Computerorientierte Mathematik I - Private...
42
Transcript of Computerorientierte Mathematik I - Private...


Kapitel 10
Sortieren in Arrays
Sortieralgorithmen gehoren zu den am haufigsten angewendeten Algorithmen in der Datenverarbei-tung. Man hatte daher bereits fruh ein großes Interesse an der Entwicklung moglichst effizienter Sor-tieralgorithmen. Zu diesem Thema gibt es umfangreiche Literatur, nahezu jedes Buchuber Algo-rithmen und Datenstrukturen beschaftigt sich mit Sortieralgorithmen, da sie besonders geeignet sind,Anfangern Programmiermethodik, Entwurf von Algorithmen und Aufwandsanalyse zu lehren.
Wir erlautern die Sortieralgorithmen vor folgendem Hintergrund. Gegeben ist ein DatentypItem.
public class Item int key;// data components and methods
Objekte dieses Typs sind “Karteikarten”, z. B. aus einer Studentenkartei. Jede Karteikarte enthaltneben den Daten (data components) einen Schlussel (key) vom Typint, z. B. die Matrikelnummer,nach denen sortiert oder gesucht werden kann. Die gesamte Kartei wird durch ein Arrayvec mitGrundtypItem dargestellt. Wir reden daher im weiteren auch vonKomponentenoderElementenstattKarteikarten.
Die Wahl vonint als Schlusseltyp ist willkurlich. Hier kann jeder andere Typ verwendet werden,fur den eine vollstandige Ordnungsrelation definiert ist, also zwischen je zwei Wertena,b genau eineder Relationena < b, a = b, a > b gilt. Dies konnen z. B. auch Strings mit der lexikographischenOrdnung sein (Meier< Mueller), nur musste dann der “eingebaute” Vergleich “<” von ganzen Zahlendurch eine selbstdefinierte Funktion zum Vergleich von Strings ersetzt werden.1
1Dies kann mit dem InterfaceComparable (vgl. Abschnitt 7.3.7) realisiert werden. Die KlasseItem muss da-zu die Methode public int compareTo(Object o) implementieren. Dabei ist das Itemx kleiner als odergleich dem Itemy wenn x.compareTo((Object)y) <= 0 gilt. Alle Sortieralgorithmen nutzen dann die Abfragex.compareTo((Object)y) <= 0 fur den Vergleich vonx undy.
Version vom 30. Dezember 2004
249

250 KAPITEL 10. SORTIEREN IN ARRAYS
10.1 Direkte Methoden
Direkt bedeutet: Sortieren der Komponenten “am Ort”. Ein typisches Beispiel dafur ist Bubblesort.
10.1.1 Sortieren durch Austauschen: Bubblesort
Bubblesort durchlauft das Array mehrmals von hinten nach vorn und lasst durch paarweise Vergleichedas kleinste Element der restlichen Menge zum linken Ende des Arrays wandern. Stellt man sichdas Array senkrecht angeordnet vor, und die Elemente als Blasen, so steigt bei jedem Durchlaufdurch das Array eine Blase auf die ihrem Gewicht (Schlusselwert) entsprechende Hohe auf (vgl.Abbildung10.1)
j vec[j].key i=1 2 3 4 5 6 7
0 63 12 12 12 12 12 12 121 24 63 18 18 18 18 18 182 12 24 63 24 24 24 24 243 53 18 24 63 35 35 35 354 72 53 35 35 63 44 44 445 18 72 53 44 44 63 53 536 44 35 72 53 53 53 63 637 35 44 44 72 72 72 72 72
Abbildung 10.1: Phasen bei Bubblesort.
Informell lasst sich Bubblesort wie folgt beschreiben:
1. Gegeben istvec[] mit n Komponenten.
2. Das Arrayvec wird n−1 mal von hinten nach vorn durchlaufen. Ein Durchlauf heißtPhase.
3. Phasei lauft von Komponentej = n− 1 bis j = i und vergleicht jeweilsvec[j].key mitvec[j-1].key. Ist vec[j-1].key > vec[j].key so werdenvec[j-1] und vec[j] ge-tauscht.
Die Korrektheitdes Algorithmus ergibt sich direkt aus folgenderSchleifeninvarianten, die nach jederPhase gilt:
Am Ende der Phasei ist vec[i-1].key der i-kleinste Schlussel invec und es gilt:vec[0].key ≤ vec[1].key ≤ . . . ≤ vec[i-1].key ≤ vec[j].key fur j = i, i +1, . . . ,n−1.
(10.1)
Dies ist klar fur die 1. Phase. Nimmt man die Richtigkeit fur Phasei an (Induktionsvoraussetzung), sofindet Phasei +1 das kleinste Element invec[i]...vec[n-1] und bringt es durch ggf. fortgesetzteAustauschoperationen an die Positioni. Also gilt die Invariante auch nach Phasei (Induktionsschluss).Fur i = n−1 folgt sofort die Korrektheit des Algorithmus.

10.1. DIREKTE METHODEN 251
Dies resultiert in die folgende Java Methode.
/*** Sorts with bubblesort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void bubbleSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();
int n = vec.length;Item temp;int bottom; // bottom for each passfor (bottom = 1; bottom < n; bottom++)
for (int i = n-1; i >= bottom; i--) if (vec[i-1].key > vec[i].key)
temp = vec[i-1];vec[i-1] = vec[i];vec[i] = temp;
Wir berechnen nun den Worst Case Aufwand von Bubblesort nach derAnzahl der Vergleiche. Dazubetrachten wir die Vergleiche pro Phase. Sein die Anzahl der Komponenten des Arrays.
Phase 1 : n−1 VergleichePhase 2 : n−2 Vergleiche
. . .Phasei : n− i Vergleiche
. . .Phasen−1 : 1 Vergleich
Also gilt fur die AnzahlC(n) der Vergleiche bein Komponenten
C(n) = 1+2+ . . .+(n−2)+(n−1) =n−1
∑i=1
i =n(n−1)
2.
Folglich istC(n) ∈O(n2). Da die Vergleiche unabhangig von der Eingabe durchgefuhrt werden (auchbei einem bereits sortierten Array) gilt:C(n) = n(n−1)
2 ≥ n2
3 fur n≥ 3, alsoC(n) ∈ Ω(n2) und damitC(n) ∈ Θ(n2).

252 KAPITEL 10. SORTIEREN IN ARRAYS
Offensichtlich kann dieser Algorithmus verbessert werden, wenn man sich merkt, ob in einer Phaseuberhaupt ein Austausch stattgefunden hat. Findet kein Austausch statt, so ist das Array sortiert undman kann abbrechen.
Eine weitere Verbesserung besteht darin, sich in einer Phase die Position (Index)k des letzten Austau-sches zu merken. In den darauf folgenden Phasen mussenvec[0]...vec[k] nicht mehruberpruftwerden.
Schließlich kann man noch die Phasen abwechselnd von hinten nach vorn und von vorn nach hintenlaufen lassen (Shakersort), um Asymmetrie zwischen “leichten” Elementen (gehen gleich ganz nachoben) und “schweren” Elementen (sinken jeweils nur um eine Position ab) zu durchbrechen.
Diese Verbesserungen bewirken aber nur eine Verringerung der mittleren Anzahl der Vergleiche. Furden Worst Case lassen sich stets (Ubung) Beispiele finden, dieC(n) = n(n−1)
2 Vergleiche benotigen.Es gilt also:
Satz 10.1Bubblesort erfordertΘ(n2) Vergleiche im Worst Case.
Neben der AnzahlC(n) der Vergleiche ist fur die Laufzeit auch dieAnzahl A(n) der Zuweisungen(As-signments) von Arraykomponenten von großer Bedeutung, da sie außer den Schlusseln noch weitere(ggf. große) Datenmengen enthalten.
Offenbar kann jeder Vergleich einen Austausch und damit 3 Zuweisungen verursachen. Es gilt alsoA(n)≤ 3·C(n). Beispiele zeigen, dassA(n) = 3·C(n) vorkommt. Also folgt:
Satz 10.2Bubblesort erfordertΘ(n2) Zuweisungen im Worst Case.
10.1.2 Sortieren durch direktes Auswahlen: Selection Sort
Wir geben zunachst eine informelle Beschreibung:
1. Gegeben istvec[] mit n Komponenten.
2. Das Arrayvec wird n−1 mal von vorn nach hinten durchlaufen. Ein Durchlauf heißtPhase(pass).
3. Phasebottom sucht den IndexminIndx einer Komponente mit kleinstem Schlusselwert imBereich
vec[bottom], vec[bottom+1],...,vec[n-1],
mittels sequentieller Suche, und tauscht diese Komponente an die Stellebottom. Es werdenalsovec[bottom] undvec[minIndx] vertauscht.
Die Korrektheit basiert hier auf derselben Invarianten wie bei Bubblesort. Es folgt eine Java Methode:

