.
Die Objektleitung kategorisiert die Anfrage. Bei Informationen wird differenziert zwi-
schen Informationen, die verbreitet werden müssen, und Informationen, die nur für
die Objektleitung bestimmt sind. Informationen, die Verbreitung finden müssen, wer-
den an die entsprechenden Stellen weitergeleitet. Die Vorgangsbearbeitung zur Stö-
rungsbeseitigung wurde in der Abbildung stark abstrahiert. Im Rahmen dieser Be-
trachtung entfällt die Entscheidung, welche Art der Störung hier vorgefunden wird.
Für den Kunden ist an dieser Stelle wichtig, dass die Störung beseitigt wird.
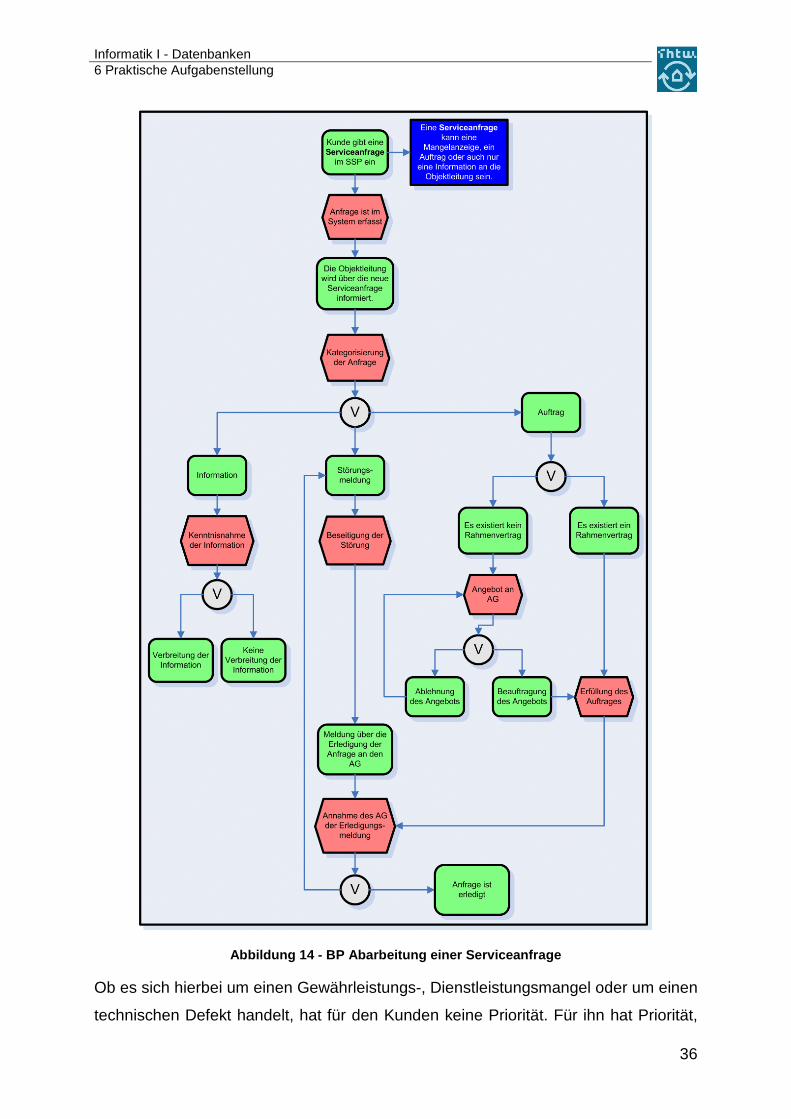
Informatik I - Datenbanken 6 Praktische Aufgabenstellung
36
Abbildung 14 - BP Abarbeitung einer Serviceanfrage
Ob es sich hierbei um einen Gewährleistungs-, Dienstleistungsmangel oder um einen
technischen Defekt handelt, hat für den Kunden keine Priorität. Für ihn hat Priorität,

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
37
dass der Mangel oder die Störung innerhalb einer vereinbarten Frist beseitigt wird.
