
Modellreduktion für parametrisierte dynamische · Damit die Reduktion numerisch stabil ist, sollte...
19
Modellreduktion für parametrisierte dynamische Systeme Seminarausarbeitung im Bachelorseminar Biomedizinische Modellierung und Modellreduktion von Julia Brunken Betreuer: Prof. Dr. Mario Ohlberger Westfälische Wilhelms-Universität Münster Fachbereich Mathematik und Informatik Institut für Numerische und Angewandte Mathematik
Transcript of Modellreduktion für parametrisierte dynamische · Damit die Reduktion numerisch stabil ist, sollte...

Modellreduktion für
parametrisierte dynamische
Systeme
Seminarausarbeitung im Bachelorseminar
Biomedizinische Modellierung und Modellreduktion
von
Julia Brunken
Betreuer: Prof. Dr. Mario Ohlberger
Westfälische Wilhelms-Universität MünsterFachbereich Mathematik und Informatik
Institut für Numerische und Angewandte Mathematik

Inhaltsverzeichnis
1 Einleitung 3
2 Problemstellung 4
3 Modellreduktion 43.1 Reduzierte-Basis-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . 43.2 Reduktion des Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4 Affine Parameterabhängigkeit 7
5 A posteriori Fehlerabschätzung 85.1 Instabile und zeitabhängige Systeme . . . . . . . . . . . . . . . . . . . . . 115.2 Offline-/Online-Zerlegung des Fehlerschätzers . . . . . . . . . . . . . . . 12
6 Duales Problem zur Verbesserung der Output-Fehlerabschätzung 13
7 Resultate 17
Literatur 19
2

1 Einleitung
Dynamische Systeme großer Dimension spielen in vielen Anwendungsbereichen einegroße Rolle – sie beschreiben die Wechselwirkungen sehr vieler einzelner Komponen-ten eines Systems oder entstehen aus der Diskretisierung einer partiellen Differential-gleichung.
Ein Beispiel für den Gebrauch großer dynamischer Systeme ist die Simulation neu-ronaler Netze im Gehirn. Milliarden von Neuronen bilden ein riesiges komplexesNetzwerk, dessen Struktur, wie zum Beispiel die Vernetzung verschiedener Areale,genauer untersucht werden soll. Hirnaktivitäten können zum Beispiel mit fMRT oderEEG gemessen werden; die Herausforderung ist also, aus den gewonnenen äußerenMessdaten Rückschlüsse auf die zugrunde liegende Hirnstruktur zu gewinnen. Dazumüssen Systeme gewöhnlicher Differentialgleichungen aufgestellt werden, die die Ver-netzung der Hirnareale oder einzelner Neuronen beschreiben. Die einzelnen Bestand-teile des Netzes entsprechen Zustandsvariablen, die miteinander verknüpft sind unddadurch gegenseitig Änderungen hervorrufen. Äußere Reize (Inputs) wirken auf dasSystem ein und verursachen eine Änderung des Zustandes, die jeweils eine spezifischeMessung im fMRT oder EEG (Output) bewirkt. Zusammen entsteht ein Input-State-Output-System, in dem insbesondere die Anzahl der Zustandsvariablen bei zuneh-mend detaillierteren Netzen sehr groß werden kann. Um verschiedene Möglichkeitender Vernetzungen zu vergleichen und zu evaluieren, können parametrisierte Systemeaufgestellt werden, die dann für viele verschiedene Parameter gelöst werden sollen,um durch Vergleich mit Experimenten die Struktur des Netzes bestimmen zu können.
Solche Systeme hoher Dimension können allerdings nur mit hohem Rechenaufwandgelöst werden. Ein Vergleich von Lösungen für viele verschiedene Parameter wird soüberaus aufwendig oder bei benötigten Echtzeitberechnungen unmöglich. Es wurdendeshalb numerische Verfahren entwickelt, um die Systeme so zu reduzieren, dass einakzeptabler Rechenaufwand erreicht wird, die Lösungen aber trotzdem hinreichendgenau für die Problemstellung sind.
In dieser Ausarbeitung wird ein Verfahren zur Modellreduktion eines parametrisier-ten linearen Differentialgleichungssystems beschrieben, das von B. Haasdonk und M.Ohlberger 2011 im Artikel [HO11] vorgestellt wurde. Dabei wird das System in einenniedrig dimensionalen linearen Unterraum des Zustandsraumes projiziert, der die Lö-sungsmenge des Systems möglichst gut approximieren soll (siehe Abschnitt 3). In Ab-schnitt 4 werden notwendige Berechnungen aufgeteilt in eine aufwendigere Offline-Phase, die nur einmal vorab durchgeführt wird, und eine schnelle Online-Phase, inder für jeden Parameter gesondert die Lösung des Systems berechnet werden kann. Aposteriori Fehlerabschätzungen ermöglichen eine Kontrolle des durch die Reduktionverursachten Fehlers (Abschnitte 5 und 6).
3

2 Problemstellung
Wir betrachten folgendes parametrisierte lineare dynamische System für einen Zu-standsvektor x(t) ∈ Rn, einen Input-Vektor u(t) ∈ Rm und einen Output-Vektory(t) ∈ Rp für t ∈ [0, ∞):
ddt
x(t) = A(t, µ)x(t) + B(t, µ)u(t)
y(t) = C(t, µ)x(t) + D(t, µ)u(t)(1)
mit Anfangsbedingung x(0) = x0(µ). Die Systemmatrizen A(t, µ) ∈ Rn×n, B(t, µ) ∈Rn×m, C(t, µ) ∈ Rp×n und D(t, µ) ∈ Rp×m hängen von einem Parameter µ ∈ P ⊂ Rd
in einem beschränkten Parametergebiet P ab und können zeitahängig sein. Währendeiner Simulation des dynamischen Systems sei der Parameter µ fest.
3 Modellreduktion
Ist die Dimension n des Systems sehr groß, wird es sehr aufwendig, das System direktzu lösen. Gerade ein parametrisiertes System verlangt oft Lösungen für sehr viele ver-schiedene Parameter. Ziel ist es, das System geschickt zu reduzieren, sodass Lösungennoch hinreichend genau bestimmt werden können, gleichzeitig aber eine akzeptableRechenzeit, gerade beim Vergleich von Lösungen bei verschiedenen Parametern, er-reicht wird.
Für ein festes µ ist die Kurve x(t), t ∈ [0, ∞) eine eindimensionale Untermannigfal-tigkeit des Rn, die „Lösungsmenge“ (vgl. [Has11, Kapitel 1.1])
M := {x(t, µ) : t ∈ [0, ∞), µ ∈ P}
ist höchstens (d+ 1)-dimensional. Da häufig n� d gilt, setzt man sich zum Ziel, einenlinearen Unterraum Xk ⊂ Rn zu finden, der bei einer Dimension k � n die MengeM möglichst gut approximiert, optimal würde Xk z.B. den maximalen Fehler in einergeeigneten Norm minimieren:
Xk = minXk⊂Rn
dim Xk=k
maxµ∈P
t∈[0,∞)
||x(t, µ)− x(t, µ)||
Das System wird dann auf diesen Unterraum projiziert, sodass nur noch ein Systemder Dimension k und nicht der Dimension n gelöst werden muss (vgl. Abbildung 1).
3.1 Reduzierte-Basis-Methode
Bei der Reduzierte-Basis-Methode wird ein Reduktionsraum konstruiert, indem für aus-gewählte Parameter (ti, µi) ∈ [0, ∞) × P Lösungen xi = x(ti, µi), die sogenannten
4