10.1. DIREKTE METHODEN 253
/*** Sorts with selectionsort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void selectionSort(Item vec[])
throws NullPointerException if (vec == null) throw new NullPointerException();
int minIndx; // Index of smallest key in each passint bottom; // bottom for each passint i;Item temp;int n = vec.length;
for (bottom = 0; bottom < n-1; bottom++) // INVARIANT (prior to test):// All vec[bottom+1..n-1] are >= vec[bottom]// && vec[0..bottom] are in ascending order// && bottom >= 0
minIndx = bottom;for (i = bottom+1; i < n; i++)
// INVARIANT (prior to test):// vec[minIndx] <= all// vec[0..i-1]// && i >= bottom+1
if (vec[i].key < vec[minIndx].key) minIndx = i;
temp = vec[bottom];vec[bottom] = vec[minIndx];vec[minIndx] = temp;
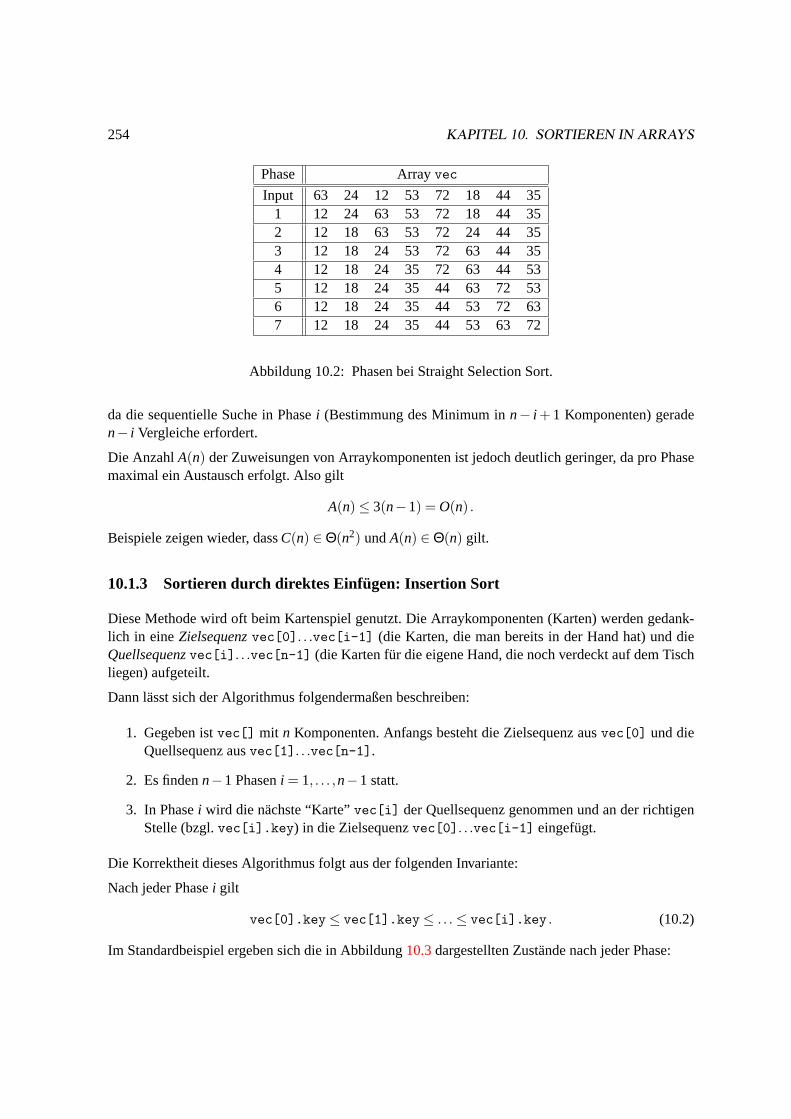
Fur das Beispiel aus Abbildung10.1ergeben sich die in Abbildung10.2dargestellten Zustande nachden einzelnen Phasen
Fur die AnzahlC(n) der Vergleiche ergibt sich analog zu Bubblesort:
C(n) =n−1
∑i=1
(n− i) =n(n−1)
2,
254 KAPITEL 10. SORTIEREN IN ARRAYS
Phase Array vec
Input 63 24 12 53 72 18 44 351 12 24 63 53 72 18 44 352 12 18 63 53 72 24 44 353 12 18 24 53 72 63 44 354 12 18 24 35 72 63 44 535 12 18 24 35 44 63 72 536 12 18 24 35 44 53 72 637 12 18 24 35 44 53 63 72
Abbildung 10.2: Phasen bei Straight Selection Sort.
da die sequentielle Suche in Phasei (Bestimmung des Minimum inn− i + 1 Komponenten) geraden− i Vergleiche erfordert.
Die AnzahlA(n) der Zuweisungen von Arraykomponenten ist jedoch deutlich geringer, da pro Phasemaximal ein Austausch erfolgt. Also gilt
A(n)≤ 3(n−1) = O(n) .
Beispiele zeigen wieder, dassC(n) ∈ Θ(n2) undA(n) ∈ Θ(n) gilt.
10.1.3 Sortieren durch direktes Einfugen: Insertion Sort
Diese Methode wird oft beim Kartenspiel genutzt. Die Arraykomponenten (Karten) werden gedank-lich in eineZielsequenzvec[0]. . .vec[i-1] (die Karten, die man bereits in der Hand hat) und dieQuellsequenzvec[i]. . .vec[n-1] (die Karten fur die eigene Hand, die noch verdeckt auf dem Tischliegen) aufgeteilt.
Dann lasst sich der Algorithmus folgendermaßen beschreiben:
1. Gegeben istvec[] mit n Komponenten. Anfangs besteht die Zielsequenz ausvec[0] und dieQuellsequenz ausvec[1]. . .vec[n-1].
2. Es findenn−1 Phaseni = 1, . . . ,n−1 statt.
3. In Phasei wird die nachste “Karte”vec[i] der Quellsequenz genommen und an der richtigenStelle (bzgl.vec[i].key) in die Zielsequenzvec[0]. . .vec[i-1] eingefugt.
Die Korrektheit dieses Algorithmus folgt aus der folgenden Invariante:
Nach jeder Phasei gilt
vec[0].key≤ vec[1].key≤ . . .≤ vec[i].key . (10.2)
Im Standardbeispiel ergeben sich die in Abbildung10.3dargestellten Zustande nach jeder Phase:

10.1. DIREKTE METHODEN 255
Phase Array vec
Input 63 24 12 53 72 18 44 351 24 63 12 53 72 18 44 352 12 24 63 53 72 18 44 353 12 24 53 63 72 18 44 354 12 24 53 63 72 18 44 355 12 18 24 53 63 72 44 356 12 18 24 44 53 63 72 357 12 18 24 35 44 53 63 72
Abbildung 10.3: Phasen bei Insertion Sort.
Die Anzahl der Vergleiche hangt davon ab, wie das Einfugen in die Zielsequenz durchgefuhrt wird.Beisequentieller Sucheder Stelle (von links nach rechts) ergeben sich im Worst Case folgende Zahlen:
Phase 1 : 1 VergleichPhase 2 : 2 Vergleiche
. . .Phasen−1 : n−1 Vergleiche
In diesem Fall ist wiederumC(n) = n(n−1)2 ∈ O(n2).
Da die Zielsequenz bereits aufsteigend sortiert ist, lasst sich statt der sequentiellen Suche diebinareSucheverwenden. Phasei erfordert dann (Zieldatei enthalt i Elemente) gemaß Satz6.1 hochstensblogic+1 Vergleiche. Also gilt dann:
C(n) ≤n−1
∑i=1
(blogic+1)
≤n−1
∑i=1
(log(n−1)+1) = (n−1)(log(n−1)+1)
= (n−1) log(n−1)+(n−1) = O(nlogn)
Bezuglich der ZahlA(n) der Zuweisungen von Arraykomponenten ist in beiden Varianten (sequentiel-le oder binare Suche) eine Verschiebung der Komponenten der Quelldatei rechts von der Einfugestellek um jeweils eine Stelle erforderlich, im schlimmsten Fall(k = 0) also i Verschiebungen in Phasei.Dies lasst sich miti +1 Zuweisungen realisieren:
temp = vec[i];for (j = i-1; j >= 0; j++) vec[j+1] = vec[j];vec[0] = temp;
Also ist
A(n) ≤n−1
∑i=1
(i +1) =n
∑i=2
i = (n
∑i=1
i)−1
= n(n+1)2 −1∈ O(n2) .

256 KAPITEL 10. SORTIEREN IN ARRAYS
Das Beispiel des absteigend sortierten Arrays zeigt, dass dieser Fall auch eintritt, alsoA(n) ∈ Ω(n2)gilt.
Straight Insertion (mit binarer Suche) ist also bezuglich der Anzahl der Vergleiche sehr gut(O(nlogn)),aber bezuglich der Anzahl der Zuweisungen schlecht(Ω(n2)).
Die hier vorgestellten direkten Methoden sind mit ihrer Worst Case Laufzeit vonΘ(n2) als sehr auf-wendig einzustufen. Wir werden im Rest des Kapitels drei “intelligentere” Sortiermethoden kennenlernen, die im Mittel, und teilweise auch im Worst Case, mitO(nlogn) Vergleichen und Zuweisungenauskommen.
10.2 Mergesort
Mergesort teilt das zu sortierende Array in zwei gleichgroße Teilfolgen (Unterschied hochstens eineKomponente), sortiert diese (durch rekursive Anwendung von Mergesort auf die beiden Teile) undmischtdie dann sortierten Teile zusammen.
10.2.1 Mischen sortierter Arrays
Wir betrachten daher zunachst dasMischenvon zwei bereits sortierten Arrays. Seien dazuvec1[]undvec2[] bereits sortierte Arrays der Langembzw.n mit Komponenten vom TypItem. Diese sindin das Arrayvec[] der Langem+n zu verschmelzen.
Dazu durchlaufen wirvec1 undvec2 von links nach rechts mit zwei Indexzeigerni undj wie folgt:
1. Initialisierung:i = 0; j = 0; k= 0;
2. Wiederhole Schritt 3 bisi = m oderj = n.
3. Falls vec1[i].key < vec2[j].key, so kopierevec1[i] an die Positionk von vec underhohei undk um 1.
Andernfalls kopierevec2[j] an die Positionk vonvec und erhohej undk um 1.
4. Ist i = m undj < n, soubertrage die restlichen Komponenten vonvec2 nachvec.
5. Ist j = n undi < m, soubertrage die restlichen Komponenten vonvec1 nachvec.
Bei jedem Wiedereintritt in die Schleife 3 gilt die Invariante
vec[0].key ≤ . . .≤ vec[k-1].keyvec[k-1].key ≤ vec1[i].key ≤ . . .≤ vec1[m-1].keyvec[k-1].key ≤ vec2[j].key ≤ . . .≤ vec2[n-1].key
(10.3)
Hieraus folgt sofort, dassvec am Ende aufsteigend sortiert ist.
Als Beispiel betrachten wir die Arrays:

10.2. MERGESORT 257
vec1: 12 24 53 63 vec2: 18 35 44 72
Die dazugehorige Folge der Werte voni,j,k undvec bei jedem Wiedereintritt in die Schleife 3 istin Abbildung10.4angegeben. Am Ende dieser Schleife isti = 4 und Schritt 4 des Algorithmus wirdausgefuhrt, d. h. der “Rest” vonvec2, also die 72, wird nachvec ubertragen.
i j k vec
1 0 1 12 - - - - - - -1 1 2 12 18 - - - - - -2 1 3 12 18 24 - - - - -2 2 4 12 18 24 35 - - - -2 3 5 12 18 24 35 44 - - -3 3 6 12 18 24 35 44 53 - -4 3 7 12 18 24 35 44 53 63 -
Abbildung 10.4: Phasen bei Merge.
SeiC(m,n) die maximale Anzahl von Schlusselvergleichen undA(m,n) die maximale Anzahl vonZuweisungen von Komponenten beim Mischen.
Vergleiche treten nur in der Schleife 3 auf, und zwar genau einer pro Durchlauf. Da die Schleifemaximalm+n−1 mal durchlaufen wird, gilt
C(m,n)≤ m+n−1.
Zuweisungen treten genaun+mmal auf, da jede Komponente vonvec einen Wert bekommt. Also ist
A(m,n) = m+n.
Wir geben nun eine Java Methode fur dieses Verfahren an, und zwar in der (spater benotigten) Version,dass zwei benachbarte, bereits sortierte Teilbereiche eines Arraysvec gemischt werden und dann indemselbenBereich vonvec aufsteigend sortiert gemischt stehen.
Wir verlangen also folgendes Input/Output Verhalten:
Input: vec
6
left6
middle6
right
mit den sortierten Bereichenvec[left]. . .vec[middle] undvec[middle+1]. . .vec[right].
Output: vec
6
left6
right
mit dem aufsteigend sortierten Bereichvec[left]. . .vec[right].
Dazu werden zunachst die beiden sortierten Bereiche auf lokale Arraysvec1 undvec2 kopiert, diedann in den entsprechenden Bereich vonvec zuruckgemischt werden.