Nach der Beseitigung der Störung macht der Betreiber eine Erledigungsmeldung an
den Nutzer. Dem Nutzer obliegt es, diese anzunehmen. Nimmt er die Erledigung an,
hat er die Möglichkeit, die Vorgangsbearbeitung zu bewerten. Lehnt er eine Aner-
kennung der Erledigung ab, wird die Störung dem Betreiber zur Beseitigung inner-
halb einer Nachfrist wiederholt vorgelegt.
Wird die Serviceanfrage als Auftrag kategorisiert, ist für den Dienstleister relevant, ob
zwischen ihm und dem Kunden ein Rahmenvertrag oder ähnliches vorliegt, der die
Vergütung dieser Leistung regelt. Ist eine solche Rahmenvereinbarung existent, führt
der Betreiber den Auftrag zu den vereinbarten Konditionen aus. Liegt eine solche
Vereinbarung nicht vor, wird die Objektleitung dem Anfragenden ein Angebot zur Be-
arbeitung der Anfrage unterbreiten. Der Auftraggeber hat dann wiederum die Mög-
lichkeit dieses anzunehmen und den Dienstleister zu beauftragen oder das Angebot
zur Nachbesserung an ihn zurückzugeben. Diese Schleife wird wiederholt, bis der
Dienstleister ein akzeptables Angebot vorlegt. Nach der Beauftragung des Betreibers
wird dieser den Auftrag ausführen und die Erfüllung des Auftrags dem Auftraggeber
durch eine Erledigungsmeldung anzeigen. Dieser hat dann, wie auch schon bei der
Störungsmeldung, die Erledigung zu akzeptieren und die Vorgangsbearbeitung zu
bewerten oder die Erledigung abzulehnen. Im Falle der Ablehnung gibt es eine Stö-
rungsmeldung zum Auftrag. Der Auftragnehmer hat nun die Möglichkeit zur Nach-
besserung innerhalb einer Nachfrist. Auch die Erledigung der Nachbesserung hat er
dem Auftraggeber anzuzeigen. Dieser entscheidet über die Anerkennung der Stö-
rungsbeseitigung.
Zur Beurteilung der Leistungsfähigkeit des Dienstleisters ist es nun erforderlich, die in
der Datenbank befindlichen Daten entsprechend auszuwerten. Hierbei finden die
Reaktions- und Ausführungszeiten Beachtung. Besondere Beachtung sollte die An-
zahl der Aufforderung zur Nachbesserung finden.
Workflows dieser Art wurden von der CAFM-Administration der Firma Müller-Altvatter
erarbeitet und ihren Kunden vorgeschlagen. Sie haben sich in verschiedenen Projek-
ten bewährt. Die Schrittfolgen unterscheiden sich innerhalb der verschiedenen Pro-
jekte nur geringfügig, da durch eine flexible Attributgestaltung der verschiedenen
Portale auf spezielle Kundenwünsche eingegangen werden kann.