Abbildung 1: Lösungsmenge und Projektion auf linearen Unterraum (aus [MoR])
„Snapshots“, berechnet werden. Aus diesen „Beispiellösungen“, die je nach Problem-stellung die Lösungen des gesamten Parametergebiets oder nur gewisser relevanterBereiche repräsentieren sollen, wird dann ein Reduktionsraum als lineare Hülle die-ser Snapshots konstruiert. Um aus den Snapshots die Basis des Reduktionsraumeszu generieren, gibt es verschiedene Vorgehensweisen und Algorithmen (vgl. [Has11,Kapitel 5]. Damit die Reduktion numerisch stabil ist, sollte die Basis orthogonal sein.Am einfachsten ist es also, Parameter ausgehend von der Problemstellung zu wählenund die Snapshots mit Gram-Schmidt’schem Orthogonalisierungsverfahren zu einerorthonormalen Basis (der sog. Gram-Schmidt-Basis) des entsprechenden Raumes zumachen. Schneidet man diese Basis allerdings ab und betrachtet statt aller k nur nochdie ersten l Vektoren für l < k, werden die „abgeschnittenen“ Parameterbereiche imAllgemeinen sehr schlecht approximiert. Dieses Verfahren eignet sich also nicht, umdie Dimension des reduzierten Raumes variabel bestimmen zu können.
Ein Verfahren, das dieses Problem behebt, ist die POD (Proper Orthogonal Decom-position). Idee ist es, Basisvektoren zu finden, die mit abnehmender Relevanz die„Hauptrichtungen“ der Snapshot-Menge darstellen, sodass für alle l ≤ k die ersten lBasisvektoren den bestmöglichen l-dimensionalen Reduktionsraum aufspannen. DieseBasis erhält man durch eine Singulärwertzerlegung der „Snapshotmatrix“ [x1, . . . , x′k] =VΣW T. Die Vektoren der Matrix V sind orthogonal; die absteigende Ordnung der Sin-gulärwerte in der Matrix Σ sorgt dafür, dass die Vektoren nach Relevanz geordnetsind. Genauer: v1 zeigt in Richtung höchster Varianz von {xi}k′
i=1, v2 ist Richtung derhöchsten Varianz der Projektionen der xi auf (span v1)
⊥, usw. (siehe Abbildung 2).Eine Möglichkeit, die Snapshots selbst effizient zu bestimmen und einen Redukti-
onsraum mit einer festen Fehlertoleranz zu erhalten, ist ein Greedy-Search-Algorithmus.Dabei wird jeweils der am schlechtesten aufgelöste Parameter (t∗, µ∗) gesucht undx(t∗, µ∗) als neuer Basisvektor gewählt. Hierfür werden Fehlerabschätzungen für denReduktionsfehler der Lösungen verschiedener Parameter benötigt, um von einer mög-lichst großen Parametermenge denjeningen mit dem größten Approximationsfehler zufinden. Hat man einen effizienten Fehlerschätzer für die Systemreduktion, kann manes so vermeiden, für zu viele verschiedene Parameter teuer die Snapshots zu berech-nen. Man schätzt stattdessen ab, für welche Parameter die komplette Berechnung desSystems sinnvoll ist. Dabei wird gleichzeitig abgeschätzt, wie gut der bisherige Re-
5

5.3. PROPER ORTHOGONAL DECOMPOSITION (POD) 53
Bemerkung:Die Projektion X ! XPOD,m wird in der statistischen Datenanalyse auchHotelling-Transformation, Principal Component Analysis (PCA) oder Karhunen-Loeve Transformation genannt.
Illustration, Abb. 5.1:
i) {!i}n!i=1 ist orthonormale Basis fur span{ui}n!
i=1, nicht eindeutig (Spiege-lung).
ii) !1 ist Richtung hochster Varianz von {ui}ni=1,
!2 ist Richtung hochster Varianz von {PX"POD,1
ui}, etc.
iii) Die Koordinaten der Daten bzgl. der POD-Basis sind unkorreliert.
iv) {!i} und{""i} sind die Hauptachsen bzw. Achsenabschnitte des Ellip-
soids (u, R#1u) = 1.
v) Falls X = RH und {ui}ni=1 normalverteilt mit Mittelwert 0 und Kovari-
anzmatrix ! so RP! ! fur n ! $
span{ui} % X
!1!2
ui
(u, R!1u) = 1
Abbildung 5.1: POD: Ellipsoide aus Kovarianzoperator
Satz 5.7 (Berechnung von "POD,m uber Gram-Matrix):Sei X HR, {ui}n
i=1 % X und K = ((ui, uj))ni,j=1 die Gram-Matrix. Dann sind
aquivalent:
i) ! & X ist Eigenvektor von R zu Eigenwert " > 0 mit Norm 1 und einerDarstellung ! =
!aiui mit a & Kern(K)'.
Abbildung 2: Wahl der POD-Basis (ui Snapshots, ϕ1, ϕ2 Basisvektoren), aus [Has11]
duktionsraum die Lösungen approximiert, sodass die Basis solange verfeinert werdenkann, bis eine gewählte Fehlertoleranz unterschritten wird.
3.2 Reduktion des Systems
Hat man einen Reduktionsraum Xk bestimmt, wird dann das ursprüngliche System inden Raum projiziert. Diese Projektion läuft nach folgendem Schema ab (vgl. [Ant09,Kapitel 1, S. 8-9]):
Sei T ∈ Rn×n eine Basiswechselmatrix, x = Tx. Wir teilen x, T und T−1 folgender-maßen auf:
x =
(xx
), T−1 =
[V T1
], T =
[W T
TT2
], mit x ∈ Rk, x ∈ Rn−k, V , W ∈ Rn×k.
V und W sind biorthogonal (d.h. W TV = Ik×k), deshalb ist VW T ∈ Rn×n eine Projekti-on ((VW T)2 = VW TVW T = VW T). Anschaulich projiziert diese einen Vektor x ∈ Rn
entlang von ker W T auf den k-dimensionalen Unterraum colspan V (Lineare Hülle derSpalten von V ). Wir wählen also V als Matrix der vorher bestimmten Basisvektorendes Reduktionsraums.
Setzen wir nun x in die System-Gleichungen (1) ein, erhalten wir
ddt
x = T AT−1 x + TBu und y = CT−1 x + Du.
Betrachten wir nur noch die ersten k Gleichungen des Systems, bleibt
ddt
x = W T A(V x + T1 x) + W TBu und y = C(V x + T1 x) + Du.
6