258 KAPITEL 10. SORTIEREN IN ARRAYS
Programm 10.1 merge/*** merges two sorted adjacent ranges of an array* @param vec the array in which this happens* @param left start of the first range* @param middle end of the first range* @param right end of the second range*/private static void merge(Item[] vec, int left, int middle, int right)
int i, j;int m = middle - left + 1; // length of first array regionint n = right - middle; // length of second array region
// make copies of array regions to be merged// (only the references to the items)Item[] copy1 = new Item[m];Item[] copy2 = new Item[n];for (i = 0; i < m; i++) copy1[i] = vec[left + i];for (j = 0; j < n; j++) copy2[j] = vec[middle + 1 + j];
i = 0; j = 0;// merge copy1 and copy2 into vec[left...right]while (i < m && j < n)
if (copy1[i].key < copy2[j].key) vec[left+i+j] = copy1[i];i++;
else vec[left+i+j] = copy2[j];j++;
//endif//endwhileif (j == n) // second array region is completely handled,
// so copy rest of first regionwhile (i < m)
vec[left+i+j] = copy1[i];i++;
// if (i == m) do nothing,// rest of second region is already in place

10.2. MERGESORT 259
10.2.2 Sortieren durch rekursives Mischen: Mergesort
Mit dieser Methodemerge() ergibt sich dann sehr einfach folgende rekursive Variante von Mergesort.
Programm 10.2 mergeSort/*** Sorts with mergesort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void mergeSort(Item vec[])
throws NullPointerException if (vec == null) throw new NullPointerException();mergeSort(vec, 0, vec.length - 1);
/*** sorts array by mergesort in a certain range* @param <code>vec</code> the array in which this happens* @param <code>first</code> start of the range* @param <code>last</code> end of the range*/private static void mergeSort(Item[] vec, int first, int last)
if (first == last) return;// devide vec into 2 equal partsint middle = (first + last) / 2;mergeSort(vec, first, middle); // sort the first partmergeSort(vec, middle+1, last); // sort the second partmerge(vec, first, middle, last); // merge the 2 sorted parts
Die public MethodemergeSort(Item[]) bekommt nur das Arrayubergeben und ruft dieprivateMethodemergeSort(Item[], int, int) in den Grenzen0 undvec.length-1 des Arraysvecauf.
Die Korrektheit vonmergeSort(Item[], int, int) ergibt sich sofort durch vollstandige Indukti-on nach der Anzahln = last - first + 1 der zu sortierenden Komponenten.
Ist n= 1, alsolast=first (Induktionsanfang), so wird im Rumpf vonmergeSort() nichts gemachtund das Arrayvec ist nach Abarbeitung vonmergeSort() trivialerweise im Bereichfirst. . .lastsortiert.
Ist n > 1, so sindfirst. . .middle und middle+1. . .last Bereiche mit weniger alsn Elementen,die also nach Induktionsvoraussetzung durch die AufrufemergeSort(vec, first, middle) und

260 KAPITEL 10. SORTIEREN IN ARRAYS
mergeSort(vec, middle+1, last) korrekt sortiert werden. Die Korrektheit vonmerge() ergibtdann die Korrektheit von mergeSort.
Fur das Standardbeispiel
a 63 24 12 53 72 18 44 35
ergibt der AufrufmergeSort(a,0,7) dann den in Abbildung10.5dargestellten Ablauf. Dabei be-schreiben die Einrucktiefe die Aufrufhierarchie (Rekursionsbaum), und die Kasten die bereits sortier-ten Teile des Arrays.
mergeSort(a,0,7) 63 24 12 53 72 18 44 35mergeSort(a,0,3) 63 24 12 53 72 18 44 35mergeSort(a,0,1) 63 24 12 53 72 18 44 35mergeSort(a,0,0) 63 24 12 53 72 18 44 35mergeSort(a,1,1) 63 24 12 53 72 18 44 35merge(a,0,0,1) 24 63 12 53 72 18 44 35
mergeSort(a,2,3) 24 63 12 53 72 18 44 35mergeSort(a,2,2) 24 63 12 53 72 18 44 35mergeSort(a,3,3) 24 63 12 53 72 18 44 35merge(a,2,2,3) 24 63 12 53 72 18 44 35
merge(a,0,1,3) 12 24 53 63 72 18 44 35mergeSort(a,4,7) 12 24 53 63 72 18 44 35mergeSort(a,4,5) 12 24 53 63 72 18 44 35mergeSort(a,4,4) 12 24 53 63 72 18 44 35mergeSort(a,5,5) 12 24 53 63 72 18 44 35merge(a,4,4,5) 12 24 53 63 18 72 44 35
mergeSort(a,6,7) 12 24 53 63 18 72 44 35mergeSort(a,6,6) 12 24 53 63 18 72 44 35mergeSort(a,7,7) 12 24 53 63 18 72 44 35merge(a,6,6,7) 12 24 53 63 18 72 35 44
merge(a,4,5,7) 12 24 53 63 18 35 44 72merge(a,0,3,7) 12 18 24 35 44 53 63 72
Abbildung 10.5: Die Rekursion beimergeSort().
10.2.3 Die Analyse von Mergesort
Wir ermitteln nun den Worst Case AufwandC(n) fur die Anzahl der Vergleiche undA(n) fur dieAnzahl der Zuweisungen vonmergeSort() beim Sortieren eines Arrays mitn Komponenten.

10.2. MERGESORT 261
Aus dem rekursiven Aufbau des Algorithmus ergeben sich sofort die folgenden Rekursionsgleichun-gen fur C(n).
C(2) = 1 C(2n) = 2·C(n)+C(n,n) fur n > 1
In Worten: Das Sortieren eines 2-elementigen Arrays erfordert einen Vergleich. Das Sortieren einesArrays der Lange 2n erfordert den Aufwand fur das Sortieren von 2 Arrays der Langen (rekursiveAufrufe von mergeSort() fur die beiden Teile), also 2·C(n), plus den AufwandC(n,n) fur dasMischen (Aufruf vonmerge()).
DaC(n,n) = 2n−1, ist also
C(2) = 1 C(2n) = 2·C(n)+2n−1 fur n > 1. (10.4)
Um diese Rekursionsgleichung zu losen, betrachten wir zunachst den Fall, dassn eine Zweierpotenzist, etwan = 2q. Dann istn genauq mal durch 2 ohne Rest teilbar und wir erhalten durch mehrfacheAnwendung der Rekursionsgleichung
C(n) = 2·C(n2)+2· n
2−1
= 2·C(n2)+n−1 1 mal angewendet
= 2(
2·C(n4)+2· n
4−1)
+n−1
= 4·C(n4)+2n−3 2 mal angewendet
= 4(
2·C(n8)+2· n
8−1)
+2n−3
= 8·C(n8)+3n−7 3 mal angewendet
. . . (insgesamtq−1 mal anwenden)
= 2q−1 ·C(2)+(q−1)n− (2q−1−1)
Wegenn = 2q undC(2) = 1 folgt hieraus
C(2q) = (q−1)2q +1.
Wir verifizieren diese eher intuitive Vorgehensweise durch einen formalen Beweis mit vollstandigerInduktion.2
Lemma 10.1 Ist n= 2q, so hat die Rekursionsgleichung10.4die Losung C(2q) = (q−1)2q +1.
Beweis: Der Beweis erfolgt durch vollstandige Induktion nachq. Ist q = 1, so istC(21) = 1 und(q− 1)2q + 1 = 1 (Induktionsanfang). Also sei die Behauptung richtig fur 2r mit 1 ≤ r ≤ q. Wir
2Eine Alternative ist die Verifikation durchEinsetzender “vermuteten” FormelC(2q) = (q−1)2q+1 in die Rekursions-gleichung und Nachrechnen der Gleichung. Dies fuhrt auf die gleichen Beweisschritte.

262 KAPITEL 10. SORTIEREN IN ARRAYS
schließen jetzt aufq+1:
C(2q+1) = 2·C(2q)+2·2q−1 Rekursionsgleichung
= 2· [(q−1)2q +1]+2·2q−1 Induktionsvoraussetzung
= (q−1)2q+1 +2+qq+1−1
= q·2q+1 +1,
was zu zeigen war.
Bezuglich der AnzahlA(n) der Zuweisungen von Arraykomponenten ergibt sich ganz analog:
A(2n) = 2·A(n)+ Zuweisungen inmerge()
In merge() werden zunachst die Teile vonvec nachvec1 undvec2 kopiert. Dies erfordert 2n Zu-weisungen. Fur das Mergen sind dann wiederA(n,n) = 2n Zuweisungen erforderlich. Also ergibt sichfolgende Rekursionsgleichung:
A(2) = 4 A(2n) = 2·A(n)+4·n fur n > 1 (10.5)
Der gleiche Losungsansatz liefert fur n = 2q
A(n) = 2q2q .
Wir betrachten nun den Fall, dassn keine Zweierpotenz ist. Dann unterscheiden sich die jeweiligenTeilarrays um maximal 1, vgl. Abbildung10.6.
0 1 2 3 4 5
@@
0 1 2
@@
3 4 5
@@
0 1
@@
3 4
@@
2 5
0 1 3 4
Abbildung 10.6: Rekursionsbaum vonmergeSort() fur n = 6.
Dies fuhrt dazu, dass im zugehorigen Rekursionsbaum nicht alle Zweige bis auf die unterste Ebenereichen. Vervollstandigt man (gedanklich) den Rekursionsbaum bis auf die unterste Ebene, so wurde

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 263
dies dem Rekursionsbaum fur ein Array der Langen′ entsprechen, wobein′ die nachstgroßere Zwei-erpotenz nachn ist, alson′ = min2r | 2r ≥ n, r = 1,2, . . ..
Sei 2q dieses Minimum. Dann ist 2q−1 < n≤ 2q = n′, alson′ = 2·2q−1 < 2n sowieq−1 < logn≤ q.Also ist (wegen der Vervollstandigung):
C(n) ≤ C(n′) = C(2q) = (q−1)2q +1
< (logn) ·n′+1 < (logn) ·2n+1
= 2nlogn+1 = O(nlogn) .
Entsprechend folgt
A(n) ≤ A(n′) = A(2q) = (q+1)2q
< (logn+2)n′ < (logn+2)2n
= 2nlogn+4n = O(nlogn) .
Wir erhalten also
Satz 10.3mergeSort() sortiert ein Array mit n Komponenten mit O(nlogn) Vergleichen und Zu-weisungen.
Betrachten wir zum Abschluss noch den Rekursionsaufwand und die Rekursionstiefe. Fur n = 2q
ist die Rekursionstiefe geradeq = logn, fur beliebigen ergibt sich aus der soeben durchgefuhrtenVervollstandigungsuberlegung
logn′ < log(2n) = logn+1
als Schranke fur die Rekursionstiefe.
Die Anzahl der rekursiven Aufrufe ergibt sich als Summe entlang der Schichten des Rekursionsbaumszu
q
∑i=0
2i = 2q+1−1 = 2n′−1 < 4n−1 = O(n) .
Rekursionsaufwand und Rekursionstiefe halten sich also in vernunftigen Grenzen.
10.3 Beschleunigung durch Aufteilung: Divide and Conquer
Mergesort ist ein typisches Beispiel fur die sogenannte”Beschleunigung durch Aufteilung“. Dieses
Prinzip tritt oft bei der Konzeption von Algorithmen auf. Daher hat man Interesse an einer allgemeinenAussageuber die Laufzeit in solchen Situationen.
10.3.1 Aufteilungs-Beschleunigungs-Satze
Gegeben ist ein Problem der Großea·n mit der Laufzeitf (a·n). Dieses zerlegt man inb Teilproblemeder Großen mit Laufzeit f (n) pro Teilproblem, alsob · f (n) fur alle Teilprobleme zusammen. Ist die