Informatik I - Datenbanken 6 Praktische Aufgabenstellung
38
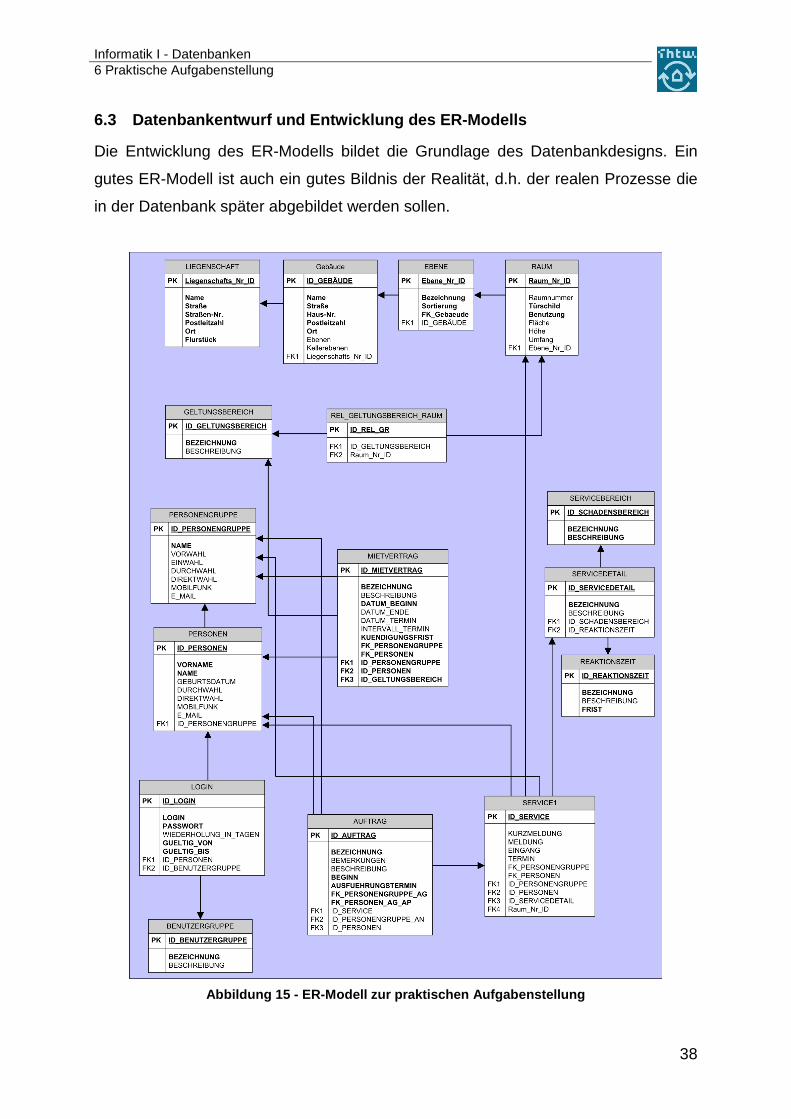
6.3 Datenbankentwurf und Entwicklung des ER-Modells
Die Entwicklung des ER-Modells bildet die Grundlage des Datenbankdesigns. Ein
gutes ER-Modell ist auch ein gutes Bildnis der Realität, d.h. der realen Prozesse die
in der Datenbank später abgebildet werden sollen.
Abbildung 15 - ER-Modell zur praktischen Aufgabenst ellung

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
39
In Abbildung 15 ist das von mir erstellte ER-Modell zu sehen, nach dem die Daten-
bank programmiert werden soll. Das von mir zur Visualisierung verwendete Pro-
gramm war Microsoft® Visio®. Aus diesem Grund gibt es in der Darstellung der
Fremdschlüssel (Foreign Keys) Abweichungen. Zum Einen werden in den Tabellen
die FK (Foreign Keys) als FK1 bis FKn in einer vorgesetzten Spalte gezeigt. Zum
Anderen gibt es weitere Fremdschlüssel, die als FK_<<Tabellenname>> eingetragen
sind. Dies ist nur eine Abbildungsdifferenz. Es ist kein Unterschied in der Funktion
der FK. In MS Visio® ist es zur Zeit noch nicht möglich, mehrfach auf eine Tabelle zu
referenzieren. Eine Mehrfachrelation von einer Tabelle auf genau eine andere Tabel-
le ist zum Beispiel notwendig, wenn es eine Personaltabelle gibt, aber an der darzu-
stellenden Vorgangsabarbeitung mehrere Personen teilnehmen. In unserem Beispiel
greifen wir von der Tabelle SERVICE1 genau zwei Mal auf die Tabelle PERSONEN
zu. Im ersten Fall speichern wir den Ansprechpartner des Auftraggebers und im zwei-
ten Fall den des Auftragnehmers.