Diese bis hier exakten zwei Mal k Gleichungen werden zu einem reduzierten Sys-tem k-ter Ordnung, indem die Terme AT1 x und CT1 x, die bei geschickter Wahl desProjektionsraumes möglichst klein sein sollten, weggelassen werden.
Das reduzierte System lautet dann:
ddt
x(t) = A(t, µ)x(t) + B(t, µ)u(t)
y(t) = C(t, µ)x(t) + D(t, µ)u(t)(2)
mit den reduzierten Systemmatrizen:
A(t, µ) := W T A(t, µ)V ∈ Rk×k
B(t, µ) := W TB(t, µ) ∈ Rk×m
C(t, µ) := C(t, µ)V ∈ Rp×k
D(t, µ) := D(t, µ) ∈ Rp×p
(3)
und der reduzierten Anfangsbedingung
x(0) = x0(µ) := W Tx(0) ∈ Rk. (4)
Für die weiteren Berechnungen ist die genaue Art der Basiswahl und der Generierungvon V und W egal, es wird nur die Biorthogonalität W TV = Ik×k vorausgesetzt; dieBasisvektoren des Reduktionsraumes bilden die Spalten von V .
4 Affine Parameterabhängigkeit
Die Reduktion der parameterabhängigen Systemmatrizen ist in der oben angegebenenForm sehr aufwendig. Insbesondere im Hinblick auf viele verschiedene zu betrachten-de Parameter ist die Annahme einer affinen Parameterabhängigkeit der Matrizen undAnfangswerte hilfreich. Das heißt, wir nehmen an, dass die Systemmatrizen zerlegtwerden können in eine gewichtete Summe von parameterunabhängigen Matrizen mitparameterabhängigen (skalaren) Gewichten:
A(t, µ) =QA
∑q=1
σqA(t, µ)A(q), B(t, µ) =
QB
∑q=1
σqB(t, µ)B(q), C(t, µ) =
QC
∑q=1
σqC(t, µ)C(q) (5)
Dabei sind die Koeffizientenfunktionen σqA, σ
qB und σ
qC parameter- und zeitabhängig,
während A(q), B(q) und C(q) parameter- und zeitunabhängige Matrizen passender Di-mension sind. Die jeweilige Anzahl der Komponenten QA, QB bzw. QC sei klein. Eben-so nehmen wir an, dass die Anfangswerte für verschiedene Parameter nicht beliebigvariieren, sondern als Funktion des Parameters in der Form
x(0) = x0(µ) =Qx0
∑q=1
σqx0(µ)xq
0 (6)
7

geschrieben werden können.Mithilfe dieser Parameterabhängigkeit kann nun sehr effizient und schnell das re-
duzierte System aufgestellt werden. Dies wird durch eine Offline-/Online-Zerlegung er-reicht.
In der Offline-Phase werden vorab alle parameterunabhängigen Berechnungen desReduktionsschemas durchgeführt. Zuerst wird die Reduzierte Basis und damit dieProjektionsmatrizen V und W generiert. Danach können die parameterunabhängigenKomponenten der Systemmatrizen und Anfangswerte berechnet werden, indem jedekonstante Matrix und jede konstante Komponente der Anfangswerte einzeln reduziertwird:
A(q) := W T A(q)V , B(q) := W TB(q), C(q) := C(q)V , xq0 := W Txq
0 (7)
In der Online-Phase ist der Parameter µ bekannt und die reduzierten Systemmatrizenkönnen schnell zusammengesetzt werden; der Rechenaufwand ist hier komplett un-abhängig von der ursprünglichen Dimension des Problems n. Es ergibt sich aus denGleichungen (5)-(7) also:
A(t, µ) =QA
∑q=1
σqA(t, µ)A(q), B(t, µ) =
QB
∑q=1
σqB(t, µ)B(q),
C(t, µ) =QC
∑q=1
σqC(t, µ)C(q) D(t, µ) = D(t, µ), x0(µ) =
Qx0
∑q=1
σqx0(µ)xq
0
Während die Berechnung der Reduzierten Basis und der reduzierten Systemmatrizenin der Offline-Phase sehr zeitaufwendig ist und vielleicht mehr Aufwand benötigtals das direkte Berechnen einer Lösung des ursprünglichen Systems für ein festesµ, ist der Aufwand in der Online-Phase im Vergleich zum detaillierten System umviele Größenordnungen verringert. Die Zerlegung lohnt sich also, sobald Lösungenfür viele verschiedene µ berechnet werden sollen: Die aufwendige Offline-Phase mussnur einmal durchgeführt werden, danach wird für jeden einzelnen Parameter µ nurnoch die jeweilige Online-Phase zur Berechnung des reduzierten Systems benötigt.
5 A posteriori Fehlerabschätzung
Eine Modellreduktion geht im Allgemeinen immer mit einer Approximation der Lö-sungen des Modells einher. Daher ist es wichtig, entstehende Fehler möglichst ge-nau abschätzen zu können. Wie oben erwähnt, können beim Greedy-Search-VerfahrenFehlerabschätzungen schon bei der Basisgenerierung eine entscheidende Rolle spie-len. In diesem Abschnitt soll deshalb nun eine a posteriori Fehlerabschätzung für denreduzierten Statusvektor x(t) und den reduzierten Output y(t) entwickelt werden.Zunächst definieren wir den Fehler und das Residuum
e(t, µ) := x(t, µ)− V x(t, µ), R(t, µ) := A(t, µ)V x(t) + B(t, µ)u(t)− Vddt
x(t). (8)
8

Liegt die exakte Lösung schon im Reduktionsraum, also x(t) ∈ colspan V , giltVW Tx(t) = x(t), also insbesondere V x(t) = x(t). Das heißt, das reduzierte Systemreproduziert die exakte Lösungohne Approximations-Fehler. Damit wird das Residu-um R(t, µ) gerade 0.
Für den Anfangsfehler e(0, µ) gilt:
e(0, µ) = x0(µ)− V x0(µ) = (In×n − VW T)x0(µ) (9)
Zur Fehlerabschätzung müssen passende Normen gewählt werden. Sei G ∈ Rn×n einesymmetrisch positiv definite Matrix, dann definieren wir damit
• das Skalarprodukt 〈x, x′〉G := xTGx′
• die induzierte Vektornorm ‖x‖G :=√〈x, x〉G auf dem Rn
• die induzierten Matrixnormen ‖A‖G := sup‖x‖G=1 ‖Ax‖G für A ∈ Rn×n
und ‖C‖G := sup‖x‖G=1 ‖Cx‖ für C ∈ Rp×n
Für den Output y(t, µ) ∈ Rp wird dabei die normale 2-Norm ‖·‖ benutzt. Setzt manG = In×n, erhält man für die Matrizen und den Zustandsvektor ebenfalls die 2-Norm.Je nach Problemstellung kann eine andere Wahl von G aber die Fehlerabschätzungverbessern.
Bevor wir die Fehlerabschätzung für die Systemreduktion entwickeln, zitieren wirzunächst zwei Ergebnisse aus der Theorie der gewöhnlichen Differentialgleichungen:
Proposition 5.1 (Lineares System mit konstanten Koeffizienten). (aus [Wal00, Satz 16.III,Abschnitte 17.XI und 29.IV]) Sei A ∈ Rn×n eine konstante Matrix, b : J → Rn eine stetigevektorwertige Funktion auf einem beliebigen Intervall J und τ ∈ J.(a) Das Anfangswertproblem
ddt
z(t) = Az(t) + b(t), z(τ) = η
besitzt die eindeutige Lösung
z(t) = exp(A(t− τ))η +∫ t
τexp(A(t− s))b(s)ds.
(b) Haben alle Eigenwerte von A negativen Realteil, ist die Lösung des Systems auf demIntervall J = [a, ∞) stabil, insbesondere ist sie damit für beliebige t ∈ [a, ∞) beschränkt.
Mit diesem Wissen kann nun die Fehlerabschätzung formuliert werden:
Proposition 5.2 (A posteriori Fehlerabschätzung). Sei A(t, µ) = A(µ) stationär und habefür alle µ nur Eigenwerte mit negativem Realteil. Sei C1(µ) (berechenbare) obere Schranke
C1(µ) ≥ supt‖exp(A(µ)t)‖G .
9