264 KAPITEL 10. SORTIEREN IN ARRAYS
Laufzeit fur das Aufteilen und das Zusammenfugen der Teillosungen durchc ·n beschrankt, so ergibtsich die folgende Rekursionsgleichung und der
Satz 10.4 (Aufteilungs-Beschleunigungs-Satz)Seien a> 0, b, c naturliche Zahlen und sei folgendeRekursionsgleichung gegeben:
f (1) ≤ ca
f (a·n) ≤ b· f (n)+c·n fur n > 1
Dann gilt:
f (n) ∈
O(n) , falls a> bO(n· log2n) , falls a= bO(nloga b) , falls a< b
Beweis:: Fur n = aq gilt
f (n)≤ ca
nq
∑i=0
(ba
)i
Dies zeigt man durch Induktionuberq. Fur q = 0 ist die Summe 1 und daherf (1)≤ ca.
Die Behauptung sei nun fur q gezeigt. Dann ergibt sich im Induktionsschluss aufq+1:
f (aq+1) = f (a·aq)≤ b· f (aq)+c·aq (Rekursionsformel)
= b· ca·aq
q
∑i=0
(ba
)i
+c·aq (Induktionsvoraussetzung)
=ca
aq+1ba
q
∑i=0
(ba
)i
+ca·aq+1
=ca
aq+1q
∑i=0
(ba
)i+1
+ca
aq+1
=ca
aq+1
(q+1
∑i=1
(ba
)i
+1
)
=ca
aq+1q+1
∑i=0
(ba
)i
.
Also ist
f (n)≤ ca
nloga n
∑i=0
(ba
)i
.
Wir betrachten jetzt 3 Falle:

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 265
1. a > b: Dann istba < 1 und daher
loga n
∑i=0
(ba
)i
<∞
∑i=0
(ba
)i
=a
a−b,
da die geometrische Reihe∑∞i=0
(ba
)iwegenb
a < 1 gegenk1 := 11− b
a= a
a−b konvergiert. Also ist
f (n) <c·k1
an ⇒ f (n) ∈ O(n) .
2. a = b: Dann ist
f (n)≤ ca
nloga n
∑i=0
1 =ca
n(logan+1) =ca
nlogan+ca
n.
Fur n≥ a ist logan≥ 1 und daher
f (n) ≤ ca
nlogan+ca
nlogan =2ca
nlogan
= (2ca· loga2) ·nlog2n∈ O(nlog2n) .
3. a < b: Dann ist
f (n) ≤ ca·n
loga n
∑i=0
(ba
)i
=ca
aqq
∑i=0
(ba
)i
dan = aq
=ca
q
∑i=0
biaq−i =ca
q
∑i=0
bq−iai
=ca
bqq
∑i=0
(ab
)i<
ca
bq∞
∑i=0
(ab
)i.
∑∞i=0
(ab
)iist wie in Fall 1 eine geometrische Reihe mit Wertk2 = b
b−a. Also ist
f (n) <ck2
abq =
ck2
abloga n =
c·k2
anloga b ∈ O(nlogab) .
Hier wurde ausgenutzt, dassbloga n = (aloga b)loga n = (aloga n)loga b = nloga b.
Die Verallgemeinerung vonn = aq auf beliebigen folgt analog zu der Verallgemeinerung auf beliebi-gen bei Mergesort.
Offenbar ist der Fall 2 gerade der auf Mergesort zutreffende Fall.
Der Aufteilungs-Beschleunigungssatz wurde hier nur in einer speziellen Form bewiesen, um den Be-weis einfacher zu halten. Wir geben nachstehend eine allgemeinere Version an und verweisen fur denBeweis auf [CLRS01].

266 KAPITEL 10. SORTIEREN IN ARRAYS
Satz 10.5 (Aufteilungs-Beschleunigungs-Satz, Allgemeine Version)Seien a> 0und b> 0naturlicheZahlen und sei die folgende Rekursionsgleichung gegeben:
f (a·n) = b· f (n)+g(n) .
Dann hat f(n) folgendes asymptotisches Wachstum:
1. Ist g(n) = O(nloga b−ε) fur eine Konstanteε > 0, so ist f(n) = Θ(nloga b).
2. Ist g(n) = Θ(nloga b), so ist f(n) = Θ(nloga b · logn)
3. Ist g(n) = Ω(nloga b+ε) fur eine Konstanteε > 0, und ist b·g(na) ≤ c ·g(n) fur eine Konstante
c < 1 und alle n≥ n0 (c,n0 geeignet gewahlt), so ist f(n) = Θ(g(n)).
Die Unterscheidung erfolgt hier also nach dem Wachstum vong(n) im Verhaltnis zunloga b. Ist g(n)deutlich kleinerals nloga b (Fall 1), so bestimmtnloga b das Wachstum vonf (n). Hat g(n) dasselbeWachstum wienloga b (Fall 2), so kommt im Wachstum vonf (n) ein logn Faktor dazu. Ist schließlichg(n) deutlich großerals nloga b und gilt die zusatzliche
”Regularitatsbedingung“ aus 3., so bestimmt
g(n) allein die Großenordnung vonf (n).
Deutlich kleinerbzw.deutlich großerbedeutet dabei jeweils mindestens um einen polynomialen Fak-tor nε .
Beispiel 10.1
1. f (3n) = 9 f (n)+n
Hier ergibt sich aus der einfachen Version des Satzes (Fall 3)f (n) = O(nlog3 9) = O(n2). Inder allgemeinen Version trifft Fall 1 zu, dag(n) ∈ O(nloga b−1) (also ε = 1), und man erhaltf (n) = Θ(nloga b) = Θ(n2).
2. f (32n) = f (n)+1
Hier ist g(n) = 1 undnlog3/2 1 = n0 = 1. Also trifft Fall 2 der allgemeinen Version zu, und manerhalt f (n) = Θ(logn).
3. f (4n) = 3 f (n)+nlogn
Hier istg(n) = nlogn undnloga b = nlog4 3 = O(n0,793). Also istg(n) = Ω(nloga b+ε) mit ε = 0,2.Es wurde also Fall 3. zutreffen, falls wir die Regularitatsbedingung fur g(n) zeigen konnen. Esist b · f (n
a) = 3 ·(
n4
)· log
(n4
)< 3
4nlogn, so dass die Regularitatsbedingung mitc = 34 gilt. Also
folgt f (n) = Θ(nlogn).
4. f (2n) = 2 f (n)+nlogn
Diese Rekursionsgleichung fallt nicht unter das allgemeine Schema, dag(n) = nlogn zwarasymptotisch großer alsnloga b = n ist, aber nicht um einen Faktornε . Dieser Fall fallt also indie
”Lucke“ zwischen Fall 2. und 3.

10.3. BESCHLEUNIGUNG DURCH AUFTEILUNG: DIVIDE AND CONQUER 267
10.3.2 Multiplikation von Dualzahlen
Als weitere Anwendung betrachten wir dieMultiplikation von zwei n-stelligen Dualzahlen. Die tra-ditionelle Methode erfordertΘ(n2) Bit Operationen. Durch Aufteilung und Beschleunigung erreichtmanO(nlog3) = O(n1,59) Operationen. Dies ist nutzlich bei der Implementation der Multiplikationbeliebig langer Dualzahlen, z. B. in Programmpaketen, die mit den Standardlong oderint Zahlennicht auskommen.
Seienx,y zwein-stellige Dualzahlen, wobein eine Zweierpotenz sei. Wir teilenx,y in zwei n2-stellige
Zahlen wie folgt:
x = a b
y = c d
Dann ist
xy = (a2n2 +b)(c2
n2 +d)
= ac2n +(ad+bc)2n2 +bd.
Man hat die Multiplikation also auf 4 Multiplikationen vonn2-stelligen Zahlen und einige Additionenund Shifts (Multiplikationen mit 2
n2 bzw. 2n), die nur linearen Aufwand erfordern) zuruckgefuhrt.
Dies fuhrt zur Rekursionsgleichung
T(n) = 4·T(n2)+c0 ·n,
mit der LosungT(n) = Θ(n2), also ohne Gewinn gegenuber der traditionellen Methode.
Die Anweisungen
u := (a+b)(c+d)v := ac
w := bd
z := v2n +(u−v−w)2n2 +w
fuhren jedoch zur Berechnung vonz= xymit 3 Multiplikation von Zahlen der Langen2 bzw. n
2 +1, dabeia+b bzw.c+d ein Ubertrag auf die
(n2 +1
)-te Position entstehen konnte.
Ignorieren wir diesenUbertrag, so erhalt man
T(n) = 3T(n
2
)+c1n
mit der gewunschten LosungT(n) = Θ(nlog2 3).
Um denUbertrag zu berucksichtigen, schreiben wira+b undc+d in der Form
a+b = α a
c+d = γ c

268 KAPITEL 10. SORTIEREN IN ARRAYS
alsoa+b = α2n2 + a, c+d = γ2
n2 + c mit den fuhrenden Bitsα,γ und denn
2-stelligen Resten ¯a, c.
Dann ist(a+b)(c+d) = αγ2n +(αa+ γ c)2
n2 + ac.
Hierin tritt nureinProdukt vonn2-stelligen Zahlen auf (namlichac). Der Rest sind Shifts bzw. lineare
Operationen aufn2-stelligen Zahlen (z. B.αa).
Daher erhalt man insgesamt die Rekursionsgleichung
T(n) = 3T(n
2
)+c2n,
wobeic2n folgenden Aufwand enthalt:
– Additionena+b, c+d : 2· n2
– Produktαγ : 1– Shift vonαγ auf αγ2n : n– Produkteαa,γ c: 2· n
2– Addition αa+ γ c: n
2 +1– Shift vonαa,γ c um n
2 Stellen: n2
– Shift vonv aufv2n: n– Additionu−v−w: 2(n
2 +1)– Shift vonu−v−w um n
2 Stellen: n2
– Addition zuz: 2n
Dieser Aufwand addiert sich zu 8,5 n+ 2≤ 9n fur n≥ 2. Also kannc2 als 9 angenommen werden.Als Losung erhalt man nach dem Aufteilung-Beschleunigungs-Satz
T(n) = Θ(nlog3) = Θ(n1,59) .
Der “Trick” bestand also darin, auf Kosten zusatzlicher Additionen und Shifts, eine “teure” Multipli-kation von n
2-stelligen Zahlen einzusparen. Die rekursive Anwendung dieses Tricks ergibt dann dieBeschleunigung vonΘ(n2) aufΘ(n1,59). Fur die normale Computerarithmetik (n= 32) zahlt sich die-ser Trick nicht aus, jedoch bedeutet er fur Computerarithmetiken mit beliebigstelligen Dualzahlen,die meist softwaremaßig realisiert werden, eine wichtige Beschleunigung.
Das Verfahren lasst sich naturlich auch im Dezimalsystem anwenden. Wir geben ein Beispiel furn = 4:
x = 4217 y = 5236
Dann ist
a = 42, b = 17 unda+b = 59;
c = 52, d = 36 undc+d = 88.