Das ER-Modell ist so aufgebaut, dass alle Tabellen dargestellt werden. Im Tabellen-
kopf, grau unterlegt, ist der Tabellenname eingetragen. In den dann folgenden Zeilen
sind die Spalten der Datenbanktabellen dargestellt.
Ich habe die Tabellen der Datenbank in die sechs Bereiche Infrastrukturdaten, Per-
sonenstammdaten, Steuerung Servicelevel, Benutzerverwaltung, Vorgangsmanage-
ment und Zuordnung Fläche/Person gegliedert.
Im Bereich zu den Infrastrukturdaten wird die Immobilie abgebildet. Da sich die meis-
ten Serviceanfragen direkt auf einen Raum beziehen werden, muss es möglich sein
diesen Raum genau zu definieren, damit die Objektleitung genau weiß, wo eine Stö-
rung aufgetreten ist.
Im Bereich der Personenstammdaten werden die Personen dargestellt, die an den
Prozessen teilnehmen können. Die Person selbst wird in der Tabelle PERSONEN
gespeichert. Die einzelnen Personen werden dann in der Tabelle PERSONEN-
GRUPPE zu einer Personengruppe zusammengefasst. Hier habe ich bewusst den
Begriff Firma vermieden, da Mieter unserer Flächen ja auch eine Familie oder ein
Verein sein könnte.
Über die Tabellen MIETVERTRAG, GELTUNGSBEREICH, RAUM und
REL_GELTUNGSBEREICH_RAUM wird den Personen über die Personengruppe
eine Fläche zugeordnet. Zu dieser Fläche können die Personen, soweit sie als Be-
nutzer registriert sind, Serviceanfragen starten. Für die Definition der Flächen wird

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
40
zuerst ein Geltungsbereich gespeichert. Voraussetzung ist auch, dass in der Tabelle
RAUM die entsprechenden Räume für das Gebäude angelegt wurden. Sind diese
beiden Voraussetzungen erfüllt, kann die Tabelle
REL_GELTUNGSBEREICH_RAUM gefüllt werden. Die Tabellen RAUM und
GELTUNGSBEREICH stehen in einer n:m-Beziehung zueinander. Aus diesem
Grund wird die Tabelle REL_GELTUNGSBEREICH_RAUM eingeführt. Durch sie
wird die n:m-Beziehung in zwei 1:n-Beziehungen aufgelöst.
GELTUNGSBEREICH � RAUM
n:m
GELTUNGSBEREICH REL_GELTUNGS-
BEREICH_RAUM
RAUM
1:n m:1
Diese n:m-Beziehung kommt zustande, weil man berücksichtigen muss, dass zu All-
gemeinflächen auch Anfragen gestellt werden könnten.
Für den Fall, dass Störungsmeldungen abgegeben werden, gibt es eine Kategorisie-
rung der Störungen, die über die Tabellen SERVICEBEREICH, SERVICEDETAIL
und REAKTIONSZEIT gewährleistet werden.
Das Vorgangsmanagement wird über die Tabellen SERVICE1 und AUFTRAG abge-
wickelt. Hier werden die eigentlichen Prozessdaten gespeichert.
Die Tabellen LOGIN und BENUTZERGRUPPE stellen den Bereich der Benutzerver-
waltung dar. Hier werden die einzelnen Benutzer angelegt und verwaltet. Über die
Tabelle Login gibt es eine Verknüpfung zu den Personen.
Bei der Entwicklung des ER-Modells wurden die Normalformen zur Entwicklung von
Datenbanken berücksichtigt.
6.4 Entscheidungsfindung für Datenbankfabrikat
Für professionelle Datenbankanwendungen wurde in den vergangenen Jahren auf
zwei Produkte zurückgegriffen, die in dieser Branche auch den Maßstab für die Per-
formance und Leistungsfähigkeit setzten. Das waren die Produkte der Firma Oracle
und auch Microsoft. Seit ca. acht Jahren gibt es jedoch eine Entwicklung, die den
Informatik I - Datenbanken 6 Praktische Aufgabenstellung
41
traditionellen Herstellern schwer zu schaffen macht. Es sind die Open Source Pro-
dukte, die es bereits in allen Anwendungsbereichen der Softwareanwendungen gibt.