Dann gilt für den Zustandsvektor folgende Fehlerabschätzung:
‖x(t, µ)− V x(t, µ)‖G ≤ ∆x(t, µ) := C1(µ)
(‖e(0, µ)‖G +
∫ t
0‖R(τ, µ)‖G dτ
). (10)
Haben wir zusätzlich eine obere Schranke
C2(µ) ≥ supt‖C(t, µ)‖G
gilt die folgende Abschätzung für den Fehler des Outputs:
‖y(t, µ)− y(t, µ)‖ ≤ ∆y(t, µ) := C2(µ)∆x(t, µ). (11)
Beweis: Da A nur Eigenwerte mit negativem Realteil hat, ist nach Prop. 5.1 das Systemstabil und eine Konstante C1 existiert, da ‖exp(A(µ)t)‖G für t ∈ [0, ∞) beschränkt ist.
Nach der Definition des Residuums (8) gilt:
Vddt
x(t) = A(µ)V x(t) + B(t, µ)u(t)− R(t, µ).
Subtrahiert man dies von der ursprünglichen System-Gleichung (1), erhält man dieEntwicklungsgleichung für den Fehler
ddt
e(t, µ) = A(µ)e(t, µ) + R(t, µ) (12)
mit der Anfangsbedingung (9). Für festes µ ist dies ein lineares System mit konstantenKoeffizienten, nach Prop. 5.1 gilt:
e(t, µ) = exp(A(µ)t)e(0, µ) +∫ t
0exp(A(µ)(t− τ))R(τ, µ)dτ.
Es folgt mit der Beschränktheit ‖exp(A(µ)s)‖G ≤ C1(µ) für alle s ∈ [0, ∞):
‖e(t, µ)‖G ≤ ‖exp(A(µ)t)‖G ‖e(0, µ)‖G +∫ t
0‖exp(A(µ)(t− τ))‖G ‖R(τ, µ)‖G dτ
≤ C1(µ)
(‖e(0, µ)‖G +
∫ t
0‖R(τ, µ)‖G dτ
)
= ∆x.
Für die zweite Abschätzung benutzen wir die ursprünglichen und reduzierten System-Gleichungen ((1) und (2)):
‖y(t, µ)− y(t, µ)‖ = ‖C(t, µ)x(t, µ) + D(t, µ)u(t)− C(t, µ)V x(t, µ)− D(t, µ)u(t)‖= ‖C(t, µ) (x(t, µ)− V x(t, µ))‖≤ ‖C(t, µ)‖G ‖x(t, µ)− V x(t, µ)‖G
≤ C2(µ)∆x
10

5.1 Instabile und zeitabhängige Systeme
Die obige Fehlerabschätzung gilt für instabile Systeme genau dann, wenn endlicheZeiträume t ∈ [0, T] betrachtet werden, da genau dann die Lösung beschränkt bleibt.
Ist die Systemmatrix A(t, µ) zeitabhängig, kann durch weitere Rechnungen eineähnliche Abschätzung erreicht werden. Dazu wird das Lemma von Gronwall benötigt:
Lemma 5.3 (Lemma von Gronwall). (siehe [Ohl10], Lemma 3.10) Seien p, q ∈ C0([a, b])mit p, q ≥ 0. Erfüllt die Funktion Φ : [a, b]→ R die Integralungleichung
0 ≤ Φ(t) ≤ p(t) +∫ t
aq(s)Φ(s)ds ∀t ∈ [a, b],
so gilt
0 ≤ Φ(t) ≤ p(t) +∫ t
aq(s)p(s) exp
(∫ t
sq(r)dr
)ds.
Nun können wir auf die folgende Weise durch Anpassung der Konstante C1 eineähnliche Abschätzung wie für stationäre Systeme erreichen: Zunächst gilt die Ent-wicklungsgleichung für den Fehler (12) wie oben auch für zeitabhängige Systeme, esist also:
e(t, µ) = e(0, µ) +∫ t
0A(s, µ)e(s, µ) + R(s, µ)ds
=⇒ ‖e(t, µ)‖G︸ ︷︷ ︸:=Φ(t)
≤ ‖e(0, µ)‖G +∫ t
0‖R(s, µ)‖G ds
︸ ︷︷ ︸:=p(t)
+∫ t
0‖A(s, µ)‖G︸ ︷︷ ︸
:=q(s)
‖e(s, µ)‖G︸ ︷︷ ︸Φ(s)
ds
Aus dem Lemma von Gronwall 5.3 folgt für alle t ∈ [0, T] und festes µ:
Φ(t) ≤ p(t) +∫ t
aq(s)p(s) exp
(∫ t
sq(r)dr
)ds
Existiert nun eine obere Schranke C3 ≥ ‖A(t, µ)‖G = q(t) ∀t ∈ [0, T], µ ∈ P , erhaltenwir, da p(t) monoton steigend ist:
Φ(t) ≤ p(t)(
1 +∫ t
0q(s) exp
(∫ t
sq(r)dr
)ds)
≤ p(t)(1 + C3t exp(C3t))
Setzen wir C1 := 1 + C3T exp(C3T), erhalten wir wieder die ursprüngliche Fehlerab-schätzung (10). Hier wächst die Konstante C1 allerdings exponentiell mit der Längedes Zeitraumes T, die Abschätzung wird also schnell sehr grob. Trotzdem ergibt beifestem T ein kleiner Fehler e(t, µ) ein kleines Residuum und somit auch einen kleinenFehlerschätzer.
11

5.2 Offline-/Online-Zerlegung des Fehlerschätzers
Der Vorteil des oben eingeführten Fehlerschätzers ist, dass seine Berechnung parallelzum reduzierten System ebenfalls in Offline- und Online-Phase zerlegt werden kann.Dadurch kann während der Reduktion der entstehende Fehler direkt und schnell mit-berechnet werden. Die Norm des Residuums ist direkt aus seiner Definition (8) bere-chenbar, da die Ableitung d
dt x während der Simulation bekannt ist. Es gilt:
‖R‖2G = RTGR =
(AV x + Bu− V
ddt
x)T
G(
AV x + Bu− Vddt
x)
= xTV T ATGAV x + uTBTGBu +
(ddt
x)T
V TGV(
ddt
x)
+ 2uTBTGAV x− 2(
ddt
x)T
V TGAV x− 2(
ddt
x)T
V TGBu
=: xT M1 x + uT M2u +
(ddt
x)T
M3
(ddt
x)
+ 2uT M4 x− 2(
ddt
x)T
M5 x− 2(
ddt
x)T
M6u
mit den Abkürzungen
• M1(t, µ) := V T A(t, µ)TGA(t, µ)V
• M2(t, µ) := B(t, µ)TGB(t, µ)
• M3 := V TGV
• M4(t, µ) := B(t, µ)TGA(t, µ)V
• M5(t, µ) := V TGA(t, µ)V
• M6(t, µ) := V TGB(t, µ)
Es wird nun die affine Parameterabhängigkeit der Matrizen A, B, und C (5) ausge-nutzt, um die Matrizen M1, M2, M4, M5 und M6 in parameter- und zeitunabhängigeMatrizen und parameter- und zeitabhängige Gewichtsfunktionen aufzuspalten:
M1(t, µ) = V T
(QA
∑q=1
σqA(t, µ)A(q)
)T
G
(QA
∑q=1
σqA(t, µ)A(q)
)V
=QA
∑q,q′=1
σqA(t, µ)σ
q′
A (t, µ)V T(A(q))TGA(q′)V︸ ︷︷ ︸:=Mq,q′
1
In der Offline-Phase können dann für q, q′ = 1, · · ·QA die Matrizen Mq,q′1 berechnet
werden, analog auch die Matrizen Mq,q′2 , Mq,q′
4 , Mq5 und Mq
6, wobei q und q′ jeweils
12