10.4. QUICKSORT 269
Es folgt
u = (a+b)(c+d) = 59·88= 5192
v = ac= 42·52= 2184
w = bd = 17·36= 612
xy = v·104 +(u−v−w) ·102 +w
= 2184·104 +2396·102 +612
= 21.840.000+239.600+612
= 22.080.212
Auf ahnliche Weise wie die Multiplikation von Zahlen lasst sich auch die Multiplikation (großer)n×nMatrizen beschleunigen, vgl. [CLRS01] Hier erhalt man die Rekursionsgleichung
T(2n) = 7·T(n)+14n2
mit der Losung (gemaß Satz10.5) Θ(nlog7) = Θ(n2,81), also eine Beschleunigung gegenuber der nor-malen Methode mit dem AufwandΘ(n3). Hier lassen sich noch weitere Beschleunigungen erzielen.Der momentane “Rekord” steht beiO(n2,39), vgl. [CW87].
10.4 Quicksort
Quicksort basiert (im Gegensatz zu Mergesort) aufvariabler Aufteilung des Eingabearrays. Es wurde1962 von Hoare entwickelt. Es benotigt zwar im Worst CaseΩ(n2) Vergleiche, im Mittel jedoch nurO(nlogn) Vergleiche, und ist aufgrund empirischer Vergleiche allen anderenO(nlogn) Sortierverfah-renuberlegen.
10.4.1 Der Algorithmus
Wir geben zunachst eine Grobbeschreibung von Quicksort an.
1. Gegeben istvec[] mit n Komponenten.
2. Wahle eine beliebige Komponentevec[pivot].
3. Zerlege das Arrayvec in zwei Teilbereichevec[0]. . .vec[k-1] undvec[k+1]. . .vec[n-1]mit
a) vec[i].key≤ vec[pivot].key fur i = 0, . . . ,k−1
b) vec[k].key = vec[pivot].key
c) vec[j].key > vec[pivot].key fur j = k+1, . . . ,n−1.
4. Sofern ein Teilbereich aus mehr als einer Komponente besteht, so wende Quicksort rekursiv aufihn an.

270 KAPITEL 10. SORTIEREN IN ARRAYS
Die Korrektheit des Algorithmus folgt leicht durch vollstandige Induktion. Die Aufteilung erzeugtArrays kleinerer Lange, die nach Induktionsvoraussetzung durch die Aufrufe von Quicksort in Schritt4. korrekt sortiert werden. Die Eigenschaften 3a)–3c) ergeben dann die Korrektheit fur das gesamteArray.
Im Standardbeispiel ergibt sich, falls man stets die mittlere Komponente wahlt (gekennzeichnet durch*) die in Abbildung 10.7 dargestellte Folge von Zustanden (jeweils nach der Aufteilung). Die um-rahmten Bereiche geben die aufzuteilenden Bereiche an.
Input 63 24 12 53* 72 18 44 351. Aufteilung 18 24 12* 35 44 53 72* 632. Aufteilung 12 24 18* 35 44 53 63 723. Aufteilung 12 18 24 35* 44 53 63 72Output 12 18 24 35 44 53 63 72
Abbildung 10.7: Phasen bei Quicksort.
Wir betrachten nun die Durchfuhrung der Aufteilung im Detail. Da sie rekursiv auf stets andere Teiledes Arraysvec angewendet wird, betrachten wir einen Bereich vonloBound bishiBound.
Grobbeschreibung der Aufteilung
1. Gegeben istvec und der Bereich zwischenloBound undhiBound.
2. Wahle eine Komponentevec[pivot].
3. Tauschevec[pivot] mit vec[loBound].
4. Setze IndexzeigerloSwap aufloBound+1 undhiSwap aufhiBound.
5. SolangeloSwap < hiSwap wiederhole:
5.1 Inkrementiere ggf.loSwap solange, bisvec[loSwap].key > vec[loBound].key.
5.2 Dekrementiere ggf.hiSwap solange, bisvec[hiSwap].key≤ vec[loBound].key.
5.3 FallsloSwap < hiSwap, so vertauschevec[loSwap] undvec[hiSwap], und inkremen-tiere bzw. dekrementiereloSwap undhiSwap um jeweils 1.
6. Tauschevec[loBound] undvec[hiSwap].
Abbildung 10.8 illustriert diese Aufteilung. und h geben die jeweilige Position vonloSwap undhiSwap an,∗ das gewahltevec[pivot] Element.
Bei jedem Eintritt in die Schleife 5 gilt die Invariante:
vec[i].key≤ vec[pivot].key fur i = loBound . . .loSwap−1,vec[j].key > vec[pivot].key fur j = hiSwap+1 . . .hiBound,loSwap < hiSwap⇒ vec[loSwap-1].key≤ vec[pivot].key≤
≤ vec[hiSwap+1].key.
(10.6)

10.4. QUICKSORT 271
Input 63 24 12 53 72 18 44 35Schritt 2 63 24 12 53* 72 18 44 35Schritt 3 53* 24 12 63 72 18 44 35Schritt 4 53* 24 12 63 72 18 44 35h
Am Ende von 5.1 53* 24 12 63` 72 18 44 35h
Am Ende von 5.2 53* 24 12 63` 72 18 44 35h
Schritt 5.3 53* 24 12 35 72 18 44h 63Am Ende von 5.1 53* 24 12 35 72` 18 44h 63Am Ende von 5.2 53* 24 12 35 72` 18 44h 63Schritt 5.3 53* 24 12 35 44 18`h 72 63Schritt 6 18 24 12 35 44 53* 72 63
Abbildung 10.8: Die Aufteilung bei Quicksort im Detail.
Beim Austritt gilt zusatzlich
loSwap≥ hiSwap, vec[hiSwap].key≤ vec[pivot].key, (10.7)
so dass der Tausch in Schritt 6 die “Pivot”-Komponente genau an die richtige Stelle tauscht.
Lemma 10.2 Enthalt der aufzuteilende Bereich m Komponenten, so ist die Anzahl der Vergleiche vonKomponenten fur die Aufteilung m−1.
Beweis: Da loSwap und hiSwap nach einem Austausch inkrementiert bzw. dekrementiert werden,wird jedes anderen Elemente genau einmal mit dem Pivotelement verglichen. Dies ergibtm−1 Ver-gleiche.
Es folgt eine Java Methode dieses Algorithmus.
Programm 10.3 quickSort/*** Sorts with quicksort algorithm* @param vec the array to be sorted* @exception NullPointerException if <code>vec</code>* is not initialized*/public static void quickSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();quickSort(vec, 0, vec.length - 1);

272 KAPITEL 10. SORTIEREN IN ARRAYS
/*** sorts array by quicksort in a certain range* @param vec the array in which this happens* @param loBound start of the range* @param hiBound end of the range*/private static void quickSort(Item[] vec, int loBound, int hiBound)
int loSwap, hiSwap;int pivotKey, pivotIndex;Item temp, pivotItem;
if (hiBound - loBound == 1) // Two items to sortif (vec[loBound].key > vec[hiBound].key)
temp = vec[loBound];vec[loBound] = vec[hiBound];vec[hiBound] = temp;
return;
pivotIndex = (loBound + hiBound) / 2; // 3 or more items to sortpivotItem = vec[pivotIndex];vec[pivotIndex] = vec[loBound];vec[loBound] = pivotItem;pivotKey = pivotItem.key;loSwap = loBound + 1;hiSwap = hiBound;do
while (loSwap <= hiSwap && vec[loSwap].key <= pivotKey)// INVARIANT (prior to test):// All vec[loBound+1..loSwap-1]// are <= pivot && loSwap <= hiSwap+1
loSwap++;while (vec[hiSwap].key > pivotKey)
// INVARIANT (prior to test):// All vec[hiSwap+1..hiBound]// are > pivot && hiSwap >= loSwap-1
hiSwap--;if (loSwap < hiSwap)
temp = vec[loSwap];vec[loSwap] = vec[hiSwap];vec[hiSwap] = temp;loSwap++;hiSwap--;

10.4. QUICKSORT 273
// INVARIANT: All vec[loBound..loSwap-1] are <= pivot// && All vec[hiSwap+1..hiBound] are > pivot// && (loSwap < hiSwap) -->// vec[loSwap] <= pivot < vec[hiSwap]// && (loSwap >= hiSwap) --> vec[hiSwap] <= pivot// && loBound <= loSwap <= hiSwap+1 <= hiBound+1
while (loSwap < hiSwap);vec[loBound] = vec[hiSwap];vec[hiSwap] = pivotItem;
if (loBound < hiSwap-1) // 2 or more items in 1st subvecquickSort(vec, loBound, hiSwap-1);
if (hiSwap+1 < hiBound) // 2 or more items in 2nd subvecquickSort(vec, hiSwap+1, hiBound);
10.4.2 Der Rekursionsaufwand von Quicksort
Da die Aufteilung (im Unterschied zur Mergesort) variabel ist, hat der Rekursionsbaum bei Quick-sort i. a. Teilbaume unterschiedlicher Hohe. Im Standardbeispiel ergibt sich der in Abbildung10.9dargestellte Baum.
QuickSort(vec,2,4)
QuickSort(vec,1,4)
QuickSort(vec,0,4)
QuickSort(vec,0,7)
QuickSort(vec,6,7)
PPPPPPP
Abbildung 10.9: Rekursionsbaum zu Quicksort.
Man sieht, dass der Baum am tiefsten wird, wenn als Vergleichselement jeweils das kleinste odergroßte Element des aufzuteilenden Bereiches gewahlt wird. In diesem Fall entartet der Rekursions-baum zu einer Liste (keine Verzweigungen). DieRekursionstiefekann also bis zun−1 betragen.
Wir zeigen durch Induktion, dass auch die AnzahlR(n) der rekursiven Aufrufe bei einem Arraybereichder Langen hochstensn−1 betragt.
Fur n = 1 erfolgt kein Aufruf, also giltR(1) = 0 (Induktionsanfang). Fur n > 1 bewirkt der ersteAufruf eine Aufteilung in Bereiche mitn1 und n2 Komponenten, wobein1 + n2 = n−1 gilt, da die