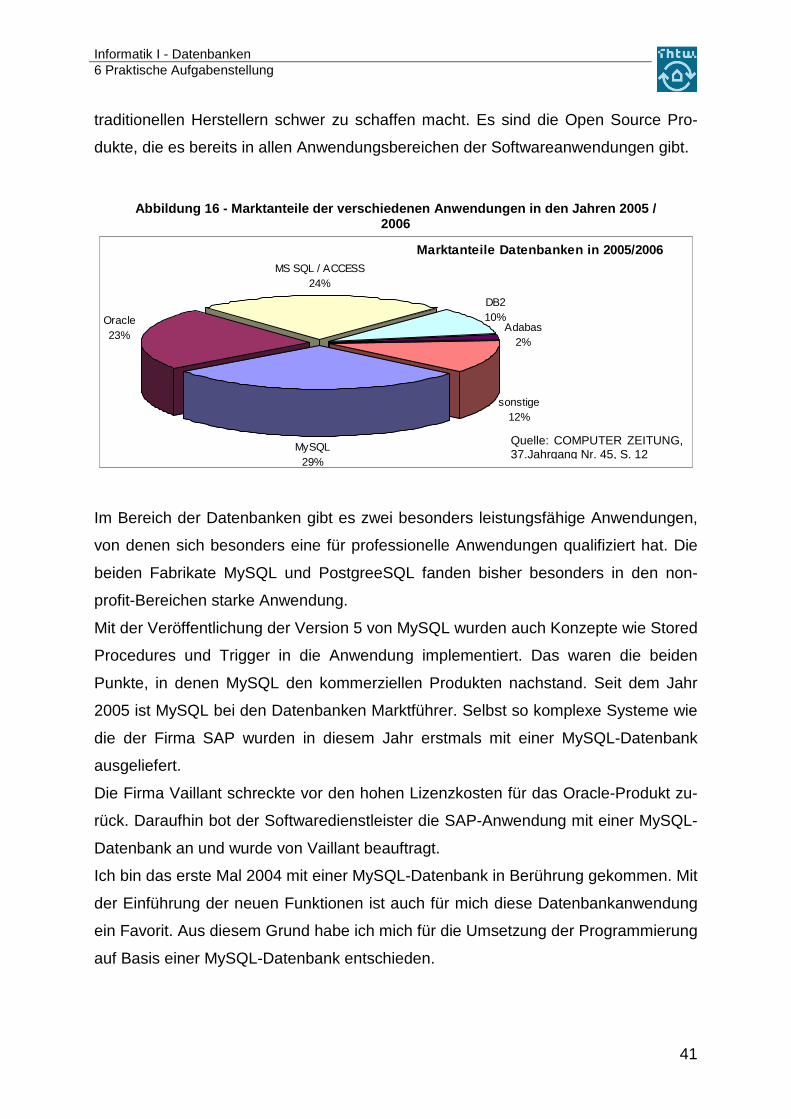
Abbildung 16 - Marktanteile der verschiedenen Anwen dungen in den Jahren 2005 / 2006
Marktanteile Datenbanken in 2005/2006
MySQL29%
MS SQL / ACCESS24%
DB210%
Adabas2%
sonstige12%
Oracle23%
Im Bereich der Datenbanken gibt es zwei besonders leistungsfähige Anwendungen,
von denen sich besonders eine für professionelle Anwendungen qualifiziert hat. Die
beiden Fabrikate MySQL und PostgreeSQL fanden bisher besonders in den non-
profit-Bereichen starke Anwendung.