passend zwischen 1 und QA/QB/QC variieren. Die Matrix M3 ist parameter- undzeitunabhängig und wird daher ebenfalls in der Offline-Phase berechnet.
In der Online-Phase werden zunächst die Matrizen M1, M2, M4, M5 und M6 zu-sammengesetzt. Während der reduzierten Simulation sind dann x(t), d
dt x(t) und u(t)bekannt, sodass die Residuumsnorm ‖R‖2
G berechnet werden kann.Für die Fehlerabschätzung (10) wird zuletzt noch der Anfangsfehler e(0, µ) benötigt.
Bei einer individuellen Wahl des Projektionsraumes kann dieser leicht auf 0 gesetztwerden, indem der Raum so gewählt wird, dass die Komponenten der Anfangswerteim reduzierten Raum liegen, also xq
0 ∈ colspan V für q = 1, . . . , Qx0 . Ist dies nichtmöglich, muss die Norm des Anfangsfehlers berechnet werden. Es ist nach (9):
‖e(0, µ)‖2G =
((In×n − VW T)x0(µ)
)TG((In×n − VW T)x0(µ)
)
Wie auch bei den Matrizen M i oben wird die Berechnung des Anfangsfehlers mithilfeder Zerlegung der Anfangswerte (6) in Offline- und Online-Phase aufgeteilt. Offlinewerden die Komponenten
mq,q′ := (xq0)
T(In×n − VW T)TG(In×n − VW T)(xq′0 )
für q, q′ = 1, · · ·Qx0 berechnet, die dann Online zusammengesetzt werden zur Normdes Anfangsfehlers
‖e(0, µ)‖2G =
Qx0
∑q,q′=1
σqx0(µ)σ
q′x0(µ)m
q,q′ .
6 Duales Problem zur Verbesserung derOutput-Fehlerabschätzung
Die bisherige Fehlerabschätzung für den Output (11) ∆y(t, µ) := C2(µ)∆x(t, µ) hängtvon der Konstante C2(µ) ≥ supt ‖C(t, µ)‖G ab, die bei ungünstigen Matrizen C mit-unter sehr groß werden kann, sodass die Abschätzung ungenau wird. In diesem Ab-schnitt soll mithilfe eines dualen Systems die a posteriori Fehlerabschätzung des Out-puts verbessert werden. Werden zum Anfang einer Simulation durch die Systemre-duktion Fehler erzeugt, ist nicht klar, welche Auswirkungen diese für die späterenZeitpunkte haben; ob sich Fehler verstärken oder sich nicht weiter auf die Lösungauswirken. Das duale System soll geeignet „rückwärts“ in der Zeit laufen bzw. si-muliert werden, und Aufschluss darüber geben, welchen Einfluss frühere Fehler aufden weiteren Lösungsverlauf haben. So können größere Fehler durch Korrekturtermeausgeglichen und die dann noch entstehenden Fehler enger eingegrenzt werden.
Hier wird das duale System nur für einen eindimensionalen Output y(t) ∈ R
entwickelt, die primalen Systemmatrizen werden zu Vektoren C(t, µ) = cT(t, µ) fürc(t, µ) ∈ Rn und D(t, µ) = dT(t, µ) für d(t, µ) ∈ Rm. Für einen größeren Output
13

y(t, µ) ∈ Rp, p > 1 können p einzelne duale Probleme betrachtet werden. Der Outputwird hier außerdem nur für einen fixen Zeitpunkt T > 0 berechnet.
Zunächst wird das duale System für die duale Variable xdu(t) ∈ Rn, t ∈ [0, T]formuliert durch
ddt
xdu(t) = Adu(t, µ)xdu(t) mit Adu(t, µ) := −G−1AT(t, µ)G
und die Bedingung für den Endzeitpunkt T
xdu(T) = G−1c(T, µ).
Die Inverse G−1 existiert, da G als symmetrisch positiv definit vorausgesetzt wur-de. Auch dieses System soll analog zum ursprünglichen System in einen kdu-dimen-sionalen Unterraum projiziert werden, seien Vdu, Wdu ∈ Rn×kdu
die entsprechendenbiorthogonalen Projektionsmatrizen. Das reduzierte duale System lautet dann
ddt
xdu(t) = Adu(t, µ)xdu(t) mit Adu
(t, µ) := (Wdu)T Adu(t, µ)Vdu
und reduzierter „Endbedingung“
xdu(T) = (Wdu)TG−1c(T, µ).
Analog zum ursprünglichen System definieren wir den dualen Fehler und das dualeResiduum
edu(t, µ) := xdu(t, µ)− Vdu xdu(t, µ), Rdu(t, µ) := Adu(t, µ)Vdu xdu(t)− Vdu ddt
x(t).
Ebenfalls wie oben ergibt sich aus der Systemgleichung und der Definition des Resi-duums die Entwicklungsgleichung für den Fehler
ddt
edu(t, µ) = Adu(t, µ)edu(t, µ) + Rdu(t, µ) (13)
mit „Endbedingung“
edu(T, µ) = (In×n − Vdu(Wdu)T)G−1c(t, µ) (14)
Analog zur a posteriori Fehlerabschätzung des primalen Fehlers 5.2 formulieren wirnun für den dualen Fehler:
Proposition 6.1 (Duale a posteriori Fehlerabschätzung). Sei −Adu(t, µ) = −Adu(µ)
stationär. Sei Cdu1 (µ) ∈ R (berechenbare) obere Schranke
Cdu1 (µ) ≥ sup
t∈[0,T]
∥∥∥exp(−Adu(µ)t)∥∥∥
G.
Dann gilt für den dualen Zustandsvektor folgende Fehlerabschätzung:∥∥∥edu(t, µ)
∥∥∥G≤ ∆du
x (t, µ) := Cdu1 (µ)
(∥∥∥edu(T, µ)∥∥∥
G+∫ T
t
∥∥∥Rdu(τ, µ)∥∥∥
Gdτ
).
14