274 KAPITEL 10. SORTIEREN IN ARRAYS
Vergleichskomponente weg fallt. Also sindn1,n2 < n und man erhalt
R(n) = 1+R(n1)+R(n2)≤ 1+(n1−1)+(n2−1) (Induktionsvoraussetzung)
= n1 +n2−1
< n−1.
Also istR(n)≤ n−1.
10.4.3 Der Worst Case Aufwand von Quicksort
Vergleiche von Schlusseln treten bei Quicksort nur bei den Aufteilungen auf. Dabei muss jeder andereSchlussel mit dem Vergleichsschlussel verglichen werden, also erfolgen bei einem Bereich vonnKomponenten mindestens (und mit Lemma10.2sogar genau)n−1 Vergleiche.
Wird nun jeweils der großte bzw. kleinste Schlusselwert als Vergleichsschlussel gewahlt, so verklei-nert sich der Bereich jeweils nur um ein Element und man erhalt:
(n−1)+(n−2)+ . . .+2+1 =n(n−1)
2Vergleiche.
Also gilt fur die Worst Case AnzahlC(n) von Vergleichen:
C(n) = Ω(n2) .
10.4.4 Der mittlere Aufwand von Quicksort
Quicksort ist also im Worst Case schlecht. Erfahrungsgemaß ist Quicksort aber sehr schnell im Ver-gleich zu anderenΩ(n2) Sortierverfahren wie Bubblesort. Dies liegt daran, dass der Worst Case nurbei wenigen Eingabefolgen auftritt.
Man wird daher Quicksort gerechter, wenn man nicht den Worst Case betrachtet, sondern den Auf-wand uber alle moglichen Eingabefolgenmittelt, also denmittleren AufwandC(n) bei Gleichver-teilung allern! Reihenfolgen der Schlussel 1,2, . . . ,n betrachtet. Gleichverteilung bedeutet hier, dassjede Reihenfolge (Permutation) der Werte 1, . . . ,n mit dem gleichen Gewicht (namlich 1) in das Mitteleingeht.3
Als Vergleichsbeispiel betrachten wir das Wurfeln mit einem Wurfel mit den Augenzahlen 1,2, . . . ,6.Dann ergibt sich die mittlere Augenzahl bei Gleichverteilung zu1+2+3+...+6
6 = 3,5. Die mittlereSchrittlange beim Mensch-argere-dich-nicht betragt also 3,5; der Worst Case (bzgl. Weiterkommen)jedoch nur 1.
Fur n = 3 ergeben sich bei Quicksort 3!= 6 Permutationen, namlich 123, 132, 213, 231, 312, 321.Die Anzahl der Vergleiche pro Permutation betragt (gemaß der Implementation in Programm10.3)
3In der Terminologie der Wahrscheinlichkeitstheorie sagt man, dass jede Reihenfolge mit der gleichen Wahrscheinlich-keit 1/n! auftritt (daher der NameGleichverteilung), und man nenntC(n) auch dieerwartete Anzahl der Vergleiche.

10.4. QUICKSORT 275
2, 4, 4, 4, 4, 2. Der mittlere Aufwand betragt also2+4+4+4+4+23! = 10
3 Vergleiche gegenuber demWorst Case von 4 Vergleichen.
SeiΠ die Menge aller Permutationen von 1, . . . ,n. Fur π ∈ Π seiC(π) die Anzahl von Vergleichen,die Quicksort benotigt, umπ zu sortieren. Dann ist
C(n) =1n! ∑
π∈ΠC(π) .
Wir werden jetztC(n) nach oben abschatzen. Dafur teilen wir die MengeΠ aller Permutationen in dieMengenΠ1,Π2, . . . ,Πn, wobei
Πk = π ∈ Π | das Vergleichselement hat den Wertk .
Fur n = 3 ergibt sichΠ1 = 213,312, Π2 = 123,321 undΠ3 = 132,231.
In Πk ist das Vergleichselement fest vorgeschrieben, die anderen Komponenten konnen jedoch in jederReihenfolge auftreten. Also ist
|Πk|= (n−1)! f ur k = 1, . . . ,n.
Fur alleπ ∈Πk ergibt die erste Aufteilung in Quicksort die Teilarrays bestehend aus einer Permutationπ1 von 1,2, . . . ,k−1 und einer Permutationπ2 von k+1, . . . ,n (da ja das Vergleichselement geradekist).
Z(π) sei die Anzahl der Vergleiche mit derπ in die Teileπ1 und π2 zerlegt wird. Dann ist fur alleπ ∈ Πk
C(π) = Z(π)+C(π1)+C(π2) .
Dabei istZ(π)≤ 2n (in der Implementation in Programm10.3, vgl. Lemma10.2). Summiertuber alleπ ∈ Πk, so ergibt sich wegen|Πk|= (n−1)!:
∑π∈Πk
C(π) = ∑π∈Πk
[Z(π)+C(π1)+C(π2)] = ∑π∈Πk
Z(π)︸ ︷︷ ︸=:S1
+ ∑π∈Πk
C(π1)︸ ︷︷ ︸=:S2
+ ∑π∈Πk
C(π2)︸ ︷︷ ︸=:S3
Hierin ist wegen Lemma10.2S1 ≤ ∑
π∈Πk
n = n(n−1)! = n! .
Wennπ alle Permutationen ausΠk durchlauft, entstehen beiπ1 alle Permutationen von 1, . . . ,k−1,und zwar jede(n−1)!/(k−1)! mal, daΠk ja insgesamt(n−1)! Permutationen enthalt, und wegender Arbeitsweise des Aufteilungsalgorithmus (und der Gleichverteilung der Permutationen inΠk jedePermutation von 1, . . . ,k−1 gleich haufig entsteht. Also ist
S2 =(n−1)!(k−1)! ∑
π1Permutation von 1,...,k−1
C(π1)
= (n−1)! C(k−1) .

276 KAPITEL 10. SORTIEREN IN ARRAYS
Entsprechend folgtS3 = (n−1)! C(n−k) .
Durch Zusammensetzen aller Gleichungen bzw. Ungleichungen ergibt sich
C(n) =1n! ∑
π∈ΠC(π)
=1n!
n
∑k=1
∑π∈Πk
C(π) =1n!
n
∑k=1
(S1 +S2 +S3)
≤ 1n!
n
∑k=1
(n! +(n−1)! C(k−1)+(n−1)! C(n−k))
=n!n!
n
∑k=1
1+(n−1)!
n!
n
∑k=1
C(k−1)+(n−1)!
n!
n
∑k=1
C(n−k)
= n+1n
n−1
∑k=0
C(k)+1n
n−1
∑k=0
C(k)
= n+2n
n−1
∑k=0
C(k) .
Wir haben damit eine Rekursionsgleichung fur C(n) gefunden. Beachtet man noch die Anfangswerte
C(0) = C(1) = 0, C(2) = 1
so ist
C(n)≤ n+2n
n−1
∑k=2
C(k) fur n≥ 2.
Lemma 10.3 Fur die Losung r(n) der Rekursionsgleichung
r(n) = n+2n
n−1
∑k=2
r(k) fur n≥ 2
mit den Anfangswerten r(0) = r(1) = 0, r(2) = 1 gilt fur alle n≥ 2
r(n)≤ 2nlnn. 4
Beweis:Der Beweis erfolgt durch vollstandige Induktion nachn mit dem Ansatzr(n)≤ 2nlnn, wobeidie Konstantec wahrend des Beweises ermittelt wird.
Induktionsanfang: Fur n = 2 ist r(2) = 1. Andererseits istc·2ln2≈ c·1,39. Also gilt der Induktions-anfang fur c≥ 1.
Induktionsvoraussetzung: Die Behauptung gelte fur 2,3, . . . ,n−1.
4ln = logen (naturlicher Logarithmus).
10.4. QUICKSORT 277
Schluss auf n:
r(n) = n+2n
n−1
∑k=2
r(k)
≤ n+2n
n−1
∑k=2
c·k lnk (nach Induktionsvoraussetzung)
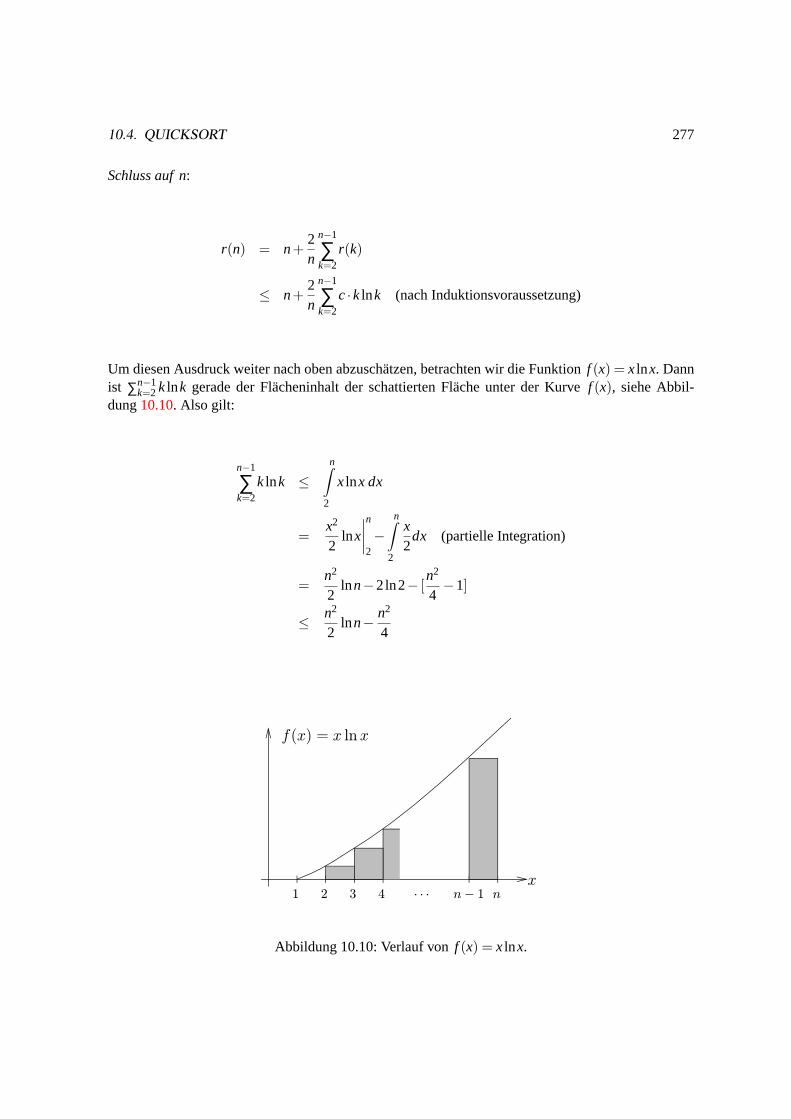
Um diesen Ausdruck weiter nach oben abzuschatzen, betrachten wir die Funktionf (x) = xlnx. Dannist ∑n−1
k=2 k lnk gerade der Flacheninhalt der schattierten Flache unter der Kurvef (x), siehe Abbil-dung10.10. Also gilt:
n−1
∑k=2
k lnk ≤n∫
2
xlnx dx
=x2
2lnx
∣∣∣∣n2−
n∫2
x2
dx (partielle Integration)
=n2
2lnn−2ln2− [
n2
4−1]
≤ n2
2lnn− n2
4
266 KAPITEL 10. SORTIEREN IN ARRAYS
x
f(x) = x lnx
1 2 3 4 n· · · n− 1
Abbildung 10.10: Verlauf von f(x) = x lnx.
= c · n lnn+ 2n−2c
4n︸ ︷︷ ︸
=:R(n)
≤ c · n lnn falls R(n) ≤ 0 .
Nun ist
R(n) = 2n−c
2n
≤ 0 fur c ≥ 4 .
Aus dem Lemma folgt:
Satz 10.6 Fur die mittlere Anzahl C(n) der Vergleiche zum Sortieren eines n-elementigenArrays mit Quicksort gilt
C(n) ∈ O(n logn) .
Beweis: Aus C(n) ≤ r(n) und Lemma 10.3 folgt
C(n) ≤ 4 · n lnn = 4 · n ·logn
log e=4
log en logn
fur alle n ≥ 2.
Also ist C(n) ∈ O(n logn) mit der O-Konstanten 4 log e ≈ 2,77.
Abbildung 10.10: Verlauf vonf (x) = xlnx.