Mit der Veröffentlichung der Version 5 von MySQL wurden auch Konzepte wie Stored
Procedures und Trigger in die Anwendung implementiert. Das waren die beiden
Punkte, in denen MySQL den kommerziellen Produkten nachstand. Seit dem Jahr
2005 ist MySQL bei den Datenbanken Marktführer. Selbst so komplexe Systeme wie
die der Firma SAP wurden in diesem Jahr erstmals mit einer MySQL-Datenbank
ausgeliefert.
Die Firma Vaillant schreckte vor den hohen Lizenzkosten für das Oracle-Produkt zu-
rück. Daraufhin bot der Softwaredienstleister die SAP-Anwendung mit einer MySQL-
Datenbank an und wurde von Vaillant beauftragt.
Ich bin das erste Mal 2004 mit einer MySQL-Datenbank in Berührung gekommen. Mit
der Einführung der neuen Funktionen ist auch für mich diese Datenbankanwendung
ein Favorit. Aus diesem Grund habe ich mich für die Umsetzung der Programmierung
auf Basis einer MySQL-Datenbank entschieden.
Quelle: COMPUTER ZEITUNG, 37.Jahrgang Nr. 45, S. 12

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
42
6.5 Umsetzung der Programmierung
6.5.1 Verwendete Datentypen
• SERIAL für Autowertdatenfelder
• DOUBLE für Fließkommazahlen
• TIMESTAMP für Archivierung der Datensätze
• CHAR(255) für einzeilige Textfelder
• LONGTEXT für mehrzeilige Textfelder
6.5.2 Verwendeter Zeichensatz und verwendet Sortier ordnung
Zeichensatz: latin1
Sortierordnung: latin1_german1_ci (Das entspricht dem DIN-1-Standard)
6.5.3 Erstellen der Tabellen
Erstellen der Tabelle Liegenschaft
CREATE TABLE `LIEGENSCHAFT` ( `liegenschaft_id` INT( 10 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY
KEY ,
`name` CHAR( 255 ) NOT NULL ,
`strasse` CHAR( 255 ) NULL ,
`hausnr` CHAR( 5 ) NULL ,
`plz` INT( 7 ) NULL ,
`ort` CHAR( 255 ) NULL ,
`flurstueck` CHAR( 255 ) NULL ,
`erstellt` TIMESTAMP NOT NULL ,
`letzte_aenderung` TIMESTAMP NULL

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
43
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Einfüllen der Testdatensätze in LIEGENSCHAFT
INSERT INTO `liegenschaft` ( `liegenschaft_id` , `name` , `strasse` , `hausnr` , `plz` , `ort` , `flurstueck` , `erstellt` , `letzte_aenderung` ) VALUES ( NULL , 'FHTW Marktstraße', 'Marktstraße', '9', '10317', 'Berlin', 'f1', NOW( ) , NULL ), ( NULL , 'FHTW Allee der Kosmonauten', 'Allee der Kosmonauten', '20-22', '10315', 'Berlin', 'f2', NOW( ) , NULL ); Erstellen der Tabelle Gebäude
CREATE TABLE `GEBAEUDE` (
`id_gebaeude` INT( 10 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY
KEY ,
`name` CHAR( 255 ) NOT NULL ,
`strasse` CHAR( 255 ) NULL ,
`hausnr` CHAR( 255 ) NULL ,
`plz` INT( 7 ) NULL ,
`ort` CHAR( 255 ) NULL ,
`ebenen` INT( 3 ) NULL ,
`kellerebenen` INT( 2 ) NULL ,
`liegenschaft_id` INT( 10 ) NOT NULL ) ENGINE = MYISAM CHARACTER SET la-
tin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle Geltungsbereich
CREATE TABLE `geltungsbereich` ( `id_geltungsbereich` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NULL )
ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle REL_GELTUNGSBEREICH_RAUM
CREATE TABLE `rel_geltungsbereich_raum` (

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
44