Beweis: Nach Proposition 5.1 kann man die explizite Lösung der Entwicklungsglei-chung für den dualen Fehler (13) und (14) schreiben als
edu(t, µ) = exp(−Adu(µ)(T − t))edu(T, µ)−∫ T
texp(−Adu(µ)(τ − t))Rdu(τ, µ)dτ.
Somit gilt:∥∥∥edu(t, µ)
∥∥∥G≤ Cdu
1 (µ)∥∥∥edu(T, µ)
∥∥∥G+ Cdu
1 (µ)∫ T
t
∥∥∥Rdu(τ, µ)∥∥∥
Gdτ
Folgendes Lemma gibt nun die Motivation für die Verbesserung der Output-Ab-schätzung. Zur besseren Lesbarkeit werden die Parameterabhängigkeiten weggelas-sen.
Lemma 6.2 (Zusammensetzung des Output-Fehlers). Für den Fehler des reduzierten Out-puts zum Zeitpunkt T gilt
y(T)− y(T) =⟨
edu(T), e(T)⟩
G︸ ︷︷ ︸:=T1
+⟨
Vdu xdu(0), e(0)⟩
G︸ ︷︷ ︸:=T2
−∫ T
0
⟨Rdu(t), e(t)
⟩G
dt︸ ︷︷ ︸
:=T3
+∫ T
0
⟨Vdu xdu(t), R(t)
⟩G
dt︸ ︷︷ ︸
:=T4
= T1 + T2 − T3 + T4
Beweis: Vorab gilt für Vektoren u, v ∈ Rn (beachte G und damit auch G−1 symme-trisch):
〈u, Av〉G = uTGAv = uTGAG−1Gv =⟨
G−1ATGu, v⟩
G=⟨−Aduu, v
⟩G
(15)
Aus der Definition des ursprünglichen und reduzierten Outputs folgt:
y(T)− y(T) = cT(T)x(T) + dT(T)u(T)− (cT(T)V x(T) + dT(T)u(T))
= cT(T)e(T) = cT(T)G−1Ge(T) =⟨
G−1c(T), e(T)⟩
G=⟨
xdu(T), e(T)⟩
G
=⟨
edu(T), e(T)⟩
G︸ ︷︷ ︸=T1
+⟨
Vdu xdu(T), e(T)⟩
G.
Umschreiben des zweiten Terms mittels Hauptsatz der Differential- und Integralrech-nung führt zu:
y(T)− y(T) = T1 +∫ T
0
ddt
⟨Vdu xdu(t), e(t)
⟩G
dt +⟨
Vdu xdu(0), e(0)⟩
G︸ ︷︷ ︸=T2
Produkt-=
regelT1 + T2 +
∫ T
0
⟨ddt
Vdu xdu(t), e(t)⟩
Gdt +
∫ T
0
⟨Vdu xdu(t),
ddt
e(t)⟩
Gdt.
15

Es bleibt also noch zu zeigen, dass die letzten beiden Terme −T3 + T4 entsprechen.Setzen wir in den letzten Term die Entwicklungsgleichung für den Fehler (12) ein undbenutzen die oben gezeigte Identität (15), erhalten wir
∫ T
0
⟨Vdu xdu(t),
ddt
e(t)⟩
Gdt =
∫ T
0
⟨Vdu xdu(t)︸ ︷︷ ︸
u
, A e(t)︸︷︷︸v
⟩
G
dt +∫ T
0
⟨Vdu xdu(t), R(t)
⟩G
dt︸ ︷︷ ︸
T4
(15)=∫ T
0
⟨−AduVdu xdu(t), e(t)
⟩G
dt + T4.
Einsetzen ergibt
y(T)− y(T)
= T1 + T2 +∫ T
0
⟨ddt
Vdu xdu(t), e(t)⟩
Gdt +
∫ T
0
⟨−AduVdu xdu(t), e(t)
⟩G
dt + T4
= T1 + T2 +∫ T
0
⟨ddt
Vdu xdu(t)− AduVdu xdu(t), e(t)⟩
Gdt + T4
= T1 + T2 +∫ T
0
⟨−Rdu(t), e(t)
⟩G
dt + T4
= T1 + T2 − T3 + T4.
Mit dieser „Aufteilung“ kann nun der Output-Fehler genauer bestimmt werden:T1 wird beliebig klein, indem der duale reduzierte Raum Vdu so gewählt wird, dassxdu(T) = G−1c(T, µ) für alle µ gut approximiert wird (also edu(T) möglichst klein).Genauso wird T2 beliebig minimiert, indem der Anfangsfehler minimiert wird; x0(µ)
soll also für alle µ möglichst gut durch V approximiert werden. Bei einer affinen Pa-rameterabhängigkeit von x0 und c können jeweils einfach die Komponenten xq
0 bzw.G−1cq in die reduzierten Räume mit einbezogen werden, dann verschwinden T1 undT2 sogar. Der Term T3 kann nicht exakt berechnet werden, da e(t) nicht bekannt ist.Durch eine gute Wahl der reduzierten Räume sollte er jedoch klein werden: Sind∥∥Rdu(t)
∥∥G , ‖e(t)‖G ≤ ε, gilt |T3| ≤ Tε2. Der letzte Term T4 ist für
∥∥Rdu(t)∥∥
G ≤ ε
von der Ordnung O(ε), da xdu nicht notwendig klein ist. Dieser trägt also am meistenzum Output-Fehler bei. Da T4 aber nur aus reduzierten Größen besteht, ist der Termwährend der Simulation vollständig berechenbar, er kann also zur Verbesserung desOutputs verwendet werden. Genauso kann auch T2 berechnet werden, falls der Termnicht verschwindet. Wir benutzen deshalb T2 und T4 als Korrekturterme und erhalteneine genauere Fehlerabschätzung für den Output.
Proposition 6.3 (Verbesserte Output-Abschätzung). Für den verbesserten Output-Schät-zer definiert durch
y∗(T) := cT(T)V x(T) + dT(T)u(T) +⟨
Vduxdu(0), e(0)⟩
G+∫ T
0
⟨Vdu xdu(t), R(t)
⟩G
dt
16