278 KAPITEL 10. SORTIEREN IN ARRAYS
Hieraus folgt
r(n) ≤ n+2n
n−1
∑k=2
c·k · lnk = n+2cn
n−1
∑k=2
k lnk
≤ n+2cn
(n2
2lnn− n2
4
)= n+
2c2
nlnn− 2c4
n
= c·nlnn+n− c2
n︸ ︷︷ ︸=:R(n)
≤ c·nlnn falls R(n)≤ 0.
Nun ist
R(n) = n− c2
n
≤ 0 fur c≥ 2.
Aus dem Lemma folgt:
Satz 10.6Fur die mittlere AnzahlC(n) der Vergleiche zum Sortieren eines n-elementigen Arrays mitQuicksort gilt
C(n) ∈ O(nlogn) .
Beweis:AusC(n)≤ r(n) und Lemma10.3folgt
C(n)≤ 2·nlnn = 2·n· lognloge
=2
logenlogn
fur allen≥ 2.
Also istC(n) ∈ O(nlogn) mit derO-Konstanten 2loge ≈ 1,386.
Entsprechend kann man fur die mittlere AnzahlA(n) von Zuweisungen beweisen (Ubung)
A(n) = O(nlogn).
Quicksort arbeitet also im Mittel beweisbar sehr schnell, und dies wird auch in allen Laufzeituntersu-chungen bestatigt. Quicksort ist der Sortieralgorithmus, den man verwenden sollte.

10.5. HEAPSORT 279
10.5 Heapsort
Heapsort basiert im Gegensatz zu Mergesort und Quicksort nicht auf dem Prinzip der Aufteilung,sondern nutzt eine spezielle Datenstruktur (denHeap), mit der wiederholt auf das großte Elementeines Arrays zugegriffen wird. Esahnelt damit eher einem verbesserten Selection Sort.
10.5.1 Die Grobstruktur von Heapsort
Ein Heap(auchPriority Queuegenannt) ist eine abstrakte Datenstruktur mit folgenden Kennzeichen:
Wertebereich: Eine Menge von Werten des (homogenen) Komponententyps. Alle Komponenten be-sitzen einen Wert (Schlussel).
Operationen:
1. Einfugen einer Komponente.
2. Zugriff auf die Komponente mit dem großten Wert.
3. Entfernen der Komponente mit dem großten Wert.
4. Anderung des Wertes einer Komponente.
Statt des großten Wertes wird auch oft der kleinste Wert in 2. und 3. genommen.
Bei der Anwendung in Heapsort sind die Komponenten vonvec die Elemente des Heaps, und dieSchlusselvec[i].key sind die Werte. Dann arbeitet Heapsort nach folgender Idee:
Grobstruktur von Heapsort
1. Gegeben sei das Arrayvec[] mit n Komponenten.
2. Initialisiere den Heap mit den Komponenten vonvec.
3. for i := n−1 downto 0 do
3.1 Greife auf das großte Element des Heaps zu.
3.2 Weise diesen Wert der Arraykomponentevec[i] zu.
3.3 Entferne das großte Element aus dem Heap.
Die Korrektheit des Algorithmus ist offensichtlich, und auch dieAhnlichkeit zu Selection Sort. Um zueinem schnellen Algorithmus zu kommen, muss man den Heap so implementieren, dass die benotigtenOperationen schnell ausgefuhrt werden konnen.
In Heapsort sind dies die Operationen 2 (in Schritt 3.1) und 3 (in Schritt 3.3), die jeweilsn malnacheinander ausgefuhrt werden. Hinzu kommt das Initialisieren des Heaps in Schritt 2.
Wir brauchen offenbar nicht alle Heapoperationen (4 wird nicht benotigt) und die anderen Opera-tionen nur in bestimmter Reihenfolge (Einfugen nur bei der Initialisierung, Zugriff und Entfernen

280 KAPITEL 10. SORTIEREN IN ARRAYS
stets nacheinander). Daher werden wir keinen allgemeinen Heap verwenden (vgl. dazu [CLRS01]),sondern die benotigten Heapoperationen direkt im Arrayvec implementieren, und zwar so, dass gilt:
Worst Case-Aufwand der hier gewahlten Heap Implementation
• Initialisierung inO(n).
• Zugriff auf das großte Element inO(1).
• Entfernen des großten Elements inO(logn).
Dabei werden sowohl Vergleiche als auch Zuweisungen von Arraykomponenten berucksichtigt. Hierausfolgt sofort:
Satz 10.7Der Worst Case Aufwand zum Sortieren eines n-elementigen Arrays mit Heapsort betragtO(nlogn).
10.5.2 Die Implementation des Heaps
Die Grundidee besteht darin, sich das Arrayvec als binaren Baum vorzustellen, wobei die Kompo-nenten der Reihe nach in die Schichten 0,1,2. . . von links nach rechts angeordnet werden.
Fur das Standardbeispiel
vec = 630
241
122
533
724
185
446
357
ergibt sich so der in Abbildung10.11dargestellte Baum.
357
533
724@@
185
446@@
241
122H
HH630
Abbildung 10.11: Array als Heap.
Fur einen Knotenv in einem binaren Baum bezeichnet man die vonv ausuber eine gerichtete Kanteerreichbaren Knoten alsSohneund nenntv denVaterdieser Sohne. Bei 2 Sohnen unterscheidet man(bzgl. einer gegebenen Darstellung) zwischenlinkemundrechtemSohn.
Mit diesen Bezeichnungen gelten fur den Baum zu einem Heap folgende Eigenschaften:

10.5. HEAPSORT 281
Lemma 10.4
a) vec[0] ist die Wurzel des Baumes.
b) Der linke Sohn vonvec[i] (falls vorhanden) istvec[2i+1].
c) Der rechte Sohn vonvec[i] (falls vorhanden) istvec[2i+2].
d) Nur Knotenvec[i] mit i ≤⌊
n2
⌋haben Sohne.
Beweis:Ubung.
Wir sagen, dassvec dieHeapeigenschaft(heap ordering) erfullt, wenn fur i = 0, . . . ,n−1 gilt:
vec[i].key ≥ vec[2i+1].key falls 2i +1 < nvec[i].key ≥ vec[2i+2].key falls 2i +2 < n
Fur jeden Knotenvec[i] mit einem oder zwei Sohnen ist also derkey-Wert der Sohne nicht großerals der des Vaters.
Hieraus ergibt sich direkt:
Lemma 10.5 Erfullt vec die Heapeigenschaft, so gilt:
a) vec[0].key ist der großte auftretende Schlusselwert.
b) Entlang jeden Weges von einem Blatt zu der Wurzel sind die Schlusselwerte aufsteigend sortiert.
Erfullt vec die Heapeigenschaft, so kann also auf die großte Komponentevec[0] in O(1) Zeit zuge-griffen werden. Wenn wir sie entfernen, so haben beide Teilbaume noch die Heapeigenschaft. Wennwir dann ein neues Element an die Wurzel stellen (einfugen), so mussen wir die Heapeigenschaftwieder herstellen.
Dazu verwenden wir die Funktionheapify(). Sie setzt voraus, dass die Heapeigenschaft bereits imBereichvec[top+1]. . .vec[bottom] gilt, fugtvec[top] hinzu und ordnet die Komponenten so um,dass hinterher die Heapordnung im Bereichvec[top]. . .vec[bottom] gilt. Dazu werden folgendeSchritte ausgefuhrt:
1. Ermittle den großeren der beiden Sohne (child) von top (falls keine Sohne existieren, so istdie Heapeigenschaft trivialerweise erfullt, falls nur ein Sohn existiert, so nehme diesen).
2. Vergleichevec[child] mit vec[top]. Fallsvec[child].key > vec[top].key so tauschevec[top] undvec[child].
3. Wendeheapify() rekursiv aufchild an.

282 KAPITEL 10. SORTIEREN IN ARRAYS
Die Korrektheitvonheapify() sieht man wie folgt:
Seienr und s die Sohne vontop und seienb = vec[r], c = vec[s] und a = vec[top] die zu-gehorigenkey-Werte. In den dazugehorigen Teilbaumen (siehe Abbildung10.12gilt nach Vorausset-zung die Heapeigenschaft. O. B. d. A. seir der großere Sohn (alsob≥ c) undb > a. Dann werdendie Inhalte der Komponententop undr getauscht. Nach dem Tausch istb = vec[top].key > a,cund somit die Heapeigenschaft intop erfullt. Im rechten Teilbaum gilt sie unverandert. Im linkenTeilbaum konnte sie verletzt sein, weshalb der rekursive Aufruf vonheapify() fur r notig wird (undper Induktionsannahme die Herstellung der Heapeigenschaft in diesem Teilbaum sichert).
br
csHHHH
atop
AAAA
AAAA
- ar
csHHHH
btop
AAAA
AAAA
Abbildung 10.12: Zur Korrektheit vonheapify()
Als Beispiel betrachten wir in Abbildung10.13 das Einfugen von 27 als Wurzel in einen Baum,dessen Teilbaume beide die Heapeigenschaft erfullen. Durchgezogene Linien bedeuten dabei, dassdie Heapeigenschaft erfullt ist, gepunktete Linien den durchheapify() durchgefuhrten Vergleichmit den Sohnen.
Es folgt eine Java Implementation vonheapify():
Programm 10.4 heapify/*** establishes heap property in a certain range* @param vec the array in which this happens* @param top start of the range* @param bottom end of the range*/private static void heapify(Item[] vec, int top, int bottom)
Item temp;int child;
if (2*top+1 > bottom) return; // nothing to do
if (2*top+2 > bottom) // vec[2*top+1] is only child of vec[top]child = 2*top+1;
else // 2 sons, determine bigger oneif (vec[2*top+1].key > vec[2*top+2].key)
child = 2*top+1;

10.5. HEAPSORT 283
357
533
244@@
185
126@@
631
p p p p p p p p442
pppppppp270 -
357
533
p p p p244
pppp185
126@@
271
442HHH
630
-
357
p p p p273
244@@
185
126@@
531
442H
HH630 -
277
353
244@@
185
126@@
531
442H
HH630
Abbildung 10.13: Ein Beispiel fur heapify().
else child = 2*top+2;
//endif
// check if exchange is necessaryif (vec[top].key < vec[child].key)
temp = vec[top];vec[top] = vec[child];vec[child] = temp;// recursive call for possible further exchangesheapify(vec, child, bottom);
//endif
heapify() lasst sich nun einfach zum Herstellen der Heapeigenschaft im gesamten Arrayvec nut-zen, indem man das Array von hinten nach vorn durchlauft und in jeder Komponentei (die Sohnehat)heapify(vec,i,n-1) aufruft. Vor dem Aufruf erfullt vec[i+1]. . .[n-1] bereits die Heapei-genschaft, und der Aufruf stellt die Heapeigenschaft fur vec[i]. . .vec[n-1] her.
Eine Java Implementation lautet:

284 KAPITEL 10. SORTIEREN IN ARRAYS
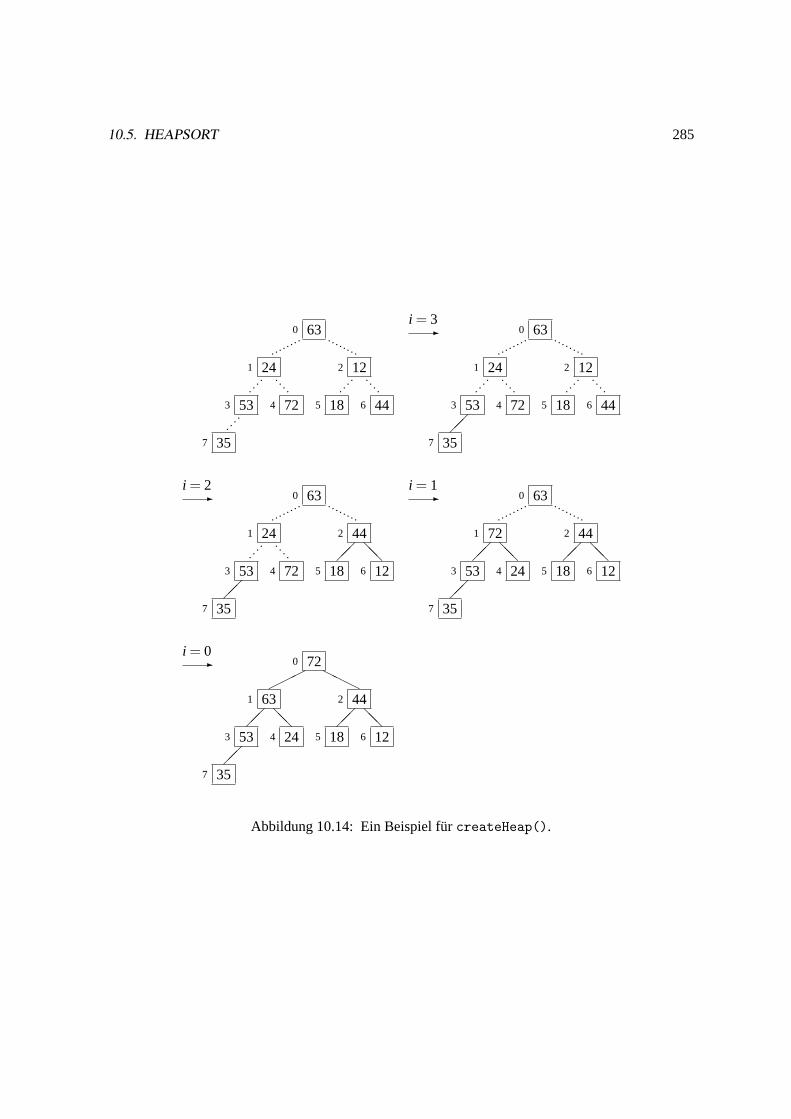
Programm 10.5 createHeap/*** turns array into a heap* @param vec the array to which this happens*/private static void createHeap(Item[] vec)
for (int i = vec.length/2 - 1; i >= 0; i--) heapify(vec, i, vec.length - 1);
Im Standardbeispiel ergeben sich die in Abbildung10.14dargestellten Zustande nach jedem Durch-lauf der Schleife. Dabei deuten durchgezogene Linien bereits hergestellte Heapbedingungen an.
10.5.3 Die Implementation von Heapsort
Mit heapify() undcreateHeap() lasst sich Heapsort jetzt einfach implementieren:
Programm 10.6 heapSort/*** sorts array by heapsort in a certain range* @param vec the array in which this happens*/public static void heapSort(Item[] vec)
throws NullPointerException if (vec == null) throw new NullPointerException();
Item temp;int last;int n = vec.length;
createHeap(vec);for (last = n-1; last > 0; last--)
// exchange top component with// current last component of vectemp = vec[0];vec[0] = vec[last];vec[last] = temp;// call Heapify to to reestablish heap propertyheapify(vec, 0, last-1);
//endfor
10.5. HEAPSORT 285
357
p p p p533
p p p p724
pppp185
p p p p446
pppp241
p p p p p p p p122
pppppppp630 -i = 3
357
533
p p p p724
pppp185
p p p p446
pppp241
p p p p p p p p122
pppppppp630
-i = 2
357
533
p p p p724
pppp185
126@@
241
p p p p p p p p442
pppppppp630 -i = 1
357
533
244@@
185
126@@
721
p p p p p p p p442
pppppppp630
-i = 0
357
533
244@@
185
126@@
631
442HHH
720
Abbildung 10.14: Ein Beispiel fur createHeap().

286 KAPITEL 10. SORTIEREN IN ARRAYS
Die Komponentenvec[0]. . .vec[last] bilden also den aktuellen Heap (mit jeweiligem großtenElementvec[0]), und die Komponentenvec[last+1]. . .vec[n-1] den bereits sortierten Teil desArrays.
Im Standardbeispiel ergeben sich jeweils beim Eintritt in diefor-Schleife die in Abbildung10.15dargestellten Heaps. Die noch verbundenen Komponenten des Arrays stellen den jeweiligen Heapvec[0]. . .vec[last] dar, die Aktionen vonheapify() werden nicht mehr dargestellt.
10.5.4 Die Analyse von Heapsort
Zur Vorbereitung der Analyse betrachten wir die Interpretation des Arrays als Baum genauer:
Da die Komponenten des Arrays schichtweise im Baum angeordnet sind, hat er die Eigenschaft, dassalle Schichteni bis auf eventuell die letztevoll sind, d. h. 2i Knoten enthalten. Ein solcher Baum heißtvoller (binarer) Baum.
Lemma 10.6 Sei T ein voller binarer Baum mit n Knoten. Sei h die Hohe von T. Dann gilt:
a) 2h ≤ n≤ 2h+1−1
b) h≤ blognc
Beweis: In T sind alle Schichten voll bis eventuell auf die letzte. Also sind in Schichti fur i =0, . . . ,h−1 genau 2i Knoten, und in Schichthzwischen 1 und 2h Knoten (vergleiche Abbildung10.16).Also ist (
h−1
∑i=0
2i
)+1≤ n≤
h
∑i=0
2i .
Wegen∑ki=02i = 2k+1−1 ergibt sich
2h ≤ n≤ 2h+1−1,
also a). Aus 2h ≤ n folgt h≤ logn und somith≤ blognc, dah eine ganze Zahl ist.
Betrachten wir jetzt den Aufwand fur einen Aufruf vonheapify() einschließlich der dadurch er-zeugten weiteren rekursiven Aufrufe.
Bei jedem Aufruf, bei dem ein Austausch erfolgt, “sinkt” das betrachtete Element um eine Stufe nachunten im Baum. Die Anzahl der Folgeaufrufe durch Rekursion ist also durch die Anzahl der Schichtenunterhalb der Ausgangsstufe des Elements beschrankt.
Diese Beobachtung ist der Kern der folgenden Abschatzung. Wir bezeichnen dieUberprufung undggf. Herstellung der Heapeigenschaft fur einen Knoten mit seinen Sohnen als einePrufaktion.

10.5. HEAPSORT 287
357
533
244@@
185
126@@
631
442HHH
720-
last = 7
727
353
244@@
185
126@@
531
442HHH
630
-last = 6
727
123
244@@
185
636
351
442H
HH530
-last = 5
727
123
244@@
535 636
351
182H
HH440
-last = 4
727
123
444 535 636
241
182HHH
350-
last = 3
727
353 444 535 636
121
182HHH
240
-last = 2
727
353 444 535 636
121
242
180-
last = 1
727
353 444 535 636
181 242
120
Abbildung 10.15: Ein Beispiel fur HeapSort.

288 KAPITEL 10. SORTIEREN IN ARRAYS
u uAA u Schichth = 3
u u@@ u u@
@Schicht 2 22 Knoten
u uQQQ
Schicht 1 21 Knoten
Schicht 0 20 Knotenu
Abbildung 10.16: Ein voller Baum.
Lemma 10.7 Fur die Anzahl P1(n) der Prufaktionen beim Herstellen der Heapeigenschaft in einemn-elementigen Array gilt
P1(n)≤ 2n.
Beweis:Wir betrachten (wie increateHeap()) die Schichten von unten nach oben. Da die Anzahlder Prufaktionen nach der angestellten Voruberlegung durch die Anzahl der Schichten unterhalb desKnotens beschrankt ist, folgt:
Schichth: keine PrufaktionenSchichth−1: hochstens 1 Prufaktionen pro Knoten der SchichtSchichth−2: hochstens 2 Prufaktionen pro Knoten der Schicht
. . .Schichth− i: hochstensi Prufaktionen pro Knoten der Schicht
. . .Schicht 0: hochstensh Prufaktionen.
Also ist
P1(n) ≤ 2h−1 ·1+2h−2 ·2+ . . .+2h−i · i + . . .+20 ·h
=h
∑i=1
2h−i · i =h
∑i=1
2h
2i i = 2hh
∑i=1
i2i
≤ 2n, da 2h ≤ n und∞
∑i=1
i2i = 2.
Die AnzahlP2(n) der Prufaktionen inHeapSort (außerhalb voncreateHeap()) ergibt sich analog.Im i-ten Durchlauf derfor-Schleife wirdheapify() fur die Komponente mit Index 0 und den Heapmit n− i Komponenten aufgerufen, dessen Hohe nach Lemma10.6hochstens log(n− i) ist. Also folgt
P2(n)≤n−2
∑i=1
log(n− i)≤n−1
∑i=1
logn = (n−1) logn.

10.6. LITERATURHINWEISE 289
Pro Prufaktion erfolgen 2 Vergleiche und maximal 3 Zuweisungen (1 Austausch). Hinzu kommenjeweils 3 Zuweisungen (1 Austausch) in derfor-Schleife vonHeapSort. Hieraus folgt:
Satz 10.8Fur die Anzahl C(n) der Vergleiche und die Anzahl A(n) der Zuweisungen bei Heapsortgilt:
C(n) = O(nlogn), A(n) = O(nlogn) .
Beweis:Nachrechnen ergibt:
C(n) ≤ 2·P1(n)+2·P2(n)≤ 4n+2nlogn
≤ 3nlogn fur n≥ 16,
A(n) ≤ 3·P1(n)+3· (n−1)+3·P2(n)≤ 9n+3nlogn
≤ 5nlogn fur n≥ 23.
10.6 Literaturhinweise
Sortieralgorithmen werden in allen Buchernuber Algorithmen und Datenstrukturen behandelt, vom Klassiker[Knu98b] bis zu [CLRS01]. Die Implementationen der Algorithmen lehnt sich zum Teil an [HR94] an.
Die allgemeine Version des Aufteilungs-Beschleunigungssatzes ist aus [CLRS01]. Dort finden sich auch wei-tere Details zur Beschleunigung der Matrixmultiplikation. Die Anwendung auf die Multiplikationn-stelligerDualzahlen ist aus [AHU83].