`id_rel_gr` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`id_geltungsbereich` INT( 10 ) NOT NULL ,
`id_raum` INT( 10 ) NOT NULL
) ENGINE = MYISAM ;
Erstellen der Tabelle PERSONENGRUPPE
CREATE TABLE `personengruppe` ( `id_personengruppe` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`name` CHAR( 255 ) NOT NULL ,
`vorwahl` CHAR( 255 ) NULL ,
`einwahl` CHAR( 255 ) NULL ,
`durchwahl` CHAR( 255 ) NULL ,
`direktwahl` CHAR( 255 ) NULL ,
`mobilphone` CHAR( 255 ) NULL ,
`email` CHAR( 255 ) NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle PERSONEN
CREATE TABLE `PERSONEN` ( `id_personen` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`vorname` CHAR( 255 ) NOT NULL ,
`name` CHAR( 255 ) NOT NULL ,
`geburtsdatum` DATE NULL ,
`durchwahl` CHAR( 255 ) NULL ,
`direktwahl` CHAR( 255 ) NULL ,
`mobilphone` CHAR( 255 ) NULL ,
`email` CHAR( 255 ) NULL ,
`id_personengruppe` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle LOGIN
CREATE TABLE `login` ( `id_login` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`login` CHAR( 255 ) NOT NULL ,
`passwort` CHAR( 255 ) NOT NULL ,

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
45
`wiederholungintagen` INT( 3 ) NULL ,
`gueltig_von` DATE NOT NULL ,
`gueltig_bis` DATE NOT NULL ,
`id_personen` INT( 10 ) NOT NULL ,
`id_benutzergruppe` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle Benutzergruppe
CREATE TABLE `benutzergruppe` ( `id_benutzergruppe` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle Mietvertrag
CREATE TABLE `mietvertrag` ( `id _mietvertrag` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NULL ,
`datum_beginn` DATE NOT NULL ,
`datum_ende` DATE NULL ,
`datum_termin` DATE NULL ,
`intervall_termin` INT( 3 ) NULL ,
`kuendigungsfrist` INT( 3 ) NOT NULL ,
`id_personengruppe_m` INT( 10 ) NOT NULL ,
`id_personen_m` INT( 10 ) NOT NULL ,
`id_personengruppe` INT( 10 ) NOT NULL ,
`id_personen` INT( 10 ) NOT NULL ,
`id_geltungsbereich` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle REAKTIONSZEIT
CREATE TABLE `reaktionszeit` ( `id_reaktionszeit` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
46
`beschreibung` LONGTEXT NULL ,
`frist` INT( 3 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle SERVICEBEREICH
CREATE TABLE `servicebereich` ( `id_servicebereich` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle SERVICEDETAIL
CREATE TABLE `servicedetail` ( `id_servicedetail` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NULL ,
`id_servicebereich` INT( 10 ) NOT NULL ,
`id_reaktionszeit` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle SERVICE1
CREATE TABLE `service1` (
`id_service1` INT( 10 ) NOT NULL AUTO_INCREMENT ,
`kurzmeldung` CHAR( 255 ) CHARACTER SET latin1 COLLATE latin1_german1_ci
NOT NULL ,
`meldung` LONGTEXT CHARACTER SET latin1 COLLATE latin1_german1_ci NOT
NULL ,
`eingang` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ,
`termin` DATETIME NOT NULL ,
`id_personengruppe_m` INT( 10 ) NOT NULL ,
`id_personen_m` INT( 10 ) NOT NULL ,
`id_personengruppe` INT( 10 ) NOT NULL ,
`id_personen` INT( 10 ) NOT NULL ,
`id_servicedetail` INT( 10 ) NOT NULL ,