gilt die folgende a posteriori Fehlerabschätzung:
|y(T)− y∗(T)| ≤ ∆∗y(µ) :=∥∥∥edu(T)
∥∥∥G
∆x(T) +∫ T
0
∥∥∥Rdu(t)∥∥∥
G∆x(t)dt (16)
Diese kann weiter abgeschätzt werden zu
∆∗y(µ) ≤1
Cdu1
∆x(T, µ)∆dux (0, µ). (17)
Beweis: Es gilt nach Definition: y∗(T) = y(T) + T2 + T4, also y(T)− y∗(T) = T1 − T3.Es folgt
|y(t)− y∗(t)| ≤ |T1|+ |T3| =∣∣∣⟨
edu(T), e(T)⟩
G
∣∣∣+∣∣∣∣∫ T
0
⟨Rdu(t), e(t)
⟩G
dt∣∣∣∣
≤∥∥∥edu(T)
∥∥∥G‖e(T)‖G︸ ︷︷ ︸≤∆x(T)
+∫ T
0
∥∥∥Rdu(t)∥∥∥
G‖e(t)‖G︸ ︷︷ ︸≤∆x(t)
dt
≤ ∆∗y(µ).
Zum Beweis von (17) benutzen wir die Definition des dualen Fehlerschätzers ∆dux (t) :=
Cdu1
(∥∥edu(T)∥∥
G +∫ T
t
∥∥Rdu(τ)∥∥
G dτ)
. Es ergibt sich, da ∆x(t) monoton steigend ist:
∆∗y(µ) ≤ ∆x(T)(∥∥∥edu(T)
∥∥∥G+∫ T
0
∥∥∥Rdu(t)∥∥∥
Gdt)
≤ ∆x(T)1
Cdu1
∆dux (0).
Diese verbesserte Output-Abschätzung kann analog zu 5.1 auch für zeitabhängigeSysteme entwickelt werden. Die Abschätzung (16) ist genauer als (17), letztere zeigtallerdings, dass die verbesserte Output-Abschätzung eine Art „quadratische“ Abhän-gigkeit vom primalen und dualen Reduktionsfehler zeigt. Nimmt man wieder wie inden vorherigen Abschnitten eine affine Parameterabhängigkeit an, kann auch das dua-le System in Offline- und Online-Berechnungen zerlegt werden, sodass auch dieses fürvariable Parameter effektiv gelöst werden kann.
7 Resultate
Das hier vorgestellte Verfahren zur effektiven Berechnung großer linearer parametri-sierter Probleme wurde im zugrunde liegenden Artikel [HO11, Abschnitt 6] getestet.Durch die Diskretisierung eines Konvektionsproblems entstand ein System von derDimension n = 65536 mit eindimensionalem Output. Die reduzierte Basis wurde aus
17
less accurate with reduced model dimension. Extrapolating the rightmost plot, there is acritical lower dimension bound, at which the error tube width is in the order of the reducedoutput itself. In these cases, the rigour of the error tubes obviously is of no practical use. Butfor well-approximating reduced models, the error tubes can indeed be very small. Ideally, theerror tubes can even be evaluated to be 0, if the reduced model is exact for a certain parameterand input. Hence, exact approximation can be verified and identified a posteriori in a fastway without any expensive operations of order O(n).
The quality of the reducedmodel in the parameter domain can now be quantified during theonline phase, as the reduced model enables parameter sweeps. Figure 3a indicates the outputerror bound for linearly varying the parameter vector fromμ! (0, 0, 0)T to μ! (1, 1, 1)T. Thesecurves are plotted for different reduced model dimensions k. As expected and accepted fromthe basis construction, the error estimators confirm that the resulting basis is good for theboundary parameters but not suitable for intermediate parameters. Interestingly, the basis fork! 1 is already excellent for the lowest parameter μ ! (0, 0, 0)T, which is because of the fact,that the process is stationary in this case, as the velocities are 0. Hence, a single vector issufficient to exactly(!) reproduce this solution trajectory which is confirmed by Δx (t, μ) ! 0.For the right-limit parameter μ! (1, 1, 1)T the model is also becoming accurate with few 8–16basis vectors. The second plot (Figure 3b), gives the true output errors of the reduced modelwith identical ranges and reduced dimensions as in the previous plot. Comparison with plot (a)shows that the error bounds indeed are upper bounds on the computationally expensive trueerror curves in (b). The overestimation of the error seems limited, as the bound and error havethe same order of magnitude.
We now want to address the claimed ‘efficiency’ of the resulting models in terms ofcomputation time. For this, we present the runtimes of a single detailed simulation and theonline phase of the reduced simulations with different dimensionalities, with and withouterror estimation. Table 1 summarizes these results obtained on a standard computer (Intel-Centrino Duo, 2 GHz, 1 GB RAM). We clearly see how the reduced models realize anacceleration of factor 10–25. This is quite remarkable because of the simplicity of the time-discretization scheme. The explicit time discretization of the detailed system has complexityO(n!) for !! 1 in each step, dominated by the single sparse matrix-vector multiplication. So,currently, we even can accelerate these simple matrix-vector multiplications with thereduced system. Therefore, we expect to obtain even higher acceleration factors if we use
(b)(a)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1!0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35k = 60
y^(t): reduced outputy^(t)+!y(t)
y^(t)!!y(t)
y(t): detailed output
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1!0.05
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0
k = 20
y^(t): reduced outputy^(t)+!y(t)
y^(t)!!y(t)y(t): detailed output
Figure 2. Output estimation over time for μ ! (1, 1, 1)T: reduced output with guaranteed error tubesand exact solution. (a) Reduced model dimension k ! 60 and (b) reduced model dimension k ! 20.
158 B. Haasdonk and M. Ohlberger
Dow
nloa
ded
by [I
nstit
ut F
uer T
iere
rnae
hrun
g/Fl
i] at
02:
38 0
2 A
pril
2013
less accurate with reduced model dimension. Extrapolating the rightmost plot, there is acritical lower dimension bound, at which the error tube width is in the order of the reducedoutput itself. In these cases, the rigour of the error tubes obviously is of no practical use. Butfor well-approximating reduced models, the error tubes can indeed be very small. Ideally, theerror tubes can even be evaluated to be 0, if the reduced model is exact for a certain parameterand input. Hence, exact approximation can be verified and identified a posteriori in a fastway without any expensive operations of order O(n).
The quality of the reducedmodel in the parameter domain can now be quantified during theonline phase, as the reduced model enables parameter sweeps. Figure 3a indicates the outputerror bound for linearly varying the parameter vector fromμ! (0, 0, 0)T to μ! (1, 1, 1)T. Thesecurves are plotted for different reduced model dimensions k. As expected and accepted fromthe basis construction, the error estimators confirm that the resulting basis is good for theboundary parameters but not suitable for intermediate parameters. Interestingly, the basis fork! 1 is already excellent for the lowest parameter μ ! (0, 0, 0)T, which is because of the fact,that the process is stationary in this case, as the velocities are 0. Hence, a single vector issufficient to exactly(!) reproduce this solution trajectory which is confirmed by Δx (t, μ) ! 0.For the right-limit parameter μ! (1, 1, 1)T the model is also becoming accurate with few 8–16basis vectors. The second plot (Figure 3b), gives the true output errors of the reduced modelwith identical ranges and reduced dimensions as in the previous plot. Comparison with plot (a)shows that the error bounds indeed are upper bounds on the computationally expensive trueerror curves in (b). The overestimation of the error seems limited, as the bound and error havethe same order of magnitude.
We now want to address the claimed ‘efficiency’ of the resulting models in terms ofcomputation time. For this, we present the runtimes of a single detailed simulation and theonline phase of the reduced simulations with different dimensionalities, with and withouterror estimation. Table 1 summarizes these results obtained on a standard computer (Intel-Centrino Duo, 2 GHz, 1 GB RAM). We clearly see how the reduced models realize anacceleration of factor 10–25. This is quite remarkable because of the simplicity of the time-discretization scheme. The explicit time discretization of the detailed system has complexityO(n!) for !! 1 in each step, dominated by the single sparse matrix-vector multiplication. So,currently, we even can accelerate these simple matrix-vector multiplications with thereduced system. Therefore, we expect to obtain even higher acceleration factors if we use
(b)(a)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1!0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35k = 60
y^(t): reduced outputy^(t)+!y(t)
y^(t)!!y(t)
y(t): detailed output
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1!0.05
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0
k = 20
y^(t): reduced outputy^(t)+!y(t)
y^(t)!!y(t)y(t): detailed output
Figure 2. Output estimation over time for μ ! (1, 1, 1)T: reduced output with guaranteed error tubesand exact solution. (a) Reduced model dimension k ! 60 and (b) reduced model dimension k ! 20.
158 B. Haasdonk and M. Ohlberger
Dow
nloa
ded
by [I
nstit
ut F
uer T
iere
rnae
hrun
g/Fl
i] at
02:
38 0
2 A
pril
2013
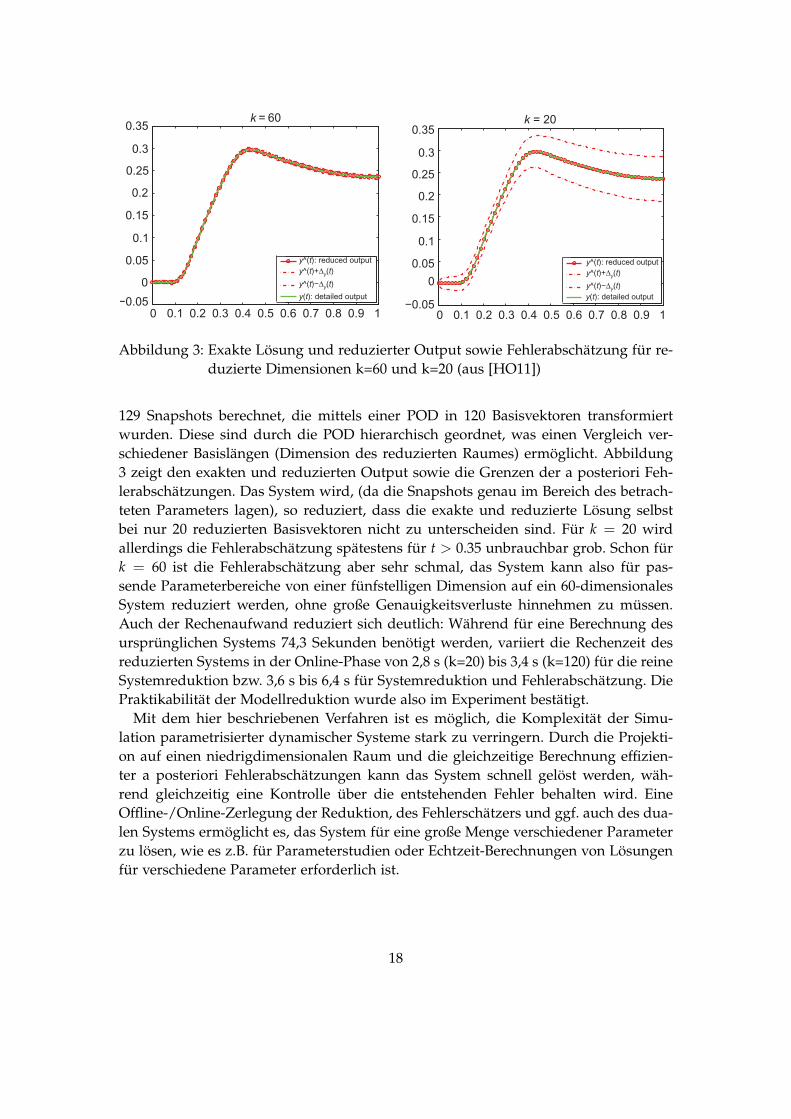
Abbildung 3: Exakte Lösung und reduzierter Output sowie Fehlerabschätzung für re-duzierte Dimensionen k=60 und k=20 (aus [HO11])
129 Snapshots berechnet, die mittels einer POD in 120 Basisvektoren transformiertwurden. Diese sind durch die POD hierarchisch geordnet, was einen Vergleich ver-schiedener Basislängen (Dimension des reduzierten Raumes) ermöglicht. Abbildung3 zeigt den exakten und reduzierten Output sowie die Grenzen der a posteriori Feh-lerabschätzungen. Das System wird, (da die Snapshots genau im Bereich des betrach-teten Parameters lagen), so reduziert, dass die exakte und reduzierte Lösung selbstbei nur 20 reduzierten Basisvektoren nicht zu unterscheiden sind. Für k = 20 wirdallerdings die Fehlerabschätzung spätestens für t > 0.35 unbrauchbar grob. Schon fürk = 60 ist die Fehlerabschätzung aber sehr schmal, das System kann also für pas-sende Parameterbereiche von einer fünfstelligen Dimension auf ein 60-dimensionalesSystem reduziert werden, ohne große Genauigkeitsverluste hinnehmen zu müssen.Auch der Rechenaufwand reduziert sich deutlich: Während für eine Berechnung desursprünglichen Systems 74,3 Sekunden benötigt werden, variiert die Rechenzeit desreduzierten Systems in der Online-Phase von 2,8 s (k=20) bis 3,4 s (k=120) für die reineSystemreduktion bzw. 3,6 s bis 6,4 s für Systemreduktion und Fehlerabschätzung. DiePraktikabilität der Modellreduktion wurde also im Experiment bestätigt.
Mit dem hier beschriebenen Verfahren ist es möglich, die Komplexität der Simu-lation parametrisierter dynamischer Systeme stark zu verringern. Durch die Projekti-on auf einen niedrigdimensionalen Raum und die gleichzeitige Berechnung effizien-ter a posteriori Fehlerabschätzungen kann das System schnell gelöst werden, wäh-rend gleichzeitig eine Kontrolle über die entstehenden Fehler behalten wird. EineOffline-/Online-Zerlegung der Reduktion, des Fehlerschätzers und ggf. auch des dua-len Systems ermöglicht es, das System für eine große Menge verschiedener Parameterzu lösen, wie es z.B. für Parameterstudien oder Echtzeit-Berechnungen von Lösungenfür verschiedene Parameter erforderlich ist.
18

Literatur
[HO11] B. Haasdonk und M. Ohlberger: Efficient reduced models and a posteriori errorestimation for parametrized dynamical systems by offline/online decomposition,Mathematical and Computer Modelling of Dynamical Systems: Methods,Tools and Applications in Engineering and Related Sciences, 17:2, 145-161,2011
[Ant09] A.C. Antoulas: Approximation of large-scale dynamical systems. Vol. 6. Societyfor Industrial and Applied Mathematics, 2009.
[Has11] B. Haasdonk: Vorlesungsskript Reduzierte-Basis-Methoden, Preprint IANS,Uni Stuttgart, 2011
[Ohl10] M. Ohlberger: Vorlesungsskript Numerische Analysis, http://wwwmath.uni-muenster.de/num/Vorlesungen/NumAna_WS10/Script/skriptum_11pt.pdf, abgerufen 04.06.2013
[Wal00] W. Walter: Gewöhnliche Differentialgleichungen, Springer-Verlag, 7. Auflage2000
[MoR] B. Haasdonk und M. Ohlberger: MoRePaS-Projekt Homepage, http://www.morepas.org/research/index.html, abgerufen 15.05.2013
19














![Funktionale Programmierung - TH Köln · Array[String]: Scala behandelt Arrays wie parametrisierte Typen. Unit is a subtype of scala.AnyVal. There is only one value of type Unit,](https://static.fdokument.com/doc/165x107/5e140e4164a5815e5f1d8968/funktionale-programmierung-th-kln-arraystring-scala-behandelt-arrays-wie.jpg)