Informatik I - Datenbanken 6 Praktische Aufgabenstellung
47
`id_raum` INT( 10 ) NOT NULL ,
`id_status` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle STATUS
CREATE TABLE `status` ( `id_status` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`beschreibung` LONGTEXT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;
Erstellen der Tabelle AUFTRAG
CREATE TABLE `auftrag` ( `id_auftrag` INT( 10 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`bezeichnung` CHAR( 255 ) NOT NULL ,
`bemerkung` LONGTEXT NOT NULL ,
`beschreibung` LONGTEXT NOT NULL ,
`beginn` DATETIME NOT NULL ,
`ausfuehrungstermin` DATETIME NOT NULL ,
`id_personengruppe_m` INT( 10 ) NOT NULL ,
`id_personengruppe` INT( 10 ) NOT NULL ,
`id_personengruppe_nu` INT( 10 ) NULL ,
`id_personen` INT( 10 ) NOT NULL ,
`id_personen_m` INT( 10 ) NOT NULL ,
`id_personen_nu` INT( 10 ) NULL ,
`id_service1` INT( 10 ) NOT NULL
) ENGINE = MYISAM CHARACTER SET latin1 COLLATE latin1_german1_ci;

Informatik I - Datenbanken 7 Abkürzungsverzeichnis
48
7 Abkürzungsverzeichnis
ANSI American National Standards Institute
BCNF Boyce-Codd-Normalform
BMA Brandmeldeanlage
CAFM Computer Aided Facility Management
COBOL Common Business Oriented Language
CODASYL COnference on DAta SYstems Languages
DB Datenbank
DBMS Datenbankmanagementsystem
EMA Einbruchmeldeanlage
ER Entity Relation
FHTW Fachhochschule für Technik und Wirtschaft Berlin
FM Facility Management
GLT Gebäude-Leit-Technik
GMS Gebäudemanagementsystem
NF Normalform
OODBMS Objektorientiertes Datenbankmanagementsystem
RDBMS Relationales Datenbankmanagementsystem
SQL Structured Querry Language

Informatik I - Datenbanken 8 Literaturverzeichnis
49
8 Literaturverzeichnis
[1] VOSSEN, GOTTFRIED:
Datenmodelle, Datenbanksprachen und Datenmanagementsysteme
Auflagen, Addison-Wesley, 1994
[2] GEISLER, FRANK:
Datenbanken, Grundlagen und Design
2. Auflage, Redline, 2006
[3] KEMPER, ALFONS UND EICKLER, ANDRE:
Datenbanksysteme
6. Auflage, Oldenbourg Verlag, 2006, ISBN 3-486-57690-9
[4] TRAUTLOF, RAINER UND LINDNER, ULRICH:
Datenbanken, Entwurf und Anwendung
1. Auflage, Verlag Technik Berlin, 1991, ISBN 3-341-00861-6
[5] KURBEL, KARL UND STRUNZ, HORST:
Handbuch Wirtschaftsinformatik
1. Auflage, C.E. Poeschel Verlag Stuttgart, 1990, ISBN
[6] ROLLAND, F.D.:
Datenbanksysteme
1. Auflage, Pearson Studium München, 2003, ISBN 3-8273-7066-3
[7] VOSSEN, GOTTFRIED
Datenmodelle, Datenbanksprachen und Datenbankmanagementsysteme
4. korrigierte und ergänzte Auflage, Oldenbourg Verlag, 2000, ISBN 3-486-
25339-5

Informatik I - Datenbanken 8 Literaturverzeichnis
50
[8] ELMASRI, RAMEZ UND NAVATHE, SHAMKANT B.
Grundlagen von Datenbanksystemen, Ausgabe Grundstudium
3. Auflage, Pearson Studium München, 2005, ISBN 3-8273-7153-8
[9] KUHLMANN, GREGOR UND MÜLLMERSTADT, FRIEDRICH
SQL - Der Schlüssel zu relationalen Datenbanken
1. Neuausgabe, Rowohlt Taschenbuch Verlag Hamburg, 2004, ISBN 3-
499-61245-3
[10] FRITZE, JÖRG UND MARSCH, JÜRGEN
Erfolgreiche Datenbankanwendungen mit SQL3
6. Auflage, Vieweg Wiesbaden, 2002, ISBN 3-528-55210-7

Informatik I - Datenbanken
51
Bemerkungen:



















